MongoDB索引详解
概述
索引是一种用来快速查询数据的数据结构。B+Tree 就是一种常用的数据库索引数据结构,MongoDB 采用 B+Tree 做索引,索引创建 colletions 上。MongoDB 不使用索引的查询,先扫描所有的文档,再匹配符合条件的文档。使用索引的查询,通过索引找到文档,使用索引能够极大的提升查询效率。
MongoDB 用的数据结构是 B-Tree,具体来说是 B+Tree,因为 B+Tree 是 B-Tree 的子集。
索引数据结构
B-Tree 说法来源于官方文档,然后就导致了分歧:有人说 MongoDB 索引数据结构使用的是 B-Tree,有的人又说是 B+Tree。
MongoDB 官方文档:https://docs.mongodb.com/manual/indexes/

WiredTiger官方文档:https://source.wiredtiger.com/3.0.0/tune_page_size_and_comp.html
WiredTiger maintains a table’s data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
WiredTiger 数据文件在磁盘的存储结构: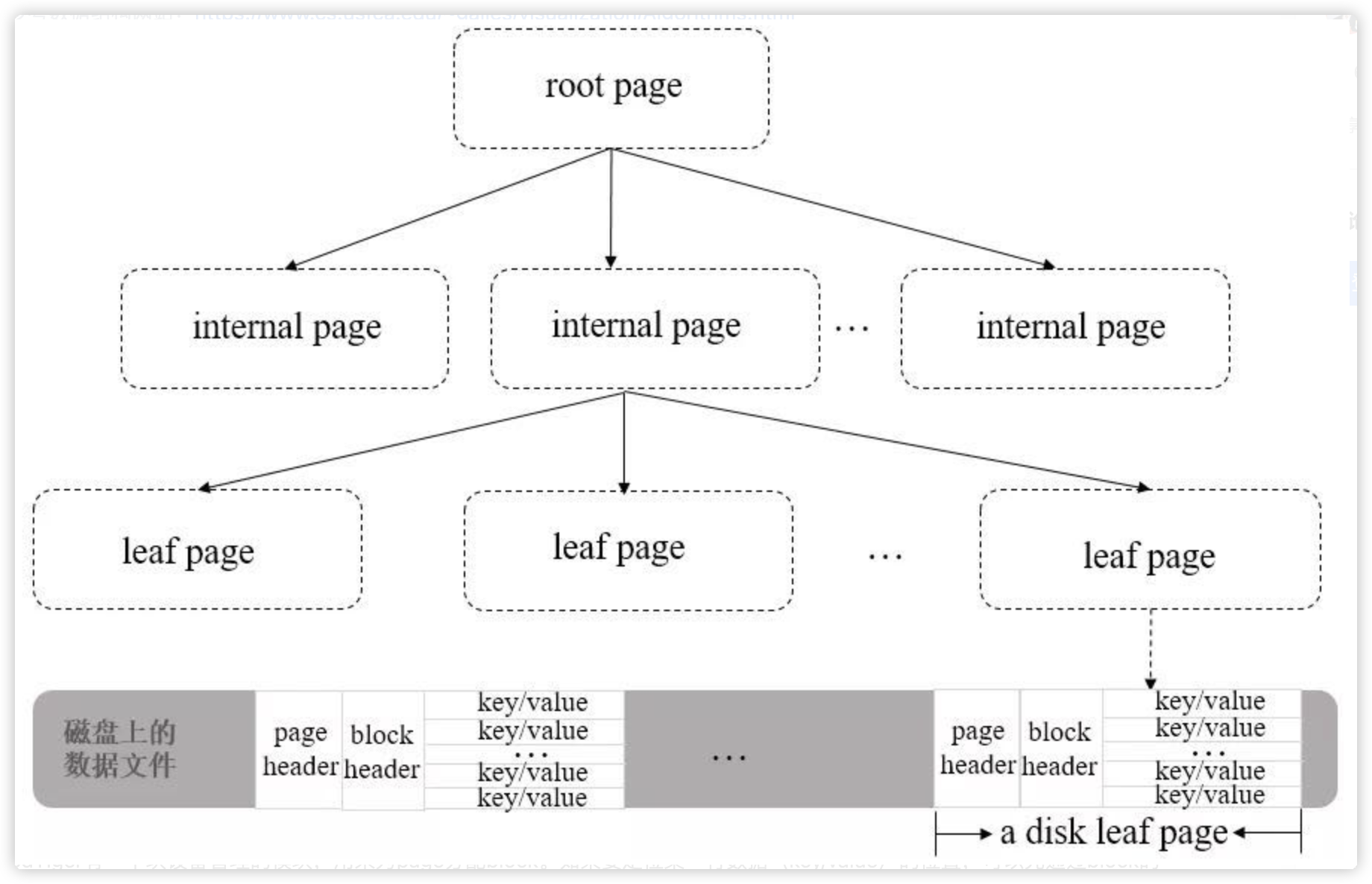
B+Tree 中的 leaf page 包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
WiredTiger 有一个块设备管理的模块,用来为 page 分配 block。如果要定位某一行数据(key/value)的位置,可以先通过 block 的位置找到此 page(相对于文件起始位置的偏移量),再通过 page 找到行数据的相对位置,最后可以得到行数据相对于文件起始位置的偏移量 offsets。
索引操作
创建索引
创建索引语法格式:
db.collection.createIndex(keys, options)
Key 值为你要创建的索引字段,1 按升序创建索引, -1 按降序创建索引。
Key 可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background 可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为 false。 |
| unique | Boolean | 建立的索引是否唯一。指定为 true 创建唯一索引。默认值为 false。 |
| name | string | 索引的名称。如果未指定,MongoDB 的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+ 版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引。这个参数需要特别注意,如果设置为 true 的话,在索引字段中不会查询出不包含对应字段的文档。默认值为 false。 |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL 设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于 mongodb 创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语。 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的 language,默认值为 language。 |
注意:3.0.0 版本前创建索引方法为 db.collection.ensureIndex()。
# 创建索引后台执行
db.values.createIndex({open: 1, close: 1}, {background: true})
# 创建唯一索引
db.values.createIndex({title:1},{unique:true})
查看索引
# 查看索引信息
db.books.getIndexes()
# 查看索引键
db.books.getIndexKeys()
删除索引
# 删除集合指定索引
db.col.dropIndex("索引名称")
# 删除集合所有索引,不能删除主键索引
db.col.dropIndexes()
索引类型
与大多数数据库一样,MongoDB 支持各种丰富的索引类型,包括单键索引、复合索引,唯一索引等一些常用的结构。由于采用了灵活可变的文档类型,因此它也同样支持对嵌套字段、数组进行索引。通过建立合适的索引,我们可以极大地提升数据的检索速度。在一些特殊应用场景,MongoDB 还支持地理空间索引、文本检索索引、TTL 索引等不同的特性。
单键索引(Single Field Indexes)
在某一个特定的字段上建立索引。MongoDB 在 ID 上建立了唯一的单键索引,所以经常会使用 id 来进行查询。在索引字段上进行精确匹配、排序以及范围查找都会使用此索引。
db.books.createIndex({title:1})
# 对内嵌文档字段创建索引
db.books.createIndex({"author.name":1})
复合索引(Compound Index)
复合索引是多个字段组合而成的索引,其性质和单字段索引类似。但不同的是,复合索引中字段的顺序、字段的升降序对查询性能有直接的影响,因此在设计复合索引时则需要考虑不同的查询场景。
db.books.createIndex({type:1,favCount:1})
# 查看执行计划
db.books.find({type:"novel",favCount:{$gt:50}}).explain()
多键(数组)索引(Multikey Index)
在数组的属性上建立索引。针对这个数组的任意值的查询都会定位到这个文档,既多个索引入口或者键值引用同一个文档。
准备 inventory 集合:
db.inventory.insertMany([
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] },
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] },
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] },
{ _id: 8, type: "food", item: "ddd", ratings: [ 9, 5 ] },
{ _id: 9, type: "food", item: "eee", ratings: [ 5, 9, 5 ] }
])
创建多键索引:
db.inventory.createIndex( { ratings: 1 } )
多键索引很容易与复合索引产生混淆,复合索引是多个字段的组合,而多键索引则仅仅是在一个字段上出现了多键(multi key)。而实质上,多键索引也可以出现在复合字段上。
# 创建复合多值索引
db.inventory.createIndex( { item:1,ratings: 1 } )
注意:MongoDB 并不支持一个复合索引中同时出现多个数组字段。
