LLM_InterLM-Demo学习
reference Github: https://github.com/InternLM/tutorial/blob/main/helloworld/hello_world.md
1- 环境配置
之前都是用科学上网在huggingFace进行的模型下载,同时还需要进行一些配置
import os
os.environ['CURL_CA_BUNDLE'] = ''
在本次的学习中发现可以设置镜像或者是通过modelscope(pip install modelscope)进行下载
# huggingface-下载
## 安装依赖: pip install -U huggingface_hub
## 直接设置环境变量: export HF_ENDPOINT=https://hf-mirror.com
import os
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="internlm/internlm-7b", filename="config.json")# modelscope 下载
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/model', revision='v1.0.3')下载完之后可以直接用transformers 无缝衔接
import torch
from transformers import AutoModelForCausalLM, AutoTokenizerdownload_dir = "xxx/internlm-chat-7b"model = (AutoModelForCausalLM.from_pretrained(download_dir, trust_remote_code=True).to(torch.bfloat16).cuda())
tokenizer = AutoTokenizer.from_pretrained(download_dir, trust_remote_code=True)
同时补齐了信息差,知道了国内镜像合集网址:MirrorZ Help
2- InterLM-Chat-7B Demo尝试
主要的项目GitHub: https://github.com/InternLM/InternLM
2.1 终端demo
其实进行demo尝试相对比较简单,主要是模型下载和GPU显存(20G : 1/4的A100-80G)的限制比较大。只用transformers.AutoModelForCausalLM加载进行尝试就行。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""messages = [(system_prompt, '')]print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")while True:input_text = input("User >>> ")input_text = input_text.replace(' ', '')if input_text == "exit":breakresponse, history = model.chat(tokenizer, input_text, history=messages)messages.append((input_text, response))print(f"robot >>> {response}")
2.2 web demo
进行web demo,主要是对终端demo进行一层streamlit的封装,同时通过ssh将端口映射到本地,资源占用的时服务器的资源。
从教程中学习到了@st.cache_resource装饰器的用法,这个在笔者之前的streamlit项目中没有用到过, 后续可以在自己项目中尝试用在保持database的连接上。
@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained("internlm/internlm-chat-7b", trust_remote_code=True)return model, tokenizer
3- Lagent 智能体工具调用 Demo尝试
主要的项目GitHub: https://github.com/InternLM/lagent
在第一节中已经了解到:大模型的局限性,需要Agent去引导优化, 这次demo尝试加深了对这个句话的理解。
在本次Demo中调用lagent,去解决数学问题: 已知 2x+3=10,求x ,此时 InternLM-Chat-7B 模型理解题意生成解此题的 Python 代码,Lagent 调度送入 Python 代码解释器求出该问题的解。
主要步骤如下:
- 模型初始化
init_model(基于选择的name)model = HFTransformerCasualLM('/root/model/Shanghai_AI_Laboratory/internlm-chat-7b')
- 构建lagent
initialize_chatbotchatbot = ReAct(llm=model, action_executor=ActionExecutor(actions=PythonInterpreter()))
- 用户输入调用
chatbotagent_return = chatbot.chat(user_input)
- 解析返回结果并展示(最后保存历史信息)
render_assistant(agent_return)- action解析展示如下
def render_assistant(self, agent_return):with st.chat_message('assistant'):for action in agent_return.actions:if (action):self.render_action(action)st.markdown(agent_return.response)def render_action(self, action):with st.expander(action.type, expanded=True):st.markdown("<p style='text-align: left;display:flex;'> <span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'>插 件</span><span style='width:14px;text-align:left;display:block;'>:</span><span style='flex:1;'>" # noqa E501+ action.type + '</span></p>',unsafe_allow_html=True)st.markdown("<p style='text-align: left;display:flex;'> <span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'>思考步骤</span><span style='width:14px;text-align:left;display:block;'>:</span><span style='flex:1;'>" # noqa E501+ action.thought + '</span></p>',unsafe_allow_html=True)if (isinstance(action.args, dict) and 'text' in action.args):st.markdown("<p style='text-align: left;display:flex;'><span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'> 执行内容</span><span