小红书搜索团队提出全新框架:验证负样本对大模型蒸馏的价值
大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错误答案的合成数据。
在 AAAI 2024 上,小红书搜索算法团队提出了一个创新框架,在蒸馏大模型推理能力的过程中充分利用负样本知识。负样本,即那些在推理过程中未能得出正确答案的数据,虽常被视为无用,实则蕴含着宝贵的信息。
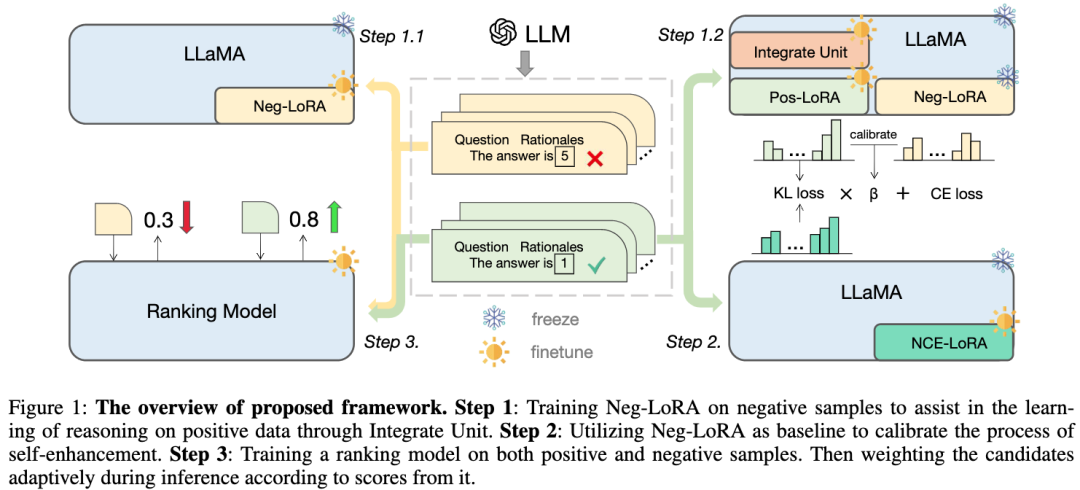
论文提出并验证了负样本在大模型蒸馏过程中的价值,构建一个模型专业化框架:除了使用正样本外,还充分利用负样本来提炼 LLM 的知识。该框架包括三个序列化步骤,包括负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC),涵盖从训练到推理的全阶段过程。通过一系列广泛的实验,我们展示了负向数据在 LLM 知识蒸馏中的关键作用。

如今,在思维链(CoT)提示的帮助下,大语言模型(LLMs)展现出强大的推理能力。然而,思维链已被证明是千亿级参数模型才具有的涌现能力。这些模型的繁重计算需求和高推理成本,阻碍了它们在资源受限场景中的应用。因此,我们研究的目标是使小模型能够进行复杂的算术推理,以便在实际应用中进行大规模部署。
知识蒸馏提供了一种有效的方法,可以将 LLMs 的特定能力迁移到更小的模型中。这个过程也被称为模型专业化(model specialization),它强制小模型专注于某些能力。先前的研究利用 LLMs 的上下文学习(ICL)来生成数学问题的推理路径,将其作为训练数据,有助于小模型获得复杂推理能力。然而,这些研究只使用了生成的具有正确答案的推理路径(即正样本)作为训练样本,忽略了在错误答案(即负样本)的推理步骤中有价值的知识。

