MoE模型性能还能更上一层楼?一次QLoRA微调实践
Fine-Tuning Mixtral 8x7B with QLoRA:Enhancing Model Performance 🚀
编者按:最近,混合专家(Mixture of Experts,MoE)这种模型设计策略展现出了卓越的语言理解能力,如何在此基础上进一步提升 MoE 模型的性能成为业界热点。
本文作者使用一种名为 QLoRA 的方法,通过量化和 LoRA 技术对 MoE 模型 Mixtral-8x7B 进行微调,以期大幅提高其性能。
作者详细阐明这种方法的诸多优势,包括显著增强 MoE 模型的理解生成能力、计算效率更高等。文中还逐步介绍了使用 QLoRA 微调 Mixtral-8x7B 的全过程。
本文探索了使用 QLoRA 推动 MoE 模型的性能改进这一技术方案。期待未来更多关于 MoE 模型的性能改进方案出现!
一、简介
目前整个业界都希望经过优化的模型能够表现出卓越的性能,这一追求不断推动着自然语言理解(natural language understanding)的发展。Mixtral-8x7B Mixture of Experts(MoE)模型就是其中之一,该模型在各种基准测试(benchmarks)中表现出优于同类产品的性能,尤其是优于 Llama 2 70B。
本教程采用一种名为 QLoRA 的创新方法对 Mixtral-8x7B 模型进行微调,该方法结合了量化(quantization)和 LoRA(Local Representation Adaptation)技术。期望通过这两种技术的结合来进一步增强Mixtral-8x7B模型的能力。
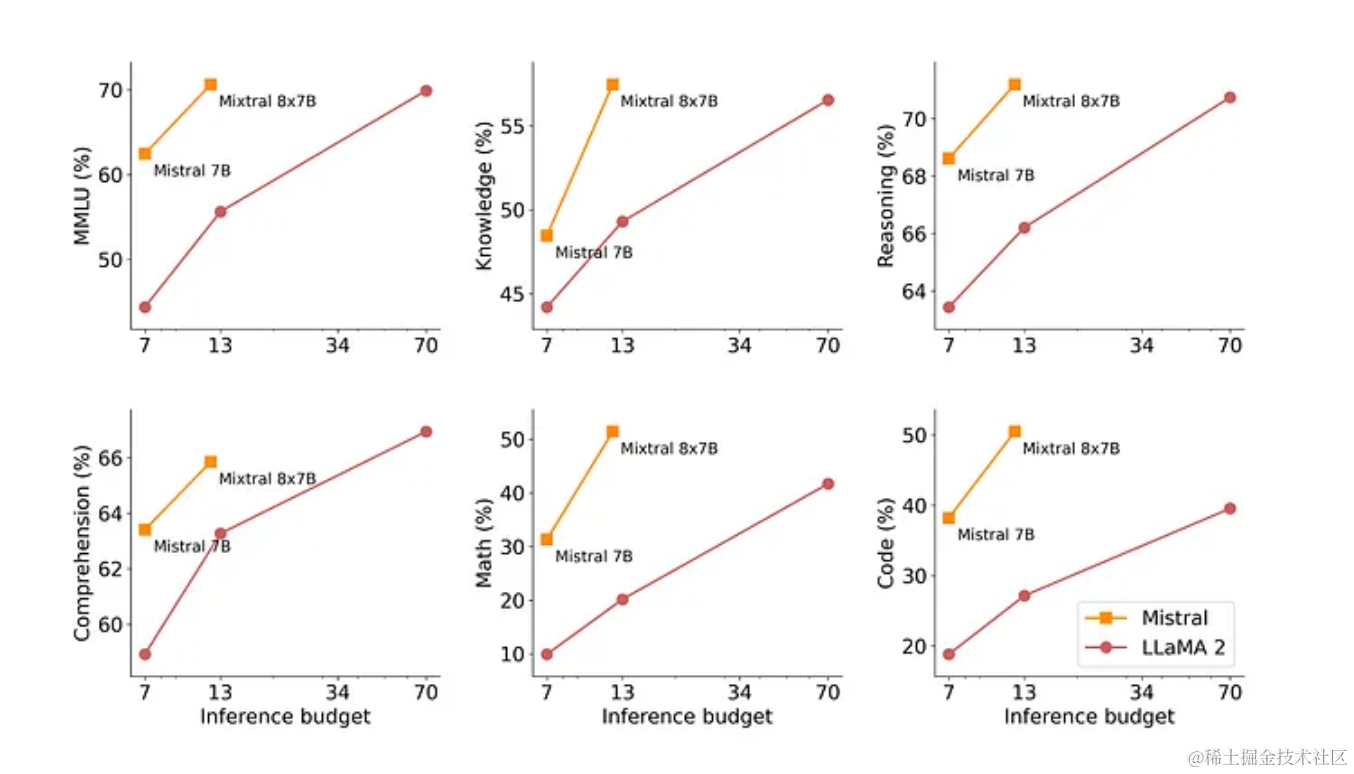
Source: Mixtral[1]
二、相关定义
● Mixtral 8x7B:一种混合专家模型,因其架构设计在自然语言处理任务中表现出色而闻名。
● QLoRA:Quantization 和 LoRA 技术相结合的缩写。量化涉及降低模型权重的精度,从而优化内存使用并加快计算速度。LoRA 可调整模型中的局部表征,增强模型对特定上下文的理解。
三、优势
● 增强性能:使用 QLoRA 对 Mixtral 8x7B 进行微调,可提高其性能,从而更好地理解和生成各种领域的文本。
● 能效比高:量化的整合降低了内存需求和计算复杂度,使模型更节省资源。
● 针对垂直领域进行微调:通过微调,该模型可针对特定任务进行定制,从而提高其在特定领域的准确性和相关性。
四、代码实现说明
本教程在 Notebook 环境中(译者注:使用Jupyter notebook 或白海IDP自研notebook)使用 Python。整个过程包括使用 "bitsandbytes "库加载 4 位精度的大型 Mixtral 模型。随后,在训练阶段使用 Hugging Face 的 PEFT 库实现 LoRA。
4.1 步骤 1:安装相关库
# You only need to run this once per machine, even if you stop/restart it
!pip install --upgrade pip
!pip install -q -U bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git
!pip install -q -U datasets scipy ipywidgets matplotlib
4.2 步骤 2:设置 Accelerator
from accelerate import FullyShardedDataParallelPlugin, Accelerator
from torch.distributed.fsdp.fully_sharded_data_parallel import FullOptimStateDictConfig, FullStateDictConfigfsdp_plugin = FullyShardedDataParallelPlugin(state_dict_config=FullStateDictConfig(offload_to_cpu=True, rank0_only=False),optim_state_dict_config=FullOptimStateDictConfig(offload_to_cpu=True, rank0_only=False),
)accelerator = Accelerator(fsdp_plugin=fsdp_plugin)
4.3 步骤 3:使用Weights & Biases追踪性能指标
!pip install -q wandb -Uimport wandb, os
wandb.login()wandb_project = "viggo-finetune"
if len(wandb_project) > 0:os.environ["WANDB_PROJECT"] = wandb_project
4.4 步骤 4:加载数据集
from datasets import load_datasetdataset_name = "databricks/databricks-dolly-15k"train_dataset = load_dataset(dataset_name, split="train[0:800]")
eval_dataset = load_dataset(dataset_name, split="train[800:1000]")
4.5 步骤 5:加载基础模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfigbase_model_id = "mistralai/Mixtral-8x7B-v0.1"
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.bfloat16
)model = AutoModelForCausalLM.from_pretrained(base_model_id, quantization_config=bnb_config, device_map="auto")# Tokenization
tokenizer = AutoTokenizer.from_pretrained(base_model_id,padding_side="left",add_eos_token=True,add_bos_token=True,
)
tokenizer.pad_token = tokenizer.eos_tokendef tokenize(prompt):result = tokenizer(prompt)result["labels"] = result["input_ids"].copy()return resultdef generate_and_tokenize_prompt(data_point):full_prompt = f"""Given a question and some additional context, provide an answer### Target sentence:Question: {data_point['instruction']}Additional Context: {f"Here is some context: {data_point['context']}" if len(data_point["context"]) > 0 else ""}Response: [/INST] {data_point['response']}</s>"""tokenized_prompt = tokenizer(full_prompt)return tokenized_prompttokenized_train_dataset = train_dataset.map(generate_and_tokenize_prompt)
tokenized_val_dataset = eval_dataset.map(generate_and_tokenize_prompt)untokenized_text = tokenizer.decode(tokenized_train_dataset[1]['input_ids'])
print(untokenized_text)# Output
<s> Given a question and some additional context, provide an answer### Target sentence:Question: Alice's parents have three daughters: Amy, Jessy, and what’s the name of the third daughter?Additional Context: Response: [/INST] The name of the third daughter is Alice</s></s>
4.6 步骤 6:获取数据集中各个样本长度的分布情况
import matplotlib.pyplot as pltdef plot_data_lengths(tokenized_train_dataset, tokenized_val_dataset):lengths = [len(x['input_ids']) for x in tokenized_train_dataset]lengths += [len(x['input_ids']) for x in tokenized_val_dataset]print(len(lengths))# Plotting the histogramplt.figure(figsize=(10, 6))plt.hist(lengths, bins=20, alpha=0.7, color='blue')plt.xlabel('Length of input_ids')plt.ylabel('Frequency')plt.title('Distribution of Lengths of input_ids')plt.show()plot_data_lengths(tokenized_train_dataset, tokenized_val_dataset)
