C++内存管理机制(侯捷)笔记2
C++内存管理机制(侯捷)
本文是学习笔记,仅供个人学习使用。如有侵权,请联系删除。
参考链接
Youtube: 侯捷-C++内存管理机制
Github课程视频、PPT和源代码: https://github.com/ZachL1/Bilibili-plus
下面是第二讲allocator具体实现的笔记。
文章目录
- C++内存管理机制(侯捷)
- 17 VC6 malloc
- 18 VC6标准分配器之实现
- 19 BC5标准分配器之实现
- 20 G2 9标准分配器之实现
- 21 G2.9 std::alloc VS G4.9 __pull_alloc
- 22 G4.9 __pull_alloc用例
- 23 G2.9 std::alloc
- 24 G2.9 std::alloc运行一瞥01-05
- 25 G2.9 std::alloc运行一瞥06-10
- 26 G2.9 std::alloc运行一瞥11-13
- 27 G2.9 std::alloc源码剖析(上)
- 28 G2.9 std::alloc源码剖析(中)
- 29 G2.9 std::alloc源码剖析(下)
- 30 G2.9 std::alloc观念大整理
- 31 G4.9 pull allocator运行观察
- 后记
17 VC6 malloc
VC6下的malloc内存块布局:从上往下分别是cookie,debug header, 实际数据的block, debug tail, pad, cookie,对应于下图。

在VC6(Visual C++ 6.0)下,malloc 函数分配的内存块的布局包含以下部分:
-
Cookie(饼干):
- Cookie 是一小段额外的标识信息,用于在边界检查中检测缓冲区溢出。它通常是一个特殊的值,放置在分配的内存块的开始位置。
-
Debug Header(调试头部):
- Debug Header 包含一些调试信息,例如分配的文件名、行号等。这些信息用于调试和跟踪内存分配的源。
-
实际数据的 Block:
- 这是分配的实际数据块,用于存储程序员请求的数据。
-
Debug Tail(调试尾部):
- Debug Tail 包含与调试信息相关的尾部数据。类似于 Debug Header,它包含一些额外的调试信息。
-
Pad(填充):
- 填充是为了确保分配的内存块满足特定的对齐要求。它可能包含一些额外的字节,使得整个内存块的大小满足特定的对齐条件。
-
Cookie(饼干):
- 与开头的 Cookie 相对应,是分配的内存块的结束位置。
这样的内存布局在 VC6 中用于调试和检测内存溢出等问题。Cookie 和调试信息是为了帮助调试过程,检测潜在的内存错误。在实际的发布版本中,这些额外的调试信息通常会被省略,以减小内存开销。 VC6 是相对较老的版本,现代的 Visual C++ 版本可能采用了更高效和精简的内存分配方案。
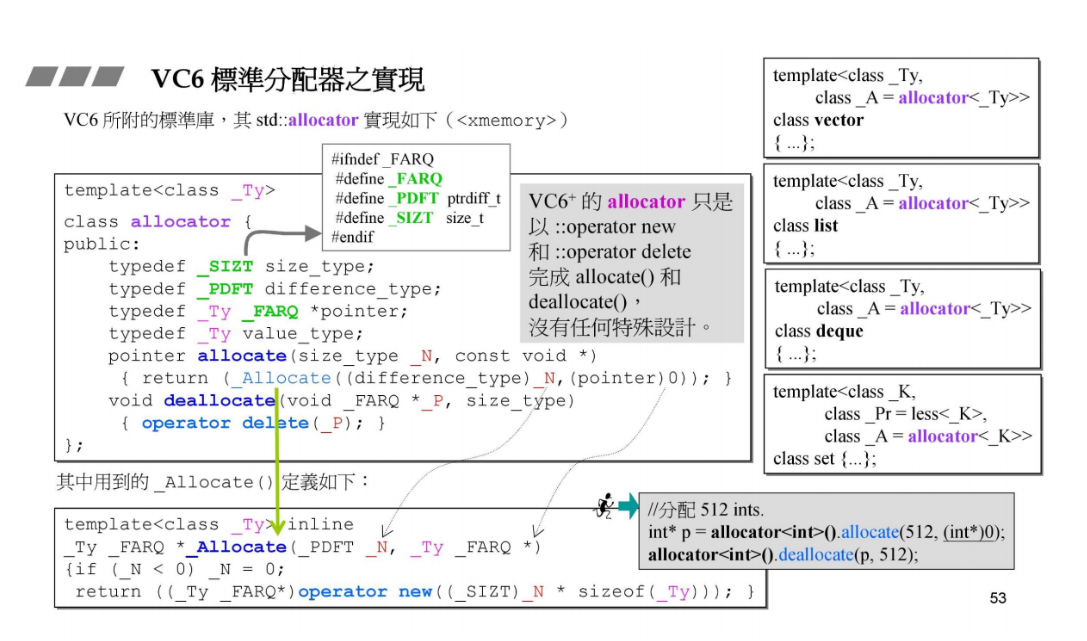
18 VC6标准分配器之实现
VC6标准分配器allocator的实现,里面的allocate和deallocate的实现只是调用::operator new 和::operator delete, 没有任何特殊设计。我们知道它们底层是malloc和free,所以具体分配的时候是带有cookie的,存在内存浪费的现象。
这里分配的单位是具体的类型,比如allocator<int>().allocate(512,(int*)0);分配的就是512个int类型的大小。而后面讲到的一个分配器是以字节为单位,不是以具体类型的大小为单位。
19 BC5标准分配器之实现
Borland5 编译器的allocator的实现,里面的allocate和deallocate的实现只是调用::operator new 和::operator delete, 没有任何特殊设计。

20 G2 9标准分配器之实现
GNU C++2.9标准分配器std::allocator的实现,里面的allocate和deallocate的实现只是调用::operator new 和::operator delete, 没有任何特殊设计。

GNU C++2.9容器使用的分配器,不是std::allocator,而是std::alloc
void* p = alloc::allocate(512); // 分配512bytes,不是512个int或者512个double类型等等

21 G2.9 std::alloc VS G4.9 __pull_alloc
G2.9 std::alloc在G4.9中是 __pull_alloc
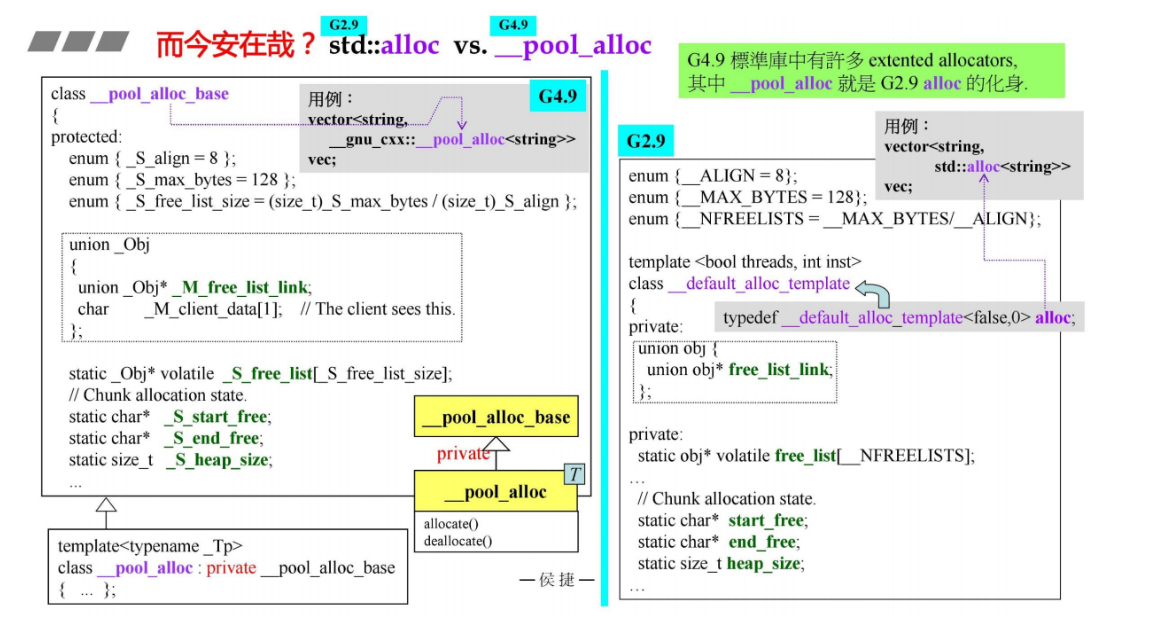
G4.9版本中标准分配器std::allocator的实现,里面的allocate和deallocate的实现只是调用::operator new 和::operator delete, 没有任何特殊设计。

