sheng的学习笔记-网络爬虫scrapy框架
基础知识:
scrapy介绍
何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分,请求、响应、解析、存储,scrapy框架都已经搭建好了。scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架,scrapy使用了一种非阻塞的代码实现并发的
整体架构图

各组件:

数据处理流程

项目示例
环境搭建
下载依赖包
pip install wheel
下载twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
安装twisted:pip install Twisted-17.1.0-cp36m-win_amd64.whl (这个文件的路劲)
pip install pywin32
pip install scrapy
测试:在终端输入scrapy指令,没有报错表示安装成功
在anaconda中,可以直接装scrapy,会自动把依赖的包都装好pyopenssl要改成22.0.0版本,否则调用request的时候报错,anaconda会自动改一下依赖的别的包的版本
创建项目
创建项目叫spider
1、打开pycharm的terminal
2、scrapy startproject spider 创建项目
3、cd spider
4、scrapy genspider douban www.xxx.com 创建爬虫程序
5、需要有main.py里面的输出,则修改settings.py里面的ROBOTSTXT_OBEY = True改为False
6、scrapy crawl main
不需要额外的输出则执行scrapy crawl main --nolog
或者在settings.py里面添加LOG_LEVEL='ERROR',main.py有错误代码会报错(不添加有错误时则不会报错)(常用)
打开spider项目,里面有个spiders文件夹,称为爬虫文件夹,在这里放爬虫业务文件

项目代码
在douban.py里,写爬虫程序
此处是爬虫业务逻辑,爬到网站地址,对于爬虫返回结果的解析,在parse中做
根据应答的数据,解析,可以用xpath或者css解析,找到对应的数据
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponsefrom spider.items import MovieItemclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250']def start_requests(self):for page in range(10):yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')def parse(self, response: HtmlResponse, **kwargs):sel = Selector(response)list_items = sel.css("#content > div > div.article > ol > li")for list_item in list_items:movie_item = MovieItem()movie_item['title'] = list_item.css('span.title::text').extract_first()movie_item['rank'] = list_item.css('span.rating_num::text').extract_first()movie_item['subject'] = list_item.css('span.inq::text').extract_first()yield movie_item# href_list = sel.css('div.paginator > a::attr(href)')# for href in href_list:# url = response.urljoin(href.extract())
其中,将返回的值转化为对象,需要在item.py里改一下代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy#爬虫获取到到数据需要组装成item对象
class MovieItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()rank = scrapy.Field()subject = scrapy.Field()
执行爬虫
执行工程:scrapy crawl douban -o douban.csv (运行douban爬虫文件,并将结果生成到douban.csv里面)
如果被识别了是爬虫程序,在setting中设置一下user agent的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36' # User-Agent字符串
保存数据
默认可以支持保存到csv,json
保存到excel
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import openpyxl#将爬虫返回的数据持久化,先存放到excel
class ExcelPipeline:# 创建excel工作簿和工作表def __init__(self):self.wb = openpyxl.Workbook()# wb.create_sheet()self.ws = self.wb.active #激活工作表self.ws.title = "Top250" #改名字self.ws.append(('标题','评分','主题'))def close_spider(self,spider):self.wb.save('电影数据.xlsx')# item就是数据def process_item(self, item, spider):title = item.get('title','')rank = item.get('rank', '')subject = item.get('subject', '')self.ws.append((title,rank,subject))return item
在setting.py中改一下配置,找到这个注释,去掉注释
前面是管道名称,如果多个管道,在这里配置多个值,数字小的先执行,数字大的后执行
值要和类名字一致,我改了名字
ITEM_PIPELINES = {'spider.pipelines.ExcelPipeline': 300,
}

