机器学习笔记一之入门概念
目录
- 一 基本分类
- 二 按模型分类
- 概率模型(Probabilistic Models)
- 非概率模型(Non-Probabilistic Models)
- 对比
- 结论
- 线性模型 (Linear Models)
- 非线性模型 (Non-linear Models)
- 对比
- 三 按算法分类
- 1.批量学习(Batch Learning)
- 2.在线学习(Online Learning)
- 对比
- 四 按技巧分类
- 五 机器学习的三要素
- 经验风险 (Empirical Risk)
- 结构风险 (Structural Risk)
- 对比
- 六 模型的评估与选择
- 1.两种误差
- 训练误差 (Training Error)
- 测试误差 (Test Error)
- 对比
- 2.拟合程度
- 过拟合 (Overfitting)
- 欠拟合 (Underfitting)
- 对比
- 七 正则化
- 正则化的主要类型
- 正则化的作用
- 八 泛化能力
- 泛化能力的重要性
- 影响泛化能力的因素
- 评估泛化能力
一 基本分类
-
监督学习 (Supervised Learning)
- 数据类型: 在监督学习中,训练数据包括输入数据和对应的标签(或“答案”)。例如,在图像识别中,每张图片(输入)会有一个标签,如“猫”、“狗”等。
- 目标: 目标是训练一个模型,使其能够根据输入数据预测出准确的标签。例如,根据病历资料预测疾病类型。
- 应用: 分类(如垃圾邮件与非垃圾邮件的识别)、回归(如房价预测)等。
-
非监督学习 (Unsupervised Learning)
- 数据类型: 训练数据只包含输入数据,而不包括任何标签。模型需要自己发现数据中的结构和模式。
- 目标: 主要是探索数据的内在结构和模式,如通过聚类分析将相似的数据点分为不同的组,或者通过降维技术发现数据的主要趋势。
- 应用: 聚类(如市场细分)、降维(如特征抽取)、异常检测等。
-
半监督学习 (Semi-Supervised Learning)
- 数据类型: 结合了监督学习和非监督学习的数据类型。大部分数据没有标签,少部分数据有标签。
- 目标: 利用有限的标签数据来指导对大量无标签数据的学习过程。模型尝试理解无标签数据的结构,并利用这些知识来提高对有标签数据的预测准确性。
- 应用: 适用于标签获取成本高昂或者标签难以获得的情况,如大规模图像或文本数据的处理。
- 强化学习、主动学习和监督学习是机器学习的三种不同范式,它们各自有独特的特点和应用场景,但也存在一些联系和区别:
-
强化学习 (Reinforcement Learning)
- 特点: 强化学习侧重于如何基于环境的反馈来采取行动以最大化某种累积奖励。它涉及一个代理(agent)在环境中学习策略的过程,通过试错来学习最佳行动。
- 应用: 如自动驾驶汽车、游戏AI、机器人控制等。
-
主动学习 (Active Learning)
- 特点: 主动学习是一种半监督学习,它允许学习算法(或模型)主动选择它希望从中学习的数据点。在主动学习中,算法试图选择最有信息量的样本来进行标记,以提高学习效率。
- 应用: 在标签成本高或标签难以获得的情况下特别有用,如医学图像分析。
二 按模型分类
机器学习中的模型可以按照它们是否基于概率理论进行分类,分为概率模型(Probabilistic Models)和非概率模型(Non-Probabilistic Models)。这两种类型的模型在处理不确定性和模型数据的方式上有所不同。
-
概率模型 (Probabilistic Models)
- 定义: 概率模型是基于概率理论构建的模型,它们在对数据进行建模时考虑了不确定性。这些模型通常提供了关于预测的不确定性的量化信息。
- 特点: 概率模型能够给出关于预测结果的概率分布,而不仅仅是一个固定的输出值。这允许它们更有效地处理数据中的噪声和不确定性。
- 示例: 朴素贝叶斯分类器、隐马尔可夫模型(HMM)、高斯混合模型(GMM)等。
-
非概率模型 (Non-Probabilistic Models)
- 定义: 非概率模型通常给出确定性的预测或决策,而不是预测的概率分布。这类模型通常关注于直接从输入数据映射到输出结果。
- 特点: 这些模型在给出预测时,通常不提供关于预测不确定性的直接信息。它们更加关注于预测的准确性和效率。
- 示例: 支持向量机(SVM)、决策树、神经网络等。
这两类模型在实际应用中各有优势。概率模型在需要对结果的不确定性进行量化或者处理数据中的噪声和不确定性时特别有用。而非概率模型在预测任务中通常更简单直接,可能在特定任务上更高效。