嵌入文档的索引数组:
db.inventory.insertMany([
{_id: 1,item: "abc",stock: [{ size: "S", color: "red", quantity: 25 },{ size: "S", color: "blue", quantity: 10 },{ size: "M", color: "blue", quantity: 50 }]
},
{_id: 2,item: "def",stock: [{ size: "S", color: "blue", quantity: 20 },{ size: "M", color: "blue", quantity: 5 },{ size: "M", color: "black", quantity: 10 },{ size: "L", color: "red", quantity: 2 }]
},
{_id: 3,item: "ijk",stock: [{ size: "M", color: "blue", quantity: 15 },{ size: "L", color: "blue", quantity: 100 },{ size: "L", color: "red", quantity: 25 }]
}
])
在包含嵌套对象的数组字段上创建多键索引:
db.inventory.createIndex( { "stock.size": 1, "stock.quantity": 1 } )db.inventory.find({"stock.size":"S","stock.quantity":{$gt:20}}).explain()
Hash 索引(Hashed Indexes)
不同于传统的 B-Tree 索引,哈希索引使用 hash 函数来创建索引。在索引字段上进行精确匹配,但不支持范围查询,不支持多键 hash。Hash 索引上的入口是均匀分布的,在分片集合中非常有用。
db.users.createIndex({username : 'hashed'})
地理空间索引(Geospatial Index)
在移动互联网时代,基于地理位置的检索(LBS)功能几乎是所有应用系统的标配。MongoDB 为地理空间检索提供了非常方便的功能。地理空间索引(2dsphereindex)就是专门用于实现位置检索的一种特殊索引。
案例:MongoDB 如何实现“查询附近商家"?
假设商家的数据模型如下:
db.restaurant.insert({restaurantId: 0,restaurantName:"兰州牛肉面",location : {type: "Point",coordinates: [ -73.97, 40.77 ]}
})
创建一个 2dsphere 索引:
db.restaurant.createIndex({location : "2dsphere"})
查询附近 10000 米商家信息:
db.restaurant.find( { location:{ $near :{$geometry :{ type : "Point" ,coordinates : [ -73.88, 40.78 ] } ,$maxDistance:10000 } }
} )
$near 查询操作符,用于实现附近商家的检索,返回数据结果会按距离排序。
$geometry 操作符用于指定一个 GeoJSON 格式的地理空间对象,type=Point 表示地理坐标点,coordinates 则是用户当前所在的经纬度位置。
$maxDistance 限定了最大距离,单位是米。
全文索引(Text Indexes)
MongoDB 支持全文检索功能,可通过建立文本索引来实现简易的分词检索。
db.reviews.createIndex( { comments: "text" } )
t e x t 操作符可以在有 t e x t i n d e x 的集合上执行文本检索。 text 操作符可以在有 text index 的集合上执行文本检索。 text操作符可以在有textindex的集合上执行文本检索。text 将会使用空格和标点符号作为分隔符对检索字符串进行分词,并且对检索字符串中所有的分词结果进行一个逻辑上的 OR 操作。
全文索引能解决快速文本查找的需求,比如有一个博客文章集合,需要根据博客的内容来快速查找,则可以针对博客内容建立文本索引。
案例
数据准备:
db.stores.insert([{ _id: 1, name: "Java Hut", description: "Coffee and cakes" },{ _id: 2, name: "Burger Buns", description: "Gourmet hamburgers" },{ _id: 3, name: "Coffee Shop", description: "Just coffee" },{ _id: 4, name: "Clothes Clothes Clothes", description: "Discount clothing" },{ _id: 5, name: "Java Shopping", description: "Indonesian goods" }]
)
创建 name 和 description 的全文索引:
db.stores.createIndex({name: "text", description: "text"})
测试:
通过 $text 操作符来查寻数据中所有包含“coffee”、“shop”、“java”列表中任何词语的商店:
db.stores.find({$text: {$search: "java coffee shop"}})
MongoDB 的文本索引功能存在诸多限制,而官方并未提供中文分词的功能,这使得该功能的应用场景十分受限。
通配符索引(Wildcard Indexes)
MongoDB 的文档模式是动态变化的,而通配符索引可以建立在一些不可预知的字段上,以此实现查询的加速。MongoDB 4.2 引入了通配符索引来支持对未知或任意字段的查询。
案例
准备商品数据,不同商品属性不一样:
db.products.insert([{"product_name" : "Spy Coat","product_attributes" : {"material" : [ "Tweed", "Wool", "Leather" ],"size" : {"length" : 72,"units" : "inches"}}},{"product_name" : "Spy Pen","product_attributes" : {"colors" : [ "Blue", "Black" ],"secret_feature" : {"name" : "laser","power" : "1000","units" : "watts",}}},{"product_name" : "Spy Book"}
])
创建通配符索引:
db.products.createIndex( { "product_attributes.$**" : 1 } )
测试:
通配符索引可以支持任意单字段查询 product_attributes 或其嵌入字段。
db.products.find( { "product_attributes.size.length" : { $gt : 60 } } )
