ShardingSphere之ShardingJDBC客户端分库分表上
目录
什么是ShardingSphere?
客户端分库分表与服务端分库分表
ShardingJDBC客户端分库分表
ShardingProxy服务端分库分表
ShardingSphere实现分库分表的核心概念
ShardingJDBC实战
什么是ShardingSphere?
ShardingSphere是一款起源于当当网内部的应用框架。2015年在当当网内部诞生,最初就叫ShardingJDBC。 ShardingSphere这个词可以分为两个部分,其中Sharding就是指的数据分片。从官网介绍上就能看到,他的核心功能就是可以将任意数据库组合,转换成为一个分布式的数据库,提供整体的数据库集群服务。后面的Sphere是生态的意思。这意味着ShardingSphere不是一个单独的框架或者产品,而是一个由多个框架以及产品构成的一个完整的技术生态。目前ShardingSphere中比较成型的产品主要包含核心的ShardingJDBC以及ShardingProxy两个产品,以及一个用于数据迁移的子项目ElasticJob,另外还包含围绕云原生设计的一系列未太成型的产品。
ShardingSphere经过这么多年的发展,已经不仅仅只是用来做分库分表,而是形成了一个围绕分库分表核心的技术生态。他的核心功能已经包括了数据分片、分布式事务、读写分离、高可用、数据迁移、联邦查询、数据加密、影子库、DistSQL庞大的技术体系。
客户端分库分表与服务端分库分表
ShardingSphere最为核心的产品有两个:一个是ShardingJDBC,这是一个进行客户端分库分表的框架。另一个是ShardingProxy,这是一个进行服务端分库分表的产品。他们代表了两种不同的分库分表的实现思路。(本篇主要介绍ShardingJDBC的5.x版本)
ShardingJDBC客户端分库分表
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等。
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
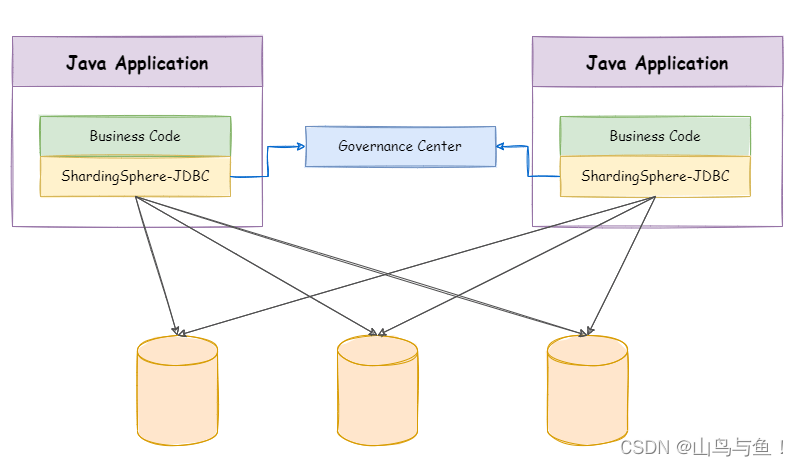
应用层只需要修改配置文件,使用跟正常单库一样。(灵活的胖子)
ShardingProxy服务端分库分表
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供MySQL和PostgreSQL协议,透明化数据库操作,对DBA更加友好。
向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
兼容MariaDB等基于MySQL协议的数据库,以及openGauss等基于PostgreSQL协议的数据库。
适用于任何兼容MySQL/PostgreSQL协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat等。