style='width:14px;text-align:left;display:block;'>:</span></p>", # noqa E501unsafe_allow_html=True)st.markdown(action.args['text'])self.render_action_results(action)def render_action_results(self, action):"""Render the results of action, including text, images, videos, andaudios."""if (isinstance(action.result, dict)):st.markdown("<p style='text-align: left;display:flex;'><span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'> 执行结果</span><span style='width:14px;text-align:left;display:block;'>:</span></p>", # noqa E501unsafe_allow_html=True)if 'text' in action.result:st.markdown("<p style='text-align: left;'>" + action.result['text'] +'</p>',unsafe_allow_html=True)if 'image' in action.result:image_path = action.result['image']image_data = open(image_path, 'rb').read()st.image(image_data, caption='Generated Image')if 'video' in action.result:video_data = action.result['video']video_data = open(video_data, 'rb').read()st.video(video_data)if 'audio' in action.result:audio_data = action.result['audio']audio_data = open(audio_data, 'rb').read()st.audio(audio_data)
简单的代码可以如下
from lagent.actions import ActionExecutor, GoogleSearch, PythonInterpreter
from lagent.agents.react import ReAct
from lagent.llms import GPTAPI
from lagent.llms.huggingface import HFTransformerCasualLM# init_model
model = HFTransformerCasualLM('/root/model/Shanghai_AI_Laboratory/internlm-chat-7b')# initialize_chatbot
chatbot = ReAct(llm=model, action_executor=ActionExecutor(actions=PythonInterpreter()))
agent_return = chatbot.chat(user_input)
4- 浦语·灵笔图文理解创作 Demo尝试
主要的项目GitHub: https://github.com/InternLM/InternLM-XComposer
这里的模型也是不一样:InternLM-XComposer是基于InternLM研发的视觉-语言大模型
InternLM-XComposer是提供出色的图文理解和创作能力,具有多项优势:
-
图文交错创作:
InternLM-XComposer可以为用户打造图文并貌的专属文章。这一能力由以下步骤实现:- 理解用户指令,创作符合要求的长文章。
- 智能分析文章,自动规划插图的理想位置,确定图像内容需求。
- 多层次智能筛选,从图库中锁定最完美的图片。
-
基于丰富多模态知识的图文理解:
InternLM-XComposer设计了高效的训练策略,为模型注入海量的多模态概念和知识数据,赋予其强大的图文理解和对话能力。 -
杰出性能:
InternLM-XComposer在多项视觉语言大模型的主流评测上均取得了最佳性能,包括MME Benchmark (英文评测), MMBench (英文评测), Seed-Bench (英文评测), CCBench(中文评测), MMBench-CN (中文评测).
4.1 生成文章
- 模型和token初始化
- 模型调用
- 快速使用的话,可以直接
llm_model.generate - 进行复杂的一些操作可以
llm_model.internlm_model.generate- 细节看笔者简单修改的
generate函数
- 细节看笔者简单修改的
- 快速使用的话,可以直接
核心示例code:
import torch
from transformers import StoppingCriteriaList, AutoTokenizer, AutoModel
from examples.utils import auto_configure_device_mapclass StoppingCriteriaSub(StoppingCriteria):def __init__(self, stops=[], encounters=1):super().__init__()self.stops = stopsdef __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor):for stop in self.stops:if torch.all((stop == input_ids[:, -len(stop):])).item():return Truereturn Falsefolder = 'internlm/internlm-xcomposer-7b'
device = 'cuda'# 1- init model and tokenizer
llm_model = AutoModel.from_pretrained(folder, trust_remote_code=True).cuda().eval()
if args.num_gpus > 1:from accelerate import dispatch_modeldevice_map = auto_configure_device_map(args.num_gpus)model = dispatch_model(model, device_map=device_map)tokenizer = AutoTokenizer.from_pretrained(folder, trust_remote_code=True)
llm_model.internlm_tokenizer = tokenizer
llm_model.tokenizer = tokenizer# 2 封装generate