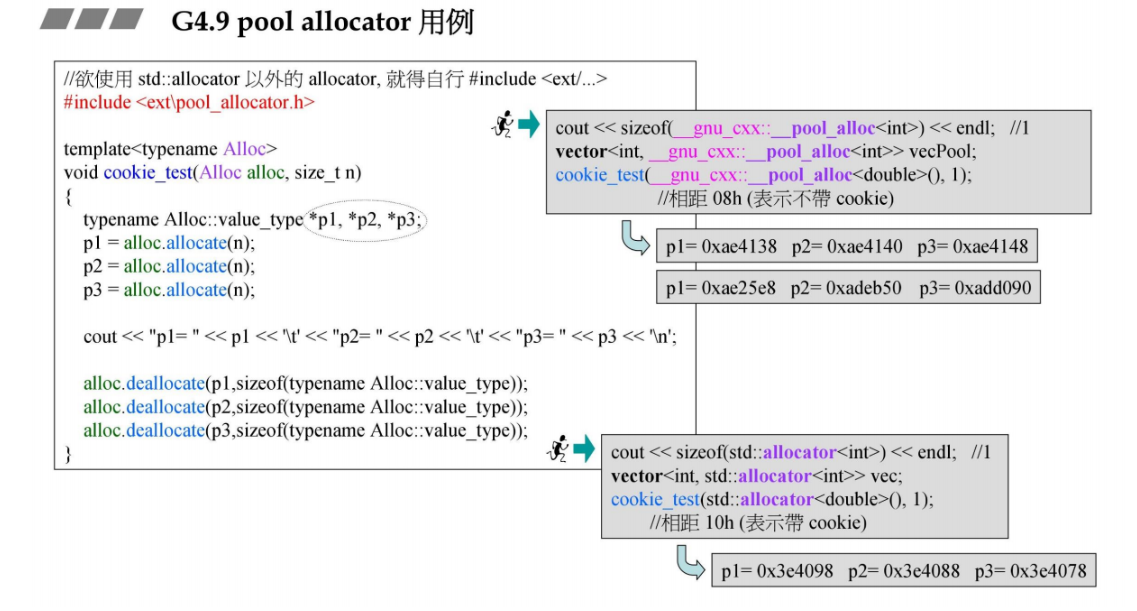
22 G4.9 __pull_alloc用例
这里的alloc(G2.9的叫法, G4.9叫做__pull_alloc)用法, 它在__gnu_cxx这个命名空间内。
vector<int, __gnu_cxx::__pool_alloc<int>> vecPool;
这个分配器是去除了cookie(一个元素带有上下两个cookie,共8B),可以省很多的内存空间。
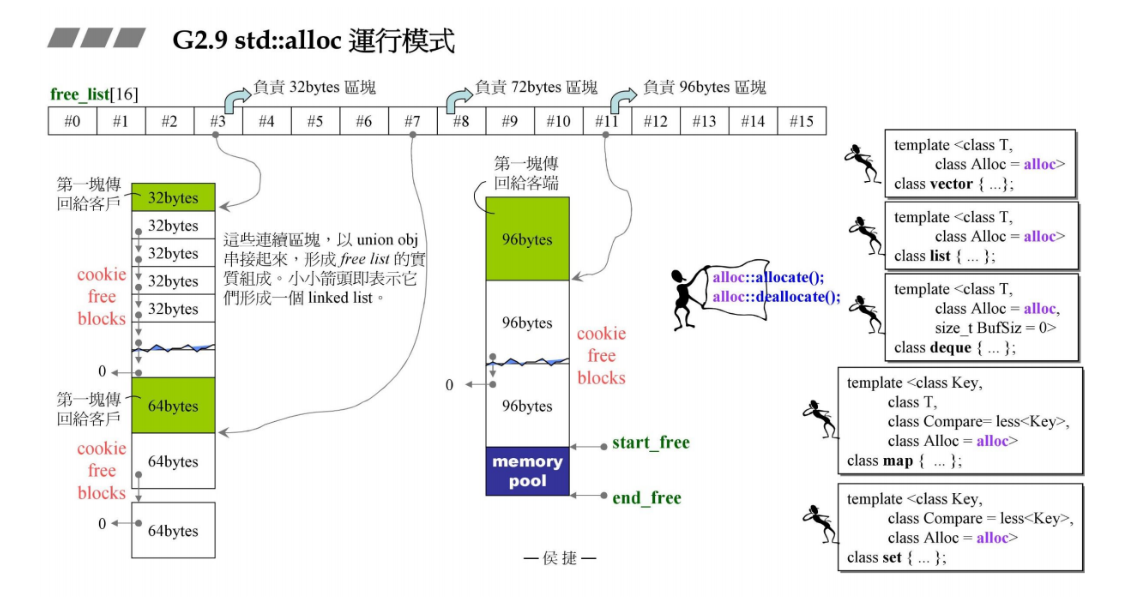
23 G2.9 std::alloc
alloc的运作模式
上文C++内存管理机制(侯捷)笔记1介绍的是Per class allocator,每个类里面重载了 operator new和operator delete,每个类都单独维护一个链表。
下面如下图所示,是std::alloc为所有的类维护16个链表,每个链表负责不同大小的区块分配,从小到大分别负责8B, 16B, 24B, 32B,…, 按8的倍数增长,最大是16 x 8 = 128B。当大小不为8的倍数的时候,分配器会自动将其对齐到8的倍数。当大小超过128B时,就交给malloc来单独处理。
当一个vector里面存了一个“stone”类型的对象,它的大小是32B,那么就会启用下面的#3的链表,它负责32B区块的分配。每次分一大块(里面有20个小块,每个都是32B,但是实际分配的时候是20个小块的两倍大小,剩余的部分暂且不用), 指定一个小块给stone即可。
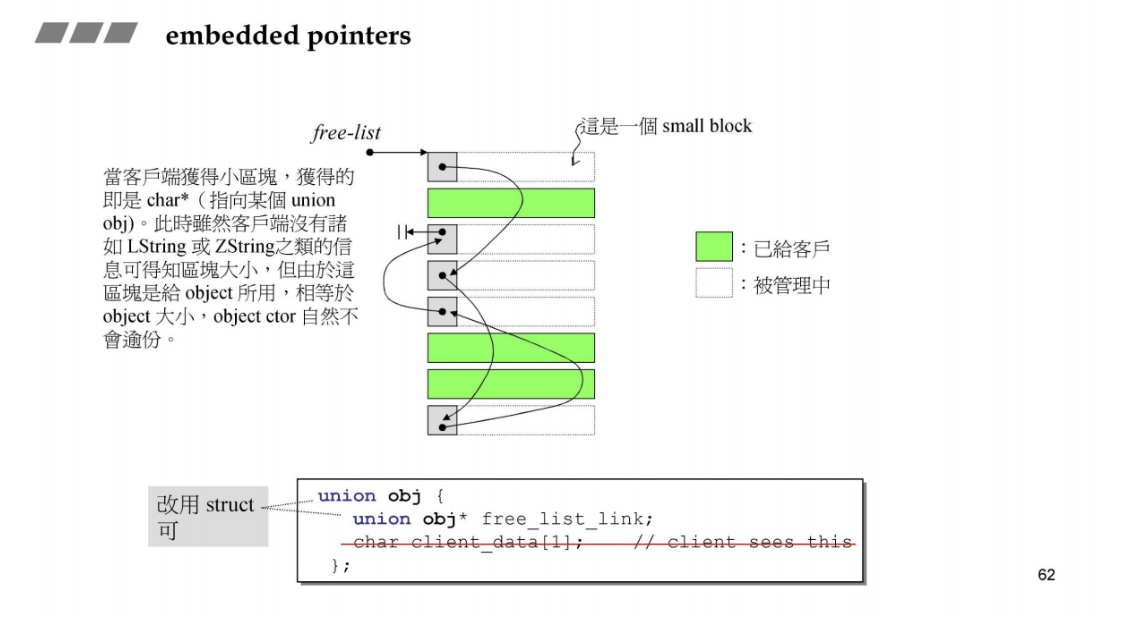
嵌入式指针embedded pointers
嵌入式指针工作原理:借用A对象所占用的内存空间中的前4个字节,这4个字节用来 链住这些空闲的内存块;
但是,一旦某一块被分配出去,那么这个块的 前4个字节 就不再需要,此时这4个字节可以被正常使用;参考:https://blog.csdn.net/qq_42604176/article/details/113871565
内存的使用方法是,使用的时候看成对象实例,空闲的时候会看成next指针.
参考:https://github.com/KinWaiYuen/KinWaiYuen.github.io/blob/master/c%2B%2B/%E4%BE%AF%E6%8D%B7%E5%86%85%E5%AD%98.md
24 G2.9 std::alloc运行一瞥01-05
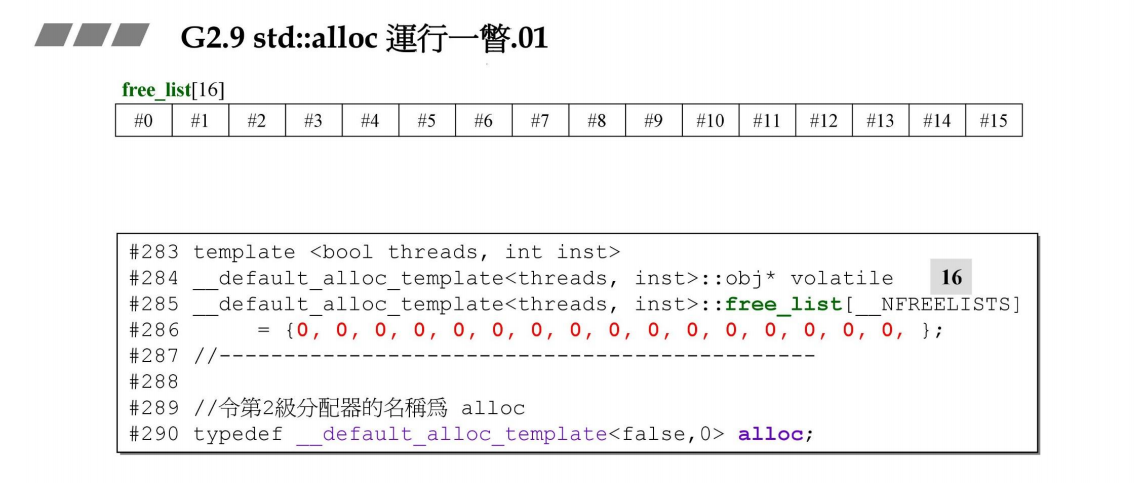
下面的free_list大小__NFREELISTS为16
enum {__ALIGN = 8}; //小區塊的上調邊界
enum {__MAX_BYTES = 128}; //小區塊的上限
enum {__NFREELISTS = __MAX_BYTES/__ALIGN}; //free-lists 個數// union obj { //G291[o],CB5[x],VC6[x]
// union obj* free_list_link; //這麼寫在 VC6 和 CB5 中也可以,
// }; //但以後就得使用 "union obj" 而不能只寫 "obj"
typedef struct __obj {struct __obj* free_list_link;
} obj;char* start_free = 0;
char* end_free = 0;
size_t heap_size = 0;
obj* free_list[__NFREELISTS]= {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
# enum {__ALIGN = 8};
size_t ROUND_UP(size_t bytes) {return (((bytes) + __ALIGN-1) & ~(__ALIGN - 1));
}
解释ROUND_UP
这段代码定义了一个常量 __ALIGN,它表示内存分配时的对齐边界,设定为 8 字节。然后,定义了一个函数 ROUND_UP,该函数接受一个大小(bytes)作为参数,然后将其上调到对齐边界。
具体来说,ROUND_UP 函数的作用是将传入的大小 bytes 上调到 __ALIGN 的倍数。这是通过以下步骤实现的:
- 将
bytes加上__ALIGN-1,即将bytes + 7。 - 对结果进行按位与操作,通过
& ~(__ALIGN - 1)将最低的 3 位清零,确保结果是__ALIGN的倍数。
这样做的目的是为了满足内存对齐的要求。在一些硬件体系结构中,访问未对齐的内存可能会导致性能问题或者错误,因此内存分配时通常需要对齐到某个特定的边界。这个函数就提供了一种简单的方法来确保分配的内存大小是对齐的。
当一个容器里面存储的元素大小是32B时,它的运作过程如下:
挂在几号链表呢?32 / 8 - 1 = 3号链表
刚开始的时候pool为空,此时要分配32 * 20 *2 + RoundUp(0 >> 4)= 1280B大小的空间为pool,然后从pool里面切割20个小块(共640B)挂在#3链表上,剩下的640B放在pool里面备用。RoundUp是追加量,里面的大小是把上次的累计申请量右移4位(除以16),由于这里是刚开始,没有累计申请量,故为0>>4。