如图所示,表 1 展示了一个有趣的现象:分别在正、负样本数据上训练的模型,在 MATH 测试集上的准确答案重叠非常小。尽管负样本训练的模型准确性较低,但它能够解决一些正样本模型无法正确回答的问题,这证实了负样本中包含着宝贵的知识。此外,负样本中的错误链路能够帮助模型避免犯类似错误。另一个我们应该利用负样本的原因是 OpenAI 基于 token 的定价策略。即使是 GPT-4,在 MATH 数据集上的准确性也低于 50%,这意味着如果仅利用正样本知识,大量的 token 会被浪费。因此,我们提出:相比于直接丢弃负样本,更好的方式是从中提取和利用有价值的知识,以增强小模型的专业化。
模型专业化过程一般可以概括为三个步骤:
1)思维链蒸馏(Chain-of-Thought Distillation),使用 LLMs 生成的推理链训练小模型。
2)自我增强(Self-Enhancement),进行自蒸馏或数据自扩充,以进一步优化模型。
3)自洽性(Self-Consistency)被广泛用作一种有效的解码策略,以提高推理任务中的模型性能。
在这项工作中,我们提出了一种新的模型专业化框架,该框架可以全方位利用负样本,促进从 LLMs 提取复杂推理能力。
- 我们首先设计了负向协助训练(NAT)方法,其中 dual-LoRA 结构被设计用于从正向、负向两方面获取知识。作为一个辅助模块,负向 LoRA 的知识可以通过校正注意力机制,动态地整合到正向 LoRA 的训练过程中。
- 对于自我增强,我们设计了负向校准增强(NCE),它将负向输出作为基线,以加强关键正向推理链路的蒸馏。
- 除了训练阶段,我们还在推理过程中利用负向信息。传统的自洽性方法将相等或基于概率的权重分配给所有候选输出,导致投票出一些不可靠的答案。为了缓解该问题,提出了动态自洽性(ASC)方法,在投票前进行排序,其中排序模型在正负样本上进行训练的。

我们提出的框架以 LLaMA 为基础模型,主要包含三个部分,如图所示:
-
步骤 1 :对负向 LoRA 进行训练,通过合并单元帮助学习正样本的推理知识;
-
步骤 2 :利用负向 LoRA 作为基线来校准自我增强的过程;
-
步骤 3 :在正样本和负样本上训练排名模型,在推理过程中根据其得分,自适应地对候选推理链路进行加权。
2.1 负向协助训练(NAT)
我们提出了一个两阶段的负向协助训练(NAT)范式,分为负向知识吸收与动态集成单元两部分:
2.1.1 负向知识吸收


2.1.2 动态集成单元

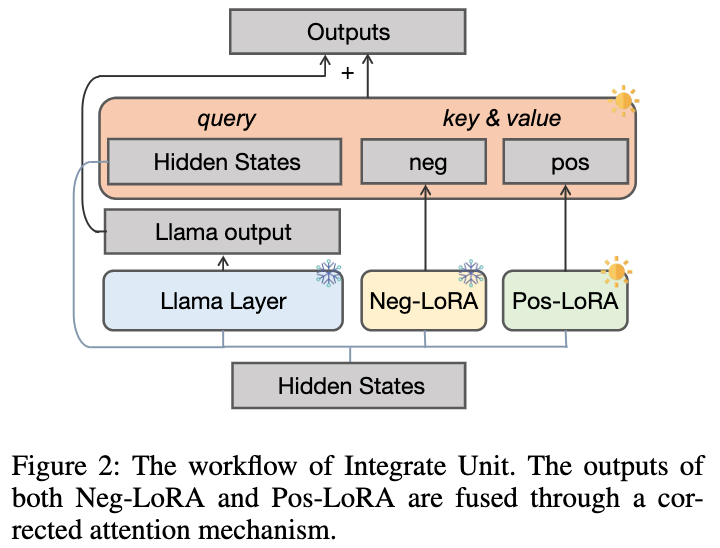

我们提出了一种纠正注意力机制来实现这一目标,如下所示:



2.2 负向校准增强(NCE)
为了进一步增强模型的推理能力,我们提出了负校准增强(NCE),它使用负知识来帮助自我增强过程。我们首先使用 NAT 为中的每个问题生成对作为扩充样本,并将它们补充到训练数据集中。对于自蒸馏部分,我们注意到一些样本可能包含更关键的推理步骤,对提升模型的推理能力至关重要。我们的主要目标是确定这些关键的推理步骤,并在自蒸馏过程中加强对它们的学习。

![]()
![]()
![]()
β 值越大,表示两者之间的差异越大,意味着该样本包含更多关键知识。通过引入 β 来调整不同样本的损失权重,NCE 将能够选择性地学习并增强 NAT 中嵌入的知识。
2.3 动态自洽性(ASC)
自洽性(SC)对于进一步提高模型在复杂推理中的表现是有效的。然而,当前的方法要么为每个候选者分配相等的权重,要么简单地基于生成概率分配权重。这些策略无法在投票阶段根据 (rˆ, yˆ) 的质量调整候选权重,这可能会使正确候选项不易被选出。为此,我们提出了动态自洽性方法(ASC),它利用正负数据来训练排序模型,可以自适应地重新配权候选推理链路。
2.3.1 排序模型训练
理想情况下,我们希望排序模型为得出正确答案的推理链路分配更高的权重,反之亦然。因此,我们用以下方式构造训练样本:

并使用 MSE loss 去训练排序模型:

2.3.2 加权策略
我们将投票策略修改为以下公式,以实现自适应地重新加权候选推理链路的目标:
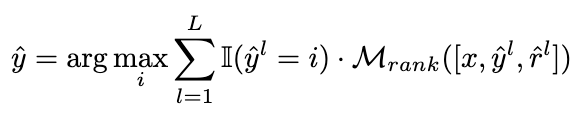
下图展示了 ASC 策略的流程:

从知识迁移的角度来看,ASC 实现了对来自 LLMs 的知识(正向和负向)的进一步利用,以帮助小模型获得更好的性能。

本研究专注于具有挑战性的数学推理数据集 MATH,该数据集共有 12500 个问题,涉及七个不同的科目。此外,我们还引入了以下四个数据集来评估所提出的框架对分布外(OOD)数据的泛化能力:GSM8K、ASDiv、MultiArith 和 SVAMP。
对于教师模型,我们使用 Open AI 的 gpt-3.5-turbo 和 gpt-4 API 来生成推理链。对于学生模型,我们选择 LLaMA-7b。
在我们的研究中有两种主要类型的基线:一种为大语言模型(LLMs),另一种则基于 LLaMA-7b。对于 LLMs,我们将其与两种流行的模型进行比较:GPT3 和 PaLM。对于 LLaMA-7b,我们首先提供我们的方法与三种设置进行比较:Few-shot、Fine-tune(在原始训练样本上)、CoT KD(思维链蒸馏)。在从负向角度学习方面,还将包括四种基线方法:MIX(直接用正向和负向数据的混合物训练 LLaMA)、CL(对比学习)、NT(负训练)和 UL(非似然损失)。
3.1 NAT 实验结果
所有的方法都使用了贪婪搜索(即温度 = 0),NAT 的实验结果如图所示,表明所提出的 NAT 方法在所有基线上都提高了任务准确性。
从 GPT3 和 PaLM 的低值可以看出,MATH 是一个非常困难的数学数据集,但 NAT 仍然能够在参数极少的情况下表现突出。与在原始数据上进行微调相比,NAT 在两种不同的 CoT 来源下实现了约 75.75% 的提升。与 CoT KD 在正样本上的比较,NAT 也显著提高了准确性,展示了负样本的价值。
对于利用负向信息基线,MIX 的低性能表明直接训练负样本会使模型效果很差。其他方法也大多不如 NAT,这表明在复杂推理任务中仅在负方向上使用负样本是不够的。

3.2 NCE 实验结果
如图所示,与知识蒸馏(KD)相比,NCE 实现了平均 10%(0.66) 的进步,这证明了利用负样本提供的校准信息进行蒸馏的有效性。与 NAT 相比,尽管 NCE 减少了一些参数,但它依然有 6.5% 的进步,实现压缩模型并提高性能的目的。

3.3 ASC 实验结果
为了评估 ASC,我们将其与基础 SC 和 加权(WS)SC 进行比较,使用采样温度 T = 1 生成了 16 个样本。如图所示,结果表明,ASC 从不同样本聚合答案,是一种更有前景的策略。

3.4 泛化性实验结果
除了 MATH 数据集,我们评估了框架在其他数学推理任务上的泛化能力,实验结果如下。


本项工作探讨了利用负样本从大语言模型中提炼复杂推理能力,迁移到专业化小模型的有效性。小红书搜索算法团队提出了一个全新的框架,由三个序列化步骤组成,并在模型专业化的整个过程中充分利用负向信息。负向协助训练(NAT)可以从两个角度提供更全面地利用负向信息的方法。负向校准增强(NCE)能够校准自蒸馏过程,使其更有针对性地掌握关键知识。基于两种观点训练的排序模型可以为答案聚合分配更适当的权重,以实现动态自洽性(ASC)。大量实验表明,我们的框架可以通过生成的负样本来提高提炼推理能力的有效性。
论文地址:https://arxiv.org/abs/2312.12832

