EasyExcel快速导出 100W 数据
一. 简介
导出是后台管理系统的常用功能,当数据量特别大的时候会内存溢出和卡顿页面,曾经自己封装过一个导出,采用了分批查询数据来避免内存溢出和使用SXSSFWorkbook方式缓存数据到文件上以解决下载大文件EXCEL卡死页面的问题。
不过一是存在封装不太友好使用不方便的问题,二是这些poi的操作方式仍然存在内存占用过大的问题,三是存在空循环和整除的时候数据有缺陷的问题,以及存在内存溢出的隐患。
无意间查询到阿里开源的EasyExcel框架,发现可以将解析的EXCEL的内存占用控制在KB级别,并且绝对不会内存溢出(内部实现待研究),还有就是速度极快,大概100W条记录,十几个字段,只需要70秒即可完成下载。
遂抛弃自己封装的,转战研究阿里开源的EasyExcel. 不过 说实话,当时自己封装的那个还是有些技术含量的,例如:外观模式,模板方法模式,以及委托思想,组合思想,可以看看。另外,微信搜索关注Java技术栈,发送:设计模式,可以获取我整理的 Java 设计模式实战教程。
EasyExcel的github地址是:https://github.com/alibaba/easyexcel
二. 案例
2.1 POM依赖
<!-- 阿里开源EXCEL -->
<dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>1.1.1</version>
</dependency>
2.2 POJO对象
package com.authorization.privilege.excel;import java.util.Date;/*** @author qjwyss* @description*/
public class User {private String uid;private String name;private Integer age;private Date birthday;public User() {}public User(String uid, String name, Integer age, Date birthday) {this.uid = uid;this.name = name;this.age = age;this.birthday = birthday;}public String getUid() {return uid;}public void setUid(String uid) {this.uid = uid;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Date getBirthday() {return birthday;}public void setBirthday(Date birthday) {this.birthday = birthday;}
}
2.3 测试环境
2.3.1.数据量少的(20W以内吧):一个SHEET一次查询导出
如果数据量过大,不要用传统分页,利用where id> #{lastMaxId} order by id limit 100,解决分页慢的问题
/*** 针对较少的记录数(20W以内大概)可以调用该方法一次性查出然后写入到EXCEL的一个SHEET中* 注意: 一次性查询出来的记录数量不宜过大,不会内存溢出即可。** @throws IOException*/
@Test
public void writeExcelOneSheetOnceWrite() throws IOException {// 生成EXCEL并指定输出路径OutputStream out = new FileOutputStream("E:\\temp\\withoutHead1.xlsx");ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);// 设置SHEETSheet sheet = new Sheet(1, 0);sheet.setSheetName("sheet1");// 设置标题Table table = new Table(1);List<List<String>> titles = new ArrayList<List<String>>();titles.add(Arrays.asList("用户ID"));titles.add(Arrays.asList("名称"));titles.add(Arrays.asList("年龄"));titles.add(Arrays.asList("生日"));table.setHead(titles);// 查询数据导出即可 比如说一次性总共查询出100条数据List<List<String>> userList = new ArrayList<>();for (int i = 0; i < 100; i++) {userList.add(Arrays.asList("ID_" + i, "小明" + i, String.valueOf(i), new Date().toString()));}writer.write0(userList, sheet, table);writer.finish();
}
2.3.2.数据量适中(100W以内):一个SHEET分批查询导出
/*** 针对105W以内的记录数可以调用该方法分多批次查出然后写入到EXCEL的一个SHEET中* 注意:* 每次查询出来的记录数量不宜过大,根据内存大小设置合理的每次查询记录数,不会内存溢出即可。* 数据量不能超过一个SHEET存储的最大数据量105W** @throws IOException*/
@Test
public void writeExcelOneSheetMoreWrite() throws IOException {// 生成EXCEL并指定输出路径OutputStream out = new FileOutputStream("E:\\temp\\withoutHead2.xlsx");ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);// 设置SHEETSheet sheet = new Sheet(1, 0);sheet.setSheetName("sheet1");// 设置标题Table table = new Table(1);List<List<String>> titles = new ArrayList<List<String>>();titles.add(Arrays.asList("用户ID"));titles.add(Arrays.asList("名称"));titles.add(Arrays.asList("年龄"));titles.add(Arrays.asList("生日"));table.setHead(titles);// 模拟分批查询:总记录数50条,每次查询20条, 分三次查询 最后一次查询记录数是10Integer totalRowCount = 50;Integer pageSize = 20;Integer writeCount = totalRowCount % pageSize == 0 ? (totalRowCount / pageSize) : (totalRowCount / pageSize + 1);// 注: 此处仅仅为了模拟数据,实用环境不需要将最后一次分开,合成一个即可, 参数为:currentPage = i+1; pageSize = pageSizefor (int i = 0; i < writeCount; i++) {// 前两次查询 每次查20条数据if (i < writeCount - 1) {List<List<String>> userList = new ArrayList<>();for (int j = 0; j < pageSize; j++) {userList.add(Arrays.asList("ID_" + Math.random(), "小明", String.valueOf(Math.random()), new Date().toString()));}writer.write0(userList, sheet, table);} else if (i == writeCount - 1) {// 最后一次查询 查多余的10条记录List<List<String>> userList = new ArrayList<>();Integer lastWriteRowCount = totalRowCount - (writeCount - 1) * pageSize;for (int j = 0; j < lastWriteRowCount; j++) {userList.add(Arrays.asList("ID_" + Math.random(), "小明", String.valueOf(Math.random()), new Date().toString()));}writer.write0(userList, sheet, table);}}writer.finish();
}
2.3.3.数据量很大(几百万都行):多个SHEET分批查询导出
/*** 针对几百万的记录数可以调用该方法分多批次查出然后写入到EXCEL的多个SHEET中* 注意:* perSheetRowCount % pageSize要能整除 为了简洁,非整除这块不做处理* 每次查询出来的记录数量不宜过大,根据内存大小设置合理的每次查询记录数,不会内存溢出即可。** @throws IOException*/
@Test