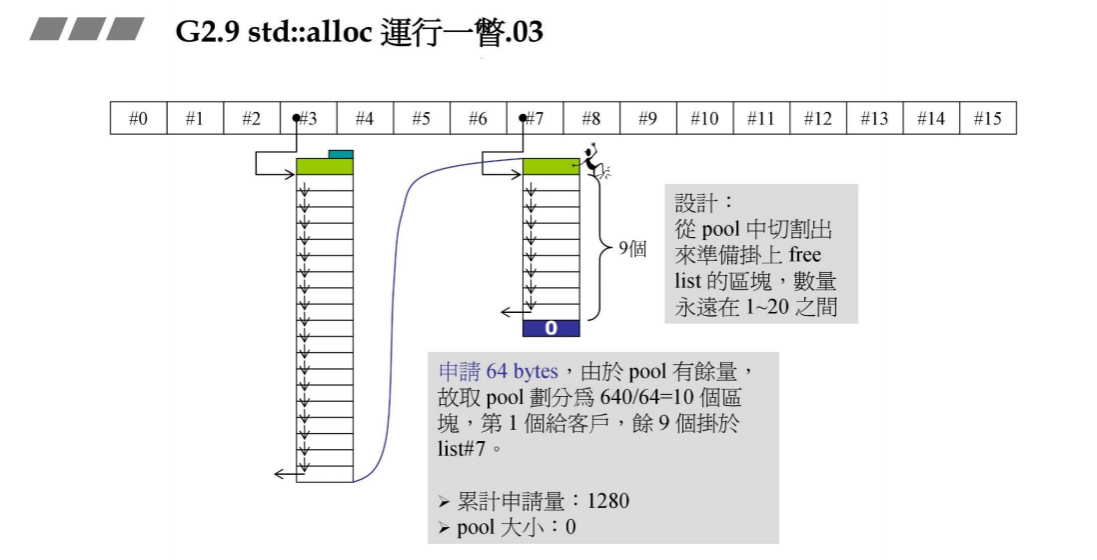
此时,又创建了新的容器,它里面的元素大小为64B(对应#7链表),此时链表为空。由于上页的pool里面还剩640B,现在将其切分为640/64 = 10个区块,第一个给容器,剩下的9个挂在list #7. 此时pool的大小为0,因为被切分挂到链表上了。
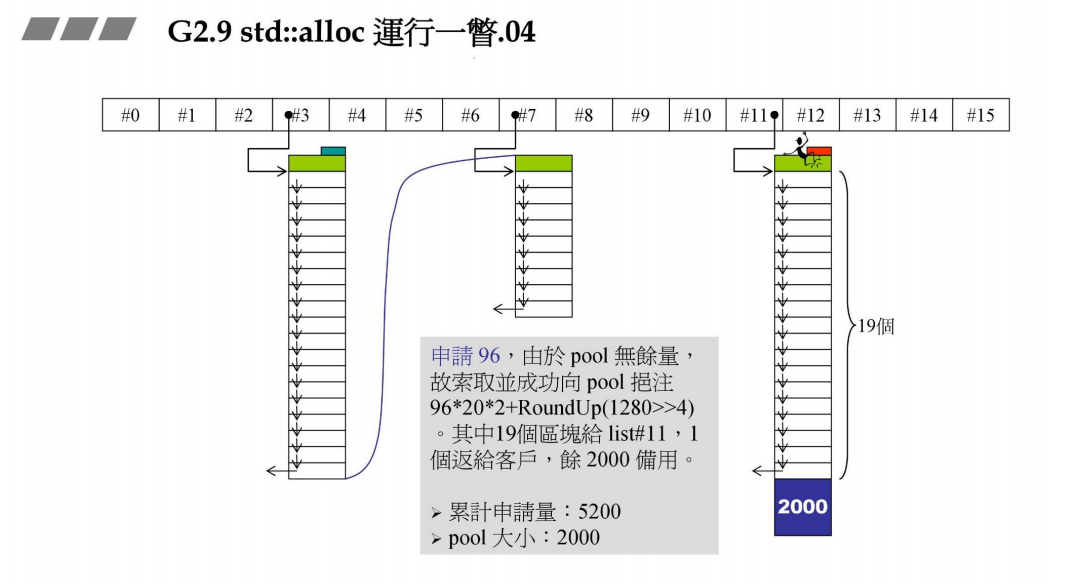
在上面的基础上,现在新建容器,它的元素大小为96B(对应96 / 8 - 1 = 11号链表),先检查pool时候有余量,由于pool为空,此时调用malloc分配一大块作为pool,总共大小为96x 20 x 2 + RoundUp(1280 >> 4) = 3840 + 80 = 3920B,其中20个区块拿出来用,1个区块返回给容器,另外19个区块挂在#11链表上,剩下的就是pool的容量,那么pool为多大呢?3920−(96×20)=3920−1920=2000 B。另外累计申请量多大呢?上次是1280,这次申请的总共是3920, 加起来共5200.,单位都是bytes。如下图所示。
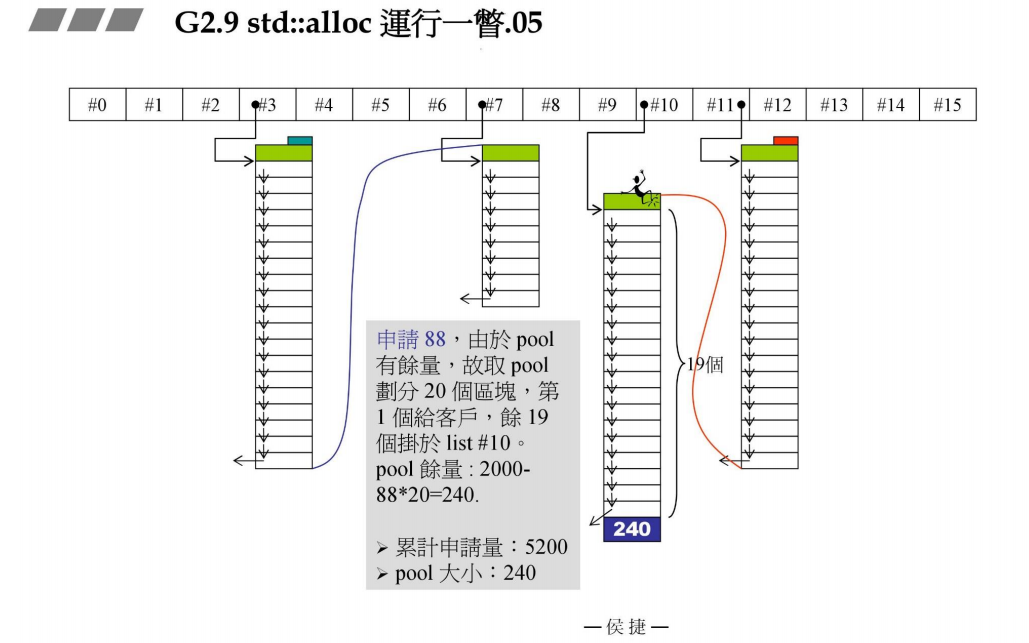
再次新建容器,里面元素大小是88B,现在是挂在几号链表呢? 88 / 8 - 1 = 10号链表。现在要看pool中的余量为2000,将2000切分为20个区块(每个区块88B),第一个区块给容器,剩下的19个区块挂在#10链表上。pool剩下的余量:2000 - 88 x 20 = 240B
25 G2.9 std::alloc运行一瞥06-10
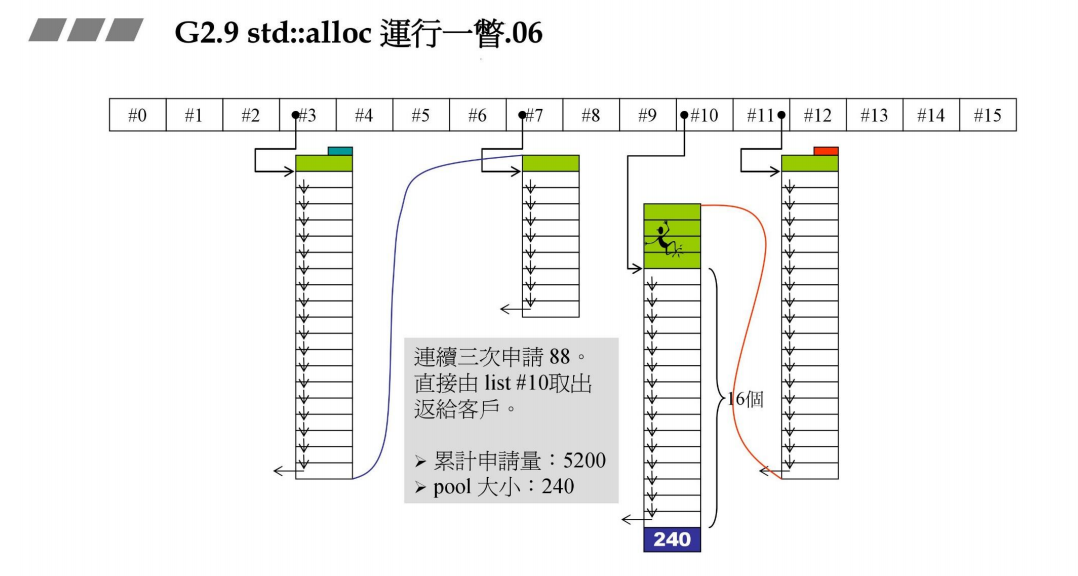
下面这张图表示容器连续申请3次88B大小的空间,由于上面已经在#10 链表上挂了19个大小为88B的区块,这时候直接从该链表上拿下来3个区块返回给容器即可。pool大小还是240没变。
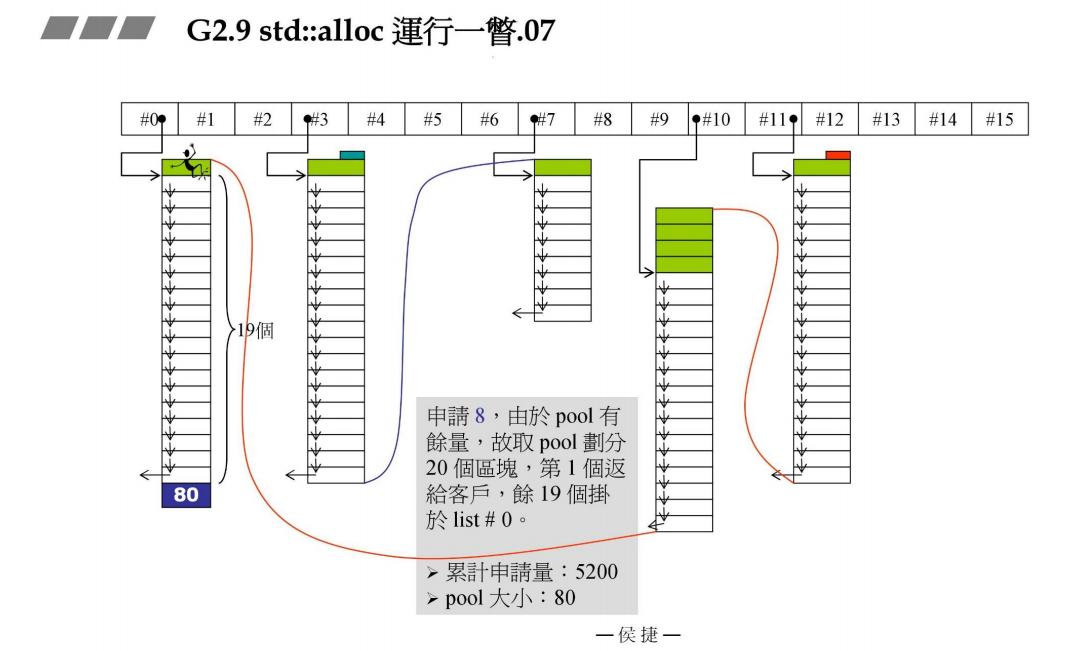
又来新的容器,它的元素大小为8B(该挂在几号链表呢?8 / 8 - 1 = 0号链表),上面的pool容量为240,从pool里面切分出20个区块,共8B x 20 = 160B大小,第一个返回给容器,其余19个区块挂在#0链表上。pool剩余多少呢?240 - 160 = 80B。
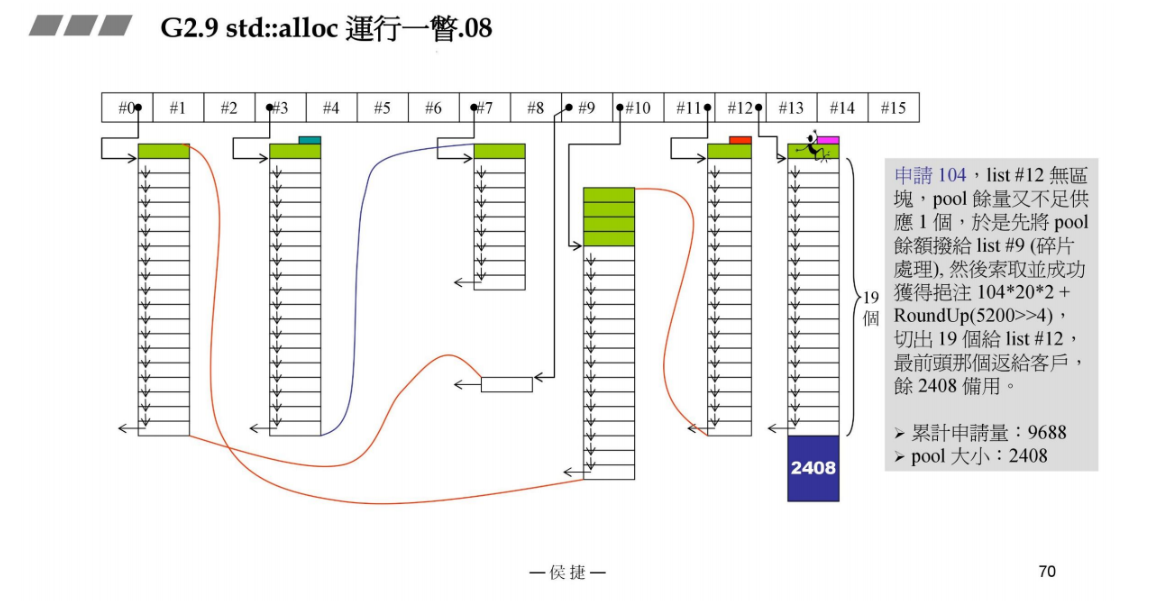
又来新的容器,它的元素大小为104B,该挂在几号链表呢?104 / 8 - 1 = 12号链表。但是pool余量为80B,一个大小为104B的区块都切分不了。此时这个80B大小的空间就是碎片,需要将其挂在某一个链表上,该挂在几号呢?80 / 8 - 1 = 9号链表。碎片处理完之后, 再来应付现在的需求:104B的分配。
现在再调用malloc分配一大块,大小为104 x 20 x 2 + RoundUp(5200 >> 4) = 4160 + RoundUp(325) = 4160 + 328 = 4488,
pool容量为4488 - 104 x 20 = 2408B
把第一个区块分配给容器,切出的19个挂在#12 list上。pool的余量为2408B。累计申请量为5200 + 4488 = 9688B
现在申请112B(挂在112 / 8 - 1 = 13号链表上),上面pool容量为2408,从里面取出112 * 20 = 2240,第一个区块返回给容器,留下19个区块挂在13号链表上。
pool余量为2408 - 2240 = 168B。
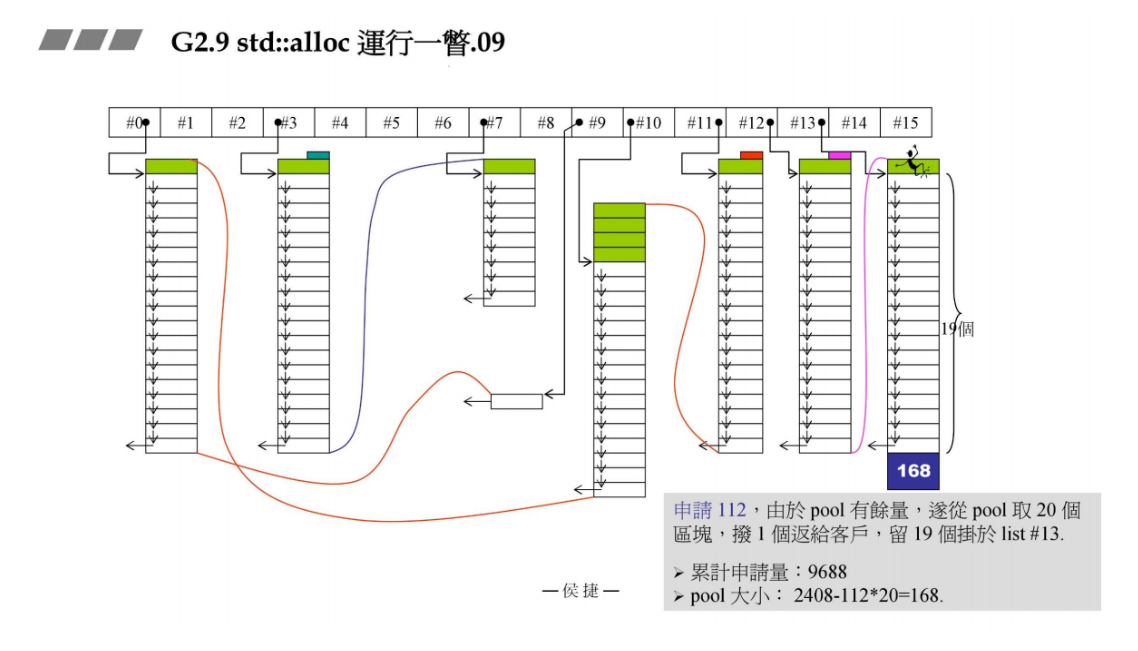
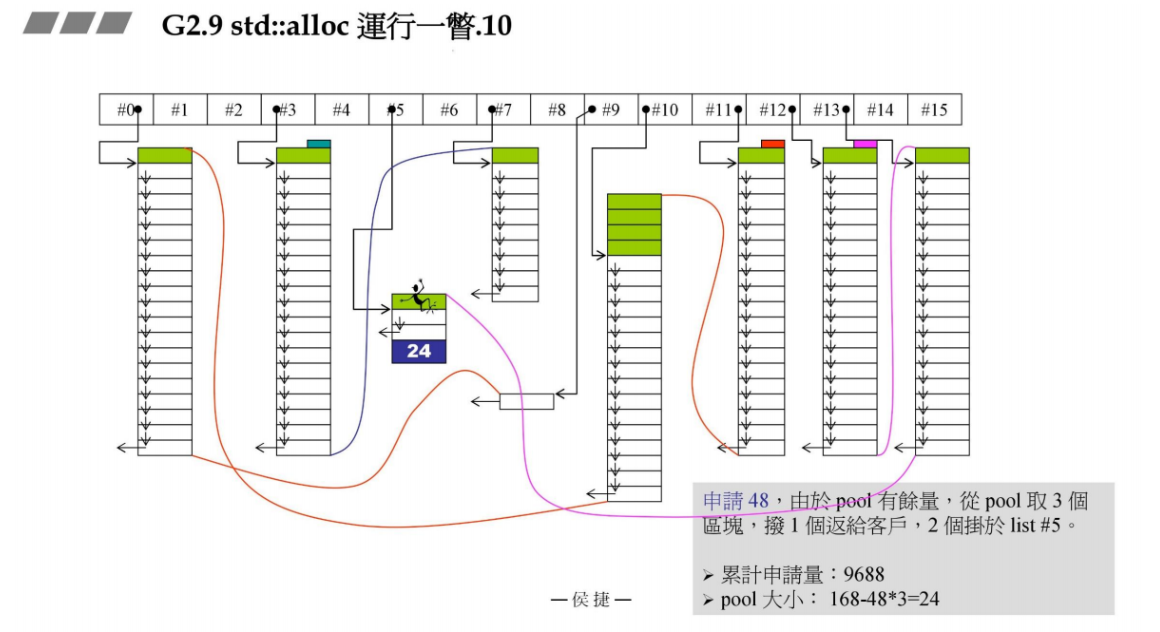
现在的新需求是申请48B(48 / 8 - 1 = 5号链表),上面的pool余量是168B,可以分配几个区块呢? 168 / 48 = 3 … 24, 所以可以分配3个大小为48的区块,pool余量为24B。
3个区块中第一个返回给容器,后面两个挂在5号链表上。
26 G2.9 std::alloc运行一瞥11-13
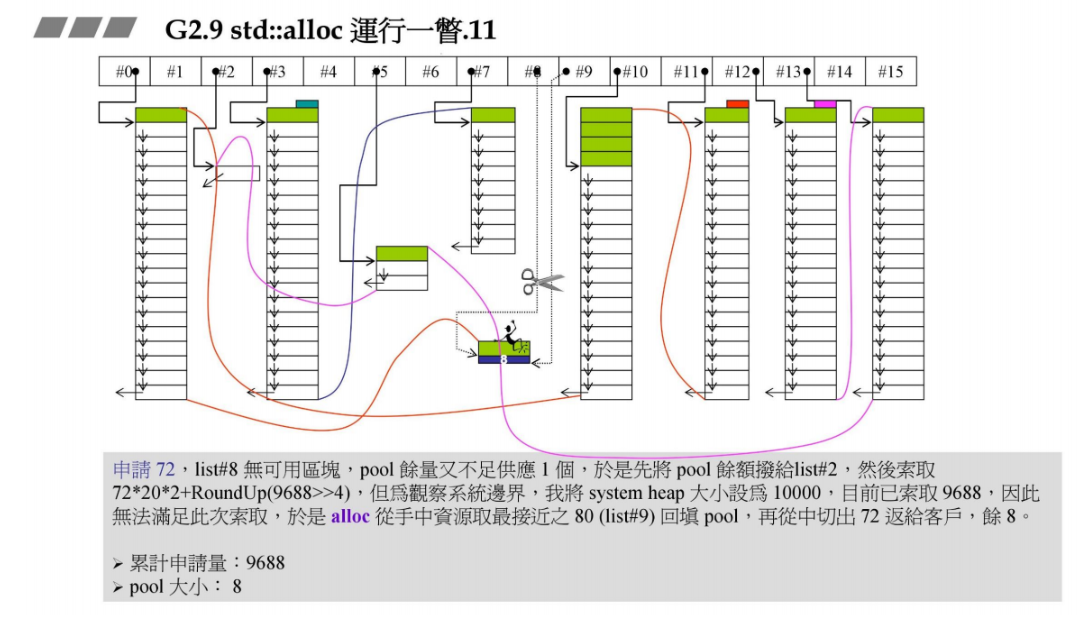
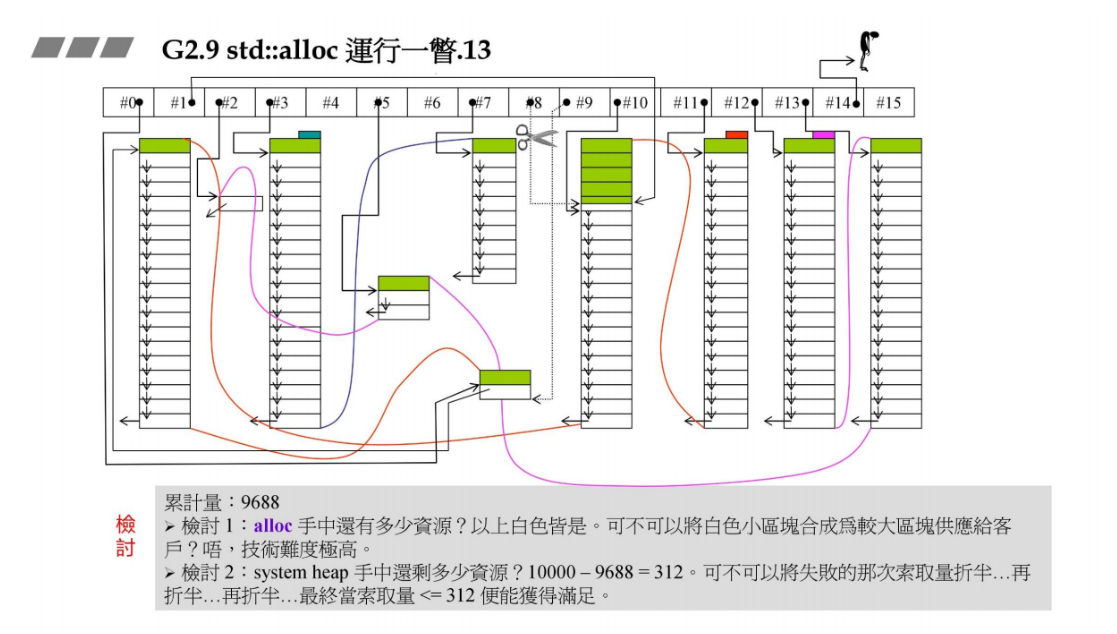
下面看一下内存分配失败的动作
新的容器请求72B的大小,挂在几号链表呢?72 / 8 - 1 = 8号链表,pool容量为24B,不足以分配一个大小为72B的区块,于是这个大小为24B的pool就成为碎片,需要挂在某一个链表上,24 / 8 - 1 = 2号链表,所以把这个pool余额挂在list #2, 然后调用malloc分配一大块:
72 x 20 x 2 + RoundUP(9688 >> 4) = 3488B , 在实验过程中把系统heap大小设置为10000,前面已经累计分配了9688B,因此无法满足本次内存分配。
alloc从手中资源取最接近72B的大小回填pool,这里最接近的是80B(9号链表有1个空的可用),然后从80B中切72B给容器,pool剩下80 - 72 = 8B。
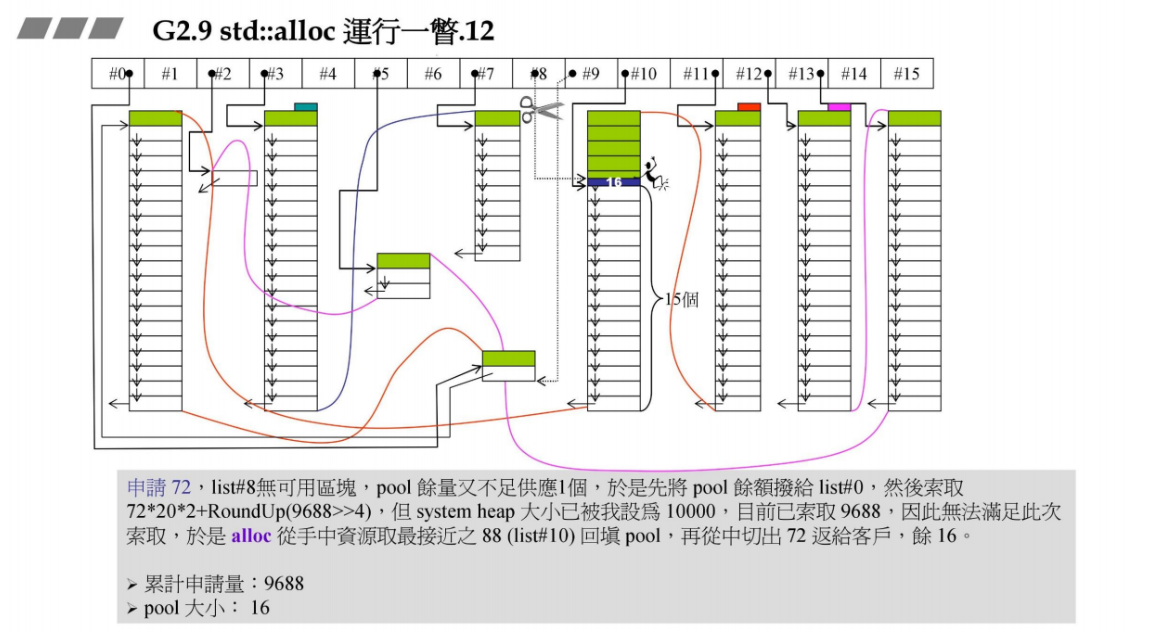
容器再申请72B,list #8没有区块可用,pool余量为8,不足以供应1个,先将pool余额挂在list #0上,然后想要调用malloc分配72 x 20 x 2 + RoundUP(9688 >> 4) = 3488B的空间,依然无法满足分配。
于是alloc从手中资源取最接近72B的88B(list #10)回填pool,因为上面的80B(list #9)已经用完了,从88B中切出72B返回给容器,pool余额:88 - 72 = 16B。
新的容器申请120B,应该挂在几号链表呢?120 / 8 - 1 = 14号链表,同样的,pool供应不足,先将上面的16B挂在1号链表上,再想要malloc分配一大块也分配不出,无法满足需求。
于是,alloc从手中资源中取最接近120B的区块回填pool,但是14号链表和15号链表都是空的,于是无法分配。

