Flink SQL Checkpoint 学习总结
前言
学习总结Flink SQL Checkpoint的使用,主要目的是为了验证Flink SQL流式任务挂掉后,重启时还可以继续从上次的运行状态恢复。
验证方式
Flink SQL流式增量读取Hudi表然后sink MySQL表,任务启动后处于running状态,先查看sink表有数据,然后将对应的yarn kill掉,再通过设置的checkpoint重启任务,任务重启后验证sink表的数据量。Flink SQL流式增量读取Hudi表可以参考:Flink SQL增量查询Hudi表
版本
- Flink 1.14.3
- Hudi 0.13.0
Checkpoint 参数
一般需要设置的常用参数
-- checkpoint间隔时间,单位毫秒,没有默认值,如果想开启checkpoint,需要将该参数设置一个大于0的数值
-- 如果想提升sink性能,比如写hudi,需要将该值设置大一点,因为间隔时间决定了批次大小
-- checkpoint间隔时间不能设置太短也不能设置太长,太短影响写入性能,太长影响数据及时性。
set execution.checkpointing.interval=1000;
-- 保存checkpoint文件的目录
set state.checkpoints.dir=hdfs:///flink/checkpoints/hudi2mysql;
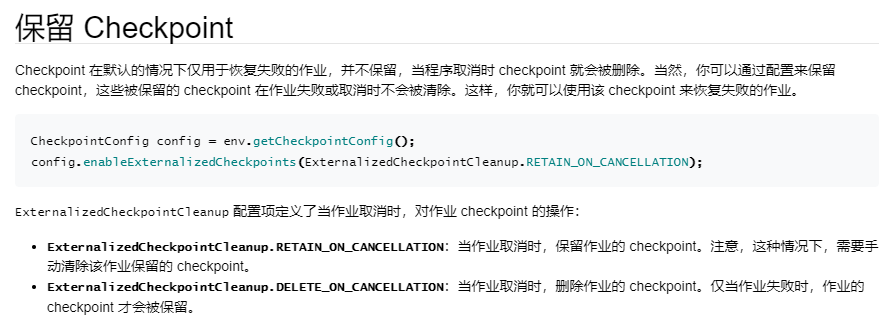
-- 任务取消后保留checkpoint,默认值NO_EXTERNALIZED_CHECKPOINTS,
-- 可选值NO_EXTERNALIZED_CHECKPOINTS、DELETE_ON_CANCELLATION、RETAIN_ON_CANCELLATION
set execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION;
从checkpoint恢复
set execution.savepoint.path=hdfs:///flink/checkpoints/hudi2mysql/255bdd01cee7486113feb1cbe8b45ee0/chk-1314;
其他参数
-- checkpoint模式,默认值EXACTLY_ONCE,可选值:EXACTLY_ONCE、AT_LEAST_ONCE
-- 要想支持EXACTLY_ONCE,需要sink端支持事务
set execution.checkpointing.mode=EXACTLY_ONCE;
-- checkpoint超时时间,默认10分钟
set execution.checkpointing.timeout=600000;
-- checkpoint文件保留数,默认1
set state.checkpoints.num-retained=3;
Checkpoint 目录结构
/user-defined-checkpoint-dir/{job-id}|+ --shared/+ --taskowned/+ --chk-1/+ --chk-2/+ --chk-3/...
验证
创建Hudi和MySQL物理表
Hudi表
CREATE TABLE hudi_source (id int PRIMARY KEY NOT ENFORCED,name string,price double,ts bigint,dt string
)
WITH ('connector' = 'hudi','path' = '/tmp/hudi_source'
);
MySQL表
CREATE TABLE `sink_mysql` (`id` int(11) NOT NULL,`name` text,`price` double DEFAULT NULL,`ts` int(11) DEFAULT NULL,`dt` text,`insert_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
造数
insert into hudi_source values(1,'hudi1',11.1,1000,'20230301');
insert into hudi_source values(2,'hudi2',22.2,1000,'20230301');
......
流读Hudi写MySQL
hudi2mysql.sql
set yarn.application.name=hudi2mysql;
set execution.checkpointing.interval=1000;
set state.checkpoints.dir=hdfs:///flink/checkpoints/hudi2mysql;
set execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION;CREATE TABLE hudi_source_incr (id int PRIMARY KEY NOT ENFORCED,name string,price double,ts bigint,dt string
)
WITH ('connector' = 'hudi','path' = '/tmp/hudi_source','read.streaming.enabled' = 'true', 'read.start-commit' = '202302', 'read.streaming.check-interval' = '4'
);create table sink_mysql (id int PRIMARY KEY NOT ENFORCED,name string,price double,ts bigint,dt string
) with ('connector' = 'jdbc','url' = 'jdbc:mysql://192.168.44.128:3306/cdc?useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8','username' = 'root','password' = 'password','table-name' = 'sink_mysql'
);insert into sink_mysql select * from hudi_source_incr;
执行上面的SQL
bin/sql-client.sh -f sql/hudi2mysql.sql
这样我们启动了一个常任务,在Flink界面上可以看到checkpoint的相关信息,如下图显示了checkpoint具体文件地址

