MySQL 中的锁有哪些类型,MySQL 中加锁的原则
锁的类型
MySQL 找那个根据加锁的范围,大致可以分成全局锁,表级锁和行级锁。
全局锁
全局锁,就是对整个数据库加锁。
加锁
flush tables with read lock解锁
unlock tables全局锁会让整个库处于只读状态,之后所有的更新操作都会被阻塞:
数据更新语句(数据的增删改);
数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
缺点
如果对主库加锁,那么执行期间就不能执行更新,业务基本上就停摆了;
如果对从库加锁,那么执行期间,从库就不能执行主库同步过来的 binlog,会导致主从延迟。
适用范围
全局锁的典型使用场景是,做全库逻辑备份。也就是把整库每个表都select出来存成文本。
不过为什么要在备份的时候加锁,不加锁的话,备份系统备份的得到的库不是一个逻辑时间点,这个视图是逻辑不一致的。
官方自带的逻辑备份工具是 mysqldump。当 mysqldump 使用参数 –single-transaction 的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。
对于 MyISAM 这种不支持事务的引擎,mysqldump 工具就不能用了,所以 全局锁 虽然缺点很多,但是还是有存在的必要。
表级锁
MySQL 中的表级别的锁包括:表锁,元数据锁(meta data lock,MDL)。
比如 InnoDB 中的意向锁和自增锁(AUTO-INC Locks)也都是表级别的锁。
下面来一一分析下
表锁
表锁,就是会锁定整张表,它是 MySQL 中最基本的锁策略,并不依赖于存储引擎,被大部分的 MySQL 引擎支持,MyISAM 和 InnoDB 都支持表级锁,由于表级锁一次会将整个表锁定,所以可以很好的避免死锁问题。当然,锁的粒度大所带来最大的负面影响就是出现锁资源争用的概率也会最高,导致并发率大打折扣。
表级别的锁,和全局锁一样可以使用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放锁。
加锁
// 表级别的共享锁,也就是读锁lock tables t1 read// 表级别的排它锁,也就是写锁 lock tables t1 write释放锁
unlock tables表锁除了会限制其它线程的读写,还会限制当前线程接下来的操作。
如果一个线程加了表级别的读锁,其他线程对该表的写操作,都会被阻塞,同时当前线程接下来对该表的写入操作也不能执行,会报错当前表有一个读锁,直到表锁的读锁被释放。
元数据锁
MDL(metadata lock) 元数据也是表级别的锁。
MDL 锁主要使用来维护表元数据的数据一致性,MDL 不需要显式使用,在访问一个表的时候会被自动加上,避免在进行读取或者写入的时候,其它线程对数据表做出修改,造成写入或者读取的结果异常。
因此,在 MySQL 5.5 版本中引入了MDL,当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查;
读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
给一个表加字段会可能会导致整个库崩掉,为什么呢?

来分析下上面的栗子
1、session A 首先启动事务,使用了一个查询,因为是查询,所以对 user 表会加一个 MDL 读锁;
2、session B 因为也是查询,所以也是加 MDL 读锁,读读不互斥,所以改该查询就正常进行了;
3、session C 是一个对表添加字段的操作,会加 MDL 写锁,因为 session A 中的读锁还没有提交,读写互斥,该线程就会被阻塞了;
4、session D 也是一个读锁,不过因为 session C 加了一个写锁,这时候 session D 的读锁会被 session C 阻塞,因为申请 MDL 锁的操作会形成一个队列,队列中写锁获取优先级高于读锁,一旦出现 MDL 写锁等待,会阻塞后续该表的所有 CRUD 操作。这样后面申请 MDL 读锁都会被阻塞,因为对表的增删改查操作都需要先申请MDL读锁,基本上这个表就完全不能读写了。
如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新 session 再请求的话,这个库的线程很快就会爆满。
MDL 锁会需要等到事务提交的时候才会被释放,这样在给表加字段的时候遇到一个长事务,就可能会导致数据表崩掉。
如何安全的对数据表添加字段呢?
设置 alter table 语句中的等待时间,如果在指定时间没有拿到 MDL 写锁,直接退出,不至于长时间阻塞后面的业务操作。失败,就后面多尝试几次。
意向锁
InnoDB 存储引擎支持多粒度锁,这种锁定允许事务在行级别上的锁和表级别上的锁同时存在。这种锁就是意向锁。
意向锁有两种:
1、意向共享锁:在使用 InnoDB 引擎的表里对某些记录加上「共享锁」之前,需要先在表级别加上一个「意向共享锁」;
2、意向独占锁:在使用 InnoDB 引擎的表里对某些纪录加上「独占锁」之前,需要先在表级别加上一个「意向独占锁」;
意向锁的作用?
