java8 列表通过 stream流 根据对象属性去重的三种实现方法
java8 列表通过 stream流 根据对象属性去重的三种实现方法
一、简单去重
public class DistinctTest {/*** 没有重写 equals 方法*/@Setter@Getter@ToString@AllArgsConstructor@NoArgsConstructorpublic static class User {private String name;private Integer age;}/*** lombok(@Data) 重写了 equals 方法 和 hashCode 方法*/@Data@AllArgsConstructor@NoArgsConstructorpublic static class User2 {private String name;private Integer age;}@Testpublic void easyTest() {List<Integer> integers = Arrays.asList(1, 1, 2, 3, 4, 4, 5, 6, 77, 77);System.out.println("======== 数字去重 =========");System.out.print("原数字列表:");integers.forEach(x -> System.out.print(x + " "));System.out.println();System.out.print("去重后数字列表:");integers.stream().distinct().collect(Collectors.toList()).forEach(x -> System.out.print(x + " "));System.out.println();System.out.println();List<User> list = Lists.newArrayList();User three = new User("张三", 18);User three2 = new User("张三", 18);User three3 = new User("张三", 24);User four = new User("李四", 18);list.add(three);list.add(three);list.add(three2);list.add(three3);list.add(four);System.out.println("======== 没有重写equals方法的话,只能对相同对象(如:three)进行去重,不能做到元素相同就可以去重) =========");// 没有重写 equals 方法时,使用的是超类 Object 的 equals 方法// 等价于两个对象 == 的比较,只能筛选同一个对象System.out.println("初始对象列表:");list.forEach(System.out::println);System.out.println("简单去重后初始对象列表:");list.stream().distinct().collect(Collectors.toList()).forEach(System.out::println);System.out.println();System.out.println();List<User2> list2 = Lists.newArrayList();User2 five = new User2("王五", 18);User2 five2 = new User2("王五", 18);User2 five3 = new User2("王五", 24);User2 two = new User2("二蛋", 18);list2.add(five);list2.add(five);list2.add(five2);list2.add(five3);list2.add(two);System.out.println("======== 重写了equals方法的话,可以做到元素相同就可以去重) =========");// 所以如果只需要写好 equals 方法 和 hashCode 方法 也能做到指定属性的去重System.out.println("初始对象列表:");list2.forEach(System.out::println);System.out.println("简单去重后初始对象列表:");list2.stream().distinct().collect(Collectors.toList()).forEach(System.out::println);}
}
二、根据对象某个属性去重
0、User对象
/*** 没有重写 equals 方法*/@Setter@Getter@ToString@AllArgsConstructor@NoArgsConstructorpublic static class User {private String name;private Integer age;}
1、使用filter进行去重
@Testpublic void objectTest() {List<User> list = Arrays.asList(new User(null, 18),new User("张三", null),null,new User("张三", 24),new User("张三5", 24),new User("李四", 18));System.out.println("初始对象列表:");list.forEach(System.out::println);System.out.println();System.out.println("======== 使用 filter ,根据特定属性进行过滤(重不重写equals方法都不重要) =========");System.out.println("根据名字过滤后的对象列表:");// 第一个 filter 是用于过滤 第二个 filter 是用于去重List<User> collect = list.stream().filter(o -> o != null && o.getName() != null).filter(distinctPredicate(User::getName)).collect(Collectors.toList());collect.forEach(System.out::println);System.out.println("根据年龄过滤后的对象列表:");List<User> collect1 = list.stream().filter(o -> o != null && o.getAge() != null).filter(distinctPredicate(User::getAge)).collect(Collectors.toList());collect1.forEach(System.out::println);}/*** 列表对象去重*/public <K, T> Predicate<K> distinctPredicate(Function<K, T> function) {// 因为stream流是多线程操作所以需要使用线程安全的ConcurrentHashMapConcurrentHashMap<T, Boolean> map = new ConcurrentHashMap<>();return t -> null == map.putIfAbsent(function.apply(t), true);}
