干货文稿|详解深度半监督学习
分享嘉宾 | 范越
文稿整理 | William
嘉宾介绍

Introduction to Semi-Supervised Learning
传统机器学习中的主流学习方法分为监督学习,无监督学习和半监督学习。这里存在一个是问题是为什么需要做半监督学习?
首先是希望减少标注成本,因为目前可以在很多现实场景中去获得大量的图片,那么需要标注的量和成本会几何增加。
第二个是目前对所有大规模的数据进行标注进而训练模型是不现实的,因此可以使用一种方法使得用未标注的数据进行性能提升。
Standard Semi-Supervised Learning
Pseudo-Labeling
这是一种伪标签方法,其核心思想是希望是自动对未标注的数据进行标注,这样可以当成标注数据去训练模型。
第一篇文章是2013年的Pseudo-Labeling:The Simple and Efficient Semi-Supervised Learning Method for DNNs。其核心公式如下:
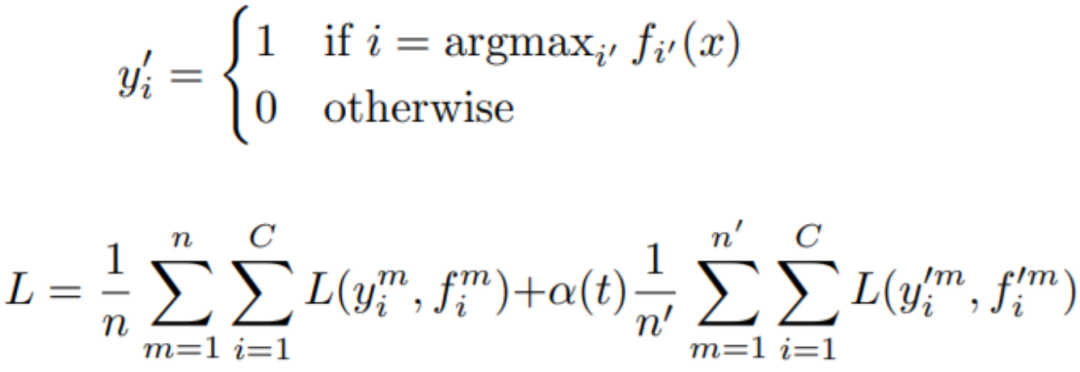
公式里的X是一个data,它所产生的label是模型预测的所有类中的最有可能的类,这里下标直接取最大值作为它对应的类。这里一个比较重要的参数是阿尔法T,可认为是一个平衡参数,且随时间发生变化。在这篇文章中,阿尔法设置是从一个比较小的值,然后再逐渐增大,最后达到饱和。这是因为模型开始刚被初始化的时候,模型预测不是很准确,需要更多的从标签中学习。
第二篇文章叫做self-training with noisy Student improves imageNet classification。这里面有一个比较常用方法的核心思路是希望模型在学完之后去标注所有的label data,之后将这些标注过所有的label data和之前的label data混在一起,再去训练一个新的模型。训练得到的新模型认为是一个新teacher,去标注那些标注过的数据,这样重新标注之后再循环这个过程,以此来提高对应的模型性能。示意图如图1所示。

图1 self-training 示意图
这里关键的一点是一定要在训练student时候加noise,这是因为Self-training的过程很容易产生累计的问题,即一张图片的标签标错,就会在训练过程中进行不断地加强错误地标签,无法纠正。所以这里使用加噪声的方式,从某种意义上可以认为student model并没有在原始的数据集上学习,而是在经过一系列变换后地数据集上学习,虽然这两个数据之前存在很强地相关性,但是实际使用地数据并不完全一样,因此可以规避这个问题。
该模型的top-1和top-5准确率上的性能表现如图2所示。比如JFT这种300M规模的没有标注数据集例子,与big transfer相比,student training的性能更佳,而且此模型参数也会小一些。另外一方面,这篇方法是完全当作是未标注数据进行处理的,而big transfer还需要一些弱标注才可以进行处理。

图2 模型性能表现
Consistency Regularization
这种方法的思路是如果存在噪声使得两次输出并不完全一致,那希望对于不同噪声版本的目标能够产生同一个目标输出,即产生不变性。
第一篇工作是2017年的temporal ensembling for semi-supervised learning.模型如图3所示。该模型比较简单,有两个分支,首先把输入X分别做augmentation再进行dropout得到特征zi和zi杠。这实际来自同一个X,所以给它加上square difference,同时希望这两者feature之间的距离要尽量小label data这里是虚线,最后总loss是cross square difference之间的权重相加。

