阶段十-分布式-Redis02
第一章 Redis 事务
1.1 节 数据库事务复习
数据库事务的四大特性
- A:Atomic ,原子性,将所以SQL作为原子工作单元执行,要么全部执行,要么全部不执行;
- C:Consistent,一致性,事务完成后,所有的数据的状态都是一致的。即A账户只要减去100,B账户就必定增加100
- I:Isolation,隔离性,如果有多个事务并发执行,每个事务做出的修改必须与其他事务隔离
- D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储
1.2 节 Redis 事务介绍
Redis事务是一组命令的集合,一个事务中的所有命令都将被序列化,按照一次性、顺序性、排他性的执行一系列的命令。
Redis事务三大特性
-
单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断;
-
没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”。
-
不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚;
1.3 节 Redis 事务的基本操作
Multi、Exec、discard
示例1:正常执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 1
QUEUED
127.0.0.1:6379(TX)> get k1
QUEUED
127.0.0.1:6379(TX)> incr k1
QUEUED
127.0.0.1:6379(TX)> get k1
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) "1"
3) (integer) 2
4) "2"示例2:放弃事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k2 1
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> incr k2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> discard
OK示例3:全部都不执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k3 1
QUEUED
127.0.0.1:6379(TX)> get k3
QUEUED
127.0.0.1:6379(TX)> set k3
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379(TX)> exec
(error) EXECABORT Transaction discarded because of previous errors注意:
命令集合中含有错误的指令(注意是语法错误),全部失败。
示例4:运行时错误
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k4 1
QUEUED
127.0.0.1:6379(TX)> incr k4
QUEUED
127.0.0.1:6379(TX)> get k4
QUEUED
127.0.0.1:6379(TX)> set name zhangsan
QUEUED
127.0.0.1:6379(TX)> incr name
QUEUED
127.0.0.1:6379(TX)> get name
QUEUED
127.0.0.1:6379(TX)> exec
1) OK
2) (integer) 2
3) "2"
4) OK
5) (error) ERR value is not an integer or out of range
6) "zhangsan"注意: 运行时错误,即非语法错误,正确命令都会执行,错误命令返回错误。
Redis有三种集群模式
-
主从模式
-
Sentinel模式
-
Cluster模式
第二章 Redis 主从复制
2.1 节 Redis 主从复制概述
什么是主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
主从复制的作用
-
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
-
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
-
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
-
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
2.2 节 Redis 主从复制搭建
在一台虚拟机上搭建
新建redis6379.conf
内容:
include /usr/local/redis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb同理:
新建redis6380.conf
include /usr/local/redis/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb新建redis6381.conf
include /usr/local/redis/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb【2】启动三台redis服务器
redis-server ./redis6379.conf
redis-server ./redis6380.conf
redis-server ./redis6381.conf【3】查看系统进程
ps -ef |grep redis会有已经运行的进程
root 122739 1 0 00:18 ? 00:00:00 redis-server 0.0.0.0:6379
root 122877 1 0 00:18 ? 00:00:00 redis-server 0.0.0.0:6380
root 122965 1 0 00:19 ? 00:00:00 redis-server 0.0.0.0:6381
root 123210 3414 0 00:19 pts/0 00:00:00 grep --color=auto redis【4】查看三台主机运行情况
info replication 查看节点相关信息
#打印主从复制的相关信息
./redis-cli -p 6379
./redis-cli -p 6380
./redis-cli -p 6381
127.0.0.1:6379> info replication
127.0.0.1:6380> info replication
127.0.0.1:6381> info replication【5】配从库不配主库
slaveof <ip> <port>示例:在6380和6381上执行
127.0.0.1:6380> SLAVEOF 192.168.184.100 6379
OK【6】在主机上写,在从机上可以读取数据
set k1 v12.3 节 Redis 主从复制原理
主从复制可以分为3个阶段
-
连接建立阶段(即准备阶段)
-
数据同步阶段
-
命令传播阶段
复制过程大致分为6个过程