def generate(llm_model, text, random, beam, max_length, repetition, use_inputs=False):"""生成文章封装llm_model: AutoModel.from_pretrained 加载的 internlm/internlm-xcomposer-7brandom: 采样beam: beam search 数量max_length: 文章最大长度repetition: repetition_penalty"""device = 'cuda'# stop critriastop_words_ids = [torch.tensor([103027]).to(device), torch.tensor([103028]).to(device), ]stopping_criteria = StoppingCriteriaList([StoppingCriteriaSub(stops=stop_words_ids)])# 输入tokensinput_tokens = llm_model.internlm_tokenizer(text, return_tensors="pt",add_special_tokens=True).to(llm_model.device)# 输入生成图像的embedsimg_embeds = llm_model.internlm_model.model.embed_tokens(input_tokens.input_ids)inputs = input_tokens.input_ids if use_inputs else None# 模型推理with torch.no_grad():with llm_model.maybe_autocast():outputs = llm_model.internlm_model.generate(inputs=inputs,inputs_embeds=img_embeds, # 生成配图stopping_criteria=stopping_criteria,do_sample=random,num_beams=beam,max_length=max_length,repetition_penalty=float(repetition),)# decode及输出output_text = llm_model.internlm_tokenizer.decode(outputs[0][1:], add_special_tokens=False)output_text = output_text.split('<TOKENS_UNUSED_1>')[0]return output_text# 调用
## 生成小文章
text = '请介绍下爱因斯坦的生平'
- 直接调用:
response = llm_model.generate(text)
print(f'User: {text}')
print(f'Bot: {response}')
- 封装调用:
generate(llm_model, text,random=False,beam=3,max_length=300,repetition=5.,use_inputs=True
)4.2 多模态对话
主要用 gradio 搭建web(可以阅读【知乎 Gradio:轻松实现AI算法可视化部署】)
- 模型和token初始化
- 模型调用
- 快速使用的话,可以直接
llm_model.chat(text=text, image=image, history=None) - 进行复杂的一些操作可以
llm_model.internlm_model.generate- 这部分embeding比较复杂(笔者梳理的
chat_answer示意了主要流程,但还是存在bug)
- 这部分embeding比较复杂(笔者梳理的
- 快速使用的话,可以直接
import torch
from transformers import StoppingCriteriaList, AutoTokenizer, AutoModel
from examples.utils import auto_configure_device_map# 模型初始化同上
state = CONV_VISION_7132_v2.copy()
def chat_answer(llm_model, state, text, image):"""state: 起到history的作用text: 输入的提问内容image: 图片"""# image 需要读取# image = gr.State()device = 'cuda'# stop critriastop_words_ids = [torch.tensor([103027]).to(device), torch.tensor([103028]).to(device), ]stopping_criteria = StoppingCriteriaList([StoppingCriteriaSub(stops=stop_words_ids)])# 输入处理img_list = []state.append_message(state.roles[0], text)with torch.no_grad():image_pt = llm_model.vis_processor(image).unsqueeze(0).to(0)image_emb = llm_model.encode_img(image_pt)img_list.append(image_emb)# 生成内容的embeddingprompt = state.get_prompt()prompt_segs = prompt.split('<Img><ImageHere></Img>')seg_tokens = [llm_model.internlm_tokenizer(seg, return_tensors="pt", add_special_tokens=i == 0).to(device).input_idsfor i, seg in enumerate(prompt_segs)]seg_embs = [llm_model.internlm_model.model.embed_tokens(seg_t) for seg_t in seg_tokens]mixed_embs = [emb for pair in zip(seg_embs[:-1], img_list) for emb in pair] + [seg_embs[-1]]mixed_embs = torch.cat(mixed_embs, dim=1)embs = mixed_embs# 模型推理outputs = llm_model.internlm_model.generate(inputs_embeds=embs,max_new_tokens=300,stopping_criteria=stopping_criteria,num_beams=3,#temperature=float(temperature),do_sample=False,repetition_penalty=float(0.5),bos_token_id=llm_model.internlm_tokenizer.bos_token_id,eos_token_id=llm_model.internlm_tokenizer.eos_token_id,pad_token_id=llm_model.internlm_tokenizer.pad_token_id,)# decode输出output_token = outputs[0]if output_token[0] == 0:output_token = output_token[1:]output_text = llm_model.internlm_tokenizer.decode(output_token, add_special_tokens=False)print(output_text)output_text = output_text.split('<TOKENS_UNUSED_1>')[0] # remove the stop sign '###'output_text = output_text.split('Assistant:')[-1].strip()output_text = output_text.replace("<s>", "")return output_text
# 图文对话
## 1st return
image = 'examples/images/aiyinsitan.jpg'
text = '图片里面的是谁?'
