离线数据仓库项目--技术选择
文章目录
- (一)技术选型
- 1)数据采集工具
- 2)数据存储
- 3)数据计算
- 4)数据可视化
- (二)整体架构设计
- (三)服务器资源规划
(一)技术选型
1)数据采集工具
除了Flume这个数据采集工具,其实还有一些类似的数据采集工具,Logstash、FileBeat,这两个也可以实现数据采集。
那这三个日志采集工具我们需要如何选择呢?
首先从性能消耗上面来说,Flume和Logstash的性能消耗差不多,都是基于JVM执行的,都是重量级的组件,支持多种数据源和目的地。
FileBeat是一个只支持文件数据采集的工具,是一个轻量级组件,性能消耗比价低,它不是基于JVM执行
的,它是使用go语言开发的。
采集数据的情况:

第一种是把采集工具部署到产生数据的服务器上面
web项目产生的日志数据直接保存在服务器上面,并且这个服务器的性能比较高,可以允许我在上面部署Flume数据采集工具,这样也不会对上面的web项目的稳定性产生什么影响。
第二种是把采集工具部署在一个独立的服务器上面
web项目产生的日志数据直接保存在服务器上面,但是这个服务器的性能一般,并且对web项目的稳定性要求非常高,如果让你在上面部署一个其它服务,这样这个服务器的稳定性就没办法保证了,进而也就无法保证web项目的稳定性了,所以这个时候可以选择在产生日志的时候使用埋点上报的方式,通过http接口把日志数据传输到日志接收服务器中。
那针对第一种情况肯定是要选择一个性能消耗比较低的数据采集工具,优先选择FileBeat针对第二种情况的话就不需要考虑性能消耗了,因为采集工具是在独立的机器上,不会影响web项目,这个时候我们需要考虑的就是采集工具的功能是否完整,因为在采集数据的时候可能需要对数据进行一些简单的处理,以及后期可能会输出到不同的存储介质中。
Flume默认不持直接采集MySQL中的数据,如果想要实现的话需要自定义Source,这样就比较麻烦了其实采集MySQL中的数据有一个比较常用的方式是通过Sqoop实现。
Sqoop中有两大功能,数据导入和数据导出
- 数据导入是指把关系型数据库中的数据导入HDFS中
- 数据导出是指把HDFS中的数据导出到关系型数据库中
我们后期在做一些报表的时候其实也是需要把数据仓库中的数据导出到MySQL中的,所以在这选择qoop也是非常实用的。
所以针对数据采集这块,我们主要选择了Flume和Sqoop。
2)数据存储
数据采集过来以后,由于我们后面要构建数据仓库,数据仓库是使用Hive实现,Hive的数据是存储在HDFS中的,所以我们把采集到的数据也直接存储到HDFS里面。
还有一点是后期在做一些数据报表的时候,是需要把数据仓库中的数据导出到MySQL中的,所以数据存储也需要使用到MySQL。
3)数据计算
在构建数据仓库的时候,我们前面说了,是使用Hive构建数据仓库,一般的数据处理通过SQL是可以搞定的,如果遇到了比较复杂的处理逻辑,可能还需要和外部的数据进行交互的,这个时候使用SQL就比较麻烦了,内置的函数有时候搞不定,还需要开发自定义函数针对复杂的数据清洗任务我们也可以考虑使用Spark进行处理。
4)数据可视化
在数据可视化层面,我们可以使用Hue进行数据查询
如果想实现写SQL直接出图表的话可以使用Zeppelin
如果想定制开发图表的话可以使用Echarts之类的图表库,这个时候是需要我们自己开发数据接口实现的。
(二)整体架构设计

