【大数据面试题】HBase面试题附答案
目录
1.介绍下HBase
2.HBase优缺点
3.介绍下的HBase的架构
4.HBase的读写缓存
5.在删除HBase中的一个数据的时候,它是立马就把数据删除掉了吗?
6.HBase中的二级索引
7.HBase的RegionServer宕机以后怎么恢复的?
8.HBase的一个region由哪些东西组成?
9.HBase高可用怎么实现的?
10.为什么HBase适合写多读少业务?
11.列式数据库的适用场景和优势?
12.HBase的rowkey设计原则
13.HBase的rowkey为什么要唯一?
14.HBase的大合并、小合并是什么?
15.HBase和关系型数据库(传统数据库)的区别(优点)?
16.HBase为什么随机查询很快?
17.HBase的Get和Scan的区别和联系?
18.HBase数据compact流程
19.MemStore Flush条件
20.既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase
21.HBase和Phoenix的区别
22.HBase支持SQL操作吗
23.HBase表设计
24.Region分配
25.HBase的Region切分
26.介绍下HBase中的LSM树
27.HBase写数据流程
28.HBase读数据流程
29.HBase优化
1.介绍下HBase
HBase是一种基于Hadoop的列式分布式非关系型数据库,它是高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价服务器上搭建起大规模结构化存储集群。它是Google论文BigTable的实现。
2.HBase优缺点
优点
a. 高容错性,高扩展性,高吞吐量
b. 强一致性和持久性,数据写入内存后异步刷新到磁盘
c. 采用k-v存储方式,意味着即使数据海量增长,查询性能也不会急剧下降
d. 列式存储,数据模型灵活,具备动态添加列簇和列的能力
e. 与大数据生态系统整合紧密,可无缝与其他大数据组件协同工作
缺点
a. 由于HBASE按照Row key来读写,不支持范围条件查询
b. 结构设计复杂,因此数据量少的时候,性能并不占优势
c. 不支持表的关联操作,并且聚合查询能力差
3.介绍下的HBase的架构
(1) Zookeeper
a. 保证HMaster的高可用;
b. 存储所有的HRegion的寻址入口;
c. 实时监控HRegionServer的上线和下线信息,并实时通知给HMaster;
d. 存储HBase的schema和table元数据;
e. Zookeeper Quorum存储-ROOT-表地址、HMaster地址
(2) HMaster
所有Region Server的管理者
a. 对于表的操作:create, delete, alter
b. 对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移
(3) HRegionServer
a. 对于数据的操作:get, put, delete
b. 对于Region的操作:splitRegion、compactRegion
(4) HFile
HBase中KeyValue数据的存储格式,
(5) HStore
存储核心由MemStore和StoreFile组成。StoreFile文件数量增长到阈值后会触发Compact合并操作,多个StoreFile合并为一个StoreFile,合并过程中会进行版本合并和数据删除。当单个StoreFile达到一定阈值后,会触发Split操作,将当前一个Regin分为两个Regin,父Regin下线,新Regin由HMaster分配到新ReginServer
(6) HLog(WAL)
每个HReginServer中有一个HLog,避免HBase意外宕机时,MemStore数据丢失。HLog定期删除已经持久化的数据。当HReginServer意外终止后,HMaster通过Zookeeper感知到,先处理遗留的HLog,将其中不同Regin的Log数据拆分,分发到相应的Regin目录下,然后再将失效的Regin重新分配,领取到这些Regin的HReginServer在Load Regin时发现有历史HLog需要处理,就将其中数据Replay到MemStore中,然后Flush到StoreFile,完成数据恢复
(7) HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持
(8) hbase-client
用来访问hbase集群
4.HBase的读写缓存
读缓存BlockCache
写缓存MemStore
5.在删除HBase中的一个数据的时候,它是立马就把数据删除掉了吗?
不是,只是将删除操作记录下来,在StoreFile文件比较多进行合并时,清理过期或者删除的数据。
