实例分割论文阅读之:《Mask Transfiner for High-Quality Instance Segmentation》
1.摘要
两阶段和基于查询的实例分割方法取得了显著的效果。然而,它们的分段掩模仍然非常粗糙。在本文中,我们提出了一种高质量和高效的实例分割Mask Transfiner。我们的Mask Transfiner不是在规则的密集张量上操作,而是将图像区域分解并表示为四叉树。我们基于变压器的方法只处理检测到的容易出错的树节点,并并行地自我纠正它们的错误。虽然这些稀疏像素只占总数的一小部分,但它们对最终的掩模质量至关重要。这使得Mask Transfiner能够以较低的计算成本预测高度准确的实例掩码。大量的实验表明,Mask Transfiner在三个流行的基准测试上优于当前的实例分割方法,显著提高了两阶段和基于查询的框架在COCO和BDD100K上的+3.0掩码AP,以及在cityscape上的+6.6边界AP。
2.介绍
图像实例分割的进步在很大程度上是由强大的目标监测范式的发展所推动的。基于Mask RCNN和最近的DETR的方法在例如COCO挑战上取得了越来越高的性能。虽然这些方法在物体的监测和定位方面表现出色,但有效预测高精度分割掩码的问题迄今仍是难以琢磨的。
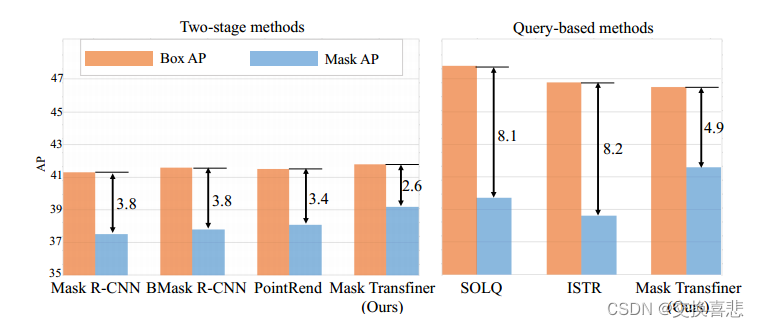
如图3所示,最近最先进的方法,特别是基于查询的方法,在边界盒和分割性能之间仍然存在较大差距,这强烈表明,掩膜质量的改进并没有跟上检测能力的进步,在图2中,先前方法的预测掩码非常粗糙,大多数情况下是过于平滑的的对象边界,实际上,高效而精确的掩膜预测是极具挑战性的,因为需要高分辨率的深度特征,而这需要大量的计算和内存成本。
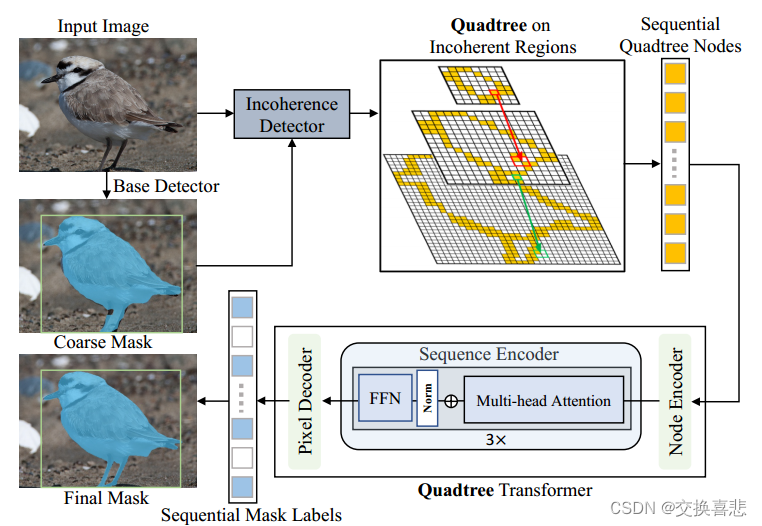
为了解决这些问题,我们提出了Mask Transfiner,这是一种高效的基于transformer的高质量实例分割方法,在图1中,我们的方法首先识别容易出错的区域,这些区域大多分布在对象边界或者高频区域,为此,我们的网络学习检测非相干区域,由下采样掩码自身时的信息损失来定义,这些非相干区域分布稀疏,仅占总像素的一小部分,然而,由于它们对最终的分割性能至关重要,它允许我们在细化过程中只处理高分辨率特征图的一小部分。因此,我们构建了一个分层四叉树来表示和处理多尺度的非相干图像像素。
为了改进非相干四叉树节点的掩码标签,我们设计了一个基于transform的改进网络,而不是标准卷积网络,因为它们需要在均匀网格上运行。我们的变压器有三个模块:节点编码器,序列编码器和像素解码器。节点编码器首先丰富了每个不相干点的特征嵌入。序列编码器然后将这些编码的特征向量跨多个四叉树级别作为输入查询。最后,像素解码器预测其对应的掩码标签。与MLP相比,序列表示和多头关注使得Mask Transfiner能够灵活地将稀疏特征点作为跨层并行的输入,对它们的逐像素关系进行建模,然后在长距离范围内传播信息。
我们在COCO, cityscape和BDD100K基准测试中广泛分析了我们的方法,其中定量和定性结果表明,Mask Transfiner不仅优于现有的两阶段和基于查询的方法,而且与标准变压器使用相比,在计算和内存成本方面效率更高。我们使用ResNet-50在41.6 APMask的COCO测试开发上建立了一个新的最先进的结果,显著优于最近的SOLQ和queryst。
3.相关工作
实例分割:两阶段实例分割方法首先检测边界框,然后在每个RoI区域中执行分割。 Mask R-CNN 使用 FCN 分支扩展了 Faster R-CNN 。后续工作 也为 Mask R-CNN 模型家族做出了贡献。一阶段方法 和基于内核的方法 ,例如 PolarMask 、YOLOACT 和 SOLO 删除了提案生成和特征重新池化步骤,以更高的效率获得可比较的结果。
基于查询的实例分割方法 受到 DETR 的启发,最近通过将分割视为集合预测问题而出现。这些方法使用查询来表示感兴趣的对象,并对它们联合执行分类、检测和掩模回归。在[15, 23]中,使用DCT或PCA算法将对象掩码压缩为编码向量,而QueryInst采用具有掩码信息流的动态掩码头。然而,图 3 中检测和分割性能之间的巨大差距表明,这些基于查询的方法产生的掩模质量仍然不能令人满意。与上述方法相比,Mask Transfiner 的目标是高质量的实例分割。在我们高效的转换器中,输入查询是不连贯的像素节点,而不是表示对象。我们的方法适用于两阶段框架和基于查询的框架,并且在其中都有效。
实例分割的细化:大多数现有的实例分割细化工作都依赖于专门设计的卷积网络 或 MLP 。 PointRend [28] 对低置信度分数的特征点进行采样,并使用共享 MLP 细化其标签,其中所选点由 Mask R-CNN 的粗略预测确定。 RefineMask [47] 结合了细粒度的特征和额外的语义头作为指导。后处理方法 BPR [36] 裁剪图像的边界块和初始掩模作为输入,并使用 [38] 进行分割。值得注意的是,一些方法 [11,14,46] 专注于细化语义分割细节。然而,由于更复杂的分割设置、每个图像的对象数量不同以及描绘重叠对象的要求,使得实例分割具有挑战性[27]。
与这些细化方法相比,Mask Transfiner 是一种端到端的实例分割方法,使用转换器来纠正错误。使用轻量级 FCN 来预测要细化的区域,而不是基于掩模分数的非确定性采样 [28]。与[28]中的MLP不同,顺序和分层输入表示使Mask Transfiner能够有效地将非局部稀疏特征点作为输入查询,其中变压器的强大全局处理非常适合我们的四叉树结构。
4.Mask Transfiner

