stable diffusion代码学习笔记
前言:本文没有太多公式推理,只有一些简单的公式,以及公式和代码的对应关系。本文仅做个人学习笔记,如有理解错误的地方,请指出。
本文包含stable diffusion入门文献和不同版本的代码。
文献资源
- 本文学习的代码;
- 相关文献:
- Denoising Diffusion Probabilistic Models : DDPM,这个是必看的,推推公式
- Denoising Diffusion Implicit Models :DDIM,对 DDPM 的改进
- Pseudo Numerical Methods for Diffusion Models on Manifolds :PNMD/PLMS,对 DDPM 的改进
- High-Resolution Image Synthesis with Latent Diffusion Models :Latent-Diffusion,必看
- Neural Discrete Representation Learning : VQVAE,简单翻了翻,示意图非常形象,很容易了解其做法
代码资源
- stable diffusion v1.1-v1.4, https://github.com/CompVis/stable-diffusion
- stable diffusion v1.5,https://github.com/runwayml/stable-diffusion
- stable diffusion v2,https://github.com/Stability-AI/stablediffusion
- stable diffusion XL,https://github.com/Stability-AI/generative-models
前向过程(训练)
- 输入一张图片+随机噪声,训练unet,网络预测图片加上的噪声
反向过程(推理)
- 给个随机噪声,不断迭代去噪,输出一张图片
总体流程
- 输入的prompt经过clip encoder编码成(3+3,77,768)特征,正负prompt各3个,默认negative prompt为空‘’,解码时正的和负的latent图片用公式计算一下才是最终结果;time step通过linear层得到(3+3,1280)特征;把prompt和time ebedding和随机生成的图片放入unet,得到的就是我们要的图片。
采样流程 text2img
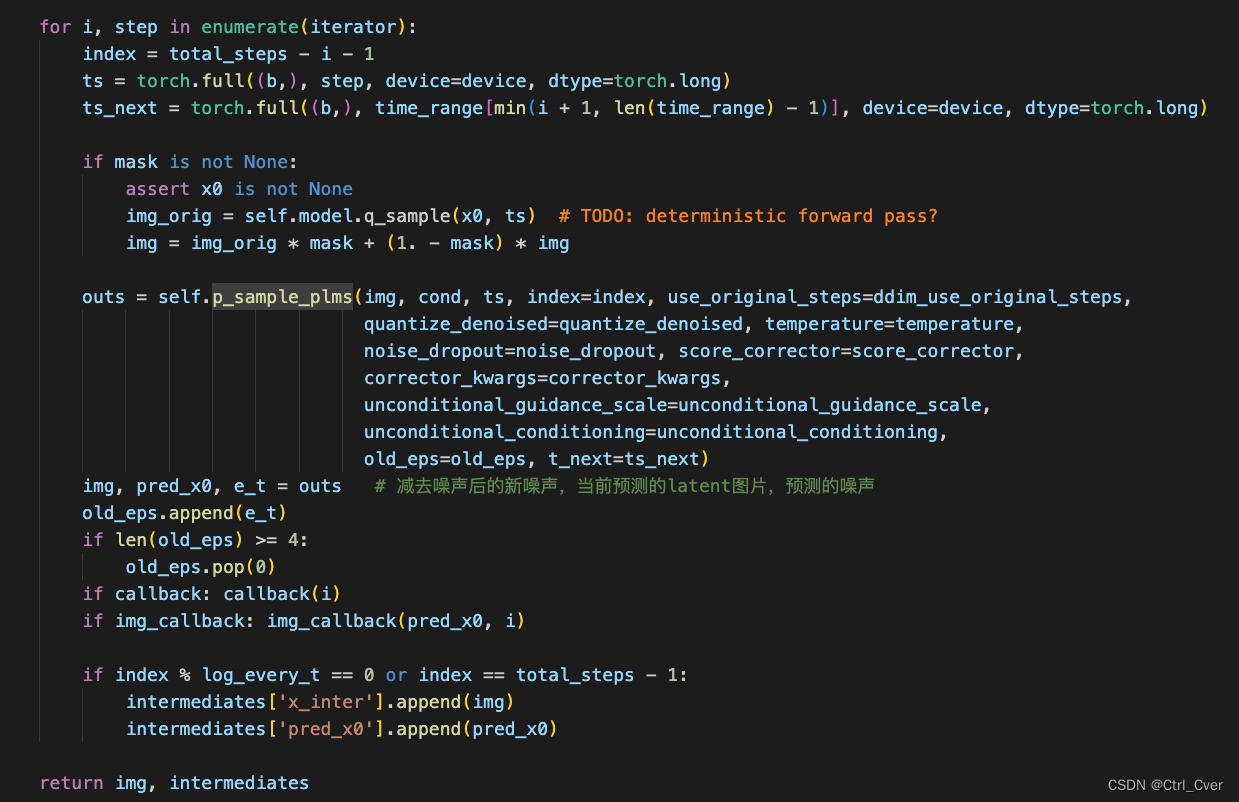
- 该函数在PLMSSampler中,输入x(噪声,(3,4,64,64))-----c(输入的prompt,(3,77,768)----t (输入的time step,第几次去噪(3,)。把这三个东西输入unet,得到预测的噪声e_t。
def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,unconditional_guidance_scale=1., unconditional_conditioning=None, old_eps=None, t_next=None):b, *_, device = *x.shape, x.devicedef get_model_output(x, t):if unconditional_conditioning is None or unconditional_guidance_scale == 1.:e_t = self.model.apply_model(x, t, c)else:x_in = torch.cat([x] * 2)t_in = torch.cat([t] * 2)c_in = torch.cat([unconditional_conditioning, c]) # 积极消极的prompt,解码时按照公式减去消极prompt的图像e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)if score_corrector is not None:assert