【Linux学习】基础IO——理解缓冲区 | 理解文件系统
🐱作者:一只大喵咪1201
🐱专栏:《Linux学习》
🔥格言:你只管努力,剩下的交给时间!

基础IO
- ☕理解缓冲区
- 🧃缓冲区的共识
- 🧃缓冲区的位置
- 🧃缓冲区的刷新策略
- 🧃简单模拟用户缓冲区
- ☕理解文件系统
- 🧃认识磁盘
- 🧃文件管理
- 🧃操作未被打开文件
- ☕总结
☕理解缓冲区
🧃缓冲区的共识
缓冲区存在的现象:
- 在我们写的第一个Linux程序中,当时就存在一个刷新缓冲区的操作,为了能够在屏幕上立刻打出我们要输出到内容,如下图所示。

- 还有在使用C语言scanf函数的时候,为了不让空格影响获取字符串,经常会使用getchar把空格字符串跳过,而且并没有接收getchar的返回值,仅仅是为了从缓冲区中将空格拿走。
在我们学习的过程中,种种迹象表明是存在缓冲区的,但是它具体是什么,一直都没有一个答案,今天本喵就给大家详细介绍一下缓冲区。
缓冲区存在的意义:
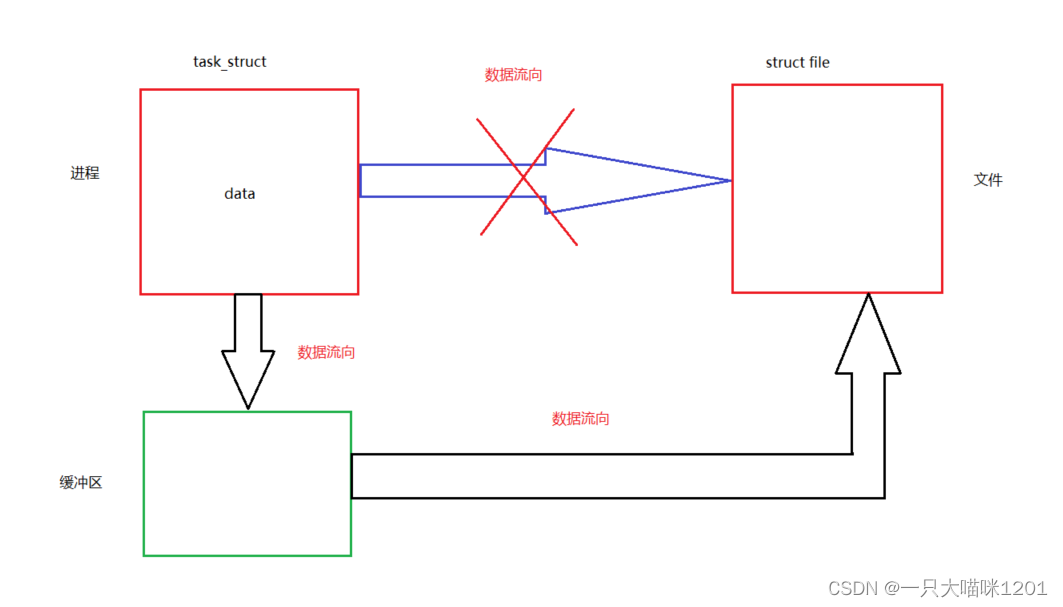
当一个进程要向文件中写入数据的时候,有两种方案:
- 进程直接将数据写入到文件中,如上图中蓝色箭头所示。
- 进程将数据写入到缓冲区中,然后再由缓冲区将数据写入到文件中,如上图黑色箭头所示。
这里两种方式哪种好呢?看起来像是第一种方案好,因为比较简单,数据直接从进程流向文件就行,但事实上不是这样。
- 第一种方案中,无论是在向磁盘上的文件写入数据,还是向显示器等其他硬件写入数据,都需要很长的时间,因为硬件的访问相对于CPU的速度来说是非常慢的,此时CPU就需要进行等待。
- 第二种方案中,将数据写入到缓冲区中,缓冲区的访问速度肯定要比访问硬件快的多,数据写入到缓冲区以后,CPU就可以去干其他的事情了,而缓冲区中的数据会由操作系统在合适的时间写入到文件中。
从上面的分析可以得出结论,缓冲区的存在是为了给发送方节省时间。
既然缓冲区的存在是为了给CPU节省时间,那么它的访问速度肯定是比文件要快的多的,所以它只能是内存。所以说,缓冲区本质上就是一段内存。
🧃缓冲区的位置
既然缓冲区是一段内存,那么这段内存是谁申请的,它是属于谁的?
来看一个现象:
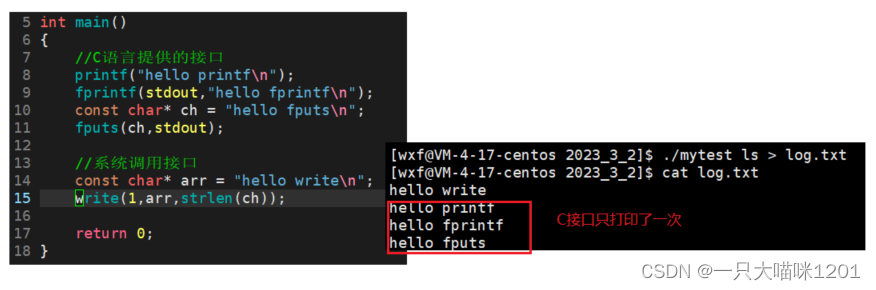
如上图所示的代码,使用C语言提供的打印函数和系统调用输出重定向到log.txt文件中,发现各个接口只调用了一次。
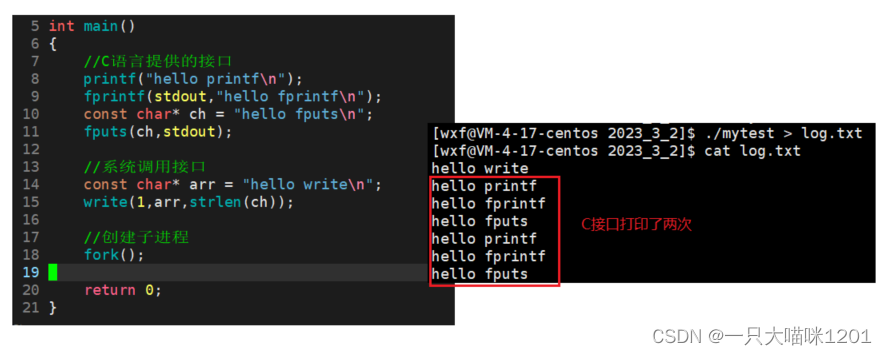
在程序执行完毕,但是进程没有结束的时候,使用fork创建子进程,再将运行结果输出重定向到log.txt文件中,发现C语言提供的接口调用了两次,而系统调用接口只调用了一次。
这是什么原因?从这个现象中能过得到什么呢?
- 这个现象肯定是和缓冲区有关。
- 缓冲区必然不在操作系统内核中。
既然缓冲区不在操作系统内核中,也就是不是由操作系统来维护的,那么它只能有进程去维护,也就是编程语言本身来维护。
拿C语言来说,和文件相关的操作,FILE*类型的指针是至关重要的,我们已经知道,FILE是一个结构体,它里面有文件描述符fd,在结构体中定义的变量名是_fileno。
所以我们大胆猜测,所谓缓冲区就在FILE这个结构体中。
来大概看看Linux的源码:
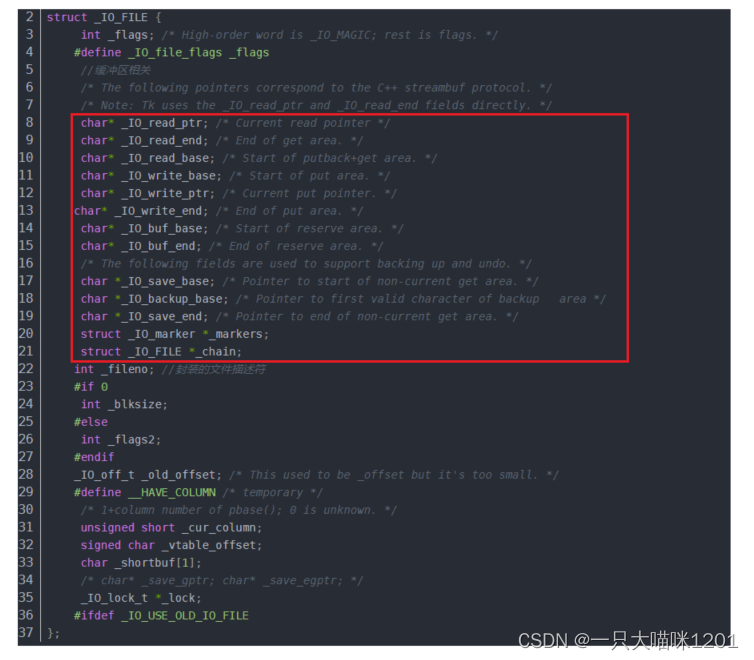
在源码中,和文件有关的结构体中有很多的指针变量,如上图中红色框所示,这些指针就是在维护缓冲区。
此时我们就可以知道,缓冲区是由要打卡文件的进程申请的,也是由这个进程来维护的,缓冲区存在于FILE结构体中。
🧃缓冲区的刷新策略
光知道缓冲区存在于FILE结构体中还不足以回答上面那个现象提出的问题,接着本喵再介绍一下缓冲区的刷新策略。
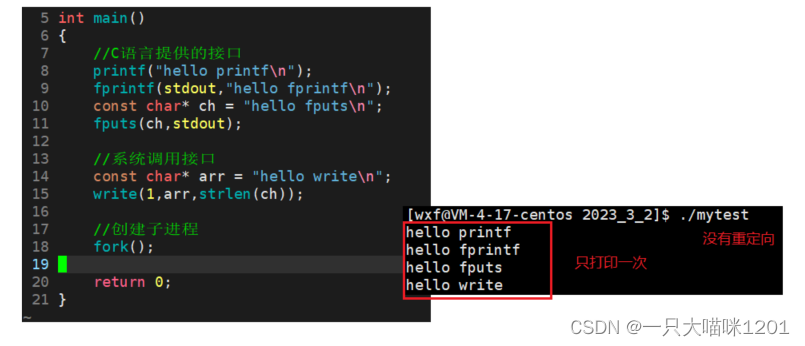
同样上面的代码,但是没有进行输出重定向,而是直接打印,虽然有fork,但是仍然是各个接口只调用了一次。
