Zuul相关问题及到案(2024)
1、什么是Zuul?它在微服务架构中有什么作用?
Zuul是Netflix开源的一种提供API网关服务的应用程序,它在微服务架构中扮演着流量的前门角色。主要功能包括以下几点:
-
路由转发:Zuul网关将外部请求转发到具体的微服务实例上。
-
负载均衡:通过与服务发现组件(如Eureka)的集成,Zuul可以实现对多个微服务实例的负载均衡。
-
请求过滤:在请求到达目标微服务之前,Zuul可以对请求进行过滤,执行各种策略,如身份认证、权限检查、动态路由、流量转发、日志记录、协议转换等。
-
安全性:Zuul提供了对微服务的保护层,可以通过设置各种过滤器来防止恶意请求访问。
-
监控和度量:Zuul可以通过集成如Hystrix、Spring Boot Actuator等组件来提供监控服务的能力,例如记录请求日志、监控服务质量、跟踪问题等。
-
弹性:Zuul整合了Hystrix来提供断路器功能,当后端服务故障时,可以防止故障的蔓延,并提供备用的响应路径。
-
静态响应处理:Zuul可以拦截请求并直接在网关层返回静态响应,减轻后端服务负担。
-
Websocket:Zuul支持Websocket协议,并可以将Websocket流量路由到后端服务。
在微服务架构中,Zuul作为边界服务,通过集中处理所有的入站和出站API流量,提供了简化微服务开发和运维的手段,同时提高了微服务的安全性和健壮性。它为开发人员和运维人员提供了一个强大的工具集来管理对微服务的访问。
2、Zuul有哪些关键组件?
Zuul的关键组件主要包括以下几个方面:
-
过滤器(Filters): 过滤器是Zuul最关键的组成部分,它可以拦截请求和响应,并在发送到目标服务之前或之后执行各种任务。根据执行时机的不同,过滤器分为以下几种类型:
- pre filters: 这些在请求被路由之前调用,用于任务如安全认证,日志记录等。
- route filters: 这些用来将请求路由到各个微服务。
- post filters: 这些在请求路由到微服务之后执行,用于添加HTTP Header,收集统计信息,以及响应内容的加工处理等。
- error filters: 这些在处理请求发生错误时调用。
-
路由(Routing): Zuul通过与服务发现机制(如Eureka)集成,或者使用静态提供的URL来将请求路由到适当的微服务。
-
请求转发和执行逻辑(Request Forwarding and Execution Logic): 它负责接收客户端请求,并将其转发到过滤器链和后端服务。
-
Zuul Server: Zuul Server是包含内嵌的Tomcat或其他容器的运行时,用于启动和运行Zuul。它接收客户端请求并将其传输到过滤器链。
-
Zuul引擎: 它是处理所有请求和执行过滤器的核心。
Zuul的组件和架构设计让它非常适合在微服务架构中作为API网关使用。过滤器的灵活性和强大的路由功能使得Zuul不仅能够管理和转发请求,还能够执行复杂的业务逻辑。
3、Zuul中的pre、route、post和error这四种过滤器类型
在Zuul中,过滤器是执行请求和响应处理逻辑的核心组件。过滤器按照其执行时机和目的被分为四种类型:pre、route、post和error。
-
Pre过滤器:
- 这些过滤器在请求路由到目标服务之前执行。
- 它们通常用于执行前置检查和预处理任务,如请求的安全性验证、日志记录、设置请求上下文和请求头的处理等。
-
Route过滤器:
- 这些过滤器负责将请求路由到合适的微服务。
- 它们可以结合服务发现机制(如Eureka)或使用静态URL将请求定向到指定的微服务。
- Route过滤器还可以用于请求的转发,比如通过Apache HttpClient或Netflix Ribbon请求后端服务。
-
Post过滤器:
- 这些过滤器在请求已被路由并且微服务已经返回响应之后执行。
- 通常用于对响应进行后处理,例如添加HTTP头到响应中、收集统计数据、响应内容的封装等。
-
Error过滤器:
- 当在其他阶段发生错误时,这些过滤器会被执行。
- 它们可以用于处理在路由或异常处理期间发生的错误,为响应设置默认的错误信息或进行错误日志记录。
每个过滤器都实现了ZuulFilter类,并且都必须提供四个核心方法的实现:
filterType(): 返回一个字符串代表过滤器的类型。filterOrder(): 返回一个int值来指定过滤器的执行顺序。shouldFilter(): 返回一个boolean值来判断该过滤器实例是否应该运行。run(): 过滤器的功能实现,执行实际的处理逻辑。
通过这些不同类型的过滤器,Zuul能够提供强大的请求处理能力,允许自定义请求和响应的处理逻辑,以满足各种API网关的需求。
4、Zuul和Eureka有什么关系?
Zuul和Eureka是Netflix开源的两个不同的项目,它们通常在微服务架构中一起使用来提供动态路由、服务发现和负载均衡的功能。
-
Eureka:
- Eureka是一个服务发现的工具,它允许服务注册它们的位置,并让其他服务通过Eureka Server查询这些服务的位置。
- Eureka Server作为注册中心,各个微服务实例在启动时会向Eureka注册自己的信息(如服务名、主机和端口)。
- 微服务实例的运行状态会定期通过心跳检查的方式报告给Eureka Server,保证服务注册信息的准确性和最新性。
-
Zuul:
- Zuul通常作为API网关使用,所有的外部请求先经过Zuul,再由Zuul路由到相应的后端服务。
- Zuul有动态路由的功能,它可以利用Eureka的服务发现能力来动态地将请求路由到正确的实例。
它们之间的关系:
- 当一个外部请求到达Zuul网关时,Zuul可以查询Eureka Server来获取后端服务的实例信息(服务的真实网络地址)。
- Zuul根据得到的信息决定将请求路由到哪个服务实例上去,这个过程通常结合了负载均衡策略。
- Zuul可以通过订阅Eureka的服务实例更新事件来动态更新其路由表,确保请求总是被发送到正确且有效的服务实例。
通过使用Zuul和Eureka,可以有效地实现服务的弹性伸缩和故障转移。Eureka作为服务注册和发现的中心,为Zuul提供了必要的服务实例信息,让Zuul能够动态地路由和负载均衡用户请求到这些服务实例。这种设计模式提高了微服务架构的可用性和可维护性。
5、Zuul的延迟和性能如何?
Zuul的延迟和性能受多个因素影响,包括硬件资源、网络条件、配置、过滤器的复杂度以及服务的响应时间等。作为Netflix的开源API网关,Zuul是设计用来处理大规模流量的,并且能够通过横向扩展来提高其性能。以下是一些影响Zuul性能和延迟的关键因素:
-
硬件资源:
- 运行Zuul的服务器的CPU、内存和I/O性能将直接影响其处理请求的能力。资源越强大,Zuul的性能通常越好。
-
网络带宽和延迟:
- Zuul服务器与客户端以及后端服务之间的网络带宽和延迟会影响整体响应时间。
-
Zuul配置:
- Zuul的线程池大小、超时设置、路由配置等都会影响处理请求的速度。
-
过滤器数量和复杂度:
- Zuul过滤器执行的操作越多或越复杂,处理请求的时间就越长。例如,大量的前置过滤器可能会增加请求的处理时间。
-
服务的响应时间:
- Zuul路由请求到后端服务,如果后端服务响应慢,那么即使Zuul本身处理很快,整体的延迟也会较高。
-
并发处理能力:
- Zuul的异步非阻塞架构设计使其能够高效地处理大量并发请求,但并发请求量极大时可能需要相应的扩容。
-
Zuul版本:
- Zuul 1.x使用阻塞I/O,而Zuul 2.x重构为使用Netty的异步非阻塞I/O,后者在性能上有所提高,特别是在高并发场景下。
为了优化Zuul的性能和延迟,你可以考虑以下策略:
- 硬件优化:增加服务器资源,如CPU和内存。
- 配置优化:合理配置Zuul的线程池和超时时间,确保配置能够应对预期流量。
- 代码优化:编写高效的过滤器代码,避免不必要的数据转换和复杂逻辑。
- 负载均衡:使用负载均衡策略分散请求,降低单个实例的压力。
- 缓存:为常见请求启用缓存以减少后端服务的调用。
- 监控和调试:实时监控Zuul的性能,分析延迟数据以定位和解决性能瓶颈。
对于任何在生产环境中运行的系统,定期的性能测试和监控是十分重要的,以确保系统运行在最优状态。
6、如果Zuul遇到性能瓶颈,你会如何解决?
当Zuul遇到性能瓶颈时,可以考虑以下步骤来诊断和解决问题:
-
性能监测和分析:
- 首先,使用性能监测工具来确定瓶颈所在。监测Zuul的实例以及后端服务的性能指标,如延迟、吞吐量、错误率等。
-
优化Zuul实例配置:
- 调整Zuul的线程池配置,包括线程数和队列大小,以更好地处理并发请求。
- 调整网络超时参数以避免不必要的延迟。
- 对Zuul的内存和垃圾回收选项进行调优,以减少延迟和避免内存溢出。
-
优化路由和过滤器:
- 检查并优化路由配置,确保路由匹配尽可能高效。
- 审查Zuul过滤器,优化或移除性能不佳的过滤器。
- 使用异步过滤器来处理耗时操作,以避免阻塞I/O操作。
-
扩展和负载均衡:
- 如果资源利用率高,可能需要增加Zuul实例的数量,并使用负载均衡器来分散流量。
- 确保后端服务也能够横向扩展,以处理通过Zuul路由的增加流量。
-
使用缓存:
- 对于某些静态或不经常变化的响应内容,可以在Zuul层面使用缓存来减少后端服务的调用次数。
-
应用最佳实践:
- 使用异步非阻塞I/O处理请求,如果使用的是Zuul 2.x,它支持异步和非阻塞操作。
- 对于Zuul 1.x,由于它基于同步阻塞I/O,应考虑升级到Zuul 2.x或其他支持异步非阻塞I/O的API网关。
-
深入源代码和依赖:
- 分析Zuul的源代码和任何自定义依赖,以确定是否有可优化的地方。
-
专业咨询和社区支持:
- 如果内部优化尝试后仍然存在瓶颈,可以考虑咨询专业人士或寻求Netflix Zuul社区的帮助。
在进行任何优化之前,建立一个可靠的性能基准是非常重要的,这样您就能明确知道每项改进是否真正带来了性能提升。
7、 Zuul有哪些限制?
Zuul是一个由Netflix开发的边缘服务,主要用于路由和过滤进入到Web应用程序的请求。尽管它广泛用于微服务架构中的API网关,但也存在一些限制:
-
性能问题:
- Zuul 1.x是基于阻塞I/O操作的,这可能导致性能瓶颈,尤其是在高并发场景下。
- Zuul 2.x改进了这一点,引入了基于Netty的异步和非阻塞I/O,但迁移到Zuul 2.x可能会涉及重构代码和配置。
-
内存消耗:
- 由于请求/响应经常在Zuul内存中完整地存储和处理,因此在高负载情况下,Zuul可能会占用大量内存。
-
复杂的配置:
- Zuul的配置可能会相当复杂,尤其是在大型系统中,正确维护和更新路由规则、安全策略和过滤器逻辑可能很有挑战性。
-
学习曲线:
- 对于新手来说,理解Zuul的工作原理以及如何编写有效的过滤器可能不是很直观。
-
依赖性和兼容性:
- Zuul通常与Spring Ecosystem(如Spring Boot和Spring Cloud)一起使用。这意味着如果不在使用Spring的上下文中,可能需要额外的工作来集成Zuul。
-
版本升级问题:
- 从Zuul 1.x迁移到Zuul 2.x可能会遇到兼容性问题,因为它们在架构和API方面有显著差异。
-
社区支持:
- 尽管Netflix和Spring社区都对Zuul提供了支持,但随着其他API网关解决方案的出现,如Amazon API Gateway、Kong和Spring Cloud Gateway,社区和Netflix对Zuul的关注可能会减少。
-
错误处理:
- Zuul的错误处理有时候可能不够直观,需要额外的配置和编码工作。
-
功能限制:
- Zuul的一些版本可能不支持WebSocket或HTTP/2,这可能限制其在某些用例中的适用性。
-
部署和维护成本:
- 如同任何基础设施组件一样,Zuul需要定期的维护和更新,这可能带来相应的成本。
在选择Zuul作为API网关时,应该基于具体的项目需求和上述限制进行权衡。在某些情况下,其他API网关解决方案可能会更加适合。
8、 如何在Zuul中添加自定义过滤器?
在Zuul中添加自定义过滤器需要几个步骤,这些步骤通常包括创建过滤器类、定义过滤逻辑以及确保过滤器被加载和执行。以下是在Spring Cloud Zuul中添加自定义过滤器的一般步骤:
-
创建过滤器类:
创建一个类并继承ZuulFilter类。在这个类中,你需要实现以下四个方法:filterType():返回一个字符串代表过滤器的类型。常见的类型包括:"pre":路由之前执行"route":路由请求时执行"post":路由请求后执行"error":处理请求时发生错误执行
filterOrder():返回一个int值来指定过滤器的执行顺序。shouldFilter():返回一个布尔值来判断该过滤器是否需要执行。run():过滤器的核心逻辑。
-
定义过滤器逻辑:
在run()方法中编写你的自定义逻辑。例如,可以在其中修改请求头、检查请求参数或记录请求日志。 -
确保过滤器被加载:
在Spring Boot应用程序中,只需将过滤器类标注为一个组件(@Component),Spring就会自动注册该过滤器。
以下是一个简单的自定义过滤器示例,它在请求被路由前记录了请求的HTTP方法和URL:
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import javax.servlet.http.HttpServletRequest;@Component
public class SimplePreFilter extends ZuulFilter {@Overridepublic String filterType() {return "pre";}@Overridepublic int filterOrder() {return 1;}@Overridepublic boolean shouldFilter() {return true;}@Overridepublic Object run() {RequestContext ctx = RequestContext.getCurrentContext();HttpServletRequest request = ctx.getRequest();// 记录日志System.out.println(String.format("Request Method : %s Request URL : %s", request.getMethod(), request.getRequestURL().toString()));return null;}