db.products.find( { "product_attributes.material" : "Leather" } )
db.products.find( { "product_attributes.secret_feature.name" : "laser" } )
注意事项
- 通配符索引不兼容的索引类型或属性

- 通配符索引是稀疏的,不索引空字段。因此,通配符索引不能支持查询字段不存在的文档。
# 通配符索引不能支持以下查询
db.products.find( {"product_attributes" : { $exists : false } } )
db.products.aggregate([{ $match : { "product_attributes" : { $exists : false } } }
])
- 通配符索引为文档或数组的内容生成条目,而不是文档/数组本身。因此通配符索引不能支持精确的文档/数组相等匹配。通配符索引可以支持查询字段等于空文档{}的情况。
# 通配符索引不能支持以下查询:
db.products.find({ "product_attributes.colors" : [ "Blue", "Black" ] } )db.products.aggregate([{$match : { "product_attributes.colors" : [ "Blue", "Black" ] }
}])
索引属性
唯一索引(Unique Indexes)
在现实场景中,唯一性是很常见的一种索引约束需求,重复的数据记录会带来许多处理上的麻烦,比如订单的编号、用户的登录名等。通过建立唯一性索引,可以保证集合中文档的指定字段拥有唯一值。
# 创建唯一索引
db.values.createIndex({title:1},{unique:true})
# 复合索引支持唯一性约束
db.values.createIndex({title:1,type:1},{unique:true})
# 多键索引支持唯一性约束
db.inventory.createIndex( { ratings: 1 },{unique:true} )
- 唯一性索引对于文档中缺失的字段,会使用 null 值代替,因此不允许存在多个文档缺失索引字段的情况。
- 对于分片的集合,唯一性约束必须匹配分片规则。换句话说,为了保证全局的唯一性,分片键必须作为唯一性索引的前缀字段。
部分索引(Partial Indexes)
部分索引仅对满足指定过滤器表达式的文档进行索引。通过在一个集合中为文档的一个子集建立索引,部分索引具有更低的存储需求和更低的索引创建和维护的性能成本。3.2 新版功能。
部分索引提供了稀疏索引功能的超集,应该优先于稀疏索引。
db.restaurants.createIndex({ cuisine: 1, name: 1 },{ partialFilterExpression: { rating: { $gt: 5 } } }
)
partialFilterExpression 选项接受指定过滤条件的文档:
等式表达式(例如:field: value 或使用 $eq 操作符)
$exists: true
$gt, $gte, $lt, $lte
$type
顶层的 $and
# 符合条件,使用索引
db.restaurants.find( { cuisine: "Italian", rating: { $gte: 8 } } )
# 不符合条件,不能使用索引
db.restaurants.find( { cuisine: "Italian" } )
唯一约束结合部分索引使用导致唯一约束失效的问题:
如果同时指定了 partialFilterExpression 和唯一约束,那么唯一约束只适用于满足筛选器表达式的文档。如果文档不满足筛选条件,那么带有惟一约束的部分索引不会阻止插入不满足惟一约束的文档。
稀疏索引(Sparse Indexes)
索引的稀疏属性确保索引只包含具有索引字段的文档的条目,索引将跳过没有索引字段的文档。
特性:只对存在字段的文档进行索引(包括字段值为 null 的文档)。
# 不索引不包含xmpp_id字段的文档
db.addresses.createIndex( { "xmpp_id": 1 }, { sparse: true } )
如果稀疏索引会导致查询和排序操作的结果集不完整,MongoDB 将不会使用该索引,除非 hint() 明确指定索引。
案例
数据准备:
db.scores.insertMany([{"userid" : "newbie"},{"userid" : "abby", "score" : 82},{"userid" : "nina", "score" : 90}
])
创建稀疏索引:
db.scores.createIndex( { score: 1 } , { sparse: true } )
测试:
# 使用稀疏索引
db.scores.find( { score: { $lt: 90 } } )# 即使排序是通过索引字段,MongoDB也不会选择稀疏索引来完成查询,以返回完整的结果
db.scores.find().sort( { score: -1 } )# 要使用稀疏索引,使用hint()显式指定索引
db.scores.find().sort( { score: -1 } ).hint( { score: 1 } )
同时具有稀疏性和唯一性的索引可以防止集合中存在字段值重复的文档,但允许不包含此索引字段的文档插入。
TTL索引(TTL Indexes)
在一般的应用系统中,并非所有的数据都需要永久存储。例如一些系统事件、用户消息等,这些数据随着时间的推移,其重要程度逐渐降低。更重要的是,存储这些大量的历史数据需要花费较高的成本,因此项目中通常会对过期且不再使用的数据进行老化处理。
通常的做法如下:
方案一:为每个数据记录一个时间戳,应用侧开启一个定时器,按时间戳定期删除过期的数据。
方案二:数据按日期进行分表,同一天的数据归档到同一张表,同样使用定时器删除过期的表。
对于数据老化,MongoDB 提供了一种更加便捷的做法:TTL(Time To Live)索引。TTL 索引需要声明在一个日期类型的字段中,TTL 索引是特殊的单字段索引,MongoDB 可以使用它在一定时间或特定时钟时间后自动从集合中删除文档。
# 创建 TTL 索引,TTL 值为3600秒
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
对集合创建 TTL 索引之后,MongoDB 会在周期性运行的后台线程中对该集合进行检查及数据清理工作。除了数据老化功能,TTL 索引具有普通索引的功能,同样可以用于加速数据的查询。
TTL 索引不保证过期数据会在过期后立即被删除。文档过期和 MongoDB 从数据库中删除文档的时间之间可能存在延迟。删除过期文档的后台任务每 60 秒运行一次。因此,在文档到期和后台任务运行之间的时间段内,文档可能会保留在集合中。
案例
数据准备:
db.log_events.insertOne( {"createdAt": new Date(),"logEvent": 2,"logMessage": "Success!"