检讨
但是system heap大小为10000,累计分配的总共为9688,还剩下312B可用,这部分内存不可以分配了吗?
另外一个问题,上图中白色区块都是可用资源,能不能将小区块合并为大区块分配给客户呢?合并技术难度极高。
27 G2.9 std::alloc源码剖析(上)
GNU C++2.9 分配器的设计:分为两级分配器,分别是第一级分配器和第二级分配器,其中第一级分配器不重要,主要模拟new handler的作用,处理一下内存分配的情况。下图便是第一级分配器的代码。
第一级分配器的代码1,侯捷老师没讲。
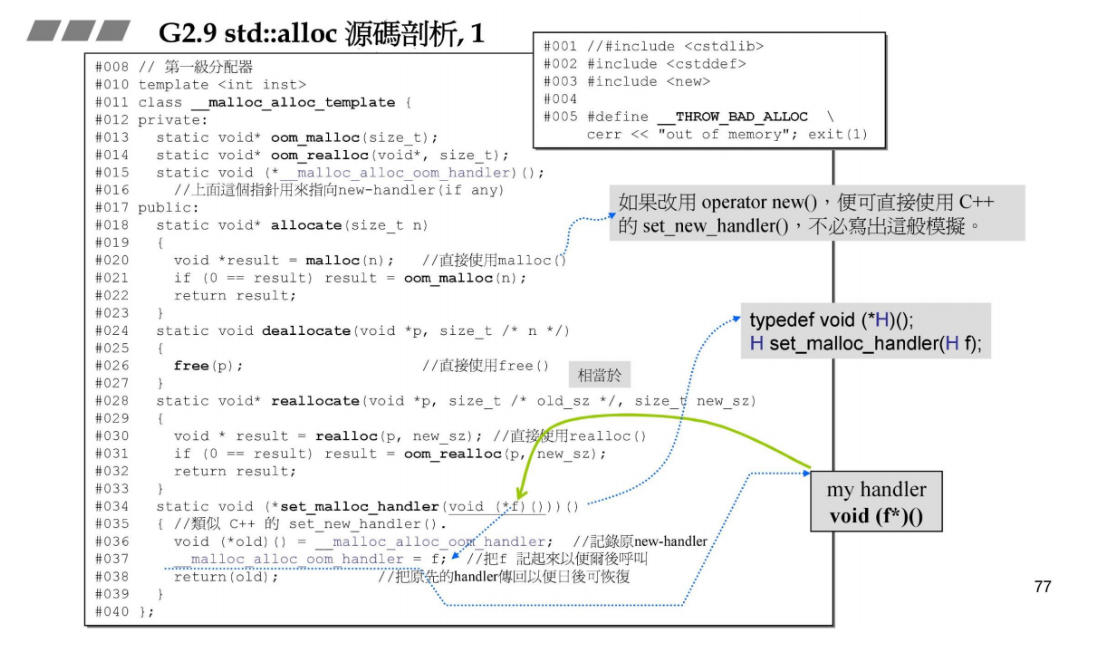
第一级分配器的代码2,侯捷老师没讲。

