ElasticSearch深度分页解决方案
一、前言
ElasticSearch是一个基于Lucene的搜索引擎,它支持复杂的全文搜索和实时数据分析。在实际应用中,我们经常需要对大量数据进行分页查询,但是传统的分页方式在处理大量数据时会遇到性能瓶颈。本文将介绍ElasticSearch分页工作原理、深度分页存在的问题以及深度分页解决方案。
二、分页执行原理
ElasticSearch的分页原理是基于游标的。当我们执行一个分页查询时,ElasticSearch会返回当前页面的数据以及一个游标(_scroll_id)。游标是一个唯一标识符,用于记录当前查询位置。当我们需要获取下一页数据时,只需要将游标传递给下一次查询即可。
From/Size参数
在ES中,分页查询默认返回最顶端的10条匹配hits。
如果需要分页,需要使用from和size参数。
from参数定义了需要跳过的hits数,默认为0;
size参数定义了需要返回的hits数目的最大值。
一个基本的ES查询语句是这样的:
POST /my_index/my_type/_search
{"query": { "match_all": {}},"from": 100,"size": 10
}上面的查询表示从搜索结果中取第100条开始的10条数据。
在ES中,搜索一般包括两个阶段,query 和 fetch 阶段,可以简单的理解,query 阶段确定要取哪些doc,fetch 阶段取出具体的 doc。
query阶段:
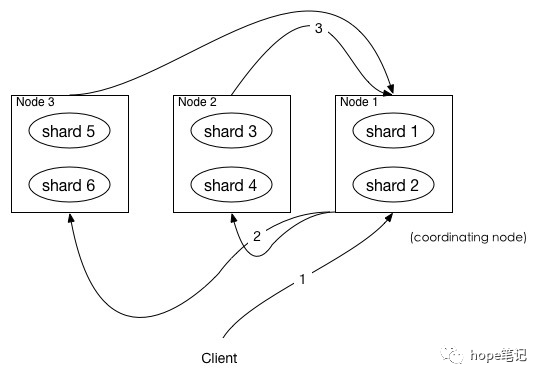
如上图所示,描述了一次搜索请求的 query 阶段:
-
Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为from + size的优先级队列用来存结果,我们管 node1 叫 coordinating node。
-
coordinating node将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为from + size 的优先级队列里,可以把优先级队列理解为一个包含top N结果的列表。
-
每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。
在上面的例子中,coordinating node 拿到(from + size) * 6条数据,然后合并并排序后选择前面的from + size条数据存到优先级队列,以便 fetch 阶段使用。
另外,各个分片返回给 coordinating node 的数据用于选出前from + size条数据,所以,只需要返回唯一标记 doc 的_id以及用于排序的_score即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
fetch 阶段:
-
coordinating node 发送 GET 请求到相关shards。
-
shard 根据 doc 的_id取到数据详情,然后返回给 coordinating node。
-
coordinating node 返回数据给 Client。
coordinating node 的优先级队列里有from + size 个_doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前100条数据是不需要取的,只需要取优先级队列里的第101到110条数据即可。
需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 「multi-get」 来避免多次去同一分片取数据,从而提高性能。
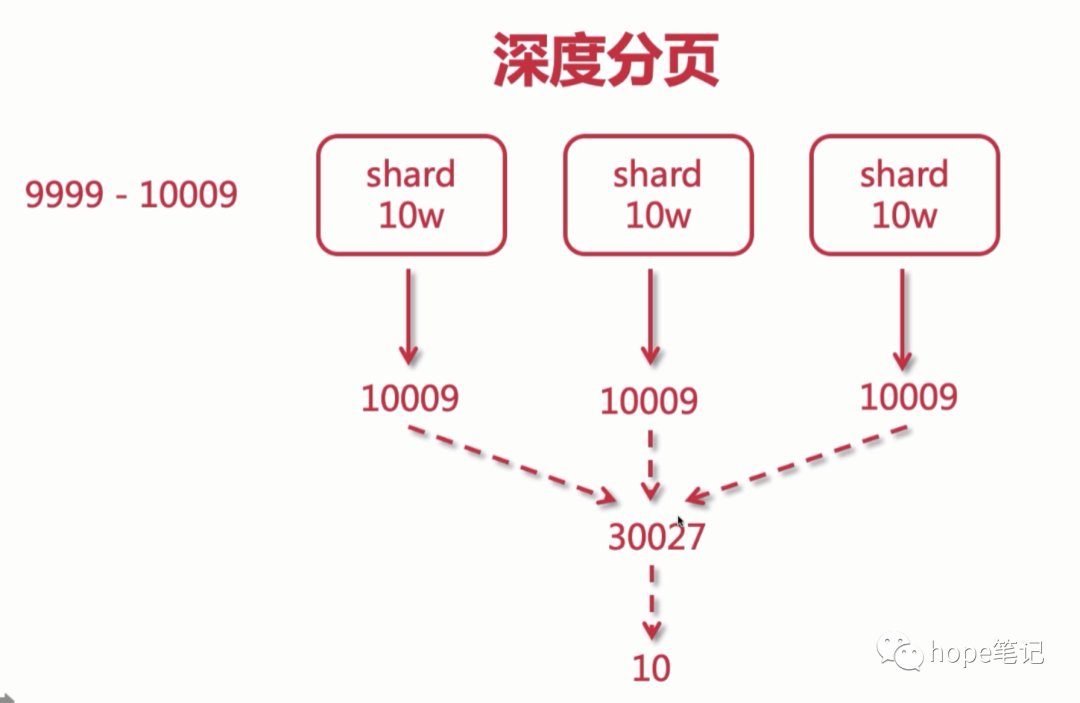