}
在这个例子中,filterType()返回"pre",表示这是一个前置过滤器;filterOrder()返回1,表示这个过滤器在执行顺序上较早被调用;shouldFilter()返回true,表示过滤器将对每个请求生效;run()方法实现了自定义的逻辑。
确保将此类添加到Spring Boot应用程序的类路径下,并用@Component注解,以便Spring容器可以发现并注册这个过滤器。然后,当Zuul代理传入的HTTP请求时,这个过滤器就会被自动应用。
9、如何处理Zuul中的路由规则?
在Spring Cloud Zuul中,处理路由规则通常涉及两个方面:配置路由规则和自定义路由行为。以下是如何处理这两方面的基本指南:
配置路由规则
Spring Cloud Zuul提供了简便的方式来配置路由规则。你可以在application.yml或application.properties文件中声明路由规则。
使用application.yml配置路由:
zuul:routes:user-service:path: /user/**serviceId: user-serviceitem-service:path: /item/**url: http://item-service-host:8080/
在上面的配置中,所有访问/user/**路径的请求将被路由到user-service服务,而/item/**路径的请求将直接被路由到指定的URL。
使用application.properties配置路由:
zuul.routes.user-service.path=/user/**
zuul.routes.user-service.serviceId=user-servicezuul.routes.item-service.path=/item/**
zuul.routes.item-service.url=http://item-service-host:8080/
这里的配置效果与YAML配置相同,只是格式有所不同。
自定义路由行为
如果你需要更复杂的路由逻辑,你可以编写自定义的Zuul过滤器。
-
创建自定义路由过滤器:
创建一个ZuulFilter的子类,通常是一个前置(pre)过滤器,因为你想在路由请求之前改变路由行为。 -
实现自定义路由逻辑:
在run()方法中实现你的自定义路由逻辑。你可以操作RequestContext来改变请求的路由目的地。
下面是一个自定义路由过滤器的示例,它根据查询参数来动态改变路由目标:
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
import javax.servlet.http.HttpServletRequest;@Component
public class DynamicRouteFilter extends ZuulFilter {@Overridepublic String filterType() {return "pre";}@Overridepublic int filterOrder() {return 1;}@Overridepublic boolean shouldFilter() {return true;}@Overridepublic Object run() {RequestContext ctx = RequestContext.getCurrentContext();HttpServletRequest request = ctx.getRequest();String param = request.getParameter("route-to");if ("item-service".equals(param)) {ctx.set("serviceId", "item-service");ctx.setRouteHost(null); // Clear any previously set route} else if ("user-service".equals(param)) {ctx.set("serviceId", "user-service");ctx.setRouteHost(null); // Clear any previously set route}return null;}
}
在这个例子中,根据请求的route-to查询参数,过滤器动态地将请求路由到不同的服务。
自定义路由行为时,要特别注意安全性和效率。确保你的逻辑不会无意中将请求路由到不安全或不可信的目的地,并且仔细测试以确保它不会对Zuul的性能造成负面影响。
10、Zuul和其他API网关(如Spring Cloud Gateway)的区别是什么?
Zuul和Spring Cloud Gateway都是在微服务架构中用于路由和过滤HTTP请求的API网关。它们都可以作为系统的入口点,为微服务提供统一的访问接口,同时提供安全、监控和弹性等功能。然而,这两个项目在设计、性能和功能上有一些关键差异:
-
异步与阻塞:
- Zuul 1.x 使用的是阻塞IO的方式。这意味着每个请求都会占用一个线程直到该请求被处理完成,这在高并发的情况下可能会导致资源的浪费。
- Spring Cloud Gateway 则是构建在Spring WebFlux之上的,使用的是非阻塞API,并且支持长连接,如WebSocket。它是为了利用异步非阻塞IO而设计的,这使得它在处理高并发请求时更加高效。
-
性能:
- 由于Spring Cloud Gateway的非阻塞和异步IO特性,它在理论上提供了比Zuul 1.x更高的性能和更低的资源消耗。而Zuul 2.x改进了这一点,引入了异步非阻塞的请求处理,但它并没有得到与Zuul 1.x同等的社区支持和使用广泛性。
-
实现技术栈:
- Zuul 1.x 基于Servlet 2.5(使用阻塞架构),它与Spring MVC紧密集成。
- Spring Cloud Gateway 基于Project Reactor和Spring WebFlux,它与Spring 5非阻塞和响应式编程模型紧密集成。
-
长连接支持:
- Spring Cloud Gateway 支持WebSocket等长连接,而Zuul 1.x不支持。
-
维护和更新:
- Netflix不再积极更新Zuul 1.x,而Zuul 2.x更新也相对缓慢。
- Spring Cloud Gateway 作为Spring Cloud项目的一部分,与Spring Boot的发行版同步更新和维护。
-
路由动态性:
- Spring Cloud Gateway 提供了更加动态的路由配置方式,可以实现基于代码的路由配置和条件。
-
易用性:
- Spring Cloud Gateway 的配置和API设计被认为更加现代化和易于使用。
选择Zuul还是Spring Cloud Gateway,很大程度上取决于具体的用例和技术栈的兼容性。如果你已经在使用Spring WebFlux并且需要非阻塞和异步的特性,那么Spring Cloud Gateway可能是更好的选择。如果你正在使用Spring MVC并且对Zuul 1.x感到满意,且没有遇到性能瓶颈,那么可能没有迁移到Spring Cloud Gateway的必要。不过,对于新的项目,Spring Cloud Gateway通常是推荐的选择,因为它提供了更现代、更高效的技术栈。
