Elasticsearch:Search tutorial - 使用 Python 进行搜索 (四)

在本节中,你将了解另一种机器学习搜索方法,该方法利用 Elastic Learned Sparse EncodeR 模型或 ELSER,这是一种由 Elastic 训练来执行语义搜索的自然语言处理模型。这是继之前的文章 “Elasticsearch:Search tutorial - 使用 Python 进行搜索 (三)” 的续篇。
ELSER 模型
在上一章中,您了解了如何使用由机器学习模型生成的嵌入填充的 dend_vector 字段来扩展 Elasticsearch 索引。 该模型安装在你的计算机本地,嵌入是从 Python 代码生成的,并在插入索引之前添加到文档中。
在本章中,你将了解另一种向量类型,sparse_vector,它旨在存储来自 Elastic Learned Sparse EncodeR 模型 (ELSER) 的推论。 该模型返回的嵌入是标签的集合(更恰当地称为特征),每个标签都具有指定的权重。
在本章中,你还将使用不同的方法来处理机器学习模型,其中 Elasticsearch 服务本身运行模型并通过管道将生成的嵌入添加到索引中。
稀疏向量字段
与上一章中使用的密集向量字段类型一样,稀疏向量类型可以存储机器学习模型返回的推论。 密集向量保存描述源文本的固定长度的数字数组,而稀疏向量则存储特征到权重的映射。
让我们向索引添加一个稀疏向量字段。 这是需要在索引映射中显式定义的类型。 下面你可以看到 create_index() 方法的更新版本,其中包含一个名为 elser_embedding 的此类型的新字段。
search.py
class Search:# ...def create_index(self):self.es.indices.delete(index='my_documents', ignore_unavailable=True)self.es.indices.create(index='my_documents', mappings={'properties': {'embedding': {'type': 'dense_vector',},'elser_embedding': {'type': 'sparse_vector',},}})# ...
部署 ELSER 模型
如上所述,在此示例中,Elasticsearch 将获得模型的所有权并在插入文档和搜索时自动执行它以生成嵌入。
Elasticsearch 客户端公开一组 API 端点来管理机器学习模型及其管道。 search.py 中的以下 deploy_elser() 方法遵循几个步骤来下载和安装 ELSER v2 模型,并创建一个使用它来填充上面定义的 elser_embedding 字段的管道。
search.py
class Search:# ...def deploy_elser(self):# download ELSER v2self.es.ml.put_trained_model(model_id='.elser_model_2',input={'field_names': ['text_field']})# wait until readywhile True:status = self.es.ml.get_trained_models(model_id='.elser_model_2',include='definition_status')if status['trained_model_configs'][0]['fully_defined']:# model is readybreaktime.sleep(1)# deploy the modelself.es.ml.start_trained_model_deployment(model_id='.elser_model_2')# define a pipelineself.es.ingest.put_pipeline(id='elser-ingest-pipeline',processors=[{'inference': {'model_id': '.elser_model_2','input_output': [{'input_field': 'summary','output_field': 'elser_embedding',}]}}])
为我们配置 ELSER 需要几个步骤。 首先,使用 Elasticsearch 的 ml.put_trained_model() 方法下载ELSER。 model_id 参数标识要下载的模型和版本(ELSER v2 适用于 Elasticsearch 8.11 及更高版本)。 input 字段是该模型所需的配置。
下载模型后,需要对其进行部署。 为此,使用 ml.start_trained_model_deployment() 方法,仅使用要部署的模型的标识符。 请注意,这是一个异步操作,因此该模型将在短时间内可供使用。
配置 ELSER 使用的最后一步是为其定义管道。 管道用于告诉 Elasticsearch 如何使用模型。 管道被赋予一个标识符和一个或多个要执行的处理任务。 上面创建的管道称为 elser-ingest-pipeline,具有单个推理任务,这意味着每次添加文档时,模型将在 input_field 上运行,并且输出将添加到 输出字段。 对于此示例,summary 字段用于生成嵌入,与上一章中的密集向量嵌入一样。 生成的嵌入将写入上一节中创建的 elser_embedding 稀疏向量字段。
为了方便调用此方法,请在 app.py 中的 Flask 应用程序中添加一个 deploy-elser 命令:
app.py
@app.cli.command()
def deploy_elser():"""Deploy the ELSER v2 model to Elasticsearch."""try:es.deploy_elser()except Exception as exc:print(f'Error: {exc}')else:print(f'ELSER model deployed.')
你现在可以使用以下命令在 Elasticsearch 服务上部署 ELSER:
(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ flask deploy-elser
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch','cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg','name': 'liuxgm.local','tagline': 'You Know, for Search','version': {'build_date': '2023-11-04T10:04:57.184859352Z','build_flavor': 'default','build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20','build_snapshot': False,'build_type': 'tar','lucene_version': '9.8.0','minimum_index_compatibility_version': '7.0.0','minimum_wire_compatibility_version': '7.17.0','number': '8.11.0'}}
ELSER model deployed.上面的命令的允许需要一段时间。等命令完成后,我们可以转到 Kibana 界面:

最后一个配置任务涉及将索引与管道链接,以便在该索引上插入文档时自动执行模型。 这是通过设置选项在索引配置上完成的。 以下是对 create_index() 方法的另一项更新,用于创建此链接:
search.py
class Search:# ...def create_index(self):self.es.indices.delete(index='my_documents', ignore_unavailable=True)self.es.indices.create(index='my_documents',mappings={'properties': {'embedding': {'type': 'dense_vector',},'elser_embedding': {'type': 'sparse_vector',},}},settings={'index': {'default_pipeline': 'elser-ingest-pipeline'}})
通过此更改,你现在可以重新生成索引并完全支持 ELSER 推理:
flask reindex(.venv) $ pwd
/Users/liuxg/python/search-tutorial
(.venv) $ flask reindex
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch','cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg','name': 'liuxgm.local','tagline': 'You Know, for Search','version': {'build_date': '2023-11-04T10:04:57.184859352Z','build_flavor': 'default','build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20','build_snapshot': False,'build_type': 'tar','lucene_version': '9.8.0','minimum_index_compatibility_version': '7.0.0','minimum_wire_compatibility_version': '7.17.0','number': '8.11.0'}}
Index with 15 documents created in 59 milliseconds.运行完上面的命令后,我们可以在 Kibana 里进行查看:

从上面的图中我们可以看出来,有一个叫做 elser_embedding 的字段生成。它里面所含的值就是通过 text expansion 所生成的。
语义查询
现在索引配备了 ELSER 嵌入,可以更改 app.py 中的 handle_search() 函数来搜索这些嵌入。 目前,你将了解如何仅通过 ELSER 进行搜索,稍后将合并以前的搜索方法以创建组合解决方案。
要在搜索时使用 ELSER 推理,请使用 text_expansion 查询类型。 下面你可以看到带有此查询的更新后的 handle_search() 函数:
app.py
@app.post('/')
def handle_search():query = request.form.get('query', '')filters, parsed_query = extract_filters(query)from_ = request.form.get('from_', type=int, default=0)results = es.search(query={'text_expansion': {'elser_embedding': {'model_id': '.elser_model_2','model_text': parsed_query,}},},size=5,from_=from_,)return render_template('index.html', results=results['hits']['hits'],query=query, from_=from_,total=results['hits']['total']['value'])
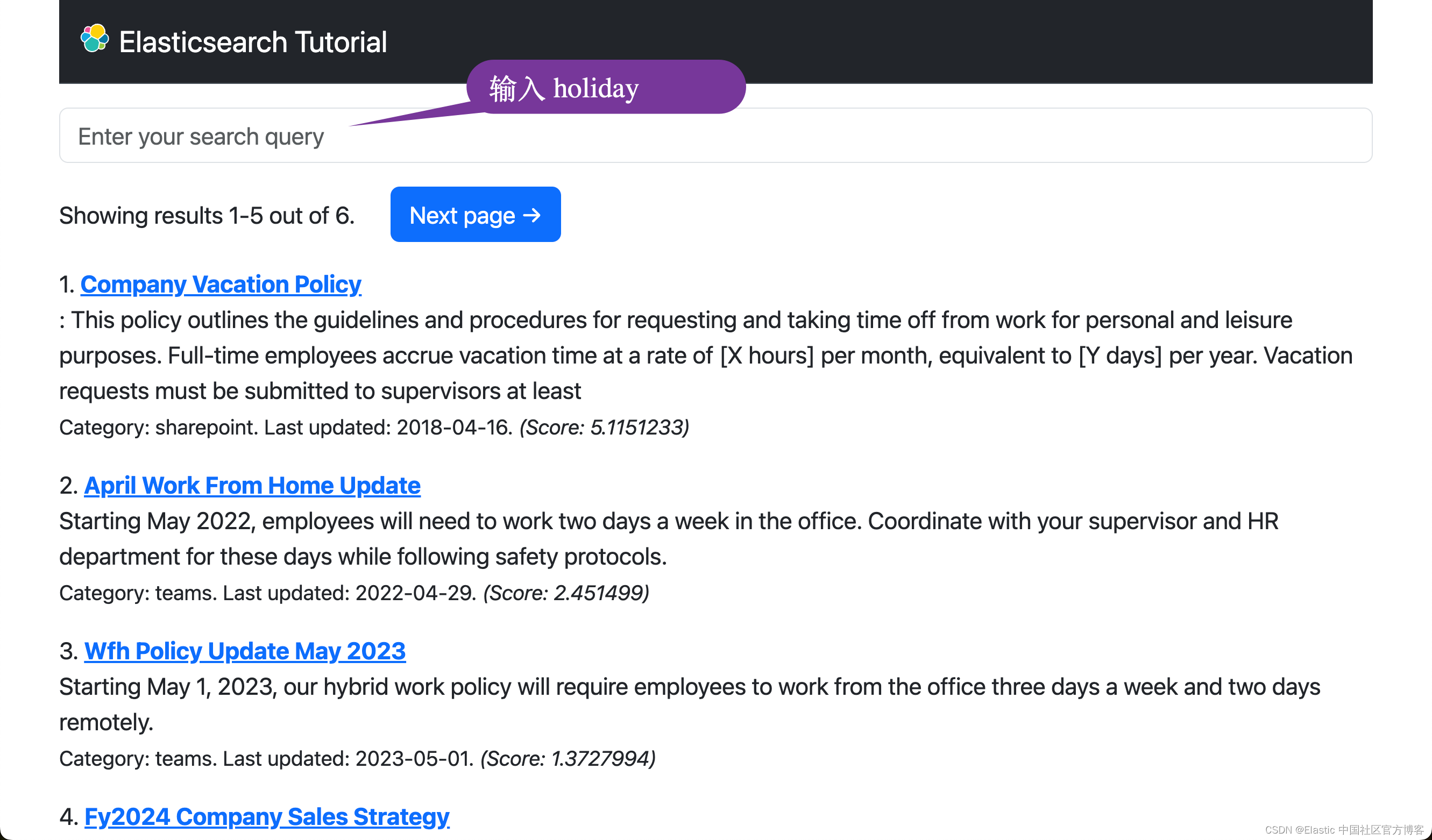
text_expansion 查询接收一个带有要搜索的字段名称的键。 在此键下,model_id 配置在搜索中使用哪个模型,model_text 定义要搜索的内容。 请注意,在这种情况下,无需为搜索文本生成嵌入,因为 Elasticsearch 管理模型并可以处理该问题。我们可以尝试如下的搜索:
在上面版本的handle_search()中,过滤器未被使用。 过滤器可以按照将其合并到全文搜索解决方案中的相同方式添加回来。 下面是更新的 handle_search() 函数,它将 text_expansion 查询移动到 bool.must 部分内,过滤器包含在 bool.filter 中。
app.py
@app.post('/')
def handle_search():query = request.form.get('query', '')filters, parsed_query = extract_filters(query)from_ = request.form.get('from_', type=int, default=0)results = es.search(query={'bool': {'must': [{'text_expansion': {'elser_embedding': {'model_id': '.elser_model_2','model_text': parsed_query,}},}],**filters,}},size=5,from_=from_,)return render_template('index.html', results=results['hits']['hits'],query=query, from_=from_,total=results['hits']['total']['value'])