可以用hdfs命令看一下checkpoint路径下有哪些文件
drwxr-xr-x - hive hdfs 0 2023-03-01 14:47 hdfs:///flink/checkpoints/hudi2mysql/255bdd01cee7486113feb1cbe8b45ee0/chk-589
drwxr-xr-x - hive hdfs 0 2023-03-01 14:36 hdfs:///flink/checkpoints/hudi2mysql/255bdd01cee7486113feb1cbe8b45ee0/shared
drwxr-xr-x - hive hdfs 0 2023-03-01 14:36 hdfs:///flink/checkpoints/hudi2mysql/255bdd01cee7486113feb1cbe8b45ee0/taskowned
其中255bdd01cee7486113feb1cbe8b45ee0为flink的jobid

将yarn任务kill
yarn app -kill application_1676855463066_0177
再看一下,发现checkpoint文件还在
hdfs:///flink/checkpoints/hudi2mysql/255bdd01cee7486113feb1cbe8b45ee0/chk-1314
重启任务验证checkpoint效果
需要先在hudi2mysql.sql,添加下面的配置
-- 从该checkpoint文件对应的状态恢复
set execution.savepoint.path=hdfs:///flink/checkpoints/hudi2mysql/255bdd01cee7486113feb1cbe8b45ee0/chk-1314;
重启flink sql任务
bin/sql-client.sh -f sql/hudi2mysql.sql
我们可以在新启动的yarn界面上看到,最新的恢复点,和我们设置的一样,这样代表我们设置恢复点生效

最后再造几条新的增量数据,在MySQL里看验证以下数据量是否一致
insert into hudi_source values(3,'hudi3',33.3,1000,'20230301');
MySQL数据量一致,且更新时间和插入时间一致,代表id=1、2的数据重启时没有重复消费,达到了预期效果。(也可以对MySQL表不设置主键,直接通过验证数据量验证效果)