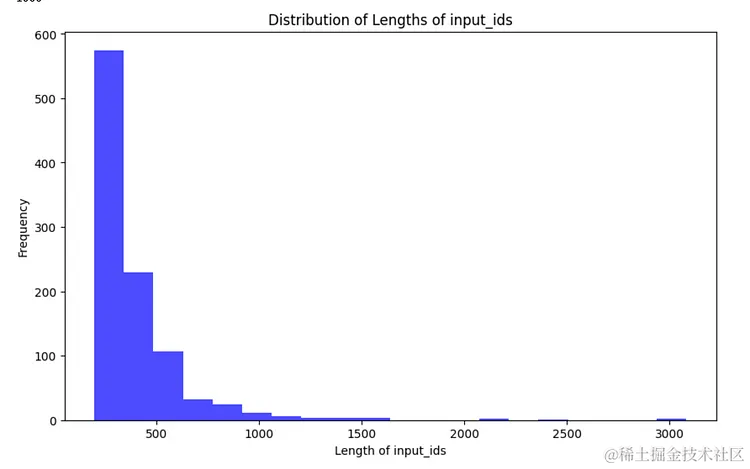
Source: Image created by Author
4.7 步骤 7:在数据的左侧添加 padding ,以减少内存的使用
max_length = 320 # This was an appropriate max length for my dataset# redefine the tokenize function and tokenizertokenizer = AutoTokenizer.from_pretrained(base_model_id,padding_side="left",add_eos_token=True, add_bos_token=True,
)
tokenizer.pad_token = tokenizer.eos_tokendef tokenize(prompt):result = tokenizer(prompt,truncation=True,max_length=max_length,padding="max_length",)result["labels"] = result["input_ids"].copy()return resulttokenized_train_dataset = train_dataset.map(generate_and_tokenize_prompt)
tokenized_val_dataset = eval_dataset.map(generate_and_tokenize_prompt)untokenized_text = tokenizer.decode(tokenized_train_dataset[4]['input_ids'])
print(untokenized_text)# Output
<s> Given a target sentence construct the underlying meaning representation of the input sentence as a single function with attributes and attribute values.This function should describe the target string accurately and the function must be one of the following ['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute', 'suggest', 'request_explanation', 'recommend', 'request_attribute'].The attributes must be one of the following: ['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating', 'genres', 'player_perspective', 'has_multiplayer', 'platforms', 'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']### Target sentence:When did Virgin Australia start operating?Here is some context: Virgin Australia, the trading name of Virgin Australia Airlines Pty Ltd, is an Australian-based airline. It is the largest airline by fleet size to use the Virgin brand. It commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route. It suddenly found itself as a major airline in Australia's domestic market after the collapse of Ansett Australia in September 2001. The airline has since grown to directly serve 32 cities in Australia, from hubs in Brisbane, Melbourne and Sydney.[/INST] Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.</s></s>
plot_data_lengths(tokenized_train_dataset, tokenized_val_dataset)
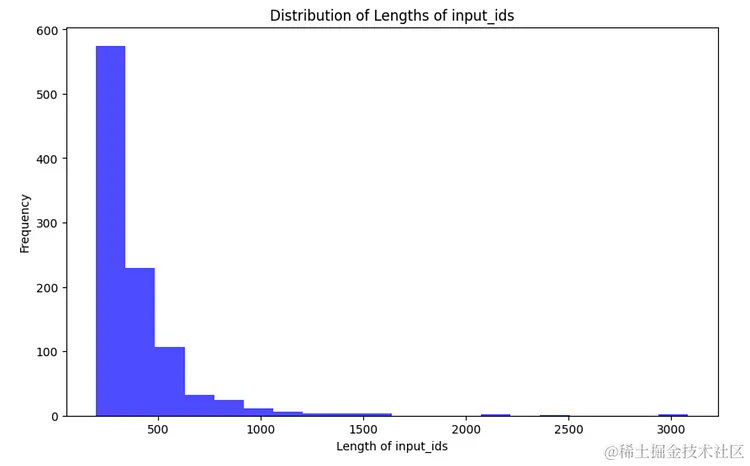
Source: Image created by Author
4.8 步骤 8:设置 LoRA
from peft import prepare_model_for_kbit_trainingmodel.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)def print_trainable_parameters(model):"""Prints the number of trainable parameters in the model."""trainable_params = 0all_param = 0for _, param in model.named_parameters():all_param += param.numel()if param.requires_grad:trainable_params += param.numel()print(f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}")from peft import LoraConfig, get_peft_modelconfig = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj","k_proj","v_proj","o_proj","w1","w2","w3","lm_head",],bias="none",lora_dropout=0.05, # Conventionaltask_type="CAUSAL_LM",
)model = get_peft_model(model, config)
print_trainable_parameters(model)# Apply the accelerator. You can comment this out to remove the accelerator.
model = accelerator.prepare_model(model)# Output
trainable params: 120350720 || all params: 23602952192 || trainable%: 0.5098968934945001
4.9 步骤 9:进行训练
import transformers
from datetime import datetimeif torch.cuda.device_count() > 1: # If more than 1 GPUmodel.is_parallelizable = Truemodel.model_parallel = Trueproject = "databricks-dolly-finetune"
base_model_name = "mixtral"
run_name = base_model_name + "-" + project
output_dir = "./" + run_nametokenizer.pad_token = tokenizer.eos_tokentrainer = transformers.Trainer(model=model,train_dataset=tokenized_train_dataset,eval_dataset=tokenized_val_dataset,args=transformers.TrainingArguments(output_dir=output_dir,warmup_steps=5,per_device_train_batch_size=1,gradient_checkpointing=True,gradient_accumulation_steps=4,max_steps=500,learning_rate=2.5e-5, logging_steps=25,fp16=True, optim="paged_adamw_8bit",logging_dir="./logs", # Directory for storing logssave_strategy="steps", # Save the model checkpoint every logging stepsave_steps=50, # Save checkpoints every 50 stepsevaluation_strategy="steps", # Evaluate the model every logging stepeval_steps=50, # Evaluate and save checkpoints every 50 stepsdo_eval=True, # Perform evaluation at the end of trainingreport_to="wandb", # Comment this out if you don't want to use weights & baisesrun_name=f"{run_name}-{datetime.now().strftime('%Y-%m-%d-%H-%M')}" # Name of the W&B run (optional)),data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
4.10 步骤 10:使用训练完毕的模型