11、为什么会出现Zuul 2,它有哪些改进?
Zuul 2是Netflix开发的Zuul网关的第二个主要版本。它主要是为了解决Zuul 1.x在性能和架构上的限制而设计的。以下是Zuul 2的一些主要改进:
-
异步非阻塞架构:
Zuul 1.x基于Servlet 2.5,使用传统的阻塞IO模型。在高并发场景下,每一个入站连接都需要一个线程去处理,这可能会导致资源利用率不高并且扩展性有限。Zuul 2采用了基于Netty的异步非阻塞IO模型,这可以显著提高资源利用率,减少延迟,并提高吞吐量。 -
完全重新设计的过滤器模型:
Zuul 2提供了一个全新的过滤器模型,它支持异步处理请求和响应,并且为过滤器的执行提供了更多的灵活性。 -
支持WebSocket和HTTP/2:
Zuul 2添加了对WebSocket和HTTP/2的支持,这在Zuul 1.x中是不可用的。这允许Zuul 2处理更多种类的流量,提供更好的性能,并且使得它能够支持更现代的应用程序。 -
动态路由:
虽然Zuul 1.x支持一些动态路由能力,Zuul 2进一步扩展了这些能力,提供更加灵活的动态路由解决方案。 -
强化的弹性特性和安全性:
Zuul 2增强了对安全性和弹性的支持,包括更好的错误处理和内置的重试机制,以及更细粒度的流量控制。 -
改进的性能监控与度量:
引入了更多的监控和度量工具,可以更好地理解和优化Zuul的运行状况。
尽管Zuul 2在技术上有了显著的改进,但社区对它的接受程度并不像Zuul 1.x那样广泛。许多用户已经转向其他解决方案,如Spring Cloud Gateway,它提供了类似的异步非阻塞IO模型,并且与Spring生态系统集成更紧密。此外,Netflix似乎没有将Zuul 2集成到Spring Cloud体系中,这也限制了其在Spring生态中的应用。因此,在选择API网关时,除了考虑技术特性外,还需要考虑社区支持、文档质量和生态系统的成熟度。
12、如何在Zuul中实现请求重试?
在Zuul中实现请求重试功能通常涉及到两个主要组件:Zuul本身和Ribbon。Ribbon是一个客户端负载均衡器,它可以与Zuul配合使用来实现对下游服务的请求重试。以下是使用Ribbon在Zuul中设置请求重试的基本步骤:
-
确保你的Zuul网关使用的是Spring Cloud Netflix Zuul依赖,它自带了Ribbon。
-
在你的Zuul配置文件中启用重试。
对于application.yml配置格式可以是:
zuul:retryable: true # 启用Zuul重试
ribbon:MaxAutoRetries: 1 # 同一个服务实例的最大重试次数MaxAutoRetriesNextServer: 1 # 切换到另一个服务实例的最大重试次数OkToRetryOnAllOperations: true # 允许对所有操作进行重试,但要小心处理非幂等请求ReadTimeout: 5000 # 设置Ribbon的超时时间ConnectTimeout: 5000 # 设置Ribbon的连接超时时间
对于application.properties配置格式可以是:
zuul.retryable=true
ribbon.MaxAutoRetries=1
ribbon.MaxAutoRetriesNextServer=1
ribbon.OkToRetryOnAllOperations=true
ribbon.ReadTimeout=5000
ribbon.ConnectTimeout=5000
- 为特定路由配置重试。
如果你不想为所有路由启用重试,可以对特定路由进行配置:
zuul:routes:users:path: /users/**serviceId: users-serviceretryable: true # 只为users服务启用重试
- 添加Spring Retry依赖(如果你的项目中还未添加)。
<dependency><groupId>org.springframework.retry</groupId><artifactId>spring-retry</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
- (可选)自定义重试策略。
如果需要更多的自定义重试策略,你可以创建一个Bean来定义重试的规则:
@Bean
public RetryTemplate retryTemplate() {RetryTemplate retryTemplate = new RetryTemplate();SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy();retryPolicy.setMaxAttempts(3); // 重试三次FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();backOffPolicy.setBackOffPeriod(2000); // 每次重试间隔2秒retryTemplate.setRetryPolicy(retryPolicy);retryTemplate.setBackOffPolicy(backOffPolicy);return retryTemplate;
}
- (可选)自定义Ribbon客户端。
如果需要对Ribbon客户端进行更多的自定义设置,你可以定义一个配置类:
@Configuration
@RibbonClients(defaultConfiguration = DefaultRibbonConfig.class)
public class RibbonConfiguration {public static class DefaultRibbonConfig {@Beanpublic IRule ribbonRule() {return new BestAvailableRule(); // 使用最少并发请求的服务器}@Beanpublic IPing ribbonPing() {return new PingUrl(); // 使用URL ping来检查服务健康}}
}
使用这些步骤,你可以在Zuul网关中设置重试机制,以提高你的微服务架构的弹性和可靠性。然而,需要注意的是,对于可能更改服务器状态的操作(如POST、PUT、DELETE等),启用重试可能导致不期望的副作用,因此需要谨慎使用。
13、Zuul的负载均衡如何工作
Zuul的负载均衡功能主要是通过与Ribbon库的集成来实现的。Ribbon是一个客户端负载均衡器,它允许通过配置来控制HTTP和TCP客户端的行为。在Spring Cloud Netflix中,Ribbon与Eureka服务发现相结合,提供了一种很好的方式来自动发现服务实例,并在这些实例之间进行负载均衡。
以下是Zuul与Ribbon进行负载均衡的过程:
-
服务注册: 在Spring Cloud微服务架构中,各个微服务实例通常会在Eureka服务注册中心进行注册。这样,它们的位置信息和可用性状态就可以被客户端查询到。
