大数据技术之——zeppelin数据清洗
一、zeppelin的安装
zeppelin解压后进入到conf配置文件界面。
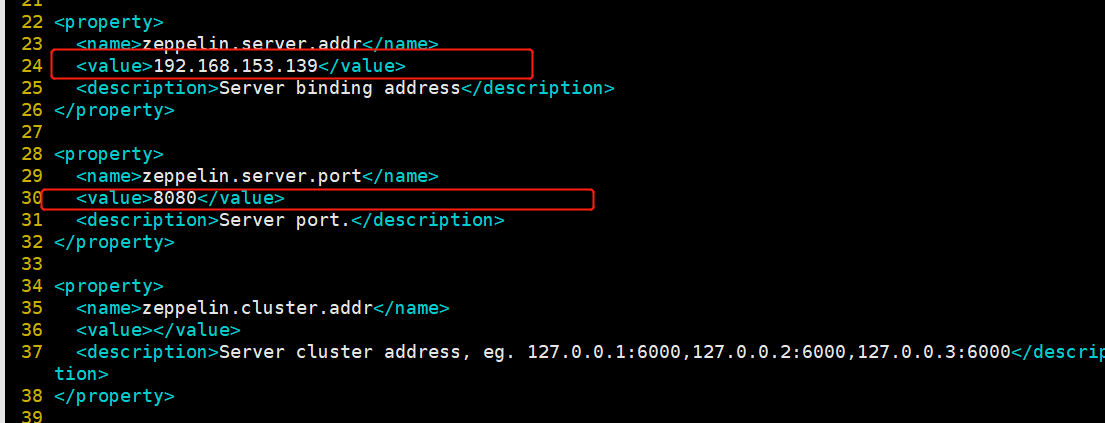
修改zeppelin-site.xml
[root@hadoop02 conf]# cp zeppelin-site.xml.template zeppelin-site.xml
[root@hadoop02 conf]# vim zeppelin-site.xml
将IP地址和端口号设置成自己的
修改 zeppelin-env.sh
export JAVA HOME=/opt/soft/jdk180
export HADOOP HOME=/opt/soft/hadoop313
export HADOOP CONF DIR=/opt/soft/hadoop313/etc/hadoop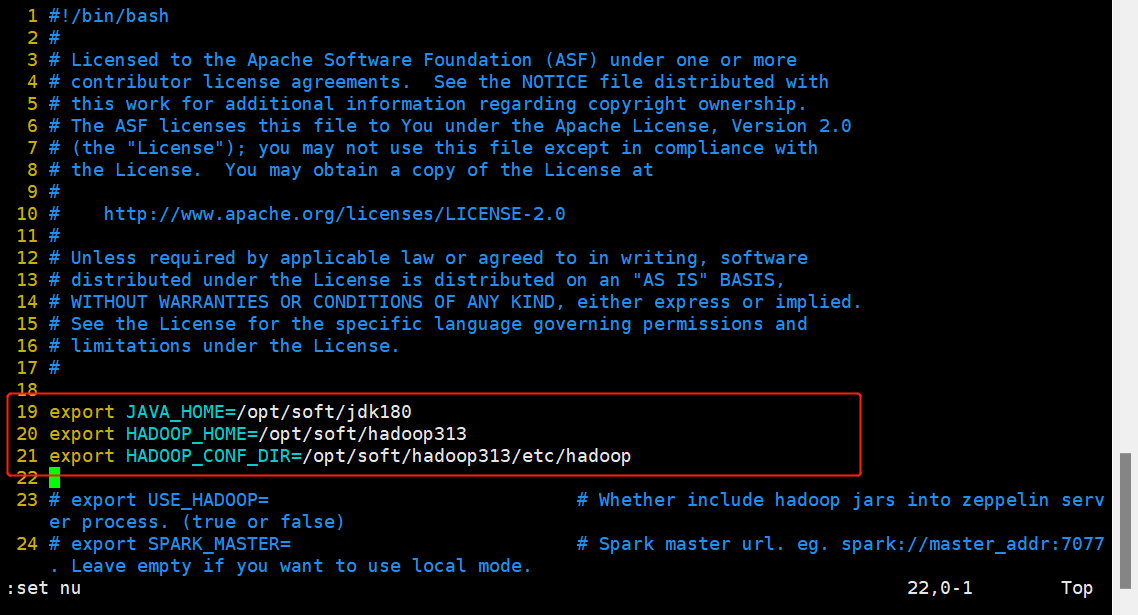
将hive-site.xml拷贝到zeppelin中
[root@hadoop02 conf]# cp /opt/soft/hive312/conf/hive-site.xml /opt/soft/zeppelin/conf添加jar包
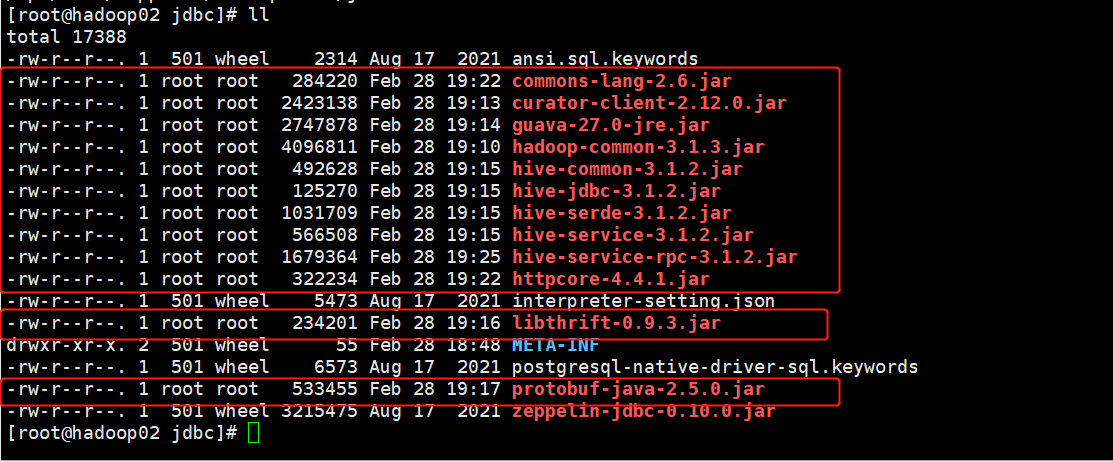
路径切换到/opt/soft/zeppelin/interpreter/jdbc下,添加如下jar包:
[root@hadoop02 jdbc]# cp /opt/soft/hadoop313/share/hadoop/common/hadoop/common-3.1.3.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/curator-client-2.12.0.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/guava-27.0-jre.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/hive-jdbc-3.1.2.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/hive-serde-3.1.2.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/hive-service-3.1.2.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/hive-service-rpc-3.1.2.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/libthrift-0.9.3.jar ./
[root@hadoop02 jdbc]# cp /opt/soft/hive312/lib/protobuf-java-2.5.0jar ./添加外部jar包:
配置profile文件
# ZEPPELIN_HOME
export ZEPPELIN_HOME=/opt/soft/zeppelin
export PATH=$PATH:$ZEPPELIN_HOME/bin
启动zeppelin
[root@hadoop02 jdbc]# zeppelin-daemon.sh start打开浏览器
二、数据结构
数据准备
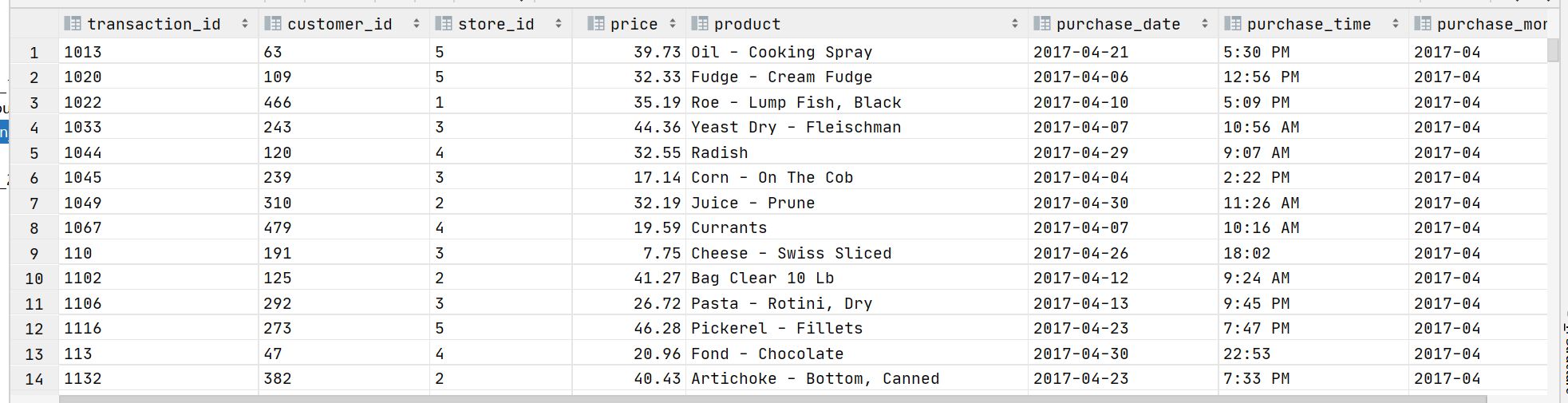
表数据存放在本地的/opt/stufile/storetransaction中。