图3 t-model模型
第二篇工作也是在2017年的weight-averaged consistency targets improve semi-supervised deep learning results。它的改变在于是把X通过同一个网络,然后得到两个不同的输出,其中一个模型叫做student model,是进行不断的训练,得到一个预测结果。另外一个是teacher model,该模型每次在算consistency loss时,会产生第二个预测。最后进行计算classification loss 得到最终的预测结果。
第三篇文章是2020年的FixMatch:simplifying semi-supervised learning with consistency and confidence,如图4所示。首先对于未标注的图片分别进行weakly-augmented和strongly-augmented,分别生成预测结果,weakly-augmented的结果是直接softmax生成的,然后和strongly-augmented当成新的图像对去训练模型,计算损失并更新最后结果。

图4 FixMatch模型
该模型是整合并简化的之前模型,因为之前图3做squaredifferent的地方其实还是在feature层面去尽可能缩小差距。但在这里是直接从weakly-augmented的位置上去得到这张图片的标签,直接当作是真实标签去计算参数。所以loss就只有两部分,首先是在X上进行最简单的求导,第二部分是计算Y上进行求导计算,最后相加得到总损失。
性能表现如图5所示,使用CIFAR-10,CIFAR-100和SVHN数据集进行实验。对于每一个类,人工的对数据进行测试,比如这里先随机拿40,再250,再4000,再400进行测试,即每次实验均需要跑五次,最后得到平均的结果。总体来讲,该模型方法并不是在所有情况下都是最好的,但是一个competitive的方法,而且该方法的simlicity比较简单。

图5 模型性能对比
第四篇文章是去年的revisiting consistency regularization for semi-supervised learning,也是从consistency regulation角度进行了一些创新。这些图片里依旧是原始图片,weak augmentation 和strong augmentation处理的图片,如果遮住原始图片和weak augmentation处理后的图片,则可能并不能判断出strong augmentation的图片到底是哪一类,所以存在一个非常大的感官差异,如图6所示。
因此,实际操作中会让模型完全的对organization产生一个不变性并不是一个好事情,希望是在特征空间里依旧映射出两个不同的点,但是这两个点需要给出同样的class label。所以最后模型是把所有的预测都缩小到同一个点或一小片区域里面,这样它的整个space coverage比较小。

图6 图像增强
具体方法如图7所示,依旧是两个分支,上分支去做特征层面的不变性。下分支去保证这两个feature得到的class level是一样的,且必须必须是同时存在。然后顺着将特征空间里的特征进行分类并计算交叉熵损失。

图7 模型结构
实验部分依旧是CIFAR-10,CIFAR-100数据集,随机抽取标签数为4,25和400进行实验,在不同的设置下,比之前的方法均有所提升,如图8所示。