三、深度分页问题
-
内存占用高:当查询结果集很大时,使用scroll API会导致内存占用过高,甚至出现OOM异常。
-
响应时间慢:由于需要将所有数据加载到内存中,所以scroll API的响应时间相对较慢。
-
游标管理复杂:使用scroll API时,需要手动管理游标,包括创建、删除和滚动游标等操作,这会增加开发难度和维护成本。
Elasticsearch 的From/Size方式提供了分页的功能,同时,也有相应的限制。
举个例子,一个索引,有10亿数据,分10个 shards,然后,一个搜索请求,from=1000000,size=100,这时候,会带来严重的性能问题:CPU,内存,IO,网络带宽。
在 query 阶段,每个shards需要返回 1000100 条数据给 coordinating node,而 coordinating node 需要接收10 * 1000,100 条数据,即使每条数据只有 _doc _id 和 _score,这数据量就很大了。
四、解决方案
1. 使用scroll API进行深度分页
scroll API可以获取大量数据,并且可以在内存中缓存这些数据。通过scroll API,我们可以在一次查询中获取所有满足条件的文档,然后根据需要对它们进行排序和过滤。这种方式适用于需要处理大量数据的场景。
Scroll,可以把scroll理解为关系型数据库里的cursor,因此,scroll并不适合用来做实时搜索,而更适合用于后台批处理任务,比如群发。scroll可以分为初始化和遍历两部,初始化时将「所有符合搜索条件的搜索结果缓存起来(注意,这里只是缓存的doc_id,而并不是真的缓存了所有的文档数据,取数据是在fetch阶段完成的)」,可以想象成快照。支持排序。
Scroll Scan,ES提供了scroll scan方式进一步提高遍历性能,但是scroll scan不支持排序,因此scroll scan适合不需要排序的场景。
POST /twitter/tweet/_search?scroll=1m
{"size": 100,"query": {"match" : {"title" : "elasticsearch"}}
}2. 使用搜索后的游标进行深度分页
在Elasticsearch中,每个分页结果都有一个游标(_scroll_id),用于标识当前分页的最后一个文档的位置。当需要获取下一页数据时,只需要将游标传递给下一次查询即可。这种方式适用于需要频繁进行分页查询的场景。
3. 使用Search After进行深度分页
Search After是Elasticsearch提供的一种分页方式,它可以根据上一次查询的结果来获取下一页的数据。Search After的原理是在上一次查询结果的基础上,跳过指定数量的文档,然后返回剩余的文档。这种方式适用于需要快速获取下一页数据的场景。
GET twitter/_search
{"size": 10,"query": {"match" : {"title" : "es"}},"search_after": [20000000, "50000"],"sort": [{"date": "asc"},{"_id": "desc"}]
}五、总结
如果数据量小(from+size在10000条内),或者只关注结果集的TopN数据,可以使用from/size 分页,简单粗暴;
数据量大,深度翻页,后台批处理任务(数据迁移)之类的任务,使用 scroll 方式;
数据量大,深度翻页,用户实时、高并发查询需求,使用 search after 方式;
ElasticSearch深度分页解决方案有很多种,不同的场景需要选择不同的方案。在使用ElasticSearch进行深度分页查询时,我们需要了解其分页原理以及各种分页方案的优缺点,以便根据实际情况选择合适的方案。