-
保存主节点(master)信息。
-
从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接
-
从节点与主节点建立网络连接
从节点会建立一个 socket 套接字,从节点建立了一个端口为51234的套接字,专门用于接受主节点发送的复制命令
-
发送ping命令
连接建立成功后从节点发送 ping 请求进行首次通信。
-
权限验证。
如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。
-
同步数据集。
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。
-
主从同步策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要, slave 在任何时候都可以发起全量同步。 redis 策略是,无论如何,首先会尝试进行增量同 步,如不成功,要求从机进行全量同步。
第三章 Redis 哨兵监控
3.1 节 Redis哨兵概述
主从复制的缺点:当主机 Master 宕机以后,我们需要人工解决切换
哨兵概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
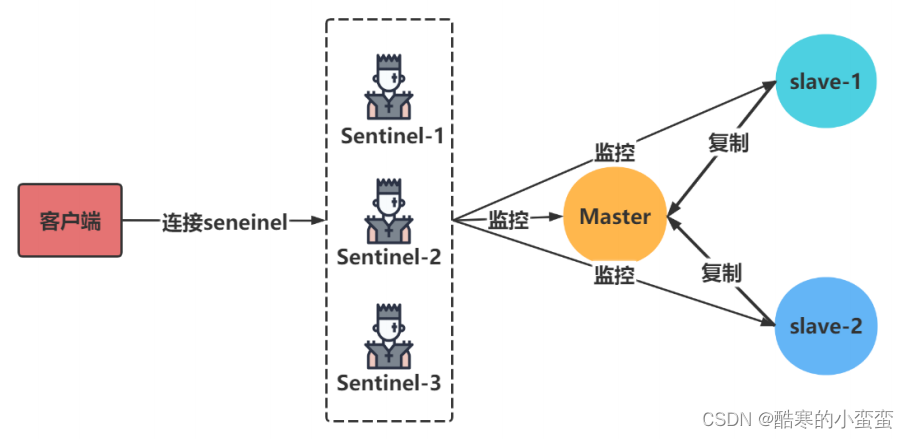
哨兵作用
-
集群监控:负责监控redis master和slave进程是否正常工作
-
消息通知:如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
-
故障转移:如果master node挂掉了,会自动转移到slave node上
-
配置中心:如果故障转移发生了,通知client客户端新的master地址
3.2 节 Redis哨兵搭建
【1】编写配置文件
新建sentinel-26379.conf文件
#端口
port 26379
#守护进程运行
daemonize yes
#日志文件
logfile "26379.log"
sentinel monitor mymaster 192.168.184.100 6379 2参数解释:
sentinel monitor mymaster 192.168.92.128 6379 2 配置的含义是:该哨兵节点监控192.168.92.128:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移。
同理
新建sentinel-26380.conf文件
#端口
port 26380
#守护进程运行
daemonize yes
#日志文件
logfile "26380.log"
sentinel monitor mymaster 192.168.184.100 6379 2新建sentinel-26381.conf文件
#端口
port 26381
#守护进程运行
daemonize yes
#日志文件
logfile "26381.log"
sentinel monitor mymaster 192.168.184.100 6379 2【2】启动哨兵节点
redis-sentinel sentinel-26379.conf
redis-sentinel sentinel-26380.conf
redis-sentinel sentinel-26381.conf【3】查看哨兵状态
先进入哨兵客户端
redis-cli -p 26379
查看哨兵信息
info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.9.133:6379,slaves=2,sentinels=3sentinel_masters:1 该哨兵为主节点
address=192.168.9.133:6379 监控的ip
slaves=2 有两个从节点
sentinels=3 总共有三个哨兵监控
【4】测试故障转移,使用kill命令杀掉主节点
查看所有服务
ps -ef | grep redis根据id杀死6379进程
kill -9 进程id哨兵会重新票选新的主节点,注意:需要等待一定的时间
【5】查看哨兵节点信息
info sentinel# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.9.133:6380,slaves=2,sentinels=3监听的ip变成了6380,6380变成了新的主节点
3.3 节 Redis 哨兵原理
3.3.1 监控阶段
注意:
-
sentinel(哨兵1)----->向master(主)和slave(从)发起info,拿到全信息。
-
sentinel(哨兵2)----->向master(主)发起info,就知道已经存在的sentinel(哨兵1)的信息,并且连接slave(从)。
-
sentinel(哨兵2)----->向sentinel(哨兵1)发起subscribe(订阅)。
3.3.2 通知阶段
sentinel不断的向master和slave发起通知,收集信息。
3.3.3 故障转移阶段
通知阶段sentinel发送的通知没得到master的回应,就会把master标记为SRI_S_DOWN,并且把master的状态发给各个sentinel,其他sentinel听到master挂了,说我不信,我也去看看,并把结果共享给各个sentinel,当有一半的sentinel都认为master挂了的时候,就会把master标记为SRI_0_DOWN。
