Python进阶--爬取美女图片壁纸(基于回车桌面网的爬虫程序)
目录
一、前言
二、爬取下载美女图片
1、抓包分析
a、分析页面
b、明确需求
c、抓包搜寻
d、总结特点
2、编写爬虫代码
a、获取图片页网页源代码
b、提取所有图片的链接和标题
c、下载并保存这组图片
d、 爬取目录页的各种类型美女图片的链接
e、实现翻页
三、各种需求的爬虫代码
1、下载所有美女图片
2、下载想要页码范围内的美女图片
3、下载想要类型的美女图片
a、下载想要类型的所有美女图片
b、下载想要类型的想要页码范围的美女图片
一、前言
回车桌面网(https://www.enterdesk.com/)是一个具备各种精美图片的网站,里面包含各种丰富的图片资源。此处,将详细讲解爬取其中美女图片资源将其下载到本地。看懂本篇内容后,自己也可以爬取其中想要的类型图片。
回车桌面的首页:
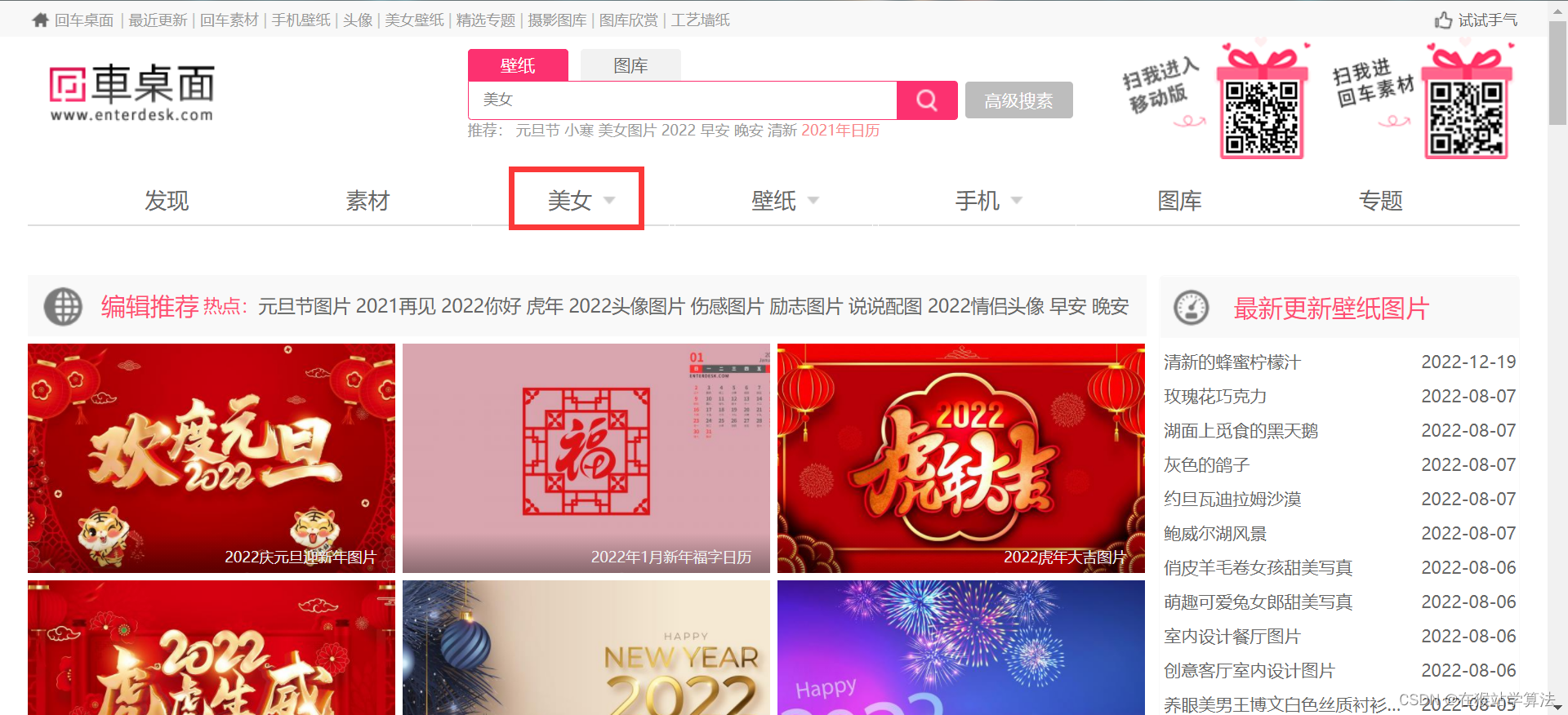
此处仅爬取所框选中的美女图片,看懂本篇后,自己也能做到爬取其他类型的图片!!!
