2024年1月9日学习总结
目录
- 学习目标
- 学习内容
- 联邦学习基础:why, what, how
- why?
- what?
- how?
- 联邦学习的例子——CIFAR-10数据集(分类问题)
- 1、import libararies
- 2、hyper-parameters
- 3、加载并且划分数据
- 4、创建神经网络模型
- 5、helper functions
- (1)client_update
- (2)server_aggregate
- (3)test
- 6、实例化模型
- 7、训练模型
- 7、整体流程
- 查看不同类型数据的方法
- 1、dataframe
- 2、ndarray
- 3、Dictionary
- 4、list
- 5、tuple
学习目标
- 完成集中学习的代码部分
- 对联邦学习进行了解
- 对学习过程中遇到的问题进行总结
学习内容
联邦学习基础:why, what, how
why?
深度学习对于数据的需求是贪得无厌的(insatiable),越多的数据训练的效果越好。ALphaGo学习了大约30万场的比赛模式才在2016年打败了人类玩家。如果能够不受限制的访问几大洲的所有医院数十亿的医疗记录,那么预测各类疾病的概率将会非常的精确。但是有数据保护法的管控,使用超级大量的数据来进行训练模型是不可能的。
高质量的数据像是一个个孤岛存储在世界各地的边缘设备上。在不违反隐私法的前提下把他们整合到一起得到他们的预测能力是非常困难的(herculean)的任务。联邦学习就是解决这一困境的!
what?
联邦学习提供了一个聪明的方式,连接机器学习模型和能够有效训练模型所需的数据。
联邦学习工作可以比喻成:殖民地(colonies)和领土(territories)是如何组成共和国(republic)或联邦(federation)的。
分布的边缘设备使用自己的数据训练自己的local model,然后组合在一起创造一个global model(听起来像是分布式学习💦),联邦学习就是分布学习的一种形式,但是它和传统的HPC(high performance computing)不同,HPC的目的是减少训练的时间,因为你也知道经历45天的训练,想要记得上一次调整的超参数是多么困难😰。但是FL的目标是无论数据在哪里,都要获取数据,并将其用于模型训练。在HPC中,训练数据首先被收集在一起并随机化,然后作为碎片跨多个计算节点共享。这些过程产生了独立且同分布(IID)的数据,从而提高了随机梯度下降的性能。但是FL学习是不能生成IID数据的,FL数据大多是非IID的,并且系统必须具有能够承受这种现象的架构。
how?
传统的FL学习结构由中心的管理员(curator)或者服务器(server)协调训练的。客户端(clients)大多数是边缘设备,数量可能多达几百万,这些设备在每次训练的过程中至少与服务器通信两次。
- 首先,客户端都从服务器接收当前的全局模型权重(global model weights)
- 然后,在每个本地数据上训练它以生成更新的参数
- 将这些参数上传到服务器进行聚合(aggregation)
联邦学习的例子——CIFAR-10数据集(分类问题)
1、import libararies
###############################
##### importing libraries #####
###############################import os
import random
from tqdm import tqdm
import numpy as np
import torch, torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data.dataset import Dataset
torch.backends.cudnn.benchmark=True
2、hyper-parameters
##### Hyperparameters for federated learning #########
num_clients = 20
num_selected = 6
num_rounds = 150
epochs = 5
batch_size = 32
- num_clients: 客户端的数量。将全部数据平均分给每个client
- num_selected: 在num_clients中随机选择num-clients个客户端进行训练(每个communication round)。通常是30%
- num_rounds: 需要运行的communication 轮数。在每一个communication round中,从num_clients中随机抽出num_selected个客户端进行原理,然后聚合各自的模型参数成为一个global model
- epoch: 每一个被选择的客户端需要训练的轮数
- batch_size: 批量的加载数据
3、加载并且划分数据
本教程使用CIFAR10数据集。它由10个类别的6万张32x32像素的彩色图像组成。有5万张训练图像和1万张测试图像。在训练批次中,每个班级有5000张图像,总共有50000张。在PyTorch中,CIFAR 10可以在torchvision模块的帮助下使用。
在本教程中,图像被平均地划分为客户机,因此表示平衡(IID)情况。
- 加载图像,并对图像进行预处理
# Image augmentation
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])# Loading CIFAR10 using torchvision.datasets
traindata = datasets.CIFAR10('./data', train=True, download=True,transform= transform_train)
- 将训练数据分给num_clients个客户端
# Dividing the training data into num_clients, with each client having equal number of images
traindata_split = torch.utils.data.random_split(traindata, [int(traindata.data.shape[0] / num_clients) for _ in range(num_clients)])
- 将训练样本转化成深度学习的格式
# Creating a pytorch loader for a Deep Learning model
train_loader = [torch.utils.data.DataLoader(x, batch_size=batch_size, shuffle=True) for x in traindata_split]