测试

①、疑惑
既然 filter 里面调用的是 distinctPredicate 方法,而该方法每次都 new 一个新的 map 对象,那么 map 就是新的,怎么能做到可以过滤呢
②、解惑
先看一下 filter 的部分实现逻辑,他使用了函数式接口 Predicate ,每次调用filter时,会使用 predicate 对象的 test 方法,这个对象的test 方法就是 null == map.putIfAbsent(function.apply(t), true)
而 distinctPredicate 方法作用就是生成了一个线程安全的 Map 集合,和一个 predicate 对象,且该对象的 test 方法为 null == map.putIfAbsent(function.apply(t), true)
之后 stream 流的 filter 方法每次都只会使用 predicate 对象的 test 方法,而该 test 方法中的 map 对象在该流中是唯一的,并不会重新初始化
@Overridepublic final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {Objects.requireNonNull(predicate);return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {@Overridepublic void begin(long size) {downstream.begin(-1);}@Overridepublic void accept(P_OUT u) {if (predicate.test(u))downstream.accept(u);}};}};}
2、使用Collectors.toMap() 实现根据某一属性去重(这个可以实现保留前一个还是后一个)
要注意 Collectors.toMap(key,value) 中 value 不能为空,会报错,key 可以为 null,但会被转换为字符串的 “null”
@Testpublic void objectTest() {List<User> list = Arrays.asList(new User(null, 18),new User("张三", null),null,new User("张三", 24),new User("张三5", 24),new User("李四", 18));System.out.println("初始对象列表:");list.forEach(System.out::println);System.out.println();System.out.println("======== 使用 Collectors.toMap() 实现根据某一属性去重 =========");System.out.println("根据名字过滤后的对象列表 写法1:");// (v1, v2) -> v1 的意思 两个名字一样的话(key一样),存前一个 value 值Map<String, User> collect = list.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getName, o -> o, (v1, v2) -> v1));// o -> o 也可以写为 Function.identity() ,两个是一样的,但后者可能比较优雅,但阅读性不高,如下// Map<String, User> collect = list.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getName, Function.identity(), (v1, v2) -> v1));List<User> list2 = new ArrayList<>(collect.values());list2.forEach(System.out::println);System.out.println("根据名字过滤后的对象列表 写法2:");Map<String, User> map2 = list.stream().filter(o -> o != null && o.getName() != null).collect(HashMap::new, (m, o) -> m.put(o.getName(), o), HashMap::putAll);list2 = new ArrayList<>(map2.values());list2.forEach(System.out::println);System.out.println("根据年龄过滤后的对象列表:");// (v1, k2) -> v2 的意思 两个年龄一样的话(key一样),存后一个 value 值Map<Integer, User> collect2 = list.stream().filter(Objects::nonNull).collect(Collectors.toMap(User::getAge, o -> o, (v1, v2) -> v2));list2 = new ArrayList<>(collect2.values());list2.forEach(System.out::println);}
测试
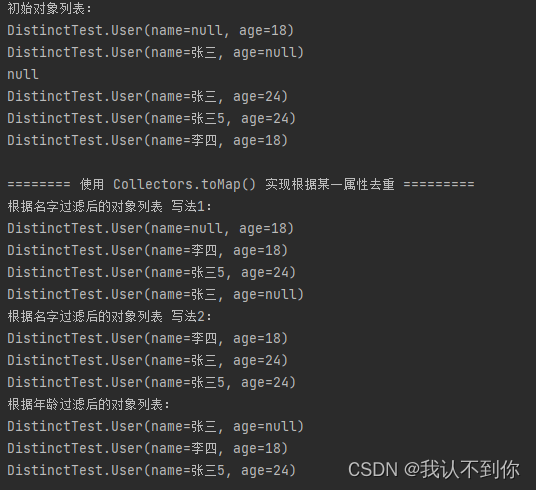
2.2、Collectors.toMap() 的变种 使用 Collectors.collectingAndThen()
Collectors.collectingAndThen()函数 它可接受两个参数,第一个参数用于reduce操作,而第二参数用于map操作。也就是,先把流中的所有元素传递给第一个参数,然后把生成的集合传递给第二个参数来处理。
@Testpublic void objectTest() {List<User> list = Arrays.asList(new User(null, 18),new User("张三", null),null,new User("张三", 24),new User("张三5", 24),new User("李四", 18));System.out.println("初始对象列表:");list.forEach(System.out::println);System.out.println();System.out.println("======== 使用 Collectors.toMap() 实现根据某一属性去重 =========");System.out.println("根据名字过滤后的对象列表:");ArrayList<User> collect1 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.collectingAndThen(Collectors.toMap(User::getName, o -> o, (k1, k2) -> k2), x-> new ArrayList<>(x.values())));collect1.forEach(System.out::println);System.out.println("======== 或者 ==========");List<User> collect = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList<User>::new));collect.forEach(System.out::println);}
