sqlachemy orm create or delete table
sqlacehmy one to one ------detial to descript
关于uselist的使用。如果你使用orm直接创建表关系,实际上在数据库中是可以创建成多对多的关系,如果加上uselist=False 你会发现你的orm只能查询出来一个,如果不要这个参数orm查询的就是多个,一对多的关系。数据库级别如果也要限制可以自行建立唯一键进行约束。
总结就是:sqlacehmy One to One 是orm级别限制
sqlacehmy 简单创建实例展示:
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime Base = declarative_base()engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8', echo=True) class Worker(Base): # 表名 __tablename__ = 'worker' id = Column(Integer, primary_key=True) name = Column(String(50), unique=True) age = Column(Integer) birth = Column(DateTime) part_name = Column(String(50)) # 创建数据表Base.metadata.create_all(engine)该方法引入declarative_base模块,生成其对象Base,再创建一个类Worker。一般情况下,数据表名和类名是一致的。tablename用于定义数据表的名称,可以忽略,忽略时默认定义类名为数据表名。然后创建字段id、name、age、birth、part_name,最后使用Base.metadata.create_all(engine)在数据库中创建对应的数据表
数据表的删除
删除数据表的时候,一定要先删除设有外键的数据表,也就是先删除part,然后才能删除worker,两者之间涉及外键,这是在数据库中删除数据表的规则。对于两种不同方式创建的数据表,删除语句也不一样。
Base.metadata.drop_all(engine)
part.drop(bind=engine)
part.drop(bind=engine) Base.metadata.drop_all(engine)
sqlachemy +orm + create table代码
from sqlalchemy import Column, String, create_engine, Integer, Text
from sqlalchemy.orm import sessionmaker,declarative_base
import time# 创建对象的基类:
Base = declarative_base()# 定义User对象:
class User(Base):# 表的名字:__tablename__ = 'wokers'# 表的结构:id = Column(Integer, autoincrement=True, primary_key=True, unique=True, nullable=False)name = Column(String(50), nullable=False)sex = Column(String(4), nullable=False)nation = Column(String(20), nullable=False)birth = Column(String(8), nullable=False)id_address = Column(Text, nullable=False)id_number = Column(String(18), nullable=False)creater = Column(String(32))create_time = Column(String(20), nullable=False)updater = Column(String(32))update_time = Column(String(20), nullable=False, default=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),onupdate=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))comment = Column(String(200))# 初始化数据库连接:
engine = create_engine('postgresql://postgres:name@pwd:port/dbname') # 用户名:密码@localhost:端口/数据库名Base.metadata.create_all(bind=engine)可级联删除的写法实例
class Parent(Base):__tablename__ = "parent"id = Column(Integer, primary_key=True)class Child(Base):__tablename__ = "child"id = Column(Integer, primary_key=True)parentid = Column(Integer, ForeignKey(Parent.id, ondelete='cascade'))parent = relationship(Parent, backref="children")sqlachemy 比较好用的orm介绍链接:https://www.cnblogs.com/DragonFire/p/10166527.html
sqlachemy的级联删除:
https://www.cnblogs.com/ShanCe/p/15381412.html
除了以上例子还列举一下创建多对多关系实例