第一级分配器的代码3,侯捷老师没讲。

现在是第二级分配器的介绍
ROUND_UP是将分配的大小变成8的倍数
size_t ROUND_UP(size_t bytes) {return (((bytes) + __ALIGN-1) & ~(__ALIGN - 1));
}
FREELIST_INDEX的作用
size_t FREELIST_INDEX(size_t bytes) {return (((bytes) + __ALIGN-1)/__ALIGN - 1);
}
这个函数的作用是根据bytes大小,指定到是哪个链表。不同的bytes分配到上面16个链表之一。
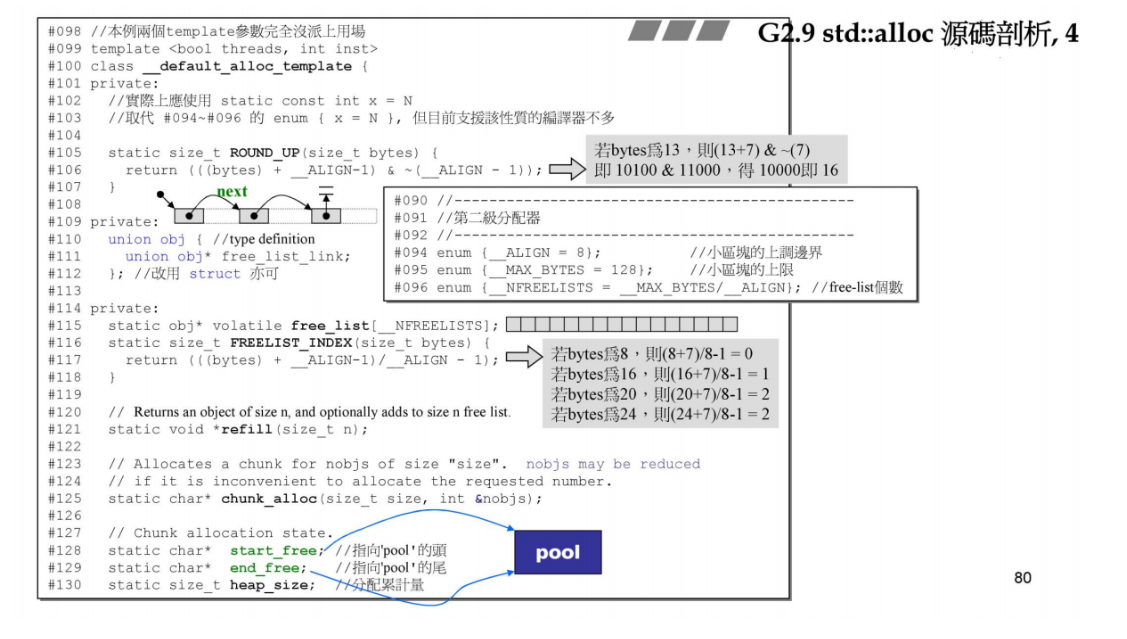
下面几个变量的作用:
char* start_free = 0; // 指向战备池pool的头
char* end_free = 0; // 指向战备池pool的尾
size_t heap_size = 0; // 累计分配大小
重要的两个函数:allocate和deallocate