应用通过访问ShardingProxy服务端来访问数据库,统一管理。(呆板的管家)
ShardingSphere实现分库分表的核心概念
1. 虚拟库: ShardingSphere的核心就是提供一个具备分库分表功能的虚拟库,他是一个 ShardingSphereDatasource实例。应用程序只需要像操作单数据源一样访问这个 ShardingSphereDatasource即可。
2. 真实库: 实际保存数据的数据库。这些数据库都被包含在ShardingSphereDatasource实例当中,由 ShardingSphere决定未来需要使用哪个真实库。
3. 逻辑表: 应用程序直接操作的逻辑表。
4. 真实表: 实际保存数据的表。这些真实表与逻辑表表名不需要一致,但是需要有相同的表结构,可以分布在 不同的真实库中。应用可以维护一个逻辑表与真实表的对应关系,所有的真实表默认也会映射成为 ShardingSphere的虚拟表。
5. 分布式主键生成算法: 给逻辑表生成唯一主键。由于逻辑表的数据是分布在多个真实表当中的,所有,单表 的索引就无法保证逻辑表的ID唯一性。ShardingSphere集成了几种常见的基于单机生成的分布式主键生成 器。比如SNOWFLAKE,COSID_SNOWFLAKE雪花算法可以生成单调递增的long类型的数字主键,还有 UUID,NANOID可以生成字符串类型的主键。当然,ShardingSphere也支持应用自行扩展主键生成算法。比 如基于Redis,Zookeeper等第三方服务,自行生成主键。
6. 分片策略: 表示逻辑表要如何分配到真实库和真实表当中,分为分库策略和分表策略两个部分。分片策略由 分片键和分片算法组成。分片键是进行数据水平拆分的关键字段。如果没有分片键,ShardingSphere将只能 进行全路由,SQL执行的性能会非常差。分片算法则表示根据分片键如何寻找对应的真实库和真实表。简单的 分片策略可以使用Groovy表达式直接配置,当然,ShardingSphere也支持自行扩展更为复杂的分片算法。
ShardingJDBC实战
ShardingJDBC是整个ShardingSphere最早也是最为核心的一个功能模块,他的 主要功能就是数据分片和读写分离,通过ShardingJDBC,应用可以透明的使用 JDBC访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数 据如何分布。
引入依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.2.1</version><exclusions><exclusion><artifactId>snakeyaml</artifactId><groupId>org.yaml</groupId></exclusion></exclusions></dependency><!-- 坑爹的版本冲突 --><dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.33</version></dependency>配置文件
# 在控制台打印SQL
spring.shardingsphere.props.sql-show = true
spring.main.allow-bean-definition-overriding = true# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#------------------------分布式序列算法配置
# 雪花算法,生成Long类型主键id。
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker.id=1
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.column=cid
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.key-generator-name=alg_snowflake
#-----------------------实际分片节点m0,m1
spring.shardingsphere.rules.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
#MOD分库策略
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-algorithm-name=course_db_algspring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.props.sharding-count=2
#给course表指定分表策略 standard-按单一分片键进行精确或范围分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.table-strategy.standard.sharding-algorithm-name=course_tbl_alg
# 分表策略-INLINE:按单一分片键分表
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{cid%2+1}
实体类
public class Course {private Long cid;
// 如果使用id作为主键,注意MyBatis会默认对id字段生成主键。
// private Long id;private String cname;private Long userId;private String cstatus;public Long getCid() {return cid;}public void setCid(Long cid) {this.cid = cid;}public String getCname() {return cname;}public void setCname(String cname) {this.cname = cname;}public Long getUserId() {return userId;}public void setUserId(Long userId) {this.userId = userId;}public String getCstatus() {return cstatus;}public void setCstatus(String cstatus) {this.cstatus = cstatus;}@Overridepublic String toString() {return "Course{" +"cid=" + cid +", cname='" + cname + '\'' +", userId=" + userId +", cstatus='" + cstatus + '\'' +'}';}
}mapper文件
public interface CourseMapper extends BaseMapper<Course> {}数据库sql
-- 创建两个数据库coursedb、coursedb2,分别执行以下sql
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (`cid` bigint(20) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(20) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Table structure for course_1
-- ----------------------------
DROP TABLE IF EXISTS `course_1`;
CREATE TABLE `course_1` (`cid` bigint(20) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(20) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Table structure for course_2
-- ----------------------------
DROP TABLE IF EXISTS `course_2`;
CREATE TABLE `course_2` (`cid` bigint(20) NOT NULL,`cname` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,`user_id` bigint(20) NOT NULL,`cstatus` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingTest {@Resourceprivate CourseMapper courseMapper;@Testpublic void addcourse() {for (int i = 0; i < 10; i++) {Course c = new Course();c.setCname("java");c.setUserId(1001L);c.setCstatus("1");courseMapper.insert(c);System.out.println(c);}}
}按照上述配置,执行结果如下:


coursedb中的course_1表有数据,coursedb2中的course_2表有数据。
本案例使用的INLINE分表策略。
如果说我们想要实现均匀的分布到两库中四个表,需要修改分表策略规则以及修改雪花算法。
#如果需要做到均匀分片,修改算法同时,还要修改雪花算法。把SNOWFLAKE换成MYSNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=MYSNOWFLAKE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{((cid+1)%4).intdiv(2)+1}
改进的雪花算法如下(来自图灵楼兰老师):
/*** 改进雪花算法,让他能够 %4 均匀分布。*/
public final class MySnowFlakeAlgorithm implements KeyGenerateAlgorithm, InstanceContextAware {public static final long EPOCH;private static final String MAX_VIBRATION_OFFSET_KEY = "max-vibration-offset";private static final String MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS_KEY = "max-tolerate-time-difference-milliseconds";private static final long SEQUENCE_BITS = 12L;private static final long WORKER_ID_BITS = 10L;private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1;private static final long WORKER_ID_LEFT_SHIFT_BITS = SEQUENCE_BITS;private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS + WORKER_ID_BITS;private static final int DEFAULT_VIBRATION_VALUE = 1;private static final int MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS = 10;private static final long DEFAULT_WORKER_ID = 0;private static TimeService timeService = new TimeService();public static void setTimeService(TimeService timeService) {MySnowFlakeAlgorithm.timeService = timeService;}private Properties props;@Overridepublic Properties getProps() {return props;}private int maxVibrationOffset;private int maxTolerateTimeDifferenceMilliseconds;private volatile int sequenceOffset = -1;private volatile long sequence;private volatile long lastMilliseconds;private volatile InstanceContext instanceContext;static {Calendar calendar = Calendar.getInstance();calendar.set(2016, Calendar.NOVEMBER, 1);calendar.set(Calendar.HOUR_OF_DAY, 0);calendar.set(Calendar.MINUTE, 0);calendar.set(Calendar.SECOND, 0);calendar.set(Calendar.MILLISECOND, 0);EPOCH = calendar.getTimeInMillis();}@Overridepublic void init(final Properties props) {this.props = props;maxVibrationOffset = getMaxVibrationOffset(props);maxTolerateTimeDifferenceMilliseconds = getMaxTolerateTimeDifferenceMilliseconds(props);}@Overridepublic void setInstanceContext(final InstanceContext instanceContext) {this.instanceContext = instanceContext;if (null != instanceContext) {instanceContext.generateWorkerId(props);}}private int getMaxVibrationOffset(final Properties props) {int result = Integer.parseInt(props.getOrDefault(MAX_VIBRATION_OFFSET_KEY, DEFAULT_VIBRATION_VALUE).toString());Preconditions.checkArgument(result >= 0 && result <= SEQUENCE_MASK, "Illegal max vibration offset.");return result;}private int getMaxTolerateTimeDifferenceMilliseconds(final Properties props) {return Integer.parseInt(props.getOrDefault(MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS_KEY, MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS).toString());}@Overridepublic synchronized Long generateKey() {long currentMilliseconds = timeService.getCurrentMillis();if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {currentMilliseconds = timeService.getCurrentMillis();}if (lastMilliseconds == currentMilliseconds) {
// if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) {currentMilliseconds = waitUntilNextTime(currentMilliseconds);
// }} else {vibrateSequenceOffset();
// sequence = sequenceOffset;sequence = sequence >= SEQUENCE_MASK ? 0:sequence+1;}lastMilliseconds = currentMilliseconds;return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence;}private boolean waitTolerateTimeDifferenceIfNeed(final long currentMilliseconds) {if (lastMilliseconds <= currentMilliseconds) {return false;}long timeDifferenceMilliseconds = lastMilliseconds - currentMilliseconds;Preconditions.checkState(timeDifferenceMilliseconds < maxTolerateTimeDifferenceMilliseconds,"Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastMilliseconds, currentMilliseconds);try {Thread.sleep(timeDifferenceMilliseconds);} catch (InterruptedException e) {}return true;}private long waitUntilNextTime(final long lastTime) {long result = timeService.getCurrentMillis();while (result <= lastTime) {result = timeService.getCurrentMillis();}return result;}@SuppressWarnings("NonAtomicOperationOnVolatileField")private void vibrateSequenceOffset() {sequenceOffset = sequenceOffset >= maxVibrationOffset ? 0 : sequenceOffset + 1;}private long getWorkerId() {return null == instanceContext ? DEFAULT_WORKER_ID : instanceContext.getWorkerId();}@Overridepublic String getType() {return "MYSNOWFLAKE";}@Overridepublic boolean isDefault() {return true;}
}通过使用此种算法,我们先清空之前的数据,然后重新执行测试方法如下:
coursedb库中两表的数据


coursedb2库中两表的数据


可以看到,数据均匀的分布到了四个表中。
数据已经插入到库中,以下测试查询
@Testpublic void queryCourse() {QueryWrapper<Course> wrapper = new QueryWrapper<Course>();wrapper.eq("cid",957728805420531713L);
// wrapper.in("cid",957728805420531713L,957728806460719106L,3L);//带上排序条件不影响分片逻辑
// wrapper.orderByDesc("user_id");List<Course> courses = courseMapper.selectList(wrapper);courses.forEach(course -> System.out.println(course));}执行SQL过程及结果