3.3.4 投票阶段
方式: 自己最先接到哪个sentinel的竞选通知就会把票投给它。
剔除一些情况:
-
不在线的
-
响应慢的
-
与原来master断开时间久的
-
优先级原则
第四章 Redis Cluster
完善哨兵模式的缺点:
-
当master挂掉的时候,sentinel 会选举出来一个 master,选举的时候是没有办法去访问Redis的,会存在访问瞬断的情况;
-
哨兵模式,对外只有master节点可以写,slave节点只能用于读。尽管Redis单节点最多支持10W的QPS,但是在电商大促的时候,写数据的压力全部在master上。
-
Redis的单节点内存不能设置过大,若数据过大在主从同步将会很慢;在节点启动的时候,时间特别长;
4.1 节 Redis Cluster概述
Redis集群的优点
-
Redis集群有多个master,可以减小访问瞬断问题的影响
-
Redis集群有多个master,可以提供更高的并发量
-
Redis集群可以分片存储,这样就可以存储更多的数据
4.2 节 Redis Cluster模式搭建
Redis的集群搭建最少需要3个master节点,我们这里搭建3个master,每个下面挂一个slave节点,总共6个Redis节点;
【1】 准备环境
三个linux虚拟机
第1台机器: 192.168.9.131 8001端口 8002端口
第2台机器: 192.168.9.132 8001端口 8002端口
第3台机器: 192.168.9.133 8001端口 8002端口拷贝配置文件
将redis安装目录下的 redis.conf 文件分别拷贝到8001和8002目录下
cp /usr/local/redis-6.2.6/redis.conf /usr/local/redis-cluster/8001
cp /usr/local/redis-6.2.6/redis.conf /usr/local/redis-cluster/8002修改redis.conf文件以下内容 8001
# 端口
port 8001
# 后台启动
daemonize yes
# 进程id
pidfile "/var/run/redis_8001.pid"
#指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据
dir /usr/local/redis-cluster/8001/
#启动集群模式
cluster-enabled yes
#集群节点信息文件,这里800x最好和port对应上
cluster-config-file nodes-8001.conf
# 节点离线的超时时间
cluster-node-timeout 5000
#去掉bind绑定访问ip信息
#bind 127.0.0.1
#关闭保护模式
protected-mode no
#启动AOF文件
appendonly yes
#如果要设置密码需要增加如下配置:
#设置redis访问密码
#requirepass 123456
#设置集群节点间访问密码,跟上面一致
#masterauth 123456修改redis.conf文件以下内容 8002
# 端口
port 8002
# 后台启动
daemonize yes
# 进程id
pidfile "/var/run/redis_8002.pid"
#指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据
dir /usr/local/redis-cluster/8002/
#启动集群模式
cluster-enabled yes
#集群节点信息文件,这里800x最好和port对应上
cluster-config-file nodes-8002.conf
# 节点离线的超时时间
cluster-node-timeout 5000
#去掉bind绑定访问ip信息
#bind 127.0.0.1
#关闭保护模式
protected-mode no
#启动AOF文件
appendonly yes
#如果要设置密码需要增加如下配置:
#设置redis访问密码
#requirepass 123456
#设置集群节点间访问密码,跟上面一致
#masterauth 123456三台机器同理
【3】启动集群
每台机器都启动服务器
redis-server /usr/local/redis-cluster/8001/redis.conf
redis-server /usr/local/redis-cluster/8002/redis.conf创建集群
redis-cli -a redis-pw --cluster create --cluster-replicas 1
192.168.9.131:8001 192.168.9.131:8002
192.168.9.132:8001 192.168.9.132:8002
192.168.9.133:8001 192.168.9.133:8002没有密码去掉 -a redis -pw
查看帮助命令
src/redis‐cli --cluster help参数:
-
create:创建一个集群环境host1:port1 ... hostN:portN
-
call:可以执行redis命令
-
