【机器学习】数据清洗之识别缺失点
🎈个人主页:甜美的江
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
数据清洗之识别缺失点
- 一 缺失值的概念及危害
- 1.1 缺失值的概念
- 1.2 缺失值的危害:
- 二 识别缺失值:
- 2.1 可视化检查:
- 2. 2 统计描述:
- 2.3 编程检查

引言:
在机器学习领域,数据的质量直接关系到模型的性能和可靠性。而在实际应用中,我们往往面临一个普遍存在的问题——缺失值。缺失值可能因为各种原因而产生,如传感器故障、数据采集错误或者主观选择性填写。因此,深入了解并识别缺失值成为数据清洗的重要步骤之一。
本文将探讨缺失值的概念及其危害,并介绍在数据清洗中如何通过可视化检查、统计描述以及编程检查等方法来有效地识别缺失值,从而为后续的数据处理和建模奠定基础。
一 缺失值的概念及危害
当涉及到数据清洗时,缺失值是一个非常重要的概念。缺失值指的是数据集中某些字段或变量中的数据项缺失或未填充的情况。
这些缺失值可能出现在数据收集、传输、存储或处理的任何阶段,其存在可能会带来许多危害。
以下是关于缺失值的概念以及其危害的详细介绍:
1.1 缺失值的概念
定义:
缺失值是指在数据集中某些字段或变量中缺少数据值或者未填充的值。这些缺失值通常用特殊的标识符(如NaN、NULL、NA等)来表示。
类型:
缺失值可以是完全随机的,也可以是有规律的(如某个特定的条件下出现缺失)。常见的缺失值类型包括单个值缺失、整行数据缺失、连续值序列缺失等。
1.2 缺失值的危害:
1 影响数据质量:
缺失值会降低数据集的质量和可用性,使数据分析和建模的结果变得不准确和不可靠。
2 偏倚分析结果:
当数据中存在缺失值时,可能会导致分析结果产生偏差,从而影响对数据的正确理解和决策制定。
3 减少数据样本量:
在数据清洗过程中,删除包含缺失值的数据项或者变量会导致数据样本量减少,进而降低模型的训练效果和泛化能力。
4 失去信息:
缺失值可能包含重要的信息,因此简单地删除缺失值可能会导致信息的丢失,从而影响数据分析的完整性和准确性。
5 影响统计分析:
缺失值会影响统计分析的结果,例如均值、方差等统计指标会因缺失值而产生偏差。
6 导致误解:
缺失值的存在可能导致对数据的误解,使得对现实世界情况的理解出现偏差或错误。
二 识别缺失值:
在处理缺失值之前,我们需要先找出缺失值,而找出缺失值主要有以下三种方法:
2.1 可视化检查:
在数据清洗中,通过可视化方法来识别缺失值是一种直观且有效的方式。
以下是一些常用的可视化检查方法:
1 热力图(Heatmap):
方法:
使用热力图可以直观地显示整个数据集中缺失值的分布情况。通常,热力图中缺失值的部分会以不同颜色或阴影表示。
工具:
可以使用Python中的Seaborn或Matplotlib库来创建热力图。
import seaborn as sns
import matplotlib.pyplot as pltsns.heatmap(data.isnull(), cbar=False, cmap='viridis')
plt.show()
2 缺失值比例柱状图:
方法:
绘制柱状图,显示每个变量中缺失值的比例。这可以帮助识别哪些变量受到缺失值的影响较大。
工具:
使用Matplotlib或Seaborn库创建柱状图。
import matplotlib.pyplot as pltmissing_percentage = (data.isnull().sum() / len(data)) * 100
missing_percentage = missing_percentage[missing_percentage > 0]
missing_percentage.sort_values(inplace=True)plt.bar(missing_percentage.index, missing_percentage)
plt.xlabel('Variables')
plt.ylabel('Missing Percentage')
plt.xticks(rotation=45)
plt.show()
3 缺失值的分布直方图:
方法:
对于特定变量,绘制其缺失值的分布直方图,以了解缺失值在该变量上的分布情况。
工具:
使用Matplotlib或Seaborn库创建直方图。
import matplotlib.pyplot as pltplt.hist(data['Variable_with_missing'], bins=20, color='skyblue', edgecolor='black')
plt.xlabel('Variable_with_missing')
plt.ylabel('Frequency')
plt.title('Distribution of Missing Values')
plt.show()
4 缺失值的模式图:
方法:
绘制缺失值的模式图,以显示数据集中缺失值的模式。
这有助于识别是否存在特定的缺失值模式。
工具:
可以使用Seaborn的clustermap方法。
import seaborn as snssns.clustermap(data.isnull(), cmap='viridis')