如果是in操作,执行结果如下


像= 和 in 这样的操作,可以拿到cid的精确值,所以都可以直接通过表达式计算出可能的真实库以及真实表, ShardingSphere就会将逻辑SQL转去查询对应的真实库和真实表。这些查询的策略,只要配置了sql-show参数, 都会打印在日志当中。
如果不使用分片键cid进行查询
@Testpublic void queryCourse() {QueryWrapper<Course> wrapper = new QueryWrapper<Course>();List<Course> courses = courseMapper.selectList(wrapper);courses.forEach(course -> System.out.println(course));}
可以看到使用union执行了两次SQL进行全表查询。
以上案例使用的INLINE策略,后续演示其他策略。
相关文章:
ShardingSphere之ShardingJDBC客户端分库分表上
目录 什么是ShardingSphere? 客户端分库分表与服务端分库分表 ShardingJDBC客户端分库分表 ShardingProxy服务端分库分表 ShardingSphere实现分库分表的核心概念 ShardingJDBC实战 什么是ShardingSphere? ShardingSphere是一款起源于当当网内部的应…...

rust for循环步长-1,反向逆序遍历
fn main() {for i in (0..3).rev().step_by(1) {print!("{}", i);} } // 打印结果:210Trait std::iter::Iterator fn rev(self) -> Rev< Self > where Self: Sized DoubleEndedIteratorfn step_by(self, step: usize) -> StepBy< Self &…...
)
编译与运行环境(C语言)
文章目录 前言编译环境编译链接 运行环境 前言 C语言代码的实现,存在两种不同的环境。 第一种是翻译环境,在这个环境中,源代码被转换为可执行的二进制指令。 翻译环境即我们日常使用编译器,将一个 " mission.c " 的文件…...
再谈Android View绘制流程