测试
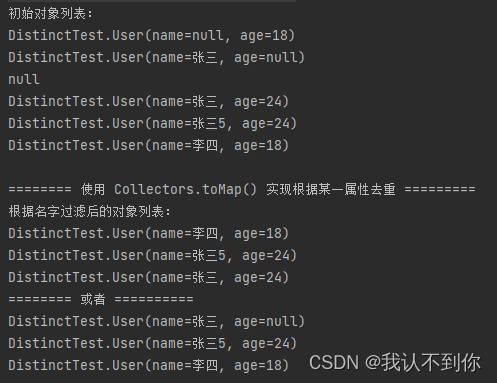
三、测试哪个方法比较快
@Testpublic void objectTest() {List<User> list = new ArrayList<>(Arrays.asList(new User(null, 18),new User("张三", null),null,new User("张三", 24),new User("张三5", 24),new User("李四", 18)));for (int i = 0; i < 100000; i++) {list.add(new User((Math.random() * 10) + "", (int) (Math.random() * 10)));}System.out.println("======== 测试速度 =========");long startTime = System.currentTimeMillis();List<User> list1 = list.stream().filter(o -> o != null && o.getName() != null).filter(distinctPredicate(User::getName)).collect(Collectors.toList());long endTime = System.currentTimeMillis();System.out.println("filter 用时 :" + (endTime - startTime));System.out.println();startTime = System.currentTimeMillis();Map<String, User> map1 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.toMap(User::getName, o -> o, (v1, v2) -> v1));List<User> list2 = new ArrayList<>(map1.values());endTime = System.currentTimeMillis();System.out.println("map1 用时 :" + (endTime - startTime));System.out.println();startTime = System.currentTimeMillis();ArrayList<User> list3 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.collectingAndThen(Collectors.toMap(User::getName, o -> o, (k1, k2) -> k2), x -> new ArrayList<>(x.values())));endTime = System.currentTimeMillis();System.out.println("map2 用时 :" + (endTime - startTime));System.out.println();startTime = System.currentTimeMillis();List<User> list4 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList<User>::new));endTime = System.currentTimeMillis();System.out.println("map3 用时 :" + (endTime - startTime));System.out.println();startTime = System.currentTimeMillis();Map<String, User> map2 = list.stream().filter(o -> o != null && o.getName() != null).collect(HashMap::new, (m, o) -> m.put(o.getName(), o), HashMap::putAll);List<User> list5 = new ArrayList<>(map2.values());endTime = System.currentTimeMillis();System.out.println("map4 用时 :" + (endTime - startTime));}
测试:
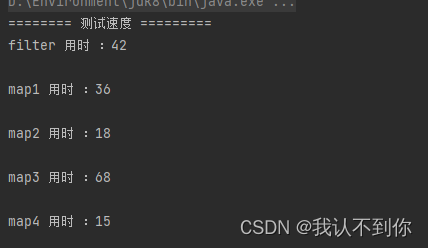
四、结论
1、去重最快:
ArrayList<User> list3 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.collectingAndThen(Collectors.toMap(User::getName, o -> o, (k1, k2) -> k2), x -> new ArrayList<>(x.values())));// 或者Map<String, User> map2 = list.stream().filter(o -> o != null && o.getName() != null).collect(HashMap::new, (m, o) -> m.put(o.getName(), o), HashMap::putAll);List<User> list5 = new ArrayList<>(map2.values());
2、其次
Map<String, User> map1 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.toMap(User::getName, o -> o, (v1, v2) -> v1));List<User> list2 = new ArrayList<>(map1.values());// distinctPredicate 是一个方法 本文中有 ,可以 ctrl + f 查找List<User> list1 = list.stream().filter(o -> o != null && o.getName() != null).filter(distinctPredicate(User::getName)).collect(Collectors.toList());
3、最慢
List<User> list4 = list.stream().filter(o -> o != null && o.getName() != null).collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList<User>::new));
相关文章:
java8 列表通过 stream流 根据对象属性去重的三种实现方法
java8 列表通过 stream流 根据对象属性去重的三种实现方法 一、简单去重 public class DistinctTest {/*** 没有重写 equals 方法*/SetterGetterToStringAllArgsConstructorNoArgsConstructorpublic static class User {private String name;private Integer age;}/*** lombo…...