我们提出了一种有效解决高质量实例分割的方法。 Mask Transfiner 的整体架构如图 5 所示。 Mask R-CNN [21],我们采用多尺度深度特征金字塔。然后,对象检测头将边界框预测为实例建议。该组件还以低分辨率生成粗略的初始掩模预测。给定这些输入数据,我们的目标是预测高度准确的实例分割掩模。
由于大部分分割错误归因于空间分辨率的损失,我们首先在 3.1 节中定义这种不相干的区域并分析它们的属性。为了识别和细化多个尺度的不相干区域,我们采用了四叉树,这将在 3.2 节中讨论。轻量级不相干区域检测器将粗略初始掩模与多尺度特征一起作为输入,并以级联方式预测每个尺度的不相干区域。这使得我们的 Mask Transfiner 能够节省巨大的计算和内存负担,因为只有一小部分高分辨率图像特征由细化网络本身处理。我们的细化transformer(第 3.3 节详述)在检测到的不相干区域中运行。由于它对构建的四叉树上的特征点进行操作,而不是在统一的网格中,因此我们设计了一个transformer架构,它联合处理四叉树各级中的所有不相干节点。最后,我们介绍了 Mask Transfiner 的训练策略以及实现细节。
3.1 不相干区域
现有实例分割方法 [15, 21] 产生的大部分分割错误是由于空间分辨率的损失造成的,例如掩模下采样操作、小 RoI 池大小和系数压缩 [15, 23],其中掩模预测本身是在粗略的特征尺度上执行的。尽管其效率很高,但由于高频细节的丢失,低空间分辨率使得预测准确的对象边界变得困难。在本节中,我们首先定义不相干区域,其中由于空间分辨率降低而丢失掩模信息。然后,通过分析它们的属性,我们观察到很大一部分错误确实位于这些区域。
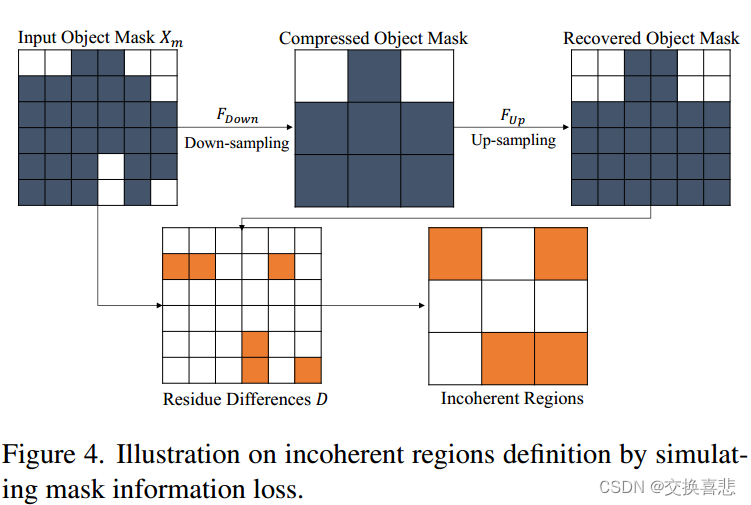
不相干区域的定义
为了识别不相干的区域,我们通过对掩模本身进行下采样来模拟由于网络中下采样而导致的信息丢失。具体来说,在无法通过后续上采样步骤正确重建掩模的区域中,信息会丢失,如图 4 所示。正式地,令 Ml 为尺度级别 l 的对象的二进制真实实例掩模。每个尺度级别的分辨率相差 2 倍,其中 l = 0 是最精细的尺度,l = L 是最粗糙的尺度。我们分别用 S↓ 和 S↑ 表示 2× 最近邻下采样和上采样。尺度 l 处的不相干区域是二元掩模,如下所示:
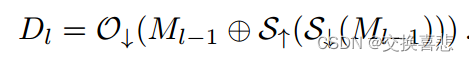
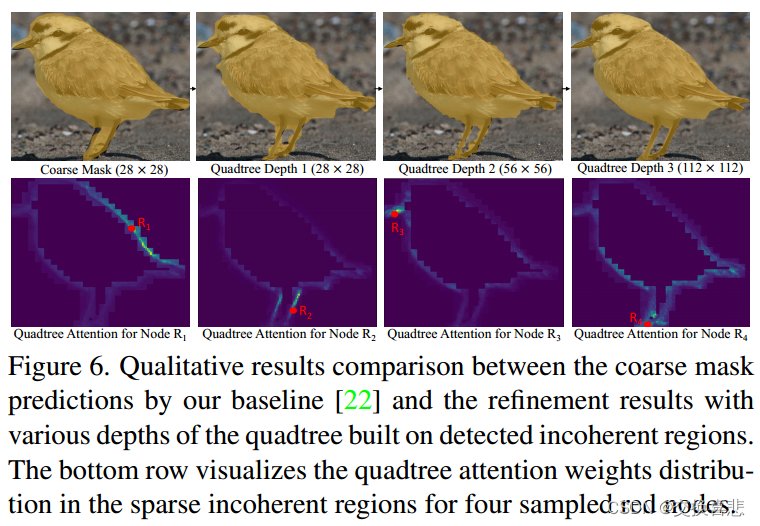
这里,⊕表示逻辑“异或”运算,O↓是通过在每个2×2邻域中执行逻辑“或”运算来进行2×下采样。因此,如果原始掩模值Ml-1在更精细尺度级别中的至少一个像素中与其重建不同,则像素(x,y)是不相干的Dl(x,y)=1。直观上,不连贯的区域大多沿着对象实例边界或高频区域散布,由粗掩模丢失或额外预测错误标签的点组成。我们在图 6 和补充中提供了它们的可视化。文件,它们稀疏且不连续地分布在典型图像上。
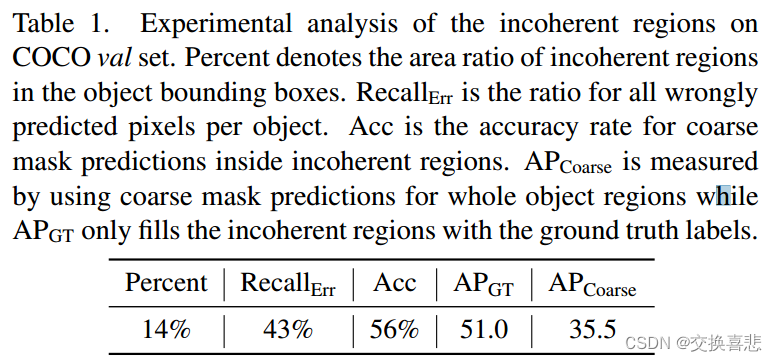
不相干区域的属性:在表 1 中,我们提供了对上面定义的不相干区域的分析。
结果表明,大部分预测误差集中在这些不相干区域,占所有错误预测像素的 43%,而对应的边界框区域仅占 14%。不相干区域的粗掩模预测准确率为 56%。通过修复边界框检测器,我们进行了预言机研究,用真实标签填充每个对象的所有这些不连贯区域,同时将其余部分保留为初始掩模预测。与在不相干区域使用初始掩模预测相比,性能从 35.5 AP 飙升至 51.0 AP,这确实证明它们对于提高最终性能至关重要。
3.2用于掩膜细化的四叉树
在本节中,我们将描述检测和细化图像中不相干区域的方法。我们的方法基于迭代检测和划分每个特征尺度中的不相干区域的思想。通过仅分割已识别的不相干像素以进一步细化,我们的方法仅关注重要区域,从而有效地处理高分辨率特征。为了形式化我们的方法,我们采用四叉树结构首先识别跨尺度的不连贯区域。然后,我们使用 3.3 节中详细介绍的网络来预测四叉树中所有不相干节点的细化分割标签。最后,我们的四叉树用于通过将校正后的掩模概率从粗尺度传播到更细尺度来融合来自多个尺度的新预测。
不相干区域的检测:图 5 的右侧部分描述了我们的轻量级模块的设计,用于有效检测多尺度特征金字塔上的不相干区域。按照级联设计,我们首先连接最小特征和粗略对象掩模预测作为输入,并使用简单的全卷积网络(四个 3×3 卷积),然后使用二元分类器来预测最粗略的不相干掩模。然后,对检测到的较低分辨率掩模进行上采样并与相邻级别中的较高分辨率特征融合,以指导更精细的不相干预测,其中仅采用单个 1×1 卷积层。在训练过程中,我们强制执行等式生成的较低级别的真实不相干点。 1 在更高级别特征图中其父点的覆盖范围内。
四叉树的定义和构造:我们定义一个点四叉树来分解检测到的不相干区域。
我们的结构如图 5 所示,其中较高级别 FPN 特征(例如特征分辨率 28×28)中的一个黄点在其相邻的较低级别 FPN 特征图中(例如分辨率 56×56)有四个象限点。这些都是特征点,但具有不同的粒度,因为它们位于不同的金字塔级别。与计算机图形学中使用的传统四叉树“单元”相反,四叉树“单元”可以有多个点,我们的点四叉树的细分单元始终在单个点上,点的划分由检测到的不相干值决定以及二元分类器的阈值。基于检测到的不相干点,我们构造一个多级分层四叉树,从使用最高级别特征图中检测到的点作为根节点开始。选择这些根节点来细分到较低级别特征图上的四个象限,具有更大的分辨率和更多的局部细节。请注意,在精细级别,只有被检测为不相干的象限点才能进一步分解,并且不相干树节点的扩展被限制在与先前粗略级别的不相干预测相对应的区域中。
四叉树细化:我们使用基于变压器的架构来细化四叉树的不相干节点的掩模预测。我们的设计在第 2 节中进行了描述。 3.3.它直接对四叉树的节点进行操作,共同提供每个不相干节点的精确掩模概率。
四叉树传播:考虑到精确的掩模预测,我们设计了一种利用四叉树结构的分层掩模传播方案。给定低分辨率下的初始粗略掩模预测,Mask Transfiner 首先校正属于四叉树根级别的点标签,然后通过最近邻插值将这些校正后的点标签传播到相邻更精细级别中相应的四个象限。标签校正过程以水平方式在不相干节点上有效地进行,直到达到最好的四叉树级别。与仅校正四叉树上最精细叶节点的标签相比,它通过将细化标记传播到中间树级别的叶节点,以可忽略的成本扩大了细化区域。
3.3 掩膜Transfiner的结构
在本节中,我们描述细化网络的架构,该网络将构建的四叉树(第 3.2 节)上的不相干点作为输入,以进行最终的分割细化。这些点沿着各个级别的高频区域稀疏分布,并且在空间上不连续。因此,在均匀网格上运行的标准卷积网络并不合适。相反,我们设计了一个细化转换器 Mask Transfiner,它可以并行纠正所有不相干四叉树节点的预测。准确分割歧义点既需要细粒度的深层特征,又需要粗粒度的语义信息。因此,网络需要强大的建模能力来充分关联点及其周围环境,包括空间和跨层相邻点。