图8 模型性能表现
Realistic Semi-Supervised Learning
Imbalanced Semi-Supervised Learning
首先讲的这篇文章叫做CoSSL:co-learning of representation and classifier for imbalanced semi-supervised learning。由于现实中标记的和未标记的数据都是类不平衡的,因此会造成模型性能的不稳定。同时,目前的长尾分布数据识别和SSL方法都是对真实环境下的测试性能存在影响。
所以,这篇文章里提出了新的解决框架,具体如图9所示。由于之前已证明了长尾数据集对模型造成性能的影响主要出现在classified层,所以沿着此思路去看该模型结构。模型分成了三大模块,最上面是做representation learning,最下面是做classified。所以在训练的时候,要把最上层的encoder和最下层的classified拼接在一起去做test,因为上面输入的是好的input,下面输入的是好的test。对。中间部分是pseudo-label generation,是对data去产生一些label。
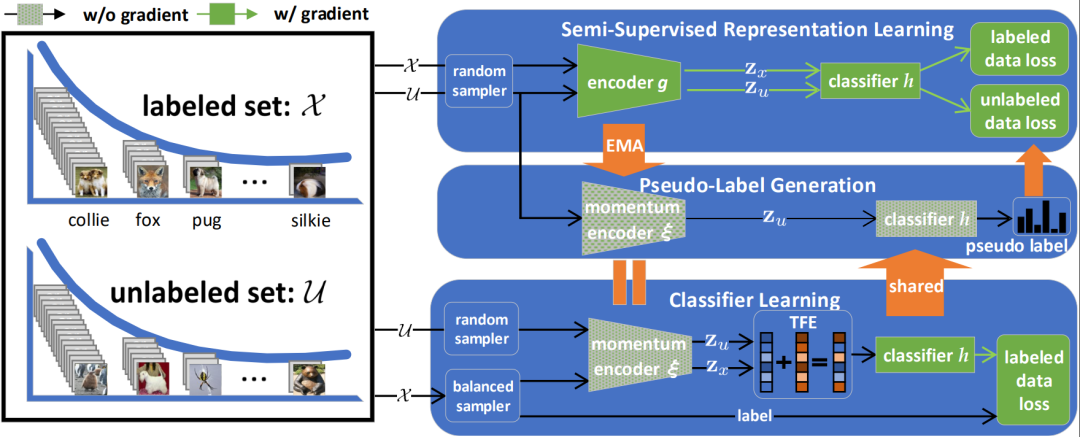
图9 模型结构
模型性能如图10所示,主要是在数据集CIFAR-100上的结果,这里的γ的值表示长尾分布的数量,γ越达则表明长尾分布问题越严重。可以看到随着γ指数增加,对比模型的性能均存在不同程度的下降,但本文模型的结果依旧能够有一个比较好的提升。
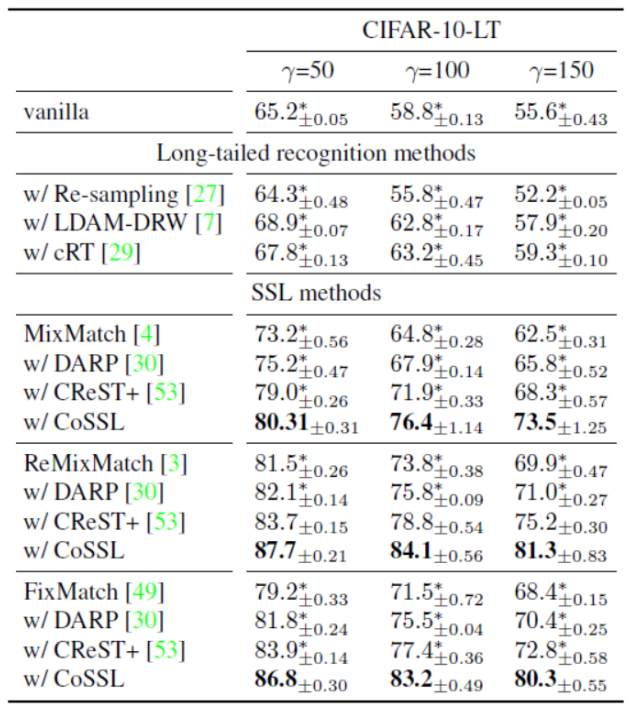
图10 模型性能对比
Open-Set Semi-Supervised Learning
在standard learning里面,如果只是关注的是bear和bird类,会确保label data以及unlabel data里面永远都只有这两个类。但往往在实际收集数据过程中,可能会不小心包含一些别的类,所以最终有了open-set learning。这样的情况下希望模型能够很好的区分这两类的情况下同时有能力去检测出哪些图片不是属于已知的两类。
这里只介绍一下2021年的OpenMatch:open-set consistency regularization for semi-supervised learning with outliers,该方法把这个问题理解为既要做检测也要做分类,所以直接将模型分为两个分支。一分支直接做分类,另外一分支做检测,如果是K分类,则判定是不是属于此类中一个。
具体在测试的时候,当输入一张新的图片,首先要给这一部分去预测一下它是哪一个类,如果是第三类,则找到对应的online,查看是否属于第三类,否则添加为新的类别。
具体在训练过程中的loss比较好理解,如果定义为二分类,从数据体上构建出one-vs-all (OVA)概率。如果是属于这一类,则提升输出权重,如果不是此类,则降低输出权重,得到一个损失。第二个损失是minilization,即对于label data的输出要尽量的是一个低状态。
性能比较如图11所示,由于此类任务是考虑检测和分类两个部分,还能够得到比之前方法更优越的结果。在这些方法上,如果class match逐渐增大,性能值会逐渐下降,是因为低于level的data。
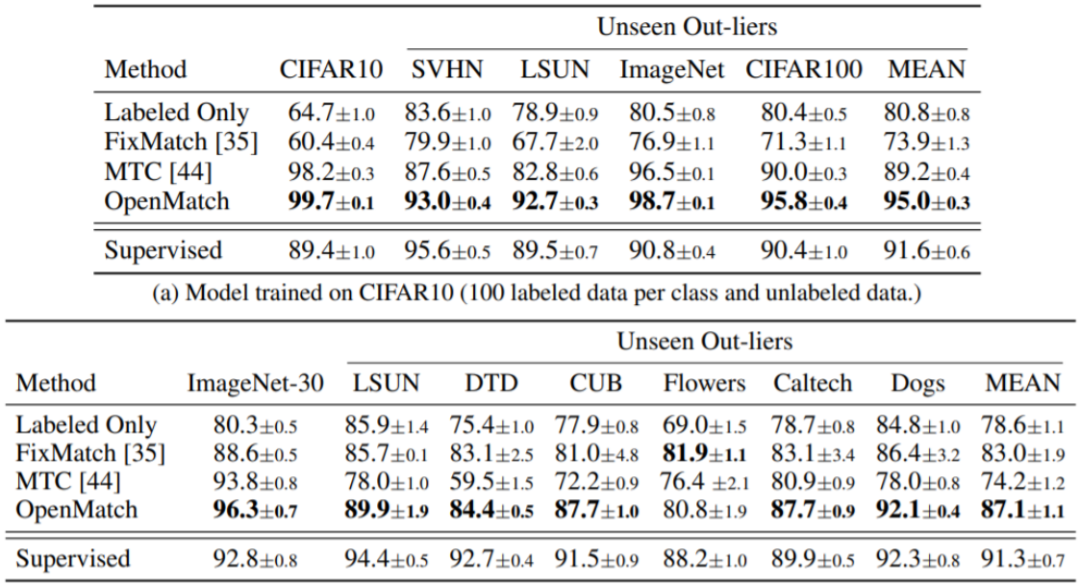
图11 OpenMatch性能对比
相关文章:
干货文稿|详解深度半监督学习
分享嘉宾 | 范越文稿整理 | William嘉宾介绍Introduction to Semi-Supervised Learning传统机器学习中的主流学习方法分为监督学习,无监督学习和半监督学习。这里存在一个是问题是为什么需要做半监督学习?首先是希望减少标注成本,因为目前可以…...
信箱|邮箱系统
技术:Java、JSP等摘要:在经济全球化和信息技术飞速发展的今天,通过邮件收发进行信息传递已经成为主流。目前,基于B/S(Browser/Server)模式的MIS(Management information system)日益…...