一,先思考何时开始绘制 笔者在这里提醒读者,Android的View是UI的高级抽象,我们平时使用的XML文件也好,本质是设计模式中的一种策略模式,其View可以理解为一种底层UI显示的Request。各种VIew的排布,来自于开…...
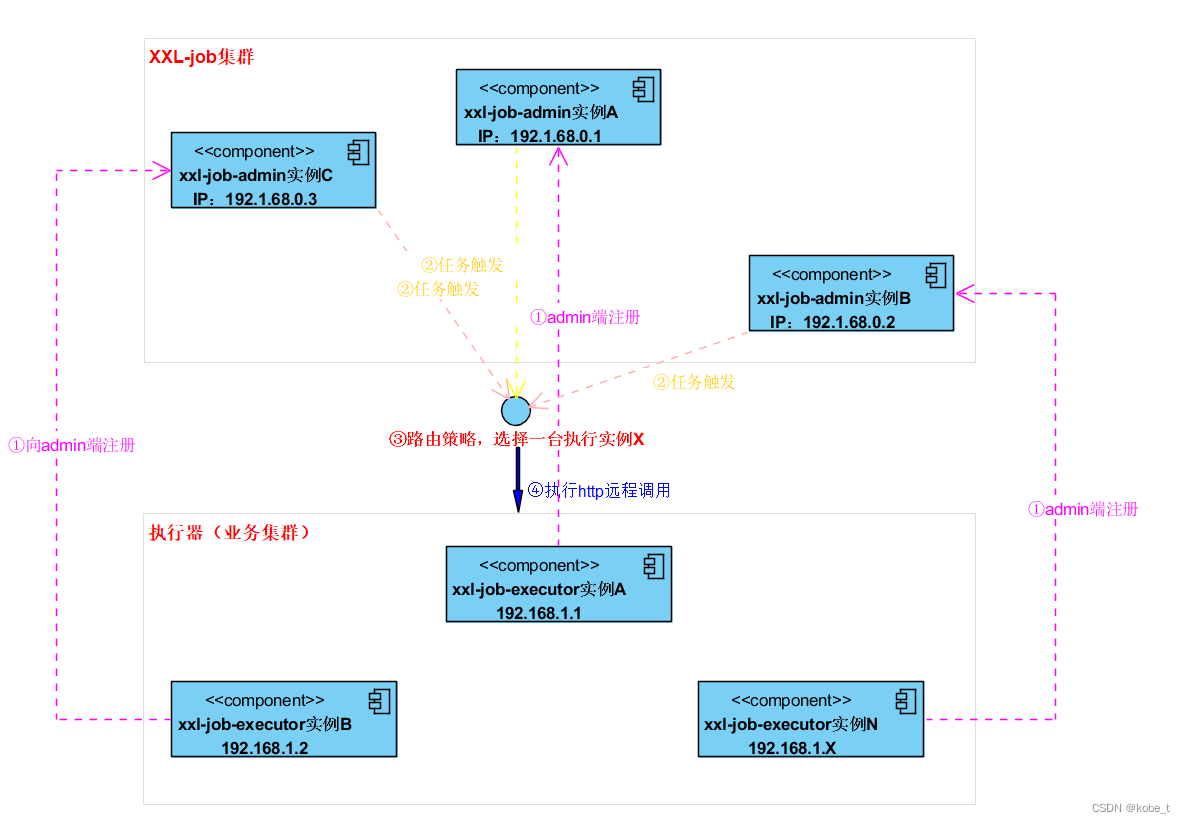
分布式定时任务系列8:XXL-job源码分析之远程调用
传送门 分布式定时任务系列1:XXL-job安装 分布式定时任务系列2:XXL-job使用 分布式定时任务系列3:任务执行引擎设计 分布式定时任务系列4:任务执行引擎设计续 分布式定时任务系列5:XXL-job中blockingQueue的应用 …...
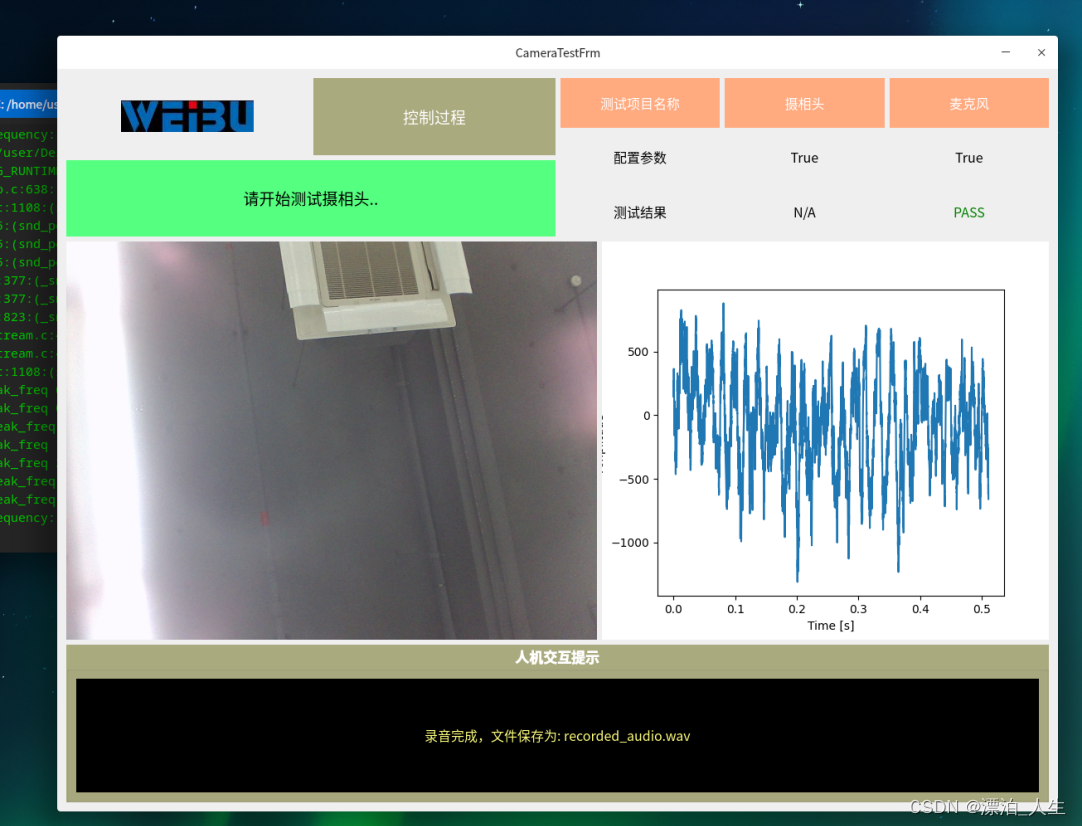
python+Qt5 UOS 摄相头+麦克风测试,摄相头自动解析照片二维条码,麦克风解析音频文件
UI图片: 源代码: # -*- coding: utf-8 -*-# Form implementation generated from reading ui file CameraTestFrm.ui # # Created by: PyQt5 UI code generator 5.15.2 # # WARNING: Any manual changes made to this file will be lost when pyuic5 is…...
MongoDB日期存储与查询、@Query、嵌套字段查询实战总结
缘由 MongoDB数据库如下: 如上截图,使用MongoDB客户端工具DataGrip,在filter过滤框输入{ profiles.alias: 逆天子, profiles.channel: },即可实现昵称和渠道多个嵌套字段过滤查询。 现有业务需求:用Java代码来查询…...
)
Windows版本Node.js常见问题及操作解决方式(小白入门必备)
npm i时ERROR:reason: certificate has expired问题 https://blog.csdn.net/m0_73360677/article/details/135774500 # 1.取消ssl验证;npm config set strict-ssl false#这个方法一般可以直接解决问题,如不能请尝试第二种方法# 2.更换npm镜像源&#x…...