-
李易为:
现博士就读于北京理工大学,小红书社区搜索实习生,在 AAAI、ACL、EMNLP、NAACL、NeurIPS、KBS 等机器学习、自然语言处理领域顶级会议/期刊上发表数篇论文,主要研究方向为大语言模型蒸馏与推理、开放域对话生成等。
-
袁沛文:
现博士就读于北京理工大学,小红书社区搜索实习生,在 NeurIPS、AAAI 等发表多篇一作论文,曾获 DSTC11 Track 4 第二名。主要研究方向为大语言模型推理与评测。
-
冯少雄:
负责小红书社区搜索向量召回。在 AAAI、EMNLP、ACL、NAACL、KBS 等机器学习、自然语言处理领域顶级会议/期刊上发表数篇论文。
-
道玄(潘博远):
小红书交易搜索负责人。在 NeurIPS、ICML、ACL 等机器学习和自然语言处理领域顶级会议上发表数篇一作论文,在斯坦福机器阅读竞赛 SQuAD 排行榜上获得第二名,在斯坦福自然语言推理排行榜上获得第一名。
-
曾书(曾书书):
小红书社区搜索语义理解与召回方向负责人。硕士毕业于清华大学电子系,在互联网领域先后从事自然语言处理、推荐、搜索等相关方向的算法工作。

小红书社区搜索算法工程师(全职 / 实习)
岗位职责:
1、对小红书搜索效果进行优化,包括搜索算法和策略的调研、设计、开发、评估等环节,提升用户体验;
2、发现并解决搜索场景中在查询分析、意图识别、排序模型、去重等方向的问题;
3、解决小红书搜索实际问题,更好地满足用户的搜索需求;
4、跟进业内搜索相关模型和算法的前沿进展,并在实际业务中进行合理应用。
任职资格:
1、本科及以上学历,计算机相关专业背景;
2、有搜索、推荐、广告、图像识别等相关背景优先;
3、熟悉机器学习、NLP、数据挖掘、知识工程的经典算法,并能在业务中灵活解决实际问题;
4、在国际顶级会议(KDD、SIGIR、WSDM、ICML、ACL 等)以第一作者发表过高水平论文者、知名数据挖掘比赛(例如 KDD Cup 等)中取得领先名次者优先;
5、积极向上,踏实勤奋,自我驱动,善于沟通,解决问题优先。
欢迎感兴趣的同学发送简历至 REDtech@xiaohongshu.com,并抄送至 luyun2@xiaohongshu.com。
相关文章:
小红书搜索团队提出全新框架:验证负样本对大模型蒸馏的价值
大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错…...

汽车销售领域相关专业术语
引言 本文是笔者在从事汽车销售领域信息化建设过程,积累的一些专业术语注解,供诸位参考交流。 专业术语清单 4S店 汽车销售服务4S店;是由经销商投资建设,按照汽车生产厂家规定的标准建造,是一种集整车销售(Sale)、零配件(Sparepart)、售后服务(Service)、信息…...

代币合约 ERC20 Token接口
代币合约 在以太坊上发布代币就要遵守以太坊的规则,那么以太坊有什么规则呢?以太坊的精髓就是利用代码规定如何运作,由于在以太坊上发布智能合约是不能修改和删除的,所以智能合约一旦发布,就意味着永久有效,不可篡改…...

判断回文字符串—C语言
题目要求 输入一个字符串,判断该字符串是否为回文。回文就是字符串中心对称,从左向右读和从右向左读的内容是一样的。 输入格式: 输入在一行中给出一个不超过80个字符长度的、以回车结束的非空字符串。 输出格式: 输出在第1行中…...
如何在Docker本地搭建流程图绘制神器draw.io并实现公网远程访问
推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 前言 提到流程图,大家第一时间可能会想到Visio,不可否认,VIsio确实是功能强大,但是软…...

Web前端篇——el-timeline+el-scrollbar时间轴数据刷新后自动显示滚动条
背景:使用el-timelineel-scrollbar显示时间轴,当时间轴数据刷新时,el-scrollbar滚动条会自动隐藏。 当给el-scrollbar设置了永久显示滚动条(如下代码),以为可以一劳永逸,发现问题仍然存在。 .…...