plt.show()
这些可视化方法能够帮助数据科学家和分析师更好地理解数据集中的缺失值分布情况,从而采取有针对性的数据清洗策略。
示例
代码:
import matplotlib.pyplot as plt
import pandas as pd# 读取数据集
height_data = pd.read_csv(r"D:\jupter notebook\base\机器学习\数据预处理\数据清洗\data\height_data.csv")# 打印缺失值的数量
missing_values = height_data['Height'].isnull().sum()
print(f"Total Missing Values: {missing_values}")# 显示缺失的ID
missing_ids = height_data[height_data['Height'].isnull()]['ID'].tolist()
print(f"Missing IDs: {missing_ids}")# 创建直方图
plt.hist(height_data['ID'], bins=10, color='skyblue', edgecolor='black', alpha=0.7, label='All IDs')
plt.hist(missing_ids, bins=10, color='red', edgecolor='black', alpha=0.7, label='Missing IDs')
plt.xlabel('ID')
plt.ylabel('Frequency')
plt.title('Distribution of IDs with Missing Values')
plt.legend()
plt.show()数据集内容如下:
ID,Height
1,170
2,165
3,180
4,NaN
5,175
6,172
7,168
8,NaN
9,185
10,170运行结果:
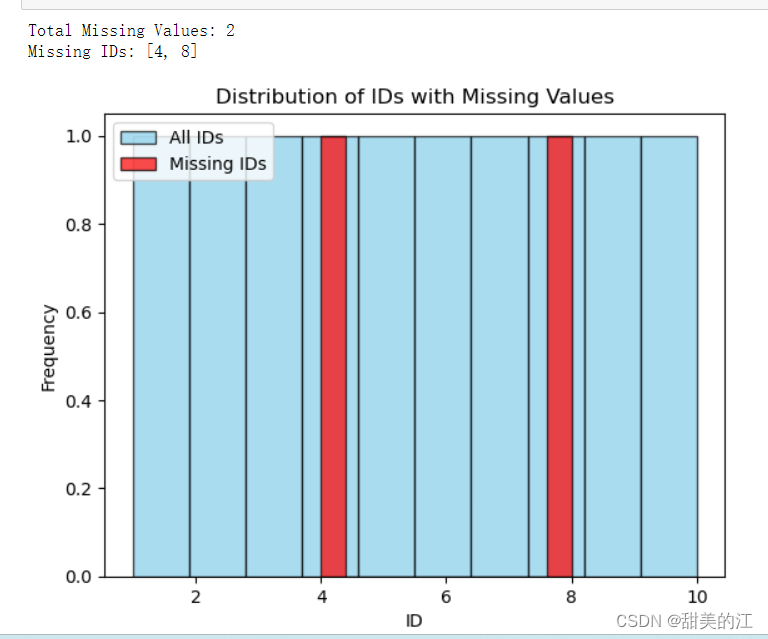
在这个示例中,使用plt.hist()函数分别绘制了所有ID和缺失ID的直方图,并在图例中添加了标签。在图表上,缺失ID的数据用红色表示。此外,代码还打印了缺失值的总数量以及缺失的具体ID,从直方图上可以明显地看出,一共有两个数据缺失,缺失数据的ID分别是4,8。
代码分析:(给小白看的)
import matplotlib.pyplot as plt
导入matplotlib库,用于绘制图表。
import pandas as pd
导入pandas库,用于数据处理。
height_data = pd.read_csv(
r"D:\jupter notebook\base\机器学习\数据预处理\数据清洗\data\height_data.csv")
使用pandas的read_csv()函数从指定路径读取名为height_data.csv的数据集文件,并将其存储在名为height_data的DataFrame中。
missing_values = height_data['Height'].isnull().sum()
使用isnull()函数检查Height列中的缺失值,并使用sum()函数计算缺失值的数量,将结果存储在变量missing_values中。
print(f"Total Missing Values: {missing_values}")
打印缺失值的总数量。
missing_ids = height_data[height_data['Height'].isnull()]['ID'].tolist()
使用布尔索引选择Height列中存在缺失值的行,并提取这些行中的ID列,然后将其转换为列表形式,存储在变量missing_ids中。
print(f"Missing IDs: {missing_ids}")
打印缺失的ID。
plt.hist(height_data['ID'], bins=10, color='skyblue',edgecolor='black', alpha=0.7, label='All IDs')
使用plt.hist()函数创建一个直方图,绘制所有ID的分布情况
height_data[‘ID’]是要绘制直方图的数据列
bins=10指定直方图的柱子数量为10个
color='skyblue’设置直方图的颜色为天蓝色
edgecolor='black’设置直方图的边框颜色为黑色
alpha=0.7设置透明度为0.7
label='All IDs’设置图例标签为"All IDs"
plt.hist(missing_ids, bins=10, color='red',edgecolor='black', alpha=0.7, label='Missing IDs')
再次使用plt.hist()函数创建一个直方图,绘制缺失ID的分布情况
missing_ids是要绘制直方图的数据,其余参数设置与上一步类似
label='Missing IDs’设置图例标签为"Missing IDs"
plt.xlabel('ID')和plt.ylabel('Frequency')