-
服务发现: 当Zuul网关收到一个转发请求时,它首先使用Ribbon来查询Eureka,获取目标服务的所有可用实例。
-
选择实例: Ribbon使用一定的规则(例如轮询、随机、权重等)从这些实例中选择一个。这个规则可以通过配置来指定。
-
发送请求: 一旦选择了实例,Zuul就将请求发送到该实例。如果请求成功,响应会被返回给原始请求者。
-
失败处理: 如果请求失败,Ribbon可以配置为重试其他实例。这通常是通过配置
ribbon.MaxAutoRetries和ribbon.MaxAutoRetriesNextServer这样的属性来实现的。 -
性能监控: Ribbon还可以使用Netflix Hystrix来监控和控制调用性能,以及为微服务提供熔断机制。
在Zuul配置文件中给出的一些与Ribbon相关的常见属性如下:
zuul:routes:user-service:path: /user/**serviceId: user-serviceribbon:eureka:enabled: true # 使用Eureka进行服务发现ReadTimeout: 5000 # 请求读取超时设置ConnectTimeout: 3000 # 连接超时设置
Ribbon的负载均衡工作流程是在Zuul发送请求到下游服务之前,自动在可用服务实例中进行选择,这样实现了客户端负载均衡。通过这种方式,Zuul网关能够处理大量的入站流量并将其高效地转发到后端服务,同时也能够处理服务实例的故障和维护高可用性。
14、怎么监控Zuul的性能和状态?
要监控Zuul的性能和状态,你可以使用几种不同的工具和方法。这里有几个主要的技术:
-
Actuator Endpoints:
Spring Boot Actuator提供了一系列即用型的端点来监控和交互。你可以添加Spring Boot Actuator依赖并通过HTTP端点获取应用的健康状态、度量指标等信息。<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId> </dependency>一旦添加了依赖,一些常用的端点包括:
/actuator/health:应用的健康情况/actuator/metrics:应用的各种度量指标/actuator/httptrace:跟踪HTTP请求和响应
-
Hystrix Dashboard:
Hystrix是一个断路器库,它可以防止系统级联失败。Zuul与Hystrix集成,允许你监控路由的延迟和失败。你可以使用Hystrix Dashboard来实时监控Hystrix Metrics。<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId> </dependency>启动Dashboard后,通过访问
http://your-zuul-host/hystrix,你可以看到断路器的状态。 -
Prometheus and Grafana:
Prometheus是一个开源系统监控和警报工具包,它可以收集并存储其规则表达式语言中定义的指标。Grafana是一个跨平台的开源可视化和分析平台,可以将Prometheus的数据可视化。你可以集成
micrometer-registry-prometheus:<dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId> </dependency>然后通过配置使Prometheus抓取Spring Boot Actuator暴露的
/actuator/prometheus端点的指标。 -
ELK Stack:
ELK(Elasticsearch, Logstash, and Kibana)是一种常用的日志分析解决方案。你可以将Zuul的日志发送到Logstash,然后存储在Elasticsearch中,并使用Kibana来查询和可视化日志数据。 -
Spring Cloud Sleuth and Zipkin:
Sleuth可以帮助你跟踪微服务架构中的请求流程。Zipkin是一个分布式跟踪系统,它可以收集由Sleuth提供的跟踪信息,并允许你查看请求的延迟等信息。<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency>启用这些后,可以访问Zipkin UI来查看服务间调用的详细跟踪。
-
自定义度量指标:
你可以使用Micrometer或其他度量库来定义并导出自定义的度量指标。这些指标可以被上述任何监控系统捕获并展示。
监控的选择取决于你的需求、已有的基础设施以及你愿意进行的投入。对于生产环境,通常建议使用多种监控工具来获取不同维度的洞察。
15、Zuul在使用中需要注意什么?
在使用Zuul时,有几个方面需要特别注意以确保它能有效地为你的微服务架构提供服务:
-
资源限制:Zuul网关会处理所有传入的请求,因此它应该配置有足够的资源来处理高峰期的流量。否则在流量高峰期,Zuul可能会成为系统瓶颈。
-
超时设置:合理配置连接超时和读取超时(包括Hystrix和Ribbon的超时)是至关重要的,不当的超时配置可能会导致服务响应缓慢或不稳定。
-
路由规则:正确配置和管理路由规则是保证网关正确转发请求到下游服务的关键。在服务众多时,管理这些路由规则可能会比较复杂。
-
安全性:Zuul可以集成Spring Security来加强安全性。应该确保网关的安全性措施能够防止不合法的请求进入内部网络。
-
异常处理:Zuul自定义的错误处理需要被妥善管理。这包括对于断路时、路由失败或者服务不可用等情况下的处理。
-
压力测试:在生产环境前对Zuul网关进行压力测试,确保它能处理预期的流量。
-
依赖性管理:保持所有的依赖组件(如Spring Cloud、Spring Boot等)保持更新和兼容,因为老版本可能会包含已知的安全问题或者性能问题。
-
监控和日志:合理配置监控和日志收集,以便能够快速定位问题。这包括使用Spring Boot Actuator、集成ELK Stack或其他监控系统。
-
熔断机制:配置Hystrix熔断策略,以防止下游服务的故障影响到整个系统。
-
API版本管理:如果你的服务有多个版本,你需要考虑如何通过Zuul路由到不同版本的服务。
-
服务发现集成:如果使用Eureka之类的服务发现工具,确保Zuul的服务发现集成配置正确,以便它可以正确地发现和路由到服务实例。
-
负载均衡策略:理解并配置合适的负载均衡策略,以根据需要分配请求负载。
-
跨域请求:如果你的前端应用需要从不同的域访问后端服务,确保Zuul正确处理CORS请求。
-
请求和响应的处理:如果需要对请求或响应进行预处理或后处理,确保正确配置Zuul过滤器。
-
限流措施:在流量剧增时,实施限流策略以保护后端服务不被压垮。
遵循这些最佳实践可以帮助确保你的Zuul网关能够稳定、安全地运行,同时为你的微服务架构提供可靠的API网关功能。
相关文章:
)
Zuul相关问题及到案(2024)
1、什么是Zuul?它在微服务架构中有什么作用? Zuul是Netflix开源的一种提供API网关服务的应用程序,它在微服务架构中扮演着流量的前门角色。主要功能包括以下几点: 路由转发:Zuul网关将外部请求转发到具体的微服务实例…...

