CMU15-445-Spring-2023-Project #2 - B+Tree
前置知识:参考上一篇博文 CMU15-445-Spring-2023-Project #2 - 前置知识(lec07-010)
CHECKPOINT #1
Task #1 - B+Tree Pages
实现三个page class来存储B+树的数据。
- B+Tree Page
- internal page和leaf page继承的基类,只包含两个子类共享的信息;

- Impl:
- src/include/storage/page/b_plus_tree_page.h
- src/storage/page/b_plus_tree_page.cpp
- B+Tree Internal Page
- 一个内部页面存储 m 个有序键和 m+1 个指向其他 B+Tree 页面的子指针(作为 page_id)。这些键和指针在内部表示为一个 key/page_id 对数组。由于指针的数量不等于键的数量,因此第一个键被设置为无效,查找应始终从第二个键开始;
- 在任何时候,每个内部页面都应至少满一半。在删除过程中,可以合并两个半满的页面,或者重新分配键和指针以避免合并。在插入过程中,可以将一个完整的页面分割成两个,也可以重新分配键和指针以避免分割;
- Impl:
- src/include/storage/page/b_plus_tree_internal_page.h
- src/storage/page/b_plus_tree_internal_page.cpp
- B+Tree Leaf Page
- leaf page存储 m 个有序键及其 m 个相应的值。值应始终是tuple实际存储位置的 64 位 record_id;参阅 src/include/common/rid.h 中的 RID 类。leaf page对k/v对数量的限制与内部页面相同,并应遵循合并、拆分和重新分配键的相同操作;
- Impl:
- src/include/storage/page/b_plus_tree_leaf_page.h
- src/storage/page/b_plus_tree_leaf_page.cpp
每个 B+Tree 的leaf/internal page都与缓冲池获取的内存页的内容(即 data_ 部分)相对应。每次读取或写入leaf/internal page时,必须先从缓冲池中获取该页(使用其唯一的 page_id),然后 reinterpret cast 成leaf/internal page,并在读取或写入该页后将其unpin。
Task #2a - B+Tree Insertion and Search for Single Values
Impl:
src/storage/index/b_plus_tree.cpp
如果插入改变了根页面的 ID,则必须更新 B+Tree 索引头页面中的 root_page_id。为此,可以访问在构造函数中给出的 header_page_id_ page。然后,通过使用 reinterpret cast,将该页面解释为 BPlusTreeHeaderPage(来自 src/include/storage/page/b_plus_tree_header_page.h),并从这里更新根页面 ID。实现 GetRootPageId(目前默认返回 0)。
使用 project 1 中的page guard类来帮助防止同步问题。在访问页面时使用 FetchPageBasic(定义于 src/include/storage/page/)。以后在task 4 中实施并发控制时,可以根据需要将其改为使用 FetchPageRead 和 FetchPageWrite。
可以选择使用 Context 类(定义于 src/include/storage/index/b_plus_tree.h)来跟踪已读取或写入的页面(通过 read_set_ 和 write_set_ 字段),或存储需要递归传递到其他函数的其他元数据。
