MongoDB聚合:$unionWith
$unionWith聚合阶段执行两个集合的合并,将两个集合的管道结果合并到一个结果集传送到下一个阶段。合并后的结果文档的顺序是不确定的。
语法
{ $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }
要包含集合的所有文档不进行任何处理,可以使用简化形式:
{ $unionWith: "<collection>" } // 包含指定集合的所有文档
使用
参数字段:
| 字段 | 描述 |
|---|---|
coll | 希望在结果集中包含的集合或视图管道的结果 |
pipeline | 可选,应用于coll的聚合管道[<stage1>, <stage2>, ....],聚合管道不能包含$out和$merge阶段。从v6.0开始,管道可以在第一个阶段包含$search阶段 |
$unionWith操作等价于下面的SQL语句:
SELECT *
FROM Collection1
WHERE ...
UNION ALL
SELECT *
FROM Collection2
WHERE ...
重复的结果
前一阶段的合并结果和$unionWith阶段的合并结果可能包含重复结果。例如,创建一个suppliers 集合和一个warehouses 集合:
db.suppliers.insertMany([{ _id: 1, supplier: "Aardvark and Sons", state: "Texas" },{ _id: 2, supplier: "Bears Run Amok.", state: "Colorado"},{ _id: 3, supplier: "Squid Mark Inc. ", state: "Rhode Island" },
])
db.warehouses.insertMany([{ _id: 1, warehouse: "A", region: "West", state: "California" },{ _id: 2, warehouse: "B", region: "Central", state: "Colorado"},{ _id: 3, warehouse: "C", region: "East", state: "Florida" },
])
下面的聚合合并了聚合suppliers和warehouse的state’字段投影结果。
db.suppliers.aggregate([{ $project: { state: 1, _id: 0 } },{ $unionWith: { coll: "warehouses", pipeline: [ { $project: { state: 1, _id: 0 } } ]} }
])
结果包含重复的文档
{ "state" : "Texas" }
{ "state" : "Colorado" }
{ "state" : "Rhode Island" }
{ "state" : "California" }
{ "state" : "Colorado" }
{ "state" : "Florida" }
要要去除重复,可以加个$group阶段,按照state字段分组:
db.suppliers.aggregate([{ $project: { state: 1, _id: 0 } },{ $unionWith: { coll: "warehouses", pipeline: [ { $project: { state: 1, _id: 0 } } ]} },{ $group: { _id: "$state" } }
])
这样结果就没有重复的文档了:
{ "_id" : "California" }{ "_id" : "Texas" }{ "_id" : "Florida" }{ "_id" : "Colorado" }{ "_id" : "Rhode Island" }
$unionWith 分片集合
如果$unionWith阶段是$lookup管道的一部分,则$unionWith的coll被分片。例如,在下面的聚合操作中,不能对inventory_q1集合进行分片:
db.suppliers.aggregate([{$lookup: {from: "warehouses",let: { order_item: "$item", order_qty: "$ordered" },pipeline: [...{ $unionWith: { coll: "inventory_q1", pipeline: [ ... ] } },...],as: "stockdata"}}
])
限制
- 聚合管道不能在事务中使用
$unionWith - 如果
$unionWith阶段是$lookup管道的一部分,则$unionWith的集合不能被分片 unionWith管道不能包含out阶段unioWith管道不能包含merge阶段
举例
用多年的数据集合创建销售报告
下面示例使用$unionWith阶段来合并数据并返回多个集合的结果,在这些示例中,每个集合都包含一年的销售数据。
填充样本数据:
分别创建sales_2017、sales_2018、sales_2019、sales_2019四个集合并填充数据:
db.sales_2017.insertMany( [{ store: "General Store", item: "Chocolates", quantity: 150 },{ store: "ShopMart", item: "Chocolates", quantity: 50 },{ store: "General Store", item: "Cookies", quantity: 100 },{ store: "ShopMart", item: "Cookies", quantity: 120 },{ store: "General Store", item: "Pie", quantity: 10 },{ store: "ShopMart", item: "Pie", quantity: 5 }
] )
db.sales_2018.insertMany( [{ store: "General Store", item: "Cheese", quantity: 30 },{ store: "ShopMart", item: "Cheese", quantity: 50 },{ store: "General Store", item: "Chocolates", quantity: 125 },{ store: "ShopMart", item: "Chocolates", quantity: 150 },{ store: "General Store", item: "Cookies", quantity: 200 },{ store: "ShopMart", item: "Cookies", quantity: 100 },{ store: "ShopMart", item: "Nuts", quantity: 100 },{ store: "General Store", item: "Pie", quantity: 30 },{ store: "ShopMart", item: "Pie", quantity: 25 }
] )
db.sales_2019.insertMany( [{ store: "General Store", item: "Cheese", quantity: 50 },{ store: "ShopMart", item: "Cheese", quantity: 20 },{ store: "General Store", item: "Chocolates", quantity: 125 },{ store: "ShopMart", item: "Chocolates", quantity: 150 },{ store: "General Store", item: "Cookies", quantity: 200 },{ store: "ShopMart", item: "Cookies", quantity: 100 },{ store: "General Store", item: "Nuts", quantity: 80 },{ store: "ShopMart", item: "Nuts", quantity: 30 },{ store: "General Store", item: "Pie", quantity: 50 },{ store: "ShopMart", item: "Pie", quantity: 75 }
] )