【CSS】讲一讲BFC、IFC、GFC、FFC
1. 前言 FC(Formatting Contexts),是CSS2.1的一个概念,是页面中的一块渲染区域,具有一套渲染规则,决定FC中子元素如何定位,以及和其他元素的关系和相互作用。在说FC之前说一下文档流。 1.1. 普…...
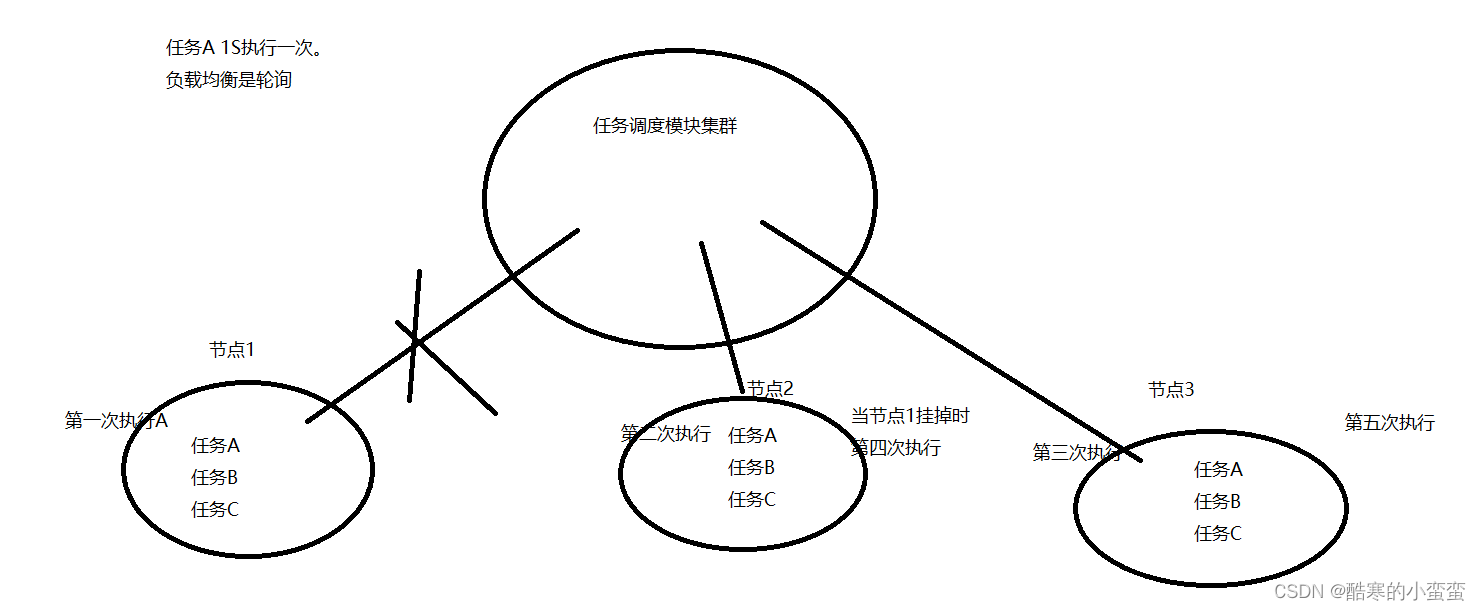
阶段十-分布式-任务调度
第一章 定时任务概述 在项目中开发定时任务应该一种比较常见的需求,在 Java 中开发定时任务主要有三种解决方案:一是使用JDK 自带的 Timer,二是使用 Spring Task,三是使用第三方组件 Quartz Timer 是 JDK 自带的定时任务工具,其…...
Godot4.2——爬虫小游戏简单制作
目录 一、项目 二、项目功能 怪物 人物 快捷键 分数 游戏说明 提示信息 三、学习视频 UI制作 游戏教程 四、总结 一、项目 视频演示:Godot4爬虫小游戏简单制作_哔哩哔哩bilibili 游戏教程:【小猫godot4入门教程 C#版 已完结】官方入门案例 第…...
对象的前世今生与和事佬(static)的故事
目录 1.对象村的秘密(对象在内存的实现) 1.1 内存的好兄弟“堆”与“栈” 1.1.1方法喜欢玩泰山压顶 1.1.2 stack的实现 1.2栈上的对象引用 1.2.1有关对象局部变量 1.2.2 如果局部变量生存在栈上,那么实例变量呢? 1.2.3创建…...
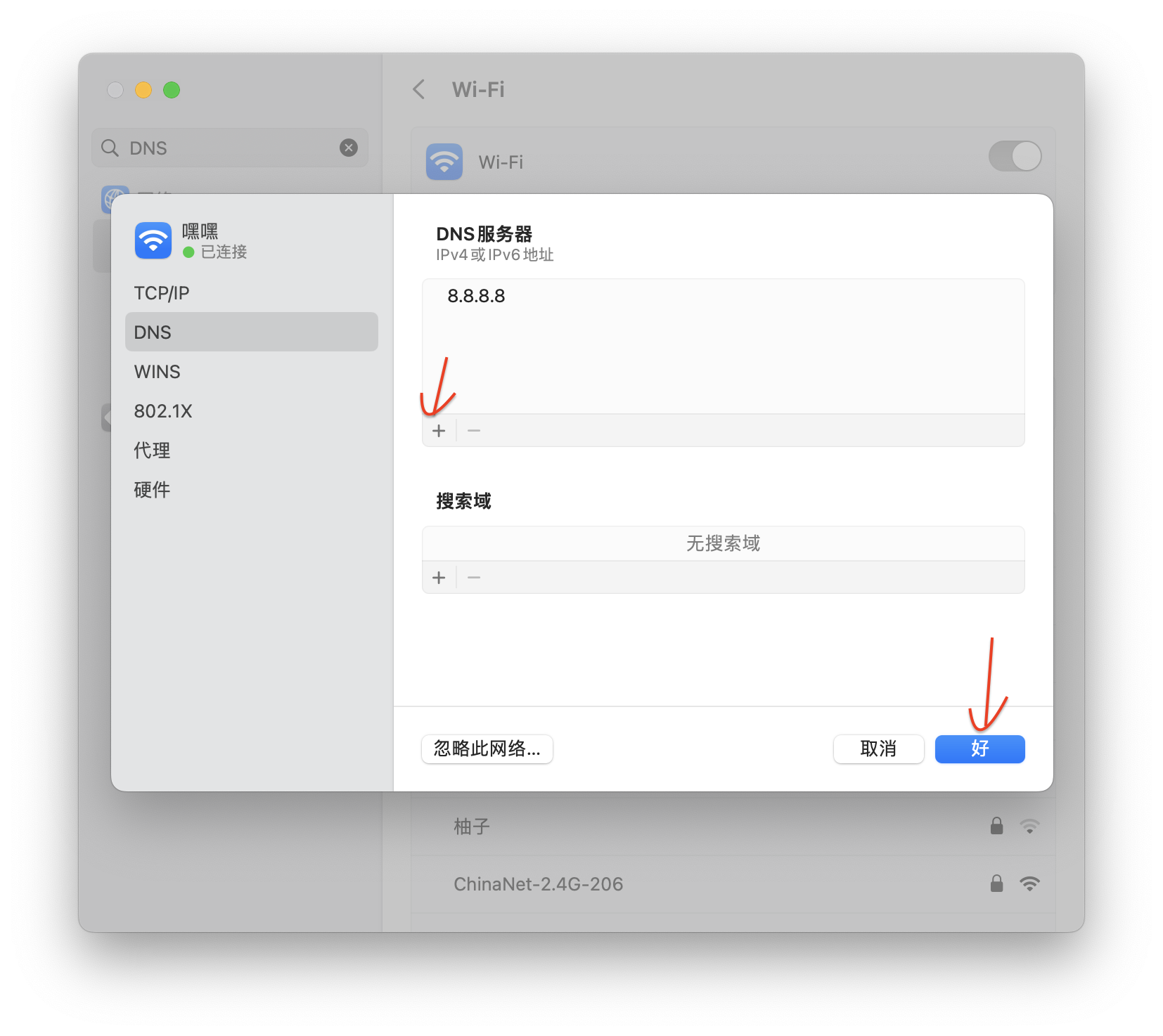
报错curl: (6) Could not resolve host: raw.githubusercontent...的解决办法
我起初想要在macOS系统安装pip包,首先在终端安装homebrew,敲了命令:/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent...)" 之后触发的报错,报错内容:curl: (6) Could not resolve host: raw.…...