Flutter 监听前台和后台切换的状态
一 前后台的切换状态监听 混入 WidgetsBindingObserver 这个类,这里提供提供了程序状态的一些监听 二 添加监听和销毁监听 overridevoid initState() {super.initState();//2.页面初始化的时候,添加一个状态的监听者WidgetsBinding.instance.addObserver…...
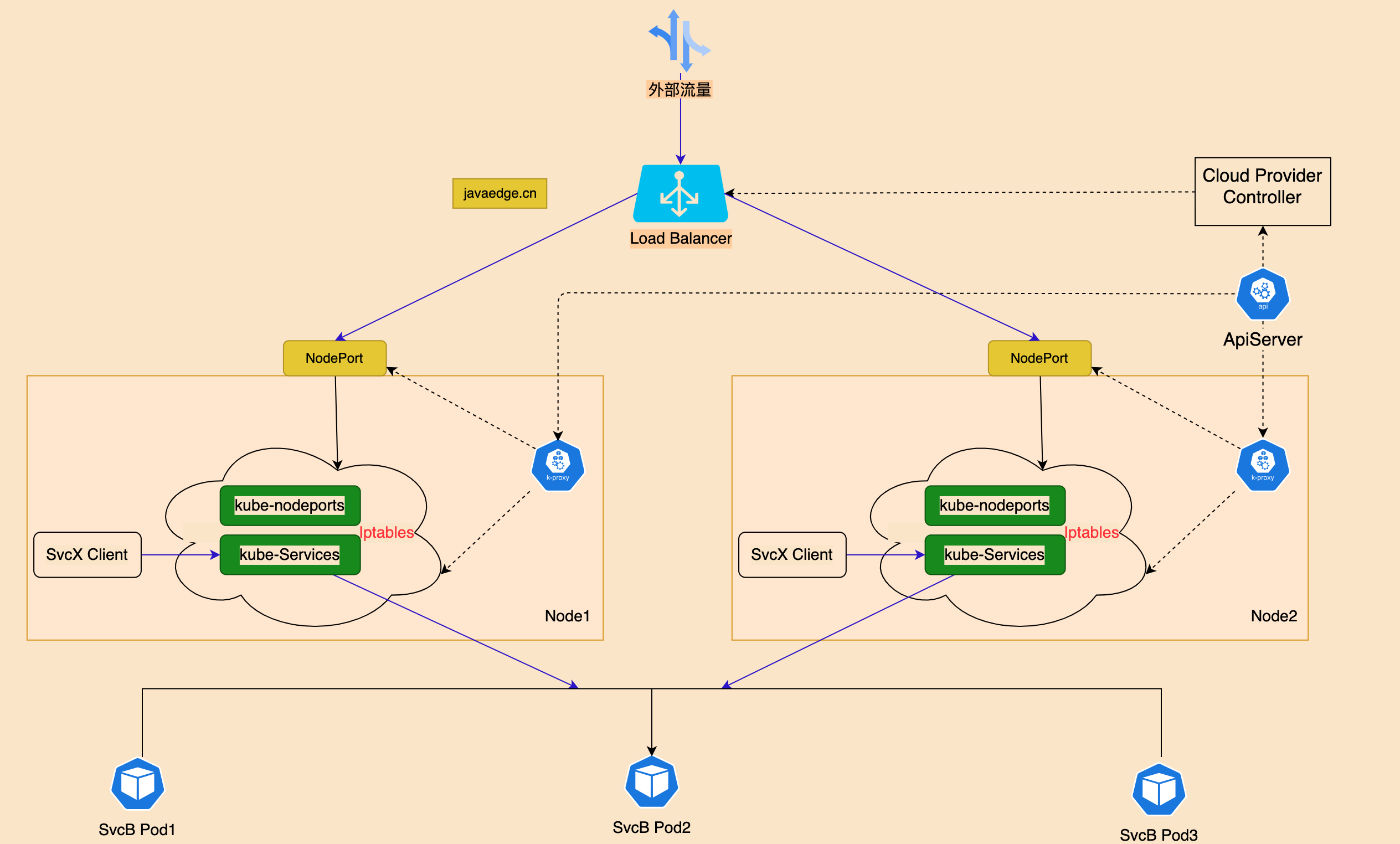
图解Kubernetes的服务(Service)
pod 准备: 不要直接使用和管理Pods: 当使用ReplicaSet水平扩展scale时,Pods可能被terminated当使用Deployment时,去更新Docker Image Version,旧Pods会被terminated,然后创建新Pods 0 啥是服务…...