} )
创建 TTL 索引:
db.log_events.createIndex( { "createdAt": 1 }, { expireAfterSeconds: 20 } )
可变的过期时间
TTL 索引在创建之后,仍然可以对过期时间进行修改。这需要使用 collMod 命令对索引的定义进行变更:
db.runCommand({collMod:"log_events",index:{keyPattern:{createdAt:1},expireAfterSeconds:600}})
使用约束
TTL 索引的确可以减少开发的工作量,而且通过数据库自动清理的方式会更加高效、可靠,但是在使用 TTL 索引时需要注意以下的限制:
- TTL 索引只能支持单个字段,并且必须是非 _id 字段。
- TTL 索引不能用于固定集合。
- TTL 索引无法保证及时的数据老化,MongoDB 会通过后台的 TTLMonitor 定时器来清理老化数据,默认的间隔时间是 1 分钟。当然如果在数据库负载过高的情况下,TTL 的行为则会进一步受到影响。
- TTL 索引对于数据的清理仅仅使用了 remove 命令,这种方式并不是很高效。因此 TTL Monitor 在运行期间对系统 CPU、磁盘都会造成一定的压力。相比之下,按日期分表的方式操作会更加高效。
隐藏索引(Hidden Indexes)
隐藏索引对查询规划器不可见,不能用于支持查询。通过对规划器隐藏索引,用户可以在不实际删除索引的情况下评估删除索引的潜在影响。如果影响是负面的,用户可以取消隐藏索引,而不必重新创建已删除的索引。4.4 新版功能。
# 创建隐藏索引
db.restaurants.createIndex({ borough: 1 },{ hidden: true });
# 隐藏现有索引
db.restaurants.hideIndex( { borough: 1} );
db.restaurants.hideIndex( "索引名称" )
# 取消隐藏索引
db.restaurants.unhideIndex( { borough: 1} );
db.restaurants.unhideIndex( "索引名称" );
案例
数据准备:
db.scores.insertMany([{"userid" : "newbie"},{"userid" : "abby", "score" : 82},{"userid" : "nina", "score" : 90}
])
创建隐藏索引:
db.scores.createIndex({ userid: 1 },{ hidden: true }
)
查看索引信息:
db.scores.getIndexes()
索引属性 hidden 只在值为 true 时返回。
测试:
# 不使用索引
db.scores.find({userid:"abby"}).explain()
# 取消隐藏索引
db.scores.unhideIndex( { userid: 1} )
# 使用索引
db.scores.find({userid:"abby"}).explain()
索引使用建议
1)为每一个查询建立合适的索引
这个是针对于数据量较大比如说超过几十上百万(文档数目)数量级的集合。如果没有索引 MongoDB 需要把所有的 Document 从盘上读到内存,这会对 MongoDB 服务器造成较大的压力并影响到其他请求的执行。
2)创建合适的复合索引,不要依赖于交叉索引
如果你的查询会使用到多个字段,MongoDB 有两个索引技术可以使用:交叉索引和复合索引。交叉索引就是针对每个字段单独建立一个单字段索引,然后在查询执行时候使用相应的单字段索引进行索引交叉而得到查询结果。交叉索引目前触发率较低,所以如果你有一个多字段查询的时候,建议使用复合索引能够保证索引正常的使用。
# 查找所有年龄小于30岁的深圳市马拉松运动员
db.athelets.find({sport: "marathon", location: "sz", age: {$lt: 30}}})
# 创建复合索引
db.athelets.createIndex({sport:1, location:1, age:1})
3)复合索引字段顺序:匹配条件在前,范围条件在后(Equality First, Range After)
前面的例子,在创建复合索引时如果条件有匹配和范围之分,那么匹配条件(sport: “marathon”) 应该在复合索引的前面。范围条件(age: <30)字段应该放在复合索引的后面。
4)尽可能使用覆盖索引(Covered Index)
建议只返回需要的字段,同时,利用覆盖索引来提升性能。
5)建索引要在后台运行
在对一个集合创建索引时,该集合所在的数据库将不接受其他读写操作。对大数据量的集合建索引,建议使用后台运行选项 {background: true}。
6)避免设计过长的数组索引