【基础篇】十二、引用计数法 可达性分析算法
文章目录 1、Garbage Collection2、方法区的回收3、堆对象回收4、引用计数法5、可达性分析算法6、查看GC Root对象 1、Garbage Collection C/C,无自动回收机制,对象不用时需要手动释放,否则积累导致内存泄漏: Java、C#、Python、…...

C语言算法(二分查找、文件读写)
二分查找 前提条件:数据有序,随机访问 #include <stdio.h>int binary_search(int arr[],int n,int key);int main(void) {}int search(int arr[],int left,int right,int key) {//边界条件if(left > right) return -1;//int mid (left righ…...

流媒体学习之路(WebRTC)——Pacer与GCC(5)
流媒体学习之路(WebRTC)——Pacer与GCC(5) —— 我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全…...

2023版本QT学习记录 -11- 多线程的使用(QT的方式)
———————多线程的使用(QT方式)——————— 🎄效果演示 两个线程都输出一些调试信息 🎄创建多线程的流程 🎄头文件 #include "qthread.h"🎄利用多态重写任务函数 class rlthread1 : public QThread {Q_OBJE…...

iOS苹果和Android安卓测试APP应用程序的差异
Hello大家好呀,我是咕噜铁蛋!我们经常需要关注移动应用程序的测试和优化,以提供更好的用户体验。在移动应用开发领域,iOS和Android是两个主要的操作系统平台。本文铁蛋讲给各位小伙伴们详细介绍在App测试中iOS和Android的差异&…...
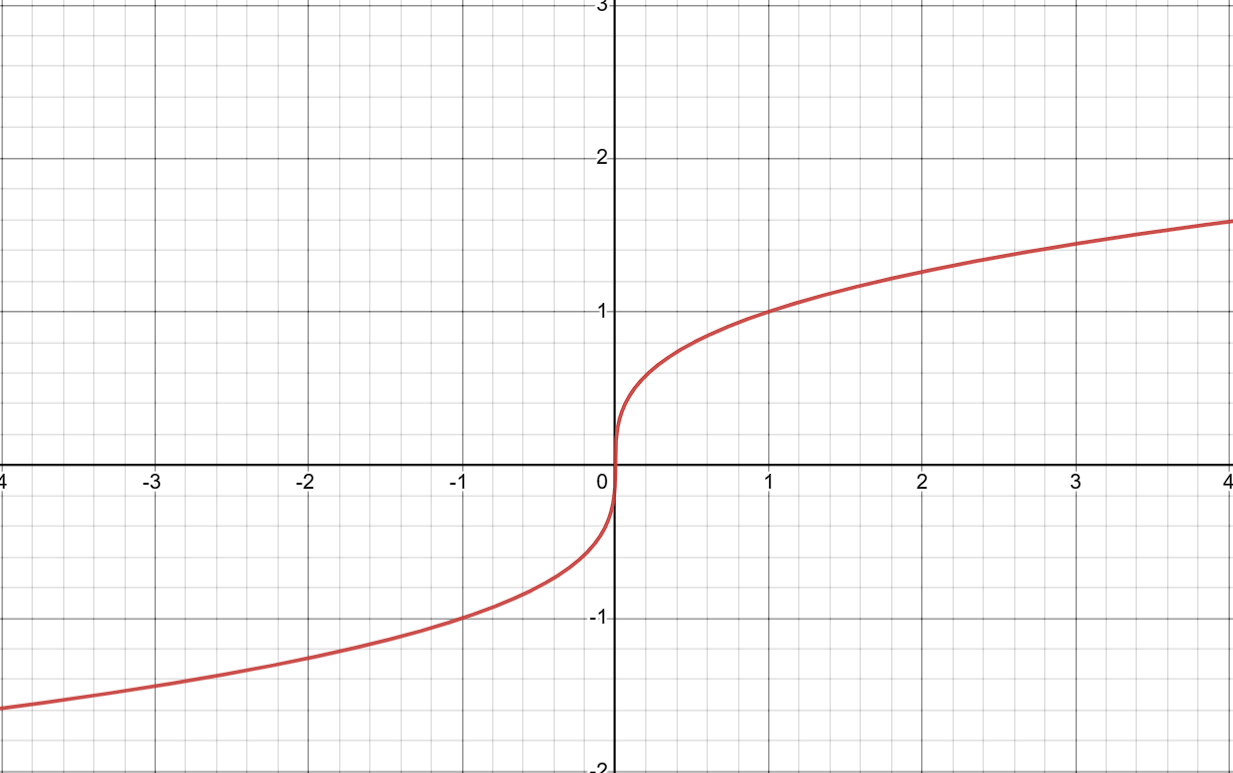
每日算法打卡:数的三次方根 day 7
文章目录 原题链接题目描述输入格式输出格式数据范围输入样例:输出样例: 题目分析示例代码 原题链接 790. 数的三次方根 题目难度:简单 题目描述 给定一个浮点数 n,求它的三次方根。 输入格式 共一行,包含一个浮…...
人机交互主板定制_基于MT8735安卓核心板的自助查询机方案
人机交互主板是一种商显智能终端主板,广泛应用于广告机、工控一体机、教学一体机、智能自助终端、考勤机、智能零售终端、O2O智能设备、取号机、计算机视觉、医疗健康设备、机器人设备等领域。 人机交互主板采用联发科MTK8735芯片平台,四核Cortex-A53架构…...