我们采集的数据主要分为服务端数据和客户端数据
什么是服务端数据,就是网站上的商品详情数据以及你下的订单信息之类的数据,这些数据都是在服务端存储着的,一般是存储在类似于MySQL之类的关系型数据库中,这些数据对事务性要求比较严格,所以会存放在关系型数据库中。
- 什么是客户端数据呢,就是用户在网站或者app上的一些滑动、点击、浏览、停留时间之类的用户行为数据,这些数据会通过埋点直接上报,这些其实就是一些日志类型的数据了,这种类型的数据没有事务性要求,并且对数据的完整性要求也不是太高,就算丢一些数据,对整体结果影响也不大。
- 针对服务端数据,在采集的时候,主要是通过Sqoop进行采集,按天采集,每天凌晨的时候把昨天的数据采集过来,存储到HDFS上面。
- 针对客户端数据,会通过埋点上报到日志接收服务器中,其实这里面就是一个Http服务,埋点上报就是调用了这个Http服务,把日志数据传输过来,日志接收服务收到数据之后,会把数据落盘,存储到本地,记录为日志文件,然后通过Flume进行采集,将数据采集到HDFS上面,按天分目录存储。
- 服务端数据和客户端数据都进入到HDFS之后,就需要对数据进行ETL,构建数据仓库了。
数据仓库构建好了以后可以选择把一些需要报表展现的数据导出到MySQL中,最终在页面进行展现。
(三)服务器资源规划
测试环境:

生产环境:

说明:
1:由于NameNode开启了HA,所以SecondaryNameNode进程就不需要了
2:NameNode需要使用单独的机器,并且此机器的内存配置要比较高,建议128G
3:DataNode和NodeManager需要部署在相同的集群上,这样可以实现数据本地化计算
5:数据接口服务器需要使用至少两台,为了实现负载均衡及故障转移,保证数据接收服务的稳定性
6:Flume部署在日志服务器上面,便于采集本机保存的用户行为日志信息;还需要有单独的Flume机
器,便于处理其它的日志采集需求
7:Hive需要部署在所有业务机器上
8:MySQL建议单独部署,至少两台,一主一备
9:Sqoop需要部署在所有业务机器上
10:Zeppelin可以单独部署在一台普通配置的机器上即可
11:Azkaban建议至少使用三台,一主两从,这样可以保证一个从节点挂掉之后不影响定时任务的调度
服务器资源计算:
针对Hadoop集群的搭建在线上环境需要使用CDH或者HDP
具体Hadoop集群需要使用多少台集群需要根据当前的数据规模来预估
假设集群中的机器配置为8T,64 Core,128G
1:如果每天会产生1T的日志数据,需要保存半年的历史数据: 1T180天=180T
2:集群中的数据默认是3副本: 180T3=540T
3:预留20%左右的空间: 540T/0.8=675T
这样计算的话就需要675T/8T=85台服务器
如果我们在数据仓库中对数据进行分层存储,这样数据会出现冗余,存储空间会再扩容1~2倍。
注意:没有必要一开始就上线全部的机器,我们可以前期上线30台,后面随着业务数据量的增长再去动态扩容机器即可。
相关文章:
离线数据仓库项目--技术选择
文章目录(一)技术选型1)数据采集工具2)数据存储3)数据计算4)数据可视化(二)整体架构设计(三)服务器资源规划(一)技术选型 1ÿ…...

GC Garbage Collectors
本质一、算法1、哪些是垃圾?引用计数法:reference countPython中使用了。个对象如果没有任何与之关联的引用,即他们的引用计数都不为 0,则说明对象不太可能再被用到,那么这个对象就是可回收对象。漏洞:循环…...