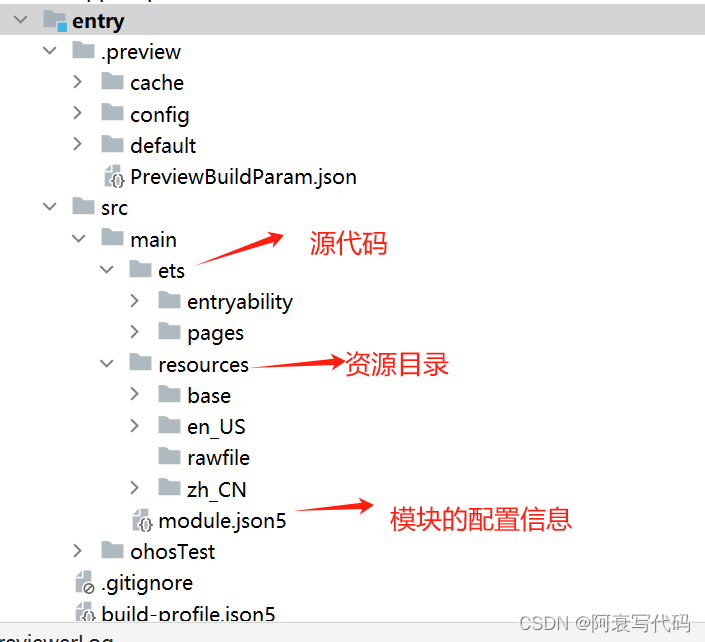
鸿蒙开发DevEco Studio Setup 工具认识及使用
1、界面认识 1.1 创建页面之前理解Ability 1.2 理解stage模式 1.3 工程级别目录结构 1.4 模块级别目录...

程序员裁员潮:技术变革下的职业危机
程序员裁员潮:技术变革下的职业危机 一对来自中国的工程师夫妻在美身亡,疑因谷歌裁员致悲剧发生。在技术变革下,裁员对于程序员的影响到底有多大?快来和我们分享一下你的看法吧~ 哎,这是悲哀,让我又想起来…...
Cesium快速入门
文章目录 0.引言1.Cesium环境搭建1.1安装Node.js环境1.2配置Cesium依赖 2.搭建第一个Cesium程序2.1引入源码编译结果2.2创建html文件2.3编写第一个Cesium程序2.4申请许可密钥2.5发布Cesium程序服务 3.界面介绍4.默认控件介绍 0.引言 现有的gis开发方向较流行的是webgis开发&am…...

Android.mk和Android.bp的区别和转换详解
Android.mk和Android.bp的区别和转换详解 文章目录 Android.mk和Android.bp的区别和转换详解一、前言二、Android.mk和Android.bp的联系三、Android.mk和Android.bp的区别1、语法:2、灵活性:3、版本兼容性:4、向后兼容性:5、编译区…...

卡尔曼滤波器原理By_DR_CAN 学习笔记
DR_CAN卡尔曼滤波器 Kalman Filter Recursive Algorithm迭代过程 数学基础正态分布和6-SigmaData FusionCovariance MatrixState Space Representation离散化推导 linearizationTaylor Series2-DSummary Step by Step Derivation of Kalman Gain矩阵求导公式 Prior / Posterio…...