09.Elasticsearch应用(九)
Elasticsearch应用(九) 1.搜索结果处理包括什么 排序分页高亮返回指定字段 2.排序 介绍 Elasticsearch支持对搜索结果排序,默认是根据相关度算分来排序 支持排序的字段 keyword数值地理坐标日期类型 排序语法 GET /[索引名称]/_sear…...

ROS2常用命令工具
ROS2常用命令工具 包管理工具ros2 pkg ros2 pkg create ros2 pkg create --build-type ament_python pkg_name rclpy std_msgs sensor_msgs –build-type : C或者C ament_cmake ,Python ament_python pkg_name :创建功能包的名字 rclpy std_msgs sens…...
Linux之快速入门
一、Linux目录结构 从Windows转到Linux最不习惯的是什么: 目录结构 Windows会分盘,想怎么放东西就怎么放东西,好处自由,缺点容易乱 Linux有自己的目录结构,不能随随便便放东西 /:根目录/bin:二进制文件&…...

C语言——操作符详解1
目录 1. 操作符的分类2. 二进制和进制转换2.1 二进制的概念2.2 二进制转十进制2.3 十进制转二进制2.4 二进制转八进制和十六进制2.4.1 二进制转八进制二进制转十六进制 3. 原码、反码和补码4. 移位操作符4.1 左移操作符4.2 右移操作符 5. 位操作符5.1 &5.2 |5.3 ^5.4 ~ 1. …...

C++学习| QT快速入门
QT简单入门 QT Creater创建QT项目选择项目类型——不同项目类型的区别输入项目名字和路径选择合适的构建系统——不同构建系统的却别选择合适的类——QT基本类之间的关系Translation File选择构建套件——MinGW和MSVC的区别 简单案例:加法器设计界面——构建加法器界…...

Android App开发-简单控件(1)——文本显示
本章介绍了App开发常见的几类简单控件的用法,主要包括:显示文字的文本视图、容纳视图的常用布局、响应点击的按钮控件、显示图片的图像视图等。然后结合本章所涉及的知识,完成一个实战项目“简单计算器”的设计与实现。 1.1 文本显示 本节介绍…...
[GYCTF2020]Ezsqli1
打开环境,下面有个提交表单 提交1,2有正确的查询结果,3以后都显示Error Occured When Fetch Result. 题目是sql,应该考察的是sql注入 简单fuzz一下 发现information_schema被过滤了,猜测是盲注了。 测试发现只要有东…...