- 对测试集进行预处理以及转成深度学习格式
# Normalizing the test images
transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])# Loading the test iamges and thus converting them into a test_loader
test_loader = torch.utils.data.DataLoader(datasets.CIFAR10('./data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])), batch_size=batch_size, shuffle=True)
4、创建神经网络模型
VGG19(16个卷积层,3个完全连接层,5个MaxPool层和1个SoftMax层)在本教程中使用。还有VGG11、VGG13和VGG16等VGG的其他变体。
#################################
##### Neural Network model #####
#################################cfg = {'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}class VGG(nn.Module):def __init__(self, vgg_name):super(VGG, self).__init__()self.features = self._make_layers(cfg[vgg_name])self.classifier = nn.Sequential(nn.Linear(512, 512),nn.ReLU(True),nn.Linear(512, 512),nn.ReLU(True),nn.Linear(512, 10))def forward(self, x):out = self.features(x)out = out.view(out.size(0), -1)out = self.classifier(out)output = F.log_softmax(out, dim=1)return outputdef _make_layers(self, cfg):layers = []in_channels = 3for x in cfg:if x == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),nn.BatchNorm2d(x),nn.ReLU(inplace=True)]in_channels = xlayers += [nn.AvgPool2d(kernel_size=1, stride=1)]return nn.Sequential(*layers)
我们定义了一个名为VGG的类,它继承了nn.Module。这个类有两个主要方法:__init__和forward。__init__方法用于初始化网络结构,包括定义卷积层和全连接层。forward方法用于前向传播输入数据通过网络,并返回输出结果。
在__init__方法中,我们首先调用父类的__init__方法,然后定义了一个名为features的成员变量,它包含了VGG网络的卷积层。接下来,我们定义了一个名为classifier的成员变量,它包含了VGG网络的全连接层。最后,我们在forward方法中定义了如何处理输入数据,并返回输出结果。
_make_layers方法用于构建VGG网络的卷积层。它首先定义了一个名为layers的空列表,用于存储网络结构中的层。然后,我们遍历cfg列表,其中cfg是一个包含VGG网络结构配置的列表。如果x等于’M’,表示这是一个最大池化层,我们添加一个nn.MaxPool2d层;否则,表示这是一个卷积层,我们添加一个nn.Conv2d层、一个nn.BatchNorm2d层和一个nn.ReLU激活层。最后,我们添加一个平均池化层,并返回nn.Sequential(*layers),即网络结构中的所有层。
5、helper functions
(1)client_update
client_update函数使用privent client data训练client模型。这是在num_selected clients中进行的本地训练
def client_update(client_model, optimizer, train_loader, epoch=5):"""This function updates/trains client model on client data"""model.train()for e in range(epoch):for batch_idx, (data, target) in enumerate(train_loader):data, target = data.cuda(), target.cuda()optimizer.zero_grad()output = client_model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()return loss.item()
- 首先,我们使用client_model.train()将客户端模型设置为训练模式。
- 然后,我们使用一个for循环遍历训练轮数。在每一轮中,我们使用另一个for循环遍历训练数据加载器中的数据。
- 对于每个数据batch,我们将数据和目标标签从CPU转移到GPU上,并使用optimizer.zero_grad()将梯度清零。
- 接下来,我们使用客户端模型对数据进行前向传播,并计算损失。output = client_model(data)
- 然后,我们使用loss.backward()计算梯度。
- 最后,我们使用optimizer.step()更新客户端模型的参数。
(2)server_aggregate
server_aggregate函数聚合从每个客户机接收到的模型权重,并用更新后的权重更新全局模型。在本教程中,采用权重的平均值并将其聚合为全局权重。
def server_aggregate(global_model, client_models):"""This function has aggregation method 'mean'"""### This will take simple mean of the weights of models ###global_dict = global_model.state_dict()for k in global_dict.keys():global_dict[k] = torch.stack([client_models[i].state_dict()[k].float() for i in range(len(client_models))], 0).mean(0)global_model.load_state_dict(global_dict)for model in client_models:model.load_state_dict(global_model.state_dict())