二、爬取下载美女图片
1、抓包分析
爬虫的第一步都是抓包分析(也就是分析网页,从网页源代码中找到自己想要的内容)。
a、分析页面
(1)在回车桌面中点击美女跳转到美女图片的网页
(2)在美女图片页面中,可以看到有各种类型的美女图片和下一页按钮。
(3)点击一种类型的美女图片会跳转到该种类型的美女图片的具体图片界面
(4)点击下一页会跳转到另一页的美女图片页面,里面包含其他的类型的美女图片
(5)在美女图片页面中还有分类标签,点击一种风格类型,则会跳转到该种类型风格的美女图片
美女网页:
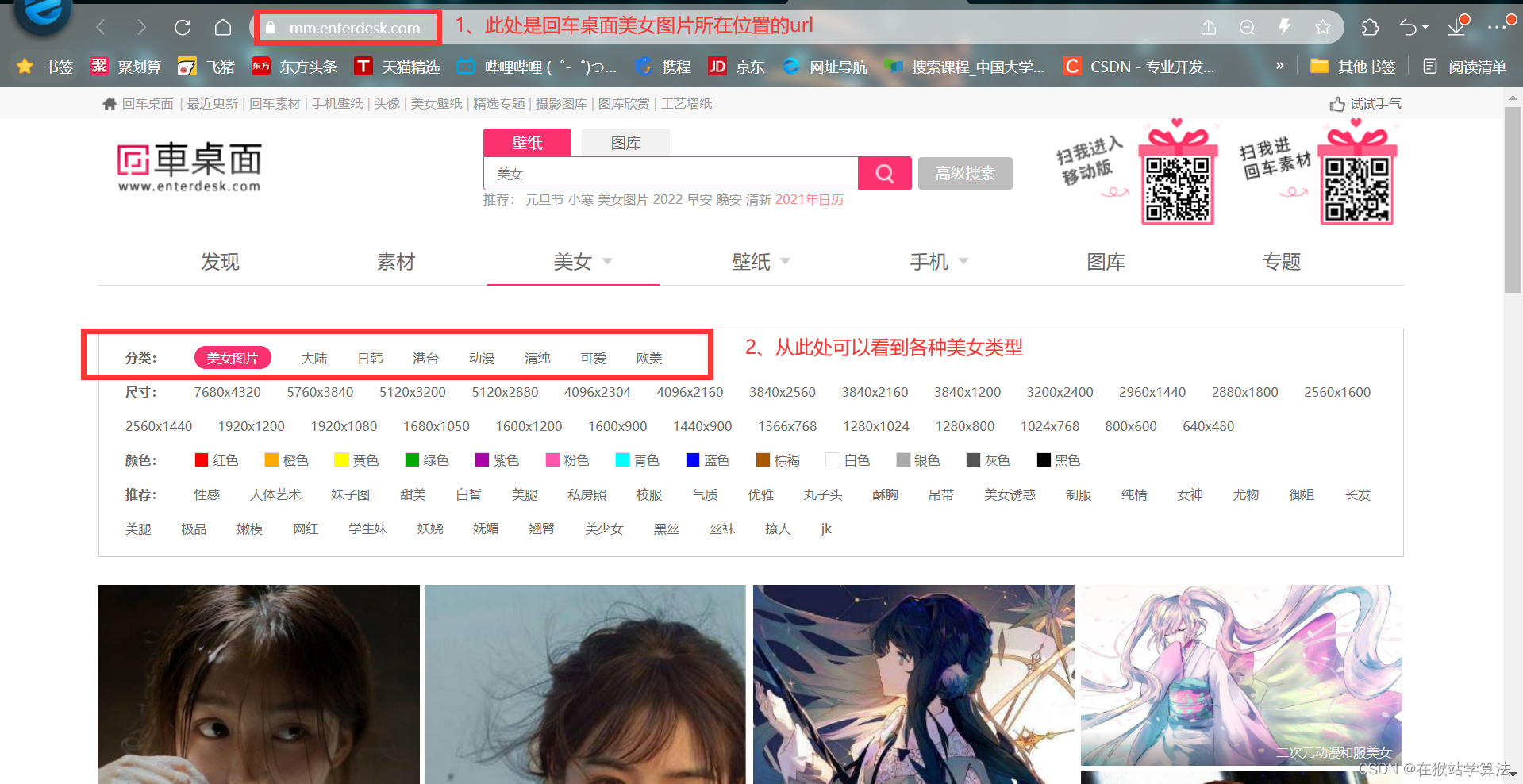
各种类型的美女图片:
 美女页面的下一页所在位置:
美女页面的下一页所在位置:
 一种类型美女图片的页面:
一种类型美女图片的页面:
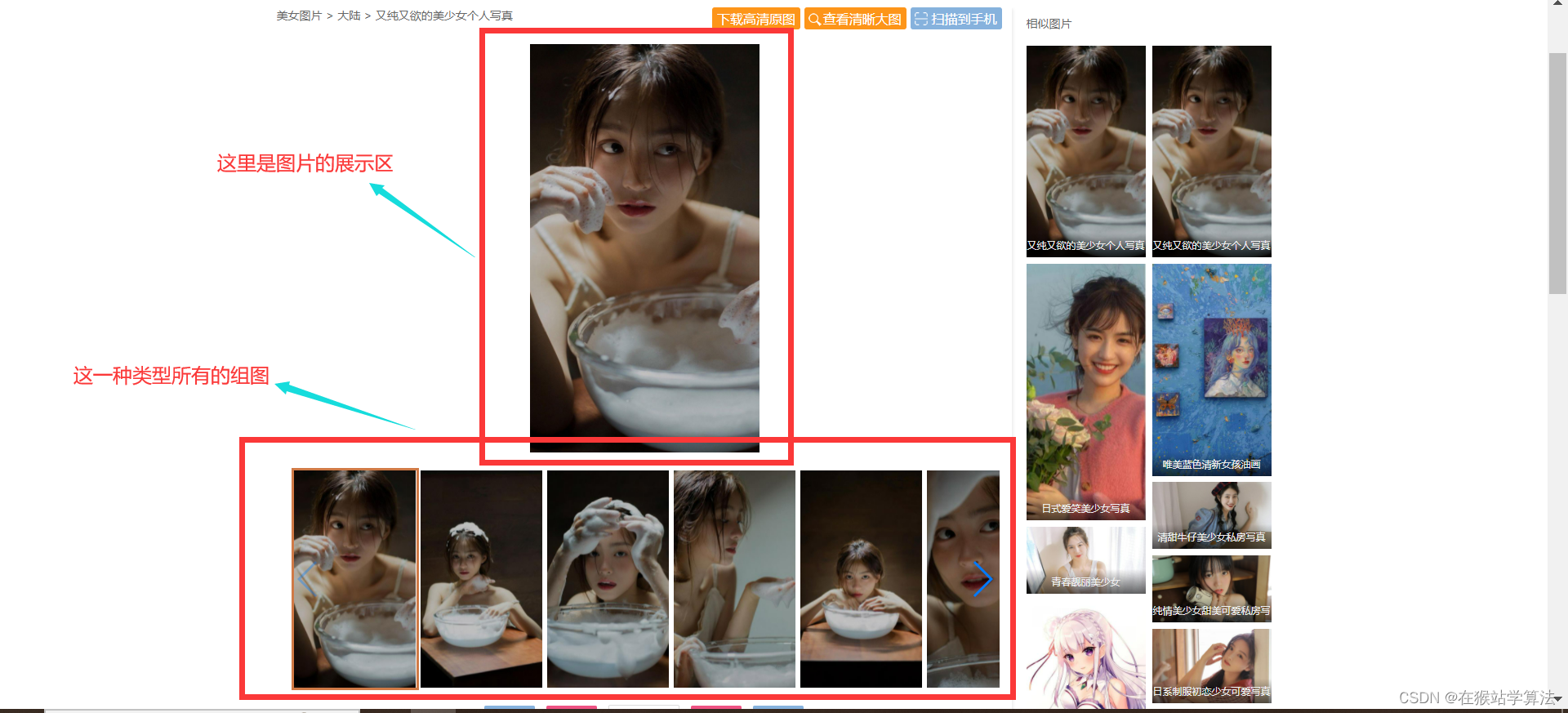
b、明确需求
根据上面的页面分析,可以明确以下需求:
- 要获取到下一页的url所在页面源代码的位置
- 要获取到每种类型美女图片的url
- 要找到一种类型美女的各种图片下载的url
- 对美女网页进行requests请求,需要有请求头,找到请求网页的url、user-agent、cookie等信息
- 找到各种分类标签的url
c、抓包搜寻
根据以上需求,分析网页源代码,找到想要的内容。
步骤:
- 在美女页面,按下F12,打开开发者界面
- 点击开发者界面左上角的鼠标箭头
- 将箭头移到在美女页面的一种类型的美女图片上并点击一下
- 在开发者界面将会出现此部分的网页源代码

通过以上步骤,抓包寻找,可以分别找到需求部分所要内容:
- 要获取到下一页的url所在页面源代码的位置
- 要获取到每种类型美女图片的url
- 要找到一种类型美女的各种图片下载的url
- 对美女网页进行requests请求,需要有请求头,找到请求网页的url、user-agent、cookie等信息
- 找到各种分类标签的url
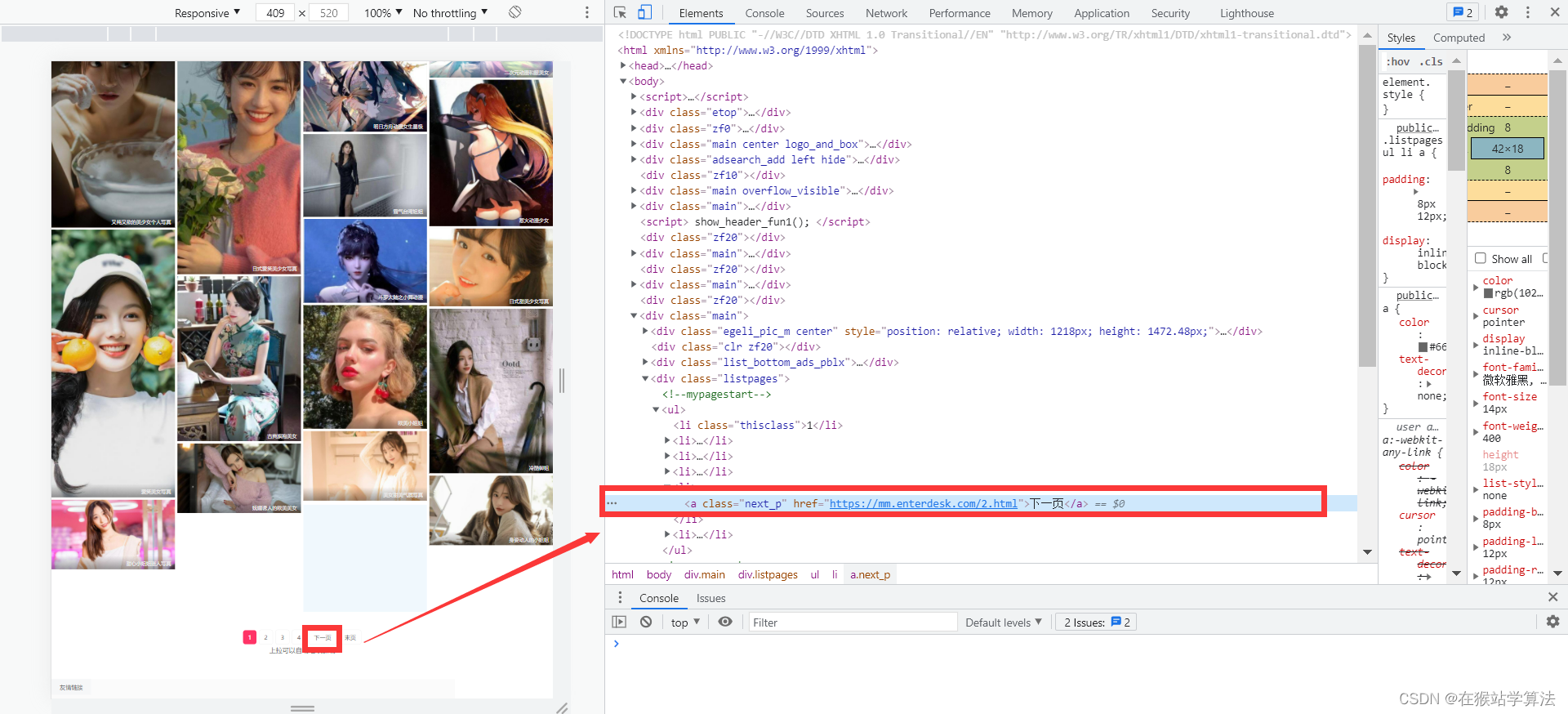


d、总结特点
经过抓包搜寻,可以发现:
- 美女页面每一页的url的构造为:以数字进行标记页码
'https://m.mm.enterdesk.com/1.html' 'https://m.mm.enterdesk.com/2.html' 'https://m.mm.enterdesk.com/3.html' 'https://m.mm.enterdesk.com/4.html' 'https://m.mm.enterdesk.com/5.html'.... 'https://m.mm.enterdesk.com/262.html' 'https://m.mm.enterdesk.com/264.html'
- 美女页面的标签的url的构造为:以风格类型的中文拼音+meinv
'https://mm.enterdesk.com/dalumeinv/' 'https://mm.enterdesk.com/rihanmeinv/' 'https://mm.enterdesk.com/gangtaimeinv/' 'https://mm.enterdesk.com/dongmanmeinv/' 'https://mm.enterdesk.com/qingchunmeinv/' 'https://mm.enterdesk.com/oumeimeinv/'
- 其他的url需要通过xPath来定位,根据所在位置的特点来定位
美女页面的各种类型的美女图片链接xPath定位://div[@class="mbig_pic_list_li"]//dd//a/@href 一种类型美女图片的标题xPath定位://h1[@class="m_h1"]/a/text() 一种类型美女图片的图片的urlxPath定位://div[@class="swiper-wrapper"]//img/@src
2、编写爬虫代码
根据上面的抓包分析,可以编写爬虫代码。
具体代码思路为:
1. 获取图片页网页源代码
2. 提取所有图片的链接和标题