分别设置X轴和Y轴的标签。
plt.title('Distribution of IDs with Missing Values')
设置图表的标题为"Distribution of IDs with Missing Values",表示具有缺失值的ID的分布情况。
plt.legend()
添加图例,用于区分不同的直方图。
plt.show()
显示创建的图表。
这段代码的主要功能是可视化身高数据集中ID的分布情况,并通过不同颜色的直方图区分具有缺失值的ID。同时,代码还打印了缺失值的总数量和缺失的ID。
2. 2 统计描述:
在数据清洗过程中,识别缺失值的统计描述方法有助于了解数据集中缺失值的分布、缺失模式和缺失值的数量。以下是一些常用的统计描述方法:
1 缺失值数量统计:
简单地计算每个变量中缺失值的数量,这可以通过使用isnull()和sum()函数实现。
示例代码:
missing_count = data.isnull().sum()
print(missing_count)
2 缺失值比例统计:
计算每个变量中缺失值的比例,通常以百分比的形式呈现。
示例代码:
missing_percentage = (data.isnull().sum() / len(data)) * 100
print(missing_percentage)
3 缺失值的汇总统计:
使用describe()函数生成有关数据集中缺失值的统计摘要,包括均值、标准差、最小值、25th、50th(中位数)、75th百分位数和最大值。
示例代码:
missing_summary = data.describe(include='all', datetime_is_numeric=True)
print(missing_summary)
4 缺失值的累积统计:
对数据集进行累积求和,生成一个累积缺失值的统计图,有助于识别哪些部分的数据更容易受到缺失值的影响。
示例代码:
cumulative_missing = data.isnull().cumsum()
print(cumulative_missing)
5 缺失模式统计:
通过统计不同缺失模式的出现频率,可以发现是否存在某些变量同时缺失的趋势。
示例代码:
missing_pattern_count = data.apply(tuple, axis=1).duplicated().sum()
print(f"Number of rows with the same missing pattern: {missing_pattern_count}")
这些统计描述方法为数据清洗提供了一个全面的视角,使数据科学家能够更好地理解数据集中缺失值的性质,为后续的处理和填充提供指导。
2.3 编程检查
识别缺失值是数据清洗中的一个关键步骤,它有助于我们理解数据集的完整性并采取适当的处理措施。以下是一些常用的编程检查方法:
1 使用isnull()函数:
在Python中,我们可以使用isnull()函数来检查数据集中的缺失值。
这个函数会返回一个布尔值的DataFrame,其中缺失值对应的位置为True,非缺失值为False。
示例代码:
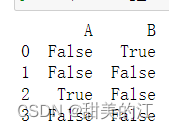
import pandas as pd# 创建一个示例DataFrame
data = pd.DataFrame({'A': [1, 2, None, 4],'B': [None, 5, 6, 7]})# 使用isnull()函数检查缺失值
missing_values = data.isnull()
print(missing_values)
运行结果:
2 使用any()函数:
any()函数用于检查DataFrame中每列是否存在至少一个True值,即是否存在缺失值。
示例代码:
# 检查是否存在缺失值
any_missing = missing_values.any()
print(any_missing)
3 使用sum()函数:
sum()函数可以对布尔值的DataFrame进行求和,统计每列中True值(缺失值)的数量。
示例代码:
# 统计每列缺失值的数量
missing_count = missing_values.sum()
print(missing_count)
4 使用info()函数:
info()函数可以提供关于DataFrame的简明摘要信息,其中包括每列的非空值数量。
通过比较非空值数量和数据集总行数,可以快速识别出缺失值的存在。
示例代码:
# 查看DataFrame的摘要信息
data.info()
三 总结
:
数据清洗中的缺失值处理是构建可靠机器学习模型的关键步骤。通过深入了解缺失值的概念及其危害,以及采用可视化检查、统计描述和编程检查等方法,我们能够全面地识别数据中的缺失点。这为后续的数据填充、插补或删除等操作奠定了基础,确保数据的完整性和可靠性,从而提高模型的准确性和鲁棒性。在实际应用中,仔细识别缺失点将为我们构建更加健壮和可信赖的机器学习模型提供重要支持。
这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是甜美的江,让我们我们下次再见