- 首先,我们使用global_model.state_dict()获取全局模型的参数字典。
- 然后,我们使用一个for循环遍历全局模型的参数字典中的每个键(参数名称)。
- 对于每个参数,我们使用torch.stack()将所有客户端模型的相应参数堆叠在一起,并使用float()将其转换为浮点数类型。
- 接下来,我们使用mean()函数计算参数的平均值。
- 最后,我们使用global_model.load_state_dict()将计算出的平均值加载到全局模型的参数字典中。
- 接下来,我们使用另一个for循环遍历客户端模型列表,并使用model.load_state_dict()将全局模型的参数字典加载到每个客户端模型中,以实现全局模型在每个客户端模型的平均值。
(3)test
test函数输入global模型和test loader,返回test loss和accuracy
def test(global_model, test_loader):"""This function test the global model on test data and returns test loss and test accuracy """global_model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.cuda(), target.cuda()output = global_model(data)test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch losspred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probabilitycorrect += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)acc = correct / len(test_loader.dataset)return test_loss, acc
- 首先,我们使用global_model.eval()将全局模型设置为评估模式,以便在测试过程中关闭dropout等正则化技术。
- 然后,我们初始化测试损失为0,正确分类的样本数为0
- 使用torch.no_grad()上下文,用于在代码块中禁用梯度计算。
- 我们遍历test_loader中的每个数据样本。
- 对于每个数据样本data,target,我们将数据和目标标签从CPU加载到GPU上
- 并使用全局模型对其进行前向传播。output = global_model(data)
- 我们使用F.nll_loss()计算输出与目标标签之间的交叉熵损失,并使用reduction='sum’将其转换为单个数值。
- 接下来,我们使用test_loss += …将每个样本的损失累加到测试损失中。
- 最后,我们使用pred = output.argmax(dim=1, keepdim=True)计算输出中最大概率的索引,并将其与目标标签进行比较。
- 使用pred.eq(target.view_as(pred))比较预测索引和实际索引,并将它们转换为布尔值。
- 使用sum().item()计算布尔值的总和,并将其除以测试数据加载器中样本的数量以获得测试准确性。
- 最后,我们返回测试损失和测试准确性。
6、实例化模型
############################################
#### Initializing models and optimizer ####
################################################ global model ##########
global_model = VGG('VGG19').cuda()############## client models ##############
client_models = [ VGG('VGG19').cuda() for _ in range(num_selected)]
for model in client_models:model.load_state_dict(global_model.state_dict()) ### initial synchronizing with global model ############### optimizers ################
opt = [optim.SGD(model.parameters(), lr=0.1) for model in client_models]
7、训练模型
###### List containing info about learning #########
losses_train = []
losses_test = []
acc_train = []
acc_test = []
# Runnining FLfor r in range(num_rounds):# select random clientsclient_idx = np.random.permutation(num_clients)[:num_selected]# client updateloss = 0for i in tqdm(range(num_selected)):loss += client_update(client_models[i], opt[i], train_loader[client_idx[i]], epoch=epochs)losses_train.append(loss)# server aggregateserver_aggregate(global_model, client_models)test_loss, acc = test(global_model, test_loader)losses_test.append(test_loss)acc_test.append(acc)print('%d-th round' % r)print('average train loss %0.3g | test loss %0.3g | test acc: %0.3f' % (loss / num_selected, test_loss, acc))
7、整体流程