1. 检查行数
[root@hadoop02 storetransaction]# wc -l customer_details.csv
501 customer_details.csv2. 查看文件header行
[root@hadoop02 storetransaction]# head -n 2 customer_details.csv
customer_id,first_name,last_name,email,gender,address,country,language,job,credit_type,credit_no
1,Spencer,Raffeorty,sraffeorty0@dropbox.com,Male,9274 Lyons Court,China,Khmer,Safety Technician III,jcb,3589373385487669
创建对应目录
1. 创建数据库
drop database if exists shopping cascade;
create database if not exists shopping;2. hdfs中创建目录,用于保存数据表
hdfs dfs -mkdir -p /shopping/data/customer
hdfs dfs -mkdir -p /shopping/data/store
hdfs dfs -mkdir -p /shopping/data/review
hdfs dfs -mkdir -p /shopping/data/transcation3. 将本地数据上传到hdfs
hdfs dfs -put ./customer_details.csv /shopping/data/customer
hdfs dfs -put ./store_details.csv /shopping/data/store
hdfs dfs -put ./store_review.csv /shopping/data/review
hdfs dfs -put ./transaction_details.csv /shopping/data/transcation4. 查看hdfs目录中保存的文件
hdfs dfs -ls /shopping/data/customer
hdfs dfs -ls /shopping/data/review
hdfs dfs -ls /shopping/data/store
hdfs dfs -ls /shopping/data/transcation建表语句
创建外部表,表相关信息存储在hdfs中。
1. 顾客详细表
create external table if not exists ext_customer_details(customer_id string,first_name string,last_name string,email string,gender string,address string,country string,language string,job string,credit_type string,credit_no string
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/customer'
tblproperties('skip.header.line.count'='1');2. 交易信息表
create external table if not exists ext_transaction_details(transaction_id string,customer_id string,store_id string,price decimal(8,2),product string,purchase_date string,purchase_time string
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/transcation'
tblproperties('skip.header.line.count'='1');3. 店铺信息表
create external table if not exists ext_store_details(store_id string,store_name string,employee_number string
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/store'
tblproperties('skip.header.line.count'='1');4. 评分表
create external table if not exists ext_review_details(transaction_id string,store_id string,review_score string
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
location '/shopping/data/review'
tblproperties('skip.header.line.count'='1');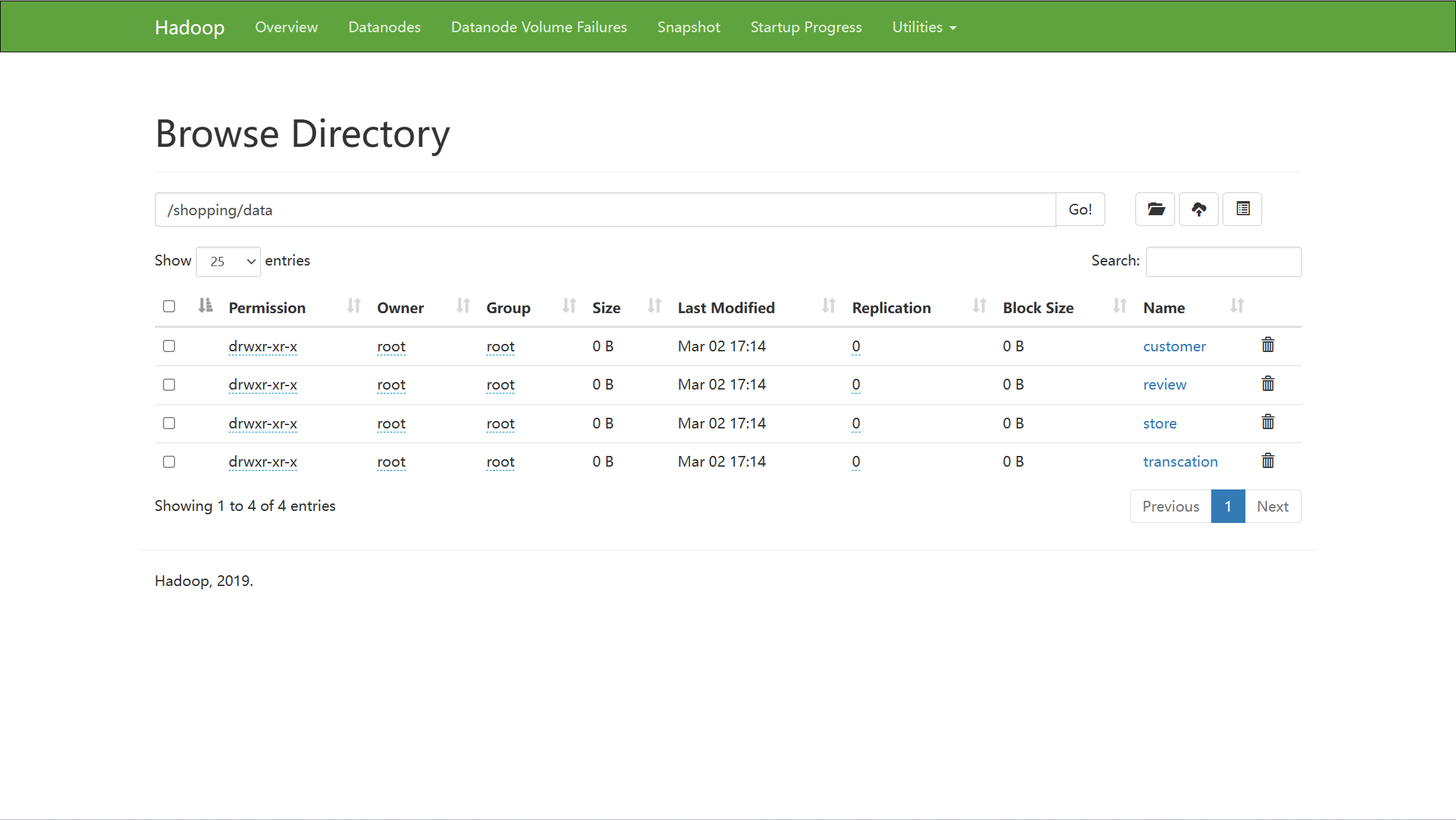
三、数据清洗
数据脱敏
在customer表中,email字段、address字段、credit_no字段不希望被显示为明文,需要对其进行加密。
drop view if exists vw_customer_details;
create view if not exists vw_customer_details as
select
customer_id,first_name,unbase64(last_name) as last_name,
unbase64(email) as email, gender,unbase64(address) as address,
country,job,credit_type,
unbase64(concat(unbase64(credit_no),'hello')) as credit_no
from ext_customer_details;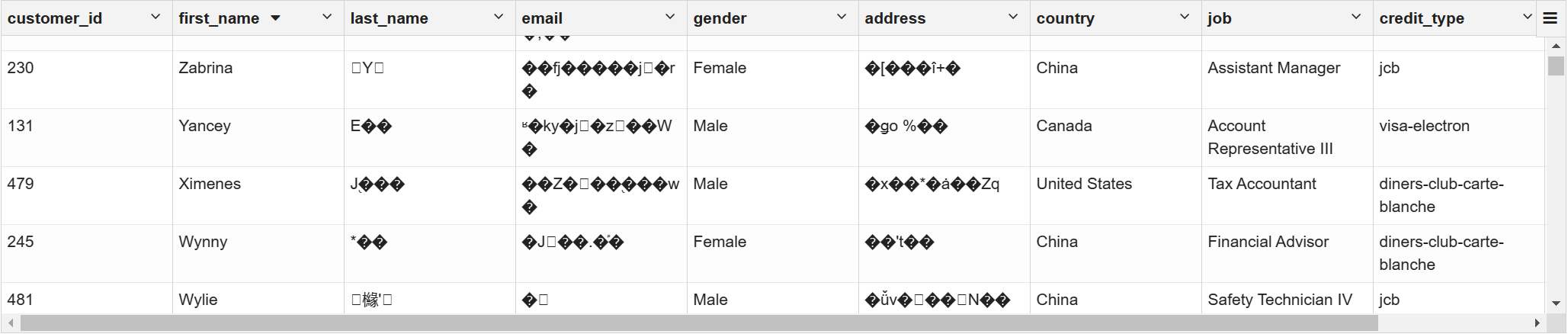
去除重复值
with