【网络】-- 网络基础
(本文是网络的宏观的概念铺垫) 目录 计算机网络背景 网络发展 认识 "协议" 网络协议初识 协议分层 OSI七层模型 TCP/IP 五层(或四层)模型 报头 以太网 碰撞 路由器 IP地址和MAC地址 IP地址与MAC地址总结 IP地址 MAC地址 计算机…...
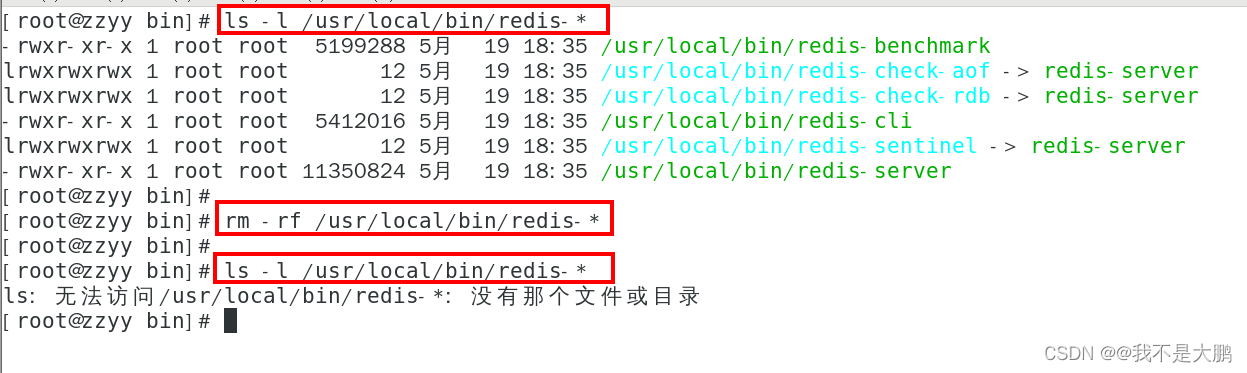
二、Redis安装配置(云服务器、vmware本地虚拟机)
一、自己购买服务器 自己购买阿里云、青牛云、腾讯云或华为云服务器, 自带CentoOS或者Ubuntu环境,直接开干 二、Vmware本地虚拟机安装 1、VMWare虚拟机的安装,不讲解,默认懂 2、如何查看自己的linux是32位还是64位 getconf L…...

【学习Docker(七)】详细讲解Jenkins部署SpringCloud微服务项目,Docker-compose启动
Jenkins部署SpringCloud微服务项目,Docker-compose启动 座右铭:《坚持有效输出,创造价值无限》 本文介绍使用Jenkins部署SpringCloud微服务项目,Docker-compose启动。 之前写过安装Jenkins的过程,这里就不写安装细节了…...
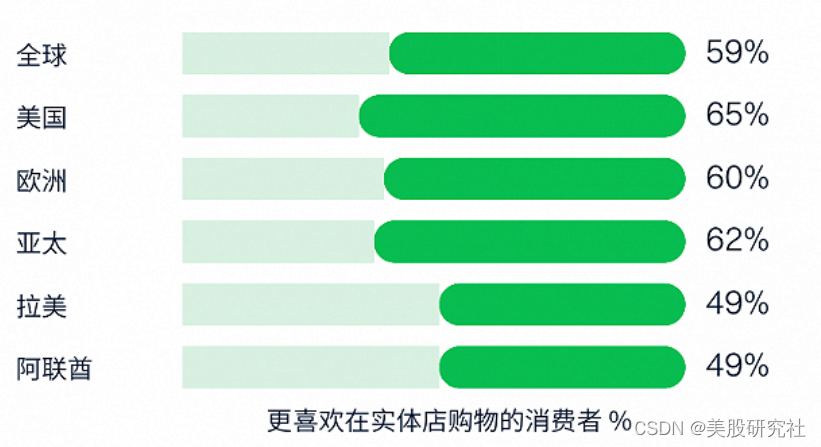
时机将至,名创优品或将再掀起一波消费热浪
北京时间2月28日,名创优品发布2023财年中报,财报显示,2023财年第二季度营收规模有所收窄,但净利润、毛利率、门店数量均实现了不错的增长,总体表现可圈可点。 (资料来源:富途牛牛) …...

深圳大学计软《面向对象的程序设计》实验8 静态与友元
A. 旅馆旅客管理(静态成员) 题目描述 编写程序,实现某旅馆的客人住宿记录功能。 定义一个Customer类,要求输入客人的姓名,创建一个Customer对象。类声明如下: 调用类的Display函数输出客人IDÿ…...

【基础算法】单链表的OJ练习(2) # 链表的中间结点 # 链表中倒数第k个结点 #
文章目录前言链表的中间结点链表中倒数第k个结点写在最后前言 对于单链表的OJ练习,需要深刻理解做题的思路,这样我们才能够在任何场景都能够熟练的解答有关链表的问题。 关于OJ练习(1):-> 传送门 <-,…...

vue路由文件拆分管理
随着项目的原来越大,路由越来越多,我们的路由也会越来越多,如果都集中在一个文件中,会很冗杂文件很长。这时候我们可以将路由文件拆分,可读、方便管理。多人合作添加路由也能更多的避免代码冲突 代码拆分目录如图&…...