allocate
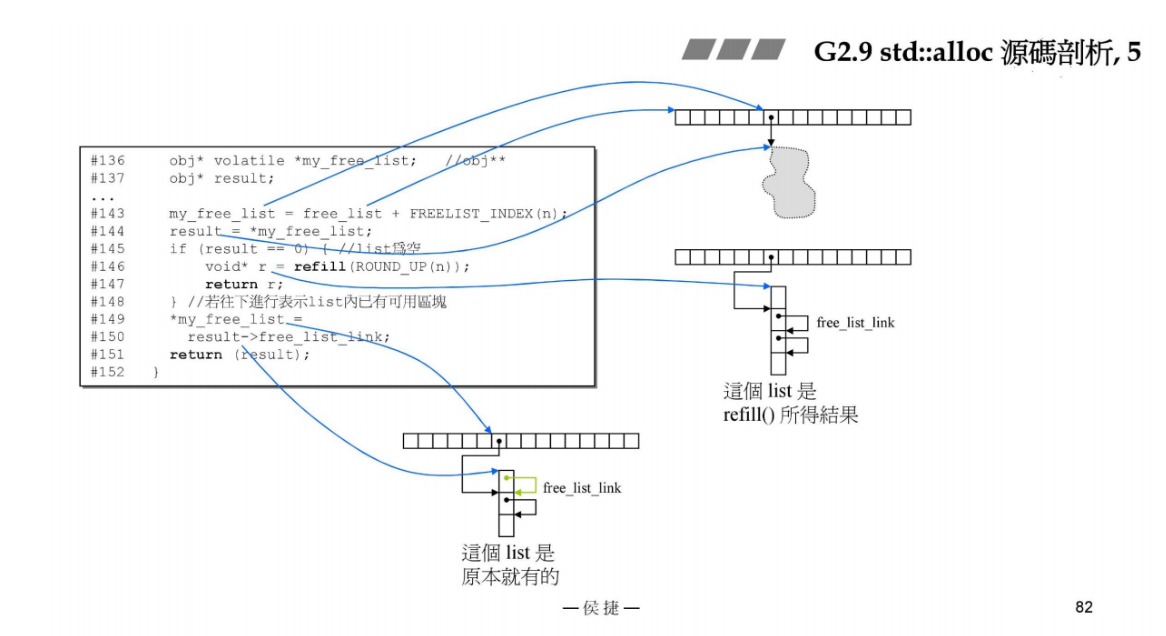
void* allocate(size_t n) //n must be > 0
{obj* volatile *my_free_list; //obj** my_free_list;obj* result;if (n > (size_t)__MAX_BYTES) { // 大于128B,交给第一级分配器来分配return(malloc_allocate(n));}my_free_list = free_list + FREELIST_INDEX(n); // 定位到几号链表result = *my_free_list;if (result == 0) { // 该链表为空void* r = refill(ROUND_UP(n)); // 链表充值,从pool中去拿区块,链表有了可用区块return r;}// 指针指向下一个可用区块*my_free_list = result->free_list_link;return (result);
}
辅助理解allocate的图:
deallocate:将指针p指向的空间回收到单向链表中
下面的free_list_link就是next指针
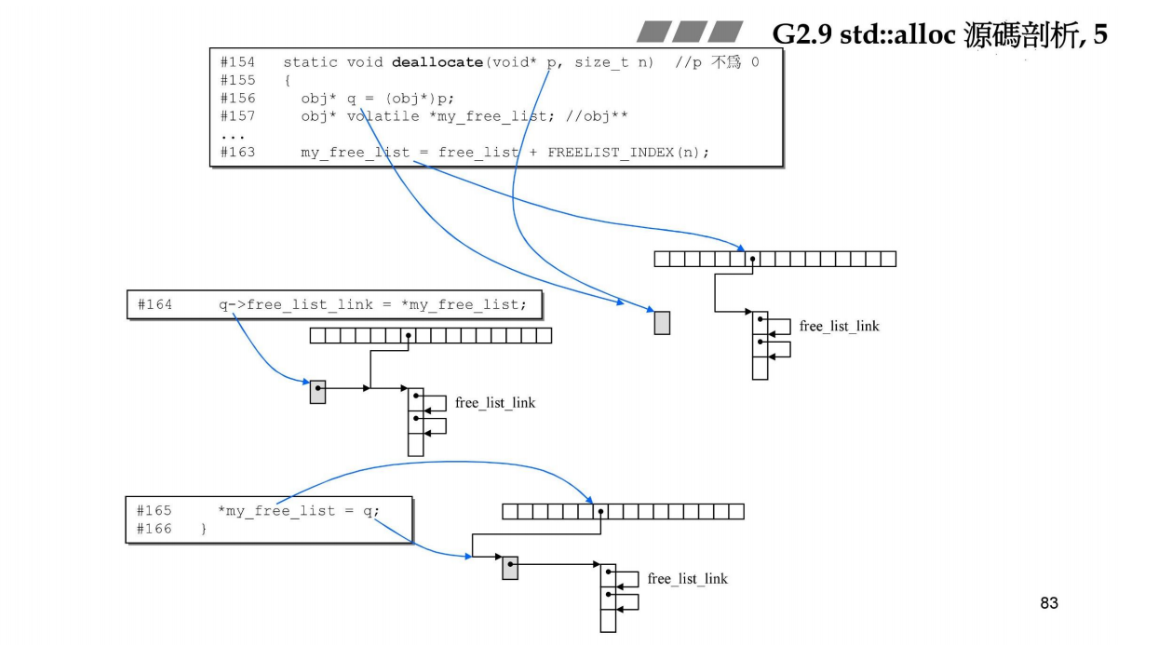
void deallocate(void *p, size_t n) //p may not be 0
{obj* q = (obj*)p;obj* volatile *my_free_list; //obj** my_free_list;if (n > (size_t) __MAX_BYTES) { // 大于128B,改用第一级分配器进行回收malloc_deallocate(p, n);return;}// 回收过来的p指针指向的区块,挂在单向链表的头my_free_list = free_list + FREELIST_INDEX(n); // 指向16个链表中的一个,比如list #6,如下图所示q->free_list_link = *my_free_list; // q的next指向单向链表的头,就是list #6指向的具体区块的单向链表*my_free_list = q; // my_free_list重新指向新的单向链表q,因为头指针被换成新的了
}
辅助理解deallocate的图:
28 G2.9 std::alloc源码剖析(中)
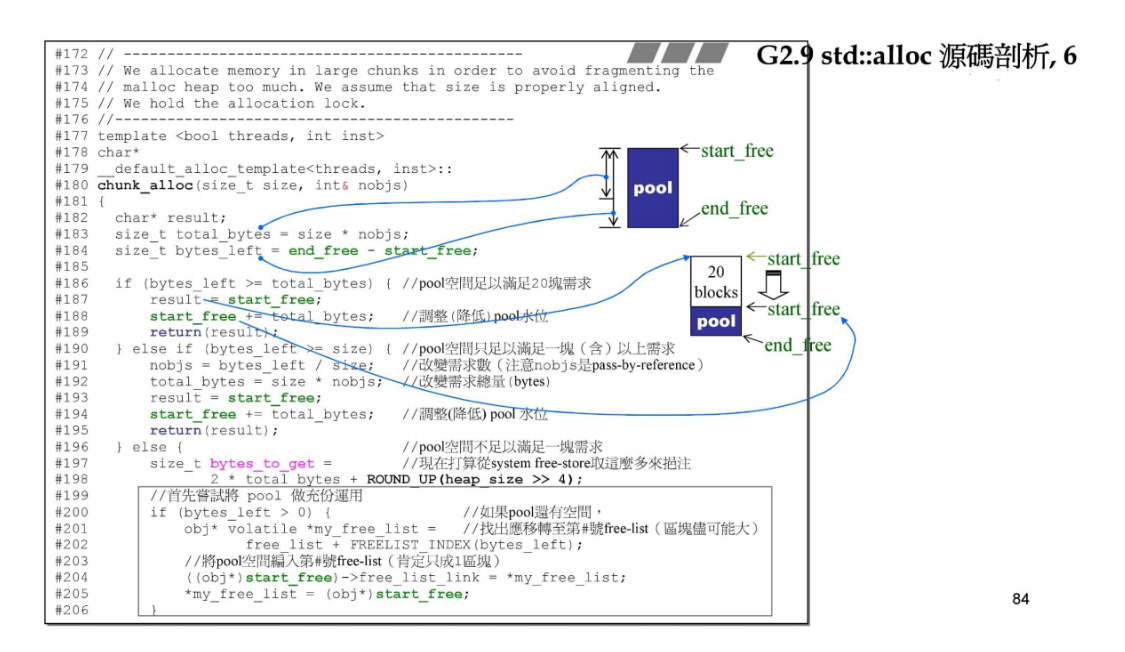
chunk_alloc函数 主要作用是分配一大块内存。
做法:要先看战备池pool,看可以分配多少个小区块,如果存在碎片也要处理。如果pool是空的,还需要调用malloc给pool分配内存。
下面是具体的逻辑
第一张ppt展示3大块逻辑(if else):
- 首先看pool空间满足20个区块的需求,
- 其次是看pool空间只能满足1到19个区块的需求,
- 最后是pool不能满足1块(pool碎片,或者pool空间为0).
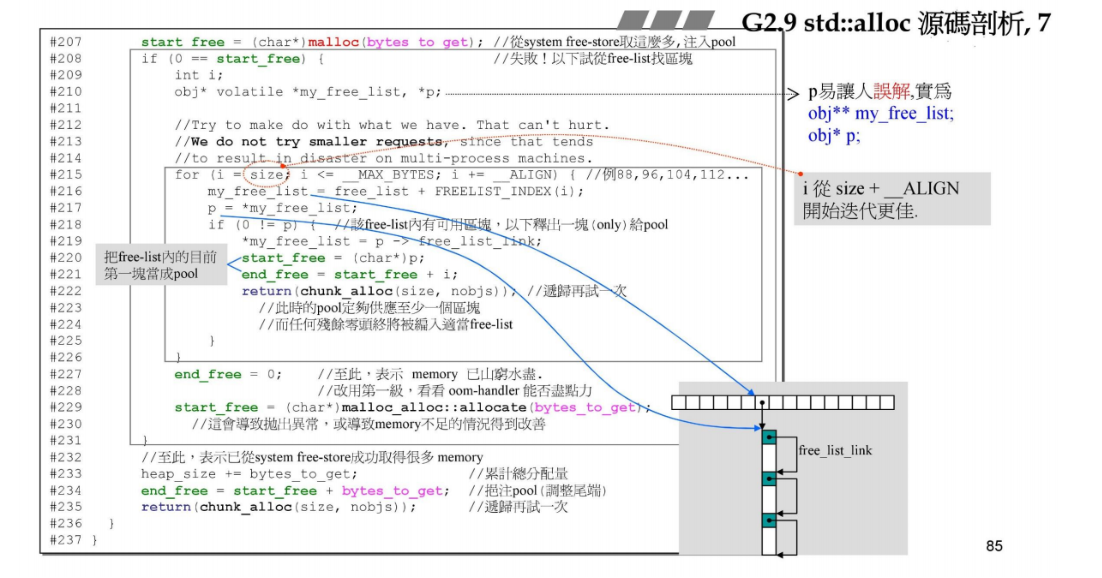
下面的ppt展示的是对3的处理:具体调用malloc分配内存,或者是往更大区块的链表请求支援(分配一个区块)。
chunk_alloc的源代码:给予了清晰的注解(根据侯捷老师的讲解)
//----------------------------------------------
// We allocate memory in large chunks in order to
// avoid fragmentingthe malloc heap too much.
// We assume that size is properly aligned.
//
// Allocates a chunk for nobjs of size "size".
// nobjs may be reduced if it is inconvenient to
// allocate the requested number.
//----------------------------------------------
//char* chunk_alloc(size_t size, int& nobjs) //G291[o],VC6[x],CB5[x]
char* chunk_alloc(size_t size, int* nobjs)
{char* result;// 调用chunk_alloc的时候,nobjs为20,所以默认total_bytes为20个区块的大小size_t total_bytes = size * (*nobjs); //原 nobjs 改為 (*nobjs)size_t bytes_left = end_free - start_free; // pool中剩余的字节个数if (bytes_left >= total_bytes) { // 1. pool空间足以满足20块需求result = start_free;start_free += total_bytes; // 调整pool水位,下降,战备池pool变小return(result);} else if (bytes_left >= size) { // 2. pool空间只能满足1个区块的需求,但不足20块*nobjs = bytes_left / size; //原 nobjs 改為 (*nobjs) // 改变需求数,看看可以切成几个区块total_bytes = size * (*nobjs); //原 nobjs 改為 (*nobjs) // 改变需求总量result = start_free;start_free += total_bytes;return(result);} else { // 3. pool空间不足以满足1块需求,pool空间可能是碎片,也可能表示pool大小为0size_t bytes_to_get = // 需要请求的一大块的大小2 * total_bytes + ROUND_UP(heap_size >> 4);// Try to make use of the left-over piece.// pool池的碎片,挂到对应大小的链表上if (bytes_left > 0) {obj* volatile *my_free_list = // 找出应转移到第#号链表free_list + FREELIST_INDEX(bytes_left);// 将pool空间编入第#号链表,next指针指向链表的头节点,编入链表的第一个节点((obj*)start_free)->free_list_link = *my_free_list;*my_free_list = (obj*)start_free;}// 上面处理完pool的碎片,pool为空,开始用malloc为pool分配内存start_free = (char*)malloc(bytes_to_get); // pool的起点if (0 == start_free) { // 分配失败,从free list中找区块(向右边更大的区块去找)int i;obj* volatile *my_free_list, *p;//Try to make do with what we have. That can't//hurt. We do not try smaller requests, since that tends//to result in disaster on multi-process machines.for (i = size; i <= __MAX_BYTES; i += __ALIGN) { // 向右侧的链表去找区块,例如88B,96B,104B, 112B等等my_free_list = free_list + FREELIST_INDEX(i);p = *my_free_list;if (0 != p) { // 找到右边的list中的可用区块,只释放一块给pool*my_free_list = p -> free_list_link;// start_free 和 end_free是战备池pool的头尾指针,指向这一块空间start_free = (char*)p; end_free = start_free + i;return(chunk_alloc(size, nobjs)); // 递归再试一次//Any leftover piece will eventually make it to the//right free list.}}end_free = 0; //In case of exception.start_free = (char*)malloc_allocate(bytes_to_get);//This should either throw an exception or//remedy the situation. Thus we assume it//succeeded.} // if结束heap_size += bytes_to_get; // 累计总分配量end_free = start_free + bytes_to_get; // 调整pool水位,pool空间变大,pool的终点return(chunk_alloc(size, nobjs)); //递归再调用一次}
}
refill函数
当第n条链表来服务时,却发现其为空,此时就调用refill函数来创建链表,分配区块。
下面的int nobjs = 20;表示默认分配20个区块,可能比20小。调用chunk_alloc函数来挖一大块内存。
当分配的区块为1时,就直接交给客户(我们上文用的容器)。
chunk指的是一大块,然后将其切割,建立free list。refill的参数n表示一小个区块的大小。
refill是充值,在一大块内存中切割成nobjs个区块,构成链表。