6.HBase中的二级索引
(1)背景
HBASE中只有RowKey作为一级索引,在查询非RowKey数据时,需要通过MR或Spark等计算框架,效率特别低,并且特别消耗资源。
(2)原理
建立各列值与行键之间的映射关系。
(3)问题
索引和数据不一致。
参考:hbase--索引概念(含二级索引)_hbase索引-CSDN博客
7.HBase的RegionServer宕机以后怎么恢复的?
(1) HMaster检测到服务器宕机(通过Zookeeper);
(2) HLog切分,一个ReginServer只有一个HLog,因此要将HLog按照Regin进行切分,完成后Regin连同对应的HLog被HMaster分往新的ReginServer;
(3) 被分配了新的Regin的ReginServer根据HLog进行丢失数据的恢复,恢复完成后继续对外服务。
8.HBase的一个region由哪些东西组成?
有一个或多个Store,每个Store存放一个列簇;
每个Store由一个MemStore和0个或多个StoreFile组成。
9.HBase高可用怎么实现的?
数据复制:数据能够在不同的ReginServer之间进行复制;
Zookeeper:用于检测和管理各个节点的状态,并触发相应的操作;
RegionServer自动恢复:出现故障后,上面的数据会被HMaster发到其他ReginServer。
10.为什么HBase适合写多读少业务?
HBase存储引擎使用LSM树实现
- 写的时候先将数据存在内存中,达到阈值后再顺序写到磁盘上,避免了随机写;
- 读的时候,HBase只有rowkey索引,并且很难命中内存中数据,需要访问较多磁盘。
11.列式数据库的适用场景和优势?
适用场景:
a. 查询过程中,可针对各列的运算并发执行,在内存中聚合完整记录集,降低查询响应时间
b. 因为各列独立存储,且数据类型已知,可以针对该列的数据类型、数据量大小等因素动态选择压缩算法,以提高物理存储利用率
优势:
a. 列存模式下,只需要读取参与计算的列即可,极大的减低了IO花费
b. 同一列中的数据属于同一类型,压缩效果显著
适合OLAP系统
12.HBase的rowkey设计原则
(1)长度
Rowkey是一个二进制码流,太长浪费磁盘,并且MemStore中存储数据量也少建议10~100长度,最佳为16,因为64位操作系统内存8字节对齐,为8的整数倍最佳;
(2)散列原则
将RowKey高位字段作为散列字段,避免热点数据集中在一个ReginServer上;
(3)唯一原则
rowkey 是按照字典顺序排序存储的,因此可以将经常读到的数据放在一起。
13.HBase的rowkey为什么要唯一?
因为HBase是k-v存储,重复的话旧数据会被新数据覆盖
14.HBase的大合并、小合并是什么?
- 小合并(Minor Compaction)
合并相邻的StoreFile为一个较大的StoreFile
- 大合并(Major Compartion)
将所有StoreFile合并为一个StoreFile,伴随着数据的删除清理
15.HBase和关系型数据库(传统数据库)的区别(优点)?
(1)数据类型
HBase只有字符串存储,传统的关系型数据有着丰富的存储类型
(2)数据的操作
HBase只有表内数据的操作,没有表之间的关联
(3)存储方式
HBase是列式存储
(4)数据维护
HBase的修改和删除不是马上执行,操作后并不是第一时间内生效
(5)可伸缩性
HBase能够很容易的增加/减少节点
16.HBase为什么随机查询很快?
(1)只需要遍历相关Regin
(2)只需要遍历相关列簇
(3)先内存再磁盘
(4)根据key遍历
17.HBase的Get和Scan的区别和联系?
区别:
a. Get根据RowKey获取唯一值;
b. Scan按照指定的条件和顺序扫描表中的多行数据;
c. Get操作在内部对数据进行缓存,因此适用于对特定行的频繁读取。而Scan操作不会缓存数据,适用于一次性读取大量数据或按顺序遍历数据。
联系:
a. Get和Scan都可以使用过滤器(Filters)进行数据过滤,以便按照特定条件筛选所需的数据;
b. Get和Scan都可以选择返回的列族和列限定符,以获取特定的列数据。
18.HBase数据compact流程
(1) 触发
(2) 选择合并目标
(3) 合并:对选中的StoreFile进行归并排序,并进行合并,合并同时处理文件版本,时间戳等信息
(4) 清理:合并完成后,原有StoreFile会废弃,HBase会将其删除,并释放相应空间
(5) 更新元数据:Compaction完成后,HBase会更新相应的元数据信息
19.MemStore Flush条件
- MemStore达到阈值,所在regin都会flush
达到MemStore的4倍(默认),停止写入MemStore
- ReginServer中MemStore总大小达到阈值,全体flush