运行命令。 scrapy crawl douban
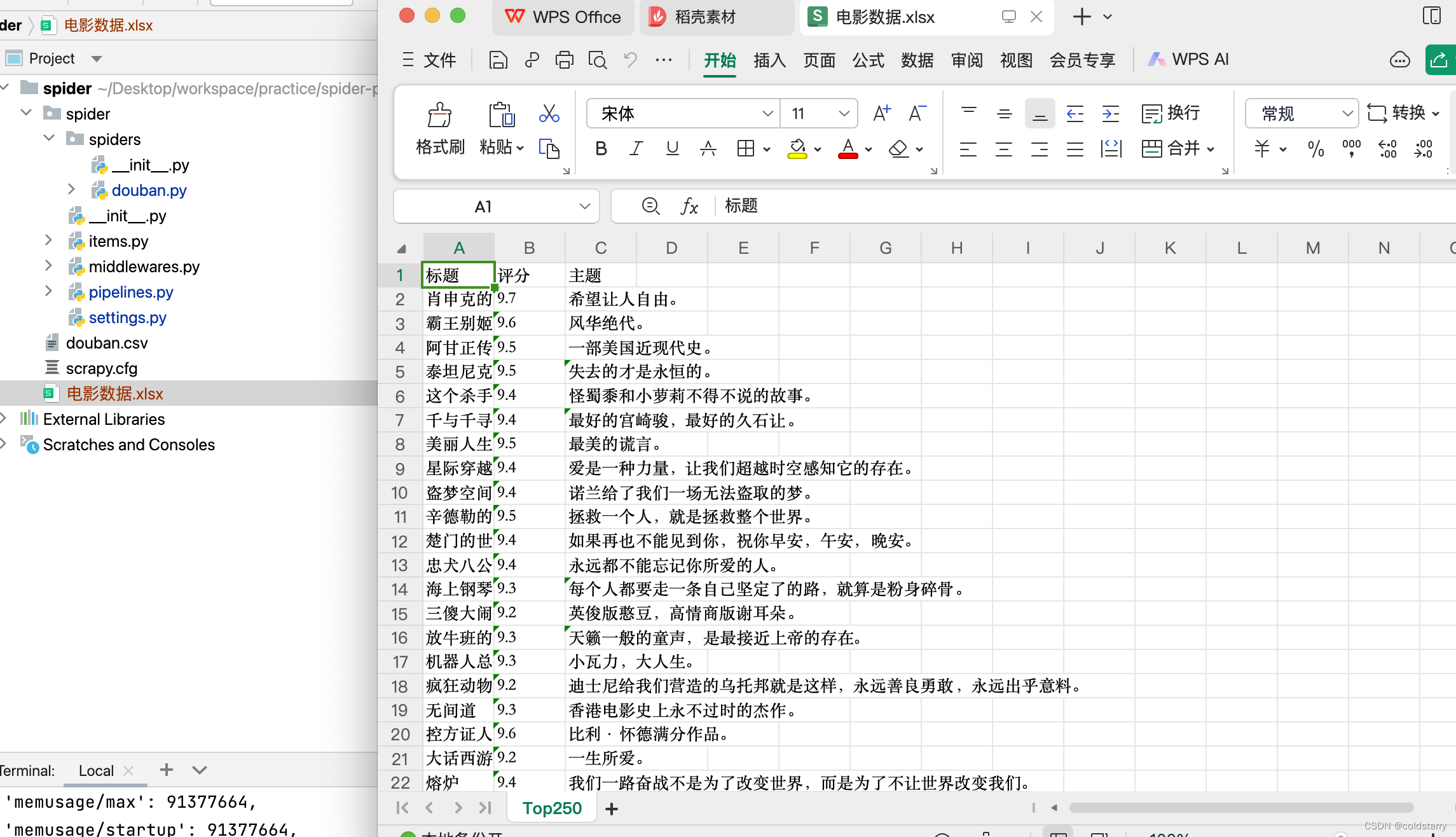
保存到数据库mysql
新增一个mysql的持久化逻辑,init的时候创建连接,process的时候插入,close的时候提交和关闭连接
建表语句
create table tb_top_move(
movie_id INT AUTO_INCREMENT PRIMARY KEY comment '编号',
title varchar(50) not null comment '标题',
rating decimal(3,1) not null comment '评分',
subject varchar(200) not null comment '主题'
) engine=innodb comment='Top电影表'# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import openpyxl
import pymysql#将爬虫返回的数据持久化,先存放到mysql
class MysqlPipeline:# 创建excel工作簿和工作表def __init__(self):#todo 设置db信息self.conn = pymysql.connect(host='127.0.0.1',port=,user='',password='',database='',charset='utf8mb4')self.cursor = self.conn.cursor()def close_spider(self,spider):self.conn.commit()self.conn.close()# item就是数据def process_item(self, item, spider):title = item.get('title', '')rank = item.get('rank', 0)subject = item.get('subject', '')self.cursor.execute('insert into tb_top_move(title,rating,subject) values (%s,%s,%s)',(title,rank,subject))return item#将爬虫返回的数据持久化,先存放到excel
class ExcelPipeline:# 创建excel工作簿和工作表def __init__(self):self.wb = openpyxl.Workbook()# wb.create_sheet()self.ws = self.wb.active #激活工作表self.ws.title = "Top250" #改名字self.ws.append(('标题','评分','主题'))def close_spider(self,spider):self.wb.save('电影数据.xlsx')# item就是数据def process_item(self, item, spider):title = item.get('title','')rank = item.get('rank', '')subject = item.get('subject', '')self.ws.append((title,rank,subject))return item
改下setting的配置
ITEM_PIPELINES = {'spider.pipelines.MysqlPipeline': 200,'spider.pipelines.ExcelPipeline': 300,
}
如果需要代理,可以用这种方式,在douban的py中修改