意向锁是放置在资源层次结构的一个级别上的锁,以保护较低级别资源上的共享锁或排它锁。
意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,同时意向锁之间也不会发生冲突。只会和表级别的共享锁和表级独占锁发生冲突。
意向锁是 InnoDB 自动加的,不需要用户干预。这样一个事务在表中一些记录加独占锁,InnoDB 就会自动加表级别的意向锁独占锁,这样其他的事务如果对该表加表级别的独占锁,就不用遍历表里面的记录,通过表级别的意向锁直接就能判断当前事务是够会被阻塞了。
简单的讲就是意向锁是为了快速判断,表里面是否有记录被加锁。
自增锁
自增锁(AUTO-INC)是一种表级锁,专门针对插入 AUTO_INCREMENT 类型的列。可以该列的值,数据库会自动赋值自增的值,这主要就是通过自增锁实现的。一般会在主键中设置 AUTO_INCREMENT。
自增锁(AUTO-INC)采用的是一种特殊的表锁机制,为了提高插入的性能,锁不是在一个事务完成后才释放,而是在完成是自增长值插入的 SQL 语句后立即释放。
不过自增锁(AUTO-INC)在进行大量插入的时候,另一个事务中的插入会被阻塞。从 MySQL 5.1.22 版本开始,InnoDB 提供了一种轻量级互斥的自增实现机制,大大提高了自增插入的性能。
通过 innodb_autoinc_lock_mode 来控制锁的类型。
innodb_autoinc_lock_mode | 说明 |
0 | 采用 AUTO-INC 锁,执行语句结束后释放锁,这种方式锁粒度大,比较重 |
1 | 针对批量插入采用 AUTO-INC 锁,针对简单插入采用轻量级的互斥锁,如果当前有事务进行批量的数据插入,后面的简单插入需要等待前面 AUTO-INC 锁的释放才可以插入,这种方式可以保证同一 insert 语句插入的自增 ID 都是连续的 |
2 | 所有的插入操作都使用轻量的互斥锁,锁的粒度小,多条语句插入存在竞争,自增长的值可能不连续 |
不过当 innodb_autoinc_lock_mode = 2 搭配 binlog 的日志格式是 statement 一起使用的时候,在主从复制的场景中会发生数据不一致的问题。下面来分析下
首先来看下 binlog 的格式
binlog 有三种格式:
1、Statement(Statement-Based Replication,SBR):每一条会修改数据的 SQL 都会记录在 binlog 中,里面记录的是执行的 SQL;
Statement 模式只记录执行的 SQL,不需要记录每一行数据的变化,因此极大的减少了 binlog 的日志量,避免了大量的 IO 操作,提升了系统的性能。
正是由于 Statement 模式只记录 SQL,而如果一些 SQL 中包含了函数,那么可能会出现执行结果不一致的情况。
比如说 uuid() 函数,每次执行的时候都会生成一个随机字符串,在 master 中记录了 uuid,当同步到 slave 之后,再次执行,就获取到另外一个结果了。
所以使用 Statement 格式会出现一些数据一致性问题。
2、Row(Row-Based Replication,RBR):不记录 SQL 语句上下文信息,仅仅只需要记录某一条记录被修改成什么样子;
Row 格式的日志内容会非常清楚的记录下每一行数据修改的细节,这样就不会出现 Statement 中存在的那种数据无法被正常复制的情况。
比如一个修改,满足条件的数据有 100 行,则会把这 100 行数据详细记录在 binlog 中。当然此时,binlog 文件的内容要比第一种多很多。
不过 Row 格式也有一个很大的问题,那就是日志量太大了,特别是批量 update、整表 delete、alter 表等操作,由于要记录每一行数据的变化,此时会产生大量的日志,大量的日志也会带来 IO 性能问题。
3、Mixed(Mixed-Based Replication,MBR):Statement 和 Row 的混合体。
在 Mixed 模式下,系统会自动判断该用 Statement 还是 Row:一般的语句修改使用 Statement 格式保存 binlog;对于一些 Statement 无法准确完成主从复制的操作,则采用 Row 格式保存 binlog。
下面分析下 当 innodb_autoinc_lock_mode = 2 搭配 binlog 的日志格式是 statement 一起使用的时候,在主从复制的场景中为什么会发生数据不一致。
CREATETABLE `t` (`id` int(11) NOTNULL AUTO_INCREMENT,`c` int(11) DEFAULTNULL,`d` int(11) DEFAULTNULL,PRIMARY KEY (`id`),UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB;session A | session B |
insert into t values(null,1,1) insert into t values(null,2,2) insert into t values(null,3,3) insert into t values(null,4,4) | |