因此,变压器可以接受顺序输入并通过多头注意力层执行强大的局部和非局部推理,是我们 Mask Transfiner 设计的自然选择。与[28]中的 MLP 相比,变压器强大的全局处理能力非常适合我们的四叉树结构。有利于不同粒度的多级特征点信息的有效融合以及两两点关系的显式建模。
图 5 显示了我们的 Mask Transfiner 的整体架构。基于分层 FPN [32],实例分割以多级、从粗到细的方式进行处理。 Mask Transfiner 没有对每个对象使用单级 FPN 特征 [21],而是将跨 RoI 特征金字塔级别的不连贯图像区域中稀疏检测到的特征点作为输入序列,并输出相应的分割标签。
ROI特征金字塔:给定输入图像,配备 FPN 的 CNN 主干网络首先提取分层特征图进行下游处理,其中我们利用 P2 到 P5 的特征级别。基础对象检测器 [15, 21] 将边界框预测为实例建议。然后通过在 FPN 的三个不同级别 {Pi , Pi−1, Pi−2} 上提取 RoI 特征来构建 RoI 特征金字塔,并增加正方形尺寸 {28, 56, 112}。起始级别 i 的计算公式为 i = 烂 i0 + log2 ( √ W H/224)兰 ,其中 i0 = 4,W 和 H 是 RoI 的宽度和高度。最粗的级别特征包含更多的上下文和语义信息,而更精细的级别则解决更多的局部细节。
输入节点序列:给定第 3.2 节中讨论的四叉树以及每个节点的相关 FPN 特征,我们为基于 Transformer 的架构构建输入序列。该序列由四叉树所有三个级别的所有不相干节点组成。因此,所得序列的大小为 C × N,其中 N 是节点总数,C 是特征通道维度。值得注意的是,由于高度稀疏,N<HW。此外,由于Transformer的排列不变性,序列的顺序并不重要。与标准Transformer编码器相比,Transfiner的编码器有两部分:节点编码器和序列编码器。
节点编码器:为了丰富不相干点特征,Mask Transfiner 的节点编码器使用以下四种不同的信息线索对每个四叉树节点进行编码: 1)从 FPN 金字塔的相应位置和级别提取的细粒度特征。 2) 来自基础检测器的初始粗略掩模预测提供了区域特定和语义信息。 3)每个RoI中的相对位置编码封装了节点之间的空间距离和关系,捕获重要的局部依赖性和相关性。 4)每个节点的周围上下文捕获局部细节以丰富信息。对于每个节点,我们使用从 3×3 邻域提取的特征,并通过全连接层进行压缩。
直观上,这有助于定位边缘和边界,以及捕获对象的局部形状。如图 5 所示,细粒度特征、粗分割线索和上下文特征首先通过 FC 层连接并融合到原始特征维度。然后将位置嵌入添加到生成的特征向量中。
序列编码器和像素解码器:然后,Transfiner的序列变换编码器联合处理四叉树中各级的编码节点。因此,变压器执行全局空间推理和跨尺度推理。每个序列编码器层都有一个标准的变压器结构,由多头自注意力模块和全连接前馈网络(FFN)组成。为了给不相干的点序列配备足够的正参考和负参考,我们还使用小尺寸 14×14 的最粗 FPN 级别的所有特征点。与具有深度关注层的标准 Transformer 解码器 [4] 不同,Mask Transfiner 中的像素解码器是一个小型双层 MLP,它对树中每个节点的输出查询进行解码,以预测最终的 mask 标签。
训练和推理:基于构建的四叉树,我们为 Mask Transfiner 开发了灵活且自适应的训练和推理方案,其中跨四叉树级别检测到的所有不相干节点都形成一个序列以进行并行预测。在推理过程中,为了获得最终的对象掩模,Mask Transfiner 在获得不相干节点的细化标签后遵循四叉树传播方案(第 3.2 节)。在训练过程中,整个Mask Transfiner框架可以以端到端的方式进行训练。我们采用多任务损失:
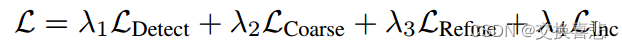
这里,LRefine 表示不相干节点的预测标签与其真实标签之间的 L1 损失的细化。二元交叉熵损失 LInc 用于检测不相干区域。检测损失 LDetect 包括基础检测器的定位和分类损失,例如更快的 R-CNN [35] 或 DETR 检测器。最后,LCoarse 表示[21]使用的初始粗分割预测的损失。 λ{1,2,3,4} 是超参数权重 {1.0, 1.0, 1.0, 0.5}
训练细节:Mask Transfiner 在两级检测器 Faster R-CNN [35] 和基于查询的检测器 [4] 上实现。我们设计了一个三级四叉树,并使用 Detectron2 [43] 中实现的 Mask RCNN 的超参数和训练计划作为主干和粗掩模头。 Mask Transfiner 编码器由三个标准转换器层组成。每层有四个注意力头,特征维度为 256。在我们的消融研究中,采用了 R-50-FPN [22] 和具有 1× 学习计划的 Faster R-CNN。对于 COCO 排行榜比较,我们采用从 [640, 800] 中随机采样的较短图像边的尺度抖动,遵循 [26, 30] 中的训练计划。更多详细信息请参阅补充材料。文件。
4.训练
4.1 实验装置
COCO:我们在 COCO 数据集 [33] 上进行实验,在 2017train 上训练我们的网络,并在 2017val 和 2017test-dev 上评估我们的结果。我们采用标准 AP 指标和最近提出的边界 IoU 指标 [10]。值得注意的是,边界 IoU 的 APB 是一种关注边界质量的度量。继[28]之后,我们还报告了 AP⋆,它使用质量显着更高的 LVIS 注释来评估 COCO 的 val 集 [20],可以更好地揭示掩模质量的改进。
Cityscapes:我们在 Cityscapes [13] 上报告了结果,这是一个高质量的实例分割数据集,包含 2975、500、1525 个分辨率为 2048×1024 的图像,分别用于训练、验证和测试。城市景观侧重于自动驾驶场景,有 8 个类别(例如汽车、人、自行车)。
BDD100K:我们在 BDD100K [45] 实例分割数据集上进一步训练和评估 Mask Transfiner,该数据集有 8 个类别,具有 120K 高质量实例掩模注释。我们遵循标准做法,分别使用 7k、1k、2k 图像进行训练、验证和测试。
4.2 消融实验
我们对 COCO 验证集进行了详细的消融研究,分析了所提出的不相干区域和 Mask Transfiner 各个组件的影响。
不相干区域的影响:表 1 对 3.1 节中描述的不相干区域的特性进行了分析。它表明它们对于最终的分割性能至关重要。表 2 通过用完整 RoI 或检测到的对象边界区域替换细化区域来分析检测到的不相干区域的有效性。由于内存限制,完整的 RoI 仅使用输出大小 28×28。比较显示了不相干区域的优势,与使用完整 RoI 和检测到的边界区域相比,分别获得了 1.8 AP 和 0.7 AP 增益。
为了研究不相干区域对不同金字塔级别的影响,在表2中,我们还通过按级别顺序删除Mask Transfiner的细化区域来进行消融实验。我们发现这三个级别都对最终性能有利,其中 L1 贡献最大,AP 增加了 0.8,其中 L1 表示具有最小特征尺寸的 Mask Transfiner 的根级别。