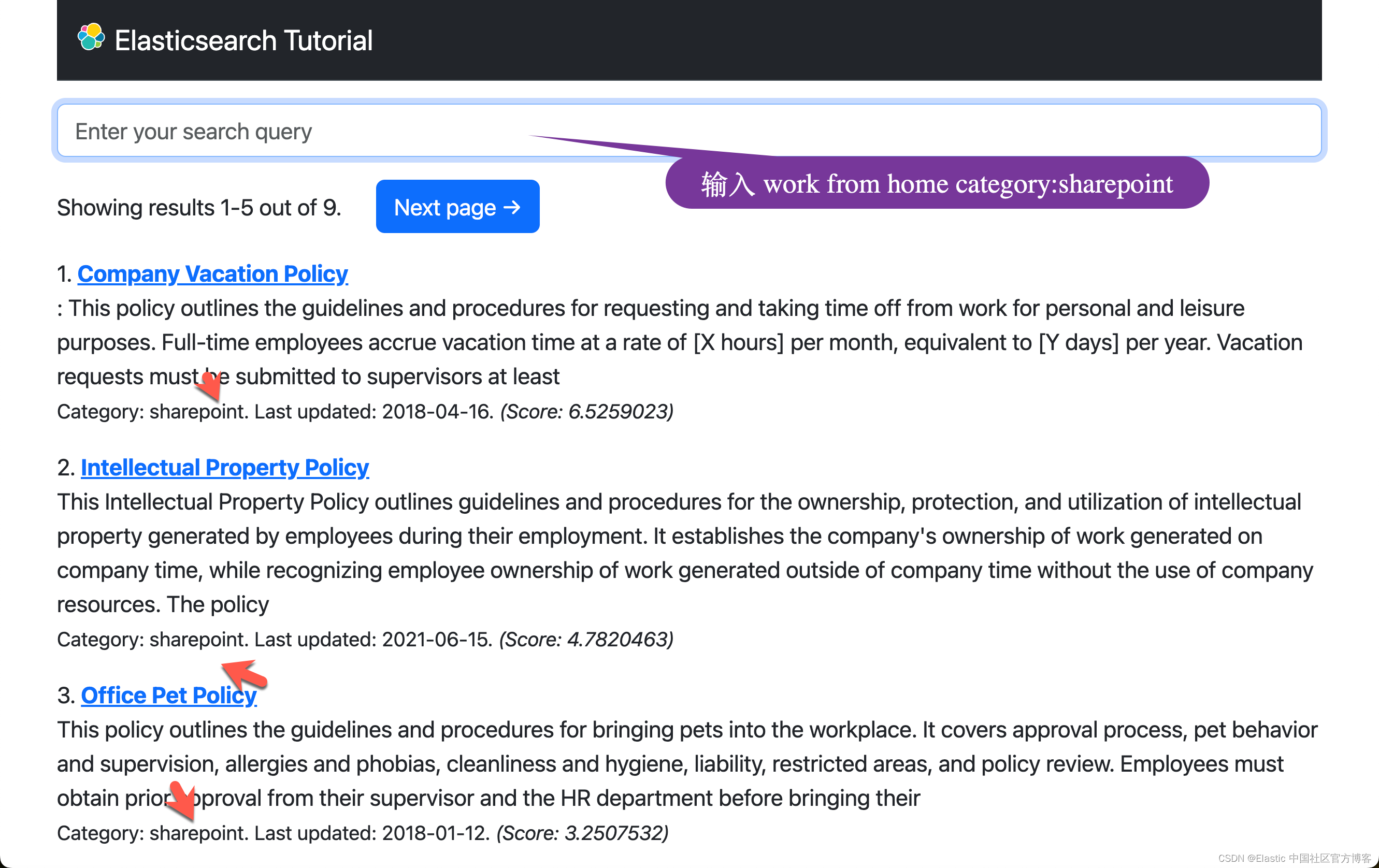
花一些时间尝试不同的搜索。 你会注意到,与密集向量嵌入一样,当索引文档中没有出现确切的单词时,由 ELSER 模型驱动的搜索比全文搜索效果更好。
work from home category:sharepoint
混合搜索:结合全文和 ELSER 结果
与上一节中的向量搜索一样,在本节中,你将学习如何使用倒数排名融合(RRF)算法组合来自全文和语义查询的最佳搜索结果。
子搜索简介
实现混合全文和密集向量搜索的解决方案是发送一个搜索请求,其中包括 query、knn 参数来请求两个搜索以及将它们合并到单个结果列表中的 rrf 参数。
当尝试执行相同操作来组合全文和稀疏向量搜索请求时,出现的复杂情况是两者都使用 query 参数。 为了能够提供需要与 RRF 算法结合的两个查询,需要包含两个查询参数,而实现这一点的解决方案是使用子搜索 (sub searches)来完成。
子搜索是一项目前处于技术预览版的功能。 因此,Python Elasticsearch 客户端本身并不支持它。 要解决此限制,可以更改 Search 类的 search() 方法以将搜索请求作为原始请求发送。 下面你可以看到一个新的但类似的实现,它使用客户端的 Perform_request() 方法发送原始请求:
search.py
class Search:# ...def search(self, **query_args):# sub_searches is not currently supported in the client, so we send# search requests as raw requestsif 'from_' in query_args:query_args['from'] = query_args['from_']del query_args['from_']return self.es.perform_request('GET',f'/my_documents/_search',body=json.dumps(query_args),headers={'Content-Type': 'application/json','Accept': 'application/json'},)
此实现不需要对应用程序进行任何更改,因为它在功能上是等效的。 唯一的区别是 search() 方法在发送请求之前验证所有参数,而 Perform_request() 是一个较低级别的方法,不执行任何验证。 无论客户端如何发送请求,服务器始终都会验证请求。
在此版本中,sub_searches 参数可用于发送多个搜索查询,如下所示:
results = es.search(sub_searches=[{'query': { ... }, # full-text search},{'query': { ... }, # semantic search},],'rank': {'rrf': {}, # combine sub-search results},size=5,from_=from_,)混合搜索实施
为了完成本节,让我们带回全文逻辑并将其与本章前面介绍的语义搜索查询相结合。
你可以在下面看到更新后的 handle_search() 端点:
app.py
@app.post('/')