- 直接调用:
response, history = llm_model.chat(text=text, image=image, history=None)
print(f'User: {text}')
print(f'Bot: {response}')
- 封装调用:
output_text = chat_answer(llm_model, state, text, image)## 2nd turn
text = '他有哪些成就?'
- 直接调用:
response, history = llm_model.chat(text=text, image=None, history=history)
print(f'User: {text}')
print(f'Bot: {response}')
- 封装调用:
output_text = chat_answer(llm_model, state, text, image)
相关文章:

LLM_InterLM-Demo学习
reference Github: https://github.com/InternLM/tutorial/blob/main/helloworld/hello_world.md 1- 环境配置 之前都是用科学上网在huggingFace进行的模型下载,同时还需要进行一些配置 import os os.environ[CURL_CA_BUNDLE] 在本次的学习中发现可以设置镜像或…...

倍思科技红海突围要义:紧随新趋势,“实用而美”理念从一而终
移动数码周边市场始终不缺热度。 销售端是业绩的节节高升,如在2023年京东双十一,移动数码周边产品销售成果丰硕,根据京东战报,大功率充电器成交额同比提升 200%,65W以上移动电源成交额同比提升 150%,自带线…...
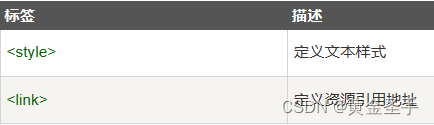
十、HTML 样式- CSS
CSS (Cascading Style Sheets) 用于渲染HTML元素标签的样式。 一、实例 1、HTML使用样式 本例演示如何使用添加到 <head> 部分的样式信息对 HTML 进行格式化。 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>HTM…...

Spring的mybatis整合