相关文章:
【机器学习】数据清洗之识别缺失点
🎈个人主页:甜美的江 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步…...
【Vue】Vue基础入门
📝个人主页:五敷有你 🔥系列专栏:Vue ⛺️稳重求进,晒太阳 Vue概念 是一个用于构建用户界面的渐进式框架优点:大大提高开发效率缺点:需要理解记忆规则 创建Vue实例 步骤: …...
正点原子-STM32通用定时器学习笔记(1)
目录 1. 通用定时器简介(F1为例) 2. 通用定时器框图 ①时钟源 ②控制器 ③时基单元 ④输入捕获 ⑤捕获/比较(公共) ⑥输出比较 3.时钟源配置 3.1 计数器时钟源寄存器设置方法 3.2 外部时钟模式1 3.3 外部时钟模式2 3…...
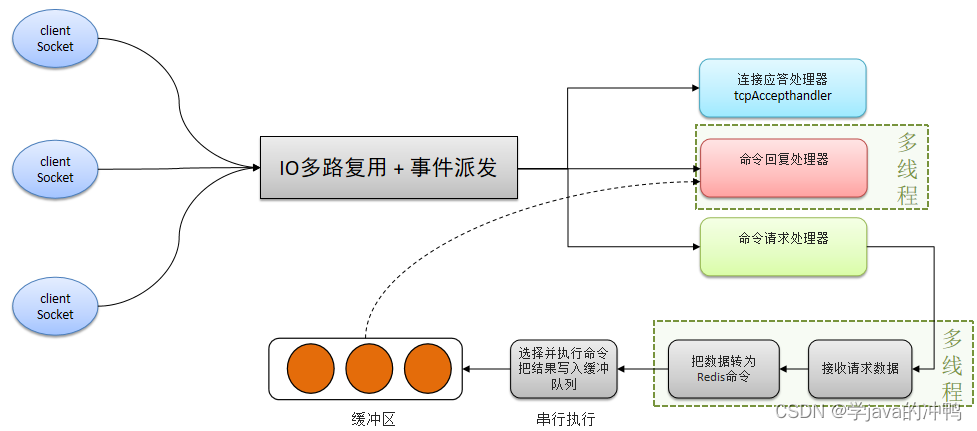
Redis篇之redis是单线程
一、redis是单线程 Redis是单线程的,但是为什么还那么快?主要原因有下面3点原因: 1. Redis是纯内存操作,执行速度非常快。 2. 采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题。 …...