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfigbase_model_id = "mistralai/Mixtral-8x7B-v0.1"
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_compute_dtype=torch.bfloat16
)base_model = AutoModelForCausalLM.from_pretrained(base_model_id, # Mixtral, same as beforequantization_config=bnb_config, # Same quantization config as beforedevice_map="auto",trust_remote_code=True,use_auth_token=True
)eval_tokenizer = AutoTokenizer.from_pretrained(base_model_id,add_bos_token=True,trust_remote_code=True,
)
from peft import PeftModelft_model = PeftModel.from_pretrained(base_model, "mixtral-databricks-dolly-finetune/checkpoint-100")
eval_prompt = """Given a question and some additional context, provide an answer### Target sentence:
Question: When was Tomoaki Komorida born?
Here is some context: Komorida was born in Kumamoto Prefecture on July 10, 1981. After graduating from high school, he joined the J1 League club Avispa Fukuoka in 2000. Although he debuted as a midfielder in 2001, he did not play much and the club was relegated to the J2 League at the end of the 2001 season. In 2002, he moved to the J2 club Oita Trinita. He became a regular player as a defensive midfielder and the club won the championship in 2002 and was promoted in 2003. He played many matches until 2005. In September 2005, he moved to the J2 club Montedio Yamagata. In 2006, he moved to the J2 club Vissel Kobe. Although he became a regular player as a defensive midfielder, his gradually was played less during the summer. In 2007, he moved to the Japan Football League club Rosso Kumamoto (later Roasso Kumamoto) based in his local region. He played as a regular player and the club was promoted to J2 in 2008. Although he did not play as much, he still played in many matches. In 2010, he moved to Indonesia and joined Persela Lamongan. In July 2010, he returned to Japan and joined the J2 club Giravanz Kitakyushu. He played often as a defensive midfielder and center back until 2012 when he retired.### Response:
"""model_input = eval_tokenizer(eval_prompt, return_tensors="pt").to("cuda")ft_model.eval()with torch.no_grad():print(eval_tokenizer.decode(ft_model.generate(**model_input, max_new_tokens=100)[0], skip_special_tokens=True))Given a question and some additional context, provide an answer### Target sentence:
Question: When was Tomoaki Komorida born?
Here is some context: Komorida was born in Kumamoto Prefecture on July 10, 1981. After graduating from high school, he joined the J1 League club Avispa Fukuoka in 2000. Although he debuted as a midfielder in 2001, he did not play much and the club was relegated to the J2 League at the end of the 2001 season. In 2002, he moved to the J2 club Oita Trinita. He became a regular player as a defensive midfielder and the club won the championship in 2002 and was promoted in 2003. He played many matches until 2005. In September 2005, he moved to the J2 club Montedio Yamagata. In 2006, he moved to the J2 club Vissel Kobe. Although he became a regular player as a defensive midfielder, his gradually was played less during the summer. In 2007, he moved to the Japan Football League club Rosso Kumamoto (later Roasso Kumamoto) based in his local region. He played as a regular player and the club was promoted to J2 in 2008. Although he did not play as much, he still played in many matches. In 2010, he moved to Indonesia and joined Persela Lamongan. In July 2010, he returned to Japan and joined the J2 club Giravanz Kitakyushu. He played often as a defensive midfielder and center back until 2012 when he retired.### Response:
Tomoaki Komorida was born on July 10, 1981.
五、结论
利用 QLoRA 对 Mixtral-8x7B 模型进行微调是自然语言处理 (NLP) 领域的一个重要进展,它将模型性能提升到了新的高度。这一缜密的过程融合了量化和 LoRA 等前沿技术,为超越基准(benchmarks)提供了一条稳健的途径,甚至在各种评估指标上超越了强大的 Llama 2 70B 模型。
本教程的核心在于使用QLoRA进行微调,利用bitsandbytes以4位精度实例化模型,并运用Hugging Face 🤗的PEFT库。该指南不仅概述了微调方法,还揭示了实践过程中可能遇到的问题,如OutOfMemory errors,为用户提供了精确的解决途径。
从本质上讲,该教程并非是一个技术指南,更像一个倡导模型微调最佳实践的指引。它倡导协作式微调,请邀请其他研究人员和从业者一同踏上推动语言理解模型发展的旅程。
前沿技术、详细的指导以及合作共赢的态度使得该教程对于NLP社区来说是一个非常重要且不可或缺的资源,期望能够引导 NLP 社区进一步提高模型性能,丰富理解能力。
Resources:
● Mixtral-8x7b[2]
● Thanks to Harper Carroll[2]
文中链接
[1]https://mistral.ai/news/mixtral-of-experts/
[2]https://huggingface.co/blog/mixtral
[3]https://twitter.com/HarperSCarroll
相关文章:
MoE模型性能还能更上一层楼?一次QLoRA微调实践
Fine-Tuning Mixtral 8x7B with QLoRA:Enhancing Model Performance 🚀 编者按:最近,混合专家(Mixture of Experts,MoE)这种模型设计策略展现出了卓越的语言理解能力,如何在此基础上进一步提升 MoE 模型的性能成为业界…...