add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port
-
del-node:移除一个节点
-
reshard:重新分片
-
check:检查集群状态
【4】测试集群
连接任意一个客户端
redis-cli -a redis-pw -c -h 192.168.9.131 -p 8001参数:
-
‐a表示服务端密码
-
‐c表示集群模式
-
-h指定ip地址
-
-p表示端口号
查看集群的信息
cluster info
4.3 节 Redis Cluster 原理
Redis Cluster将所有数据划分为16384个slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。只有master节点会被分配槽位,slave节点不会分配槽位。
槽位定位算法: k1 = 127001
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH_SLOT = CRC16(key) % 16384
命令执行
set k1 v1
存入了12706槽位中
可以通过{}来定义组的概念,从而是key中{}内相同内容的键值对放到同一个slot中。
mset k1{test} v1 k2{test} v2 k3{test} v3让三个key在同一个槽位之中
故障恢复案例:
杀死Master节点之后还会重新选举
观察节点信息
cluster nodes
第五章 SpringDataRedis 连接集群
【1】添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>【2】编写配置
spring:redis:cluster:nodes: 192.168.9.131:8001,192.168.9.131:8002,192.168.9.132:8001,192.168.9.132:8002,192.168.9.133:8001,192.168.9.133:8002【3】编写测试
@SpringBootTest
class RedisDemo2ApplicationTests {@Autowiredprivate RedisTemplate redisTemplate;@Testvoid contextLoads() {redisTemplate.opsForValue().set("k6","v6");System.out.println(redisTemplate.opsForValue().get("k6"));}
}第六章 Redis常见问题探析(面试题)
6.1 节 Redis脑裂问题
6.1.1 什么是集群脑裂
Redis的集群脑裂是指因为网络问题,导致Redis Master节点跟Redis slave节点和Sentinel集群处于不同的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。
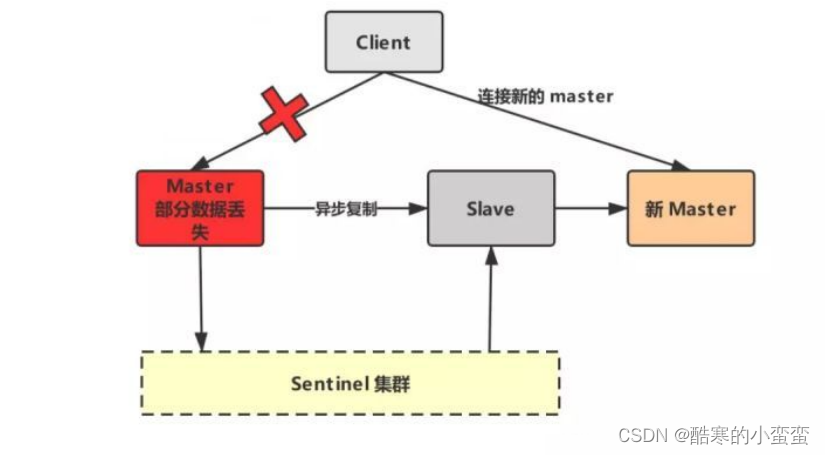
个人理解就是有一个主节点宕机了,无法与客户端进行连接,就不会参与新的选举,在其恢复状态后还是以主节点的身份参与工作,造成了多个主节点同时存在的问题,这就是脑裂问题。
6.1.2 解决方案
redis.conf配置参数:
min-replicas-to-write 1
min-replicas-max-lag 5参数:
-
第一个参数表示最少的slave节点为1个
-
第二个参数表示数据复制和同步的延迟不能超过5秒
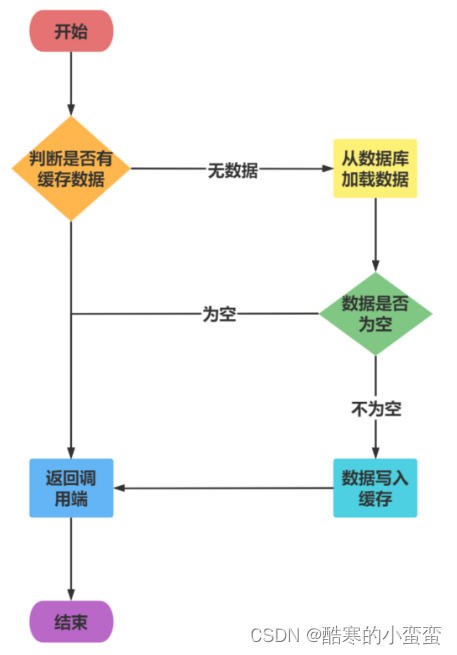
6.2 节 Redis 缓存预热问题
6.2.1 缓存冷启动
缓存中没有数据,由于缓存冷启动一点数据都没有,如果直接就对外提供服务了,那么并发量上来Mysql就裸奔挂掉了。
6.2.2 冷启动应用场景
新启动的系统没有任何缓存数据,在缓存重建数据的过程中,系统性能和数据库负载都不太好,所以最好是在系统上线之前就把要缓存的热点数据加载到缓存中,这种缓存预加载手段就是缓存预热。
6.2.3 解决思路
-
提前给redis中灌入部分数据,再提供服务
-
如果数据量非常大,就不可能将所有数据都写入redis,因为数据量太大了,第一是因为耗费的时间太长了,第二根本redis容纳不下所有的数据
-
需要根据当天的具体访问情况,实时统计出访问频率较高的热数据
-
然后将访问频率较高的热数据写入redis中,肯定是热数据也比较多,我们也得多个服务并行读取数据去写,并行的分布式的缓存预热
6.3 节 Redis缓存穿透问题
6.3.1 概念
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
即用户访问空的数据库与缓存
解释:
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
6.3.2 解决方案
-
对空值缓存:如果一个查询返回的数据为空(不管数据是否存在),我们仍然把这个空结果缓存,设置空结果的过期时间会很短,最长不超过5分钟。简单的说就是返回一个空值
-
布隆过滤器:如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
6.3.3 布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
所以判断不存在的数据最快