查看不同类型数据的方法
首先要查看变量的数据类型:type(object)
1、dataframe
使用万能函数
def basic_eda(df):print("-------------------------------TOP 5 RECORDS-----------------------------")print(df.head(5))print("-------------------------------INFO--------------------------------------")print(df.info())print("-------------------------------Describe----------------------------------")print(df.describe())print("-------------------------------Columns-----------------------------------")print(df.columns)print("-------------------------------Data Types--------------------------------")print(df.dtypes)print("----------------------------Missing Values-------------------------------")print(df.isnull().sum())print("----------------------------NULL values----------------------------------")print(df.isna().sum())print("--------------------------Shape Of Data---------------------------------")print(df.shape)print("============================================================================ \n")
- df.head():查看前几行数据,默认是5
- df.info:打印dataframe的简要摘要,包括索引的数据类型dtype和列的数据类型dtype,非空值的数量和内存使用情况。

- df.describe:describe()函数用于生成描述性统计信息。 描述性统计数据:数值类型的包括均值,标准差,最大值,最小值,分位数等;类别的包括个数,类别的数目,最高数量的类别及出现次数等;输出将根据提供的内容而有所不同

- df.colunms:查看列
- df.dtypes:查看元素的数据类型
- df.shape:查看dataframe的形状
2、ndarray
- ndarray.type:查看元素类型
- ndarray.shape:查看数组的形状
- ndarray.ndim:查看数组维度
- ndarry.size:查看数组的全部元素个数
- len(ndarray):计算的是数组的行数,相当于ndarray.shape[0]
3、Dictionary
- dict.keys():返回字典全部的key
- dict.size❌‘dict’ object has no attribute ‘size’
- numpy.size(dict)❌无法获得字典大小
- len(dict):返回字典key-value对的个数
4、list
- list.size❌‘list’ object has no attribute ‘size’
- numpy.size(list):查看列表全部元素的个数
- len(list):同numpy.size(list)一样
5、tuple
- tuple.size❌‘tuple’ object has no attribute ‘size’
- numpy.size(tuple):查看元组全部元素的个数
- len(tuple):同numpy.size(tuple)一样
okkksleeeeep!

相关文章:
2024年1月9日学习总结
目录 学习目标学习内容联邦学习基础:why, what, howwhy?what?how? 联邦学习的例子——CIFAR-10数据集(分类问题)1、import libararies2、hyper-parameters3、加载并且划分数据4、创建神经网络模型5、helper…...

Nacos使用MySQL8时区问题导致启动失败
文章目录 配置下mysql的时区方式一 (永久)方式二(临时) 由于mysql8需要配置时区,如果不配置时区,nacos就连不上mysql,从而也就无法登录nacos自带的图形化界面 配置下mysql的时区 方式一 (永久) 直接修改配置文件&…...
在k8s集群中部署多nginx-ingress
关于ingress的介绍,前面已经详细讲过了,参考ingress-nginx详解和部署方案。本案例ingress的部署使用deploymentLB的方式。 参考链接: 多个ingress部署 文章目录 1. 下载ingress的文件2. 文件资源分析3. 部署ingress3.1 部署第一套ingress3.1…...

SLF4J Spring Boot日志框架
JAVA日志框架 JAVA有好多优秀的日志框架,比如log4j、log4j2、logback、JUL(java.util.logging)、JCL(JAVA Common Logging)等等,logback是后起之秀,是Spring Boot默认日志框架。 今天文章的目…...

mysql之导入导出远程备份
文章目录 一、navicat导入导出二、mysqldump命令导入导出2.1导出2.1.1 导出表数据和表结构2.1.2 只导出表结构() 2.2 导入(使用mysqldump导入 包含t _log表的整个数据库 共耗时 20s;)方法一:方法二: 三、LOAD DATA INFILE命令导入导出(只针对单表)设置导…...