Java线程学习笔记
1、判断线程存活 1. 当线程run()或者call()方法执行结束,线程进入终止状态 2. 当线程内发生异常,并且异常没有被捕获,线程进入终止状态 3. 线程调用stop()方法后,线程进入终止状态(不推荐使用) 当主线程结束时,其他线程…...
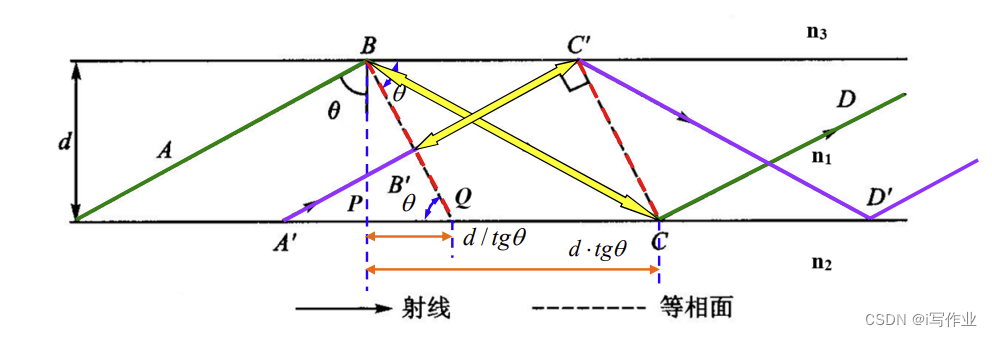
平面光波导_三层均匀平面光波导_射线分析法
平面光波导_三层均匀平面光波导_射线分析法 三层均匀平面光波导: 折射率沿 x x x 方向有变化,沿 y y y、 z z z 方向没有变化三层:芯区( n 1 n_1 n1) > > > 衬底( n 2 n_2 n2) ≥ \geq ≥ 包层( n 3 n_3 n3)包层通常为空…...