self.model.parameterization == "eps"e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)return e_talphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphasalphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prevsqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphassigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmasdef get_x_prev_and_pred_x0(e_t, index):# select parameters corresponding to the currently considered timestepa_t = torch.full((b, 1, 1, 1), alphas[index], device=device)a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)# current prediction for x_0pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()if quantize_denoised:pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)# direction pointing to x_tdir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_tnoise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperatureif noise_dropout > 0.:noise = torch.nn.functional.dropout(noise, p=noise_dropout)x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noisereturn x_prev, pred_x0e_t = get_model_output(x, t) # 模型预测的噪声if len(old_eps) == 0:# Pseudo Improved Euler (2nd order)x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index) # 输入噪声减去预测噪声得到新的噪声,当前预测的latent图片e_t_next = get_model_output(x_prev, t_next)e_t_prime = (e_t + e_t_next) / 2 # 两次噪声的均值?elif len(old_eps) == 1:# 2nd order Pseudo Linear Multistep (Adams-Bashforth)e_t_prime = (3 * e_t - old_eps[-1]) / 2elif len(old_eps) == 2:# 3nd order Pseudo Linear Multistep (Adams-Bashforth)e_t_prime = (23 * e_t - 16 * old_eps[-1] + 5 * old_eps[-2]) / 12elif len(old_eps) >= 3:# 4nd order Pseudo Linear Multistep (Adams-Bashforth)e_t_prime = (55 * e_t - 59 * old_eps[-1] + 37 * old_eps[-2] - 9 * old_eps[-3]) / 24x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t_prime, index)return x_prev, pred_x0, e_t