相关文章:
ElasticSearch深度分页解决方案
一、前言 ElasticSearch是一个基于Lucene的搜索引擎,它支持复杂的全文搜索和实时数据分析。在实际应用中,我们经常需要对大量数据进行分页查询,但是传统的分页方式在处理大量数据时会遇到性能瓶颈。本文将介绍ElasticSearch分页工作原理、深…...

nginx下upstream模块详解
目录 一:介绍 二:特性介绍 一:介绍 Nginx的upstream模块用于定义后端服务器组,以及与这些服务器进行通信的方式。它是Nginx负载均衡功能的核心部分,允许将请求转发到多个后端服务器,并平衡负载。 在upst…...
基于ssm的双减后初小教育课外学习生活活动平台的设计与实现论文
双减后初小教育课外学习生活活动平台的设计与实现 摘 要 当下,正处于信息化的时代,许多行业顺应时代的变化,结合使用计算机技术向数字化、信息化建设迈进。以前学校对于课外学习活动信息的管理和控制,采用人工登记的方式保存相关…...
wblogic中间件配置数据源
配置数据源 1.服务-数据源-配置-新建 2.单机选一般数据源 3.选择源名称、jndi名称、数据库类型 4.选择驱动 5.下一步 6.输入连接串信息 参考: 格式二:jdbc:oracle:thin:<host>:<port>:<SID> 数据库名称配置的sid 7.测试配置ÿ…...
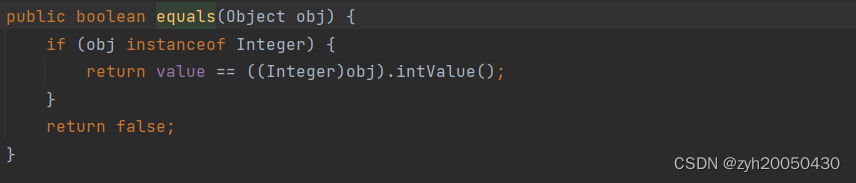
Java数据结构之装箱拆箱
装箱和拆箱 也叫装包拆包,装包是把那八种基本数据类型转换为它的包装类,拆包则相反 上面这俩种方式都是装包,下面是它的字节码文件 用到了Integer的ValueOf方法: 就是返回了一个Integer类的对象,把它的value属性设置成…...
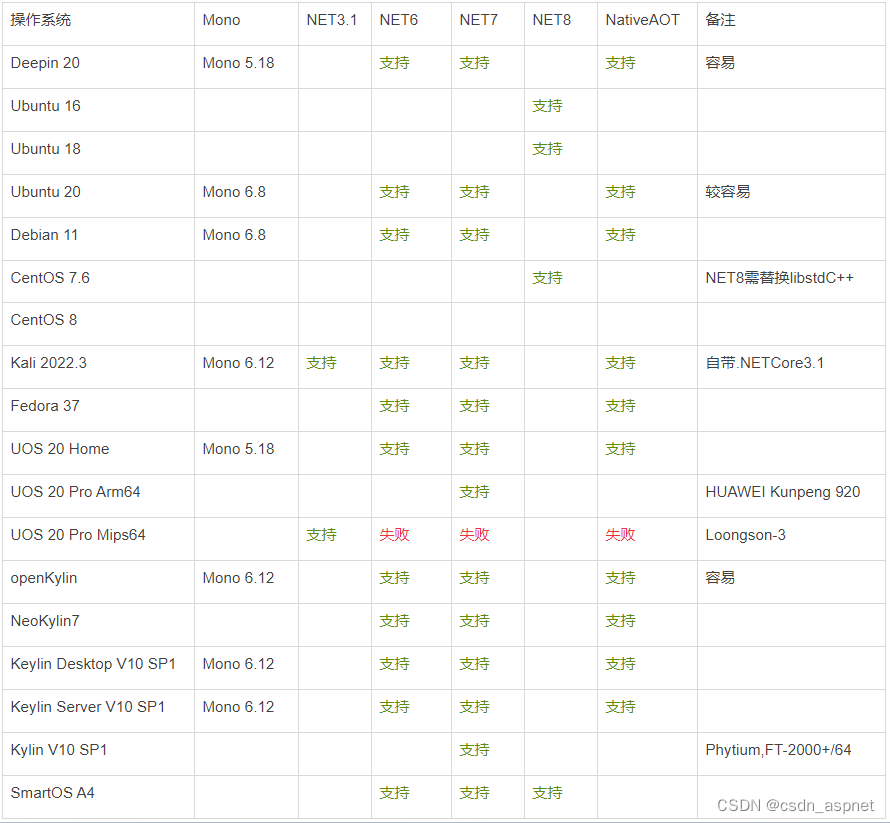
各版本 操作系统 对 .NET Framework 与 .NET Core 支持
有两种类型的受支持版本:长期支持 (LTS) 版本和标准期限支持 (STS) 版本。 所有版本的质量都是一样的。 唯一的区别是支持的时间长短。 LTS 版本可获得为期三年的免费支持和补丁。 STS 版本可获得 18 个月的免费支持和修补程序。 有关详细信息,请参阅 .N…...

