机器学习 -- k近邻算法
场景
我学习Python的初衷是学习人工智能,满足现有的业务场景。所以必须要看看机器学习这一块。今天看了很久,做个总结。
机器学习分为深度学习和传统机器学习
深度学习
深度学习模型通常非常复杂,包含多层神经网络,每一层都包含大量的神经元(节点)。这些模型可以包含数百万甚至数十亿个参数。深度学习模型可以自动学习数据的特征表示,而无需手动设计特征。通过多层神经网络,深度学习模型可以逐层提取和组合特征,从而更好地捕捉数据中的复杂模式。深度学习模型通常需要大量的数据来进行训练,以充分学习复杂的参数。这意味着深度学习在大规模数据集上表现良好,但在小数据集上可能会过拟合。而且深度学习更像是一个黑盒子,你也不知道它为什么会得到这个结果。还有,深度学习通常需要大量的计算资源,例如高性能GPU,以加速模型的训练。这使得深度学习在硬件要求上更为苛刻。深度学习更适合于计算机视觉,自然语言处理,自动驾驶等场景。
传统机器学习
传统机器学习模型通常比深度学习模型简单,包括线性回归、决策树、支持向量机(SVM)、K近邻(K-NN)等。这些模型具有较少的参数。传统机器学习通常需要手动设计和提取特征。特征工程是一个关键的步骤,需要领域专业知识和经验来选择和创建适当的特征。传统机器学习模型在小规模数据集上也可以表现良好,并且通常不容易过拟合。相对于深度学习,传统机器学习算法通常需要较少的计算资源,因此在资源受限的环境中更具可行性。传统学习很适用于有明确输入与输出数据的场景,如图像识别、语音识别和文本分类。在这些任务中,算法通过训练数据集来学习,其中包含输入数据及其对应的正确输出。
在传统机器分类学习中,有一个很经典的算法叫做 “k近邻算法”。
k近邻算法
众所周知,有很多种类电影,爱情电影,动作电影。爱情电影里有kiss片段,但是可能也会有武打片段。动作片里有动作片段,可能也有Kiss片段。但是,经常看电影的肯定知道,爱情片里的动作片段远远小于动作片段,反之亦然。基于某一场景是否可以给电影分类呢?这种场景就很适合k近邻算法。
概述
k近邻算法是一种简单但非常有效的机器学习算法,主要用于分类和回归问题。其核心思想是基于相似性原则进行预测:即相似的数据点具有相似的输出。
距离度量:改算法首先计算测试数据与每个训练数据点之间的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离和闵可夫斯基距离。 例如:测试样例特征是 [0,0],样本集特征是 [1,2] 那么距离就是
[(1-0) **2 + (2-0) **2] **0.5 (欧氏距离) 如果距离测试样例的三个样本的值分别是 0,1,2 k是2 ,那么样本1类型如果为A,样本2类型为A,那么测试类型为A。
决策规则:
分类:对于分类问题,算法通常采用“多数投票”原则,即测试数据点被分配到邻居中最常见的类别。
回归:对于回归问题,算法通常计算K个邻居的输出值的平均值,作为预测值。
特点
简单有效:k近邻算法是一种理解起来直观且实现简单的算法。
惰性学习:与其他机器学习算法不同,k近邻算法不需要在训练阶段进行显著的学习过程。它在预测阶段才进行计算,因此属于惰性学习算法。
无参数:k近邻算法不假设数据的分布,因此是一种非参数算法。
内存密集型:由于算法需要存储所有训练数据,因此对内存要求较高。
缺点
K值的选择:K的选择对算法的性能有重要影响。较小的K值使模型对噪声数据更敏感,而较大的K值则可能导致分类/回归边界的平滑化。
维度诅咒:在高维数据中,计算距离变得困难,这会影响k近邻算法算法的性能。
标准化:k近邻算法对数据的尺度非常敏感,因此通常需要进行特征标准化。
计算成本:对于大型数据集,计算每个测试实例的邻居可能非常耗时。
demo
我们根据上述所说,编写k近邻算法的代码:
def classify0(inX, dataSet, labels, k):# 获取数据集的行数dataSetSize = dataSet.shape[0]# 计算输入向量与数据集中每个数据点的差值矩阵diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet# 计算差值矩阵中每个元素的平方sqDiffMat = diffMat ** 2# 计算每行的平方差值和,得到平方距离的数组sqDistances = sqDiffMat.sum(axis=1)# 对平方距离数组开平方,得到距离数组distances = sqDistances ** 0.5# 对距离数组进行排序,返回排序后的索引sortedDistIndices = distances.argsort()# 创建一个字典,用于存储最近的 k 个数据点的类别及其出现次数classCount = {}# 遍历排序后的前 k 个索引for i in range(k):# 获取当前最近数据点的类别voteIlabel = labels[sortedDistIndices[i]]# 更新字典中该类别的出现次数classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1# 对字典中的类别及其出现次数进行排序,按出现次数降序排列sortedClassCount = sorted(classCount.items(), key=lambda x: x[1], reverse=True)# 返回最频繁出现的类别return sortedClassCount[0][0]
作为java老本行,自然得有java版。
/*** k近邻算法* @Author: Herche Jane* @Date: 2024/01/04*/
public class KNNClassifier {public static String classify0(double[] inX, double[][] dataSet, String[] labels, int k) {int dataSetSize = dataSet.length;// 计算距离double[] distances = new double[dataSetSize];for (int i = 0; i < dataSetSize; i++) {double[] data = dataSet[i];double distance = 0;for (int j = 0; j < inX.length; j++) {distance += Math.pow(inX[j] - data[j], 2);}distances[i] = Math.sqrt(distance);}// 获取距离的排序索引Integer[] sortedDistIndices = getSortedIndices(distances);// 计算前k个最近邻的类别及其出现次数Map<String, Integer> classCount = new HashMap<>();for (int i = 0; i < k; i++) {String label = labels[sortedDistIndices[i]];classCount.put(label, classCount.getOrDefault(label, 0) + 1);}// 对类别出现次数进行排序List<Map.Entry<String, Integer>> sortedClassCount = new ArrayList<>(classCount.entrySet());sortedClassCount.sort((o1, o2) -> o2.getValue().compareTo(o1.getValue()));// 返回最频繁的类别return sortedClassCount.get(0).getKey();}private static Integer[] getSortedIndices(double[] array) {Integer[] indices = new Integer[array.length];for (int i = 0; i < array.length; i++) {indices[i] = i;}Arrays.sort(indices, Comparator.comparingDouble(i -> array[i]));return indices;}
}测试调用
致敬java
public static void main(String[] args) {// 示例:数据集和标签double[][] dataSet = {{1.0, 2.0}, {2.0, 3.0}, {3.0, 4.0}};String[] labels = {"A", "B", "B"};double[] inX = {1.5, 2.5};// 使用KNN进行分类String result = classify0(inX, dataSet, labels, 3);System.out.println("分类结果: " + result);}
调用结果:
分类结果: B
结束
k近邻算法是分类最简单最有效的方案,k近邻算法必须保存所有的训练集,这就意味着很吃内存。这个算法我们根本就不知道平均实例样本和典型实例样本是什么。当K值较小,即考虑的邻居数量较少时,如果有噪声和脏数据,那么这个训练算是废了。没有自己纠正自己的能力,这就要求数据必须要有预处理,否则很容易出问题!
相关文章:

机器学习 -- k近邻算法
场景 我学习Python的初衷是学习人工智能,满足现有的业务场景。所以必须要看看机器学习这一块。今天看了很久,做个总结。 机器学习分为深度学习和传统机器学习 深度学习 深度学习模型通常非常复杂,包含多层神经网络,每一层都包含…...

安全测试之SSRF请求伪造
前言 SSRF漏洞是一种在未能获取服务器权限时,利用服务器漏洞,由攻击者构造请求,服务器端发起请求的安全漏洞,攻击者可以利用该漏洞诱使服务器端应用程序向攻击者选择的任意域发出HTTP请求。 很多Web应用都提供了从其他的服务器上…...

php composer安装
引言 Composer 是 PHP 中的依赖管理工具。它允许您声明您的项目所依赖的库,并且它将为您管理(安装/更新)它们。 官网链接:Introduction - Composer 安装 要在当前目录中快速安装 Composer,请在终端中运行以下脚本。…...

【MyBatis】MyBatis基础操作
文章目录 前言注解方式书写 MyBatis打印 MyBatis 日志参数传递MyBatis 增加操作返回主键 MyBatis 删除操作MyBatis 修改操作MyBatis 查找操作1. 对查询结果进行别名2. Results注解3. 开启驼峰命名(推荐) XML 配置文件方法书写 MyBatis配置数据库的相关配…...

Automatic merge failed; fix conflicts and then commit the result.如何处理
当你在Git中遇到 “Automatic merge failed; fix conflicts and then commit the result.” 的错误时,这意味着你尝试合并两个分支时出现了冲突。Git无法自动解决这些冲突,因此需要你手动解决。以下是处理这种情况的步骤: 找出冲突文件: 运行…...

一文读懂 $mash 通证 “Fair Launch” 规则(幸运池玩法解读篇)
Solmash 是 Solana 生态中由社区主导的铭文资产 LaunchPad 平台,该平台旨在为 Solana 原生铭文项目,以及通过其合作伙伴 SoBit 跨链桥桥接到 Solana 的 Bitcoin 生态铭文项目提供更广泛的启动机会。有了 Solmash,将会有更多的 Solana 生态的铭…...

Qt3D QGeometryRenderer几何体渲染类使用说明
Qt3D中的QGeometryRenderer派生出来的几何体类包括: Qt3DExtras::QConeMesh, Qt3DExtras::QCuboidMesh, Qt3DExtras::QCylinderMesh, Qt3DExtras::QExtrudedTextMesh, Qt3DExtras::QPlaneMesh, Qt3DExtras::QSphereMesh, Qt3DExtras::QTorusMesh, and Qt3DRender::QMesh 有球…...

pandasDataFrame读和写csv文件
从.csv文件读数据 import pandas as pd# 从CSV文件中读取数据 train_df pd.read_csv("datasets/train01.csv") val_df pd.read_csv("datasets/val01.csv") test_df pd.read_csv("datasets/test01.csv")# 显示数据框的前几行,确保…...

力扣122. 买卖股票的最佳时机 II
动态规划 思路: 假设 dp[i][0] 是第 i 天手上没有股票时的最大利润, dp[i][1] 是第 i 天手上有 1 支股票的最大利润;dp[i][0] 的迁移状态为: dp[i - 1][0],前一天手上已经没有股票,没有发生交易࿱…...

Go语言断言和类型查询
Go语言断言和类型查询 1、类型断言 类型断言(Type Assertion)是一个使用在接口值上的操作,用于检查接口类型变量所持有的值是否实现了期望的接 口或者具体的类型。 在Go语言中类型断言的语法格式如下: // i.(TypeNname) value, ok : x.(T)其中&…...

02 Deep learning algorithm
Neural Networks target: inference(prediction)training my own modelpractical advice for building machine learning systemdecision Tress application: speech(语音识别) ----> images(计算机视觉)—> t…...