3. 下载并保存这组图片
4. 爬取目录页的各种类型美女图片的链接
5. 实现翻页下载
a、获取图片页网页源代码
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36','cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)b、提取所有图片的链接和标题
def get_curindex_titlecontent(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)titles = html.xpath('//h1[@class="m_h1"]/a/text()')pictures = html.xpath('//div[@class="marc_pandn"]//div[@class="swiper-slide"]//img/@src')return titles, picturesc、下载并保存这组图片
def updownload(index_url):titles,pictures = get_curindex_titlecontent(index_url)titles = titles[0]# 创建目录if not os.path.exists(f'图片/{titles}/'):os.makedirs(f'图片/{titles}')num = 1for link in pictures:r = requests.get(link, headers=header).contentwith open(f'图片/{titles}/{titles}{num}.jpg', 'wb') as f:f.write(r)print(f"已下载...{titles}...编号为{num}的图片")num+=1d、 爬取目录页的各种类型美女图片的链接
def get_curindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')return linkse、实现翻页
def get_nextindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="listpages"]//a[@class="next_p"]/@href')return links三、各种需求的爬虫代码
1、下载所有美女图片
由于美女图片数量较大,不建议使用这种情况。
思路:想要下载所有图片。在第一页的美女页面,下载完这一页图片后,通过获取下一页的链接,来刷新到第二页的美女页面,继续下载第二页的美女图片。然后继续获取下一页来刷新,直到下载到最后一页。最后一页是没有下一页的链接的,所以到了最后一页,获取下一页的代码会报错。但是没有关系,这里已经下载完了所有美女图片。
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36','cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')return links
# 3、获取下一页的美女页面链接
def get_nextindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="listpages"]//a[@class="next_p"]/@href')return links
# 4、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)titles = html.xpath('//h1[@class="m_h1"]/a/text()')pictures = html.xpath('//div[@class="swiper-wrapper"]//img/@src')return titles, pictures
# 5、将图片进行下载保存到新的目录中
def updownload(index_url):titles,pictures = get_curindex_titlecontent(index_url)titles = titles[0]# 创建目录if not os.path.exists(f'图片/{titles}/'):os.makedirs(f'图片/{titles}')num = 1for link in pictures:r = requests.get(link, headers=header).contentwith open(f'图片/{titles}/{titles}{num}.jpg', 'wb') as f:f.write(r)print(f"已下载...{titles}...编号为{num}的图片")num+=1
# 6、根据顺序来调整调用顺序
# a、获取各种类型美女图片的链接
num = 1
a = 1
while 1:links = get_curindex_links(index_url)print(f"正在下载第{num}页")print(f"下载链接为:{index_url}")for link in links:
# b、获取其中一个链接的内容和标题并下载保存print(f"正在下载第{a}种类型的美女图片")updownload(link)a+=1num+=1next_page = get_nextindex_links(index_url)# 将列表转换成字符串index_url ="".join(next_page)
部分运行结果截图 :
2、下载想要页码范围内的美女图片
根据前面的总结特点,美女目录页面是根据1,2,3,4...来标记当前是第几页的。据此,可以通过读取键盘消息来下载自己想要范围内的美女图片。
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36','cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')return links
# 3、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)titles = html.xpath('//h1[@class="m_h1"]/a/text()')pictures = html.xpath('//div[@class="swiper-wrapper"]//img/@src')return titles, pictures
# 4、将图片进行下载保存到新的目录中
def updownload(index_url):titles,pictures = get_curindex_titlecontent(index_url)titles = titles[0]# 创建目录if not os.path.exists(f'图片/{titles}/'):os.makedirs(f'图片/{titles}')num = 1for link in pictures:r = requests.get(link, headers=header).contentwith open(f'图片/{titles}/{titles}{num}.jpg', 'wb') as f:f.write(r)print(f"已下载...{titles}...编号为{num}的图片")num+=1
# 5、根据顺序来调整调用顺序
# a、获取各种类型美女图片的链接
a = 1
# 输入自己想要的页码范围内的美女图片
x = input("请输入起始页的页码:")
y = input("请输入结束页的页码:")
# 因为range函数是左闭右开的情况,所以y需要自增1
for page in range(int(x), int(y)+1):new_index = index_url + str(page) + '.html'links = get_curindex_links(new_index)print(f"正在下载第{page}页")print(f"下载链接为:{new_index}")for link in links:# b、获取其中一个链接的内容和标题并下载保存print(f"正在下载第{a}种类型的美女图片")updownload(link)a+=1部分运行结果截图:

3、下载想要类型的美女图片
根据前面总结特点,可知各种标签的美女类型的url是通过输入中文拼音+meinv来进行标记的。则,可以通过读取键盘输入美女类型来下载想要类型的美女图片。这种情况下,存在两种需求。一是下载想要类型的所有的美女图片,二是下载想要类型的想要页码范围的美女图片。
a、下载想要类型的所有美女图片
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36','cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')return links
# 3、获取下一页的美女页面链接
def get_nextindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="listpages"]//a[@class="next_p"]/@href')return links
# 4、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)titles = html.xpath('//h1[@class="m_h1"]/a/text()')pictures = html.xpath('//div[@class="marc_pandn"]//div[@class="swiper-slide"]//img/@src')return titles, pictures
# 5、将图片进行下载保存到新的目录中
def updownload(index_url):titles,pictures = get_curindex_titlecontent(index_url)titles = titles[0]# 创建目录if not os.path.exists(f'图片/{keyword}/{titles}/'):os.makedirs(f'图片/{keyword}/{titles}')num = 1for link in pictures:r = requests.get(link, headers=header).contentwith open(f'图片/{keyword}/{titles}/{titles}{num}.jpg', 'wb') as f:f.write(r)print(f"已下载...{titles}...编号为{num}的图片")num+=1
# 6、根据键盘的输入来下载想要类型的美女图片
# a、读取键盘消息
keyword = input("请输入想要下载的类型的美女图片(中文拼音):")
index_url = index_url + keyword
num = 1
a = 1
while 1:links = get_curindex_links(index_url)print(f"正在下载第{num}页")print(f"下载链接为:{index_url}")for link in links:
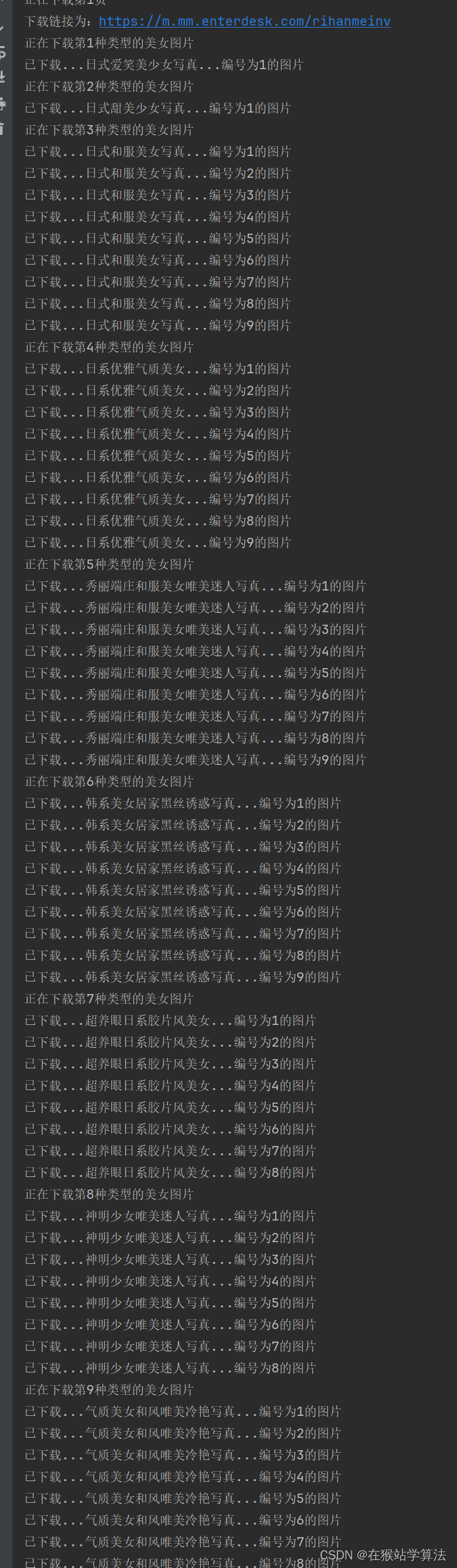
# b、获取其中一个链接的内容和标题并下载保存print(f"正在下载第{a}种类型的美女图片")updownload(link)a+=1num+=1next_page = get_nextindex_links(index_url)# 将列表转换成字符串index_url ="".join(next_page)部分截图如下:
b、下载想要类型的想要页码范围的美女图片
代码如下:
import os.path
from lxml import etree
import requests
# 1、获取回车桌面美女图片的网页源代码
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36','cookie':'Hm_lvt_86200d30c9967d7eda64933a74748bac=1707274876; t=8207bbae9940b5f445e4f3aa1907d202; r=9737; Hm_lpvt_86200d30c9967d7eda64933a74748bac=1707276063'}