数组索引是多值的,在存储时需要使用更多的空间。如果索引的数组长度特别长,或者数组的增长不受控制,则可能导致索引空间急剧膨胀。
explain 执行计划
通常我们需要关心的问题:
- 查询是否使用了索引
- 索引是否减少了扫描的记录数量
- 是否存在低效的内存排序
MongoDB 提供了 explain 命令,它可以帮助我们评估指定查询模型(querymodel)的执行计划,根据实际情况进行调整,然后提高查询效率。
explain() 方法的形式如下:
db.collection.find().explain(<verbose>)
verbose:可选参数,表示执行计划的输出模式,默认 queryPlanner
verbose 枚举如下:
| **模式名字 ** | 描述 |
|---|---|
| queryPlanner | 执行计划的详细信息,包括查询计划、集合信息、查询条件、最佳执行计划、查询方式和 MongoDB 服务信息等。 |
| exectionStats | 最佳执行计划的执行情况和被拒绝的计划等信息。 |
| allPlansExecution | 选择并执行最佳执行计划,并返回最佳执行计划和其他执行计划的执行情况。 |
queryPlanner
# 未创建title的索引
db.books.find({title:"book-1"}).explain("queryPlanner")
结果: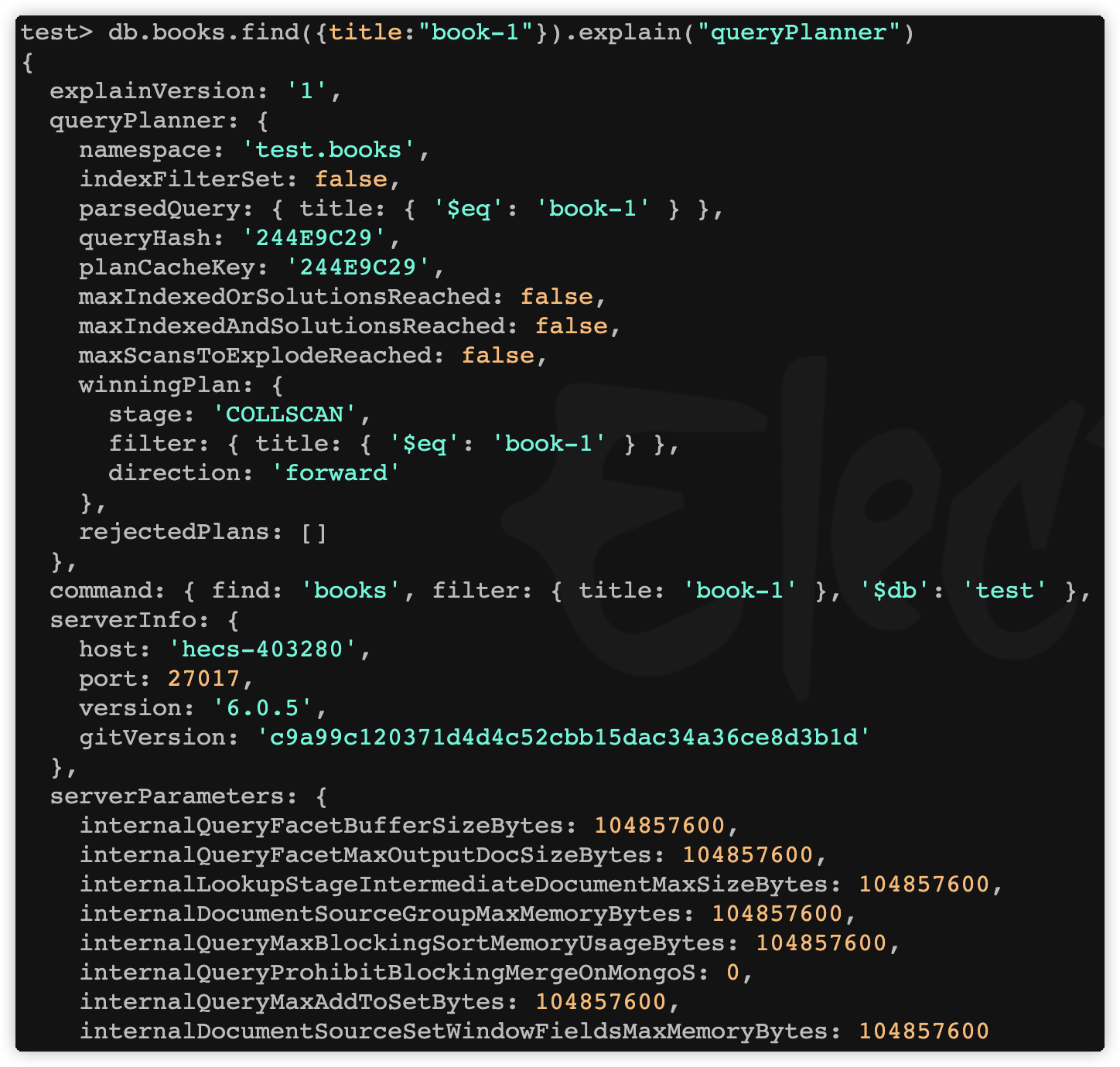
字段说明:
| **字段名称 ** | 描述 |
|---|---|
| plannerVersion | 执行计划的版本 |
| namespace | 查询的集合 |
| indexFilterSet | 是否使用索引 |
| parsedQuery | 查询条件 |
| winningPlan | 最佳执行计划 |
| stage | 查询方式 |
| filter | 过滤条件 |
| direction | 查询顺序 |
| rejectedPlans | 拒绝的执行计划 |
| serverInfo | mongodb 服务器信息 |
executionStats
executionStats 模式的返回信息中包含了 queryPlanner 模式的所有字段,并且还包含了最佳执行计划的执行情况
# 创建索引
db.books.createIndex({title:1})db.books.find({title:"book-1"}).explain("executionStats")
结果: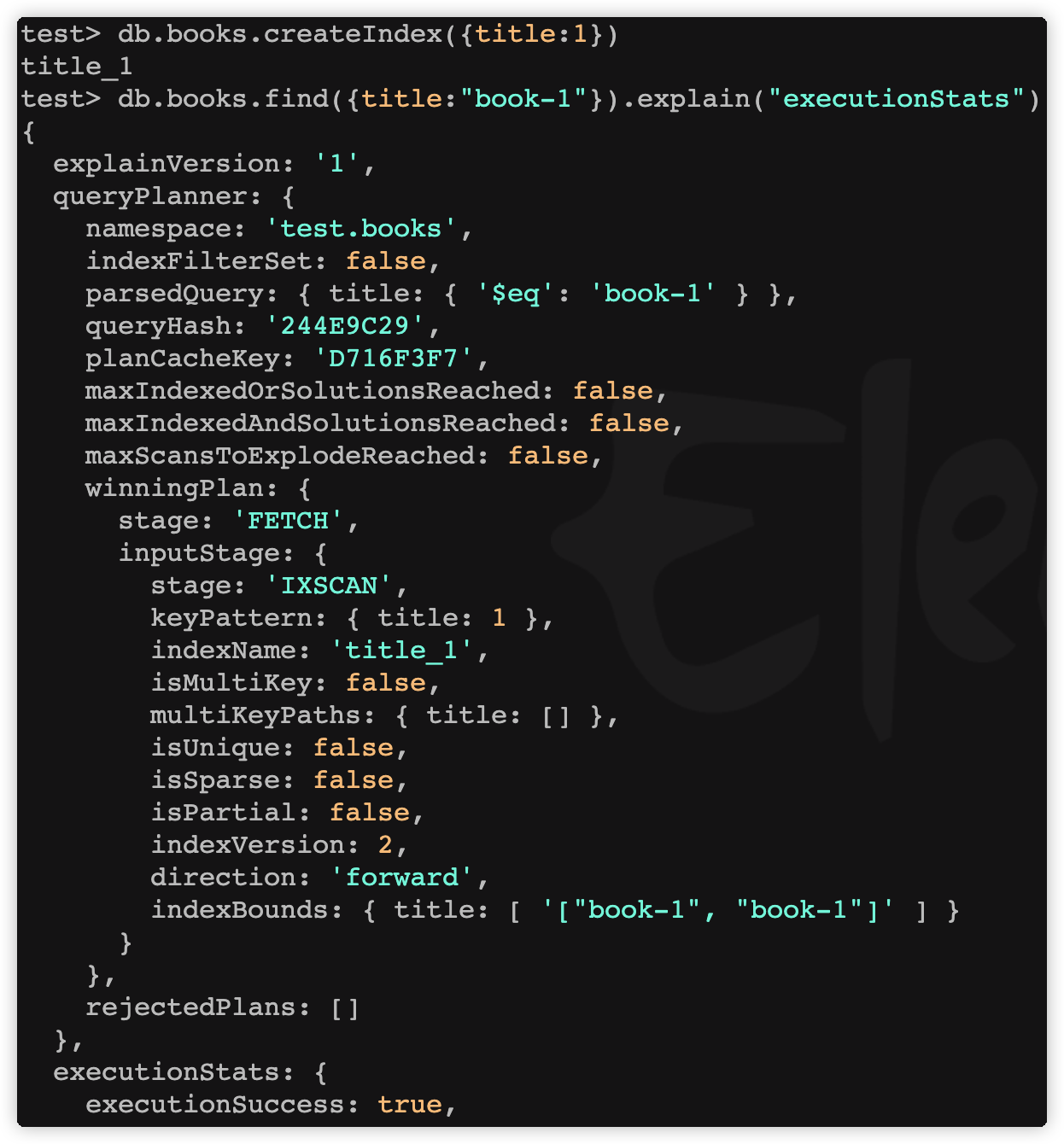
字段说明:
| **字段名称 ** | 描述 |
|---|---|
| winningPlan.inputStage | 用来描述子 stage,并且为其父 stage 提供文档和索引关键字 |
| winningPlan.inputStage.stage | 子查询方式 |
| winningPlan.inputStage.keyPattern | 所扫描的 index 内容 |
| winningPlan.inputStage.indexName | 索引名 |
| winningPlan.inputStage.isMultiKey | 是否是 Multikey。如果索引建立在 array 上,将是 true |
| executionStats.executionSuccess | 是否执行成功 |
| executionStats.nReturned | 返回的个数 |
| executionStats.executionTimeMillis | 这条语句执行时间 |
| executionStats.executionStages.executionTimeMillisEstimate | 检索文档获取数据的时间 |
| executionStats.executionStages.inputStage.executionTimeMillisEstimate | 扫描获取数据的时间 |
| executionStats.totalKeysExamined | 索引扫描次数 |
| executionStats.totalDocsExamined | 文档扫描次数 |
| executionStats.executionStages.isEOF | 是否到达 steam 结尾,1 或者 true 代表已到达结尾 |
| executionStats.executionStages.works | 工作单元数,一个查询会分解成小的工作单元 |
| executionStats.executionStages.advanced | 优先返回的结果数 |
| executionStats.executionStages.docsExamined | 文档检查数 |
allPlansExecution