随机MM引流源码PHP开源版
引流源码最新随机MM开源版PHP源码,非常简洁好看的单页全解代码没任何加密 直接上传即可用无需数据库支持主机空间...

【C++修行之道】(引用、函数提高)
目录 一、引用 1.1引用的基本使用 1.2 引用注意事项 1.3 引用做函数参数 1.4 引用做函数返回值 1.5 引用的本质 1.6 常量引用 1.7引用和指针的区别 二、函数提高 2.1 函数默认参数 2.2函数占位参数 2.3 函数重载 2.4函数重载注意事项 一、引用 1.1引用的基本使用 …...
从零开始手写mmo游戏从框架到爆炸(十一)— 注册与登录
导航:从零开始手写mmo游戏从框架到爆炸(零)—— 导航-CSDN博客 从这一章开始,我们进入业务的部分,从注册登录开始。 创建注册和登录的路由 package com.loveprogrammer.command.server;public interface Se…...

【SpringBoot】Redis集中管理Session和自定义用户参数解决登录状态及校验问题
🏡浩泽学编程:个人主页 🔥 推荐专栏:《深入浅出SpringBoot》《java对AI的调用开发》 《RabbitMQ》《Spring》《SpringMVC》 🛸学无止境,不骄不躁,知行合一 文章目录 前言一、分布…...
(二))
【0256】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(二)
上一篇:【0255】揭晓pg内核中MyBackendId的分配机制(后端进程Id,BackendId)(一) 文章目录 1. 前言2. 分配BackendId2.1 何时为backend process分配BackendId2.1.1 找出未使用的slot(inactive slot)2.3 BackendId序号从多少开始?2.4 后端进程退出后,其BackendId被释放…...

eclipse4.28.0版本如何安装FatJar插件
场景: 今天准备温故下以前的老项目,于是下载了最新版本的Eclipse IDE for Enterprise Java and Web Developers - 2023-06,老项目中有些需要将程序打成jar包,于是考虑安装FatJar插件。 问题描述 一顿操作后,发现FatJar死活安装了,在线安装提示content.xml异常;离线安装…...

查大数据检测到风险等级太高是怎么回事?
随着金融风控越来越多元化,大数据作为新兴的技术被运用到贷前风控中去了,不少人也了解过自己的大数据,但是由于相关知识不足,看不懂报告,在常见的问题中,大数据检测到风险等级太高是怎么回事呢?小易大数据…...

Leetcode 30天高效刷数据结构和算法 Day1 两数之和 —— 无序数组
两数之和 —— 无序数组 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现…...

Hair Tool for Blender3D
CGer.com - Hair Tool for Blender3D - CGer资源网 Hair Tool 1.5 for Blender3D 链接: https://pan.baidu.com/s/1kVABn6n 密码: gwprHair Tool 1.65-1.8 for Blender链接: https://pan.baidu.com/s/1A7cW_Ms2baGQ2M0iE1dQhQ 密码: 81bqHair Tool for Blender 1.9.2链接: http…...

【最详解】如何进行点云的凹凸缺陷检测(opene3D)(完成度80%)
文章目录 前言实现思路想法1想法2想法3 补充实现想法1想法2代码 想法3代码 总结 前言 读前须知: 首先我们得确保你已经完全知晓相关的基本的数学知识,其中包括用最小二乘法拟合曲二次曲面,以及曲面的曲率详细求解。若还是没弄清楚࿰…...

海外云手机——平台引流的重要媒介
随着互联网的飞速发展,跨境电商、短视频引流以及游戏行业等领域正经历着迅猛的更新换代。在这个信息爆炸的时代,流量成为至关重要的资源,而其中引流环节更是关乎业务成功的关键。海外云手机崭露头角,成为这一传播过程中的重要媒介…...

数据库-计算机三级学习记录-4DBAS功能概要设计
DBAS功能概要设计 参照b站【计算机三级数据库技术】 DBAS功能设计包括应用软件中的数据库事务设计和应用程序设计。 功能设计过程一般被划分为总体设计、概要设计和详细设计。而具体到数据库事务设计部分,又可分成事务概要设计和事务详细设计。完成系统设计工作之后…...

JVM-虚拟机栈
虚拟机栈 Java虚拟机栈(Java Virtual Machine Stack)采用栈的数据结构来管理方法调用中的基本数据,先进后出(First In Last Out),每一个方法的调用使用一个栈帧(Stack Frame)来保存。 接下来以…...