public void writeExcelMoreSheetMoreWrite() throws IOException {// 生成EXCEL并指定输出路径OutputStream out = new FileOutputStream("E:\\temp\\withoutHead3.xlsx");ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);// 设置SHEET名称String sheetName = "测试SHEET";// 设置标题Table table = new Table(1);List<List<String>> titles = new ArrayList<List<String>>();titles.add(Arrays.asList("用户ID"));titles.add(Arrays.asList("名称"));titles.add(Arrays.asList("年龄"));titles.add(Arrays.asList("生日"));table.setHead(titles);// 模拟分批查询:总记录数250条,每个SHEET存100条,每次查询20条 则生成3个SHEET,前俩个SHEET查询次数为5, 最后一个SHEET查询次数为3 最后一次写的记录数是10// 注:该版本为了较少数据判断的复杂度,暂时perSheetRowCount要能够整除pageSize, 不去做过多处理 合理分配查询数据量大小不会内存溢出即可。Integer totalRowCount = 250;Integer perSheetRowCount = 100;Integer pageSize = 20;Integer sheetCount = totalRowCount % perSheetRowCount == 0 ? (totalRowCount / perSheetRowCount) : (totalRowCount / perSheetRowCount + 1);Integer previousSheetWriteCount = perSheetRowCount / pageSize;Integer lastSheetWriteCount = totalRowCount % perSheetRowCount == 0 ?previousSheetWriteCount :(totalRowCount % perSheetRowCount % pageSize == 0 ? totalRowCount % perSheetRowCount / pageSize : (totalRowCount % perSheetRowCount / pageSize + 1));for (int i = 0; i < sheetCount; i++) {// 创建SHEETSheet sheet = new Sheet(i, 0);sheet.setSheetName(sheetName + i);if (i < sheetCount - 1) {// 前2个SHEET, 每个SHEET查5次 每次查20条 每个SHEET写满100行 2个SHEET合计200行 实用环境:参数:currentPage: j+1 + previousSheetWriteCount*i, pageSize: pageSizefor (int j = 0; j < previousSheetWriteCount; j++) {List<List<String>> userList = new ArrayList<>();for (int k = 0; k < 20; k++) {userList.add(Arrays.asList("ID_" + Math.random(), "小明", String.valueOf(Math.random()), new Date().toString()));}writer.write0(userList, sheet, table);}} else if (i == sheetCount - 1) {// 最后一个SHEET 实用环境不需要将最后一次分开,合成一个即可, 参数为:currentPage = i+1; pageSize = pageSizefor (int j = 0; j < lastSheetWriteCount; j++) {// 前俩次查询 每次查询20条if (j < lastSheetWriteCount - 1) {List<List<String>> userList = new ArrayList<>();for (int k = 0; k < 20; k++) {userList.add(Arrays.asList("ID_" + Math.random(), "小明", String.valueOf(Math.random()), new Date().toString()));}writer.write0(userList, sheet, table);} else if (j == lastSheetWriteCount - 1) {// 最后一次查询 将剩余的10条查询出来List<List<String>> userList = new ArrayList<>();Integer lastWriteRowCount = totalRowCount - (sheetCount - 1) * perSheetRowCount - (lastSheetWriteCount - 1) * pageSize;for (int k = 0; k < lastWriteRowCount; k++) {userList.add(Arrays.asList("ID_" + Math.random(), "小明1", String.valueOf(Math.random()), new Date().toString()));}writer.write0(userList, sheet, table);}}}}writer.finish();
}
2.4 生产环境
2.4.0.Excel常量类
package com.authorization.privilege.constant;/*** @author qjwyss* @description EXCEL常量类*/
public class ExcelConstant {/*** 每个sheet存储的记录数 100W*/public static final Integer PER_SHEET_ROW_COUNT = 1000000;/*** 每次向EXCEL写入的记录数(查询每页数据大小) 20W*/public static final Integer PER_WRITE_ROW_COUNT = 200000;}
注:为了书写方便,此处俩个必须要整除,可以省去很多不必要的判断。另外如果自己测试,可以改为100,20。
分享给你: Spring Boot 学习笔记。
2.4.1.数据量少的(20W以内吧):一个SHEET一次查询导出
@Override
public ResultVO<Void> exportSysSystemExcel(SysSystemVO sysSystemVO, HttpServletResponse response) throws Exception {ServletOutputStream out = null;try {out = response.getOutputStream();ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);// 设置EXCEL名称String fileName = new String(("SystemExcel").getBytes(), "UTF-8");// 设置SHEET名称Sheet sheet = new Sheet(1, 0);sheet.setSheetName("系统列表sheet1");// 设置标题Table table = new Table(1);List<List<String>> titles = new ArrayList<List<String>>();titles.add(Arrays.asList("系统名称"));titles.add(Arrays.asList("系统标识"));titles.add(Arrays.asList("描述"));titles.add(Arrays.asList("状态"));titles.add(Arrays.asList("创建人"));titles.add(Arrays.asList("创建时间"));table.setHead(titles);// 查数据写EXCELList<List<String>> dataList = new ArrayList<>();List<SysSystemVO> sysSystemVOList = this.sysSystemReadMapper.selectSysSystemVOList(sysSystemVO);if (!CollectionUtils.isEmpty(sysSystemVOList)) {sysSystemVOList.forEach(eachSysSystemVO -> {dataList.add(Arrays.asList(eachSysSystemVO.getSystemName(),eachSysSystemVO.getSystemKey(),eachSysSystemVO.getDescription(),eachSysSystemVO.getState().toString(),eachSysSystemVO.getCreateUid(),eachSysSystemVO.getCreateTime().toString()));});}writer.write0(dataList, sheet, table);// 下载EXCELresponse.setHeader("Content-Disposition", "attachment;filename=" + new String((fileName).getBytes("gb2312"), "ISO-8859-1") + ".xls");response.setContentType("multipart/form-data");response.setCharacterEncoding("utf-8");writer.finish();out.flush();} finally {if (out != null) {try {out.close();} catch (Exception e) {e.printStackTrace();}}}return ResultVO.getSuccess("导出系统列表EXCEL成功");
}
2.4.2.数据量适中(100W以内):一个SHEET分批查询导出
@Override