- 接下来看公式:

- 网络得到e_t后,进入到get_x_prev_and_pred_x0函数,可以看到
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()就是上述公式,也就是说网络的预测结果通过公式计算,我们可以得到预测的pred_x0原始图片和前一刻的噪声图像x_prev。
def get_x_prev_and_pred_x0(e_t, index):# select parameters corresponding to the currently considered timestepa_t = torch.full((b, 1, 1, 1), alphas[index], device=device)a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)# current prediction for x_0pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()if quantize_denoised:pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)# direction pointing to x_tdir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_tnoise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperatureif noise_dropout > 0.:noise = torch.nn.functional.dropout(noise, p=noise_dropout)x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noisereturn x_prev, pred_x0
-
前一刻的噪声图像的推理公式如图:
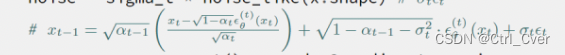
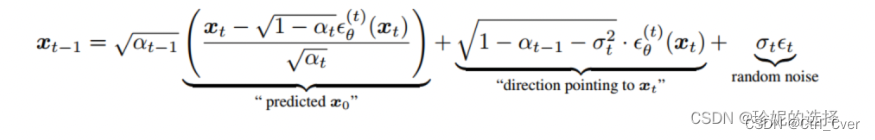
-
得到了上一刻的噪声图片x_prev后(也就是函数返回的img),继续迭代,最终生成需要的图片。
额外说明
这部分代码应该就是PLMS加速采样用的,论文中有公式推理

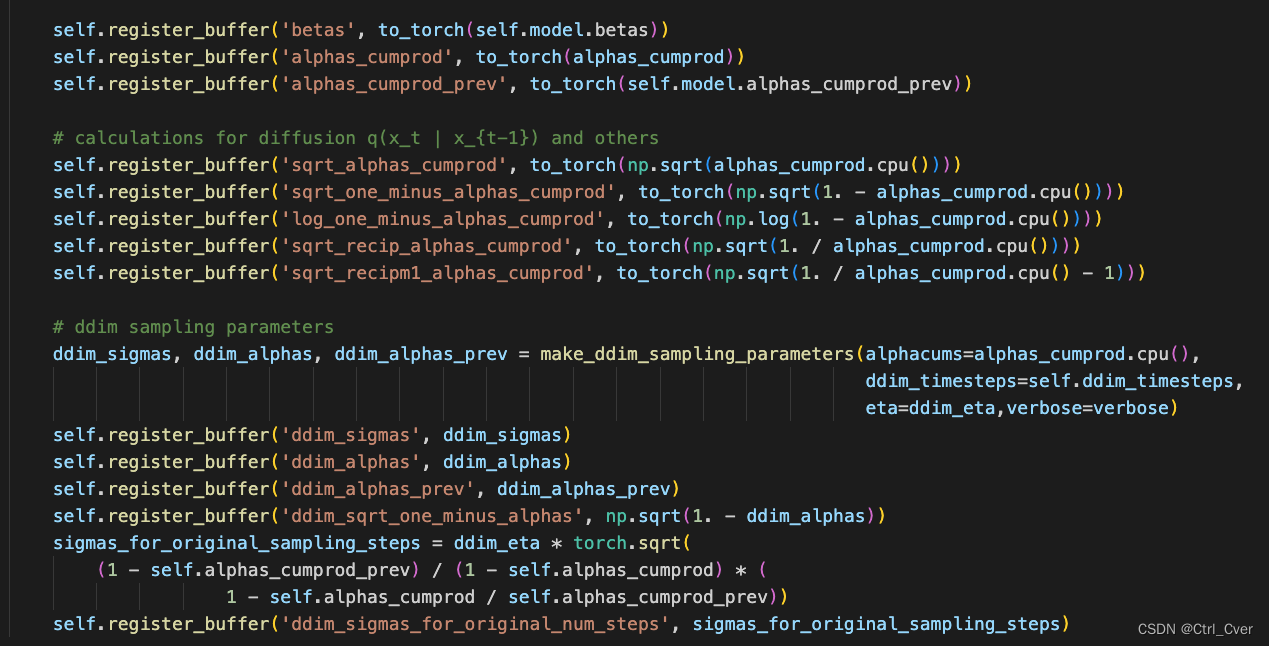
另外,还有一些参数是训练时候保存的,betas逐渐增大,用来控制噪声的强度。变量名解析 log_one_minus_alphas_cumprod其实就是log(1-alpha(右下角t)(头上直线)),没有带prev的都是当前时刻t,带prev的是前一时刻t-1。
参考文献:
https://blog.csdn.net/Eric_1993/article/details/129600524?spm=1001.2014.3001.5502
https://zhuanlan.zhihu.com/p/630354327
相关文章:
stable diffusion代码学习笔记
前言:本文没有太多公式推理,只有一些简单的公式,以及公式和代码的对应关系。本文仅做个人学习笔记,如有理解错误的地方,请指出。 本文包含stable diffusion入门文献和不同版本的代码。 文献资源 本文学习的代码&…...
腾讯云服务器怎么买?两种购买方式更省钱
腾讯云服务器购买流程很简单,有两种购买方式,直接在官方活动上购买比较划算,在云服务器CVM或轻量应用服务器页面自定义购买价格比较贵,但是自定义购买云服务器CPU内存带宽配置选择范围广,活动上购买只能选择固定的活动…...

基于SpringBoot自定义控制是否需要开启定时功能
在基于SpringBoot的开发过程中,有时候会在应用中使用定时任务,然后服务器上启动定时任务,本地就不需要开启定时任务,使用一个参数进行控制,通过查资料得知非常简单。 参数配置 在application-dev.yml中加入如下配置 …...