- 达到时间阈值,触发flush
- WAL文件数量超过阈值,regin整体flush
20.既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase
- HDFS更多的功能是大文件的存储,创建/删除文件,管理权限,对大文件的数据读取/追加。但是如果要对所存储的数据做修改/删除/插入/随机写,HDFS就做不到了
- HBase是基于HDFS进行超大数据集的分布式存储以及对数据的增删改查
21.HBase和Phoenix的区别
- Phoenix是HBase的开源SQL中间层,允许使用JDBC方式操作HBase上的数据
- HBase创建的表Phoenix看不到,Phoenix创建的表HBase能看到
- Phoenix具备二级索引
- Phoenix支持表之间的Join操作
22.HBase支持SQL操作吗
不直接支持传统SQL语句,使用自身API实现操作数据
23.HBase表设计
- 列簇设计在合理范围内能尽量少的减少列簇就尽量减少列簇数据保留的版本数数据保留时间
- rowkey设计预分区
主要解决热点问题,避免数据吞吐量过大时单个Regin负载过大
- rowkey长度不宜过大
- 唯一性原则
24.Region分配
- 任何时刻,一个Regin只能分给一个ReginServer
- Master记录了有哪些可用的ReginServer,以及当前有哪些Regin分配给了哪些ReginServer。当需要分配新的Regin,并且一个ReginServer有空间时,Master则会向ReginServer发送装载请求,ReginServer开始提供服务。
25.HBase的Region切分
(1)prepare阶段
在内存中初始化两个HReginInfo对象,包含tableName,reginName,startKey,endKey以及transaction journal用来记录切分的进展。
(2)execute阶段
a. RegionServer 更改ZK节点 /region-in-transition 中该Region的状态为SPLITING
b. Master通过watch节点/region-in-transition检测到Region状态改变,并修改内存中Region的状态
c. 在父存储目录下新建临时文件夹.split保存split后的daughter region信息
d. 关闭parent regin(会触发flush操作,确保数据全部落盘)
e. 核心分裂步骤:在.split文件夹下新建两个子文件夹,称之为daughter A、daughter B,并在文件夹中生成reference文件,分别指向父region中对应文件
f. 父region分裂为两个子region后, 将daughter A、daughter B拷贝到HBase根目录下,形成两个新的region
g. parent region通知修改 hbase.meta 表后下线,不再提供服务
h. 开启daughter A、daughter B两个子region。通知修改 hbase.meta 表,正式对外提供服务
(3)rollback阶段
如果execute阶段出现异常,则执行rollback操作
26.介绍下HBase中的LSM树
(1)设计思想
将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的来说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
本质是将写入操作全部转化成磁盘的顺序写入,极大地提高了写入操作的性能。
(2)数据写
a. 数据首先会插入到内存中的树,为了防止数据丢失,写内存的同时需要暂时持久化到磁盘(WAL),即输入数据时数据会以完全有序的形式先存储在日志文件中(对应HBase的MemStore和HLog)。当日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
b. 当内存中树的数据大小达到阈值时,会进行合并操作。合并操作会从左至右遍历内存中的叶子节点与磁盘中树的叶子节点进行合并,当合并的数据量达到磁盘的存储页的大小时,会将合并的数据持久化到磁盘。同时更新父亲节点对叶子节点的指针。
27.HBase写数据流程
a. Client先访问zookeeper,获取hbase:meta表位于哪个RegionServer
b. 访问对应的RegionServer,获取hbase:meta表中数据,查询要写入数据Region所在RegionServer
c. 访问RegionServer,发送写请求
d. ReginServer将数据顺序写入(追加)到HLog(WAL)
e. 将数据写入对应的MemStore,数据会在MemStore进行排序
f. 向客户端发送ack
g. 等达到MemStore的刷写时机后,将数据刷写到HFile