allPlansExecution 返回的信息包含 executionStats 模式的内容,且包含 allPlansExecution:[] 块
"allPlansExecution" : [{"nReturned" : <int>,"executionTimeMillisEstimate" : <int>,"totalKeysExamined" : <int>,"totalDocsExamined" :<int>,"executionStages" : {"stage" : <STAGEA>,"nReturned" : <int>,"executionTimeMillisEstimate" : <int>,...}}},...]
stage 状态
| **状态 ** | 描述 |
|---|---|
| COLLSCAN | 全表扫描 |
| IXSCAN | 索引扫描 |
| FETCH | 根据索引检索指定文档 |
| SHARD_MERGE | 将各个分片返回数据进行合并 |
| SORT | 在内存中进行了排序 |
| LIMIT | 使用 limit 限制返回数 |
| SKIP | 使用 skip 进行跳过 |
| IDHACK | 对 _id 进行查询 |
| SHARDING_FILTER | 通过 mongos 对分片数据进行查询 |
| COUNTSCAN | count 不使用 Index 进行 count 时的 stage 返回 |
| COUNT_SCAN | count 使用了 Index 进行 count 时的 stage 返回 |
| SUBPLA | 未使用到索引的 $or 查询的 stage 返回 |
| TEXT | 使用全文索引进行查询时候的 stage 返回 |
| PROJECTION | 限定返回字段时候 stage 的返回 |
执行计划的返回结果中尽量不要出现以下 stage:
- COLLSCAN(全表扫描)
- SORT(使用 sort 但是无 index)
- 不合理的 SKIP
- SUBPLA(未用到 index 的 $or)
- COUNTSCAN(不使用 index 进行 count)
相关文章:
MongoDB索引详解
概述 索引是一种用来快速查询数据的数据结构。BTree 就是一种常用的数据库索引数据结构,MongoDB 采用 BTree 做索引,索引创建 colletions 上。MongoDB 不使用索引的查询,先扫描所有的文档,再匹配符合条件的文档。使用索引的查询&…...

一文搞定JVM内存模型
鲁大猿,寻精品资料,帮你构建Java全栈知识体系 www.jiagoujishu.cn 运行时数据区 内存是非常重要的系统资源,是硬盘和 CPU 的中间仓库及桥梁,承载着操作系统和应用程序的实时运行。JVM 内存布局规定了 Java 在运行过程中内存申请、…...

月报总结|Moonbeam 12月份大事一览
一转眼已经到年底啦。本月,Moonbeam基金会发布四个最新战略重点:跨链解决方案、游戏、真实世界资产(RWA)、新兴市场。其中在新兴市场方面,紧锣密鼓地推出与巴西公司Grupo RO的战略合作。 用户教育方面,为了…...
现有网络模型的使用及修改(VGG16为例)
VGG16 修改默认路径 import os os.environ[TORCH_HOME] rD:\Pytorch\pythonProject\vgg16 # 下载位置太大了(140多G)不提供直接下载 train_set torchvision.datasets.ImageNet(root./data_image_net, splittrain, downloadTrue, transformtorchvis…...
MacOS M1/M2 Go Debug 配置
前言 换电脑,Go 环境带来一些麻烦,耽误很多时间,稍作记录。 原始电脑是 Mac 旧款,CPU x86 构型,新电脑 M2,因为旧电脑里本地文件很多,为了简化搬迁,还是用了 Mac 自带的迁移&#x…...

paddlehub 文本检测使用
PaddleHub负责模型的管理、获取和预训练模型的使用。 参考:https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_recognition/chinese_text_detection_db_server import paddlehub as hub import cv2 # from utils import cv_show import…...
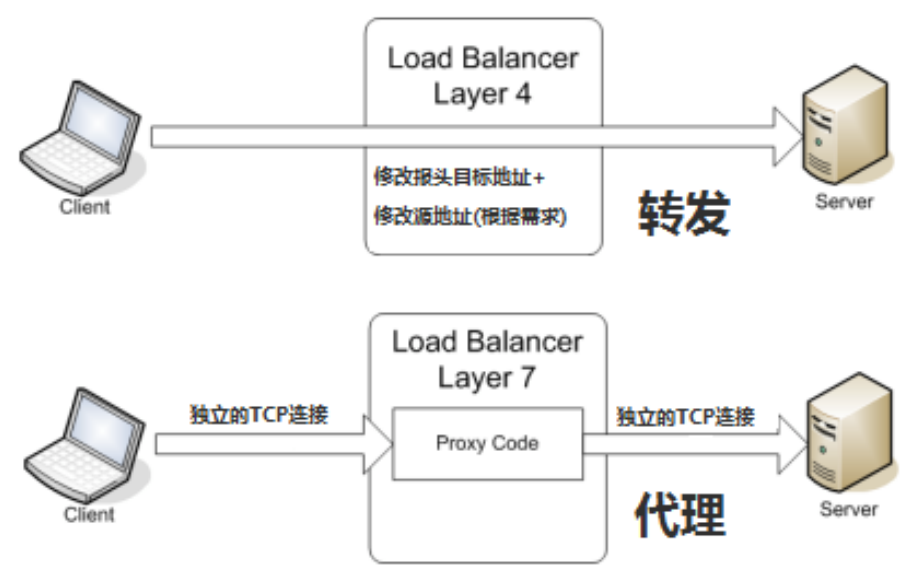
负载均衡概述
负载均衡 负载均衡 建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。 四层负载均衡 vs 七层负载均衡 四层负载均衡(目标地址和端口交换)…...