全志F1C100s Linux 系统编译出错:不能连接 github
环境 Ubuntu 20.04 LTS 64 位虚拟机 开发板:Lichee Pi Nano 源代码:GitHub - florpor/licheepi-nano 问题描述 该源码库使用了 git 子模块的概念,一个库中包含了 u-boot、Linux等代码库。不需要分别编译,一个 make 全搞定 编译时提示错误: >>> linux-hea…...

如何保障 MySQL 和 Redis 的数据一致性?
数据一致性问题是如何产生的? 数据一致性问题通常产生于数据在不同的时间点、地点或系统中存在多个副本的情况, 系统只存在一个副本的情况下也完全可能会产生。 设想一下,你在一家连锁咖啡店有一张会员卡这张会员卡可以绑定两个账号&#x…...

Leetcode 2999. Count the Number of Powerful Integers
Leetcode 2999. Count the Number of Powerful Integers 1. 解题思路2. 代码实现 题目链接:10034. Count the Number of Powerful Integers 1. 解题思路 这一题的话其实还是一个典型的求不大于 N N N的特殊数字个数的问题。 这道题本质上进行一下替换还是要求如…...

【Reading Notes】(2)
文章目录 FreestyleHip-hop dance and MusicProgrammerMaster Freestyle 都说人的成长有三个阶段,第一个阶段认为自己独一无二,天之骄子;第二个阶段发现自己原来如此渺小,如此普通,沮丧失望;第三阶段&#…...

【设计模式之美】SOLID 原则之一:怎么才算是单一原则、如何取舍单一原则
文章目录 一. 如何判断类的职责是否足够单一?二. 类的职责是否设计得越单一越好? 开始学习一些经典的设计原则,其中包括,SOLID、KISS、YAGNI、DRY、LOD 等。 本文主要学习单一职责原则的相关内容。 单一职责原则的定义:…...

# [NOIP2015 普及组] 扫雷游戏#洛谷
题目背景 NOIP2015 普及组 T2 题目描述 扫雷游戏是一款十分经典的单机小游戏。在 n n n 行 m m m 列的雷区中有一些格子含有地雷(称之为地雷格),其他格子不含地雷(称之为非地雷格)。玩家翻开一个非地雷格时&#…...

Unity中Shader的_Time精度问题
文章目录 前言一、U方向上优化二、V方向上优化在这里插入图片描述 三、最终代码1、效果2、Shader 前言 在Unity的Shader中,使用了_Time来达到UV的流动效果,普遍会出现一个问题。我们的UV值会随着时间一直增加(uv值增加了,但是因为…...

1.47寸ST7789V3彩色TFT LCD嵌入式驱动详解
1. 1.47寸彩色TFT LCD模块硬件与驱动技术解析1.1 模块核心规格与硬件架构1.47寸彩色TFT LCD模块是一款面向嵌入式系统设计的紧凑型显示单元,其物理尺寸为30mm(高)37mm(宽),采用标准2.54mm间距排针接口&…...

Java数据结构入门:栈与队列的核心原理、实现及应用
Java 栈(Stack)与队列(Queue)超详细总结(附代码示例)一、前言栈和队列是最基础、最常用的线性数据结构,它们本质上都是对“线性表”的使用限制,区别只在于进出元素的规则不同。- 栈&…...
Pixel Dimension Fissioner实战教程:自媒体博主爆款标题批量裂变工作流
Pixel Dimension Fissioner实战教程:自媒体博主爆款标题批量裂变工作流 1. 工具介绍与核心价值 Pixel Dimension Fissioner(像素语言维度裂变器)是一款专为内容创作者设计的智能文本增强工具。不同于传统AI工具的机械感,它以16-…...

国密算法C实现必须避开的7个隐性陷阱,第4个让国密SSL握手延迟飙升200ms!
第一章:国密算法C实现的性能瓶颈全景图国密算法(如SM2、SM3、SM4)在嵌入式设备、金融终端及政务系统中广泛部署,其C语言实现虽具备跨平台优势,但在实际运行中常遭遇多维度性能制约。深入剖析这些瓶颈,是优化…...

Nanbeige 4.1-3B参数详解:top_k采样对像素风输出创意性与稳定性平衡
Nanbeige 4.1-3B参数详解:top_k采样对像素风输出创意性与稳定性平衡 1. 引言:像素风对话系统的独特挑战 在AI对话系统设计中,Nanbeige 4.1-3B模型的"像素冒险"风格界面带来了独特的交互体验,也对文本生成质量提出了特…...

MedGemma多模态系统展示:支持‘请用住院医师水平’‘请用主任医师水平’分级输出
MedGemma多模态系统展示:支持‘请用住院医师水平’‘请用主任医师水平’分级输出 1. 系统核心能力概览 MedGemma Medical Vision Lab 是一个基于 Google MedGemma-1.5-4B 多模态大模型构建的医学影像智能分析 Web 系统。这个系统最独特的地方在于,它能…...
)
手把手解析:如何用CVD生长晶圆级二维半导体(附避坑指南)
手把手解析:如何用CVD生长晶圆级二维半导体(附避坑指南) 走进任何一家先进半导体实验室,你都会看到研究人员围在CVD设备前眉头紧锁——有人刚得到完美的单层MoS2薄膜,也有人正对着布满裂纹的样品发愁。这种场景每天都在…...

警惕你身边做AI for Science的人
警惕你身边做AI for Science的人他们手持显卡账单,口称改变人类命运,用一张模型架构图解释一切,用一篇Nature子刊圆所有谎言。我先声明,我不是反对AI,也不是反对科学。我反对的,是那种特定的人。他们活在一…...

WhisperLive:如何实现近乎实时的OpenAI Whisper语音转录?
WhisperLive:如何实现近乎实时的OpenAI Whisper语音转录? 【免费下载链接】WhisperLive A nearly-live implementation of OpenAIs Whisper. 项目地址: https://gitcode.com/gh_mirrors/wh/WhisperLive WhisperLive是一个革命性的实时语音转文本解…...

查重90%以为要延毕?2026最新实测:DeepSeek四大免费降AI指令+3款救命工具,一把拉回10%安全线
知网AIGC检测又升级了,现在除了查重复率,AIGC检测更是必须要过的硬指标。 我之前的一篇内容AI率测出59.2%,后来我花了一周时间研究,发现想降低ai,不能只是简单的替换词汇,必须要改变文本的生成逻辑&#x…...