Golang 线程安全与 sync.Map
前言 线程安全通常是指在并发环境下,共享资源的访问被适当地管理,以防止竞争条件(race conditions)导致的数据不一致 Go语言中的线程安全可以通过多种方式实现 实现方式 互斥锁(Mutexes) Go的sync包提供…...

1.2 Hadoop概述
小肥柴的Hadoop之旅 1.2 Hadoop概述 目录1.2 Hadoop概述1.2.1 回归问题1.2.2 Google的三篇论文1.2.3 Hadoop的诞生过程1.2.4 Hadoop特点简介 参考文献和资料 ) 目录 1.2 Hadoop概述 1.2.1 回归问题 通过前一篇帖子的介绍,特别是问题思考部分的说明,我…...

Adams许可管理安全控制策略
随着全球信息化的快速发展,信息安全和许可管理问题日益凸显。在这场无形的挑战中,Adams许可管理安全控制策略以其卓越的性能和可靠性,引领着解决这类问题的新潮流。 Adams许可管理安全控制策略是一种全方位、多层次的安全控制方案࿰…...

无人地磅系统|内蒙古中兴首创无人地磅和远程高效管理的突破
走进标杆企业,感受名企力量,探寻学习优秀企业领先之道。 本期要跟砼行们推介的标杆企业是内蒙古赤峰市砼行业的龙头企业:赤峰中兴首创混凝土搅拌有限责任公司(以下简称为中兴首创)。 中兴首创成立于2011年初ÿ…...

【SpringCloud】7、Spring Cloud Gateway限流配置
1、限流介绍 Spring Cloud Gateway 的限流配置主要涉及到令牌桶算法的实现。令牌桶算法可以对某一时间窗口内的请求数进行限制,保持系统的可用性和稳定性,防止因流量暴增而导致的系统运行缓慢或宕机。 在 Spring Cloud Gateway 中,官方提供了 RequestRateLimiterGatewayFi…...
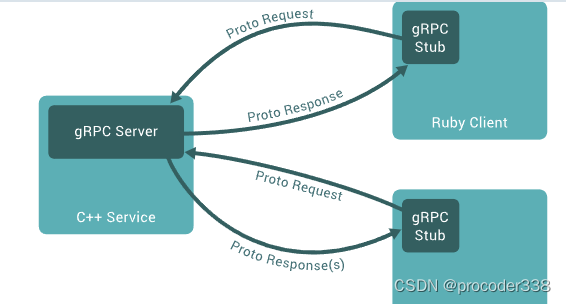
【gRPC学习】使用go学习gRPC
个人博客:Sekyoro的博客小屋 个人网站:Proanimer的个人网站 RPC是远程调用,而google实现了grpc比较方便地实现了远程调用,gRPC是一个现代的开源远程过程调用(RPC)框架 概念介绍 在gRPC中,客户端应用程序可以直接调用另一台计算机上的服务器应用程序上的方法&#…...
C语言中常用的字符串函数(strlen、sizeof、sscanf、sprintf、strcpy)
C语言中常用的字符串函数 文章目录 C语言中常用的字符串函数1 strlen函数2 sizeof函数2.1 sizeof介绍2.2 sizeof用法 3 sscanf函数3.1 sscanf介绍3.2 sscanf用法3.3 sscanf高级用法 4 sprintf函数4.1 背景4.2 sprintf用法 5 strcpy函数5.1 strcpy介绍5.1 strcpy用法 1 strlen函…...