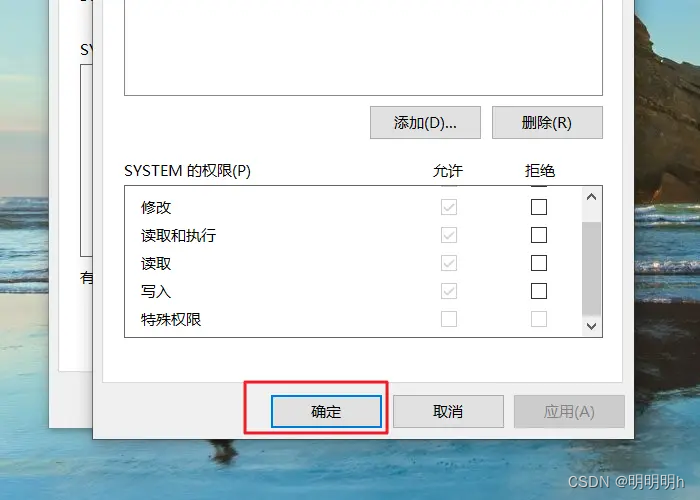
“确定要在不复制其属性的情况下复制此文件?”解决方案(将U盘格式由FAT格式转换为NTFS格式)
文章目录 1.问题描述2.问题分析3.问题解决3.1 方法一3.2 方法二3.3 方法三 1.问题描述 从电脑上复制文件到U盘里会出现“确定要在不复制其属性的情况下复制此文件?”提示。 2.问题分析 如果这个文件在NTFS分区上,且存在特殊的安全属性。那么把它从NT…...

视频监控系统EasyCVR如何通过调用API接口查询和下载设备录像?
智慧安防平台EasyCVR是基于各种IP流媒体协议传输的视频汇聚和融合管理平台。视频流媒体服务器EasyCVR采用了开放式的网络结构,支持高清视频的接入和传输、分发,平台提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联…...
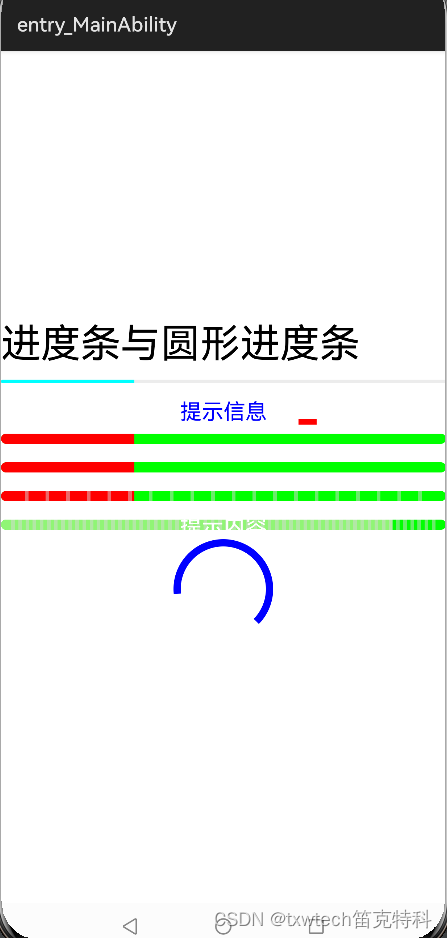
15.鸿蒙HarmonyOS App(JAVA)进度条与圆形进度条
15.鸿蒙HarmonyOS App(JAVA)进度条与圆形进度条 progressBar2.setIndeterminate(true);//设置无限模式,运行查看动态效果 //创建并设置无限模式元素 ShapeElement element new ShapeElement(); element.setBounds(0,0,50,50); element.setRgbColor(new RgbColor(255,0,0)); …...

【FastAPI】路径参数
路径参数 from fastapi import FastAPIapp FastAPI()app.get("/items/{item_id}") async def read_item(item_id):return {"item_id": item_id}其中{item_id}就为路径参数 运行以上程序当访问 :http://127.0.0.1:8000/items/fastapi时候 将会…...