Java虚拟机ART 读书笔记 第2章 深入理解Class文件格式
GitHub - Omooo/Android-Notes: ✨✨✨这有一包小鱼干,确定不要吃嘛?( 逃 深入理解Android:Java虚拟机ART 读书笔记 以下内容均来自书中内容 建议看原书哦 第2章 深入理解Class文件格式 2.1 class文件总览 Class文件格式全貌 u4ÿ…...

编程基础 - 初识Linux
编程基础 - 初识Linux 返回序言及专栏目录 文章目录 编程基础 - 初识Linux前言一、Linux发展简介二、现代Linux三、Linux系统各发行版小结 前言 为什么要学习Linux呢?我这Windows用得好好的,简单易用傻瓜式、用的人还超多!但是我要告诉你的…...

c yuv422转yuv420p
思路: yuv422 存储格式为 y u y v y u y v y u y v y u y v yuv420p 存储最简单,先存所以的y,再存u,最后v 所以先把422所有的y存在一起,再提奇数行的u ,偶数行舍弃。提…...
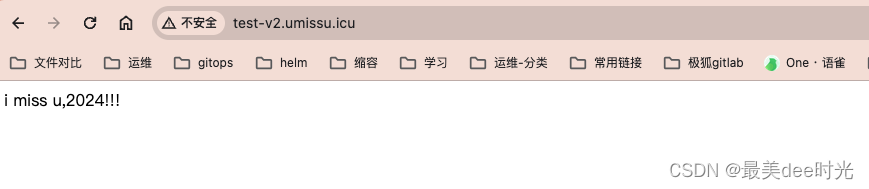
计算机网络 - 路由器查表过程模拟 C++(2024)
1.题目描述 参考计算机网络教材 140 页 4.3 节内容,编程模拟路由器查找路由表的过程,用(目的地址 掩码 下一跳) 的 IP 路由表以及目的地址作为输入,为目的地址查找路由表,找出正确的下一跳并输出结果。 1.…...
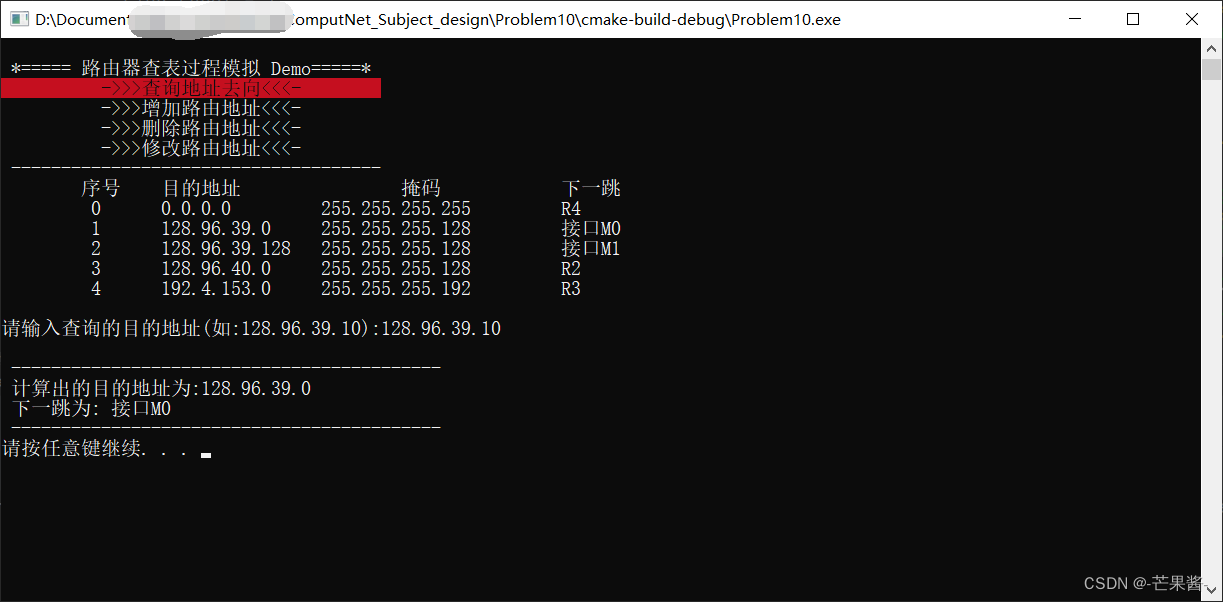
实现pytorch版的mobileNetV1
mobileNet具体细节,在前面已做了分析记录:轻量化网络-MobileNet系列-CSDN博客 这里是根据网络结构,搭建模型,用于图像分类任务。 1. 网络结构和基本组件 2. 搭建组件 (1)普通的卷积组件:CBL …...

