【OCR】实战使用 - 如何提高识别文字的精准度?
实战使用 - 如何提高文字识别的精准度
我们在平常使用OCR的时候,经常会出现文字识别不精准的情况,我们改如何提高文字识别的精度呢?
以下是一些提高OCR(Optical Character Recognition,光学字符识别)文字识别精准度的方法:
- 图像预处理:
- 转换为灰度图像:将彩色图像转换为灰度图像可以减少噪音和干扰,提高识别精度。
- 二值化:将图像转换为黑白二值图像,使得文本和背景对比更明显。
- 去噪:去除图像中的噪点和不必要的元素,如线条、污渍等。
- 边缘检测和轮廓提取:通过边缘检测和轮廓提取来增强文本区域的边界。
- 调整图像参数:
- 改变亮度和对比度:调整图像的亮度和对比度可以改善文本的可见性。
- 使用滤波器:应用高斯滤波器、中值滤波器等可以平滑图像并减少噪声。
- 选择合适的字体库:
- 确保你的Tesseract OCR引擎安装了正确的语言数据包,并且包含了你需要识别的字体类型。
- 设置识别参数:
- 使用image_to_data函数获取详细的识别结果,包括每个字符的坐标、置信度等信息。
- 根据实际情况调整识别参数,如使用psm(页面分割模式)来指定图像的布局。
- 训练自定义模型:
- 如果现有的Tesseract OCR引擎无法满足你的识别需求,你可以考虑训练一个自定义的OCR模型。这通常需要大量的标注数据和一定的机器学习知识。
- 优化图像质量:
- 提供清晰、高质量的图像作为输入,避免模糊、倾斜、旋转或有遮挡的文本。
- 使用更高级的OCR工具或服务:
- 如果上述方法仍然无法达到满意的识别精度,你可以考虑使用更先进的OCR工具或服务,如Google Cloud Vision API、Amazon Textract等。
综合运用以上方法,你可以逐步提高OCR文字识别的精准度。但是请注意,对于某些复杂的图像或特定类型的文本,可能无法达到完美的识别效果。
实现
以下是一个使用Python和Tesseract OCR进行图像预处理和文字识别的简单示例,展示了如何应用一些提高OCR识别精度的方法:
import pytesseract
from PIL import Image, ImageFilter, ImageEnhancedef preprocess_image(image_path):# 打开图片文件img = Image.open(image_path)# 转换为灰度图像gray_img = img.convert('L')# 二值化binary_img = gray_img.point(lambda x: 0 if x < 128 else 255, '1')# 使用中值滤波器去噪filtered_img = binary_img.filter(ImageFilter.MedianFilter(size=3))# 提高对比度enhancer = ImageEnhance.Contrast(filtered_img)enhanced_img = enhancer.enhance(2.0)return enhanced_imgdef ocr_image(image_path, lang='eng'):# 预处理图像processed_img = preprocess_image(image_path)# 使用pytesseract进行文字识别text = pytesseract.image_to_string(processed_img, lang=lang)return text# 设置识别语言为中文(简体)
pytesseract.pytesseract.tesseract_cmd = '/usr/bin/tesseract' # 如果需要指定Tesseract路径
language = 'chi_sim'# 识别图像中的文字
image_path = 'your_image_file_path.jpg'
text = ocr_image(image_path, lang=language)# 打印识别出的文字
print(text)
在这个示例中:
- preprocess_image函数负责图像预处理,包括转换为灰度图像、二值化、应用中值滤波器去噪和提高对比度。
- ocr_image函数负责打开图像、预处理图像并使用Tesseract进行文字识别。
注意:这只是一个基本的示例,实际的图像预处理步骤可能需要根据你的具体需求和图像的特性进行调整。此外,你可能还需要考虑其他提高识别精度的方法,如设置识别参数、使用更高级的OCR工具或服务等。
问题1: 1.ValueError: image has wrong mode
这个ValueError: image has wrong mode错误通常在使用Tesseract OCR进行文字识别时出现,原因是传递给Tesseract的图像模式(mode)不正确。Tesseract期望图像为单色(黑白)或彩色(RGB/RGBA),而你提供的图像可能是其他模式,如CMYK、P等。
要解决这个问题,你可以尝试以下步骤:
- 确保你的图像已经被正确地转换为Tesseract支持的模式。例如,如果你的图像已经是灰度图像,可以使用以下代码检查其模式:
from PIL import Imageimage = Image.open('your_image_file_path.jpg')print(image.mode)
如果输出不是L(表示灰度图像),你需要将其转换为灰度模式:
image = image.convert('L')
- 如果你的图像已经是彩色图像,确保其模式为RGB或RGBA。如果不是,可以使用以下代码将其转换为RGB模式:
if image.mode != 'RGB':image = image.convert('RGB')
- 在调用pytesseract.image_to_string()函数之前,确保你的图像已经过正确的预处理和模式转换。
以下是一个完整的示例:
import pytesseract
from PIL import Imagedef ocr_image(image_path, lang='eng'):# 打开图片文件img = Image.open(image_path)# 确保图像模式为RGB或Lif img.mode == 'RGB':pass # 图像已经是RGB模式,无需转换elif img.mode == 'L':pass # 图像是灰度模式,无需转换else:# 将图像转换为RGB模式img = img.convert('RGB')# 使用pytesseract进行文字识别text = pytesseract.image_to_string(img, lang=lang)return text# 设置识别语言为中文(简体)
pytesseract.pytesseract.tesseract_cmd = '/usr/bin/tesseract' # 如果需要指定Tesseract路径
language = 'chi_sim'# 识别图像中的文字
image_path = 'your_image_file_path.jpg'
text = ocr_image(image_path, lang=language)# 打印识别出的文字
print(text)
这个示例会检查图像模式,并在必要时将其转换为Tesseract支持的模式。这应该可以避免ValueError: image has wrong mode的错误。
如果对于文字识别还未入门可以先看我前一篇文章:
【OCR】实战使用 - ocr 识别图片中的文字
相关文章:

【OCR】实战使用 - 如何提高识别文字的精准度?
实战使用 - 如何提高文字识别的精准度 我们在平常使用OCR的时候,经常会出现文字识别不精准的情况,我们改如何提高文字识别的精度呢? 以下是一些提高OCR(Optical Character Recognition,光学字符识别)文字识…...

css3浮动定位
css3浮动定位 前言浮动float的基本概念浮动的使用浮动的顺序贴靠特性浮动的元素一定能设置宽高 使用浮动实现网页布局BFC规范和浏览器差异如何创建BFCBFC的其他作用浏览器差异 清除浮动相对定位 relative绝对定位 absolute绝对定位脱离标准文档流绝对定位的参考盒子绝对定位的盒…...
Linux 上 Nginx 配置访问 web 服务器及配置 https 访问配置过程记录
目录 一、前言说明二、配置思路三、开始修改配置四、结尾 一、前言说明 最近自己搭建了个 Blog 网站,想把网站部署到服务器上面,本文记录一下搭建过程中 Nginx 配置请求转发的过程。 二、配置思路 web项目已经在服务器上面运行起来了,运行的端…...

css less sass 动态宽高
less height: ~"calc(100% - 30px)";若要需要按照某个比例固定高度可以用 min-height: e("calc(100vh - 184px)")css height: calc(100% - 50px);sass height:calc(100% - var(--height) );...

sqlserver导出数据为excel再导入到另一个数据库
要将SQL Server中的数据导出为Excel文件,然后再将该Excel文件导入到另一个数据库中,你可以按照以下步骤进行操作: 导出数据为Excel文件 echo offset SourceServer源服务器名称 set SourceDB数据库名称 set ExcelFilePath导出到的Excel文件路…...