运行爬虫
scrapy crawl douban

多层爬虫
在爬了第一个页面,跟进内容爬第二个页面,比如在第一个汇总页面,想要知道《霸王别姬》中的时长和介绍,要点进去看到第二个页面

核心是douban.py中,parse函数yield返回的,是一个新的请求,并通过parse_detail作为回调函数进行第二层页面的解析
代码:
douban.py
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponsefrom spider.items import MovieItemclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250']def start_requests(self):for page in range(1):yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')def parse(self, response: HtmlResponse, **kwargs):sel = Selector(response)list_items = sel.css("#content > div > div.article > ol > li")for list_item in list_items:detail_url = list_item.css("div.info > div.hd > a::attr(href)").extract_first()movie_item = MovieItem()movie_item['title'] = list_item.css('span.title::text').extract_first()movie_item['rank'] = list_item.css('span.rating_num::text').extract_first()movie_item['subject'] = list_item.css('span.inq::text').extract_first() or ''# yield movie_itemyield Request(url=detail_url, callback=self.parse_detail,cb_kwargs={'item':movie_item})# href_list = sel.css('div.paginator > a::attr(href)')# for href in href_list:# url = response.urljoin(href.extract())def parse_detail(self,response,**kwargs):movie_item = kwargs['item']sel = Selector(response)movie_item['duration']=sel.css('span[property="v:runtime"]::attr(content)').extract()movie_item['intro']=sel.css('span[property="v:summary"]::text').extract_first() or ''yield movie_item/items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy#爬虫获取到到数据需要组装成item对象
class MovieItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()rank = scrapy.Field()subject = scrapy.Field()duration = scrapy.Field()intro = scrapy.Field()
/pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import openpyxl
import pymysql'''
建表语句
create table tb_top_move(
movie_id INT AUTO_INCREMENT PRIMARY KEY comment '编号',
title varchar(50) not null comment '标题',
rating decimal(3,1) not null comment '评分',
subject varchar(200) not null comment '主题',
duration int comment '时长',
intro varchar(10000) comment '介绍'
) engine=innodb comment='Top电影表'
'''#将爬虫返回的数据持久化,先存放到excel
class MysqlPipeline:# 创建excel工作簿和工作表def __init__(self):#todo 设置db信息self.conn = pymysql.connect(host='127.0.0.1',port=3306,user='lzs_mysql',password='lzs',database='mysql',charset='utf8mb4')self.cursor = self.conn.cursor()def close_spider(self,spider):self.conn.commit()self.conn.close()# item就是数据def process_item(self, item, spider):title = item.get('title', '')rank = item.get('rank', 0)subject = item.get('subject', '')duration = item.get('duration', '')intro = item.get('intro', '')self.cursor.execute('insert into tb_top_move(title,rating,subject,duration,intro) values (%s,%s,%s,%s,%s)',(title,rank,subject,duration,intro))return item#将爬虫返回的数据持久化,先存放到excel
class ExcelPipeline:# 创建excel工作簿和工作表def __init__(self):self.wb = openpyxl.Workbook()# wb.create_sheet()self.ws = self.wb.active #激活工作表self.ws.title = "Top250" #改名字self.ws.append(('标题','评分','主题'))def close_spider(self,spider):self.wb.save('电影数据.xlsx')# item就是数据def process_item(self, item, spider):title = item.get('title','')rank = item.get('rank', '')subject = item.get('subject', '')self.ws.append((title,rank,subject))return item
运行爬虫
scrapy crawl douban