域名解析服务器:连接你与互联网的桥梁
域名解析服务器:连接你与互联网的桥梁 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨一个网络世界中至关重要却鲜为人知的角…...

理论物理在天线设计和射频电路设计中的应用
理论物理的基本原理可以应用于电路中的电磁场分析和电磁波传播问题,例如天线设计和射频电路设计。通过应用麦克斯韦方程组和电磁波传播理论,可以优化电路的性能,提高天线的辐射效率和射频电路的传输效率。麦克斯韦方程组是描述电磁场行为的基…...

MySql01:初识
1.mysql数据库2.配置环境变量3. 列的类型和属性,索引,注释3.1 类型3.2 属性3.3 主键(主键索引)3.4 注释 4.结构化查询语句分类:5.列类型--表列类型设置 1.mysql数据库 数据库: 数据仓库,存储数据,以前我…...

Python——运算符
num 1 num 1 print("num1:", num) num - 1 print("num-1:", num) num * 4 print("num*4:", num) num / 4 print("num/4:", num) num 3 num % 2 print("num%2:", num) num ** 2 print("num**2:", num) 运行结果…...

赋能软件开发:生成式AI在优化编程工作流中的应用与前景
随着人工智能(AI)技术的快速发展,特别是生成式AI模型如GPT-3/4的出现,软件开发行业正经历一场变革,这些模型通过提供代码生成、自动化测试和错误检测等功能,极大地提高了开发效率和软件质量。 本文旨在深入…...
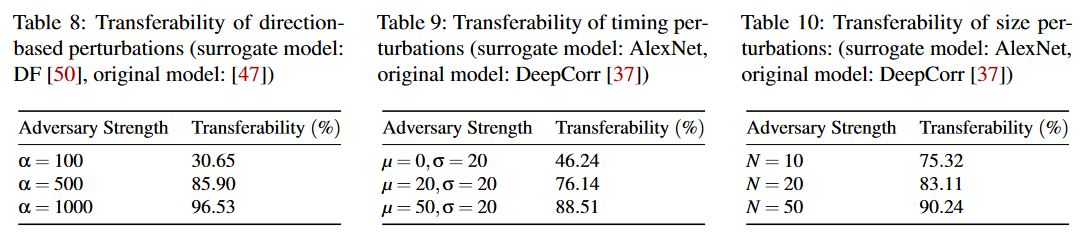
通过盲对抗性扰动实时击败基于DNN的流量分析系统
文章信息 论文题目:Defeating DNN-Based Traffic Analysis Systems in Real-Time With Blind Adversarial Perturbations 期刊(会议):30th USENIX Security Symposium 时间:2021 级别:CCF A 文章链接&…...
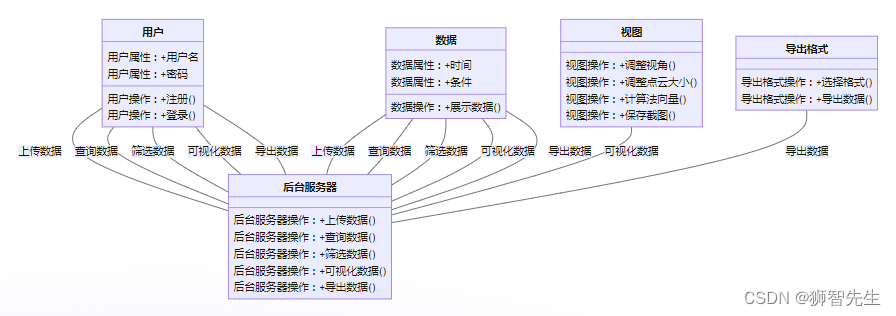
【Project】TPC-Online Module (manuscript_2024-01-07)
PRD正文 一、概述 本模块实现隧道点云数据的线上汇总和可视化。用户可以通过注册和登录功能进行身份验证,然后上传原始隧道点云数据和经过处理的数据到后台服务器。该模块提供数据查询、筛选和可视化等操作,同时支持对指定里程的分段显示和点云颜色更改…...
)
基于MATLAB的悬臂梁前3阶固有频率和振型求解(假设模态法、解析法、瑞利里兹法)
基于matlab的求解悬臂梁前3阶固有频率和振型 基于matlab的求解悬臂梁前3阶固有频率和振型,采用的方法分别是(假设模态法,解析法,瑞利里兹法) 程序已调通,可直接运行悬臂梁的振动分析总带着点工程师的浪漫——既要数学的…...