只需要在插入或删除时使用 write_set_。可能不需要使用 read_set_,这取决于实现。
在context中存储根页面 id,并在修改 B+Tree 时获取头页面的写保护。
write_set_ 的尾部保存当前节点的父节点,它应该包含访问路径上的所有节点。
如果要拆分节点(根节点除外),要确保 write_set_ 中至少还有一个节点。
要解锁header page,只需将 header_page_ 设为 std::nullopt。要解锁其他页面,只需从 write_set_ 中弹出即可。
插入后,当值的数量达到 max_size 时,分割叶节点;插入前,当值的数量达到 max_size 时,分割内部节点。这将确保在进行 InsertIntoLeaf 等操作后再重新分配时,插入叶节点不会导致页面数据溢出;这也将防止内部节点只有一个子节点。
当叶页面无法获取同级页面的latch时,需要抛出一个 std::exception 异常,以避免潜在的死锁。
每个线程将始终从头页到底部获取锁存器。释放锁存器时,请确保以相同的顺序(从页眉到底部)释放。
在插入时,即使拥有父节点的锁,也应始终获取子节点的锁。想想这样一种情况:一些线程正在使用读锁从叶子页中获取值,而另一些线程正在更新页面(例如,在聚合时)。如果不加锁,就会出现race。
- GetValue()
- 使用ReadPageGuard访问页面。通过header_page_id_访问header page,header page的root_page_id_指向根节点的第一个k/v对;
- 当获取了根节点的页面的latch后,释放header page的latch;
- 通过二分搜索key在页面中的位置,迭代向下查找到leaf page,然后找到leaf page中相应的value(rid)。
- Insert()
- 同样,先获取根页面,若根为空,通过NewPageGuarded获取一个新页面,然后插入;
- 若根节点不为空,通过write_set_维护向下搜索的path,直到到达leaf page,并且通过prev_和next_维护路径上节点的左右兄弟节点(插入分裂优化);
- 若搜索过程中某个internal page的size小于max size,就可以将write_set_中的节点弹出,因为即使叶子节点需要分裂,internal page需要插入新k/v对,size也是够的;
- 插入分裂优化:若leaf page插入后超过了max size,但是其兄弟节点没满,会将最左/右记录移动到其兄弟节点上,默认先向左移动;(参考InnoDB,充分利用索引页,还有一种方法就是在特定的递增key插入情况下,如果检测到三个连续递增的key,那么就不进行分裂,而是直接往右新建一个页面插入,避免频繁分裂)常规分裂就是50%。
- leaf page分裂会产生新的k/v,继续向上往internal page插入(根据write_set_维护的path),同样进行插入分裂优化;
- 若write_set_遍历完后还需要向上插入,那么通过NewPageGuarded获取新页面作为根节点,然后更新即可;
CHECKPOINT #2
Task #2b - B+Tree Deletions
支持key的删除,包括页面的合并或重新分配键。与插入一样,如果根页面发生变化,必须正确更新 B+Tree 的根页面 ID。
Impl:
src/storage/index/b_plus_tree.cpp
- Remove()
- 几乎与Insert同样的思路,进行合并优化,优先从兄弟节点拉取单个k/v到本节点;
Task #3 - An Iterator for Leaf Scans
添加一个 C++ 迭代器,以有效支持对leaf page中的数据进行顺序扫描。基本思路是存储同胞指针,以便高效地遍历leaf page,然后实现一个迭代器,按顺序遍历每个leaf page中的每个键值对。