这样我们通过一个简单的示例,了解了checkpoint的具体使用。大致过程
1、设置开启checkpoint和保存的路径,
2、任务运行时会根据设置的时间间隔不断生成新的ckp文件,
3、等任务挂掉后,重启任务时先设置execution.savepoint.path为我们最后一次保存的ckp文件
这样就达到了任务重启时继续从上次的运行状态恢复。
Checkpoint和Hudi
流任务写hudi时,必须设置checkpoint,不然不会生成commit,感觉像是卡住一样,具体表现为只生成.commit.requested和.inflight,然后不写文件、不生成.commit也不报错,对于新手来说很费劲,很难找到解决方法。
大概原因是因为写文件、生成commit的动作是在coordinator里面,只有当checkpoint完成后才会调用coordinator,所以不设置checkpoint就不会生成commit,这里的逻辑是在Hudi源码里(具体没看),也就是说checkpoint和生成hudi commit是绑定一起的,这样才能保证流写Hudi的事务性,从而保证checkpoint的EXACTLY_ONCE。
StateBackend
在启动 CheckPoint 机制时,状态会随着 CheckPoint 而持久化,以防止数据丢失、保障恢复时的一致性。 状态内部的存储格式、状态在 CheckPoint 时如何持久化以及持久化在哪里均取决于选择的 State Backend。
在学习Flink SQL Checkpoint时,发现网上的资料有下面的这个配置,本来以为这样设置后,就会将checkpoint文件保存到文件系统中,后来发现并不是这样。并且官网文档和源码描述的也不是很清楚,所以专门研究了一下这一块
set state.backend=filesystem;
从 Flink 1.13 版本开始,社区改进了 state backend 的公开类,进而帮助用户更好理解本地状态存储和 checkpoint 存储的区分。 这个变化并不会影响 state backend 和 checkpointing 过程的运行时实现和机制,仅仅是为了更好地传达设计意图。 用户可以将现有作业迁移到新的 API,同时不会损失原有 state。
旧版本的 MemoryStateBackend 等价于使用 HashMapStateBackend 和 JobManagerCheckpointStorage。
新版本的有两个参数state.backend和state.checkpoint-storage
state.backend可选参数:hashmap、roksdb,另外也支持filesystem(弃用)和jobmanager(弃用),官方文档并没有说明filesystem和jobmanager已经弃用


只设置state.backend:
| state.backend | Checkpoint Storage | State Backend |
|---|---|---|
| 默认 | JobManagerCheckpointStorage | HashMapStateBackend |
| hashmap | JobManagerCheckpointStorage | HashMapStateBackend |
| filesystem(弃用) | JobManagerCheckpointStorage | HashMapStateBackend |
| roksdb | JobManagerCheckpointStorage | EmbeddedRocksDBStateBackend |
| jobmanager (弃用) | MemoryStateBackend(弃用) | MemoryStateBackend (弃用) |
总结:对于State Backend,只有HashMapStateBackend和EmbeddedRocksDBStateBackend,另外还有一个弃用的MemoryStateBackend
state.checkpoint-storage可选参数:jobmanager、filesystem,当设置了state.checkpoints.dir,flink会自动使用filesystem对应的FileSystemCheckpointStorage
只设置state.checkpoint-storage:
| state.checkpoint-storage | Checkpoint Storage | State Backend |
|---|---|---|
| 默认 | JobManagerCheckpointStorage | HashMapStateBackend |
| jobmanager | JobManagerCheckpointStorage | HashMapStateBackend |