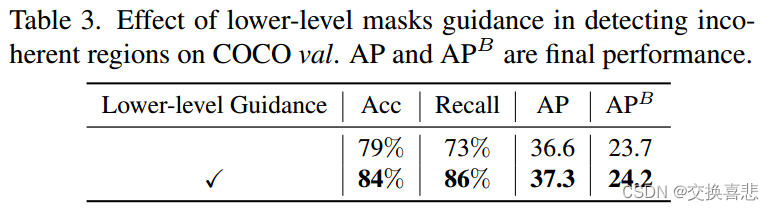
非相干区域探测器上的消融:我们通过计算轻量级非相干区域检测器的召回率和准确率来评估其性能。在表3中,在从较低级别上采样的预测不相干掩模的指导下(图5),检测到的不相干区域的召回率有明显的提高,从74%提高到86%,准确率也从79%提高至 84%。请注意,召回率在这里更为重要,因为它可以覆盖所有容易出错的区域,以便进一步细化。
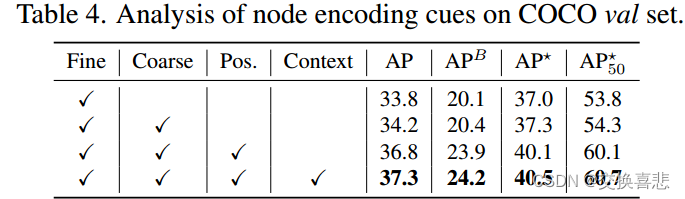
不相干编码的影响:我们分析了四个信息线索在不相干点编码中的效果。在表4中,与仅使用细粒度特征相比,带有语义信息的粗分割特征带来了0.4点AP的增益。位置编码特征对模型性能影响很大,在 AP 上分别显着提高了 2.6 个点,在 APB 上显着提高了 3.5 个点。不相干点的位置编码至关重要,因为 Transformer 架构是排列不变的,并且分割任务是位置敏感的。周围上下文特征通过聚合局部邻近细节,进一步将分割结果从 36.8 AP 提升到 37.3 AP。
四叉树深度的影响:在表 5 中,我们通过在 Mask Transfiner 中构建不同深度的四叉树来研究对分层细化阶段的影响。深度 0 表示使用粗头掩模预测(不带细化步骤)的基线。输出大小比前一阶段大两倍。通过将输出大小从 28×28 更改为 224×224,随着树深度的增加,掩码 AP⋆ 从 38.4 增加到 40.7。这表明,具有更多级别和更大输出尺寸的对象确实可以为分割性能带来更多收益。大型物体从尺寸增加中获益最多,APL 提高了 2.8 个点。我们进一步发现,当输出尺寸大于 112×112 时,性能饱和,而 3 级 Transfiner 的计算成本也较低,运行速度为 7.1 fps。图 6 显示了随着四叉树深度的增加而产生的结果,其中掩模在对象边界周围变得更加精细。
Mask Transfiner 与 MLP 和 CNN:我们比较了细化网络的不同流行选择,包括 MLP 和 CNN 结构。 MLP 通过 256 个通道的三个隐藏层实现 [28],而 CNN 是具有四个 3×3 内核的卷积层的 FCN [21]。请注意,对于完全细化的区域,由于内存限制,CNN 和 MLP 仅限于 RoI 大小 56 × 56,并且 CNN 不适合不相干的区域,因为需要均匀的网格。在表 6 中,我们的 Mask Transfiner 的性能优于 MLP 0.9 AP,这得益于非局部像素级关系建模,其中我们在所有三个四叉树级别上使用相同的不相干区域进行公平比较。此外,我们研究了 Mask Transfiner 的层深 D 和宽度 W 的影响,发现更深和更宽的注意力层只会导致较小的性能变化。在图 6 中,我们可视化 Transfiner 最后一个序列编码器层的稀疏四叉树注意力图,重点关注一些不连贯的点。编码器似乎已经区分了前景实例和背景,其中点 R1 的相邻关注区域由对象边界分隔开。