终极fswatch过滤器配置指南:如何用正则表达式精准控制文件监控范围
终极fswatch过滤器配置指南:如何用正则表达式精准控制文件监控范围 【免费下载链接】fswatch A cross-platform file change monitor with multiple backends: Apple OS X File System Events, *BSD kqueue, Solaris/Illumos File Events Notification, Linux inoti…...

ArduinoEigen:嵌入式平台轻量级Eigen线性代数库移植
1. ArduinoEigen:面向嵌入式平台的轻量化Eigen线性代数库移植1.1 项目定位与工程价值ArduinoEigen 是一个专为资源受限嵌入式平台定制的 Eigen 线性代数库移植版本,其核心目标并非简单地将桌面级 C 数值计算库“搬上”MCU,而是通过深度裁剪、…...

开源工具Wand-Enhancer功能增强技术解析与实战指南
开源工具Wand-Enhancer功能增强技术解析与实战指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 一、问题定位:WeMod功能增强的核心挑战 …...

SEO 实战培训班在哪里_SEO 优化师培训在哪里
SEO 实战培训班在哪里_SEO 优化师培训在哪里 在当今数字化时代,网站的流量和排名直接关系到企业的生存和发展。这就是为什么越来来越多的企业和个人希望掌握SEO优化技能,成为一名优秀的SEO优化师。SEO 实战培训班在哪里呢?SEO 优化师培训在哪…...

有了这个Python备忘录,代码拿来即用
这段时间代码写的少了,周末用python写一个小爬虫,却发现连线程的一些方法都不记得了,还得百度查教程。工作越忙,记性越差,发现我疏远了代码,代码也疏远了我。 PS:对于小白来说自学也不是件容易…...

百川2-13B-4bits量化版模型蒸馏:为OpenClaw定制更小尺寸专用模型
百川2-13B-4bits量化版模型蒸馏:为OpenClaw定制更小尺寸专用模型 1. 为什么需要为OpenClaw定制专用模型 去年冬天,当我第一次尝试在树莓派上部署OpenClaw时,遇到了一个尴尬的问题——即使是最轻量级的开源模型,也会让这个小家伙…...

RailSAM:驯 服 SAM与 适 配 器 的 铁 路 分 割精读
一、整体总结研究领域: 基于视觉基础模型的铁路场景语义分割(轨道分割)解决问题: 解决传统铁路分割方法依赖大量标注数据、泛化能力差、计算开销大的问题,同时探索如何将通用大模型(SAM)有效迁移…...

新手福音:通过快马生成图文并茂的ccswitch安装教程代码,轻松上手
最近在折腾一个叫ccswitch的工具,作为刚入门的新手,真的被各种环境配置搞得头大。好在发现了InsCode(快马)平台,它能直接生成带详细注释的安装教程代码,简直是救命稻草!今天就把这个图文并茂的教程项目分享给大家。 c…...

人机互信的瓶颈在于……
人机互信的核心瓶颈在于技术透明度不足、责任归属模糊、伦理对齐困难以及人类对技术的过度依赖与误解,这些因素共同导致了人机协作中的信任危机。一、技术层面的瓶颈1. 算法"黑箱"效应决策过程不透明,深度学习模型的内部运算过程难以解释&…...