basetb as (select row_number()over(partition by transaction_id) as rn,transaction_id,customer_id,store_id,price,product,purchase_date,purchase_time,substr(purchase_date,0,7) purchase_month from ext_transaction_details),
basetb2 as (select if(rn=1,transaction_id,concat(transaction_id,'_fix',rn)) transaction_id ,customer_id,store_id,price,product,purchase_date,purchase_time,purchase_month from basetb)
select * from basetb2 where transaction_id like '%fix%' limit 100;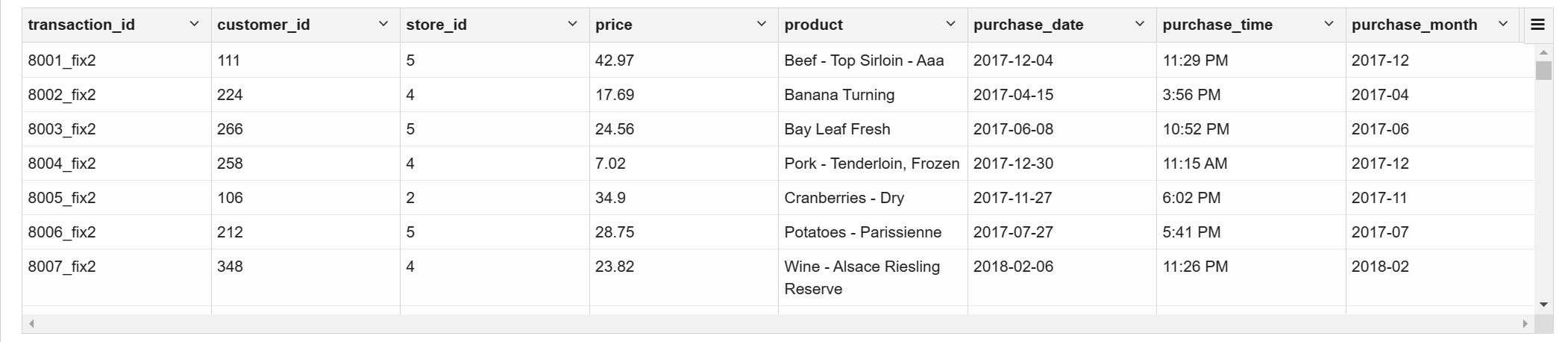
过滤掉缺失内容
create view if not exists vm_store_review as
select * from ext_store_review where review_score <> '';四、数据分析
Customer分析
1.1 找出顾客最常用的信用卡
select credit_type, count(customer_id)
from ext_customer_details group by credit_type;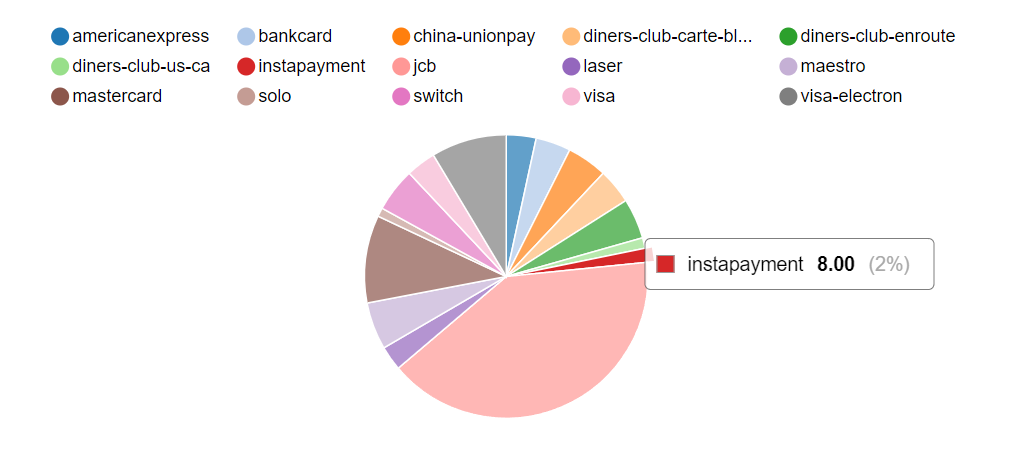
1.2 找出客户资料中排名前五的职位名称
selectcredit_type,count(credit_type) count_credit_type
from vw_customer_details group by credit_type order by credit_type having gender='female';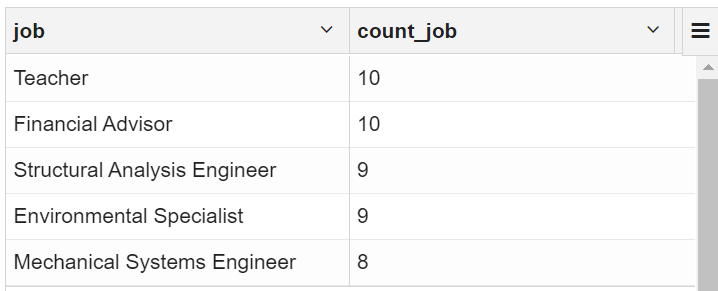
1.3 在美国女性最常用的信用卡
selectcredit_type,count(credit_type) count_credit_type
from vw_customer_details
where gender='Female' and country='United States'
group by credit_type
order by count_credit_type desc limit 3 ;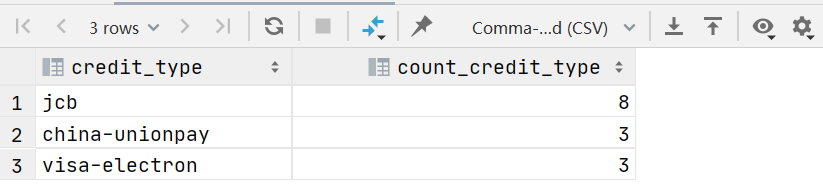
1.4 按性别和国家进行客户统计
selectgender,country,count(*)
from vw_customer_details group by gender,country;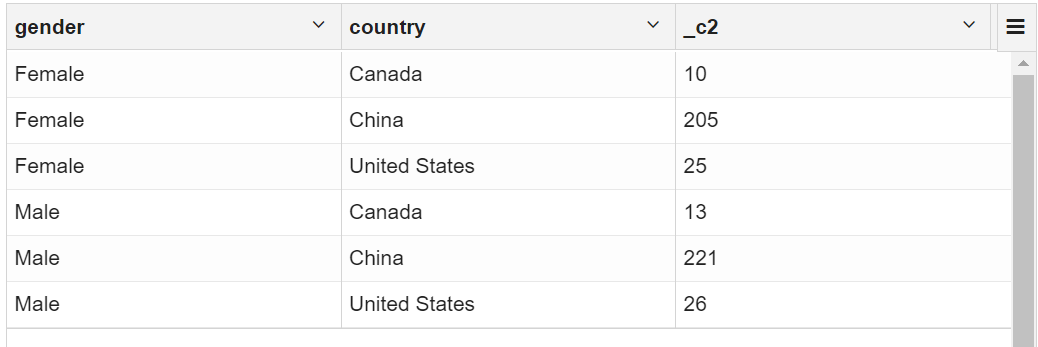
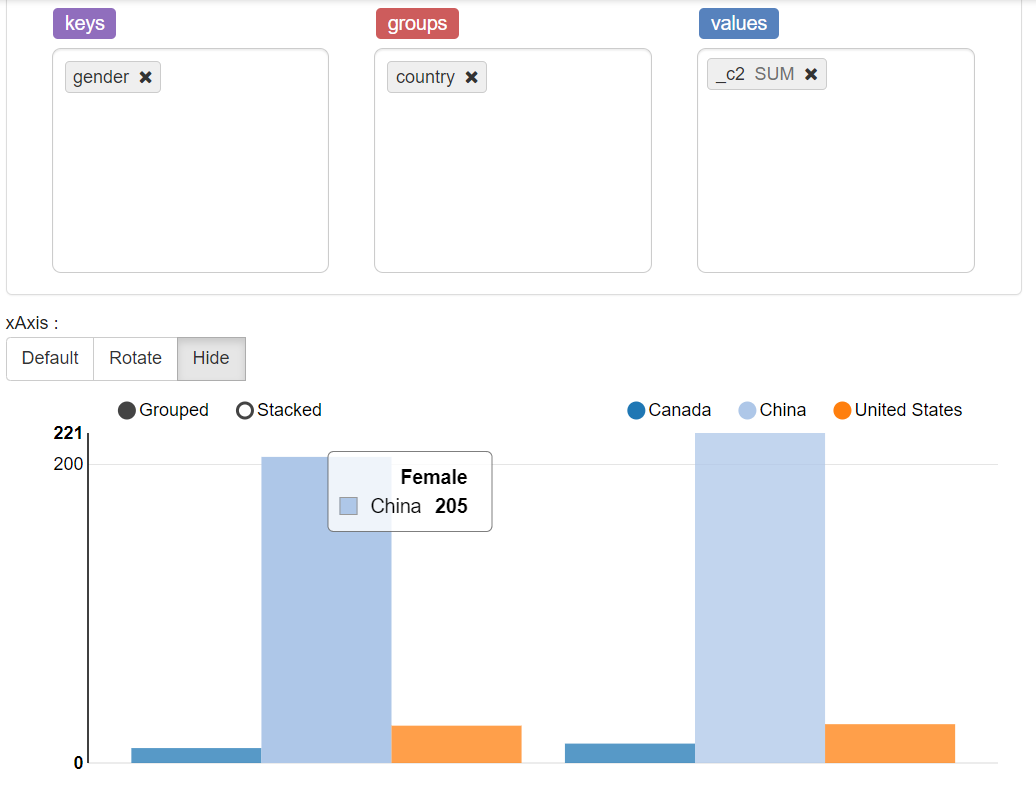
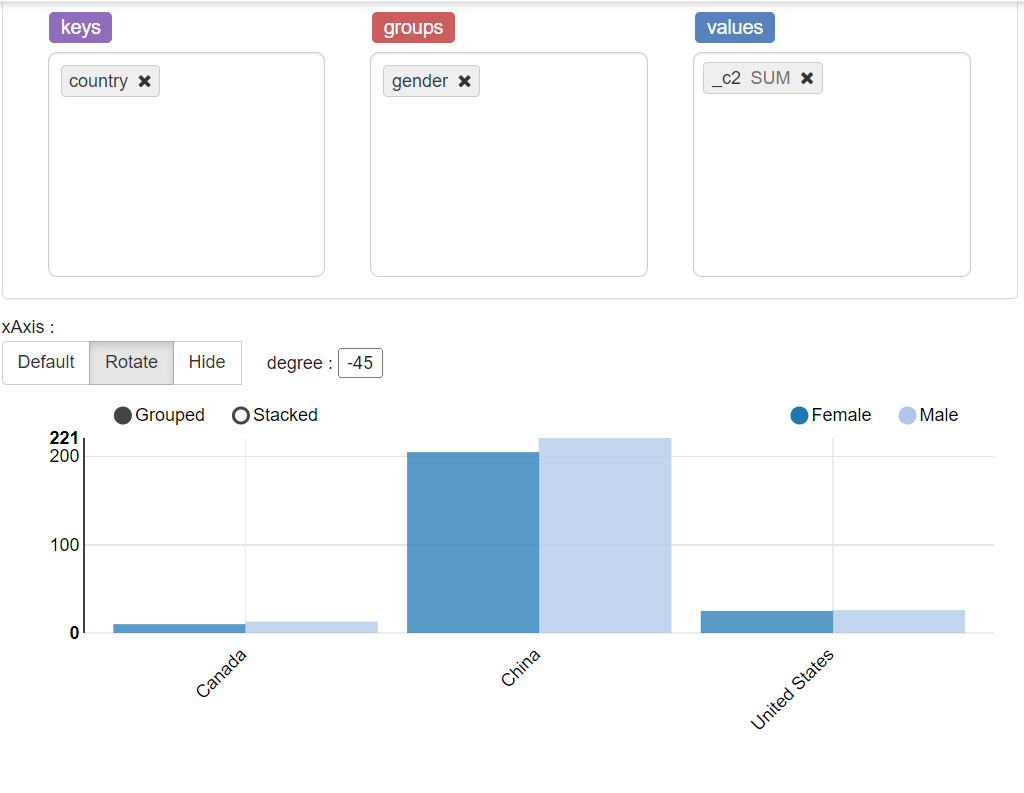
Transaction分析
2.1 计算每月总收入
selectpurchase_month,sum(price)
from transaction_details group by purchase_month;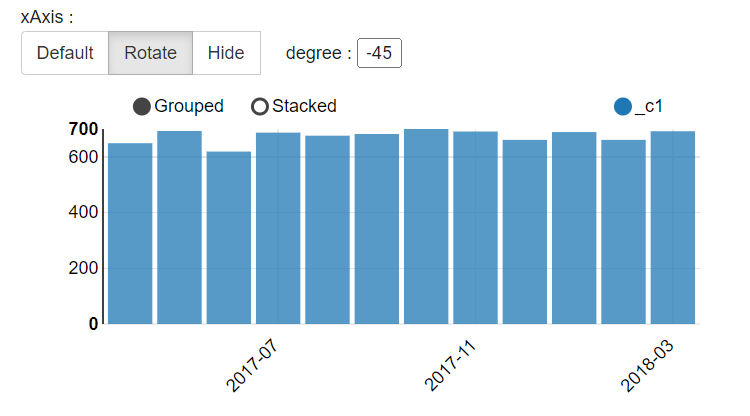
2.2 计算每个季度的总收入
with t2 as (select concat_ws('-',cast(year(purchase_date) as string),cast(ceil(month(purchase_date)/3) as string)) as concat_quarter1,price
from transaction_details)
select concat_quarter1,sum(price) from t2 group by concat_quarter1;或者直接使用季度函数
with t2 as (select concat_ws('-',cast(year(purchase_date) as string),cast(ceil(month(purchase_date)/3) as string)) as concat_quarter1,price
from transaction_details)
select concat_quarter1,sum(price) from t2 group by concat_quarter1;
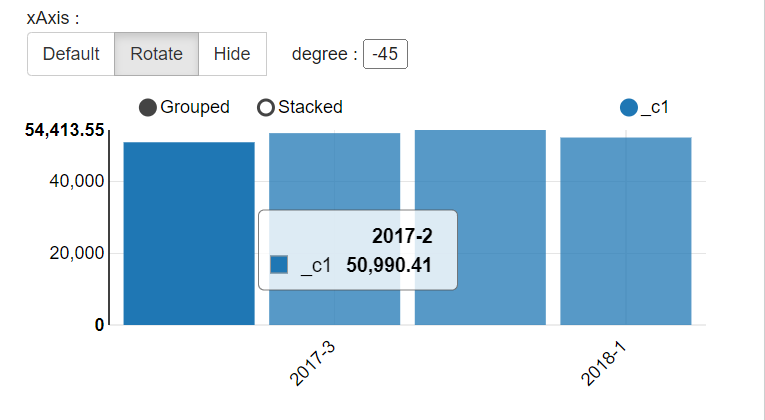
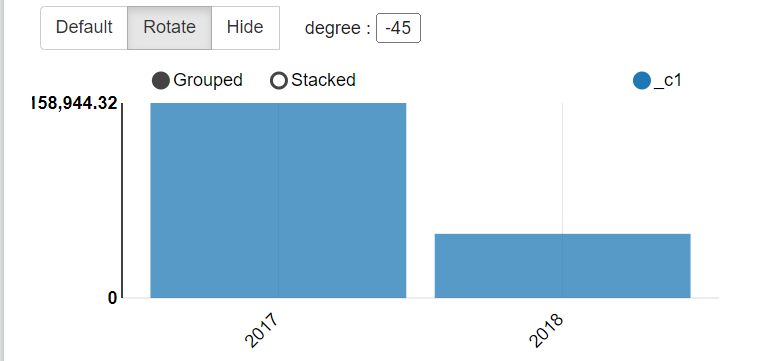
2.3 按年计算总收入
selectyear(purchase_date),sum(price)
from transaction_details group by year(purchase_date);
2.4 按工作日计算总收入
selectdayofweek(purchase_date) week_day,sum(price)
from transaction_details
where dayofweek(purchase_date) between 1 and 5
group by dayofweek(purchase_date);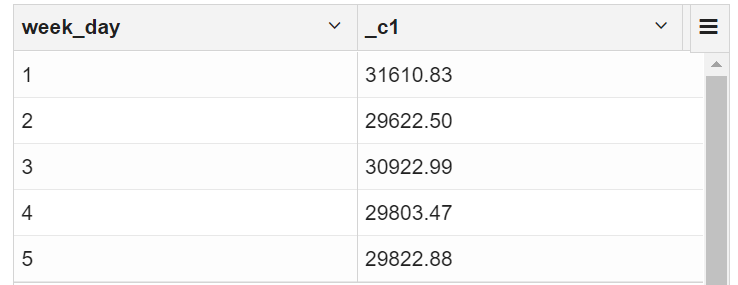
按照工作日、月、季度、年计算总收入
with basetb as(
SELECTprice,dayofweek(purchase_date) as weekday,month(purchase_date) as month,concat_ws('-',cast(year(purchase_date) as string),cast(ceil(month(purchase_date)/3) as string)) as quarter,year(purchase_date) as year
from transaction_details)
select sum(price) as sumMoney,weekday,month,quarter,year from basetb group by weekday,month,quarter,year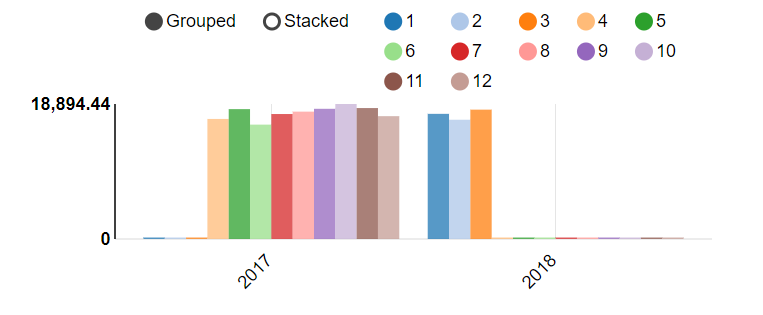