create table t2 like t; | |
insert into t2 values(null,5,5) | insert into t2(c,d) select c,d from t; |
分析下上面语句的执行
首先 session A 先写入了4条数据,然后 session B 创建了相同的 t2 表。
接下来 session A 和 session B 在相同的时刻写入数据到表 t 中。
因为 innodb_autoinc_lock_mode = 2 插入语句在申请万自增主键之后就会马上释放自增锁,不需要等待插入语句执行完成。
那么就可能出现下面的情况
1、session B 首先插入语句 (1,1,1),(2,2,2),(3,3,3);
2、session A 申请到了自增的 id = 4,插入数据 (4,5,5);
3、session B 继续执行插入数据 (5,4,4)。
这样看下来没什么影响,表 t 中的数据也都插入到了 t2 中,只是主键 ID 有点不同。
当 binlog_format=statement 的时候在来看下 binlog 是如何同步从库的数据。
因为两个 session 是同时插入数据的,binlog 对表 t2 的更新日志只会有两种情况,先记录 session A 的或者先记录 session B 的,同时 binlog 在从库中的数据执行,也都是顺序性的,生成的id都是连续的,不会出现主库中,两个 session 并行间隙插入的情况,这样就会出现从库和主库数据不一致的情况。
如何解决呢?可以设置 binlog 的类型为 row,这样 binlog 会把插入数据的操作都如实记录进来,到备库执行的时候,不再依赖于自增主键去生成,同时 innodb_autoinc_lock_mode 设置为 2。
对于普通的 insert 语句里面包含多个 value 值,即使 innodb_autoinc_lock_mode 设置为 1,也不会等语句执行完成才释放锁。因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。
对于批量的数据插入,类似 insert … select、replace … select和 load data 语句。这种是不能这样操作的,因为不知道预先要申请多少个 ID。
批量的数据插入,如果一个个的申请 id,不仅速度很慢,同时也会影响插入的性能,这肯定是不合适的。
因此,对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
1、语句执行过程中,第一次申请自增id,会分配1个;
2、1个用完以后,这个语句第二次申请自增id,会分配2个;
3、2个用完以后,还是这个语句,第三次申请自增id,会分配4个;
4、依此类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍。
insertinto t values(null, 1,1);
insertinto t values(null, 2,2);
insertinto t values(null, 3,3);
insertinto t values(null, 4,4);
createtable t2 like t;
insertinto t2(c,d) select c,d from t;
insertinto t2 values(null, 5,5);insert…select,实际上往表 t2 中插入了 4 行数据。但是,这四行数据是分三次申请的自增 id,第一次申请到了 id=1,第二次被分配了 id=2 和 id=3, 第三次被分配到 id=4 到 id=7。
由于这条语句实际只用上了 4 个 id,所以 id=5 到 id=7 就被浪费掉了。之后,再执行 insert into t2 values(null, 5,5),实际上插入的数据就是(8,5,5)。
所以总结下来数据插入,主键 ID 不连续的情况大概有下面几种:
1、事务回滚,事务在执行过程中出错,主键冲突,或者主动发生回滚,会导致已经申请的自增 ID 被弃用;
2、批量数据插入的插入优化,批量数据插入 MySQL 会有一个批量的预申请自增 ID 的策略。
行锁
MySQL 的行锁是在引擎层由各个引擎自己实现的,但并不是所有的引擎都支持行锁的,比如 MyISAM 引擎就不支持行锁,InnoDB 是支持行锁的,这也是 MyISAM 被 InnoDB 替代的重要原因之一。
下面主要来介绍下 InnoDB 中的行锁。
行锁主要有下面三类:
1、Record Lock,记录锁,也就是仅仅把一条记录锁上;
2、Gap Lock,间隙锁,锁定一个范围,但是不包含记录本身;
3、Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。
Record Lock
Record Lock 记录锁,这个很好理解,比如事务 A 更新了一行,而这时候事务 B 也更新了同一行,则必须等待事务 A 的操作完成才能更新。
在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。