四叉树结构的功效:表 7 比较了 Mask Transfiner 与不同的注意力机制。与使用 3 层非局部注意力 [39] 或标准转换器 [4, 37] 的像素关系建模相比,Mask Transfiner 不仅获得了更高的精度,而且在计算和内存消耗方面也非常高效。例如,由于不相干的像素数量较少,在相同输出大小的情况下,具有多头注意力的 Mask Transfiner 使用的内存比非局部注意力少 3 倍。与在尺寸小得多的 56×56 完整 RoI 区域上运行的标准 Transformer 相比,四叉树细分和推理允许 Mask Transfiner 仅使用一半的 FLOP 计算即可生成高分辨率 224×224 预测。请注意,在我们的实验中,输出大小为 112×112 的标准变压器会耗尽内存。
多级联合细化的效果 :给定 3 级四叉树中的不相干节点,Transfiner 将所有节点形成一个序列,以便在单次前向传递中进行联合细化。在表8中,我们将其与使用多个序列单独细化每个级别的四叉树节点进行比较。 0.6 AP⋆ 的性能提升显示了多尺度特征融合和全局推理中更丰富的上下文的好处。
四叉树掩码传播的效果:在推理过程中,在掩码 Transfiner 细化了所有不相干点之后,我们沿四叉树级别利用分层从粗到细的掩码传播方案来获得最终预测。与仅校正表 8 中四叉树上最细叶节点的标签相比,传播扩大了细化区域并将性能从 36.5 AP 提高到 37.0 AP。传播带来的计算量可以忽略不计,因为中间树级别中象限叶(相干)节点的新标签是通过复制其父代的细化标签值获得的。