2.5 按时间段计算总收入(需要清理数据)
这里的时间格式不统一,有24时记时,也有12时记时,需要对数据进行整合。
解体思路:
按时间段计算总收入
early morning(5:00-8:00)
morning(8:00-11:00)
noon(11:00-13:00)
afternoon(13:00-18:00)
evening(18:00-22:00)
night(22:00-5:00)
1. 将12时转换为24时
selectif(purchase_time like '%M',from_unixtime(unix_timestamp(purchase_time,'hh:mm aa'),'HH:mm'),purchase_time) as time_form
from transaction_details;2.分段进行分析
with
basetb as (
selectprice,purchase_time,if(purchase_time like '%M',from_unixtime(unix_timestamp(purchase_time,'hh:mm aa'),'HH:mm'),purchase_time) as time_format
from transaction_details),
basetb2 as (
select price,purchase_time,time_format,cast(split(time_format,':')[0] as decimal(4,2)) +cast(split(time_format,':')[1] as decimal(4,2))/60 as `purchase_time_num`
from basetb
)
select price,purchase_time,if(purchase_time_num>5 and purchase_time_num<=8,'early morning',if(purchase_time_num>8 and purchase_time_num<=11,'morning',if(purchase_time_num>11 and purchase_time_num<=13,'noon',if(purchase_time_num>13 and purchase_time_num<=18,'afternoon',if(purchase_time_num>18 and purchase_time_num<=22,'evening','night'))))) as time_bucket
from basetb2;3. 对数据进行分析
select time_bucket1,sum(price) from basetb3
group by time_bucket1;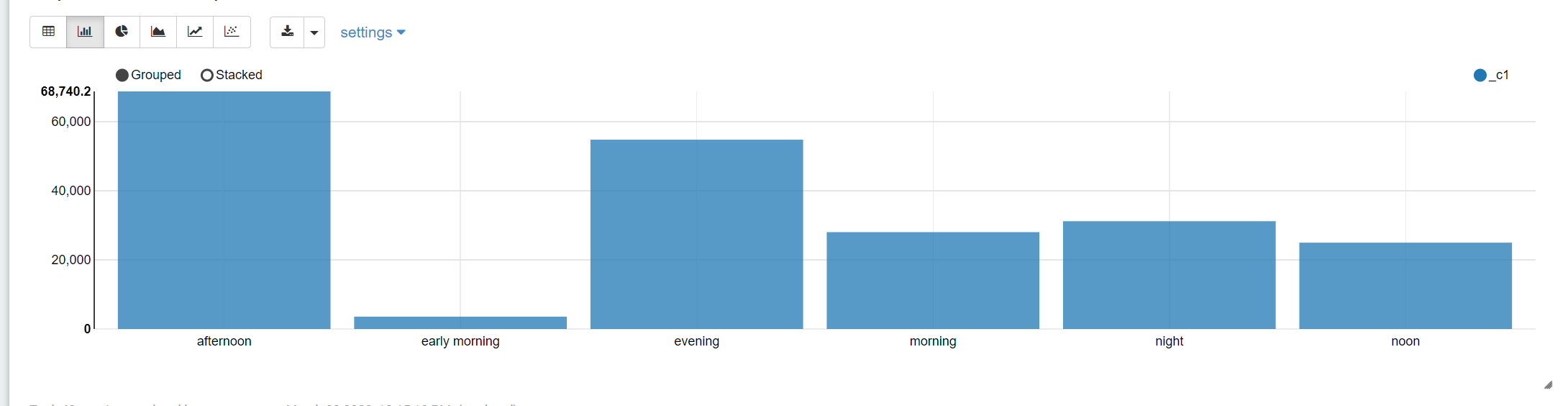
2.6 按时间段计算平均消费
select time_bucket1,avg(price) from basetb3
group by time_bucket1;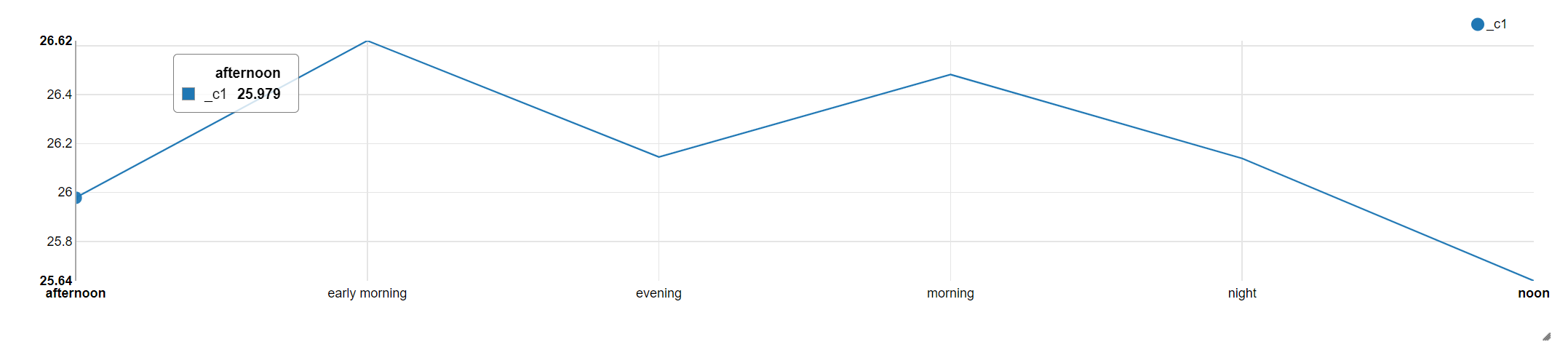
2.7 按工作日计算平均消费
selectdayofweek(purchase_date),avg(price)
from transaction_details
where dayofweek(purchase_date) between 1 and 5
group by dayofweek(purchase_date)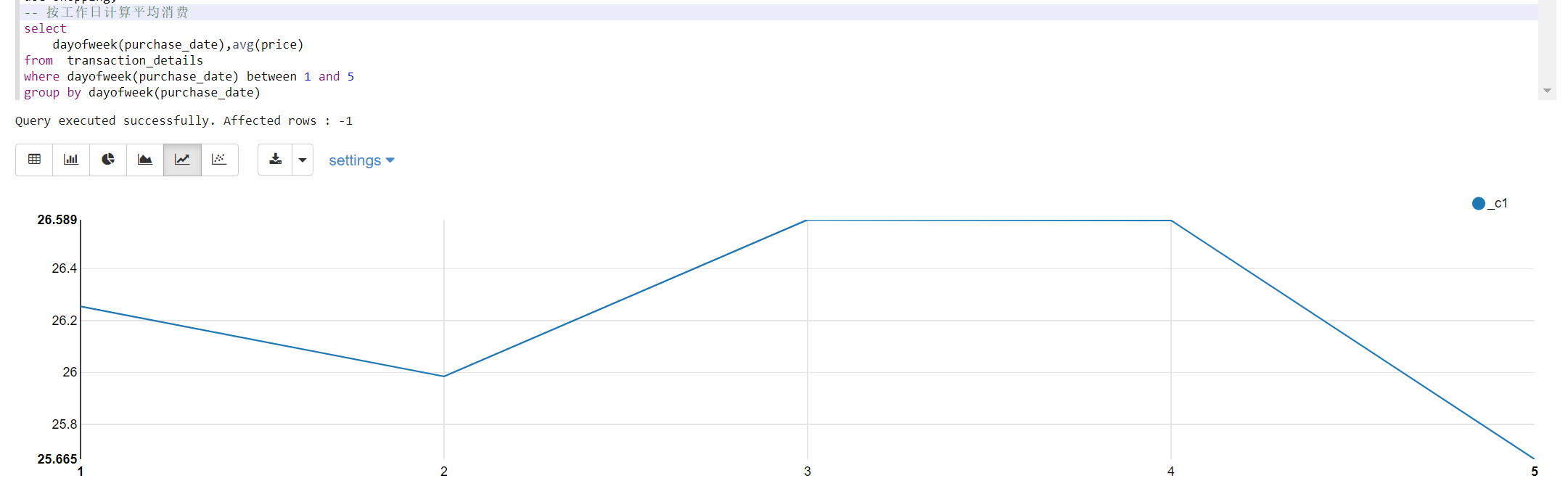
2.8 计算年、月、日的交易总数
selectcount(1) over(partition by year(purchase_date)) year,count(1) over(partition by year(purchase_date),month(purchase_date)) month,count(1) over(partition by year(purchase_date),month(purchase_date),day(purchase_date)) day
from transaction_details 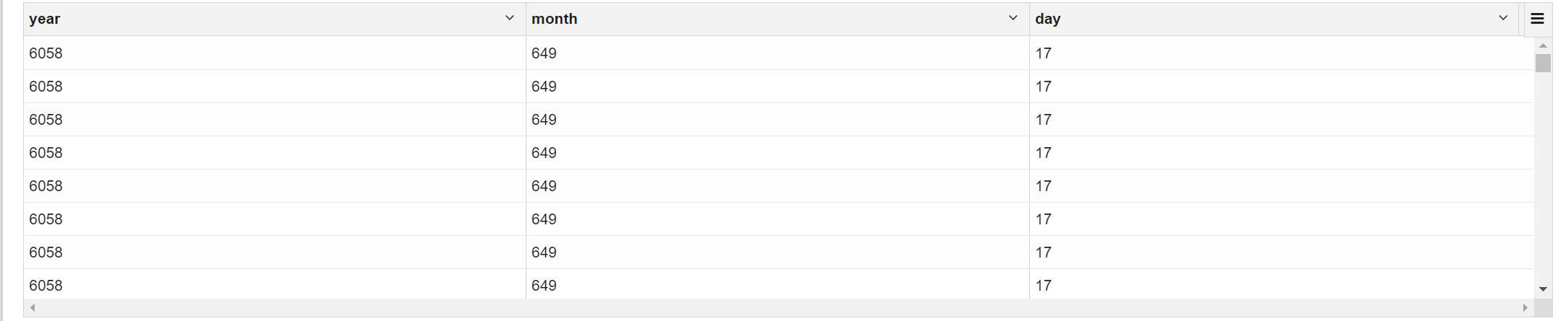
2.9 找出交易量最大的10个客户
selectcustomer_id,count(1) a
from transaction_details group by customer_id order by a desc limit 10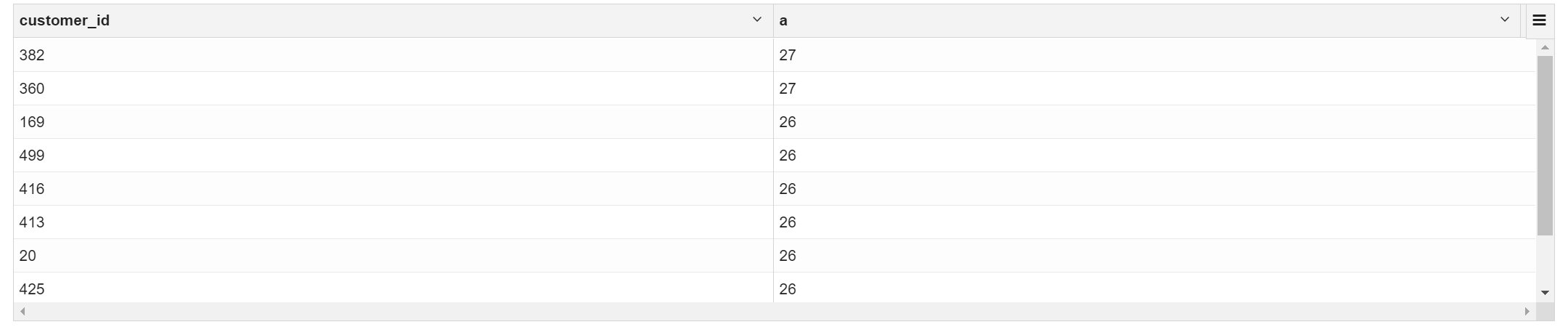
2.10 找出消费最多的前10位顾客
selectcustomer_id,sum(price) a
from transaction_details group by customer_id order by a desc limit 10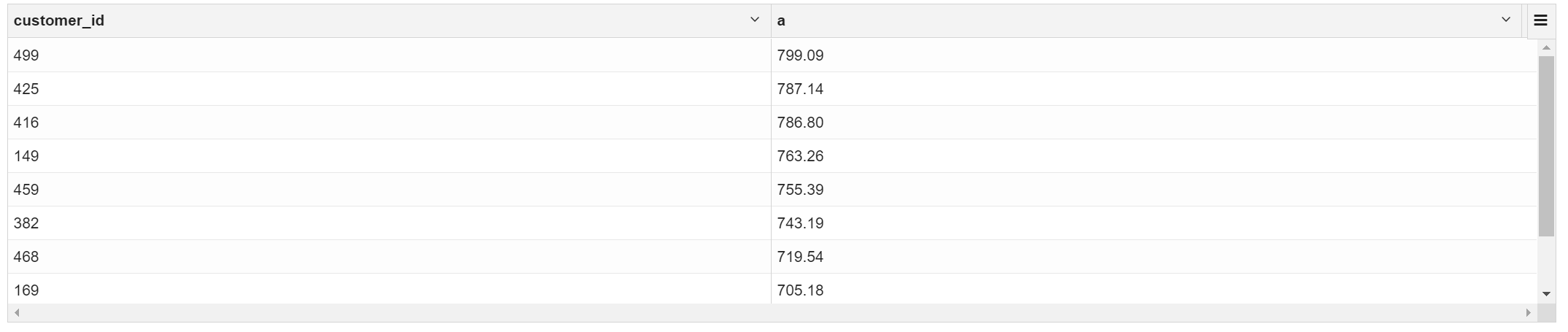
2.11 统计该期间交易数量最少的用户
selectcustomer_id,count(1) a
from transaction_details group by customer_id order by a asc limit 5
2.12 计算每个季度的独立客户总数
1. 每个季度的用户总数
select count(1),year(purchase_date),quarter(purchase_date)
from transaction_details group by year(purchase_date),quarter(purchase_date)2. 去除掉重复的用户
select count(1),year(purchase_date),quarter(purchase_date)
from(select row_number() over (partition by customer_id,year(purchase_date),quarter(purchase_date)) rm1 ,* from transaction_details) t1where t1.rm1=1 group by year(purchase_date),quarter(purchase_date)