所以当事务中需要锁多个行,要把最可能造成锁冲突。最可能影响并发度的锁尽量往后放。
同时记录锁还分成读锁和写锁:
共享锁(S锁)也叫读锁,满足读读共享,读写互斥。
独占锁(X锁)也叫写锁,满足写写互斥、读写互斥。
如果一个事务 A 对一条数据加了读锁,那么另外一个事务 B 如果同样也加了读锁,这两个事务不会互斥,都能正常读取,如果事务 B 加的是写锁,那么事务 B 就需要等待事务 A 的读锁释放之后,才能操作加锁。
如果一个事务 A 对一条数据加了写锁,那么其他的事务对这条数据加锁,无论是读锁还是写锁都需要等待事务 A 释放才能继续加锁。
如何加锁
//对读取的记录加共享锁select ... lockin share mode;//对读取的记录加独占锁select ... for update;不过需要注意的是当一条记录被加了记录锁,其它事务如果只是简单的查询,没有使用当前读,那么是不会被阻塞的,因为会通过 MVCC 找到当前可读取的版本数据,直接返回数据即可。
Gap Lock
间隙锁(Gap Lock)是 Innodb 在可重复读提交下为了解决幻读问题时引入的锁机制。
幻读的问题存在是因为新增或者更新操作,这时如果进行范围查询的时候(加锁查询),会出现不一致的问题,这时使用普通的行锁已经没有办法满足要求,需要对一定范围内的数据进行加锁,间隙锁就是解决这类问题的。
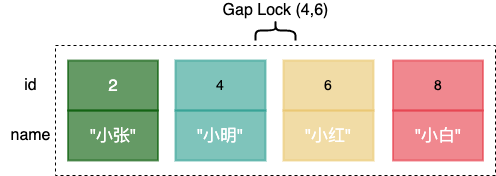
如上图,上面加了 id 范围为 (4,6) 的间隙锁 ,那么其他事务进行 id 为 5 的主键数据插入就会被阻塞,直到间隙锁被释放。
间隙锁之间是兼容的,两个事务之间可以共同持有包含相同间隙的间隙锁,同时也不存在互斥关系,间隙锁的目的只是为了解决幻读问题而提出的。
Next-Key Lock
Next-Key Lock,是 Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身。

如果对 id 范围为 (4,6] 加了 Next-Key Lock,除了 id 为 5 的主键数据插入就会被阻塞,同时 id 为 5 的主键数据修改也会被阻塞。
插入意向锁
插入意向锁是一种间隙锁形式的意向锁,在真正执行 INSERT 操作之前设置。
一个事务在数据插入的是时候会判断插入的位置是否加了被其它的事务加了间隙锁或临键锁。如果有的话,就会阻塞,直到间隙锁或临键锁被释放才能执行后面的插入。
因为插入意向锁也是一种意向锁,意向锁只是表示一种意向,所以插入意向锁之间不会互相冲突,多个插入操作同时插入同一个 gap 时,无需互相等待。
加锁的原则
分析完了 MySQL 中几个主要的锁,再来看下这几个锁在 MySQL 中的使用。
这里引用下丁奇大佬在极客时间专栏中的总结
MySQL 后面的版本可能会改变加锁策略,这个原则是在下面版本中总结的,5.x系列<=5.7.24,8.0系列 <=8.0.13。
加锁原则:
1、加锁的对象是索引,加锁的基本单位是 next-key lock,是前开后闭区间;
2、只有语句查找过程中访问到的对象才会加锁;
加锁优化:
1、索引中的等值查询,如果加锁的对象是唯一索引,这时候锁就从 next-key lock,变成行锁了,因为只需要锁住对应的一行就行了;
2、索引中的等值查询,索引是唯一索引,查询的值没有找到,或者索引是普通索引 就会锁住一个范围,向右遍历最后一个不满足条件的值,并将其锁住,这时候next-key lock,就会变成 Gap Lock 了,这个条件是确定加锁的右边范围;
同时,唯一索引上的范围查询会访问到不满足条件的第一个值为止。
下面来几个栗子来具体的分析下
CREATETABLE `t` (
`id` int(11) NOTNULL,
`c` int(11) DEFAULTNULL,
`d` int(11) DEFAULTNULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;insertinto t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);1、主键等值查询
session A | session B | session C |
begin update t set d=d+1 where id=7 | ||
insert into t values(8,8,8) (blocked) | ||
update t set d=d+1 where id=10 |
可以看到 session B 中的插入操作被阻塞了,下面来分析下
session A:
1、加锁的对象是索引,加锁的基本单位是 next-key lock,首先会加 next-key lock (5,10];
2、又因为 id = 7 这行数据,数据库中不存在,索引中的查询,如果没有找到对应的数据,就会锁住满足条件的范围数据,向右遍历最后一个不满足条件的值,并将其锁住,这时候next-key lock,就会变成 Gap Lock 了;
所以 session A 首先会加一把 (5,10) 的间隙锁。
session B:
因为是数据插入操作,会加插入意向锁,因为 (5,10)已经被 session A 锁住了,所以 id = 8 的数据就不能插入了,会被阻塞。
session C:
session C 因为 id = 10 这行数据是存在的,并且 id 为主键索引。根据上面的加锁原则,首先加锁的基本单位是 next-key lock,索引中的等值查询,如果加锁的对象是唯一索引,这时候锁就从 next-key lock,变成行锁了。
2、非唯一索引等值查询
session A | session B | session C | session D |
begin select id from t where c=5 lock in share mode | |||
update t set d=d+1 where id=5 | |||
insert into t values(7,7,7) (blocked) | insert into t values(2,2,2) (blocked) |
可以看到 session C 被阻塞了,下面来分析下
session A:
首先 session A 加了一个 id = 5 的读锁。
1、加锁的基本单位是 next-key lock,首先会加 next-key lock (0,5];
2、索引中的等值查询,索引是唯一索引,查询的值没有找到,或者索引是普通索引 就会锁住一个范围,向右遍历最后一个不满足条件的值,并将其锁住,这时候next-key lock,就会变成 Gap Lock了, (5,10) 同样也会被锁住;
这样加锁的范围就是 (0,10)
session B:
只有访问到的对象才会加锁,session A 的查询使用覆盖索引,并不需要访问主键索引,所以主键索引上上的查询不会被阻塞。
session C 和 session B=D:
两个插入操作,都会加插入意向锁,因为间隙 (0,10) 被 session A 锁住了,所以插入操作就会被阻塞了。
3、主键索引范围锁
例如下面的栗子
select*from t where id=10forupdate; select*from t where id>=10and id<11forupdate;上面这两个查询,看起来是等价的,其实他们加锁的方式是不同的,下面来分析下
session A | session B | session C |
begin select * from t where id>=10 and id <11 for update | ||
insert into t values(8,8,8) (Query OK) insert into t values(13,13,13) (blocked) | ||
update t set d=d+1 where id=15 (blocked) |
可以看到上面插入的 id=13 的数据会被阻塞,还有 id=15 的数据修改也会被阻塞,下面来分析下
session A
首先 id>=10 这个条件,按照加锁的基本对象首先加 next-key lock (5,10],因为 id 是主键,等值查询会退化成行锁,所以 next-key lock (5,10]就会退化成 id=10 的行锁;
同时因为是范围查询,向右查询,所以右边界会找到 15,会加 next-key lock (10,15];
所以加的锁就是 (10,15] 的 next-key lock 还有 id=10 的行锁。
4、非唯一索引范围查询
session A | session B | session C |
begin select * from t where c>=10 and c <11 for update | ||
insert into t values(8,8,8) (blocked) | ||
update t set d=d+1 where id=15 (blocked) |
可以看到上面插入的 id=13 的数据会被阻塞,还有 id=15 的数据修改也会被阻塞,下面来分析下
session A
按照加锁的基本对象首先加 c 的 next-key lock (5,10],因为 c 是普通索引,等值查询不会退化成行锁;
同时因为是范围查询,向右查询,所以右边界会找到 15,会加 c 的 next-key lock (10,15];
所以 session A 会加索引 c 上的 (5,10] 和 (10,15] 这两个 next-key lock。
5、非唯一索引等值查询
假定目前表中的数据见下文,有两条 c=10 的数据。

来看下下面的查询栗子
session A | session B | session C |
begin select * from t where c=10 for update | ||
insert into t values(12,12,12) (blocked) | ||
update t set d=d+1 where id=15 |
可以看到上面 session B 中 id=12 的数据插入被阻塞了,来分析下原因
session A
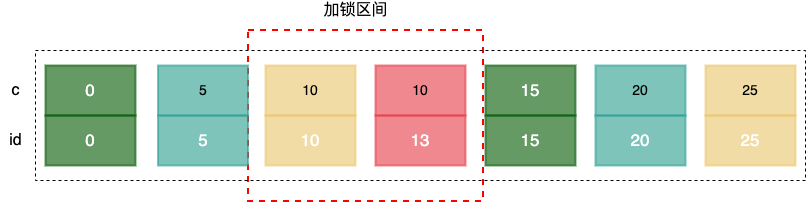
查询的条件是 c=10,上面的图示可以看到 c=10 的书有两条;