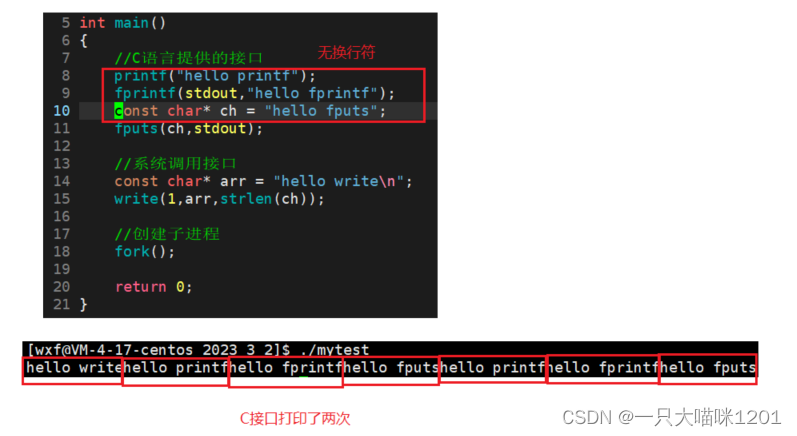
将上面代码中字符串的换行符去掉,不进行重定向,直接打印,发现C接口也被调用了两次。
这是什么原因?从这个现象中又可以看出什么呢?
- 缓冲区如果及时刷新,那么各个接口只调用一次。
- 缓冲区的刷新和换行符\n有关。
这种缓冲区的刷新和换行符\n相关的策略叫做行缓冲。
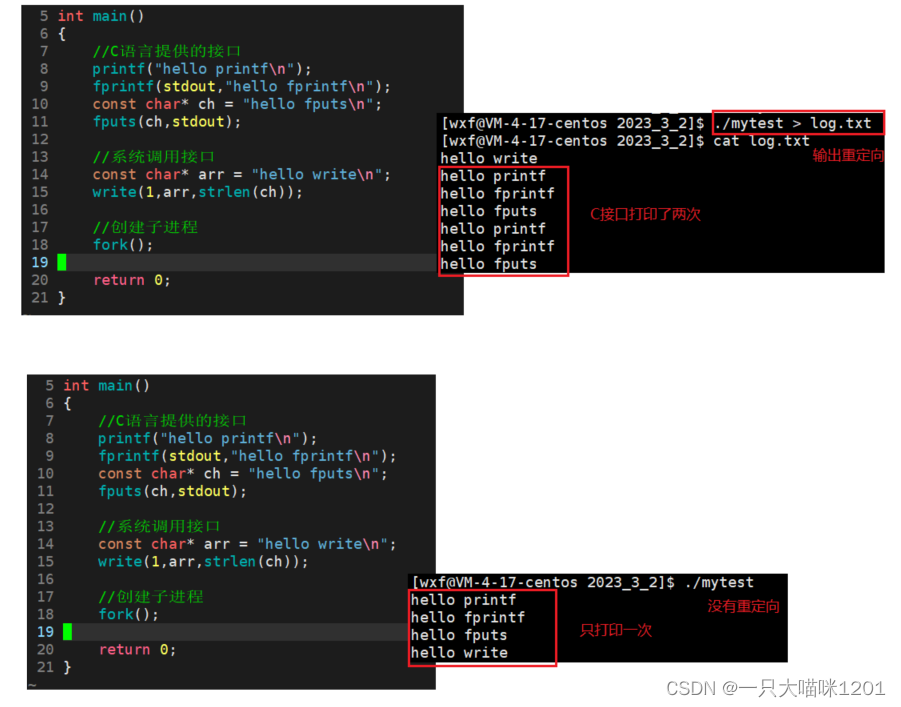
再看,同样的代码,都是有换行符的,进行输出重定向以后,C接口就调用了两次,没有进行重定向C接口就只调用了一次。
这又是为什么?从这个现象中可以看出什么?
- 输出重定向后,输出终端变成了文件,没有重定时,输出终端是显示器。
- 行缓冲的策略在文件和显示器上作用效果不同。
文件采用的是全缓冲的方式,只有当缓冲区满了以后,操作系统才会刷新缓存区。
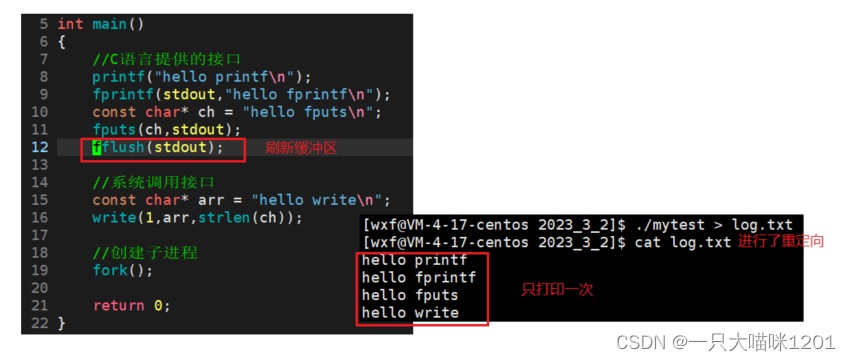
在程序中,在C语言的打印函数接口调用完之后,使用了fflush将缓冲区立刻刷新,然后进行输出重定向到log.txt文件中,此时C语言接口也是只打印了一次。
进行了重定向,又仅打印了一次,和上面进行重定向后只打印一次的结果完全不同。
这是为什么?从这个现象中又可以看出什么?
- fflush进行缓冲区的刷新。
- 没有遵循行缓冲或者全缓冲的策略。
这种使用fflush进行刷新缓冲区的刷新策略叫做**误缓冲。**它是由用户控制的,直接将缓冲区中的全部内容都刷新都对应的终端上去。
还有两种情况下,缓冲区同样也会刷新,其一就是当一个进程结束后,操作系统会自动将属于该进程的缓冲区进行刷新,并且将对应的内存空间释放。
其二就是当一个文件被关闭的时候,操作系统也会自动将属于该进程的缓冲区进行刷新。
来总结一下缓冲区的刷新策略:
| 体现 | 策略 | 适用范围 |
|---|---|---|
| 立即刷新 | 无缓冲 | 通常由用户控制进行强制刷新 |
| 行刷新 | 行缓冲 | 显示器 |
| 满了刷新 | 全缓冲 | 磁盘文件 |
| 进行结束后刷新 | 所有进程 | |
| 文件关闭时 | 所有文件 |
不同的缓冲策略是根据一定的情况定死的,我们一般情况下是不会进程重新定义的。
- 显示器:直接给用户看的,一方面要照顾到效率,另一方面要考虑到用户是一行一行看文本的,所以次用行缓冲策略。
- 磁盘文件:用户不需要立马看见文件中的内容,为了效率,采用全缓冲的方式。
缓冲区刷新一次是很耗费时间的,比如1000个字节的数据,刷新一次是1000个,刷新十次也是1000个,但是十次使用的时间会必一次长的多的多。
在进行缓冲区刷新的时候,数据量的大小不是主要矛盾,和外设预备IO的过程才是最耗费时间的。
解答疑惑:
此时这个现象就可以解答了。
只有C接口被调用的次数发生了变化,系统调用一直都是只调用一次,说明系统调用不存在缓冲区。
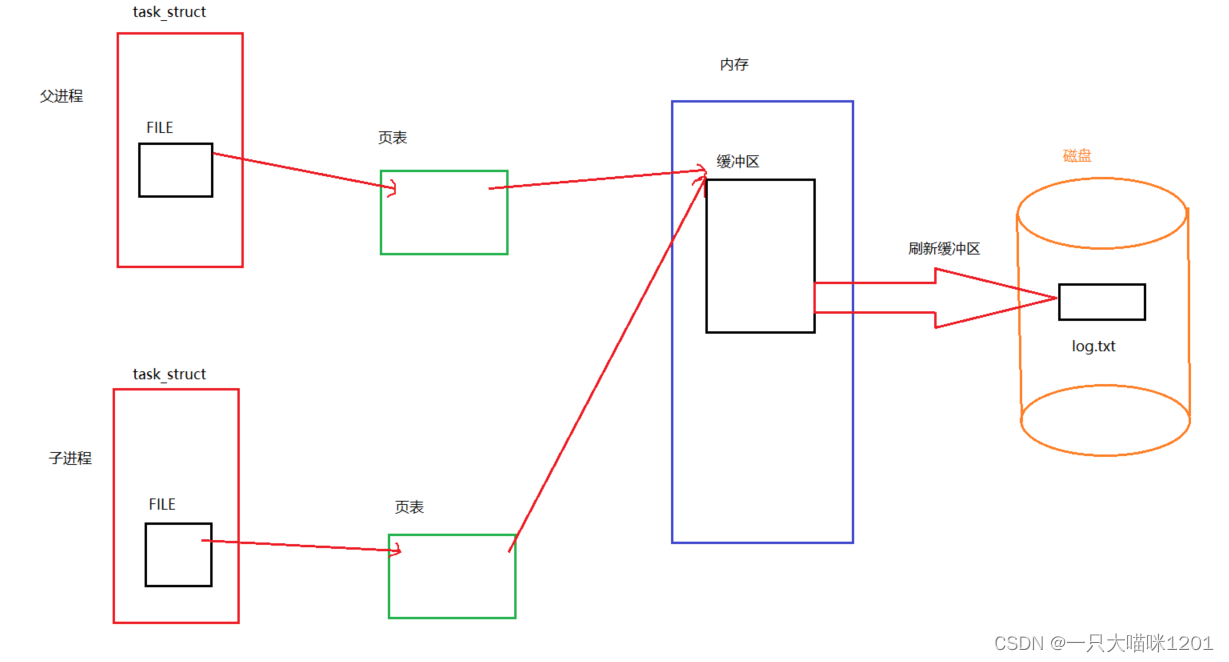
- 父进程创建以后,在调用C接口时,将数据写到了它的缓冲区中,并且通过页表在内存中映射了一段物理空间。
- 在执行到return 0 之前的fork时,创建了子进程,子进程会拷贝父进程缓冲区中的全部内容,并且通过页表映射到相同的物理空间。
- 在fork之后,父子两个进程什么都没有干进程将结束了,在进程结束的时候会刷新它们各自缓冲区中的数据到磁盘文件中。
- 因为有两个进程要结束,所以缓冲区就会刷新两次,而且内容是一样的。
- 然后释放这块物理空间,由于父子进程都没有对各自的缓冲区进行修改,所以没有发生写时拷贝。
在没有重定向到程序中,打印终端是显示器,采用的是行缓冲的方式,每个C接口打印的字符串中都有换行符,所以每次调用完C接口后都会刷新缓存区中的内容。
在fork之后,父子两个进程各自的缓冲区中什么都没有,都已经被刷新走了,所以它们两在结束的时候也不会再次刷新缓冲区,所以表现出来C接口各自打印一次。
🧃简单模拟用户缓冲区
为了能够对缓冲区有更深的了解,下面本喵带大家简单的模拟实现一下用户缓冲区。
