python 八大排序_python-打基础-八大排序
## 排序篇
#### 二路归并排序
- 介绍
- 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段 间有序。若将两个有序表合并成一个有序表,称为2-路归并。
- 算法思路
1. 把长度为n的输入序列分成两个长度为n/2的子序列;
2. 对这两个子序列分别采用归并排序;
3. 将两个排序好的子序列合并成一个最终的排序序列。
- 复杂度与稳定性
- 空间复杂度:
- 时间复杂度:
- 最佳情况:最佳情况:T(n) = O(n)
- 最差情况:T(n) = O(nlogn)
- 平均情况:T(n) = O(nlogn)
- 属于稳定性排序
- 代码
```Python
def merge_array(L, first, mid, last, temp):
"""合并的函数,合并数组# 将序列L[first...mid]与序列L[mid+1...last]进行合并"""
# 对i,j,k分别进行赋值
i, j, k = first, mid + 1, 0
# 当左右两边都有数时进行比较,取较小的数
while i <= mid and j <= last: # 等号必须要有,否则会出现遗漏
if L[i] <= L[j]:
temp[k] = L[i]
i += 1
else:
temp[k] = L[j]
j += 1
k += 1
# 以下两个while只会执行两个
# 如果左边序列还有数
while i <= mid:
temp[k] = L[i]
i += 1
k += 1
# 如果右边序列还有数
while j <= last:
temp[k] = L[j]
j += 1
k += 1
# 将temp当中该段有序元素赋值给L待排序列使之部分有序
for x in range(0, k):
L[first + x] = temp[x] # 将辅助空间的值加入到原数组中对应的位置
def divide_array(L, first, last, temp):
"""分组"""
if first < last: # 这里不可以等号,否则无法递归退出
mid = (last-first)//2 + first)
# 使左边序列有序
divide_array(L, first, mid, temp)
# 使右边序列有序
divide_array(L, mid + 1, last, temp)
# 将两个有序序列合并
merge_array(L, first, mid, last, temp)
# 归并排序的函数
def merge_sort(L):
# 声明一个长度为len(L)的空列表
temp = len(L) * [None] # 不能写成temp=[]
# 调用归并排序
divide_array(L, 0, len(L) - 1, temp)
return L
```
#### 基数排序
- 介绍
- 基数排序也是非比较的排序算法,对每一位进行排序,从最低位开始排序,复杂度为O(kn),为数组长度,k为数组中的数的最大的位数
- 算法思路
1. 取得数组中的最大数,并取得位数;
2. arr为原始数组,从最低位开始取每个位组成radix数组;
3. 对radix进行计数排序(利用计数排序适用于小范围数的特点);
- 复杂度与稳定性
- 空间复杂度:O(k),辅助空间需要k个队列
- 时间复杂度:
- 最佳情况:最佳情况:T(n) = O(n * k)
- 最差情况:T(n) = O(n * k)
- 平均情况:T(n) = O(n * k)
- 属于稳定性排序
- 队列,先进先出
- 代码
```Python
def radix_sort(lst):
"""基数排序"""
if not lst:
return lst
RADIX = 10
placement = 1
# 获取最大值,最后为循环退出出口
max_digit = max(lst)
while placement < max_digit:
# 0到9的柱状桶,使用列表表示,用于存放基数相同的数据
buckets = [list() for _ in range(RADIX)]
# 遍历列表,按基数分类放入桶中
for i in lst:
tmp = (i // placement) % RADIX
buckets[tmp].append(i)
# 从低到高,将桶中数据依次放入到列表中
a = 0
# 相同的数据,在原列表中靠前,分配到桶中时也靠前,取出时也先取出,b也从0开始,所以是稳定性排序
for b in range(RADIX):
buck = buckets[b]
for i in buck:
lst[a] = i
a += 1
# 进入下一个循环
placement *= RADIX
return lst
```
### 交换排序
#### 交换排序之冒泡排序
- 算法思路
1. 将序列当中的左右元素,依次比较,保证右边的元素始终大于左边的元素;( 第一轮结束后,序列最后一个元素一定是当前序列的最大值)
2. 对序列当中剩下的n-1个元素再次执行步骤1。
3. 对于长度为n的序列,一共需要执行n-1轮比较
- 复杂度与稳定性
- 空间复杂度:
- 时间复杂度:
- 最佳情况:T(n) = O(n) 当输入的数据已经是正序时
- 最差情况:T(n) = O(n2) 当输入的数据是反序时
- 平均情况:T(n) = O(n2)
- 属于稳定性排序
- 代码
```Python
def bubble_sort(collection):
"""冒泡排序"""
length = len(collection)
for i in range(length - 1):
swapped = False
for j in range(length - 1 - i):
if collection[j] > collection[j + 1]:
swapped = True
collection[j], collection[j + 1] = collection[j + 1], collection[j]
# 当某趟遍历时未发生交换,则已排列完成,跳出循环
if not swapped:
break
return collection
```
- 代码优化方向之一:设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
```Python
def bubble_sort(collection):
"""冒泡排序优化之记录每一趟最后交换的位置"""
length = len(collection)
i = length-1
# pos用于记录最后一次交换的位置,并将其赋值给i
while i > 0:
pos = 0
for j in range(i):
if collection[j] > collection[j + 1]:
pos = j
collection[j], collection[j + 1] = collection[j + 1], collection[j]
i = pos
return collection
```
- 代码优化方向之二:传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值,我们考虑利用在每趟排序中进行正向和反向两遍冒泡的方法一次可以得到两个最终值(最大者和最小者) , 从而使排序趟数几乎减少了一半
```Python
def bubble_sort(collection):
"""冒泡排序优化之正反两方向冒泡"""
# 标记反向
low =0
# 标记正向比较结束位置
high = len(collection)-1
while low < high:
# 正向找最大
for j in range(low,high):
if collection[j] > collection[j + 1]:
collection[j], collection[j + 1] = collection[j + 1], collection[j]
high -= 1
# 反向找最小
for j in range(high,low,-1):
if collection[j] > collection[j - 1]:
collection[j], collection[j - 1] = collection[j - 1], collection[j]
low += 1
return collection
```
### 选择排序
#### 选择排序之简单选择排序
- 算法思路:
1. 初始状态:无序区为R[1..n],有序区为空;
2. 第i趟排序(i=1,2,3...n-1)开始时,当前有序区和无序区分别为R[1..i-1]和R(i..n)。该趟排序 从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1..i]和R[i+1..n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
3. n-1趟结束,数组有序化了
- 主要的两层循环
- 第一层循环:依次遍历序列当中的每一个元素
- 第二层循环:将遍历得到的当前元素依次与余下的元素进行比较,符合最小元素的条件,则交换
- 复杂度与稳定性
- 空间复杂度:
- 时间复杂度:
- 最佳情况:T(n) = O(n2)
- 最差情况:T(n) = O(n2)
- 平均情况:T(n) = O(n2)
- 属于不稳定性排序:
- 比如:[2,2,1]
- 优缺点及应用场景
- 注意与直接插入排序比较,当初始表基本有序时选择直接插入排序,其时间复杂度O(n)
- 代码
```Python
# 简单选择排序的关键点在于:从未排序的序列中选择出最小的放在未排序序列的最前端
def select_sort(nums):
'''简单选择排序'''
# 依次遍历序列中的每一个元素,n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果
for x in range(0, len(nums) - 1):
# 将当前位置的元素定义此轮循环当中的最小值
minimum = nums[x]
# 将该元素与剩下的元素依次比较寻找最小元素
for i in range(x + 1, len(nums)):
# 当小时才交换,则是稳定排序
if nums[i] < minimum:
# 每一次比较,当发现比当前临时最小值还要小时,及时交换更新
nums[i], minimum = minimum, nums[i]
# 遍历比较后,将比较后得到的真正的最小值赋值给当前位置
nums[x] = minimum
return nums
```
#### 选择排序之堆排序
- 算法思路:
1. 将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2. 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3. 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后 再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元 素个数为n-1,则整个排序过程完成。
- 复杂度与稳定性
- 空间复杂度:O(1)
- 时间复杂度:
- 最佳情况:T(n) = O(nlogn)
- 最差情况:T(n) = O(nlogn)
- 平均情况:T(n) = O(nlogn)
- 属于不稳定性排序:
- 例如L=[1,2,2]
- 优缺点及应用场景
- 堆排序需要的辅助空间小于快速排序,不会出现快速排序可能出现的最坏情况
- 代码
```Python
def heapify(unsorted, index, heap_size):
'''构建大根堆'''
# 定义当前节点为临时最大值的索引largest
largest = index
# 获取当前节点下标(index)的左右子节点下标
left_index = 2 * index + 1
right_index = 2 * index + 2
# 在不超过堆容量时,进行左节点与父节点的比较,若比父节点大则更新最大值的下标
if left_index < heap_size and unsorted[left_index] > unsorted[largest]:
largest = left_index
# 在不超过堆容量时,进行右节点与父节点的比较,若比父节点大则更新最大值的下标
if right_index < heap_size and unsorted[right_index] > unsorted[largest]:
largest = right_index
# 若当前节点并不是最大值,则进行交换调整,同时此处也是递归出口
if largest != index:
# 将当前节点的值与最大值进行互换,即父节点与子节点数据交换
unsorted[largest], unsorted[index] = unsorted[index], unsorted[largest]
# 针对交换后的孩子节点的左右孩子节点进行递归调整判断
# 这一步必须要
heapify(unsorted, largest, heap_size)
def heap_sort(unsorted):
'''堆排序'''
n = len(unsorted)
# 从n // 2 - 1节点处依次构建堆,为最后一个叶子节点的父节点
for i in range(n // 2 - 1, -1, -1):
# 总共有n//2次遍历,每次遍历都有一个递归函数
heapify(unsorted, i, n)