首先加锁的基本单位是 next-key lock,所以会加一个 (c=5,id=5) 到 (c=10,id=10) 的 next-key lock;
因为这是个等值查询的索引,索引中的等值查询,索引是唯一索引,查询的值没有找到,或者索引是普通索引 就会锁住一个范围,向右遍历最后一个不满足条件的值,并将其锁住,这时候next-key lock,就会变成 Gap Lock 了,所以 (c=10,id=10) 到 (c=15,id=15) 也会被加一个间隙锁。
所以 session A 中的锁就是 (c=5,id=5) 到 (c=15,id=15) 的间隙锁。
6、limit 语句加锁
session A | session B |
begin select * from t where c=10 limit 2 for update | |
insert into t values(12,12,12) |
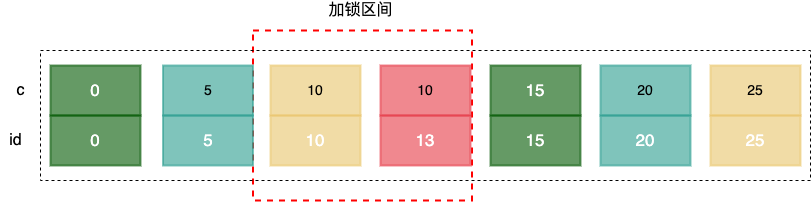
session A 中加入了 limit 查询,还是栗子5 中的插入语句,这时候 session B 的插入就不会被阻塞了。
因为有 limit 2 的限制,因此在遍历到 (c=10, id=13) 这一行之后,满足条件的语句已经有两条,循环就结束了。
因此,索引c上的加锁范围就变成了从(c=5,id=5) 到 (c=10,id=13) 这个前开后闭区间。
所以业务中如果加入 limit 条件,能够减小锁的范围。
总结
锁大概分成三类 全局锁,表级锁和行锁。
加锁原则:
1、加锁的对象是索引,加锁的基本单位是 next-key lock,是前开后闭区间;
2、只有语句查找过程中访问到的对象才会加锁;
加锁优化:
1、索引中的等值查询,如果加锁的对象是唯一索引,这时候锁就从 next-key lock,变成行锁了,因为只需要锁住对应的一行就行了;
2、索引中的等值查询,索引是唯一索引,查询的值没有找到,或者索引是普通索引 就会锁住一个范围,向右遍历最后一个不满足条件的值,并将其锁住,这时候 next-key lock,就会变成 Gap Lock 了,这个条件是确定加锁的右边范围;
同时,唯一索引上的范围查询会访问到不满足条件的第一个值为止。
相关文章:
MySQL 中的锁有哪些类型,MySQL 中加锁的原则
锁的类型MySQL 找那个根据加锁的范围,大致可以分成全局锁,表级锁和行级锁。全局锁全局锁,就是对整个数据库加锁。加锁flush tables with read lock解锁unlock tables全局锁会让整个库处于只读状态,之后所有的更新操作都会被阻塞&a…...
Winform中操作Sqlite数据增删改查、程序启动时执行创建表初始化操作
场景 Sqlite数据库 SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。 它是一个零配置的数据库,这意味着与其他数据库不一样,您不需要在系统中配置。 就像其他数据库,SQLite 引擎不…...
2023最新版本RabbitMQ下载安装教程
一、RabbitMQ简介 RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。主要用于在进程、应用程序和服务器之间交换数据,可以通过插件支持进行扩展,支持许多协议,并提供高性能、可靠性、集群和高可用队列。 AMQP :Advanced Me…...

如何使用码匠连接 Elasticsearch
目录 在码匠中集成 Elasticsearch 在码匠中使用 Elasticsearch 关于码匠 Elasticsearch 是一个开源的分布式搜索和分析引擎,常用于处理大规模数据集的搜索、实时数据分析和数据挖掘任务。它支持多种数据源,包括关系型数据库(如 MySQL、Pos…...

jmeter学习笔记二(jmeter函数与后置处理器)
Jmeter重要的函数 ${__counter(,)} 计数器 ${__counter(TRUE,)} 默认加1; TRUE,每个用户有自己的计数器;FALSE,使用全局计数器 计数器元件,可以设置起始值,间隔值,最大值。运行结果超过最大值时&a…...

【独家】华为OD机试提供C语言题解 - 子序列长度
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明子序…...

Java之注解
注解1.1 注解的概念1.2 内置注解1.3 元注解1.4 自定义注解1.1 注解的概念 Annotation 是从JDK5.0 开始引入的新技术 Annotation的作用: 不是程序本身,可以对程序做出解释(这一点和注释comment没什么区别)可以被其他程序ÿ…...

【C++】string
【C修炼秘籍】string 目录 【C修炼秘籍】string 文章目录 前言 一、标准库里的string 二、string常用接口功能简介(具体使用和底层转到模拟实现) 1、string类的常见构造函数 2、string类对象的容量操作 3、string类对象的访问及遍历操作 4、 string类对象…...