2.13 计算每周的独立客户总数
select count(1),weekofyear(purchase_date)
from(select row_number() over (partition by customer_id,year(purchase_date),quarter(purchase_date)) rm1 ,* from transaction_details) t1where t1.rm1=1 group by weekofyear(purchase_date)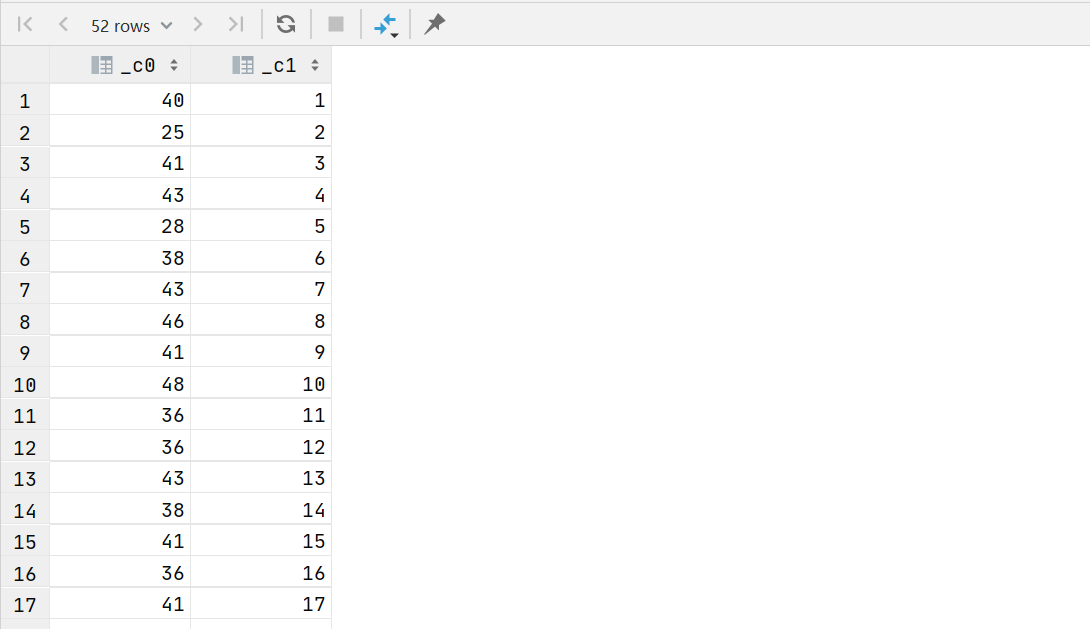
2.14 计算整个活动客户平均花费的最大值
select customer_id,max(tb.avg1) from(select customer_id,avg(price) avg1 from transaction_details group by customer_id) tb;
2.15 统计每月花费最多的客户
with t1 as ( selectpurchase_month,customer_id,sum(price) sp
from transaction_details group by purchase_month,customer_id )
select purchase_month,max(sp) from t1 group by purchase_month
2.16 统计每月访问次数最多的客户
with t1 as (
selectpurchase_month,customer_id,count(price) cp,rank() over (partition by purchase_month order by count(price) desc) rk
from transaction_details group by purchase_month,customer_id)
select purchase_month,customer_id,cp from t1 where rk=1;
2.17 按总价找出最受欢迎的5种产品
select product,sum(price) sp from transaction_details
group by product
order by sp desc limit 5;
2.18根据购买频率找出最畅销的5种产品
select product,count(price) cp from transaction_details
group by product
order by cp desc limit 5;
2.19根据客户数量找出最受欢迎的5种产品
select product,count(distinct customer_id) cp from transaction_details
group by product
order by cp desc limit 5;
2.20 验证前5个details
Store分析
3.1 按客流量找出最受欢迎的商店
selectstore_name,count(distinct customer_id) as visit
from transaction_details td join ext_store_details sd on td.store_id=sd.store_id
group by store_name order by visit
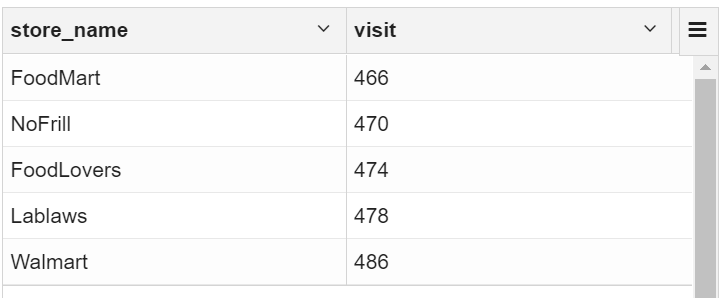
3.2 根据顾客消费价格找出最受欢迎的商店
selectstore_name,sum(price) as visit
from transaction_details td join ext_store_details sd on td.store_id=sd.store_id
group by store_name order by visit
3.3 根据顾客交易情况找出最受欢迎的商店
selectstore_name,count(customer_id) as c
from transaction_details td join ext_store_details sd on td.store_id=sd.store_id
group by store_name order by c desc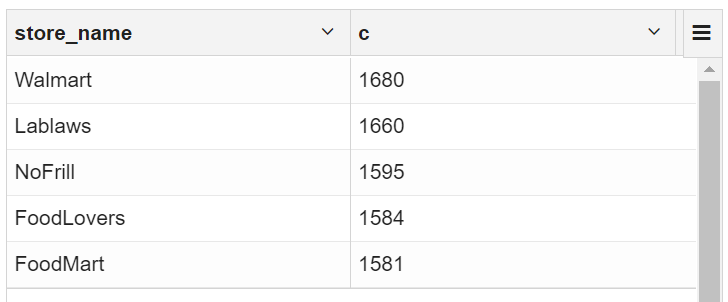
3.4 根据商店和唯一的顾客id获取最受欢迎的产品
with t1 as(
selectstore_name,product,count(distinct customer_id) cdc
from transaction_details td join ext_store_details sd on td.store_id=sd.store_id
group by store_name,product having cdc>3 order by cdc desc
),
t2 as(
select store_name,product,cdc,row_number() over (partition by store_name order by cdc desc ) rn from t1
)
select store_name,product,cdc from t2 where rn=1;
3.5 获取每个商店的员工与顾客比
with
t1 as ( select count(1) c1,store_idfrom transaction_details tdgroup by td.store_id )
select concat(substring(cast(esd.employee_number/t1.c1 as decimal(9,8))*100.0,0,4),'%'),t1.store_id,esd.store_name from t1
join shopping.ext_store_details esd on t1.store_id=esd.store_id
3.6 按年和月计算每家店的收入
with t1 as (select year(purchase_date) year, month(purchase_date) month, store_id si, sum(price) spfrom transaction_detailsgroup by year(purchase_date), month(purchase_date), store_id
)
select esd.store_id,esd.store_name,t1.year,t1.month,t1.sp from t1
join shopping.ext_store_details esd on t1.si=esd.store_id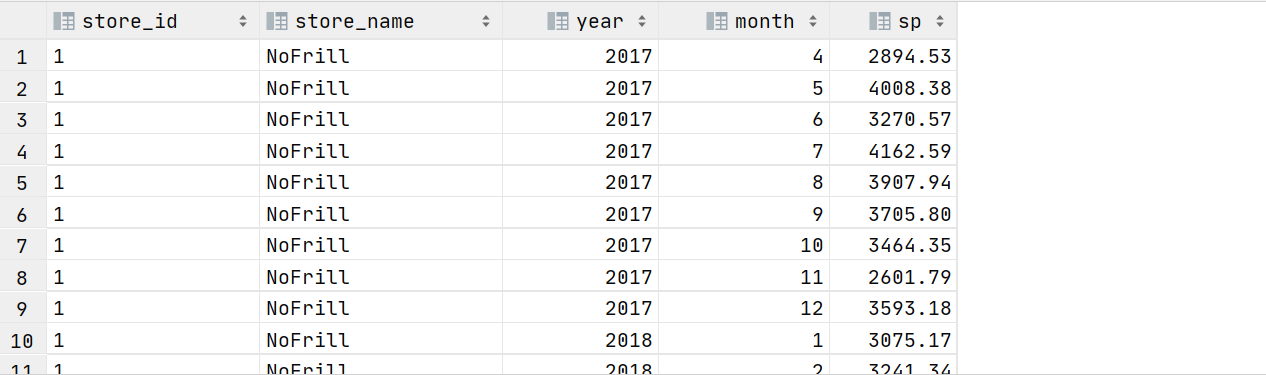
3.7 按店铺制作总收益饼图
selectstore_id,sum(price)
from transaction_details group by store_id
3.8 找出每个商店最繁忙的时间段
with t1 as(
selectprice,purchase_time,store_id,if(purchase_time like '%M',from_unixtime(unix_timestamp(purchase_time,'hh:mm aa'),'HH:mm'),from_unixtime(unix_timestamp(purchase_time,'HH:mm'),'HH:mm')) time1
from transaction_details
),t2 as (
selectprice,purchase_time,store_id,time1,cast(split(time1,':')[0] as int)+cast(split(time1,':')[1] as decimal(4,2))/60 time2
from t1),t3 as (
selectprice,purchase_time,store_id,time1,case when time2>5 and time2<=8 then 'early morning'when time2<=11 and time2>8 then 'morning'when time2<=13 and time2>11 then 'noon'when time2<=18 and time2>13 then 'afternoon'when time2<=22 and time2>18 then 'evening'else 'night' end time3
from t2)select store_id,time3,count(1) sp from t3 group by time3,store_id order by sp desc;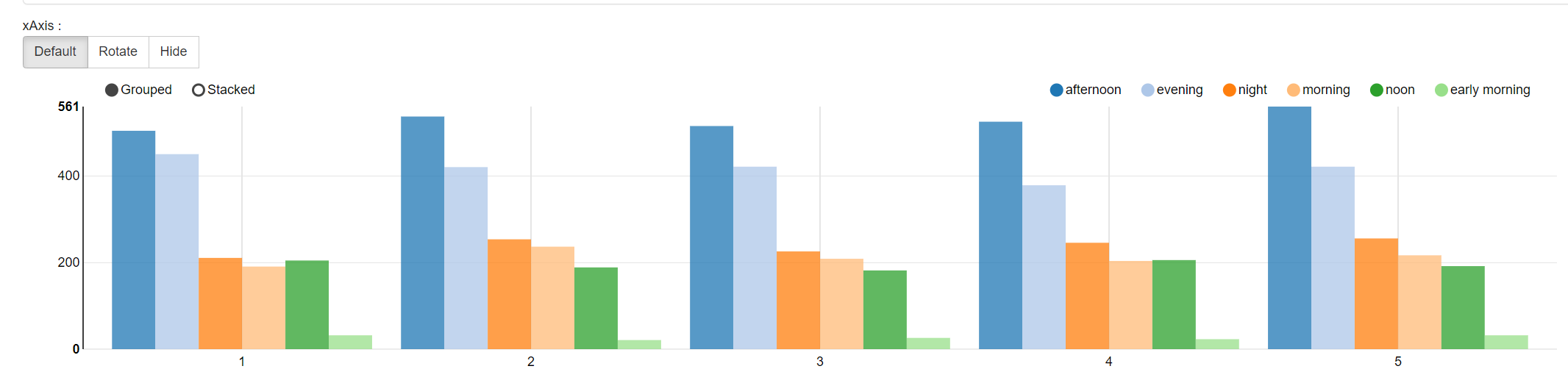
3.9 找出每家店的忠实顾客
with t1 as ( selectrow_number() over (partition by customer_id,store_id) ro,*from transaction_details )
select customer_id,store_id,count(1) c from t1
group by customer_id,store_id having c>=8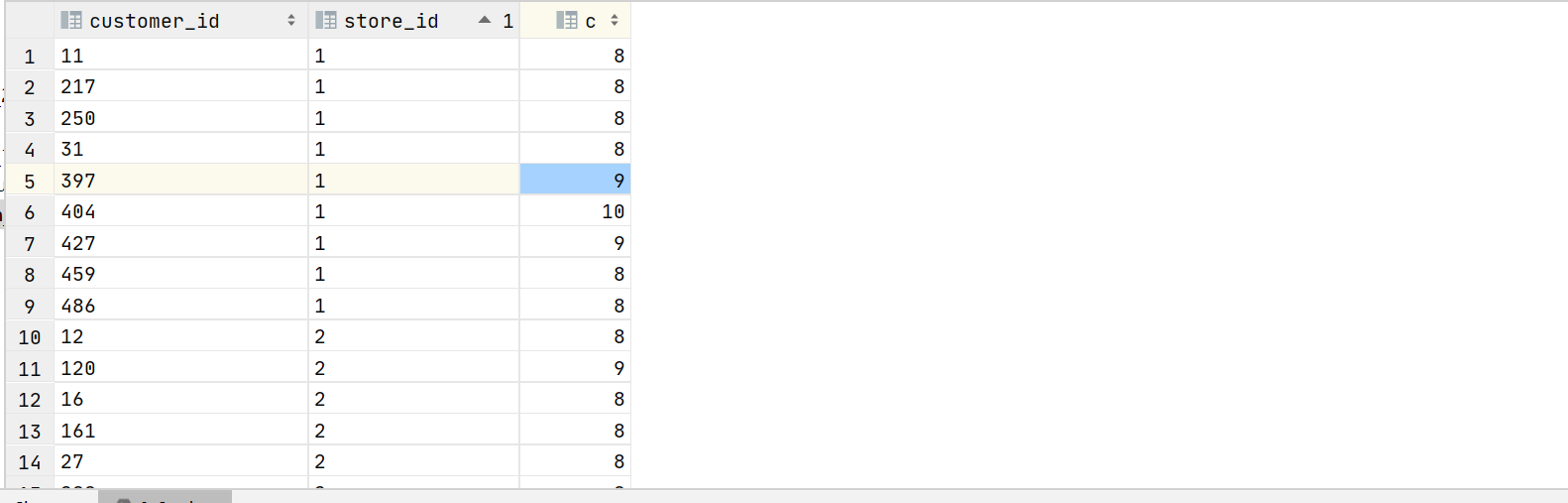
3.10 根据每位员工的最高收入找出明星商店
select distinct td.store_id,esd.store_name,esd.employee_number,t1.sp/esd.employee_number rk from transaction_details tdjoin ext_store_details esd on td.store_id = esd.store_idjoin (select store_id,sum(price) sp from transaction_details group by store_id) t1 on td.store_id=t1.store_id
order by rk desc
Review分析
4.1 在ext_store_review中找出存在冲突的交易映射关系
with basetb as(
select row_number() over (partition by transaction_id) as row_number1,* from ext_review_details
)
select row_number1,a.transaction_id,a.store_id,b.store_id,a.review_score,b.review_score from basetb a
join ext_review_details b on a.transaction_id=b.transaction_id
where row_number1 >1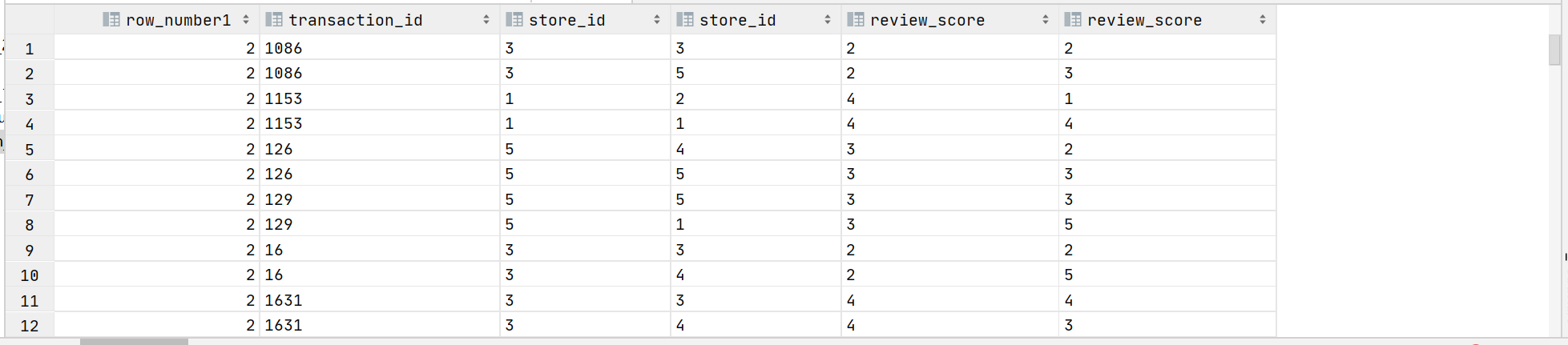
4.2 了解客户评价的覆盖率
with t1 as (
select count(1) c1 from ext_review_details where review_score <> ''),
t2 as (
select count(1) c2 from ext_review_details where review_score = ''
)
select concat(cast((c1-c2)/c1*100 as decimal(4,2)),'%') from t1 join t2