# 执行循环:
# 1. 每次取出堆顶元素置于序列的最后(len - 1, len - 2, len - 3...)
# 2. 调整堆,使其继续满足大顶堆的性质,注意实时修改堆中序列的长度
for i in range(n - 1, 0, -1):
# i为序列下标从后往前移动,所以最大值为于列表的最后
# 将抽象数据结构堆的最大值即索引0位置的数值移动i位置
unsorted[0], unsorted[i] = unsorted[i], unsorted[0]
heapify(unsorted, 0, i)
return unsorted
```
### 插入排序
#### 插入排序之简单插入排序
- 算法思路:
1. 从第一个元素开始,该元素可以认为已经被排序;
2. 取出下一个元素,在已经排序的元素序列中从后向前扫描;
3. 如果该元素(已排序)大于新元素,将该元素移到下一位置;
4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
5. 将新元素插入到该位置后;
6. 重复步骤2~5。
- 主要的两层循环:
- 第一层循环:遍历待比较的所有数组元素(从第二个元素开始)
- 第二层循环:将上层循环选择的元素(selected)与已经排好序的所有元素(ordered)相比较,从选择元素的前面一个开始直到数组的起始位置。如果selected < ordered,那么将二者交换位置,继续遍历;反之,留在原地,选择下一个元素
- 复杂度与稳定性
- 空间复杂度:O(1)
- 时间复杂度:
- 最佳情况:输入数组按升序排列。T(n) = O(n)
- 最坏情况:输入数组按降序排列。T(n) = O(n2)
- 平均情况:T(n) = O(n2)
- 属于稳定性排序
- 优缺点及应用场景
- 代码
```PYTHON
# 这种写法时错误的
def insert_sort(nums):
'''直接插入排序'''
# 遍历数组中的所有元素,其中0号索引元素默认已排序,因此从1开始
# 当nums元素数量为空或者1时,不会进入for循环
# i为待插入元素的索引位置,此次遍历将确认nums[i]应该插入的位置
for i in range(1, len(nums)):
# 将该元素与已排序好的前序数组依次比较,如果该元素小,则交换
# range(x,0,-1):从x倒序循环到1,依次比较,
# 每次比较如果小于会交换位置,正好按递减的顺序
# 每次内层循环开始时,j为待插入元素位置,最终循环结束时,j即为插入位置
for j in range(i, 0, -1): #这里j时取不到0的
# 判断:如果符合条件则交换,并由此处可见直接插入排序为稳定性排序
if nums[j] < nums[j - 1]:
# 交换需要辅助空间,空间复杂度O(1),交换三次不是真正的插入算法
nums[j], nums[j - 1] = nums[j - 1], nums[j]
else:
break
return nums
# 插入算法特点,选找到插入点后再插入,之前只交换一次,而非三次
def insert_sort(nums):
"""直接插入排序:param nums::return:"""
# 遍历数组中的所有元素,其中0号索引元素默认已排序,因此从1开始
# 当nums元素数量为空或者1时,不会进入for循环
for i in range(1, len(nums)):
# 将该元素与已排序好的前序数组依次比较,如果该元素小,则交换
# range(i,0,-1):从i倒序循环到0,依次比较,
# 每次比较如果小于会交换位置,正好按递减的顺序
temp = nums[i]
for j in range(i - 1, -1, -1):
# 判断:如果符合条件则交换,并由此处可见直接插入排序为稳定性排序
if nums[j] > temp:
nums[j + 1] = nums[j]
elif nums[j] == temp:
j += 1
break
else:
break
# 最后插入点
nums[j] = temp
return nums
```
#### 插入排序之折半插入排序
- 在直接插入排序中,查找插入位置时使用二分查找的方式
```
def binary_insert_sort(nums):
"""折半插入排序:param nums::return:"""
# 遍历数组中的所有元素,其中0号索引元素默认已排序,因此从1开始
# 当nums元素数量为空或者1时,不会进入for循环
for i in range(1, len(nums)):
# 二分查找在已排序中寻找待插入位置确定待插入点
left = 0
right = i - 1
target = nums[i]
while left <= right:
mid = (right - left) // 2 + left
if nums[mid] < target:
left = mid + 1
else:
right = mid - 1
print(left,right)
for j in range(i, right+1, -1):
# 交换,并由此处可见折半插入排序为稳定性排序
nums[j], nums[j - 1] = nums[j - 1], nums[j]
nums[right+1] = target
print(nums)
return nums
if __name__ == '__main__':
binary_insert_sort([5, 3, 2, 2, 0])
```
#### 插入排序之希尔排序
- 学习基础:希尔排序是基于简单插入排序的
- 算法思路:
- 复杂度与稳定性
- 空间复杂度:O(1)
- 时间复杂度:
- 最佳情况:
- 最坏情况:当n在特定范围时,为O(n2)
- 平均情况:当n在特定范围时,为O(n1.3)
- 属于不稳定性排序
- 优缺点及应用场景
- 适用性:只适用于当线性表为顺序存储的情况
- 代码
```PYTHON
def shell_sort(nums):
# 初始化gap值,此处利用序列长度的一半为其赋值
gap = len(nums) // 2
# 第一层循环:依次改变gap值对列表进行分组,当gap等于1时进行最后一遍循环
while gap >= 1:
# 下面:利用直接插入排序的思想对分组数据进行排序
# range(gap, len(L)):由于数组下标从0开始,所以从gap开始依次比较
# gap分组比较,同等的数值可能分部不同组而导致后一组比较后交换,而前一组比较后不交换
# 故而破坏稳定性,成为不稳定性排序
# 这两个for循环则是一个小型的直接插入排序
for i in range(gap, len(nums)):
# range(i, 0, -gap):从i开始与选定元素开始倒序比较
# 每个比较元素之间间隔gap
for j in range(i, 0, -gap):
# 如果该组当中两个元素满足交换条件,则进行交换
if nums[j] < nums[j-gap]:
nums[j],nums[j-gap] = nums[j-gap],nums[j]
else:
break
gap = gap // 2
return nums
# 自定义gap
def shell_Sort(nums):
lens = len(nums)
gap = 1
# 动态定义间隔序列
while gap < lens // 3:
gap = gap * 3 + 1
while gap > 0:
for i in range(gap, lens):
curNum, preIndex = nums[i], i - gap # curNum 保存当前待插入的数
while preIndex >= 0 and curNum < nums[preIndex]:
nums[preIndex + gap] = nums[preIndex] # 将比 curNum 大的元素向后移动
preIndex -= gap
nums[preIndex + gap] = curNum # 待插入的数的正确位置
gap //= 3 # 下一个动态间隔
return nums
```
对比记忆
1. 简单选择排序与直接插入排序的区别,应用选择,稳定性
选取排序算法需要考虑的因素:
1. 待排序的元素数量n;
2. 元素本身信息量的大小;
1. 当n较少时(n< 50),直接插入排序或者简单选择排序,由于插入排序移动较多,当记录本身信息很多时,使用简单选择排序;
相关文章:

python 八大排序_python-打基础-八大排序
## 排序篇 #### 二路归并排序 - 介绍 - 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列…...

运维知识点-Sqlite
Sqlite 引入 依赖 引入 依赖 <dependency><groupId>org.xerial</groupId><artifactId>sqlite-jdbc</artifactId><version>3.36.0.3</version></dependency>import javafx.scene.control.Alert; import java.sql.*;public clas…...

我为什么要写RocketMQ消息中间件实战派上下册这本书?
我与RocketMQ结识于2018年,那个时候RocketMQ还不是Apache的顶级项目,并且我还在自己的公司做过RocketMQ的技术分享,并且它的布道和推广,还是在之前的首席架构师的带领下去做的,并且之前有一个技术神经质的人࿰…...