IPV6学习记录
IPV6的意义 从广义上来看IPV6协议包含的内容很多: IPV6地址的生成与分配 IPV6的报头的功能内容 IPV4网络兼容IPV6的方案 ICMPv6的功能(融合了arp和IGMP功能) IPV6的路由方式 ipv6的诞生除了由于ipv4的地址枯竭外,很大程度上也是因为ipv4多年的发展产生了很多…...

使用proteus进行主从JK触发器仿真失败原因的分析
在进行JK触发器的原理分析的时候,我首先在proteus根据主从JK触发器的原理进行了实验根据原理图,如下图: 我进行仿真,在仿真的过程中,我向电路图中添加了外部的置0/1端口,由此在proteus中得到下面的电路图 …...
Golang基础入门及Gin入门教程(2024完整版)
Golang是Google公司2009年11月正式对外公开的一门编程语言,它不仅拥有静态编译语言的安全和高性能,而 且又达到了动态语言开发速度和易维护性。有人形容Go语言:Go C Python , 说明Go语言既有C语言程序的运行速度,又能达到Python…...
等级考试试卷(四级)电子学会真题)
202312 青少年软件编程(C/C++)等级考试试卷(四级)电子学会真题
2023年12月 青少年软件编程(C/C)等级考试试卷(四级)电子学会真题 1.移动路线 题目描述 桌子上有一个m行n列的方格矩阵,将每个方格用坐标表示,行坐标从下到上依次递增,列坐标从左至右依次递增…...