index_url = 'https://m.mm.enterdesk.com/'
r = requests.get(index_url, headers=header)
# 2、获取当前回车桌面美女页面的各种美女类型图片的链接
def get_curindex_links(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)links = html.xpath('//div[@class="mbig_pic_list_li"]//dd//a/@href')return links
# 3、获取一种美女类型的图片及类型名
def get_curindex_titlecontent(index_url):r = requests.get(index_url, headers=header)html = etree.HTML(r.text)titles = html.xpath('//h1[@class="m_h1"]/a/text()')pictures = html.xpath('//div[@class="swiper-wrapper"]//img/@src')return titles, pictures
# 4、将图片进行下载保存到新的目录中
def updownload(index_url):titles,pictures = get_curindex_titlecontent(index_url)titles = titles[0]print(titles)# 创建目录if not os.path.exists(f'图片/{keyword}/{titles}/'):os.makedirs(f'图片/{keyword}/{titles}')num = 1for link in pictures:r = requests.get(link, headers=header).contentwith open(f'图片/{keyword}/{titles}/{titles}{num}.jpg', 'wb') as f:f.write(r)print(f"已下载...{titles}...编号为{num}的图片")num+=1
# 5、根据键盘的输入来下载想要类型的美女图片
# a、读取键盘消息
keyword = input("请输入想要下载的类型的美女图片(中文拼音):")
index_url = index_url + keyword +'/'
# 输入自己想要的页码范围内的美女图片
x = input("请输入起始页的页码:")
y = input("请输入结束页的页码:")
# 因为range函数是左闭右开的情况,所以y需要自增1
for page in range(int(x), int(y)+1):new_index = index_url + str(page) + '.html'links = get_curindex_links(new_index)print(f"正在下载第{page}页")print(f"下载链接为:{new_index}")for a, link in enumerate(links):# b、获取其中一个链接的内容和标题并下载保存print(f"正在下载第{page}页的第{a}种类型的美女图片")updownload(link)部分截图如下: 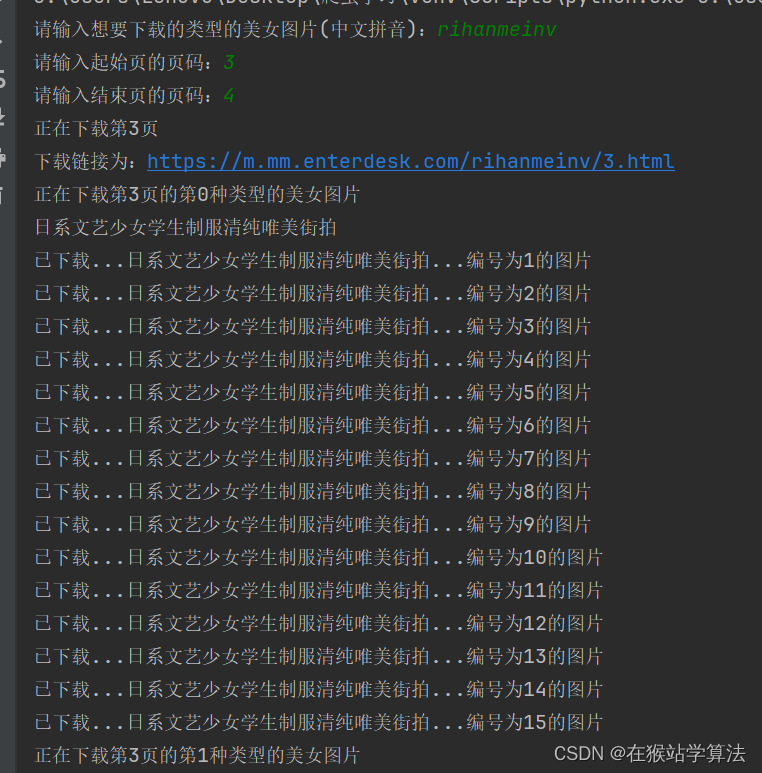
相关文章:
Python进阶--爬取美女图片壁纸(基于回车桌面网的爬虫程序)
目录 一、前言 二、爬取下载美女图片 1、抓包分析 a、分析页面 b、明确需求 c、抓包搜寻 d、总结特点 2、编写爬虫代码 a、获取图片页网页源代码 b、提取所有图片的链接和标题 c、下载并保存这组图片 d、 爬取目录页的各种类型美女图片的链接 e、实现翻页 三、各…...