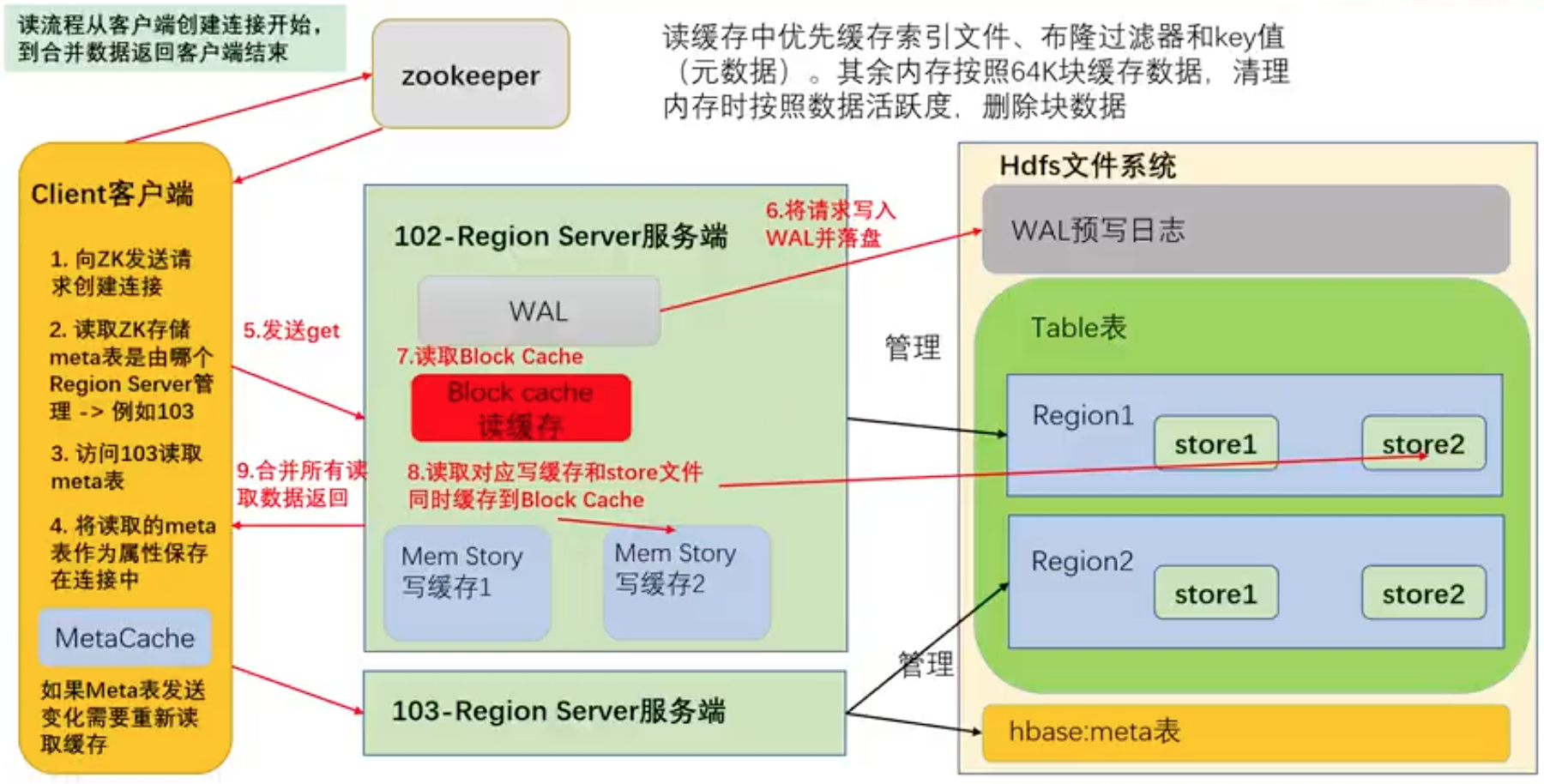
28.HBase读数据流程
a. Client先访问zookeeper,获取hbase:meta表位于哪个Region Server
b. 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问
c. 与目标RegionServer进行通讯
d. 分别在MemStore、Block Cache和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)
e. 将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache
f. 将合并后的最终结果返回给客户端
29.HBase优化
(1)预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能
(2)RowKey设计
生成随机数、hash、散列值;
字符串反转;
字符串拼接。
(3)内存优化
适合就好,过大的话虽然性能高,但是GC时候时间特别长。
(4)设置RPC监听数量
默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
(RPC监听是指Region Compact后的监听器,当一个Region没有被写入新数据,并且仅存在较少的数量的旧数据时,HBase会自动压缩该Region。在这种情况下,HBase将触发rck监听器,以便通知相关进程可以将该Region从内存中卸载,以释放更多的资源。通过这种方式,rck监听器可以帮助保持HBase集群的高性能和稳定性。)
(5)手动控制Major Compaction
默认值:604800000秒(7天), Major Compaction的周期,若关闭自动Major Compaction,可将其设为0
(6)优化HStore文件大小
默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile
(7)优化HBase客户端缓存
默认值2097152bytes(2M)用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的
(8)指定scan.next扫描HBase所获取的行数
用于指定scan.next方法获取的默认行数,值越大,消耗内存越大
(9)BlockCache占用RegionServer堆内存的比例默认0.4,读请求比较多的情况下,可适当调大
(10)MemStore占用RegionServer堆内存的比例默认0.4,写请求较多的情况下,可适当调大
相关文章:
【大数据面试题】HBase面试题附答案
目录 1.介绍下HBase 2.HBase优缺点 3.介绍下的HBase的架构 4.HBase的读写缓存 5.在删除HBase中的一个数据的时候,它是立马就把数据删除掉了吗? 6.HBase中的二级索引 7.HBase的RegionServer宕机以后怎么恢复的? 8.HBase的一个region由哪些东西组成? 9.…...