public ResultVO<Void> exportSysSystemExcel(SysSystemVO sysSystemVO, HttpServletResponse response) throws Exception {ServletOutputStream out = null;try {out = response.getOutputStream();ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);// 设置EXCEL名称String fileName = new String(("SystemExcel").getBytes(), "UTF-8");// 设置SHEET名称Sheet sheet = new Sheet(1, 0);sheet.setSheetName("系统列表sheet1");// 设置标题Table table = new Table(1);List<List<String>> titles = new ArrayList<List<String>>();titles.add(Arrays.asList("系统名称"));titles.add(Arrays.asList("系统标识"));titles.add(Arrays.asList("描述"));titles.add(Arrays.asList("状态"));titles.add(Arrays.asList("创建人"));titles.add(Arrays.asList("创建时间"));table.setHead(titles);// 查询总数并 【封装相关变量 这块直接拷贝就行 不要改动】Integer totalRowCount = this.sysSystemReadMapper.selectCountSysSystemVOList(sysSystemVO);Integer pageSize = ExcelConstant.PER_WRITE_ROW_COUNT;Integer writeCount = totalRowCount % pageSize == 0 ? (totalRowCount / pageSize) : (totalRowCount / pageSize + 1);// 写数据 这个i的最大值直接拷贝就行了 不要改for (int i = 0; i < writeCount; i++) {List<List<String>> dataList = new ArrayList<>();// 此处查询并封装数据即可 currentPage, pageSize这个变量封装好的 不要改动PageHelper.startPage(i + 1, pageSize);List<SysSystemVO> sysSystemVOList = this.sysSystemReadMapper.selectSysSystemVOList(sysSystemVO);if (!CollectionUtils.isEmpty(sysSystemVOList)) {sysSystemVOList.forEach(eachSysSystemVO -> {dataList.add(Arrays.asList(eachSysSystemVO.getSystemName(),eachSysSystemVO.getSystemKey(),eachSysSystemVO.getDescription(),eachSysSystemVO.getState().toString(),eachSysSystemVO.getCreateUid(),eachSysSystemVO.getCreateTime().toString()));});}writer.write0(dataList, sheet, table);}// 下载EXCELresponse.setHeader("Content-Disposition", "attachment;filename=" + new String((fileName).getBytes("gb2312"), "ISO-8859-1") + ".xls");response.setContentType("multipart/form-data");response.setCharacterEncoding("utf-8");writer.finish();out.flush();} finally {if (out != null) {try {out.close();} catch (Exception e) {e.printStackTrace();}}}return ResultVO.getSuccess("导出系统列表EXCEL成功");
}
2.4.3.数据里很大(几百万都行):多个SHEET分批查询导出
@Override
public ResultVO<Void> exportSysSystemExcel(SysSystemVO sysSystemVO, HttpServletResponse response) throws Exception {ServletOutputStream out = null;try {out = response.getOutputStream();ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);// 设置EXCEL名称String fileName = new String(("SystemExcel").getBytes(), "UTF-8");// 设置SHEET名称String sheetName = "系统列表sheet";// 设置标题Table table = new Table(1);List<List<String>> titles = new ArrayList<List<String>>();titles.add(Arrays.asList("系统名称"));titles.add(Arrays.asList("系统标识"));titles.add(Arrays.asList("描述"));titles.add(Arrays.asList("状态"));titles.add(Arrays.asList("创建人"));titles.add(Arrays.asList("创建时间"));table.setHead(titles);// 查询总数并封装相关变量(这块直接拷贝就行了不要改)Integer totalRowCount = this.sysSystemReadMapper.selectCountSysSystemVOList(sysSystemVO);Integer perSheetRowCount = ExcelConstant.PER_SHEET_ROW_COUNT;Integer pageSize = ExcelConstant.PER_WRITE_ROW_COUNT;Integer sheetCount = totalRowCount % perSheetRowCount == 0 ? (totalRowCount / perSheetRowCount) : (totalRowCount / perSheetRowCount + 1);Integer previousSheetWriteCount = perSheetRowCount / pageSize;Integer lastSheetWriteCount = totalRowCount % perSheetRowCount == 0 ?previousSheetWriteCount :(totalRowCount % perSheetRowCount % pageSize == 0 ? totalRowCount % perSheetRowCount / pageSize : (totalRowCount % perSheetRowCount / pageSize + 1));for (int i = 0; i < sheetCount; i++) {// 创建SHEETSheet sheet = new Sheet(i, 0);sheet.setSheetName(sheetName + i);// 写数据 这个j的最大值判断直接拷贝就行了,不要改动for (int j = 0; j < (i != sheetCount - 1 ? previousSheetWriteCount : lastSheetWriteCount); j++) {List<List<String>> dataList = new ArrayList<>();// 此处查询并封装数据即可 currentPage, pageSize这俩个变量封装好的 不要改动PageHelper.startPage(j + 1 + previousSheetWriteCount * i, pageSize);List<SysSystemVO> sysSystemVOList = this.sysSystemReadMapper.selectSysSystemVOList(sysSystemVO);if (!CollectionUtils.isEmpty(sysSystemVOList)) {sysSystemVOList.forEach(eachSysSystemVO -> {dataList.add(Arrays.asList(eachSysSystemVO.getSystemName(),eachSysSystemVO.getSystemKey(),eachSysSystemVO.getDescription(),eachSysSystemVO.getState().toString(),eachSysSystemVO.getCreateUid(),eachSysSystemVO.getCreateTime().toString()));});}writer.write0(dataList, sheet, table);}}// 下载EXCELresponse.setHeader("Content-Disposition", "attachment;filename=" + new String((fileName).getBytes("gb2312"), "ISO-8859-1") + ".xls");response.setContentType("multipart/form-data");response.setCharacterEncoding("utf-8");writer.finish();out.flush();} finally {if (out != null) {try {out.close();} catch (Exception e) {e.printStackTrace();}}}return ResultVO.getSuccess("导出系统列表EXCEL成功");
}
三、总结
造的假数据,100W条记录,18个字段,测试导出是70s。在实际上产环境使用的时候,具体的还是要看自己写的sql的性能。sql性能快的话,会很快。
有一点推荐一下:在做分页的时候使用单表查询, 对于所需要处理的外键对应的冗余字段,在外面一次性查出来放到map里面(推荐使用@MapKey注解),然后遍历list的时候根据外键从map中获取对应的名称。
一个宗旨:少发查询sql, 才能更快的导出。
题外话:如果数据量过大,不要用传统分页,利用where id> #{lastMaxId} order by id limit 100,解决分页慢的问题
相关文章:

EasyExcel快速导出 100W 数据
一. 简介 导出是后台管理系统的常用功能,当数据量特别大的时候会内存溢出和卡顿页面,曾经自己封装过一个导出,采用了分批查询数据来避免内存溢出和使用SXSSFWorkbook方式缓存数据到文件上以解决下载大文件EXCEL卡死页面的问题。 不过一是存…...