【npm包】如何发布自己的npm包
随着Node.js的普及,npm(Node Package Manager)已成为JavaScript开发者中不可或缺的一部分。发布自己的npm包,不仅可以将自己的项目分享给更多人,还可以为社区做出贡献。本文将详细介绍如何从零开始发布自己的npm包。 …...
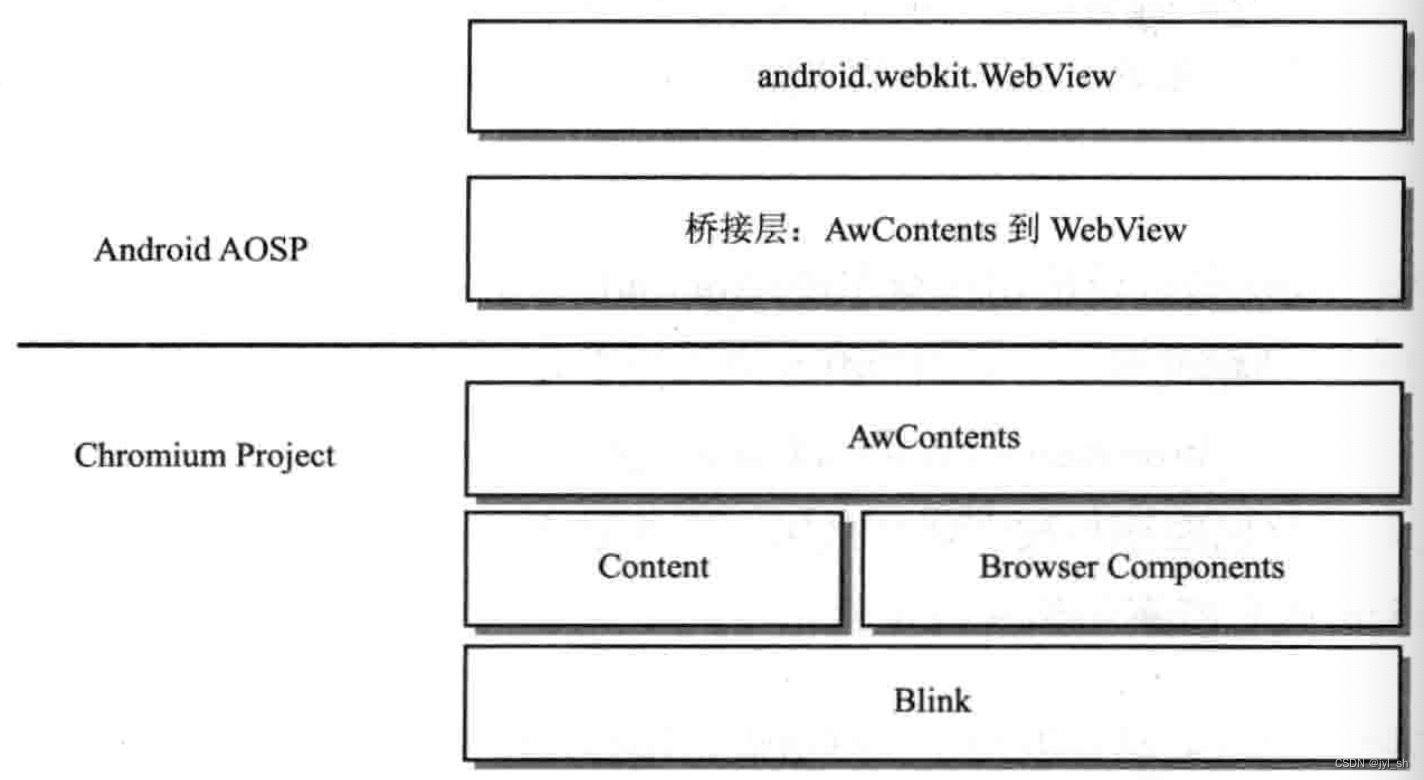
《WebKit技术内幕》学习之十五(2):Web前端的未来
2 嵌入式应用模式 2.1 嵌入式模式 读者可能会奇怪本章重点表达的是Web应用和Web运行平台,为什么会介绍嵌入式模式(Embedded Mode)呢?这是因为很多Web运行平台是基于嵌入式模式的接口开发出来的,所以这里先解释一下什…...

【教学类-综合练习-11】20240116 大4班 最后一次
只有图片 加了两条链接 背景需求 年终了,清理库存,各种打印的题型纸都拿出来,当个别化学习材料 教学过程: 时间:2024年1月5日下午 班级:大4班(额外带班 真正的最后一次大班) 人…...
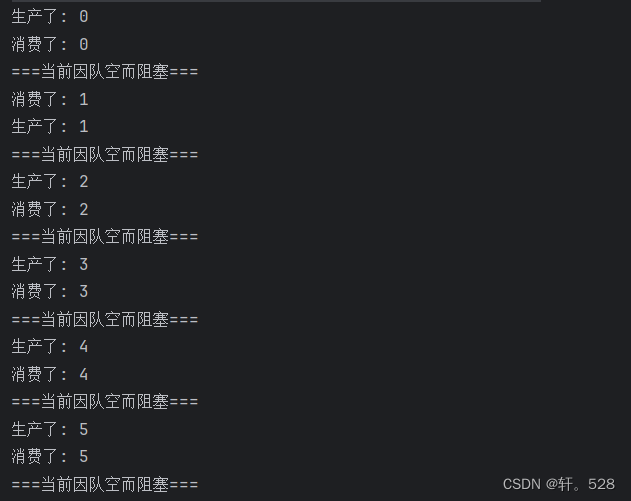
【阻塞队列】阻塞队列的模拟实现及在生产者和消费者模型上的应用
文章目录 📄前言一. 阻塞队列初了解🍆1. 什么是阻塞队列?🍅2. 为什么使用阻塞队列?🥦3. Java标准库中阻塞队列的实现 二. 阻塞队列的模拟实现🍚1. 实现普通队列🍥2. 实现队列的阻塞功…...