实例解析Java反射
反射是大多数语言里都必不不可少的组成部分,对象可以通过反射获取他的类,类可以通过反射拿到所有方法(包括私有),拿到的方法可以调用,总之通过“反射”,我们可以将Java这种静态语言附加上动态特…...

Android 9适配经验总结
目录四大组件适配Activity启动方式适配Service启动方式适配前台服务需要添加权限限制静态广播的接收限制ContentResolver数据更新操作权限与安全相关主要适配点运行时动态权限申请默认不支持 http 请求SharedPreferences 适配四大组件适配 Android 应用的开发离不开 Android 四…...
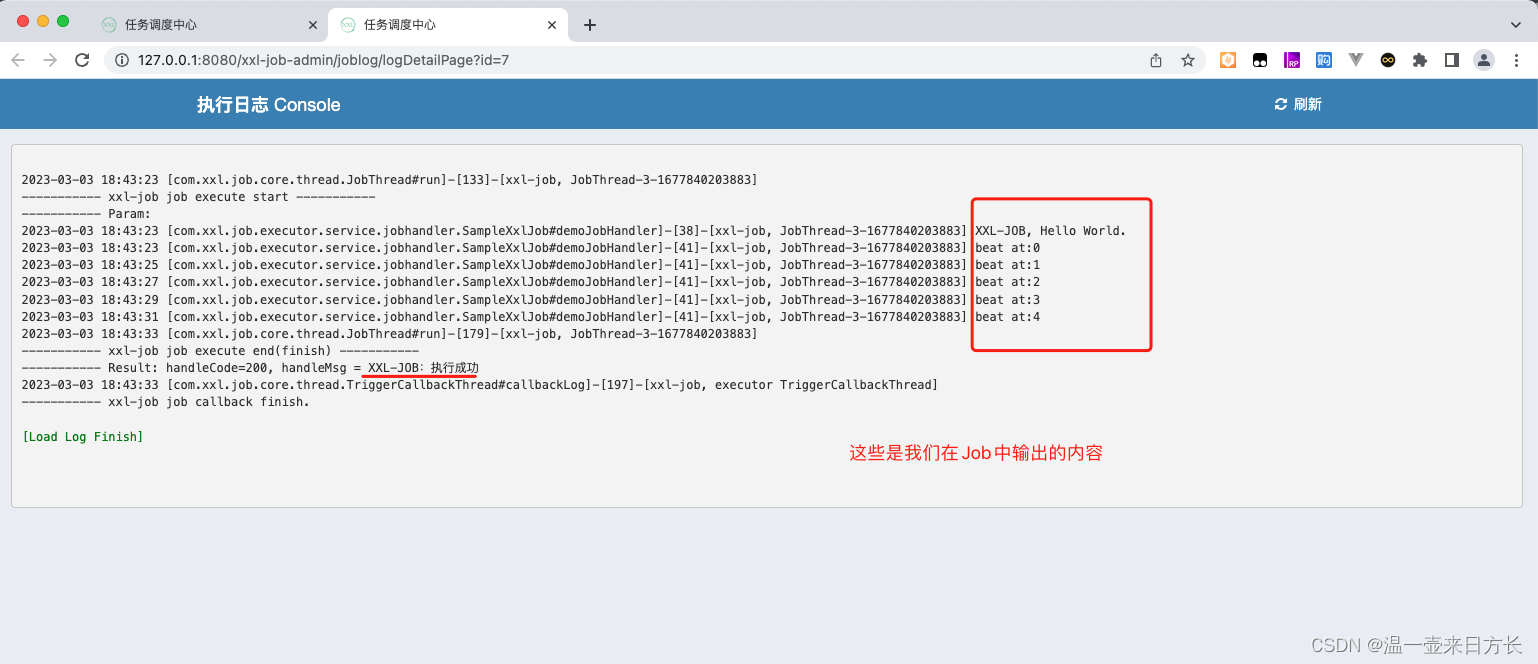
定时任务调度方案——Xxl-Job
定时任务调度方案 随着系统规模的发展,项目的组织结构以及架构越来越复杂,业务覆盖的范围越来越广,定时任务数量日益增多,任务也变得越来越复杂,尤其是为了满足在用户体量日历增大时,系统能够稳定运行&…...