代码随想录算法训练营第二十四天 | 回溯算法
理论基础 代码随想录原文 什么是回溯法 回溯也可以叫做回溯搜索法,它是一种搜索的方式。 回溯是递归的副产品,只要有递归就会有回溯。 回溯法的效率 虽然回溯法很难,不好理解,但是回溯法并不是什么高效的算法。因为回溯的本…...
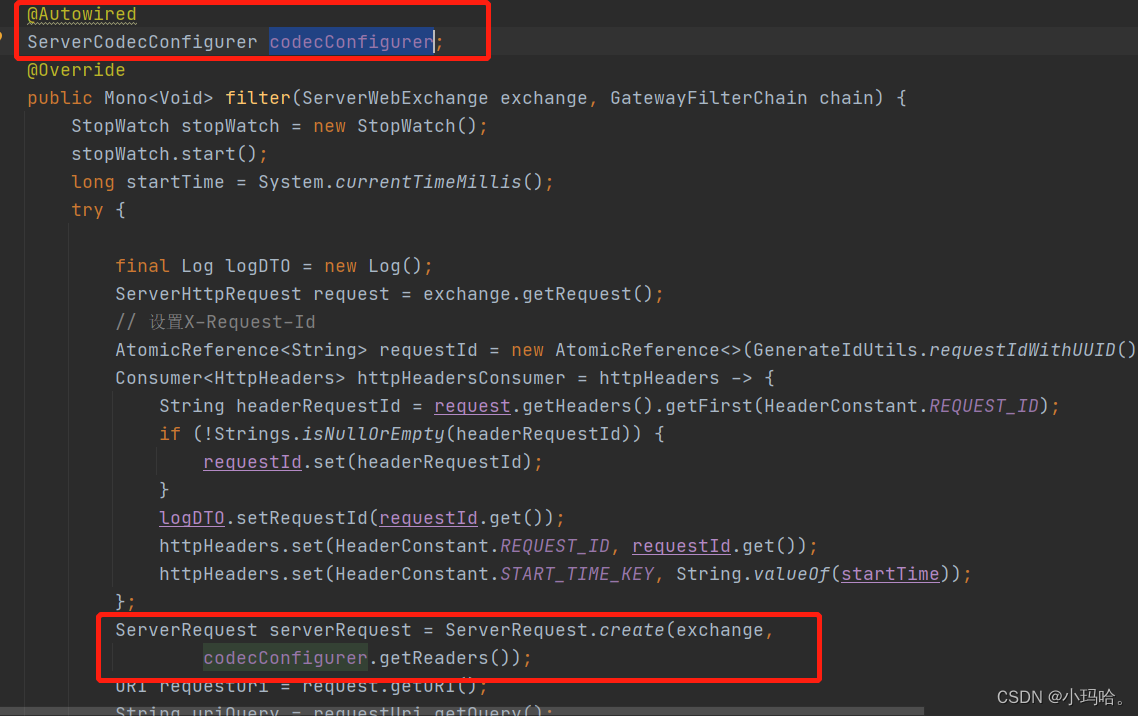
Spring Cloud Gateway 缓存区异常
目录 1、问题背景 2、分析源码过程 3、解决办法 最近在测试环境spring cloud gateway突然出现了异常,在这里记录一下,直接上干货 1、问题背景 测试环境spring cloud gateway遇到以下异常 DataBufferLimitException: Exceeded limit on max bytes t…...
Spring Boot依赖版本声明
链接 官网 Spring Boot文档官网:https://docs.spring.io/spring-boot/docs/https://docs.spring.io/spring-boot/docs/ Spring Boot 2.0.7.RELEASE Spring Boot 2.0.7.RELEASE reference相关:https://docs.spring.io/spring-boot/docs/2.…...
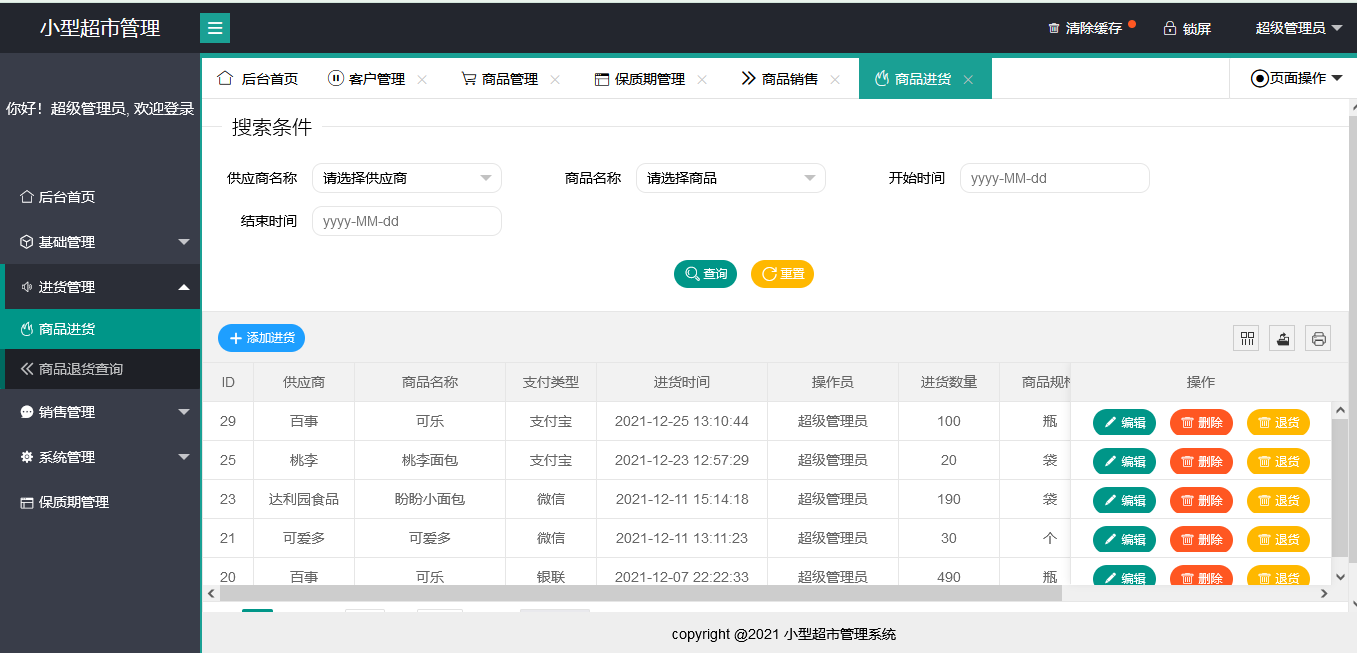
Java项目:109SpringBoot超市仓管系统
博主主页:Java旅途 简介:分享计算机知识、学习路线、系统源码及教程 文末获取源码 一、项目介绍 超市仓管系统基于SpringBootMybatis开发,系统使用shiro框架做权限安全控制,超级管理员登录系统后可根据自己的实际需求配角色&…...