JS数组拓展
1、Array.from Array.from 方法用于将两类对象转为真正的数组: 类似数组的对象,所谓类似数组的对象,本质特征只有一点,即必须有length属性。 因此,任何有length属性的对象,都可以通过Array.from方法转为数组 和 可遍历…...

一道很考验数据结构与算法的功底的笔试题:用JAVA设计一个缓存结构
我在上周的笔试中遇到了这样一道题目,觉得有难度而且很考验数据结构与算法的功底,因此Mark一下。 需求说明 设计并实现一个缓存数据结构: 该数据结构具有以下功能: get(key) 如果指定的key存在于缓存中,则返回与该键关联的值&am…...
C#传智:命名空间、String/StringBuilder、指针、继承New(第10天))
(10)C#传智:命名空间、String/StringBuilder、指针、继承New(第10天)
内容开始多了,慢品慢尝才有滋味。 一、命名空间namespace 用于解决类重名问题,可以看作类的文件夹. 若代码与被使用的类,与当前的namespace相同,则不需要using. 若namespace不同时,调用的方法:…...

基于Jetson Tx2 Nx的Qt、树莓派等ARM64架构的Ptorch及torchvision的安装
前提 已经安装好了python、pip及最基本的依赖库 若未安装好点击python及pip安装请参考这篇博文 https://blog.csdn.net/m0_51683386/article/details/129320492?spm1001.2014.3001.5502 特别提醒 一定要先根据自己板子情况,找好python、torch、torchvision的安…...

MySQL存储引擎详解及对比和选择
什么是存储引擎? MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善…...

【推拉框-手风琴】vue3实现手风琴效果的组件
简言 在工作时有时会用到竖形手风琴效果的组件。 在此记录下实现代码和实现思路。 手风琴实现 结构搭建 搭建结构主要实现盒子间的排列效果。 用flex布局或者其他布局方式将内容在一行排列把每一项的内容和项头用盒子包裹, 内容就是这一项要展示的内容…...
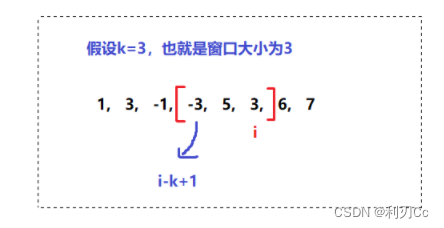
滑动窗口最大值:单调队列
239. 滑动窗口最大值 难度困难2154收藏分享切换为英文接收动态反馈 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例…...