mybatis整合 主要是处理dao包下的接口和xml文件,以及service下的类和接口 第一步 在resource目录下创建mybatis-config.xml文件【注意点:mybatis-config.xml文件下通常都是写别名、和mappers】 <?xml version"1.0" encoding"U…...
React 入门 - 01
本章内容 目录 1. 简介1.1 初始 React1.2 React 相关技术点1.3 React.js vs Vue.js 2. React 开发环境准备2.1 关于脚手架工具2.2 create-react-app 构建一个 React 项目工程 1. 简介 1.1 初始 React React JS 是 Facebook 在 2013年5月开源的一款前端框架,其带来…...
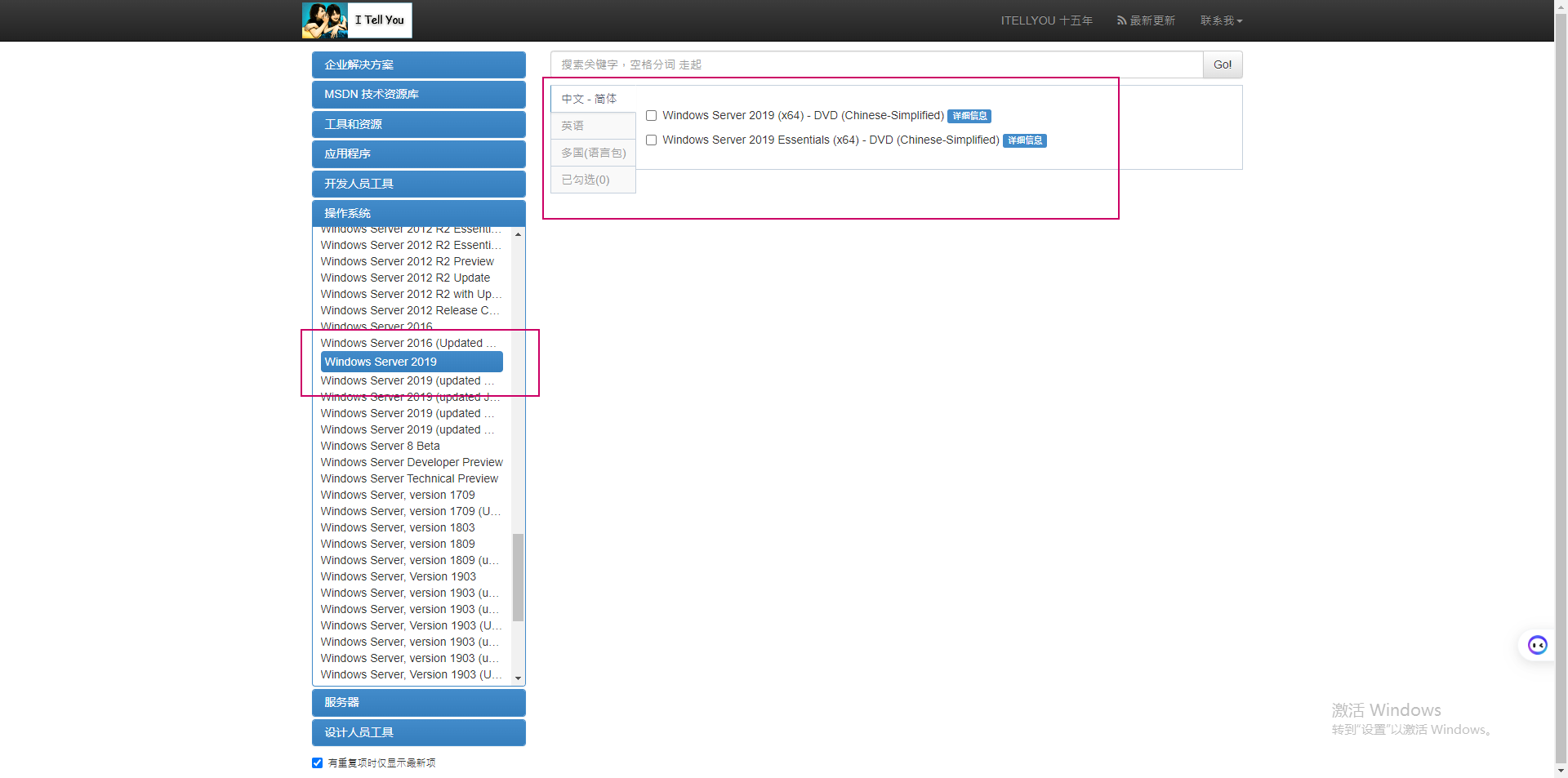
Windows Server 2019 Standard 和 Datacenter 版本差异比较
文章目录 正式版本的通用功能差异锁定和限制差异服务器角色差异可用功能差异Windows 2019 ISO下载推荐阅读 在测试hyper-V的过程中,计划安装一个Windows 2019的OS,顺便了解Windows Server 2019 的 Standard 和 Datacenter 版本有哪些差异?我们…...

计算机网络的交通灯:停止-等待协议
停止-等待协议是一种在计算机网络通信中常用的协议,用于在数据传输过程中进行流量控制。它的核心思想是在发送端发送数据后,等待接收端的确认信号,确保数据的可靠传输。本文将深入探讨停止-等待协议的原理、优缺点以及在实际应用中的局限性。…...

命令行模式的rancher如何安装?
在学习kubectl操作的时候,发现rancher也有命令行模式,学习整理记录此文。 说明 rancher 命令是 Rancher 平台提供的命令行工具,用于管理 Rancher 平台及其服务。 前提 已经参照前文安装过了rancher环境了,拥有了自己的k8s集群…...

苍穹外卖Day01——总结1
总结1 1. 软件开发整体介绍1.1 软件开发流程1.2 角色分工1.3 软件环境 2. 苍穹外卖项目介绍2.1 项目介绍2.2 技术选项 3. Swagger4. 补充内容(待解决...) 1. 软件开发整体介绍 1.1 软件开发流程 1.2 角色分工 从角色分工里面就可以查看自己以后从事哪一…...