【React系列】Redux(三) state如何管理
本文来自#React系列教程:https://mp.weixin.qq.com/mp/appmsgalbum?__bizMzg5MDAzNzkwNA&actiongetalbum&album_id1566025152667107329) 一. reducer拆分 1.1. reducer代码拆分 我们来看一下目前我们的reducer: function reducer(state ini…...
3D 纹理的综合指南
在线工具推荐:3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 我们经常看到超现实主义的视频游戏和动画电影角色出现在屏幕上。他们皮肤上的…...
LLM之RAG实战(十一)| 使用Mistral-7B和Langchain搭建基于PDF文件的聊天机器人
在本文中,使用LangChain、HuggingFaceEmbeddings和HuggingFace的Mistral-7B LLM创建一个简单的Python程序,可以从任何pdf文件中回答问题。 一、LangChain简介 LangChain是一个在语言模型之上开发上下文感知应用程序的框架。LangChain使用带prompt和few-…...

VLOOKUP的使用方法
VLOOKUP是Excel中一个非常有用的函数,用于在一个表格或范围中查找某个值,并返回该值所在行或列的相应数据。 VLOOKUP函数的基本语法如下: VLOOKUP(lookup_value, table_array, col_index_num, [range_lookup])lookup_value:要查…...

数据加密、端口管控、行为审计、终端安全、整体方案解决提供商
PC端访问地址: https://isite.baidu.com/site/wjz012xr/2eae091d-1b97-4276-90bc-6757c5dfedee 以下是关于这几个概念的解释: 数据加密:这是一种通过加密算法和密钥将明文转换为密文,以及通过解密算法和解密密钥将密文恢复为明文…...