- C++17 style;
- isEnd():返回此迭代器是否指向最后一个键/值对;
- operator++():移动到下一个键/值对;
- operator*():返回该迭代器当前指向的键/值对;
- operator==():返回两个迭代器是否相等;
- operator!=():返回两个迭代器是否不相等;
- Begin() & End():返回最左/右的leaf page的迭代器;
Impl:
src/include/storage/index/index_iterator.h
src/index/storage/index_iterator.cpp
src/storage/index/b_plus_tree.cpp
IndexIterator内部维护三个值:bpm、page id、page内部index。
Task #4 - Concurrent Index
FetchPageWrite or FetchPageRead
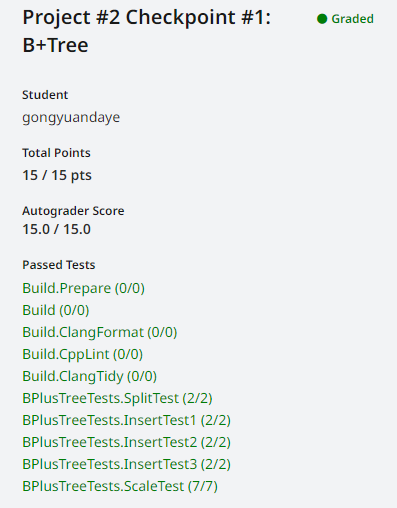
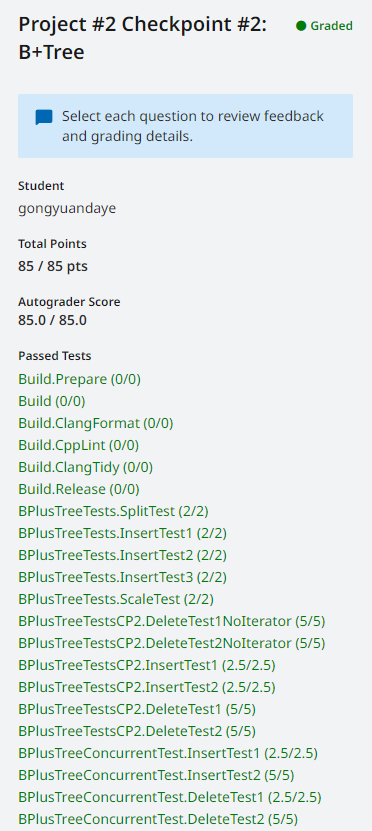
实验结果
相关文章:
CMU15-445-Spring-2023-Project #2 - B+Tree
前置知识:参考上一篇博文 CMU15-445-Spring-2023-Project #2 - 前置知识(lec07-010) CHECKPOINT #1 Task #1 - BTree Pages 实现三个page class来存储B树的数据。 BTree Page internal page和leaf page继承的基类,只包含两个…...
matplotlib:热图、箱形图、小提琴图、堆叠面积图、雷达图、子图
简介:在数字化的世界里,从Web、HTTP到App,数据无处不在。但如何将这些复杂的数据转化为直观、易懂的信息?本文将介绍六种数据可视化方法,帮助你更好地理解和呈现数据。 热图 (Heatmap):热图能有效展示用户…...
Django数据库选移的preserve_default=False是什么意思?
有下面的迁移命令: migrations.AddField(model_namemovie,namemov_group,fieldmodels.CharField(defaultdjango.utils.timezone.now, max_length30),preserve_defaultFalse,),迁移命令中的preserve_defaultFalse是什么意思呢? 答:如果模型定…...
逸学Docker【java工程师基础】2.Docker镜像容器基本操作+安装MySQL镜像运行
基础的镜像操作 在这里我们的应用程序比如redis需要构建成镜像,它作为一个Docker文件就可以进行构建,构建完以后他是在本地的,我们可以推送到镜像服务器,逆向可以拉取到上传的镜像,或者说我们可以保存为压缩包进行相互…...
基于Java SSM框架实现医院管理系统项目【项目源码】计算机毕业设计
基于java的SSM框架实现医院管理系统演示 SSM框架 当今流行的“SSM组合框架”是Spring SpringMVC MyBatis的缩写,受到很多的追捧,“组合SSM框架”是强强联手、各司其职、协调互补的团队精神。web项目的框架,通常更简单的数据源。Spring属于…...
【java八股文】之Spring系列篇
【java八股文】之JVM基础篇-CSDN博客 【java八股文】之MYSQL基础篇-CSDN博客 【java八股文】之Redis基础篇-CSDN博客 【java八股文】之Spring系列篇-CSDN博客 【java八股文】之分布式系列篇-CSDN博客 【java八股文】之多线程篇-CSDN博客 【java八股文】之JVM基础篇-CSDN博…...