选择哪种类型的模型通常取决于具体的应用场景、数据特性和问题的需求。例如,如果问题需要对预测的可信度进行量化,概率模型可能是更好的选择;如果问题更关注于预测的速度和精度,非概率模型可能更适合。
具体的例子来解释这两种模型。
概率模型(Probabilistic Models)
假设您是一位医生,您要根据病人的一些症状来判断他们是否患有某种疾病。在这种情况下,概率模型会非常有用。
例子:朴素贝叶斯分类器(Naive Bayes Classifier)
- 应用场景: 用于诊断疾病。
- 工作原理: 这种模型会基于病人的症状(如发热、咳嗽等)来计算患有特定疾病(如流感)的概率。
- 优势: 它提供了一个概率值,让医生知道这个诊断有多可靠。例如,模型可能显示有90%的概率患有流感,这可以帮助医生做出更加信息化的决策。
非概率模型(Non-Probabilistic Models)
假设您是一名银行贷款官员,您需要决定是否批准客户的贷款申请。在这种场景下,非概率模型是一个很好的工具。
例子:支持向量机(Support Vector Machine, SVM)
- 应用场景: 用于贷款审批。
- 工作原理: SVM会使用客户的财务数据(如收入、信用评分等)来决定他们是否是贷款违约的高风险。该模型会将客户分类为“高风险”或“低风险”。
- 优势: 这种模型给出一个明确的决策,而不是概率。它适用于需要快速、明确决策的情况。
对比
在医疗诊断的例子中,概率模型(如朴素贝叶斯)提供的概率信息对于处理诊断的不确定性非常有帮助。医生需要知道诊断结果的可信度,以便在需要时进一步检查。
相反,在贷款审批的例子中,非概率模型(如SVM)提供了直接的“是”或“否”的决策,这对于快速处理大量贷款申请非常重要。
结论
选择使用概率模型还是非概率模型取决于具体问题和场景的需求。需要评估结果不确定性时,概率模型更为适宜;而在需要快速、明确决策的场合,非概率模型可能更加合适。
在机器学习中,线性模型和非线性模型是两类基本的模型类型,它们根据输入特征与预测输出之间的关系来进行区分。
线性模型 (Linear Models)
-
定义: 线性模型假设输入特征和输出结果之间存在线性关系。这意味着模型的输出是输入特征的加权和,可能再加上一个常数(偏差项)。
-
数学表示: 对于一个具有特征 ( x_1, x_2, …, x_n ) 的数据点,线性模型的预测 ( y ) 可以表示为:
[ y = w_1x_1 + w_2x_2 + … + w_nx_n + b ]
其中,( w_1, w_2, …, w_n ) 是模型参数,( b ) 是偏差项。 -
示例: 线性回归、逻辑回归。
-
应用: 线性模型通常用于预测分析(如股票价格预测)、分类问题(如垃圾邮件检测)等。
-
优点: 简单、易于理解和解释,计算效率高。
-
局限性: 不能很好地处理数据间复杂的非线性关系。
非线性模型 (Non-linear Models)
-
定义: 非线性模型指的是输入特征与输出结果之间存在非线性关系的模型。这些模型能够捕捉数据中更复杂的模式。
-
数学表示: 非线性模型的数学形式可以是多种多样的,不限于加权和。例如,它们可能包含输入特征的高次项、指数、对数等。
-
示例: 决策树、神经网络、支持向量机(使用非线性核函数)。
-
应用: 非线性模型适用于复杂的预测任务,如图像和语音识别、自然语言处理等。
-
优点: 能够处理数据之间的复杂关系,适用于更广泛的应用场景。
-
局限性: 通常更复杂,需要更多的数据来训练,且可能难以解释。
对比
- 复杂性: 非线性模型通常比线性模型更复杂,能够处理更复杂的任务,但也更难以训练和解释。
- 适用性: 线性模型适用于简单或者数据量较小的问题,而非线性模型适用于复杂且数据量大的问题。
- 解释性: 线性模型通常更容易解释,而非线性模型的决策过程可能不那么直观。
在选择模型时,重要的是根据具体问题的性质、数据的复杂度以及解释性要求来做出选择。对于一些简单任务,使用复杂的非线性模型可能是不必要的,而对于一些高度复杂的任务,线性模型可能无法提供足够的性能。
三 按算法分类
按照数据处理方式的不同,机器学习算法可以分为在线学习(Online Learning)和批量学习(Batch Learning)两种主要类型。这两种类型的区分主要基于算法是如何从数据中学习的。
1.批量学习(Batch Learning)
- 定义: 在批量学习中,算法在训练过程中使用固定的数据集。这意味着它在开始学习之前需要收集并准备好所有的训练数据。
- 特点:
- 所有的学习过程都是在一次性处理整个训练集后完成的。
- 在学习完成后,模型就固定下来了,如果要处理新数据或更新模型,就需要重新训练整个模型。