4.3 与最先进的比较
我们将我们的方法与基准 COCO、Cityscapes 和 BDD100K 上最先进的方法进行比较,其中 Mask Transfiner 优于所有现有方法,没有任何附加功能,证明了在两阶段和基于查询的分割框架上的有效性。
COCO :表 9 将 Mask Transfiner 与 COCO 数据集上最先进的实例分割方法进行了比较。
Transfiner 在不同的主干网和目标检测器上实现了一致的改进,通过使用 R101-FPN 和 Faster R-CNN 超越 RefineMask [47] 和 BCNet [26] 1.3 AP 和 0.9 AP,并超越 QueryInst [17] 1.7 AP,证明了其有效性使用基于查询的检测器[4]。注意 QueryInst 由并行的六阶段细化组成,需要优化更多参数。此外,我们发现 Transfiner 使用 Faster R-CNN 和 R50-FPN 的目标检测性能低得多,但在掩模 AP 上仍然实现了与基于查询的方法 [15,23] 相当的分割结果,并且在边界 APB 中获得了超过 2 个点的增益,进一步验证了Transfiner取得的较高AP确实是细粒度掩模的贡献。



Cityscapes :Cityscapes 基准测试的结果列于表 10,其中 Mask Transfiner 实现了最佳掩模 AP 37.6 和边界 APB 18.0。我们的方法显着超越了现有的 SOTA 方法,包括 PointRend [28] 和 BMask R-CNN [12],使用相同的 Faster R-CNN 检测器分别领先 1.3 APB 和 2.3 APB。与我们的基线 Mask R-CNN [21] 相比,Transfiner 极大地将边界 AP 从 11.4 提高到 18.0,这显示了四叉树细化的有效性。
BDD100K :表 11 显示了 BDD100K 数据集的结果,其中 Mask Transfiner 获得了最高的 APmask 23.5,并且在可比较的 APBox 下比基线 [22] 好 3 个点。这一重大进步揭示了 Transfiner 预测掩模的高精度。

定性结果: 图 7 显示了对城市景观的定性比较,其中我们的 Mask Transfiner 生产的掩模比以前的方法 [12,21,28] 具有更高的精度和质量,特别是对于硬区域,例如小后视镜和高跟鞋。请参阅补充文件以进行更多视觉比较。
5.结论
我们提出了 Mask Transfiner,一种新的高质量、高效的实例分割方法。 Transfiner 首先检测并分解图像区域以构建分层四叉树。然后,四叉树上的所有点都转换为查询序列,供我们的变压器预测最终标签。与之前使用受统一图像网格限制的卷积的分割方法相比,Mask Transfiner 可以以较低的计算和内存成本生成高质量的掩模。我们在两阶段和基于查询的分割框架上验证了 Transfiner 的功效,并表明 Transfiner 在 COCO、Cityscapes 和 BDD100K 上实现了巨大的性能优势。当前的限制是我们的 Mask Transfiner 以及竞争方法所需的完全监督培训。未来的工作将努力放宽这一假设。
相关文章:
实例分割论文阅读之:《Mask Transfiner for High-Quality Instance Segmentation》
1.摘要 两阶段和基于查询的实例分割方法取得了显著的效果。然而,它们的分段掩模仍然非常粗糙。在本文中,我们提出了一种高质量和高效的实例分割Mask Transfiner。我们的Mask Transfiner不是在规则的密集张量上操作,而是将图像区域分解并表示…...

阿里 EasyExcel 表头国际化
实体类字段使用EasyExcel提供的注解ExcelProperty,value 值写成占位符形式 ,匹配 i18n 文件里面的编码。 如: /*** 仓库名称*/ ExcelProperty("{warehouse.record.warehouseName}") private String warehouseName;占位符解析器 A…...
跨境电商新风潮:充分发挥海外云手机的威力
在互联网行业迅速发展的大环境下,跨境电商、海外社交媒体营销以及游戏产业等重要领域都越来越需要借助海外云手机的协助。 特别是在蓬勃发展的跨境电商领域,像亚马逊、速卖通、eBay等平台,结合社交电商营销和短视频内容成为最有效的流量来源。…...
Kubernetes实战(二十七)-HPA实战
1 HPA简介 HPA 全称是 Horizontal Pod Autoscaler,用于POD 水平自动伸缩, HPA 可以 基于 POD CPU 利用率对 deployment 中的 pod 数量进行自动扩缩容(除了 CPU 也可以基于自定义的指标进行自动扩缩容)。pod 自动缩放不适用于无法…...
IDEA 配置以及一些技巧
1. IDEA设置 1.1 设置主题 1.2 设置字体和字体大小 1.3 编辑区的字体用ctrl鼠标滚轮可以控制大小 1.4 自动导包和优化多余的包 1.5 设置编码方式 1.6 配置 maven 1.7 设置方法形参参数提示 1.8 设置控制台的字体和大小 注意:设置控制台字体和大小后需要重启IDEA才会…...

Android 11 访问 Android/data/或者getExternalCacheDir() 非root方式
前言: 需求要求安装三方应用ExternalCacheDir()下载下来的apk文件。 getExternalCacheDir() : /storage/emulated/0/Android/data/com../cache/ 获取访问权限 如果手机安卓版本为Android10的时候,可以在AndroidManifest.xml中添加下列代码 android:requestLegacyExt…...
Eclipse安装配置、卸载教程(Windows版)
Eclipse是一个开放源代码的集成开发环境(IDE),最初由IBM公司开发,现在由Eclipse基金会负责维护。它是一个跨平台的工具,可以用于开发多种编程语言,如Java、C/C、Python、PHP、Rust等。 Eclipse提供了一个可…...
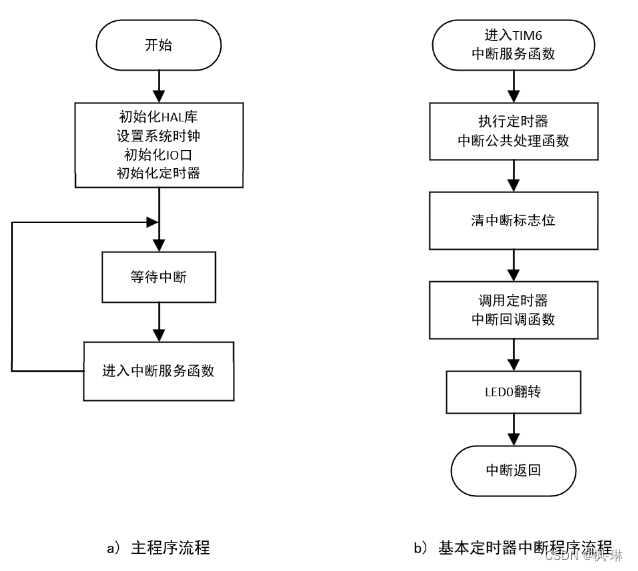
正点原子--STM32基本定时器学习笔记(2)
目录 1. 相关寄存器介绍 1.1 控制寄存器 1(TIMx_CR1)编辑 1.2 DMA/中断使能寄存器(TIMx_DIER) 1.3 状态寄存器(TIMx_SR) 1.4 计数器(TIMx_CNT) 1.5 预分频器(TIMx_PSC) 1.6 自动重装载寄存器(TIMx_ARR) 2. 工程建立 3. 导入tim.c文件 4. 相关HAL库函数介绍 4.1 H…...