关于MySQL源码的学习 这里是一些建议
学习MySQL源码需要一定的编程基础,特别是C语言和数据结构。以下是一些建议,帮助你更好地入手学习MySQL源码: 基础知识 熟悉C语言编程基本概念、数据结构和算法。了解Linux操作系统基本概念,如进程、线程、内存管理、文件系统等。…...
Mysql是怎样运行的--下
文章目录 Mysql是怎样运行的--下查询优化explainoptimizer_trace InnoDB的Buffer Pool(缓冲池)Buffer Pool的存储结构空闲页存储--free链表脏页(修改后的数据)存储--flush链表 使用Buffer PoolLRU链表的管理 事务ACID事务的状态事…...

yum来安装php727
yum 安装php727,一键安装,都是安装在系统的默认位置,方便快捷 先确定linux平台中centos的版本信息,一下内容针对el7 查看linux版本 : cat /etc/redhat-release 查看内核版本命令: cat /proc/version (0)如果有安装好…...

基于jackson封装的json字符串与javaBean对象转换工具
文章目录 一、概述二、编码实现1. pom文件引入组件2. 核心代码 三、功能测试1. 测试文件2. 测试代码 四,完整代码 一、概述 带有API接口交互的web项目开发过程中,json字符串与javaBean对象之间的相互转换是比较常见的需求,基于jackson Objec…...

js中的数据类型
JavaScript 中有以下几种常见的数据类型: 基本类型(原始类型): 字符串(String):表示文本数据。数字(Number):表示数值数据。布尔(Boolean…...

vue3+vant+cropper.js实现移动端图片裁剪功能
一、前言 最近做项目中遇到一个需求,需要对海报图片按照一定的比例进行裁剪并上传到oss。一开始这个需求思路有两个,使用canvas原生或者寻找现成的第三方库,对比了一番觉得canvas实现时间耗费较长,且秉承着不重复造轮子的原则&am…...