4.3 根据评分了解客户的分布情况
select c.country,r.review_score,count(price) from ext_review_details rjoin transaction_details t on r.transaction_id=t.transaction_idjoin ext_customer_details c on t.customer_id = c.customer_id
group by review_score,c.country;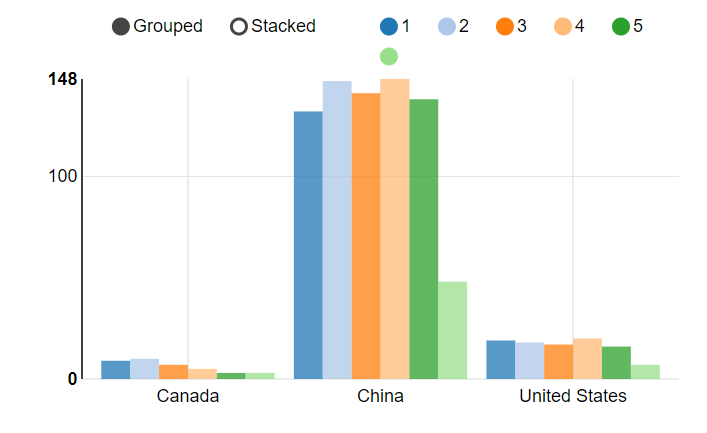
4.4 根据交易了解客户的分布情况
selectcountry,sum(price),count(price)
from transaction_details tdjoin ext_customer_details cd on td.customer_id = cd.customer_id
group by cd.country
4.5 客户给出的最佳评价是否总是同一家门店
相关文章:
大数据技术之——zeppelin数据清洗
一、zeppelin的安装zeppelin解压后进入到conf配置文件界面。修改zeppelin-site.xml[roothadoop02 conf]# cp zeppelin-site.xml.template zeppelin-site.xml[roothadoop02 conf]# vim zeppelin-site.xml将IP地址和端口号设置成自己的修改 zeppelin-env.shexport JAVA HOME/opt/…...
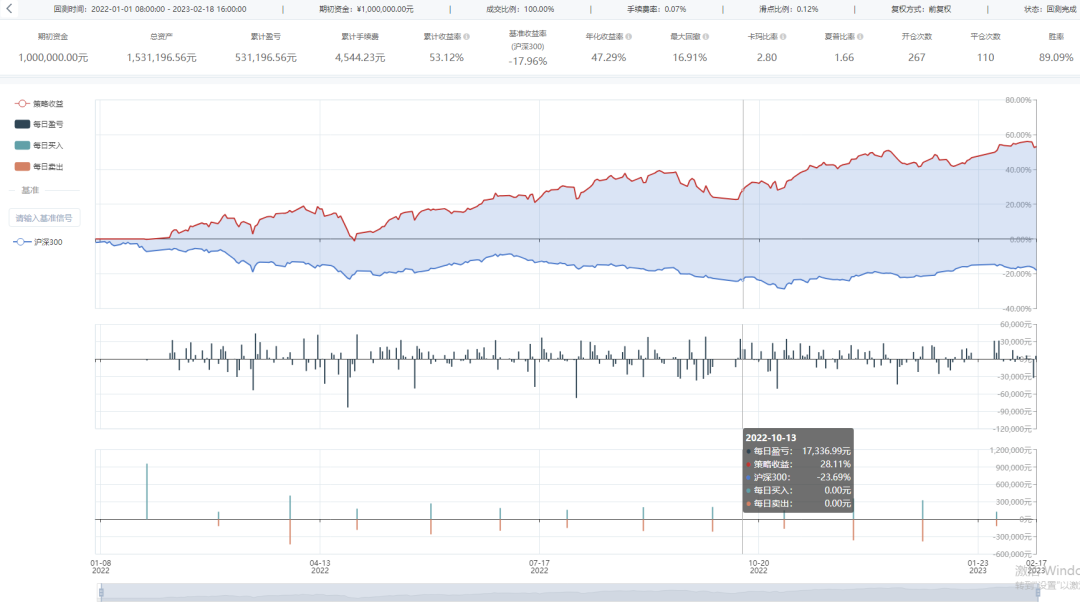
Barra模型因子的构建及应用系列五之NonLinear Size因子
一、摘要 在前期的Barra模型系列文章中,我们构建了Size因子、Beta因子、Momentum因子和Residual Volatility因子,并分别创建了对应的单因子策略,本节文章在该系列下进一步构建NonLinear Size因子。从回测结果看,自2022年以来&…...