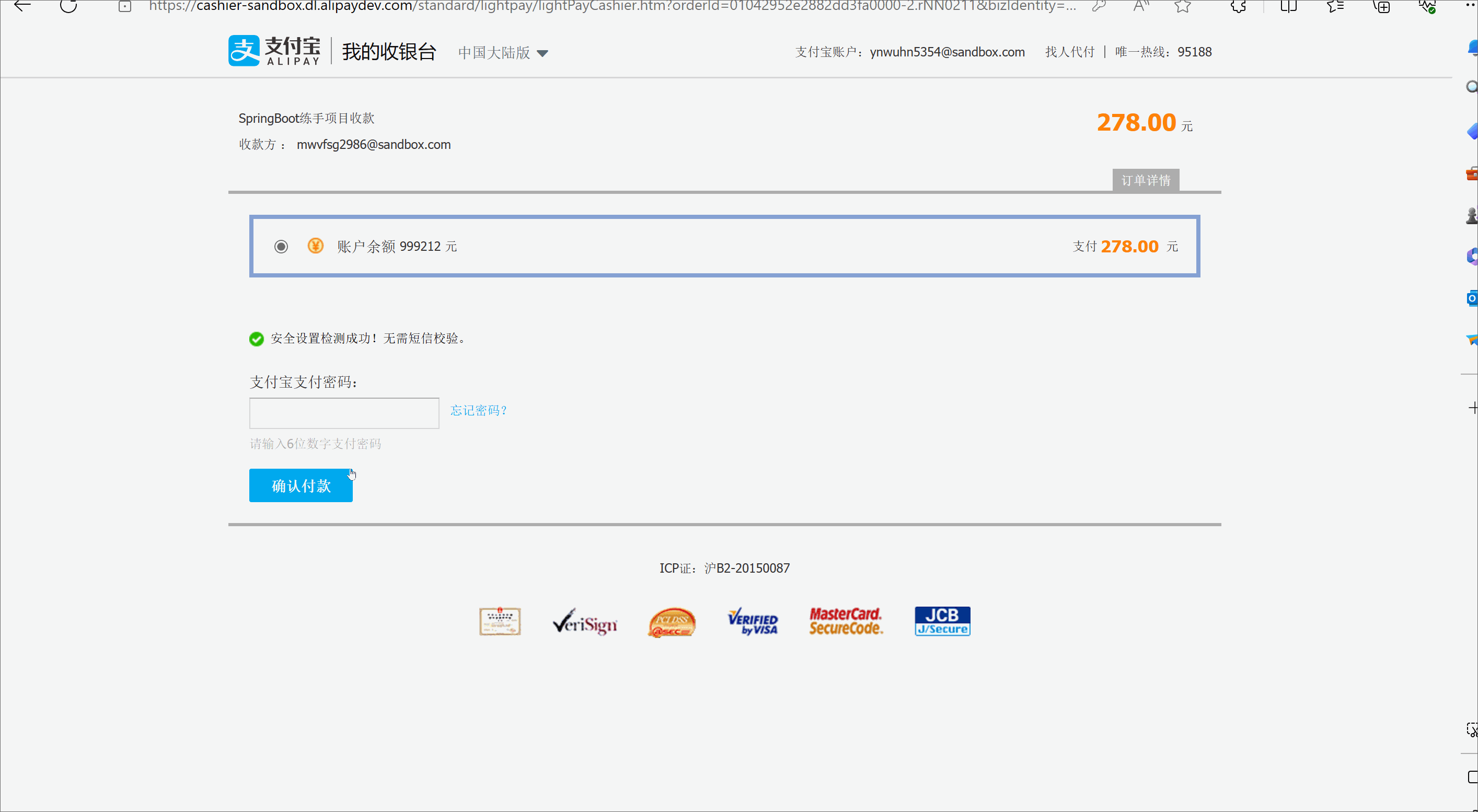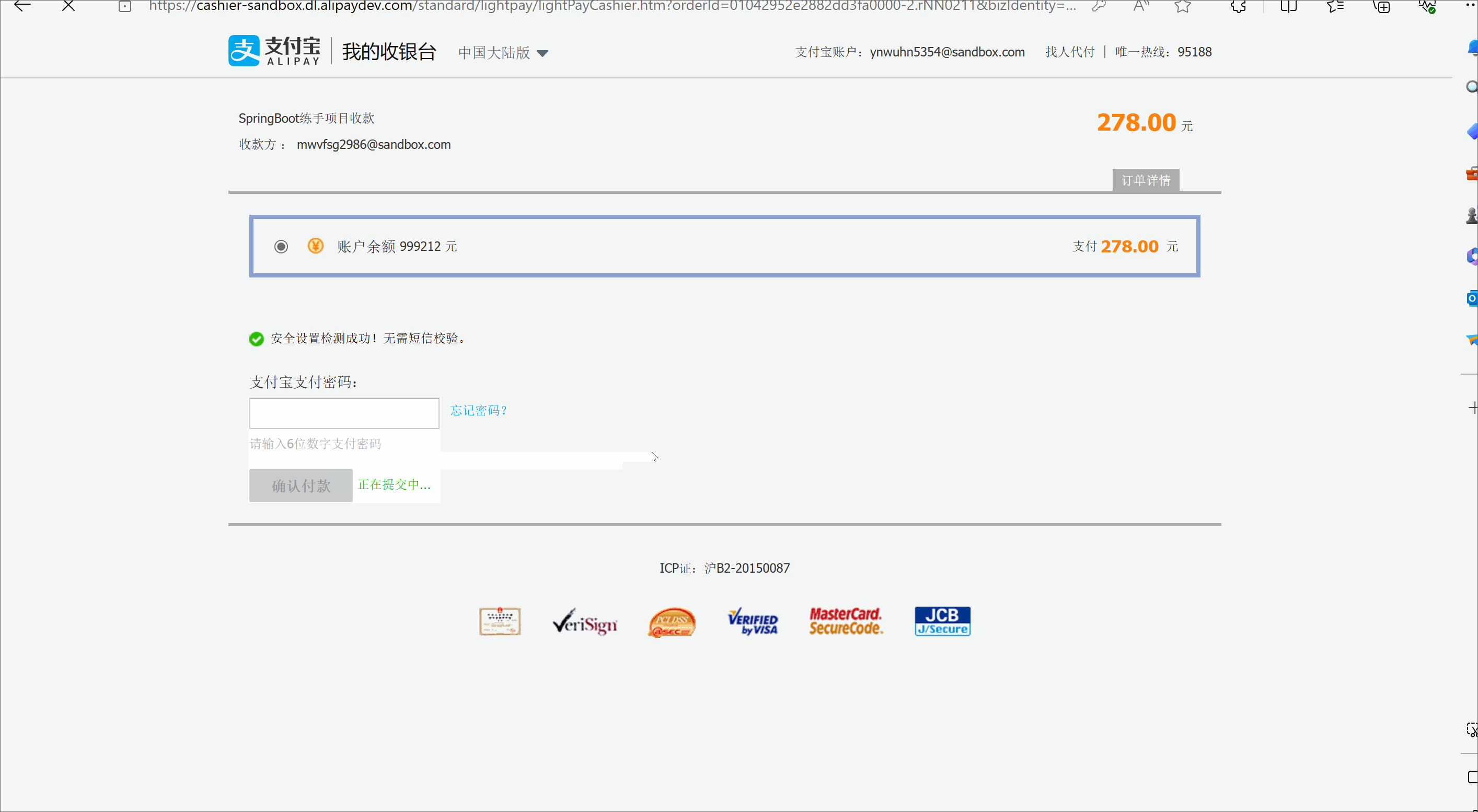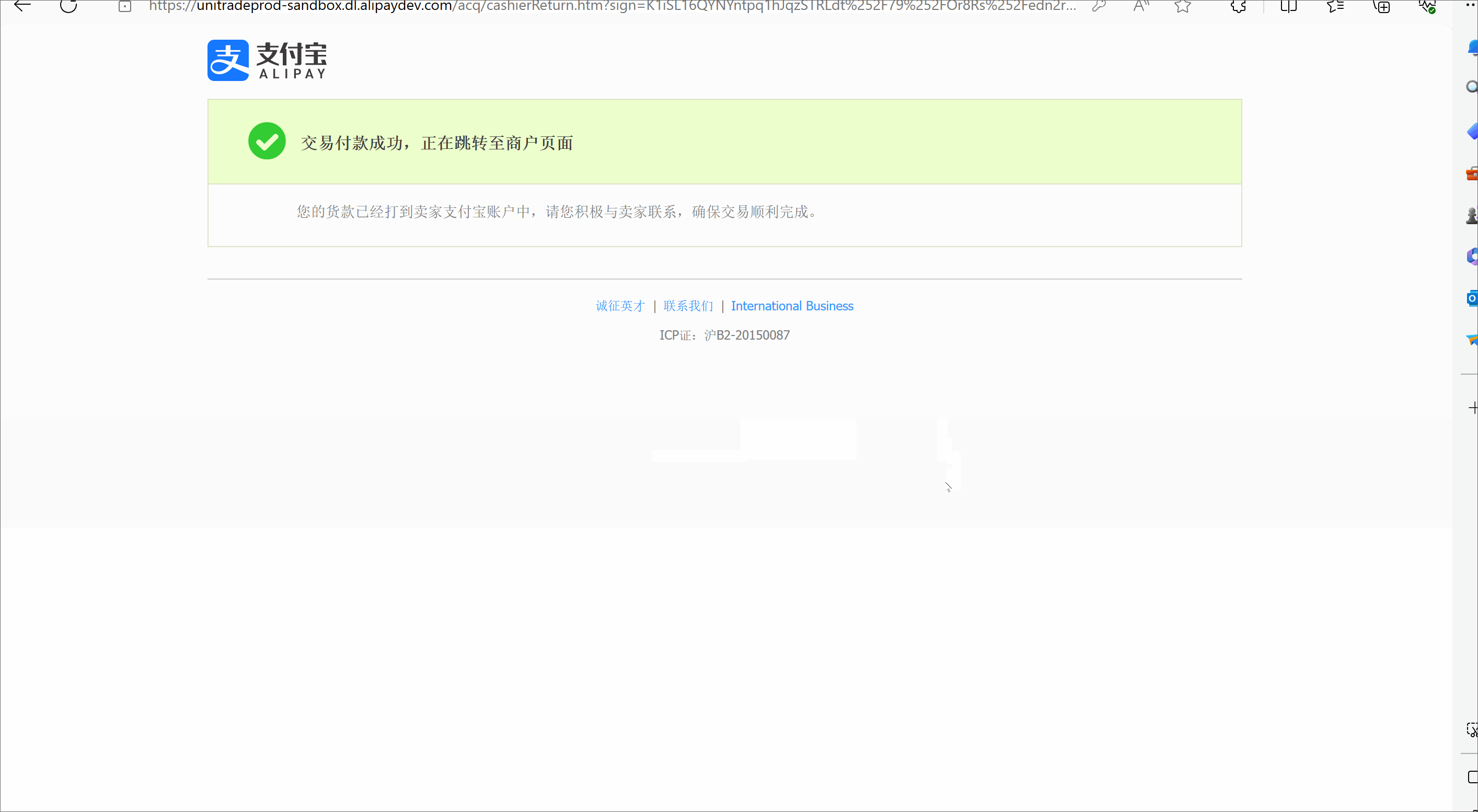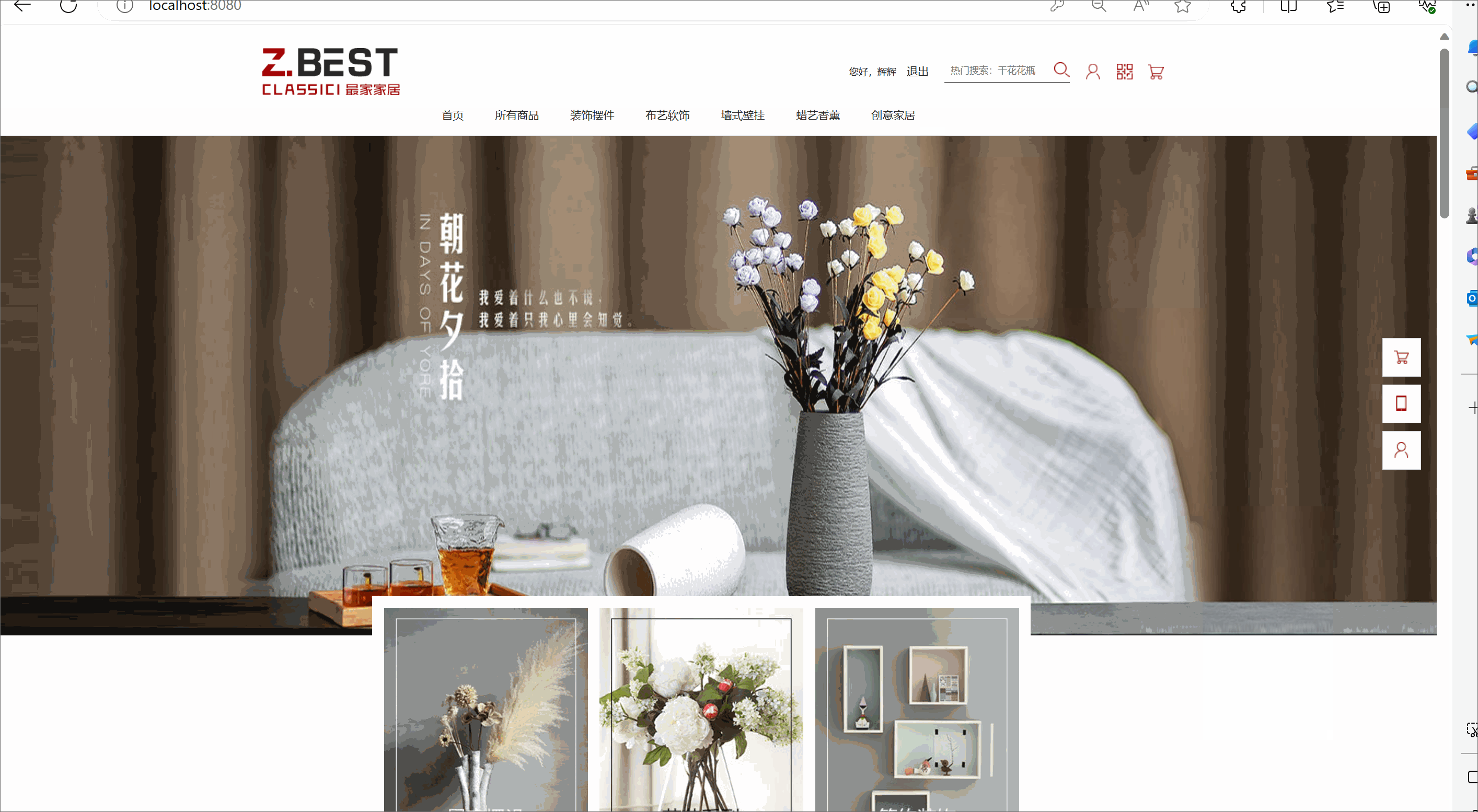
SpingBoot的项目实战--模拟电商【5.沙箱支付】
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于SpringBoot电商项目的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一. 