中间件
中间件分为蜘蛛中间件和下载中间件
蜘蛛中间件一般不动
如果想要在请求中加上cookie,可以在中间件上的请求加上cookie信息
在middlewares.py类中,加上一个方法,获取cookie信息

修改middle的类

修改配置setting

参考文章:
02.使用Scrapy框架-1-创建项目_哔哩哔哩_bilibili
https://www.cnblogs.com/12345huangchun/p/10501673.html
Scrapy框架(高效爬虫)_scrapy爬虫框架-CSDN博客
相关文章:
sheng的学习笔记-网络爬虫scrapy框架
基础知识: scrapy介绍 何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总…...

Qt PCL学习(三):点云滤波
注意事项 版本一览:Qt 5.15.2 PCL 1.12.1 VTK 9.1.0前置内容:Qt PCL学习(一):环境搭建、Qt PCL学习(二):点云读取与保存、PCL学习六:Filtering-滤波 0. 效果演示 1. vo…...

Ainx-V0.2-简单的连接封装与业务绑定
📕作者简介: 过去日记,致力于Java、GoLang,Rust等多种编程语言,热爱技术,喜欢游戏的博主。 📗本文收录于Ainx系列,大家有兴趣的可以看一看 📘相关专栏Rust初阶教程、go语言基础系列…...

《杨绛传:生活不易,保持优雅》读书摘录
目录 书简介 作者成就 书中内容摘录 良好的家世背景,书香门第为求学打基础 求学相关 念大学 清华研究生 自费英国留学 法国留学自学文学 战乱时期回国 当校长 当小学老师 创造话剧 支持钱锺书写《围城》 出任震旦女子文理学院的教授 接受清华大学的…...

ChatGPT在肾脏病学领域的专业准确性评估
ChatGPT在肾脏病学领域的专业表现评估 随着人工智能技术的飞速发展,ChatGPT作为一个先进的机器学习模型,在多个领域显示出了其对话和信息处理能力的潜力。近期发表在《美国肾脏病学会临床杂志》(影响因子:9.8)上的一项…...