| filesystem | FileSystemCheckpointStorage | HashMapStateBackend |
| 设置state.checkpoints.dir | FileSystemCheckpointStorage | HashMapStateBackend |
| 总结:对于Checkpoint Storage只有JobManagerCheckpointStorage和FileSystemCheckpointStorage | ||
| 另外,当设置state.checkpoint-storage=filesystem时,必须同时设置state.checkpoints.dir,否则会有异常: |
Caused by: org.apache.flink.configuration.IllegalConfigurationException: Cannot create the file system state backend: The configuration does not specify the checkpoint directory 'state.checkpoints.dir'
其实可以不设置state.checkpoint-storage,当设置了state.checkpoints.dir时Checkpoint Storage 自动使用FileSystemCheckpointStorage,不设置的话就使用默认的JobManagerCheckpointStorage
一开始对于默认的JobManagerCheckpointStorage、HashMapStateBackend不是很理解,不明白这样的checkpoint有啥用,因为是保存到内存中,不是保存到文件系统中,所以任务挂掉后就没办法恢复。
后来发现这种默认保存在内存中的checkpoint可以用于flink作业失败时自动恢复,而不是任务挂掉后手动恢复,另外默认情况下,程序取消时也不保存checkpoint
其他总结
- 对于flink sql读取mysql,设置checkpoint恢复不生效(不是flink cdc)
- checkpoint 一个时间间隔内只有一个批次,这样才能保证eos,时间间隔大小影响写入性能
- 对于kafka2hudi的场景,checkpoint时间间隔如果比较小(1s),会因为时间不够导致第一个批次卡住,等超时(默认10分钟)后才会报错,所以需要间隔时间设置大一点,10s以上即可
- 默认情况,只有全部任务running才会生成checkpoint,可以通过参数修改:execution.checkpointing.checkpoints-after-tasks-finish.enabled=true
pipeline.operator-chaining
set pipeline.operator-chaining=false;
将该参数设置为false,实现将多个算子拆分,利于观察每个任务的运行情况。对于上面说的kafka2hudi的场景,本来只是为了观察任务卡住的原因,但是发现设置了该参数后,任务不卡了
原因是虽然官方文档说的是将该参数设置为false后,会影响性能,但是我测试的kafka2hudi的场景反而提升了性能~,所以不卡了(不增加checkpoint时间间隔的情况)
下面是我测试的结果,总数据量:1000万,checkpoint间隔:10s
| pipeline.operator-chaining | 第一个批次的数据量 | 第二个批次的数据量 | 第三个批次的数据量 | … | 总用时 |
|---|---|---|---|---|---|
| false | 774270 | 1409025 | 1552195 | … | 66s |
| true | 838610 | 896459 | 1245142 | … | 79s |
相关文章:
Flink SQL Checkpoint 学习总结
前言 学习总结Flink SQL Checkpoint的使用,主要目的是为了验证Flink SQL流式任务挂掉后,重启时还可以继续从上次的运行状态恢复。 验证方式 Flink SQL流式增量读取Hudi表然后sink MySQL表,任务启动后处于running状态,先查看sin…...
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书 一、竞赛时间 总计:360分钟 竞赛阶段竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 A模块 A-1 登录安全加固 180分钟 200分 A-2 本地安全策略配置 A-3 流量完整性保护 A-4 事件监控 …...