首先需要简历FILE结构体,根据我们学习到的内容,有文件描述符fd,缓冲区。
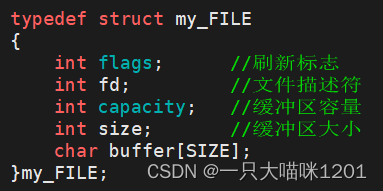
同样需要一个刷新策略标志,用32位中的3个比特来表示无缓冲,行缓冲,全缓冲。
这里仅仅是模拟一个缓冲区,实际的缓冲区肯定不是一个数组。
打开文件函数:
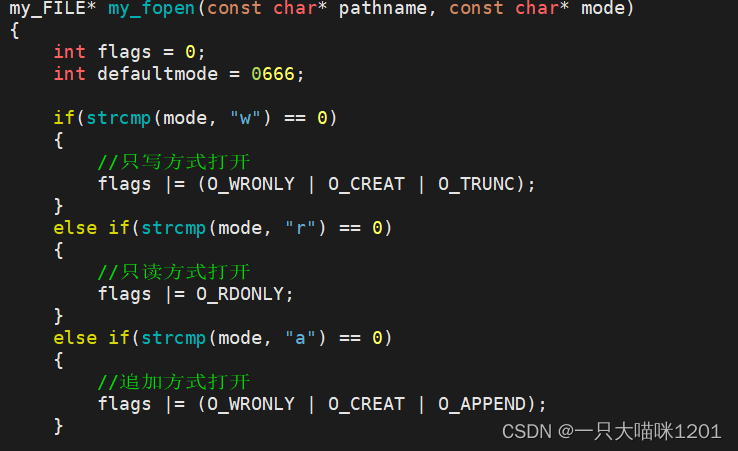
对于不同的打开方式,给打开标志flags不同比特位赋值,如上图中代码。
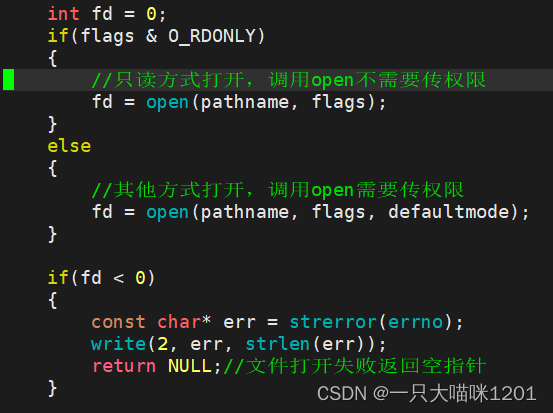
只读方式打开的话,调用只有两个参数的系统调用open,其他以写方式打开时,调用有三个参数的open。从这里也可以看出,无论上层语言是什么,打开文件时最终都会调用系统调用open函数。
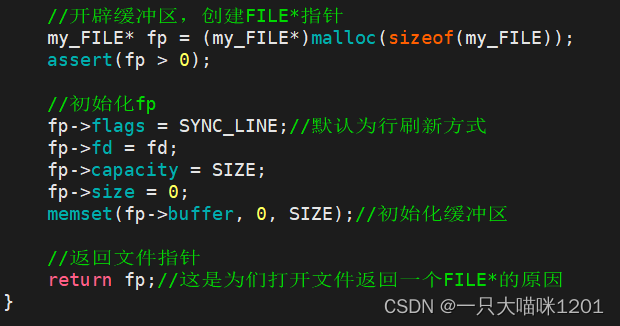
将文件成功打开以后,对我们自定义的my_FILE结构体初始化。
- 结构体中的刷新方式默认采用行缓冲方式。
- 将使用系统调用open返回的文件描述符fd赋值给结构体中的fd。
- 将缓冲区(数组)进行初始化。
最后返回动态开辟的my_FILE指针。
写入函数:
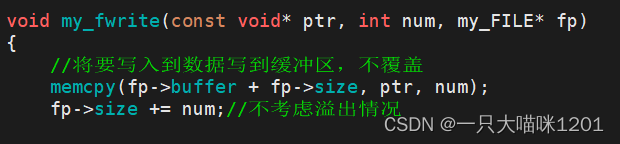
无论写入到内容是什么,都要放在my_FILE结构体中的缓冲区中。
- 这里使用了memcpy函数,从这里可以看出:
- 使用write系统调用后,与其认为将数据写入到了文件中,不如认为是将数据复制到了文件中。
- 与其认为write是一个写入函数,不如认为它是一个复制函数。
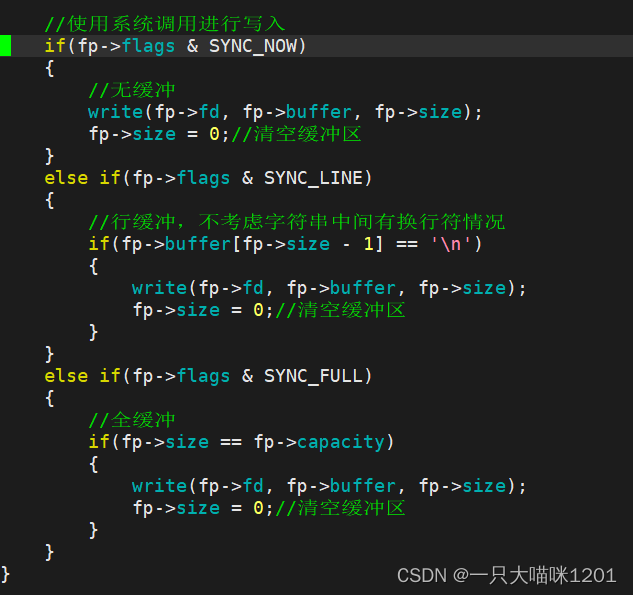
根据设定的不同刷新策略,将my_FILE结构体中缓冲区里的数据通过系统调用write写到Linux内核中,也就是写到文件中。
缓冲区刷新函数:
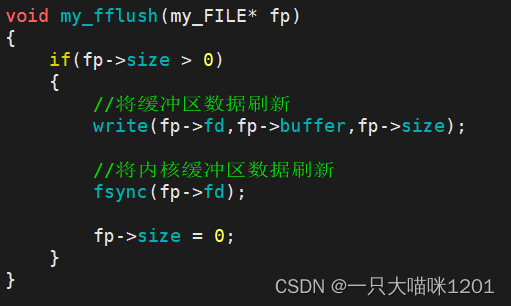
如果缓冲区中有数据,调用该函数时,立刻将缓冲区中的数据写到Linux内核中。再将内核中的数据写入到文件中。
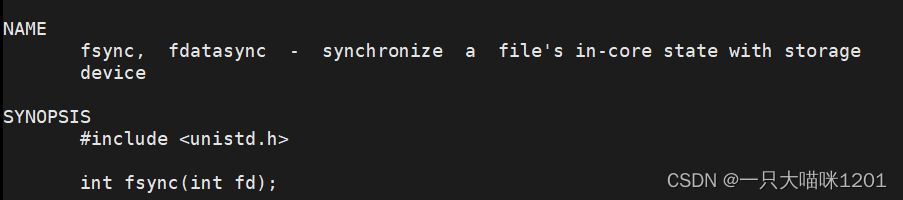
这里调用了一个fsync函数,该函数的作用就将内核缓冲区中的数据刷新到文件描述符fd所执行的文件中。
- 我们使用系统调用write时,其实是将数据写入到了内核缓冲区中,而不是直接写入到了文件中。
- 操作系统会将内核缓冲区中的数据再写入到文件中。
这里使用该函数来强制刷新内核缓冲区中的数据,而没有让操作系统自主去刷新数据,是为了防止内核缓冲区中的数据还没有刷新出去的时候系统就宕机了,此时会导致数据的丢失。
至于操作系统是如何将内核缓冲区中的数据刷新到文件中的,这是操作系统的事情了,我们不需要再了解,我们要掌握的是用户层语言所维护的缓冲区。
文件关闭函数:
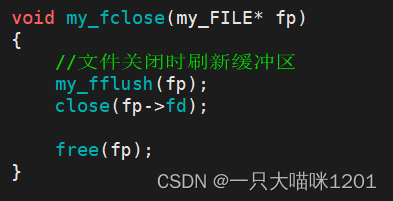
在关闭文件时,将缓冲区中的数据刷新到内核中,然后再通过系统调用关闭文件描述符所指向的文件。最后再释放my_FILE结构体,以防造成内存泄露。
验证:
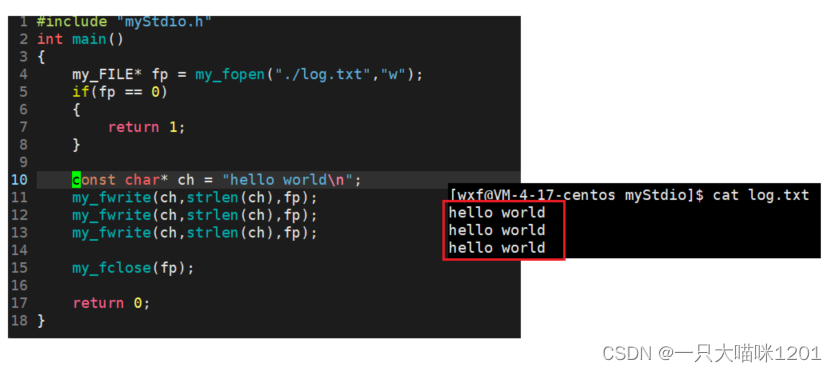
可以看到,使用我们自己模拟的fwrite函数,可以实现和C接口一样的功能。
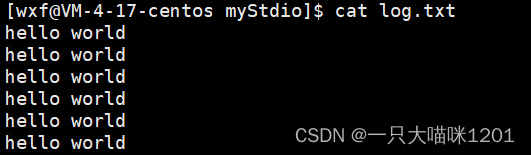
同样也可以实现追加。
☕理解文件系统
在前面我们一直学习到都是被打开的文件和进程间的关系。事实上除了被打开的文件,还有需要没有被打开的文件,这些没有被打开的文件,它们放在哪里呢?又是如何被管理的呢?
- 没有被打开的文件都静静的在磁盘上放着。
- 磁盘上有大量的文件,都被管理着,方便我们随时打开。
要想了解文件时如何被管理的,就需要对磁盘有一定的认识。
🧃认识磁盘
物理结构:
磁盘属于外设,是一个机械结构,所以相对CPU,内存而言,它相当的慢。