沙箱支付是什么 二.Sp…...

How to collect data
How to collect data 爬虫JavaPythonurllibrequestsBeautifulSoup 反爬虫信息校验型反爬虫动态渲染反爬虫文本混淆反爬虫特征识别反爬虫App反爬虫验证码 自动化测试工具SeleniumAppiumQMetry Automation StudioTestComplete RPA商业化产品艺赛旗影刀UIPath 开源产品Robot Frame…...
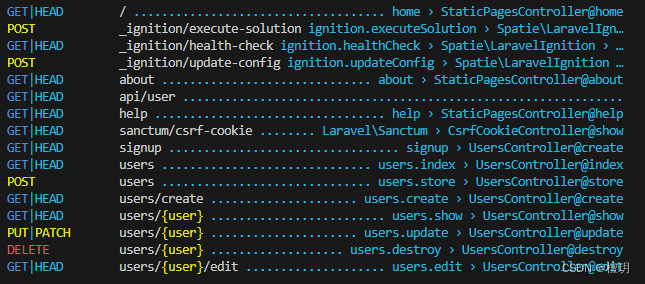
二刷Laravel 教程(用户注册)总结Ⅳ
一、显示用户信息 1)resource Route::resource(users, UsersController); 相当于下面这7个路由 我们先用 Artisan 命令查看目前应用的路由: php artisan route:list 2) compact 方法 //我们将用户对象 $user 通过 compact 方法转化为一个关联…...
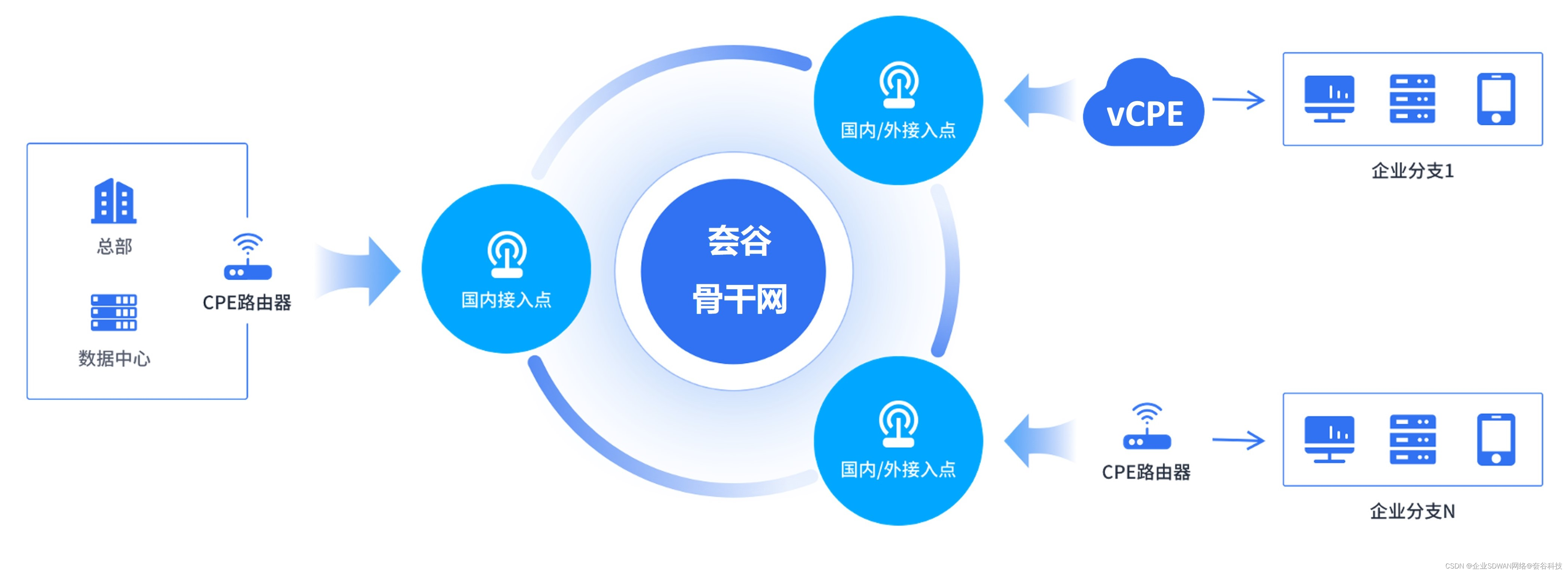
跨国制造业组网方案解析,如何实现总部-分支稳定互联?