SpringBoot中从HikariCP迁移到Oracle UCP指南
本博客文章的目标是作为从 HikariCP 和Oracle UCP(通用连接池)迁移的指南,因为它是连接到Oracle 数据库时的推荐方法。 HikariCP 简介 HikariCP是与 Spring Boot 应用程序一起使用的 JDBC 连接池。 简而言之,从 Java 开发人员的…...

第3章 接口和API设计
第15条:用前缀避免命名空间冲突 OC没有其他语言那种内置的命名空间机制。因此,我们在起名时要设法避免潜在的命名冲突,否则很容易就重名了。若是发生重名冲突,那么应用程序相应的链接过程就会出错。例如: 错误原因在…...
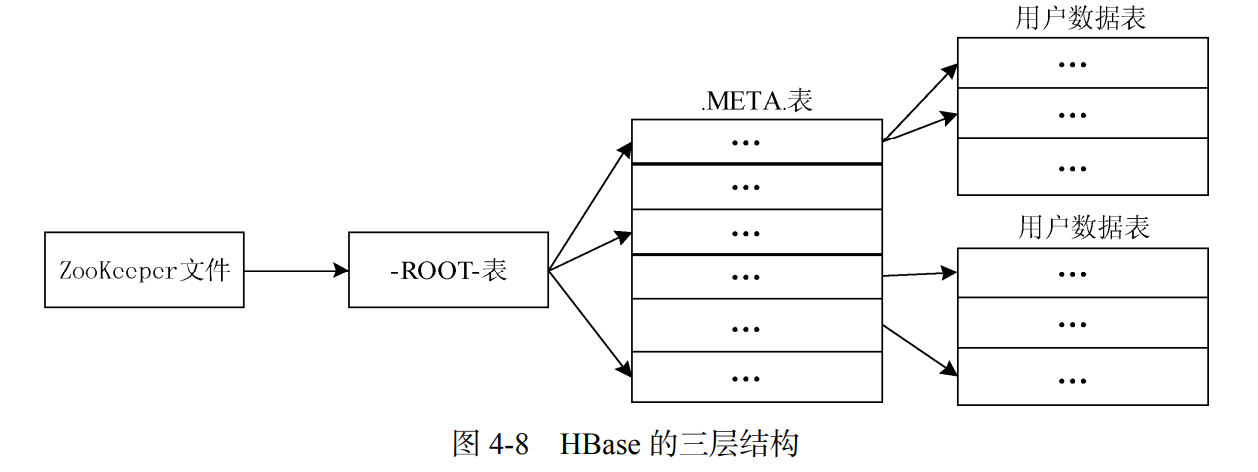
HBase入门:实现原理
文章目录 说明HBase的实现原理HBase功能组件表和 RegionRegion 的定位 说明 本文参考自林子雨老师的《大数据技术原理与应用(第三版)》教材内容,仅供学习和交流 HBase的实现原理 HBase功能组件 HBase 的实现包括 3 个主要的功能组件:库函数ÿ…...
Redis入门到实战-基础篇+实战篇+高级篇+原理篇
Redis入门到实战-基础篇实战篇高级篇原理篇 文章目录 Redis入门到实战-基础篇实战篇高级篇原理篇一、基础篇二、实战篇三、高级篇四、原理篇 一、基础篇 1.基础篇笔记:https://blog.csdn.net/cygqtt/article/details/126974142 二、实战篇 1.实战篇笔记:…...