class UserModel(BaseModel):__tablename__ = "system_user"__table_args__ = ({'comment': '用户表'})username = Column(String(150), nullable=False, comment="用户名")password = Column(String(128), nullable=False, comment="密码")name = Column(String(40), nullable=False, comment="姓名")mobile = Column(String(20), nullable=True, comment="手机号")email = Column(String(255), nullable=True, comment="邮箱")gender = Column(Integer, default=1, nullable=False, comment="性别")avatar = Column(String(255), nullable=True, comment="头像")available = Column(Boolean, default=True, nullable=False, comment="是否可用")is_superuser = Column(Boolean, default=False, nullable=False, comment="是否超管")last_login = Column(DateTime, nullable=True, comment="最近登录时间")dept_id = Column(BIGINT,ForeignKey('system_dept.id', ondelete="CASCADE", onupdate="RESTRICT"),nullable=True, index=True, comment="DeptID")dept_part = relationship('DeptModel',back_populates='user_part')roles = relationship("RoleModel", back_populates='users', secondary=UserRolesModel.__tablename__, lazy="joined")positions = relationship("PositionModel", back_populates='users_obj', secondary=UserPositionModel.__tablename__, lazy="joined")class PositionModel(BaseModel):__tablename__ = "system_position_management"__table_args__ = ({'comment': '岗位表'})postion_number = Column(String(50), nullable=False, comment="岗位编号")postion_name = Column(String(50), nullable=False, comment="岗位名称")remark = Column(String(100), nullable=True, default="", comment="备注")positon_status = Column(Integer, nullable=False, default=0, comment="岗位状态")create_user = Column(Integer, nullable=True, comment="创建人")update_user = Column(Integer, nullable=True, comment="修改人")users_obj = relationship("UserModel", back_populates='positions', secondary=UserPositionModel.__tablename__, lazy="joined")class UserPositionModel(BaseModel):__tablename__ = "system_user_position"__table_args__ = ({'comment': '用户岗位关联表'})user_id = Column(BIGINT,ForeignKey("system_user.id", ondelete="CASCADE", onupdate="RESTRICT"),primary_key=True, comment="用户ID")position_id = Column(BIGINT,ForeignKey("system_position_management.id", ondelete="CASCADE", onupdate="RESTRICT"),primary_key=True, comment="岗位ID")
以上实例是多对多关系,主要是由PositionModel进行量表之间的多对多关系的关联
多对多关系查询
Session=sessionmaker(bind=engine)
sessions=Session()
Userobj=sessions.query(UserModel).filter(UserModel.id == 1).first()
# Positionobj=sessions.query(PositionModel).filter(PositionModel.id == 14).first()
# Userobj.positions.append(Positionobj)
for item in Userobj.positions:print(item.postion_name)
sessions.commit()
sessions.close()2个对象之间是通过relationship 关联参数进行 append 来创建关系
还可以通过remove来删除之间的关系
相关文章:

sqlachemy orm create or delete table
sqlacehmy one to one ------detial to descript 关于uselist的使用。如果你使用orm直接创建表关系,实际上在数据库中是可以创建成多对多的关系,如果加上uselistFalse 你会发现你的orm只能查询出来一个,如果不要这个参数orm查询的就是多个,一对多的…...
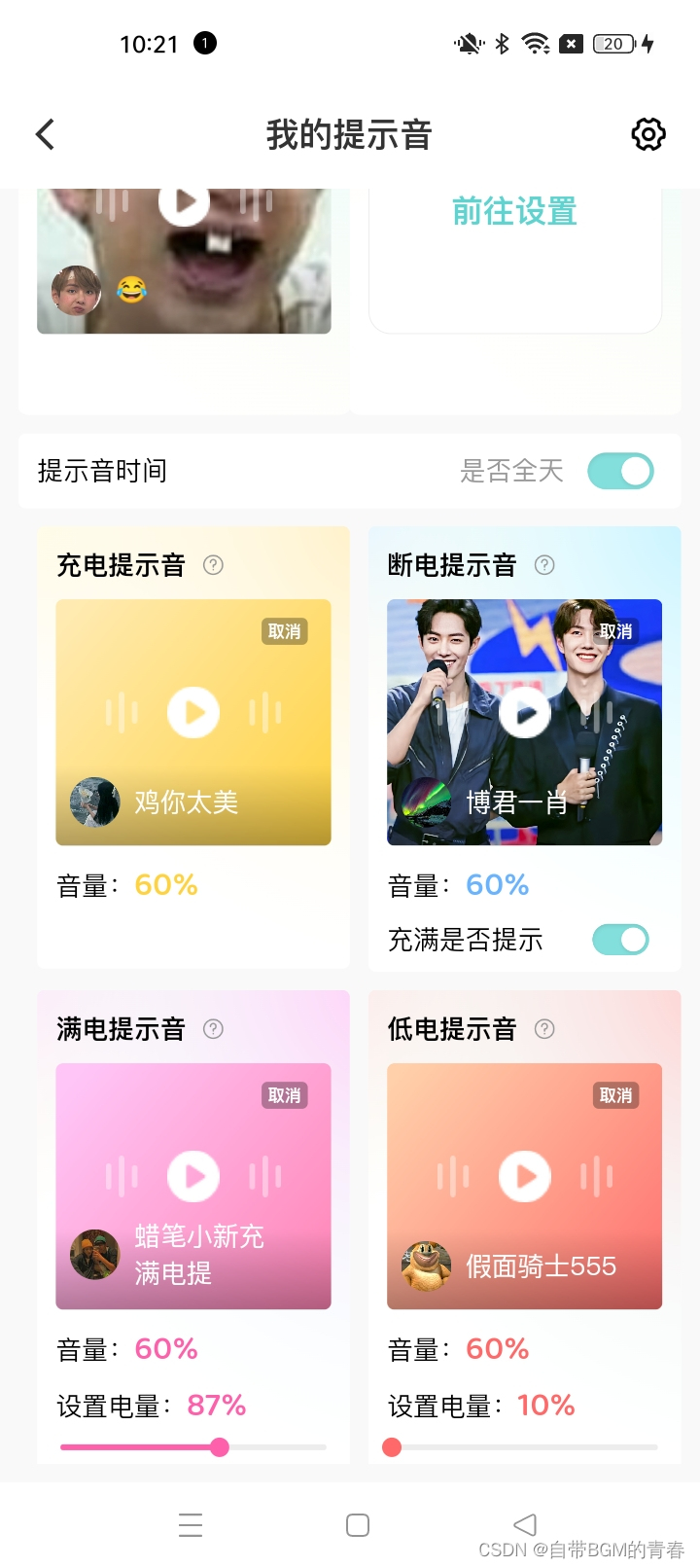
科普小米手机、华为手机、红米手机、oppo手机、vivo手机、荣耀手机、一加手机、realme手机如何设置充电提示音
用空空鱼就可以设置,上面还有很多提示音素材还可以设置满电和低电提醒...
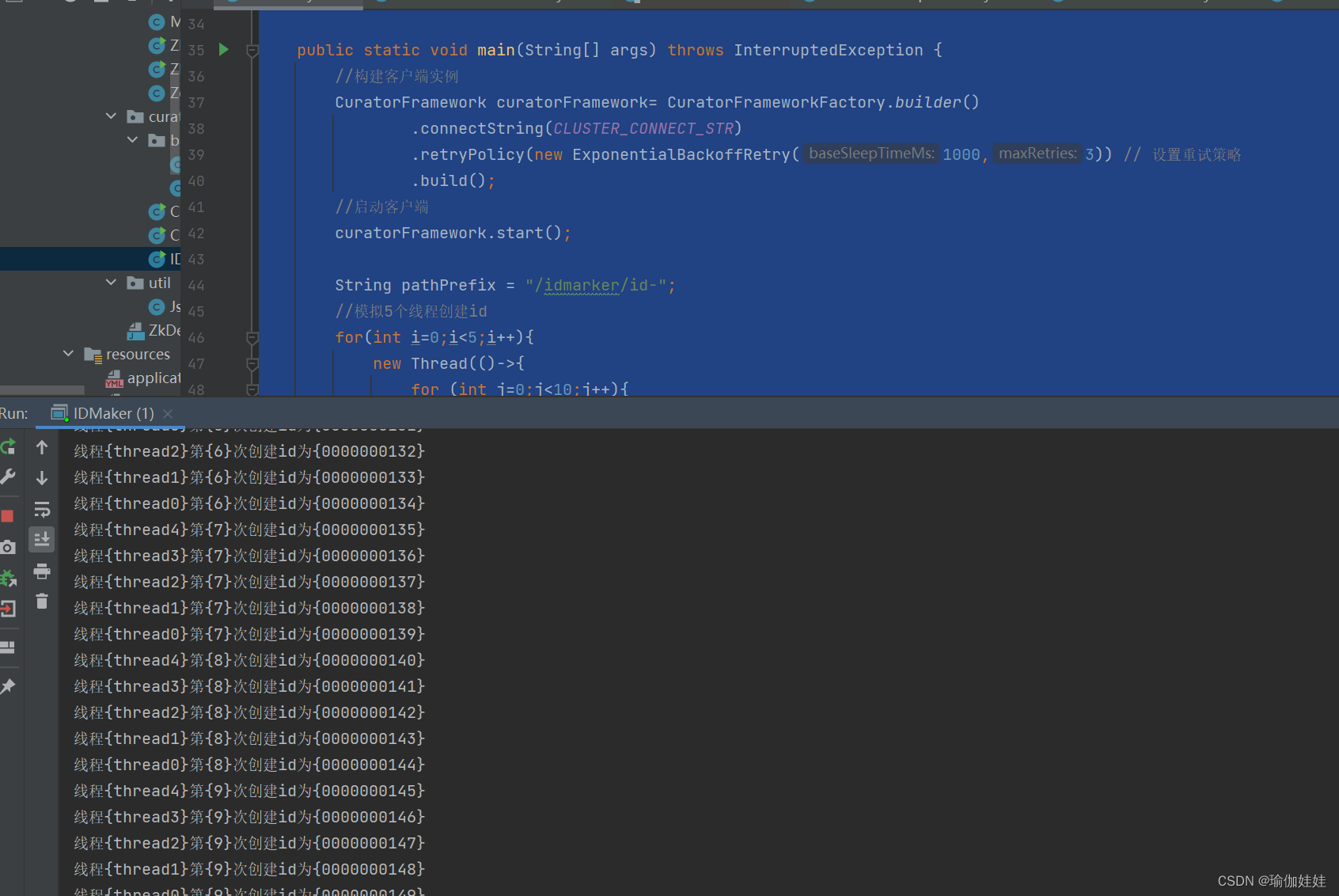