C++ 常用命令行开发工具(Linux)
文章目录1、简介2、gcc / g2.1 system(执行shell 命令)2.2 popen(建立管道I/O)2.3 vforkexec(新建子进程)3、clang3.1 下载和安装clang3.2 clang和gcc比较3.2.1 gcc3.2.2 clang3.2.3 LLVM4、make4.1 例子14…...
)
java基础学习 day47(抽象类,抽象方法)
1. 抽象方法 将共性的行为(方法)抽取到父类之后,由于每一个子类执行的内容是不一样的,所以,在父类中不能确定具体的方法体,该方法就可以定义为抽象方法。抽象方法定义格式: public abstract 返…...
)
Java代码弱点与修复之——Open redirect(开放重定向)
弱点描述 Open redirect , 开放重定向,是一种常见的安全漏洞,也被称为“重定向漏洞”。该漏洞通常出现在 Web 应用程序中,攻击者可以利用它将用户重定向到恶意站点,从而进行钓鱼攻击、恶意软件传播、诱骗等活动。 在 Java 中,通过重定向 HTTP 请求来实现应用程序中的跳转…...

Go 指针
指针在编程中,一个内存地址用来定位一段内存。通常地,一个内存地址用一个操作系统原生字(native word)来存储。 一个原生字在32位操作系统上占4个字节,在64位操作系统上占8个字节。 所以,32位操作系统上的理…...
shardingsphere5.1.1分表分库yaml配置 自定义策略
前言通过阅读官方稳定给出示例 https://shardingsphere.apache.org/document一、基本配置示例spring:sharding:datasource:names: ds0, ds1ds0:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/db0username: rootpassword: rootds1:driver-class-na…...