db.sales_2020.insertMany( [{ store: "General Store", item: "Cheese", quantity: 100, },{ store: "ShopMart", item: "Cheese", quantity: 100},{ store: "General Store", item: "Chocolates", quantity: 200 },{ store: "ShopMart", item: "Chocolates", quantity: 300 },{ store: "General Store", item: "Cookies", quantity: 500 },{ store: "ShopMart", item: "Cookies", quantity: 400 },{ store: "General Store", item: "Nuts", quantity: 100 },{ store: "ShopMart", item: "Nuts", quantity: 200 },{ store: "General Store", item: "Pie", quantity: 100 },{ store: "ShopMart", item: "Pie", quantity: 100 }
] )
按照year、store和item的销售额
db.sales_2017.aggregate( [{ $set: { _id: "2017" } },{ $unionWith: { coll: "sales_2018", pipeline: [ { $set: { _id: "2018" } } ] } },{ $unionWith: { coll: "sales_2019", pipeline: [ { $set: { _id: "2019" } } ] } },{ $unionWith: { coll: "sales_2020", pipeline: [ { $set: { _id: "2020" } } ] } },{ $sort: { _id: 1, store: 1, item: 1 } }
] )
$set阶段用于更新_id字段,使其包含年份$unionWith阶段,将四个集合中的所有文档合并在一起,每个文档也使用$set阶段$sort阶段,按照_id(年份)、store和item进行排序
管道输出:
{ "_id" : "2017", "store" : "General Store", "item" : "Chocolates", "quantity" : 150 }
{ "_id" : "2017", "store" : "General Store", "item" : "Cookies", "quantity" : 100 }
{ "_id" : "2017", "store" : "General Store", "item" : "Pie", "quantity" : 10 }
{ "_id" : "2017", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 50 }
{ "_id" : "2017", "store" : "ShopMart", "item" : "Cookies", "quantity" : 120 }
{ "_id" : "2017", "store" : "ShopMart", "item" : "Pie", "quantity" : 5 }
{ "_id" : "2018", "store" : "General Store", "item" : "Cheese", "quantity" : 30 }
{ "_id" : "2018", "store" : "General Store", "item" : "Chocolates", "quantity" : 125 }
{ "_id" : "2018", "store" : "General Store", "item" : "Cookies", "quantity" : 200 }
{ "_id" : "2018", "store" : "General Store", "item" : "Pie", "quantity" : 30 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Cheese", "quantity" : 50 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 150 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Cookies", "quantity" : 100 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Nuts", "quantity" : 100 }
{ "_id" : "2018", "store" : "ShopMart", "item" : "Pie", "quantity" : 25 }
{ "_id" : "2019", "store" : "General Store", "item" : "Cheese", "quantity" : 50 }
{ "_id" : "2019", "store" : "General Store", "item" : "Chocolates", "quantity" : 125 }
{ "_id" : "2019", "store" : "General Store", "item" : "Cookies", "quantity" : 200 }
{ "_id" : "2019", "store" : "General Store", "item" : "Nuts", "quantity" : 80 }
{ "_id" : "2019", "store" : "General Store", "item" : "Pie", "quantity" : 50 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Cheese", "quantity" : 20 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 150 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Cookies", "quantity" : 100 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Nuts", "quantity" : 30 }
{ "_id" : "2019", "store" : "ShopMart", "item" : "Pie", "quantity" : 75 }
{ "_id" : "2020", "store" : "General Store", "item" : "Cheese", "quantity" : 100 }
{ "_id" : "2020", "store" : "General Store", "item" : "Chocolates", "quantity" : 200 }
{ "_id" : "2020", "store" : "General Store", "item" : "Cookies", "quantity" : 500 }
{ "_id" : "2020", "store" : "General Store", "item" : "Nuts", "quantity" : 100 }
{ "_id" : "2020", "store" : "General Store", "item" : "Pie", "quantity" : 100 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Cheese", "quantity" : 100 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Chocolates", "quantity" : 300 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Cookies", "quantity" : 400 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Nuts", "quantity" : 200 }
{ "_id" : "2020", "store" : "ShopMart", "item" : "Pie", "quantity" : 100 }
根据item汇总销售额
db.sales_2017.aggregate( [{ $unionWith: "sales_2018" },{ $unionWith: "sales_2019" },{ $unionWith: "sales_2020" },{ $group: { _id: "$item", total: { $sum: "$quantity" } } },{ $sort: { total: -1 } }
] )
$unionWith阶段将文档从指定的集合检索到管道中$group阶段按item字段分组,并使用$sum计算每个item的总销售量$sort阶段按合计降序排列文档
结果:
{ "_id" : "Cookies", "total" : 1720 }
{ "_id" : "Chocolates", "total" : 1250 }
{ "_id" : "Nuts", "total" : 510 }
{ "_id" : "Pie", "total" : 395 }
{ "_id" : "Cheese", "total" : 350 }
相关文章:

MongoDB聚合:$unionWith
$unionWith聚合阶段执行两个集合的合并,将两个集合的管道结果合并到一个结果集传送到下一个阶段。合并后的结果文档的顺序是不确定的。 语法 { $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }要包含集合的所有文档不…...

人工智能三子棋-人机对弈-人人对弈,谁会是最终赢家?
✅作者简介:大家好我是原始豌豆,感谢支持。 🆔本文由 原始豌豆 原创 CSDN首发🐒 如需转载还请通知⚠ 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:C语言项目实践…...
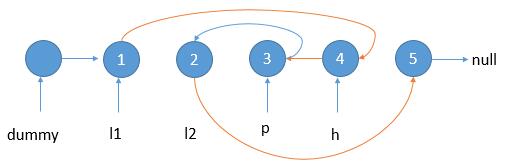
【leetcode热题100】反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出:[1,4,3,2…...

谷歌 DeepMind 联合斯坦福推出了主从式遥操作双臂机器人系统增强版ALOHA 2
谷歌 DeepMind 联合斯坦福推出了 ALOHA 的增强版本 ——ALOHA 2。与一代相比,ALOHA 2 具有更强的性能、人体工程学设计和稳健性,且成本还不到 20 万元人民币。并且,为了加速大规模双手操作的研究,ALOHA 2 相关的所有硬件设计全部开…...

金融行业专题|证券超融合架构转型与场景探索合集(2023版)
更新内容 更新 SmartX 超融合在证券行业的覆盖范围、部署规模与应用场景。新增操作系统信创转型、Nutanix 国产化替代、网络与安全等场景实践。更多超融合金融核心生产业务场景实践,欢迎阅读文末电子书。 在金融行业如火如荼的数字化转型大潮中,传统架…...

【C语言】C的整理记录
前言 该笔记是建立在已经系统学习过C语言的基础上,笔者对C语言的知识和注意事项进行整理记录,便于后期查阅,反复琢磨。C语言是一种面向过程的编程语言。 原想在此阐述一下C语言的作用,然而发觉这些是编程语言所共通的作用&#…...
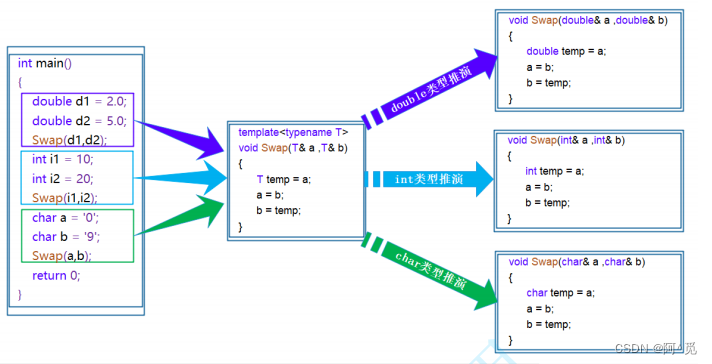
C/C++模板初阶
目录 1. 泛型编程 2. 函数模板 2.1 函数模板概念 2.1 函数模板格式 2.3 函数模板的原理 2.4 函数模板的实例化 2.5 模板参数的匹配原则 3. 类模板 3.1 类模板的定义格式 3.2 类模板的实例化 1. 泛型编程 如何实现一个通用的交换函数呢? void Swap(int&…...
linux系统下vscode portable版本的c++/Cmake环境搭建001
linux系统下vscode portable版本的Cmake环境搭建 vscode portable 安装安装基本工具安装 build-essential安装 CMake final script code安装插件CMake Tools & cmakeC/C Extension Pack Testsettings,jsonCMakeLists.txt调试和运行工具 CG 目的:希望在获得一个新…...