操作系统引导
操作系统是一种程序,程序以数据的形式存放在硬盘中,而硬盘通常分为多个区,一个计算机中又有多个或多种外部设备。 操作系统引导指的是计算机利用CPU运行特定程序,通过程序识别硬盘,识别硬盘分区,识别硬盘分…...

[C#] 多线程单例子,分为阻塞型和分阻塞型, 在unity里的应用
在单例中使用多线程时,需要注意以下几点: 线程安全:在多线程环境下,单例对象可能被多个线程同时访问,因此需要确保单例的线程安全,避免出现数据竞争等问题。 对象创建:如果在单例对象的构造函数…...
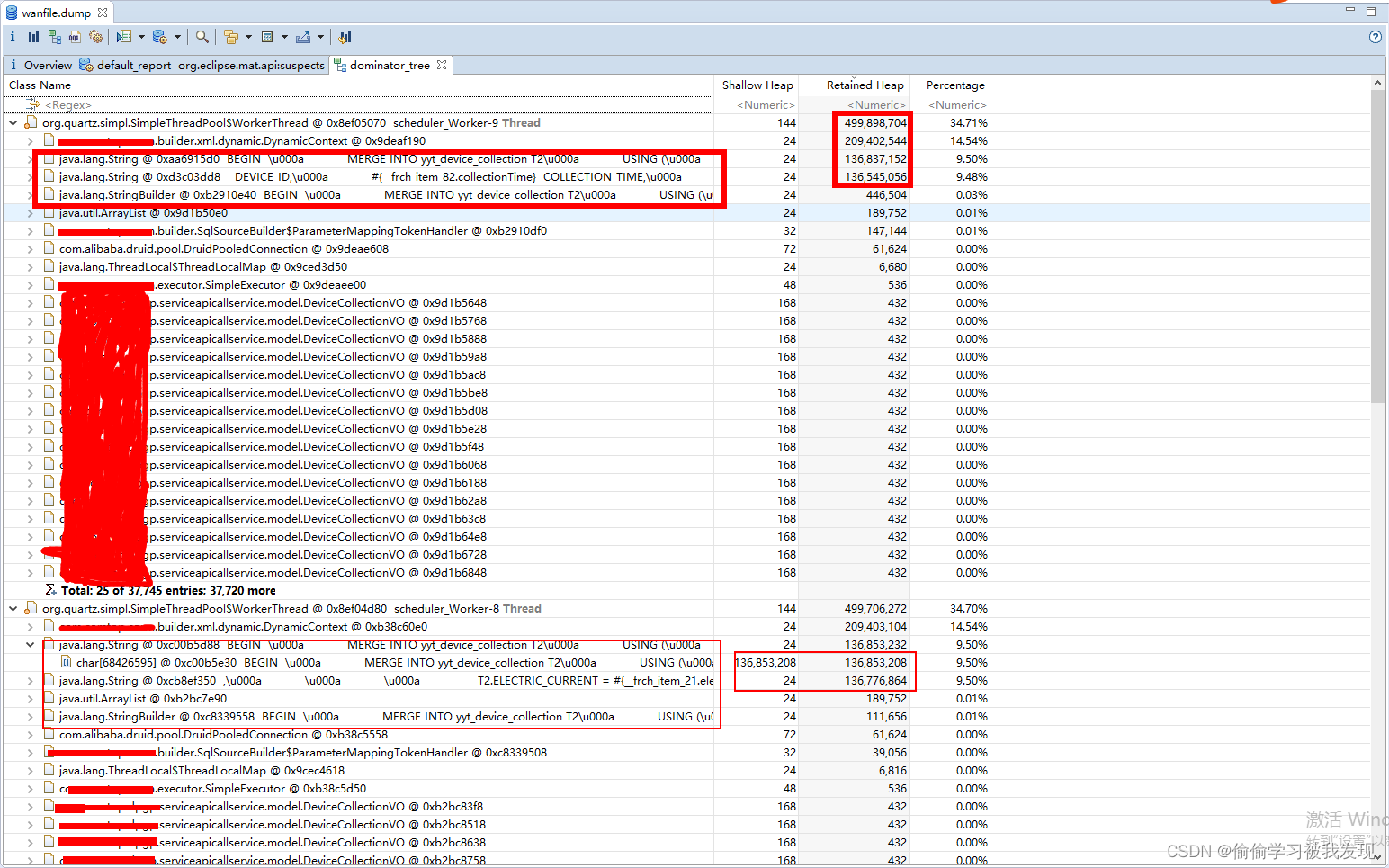
使用MAT进行内存分析,并找到OOM问题
前言 在处理一次现场问题时,发现服务还在运行,但是出现假死情况,后通过分析GC日志以及使用MAT分析确定问题是内存溢出OutOfMemery(OOM);这里只记录MAT分析学习过程,最近工作忙,补记录。 GC日志分析 首先,如…...