)
Java 基础(二)
数组 数组就是一个容器,用来存一批同类型的数据 数组关键要素:定义及初始化、元素访问和元素遍历 1.静态初始化数组 // 完整格式 数据类型[] 数组名 new 数据类型[]{元素1,元素2 ,元素3… };// 简化格式数据类型[] 数组名 …...
BERT 模型是什么
科学突破很少发生在真空中。相反,它们往往是建立在积累的人类知识之上的阶梯的倒数第二步。要了解 ChatGPT 和 Google Bart 等大型语言模型 (LLM) 的成功,我们需要回到过去并谈论 BERT。 BERT 由 Google 研究人员于 2018 年开发&…...

Elasticsearch中object类型与nested类型以及数组之间的区别
一、区别: 0、一般情况下用object 类型来查es中为json对象的字段数据,用nested来查es中为JsonArray数组类型的字段数据。 1、默认情况下ES会把JSON对象直接映射为object类型,只有手动设置才会映射为nested类型 2、object类型可以直接使用普…...

办公文档,私人专用
一、安装Minio 1.1、创建文件夹,并在指定文件夹中下载minio文件 cd /opt mkdir minio cd minio touch minio.log wget https://dl.minio.io/server/minio/release/linux-amd64/minio1.2、赋予minio文件执行权限 chmod 777 minio1.3、启动minio ./minio server /…...
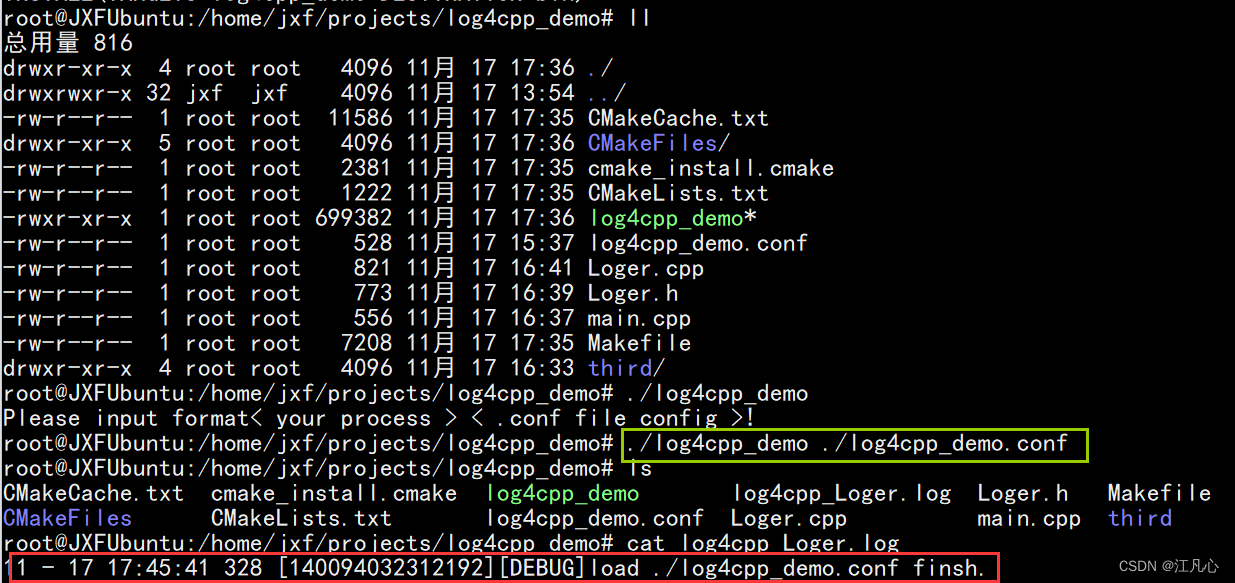
linux 使用log4cpp记录项目日志
为什么要用log4cpp记录项目日志 在通常情况下,Linux/UNIX 每个程序在开始运行的时刻,都会打开 3 个已经打开的 stream. 分别用来输入,输出,打印错误信息。通常他们会被连接到用户终端。这 3 个句柄的类型为指向 FILE 的指针。可以…...