springCould中的Bus-从小白开始【11】
目录 🧂1.Bus是什么❤️❤️❤️ 🌭2.什么是总线❤️❤️❤️ 🥓3.rabbitmq❤️❤️❤️ 🥞4.新建模块3366❤️❤️❤️ 🍳5.设计思想 ❤️❤️❤️ 🍿6.添加消息总线的支持❤️❤️❤️ ǹ…...

xshell和xftp
1.xshell和xftp的关系 Xftp和Xshell都是Xmanager Power Suite的组件,它们的功能和用途有所不同。 Xshell是一个用于MS Windows平台的强大的SSH、telnet和rlogin终端仿真软件,它使得用户能轻松和安全地从Windows PC上访问Unix/Linux主机。 Xftp是一个用…...

python for...else用法,一个实例就能让你明白
直接上代码,很简单,不用讲解吧,看不懂的话,就需要补充下基础知识了。 def funct2():for i in range(4):try:assert i>2print("success")breakexcept Exception as e:print(error)continueelse:print(循环不合预期)d…...

windows 设置ip命令bat脚本
您可以使用以下命令创建一个批处理文件(.bat)来添加IP地址: echo off set ipaddress set subnetmask set gatewaynetsh interface ip set address name"以太网" sourcestatic address%ipaddress% mask%subnetmask% gateway%gatewa…...

Openharmony 对应Android内存查看
众所周知,内存查看是一个很重要的部分,大多数情况,我们都是使用dumpsys的方法对android的内存进行查看,但是对于openharmony而言好像又不太一样了。 Android内存查看 命令行: adb shell dumpsys meminfo <packag…...
:通过ID选择,返回一个地层年代段的基本信息)
R语言【paleobioDB】——pbdb_interval():通过ID选择,返回一个地层年代段的基本信息
Package paleobioDB version 0.7.0 paleobioDB 包在2020年已经停止更新,该包依赖PBDB v1 API。 可以选择在Index of /src/contrib/Archive/paleobioDB (r-project.org)下载安装包后,执行本地安装。 Usage pbdb_interval (id, ...) Arguments 参数【id】…...
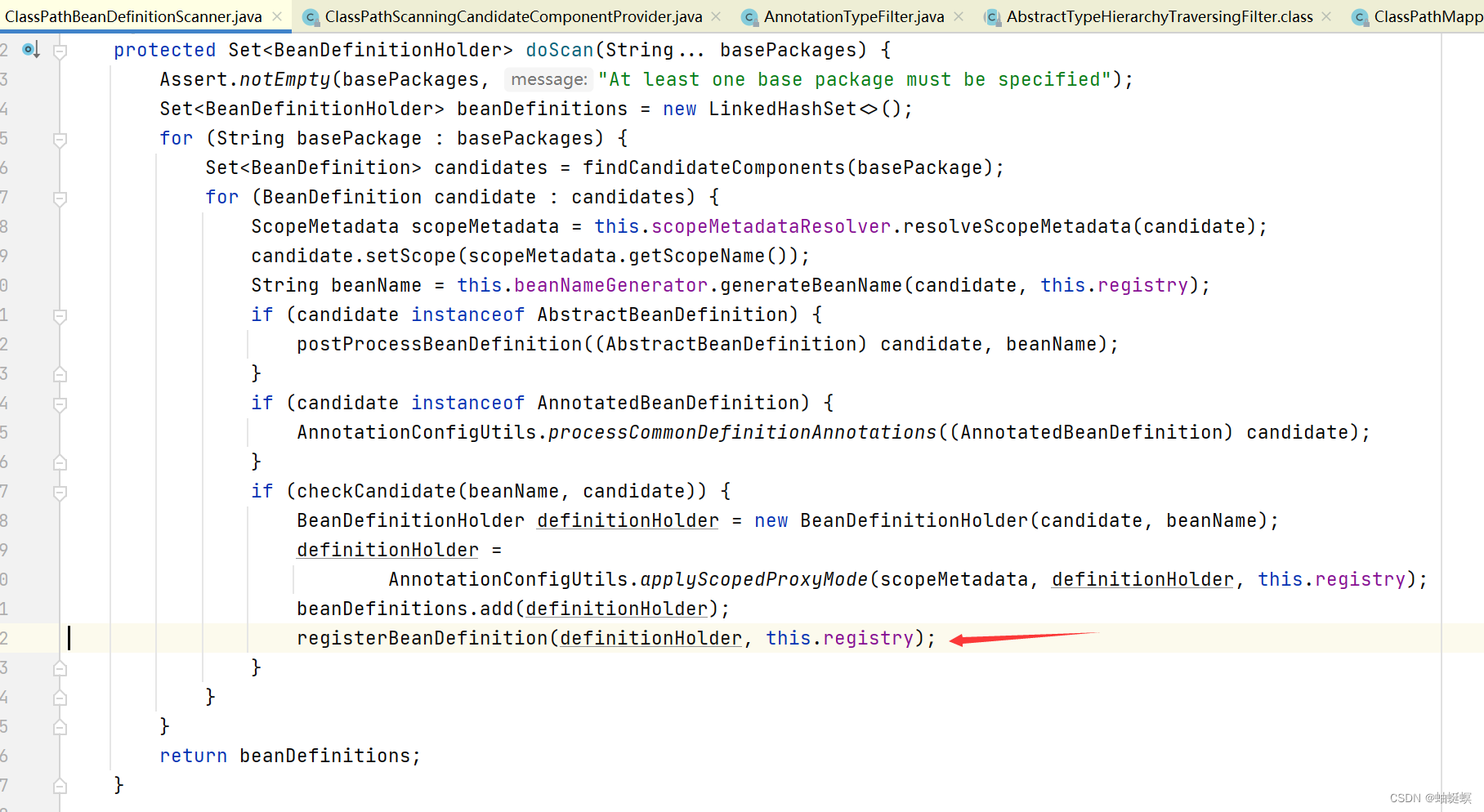
spring boot mybatis plus mapper如何自动注册到spring bean容器
##Import(AutoConfiguredMapperScannerRegistrar.class) ##注册MapperScannerConfigurer ##MapperScannerConfigurer.postProcessBeanDefinitionRegistry方法扫描注册mapper ##找到mapper候选者 ##过滤mapper 类 候选者 ##BeanDefinitionHolder注册到spring 容器...