- 应用场景: 适用于数据量不太大,或者不经常更新的情况,如历史数据分析、固定数据集上的模式识别等。
- 示例: 大多数传统的机器学习算法,如线性回归、支持向量机、决策树等,在默认情况下都是作为批量学习进行的。
2.在线学习(Online Learning)
- 定义: 在线学习算法可以逐步处理数据,一次接受一个样本或者小批量样本,并对模型进行即时更新。
- 特点:
- 能够不断地从新数据中学习和适应,适合于数据不断流入的情况。
- 对于处理大规模数据集或需要实时反应的应用特别有用。
- 应用场景: 适用于数据不断变化或数据量太大无法一次性处理的情况,如股票市场预测、在线用户行为分析等。
- 示例: 某些神经网络模型、随机梯度下降(SGD)等。
对比
- 数据更新: 批量学习不适合频繁更新的数据,而在线学习可以实时更新模型。
- 资源需求: 在线学习通常对计算资源的要求更低,因为它一次只处理少量数据。
- 适用性: 批量学习适合于数据量有限且不经常更新的场景,而在线学习适合于数据源持续更新的动态环境。
根据具体的应用需求和数据的特性,可以选择最合适的学习方式。例如,对于需要快速适应新数据的应用,如推荐系统或实时监控系统,在线学习是更佳的选择。而对于数据集固定不变的应用,如静态数据集上的统计分析,批量学习则更为合适。
四 按技巧分类
按照技巧或方法的特性分类,机器学习算法可以划分为几个不同的类别,每个类别包括了一系列具有相似特点的算法。以下是一些主要的分类及其特点:
-
基于实例的学习 (Instance-based Learning)
- 算法依赖于具体的数据实例来进行预测。
- 例如,最近邻(k-NN)算法会根据与新数据点最接近的已知数据点来进行分类或回归。
- 特点:简单、直观,易于实现,但可能需要较大的存储空间和计算资源。
-
基于模型的学习 (Model-based Learning)
- 这类算法先从训练数据构建一个模型,然后用这个模型来做出预测。
- 例如,决策树、支持向量机、神经网络等。
- 特点:能够捕捉数据中的复杂模式,适用于复杂任务,但可能需要更多的训练时间和数据。
-
集成学习 (Ensemble Learning)
- 集成方法结合了多个模型来提高预测的准确性和稳健性。
- 例如,随机森林(Random Forests)结合了多个决策树的结果。
- 特点:通常比单个模型更准确,能够减少过拟合的风险,但计算成本较高。
-
深度学习 (Deep Learning)
- 深度学习使用具有多层结构的神经网络来学习数据的高级特征。
- 例如,卷积神经网络(CNNs)适用于图像处理,循环神经网络(RNNs)适用于序列数据。
- 特点:在处理大规模数据集和复杂问题上表现优异,但需要大量的训练数据和计算资源。
-
规则学习 (Rule-based Learning)
- 依靠一系列规则来进行决策。
- 例如,决策树算法就是提取出一系列的决策规则。
- 特点:生成的模型易于理解,透明度高,但可能无法处理非常复杂的模式。
-
概率学习 (Probabilistic Learning)
- 使用概率模型来预测结果。
- 例如,朴素贝叶斯分类器和隐马尔可夫模型。
- 特点:能够处理不确定性和噪声数据,提供预测的概率估计。
这些分类不是互斥的;实际上,许多机器学习算法可以归入多个类别。例如,深度学习是基于模型的学习的一种,同时也可以视为一种特殊的集成学习(多层神经网络可以视为多个处理层的集合)。选择哪种类型的方法取决于具体问题、数据的特性和可用资源。
五 机器学习的三要素
三个要素各自的含义:
-
模型 (Model)
- 定义: 在机器学习中,模型是指从输入数据到输出预测的映射。这个映射是通过数据学习得到的,可以是一个简单的线性关系,也可以是复杂的非线性关系,如深度学习模型。
- 作用: 模型定义了数据特征如何转换为预测或决策。
-
策略 (Strategy)
- 定义: 策略涉及到选择何种损失函数和正则化方法,它定义了如何从模型的预测中评估误差或损失。换言之,策略决定了我们如何通过损失函数来衡量模型的好坏。
- 作用: 策略指导我们如何通过比较预测和实际结果来优化模型。
- 损失函数和风险函数
- 经验风险和结构风险
- 结构风险(Structural Risk)和经验风险(Empirical Risk)是机器学习领域中的两个重要概念,尤其是在统计学习理论中。它们与模型的泛化能力和训练过程密切相关。
经验风险 (Empirical Risk)
- 定义: 经验风险是指模型在训练数据集上的平均损失。它反映了模型对训练数据的拟合程度。
- 计算: 通常通过损失函数来计算,例如,使用均方误差(MSE)或交叉熵损失来衡量。