24校招,Moka测试开发工程师一面
前言 大家好,今天回顾一下楼主当时参加moka测试开发工程师的面试 对其中一些重要问题,我也给出了相应的答案 过程 自我介绍挑一个项目,详细介绍你在其中担任的职责如何安排工作的,有什么成果?回归测试如何设计&…...
)
Docker(网络,网络通信,资源控制,数据管理,CPU优化,端口映射,容器互联)
目录 docker网络 网络实现原理 网络实现实例 网络模式 查看Docker中的网络列表: 指定容器网络模式 模式详解 Host模式(主机模式): Container模式(容器模式): None模式(无网…...
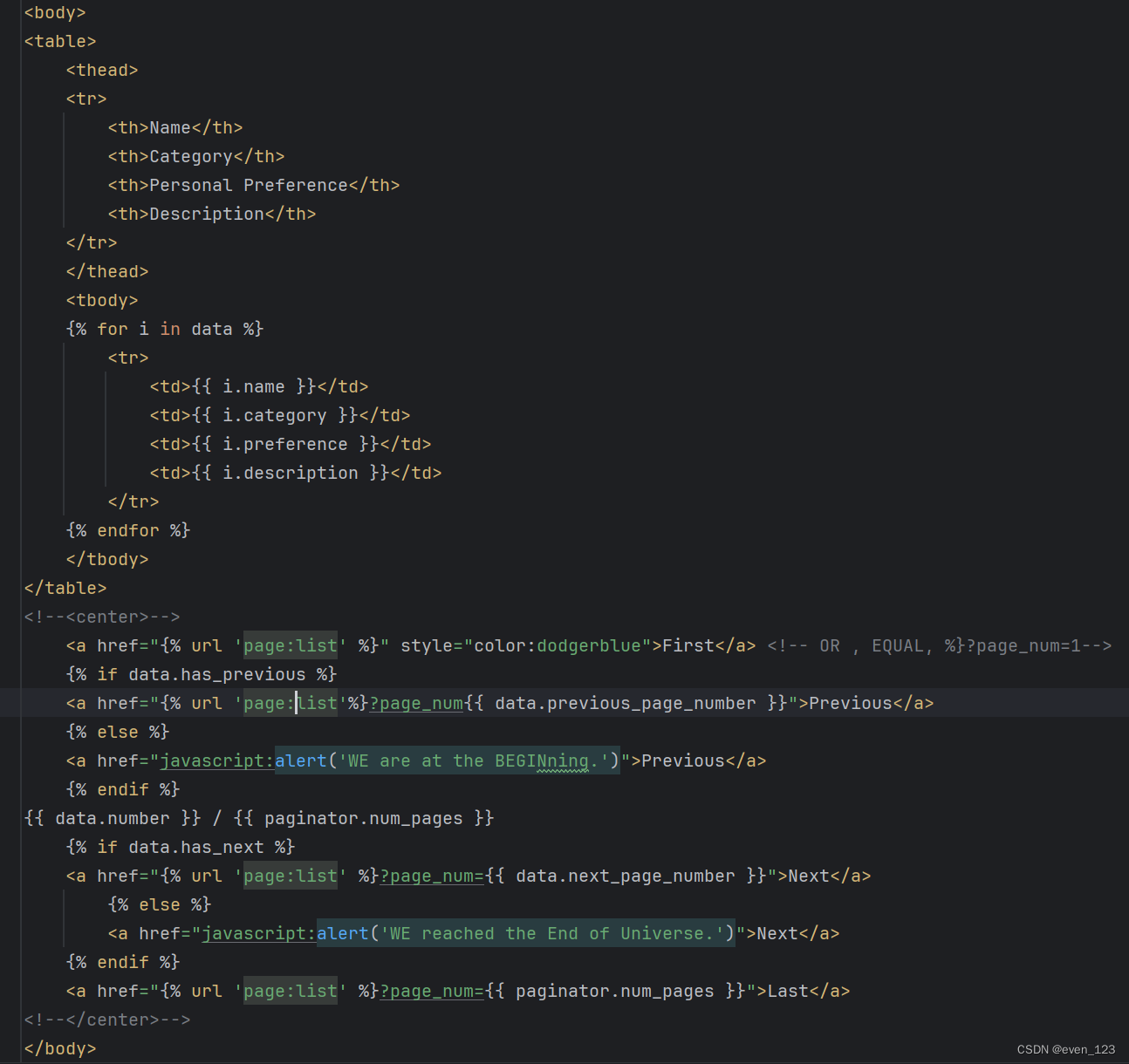
开发实践5_project
要求: (对作业要求的"Student"稍作了变换,表单名称为“Index”。)获得后台 Index 数据,作展示,要求使用分页器,包含上一页、下一页、当前页/总页。 结果: ① preparatio…...