异构微服务远程调用如何打jar包
1.服务提供方打 jar 包 RemoteUserService.java package com.finance.system.api;import com.finance.system.api.domain.dto.Enterprise; import org.springframework.cloud.openfeign.FeignClient; import org.springframework.stereotype.Component; import org.springfra…...

赋能智慧农业生产,基于YOLOv7开发构建农业生产场景下油茶作物成熟检测识别系统
AI赋能生产生活场景,是加速人工智能技术落地的有利途径,在前文很多具体的业务场景中我们也从实验的角度来尝试性地分析实践了基于AI模型来助力生产生活制造相关的各个领域,诸如:基于AI硬件实现农业作物除草就是一个比较熟知的场景…...

Docker入门介绍
【一】从 dotCloud 到 Docker——低调奢华有内涵 1、追根溯源:dotCloud 时间倒回到两年前,有一个名不见经传的小公司,他的名字叫做:dotCloud。 dotCloud 公司主要提供的是基于 PaaS(Platform as a Service,平台及服务) 平台为开发者或开发商…...
第四站:指针的进阶-(二级指针,函数指针)
目录 二级指针 二级指针的用途 多级指针的定义和使用 指针和数组之间的关系 存储指针的数组(指针数组:保存地址值) 指向数组的指针(数组指针) 传参的形式(指针) 数组传参时会退化为指针 void类型的指针 函数指针 定义: 调用:两种方式:(*指针名)(参数地址) 或者 指针…...
)
浏览器渲染原理(面试重点)
一、浏览器是如何渲染页面的 常见的简洁答案: 浏览器内核拿到内容后,渲染流程大致如下:解析HTML,构建Dom树;解析CSS,构建Render树;(将CSS代码解析成树形的数据结构,与D…...
将t指向的字符串复制到s指向的字符串的尾部。)
C //练习 5-3 用指针方式实现第2章中的函数strcat。函数strcat(s, t)将t指向的字符串复制到s指向的字符串的尾部。
C程序设计语言 (第二版) 练习 5-3 练习 5-3 用指针方式实现第2章中的函数strcat。函数strcat(s, t)将t指向的字符串复制到s指向的字符串的尾部。 注意:代码在win32控制台运行,在不同的IDE环境下,有部分可能需要变更。…...

深度剖析Redis:从基础到高级应用
目录 引言 1、 Redis基础 1.1 Redis数据结构 1.1.1 字符串(String) 1.1.2 列表(List) 1.1.3 集合(Set) 1.1.4 散列(Hash) 1.1.5 有序集合(Sorted Set)…...