既要控制成本,又要稳定高效,可能吗? 在制造企业积极向“智造”发展、数字化转型的当下,物联网、人工智能、机器人等新型设备加入到生产、管理环节,为企业内部数据传输提出了更高的要求。而当企业规模扩大,数…...

网络的设置
一、网络设置 1.1查看linux基础的网络设置 网关 route -n ip地址ifconfigDNS服务器cat /etc/resolv.conf主机名hostname路由 route -n 网络连接状态ss 或者 netstat域名解析nslookup host 例题:除了ping,什么命令可以测试DNS服务器来解…...

CentOS常用命令
CentOS常用命令 1 背景知识1.1 Centos 简介1.2 centos 和ubuntu的区别1.3 安装centos的时候需要注意什么 2 常用命令集锦2.1 文件目录类:2.2 驱动挂载类:2.3 关机命令:2.4 查看系统信息命令:2.5 文本命令2.6 系统管理命令…...

Linux运维之切换到 root 用户
春花秋月何时了,往事知多少。此付费专栏不要订阅,不要订阅,听人劝。 🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列专栏目录 [Java项目实战] 介绍Java…...

【2024系统架构设计】 系统架构设计师第二版-层次式架构设计理论与实践
目录 一 表现层框架设计 二 中间层架构设计 三 数据访问层设计 四 数据架构规划与设计 五 物联网层次架构设计 六 层次式架构案例分析...

SpringSecurity的注解@PreAuthorize的失效问题
问题:测试响应式框架时,测试框架对于权限与角色的拦截问题,对于/delete的访问报错访问拒绝,但是数据里面配置了权限。 配置详情 原因:调用roles方法时源码会重新new一个list将authorities的数据覆盖,导致…...
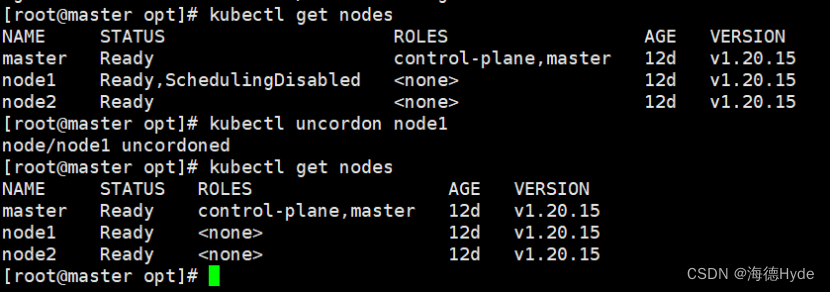
k8s的集群调度
1、scheduler:负责调度资源,把pod调度到指定的node节点 (1)预算策略 (2)优先策略 2、List-watch (1)在k8s集群中,通过List-watch的机制进行每个组件的协作࿰…...
简单易懂的理解 PyTorch 中 Transformer 组件
目录 torch.nn子模块transformer详解 nn.Transformer Transformer 类描述 Transformer 类的功能和作用 Transformer 类的参数 forward 方法 参数 输出 示例代码 注意事项 nn.TransformerEncoder TransformerEncoder 类描述 TransformerEncoder 类的功能和作用 Tr…...

搭建Eureka服务注册中心
一、前言 我们在别的章节中已经详细讲解过eureka注册中心的作用,本节会简单讲解eureka作用,侧重注册中心的搭建。 Eureka作为服务注册中心可以进行服务注册和服务发现,注册在上面的服务可以到Eureka上进行服务实例的拉取,主要作用…...

【React】react-router-dom中的HashRouter和BrowserRouter实现原理
1. 前言 在之前整理BOM的五个对象时,提到: location.hash发生改变后,会触发hashchange事件,且history栈中会增加一条记录,但页面不会重新加载——实现HashRouter的关键history.pushState(state, , URL)执行后…...

生物信息学中的可重复性研究
科学就其本质而言,是累积渐进的。无论你是使用基于网络的还是基于命令行的工具,在进行研究时都应保证该研究可被其他研究人员重复。这有利于你的工作的累积与进展。在生物信息学领域,这意味着如下内容。 工作流应该有据可查。这可能包括在电脑…...

css-img图像同比缩小
1. HTML 中使图像按比例缩小 CSS 来控制图像的大小,并保持其宽高比 <!DOCTYPE html> <html> <head><style>.image-container {width: 300px; /* 设置容器宽度 */height: auto; /* 让高度自适应 */}.image-container img {width: 100%; /* …...