Kafka集群部署
文章目录 一、实例配置二 、zookeeper集群安装三、kafka集群安装四、验证 没有提示,所有机器都执行 在kafka集群中引入zookeeper,主要是为了管理kafka集群的broker。负责管理集群的元数据信息,确保 Kafka 集群的高可用性、高性能和高可靠性。…...

软件测试|深入理解SQL CROSS JOIN:交叉连接
简介 在SQL查询中,CROSS JOIN是一种用于从两个或多个表中获取所有可能组合的连接方式。它不依赖于任何关联条件,而是返回两个表中的每一行与另一个表中的每一行的所有组合。CROSS JOIN可以用于生成笛卡尔积,它在某些情况下非常有用ÿ…...
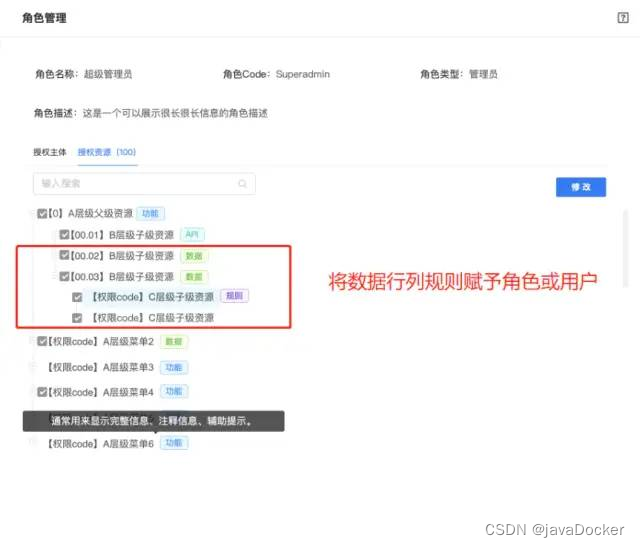
数据权限-模型简要分析
权限管控可以通俗的理解为权力限制,即不同的人由于拥有不同权力,他所看到的、能使用的可能不一样。对应到一个应用系统,其实就是一个用户可能拥有不同的数据权限(看到的)和操作权限(使用的)。 …...
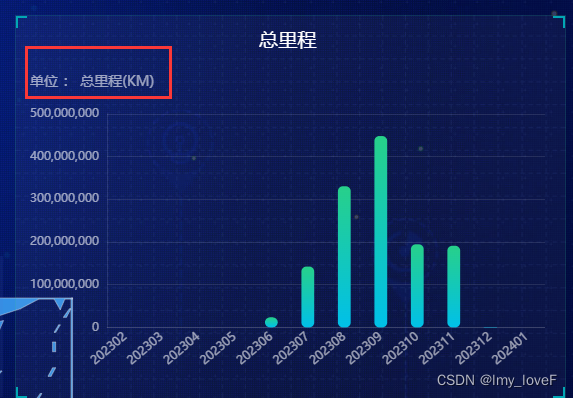
echarts柱状图加单位,底部文本溢出展示
刚开始设置了半天都不展示单位,后来发现是被挡住了,需要调高top值 // 基于准备好的dom,初始化echarts实例var myChart echarts.init(document.getElementById("echartD"));rankOption {// backgroundColor: #00265f,tooltip: {…...

x-cmd pkg | gh - GitHub 官方 CLI
目录 简介首次用户功能特点与 x-cmd gh 模块的关系相关作品进一步探索 简介 gh,是由 GitHub 官方使用 Go 语言开发和维护的命令行工具,旨在脚本或是命令行中便捷管理和操作 GitHub 的工作流程。 注意: 由于 x-cmd 提供了同名模块,因此使用官…...

Python解析XML,简化复杂数据操作的最佳工具!
更多Python学习内容:ipengtao.com XML(可扩展标记语言)是一种常见的文本文件格式,用于存储和交换数据。Python提供了多种库和模块,用于解析和操作XML文件。本文将深入探讨如何使用Python操作XML文件,包括XM…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...