zookeeper应用场景之分布式的ID生成器
1. 分布式ID生成器的使用场景 在分布式系统中,分布式ID生成器的使用场景非常之多: 大量的数据记录,需要分布式ID。大量的系统消息,需要分布式ID。大量的请求日志,如restful的操作记录,需要唯一标识&#x…...
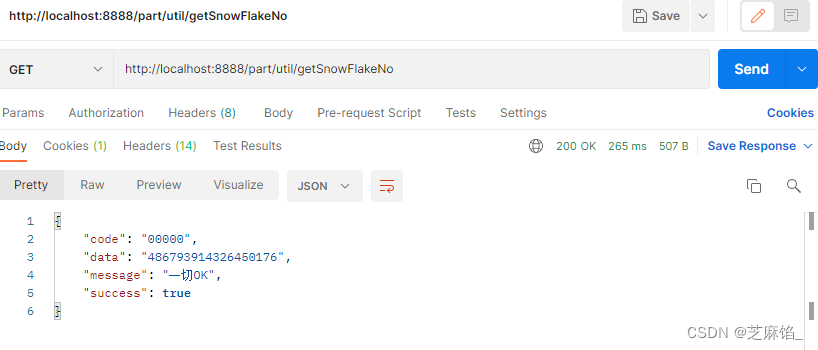
Java--Spring项目生成雪花算法数字(Twitter SnowFlake)
文章目录 前言步骤查看结果 前言 分布式系统常需要全局唯一的数字作为id,且该id要求有序,twitter的SnowFlake解决了这种需求,生成了符合条件的这种数字,本文将提供一个接口获取雪花算法数字。以下为代码。 步骤 SnowFlakeUtils …...