013 异常
文章目录 异常人为创造异常 异常 定义:运行时检测的错误 try:可能触发异常的语句 except 错误类型1 [as 变量1]:处理语句1 except 错误类型2:处理语句2 except Exception:不是以上错误类型的处理语句 else:未发生异常的语句 finally:无论是否发生异常的语句异常处理:保障程序…...
微服务Spring Cloud架构详解
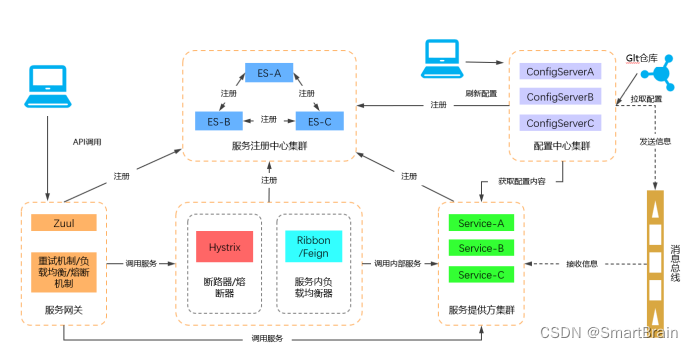
"Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智能路由,微代理,控制总线)。分布式系统的协调导致了样板模式, 使用Spring Cloud开…...

推荐一一款小众黑科技工具,低调使用建议收藏
wireshark是个啥就不多说了,非常流行的网络封包分析软件。 可以截取各种网络封包,显示网络封包的详细信息。 软件功能十分强大,操作也不复杂。 很多小友都在后台问能不能出一期完整的抓包分析贴,今天给你们安排上了哈。 01 W…...

HiP框架:多AI模型联手,助力机器人驾驭复杂规划大局
原创 | 文 BFT机器人 你的日常待办清单或许只是些稀松平常的小事:清洗堆积如山的碗盘、采购琳琅满目的食品杂货等。在执行这些任务时,你无需逐一写下“捧起那只满是油污的盘子”或“用湿润的海绵仔细擦洗这个盘子”这样的琐碎步骤,因为在你的…...

关于OC中变量相关知识点
众所周知,变量是用来存储数据的 围绕着变量,有很多知识点,总结归纳一下 变量的类型变量的作用区域局部变量全局变量静态变量变量的访问范围属性成员变量实例变量synthesizedynamic… 变量的类型 变量大致分为两大类型: 基本数据…...
机器学习分类模型评价指标总结(准确率、精确率、召回率、Fmax、TPR、FPR、ROC曲线、PR曲线,AUC,AUPR)
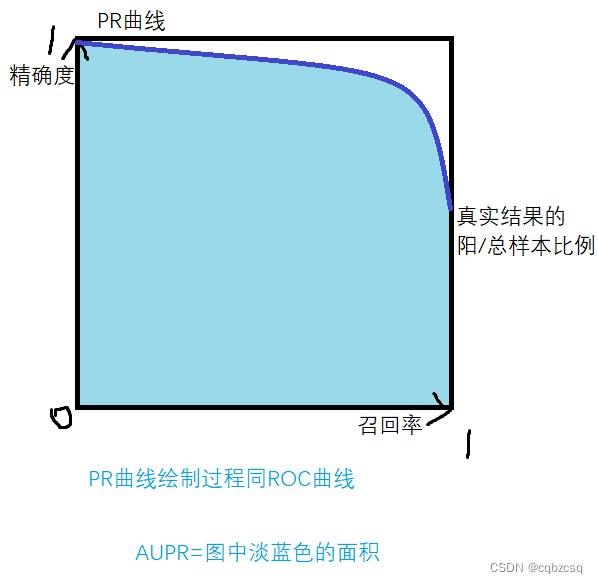
为了看懂论文,不得不先学一些预备知识((55555 主要概念 解释见图 TP、FP、TN、FN 准确率、精确率(查准率)、召回率(查全率) 真阳性率TPR、伪阳性率FPR F1-score2TP/(2*TPFPFN) 最大响应分…...