redis 工具类
在Spring Boot项目中,Redis是一个常用的分布式缓存解决方案。下面展示的RedisCache工具类封装了对Redis进行基本操作的方法,包括存储和获取各种类型的数据、设置过期时间以及处理集合类型的缓存。 /*** redis 工具类***/ SuppressWarnings(value { &q…...

焕新升级,不同以“网” | AnyCase客户端全新上线
升级啦~ 2024年1月23日 箱讯AnyCase官网全新改版上线! 全球贸易All in One集成平台 集物流服务、外贸服务、供应链金融服务、企业风控服务、碳中和服务于一体 添加图片注释,不超过 140 字(可选) 优化首页布局→体验升级 此次…...
导出 MySQL 数据库表结构、数据字典word设计文档
一、第一种 :利用sql语句查询 需要说明的是该方法应该适用很多工具,博主用的是navicat SELECT TABLE_NAME 表名,( i : i 1 ) AS 序号,COLUMN_NAME 列名, COLUMN_TYPE 数据类型, DATA_TYPE 字段类型, CHARACTER_MAXIMUM_LENGTH 长度, IS_NULLABLE…...

conda管理python安装包与虚拟环境的相关命令汇总
conda的简单介绍 Anaconda,是一个开源的Python发行版本,包含了conda、Python以及一大堆安装好的工具包及依赖项。 conda是Anaconda中的一个开源的、Python包和环境的管理工具,包含于Anaconda的所有版本当中。因此使用conda需要先安装Anacon…...

Vue3引用echart5 报错解决
一、TypeError: Cannot read properties of undefined (reading type) 原因:由于把echart实例绑定到了一个响应式的变量上 解决方案 【1】使用markRaw 把响应式变量定为非响应式变量 import { markRaw } from vue; export default {data() {return {chartConta…...
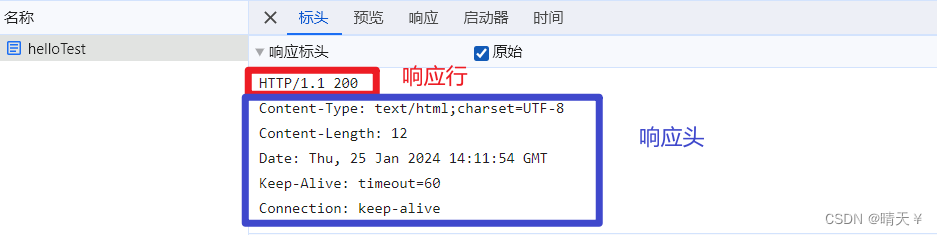
浅析HTTP协议
首先,前端请求后端数据,后端响应数据给前端,这是我们大家都知道的,那其中所涉及到的数据传输协议又是什么呢?这个传输规范就是我们大名鼎鼎的HTTP协议! 什么是HTTP协议? HTTP(超文本…...
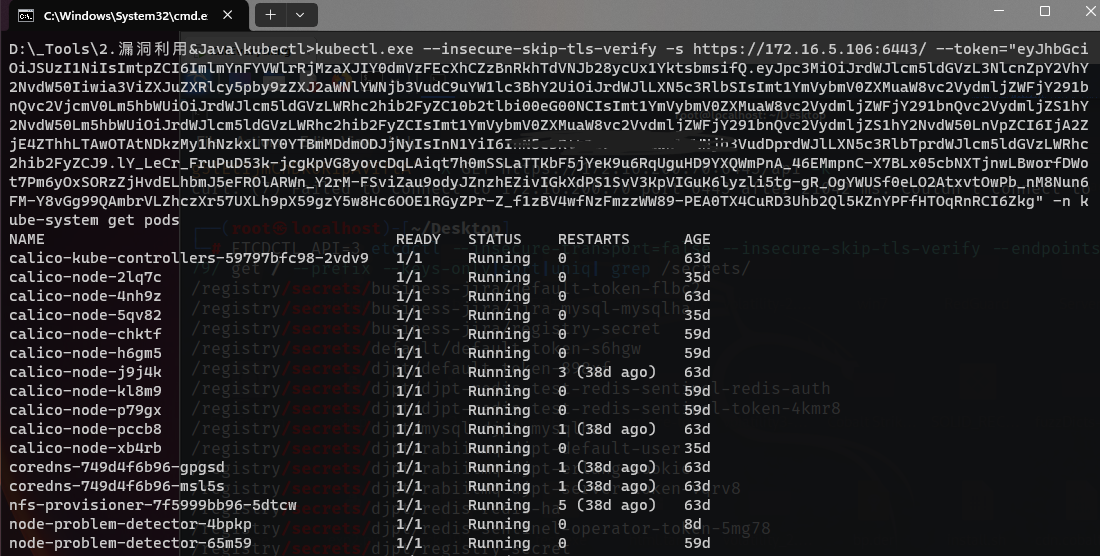
etcd未授权到控制k8s集群
在安装完 K8s 后,默认会安装 etcd 组件,etcd 是一个高可用的 key-value 数据库,它为 k8s 集群提供底层数据存储,保存了整个集群的状态。大多数情形下,数据库中的内容没有加密,因此如果黑客拿下 etcd&#x…...