leetcode-合并两个有序数组
88. 合并两个有序数组 题解: 这是一个经典的双指针问题,我们可以使用两个指针分别指向nums1和nums2的最后一个元素,然后比较两个指针所指向的元素大小,将较大的元素放入nums1的末尾,并将对应的指针向前移动一位。重复…...
网站怎么做google搜索引擎优化?
网站想做google搜索引擎优化,作为大前提,您必须确保网站本身符合google规范,我们不少客户实际上就连这点都无法做到 有不少客户公司自己本身有技术,就自己弄一个网站出来,做网站本身不是难事,但前提是您需要…...

TDengine 签约西电电力
近年来,随着云计算和物联网技术的迅猛发展,传统电力行业正朝着数字化、信息化和智能化的大趋势迈进。在传统业务基础上,电力行业构建了信息网络、通信网络和能源网络,致力于实现发电、输电、变电、配电和用电的实时智能联动。在这…...

赛门铁克OV代码签名证书一年多少钱?
在当前,软件和应用程序的安全性变得尤为重要。为了保护软件的完整性和安全性,越来越多的开发者和厂商开始采用代码签名的方式来确保软件的真实性和完整性。赛门铁克OV代码签名证书成为了其中一个备受信任的选择。那么,赛门铁克OV代码签名证书…...