负载均衡算法
静态负载均衡 轮询 将请求按顺序轮流地分配到每个节点上,不关心每个节点实际的连接数和当前的系统负载。 优点:简单高效,易于水平扩展,每个节点满足字面意义上的均衡; 缺点:没有考虑机器的性能问题&…...
C语言数组二维数组
C 语言支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。 数组的声明并不是声明一个个单独的变量,比如 runoob0、runoob1、…、runoob99,而是…...
7年测试工程师,裸辞掉17K的工作,想跳槽找更好的,还是太高估自己了....
14年大学毕业后,在老师和朋友的推荐下,进了软件测试行业,这一干就是7年时间,当时大学本来就是计算机专业,虽然专业学的一塌糊涂,但是当年的软件测试属于新兴行业,人才缺口比较大,而且…...

企业为什么需要做APP安全评估?
近几年新型信息基础设施建设和移动互联网技术的不断发展,移动APP数量也呈现爆发式增长,进而APP自身的“脆弱性”也日益彰显,这对移动用户的个人信息及财产安全带来巨大威胁和挑战。在此背景下,国家出台了多部法律法规,…...

重回利润增长,涪陵榨菜为何能跑赢周期?
2022年消费市场持续低迷,疫情寒冬之下,不少食品快消企业均遭遇严重的业绩下滑,但一年里不断遭遇利空打击的“榨菜茅”涪陵榨菜,不仅安然躲过“酸菜劫”、走出“钠”争议,而且顺利将产品价格提起来,并在寒冬…...

这6个高清图片素材库,马住,马住~
网上找的图片素材清晰度不够,版权不明确怎么办。看看这几个可商用图片素材网站,解决你的所有图片需求,高清无水印,赶紧马住! 1、菜鸟图库 美女图片|手机壁纸|风景图片大全|高清图片素材下载网 - 菜鸟图库 网站素材…...
)
绝对零基础的C语言科班作业(期末模拟考试)
编程题(共10题; 共100.0分)模拟1(输出m到n的素数)从键盘输入两个整数[m,n], 输出m和n之间的所有素数。 输入样例:3,20输出样例:3 5 7 11 13 17 19 (输出数据之间用空格间…...

注解开发定义bean
注解开发定义bean 使用Component定义bean在核心配置文件中通过组件扫描加载bean,需要指定扫描包的范围 当然也可以使用Component的衍生注解,可以更加形象的表示 纯注解的开发模式 使用java类来代替了以前的 配置文件,在java类中ÿ…...

剑指 Offer 19. 正则表达式匹配
摘要 剑指 Offer 19. 正则表达式匹配 请实现一个函数用来匹配包含. 和*的正则表达式。模式中的字符.表示任意一个字符,而*表示它前面的字符可以出现任意次(含0次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如&#x…...
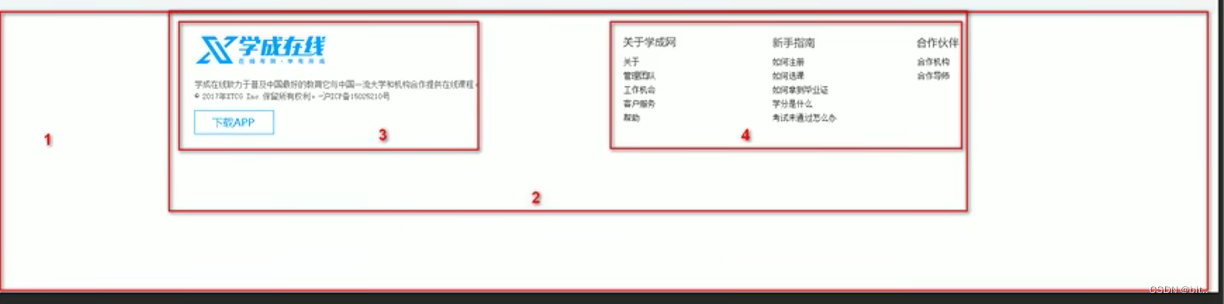
CSS——学成在线案例
🍓个人主页:bit.. 🍒系列专栏:Linux(Ubuntu)入门必看 C语言刷题 数据结构与算法 HTML和CSS3 目录 1.案例准备工作 2.CSS属性书写顺序(重点) 3.页面布局整体思路 4.头部的制作编辑 5.banner制作…...