“探索未来:VR全景直播技术引领新媒体时代”
随着虚拟现实技术的不断发展,VR全景直播已经成为了越来越受欢迎的直播形式。VR全景直播可以让观众通过虚拟现实设备亲临直播现场,享受身临其境的观看体验。VR全景直播是什么? VR全景直播是虚拟现实技术和直播的结合。相对于传统直播ÿ…...

Spring Cloud(微服务)学习篇(六)
Spring Cloud(微服务)学习篇(六) 2 Sentinel实现流量规则(控制台版) 2.1 变更pom.xml(shop-user-server项目)代码 2.1.1 加入如下依赖 <!--熔断限流--> <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-…...
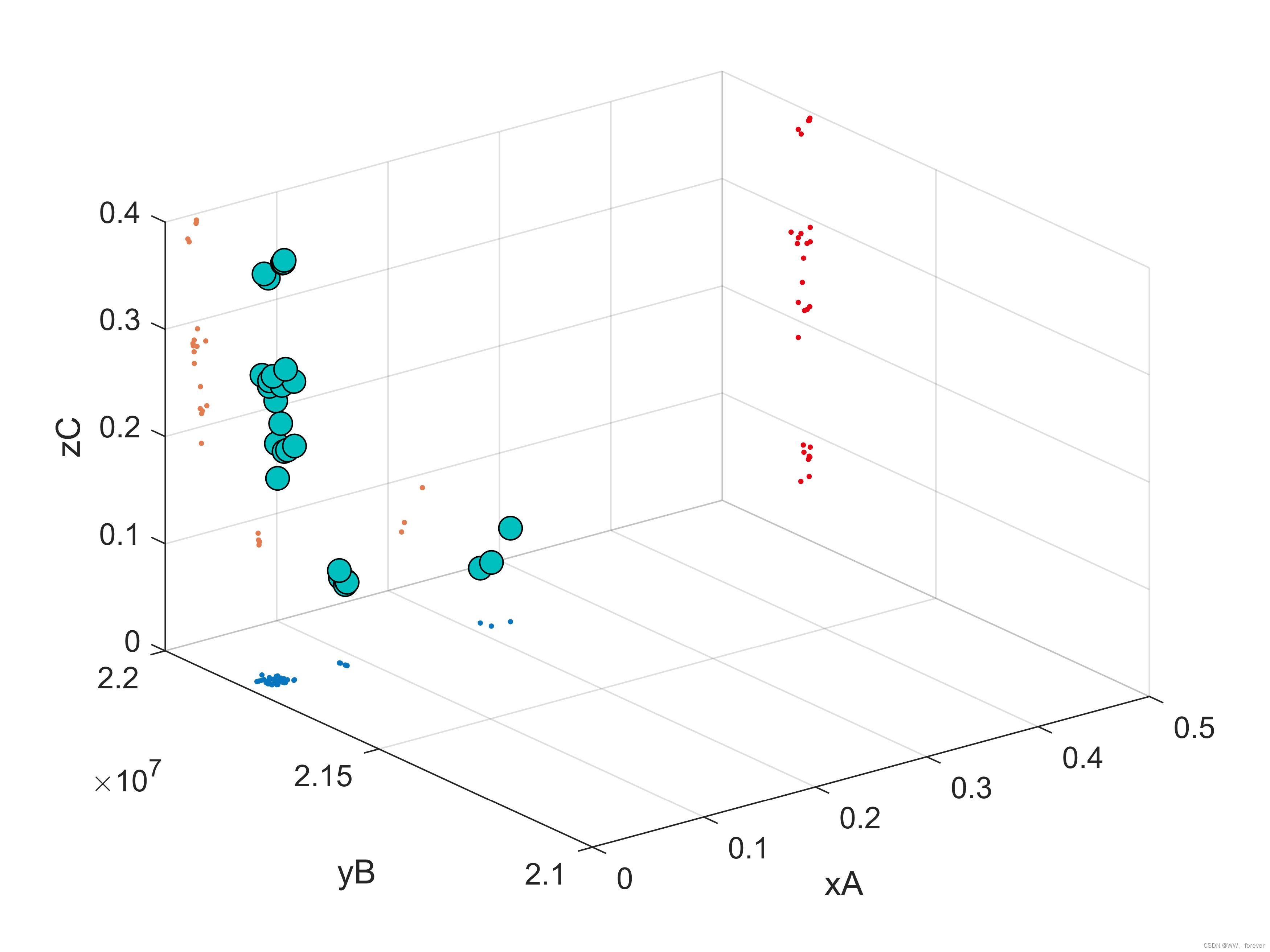
MATLAB-Scatter3-三维散点图投影至XYZ三个平面
MATLAB-Scatter3函数可以绘制立体的三维散点图,但有时候需要在该立体图中分析X-Y-Z三者的关系,即1副图呈现出4个信息,XYZ综合信息、XY信息、XZ信息、YZ信息。现有的Scatter3无法实现该功能,本文可实现Scatter3三维立体散点图在三个…...
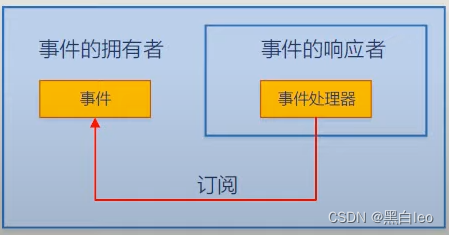
Unity/C#------委托与事件(一篇文章彻底搞懂...)
一:委托 所有的代码语言创造者母语都是英语,我们从英语翻译到中文的过程中难免会存在一些不太能还原本意的词,比如我之前一直不理解构造函数和析构函数,只知道这俩货作用相反,直到我看到了它的英文意思,Con…...
别再为 Jenkins 安装烦恼,Docker 帮你轻松解决
前言 大家好,又见面了,我是沐风晓月,本文收录与云原生相关的专栏,以下是我的简介: 🏠个人主页:我是沐风晓月 🧑个人简介:大家好,我是沐风晓月,双…...

汇编语言程序设计(一)
前言 在学习汇编语言之前,我们应该要知道汇编语言他是一门怎么样的语言。汇编语言是直接工作在硬件上的一门编程语言,学习汇编语言之前最好先了解一下计算机硬件系统的结构和工作原理。学习汇编语言的重点是学习如何利用硬件系统的编程结构和指令集进而…...

【uni-app教程】四、UniAPP 路由配置及页面跳转
四、UniAPP 路由配置及页面跳转 (1) 路由配置 uni-app页面路由为框架统一管理,开发者需要在pages.json里配置每个路由页面的路径及页面样式。类似小程序在 app.json 中配置页面路由一样。所以 uni-app 的路由用法与 Vue Router 不同,如仍希望采用 Vue …...
-- ROS控制器图形化界面开发)
ROS从入门到精通系列(二十八)-- ROS控制器图形化界面开发
ROS (Robot Operating System, 机器人操作系统) 作为机器人软件中的通信及控制中间件,提供一系列程序库和工具以帮助软件开发者创建机器人应用软件。它提供了硬件抽象、设备驱动、函数库、可视化工具、消息传递和软件包管理等诸多功能。ROS遵循BSD开源许可协议。 随着机器人智…...
Submodule命令:android如何将自己项目中的某个Module作为gitlab中第三方公共库
一、创建远程公共库 1、Android Studio创建本地仓库 创建一个新的module 在新建module中添加代码(此处示例代码) 右击新建的module,打开新建module的命令行界面, 因为我们只上传这个module的代码,而不是整个项目的代码 命令行中输入以下命令…...

MySQL索引事务
1.索引1.1概念索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结果实现。(这里只用通俗的语言和图片进行介绍)1.2作用数据库中的表…...

ISO27001信息安全管理体系认证
ISO信息安全管理体系认证 一、什么是ISO信息安全管理体系认证? ISO是信息安全管理体系认证,是由国际标准化组织(ISO)采纳英国标准协会BS-2标准后实施的管理体系,成为了“信息安全管理”的国际通用语言,企…...
Linux应用GUI开发C++ 之gtkmm4(1)
目录概述GTKgtkmm安装gtkmm4hello,worldcodelite配置代码解释概述 GTK GTK是一个小部件工具包。GTK创建的每个用户界面都由小部件组成。这是在C语言中使用GObject实现的,GObject是一个面向对象的C语言框架。窗口小部件是主容器。然后通过向窗口中添加按钮、下拉菜…...
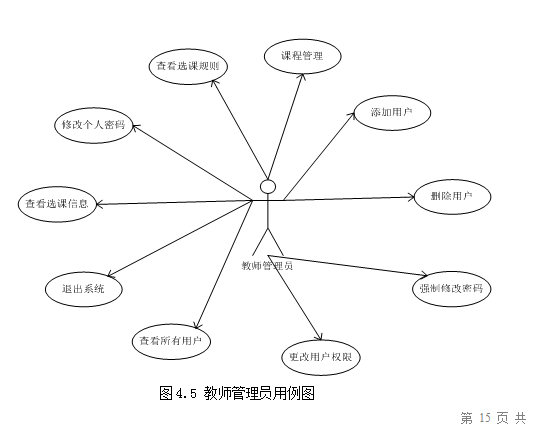
选课系统的设计与实现
技术:Java等摘要:目前国内各高校的规模越来越大,进而造成教师教学管理等工作量日趋加大。然而,现代教育的信息化、网络化已经成为教育发展的一个重要方向,同时也为解决高校教学管理效率低下的现状,使管理突…...

从案例学习Verilog for循环:如何高效实现信号赋值与多路选择器
Verilog for循环实战:从信号赋值到多路选择器的工程化实现 1. 硬件描述语言中的循环思维 在软件编程中,for循环是最基础的控制结构之一,但在硬件描述语言(HDL)如Verilog中,循环的使用却需要完全不同的思维方式。硬件工程师必须时刻…...

Gemma-3-12b-it开发者部署教程:Linux环境多卡CUDA性能调优步骤
Gemma-3-12b-it开发者部署教程:Linux环境多卡CUDA性能调优步骤 想在自己的Linux服务器上部署一个能“看懂”图片并流畅对话的大模型吗?面对12B参数的大模型,你是不是担心显存不够、速度太慢,或者多张显卡用不起来?今天…...
)
避坑指南:ROS Noetic串口通讯常见错误排查(从设备权限到波特率设置)
ROS Noetic串口通讯实战:从权限配置到数据解析的完整解决方案 在机器人开发中,串口通讯作为硬件交互的基础通道,其稳定性直接影响整个系统的可靠性。ROS Noetic作为当前长期支持版本,对串口通讯的支持有了新的优化,但开…...

Flutter环境搭建全攻略:从安装到解决常见问题
1. Flutter开发环境搭建前的准备 在开始Flutter开发之前,我们需要做好一些基础准备工作。首先确保你的电脑满足以下最低配置要求: 操作系统:Windows 10或更高版本(64位)磁盘空间:至少5GB可用空间内存&#…...
)
Escrcpy - 免费开源!电脑控制安卓手机的投屏工具 (屏幕镜像 / 无线 / AI 自动化 / 录屏)
上班时想要看手机不方便?在电脑前办公时常要用到一些手机 APP?或你是开发者,需要在电脑上测试手机应用?又或是想在电脑上管理手机文件,甚至希望能直接远程操控手机? 在 iOS 都推出了官方 iPhone 镜像功能&…...

1.1 数据采集全景指南:从理论到工具选型
1. 数据采集的本质与价值 第一次接触数据采集时,我把它想象成超市里的自助结账机——你需要把商品(数据)一件件扫码(采集),才能完成付款(分析)。这个看似简单的过程,实际…...
)
微信H5开发实战:5分钟搞定公众号token与用户Openid获取(附完整代码)
微信H5开发实战:高效获取公众号token与用户Openid的完整指南 在移动互联网时代,微信生态已成为企业营销和用户互动的重要阵地。无论是电商促销、会员服务还是互动活动,快速准确地获取用户身份信息都是实现个性化服务的基础。本文将带你深入理…...

Qwen3-ASR-1.7B在音乐识别中的惊艳表现:RAP歌词转写准确率突破
Qwen3-ASR-1.7B在音乐识别中的惊艳表现:RAP歌词转写准确率突破 当语速飞快的RAP遇上AI语音识别,会发生什么?传统语音识别模型在快速说唱面前往往"听不清、跟不上",但Qwen3-ASR-1.7B却给出了令人惊喜的答案。 1. 为什么R…...

快速上手Python开发:Miniconda-Python3.8镜像环境搭建与问题解决
快速上手Python开发:Miniconda-Python3.8镜像环境搭建与问题解决 1. 为什么选择Miniconda-Python3.8 Python作为当今最流行的编程语言之一,在数据科学、机器学习和Web开发等领域广泛应用。但Python版本和依赖管理一直是开发者面临的挑战。Miniconda-Py…...

一文带你深入了解Linux五种I/O模型和I/O多路复用
一文带你深入了解Linux五种I/O模型和I/O多路复用 文章目录一文带你深入了解Linux五种I/O模型和I/O多路复用一、几种典型 I/O 模型1. 阻塞 I/O2. 非阻塞 I/O3. 信号驱动 I/O4. I/O 多路复用(高级 I/O)5. 异步 I/O(AIO)二、阻塞与非…...