- 意义: 经验风险最小化(ERM, Empirical Risk Minimization)是一种模型训练方法,其目标是最小化模型在训练数据上的损失。
- 局限: 仅关注于最小化训练误差可能导致过拟合,尤其是当训练数据量不足或包含噪声时。
结构风险 (Structural Risk)
- 定义: 结构风险考虑了模型复杂度对泛化能力的影响。它是经验风险和模型复杂度的综合考量。
- 计算: 结构风险通常由经验风险和一个与模型复杂度相关的正则化项组成。
- 意义: 结构风险最小化(SRM, Structural Risk Minimization)是一种更综合的训练方法,它旨在找到经验风险和模型复杂度之间的最佳平衡。
- 作用: 通过考虑模型复杂度,结构风险最小化有助于提高模型在未见数据上的泛化能力,降低过拟合的风险。
对比
- 关注点不同: 经验风险关注于模型在训练数据上的表现,而结构风险还考虑了模型复杂度对泛化能力的影响。
- 过拟合防范: 经验风险最小化可能导致过拟合,特别是在数据有限的情况下。结构风险最小化通过考虑模型复杂度来减轻这一问题。
- 适用性: 在数据量较小或者数据质量不高的情况下,结构风险最小化通常比经验风险最小化更为有效。
简而言之,结构风险最小化是对经验风险最小化的一个重要补充,它通过引入正则化项来控制模型复杂度,从而在模型的拟合能力和泛化能力之间寻求平衡。
- 算法 (Algorithm)
- 定义: 算法是指具体的计算过程,用于在给定的策略下优化模型参数。算法通过最小化损失函数来调整模型参数,以训练出最佳的模型。
- 作用: 算法是实际执行模型训练的步骤和方法,如梯度下降、随机森林等。
这种分类方式强调了机器学习中的不同方面:模型定义了学习任务的结构,策略定义了评价模型的准则,而算法则是实现模型优化的具体计算方法。这三者共同工作,使机器学习能够有效地从数据中学习。
六 模型的评估与选择
1.两种误差
训练误差(Training Error)和测试误差(Test Error)是机器学习中评估模型性能的两个重要概念。它们反映了模型在训练阶段和测试阶段对数据的拟合程度和预测准确性。
训练误差 (Training Error)
- 定义: 训练误差是指模型在训练数据集上的误差。它衡量了模型对用于学习的数据的拟合程度。
- 计算: 通常通过计算模型在训练集上的平均误差来得到,如均方误差(MSE)或交叉熵损失。
- 意义: 训练误差低可能表示模型已经很好地学习了训练数据的特征和模式。
- 局限: 低训练误差并不总是意味着模型一定优秀,因为它可能是由于过拟合(Overfitting)造成的,即模型对训练数据学得太好,包括了数据中的噪声,而失去了泛化能力。
测试误差 (Test Error)
- 定义: 测试误差是指模型在新的、未见过的数据(测试数据集)上的误差。它衡量了模型对新数据的预测准确性。
- 计算: 通过评估模型在一个独立的测试数据集上的性能来得到。
- 意义: 测试误差是对模型泛化能力的一个更好的衡量。低测试误差表明模型不仅在训练数据上表现良好,而且能够将学到的知识有效地应用于新数据。
- 局限: 测试数据集的选择和大小可能会影响测试误差的准确性。
对比
- 目的差异: 训练误差用于衡量模型对训练数据的拟合程度,而测试误差用于评估模型对新数据的泛化能力。
- 重要性: 测试误差通常被认为比训练误差更重要,因为它更能代表模型在实际应用中的性能。
- 过拟合风险: 过分关注降低训练误差可能导致过拟合,即模型对训练数据过度敏感,对新数据的预测性能下降。
在实际应用中,理想的模型是训练误差和测试误差都较低,这意味着模型既能够很好地学习训练数据,又具有良好的泛化能力。
2.拟合程度
在机器学习中,过拟合(Overfitting)和欠拟合(Underfitting)是两种常见的问题,它们分别描述了模型对训练数据的拟合程度过高或过低的情况。
过拟合 (Overfitting)
- 定义: 过拟合发生在模型对训练数据学得“太好”时,以至于它开始学习训练数据中的噪声和异常点。
- 表现: 在训练数据上表现出色(训练误差低),但在新的、未见过的数据上表现不佳(测试误差高)。
- 原因:
- 训练数据不足,或者数据质量差(噪声太多)。
- 模型过于复杂,有过多的参数或层次。
- 解决方法:
- 获取更多或更高质量的训练数据。
- 简化模型,减少参数数量。
- 使用正则化技术(如L1或L2正则化)。
- 早停法(Early Stopping):在验证集误差开始增加时停止训练。
欠拟合 (Underfitting)
- 定义: 欠拟合发生在模型没有很好地学习训练数据的基本结构时,通常是因为模型过于简单。