树莓派5 MIPI摄像头配置与实战:从CSI/DSI接口到图像采集
1. 树莓派5的MIPI摄像头接口解析 树莓派5最大的硬件改进之一就是将CSI和DSI接口合并为两个通用的CSI/DSI(MIPI)端口。这种设计让接口使用更加灵活,你可以根据需要自由选择连接摄像头或显示屏。这两个接口都采用15针FPC排线连接器,…...

如何用BetterGenshinImpact解决原神日常任务负担?实测效率提升300%的智能辅助方案
如何用BetterGenshinImpact解决原神日常任务负担?实测效率提升300%的智能辅助方案 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄…...

YOLOv8与Lingbot-Depth-Pretrain-ViTL-14协同的机器人视觉系统
YOLOv8与Lingbot-Depth-Pretrain-ViTL-14协同的机器人视觉系统 想象一下,一个机器人在仓库里自如穿梭,不仅能一眼认出货架上的螺丝刀和扳手,还能精准判断出哪个离自己最近、哪个最容易抓取。这背后需要的,不仅仅是“看见”物体&a…...

LangGraph应用:设计MusicGen的自动化工作流
LangGraph应用:设计MusicGen的自动化工作流 1. 引言 想象一下这样的场景:你有一个绝佳的音乐创意,想要创作一首完整的歌曲,但面对复杂的音乐制作流程却无从下手。传统的音乐制作需要经历作词、编曲、混音、母带处理等多个环节&a…...

Navicat Premium 16快捷键全攻略:从SQL注释到窗口切换,提升效率的10个必备技巧
Navicat Premium 16快捷键全攻略:从SQL注释到窗口切换,提升效率的10个必备技巧 在数据库管理的日常工作中,效率往往取决于细节。Navicat Premium 16作为一款功能强大的数据库管理工具,其快捷键系统就像隐藏在界面之下的效率引擎。…...

新手必看!Qwen3-4B-Instruct-2507从部署到对话:vLLM+Chainlit全步骤解析
新手必看!Qwen3-4B-Instruct-2507从部署到对话:vLLMChainlit全步骤解析 1. 模型介绍与准备工作 1.1 Qwen3-4B-Instruct-2507核心优势 Qwen3-4B-Instruct-2507是阿里巴巴推出的轻量级大语言模型,专为指令跟随任务优化。相比前代版本&#x…...

Phi-4-mini-reasoning助力C语言项目:代码逻辑分析与缺陷检测
Phi-4-mini-reasoning助力C语言项目:代码逻辑分析与缺陷检测 1. 为什么C语言开发者需要AI辅助 在嵌入式系统、操作系统内核等对性能要求极高的领域,C语言依然是无可替代的选择。但随之而来的是复杂的内存管理、指针操作和并发控制带来的挑战。一个看似…...

丹青识画完整体验:铺卷、参详、点睛、获墨,四步感受AI艺术
丹青识画完整体验:铺卷、参详、点睛、获墨,四步感受AI艺术 1. 艺术与科技的完美邂逅 当人工智能遇上东方美学,会碰撞出怎样的火花?「丹青识画」智能影像雅鉴系统给出了令人惊艳的答案。这款融合深度学习技术与传统书画艺术的产品…...

【2026知网预警】不想论文被直接退稿?10款降AI工具实测红黑榜,带你避开90%的坑
说真的,现在写论文难,改论文更难。交稿前一查,心都凉半截。AI痕迹动不动就飘红,导师那边没法交代,系统检测也过不了关。为了找出靠谱的降AI法子,我也是折腾了好几天。 我把以下10个降AI工具一个个试过来了…...

骨干网为什么偏爱IS-IS?从报文结构到PRC算法详解运营商级路由协议设计
骨干网为何青睐IS-IS?从协议设计到现网实践的深度解析 在互联网基础设施的底层,运营商骨干网如同数字时代的高速公路系统,承载着全球90%以上的跨域流量。而这条"信息高速公路"的交通指挥系统,则高度依赖IS-IS࿰…...