6.3.4 代码实现
【1】引入依赖
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.17</version>
</dependency>【2】java代码实现
// 初始化 注意 构造方法的参数大小10 决定了布隆过滤器BitMap的大小
BitMapBloomFilter filter = new BitMapBloomFilter(10);
filter.add("123");
filter.add("abc");
filter.add("ddd");
boolean abc = filter.contains("abc");
System.out.println(abc);6.4 节 Redis 缓存击穿问题
6.4.1 概念
某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
6.4.2 解决方案
-
互斥锁:在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,其他线程直接查询缓存。
-
热点数据不过期:直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存(不咋靠谱)
6.4.3 代码实现(有待改进)
理念是对的,但是满足不了的企业的实际需求
真正的解决方案是使用第三方的软件进行控制
public String get(String key) throws InterruptedException {String value = jedis.get(key);// 缓存过期if (value == null){// 设置3分钟超时,防止删除操作失败的时候 下一次缓存不能load db//setnx 如果有值返回0,如果没有值设置值返回1Long setnx = jedis.setnx(key +"mutex", "1"); jedis.pexpire(key + "mutex", 3 *60);// 代表设置成功if (setnx == 1){// 数据库查询//value = db.get(key);//保存缓存jedis.setex(key,3*60,"");jedis.del(key + "mutex");return value;}else {// 这个时候代表同时操作的其他线程已经load db并设置缓存了。需要重新重新获取缓存 //这个睡眠不够严谨,不能保证操作完成,value的值已经更新完成Thread.sleep(50);// 重试return get(key);}}else {return value;}
}6.5 节 Redis缓存雪崩问题
6.5.1 概念
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
就是大量的数据同时过期
6.5.2 解决方案
用二级缓存解决:先查询本地nginx缓存查询有没有数据,有数据,直接返回;nginx缓存没有数据再去redis分布式缓存查询,如果有将redis缓存同步nginx缓存在返回;如果redis没有,取数据库查询,数据库存在将数据同步到redis并返回。只要nginx的过期时间和redis的过期时间不一样就解决了缓存雪崩问题,并合理使用了本地缓存和分布式缓存。
6.6 节 Redis 开发规范
6.6.1 key设计技巧
-
把表名转换为key前缀,如 tag:
-
把第二段放置用于区分key的字段,对应msyql中主键的列名,如 user_id
-
第三段放置主键值,如 2,3,4
-
第四段写存储的列名
6.6.2 value设计
拒绝bigkey
防止网卡流量、慢查询,string类型控制在10KB以内,hash、 list、set、zset元素个数不要超过5000。
6.6.3 命令使用
-
禁用命令 :禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
-
合理使用select :redis的多数据库较弱,使用数字进行区分,很多客户端支持较差, 同时多业务用多数据库实际还是单线程处理,会有干扰。
-
使用批量操作提高效率
-
原生命令:例如mget、mset。
-
非原生命令:可以使用pipeline提高效率
-
注意:但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
-
不建议过多使用Redis事务功能
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot上。
6.7 节 Redis 数据一致性问题
三种更新策略
-
先更新数据库,再更新缓存
-
先删除缓存,再更新数据库
-
先更新数据库,再删除缓存
先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?
线程安全角度 ,同时有请求A和请求B进行更新操作,那么会出现
(1)线程A更新了数据库
(2)线程B更新了数据库
(3)线程B更新了缓存