MyBatis中主键回填的两种实现方式
主键回填其实是一个非常常见的需求,特别是在数据添加的过程中,我们经常需要添加完数据之后,需要获取刚刚添加的数据 id,无论是 Jdbc 还是各种各样的数据库框架都对此提供了相关的支持,本文我就来和和大家分享下数据库主…...

Windows11如何打开ie浏览器
目录1.背景:2.方法一:在 edge 中配置使用 ie 模式3.方法二:通过 Internet 选项 打开1.背景: 昨天电脑自动从win10升级为win11了,突然发现电脑找不到ie浏览器了,打开全都是直接跳转到 edge 浏览器࿰…...

Linux:进程间通信
目录 进程间通信目的 进程间通信分类 管道 System V IPC POSIX IPC 什么是管道 站在文件描述符角度-深度理解管道 管道使用 管道通信的四种情况 管道通信的特点 进程池管理 命名管道 创建一个命名管道 命名管道的打开规则 命名管道通信实例 匿名管道与命名管道的…...

【java】将LAC改造成Elasticsearch分词插件
目录 为什么要将LAC改造成ES插件? 怎么将LAC改造成ES插件? 确认LAC java接口能work 搭建ES插件开发调试环境 编写插件 生成插件 安装、运行插件 linux版本的动态链接库生成 总结 参考文档 为什么要将LAC改造成ES插件? ES是著名的非…...
)
TPM 2.0实例探索3 —— LUKS磁盘加密(5)
接前文:TPM 2.0实例探索3 —— LUKS磁盘加密(4) 本文大部分内容参考: Code Sample: Protecting secret data and keys using Intel Platform... 二、LUKS磁盘加密实例 4. 将密码存储于TPM的PCR 现在将TPM非易失性存储器中保护…...
mybatisplus复习(黑马)
学习目标能够基于MyBatisPlus完成标准Dao开发能够掌握MyBatisPlus的条件查询能够掌握MyBatisPlus的字段映射与表名映射能够掌握id生成策略控制能够理解代码生成器的相关配置一、MyBatisPlus简介MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工…...