视频监控录像服务器(中心录像服务器)功能详细介绍
目 录 一、概述 (一)定义 (二)视频监控中心录像服务器 二、存储策略服务 (一)存储策略配置 1、 录入页面 2、 选择需要进行录像的视频 3、批量选择多个通道号 4、其他关键参数…...
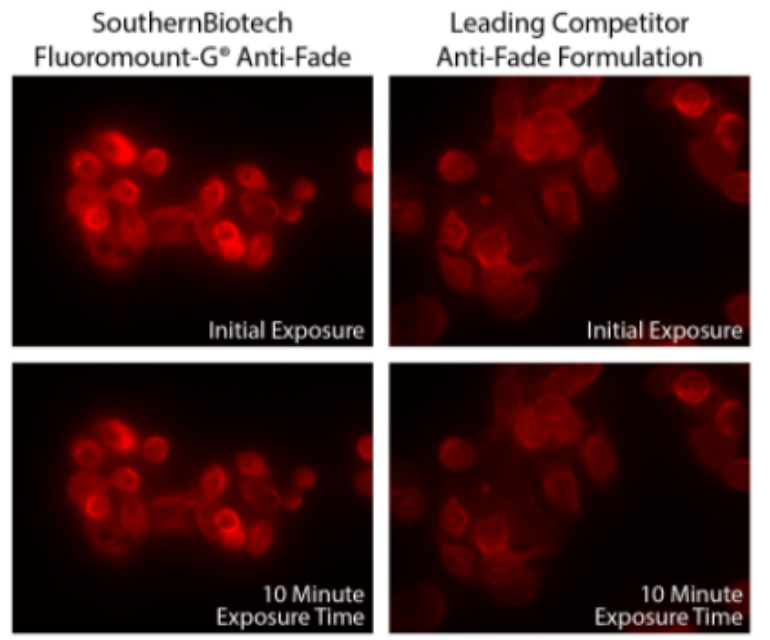
SouthernBiotech抗荧光淬灭封片剂
荧光淬灭又称荧光熄灭或萃灭,是指导致特定物质的荧光强度和寿命减少的所有现象。引起荧光淬灭的物质称为荧光淬灭剂。SouthernBiotech专门开发的Fluoromount-G系列荧光封片剂是以甘油为基础,加入抗荧光淬灭剂,可明显降低荧光淬灭现象…...
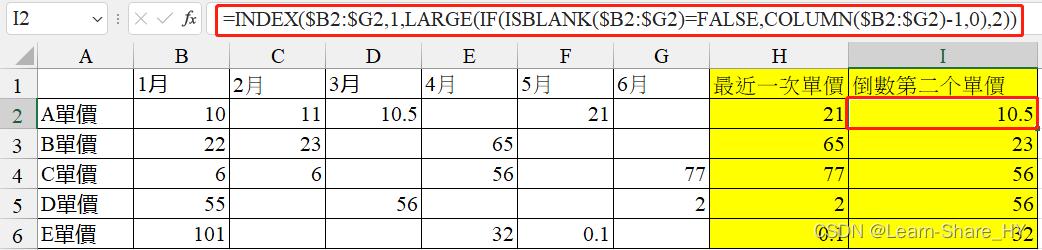
[Excel]如何找到非固定空白格數列的條件數據? 以月份報價表單為例
在群組中看到上述問題,研判應是一份隨月份變動的產品報價表單,空白欄可能表示該月份價格與上個月份一致。這個問題是需要取得最近一次單價和倒數第二次單價,常用且實務的excel案例值得紀錄。 最近一次單價: INDEX($B2:$G2,1,LARGE(IF(ISBLAN…...

TypeScript进阶(二)深入理解装饰器
✨ 专栏介绍 TypeScript是一种由微软开发的开源编程语言,它是JavaScript的超集,意味着任何有效的JavaScript代码都是有效的TypeScript代码。TypeScript通过添加静态类型和其他特性来增强JavaScript,使其更适合大型项目和团队开发。 在TypeS…...
书生·浦语第三次作业
我最近在参加书生浦语大模型实战营,这是第三次作业打卡! 如果你也想两周玩转大模型微调,部署与测评全链路。报名链接:invite 书生浦语大模型实战营报名 邀请码可以填026014 一、基础作业:复现课程知识库助手搭建过程…...

GPT实战系列-LangChain + ChatGLM3构建天气查询助手
GPT实战系列-LangChain ChatGLM3构建天气查询助手 用ChatGLM的工具可以实现很多查询接口和执行命令,而LangChain是很热的大模型应用框架。如何联合它们实现大模型查询助手功能?例如调用工具实现网络天气查询助手功能。 LLM大模型相关文章: …...

LeetCode 2696.删除子串后的字符串最小长度:栈
【LetMeFly】2696.删除子串后的字符串最小长度:栈 力扣题目链接:https://leetcode.cn/problems/minimum-string-length-after-removing-substrings/ 给你一个仅由 大写 英文字符组成的字符串 s 。 你可以对此字符串执行一些操作,在每一步操…...

Xcode15 升级问题记录
这里写自定义目录标题 新版本Xcode15升级问题1:rsync error: some files could not be transferred (code 23) at ...参考 新版本Xcode15升级 下载地址:https://developer.apple.com/download/all/ 我目前使用的版本是Xcode15.2 我新创建了一个项目&…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...