学习笔记:正则表达式
正则表达式是文本处理方面功能最强大的工具之一。正则表达式语言用来构造正则表达式,最终构造出来的字符串就称为正则表达式,正则表达式用来完成搜索和替换操作。 本文参考《正则表达式必知必会(修订版)》《Learning Regular Exp…...
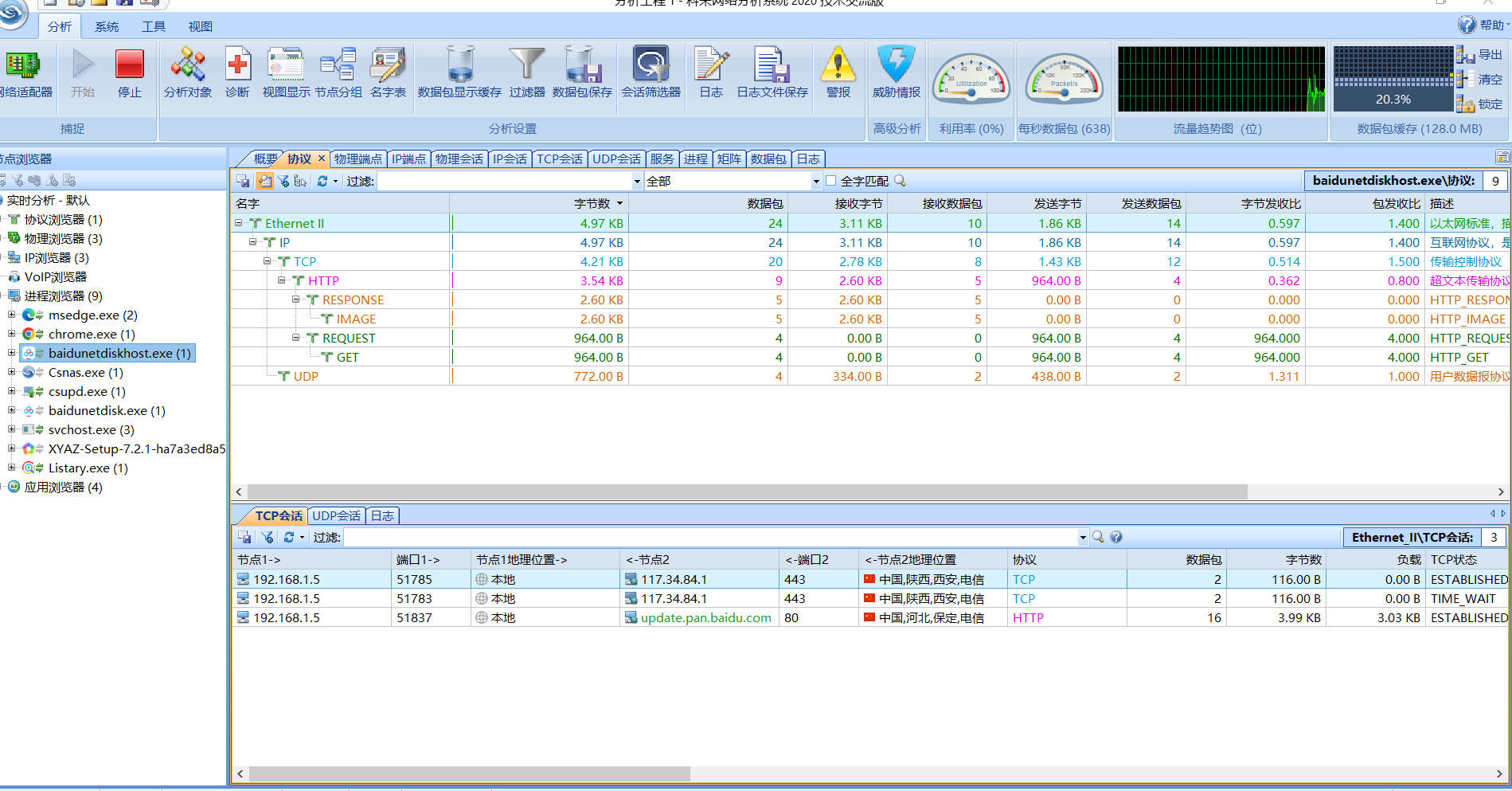
03-抓包_封包_协议_APP_小程序_PC应用_WEB应用
抓包_封包_协议_APP_小程序_PC应用_WEB应用 一、参考工具二、演示案例:2.1、WEB应用站点操作数据抓包-浏览器审查查看元素网络监听2.2、APP&小程序&PC抓包HTTP/S数据-Charles&Fiddler&Burpsuite2.3、程序进程&网络接口&其他协议抓包-WireSh…...
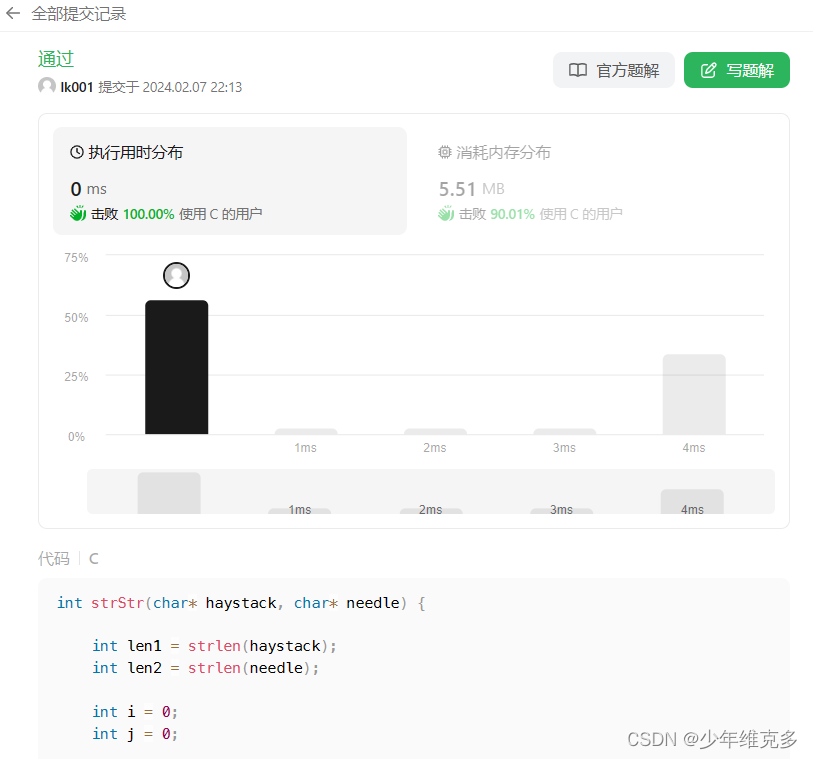
C语言笔试题之实现C库函数 strstr()(设置标志位)
实例要求: 1、请你实现C库函数strstr()(stdio.h & string.h),请在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始);2、函数声明:int strStr(char* h…...