Cocos Creator使用VS Code调试代码配置
创建项目 首先我们先打开cocos创建一个项目 随便添加一个Cube和脚本,然后保存场景: 添加Chrome Debug配置 在Cocos 中选择添加Chrome Debug配置 然后再VS Code中就可以看到有一个cocos launch Chrome: 然后,就可以按快捷键F…...

[Vulhub] PHP环境下XXE漏洞实战:从原理到防御
1. XXE漏洞:藏在XML里的隐形杀手 第一次听说XXE漏洞时,我正调试一个PHP项目。那天服务器突然开始疯狂读取系统文件,吓得我差点从椅子上摔下来。后来才发现,原来是一个看似无害的XML接口被恶意利用了。XXE(XML External…...
)
基于深度学习预测+MPC的车辆轨迹跟踪自动驾驶汽车预测控制Matlab仿真(带参考文献)
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。 🍎 往期回顾关注个人主页:Matlab科研工作室 👇 关注我领取海量matlab电子…...

tao-8k如何支持8192长文本?深度解析其向量表征能力与实践价值
tao-8k如何支持8192长文本?深度解析其向量表征能力与实践价值 在AI应用开发中,我们常常遇到一个头疼的问题:模型处理不了太长的文本。比如,你想让AI理解一篇完整的报告、一份详细的产品文档,或者一次冗长的对话记录&a…...
)
别再折腾源码编译了!宝塔面板一键安装Nginx-RTMP模块的保姆级教程(附OBS推流配置)
宝塔面板零代码实现Nginx-RTMP直播服务器:图形化配置全指南 直播技术正在重塑内容传播方式,但对于大多数中小站长和内容创作者而言,搭建直播服务器仍然是一项技术门槛极高的任务。传统方式需要手动编译Nginx源码、修改配置文件、处理各种依赖…...

Youtu-2B快速上手教程:WebUI交互界面部署详解
Youtu-2B快速上手教程:WebUI交互界面部署详解 想体验一个既轻快又聪明的AI对话助手吗?今天要介绍的Youtu-2B,就是一个能在普通电脑上流畅运行,还能帮你写代码、解数学题、创作文案的全能小帮手。它基于腾讯优图实验室开源的轻量化…...

拒绝从入门到放弃:自学C语言前的“必修课”——一些重要基础概念的解析
C语言基础教程:变量和数据类型 大家好!我本身作为C语言的初学者,深知学习过程中对一些问题和概念的理解只停留在知其然而不知其所以然的状态,因而在系统性的查找文献和询问业内从业者后写出了这篇推文。这是我将新学的知识内化的…...
)
基于蚂蚁-遗传优化算法的路径规划问题(Matlab代码实现)
💥💥💥💞💞💞欢迎来到本博客❤️❤️❤️💥💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑…...

3D Face HRN人脸重建模型与Python实战:从单张图片生成3D人脸
3D Face HRN人脸重建模型与Python实战:从单张图片生成3D人脸 1. 引言 你有没有想过,用一张普通的自拍照片就能生成一个精细的3D人脸模型?这听起来像是科幻电影里的场景,但现在通过3D Face HRN模型,这个想法已经变成了…...

[特殊字符] Meixiong Niannian画图引擎快速部署:NVIDIA Container Toolkit配置避坑指南
Meixiong Niannian画图引擎快速部署:NVIDIA Container Toolkit配置避坑指南 1. 项目简介 Meixiong Niannian画图引擎是一款专为个人GPU设计的轻量化文本生成图像系统。它基于Z-Image-Turbo底座,深度融合了Niannian专属Turbo LoRA微调权重,针…...
)
iTerm2 + SSH密钥对:比Trigger更安全的免密登录方案(附密钥管理技巧)
iTerm2 SSH密钥对:比Trigger更安全的免密登录方案(附密钥管理技巧) 在远程服务器管理中,免密登录是提升效率的刚需,但安全性常被忽视。许多开发者习惯使用iTerm2的Trigger功能自动输入密码,这种看似便捷的…...