来看它的物理结构,如上图所示,之所以叫做磁盘,是因为它是盘状的,而且不止一片,有很多片叠放在一起。
- 主轴和马达电机:在主轴上套着多张盘片,它们和轴相固定,通过马达电机来驱动这些盘片一起转动。
- 磁头:每一张盘片都有两个盘面,每一个盘面上都有一个磁头,该磁头是用来向磁盘中读写数据的。多个磁头也是叠放在一起的,它们的运动是一致的。
- 音圈马达:该马达驱动磁头组进行摆动,它可以从盘片的内圈滑到外圈,再结合盘片自身的转动,从而向磁盘读写数据。
存储结构:
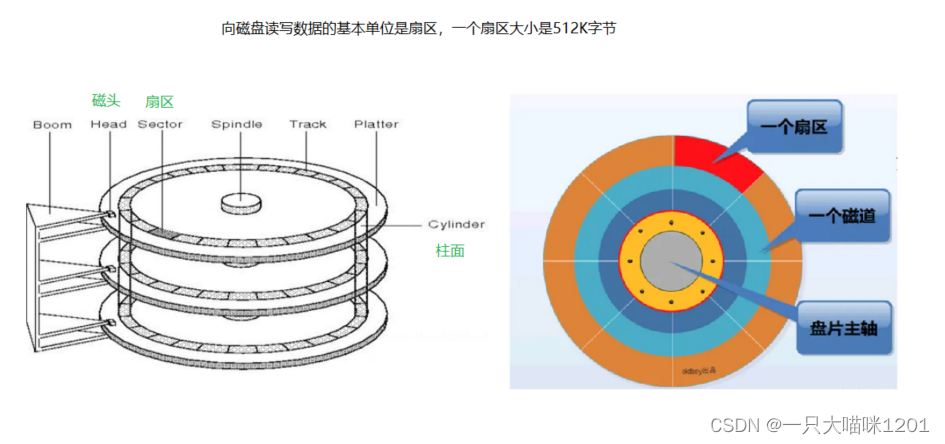
- 磁头:向磁盘中读写数据,如上图中有三个盘片,那么就有六个磁头,给它编号从0到5。
- 柱面:从俯视图中来看,一个盘面可以看做是多个同心圆,每一个同心圆被叫做一个磁道,一叠盘片中的相同磁道所组成的圆柱就这里的柱面,从内到外给柱面编号从0到3。
- 扇区:在俯视图中,以相同圆心角将盘片分为多个扇形,每个扇形和每个磁道相交产生的区域就被叫做扇区。一个盘面上每个磁道所包含的扇区个数是相同的,同样给每个扇区编号。
每个扇区的大小是512K字节,所以内磁道的扇区密度高,外磁道的扇区密度低。
这样一来,我们就可以定位任意一个扇区,然后进行读写数据。比如,0号磁头,0号柱面,0号扇区,此时,磁头就会摆动到0号柱面处,当0号磁头对应的盘面中的0号磁道里的0号扇区旋转到磁头位置时,就可以向磁盘中读写数据。
这种定位方法称为CHS定位法。
逻辑结构:

每个磁面上都有多个磁道,每个磁道上有多个扇区,类比磁带,扇区就可以看成一圈一圈缠绕在一起的。
- 将缠绕在一起的扇区,像拉磁带一样全部拉出来,拉成一条直线。
- 多个磁面可以拉成多个直线,将所有面拉成的直线首尾相连组成一条长直线。
- 这条长直线可以看成一个数组,这个数组是以扇区为单位的,所以每个数组元素的大小是512K。
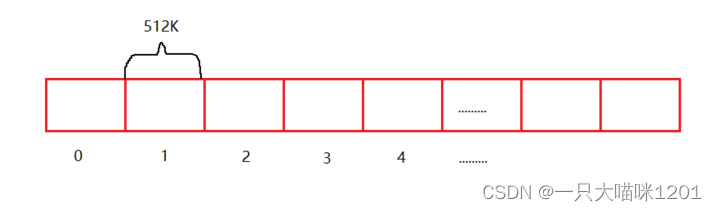
此时,磁盘就被我们抽象成了上图所示的数组,并且给每一个扇区进行编号。站在操作系统的角度,操作系统访问这个数组就是在访问磁盘。
那么这个数组的下标是怎么和磁盘的CHS对应起来的呢?

如上图所示,可以根据给定的逻辑数组下标转换成CHS定位法,定位到磁盘上具体的某个扇区。
- 其中,数组的下标被叫做逻辑块地址,简称LBA。操作系统使用的就是逻辑块地址来访问磁盘的。
采用LBA而不用CHS的原因:
- 便于管理,因为数组管理起来更加方便。
- 不想让操作系统的代码和硬件强耦合。
🧃文件管理
操作系统看到的磁盘就是一个数组,这个数组每个元素的大小是512K字节(一个扇区),同样我们也知道,每次向磁盘中读写数据都很耗费时间。
- 为了提高效率,磁头每次访问磁盘的基本单位是4KB(绝大多数情况下)。
- 即使访问磁盘的一个bit,磁头也是将包过这一个bit在内的周围4KB大小的数据加载到内存。
正因为磁头每次访问的是4KB大小的数据块,所以内存也被划分成了多个4KB大小的空间,每一个空间被叫做页框。
同样的,磁盘中的文件,尤其是可执行文件,也被划分成了多个4KB大小的数据块,每一个块被叫做页帧。
假设现在有一个500GB大小的磁盘,操作系统如果统一管理的话成本会很高,所以采用分治的思想来管理整个磁盘。
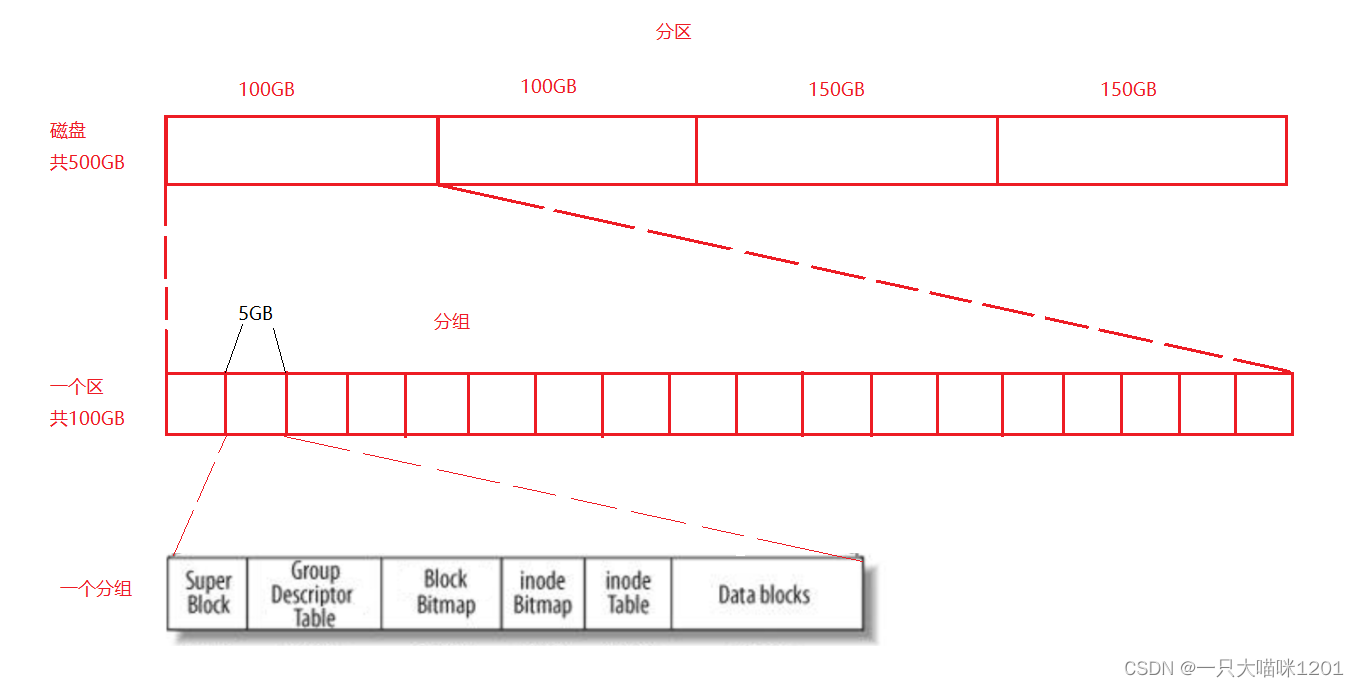
- 将500GB的磁盘分成4个区,只需要管理好一个区,其他三个区便可以复用这套方法。
- 再将每个区分为多个组,只需要管理好一个组,其他剩下的组便可以复用这套方法,从而管理好这个区。
每个分区以及每个分组是多大要看具体情况。
这种思想有点像递归的思想,所以我们要学习到重点就是如何管理好一个组。
最小分组的管理