//----------------------------------------------
// Returns an object of size n, and optionally adds
// to size n free list. We assume that n is properly aligned.
// We hold the allocation lock.
//----------------------------------------------
void* refill(size_t n)
{int nobjs = 20;char* chunk = chunk_alloc(n,&nobjs);obj* volatile *my_free_list; //obj** my_free_list;obj* result;obj* current_obj;obj* next_obj;int i;if (1 == nobjs) return(chunk);my_free_list = free_list + FREELIST_INDEX(n);//Build free list in chunkresult = (obj*)chunk;*my_free_list = next_obj = (obj*)(chunk + n);for (i=1; ; ++i) {current_obj = next_obj;next_obj = (obj*)((char*)next_obj + n);if (nobjs-1 == i) {current_obj->free_list_link = 0;break;} else {current_obj->free_list_link = next_obj;}}return(result);
}
在这段代码中,next_obj 的计算是为了在内存块(chunk)上构建一个链表,以形成一个自由链表(free list)。这个链表将被用于分配对象。让我们解释一下这行代码的目的:
next_obj = (obj*)((char*)next_obj + n);
next_obj是一个指向当前空闲块的指针,它一开始指向chunk + n,即第一个可用的内存块。(char*)next_obj将next_obj强制类型转换为char*类型,这是因为我们希望按字节递增,而不是按对象递增。((char*)next_obj + n)表示将指针移动到下一个内存块的起始位置,即当前内存块的末尾加上一个对象的大小n。(obj*)((char*)next_obj + n)将移动后的指针重新转换为obj*类型,以便正确指向下一个空闲块的起始位置。
这样,通过不断地按对象大小 n 的步长在内存块上移动,构建了一个包含多个空闲块的链表。这个链表可以有效地用于分配对象。这种处理方式是为了确保链表中相邻的空闲块之间的间隔是 n 字节,从而满足对象的对齐需求。
在上述代码中,for 循环的第二个条件 ; 是一个空语句,表示没有额外的条件来控制循环的执行。这意味着 for 循环会一直执行,直到执行到 break 语句为止。
在这个具体的代码中,循环的目的是为了在内存块上构建一个链表,将多个空闲块连接在一起。循环体中的 if 语句用于判断是否已经遍历了 nobjs-1 个空闲块。如果是,则最后一个空闲块的 free_list_link 设置为 0,表示链表的结束。此时,break 语句被执行,跳出循环。
因此,循环终止的条件是遍历了 nobjs-1 个空闲块,确保链表的正确构建,并在最后一个空闲块处设置了结束标志。循环的终止是由 break 语句触发的,而不是由循环条件控制的。
29 G2.9 std::alloc源码剖析(下)
分析chunk_alloc函数,本笔记将其放到了28 G2.9 std::alloc源码剖析(中)进行。
具体一些数据的初始定义

30 G2.9 std::alloc观念大整理
alloc观念大整理
list<Foo> c;
c.push_back(Foo(1)); // Foo(1)临时对象,创建在栈stack中
//容器c使用alloc分配空间,看16条链表中哪一条可以提供区块,分配给它。所以它不带cookie
Foo* p = new Foo(2); // 采用new,创建在heap中
// new是调用operator new,底层是调用malloc,它带有cookie
c.push_back(*p); // 容器c push_back的时候不带cookie
delete p;
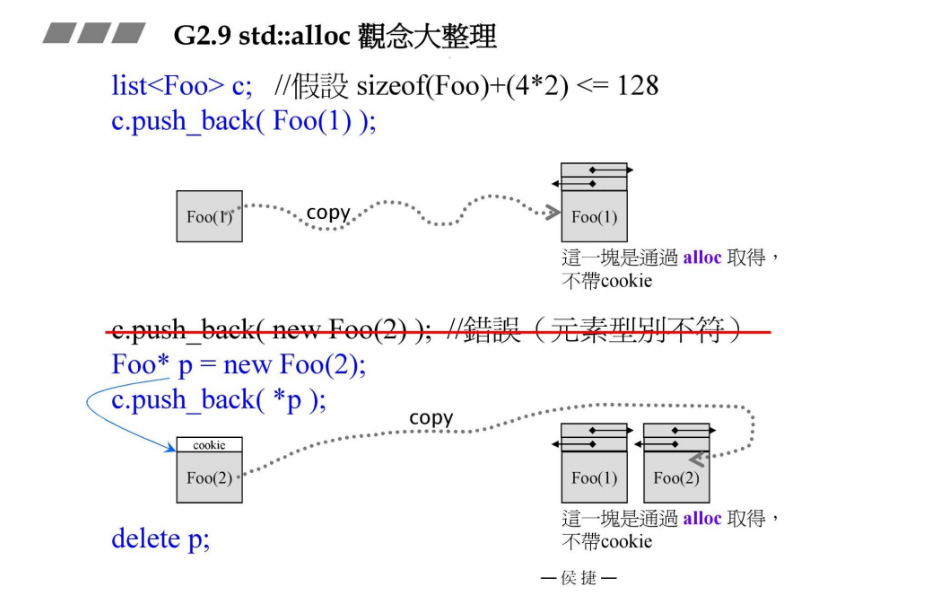
GNU C++2.9的alloc批斗大会
需要学习的地方
比较判断的时候把具体的值写在前面,防止出现将==写成=赋值的情况。
if(0 == start_free)
if(0 != p)
if(1 == nobjs)
不好的地方
变量定义的地方不要和使用的地方间隔太远,尤其是指针的使用。
第一级分配器使用的一个函数:炫技,没有人看得懂
void (*set_malloc_handler(void (*f)()))()
{ //類似 C++ 的 set_new_handler().void (*old)() = oom_handler;oom_handler = f;return(old);
}
等价于
typedef void (*H)();
H set_malloc_handler(H f);
还有deallocate的时候并没有free掉,这是由设计的先天缺陷造成的。

31 G4.9 pull allocator运行观察
在GNU C++4.9版本下的测试,由于2.9版本分配内存都是调用malloc,无法重载,即无法接管到我们用户手中,无法记录总分配量和总释放量。而在4.9版本中,它的内存分配动作是调用operator new,这样我们就可以接管operator new,对其进行重载。

下面测试两个分配器使用情况,分别对list容器进行100万次分配。
由于GNU C++4.9版本标准分配器是allocator,并不是2.9版本alloc,所以容器(客户)分配内存的时候每个元素(100万个)都带cookie(每个cookie占8B)。这个如下图右侧所示。
下图左侧使用4.9版本好的分配器__pool_alloc,这个是2.9版本的alloc,显示分配的次数timesNew为122次(调用malloc的次数),这比右侧标准分配器好上不少。

后记
截至2024年1月11日19点39分,完成《C++内存管理》第二讲allocator的学习,主要涉及GNU C++2.9版本alloc分配器的具体实现与源码剖析。功力提升不少,希望更进一步。
相关文章:
C++内存管理机制(侯捷)笔记2
C内存管理机制(侯捷) 本文是学习笔记,仅供个人学习使用。如有侵权,请联系删除。 参考链接 Youtube: 侯捷-C内存管理机制 Github课程视频、PPT和源代码: https://github.com/ZachL1/Bilibili-plus 下面是第二讲allocator具体实…...