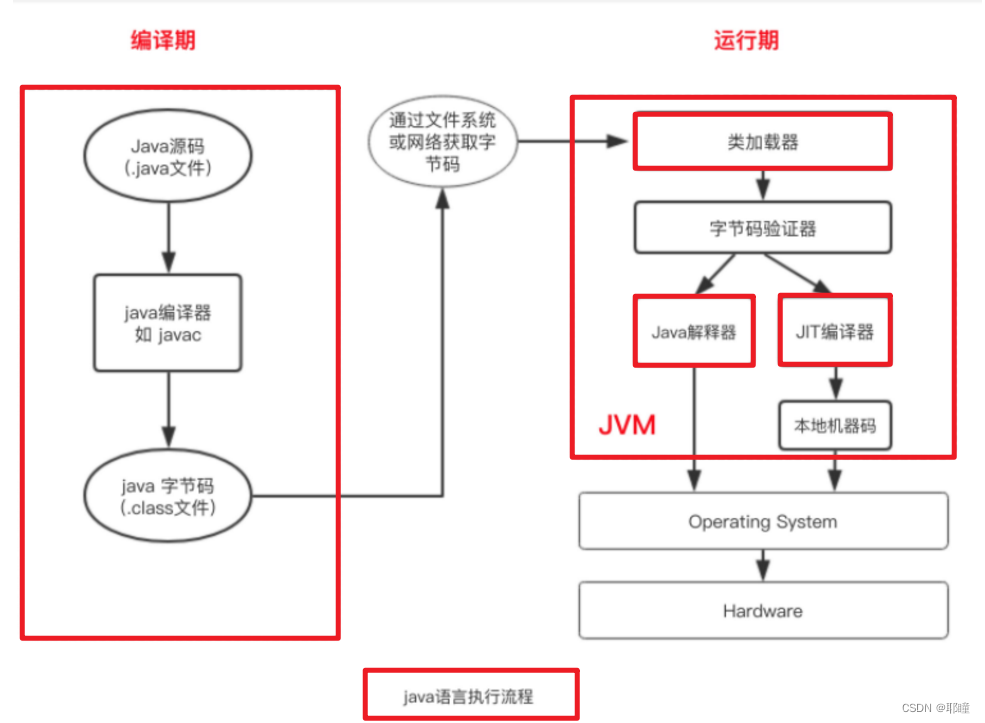
JVM详解——执行引擎
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:耶瞳空间 一:执行引擎介绍 “虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器、缓存、指令集和…...
python学习——【第二弹】
前言 上一篇文章 python学习——【第一弹】给大家介绍了python中的基本数据类型等,这篇文章接着学习python中的运算符的相关内容。 运算符 python中的运算符主要有:算术运算符,赋值运算符,比较运算符,布尔运算符以及…...

242. 有效的字母异位词 349. 两个数组的交集
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意: 若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例 1: 输入: s “anagram”, t “nagaram” 输出: true 示例 2: 输入: s “rat…...

web网页设计——JavaScript一些语法
1、事件监听 语法: <1> 元素对象.addEventListener(‘事件类型’,要执行的函数) 三要素:(1)、事件源 (2)事件类型 (3)执行的函数 <2>元素对象.on事件类型 …...

php宝塔搭建部署实战CSM会议室预约系统源码
大家好啊,我是测评君,欢迎来到web测评。 本期给大家带来一套基于fastadmin开发的CSM会议室预约系统的源码。感兴趣的朋友可以自行下载学习。 技术架构 PHP7.2 nginx mysql5.7 JS CSS HTMLcnetos7以上 宝塔面板 文字搭建教程 下载源码࿰…...
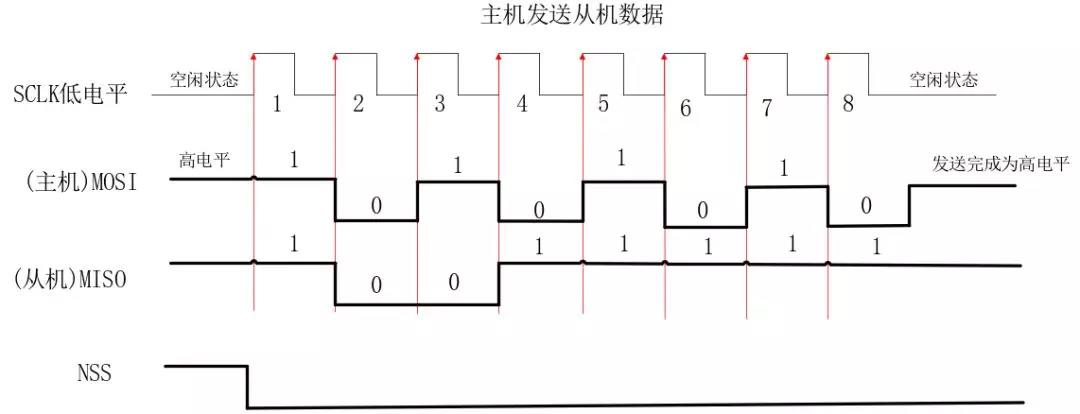
嵌入式知识点-SPI通讯
该文原自 : 正点原子 01 SPI概述 SPI (Serial Peripheralinterface),顾名思义就是串行外围设备接口。SPI是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同…...