- 表现: 在训练数据上和新数据上都表现不佳(训练误差和测试误差都高)。
- 原因:
- 模型过于简单,无法捕捉数据的复杂性。
- 训练不充分,模型没有足够的时间学习数据。
- 解决方法:
- 使用更复杂的模型。
- 增加更多特征,或进行特征工程。
- 增加训练时间或更改训练方法。
对比
- 问题本质: 过拟合是由于模型太复杂或训练过度,而欠拟合是由于模型太简单或训练不足。
- 表现: 过拟合在训练集上表现良好但泛化能力差,欠拟合在训练集和测试集上都表现不佳。
- 解决: 过拟合需要简化模型或获取更多数据,欠拟合需要复杂化模型或增加特征。
在机器学习中,找到一个既不过拟合也不欠拟合的模型是一个关键挑战,这通常需要通过调整模型的复杂性、增加数据量或改变训练策略来实现。
七 正则化
正则化是一种用于减少模型过拟合的技术,在机器学习和统计学中非常常见。它通过添加一个额外的惩罚项到损失函数中,来限制模型的复杂度。这个惩罚项通常是对模型参数的大小的惩罚,目的是防止模型过度依赖训练数据的特定特征,从而提高模型的泛化能力。
正则化的主要类型
-
L1 正则化(Lasso 正则化)
- 惩罚项是模型所有参数绝对值的和。
- 数学表示: ( λ ∑ ∣ w i ∣ ( \lambda \sum |w_i| (λ∑∣wi∣),其中 ( λ ( \lambda (λ) 是正则化强度, ( w i ( w_i (wi) 是模型参数。
- 特点:它倾向于生成一个稀疏模型,即许多参数值为零,这有助于特征选择。
-
L2 正则化(Ridge 正则化)
- 惩罚项是模型所有参数的平方和。
- 数学表示: ( λ ∑ w i 2 ( \lambda \sum w_i^2 (λ∑wi2)。
- 特点:它倾向于使参数值较小,但不会是零,这有助于处理参数间的共线性问题。
-
弹性网(Elastic Net)
- 结合了 L1 和 L2 正则化。
- 数学表示:包含两部分,一部分是 L1 正则化,另一部分是 L2 正则化。
- 特点:结合了 L1 和 L2 的优点,对于具有相关特征的数据集特别有效。
正则化的作用
- 减少过拟合: 通过惩罚大的参数值,正则化降低了模型对训练数据中噪声的敏感性。
- 提高泛化能力: 增加正则化可以使模型在新的、未见过的数据上表现得更好。
- 处理共线性(多重共线性): 特别是 L2 正则化,有助于处理特征间高度相关的情况。
在实际应用中,正则化强度(通常由参数 ( λ ( \lambda (λ) 控制)的选择非常重要。 ( λ ( \lambda (λ) 值过大可能导致模型欠拟合(过于简单),而 ( λ ( \lambda (λ) 值过小则可能导致过拟合(复杂度过高)。通常通过交叉验证来找到最佳的 ( λ ( \lambda (λ) 值。
八 泛化能力
泛化能力是指机器学习模型对新的、未见过的数据进行预测的能力。简而言之,一个具有良好泛化能力的模型能够在新数据上表现得和在训练数据上一样好。泛化能力是评估机器学习模型性能的关键指标之一。
泛化能力的重要性
- 实际应用: 在实际应用中,我们通常更关心模型在新数据上的表现,而不仅仅是其在训练集上的表现。
- 避免过拟合: 一个过拟合的模型可能在训练数据上表现出色,但在新数据上表现糟糕。良好的泛化能力意味着模型在新数据上也能保持可靠的性能。
影响泛化能力的因素
-
模型复杂度:
- 过于复杂的模型可能会学习到训练数据中的噪声和特定样本的特征,导致在新数据上表现不佳。
- 适度的模型复杂度可以帮助模型捕捉数据中的真实模式,而不是噪声。
-
训练数据量和质量:
- 足够多且多样的训练数据可以帮助模型更好地泛化。
- 数据质量差(如有噪声或错误标签)会影响模型的泛化能力。
-
正则化:
- 正则化技术(如L1、L2正则化)可以防止过拟合,提高模型的泛化能力。
-
训练技术:
- 例如,交叉验证可以帮助评估模型在新数据上的表现,从而选择更能泛化的模型。
评估泛化能力
- 通常通过在一个独立的测试集上评估模型的性能来估计其泛化能力。
- 交叉验证是另一种评估模型泛化能力的常用方法,它通过将数据分成多个部分并在这些部分上多次训练和测试模型来减少评估的偏差。
总的来说,泛化能力是衡量机器学习模型在面对新数据时能否做出准确预测的一个关键指标。它影响着模型在现实世界问题中的实际应用价值。
相关文章:

机器学习笔记一之入门概念
目录 一 基本分类二 按模型分类概率模型(Probabilistic Models)非概率模型(Non-Probabilistic Models)对比结论线性模型 (Linear Models)非线性模型 (Non-linear Models)对比 三 按算法分类1.批量学习(Batch Learning&…...