[office] excel如何计算毛重和皮重的时间间隔 excel计算毛重和皮重时间间隔方法 #笔记#学习方法
excel如何计算毛重和皮重的时间间隔 excel计算毛重和皮重时间间隔方法 在日常工作中经常会到用excel,有时需要计算毛重和皮重的时间间隔,具体的计算方式是什么,一起来了解一下吧 在日常工作中经常会到用excel,在整理编辑过磅数据…...

Pandas 对带有 Multi-column(多列名称) 的数据排序并写入 Excel 中
Pandas 从Excel 中读取带有 Multi-column的数据 正文 正文 我们使用如下方式写入数据: import pandas as pd import numpy as npdf pd.DataFrame(np.array([[10, 2, 0], [6, 1, 3], [8, 10, 7], [1, 3, 7]]), columns[[Number, Name, Name, ], [col 1, col 2, co…...
)
如何为Kafka加上账号密码(一)
Kafka认证基本概念 一直以来,我们公司内网的Kafka集群都是在裸奔,只要知道端口号,任何人都能连上集群操作一番。直到有个主题莫名消失,才引起我们的警觉,是时候该考虑为它添加一套认证策略了。 认证和授权就是一对孪生…...
)
Elasticsearch的Index Lifecycle Management(ILM)
Elasticsearch的Index Lifecycle Management(ILM)功能提供了一种自动化管理索引生命周期的方式。ILM使得用户可以基于特定的条件(如索引的年龄、大小等)来自动执行如回滚、删除等操作,进而优化存储和提高查询性能。ILM…...

2、学习 Nacos 注册中心
学习 Nacos 注册中心 一、使用Nacos作为注册中心1、父pom.xml文件配置SpringCloudAlibaba的dependency-management依赖2、在微服务中添加Nacos客户端依赖3、配置Nacos服务地址 二、服务的分级存储模型1、配置实例的集群属性2、权重配置 三、命名空间 一、使用Nacos作为注册中心…...

Java 如何操作 nginx 服务器上的文件?
随着Java技术的不断发展,越来越多的开发人员开始使用Java来操作服务器上的文件。其中,如何操作nginx服务器上的文件也是许多Java开发人员所关注的重点之一。本文将介绍Java操作nginx服务器上文件的基本方法。 一、使用Java的File类 Java的File类可以用…...
时序预测 | MATLAB实现基于CNN-GRU-AdaBoost卷积门控循环单元结合AdaBoost时间序列预测
时序预测 | MATLAB实现基于CNN-GRU-AdaBoost卷积门控循环单元结合AdaBoost时间序列预测 目录 时序预测 | MATLAB实现基于CNN-GRU-AdaBoost卷积门控循环单元结合AdaBoost时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于CNN-GRU-AdaBo…...

中创ET4410 台式LCR数字电桥 简单开箱测评
最近买了一台LCR电桥,完善一下自己实验室的设备,选了中创ET4410,这款性价比高一点。 1199元在PDD买的,好像胜利的VC4090C也是找中创代工的。 ET4410介绍 本系列LCR数字电桥是采用自动平衡电桥原理设计的元件参数分析仪…...

格式化dingo返回内容
dingo api返回的内容中添加code 和 message ,保持与异常返回的内容格式相一致。 失败会存在code 和 message ,我们只需要关注成功的情况 非分页返回,可以创建一个父类controller,通过调用sucess方法来返回 class Controller ext…...
之四十六:minizip编译(Windows、Linux、MacOS环境下编译))
QGIS编译(跨平台编译)之四十六:minizip编译(Windows、Linux、MacOS环境下编译)
文章目录 一、minizip介绍二、minizip下载三、Linux下编译四、MacOS下编译五、Windows下编译一、minizip介绍 Minizip 是一个用于处理 ZIP 文件的开源库,它基于 zlib 库构建。zlib 是一个广泛使用的、免费的、开源的压缩库,提供数据压缩和解压缩功能。Minizip 扩展了 zlib 的…...
-索引的类型与创建)
MySQL进阶查询篇(1)-索引的类型与创建
MySQL数据库索引是提高查询效率的重要手段之一。索引是一种特殊的数据结构,用于快速定位数据。通过创建索引,可以大大提高查询性能,减少数据库的IO操作。 MySQL数据库支持多种不同类型的索引,常用的索引类型包括: B-…...