蓝桥杯准备
书籍获取:Z-Library – 世界上最大的电子图书馆。自由访问知识和文化。 (zlibrary-east.se) 书评:(豆瓣) (douban.com) 一、观千曲而后晓声 别人常说蓝桥杯拿奖很简单,但是拿奖是一回事,拿什么奖又是一回事。况且,如果…...

AtCoder Beginner Contest 336 A-E 题解
比赛链接:https://atcoder.jp/contests/abc336比赛时间:2024 年 1 月 14 日 20:00-21:40 A题:Long Loong 标签:模拟题意:给定一个 n n n,输出 L L L、 n n n个 o o o和 n g ng ng。题解:按题意…...
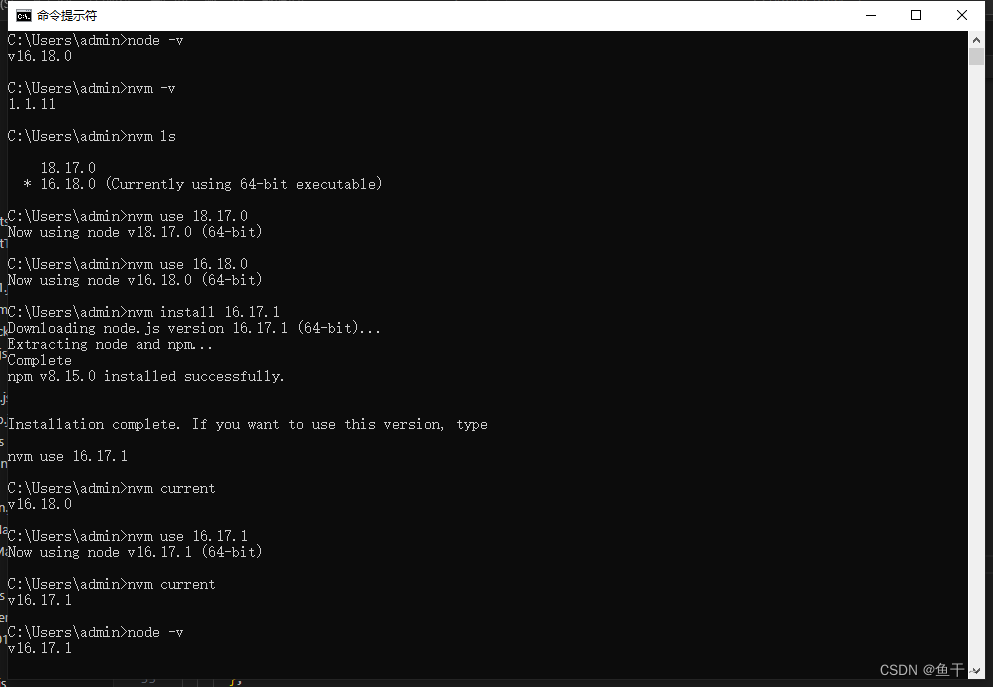
node各个版本的下载地址
下载地址: https://nodejs.org/dist/ 可以下载多个版本,使用nvm控制切换(需要先安装nvm再安装node) nvm下载地址(访问的是github,请科学上网,下载后解压安装exe即可):h…...
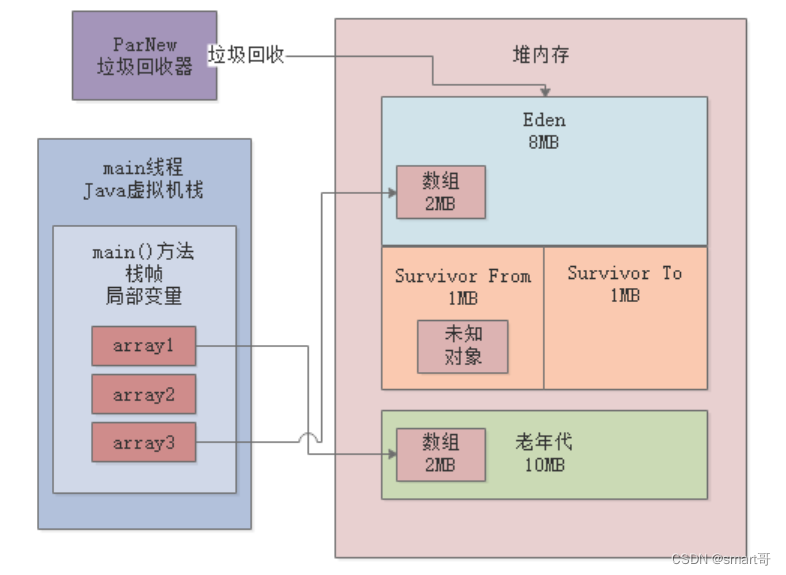
JVM实战(17)——模拟对象晋升
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 学习必须往深处挖&…...