(4)线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
先删缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库
注意: 该数据永远都是脏数据。
先更新数据库,再延时删缓存
这种情况存在并发问题吗?
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存
发生这种情况的概率又有多少?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的,因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
后续使用其他工具监听mysql日志,自动就可将缓存更新
第七章 总结
【1】简述以下redis事务?
答:redsi的事务和关系型数据库事务解决问题不一样,原则也不一样,没有acid原则,redis事务保证命令按照队列顺序执行问题,所以redis事务分为两个阶段,第一个阶段是命令入队,第二个阶段是命令执行。
如果队列中命令都证正确,那么按照入队顺序执行,如果队列中命令语法错误,队列所有命名都不执行,如果队列命令语法没错,但是执行失败,只有该命令本身不会执行,其他命令都会执行
redis事务命令
multi 开启事务 exec 执行事务 discard 取消事务
【2】简述一下Redis的主从复制模式
答:Redis集群模式分三种
-
主从模式
-
哨兵模式
-
集群模式
主从模式从一定程度上解决单机Redis的并发问题和可用性问题。但是主从模式问题很大,主节点挂了,需要手动将从节点切换为主节点,所以实际开发很少用到。然后Redis主从复制是哨兵机制和集群机制的根本,所以理解主从模式很重要。
主从模式原理如下:
-
从节点保存主节点(master)信息。
-
从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
-
从节点与主节点建立网络连接 。
-
发送ping命令 :连接建立成功后从节点发送 ping 请求进行首次通信
-
权限验证:如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。
-
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。
-
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。 redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
【3】简述一下哨兵模式
答:哨兵模式主要解决主从复制master节点挂掉之后的,切换从节点为主节点问题,哨兵模式通过监控主从复制主节点和从节点完成自动切换主节点功能。
原理如下:
【4】简述以下Redis集群模式
答:集群模式至少需要6个redis服务器,集群模式就是n个主从复制模式,但是需要根据插槽机制分配每个节点存取数据范围。来解决单个主从redis不能存取数据过大问题,因为会降低从节点复制速度。
原理:
【5】Redis脑裂问题解决?
答:Redis主从模式下,由于主节点挂了,从节点新选出主节点,由于网络情况,挂掉主节点没有降级为从节点,导致有两个主节点可以写数据。导致挂掉的主节点的数据无法同步而丢失问题。解决办法
min-replicas-to-write 1 min-replicas-max-lag 5
【6】如何解决缓存冷启动问题?
答:冷启动是指服务器缓存中没有数据直接启动,访问量有比较大,mysql直接裸机运行。通过缓存预热解决,通过storm实时计算出热点数据,然后定时将热点数据写入缓存。
【7】如何解决缓存穿透问题?
答:查询一个redis和mysql肯定都不存在的数据是缓存穿透,例如查询id为-1的数据,多半为认为恶意攻击。解决方案:去数据库查不存在在redis存null,并且设置过期时间5分钟。
或者用布隆过器解决:布隆过滤器是一个bitMap数组,它说不存在的元素一定不存在,他说存在的未必存在。
【8】如何缓存击穿问题?
答:某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。从造成问题的原因去解决,当热点Key失效的一刹那,大并发裸奔访问数据库,数据库被打垮。我们只需要在热点Key失效的一刹那保证只有一个请求过来就可以了。这种需求肯定用锁解决,理论上可以用同步锁解决,但这个不靠谱,锁只能锁一个进程,但是微服务是多个服务是多个进程,根本不起作用。所以用分布式锁解决。
【9】如何解决缓存雪崩问题?
答:大量缓存同时失效,数据库被击垮问题。解决思路不让缓存同时失效,比如加给缓存过期时间加随机数,但是当缓存数据足够大时,这个效果不那么明显了,可以通过二级缓存技术实现。
相关文章:
阶段十-分布式-Redis02
第一章 Redis 事务 1.1 节 数据库事务复习 数据库事务的四大特性 A:Atomic ,原子性,将所以SQL作为原子工作单元执行,要么全部执行,要么全部不执行;C:Consistent,一致性࿰…...