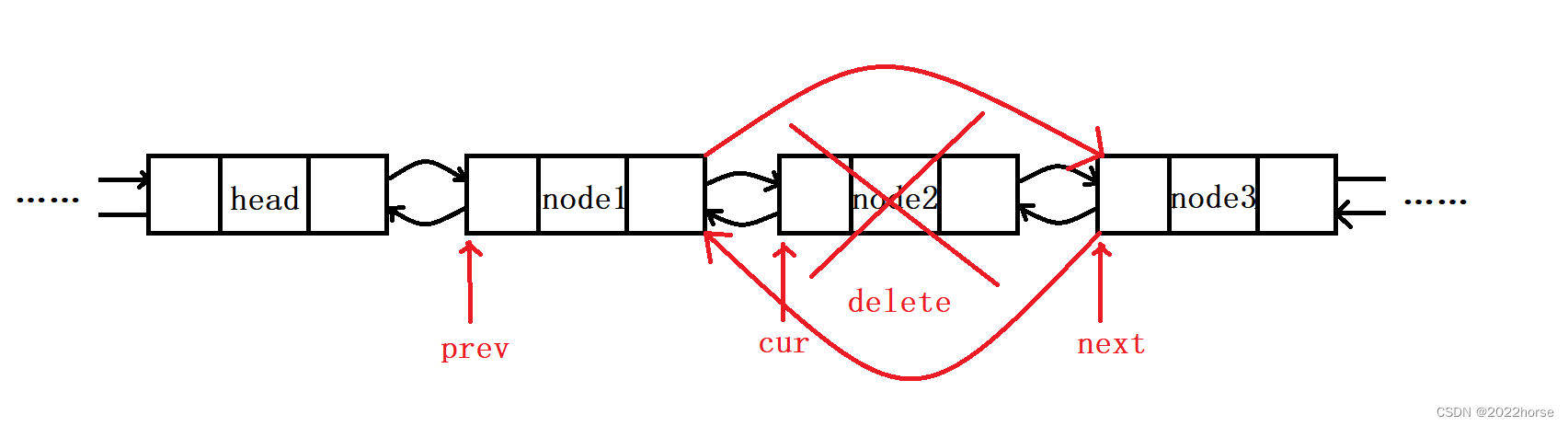
【STL】list模拟实现
vector模拟实现 一、接口大框架函数声明速览二、结点类的模拟实现1、构造函数 三、迭代器类的模拟实现1、迭代器类存在的意义2、迭代器类的模板参数说明3、构造函数4、运算符的重载(前置和后置)(1)前置(2)后…...

常用的文件系统、存储类型小整理
最近接触到了五花八门的文件系统、存储类型,名词听得头大,趁假期整理学习一番~ 名称OSSFastDFSJuiceFSCIFSCephFSEFSNFS全称Object Storage Service (对象存储服务)Fast Distributed File System (快速分布式文件系统)Juice File System (Juice 文件系统…...

Java写标准输出进度条
学Java这么久了,突发奇想写一个 进度条 玩玩,下面展示一下成功吧! Java代码实现如下 public class ProcessBar {public static void main(String[] args) {//进度条StringBuilder processBarnew StringBuilder();//进度条长度int total100;/…...
leetcode 算法 69.x的平方根(python版)
需求 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。 由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。 注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。 示例 1&#…...

【golang】24、go get 和 go mod:indrect 与 go mod tidy
文章目录 go get 会执行如下操作: 操作 go.mod 文件(add、update、remove)下载依赖到 $GOPATH/pkg/mod 中若已安装,则更新该包,到最新版本 试验前置准备:首先删除已下载的依赖,rm -rf $GOPATH…...

AI算法工程师-非leetcode题目总结
AI算法工程师-非leetcode题目总结 除了Leetcode你还需要这些实现nms旋转矩形IOU手动实现BN手动实现CONV实现CrossEntropyLoss 除了Leetcode你还需要这些 希望大家留言,我可以进行补充。持续更新~~~ 实现nms import numpy as np def nms(dets, threshold):x1 dets…...
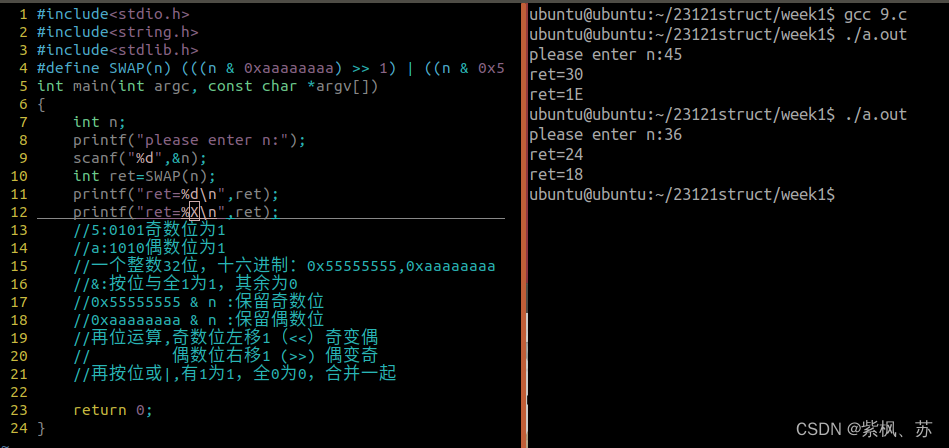
2.6:冒泡、简选、直插、快排,递归,宏
1.冒泡排序、简单选择排序、直接插入排序、快速排序(升序) 程序代码: 1 #include<stdio.h>2 #include<string.h>3 #include<stdlib.h>4 void Bubble(int arr[],int len);5 void simple_sort(int arr[],int len);6 void insert_sort(int arr[],in…...
FastDFS安装并整合Openresty
FastDFS安装并整合Openresty 一、安装环境准备【CentOS7.9】二、FastDFS--tracker安装2.1.下载fastdfs2.2.FastDFS安装环境2.3.安装FastDFS依赖libevent库2.4.安装libfastcommon2.5.安装 libserverframe 网络框架2.6.tracker编译安装2.7.安装之后文件目录介绍2.8.错误处理2.9.配…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...