What is `@PathVariable` does?
PathVariable 是SpringMVC中的注解,用于将HTTP请求的URI路径变量映射到Controller方法参数上。 当URL路径中包含占位符(由大括号 {} 包围的部分)时,可以使用此注解来绑定这些动态部分到方法参数。 使用样例 获取单个路径变量 …...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...
AI语音助手的Python实现
引言 语音助手(如小爱同学、Siri)通过语音识别、自然语言处理(NLP)和语音合成技术,为用户提供直观、高效的交互体验。随着人工智能的普及,Python开发者可以利用开源库和AI模型,快速构建自定义语音助手。本文由浅入深,详细介绍如何使用Python开发AI语音助手,涵盖基础功…...
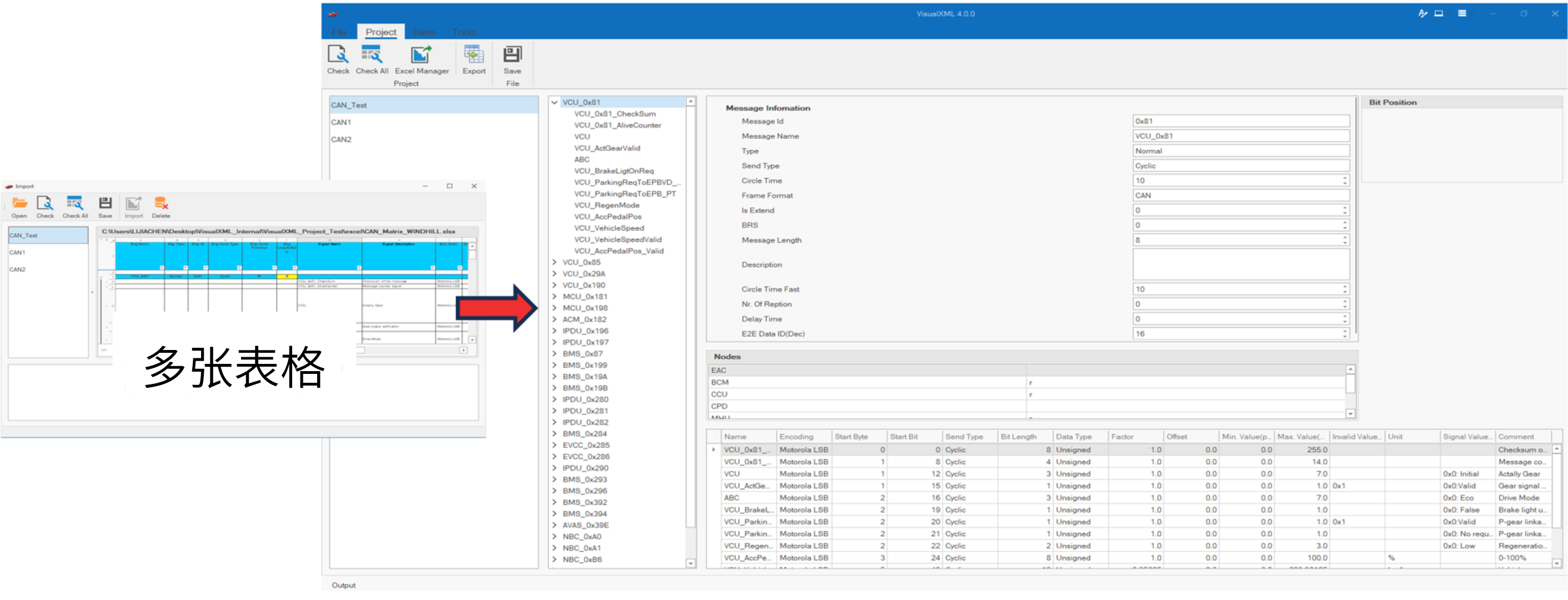
VisualXML全新升级 | 新增数据库编辑功能
VisualXML是一个功能强大的网络总线设计工具,专注于简化汽车电子系统中复杂的网络数据设计操作。它支持多种主流总线网络格式的数据编辑(如DBC、LDF、ARXML、HEX等),并能够基于Excel表格的方式生成和转换多种数据库文件。由此&…...
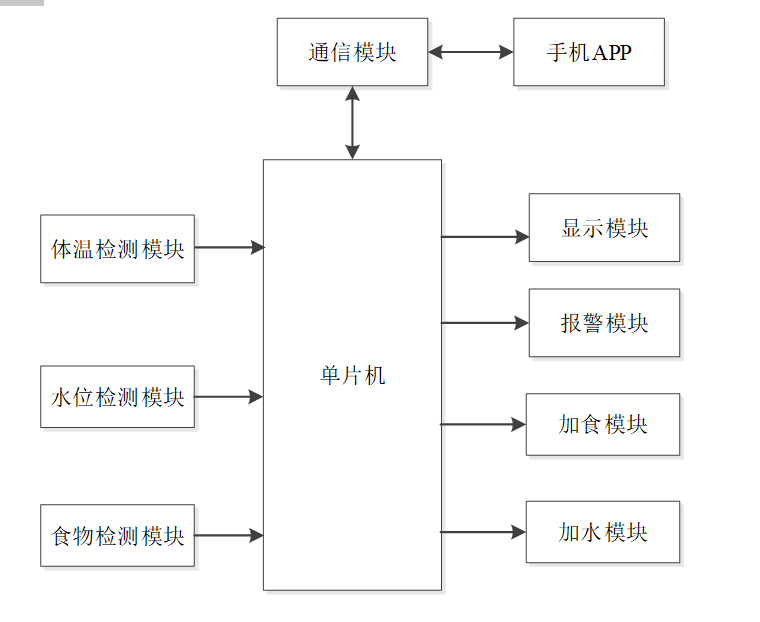
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...

FOPLP vs CoWoS
以下是 FOPLP(Fan-out panel-level packaging 扇出型面板级封装)与 CoWoS(Chip on Wafer on Substrate)两种先进封装技术的详细对比分析,涵盖技术原理、性能、成本、应用场景及市场趋势等维度: 一、技术原…...

基于stm32F10x 系列微控制器的智能电子琴(附完整项目源码、详细接线及讲解视频)
注:文章末尾网盘链接中自取成品使用演示视频、项目源码、项目文档 所用硬件:STM32F103C8T6、无源蜂鸣器、44矩阵键盘、flash存储模块、OLED显示屏、RGB三色灯、面包板、杜邦线、usb转ttl串口 stm32f103c8t6 面包板 …...