紫光展锐M6780丨画质增强——更炫的视觉体验
智能显示被认为是推动数字化转型和创新的重要技术之一。研究机构数据显示,预计到2035年底,全球智能显示市场规模将达到1368.6亿美元,2023-2035年符合年增长率为36.4%。 随着消费者对高品质视觉体验的需求不断增加,智能手机、平板…...

控制el-table的列显示隐藏
控制el-table的列显示隐藏,一般的话可以通过循环来实现,但是假如业务及页面比较复杂的话,list数组循环并不好用。 在我们的页面中el-table-column是固定的,因为现在是对现有的进行维护和迭代更新。 对需要控制列显示隐藏的页面进…...

2024上海国际冶金及材料分析测试仪器设备展览会
2024上海国际冶金及材料分析测试仪器设备展览会 时间:2024年12月18~20日 地点:上海新国际博览中心 ◆ 》》》组织机构: 主办单位:全联冶金商会、中国宝武钢铁集团有限公司、上海市金属学会 支持单位ÿ…...

商业定位,1元平价商业咨询:豪威尔咨询!平价咨询。
在做生意之前,就需要对企业整体进行一完整的商业定位,才能让商业定位带动企业进行飞速发展。 所以,包含商业定位的有效工作内容就显得极为重要,今天,小编特地为大家整理出了商业定位所需要的筹备的工作,如下…...
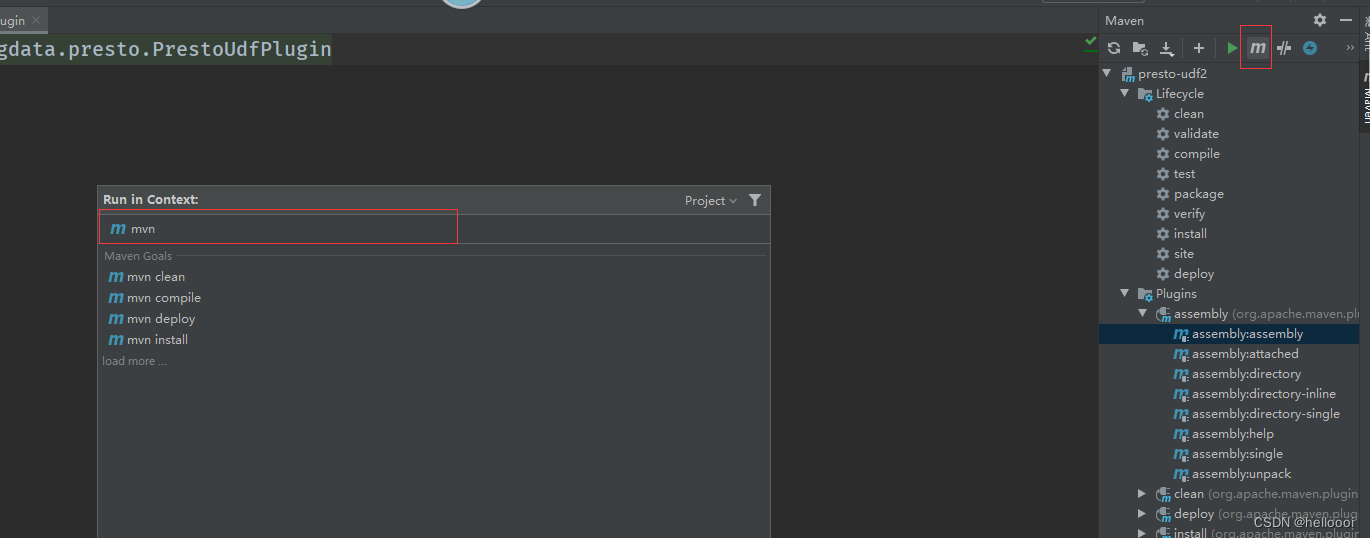
2. Presto应用
该笔记来源于网络,仅用于搜索学习,不保证所有内容正确。文章目录 1、Presto安装使用2、事件分析3、漏斗分析4、漏斗分析UDAF开发开发UDF插件开发UDAF插件 5、漏斗测试 1、Presto安装使用 参考官方文档:https://prestodb.io/docs/current/ P…...

工业级安卓PDA超高频读写器手持掌上电脑,RFID电子标签读写器
掌上电脑,又称为PDA。工业级PDA的特点就是坚固,耐用,可以用在很多环境比较恶劣的地方。 随着技术的不断发展,加快了数字化发展趋势,RFID技术就是RFID射频识别及技术,作为一种新兴的非接触式的自动识别技术&…...