用于脚本支持的 CSS 媒体查询
Chrome 120 于近日发布,在这个版本中,我们获得了用于脚本支持的 CSS 媒体查询。简单地说,此媒体查询允许我们测试脚本语言是否可用,并根据支持定制页面内容和样式。我是白特,让我们一起来学习下吧。 媒体查询语法 媒…...

【HBase】——整合Phoenix
1 概述 Phoenix 是 HBase 的开源 SQL 皮肤。可以使用标准 JDBC API 代替 HBase 客户端 API 来创建表,插入数据和查询 HBase 数据。 Phoenix 在 5.0 版本默认提供有两种客户端使用(瘦客户端和胖客户端),在 5.1.2 版本 安装包中…...

【操作系统xv6】学习记录5--实验1 Lab: Xv6 and Unix utilities
ref:https://pdos.csail.mit.edu/6.828/2020/xv6.html 实验:Lab: Xv6 and Unix utilities 环境搭建 实验环境搭建:https://blog.csdn.net/qq_45512097/article/details/126741793 搭建了1天,大家自求多福吧,哎。~搞环境真是折磨…...
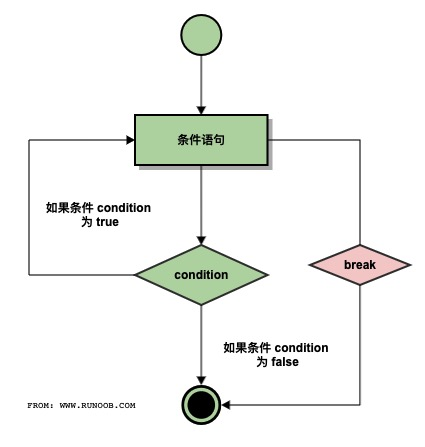
Python从入门到网络爬虫(控制语句详解)
前言 做任何事情都要遵循一定的原则。例如,到图书馆去借书,就需要有借书证,并且借书证不能过期,这两个条件缺一不可。程序设计亦是如此,需要使用流程控制实现与用户的交流,并根据用户需求决定程序“做什么…...
transbigdata笔记:数据预处理
0 数据 使用 transbigdata/docs/source/gallery/data/TaxiData-Sample.csv at main ni1o1/transbigdata (github.com) 和transbigdata/docs/source/gallery/data/sz.json at main ni1o1/transbigdata (github.com) 0.1 导入库 import transbigdata as tbd import pandas …...
java中解码和编码出现乱码原因
一、UTF-8和GBK编码方式 如果采用的是UTF-8的编码方式,那么1个英文字母 占 1个字节,1个中文占3个字节如果采用GBK的编码方式,那么1个英文字母 占 1个字节,1个中文占2个字节 二、idea和eclipse的默认编码方式 其实idea和eclipse的…...
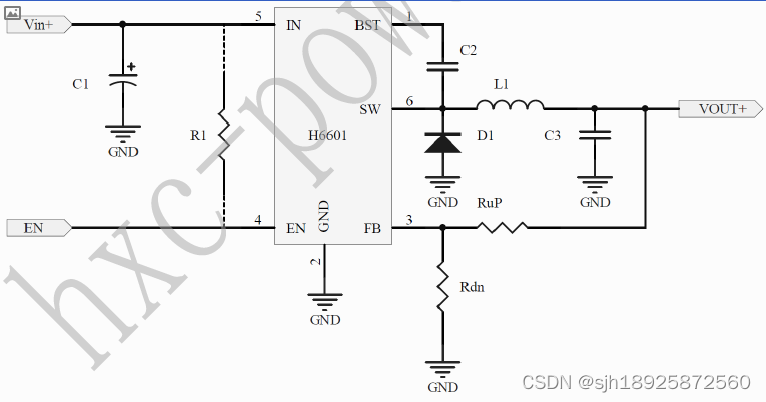
60V降压3.3V稳压芯片 60V降压5V稳压芯片60V降压12V稳压芯片
60V降压3.3V稳压芯片、60V降压5V稳压芯片和60V降压12V稳压芯片是针对不同输出电压需求的降压稳压芯片。这些芯片通常被用于工业控制、通信设备、汽车电子和其他需要高电压输入并提供稳定输出电压的场合。 这些芯片通常具有高效率、低功耗和高稳定性的特点,能够在输…...
01第一个Mybatis程序+引入Junit+引入日志文件logback
Mybatis MyBatis本质上就是对JDBC的封装,通过MyBatis完成CRUD。而对于JDBC,SQL语句写死在Java程序中,不灵活。改SQL的话就要改Java代码。违背开闭原则OCP。对于事务机制,MyBatis支持 或managed模式,JDBC模式中MyBatis…...