go语言(十一)----面向对象继承
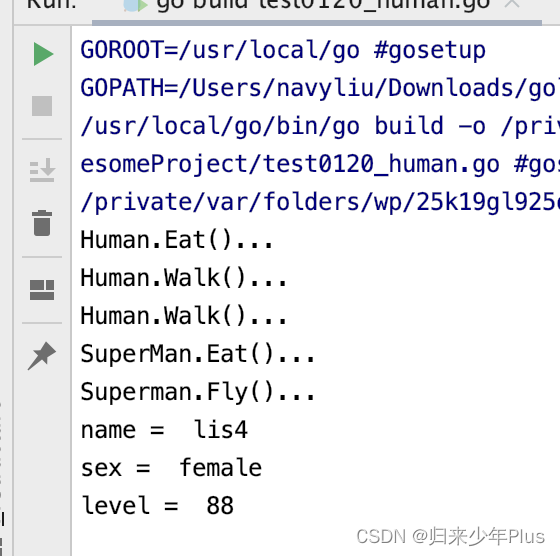
一、面向对象继承 写一个父类 package mainimport "fmt"type Human struct {name stringsex string }func (this *Human) Eat() {fmt.Println("Human.Eat()...") }func (this *Human) Walk() {fmt.Println("Human.Walk()...") }func main() {h…...
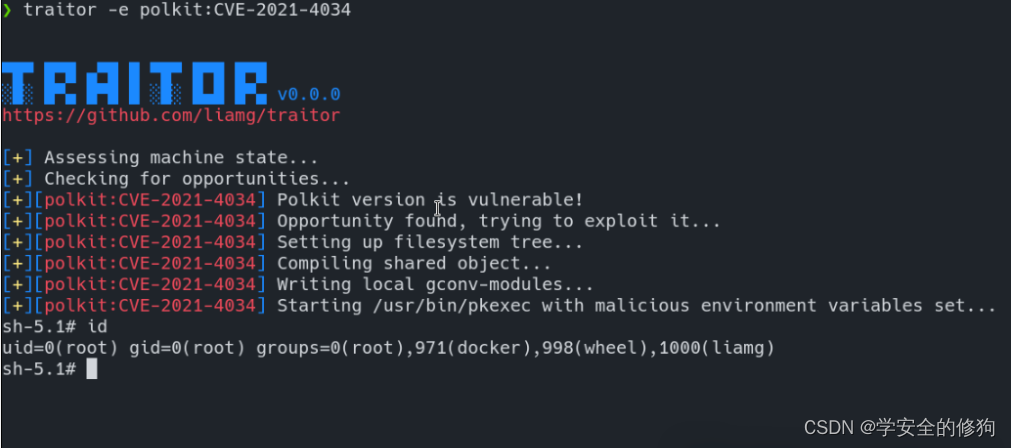
一款自动化提权工具
免责声明 请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任。工具来自网络,安全性自测,如有侵权请联系删除。…...