每个分组中又分为这6个区域。
- Super Block:文件系统的属性信息,整个分区属性的属性集,多个组都有 ,但不一定是每个组都有。是为了防止磁盘被刮伤而找不到文件属性。
- inode Table:存放了这个分组中所有的inode(已经使用的和没有使用的),每个分组中inode的个数是确定的。
- inode Bitmap:inode位图,该分组中有多少个inode,这个位图就有多少个bit,并且每一个比特位都与一个inode一一对应。每使用一个inode,对应的位图就会被置1。
- Data blocks:保存这该分组内,所有文件的内容,该块区又被分为多个数据块。
- Block Bitmap:数据块位图,该分组的Data blocks中有多少个数据块,这个位图就有多少个bit,并且每一个比特位都和一个数据块一一对应。每使用一个数据块,对应的位图就会被置1。
- GDT描述表:记录该分组中inode和数据块的使用率等宏观属性。
这样来看肯定是一头雾水,下面本喵继续来解释。
文件 = 属性 + 内容,所以在磁盘上管理一个文件,也要管理它的属性和内容,而文件的属性就放在一个叫inode的结构体中,文件的内容就放在数据块中。
文件属性存储:
struct inode
{int id;mode_t mode;size;.......//多种属性int blocks[15];
}
一个文件的所有属性都在inode中,但是唯独没有文件名。
查找一个文件的时候,统一使用的是:inode编号。
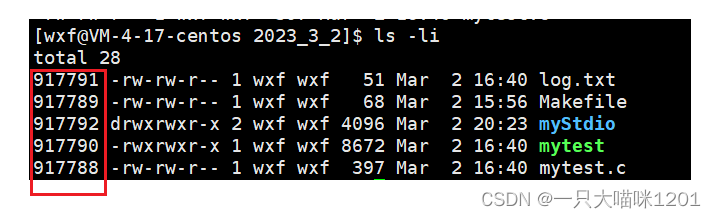
可以看到,每个文件都有一个独一无二的编号,这就是inode编号,这个编号其实就是一个结构体对象。
每创建一个文件,就会在inode Table中申请一个未被使用的inode,并且将对应的位图置1。
- 每一个inode的大小都是128B,并且每个分组中inode的个数都是固定的。
文件内容存储:
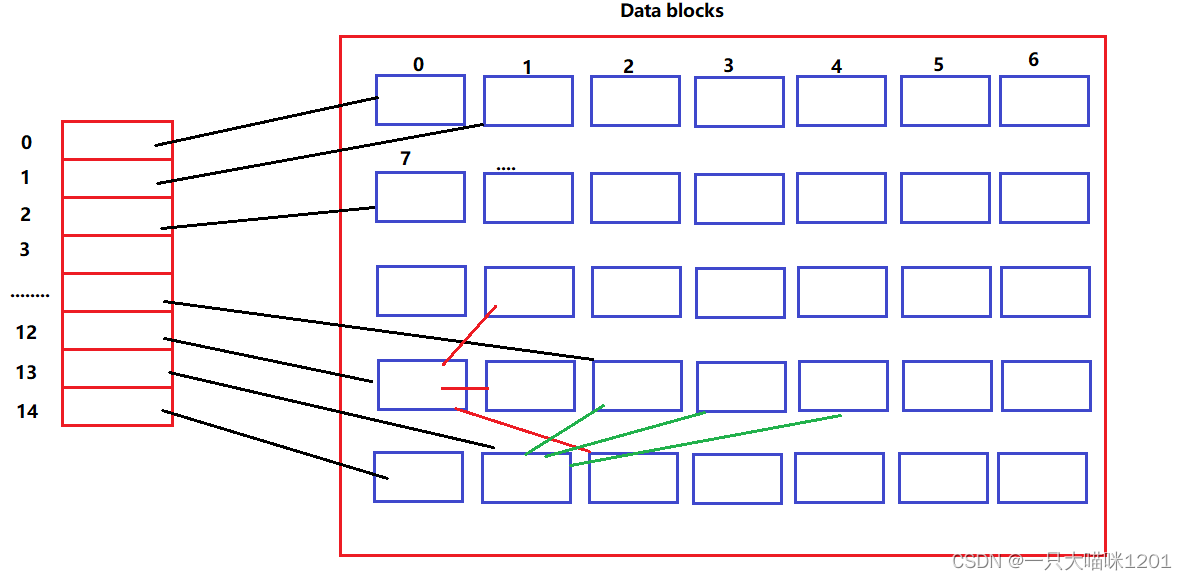
文件的内存就存储在这个Data blocks中,而这个块区中又有多个数据块,并且有相应的编号。
现在属性被存放好了,内容也被存放好了,下面就是将一个文件的属性和内容对应起来。
inode结构体中的数字blocks[15]就是干这个事情的。
- 数组中每个元素存放着一个一个数据块的block id(编号)。
- 每个数据块中存放着内容数据。
一个文件对应着一个ionde,该文件的内容存放在多个数据块中,所以inode中的数组中记录着这些数据块的block id。
这个数组一共才能放15个编号,如果这个文件的内容有很多呢,需要很多的数据块(超出了15个)呢?
数组最后的三个位置,下标为12,13,14,它们存放的数据块编号所指向的数据块中存放的不是文件内容,同样是属于该文件数据块的编号。
虽然一个数组中的一个元素只能存放一个数据块的下标,但是指向的数据块中可以存放多个数据块的下标,这样一来,再大的文件也能存放的下。
- 每使用一个数据块,就会将它所对应的位图置1。
现在我们知道了文件在磁盘上是如何存放的,以及操作系统是如何管理它们的。根据前面所讲,inode是文件的唯一标识,但是我们在使用文件的时候并没有使用inode啊,我们使用的是文件名,这是为什么?
- 一个目录中,可以包含多个文件,但是这些文件的名字不能重。
- 目录也是文件,它也有自己的inode,也有自己的数据块。
目录的data blocks中存放的是:它所包含文件的文件名和inode之间的映射关系。
所以我们在使用一个文件的文件名时,就会自动映射到它的inode,本质上还是在使用一个文件的inode。
此时我们就清楚了为什么inode中包含文件的所有属性,但是就是没有文件名了,因为文件的文件名和它对应的inode存在上级目录的data blocks中。
🧃操作未被打开文件
创建文件:
- 在创建文件的时候,会向inode Table中申请为被使用的inode,并且将相应的inode Bitmap置1,然后将该文件的各种属性存入到inode中。
- 还会将这个文件的文件名和inode的映射关系写入到上级目录的data blocks中。
向文件中写入:
- 根据文件名和inode的映射关系,找到文件对应的inode。
- 根据inode中blocks数组,找到存放文件内容的数据块进行数据的写入,如果发生数据块数量上的变化,还要将对应的Blocks Bitmap位图的相应位改变。
- 再改变inode中对应的属性信息。
读取文件内容:
- 根据文件名和inode的映射关系,找到文件对应的inode。
- 再从inode中找到文件对应的数据块。
- 将数据块中内容加载到内存中供进程使用。
文件删除:
- 根据文件名和inode的映射关系,找到文件对应的inode。
- 再根据inode找到数据块所对应的Blocks Bitmap,将对应位清0。
- 最后再将inode对应的inode Bitmap清0。
文件的删除并不会去清理磁盘上数据块中的内容,只是将对应的位图清0,后续再来的内容进行覆盖就可以。这也是为什么拷贝一个文件比较慢,但是删除一个文件很快的原因。
- 当你误删一个文件的时候,最好的做法就是什么都不要做,只要对应的inode和data blocks没有被覆盖,这个文件时可以恢复的。
如此一来,磁盘的一个分组就能被操作系统井井有条的管理好了,这也意味着整个磁盘也就被管理好了。
☕总结
在平时我们看不见摸不着的缓冲区,此时便揭下了它神秘的面纱,它的位置,刷新策略,以及因为它而导致的种种异常现象,此时便都明白了。虽然文件系统的讲解更多的是理论,但是这对于我们更好的理解文件系统有很大的帮助,尤其是每个分组中的那个六个区域至关重要。
相关文章:
【Linux学习】基础IO——理解缓冲区 | 理解文件系统
🐱作者:一只大喵咪1201 🐱专栏:《Linux学习》 🔥格言:你只管努力,剩下的交给时间! 基础IO☕理解缓冲区🧃缓冲区的共识🧃缓冲区的位置🧃缓冲区的刷…...