音乐制作软件Studio One mac有哪些特点
Studio One mac是一款专业的音乐制作软件,该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One mac软件特点 1. 直观易用的界面&…...

开源C语言库Melon之日志模块
本文向大家介绍一个名为Melon的开源C语言库的日志模块。 简述Melon Melon是一个包含了开发中常用的各类组件的开源C语言库,支持Linux、MacOS、Windows系统,可用于服务器开发亦可用于嵌入式开发,无第三方软件依赖,安装简单&…...

[NOIP2006 提高组] 作业调度方案(修改)
题目: 这里对于之前的题目进行修改记录。果然还是受不了等待,利用晚饭时间又看了这个题目。于是发现了问题。 之前的博客:https://blog.csdn.net/KLSZM/article/details/135522867?spm1001.2014.3001.5501 问题修改描述 上午书写的代码中是…...

uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -全局异常统一处理实现
锋哥原创的uniapp微信小程序投票系统实战: uniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )_哔哩哔哩_bilibiliuniapp微信小程序投票系统实战课程 (SpringBoot2vue3.2element plus ) ( 火爆连载更新中... )共计21条视频…...
浏览器缓存引发的odoo前端报错
前两天,跑了一个odoo16项目,莫名其妙的前端报错, moment.js 报的错, 这是一个时间库,不是我自己写的代码,我也没做过任何修改,搞不清楚为什么报错。以为是odoo的bug,所以从gitee下载…...
如何搭建开源知识库软件AFFiNE并实现公网环境远程协作【内网穿透】
目录 前言 1. 使用Docker安装AFFINE 2. 安装cpolar内网穿透工具 3. 配置AFFINE公网访问地址 4. 实现公网远程访问AFFINE 结语 作者简介: 懒大王敲代码,计算机专业应届生 今天给大家聊聊如何搭建开源知识库软件AFFiNE并实现公网环境远程协作【内网穿…...

记忆泊车信息安全技术要求
一.概述 1.1 编写目的 记忆泊车过程涉及车辆通信、远程控制车辆等关键操作,因此需要把信息安全考虑进去,确保整个自动泊车过程的信息安全。 1.2 编写说明 此版为信息安全需求,供应商需要整体的信息安全方案。 1.3 适用范围 …...
开源分布式任务调度系统DolphinScheduler本地部署与远程访问
文章目录 前言1. 安装部署DolphinScheduler1.1 启动服务 2. 登录DolphinScheduler界面3. 安装内网穿透工具4. 配置Dolphin Scheduler公网地址5. 固定DolphinScheduler公网地址 前言 本篇教程和大家分享一下DolphinScheduler的安装部署及如何实现公网远程访问,结合内…...

C++day3作业
完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳转到其他界面 如果账号和密码不匹配…...

设计模式⑤ :一致性
一、前言 有时候不想动脑子,就懒得看源码又不像浪费时间所以会看看书,但是又记不住,所以决定开始写"抄书"系列。本系列大部分内容都是来源于《 图解设计模式》(【日】结城浩 著)。该系列文章可随意转载。 …...

Android通过Recyclerview实现流式布局自适应列数及高度
调用 FlowAdapter 跟普通recyclerview一样使用 RecyclerView rvLayout holder.getView(R.id.spe_tag_layout); FlowAdapter rvAdapter new FlowAdapter(); FlowLayoutManager flowLayoutManager new FlowLayoutManager(); rvLayout.setLayoutManager(flowLayoutManager); r…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

LangChain【6】之输出解析器:结构化LLM响应的关键工具
文章目录 一 LangChain输出解析器概述1.1 什么是输出解析器?1.2 主要功能与工作原理1.3 常用解析器类型 二 主要输出解析器类型2.1 Pydantic/Json输出解析器2.2 结构化输出解析器2.3 列表解析器2.4 日期解析器2.5 Json输出解析器2.6 xml输出解析器 三 高级使用技巧3…...
:处理原始数据命令)
ffmpeg(三):处理原始数据命令
FFmpeg 可以直接处理原始音频和视频数据(Raw PCM、YUV 等),常见场景包括: 将原始 YUV 图像编码为 H.264 视频将 PCM 音频编码为 AAC 或 MP3对原始音视频数据进行封装(如封装为 MP4、TS) 处理原始 YUV 视频…...