C# WinForm MessageBox自定义按键文本 COM组件版
c# 更改弹窗MessageBox按钮文字_c# messagebox.show 字体-CSDN博客 需要用到大佬上传到百度云盘的Hook类,在大佬给的例子的基础上改动了点。 应用时自己加GUID和ProgID。 组件实现: using System; using System.Collections.Generic; using System.L…...
基于SpringBoot微信小程序的宠物美容预约系统设计与实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行交流合作✌ 主要内容:SpringBoot、Vue、SSM、HLM…...
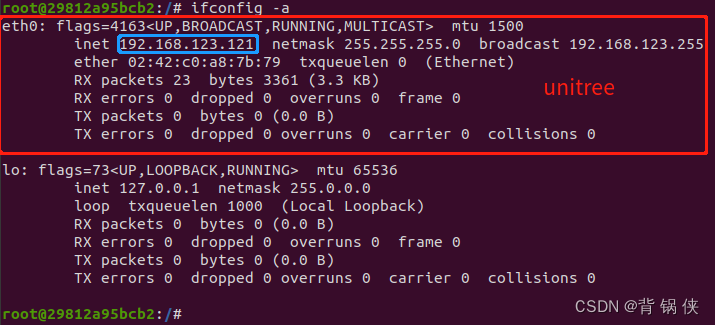
在 docker 容器中配置双网卡,解决通讯的问题
目录 1. 查看当前网络信息 2. 创建自定义网络桥 3. 创建双网卡模式 4. 删除默认网卡 已经创建好了的 Docker 容器,要修改它的IP比较麻烦,网上找了几种不同的方法,经过试验都没有成功,下面通过配置双网上来解决 IP 的问题。…...

uniapp中uview组件库CircleProgress 圆形进度条丰富的使用方法
目录 #内部实现 #平台差异说明 #基本使用 #设置圆环的动画时间 #API #Props 展示操作或任务的当前进度,比如上传文件,是一个圆形的进度环。 #内部实现 组件内部通过canvas实现,有更好的性能和通用性。 #平台差异说明 AppH5微信小程…...
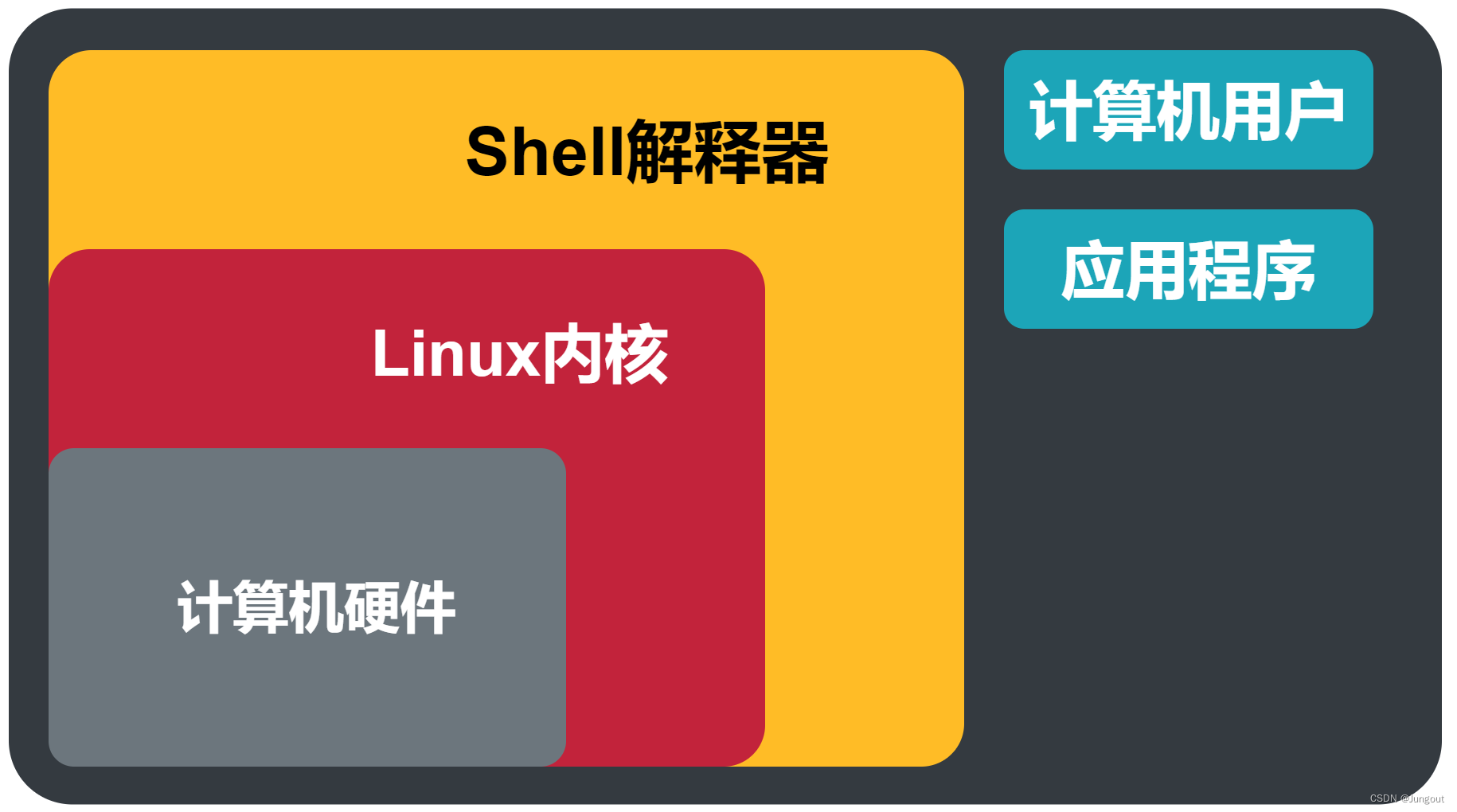
Linux操作系统基础(12):Linux的Shell解释器
1. Shell的介绍 在Linux中,Shell 是一种命令行解释器,它是用户与操作系统内核之间的接口,它负责解释用户输入的命令,并将其转换成系统调用或其他操作系统能够执行的指令。 Shell 提供了一种交互式的方式来与操作系统进行通信&am…...