RHCSA-重置root密码(3.3)
方法1:rd.break (1)首先重启系统,在此页面按e键,在屏幕上显示内核启动参数 (2)知道linux这行,末尾空格后输入rd.break,然后按ctrlx (3)查看&#…...
无公网IP快解析实现U+随时随地访问
现阶段商品从生产到消费者手中要经过多个环节,为实现对每一个环节进行管理,越来越多的企业选择通过信息化手段来实现。供应链管理系统配合供应链中各实体的业务需求,使操作流程和信息系统紧密配合,做到各环节无缝链接,…...

UVa 307 Sticks 木棍拼接 ID 迭代加深搜
题目链接:Sticks 题目描述: 小明一开始有一些长度相等的木棍,小明现在将木棍砍成了一些长度为整数的木棍,他现在忘记了最开始木棍的长度,你需要找到最短的可能木棍长度,例如给定5,2,1,5,2,1,5,2,15,2,1,5,2…...
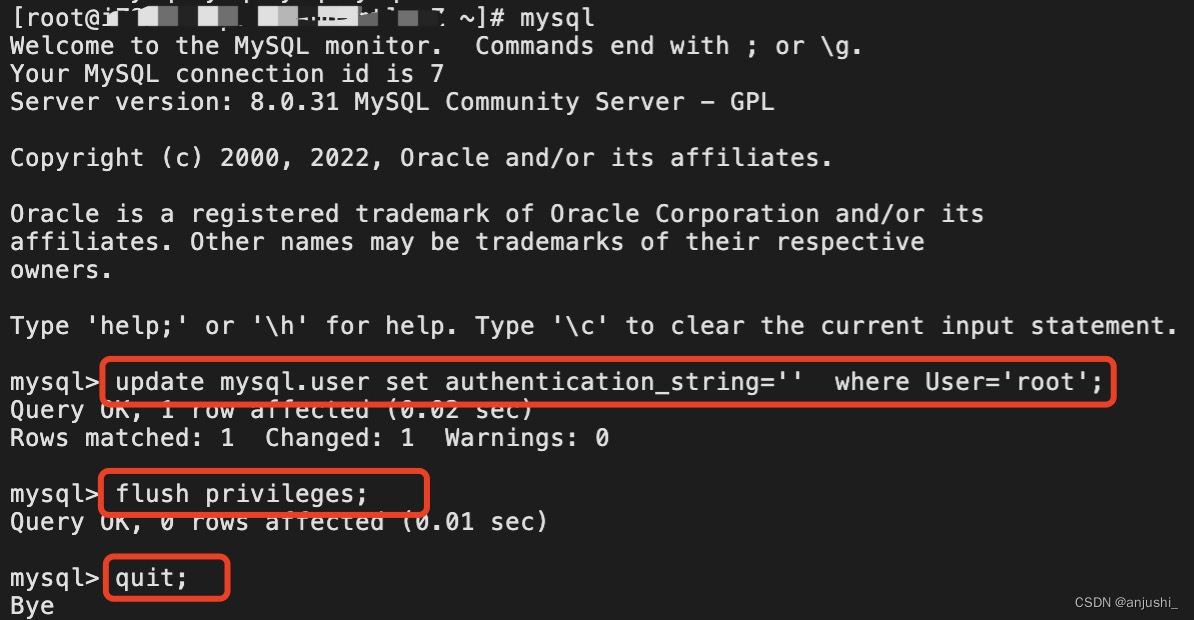
阿里云(CentOS)中MySQL8忘记密码的解决方法
阿里云(CentOS)中MySQL8忘记密码的解决方法 方法 在 skip-grant-tables 模式下启动 MySQL,该模式下启动 MySQL 时不启动授权表功能,可以直接免密码登录 实现 编辑 /etc/my.cnf 文件 vim /etc/my.cnf在 [mysqld] 区域末尾添加配置,设置免密…...
三、Spring的入门程序
第一个Spring程序 创建新的空工程spring6 设置JDK版本17,编译器版本17 设置IDEA的Maven:关联自己的maven 在空的工程spring6中创建第一个maven模块:spring6-001-first 在pom.xml添加spring context依赖和junit依赖, <?x…...
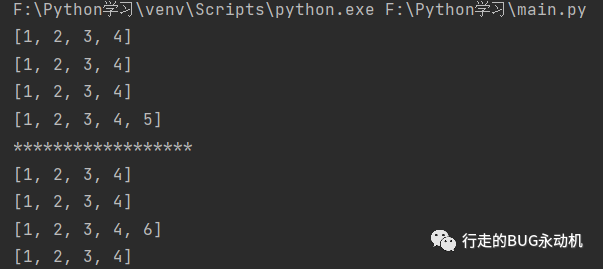
摘录一下Python列表和元组的学习笔记
1 基础概念 列表一个值,列表值指的是列表本身,而不是列表中的内容 列表用[]表示 列表中的内容称为 表项 len()函数可以显示列表中表项的个数,比如下面这个例子 spam [cat, bat, dog, rat]print(len(spam))列表的范围选取中,比…...

【量化金融】收益率、对数收益率、年华收益、波动率、夏普比率、索提诺比率、阿尔法和贝塔、最大回撤
【量化金融】收益率、对数收益率、年华收益、波动率、夏普比率、索提诺比率、阿尔法和贝塔、最大回撤 1 收益率 在学术界,建模一般不直接使用资产价格,而是使用资产收益率(Returns)。因为收益率比价格具有更好的统计特性,更便于建模。下经典…...
1_机器学习概述—全流程
文章目录1 机器学习定义2 机器学习常见应用框架(重点)3 机器学习分类3.1 监督学习(Supervised learning)3.2 无监督学习(Unsupervised learning)3.3 半监督学习(Semi-Supervised Learning&#…...

VUE中给对象添加新属性时,界面不刷新怎么办
一、直接添加属性的问题 举例: 定义一个p标签,通过v-for指令进行遍历 然后给botton标签绑定点击事件,我们预期点击按钮时,数据新增一个属性,界面也 新增一行。 <p v-for"(value,key) in item" :key&qu…...

视频号频出10w+,近期爆红的账号有哪些?
回顾2月,视频号持续放出大动作,不仅进行了16小时不间断的NBA全明星直播,还邀请国际奥委会入驻,分享奥运的最新资讯。视频号成为越来越多官方机构宣传推广的有效渠道。官方积极入驻,内容创作生态也在同步繁荣发展&#…...
企业寄件现代化管理教程
现代化企业为了跟上时代发展的步伐,在不断完善着管理制度,其中公司寄件管理,也是重要的一个模块。为了提高公司快递的寄件效率,以及节约寄件成本,实现快递寄件的规范化,越来越多的现代化企业,开…...

django 在网页显示后台进度
1、定义函数打开网页 def PeformanceIndex(request): citys{‘wuhu’: ‘芜湖’, ‘xuancheng’: ‘宣城’, ‘tongling’: ‘铜陵’, ‘suzhou’: ‘宿州’, ‘maanshan’: ‘马鞍山’, ‘liuan’: ‘六安’, ‘huainan’: ‘淮南’, ‘huabei’: ‘淮北’, ‘hefei’: ‘合肥…...
)
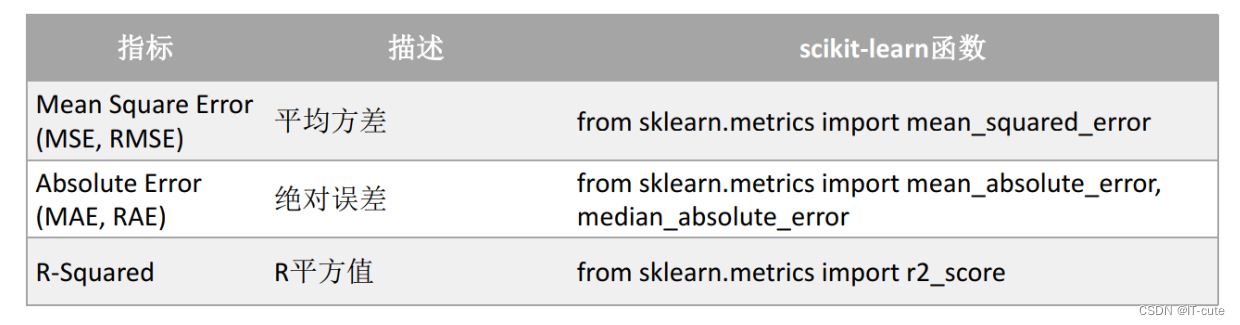
机器学习库(Numpy, Scikit-learn)
Numpy 创建数组 import numpy as npa np.array([1,2,3]) b np.array([(1.5,2,3), (4,5,6)], dtype float) c np.array([[(1.5,2,3), (4,5,6)], [(3,2,1), (4,5,6)]],dtype float)创建占位符 z1np.zeros((3,4)) z2np.ones((2,3,4),dtypenp.int16) z3d np.arange(10,25,5)…...