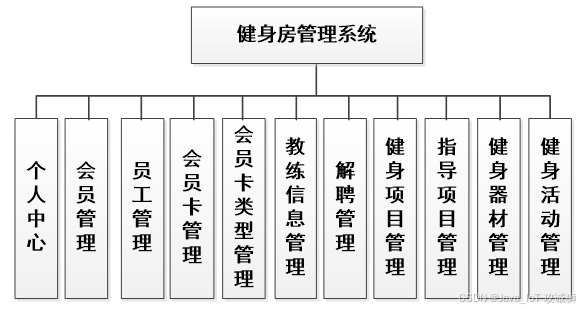
基于django+vue的健身房管理系统-vue
开发语言:Python框架:djangoPython版本:python3.8数据库:mysql 5.7数据库工具:Navicat12开发软件:PyCharm 系统展示 会员信息管理 员工信息管理 会员卡类型管理 健身项目管理 会员卡管理 摘要 健身房管理…...
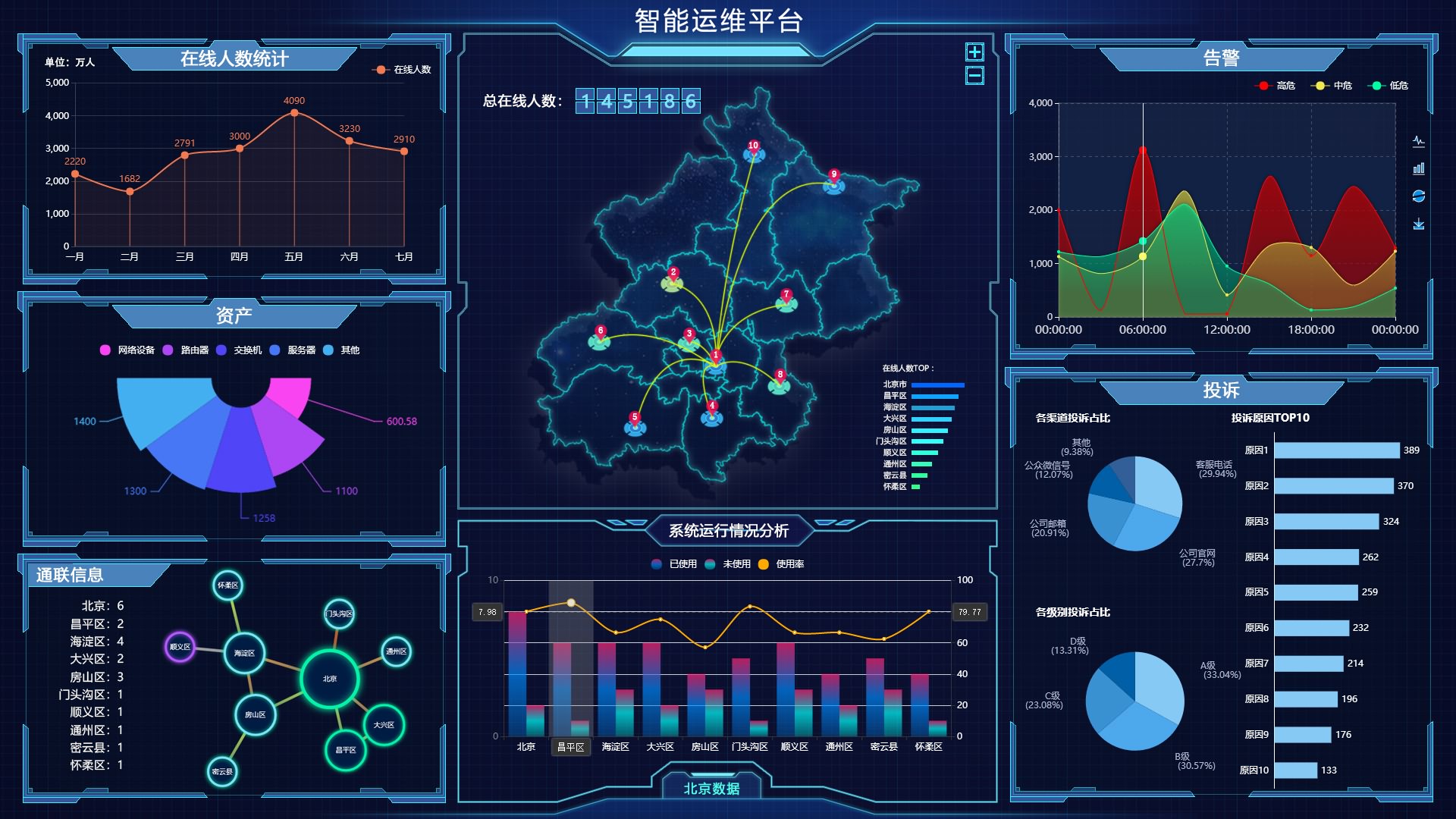
可视化预警系统:如何实现生产风险的实时监控?
在生产环境中,风险无处不在,而传统的监控方式往往只能事后补救,难以做到提前预警。但如今,可视化预警系统正在改变这一切!它能够实时收集和分析生产数据,通过直观的图表和警报,让管理者第一时间…...