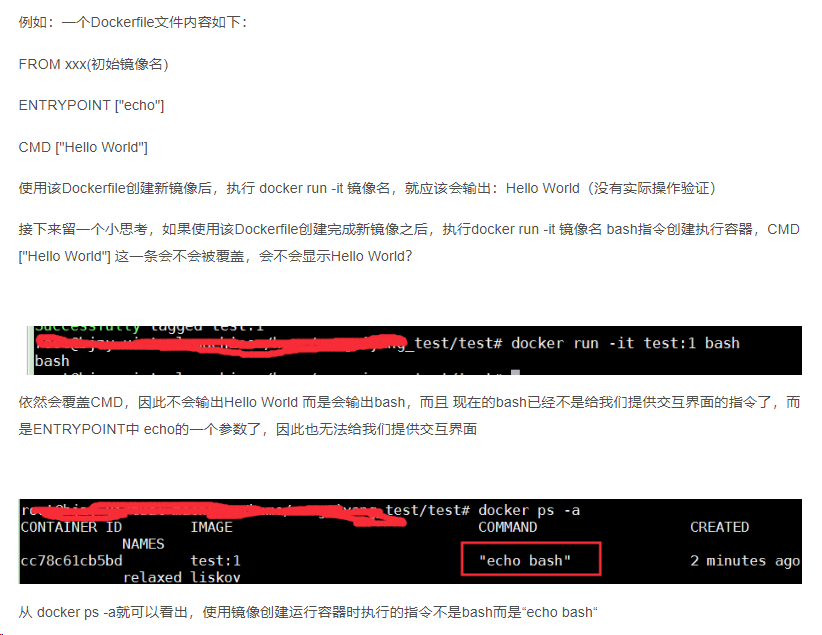
【docker笔记】DockerFile
DockerFile Docker镜像结构的分层 镜像不是一个单一的文件,而是有多层构成。 容器其实是在镜像的最上面加了一层读写层,在运行容器里做的任何文件改动,都会写到这个读写层。 如果删除了容器,也就是删除了其最上面的读写层&…...

React项目搭建流程
第一步 利用脚手架创建ts类型的react项目: 执行如下的命令:create-react-app myDemo --template typescript ; 第二步 清理项目目录结构: src/ index.tsx, app.txs, react-app-env.d.ts public/index.ht…...
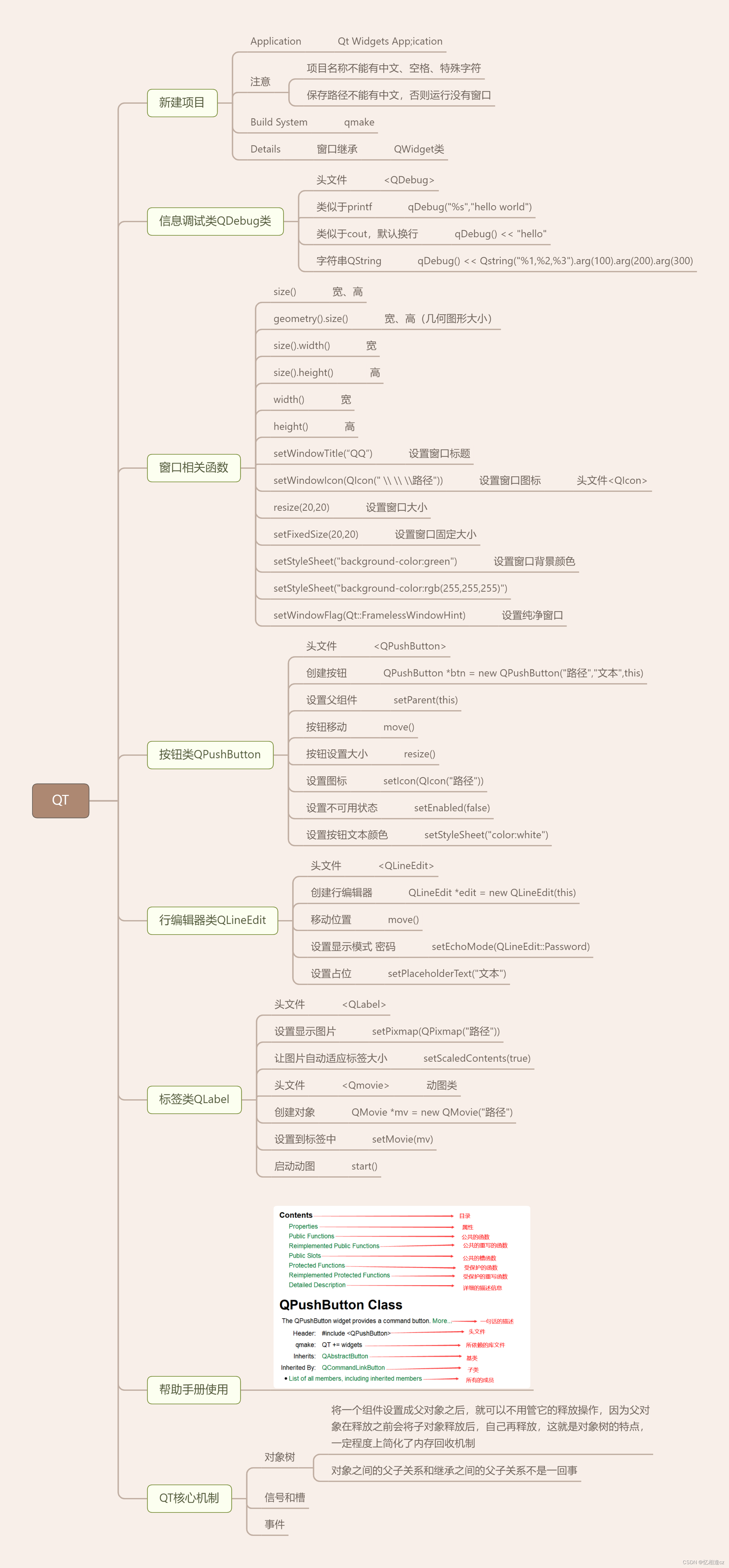
QT DAY1作业
1.QQ登录界面 头文件代码 #ifndef MYWIDGET_H #define MYWIDGET_H#include <QWidget> #include <QIcon> #include <QLabel> #include <QPushButton> #include <QMovie> #include <QLineEdit>class MyWidget : public QWidget {Q_OBJECTpu…...