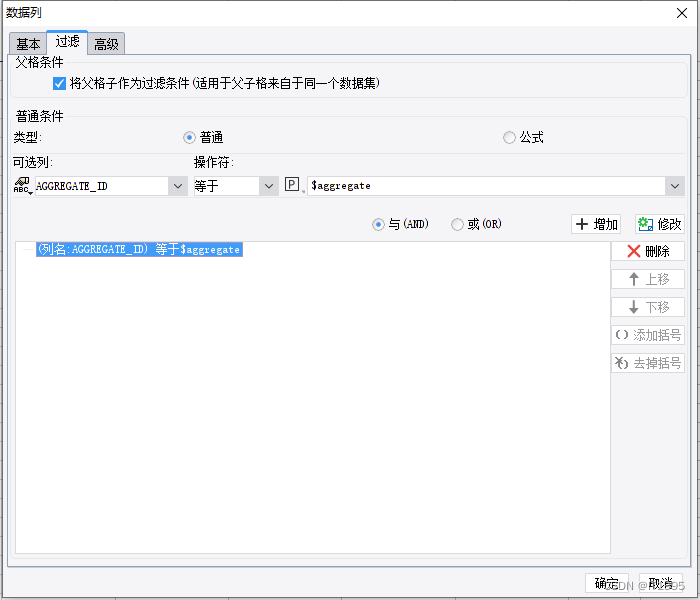
帆软笔记-决策表报对象使用(两表格联动)
效果描述如下: 数据库中有个聚合商表,和一个储能表,储能属于聚合商,桩表中有个字段是所属聚合商。 要求帆软有2个表格,点击某个聚合商,展示指定的储能数据。 操作: 帆软选中表格单元…...

DataGear专业版 1.0.0 发布,数据可视化分析平台
DataGear专业版 1.0.0 正式发布,欢迎大家试用! http://datagear.tech/pro/ DataGear专业版 基于 开源版 开发,新增了诸多企业级特性,包括: MySQL、PostgreSQL、Oracle、SQL Server以及更多兼容部署数据库支持OAuth2…...

AS,android SDK
android sdk中包含什么? Android平台工具(Android Platform Tools): 这包括 adb(Android Debug Bridge)等工具,用于在计算机和 Android 设备之间进行通信、调试和数据传输。 Android命令行工具…...

LeetCode第155题 - 最小栈
题目 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 push(x) —— 将元素 x 推入栈中。 pop() —— 删除栈顶的元素。 top() —— 获取栈顶元素。 getMin() —— 检索栈中的最小元素。 示例: 输入: [&q…...

Java微服务系列之 ShardingSphere - ShardingSphere-JDBC
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄 🌹简历模板、学习资料、面试题库、技术互助 🌹文末获取联系方式 📝 系列专栏目录 [Java项…...
)
Unity中URP下实现能量罩(外发光)
文章目录 前言一、实现菲涅尔效果1、求 N ⃗ \vec{N} N 2、求 V ⃗ \vec{V} V 3、得出菲涅尔效果4、得出菲涅尔相反效果5、增加菲涅尔颜色二、能量罩 交接处高亮 和 外发光效果结合1、修改混合模式,使能量罩透明2、限制 0 ≤ H i g h L i g h t C o l o r ≤ 1 0\leq HighL…...

Golang 中哪些类型可以作为 map 类型的 key?
目录 可以作为 map 键的类型 不能作为 map 键的类型 最佳实践 小结 在 Go 语言中,map 是一种内置的关联数据结构类型,由一组无序的键值对组成,每个键都是唯一的,并与一个对应的值相关联。本文将详细介绍哪些类型的变量可以作为…...