制作一个简单的HTML个人网站
在当今数字化的世界里,拥有一个个人网站已经成为了展示个人品牌、分享作品和信息的必备工具。虽然有各种复杂的内容管理系统(CMS)和平台可以帮助我们快速搭建个人网站,但对于初学者或者想要了解更多技术细节的人来说,从…...

头歌C语言字符数组
目录 第1关:字符逆序 任务描述 相关知识(略) 编程要求 测试说明 第2关:字符统计 任务描述 相关知识(略) 编程要求 测试说明 第3关:字符插入 任务描述 相关知识(略) 编程要求 测试说明 第4关:字符串处理 任务描述 相关知识(略)...
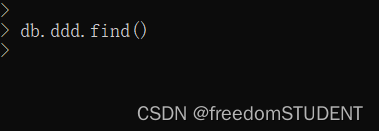
【mongoDB】文档 CRUD
目录 1.插入文档 批量插入: 2.查询文档 3.更新文档 4.删除文档 deleteOne() deleteMany() findOneAndDelete() 1.插入文档 可以使用 insert () 方法或者 save() 方法向集合中插入文档 语法如下: db.collection_name.insert(document) collectio…...

每日一题——LeetCode1337.矩阵中战斗力最弱的K行
方法一 个人方法 排序 题目要求就是找出每行有多少个1,根据每行1的个数进行排序,但是是把每行在数组中的位置索引进行排序,并返回前k项 所以先统计每行1的个数,并将数组转化为[index,count]就是索引加个数的数组形式,…...
docker指令存档
目录 Docker 1、概念 2、架构图 3、安装 4、Docker怎么工作的? 5、Docker常用命令 帮助命令 镜像命令 1、查看镜像 2、帮助命令 3、搜索镜像 4、拉取镜像 5、删除镜像 容器命令 1、启动 2、查看运行的容器 3、删除容器 4、启动&停止 其他命令…...