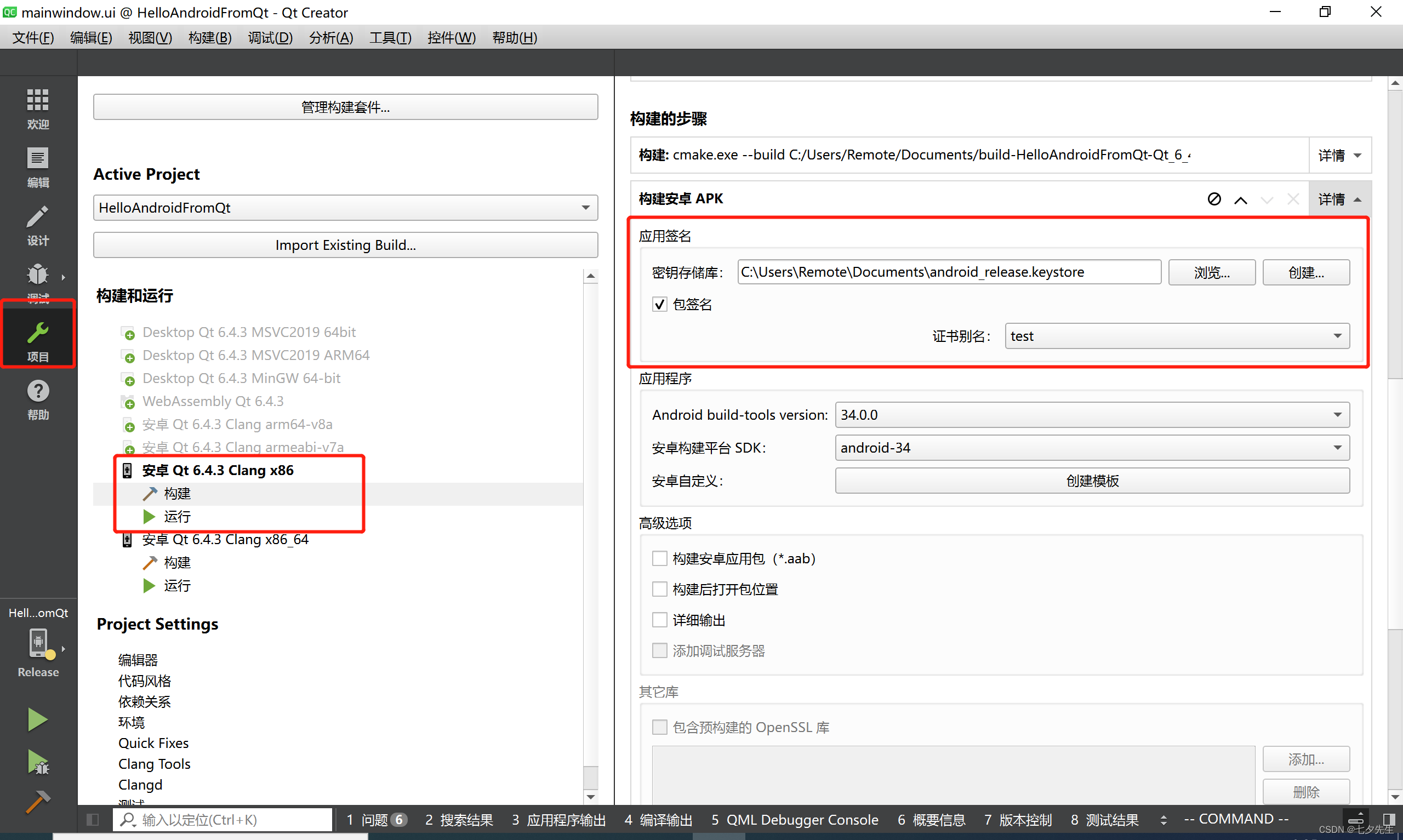
【Qt】最详细教程,如何从零配置Qt Android安卓环境
这里写自定义目录标题 安装Qt Creator & Qt安装下载&安装JDK设置Android SDKAndroid模拟器下载创建android设备(模拟器) Gradle安装问题解决无法打开安卓模拟器Build失败方案一:不适用Qt自带SDK管理器(失败)方…...

spring与spring boot的区别
spring与spring boot的区别 项目配置: Spring: 在Spring中,项目的配置通常需要在XML文件中进行,包括配置数据源、事务管理、AOP等。这需要开发人员手动配置很多细节。 <!-- 在Spring中使用XML配置数据源 --> <bean id…...
http网络编程——在ue5中实现文件传输功能
http网络编程在ue5中实现 需求:在unreal中实现下载功能,输入相关url网址,本地文件夹存入相应文件。 一、代码示例 1.Build.cs需要新增Http模块,样例如下。 PublicDependencyModuleNames.AddRange(new string[] { "Core&q…...