facebook广告素材制作要注意哪些
在制作Facebook广告素材时,需要注意以下几点: 目标受众:了解目标受众的喜好、需求和兴趣,以便制作能够吸引他们的广告素材。广告格式:选择适合广告内容的格式,如图片、视频、幻灯片等。同时,要…...
Android 应用流量监控实践
背景 得物Apm系统本身包含网络接口性能监控的能力,但接口监控主要关注的是接口的耗时、异常率等信息,没有流量消耗相关维度的统计信息,并且一部分流量消耗可能来自于音视频等其他特殊场景,在接口监控的盲区外。 为了了解用户目前…...
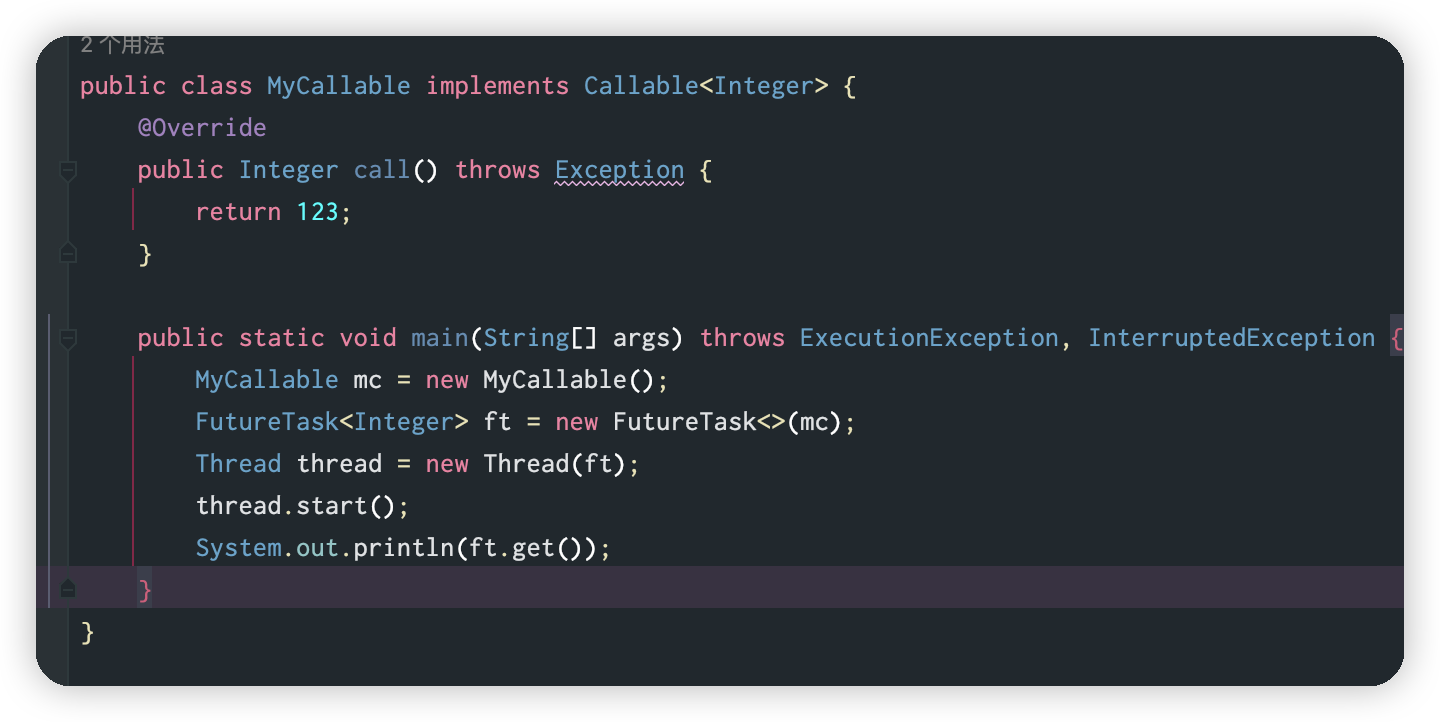
并发前置知识一:线程基础
一、通用的线程生命周期:“五态模型” 二、java线程有哪几种状态? New:创建完线程Runable:start(),这里的Runnable包含操作的系统的Running(运行状态)和Ready(上面的可运行状态)Blo…...
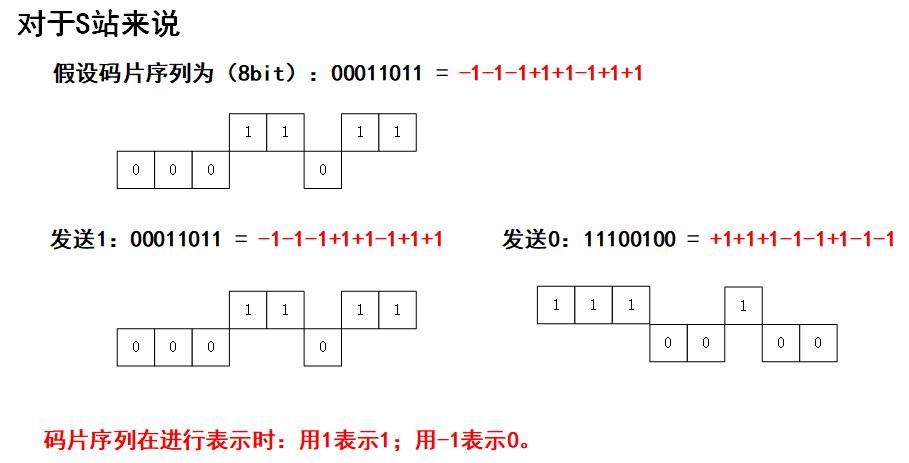
计算机网络 物理层
文章目录 物理层物理层的基本概念数据通信的基础知识数据通信系统的模型有关信道的几个基本概念信道的极限容量 物理层下面的传输媒体导引型传输媒体非引导型传输媒体 信道复用技术波分复用码的复用 宽带接入技术ADSL 技术光纤同轴混合网 (HFC 网)FTTx 技术 物理层 …...