Centos7.9安装SQLserver2017数据库
Centos7.9安装SQLserver2017数据库 一、安装前准备 挂载系统盘 安装依赖 yum install libatomic* -y 二、yum方式安装 # 配置 yum 源 wget -O /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/7/mssql-server-2017.repoyum clean all yum…...
spring boot和spring cloud项目中配置文件application和bootstrap中的值与对应的配置类绑定处理
在前面的文章基础上 https://blog.csdn.net/zlpzlpzyd/article/details/136065211 加载完文件转换为 Environment 中对应的值之后,接下来需要将对应的值与对应的配置类进行绑定,方便对应的组件取值处理接下来的操作。 对应的配置值与配置类绑定通过 Con…...
)
每天一个数据分析题(一百五十四)
给定下面的Python代码片段,哪个选项正确描述了代码可能存在的问题? from scipy import stats 返回异常值的索引 z stats.zscore(data_raw[‘Age’]) z_outlier (z > 3) | (z < -3) z_outlier.tolist().index(1) A. 代码将返回数据集Age列中第…...

Django从入门到放弃
Django从入门到放弃 Django最初被设计用于具有快速开发需求的新闻类站点,目的是实现简单快捷的网站开发。 安装Django 使用anaconda创建环境 conda create -n django_env python3.10 conda activate django_env使用pip安装django python -m pip install Django查…...
C++中类的6个默认成员函数【构造函数】 【析构函数】
文章目录 前言构造函数构造函数的概念构造函数的特性 析构函数 前言 在学习C我们必须要掌握的6个默认成员函数,接下来本文讲解2个默认成员函数 构造函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,…...
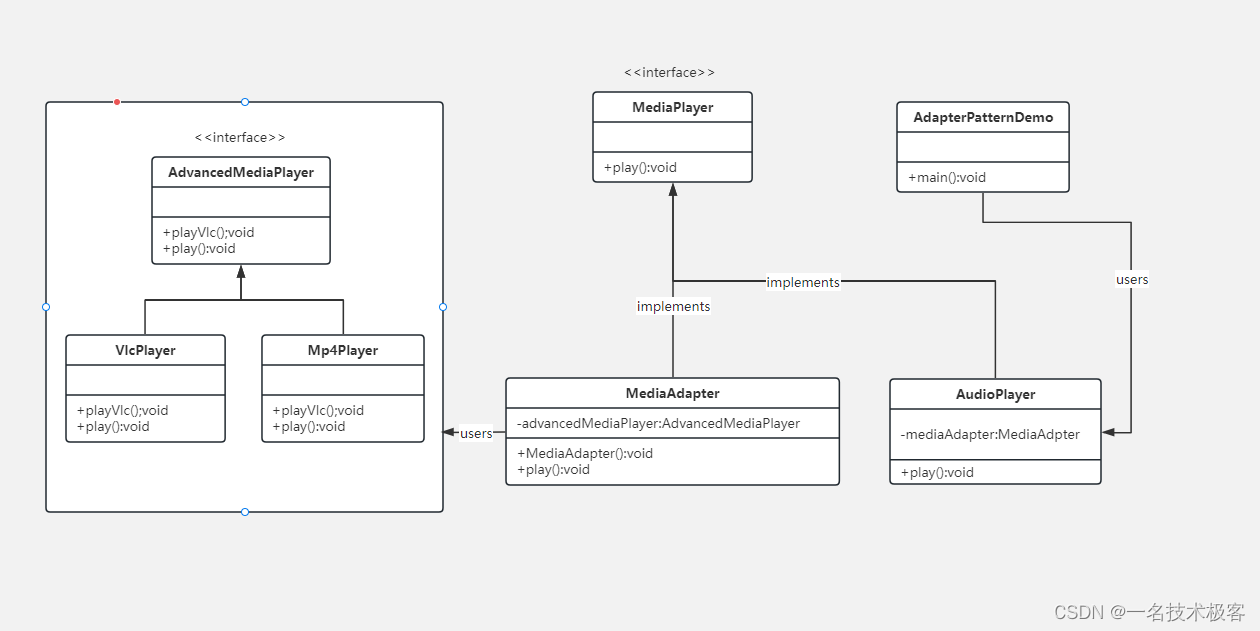
06-Java适配器模式 ( Adapter Pattern )
原型模式 摘要实现范例 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁 适配器模式涉及到一个单一的类,该类负责加入独立的或不兼容的接口功能 举个真实的例子,读卡器是作为内存卡和笔记本之间的适配器。您将内…...
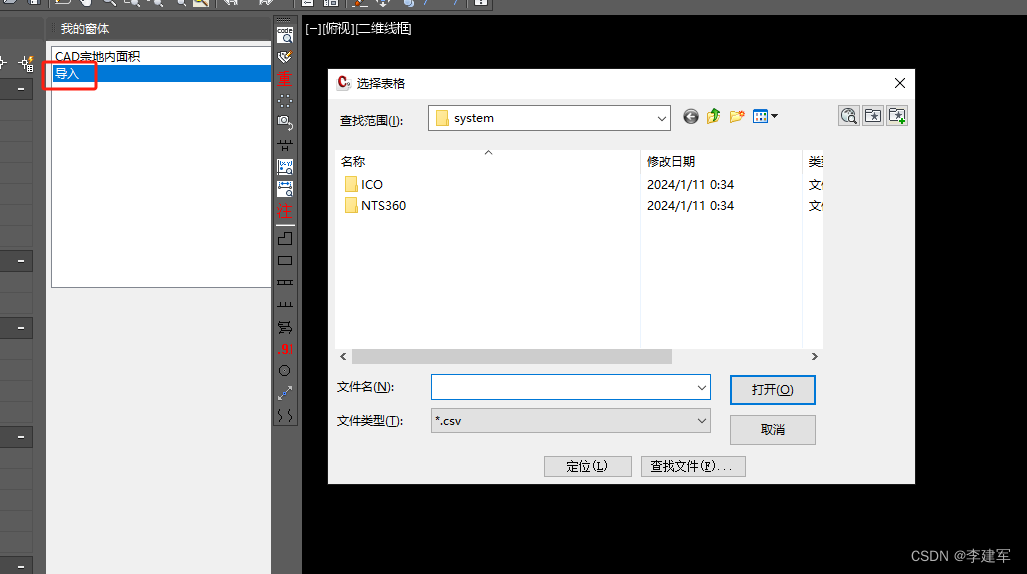
C# CAD交互界面-自定义面板集-添加快捷命令(五)
运行环境 vs2022 c# cad2016 调试成功 一、引用 using Autodesk.AutoCAD.ApplicationServices; using Autodesk.AutoCAD.Runtime; using Autodesk.AutoCAD.Windows; using System; using System.Drawing; using System.Windows.Forms; 二、代码说明 [CommandMethod("Cre…...