【数据聚类|深度聚类】Deep Comprehensive Correlation Mining for Image Clustering(DCCM)论文研读
Abstract 翻译 最近出现的深度无监督方法使我们能够联合学习表示和对未标记数据进行聚类。这些深度聚类方法主要关注样本之间的相关性,例如选择高精度对来逐步调整特征表示,而忽略了其他有用的相关性。本文提出了一种新的聚类框架,称为深度全面相关挖掘(DCCM),从三个方面…...

CE认证机构有哪些机构?
CE认证机构有哪些机构? 所有出口欧盟的产品都需要办理CE证明,而电子电器以及玩具是强制性要做CE认证。很多人以为只有办理欧盟NB公告机构的CE认证才可以被承认,实际上并不是。那么,除了NB公告上的机构,还有哪些认证机…...
解决方法)
MYSQL5.7:Access denied for user ‘root‘@‘localhost‘ (using password:YES)解决方法
一、打开MySQL目录下的my.ini文件,在文件的[mysqld]下面添加一行 skip-grant-tables,保存并关闭文件;skip-grant-tables :跳过密码登录,登录时无需密码。my.ini :一般在和bin同目录下,如果没有的话可自己创…...

单目运算符、双目运算符、三目运算符
单目运算符是什么 单目运算符是指运算所需变量为一个的运算符 又叫一元运算符,其中有逻辑非运算符:!、按位取 反运算符:~、自增自减运算符:,-等。 逻辑非运算符【!】、按位取反运算符【~】、 自…...
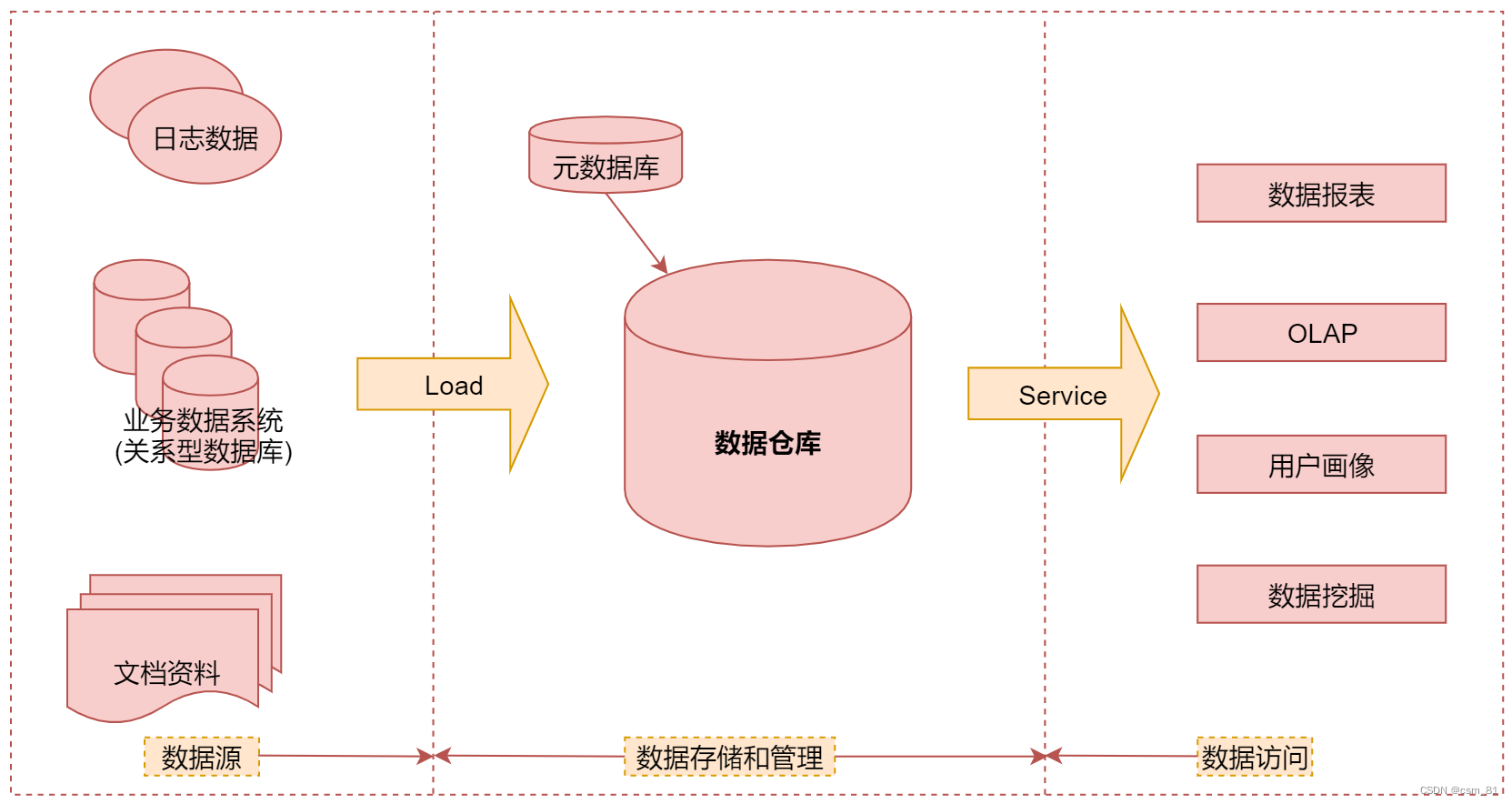
离线数据仓库项目搭建——准备篇
文章目录(一)什么是数据仓库(二)数据仓库基础知识(三)数据仓库建模方式(1)星行模型(2)雪花模型(3)星型模型 VS 雪花模型(四…...
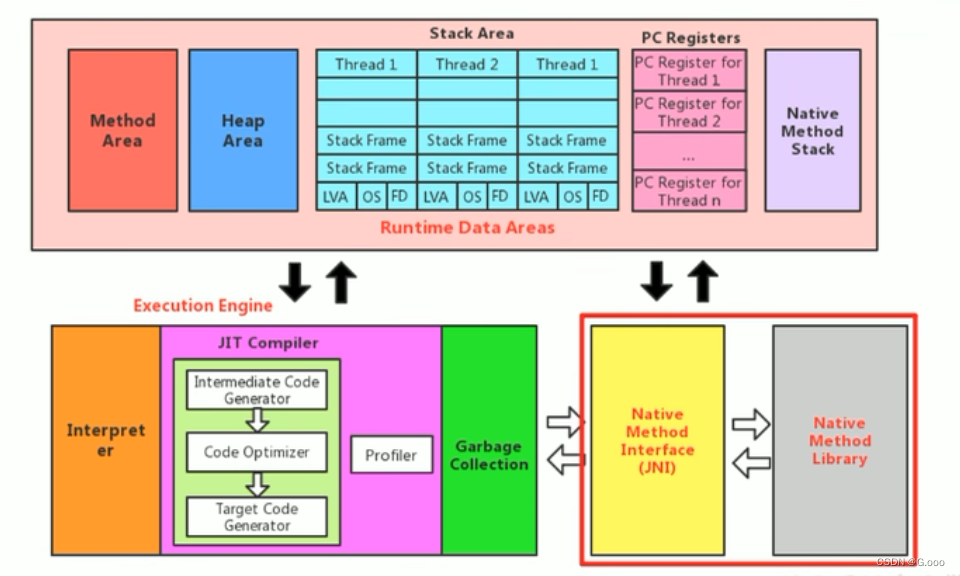
十七、本地方法接口的理解
什么是本地方法? 1.简单来讲,一个Ntive method 就是一个Java调用非Java代码的接口.一个Native Method 是这样一个Java方法:该方法的实现由非Java语言实现,比如C,这个特征并非Java所特有,很多其他的编程语言都由这一机制,比如在C中…...
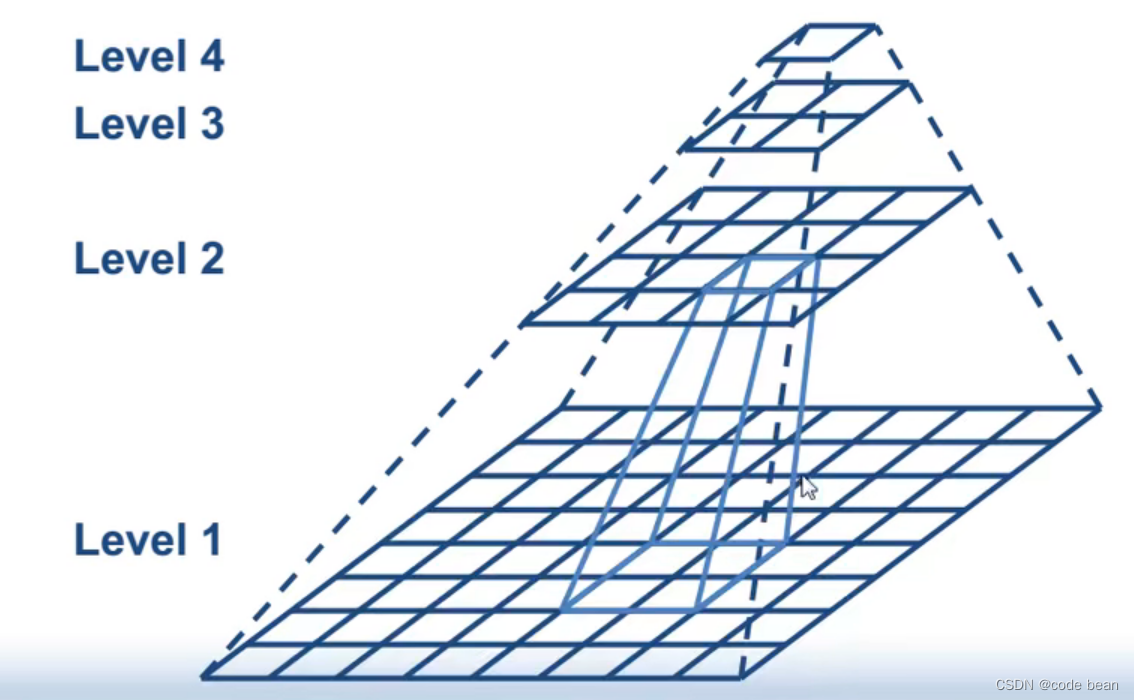
【halcon】模板匹配参数之金字塔级数
背景 今天,在使用模板匹配的时候,突然程序卡死,CPU直接飙到100%。最后排查发现是模板匹配其中一个参数 NumLevels 导致的: NumLevels: The number of pyramid levels used during the search is determined with numLevels. If n…...