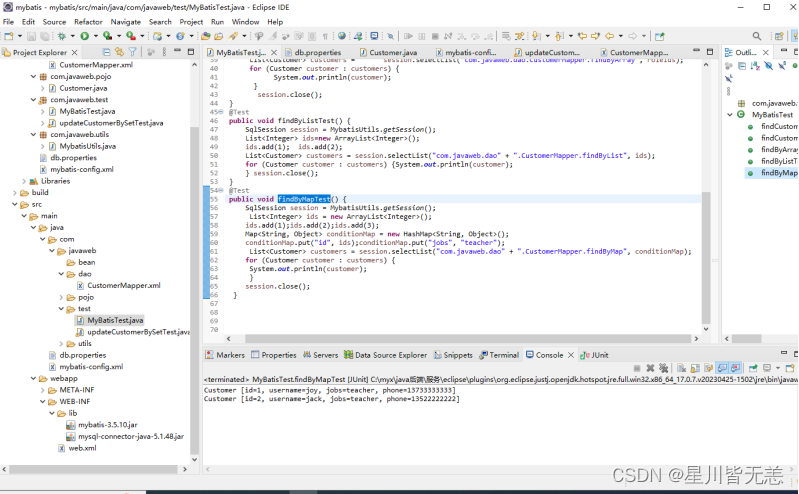
Java后端开发——Mybatis实验
文章目录 Java后端开发——Mybatis实验一、MyBatis入门程序1.创建工程2.引入相关依赖3.数据库准备4.编写数据库连接信息配置文件5.创建POJO实体6.编写核心配置文件和映射文件 二、MyBatis案例:员工管理系统1.在mybatis数据库中创建employee表2.创建持久化类Employee…...

【UE Niagara 网格体粒子系列】02-自定义网格
目录 步骤 一、创建自定义网格体 二、创建Niagara系统 步骤 一、创建自定义网格体 1. 打开Blender,按下ShiftA来创建一个平面 将该平面旋转90 导出为fbx 设置导出选定的物体,这里命名为“SM_PlaneFaceCamera.fbx” 按H隐藏刚才创建的平面&#x…...

k8s 检测node节点内存使用率平衡调度脚本 —— 筑梦之路
直接上脚本: #! /bin/bash#对实际使用内存大于85%的机器停止调度,对实际使用内存小于70%的 关闭调度# 获取实际内存小于或等于70%的机器 memory_lt_70kubectl top nodes |awk NR>1{if($50<70) print $1} # 获取实际内存大于或等于85%的机器 memor…...