微信小程序实战-02翻页时钟-2
微信小程序实战系列 《微信小程序实战-01翻页时钟-1》 文章目录 微信小程序实战系列前言计时功能实现clock.wxmlclock.wxssclock.js 运行效果总结 前言 接着《微信小程序实战-01翻页时钟-1》,继续完成“6个页面的静态渲染和计时”功能。 计时功能实现 clock.wxm…...

每天刷两道题——第十一天
1.1滑动窗口最大值 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值 。 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输出&…...

Git提交规范
一. 修改类型 每个类型值都表示了不同的含义,类型值必须是以下的其中一个: feat:提交新功能fix:修复了bugdocs:只修改了文档style:调整代码格式,未修改代码逻辑(比如修改空格、格式…...

apache2的虚拟主机的配置
APACHE2的虚拟主机配置 本章中心概括: 虚拟web主机的初步认识,在redhat系列系统中如何配置,在Debian系列系统中如何配置。 什么是apache2虚拟主机: 简单点讲,就是在同一个物理机中配置多个虚拟主机,从而达…...
Provide/Inject 依赖注入(未完待续)
父组件传递给子组件数据,通过props,但是需要逐层传递 provide/Inject 的推出就是为了解决这个问题,它提供了一种组件之间共享此类值的方式,不必通过组件树每层级显示地传递props 目的是为了共享那些被 认为对于一个组件树而言是全局的数据 p…...

力扣173. 二叉搜索树迭代器
深度优先搜索 思路: 遍历二叉搜索树,左子树总比根节点小,右子树总比根节点大;先深度遍历左子树,然后返回其父节点,然后遍历其右子树节点;使用栈数据结构存储节点数据,借用其“后进先…...
电脑找不到d3dcompiler43.dll怎么修复,教你5个可靠的方法
d3dcompiler43.dll是Windows操作系统中的一个重要动态链接库文件,主要负责Direct3D编译器的相关功能。如果“d3dcompiler43.dll丢失”通常会导致游戏无法正常运行或者程序崩溃。为了解决这个问题,我整理了以下五个解决方法,希望能帮助到遇到相…...
)
5.3 Android BCC环境搭建(eadb版 上)
写在前面 eadb即eBPF Android Debug Bridge,它是基于adeb的重构。后者曾随aosp 10发布在platform/external目录下。 一,root权限 这里再HighLight下,当前整个专栏都是基于开发环境来展开的,也就是Android设备需要具有root权限。因此该专栏下每一篇博客都是默认了当前开发…...

【算法题】44. 通配符匹配
题目 给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。 * 可以匹配任意字符序列(包括空字符序列)。 判定匹配成功的充要条件是:字符模式必须能…...
vscode配置与注意事项
中文设置 https://zhuanlan.zhihu.com/p/263036716 应用搜索输入“Chinese (Simplified) Language Pack for Visual Studio Code”并敲回车键 底部信息窗没有的话 首先使用快捷键ctrlshiftp,Mac用户使shiftcommandp,然后输入settings.json 将下面的选…...

设计模式篇章(3)——七种结构型模式
结构型设计模式主要思考的是如何将对象进行合理的布局来组成一个更大的功能体或者结构体,这个现在讲有点抽象,用大白话讲就是利用现有的对象进行组合或者配合,使得组合后的这个系统更加好。好是相对于不使用设计模式,按照自己的堆…...