Pandas ------ 向 Excel 文件中写入含有 multi-index 和 Multi-column 表头的数据
Pandas ------ 向 Excel 文件中写入含有 multi-index 和 Multi-column 表头的数据 引言正文 引言 之前在 《pandas向已经拥有数据的Excel文件中添加新数据》 一文中我们介绍了如何通过 pandas 向 Excel 文件中写入数据。那么对于含有多表头的数据,我们该如何将它们…...
ChatGPT 和文心一言 | 两大AI助手哪个更胜一筹
欢迎来到英杰社区: https://bbs.csdn.net/topics/617804998 欢迎来到阿Q社区: https://bbs.csdn.net/topics/617897397 📕作者简介:热爱跑步的恒川,致力于C/C、Java、Python等多编程语言,热爱跑步ÿ…...
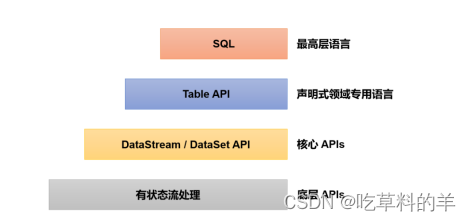
flink学习之窗口处理函数
窗口处理函数 什么是窗口处理函数 Flink 本身提供了多层 API,DataStream API 只是中间的一环,在更底层,我们可以不定义任何具体的算子(比如 map(),filter(),或者 window()),而只是…...

3步掌控笔记本性能:GHelper让ROG设备告别噪音与高温困扰
3步掌控笔记本性能:GHelper让ROG设备告别噪音与高温困扰 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, …...
)
HX711压力传感器模块的5个常见调试“坑”及解决方法(基于STM32 HAL库)
HX711压力传感器模块的5个常见调试“坑”及解决方法(基于STM32 HAL库) 当你第一次尝试在STM32上驱动HX711压力传感器时,可能会遇到各种令人困惑的问题。作为一名经历过无数次深夜调试的工程师,我想分享几个最常见的"坑"…...

competitive-ads-extractor技能:分析竞争对手广告的完整教程
competitive-ads-extractor技能:分析竞争对手广告的完整教程 【免费下载链接】awesome-codex-skills A curated list of practical Codex skills for automating workflows across the Codex CLI and API. 项目地址: https://gitcode.com/GitHub_Trending/aw/awes…...

神经网络层数与节点配置的黄金法则与实践
1. 神经网络层数与节点配置的核心逻辑神经网络的结构设计就像建造一栋大楼,层数和每层的节点数决定了整个建筑的承重能力与空间利用率。我在实际项目中发现,90%的模型性能问题都源于结构配置不当。这里有个反直觉的事实:更多层和节点并不总是…...

NitroGen通用游戏AI:从像素到动作的行为克隆模型实战解析
1. 项目概述:从像素到操作,一个通用游戏智能体的诞生 如果你玩过游戏,尤其是那些需要快速反应的动作或射击游戏,你肯定有过这样的体验:看着高手行云流水的操作,心里想着“这操作我上我也行”,结…...

NDIR CO2传感器技术与RRH47000-EVK评估板应用
1. RRH47000-EVK评估板与NDIR CO2传感器技术解析在环境监测和工业自动化领域,精确的CO2浓度测量正变得日益重要。Renesas最新推出的RRH47000-EVK评估板搭载了基于非分散红外(NDIR)技术的RRH47000 CO2传感器,为工程师提供了一套完整的开发解决方案。这套系…...

Arm A-profile架构内存管理与原子操作优化解析
1. Arm A-profile架构内存管理机制解析作为现代处理器架构的核心子系统,内存管理单元(MMU)的设计直接影响着系统的安全性、隔离性和性能表现。Arm A-profile架构通过多级页表转换和细粒度访问控制,为从嵌入式系统到云计算平台的各种应用场景提供了灵活的…...

DeepXDE完整安装指南:5种方法快速配置科学机器学习环境
DeepXDE完整安装指南:5种方法快速配置科学机器学习环境 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde DeepXDE是一款功能强大的开源科学机器学习…...

11_《智能体微服务架构企业级实战教程》开发环境搭建之Miniconda安装配置
前言 配套视频教程: 👉《智能体微服务架构企业级实战教程》共72节 更多文章专栏内容: 👉《智能体微服务架构企业级实战教程》专栏 本文提供了Miniconda3的完整安装与配置指南。首先从官网下载安装包,双击运行并按提示完成安装(接受协议、选择安装目录等)。安装后通…...

SECS/GEM如何实现越南现场自定义消息
今天给大家解答一下大家长期的疑问,大家想知道SECS/GEM如何实现自定义消息2025年越南半导体爆发,大量的国内设备厂商售卖设备过去。由于生产的半导体产品不一样,现场是出现少量的自定义消息,采用金南瓜SECS/GEM成熟的方案…...