Spring boot集成各种数据源操作数据库
一、最基础的数据源方式 1.导入maven依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency <dependency><groupId>com.mysql</groupId><art…...
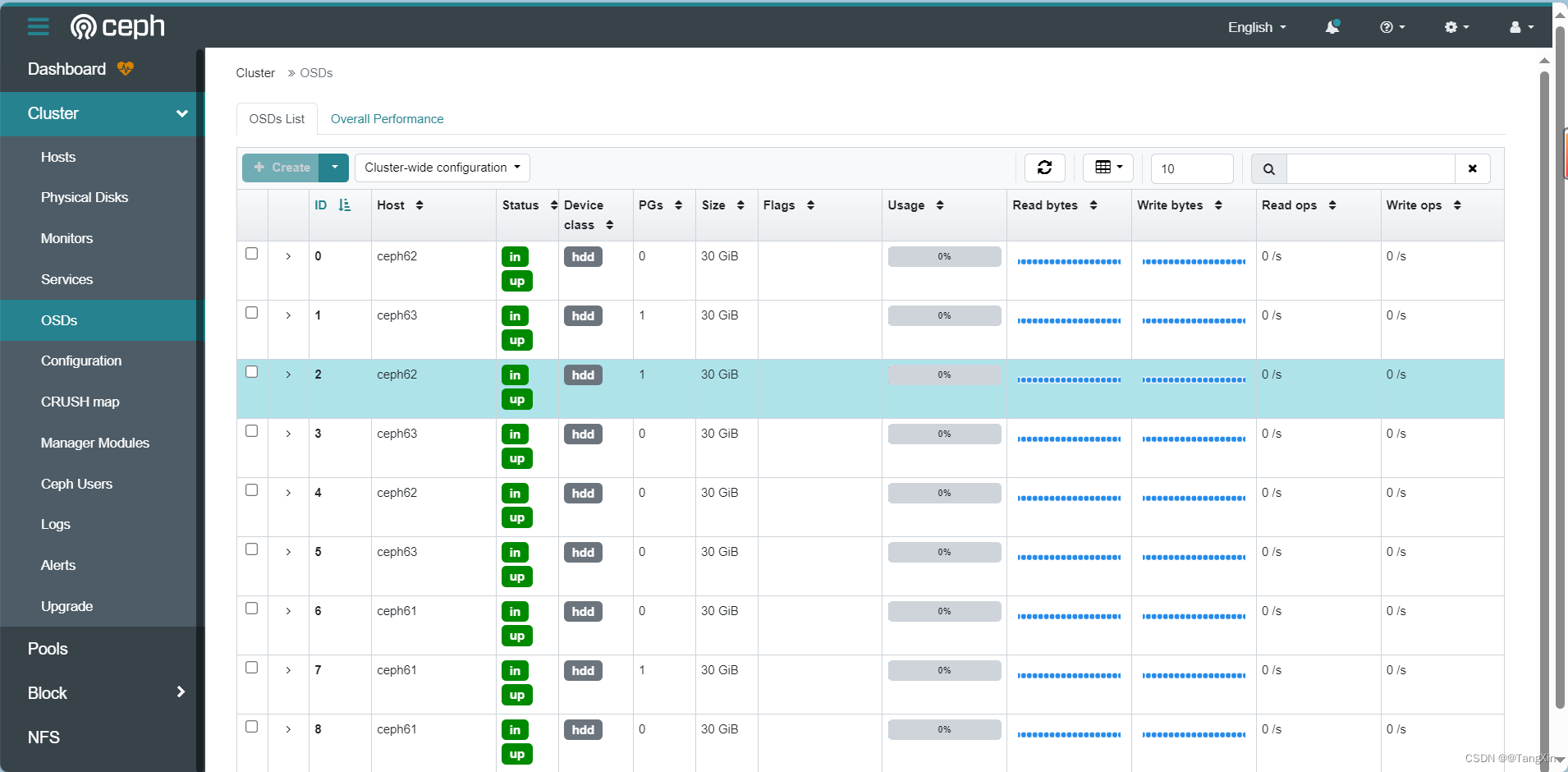
K8s环境下rook-v1.13.3部署Ceph-v18.2.1集群
文章目录 1.K8s环境搭建2.Ceph集群部署2.1 部署Rook Operator2.2 镜像准备2.3 配置节点角色2.4 部署operator2.5 部署Ceph集群2.6 强制删除命名空间2.7 验证集群 3.Ceph界面 1.K8s环境搭建 参考:CentOS7搭建k8s-v1.28.6集群详情,把K8s集群完成搭建&…...