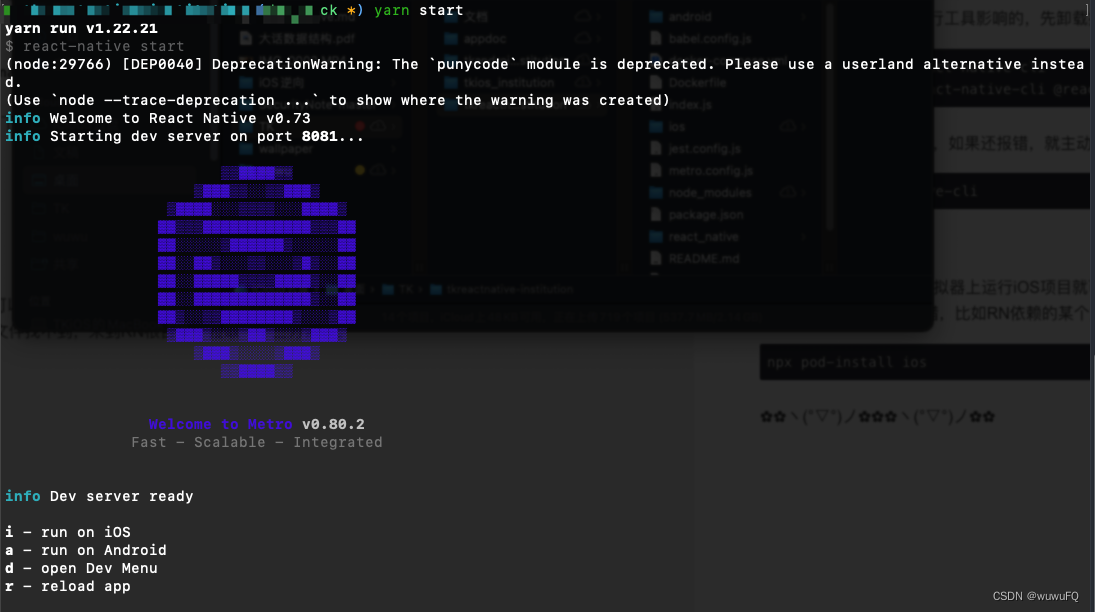
React Native集成到现有原生应用
本篇文章以MacOS环境开发iOS平台为例,记录一下在原生APP基础上集成React Native React Native中文网 详细介绍了搭建环境和集成RN的步骤。 环境搭建 必须安装的依赖有:Node、Watchman、Xcode 和 CocoaPods。 安装Homebrew Homebrew是一款Mac OS平台下…...
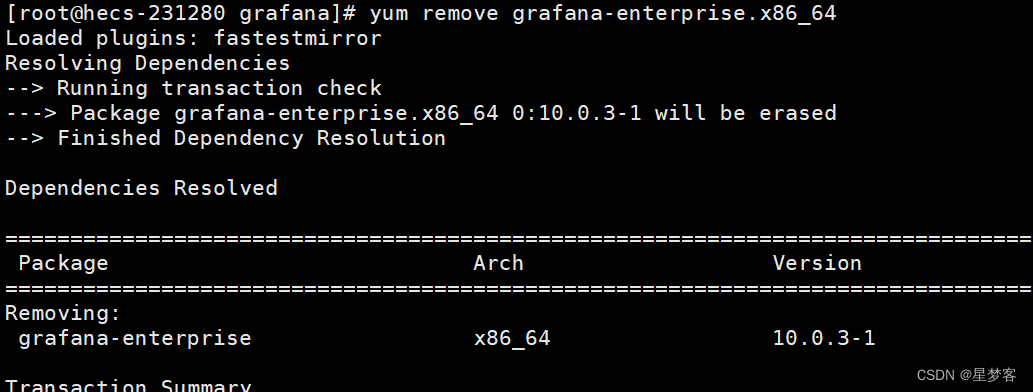
完全卸载grafana
先停掉grafana sudo systemctl stop grafana-server 查看要卸载的包的名字 yum list installed yum remove grafana-enterprise.x86_64 成功 删除grafana的数据目录 sudo rm -rf /etc/grafana/sudo rm -rf /usr/share/grafana/sudo rm -rf /var/lib/grafana/...
Vue2.组件通信
样式冲突 写在组件中的样式默认会全局生效。容易造成多个组件之间的样式冲突问题。 可以给组件加上scoped属性,让样式只作用于当前组件。 原理: 给当前组件模板的所有元素,加上一个自定义属性data-v-hash值,用以区分不同的组件。…...