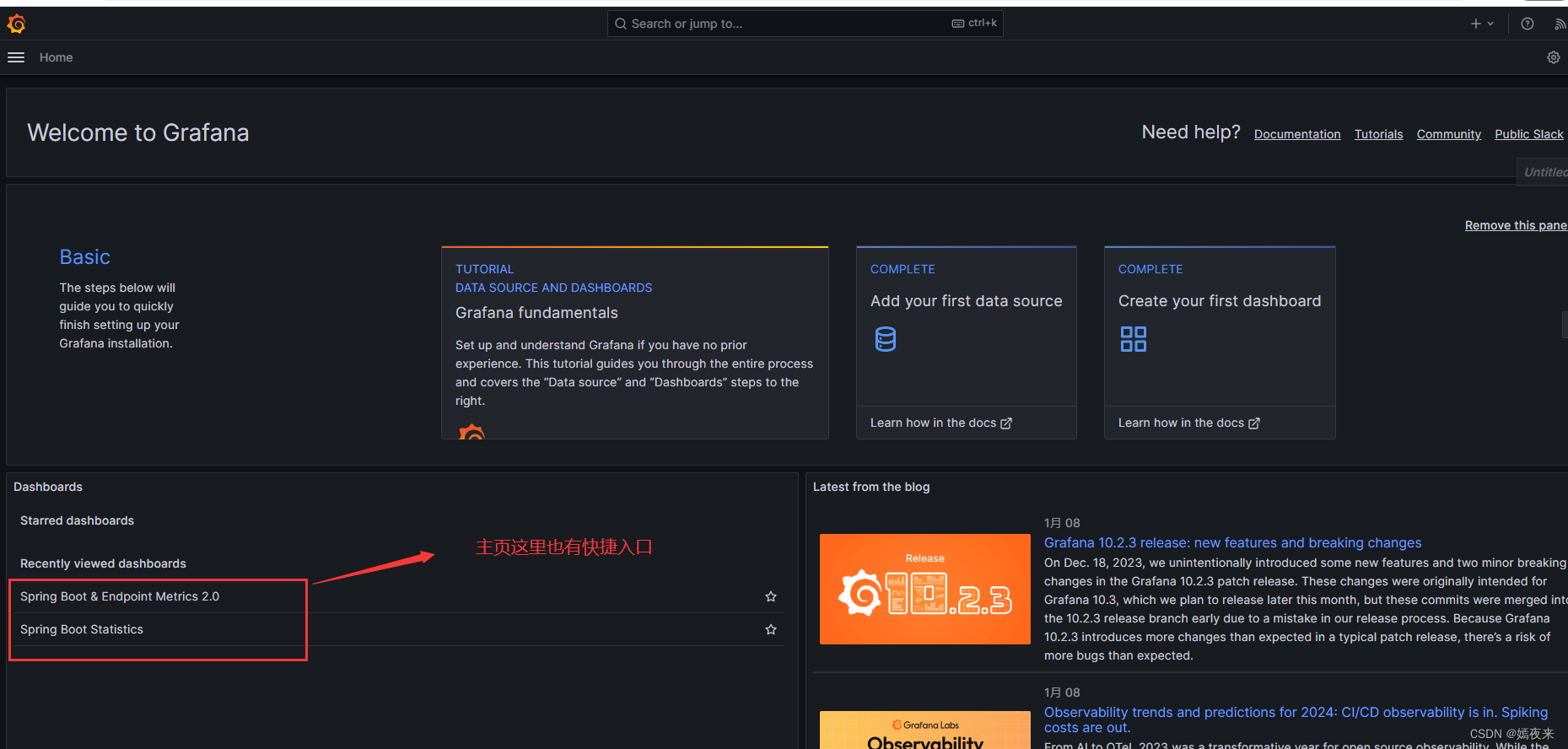
SpringBoot+Prometheus+Grafana搭建应用监控系统
1.应用监控系统介绍 SpringBoot的应用监控方案比较多,SpringBootPrometheusGrafana是比较常用的一种解决方案,主要的监控数据的处理逻辑如下: SpringBoot 的 actuator 提供了应用监控端点,可以对外暴露监控数据信息。Prometheu…...
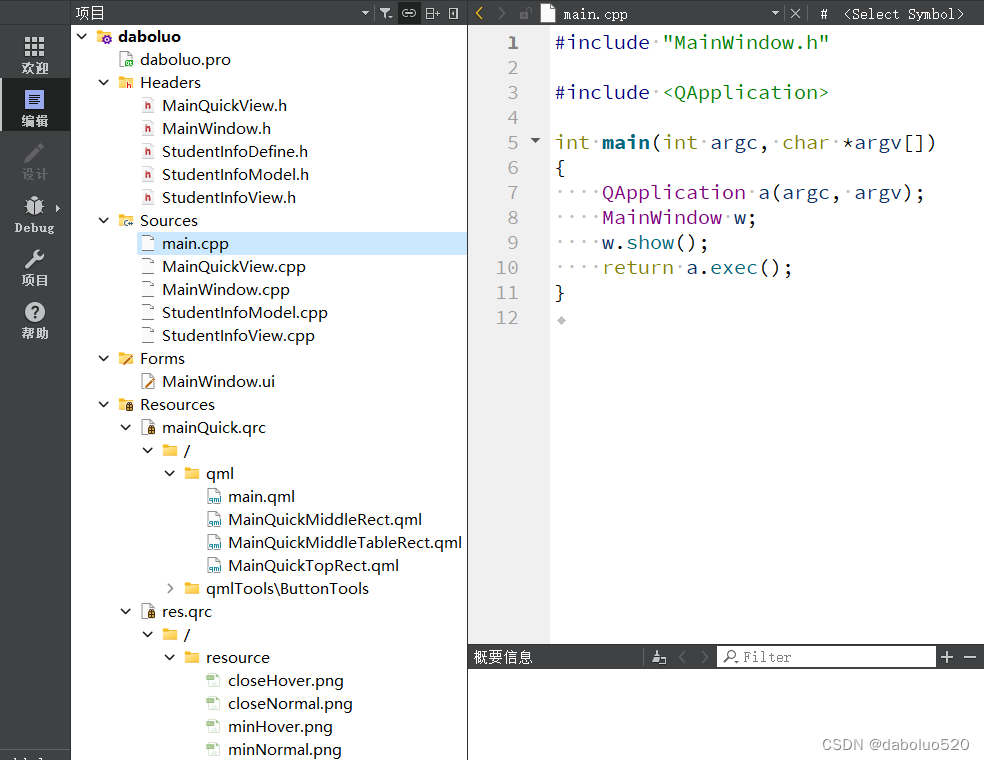
QT c++和qml交互实例
文章目录 一、demo效果图二、c和qml交互的基本方式1、qml 调用 C 类对象2、C 类对象调用 qml3、qml 给 C 发送信号4、C 给 qml 发送信号 三、关键代码1、工程结构图2、c代码MainWindow.cppMainQuickView.cppStudentInfoView.cppStudentInfoModel.cpp 3、qml代码main.qmlMainQui…...
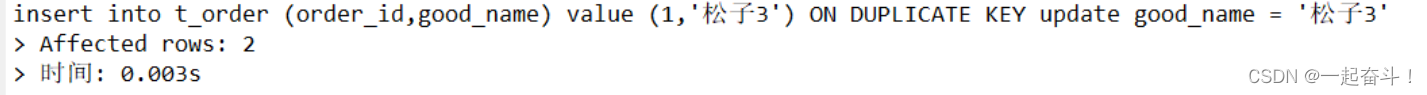
mysql基础-数据操作之增删改
目录 1.新增数据 1.1单条数据新增 1.2多条数据新增 1.3查询数据新增 2.更新 2.1单值更新 2.2多值更新 2.3批量更新 2.3.1 批量-单条件更新 2.3.2批量-多条件更新 2.4 插入或更新 2.5 联表更新 3.删除 本次分享一下数据库的DML操作语言。 操作表的数据结构…...
)
写字母(文件)
请编写函数,将大写字母写入文件中。 函数原型 void WriteLetter(FILE *f, int n);说明:参数 f 为文件指针,n 为字母数目(1 ≤ n ≤ 26)。函数将前 n 个大写英文字母写入 f 所指示的文件中。 裁判程序 #include <stdio.h> #include &…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...