Dockerfile详解
文章目录 一、Dockerfile介绍二、常用指令三、Dockerfile示例四、最佳实践 一、Dockerfile介绍 Dockerfile是一个包含创建镜像所有命令的文本文件,通过docker build命令可以根据Dockerfile的内容构建镜像。 一般的,Dockerfile分为四部分:基础…...

零基础小白如何自学sql?
学习SQL对于数据分析和处理来说非常重要。SQL是一种强大的工具,可以帮助你与数据库沟通,提取,整理和理解数据。 以下是一些学习SQL的建议: 01 前期:SQL数据库学习 了解SQL的基本概念:首先,你…...

【刷题笔记2】
刷题笔记2 最小公倍数、最大公约数 两个数的最大公约数两数乘积/最小公倍数 #<include> cmath; int a,b; int mgcd(a,b);//求最大公约数复制字符串substr()函数 s.substr(pos, len) :pos的默认值是0,len的默认值是s.size() - pos string a1;in…...

Kafka之集群搭建
1. 为什么要使用kafka集群 单机服务下,Kafka已经具备了非常高的性能。TPS能够达到百万级别。但是,在实际工作中使用时,单机搭建的Kafka会有很大的局限性。 消息太多,需要分开保存。Kafka是面向海量消息设计的,一个T…...

Linux备忘手册
常⽤命令 作⽤ shutdown -h now 即刻关机 shutdown -h 10 10分钟后关机 shutdown -h 11:00 11:00关机 shutdown -h 10 预定时间关机(10分钟后) shutdown -c 取消指定时间关机 shutdown -r now 重启 shutdown -r 10 10分钟之后重启 shutdown -…...

Qt中QGraphicsView总体架构学习
前沿 前段时间学习了下如何在QGraphicsView架构中绘制刻度尺,主要是与OnPainter中进行比较的,那么今天就来详细讲解下我对QGraphicsView框架的认知吧~ 最近一段时间想学习下,如果我有不正确的,欢迎留言探讨哟~ QGraphicsView架…...
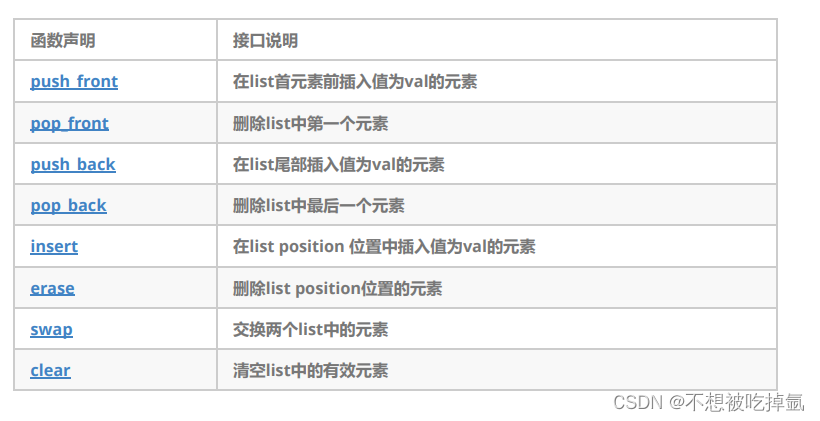
STL-list的使用简介
目录 编辑 一、list的底层实现是带头双向循环链表 二、list的使用 1、4种构造函数(与vector类似)编辑 2、迭代器iterator 3、容量(capicity)操作 4、element access 元素获取 5、增删查改 list modifiers 6、list的迭…...

MySQL:索引失效场景总结
1 执行计划查索引 通过执行计划命令可以查看查询语句使用了什么索引。 EXPLAIN SELECT * FROM ods_finebi_area WHERE areaName = 福建 执行查询计划后,key列的值就是被使用的索引的名称,若key列没有值表示查询未使用索引。 2 在什么列上创建索引 (1)列经常被用于where…...