C#教程--01 简介
简介 C# 是一个简单的、现代的、通用的、面向对象的编程语言,它是由微软(Microsoft)开发的。 C#的特性 现代的、通用的编程语言。 面向对象。 面向组件。 容易学习。 结构化语言。 它产生高效率的程序。 它可以在多种计算机平台上编译。 .Net 框架的一部分。 C#强大的编程…...
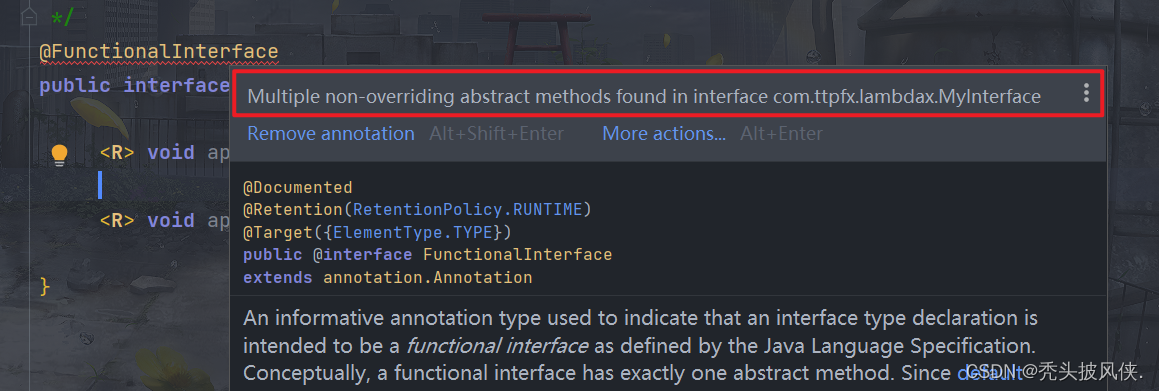
【java基础】一篇文章彻底搞懂lambda表达式
文章目录lambda表达式是什么lambda表达式的语法函数式接口初次使用深入理解方法引用 :: 用法快速入门不同形式的::情况1 object::instanceMethod情况2 Class::instanceMethod情况3 Class::staticMethod对于 :: 的一些示例及其注意事项构造器引用变量作用域使用外部变量定义内部…...
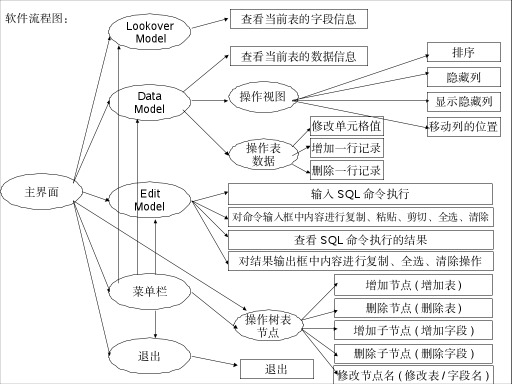
通用SQL查询分析器
技术:Java、JSP等摘要:本文主要针对当前很多软件都无法实现跨数据库、跨平台来执行sql语句而用户又仅需做一些基本的增删改查操作的矛盾,设计了一个能够跨平台跨数据库的软件。此软件是一个通用SQL查询分析器,利用java语言本身的跨…...
:038 朴素贝斯-处理离散数据)
机器学习100天(三十八):038 朴素贝斯-处理离散数据
《机器学习100天》完整目录:目录 机器学习100天,今天讲的是:朴素贝斯-处理离散数据! 打开 spyder,新建一个 naive_bayes_category.py 脚本。上一节我们引入了一批西瓜样本。并使用朴素贝叶斯公式计算出一个瓜蒂脱落、圆形、青色的西瓜是熟瓜的概率。下面我们来使用 pytho…...

【3.3】指针、二分、SSM项目
二分查找 class Solution {public int search(int[] nums, int target) {int n nums.length;int left 0;int right n - 1;while(left < right){int mid left (right - left) / 2;if(nums[mid] < target){left mid 1;}else if(nums[mid] > target){right mid …...

buu [INSHack2017]rsa16m 1
题目描述: 打开的 rsa_16m 文件 : (在此我只想说神人才找得到 c 的位置) ,这位置是真的难找啊 题目分析: 首先打开 description.md 文件,得到: 翻译下来: 当您需要真正…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...