def handle_search():query = request.form.get('query', '')filters, parsed_query = extract_filters(query)from_ = request.form.get('from_', type=int, default=0)if parsed_query:search_query = {'sub_searches': [{'query': {'bool': {'must': {'multi_match': {'query': parsed_query,'fields': ['name', 'summary', 'content'],}},**filters}}},{'query': {'bool': {'must': [{'text_expansion': {'elser_embedding': {'model_id': '.elser_model_2','model_text': parsed_query,}},}],**filters,}},},],'rank': {'rrf': {}},}else:search_query = {'query': {'bool': {'must': {'match_all': {}},**filters}}}results = es.search(**search_query,size=5,from_=from_,)return render_template('index.html', results=results['hits']['hits'],query=query, from_=from_,total=results['hits']['total']['value'])
你还记得,extract_filters() 函数查找用户在搜索提示中输入的类别过滤器,并将剩余部分作为 parsed_query 返回。 如果 parsed_query 为空,则意味着用户仅输入类别过滤器,在这种情况下,查询应该是简单的 match_all,并以所选类别作为过滤器。 这是在大条件的 else 部分中实现的。
当存在搜索查询时,如上一节所示,使用 sub_searches 选项来包含 multi_match 和 text_expansion 查询,而排名选项则要求将两个子搜索的结果合并到单个排名结果列表中。 为了完成查询,提供了 size 和 from_ 参数以维持对分页的支持。
我们可以尝试上面同样的搜索:
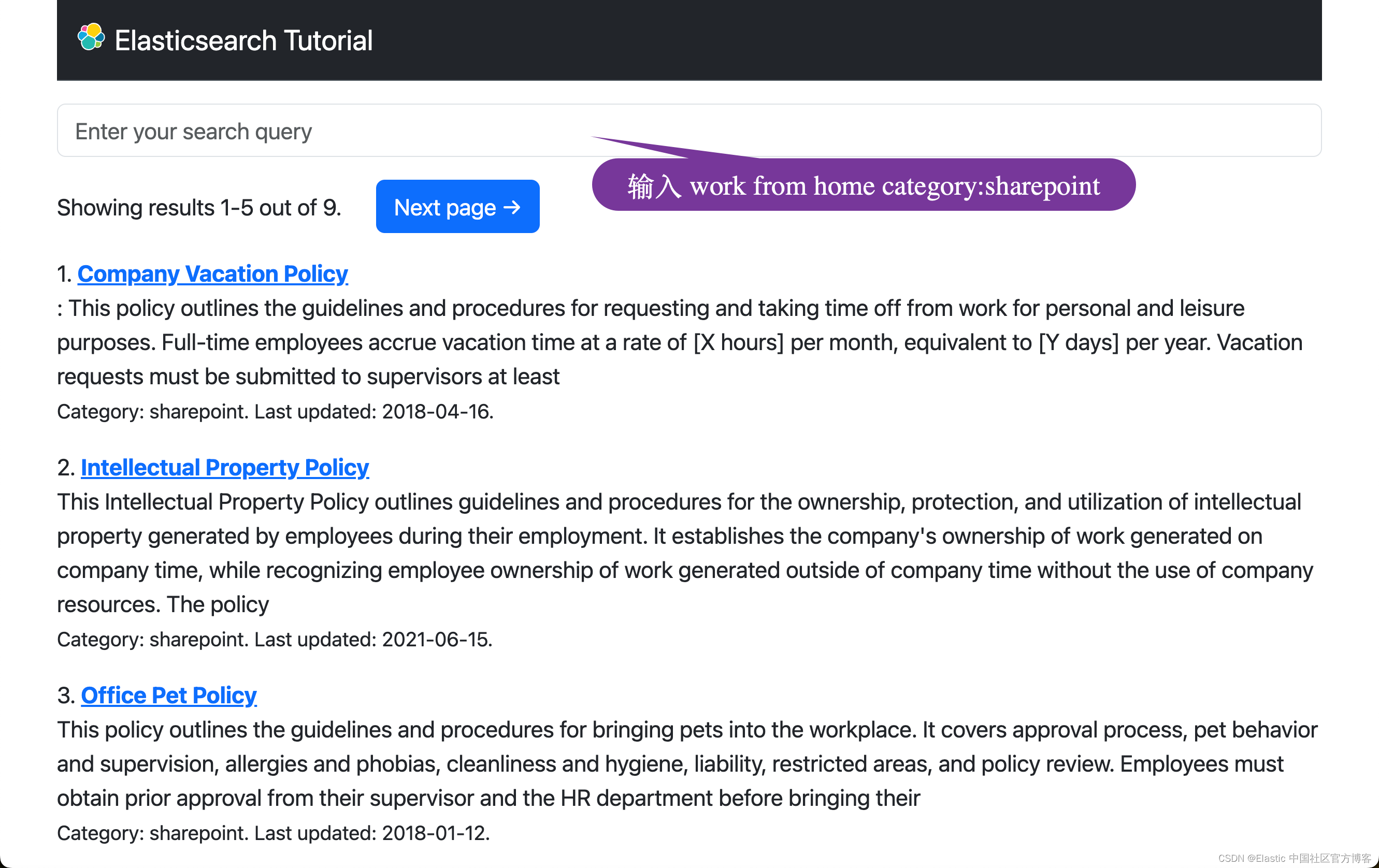
从上面的输出结果中,我们可以看出来它的搜索结果和之前的很相似,但是它融合了关键字搜索及语义搜索。在某些应用场合,它会更为精确。
我们可以在地址下载最后完整的代码:
git clone https://github.com/liu-xiao-guo/search-tutorial-3结论
恭喜你已完成搜索教程!
我们希望本教程为你提供了一个基础,你可以在此基础上开始使用 Elasticsearch 进行实验并创建你的搜索解决方案!
相关文章:
Elasticsearch:Search tutorial - 使用 Python 进行搜索 (四)
在本节中,你将了解另一种机器学习搜索方法,该方法利用 Elastic Learned Sparse EncodeR 模型或 ELSER,这是一种由 Elastic 训练来执行语义搜索的自然语言处理模型。这是继之前的文章 “Elasticsearch:Search tutorial - 使用 Pyth…...