jupyter lab安装和配置
jupyter lab 安装和配置 一、jupyter lab安装并配置 安装jupyterlab pip install jupyterlab启动 Jupyter lab默认会打开实验环境的,也可以自己在浏览器地址栏输入127.0.0.1:8888/lab 汉化 pip install jupyterlab-language-pack-zh-CN刷新一下网页࿰…...

用Docker搭建yolov5开发环境
拉取镜像 sudo docker pull pytorch/pytorch:latest 创建容器 sudo docker run -it -d --gpus "device0" pytorch/pytorch bash 查看所有容器 sudo docker ps -a 查看运行中的容器 sudo docker ps 进入容器 docker start -i 容器ID 将依赖包全都导入到requiremen…...
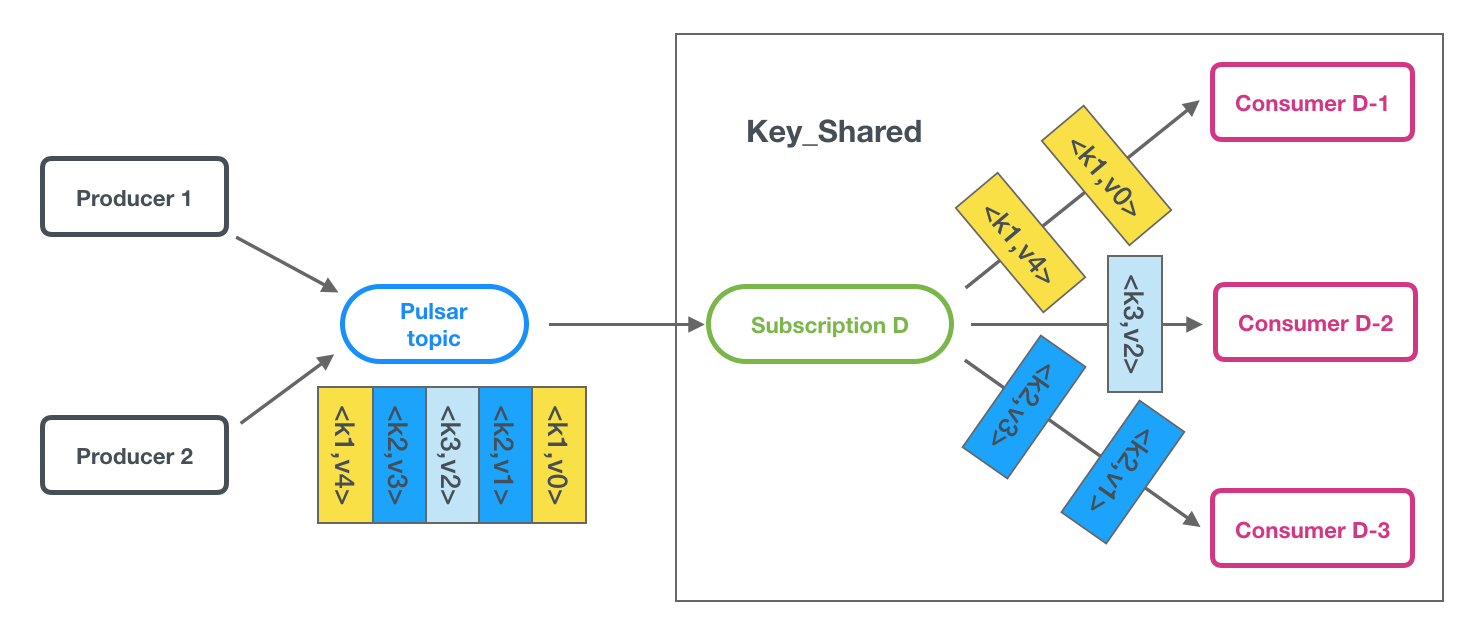
Apache Pulsar 云原生消息中间件之王
一、简介 pulsar,消息中间件,是一个用于服务器到服务器的消息系统,具有多租户、高性能等优势。 pulsar采用发布-订阅的设计模式,producer发布消息到topic,consumer订阅这些topic处理流入的消息,并当处理完…...
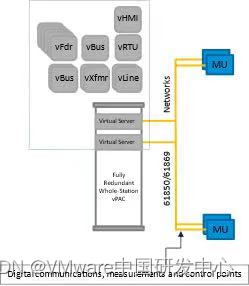
精选博客系列|公用事业中的VMware:在边缘重新定义价值
VMware 已经成为公用事业行业的核心。您可以在那里找到例如 VMware vSphere(包括基础 Hypervisor ESXi 和 VMware vCenter 建立的整体控制平面)的核心产品。来自软件定义的基础架构带来的诸多好处使 IT 团队将其先前基于硬件的系统转变为 VMware Cloud F…...

数字档案室测评的些许感悟
我是甲方,明明我家是档案“室”,为什么申请的是数字档案“馆”? 笔者正对着手里的一份方案苦笑,甲方爸爸是某机关单位档案室,方案最后的附件赫然写着几个大字:“申请国家级数字档案馆……“。这样的事屡见…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...
一些实用的chrome扩展0x01
简介 浏览器扩展程序有助于自动化任务、查找隐藏的漏洞、隐藏自身痕迹。以下列出了一些必备扩展程序,无论是测试应用程序、搜寻漏洞还是收集情报,它们都能提升工作流程。 FoxyProxy 代理管理工具,此扩展简化了使用代理(如 Burp…...