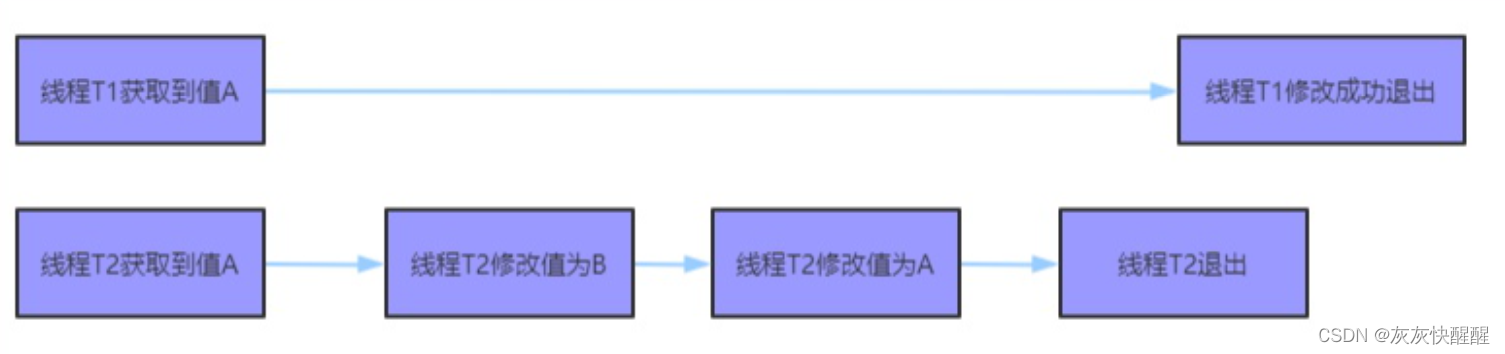
CAS的超~详细介绍
什么是CAS CAS全称Compare and swap,是一种比较特殊的CPU指令. 字面意思:"比较并交换", 一个CAS涉及到以下操作: 我们假设内存中的原数据为V,旧的预期值A,需要修改的新值B. 1.比较A和V是否相等(比较) 2.如果相等,将B写入V.(交换) 3.返回操作是否成功. 伪代码 下面…...

Scott用户数据表的分析
Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 如果想要知道某个用户所有的数据表: select * from tab; 此时结果中一共返回了四张数据表,分别为部门表(dept) ,员工表(emp&a…...
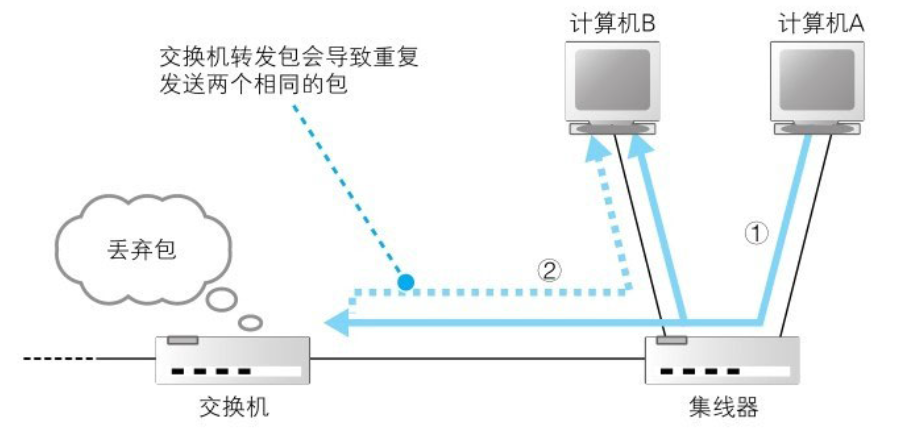
网络基础学习(3):交换机
1.交换机结构 (1)网线接口和后面的电路部分加在一起称为一个端口,也就是说交换机的一个端口就相当于计算机上的一块网卡。 如果在计算机上安装多个网卡,并让网卡接收所有网络包,再安装具备交换机功能的软件࿰…...

【软件测试学习笔记2】用例设计方法
1.能对穷举场景设计测试点(等价法) 等价类: 说明:在所有测试数据中,具有某种共同特征的数据集合进行划分 分类:有效等价类:满足需求的数据集合 无效等价类:不满足需求的数据集合 步…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...