Python之Matplotlib绘图调节清晰度
Python之Matplotlib绘图调节清晰度 文章目录 Python之Matplotlib绘图调节清晰度引言解决方案dpi是什么?效果展示总结 引言 使用python中的matplotlib.pyplot绘图的时候,如果将图片显示出来,或者另存为图片,常常会出现清晰度不够的…...

pygame.error: video system not initialized
错误处理方式: pygame.init() 增加此行...

java面试题2024
前言 准备换工作了,给自己定个目标,每天至少整理出一道面试题。题型会比较随机,感觉这样更容易随机到面试官要问的东西。整理时我会把我认为正确的回答写出来,比较复杂的也尽量把原理贴出来,争取做到无论为了应付面试&…...
配置git服务器
第一步: jdk环境配置 (1)搜索【高级系统设置】,选择【高级】选项卡,点【环境变量】 (2)在【系统变量】里面,点击【新建】 (3)添加JAVA_HOME环境变量JAVA_HO…...

vue3环境下,三方组件中使用echarts,无法显示问题
问题描述: vue3中,使用了三方组件primevue的侧边栏Sidebar,在其中注册echarts dom节点,无法显示,提示dom不存在 问题分析: 使用原生div,通过document.getElementById(),将echarts…...
FAST OS DOCKER 可视化Docker管理工具
介绍 FAST OS DOCKER 界面直观、简洁,非常适合新手使用,方便大家轻松上手 docker部署运行各类有趣的容器应用,同时 FAST OS DOCKER 为防止服务器负载过高,进行了底层性能优化;其以服务器安全为基础,对其进…...

MOJO基础语法
文章目录 打印变量及方法声明结构体python集成 打印 print("Hello Mojo!")变量及方法声明 变量: 使用’ var ‘创建一个可变的值,或者用’ let 创建一个不可变的值。 方法: 方法可以使用python中的def 方法声明,也引…...

java基础之IO流之字符流
字符流 传输char和String类型的数据 输入流 抽象父类:Reader 节点流:FileReader 常用方法 int read():读取一个字符,读取到达末尾,返回-1 package com.by.test2; import java.io.FileNotFoundException; import…...
-mojo binding)
chromium通信系统-ipcz系统(十一)-mojo binding
关于mojo binding的官方文档为mojo docs。 由于比较复杂,这里只做简单源码分析。 我们知道要实现rpc,必须实现客户端和服务端。 mojo 实现了一套领域语言,通过领域语言描述接口和数据, 再通过特有编译器编译成c代码。 这个过程会…...
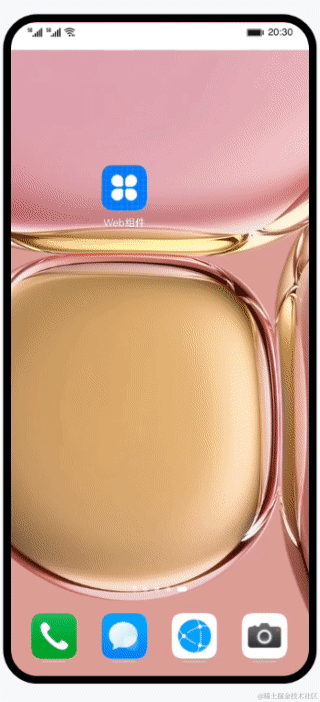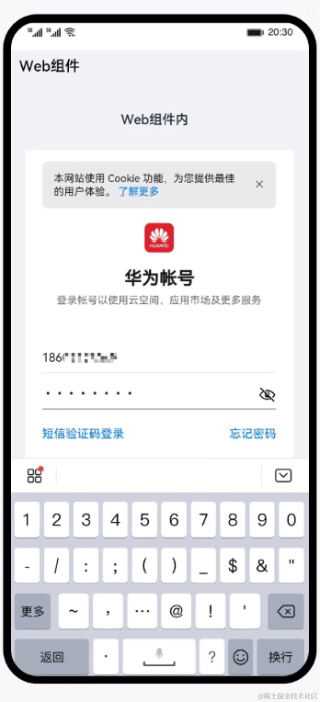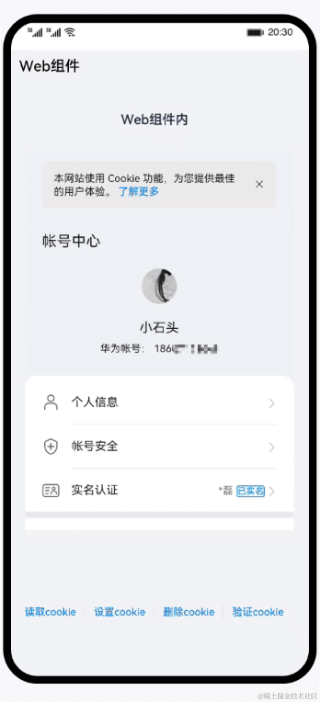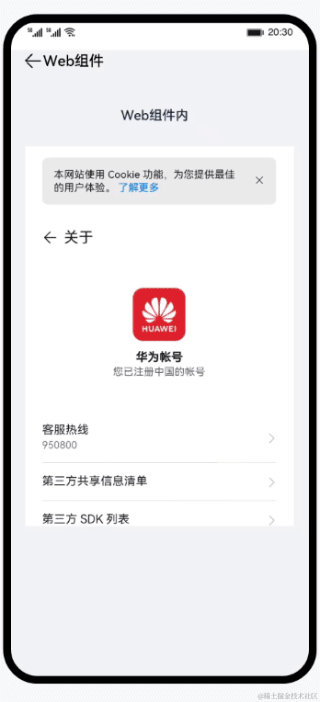
鸿蒙开发基础-Web组件之cookie操作
使用ArkTS语言实现一个简单的免登录过程,向大家介绍基本的cookie管理操作。主要包含以下功能: 获取指定url对应的cookie的值。设置cookie。清除所有cookie。免登录访问账户中心。 cookie读写操作 首次打开应用时,应用首页的Web组件内呈现的…...