元数据的类型
元数据通常分为三种类型:业务元数据、技术元数据和操作元数据。这些类别使人们能够理解属于元数据总体框架下的信息范围,以及元数据的产生过程。也就是说,这些类别也可能导致混淆,特别是当人们对一组元数据属于哪个类别或应该由谁…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...
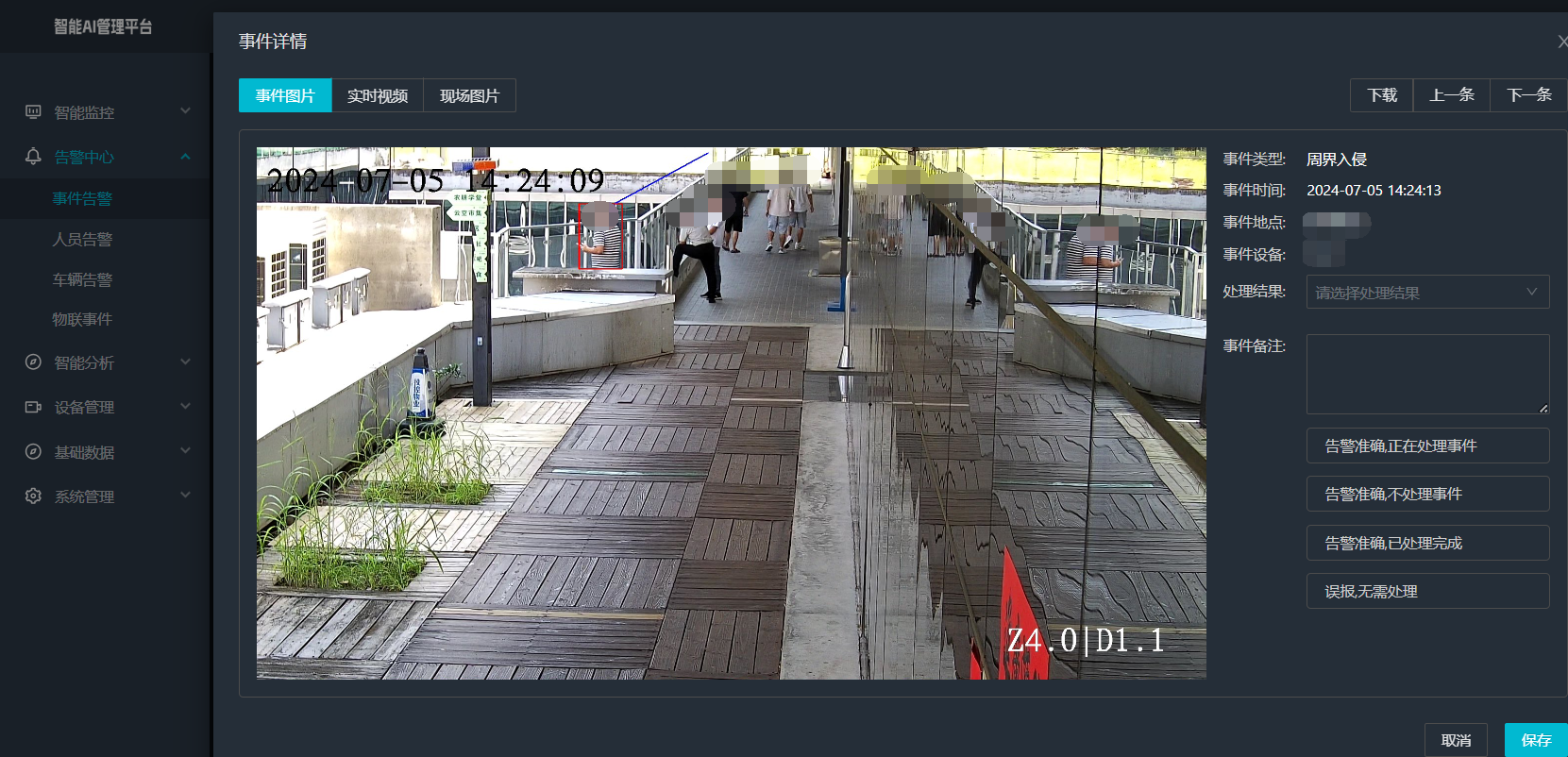
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...