什么是IDE,新手用哪个IDE比较好
什么是IDE IDE(Integrated Development Environment,集成开发环境)是一种为程序员提供软件开发所需的代码编辑、构建、调试等功能于一体的应用程序。IDE通常包含了代码编辑器、编译器、调试器和图形用户界面等工具,这些工…...
Flask 入门6:模板继承
1. 一个网站中,大部分网页的模块是重复的,比如顶部的导航栏,底部的备案信息。如果在每个页面中都重复的去写这些代码,会让项目变得臃肿,提高后期的维护成本。比较好的做法是,通过模板继承,把一…...

欢迎来到操作系统的世界
🌞欢迎来到操作系统的世界 🌈博客主页:卿云阁 💌欢迎关注🎉点赞👍收藏⭐️留言📝 🌟本文由卿云阁原创! 🙏作者水平很有限,如果发现错误ÿ…...

寒假作业-day5
1>现有无序序列数组为23,24,12,5,33,5347,请使用以下排序实现编程 函数1:请使用冒泡排序实现升序排序 函数2:请使用简单选择排序实现升序排序 函数3:请使用直接插入排序实现升序排序 函数4:请使用插入排序实现升序排序 代码: #include<stdio.h&g…...

互联网加竞赛 基于深度学的图像修复 图像补全
1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学的图像修复 图像补全 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-se…...

用于制作耳机壳的UV树脂耳机壳UV胶价格高不高?
制作耳机壳的UV树脂价格相对于一些其他材料可能会略高,但具体的价格取决于多个因素,如品牌、型号、质量等。一些高端的UV树脂品牌和型号可能会价格较高,但它们也通常具有更好的性能和更广泛的应用范围。 此外,UV树脂的价格也与购买…...

【开源】JAVA+Vue+SpringBoot实现房屋出售出租系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 房屋销售模块2.2 房屋出租模块2.3 预定意向模块2.4 交易订单模块 三、系统展示四、核心代码4.1 查询房屋求租单4.2 查询卖家的房屋求购单4.3 出租意向预定4.4 出租单支付4.5 查询买家房屋销售交易单 五、免责说明 一、摘…...

Golang 并发 生产者消费者模式
Golang 并发 生产者消费者模式 生产者-消费者模式能够带来的好处 生产者消费者模式是一种常见的并发编程模式,用于解决生产者和消费者之间的数据传递和处理问题。在该模式中,生产者负责生成数据(生产),而消费者负责处…...
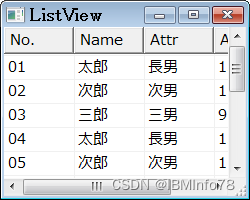
Win32 SDK Gui编程系列之--ListView自绘OwnerDraw
ListView自绘OwnerDraw 1.ListView自绘OwnerDraw 正在试错是否使用了列表视图,尽量制作出智能的表格编辑器。本页显示了业主抽签的表格数据(二维数组数据)的显示方法。 显示画面和整个程序如下所示。使用ListView_GetSubItemRect宏的话,就不需要getRect函数了。 当nCol的…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

Elastic 获得 AWS 教育 ISV 合作伙伴资质,进一步增强教育解决方案产品组合
作者:来自 Elastic Udayasimha Theepireddy (Uday), Brian Bergholm, Marianna Jonsdottir 通过搜索 AI 和云创新推动教育领域的数字化转型。 我们非常高兴地宣布,Elastic 已获得 AWS 教育 ISV 合作伙伴资质。这一重要认证表明,Elastic 作为 …...
保姆级【快数学会Android端“动画“】+ 实现补间动画和逐帧动画!!!
目录 补间动画 1.创建资源文件夹 2.设置文件夹类型 3.创建.xml文件 4.样式设计 5.动画设置 6.动画的实现 内容拓展 7.在原基础上继续添加.xml文件 8.xml代码编写 (1)rotate_anim (2)scale_anim (3)translate_anim 9.MainActivity.java代码汇总 10.效果展示 逐帧…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...
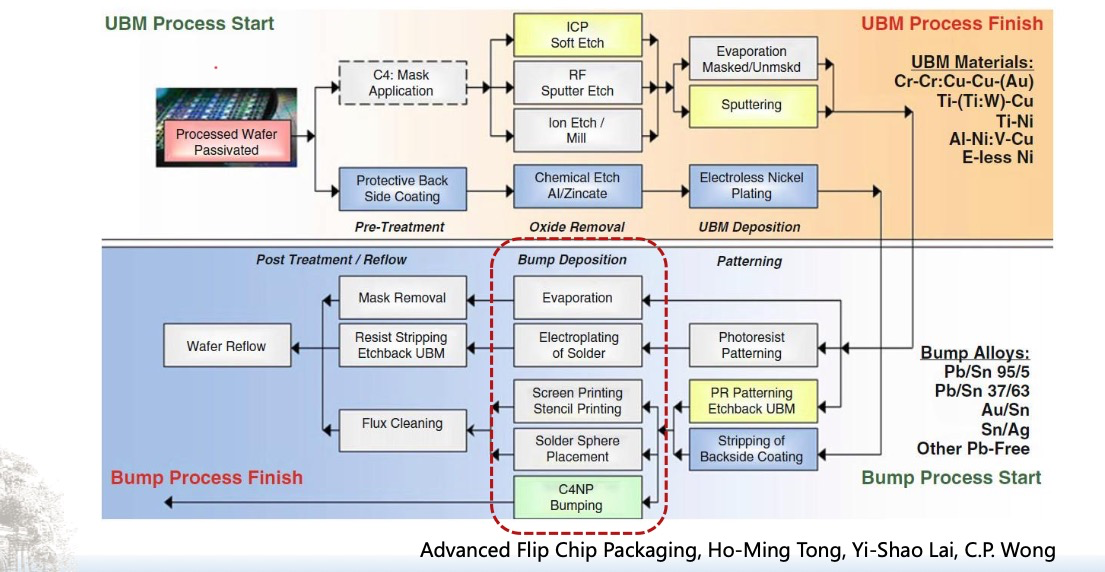
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...