什么是k8s和声明式编程?
认识k8s之后,他的操作模式对我来说是一种很不错的体验。他提供了更接近现实世界的面向对象接口。 什么是k8s? Kubernetes(K8s)是一种开源容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它简化了容器化应用…...
Fluids —— MicroSolvers DOP
目录 Gas SubStep —— 重复执行对应的子步 Switch Solver —— 切换解算器 Gas Attribute Swap —— 交换、复制或移动几何体属性 Gas Intermittent Solve —— 固定时间间隔计算子解算器 Gas External Forces —— 计算外部力并更新速度或速度场 Gas Particle Separate…...

工业智能网关:HiWoo Box远程采集设备数据
工业智能网关:HiWoo Box远程采集设备数据 在工业4.0和智能制造的浪潮下,工业互联网已成为推动产业升级、提升生产效率的关键。而在这其中,工业智能网关扮演着至关重要的角色。今天,我们就来深入探讨一下工业智能网关。 一、什么…...

Apollo之原理和使用讲解
文章目录 1 Apollo1.1 简介1.1.1 背景1.1.2 简介1.1.3 特点 1.2 基础模型1.3 Apollo 四个维度1.3.1 application1.3.2 environment1.3.3 cluster1.3.4 namespace 1.4 本地缓存1.5 客户端设计1.5.1 客服端拉取原理1.5.2 配置更新推送实现 1.6 总体设计1.7 可用性考虑 2 操作使用…...
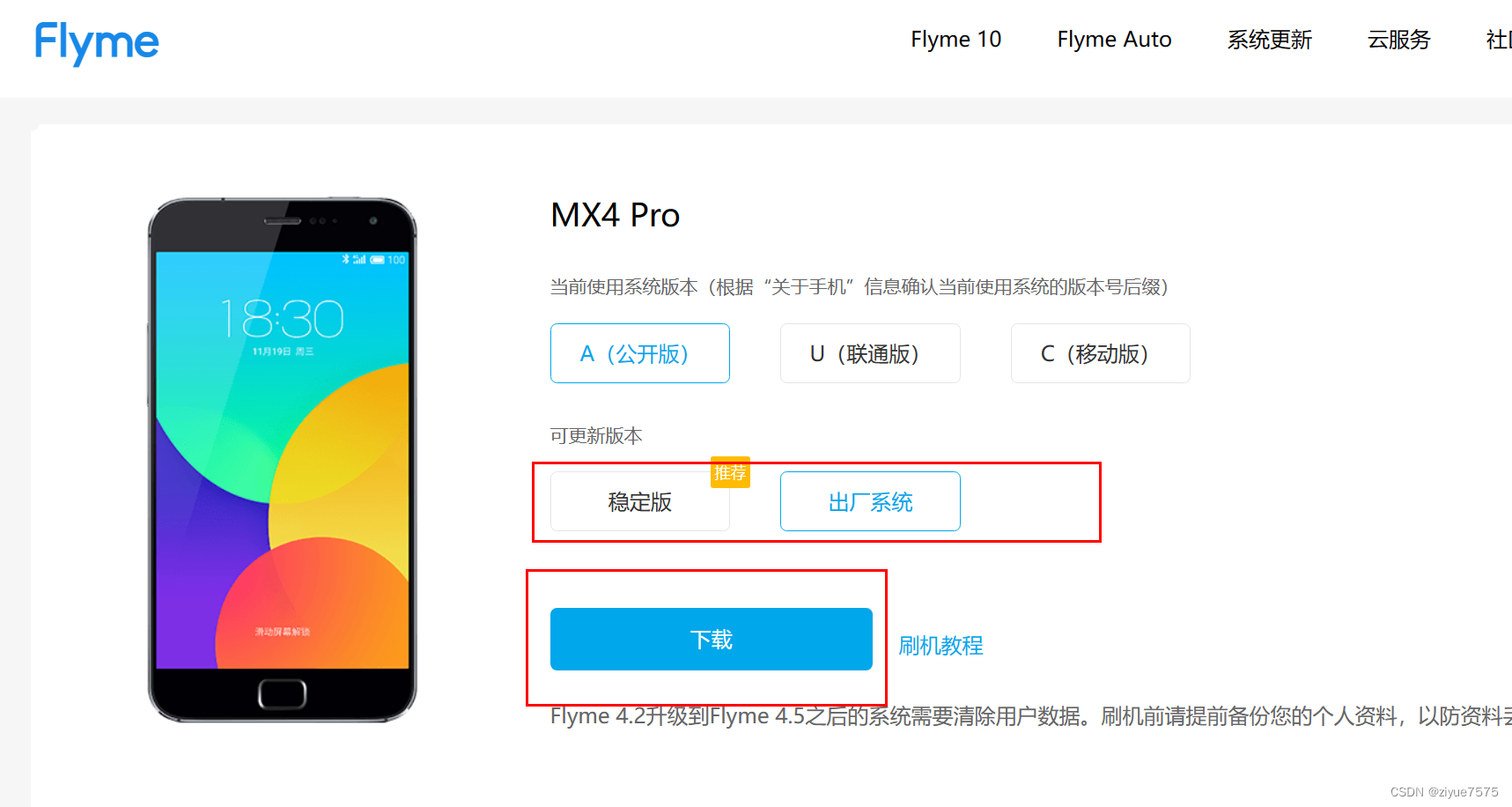
魅族MX4pro系统升级、降级
网上的教程都是按住开机键音量上或者下键,但是我按了没用,还是直接点击压缩包管用。 下载系统 官网地址(所有手机固件):https://flyme.cn/firmware.html 官方魅族mx4Pro系统:https://flyme.cn/firmwarelis…...