java基础之异常练习题
异常 1.Java 中所有的错误/异常都继承自 Throwable类;在该类的子类中, Error 类表示严重的底层错误, 对于这类错误一般处理的方式是 直接报告并终止程序 ; Exception 类表示异常。 2.查阅API,完成以下填空:…...
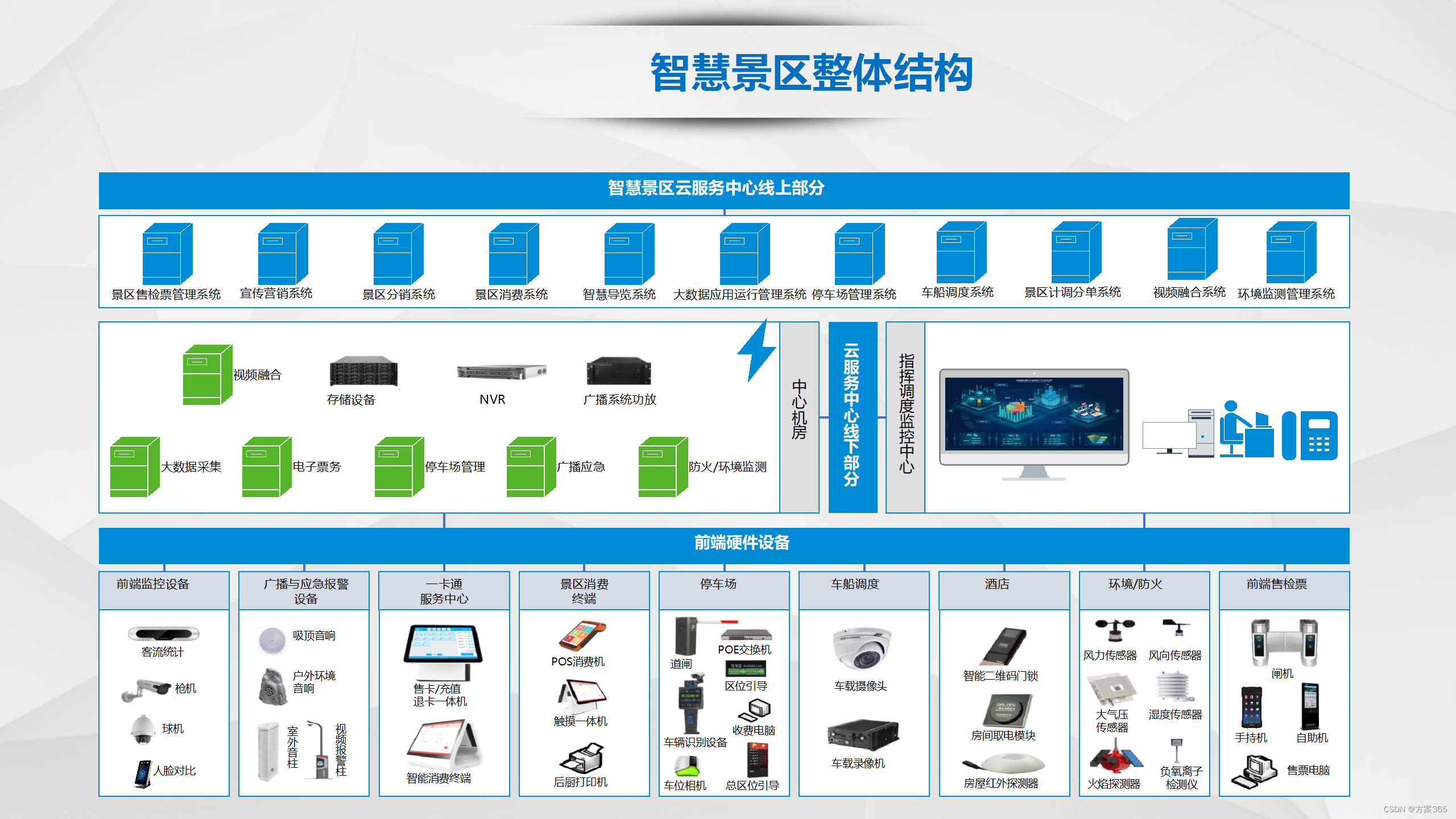
智慧旅游景区解决方案:PPT全文49页,附下载
关键词:智慧景区建设,智慧旅游平台,智慧旅游运营检测系统项目,智慧文旅,智慧景区开发与管理,智慧景区建设核心,智慧景区开发与管理 一、智慧景区建设现状 1、基础设施建设:智慧景区…...

Demo: 给图片添加自定义水印并下载
给图片添加自定义水印并下载 <template><div class"wrap"><div class"optea"><div class"file-upload"><p>选择图片</p><el-button type"text" style"color: #c00;"><label f…...

黑马苍穹外卖学习Day5
文章目录 Redis学习Redis简介准备工作Redis常用数据类型介绍各数据类型的特点Redis常用命令字符串操作命令哈希操作命令列表操作命令集合操作命令有序集合操作命令通用操作命令 在Java中操作Redis导入Spring Data Redis坐标配置Redis数据源编写配置类,创建RedisTemp…...

【.NET Core】可为null类型详解
【.NET Core】可为null类型详解 文章目录 【.NET Core】可为null类型详解一、概述二、可为空的值类型2.1 声明和赋值2.2 检查可为空值类型2.3 基础类型与可为空的值类型互换2.4 可为空的值类型装箱和取消装箱2.5 如何确定可为空的值类型 三、可为 null 的引用类型 一、概述 nu…...

基于知识图谱的健康知识问答系统
基于知识图谱的健康知识问答系统 引言数据集与技术选型数据集技术选型 系统功能与实现数据导入与图数据库构建问答任务设计与实现1. 实体提取2. 用户意图识别 前端聊天界面与问答系统 结语 引言 随着互联网的发展,人们对健康知识的需求逐渐增加。为了更方便地获取健…...

橘子学K8S03之容器的理解
前面我们知道了容器是通过对一个普通的linux进程进行隔离和限制实现的一种特殊视角下的进程表现。而隔离和限制的实现技术分别是"Namespace"和“Cgroups”,在这两种机制的控制下,我们需要知道容器的本质是一种特殊的进程。 我们现在有了这个认知之后&…...
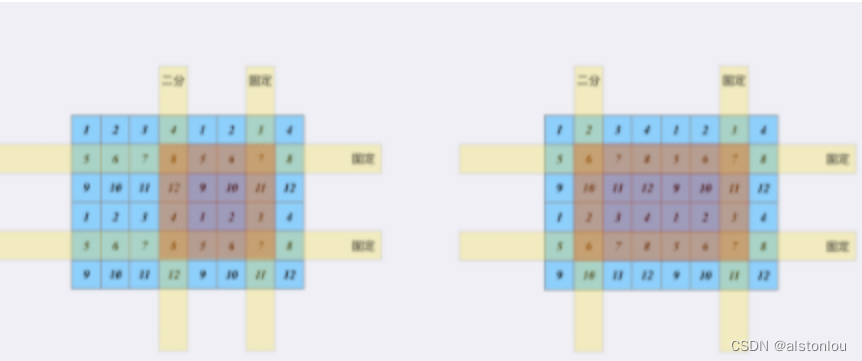
算法第十二天-矩形区域不超过K的最大数值和
矩形区域不超过K的最大数值和 题目要求 解题思路 来自[宫水三叶] 从题面来看显然是一道[二维前缀和]的题目。本题预处理前缀和的复杂度为O(m* n) 搜索所有子矩阵需要枚举[矩形左上角]和[矩形右下角],复杂度是 O ( m 2 ∗ n 2 ) O(m^2 * n^2) O(m2∗n2),…...

【js】js数组对象去重:
文章目录 一、Map()二、对象访问属性的方法三、indexOf()四、双层for循环 let arrObj [{ name: "小红", id: 1 },{ name: "小橙", id: 1 },{ name: "小黄", id: 4 },{ name: "小绿", id: 3 },{ name: "小青", id: 1 },{ na…...
python高校舆情分析系统+可视化+情感分析 舆情分析+Flask框架(源码+文档)✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏) 毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总 🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题ÿ…...

Phaser详解
Phaser是一个相对较新且功能强大的同步原语,它于Java 7中引入,用于协调并行任务的执行。与CyclicBarrier和CountDownLatch等传统的同步工具相比,Phaser提供了更灵活和更高级的功能,特别是在处理动态和可变的并行任务集合时。 1.P…...

2个nodejs进程利用redis 实现订阅发布
1.新建文件 redis_db.js use strict;const redis require(redis); const options {host: "127.0.0.1",port: 6379,password: "123456", // CONFIG SET requirepass "123456" }var array [] for(var i0; i<3; i){const client redis.crea…...

LeetCode——2397. 被列覆盖的最多行数
通过万岁!!! 题目:给你一个二维数组,然后里面是0和1,然后让你从里面选择numSelect列,使得去掉选择的列以后不存在1的行的数量最少。思路: 看到这个题目,本来以为是每一列…...

java通过HttpClient方式实现https请求的工具类(绕过证书验证)
目录 一、引入依赖包二、HttpClient方式实现的https请求工具类三、测试类 一、引入依赖包 引入相关依赖包 <!--lombok用于简化实体类开发--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><option…...

【自学笔记】01Java基础-07面向对象基础-04接口与内部类详解
记录学习Java基础中有关接口类和内部类的知识。 1 接口 interface 关键字用于定义接口类,接口类是一系列方法的声明,一般只有方法的特征没有方法的实现,因此可以被不同的类接入实现,而这些实现可以具有不同的行为(功…...

【cmu15445c++入门】(5)c++中的模板类
一、template模板类 除了模板方法【cmu15445c入门】(4)c中的模板方法 模板也可以用来实现类 二、代码 /*** file templated_classes.cpp* author Abigale Kim (abigalek)* brief Tutorial code for templated classes.*/// Includes std::cout (printing). #include <io…...

MongoDB聚合:$bucket
$bucket将输入文档按照指定的表达式和边界进行分组,每个分组为一个文档,称为“桶”,每个桶都有一个唯一的_id,其值为文件桶的下线。每个桶中至少要包含一个输入文档,也就是没有空桶。 使用 语法 {$bucket: {groupBy…...

从优化设计到智能制造:生成式AI在可持续性3D打印中的潜力和应用
可持续性是现代工业中一个紧迫的问题,包括 3D 打印领域。为了满足环保制造实践日益增长的需求,3D 打印已成为一种有前景的解决方案。然而,要使 3D 打印更具可持续性,还存在一些需要解决的挑战。生成式人工智能作为一股强大的力量&…...
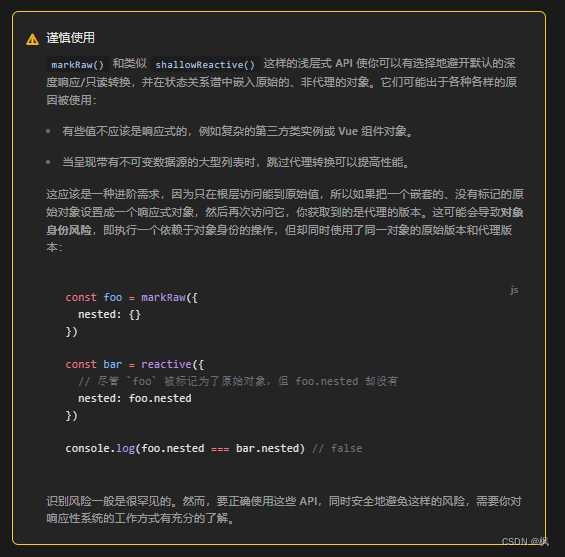
vue3 响应式api中特殊的api
系列文章目录 TypeScript 从入门到进阶专栏 文章目录 系列文章目录一、shallowRef()二、triggerRef()三、customRef()四、shallowReactive()五、shallowReadonly()六、toRaw()七、markRaw()八、effectScope()九、getCurrentScope() 一、shallowRef() shallowRef()是一个新的响…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...