linux系统上tomcat简介以及安装tomcat
tomcat简介以及安装 Tomcat简介安装环境安装jdk安装tomcat浏览器访问 Tomcat简介 Tomcat是一个开源的Web服务器和servlet容器,由Apache软件基金会开发和维护。它是一种流行的Java Web应用服务器,用于运行Java编写的Web应用程序。 Tomcat提供了一个轻量级…...
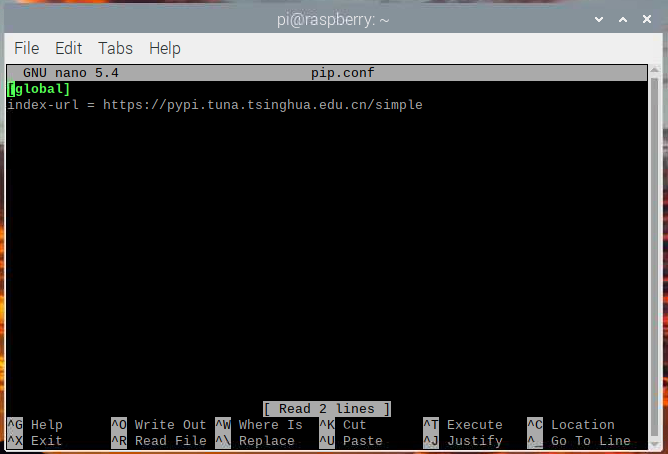
树莓派的pip安装时候添加清华源
每次都要去找镜像网址,太麻烦了,通过改配置可以一次性解决。 首先创建一个.pip 目录 mkdir ~/.pip意味着在当前目录下创建.pip文件,不过这个是隐藏文件,一般情况下是关闭隐藏文件的可视的,于是我绕了点弯弯。 编辑…...
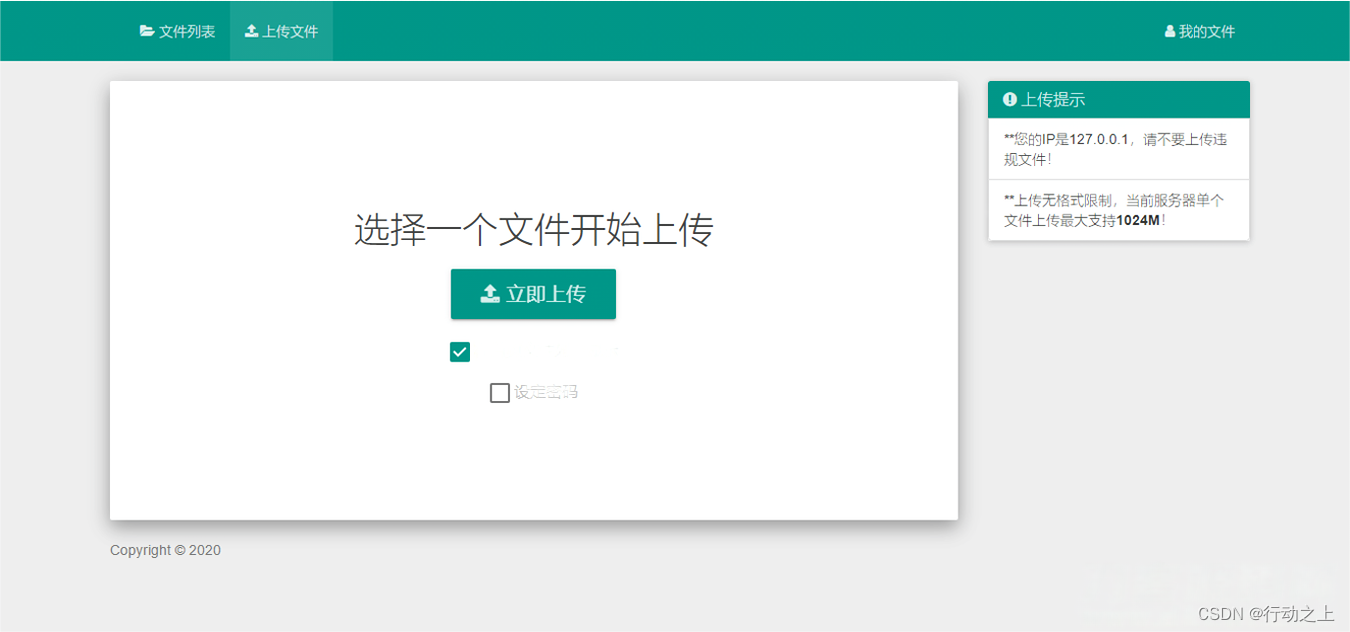
共享网盘系统PHP源码
新V5.0版本,支持上传视频、支持视频播放、支持共享,也可以自己用。 可以自动生成视频外链,下载地址,播放器代码,html代码,ubb代码等等。 使用方法: 源码上传到服务器,打开网站根据…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...