Android开发编程从入门到精通,安卓技术从初级到高级全套教学
一、教程描述 本套教程基于JDK1.8版本,教学内容主要有,1、环境搭建,UI布局,基础UI组件,高级UI组件,通知,自定义组件,样式主题;2、四大组件,Intent࿰…...
HackTheBox - Medium - Linux - BroScience
BroScience BroScience 是一款中等难度的 Linux 机器,其特点是 Web 应用程序容易受到“LFI”的攻击。通过读取目标上的任意文件的能力,攻击者可以深入了解帐户激活码的生成方式,从而能够创建一组可能有效的令牌来激活新创建的帐户。登录后&a…...

`nginx/conf/nginx.conf`最简配置说明
nginx/conf/nginx.conf最简配置说明 代码 nginx/conf/nginx.conf worker_processes 1; #工作进程个数;一般对应CPU内核对应一个worker_processes;太多反而让效率变差;# 事件驱动模块; events {worker_connections 1024;#设置每个worker_processes对应多少个联接; }# 网络请…...

商务智能|描述性统计分析与数据可视化
一、商务智能的三大方面 三个主要方面是描述性的统计分析、预测性的分析和指导性的数据分析。 A. 商务智能的知识体系下,数据分析包含了哪三个工作?商务智能体系架构里边关于数据分析的术语是什么? 商务智能的知识体系下,数据分析包含了三个工作,即描述性分析,预测性分析…...

【游记】GDKOI2024
去年稳定 Cu,希望今年来块 Ag。 Day − ∞ -\infty −∞ 不知道什么时候报名交钱的,赶紧问一问。 周四把设备送过来了。最近备战期末 选科 演讲比赛,有点忙不过来。 Day0 下午两点半出发,车程 2h。路上给小绿打肉鸽 1h 掉电…...

linux支持的零拷贝类型以及java对应的支持
在之前整理的零拷贝文章基础上 https://blog.csdn.net/zlpzlpzyd/article/details/135321197 https://blog.csdn.net/zlpzlpzyd/article/details/135317834 得出如下 因为开发的程序很多运行在 linux 操作系统上,所以用 linux 进行讲解 linux 调用方式 dma复制次数…...

【TypeScript】声明文件
一、定义 TypeScript 的声明文件包含 .d.ts 扩展名,并用于为 TypeScript 提供关于 JavaScript 代码的类型信息这些文件通常定义了接口、类型别名、类等,但并不包含实际的执行代码当你使用 JavaScript 库或框架时,声明文件就显得非常有用&…...
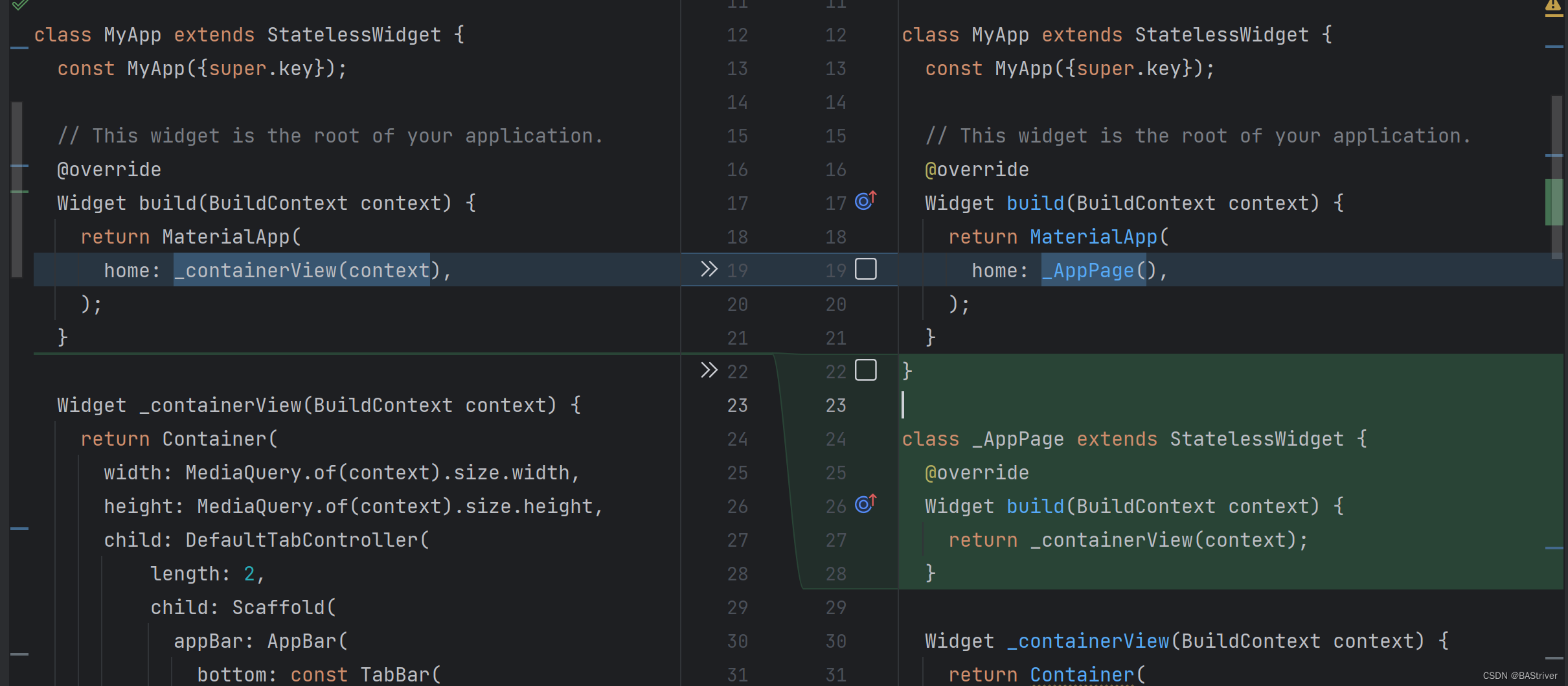
基于Flutter构建小型新闻App
目录 1. 概述 1.1 功能概述 1.2 技术准备 1.3 源码地址 2. App首页 2.1 pubspec依赖 2.2 热门首页组件 2.2.1 DefaultTabController 2.2.2 Swiper 2.3 新闻API数据访问 2.4 热门首页效果图 3. 新闻分类 3.1 GestureDetector 3.2 新闻分类效果图 4. 收藏功能 4…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...