Prompt提示工程上手指南:基础原理及实践(一)
想象一下,你在装饰房间。你可以选择一套标准的家具,这是快捷且方便的方式,但可能无法完全符合你的个人风格或需求。另一方面,你也可以选择定制家具,选择特定的颜色、材料和设计,以确保每件家具都符合你的喜…...

Redis如何保证缓存和数据库一致性?
背景 现在我们在面向增删改查开发时,数据库数据量大时或者对响应要求较快,我们就需要用到Redis来拿取数据。 Redis:是一种高性能的内存数据库,它将数据以键值对的形式存储在内存中,具有读写速度快、支持多种数据类型…...

学完C/C++,再学Python是一种什么体验?
你好,我是安然无虞。 文章目录 变量及类型变量类型动态类型特性 注释输入输出通过控制台输出通过控制台输入 运算符算术运算符关系运算符逻辑运算符赋值运算符 条件循环语句条件语句语法格式代码案例缩进和代码块空语句pass 循环语句while循环语法格式代码案例 for…...
ssm基于Java的壁纸网站设计与实现论文
目 录 目 录 I 摘 要 III ABSTRACT IV 1 绪论 1 1.1 课题背景 1 1.2 研究现状 1 1.3 研究内容 2 2 系统开发环境 3 2.1 vue技术 3 2.2 JAVA技术 3 2.3 MYSQL数据库 3 2.4 B/S结构 4 2.5 SSM框架技术 4 3 系统分析 5 3.1 可行性分析 5 3.1.1 技术可行性 5 3.1.2 操作可行性 5 3…...

零基础也可以探索 PyTorch 中的上采样与下采样技术
目录 torch.nn子模块Vision Layers详解 nn.PixelShuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.PixelUnshuffle 用法与用途 使用技巧 注意事项 参数 示例代码 nn.Upsample 用法与用途 使用技巧 注意事项 参数 示例代码 nn.UpsamplingNearest2d …...

代码随想录算法训练营Day23|669. 修剪二叉搜索树、108.将有序数组转换为二叉搜索树、538.把二叉搜索树转换为累加树
目录 669. 修剪二叉搜索树 前言 思路 递归法 108.将有序数组转换为二叉搜索树 前言 递归法 538.把二叉搜索树转换为累加树 前言 递归法 总结 669. 修剪二叉搜索树 题目链接 文章链接 前言 本题承接昨天二叉搜索树的插入和删除操作题目,要对整棵二叉搜索树…...

乱 弹 篇(一)
题记 对于“乱弹”这个词汇的释义,《辞海》上仅有“ 戏曲剧种,亦指声腔 ”8个字。而由于“乱弹 ”的“ 弹”谐音谈”,这就容易让人联想到“乱谈”。不过从文体上看,“乱谈”也非乱七八糟之谈,反倒是“东西南北&#x…...
)
《JVM由浅入深学习【八】 2024-01-12》JVM由简入深学习提升分(JVM的垃圾回收算法)
目录 JVM的垃圾回收算法1. 标记-清除算法(Mark-Sweep)原理步骤优点缺点 2. 复制算法(Copying)原理步骤优点缺点 3. 标记-整理算法(Mark-Compact)原理步骤优点缺点 4. 分代收集算法(Generational…...

在矩阵回溯中进行累加和比较的注意点
1 总结 在回溯时,如果递归函数采用void返回,在入口处使用了sum变量,那么一般在初次调用dfs的地方,这个sum的初始值可能不是0,而是数组的对应指针的值,在比较操作的时候,需要在for循环开始之前进行…...
AI语音机器人的发展
第一代AI语音机器人具体投入研发的开始时间不太清楚,只记得2017年的下半年就已经开始接触到成型的AI语音机器人,并且正式商用。语音识别效果还不多,大多都是接入的科大讯飞或者百度的ASR。 2018年算是AI语音机器人的“青春期”吧,…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...