初识Python
目录初识Python1.Python简介Python的优缺点Python的应用领域2.安装Python解释器Windows环境Linux环境macOS环境3.运行Python程序确认Python的版本编写Python源代码运行程序代码中的注释4.Python开发工具IDLE - 自带的集成开发工具IPython - 更好的交互式编程工具Sublime Text -…...
tmux终端复用软件
一、安装[rootpool-100-1-1-159 test]# yum install tmux [rootpool-100-1-1-159 test]# yum search tmux Repository extras is listed more than once in the configuration Last metadata expiration check: 0:33:52 ago on Fri 03 Mar 2023 09:10:34 AM CST.Name Exactly M…...
IO详解(文件,流对象,一些练习)
目录 文件 文件概念 文件的路径 路径有俩种表示风格 文件类型 如何区分文本文件还是二进制文件? java对文件的操作 File类中的一些方法 流对象 流对象的简单概念 java标准库的流对象 1.字节流,(操作二进制数据的) 2.字符流 (操作文本数据的) 流对象最核心的四个…...
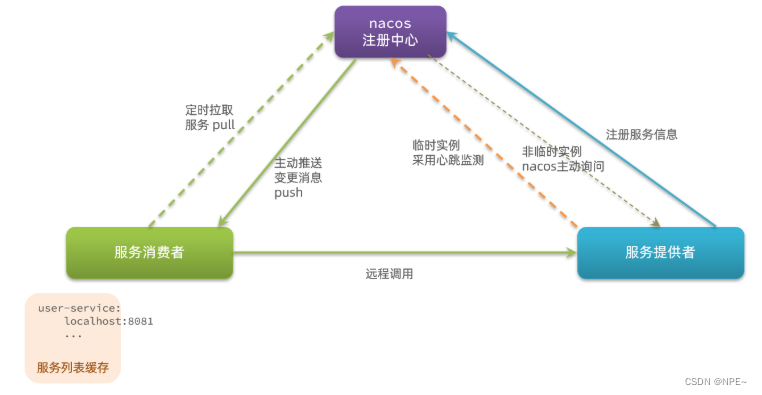
SpringCloud全家桶— — 【1】eureka、ribbon、nacos、feign、gateway
SpringCloud全家桶— — 组件搭建 1 Eureka 1.1 Eureka-server 创建eureka-server的SpringBoot项目 ①导入依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId…...
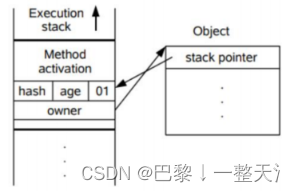
【线程安全篇】
线程安全之原子性问题 x ,在字节码文件中对应多个指令,多个线程在运行多个指令时,就存在原子性、可见性问题 赋值 多线程场景下,一个指令如果包含多个字节码指令,那么就不再是原子操作。因为赋值的同时,…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...