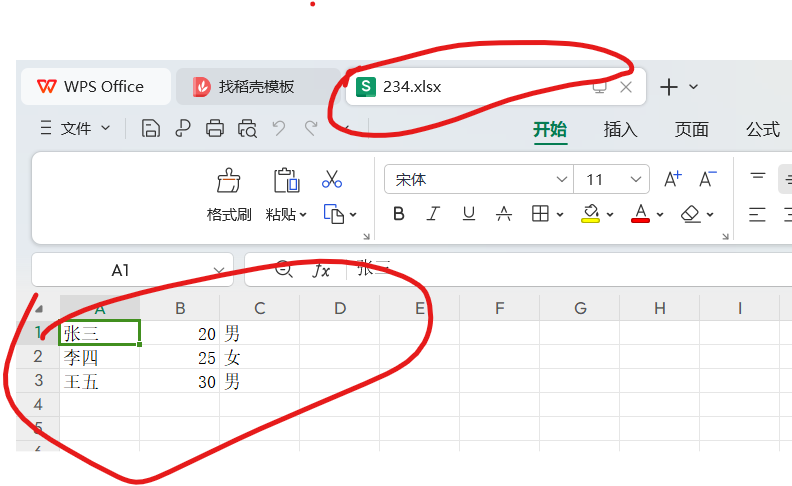
C# 导出EXCEL 和 导入
使用winfrom简单做个界面 选择导出路径 XLSX起名字 打开导出是XLSX文件 // 创建Excel应用程序对象Excel.Application excelApp new Excel.Application();excelApp.Visible false;// 创建工作簿Excel.Workbook workbook excelApp.Workbooks.Add(Type.Missing);Excel.Works…...
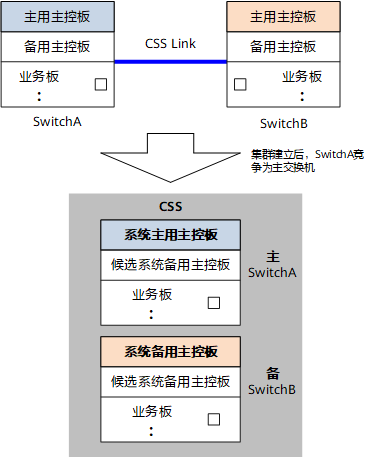
学网络必懂的华为CSS堆叠技术
知识改变命运,技术就是要分享,有问题随时联系,免费答疑,欢迎联系! 厦门微思网络https://www.xmws.cn 华为认证\华为HCIA-Datacom\华为HCIP-Datacom\华为HCIE-Datacom Linux\RHCE\RHCE 9.0\RHCA\ Oracle OC…...

SV-7041T 30W网络有源音箱校园教室广播音箱,商场广播音箱,会议广播音箱,酒店广播音箱,工厂办公室广播音箱
SV-7041T 30W网络有源音箱 校园教室广播音箱,商场广播音箱,会议广播音箱,酒店广播音箱,工厂办公室广播音箱 SV-7041T是深圳锐科达电子有限公司的一款2.0声道壁挂式网络有源音箱,具有10/100M以太网接口,可将…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...
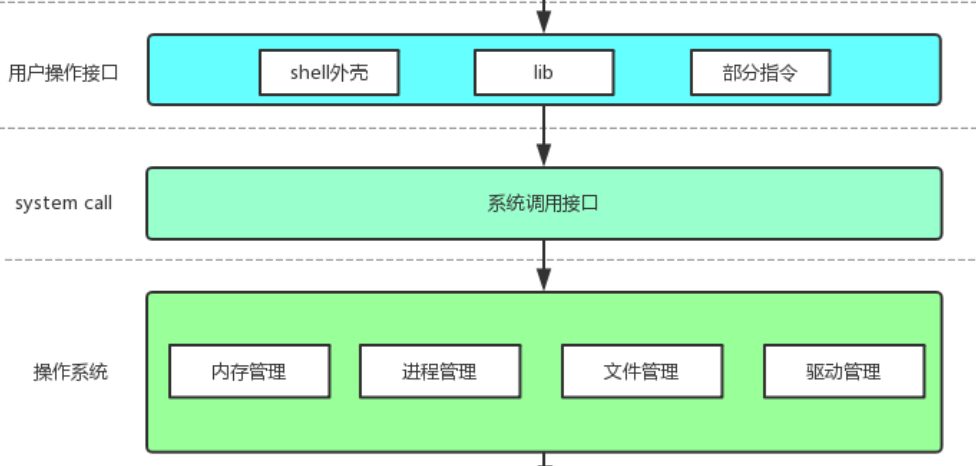
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...