Linux操作系统学习(进程替换)
文章目录进程替换进程替换是什么?替换的方法进程替换简易shell模拟进程替换 进程替换是什么? 如下图所示: 进程替换就是,把进程B的代码和数据,替换正在执行的进程A的代码和数据在内存中的位置(若代码…...

【C++从入门到放弃】类和对象(中)———类的六大默认成员函数
🧑💻作者: 情话0.0 📝专栏:《C从入门到放弃》 👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢! 类和对…...

白盒测试重点复习内容
白盒测试白盒测试之逻辑覆盖法逻辑覆盖用例设计方法1.语句覆盖2.判定覆盖(分支覆盖)3.条件覆盖4.判定条件覆盖5.条件组合覆盖6.路径覆盖白盒测试之基本路径测试法基本路径测试方法的步骤1.根据程序流程图画控制流图2.计算圈复杂度3.导出测试用例4.准备测试用例5.例题白盒测试总…...

【13】linux命令每日分享——groupadd建立组
大家好,这里是sdust-vrlab,Linux是一种免费使用和自由传播的类UNIX操作系统,Linux的基本思想有两点:一切都是文件;每个文件都有确定的用途;linux涉及到IT行业的方方面面,在我们日常的学习中&…...
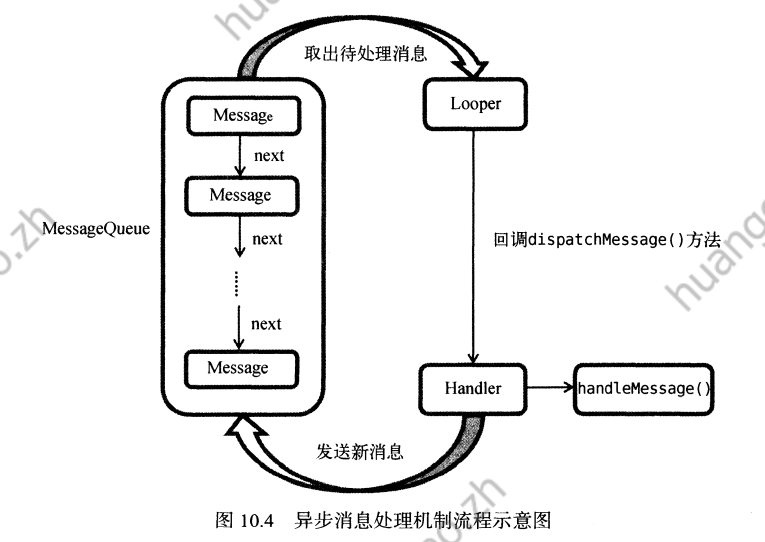
《第一行代码》 第十章:服务
一,在子线程中更新UI 1,新建项目,修改布局代码 <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"&g…...
简单介绍编程进制
十进制 十进制的位权为 10,比如十进制的 123,123 1 * 10 ^ 2 2 * 10 ^ 1 3 * 10 ^ 0。 二进制 二进制的位权为 2,比如十进制的 4,二进制为 100,4 1 * 2 ^ 2 0 * 2 ^ 1 0 *2 ^ 0。 Java7 之前,不支…...

别等审计通报才行动:MCP OAuth 2026强制合规窗口仅剩89天,这份含12个可执行checklist的速通手册已内部封存
第一章:MCP OAuth 2026强制合规的底层逻辑与倒计时警讯MCP(Multi-Cloud Provider)OAuth 2026规范并非演进式升级,而是由全球主要云服务商联合签署的强制性互操作协议,其核心驱动力源于监管层面对身份联邦治理失效的系统…...

第 2 章 应用层 总述|《计算机网络:自顶向下方法》精读版
本文是计算机网络经典教材精读系列的第二章,承接第一章因特网总述,正式进入自顶向下的核心学习路径 —— 从用户最直观接触的应用层出发,拆解网络应用的工作原理、通信范式与核心协议,搭建应用层完整知识框架。一、应用层定位&…...

公考图形推理实战:从基础规律到快速解题技巧
1. 图形推理基础规律全解析 图形推理作为公考判断推理的必考题型,考察的是考生对图形特征的敏感度和规律提取能力。我刚开始备考时经常被各种图形绕晕,后来发现只要掌握核心规律体系,80%的题目都能快速破解。下面就把我实战总结的六大基础规律…...

AI股票分析师Web前端开发:Vue3实战
AI股票分析师Web前端开发:Vue3实战 1. 引言 每天盯着股票行情软件,在密密麻麻的K线图和数字中寻找投资机会,是很多投资者的日常。但传统股票软件往往只提供数据,不提供洞察——它们告诉你"价格是多少",却不…...

快速搭建Python3.10开发环境:Miniconda镜像实战体验分享
快速搭建Python3.10开发环境:Miniconda镜像实战体验分享 1. 为什么选择Miniconda-Python3.10镜像 Python作为当今最流行的编程语言之一,版本管理一直是开发者面临的挑战。传统Python安装方式存在以下痛点: 版本冲突:系统预装Py…...

MT5 Zero-Shot中文数据增强效果展示:10组高质量 paraphrasing 实际案例
MT5 Zero-Shot中文数据增强效果展示:10组高质量 paraphrasing 实际案例 1. 引言:当AI学会“换句话说话” 你有没有遇到过这样的场景?写了一段文案,总觉得表达不够丰富;训练一个模型,却发现数据太单一&…...

2025_NIPS_Scaffolding Dexterous Manipulation with Vision-Language Models
文章主要内容总结 该研究提出一种结合视觉语言模型(VLMs)与强化学习(RL)的灵巧机器人操作框架,核心是用VLM生成粗粒度运动轨迹(“支架”),指导低层级残差RL策略完成复杂操作任务。框架无需人工演示或手工设计奖励函数,通过自然语言指令和场景图像,让VLM识别任务相关…...

OpenClaw技能扩展:基于GLM-4.7-Flash开发自定义自动化模块
OpenClaw技能扩展:基于GLM-4.7-Flash开发自定义自动化模块 1. 为什么需要自定义技能? 去年冬天,我发现自己每周都要重复处理几十份客户反馈表——从邮件下载附件、提取关键字段、整理成Excel再发给团队。当我第三次在深夜加班做这项工作时&…...

乙巳马年·皇城大门春联生成终端W一键部署教程:3步完成NodeJS环境配置
乙巳马年皇城大门春联生成终端W一键部署教程:3步完成NodeJS环境配置 最近在星图GPU平台上看到了一个挺有意思的AI镜像,叫“乙巳马年皇城大门春联生成终端W”。名字听着挺有年味儿,功能也直接,就是帮你生成春节对联。对于想快速体…...

无电软触摸板:气动传感技术突破极端环境限制
坦佩雷大学的研究人员开发出了全球首款无需电力即可感知接触力、面积和位置的软性触摸板。该设备利用气动通道,使其能够在磁共振成像仪等不适合电子设备的环境中使用。软体机器人和康复辅助设备等软性装置也能受益于这项新技术。 这款触摸板完全由软硅胶制成&#x…...