vue多tab页面全部关闭后自动退出登录
业务场景:主项目是用vue写的单页面应用,但是有多开页面的需求,现在需要在用户关闭了所有的浏览器标签页面后,自动退出登录。 思路:因为是不同的tab页面,我只能用localStorage来通信,新打开一个…...

记一个集群环境部署不完整导致的BUG
一 背景 产品有三个环境:开发测试环境、验收环境、生产环境。 开发测试环境,保持最新的更新; 验收环境,阶段待发布内容; 生产环境,部署稳定内容。 产品为BS架构,后端采用微服务…...

Go zero copy,复制文件
这里使用零拷贝技术复制文件,从内核态操作源文件和目标文件。避免了在用户态开辟缓冲区,然后从内核态复制文件到用户态的问题。 由内核态完成文件复制操作。 调用的是syscall.Sendfile系统调用函数。 //go:build linuxpackage zero_copyimport ("f…...

http协议九种请求方法介绍及常见状态码
http1.0定义了三种: GET: 向服务器获取资源,比如常见的查询请求POST: 向服务器提交数据而发送的请求Head: 和get类似,返回的响应中没有具体的内容,用于获取报头 http1.1定义了六种 PUT:一般是用于更新请求,…...

详解flink exactly-once和两阶段提交
以下是我们常见的三种 flink 处理语义: 最多一次(At-most-Once):用户的数据只会被处理一次,不管成功还是失败,不会重试也不会重发。 至少一次(At-least-Once):系统会保…...
)
Qt/QML编程学习之心得:QDbus实现service接口调用(28)
D-Bus协议用于进程间通讯的。 QString value = retrieveValue();QDBusPendingCall pcall = interface->asyncCall(QLatin1String("Process"), value);QDBusPendingCallWatcher *watcher = new QDBusPendingCallWatcher(pcall, this);QObject::connect(watcher, SI…...

前端nginx配置指南
前端项目发布后,有些接口需要在服务器配置反向代理,资源配置gzip压缩,配置跨域允许访问等 配置文件模块概览 配置示例 反向代理 反向代理是Nginx的核心功能之一,是指客户端发送请求到代理服务器,代理服务器再将请求…...
接口测试到底怎么做,5分钟时间看完这篇文章彻底搞清楚
01、通用的项目架构 02、什么是接口 接口:服务端程序对外提供的一种统一的访问方式,通常采用HTTP协议,通过不同的url,不同的请求类型(GET、POST),不同的参数,来执行不同的业务逻辑。…...

显示管理磁盘分区 fdisk
显示管理磁盘分区 fdisk fdisk是用于检查一个磁盘上分区信息最通用的命令。 fdisk可以显示分区信息及一些细节信息,比如文件系统类型等。 设备的名称通常是/dev/sda、/dev/sdb 等。 对于以前的设备有可能还存在设备名为 /dev/hd* (IDE)的设备,这个设…...

Hyperledger Fabric 管理链码 peer lifecycle chaincode 指令使用
链上代码(Chaincode)简称链码,包括系统链码和用户链码。系统链码(System Chaincode)指的是 Fabric Peer 中负责系统配置、查询、背书、验证等平台功能的代码逻辑,运行在 Peer 进程内,将在第 14 …...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...