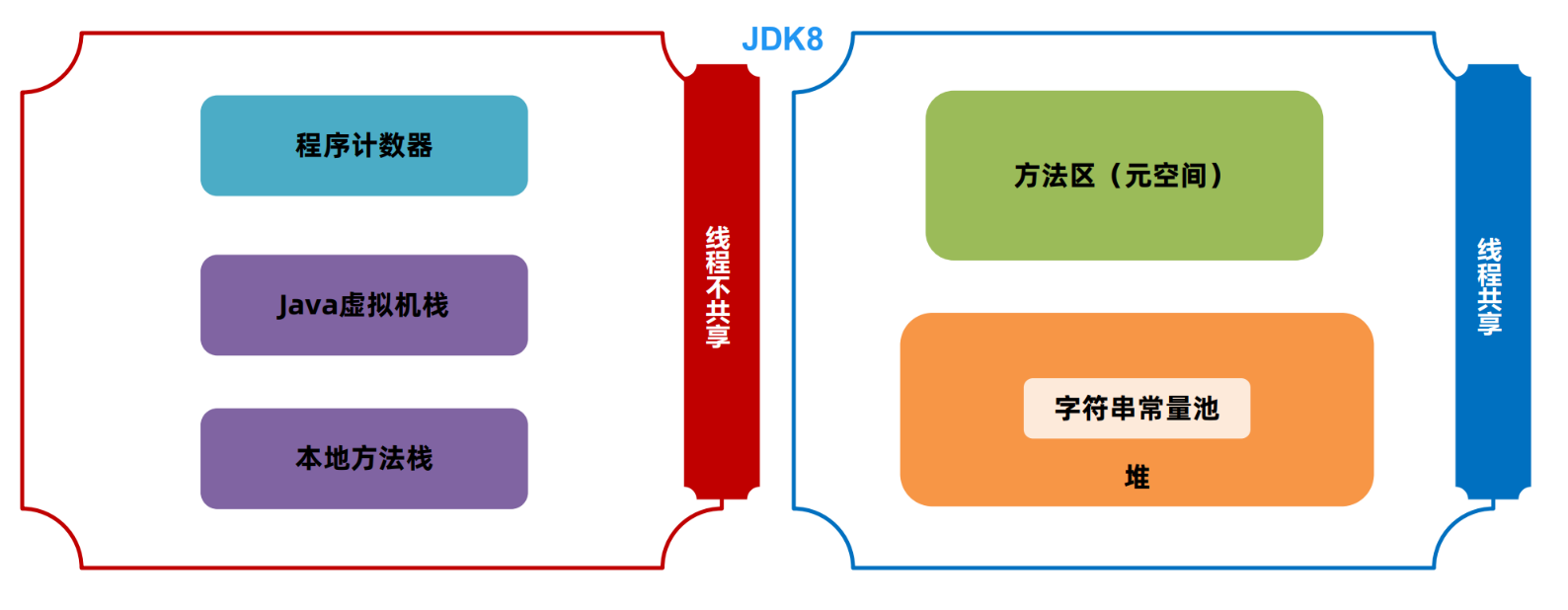
JVM之java内存区域[2](堆、方法区、直接内存)
文章目录 版权声明一 堆1.1 java堆1.2 模拟堆区的溢出1.3 arthas中堆内存相关的功能1.4 设置大小 二 方法区2.1 方法区简介2.2 补充:字符串常量池和运行时常量池2.3 方法区的大小设计2.4 arthas中查看方法区2.5 模拟方法区的溢出2.7 StringTable的练习题 三 神奇的i…...

k8s-kubectl常用命令
一、基础命令 1.1 get 查询集群所有资源的详细信息,resource包括集群节点、运行的Pod、Deployment、Service等。 1.1.1 查询Pod kubectl get po -o wid 1.1.2 查询所有NameSpace kubectl get namespace 1.1.3 查询NameSpace下Pod kubectl get po --all-namespaces…...

如何在Docker上运行Redis
环境: 1.windows系统下的Docker deckstop 1.Pull Redis镜像 2.运行Redis镜像 此时,Redis已经启动,我们登录IDEA查看下是否连接上了 显示连接成功,证明已经连接上Docker上的Redis了...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...