【JavaEE】传输层网络协议
传输层网络协议 1. UDP协议 1.1 特点 面向数据报(DatagramSocket)数据报大小限制为64k全双工不可靠传输有接收缓冲区,无发送缓冲区 UDP的特点,我理解起来就是工人组成的**“人工传送带”**: 面向数据报(…...
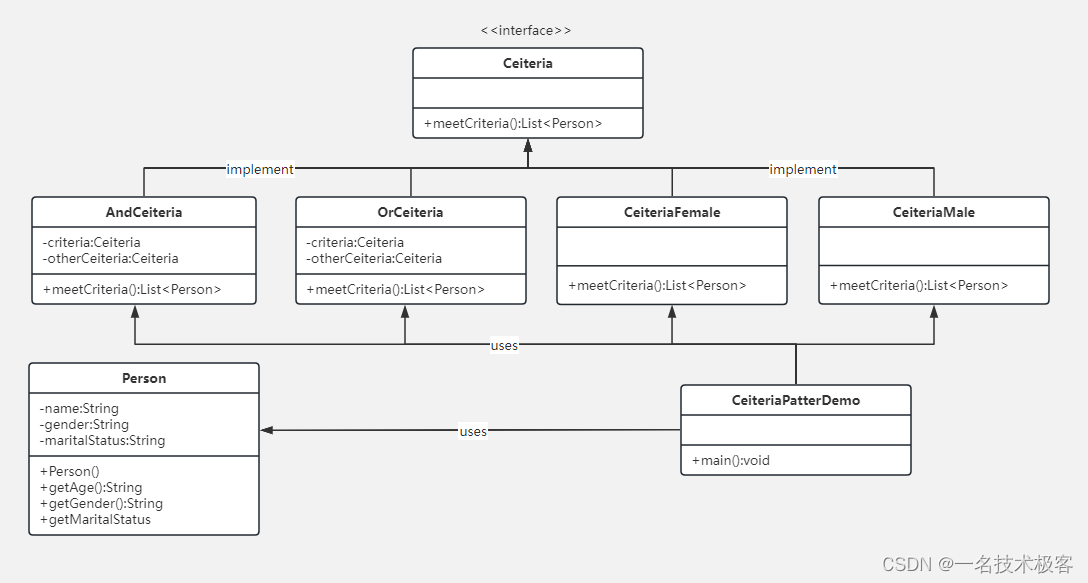
08-Java过滤器模式 ( Filter Pattern )
Java过滤器模式 实现范例 过滤器模式(Filter Pattern)或允许开发人员使用不同的标准来过滤一组对象,通过逻辑运算以解耦的方式把它们连接起来 过滤器模式(Filter Pattern) 又称 标准模式(Criteria Pattern…...