【QT+QGIS跨平台编译】之三十一:【FreeXL+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、FreeXL介绍二、文件下载三、文件分析四、pro文件五、编译实践一、FreeXL介绍 【FreeXL跨平台编译】:Windows环境下编译成果(支撑QGIS跨平台编译,以及二次研发) 【FreeXL跨平台编译】:Linux环境下编译成果(支撑QGIS跨平台编译,以及二次研发) 【FreeXL跨平台…...

2024年 前端JavaScript入门到精通 第一天
主要讲解JavaScript核心知识,包含最新ES6语法,从基础到API再到高级。让你一边学习一边练习,重点知识及时实践,同时每天安排大量作业,加深记忆,巩固学习成果。 1.1 基本软件与准备工作 1.2 JavaScript 案例 …...

155基于matlab 的形态学权重自适应图像去噪
基于matlab 的形态学权重自适应图像去噪;通过串并联的滤波降噪对比图,说明并联降噪的优越性。输出降噪前后图像和不同方法的降噪情况的信噪比。程序已调通,可直接运行。 155matlab 自适应图像降噪 串并联降噪 (xiaohongshu.com)...
操作系统——内存管理(附带Leetcode算法题LRU)
目录 1.内存管理主要用来干什么? 2.什么是内存碎片? 3.虚拟内存 3.1传统存储管理方式的缺点? 3.2局部性原理 3.3什么是虚拟内存?有什么用? 3.3.1段式分配 3.3.2页式分配 3.3.2.1换页机制 3.3.2.2页面置换算法…...

I/O多路复用简记
IO多路复用(服务器如何处理多个socket的同时数据传输):1、select。2、poll。3、epoll。 select使用bitmap存socket文件描述符,由bitmap槽位的每一位为0或1决定对应序的socket连接是否有数据到来。由单线程(多线程处理每…...

SPECCPU2017操作说明
1、依赖包下载 yum install gcc* gfortran* 2、将软件包放至被测机器 3、增加权限 chmod X install.sh 4、运行安装 ./install.sh 5、运行 引入编译时所需的环境变量和相关库文件 source shrc 进入/spec2017,执行 ./runcpu -c ../config/Example-gcc-linux-ar…...

openresty (nginx)快速开始
文章目录 一、什么是openresty?二、openresty编译安装1. 编译安装命令1.1 编译完成后路径1.2 常用编译选项解释 2. nginx配置文件配置2.1 nginx.conf模板 3. nginx常见配置一个站点配置多个域名nginx配置中location匹配规则 三、OpenResty工作原理OpenResty工作原理…...

相机图像质量研究(11)常见问题总结:光学结构对成像的影响--像差
系列文章目录 相机图像质量研究(1)Camera成像流程介绍 相机图像质量研究(2)ISP专用平台调优介绍 相机图像质量研究(3)图像质量测试介绍 相机图像质量研究(4)常见问题总结:光学结构对成像的影响--焦距 相机图像质量研究(5)常见问题总结:光学结构对成…...
【深度学习】基于多层感知机的手写数字识别
案例2:构建自己的多层感知机: MNIST手写数字识别 相关知识点: numpy科学计算包,如向量化操作,广播机制等 1 任务目标 1.1 数据集简介 MNIST手写数字识别数据集是图像分类领域最常用的数据集之一,它包含60,000张训练图片&am…...
,构造一个n*m的矩阵a,使得每个4*4的子矩阵,左上角2*2的子矩阵的异或和等于右下角的,左下角的异或和等于右上角的)
给定n,m(200),构造一个n*m的矩阵a,使得每个4*4的子矩阵,左上角2*2的子矩阵的异或和等于右下角的,左下角的异或和等于右上角的
题目 #include <bits/stdc.h> using namespace std; #define int long long #define pb push_back #define fi first #define se second #define lson p << 1 #define rson p << 1 | 1 const int maxn 1e6 5, inf 1e18 5, maxm 4e4 5, mod 998244353…...

【开源】基于JAVA+Vue+SpringBoot的假日旅社管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 系统介绍2.2 QA 问答 三、系统展示四、核心代码4.1 查询民宿4.2 新增民宿评论4.3 查询民宿新闻4.4 新建民宿预订单4.5 查询我的民宿预订单 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的假日旅社…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...