LNMP平台对接redis服务
目录 1、安装 LNMP 各个组件 2、安装 redis 服务 3、安装 redis 扩展 4、修改 php 配置文件 5、测试连接 1、安装 LNMP 各个组件 2、安装 redis 服务 3、安装 redis 扩展 官网:http://redis.io/ 下载包: https://codeload.github.com/phpredis/p…...
仓储空间智能基础设施构建路径研究: 融合动态建模与 Pixel-to-Space 的三维空间认知与决策体系(面向“十五五”的关键技术突破与工程应用)
仓储空间智能基础设施构建路径研究 —— 融合动态建模与 Pixel-to-Space 的三维空间认知与决策体系(面向“十五五”的关键技术突破与工程应用) 一、研究背景:迈向空间智能基础设施时代 随着数字经济、智能制造与新型基础设施建设的持续推进…...

必知的AI写专著工具,高效完成专著,提升学术产出效率
学术专著写作挑战与AI工具应对 学术专著的生命力主要体现在逻辑的严密性上,但恰恰是逻辑论证部分最容易出现问题。撰写专著时,需围绕核心观点进行系统论证,既要充分阐述每个论点,还要妥善处理不同学派的争议观点,同时…...

分布式协调双雄深度拆解:ZooKeeper 与 Nacos 从底层原理到生产实战全指南
引言分布式系统的核心痛点,是如何让多个独立的节点对系统状态达成一致共识:谁是集群的Master节点、全集群配置是否同步、分布式锁该由谁持有、服务实例上下线如何实时感知。这些问题如果由业务自行实现,不仅会重复造轮子,更极易出…...

bug.n多显示器支持完全指南:跨屏工作流优化方案
bug.n多显示器支持完全指南:跨屏工作流优化方案 【免费下载链接】bug.n Tiling Window Manager for Windows 项目地址: https://gitcode.com/gh_mirrors/bu/bug.n bug.n 作为一款专为 Windows 设计的平铺窗口管理器(Tiling Window Manager&#x…...

从光流到TOF:ArduPilot EKF3如何玩转室内定位?手把手教你配置非GPS导航源
室内无人机定位实战:ArduPilot EKF3融合光流与TOF的深度配置指南 当GPS信号被钢筋混凝土阻隔,如何让无人机在室内环境中保持精准定位?这不仅是技术挑战,更是工程实践的艺术。本文将带您深入ArduPilot的EKF3扩展卡尔曼滤波系统&…...

Qwen3-Reranker-0.6B入门必看:Qwen3-Reranker与Qwen3-Embedding协同优化方案
Qwen3-Reranker-0.6B入门必看:Qwen3-Reranker与Qwen3-Embedding协同优化方案 1. 从零开始部署Qwen3-Reranker服务 如果你正在构建RAG(检索增强生成)系统,那么Qwen3-Reranker-0.6B绝对是你需要了解的利器。这个轻量级重排序模型只…...

PCB设计避坑指南:Cadence Allegro地孔设计与后期处理的5个常见错误及解决方法
PCB设计避坑指南:Cadence Allegro地孔设计与后期处理的5个常见错误及解决方法 在高速PCB设计中,地孔(Via)的处理往往是决定信号完整性和EMC性能的关键因素之一。作为Cadence Allegro用户,我们经常在地孔设计和后期处理…...

TTP224四路电容触摸传感器模块原理与低功耗集成指南
1. TTP224四路电容式触摸传感器模块技术解析1.1 模块核心功能与工程定位TTP224是一种集成化四通道电容式触摸检测模块,其核心IC为TTP223B的多通道衍生版本。该模块并非简单的模拟信号采集单元,而是一个具备完整状态机管理能力的智能传感节点。在常态下&a…...

VS1053 DREQ信号量同步机制设计与RTOS集成
1. 项目概述VS1053-Semaphore是一个面向嵌入式音频播放场景的轻量级同步机制实现,专为基于 VS1053 音频解码芯片的多线程/多任务系统设计。其核心目标并非提供完整的 MP3 播放器功能,而是解决在 RTOS(如 FreeRTOS、Zephyr 或 CMSIS-RTOS&…...

从截图到搜图翻译一条龙:我是如何用‘二箱’和‘百度截图翻译’搞定全英文技术文档的
从截图到搜图翻译一条龙:高效处理英文技术文档的实战技巧 第一次打开全英文的Kubernetes官方文档时,我盯着满屏的专业术语和复杂图表足足发呆了十分钟。作为非英语母语的开发者,这种挫败感太熟悉了——每个单词都似曾相识,连在一起…...