ChatGPT高效提问—prompt常见用法(续篇八)
ChatGPT高效提问—prompt常见用法(续篇八) 1.1 对抗 对抗是一个重要主题,深入探讨了大型语言模型(LLM)的安全风险。它不仅反映了人们对LLM可能出现的风险和安全问题的理解,而且能够帮助我们识别这些潜在的风险,并通过切实可行的技术手段来规避。 截至目前,网络…...

微软.NET6开发的C#特性——接口和属性
我是荔园微风,作为一名在IT界整整25年的老兵,看到不少初学者在学习编程语言的过程中如此的痛苦,我决定做点什么,下面我就重点讲讲微软.NET6开发人员需要知道的C#特性,然后比较其他各种语言进行认识。 C#经历了多年发展…...

容器基础知识:容器和虚拟化的区别
虚拟化与容器化对比 容器化和虚拟化都是用于优化资源利用率并实现高效应用程序部署的技术。然而,它们在方法和关键特征上存在差异: 虚拟化: 可以理解为创建虚拟机 (VM)。虚拟机模拟一台拥有自己硬件(CPU、内存、存储)和操作系统…...
【Linux】vim的基本操作与配置(下)
Hello everybody!今天我们继续讲解vim的操作与配置,希望大家在看过这篇文章与上篇文章后都能够轻松上手vim! 1.补充 在上一篇文章中我们说过了,在底行模式下set nu可以显示行号。今天补充一条:set nonu可以取消行号。这两条命令大家看看就可…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...

es6+和css3新增的特性有哪些
一:ECMAScript 新特性(ES6) ES6 (2015) - 革命性更新 1,记住的方法,从一个方法里面用到了哪些技术 1,let /const块级作用域声明2,**默认参数**:函数参数可以设置默认值。3&#x…...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...