Window端口占用处理
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…...

算法实战(二)
基础算法编程 题目来源([PAT题目](https://pintia.cn/problem-sets/14/exam/problems/type/6))7-2 然后是几点7-3 逆序的三位数7-6 混合类型数据格式化输入 题目来源(PAT题目) 7-2 然后是几点 有时候人们用四位数字表示一个时间,比如 1106 表示 11 点零 6 分。现在…...

网工内推 | 上市公司网工,NP认证优先,最高15薪+项目奖金
01 广东轩辕网络科技股份有限公司 招聘岗位:网络工程师 职责描述: 1、主要负责教育行业园区网的有线及无线网络项目的实施、维护、巡检等工作; 2、协助windows/linux平台服务器OS的安装、部署、配置与维护; 3、协助服务器、存储、…...

【LLM 论文阅读】NEFTU N E: LLM微调的免费午餐
指令微调的局限性 指令微调对于训练llm的能力至关重要,而模型的有用性在很大程度上取决于我们从小指令数据集中获得最大信息的能力。在本文中,我们提出在微调正向传递的过程中,在训练数据的嵌入向量中添加随机噪声,论文实验显示这…...

JS新手入门笔记整理:对象
对象可以分为两种:一种是“自定义对象”,另外一种是“内置对象”。自定义对象,指的是需要我们自己定义的对象。内置对象,指的是不需要我们自己定义的(即系统已经定义好的)、可以直接使用的对象。在JavaScri…...

Python GIL 一文全知道!
GIL 作为 Python 开发者心中永远的痛,在最近即将到来的更新中,终于要彻底解决了,整个 Python 社群都沸腾了 什么是GIL? GIL是英文学名global interpreter lock的缩写,中文翻译成全局解释器锁。GIL需要解决的是线程竞…...

数据库级别的MD5加密(扩展)
首先,我们要知道什么是MD5? 1.主要是增强算法的复杂性和不可逆性 2.MD5不可逆,具体的值MD5是一样的 3.MD5破解网站的原理,背后有一个字典 代码案例: -- 加密 update testMD5 set pwdmd5(pwd) where id1; update testMD5 set…...
Docker安装Jenkins,配置Maven和Java
前言 这是一个java的springboot项目,使用maven构建 安装准备 需要将maven和jdk安装在服务器上,Jenkins需要用到,还有创建一个jenkins的目录,安装命令如下: docker run -d -uroot -p 9095:8080 -p 50000:50000 --n…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...
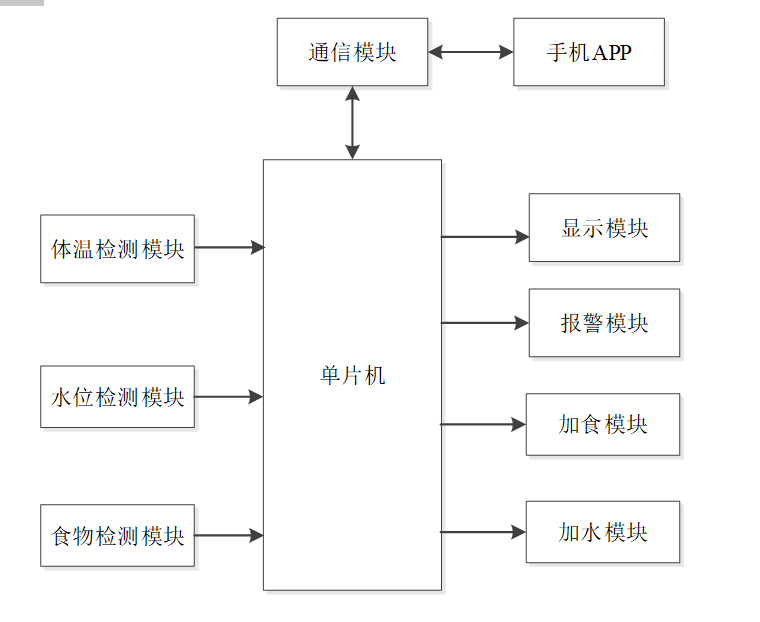
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...