浅谈轻量级Kubernetes—K3s
1.什么是K3s K3s 被设计为小于 40MB 的单个二进制文件,完全实现了 Kubernetes API。为了实现这一目标,他们删除了许多不需要成为核心一部分的额外驱动程序,并且很容易被附加组件替换。 K3s 是完全 CNCF(云原生计算基金会&…...
Web APIs知识点讲解
学习目标: 能获取DOM元素并修改元素属性具备利用定时器间歇函数制作焦点图切换的能力 一.Web API 基本认知 1.作用和分类 作用: 就是使用 JS 去操作 html 和浏览器分类:DOM (文档对象模型)、BOM(浏览器对象模型) 2.DOM DOM(Document Ob…...

Python商业数据挖掘实战——爬取网页并将其转为Markdown
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 ChatGPT体验地址 文章目录 前言前言正则表达式进行转换送书活动 前言 在信息爆炸的时代,互联网上的海量文字信息如同无尽的沙滩。然而,其中真正有价值的信息往往埋…...

初识 Elasticsearch 应用知识,一文读懂 Elasticsearch 知识文集(1)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

StampedLock详解
在现代的Java应用中,同步是一个核心问题,尤其是在高并发环境下。Java提供了多种同步机制,从基本的synchronized关键字到更高级的ReentrantLock。但在Java 8中,引入了一个新的同步原语——StampedLock,它旨在提供更高的…...
Linux中DCHP与时间同步
目录 一、DHCP (一)工作原理 1.获取 2.续约 (二)分配方式 (三)服务器配置 1.随机地址分配 2.固定地址分配 二、时间同步 (一)ntpdate (二)chrony …...

国产系统-银河麒麟桌面版V10安装字体-wps安装字体
安装系统:银河麒麟V10 demodemo-pc:~/桌面$ cat /proc/version Linux version 5.10.0-8-generic (builddfa379600e539) (gcc (Ubuntu 9.4.0-1kylin1~20.04.1) 9.4.0, GNU ld (GNU Binutils for Ubuntu) 2.34) #33~v10pro-KYLINOS SMP Wed Mar 22 07:21:49 UTC 20230.系统缺失…...

python 10常用自动化脚本收藏好
01、 图片优化器 使用这个很棒的自动化脚本,可以帮助把图像处理的更好,你可以像在 Photoshop 中一样编辑它们。 该脚本使用流行的是 Pillow 模块 # Image Optimizing # pip install Pillow import PIL # Croping im PIL.Image.open("Image1.jp…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...