【Docker】快速入门之Docker的安装及使用
一、引言 1、什么是Docker Docker是一个开源的应用容器引擎,它让开发者可以将他们的应用及其依赖打包到一个可移植的镜像中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之…...

记录汇川:H5U于Factory IO测试13
主程序: 子程序: IO映射 子程序: 辅助出料 子程序: 模式选择 子程序: 示教程序 子程序: 手动程序 子程序: 统计程序 子程序: 异常报警 子程序: 自动程序: F…...

PYTHON通过跳板机巡检CENTOS的简单实现
实现的细节和引用的文件和以前博客记录的基本一致 https://shaka.blog.csdn.net/article/details/106927633 差别在于,这次是通过跳板机登陆获取的主机信息,只记录差异的部份 1.需要在跳板机相应的路径放置PYTHON的脚本resc.py resc.py这个脚本中有引用的文件(pm.sh,diskpn…...

网络配置以及命令详解
传统linux中,网络接口为eth0,eth1,eth2,..... RHEL 7以上版本默认命名是基于分配上的固定名称,ens33 接口类型: en:以太网有线接口 wl:无线局域网接口 ww:无线广域网 dmesg:显示开机信息 适配器类型: s:热插拔插槽 o:板载 p:pci类型 ifconfig ens160(命令行配置,临时生效):查…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
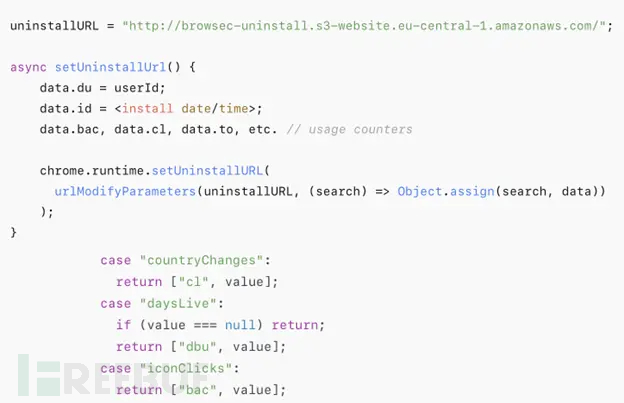
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...

算法—栈系列
一:删除字符串中的所有相邻重复项 class Solution { public:string removeDuplicates(string s) {stack<char> st;for(int i 0; i < s.size(); i){char target s[i];if(!st.empty() && target st.top())st.pop();elsest.push(s[i]);}string ret…...

用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法
用神经网络读懂你的“心情”:揭秘情绪识别系统背后的AI魔法 大家好,我是Echo_Wish。最近刷短视频、看直播,有没有发现,越来越多的应用都开始“懂你”了——它们能感知你的情绪,推荐更合适的内容,甚至帮客服识别用户情绪,提升服务体验。这背后,神经网络在悄悄发力,撑起…...