LLM大模型常见问题解答(2)
对大模型基本原理和架构的理解
大型语言模型如GPT(Generative Pre-trained Transformer)系列是基于自注意力机制的深度学习模型,主要用于处理和生成人类语言。
基本原理
- 自然语言理解:模型通过对大量文本数据的预训练,学习到语言的统计规律,从而能够在不同的语言任务上表现出自然语言理解的能力。
- 迁移学习:GPT类模型首先在一个广泛的数据集上进行预训练,以掌握语言的通用表示,然后可以在特定任务上进行微调(fine-tuning),以适应特定的应用场景。
- 生成能力:这类模型不仅能够理解输入的文本,还能够生成连贯、相关的文本,使其在对话系统、文本生成、摘要等应用中非常有价值。
架构特点
- Transformer架构:GPT模型基于Transformer架构,该架构由编码器和解码器组成,但GPT仅使用了解码器部分。Transformer利用自注意力机制来捕获输入序列中不同位置之间的关系。
- 自注意力机制:允许模型在处理序列的每个元素时动态地聚焦于序列中的其他元素,这在理解上下文关系时尤其重要。
- 多层堆叠:GPT模型由多层Transformer解码器块堆叠而成,每层包括自注意力层和前馈神经网络,以及归一化层和残差连接,以帮助避免在训练深层网络时出现的梯度消失问题。
- 位置编码:
对于输入文本序列,首先通过输入层(InputEmbedding)将每个单词转换为其相对应的向量表示。序列中不再有任何信息能够提示模型单词之间的相对位置关系。在送入编码器端建模其上下文语义之前,一个非常重要的操作是在词嵌入中加入位置编码(PositionalEncoding)这一特征。
位置编码(Positional Encoding) 是在 Transformer 模型中引入的一种技术,用于为序列中的每个位置添加位置信息。由于 Transformer 模型没有使用循环神经网络或卷积神经网络,无法直接捕捉到序列中单词之间的相对位置关系。位置编码的目的是为了提供序列中单词的位置信息,以便模型能够更好地理解序列中单词之间的顺序关系。位置编码使用正弦和余弦函数生成。具体公式如下.

其中 pos 表示单词在序列中的位置(索引),i表示位置编码向量中对应的维度(索引),dmodel 表示位置编码的总维度(模型的隐藏单元数目)。
位置编码可以通过将其与词嵌入相加来获得最终的输入表示。这样做可以将位置信息与语义信息相结合,使模型能够更好地理解序列中单词之间的相对位置关系。
使用大模型以及优化模型的方法
项目中使用大模型的方法
在项目中使用大型模型通常遵循以下步骤:
(1)需求分析与确定目标
- 确定项目需求和业务目标,明确大模型需要解决的问题或提升的性能指标。
(2)数据收集与预处理
- 收集足够的、高质量的训练数据。
- 进行数据清洗,去除噪声和异常值,确保数据质量。
- 实施数据预处理,如标准化、归一化、编码分类变量等。
(3)模型选择
- 根据问题的特性选择合适的大模型框架,如BERT,GPT等。
- 评估是否需要自定义模型或使用预训练模型。
(4)功能实现
- 设计模型输入输出及其结构,例如确定神经网络层数、连接方式、激活函数等。
- 实现数据到模型的输入流程,如特征工程、embedding层的设计等。
(5)模型训练与验证
- 使用GPU或TPU等硬件加速训练过程。
- 应用诸如交叉验证等技术来评估模型的泛化能力。
- 监控训练过程中的关键指标,如损失函数值、准确率等。
(6)模型评估
- 在独立测试集上评估模型表现。
- 使用适当的评价指标,如精确度、召回率、F1分数、ROC-AUC等。
(7)模型部署
- 将训练好的模型部署到生产环境。
- 实现API接口供其他系统或用户调用模型。
- 确保模型在部署环境下的稳定性和可扩展性。
(8)监控与更新
- 持续监控模型的性能,以便及时发现退化情况。
- 定期使用新数据更新模型以维持其准确性和相关性。
微调大模型
微调大型语言模型(LLM)是一种自定义模型以适应特定任务或数据集的方法。以下是微调大型语言模型的典型步骤:
1. 明确微调目标
确定你希望通过微调模型达到什么目的,例如提高在特定领域数据上的表现、适应新的文本风格或术语、解决一个具体的问题。
2. 数据准备
- 数据收集:根据微调的目标,收集或创建一个与目标任务相关的数据集。
- 数据预处理:清洗数据、去除噪音、执行必要的文本规范化等。
- 数据分割:将数据分为训练集、验证集和测试集。
3. 选择基础模型
选择一个适合你任务的预训练语言模型作为起点。这可以是GPT-3、BERT、chatgml等。
4. 定义微调设置
- 微调超参数:设置学习率、批大小、epoch数等。
- 模型架构调整(可选):如果需要,可以对模型的架构进行修改,如增加层、改变激活函数等。
5. 微调环境准备
- 硬件准备:确保有足够的计算资源,通常需要使用GPU或TPU。
- 软件依赖:安装所有必要的库和框架,如PyTorch、TensorFlow等。
6. 微调过程
- 加载预训练模型:使用所选的框架加载预训练模型。
- 微调训练:在特定于任务的数据上训练模型,调整模型权重。
- 监控:在训练过程中监控性能指标,如损失函数值和验证集上的精度。
7. 模型评估
- 使用测试集来评估微调后模型的性能。
- 如果有必要,根据评估结果反复调整超参数并重新训练模型。
8. 应用与部署
- 将微调后的模型集成到下游应用中。
- 部署模型到生产环境。
9. 监测与维护
- 监控模型在实际使用中的表现。
- 根据需要进行维护和进一步微调。
注意事项
- 伦理与合规性: 在数据收集和使用模型时,确保遵守隐私、伦理和法律标准。
- 偏见和公平性: 检查和缓解可能在数据或模型中存在的任何偏见。
- 数据代表性: 确保数据集能够代表实际应用场景中的数据分布。
优化模型的方法
优化大型模型涉及多个方面,包括但不限于:
1.计算效率优化
1)模型剪枝(Model Pruning)
模型剪枝通过移除模型中不重要的参数或神经元来减少模型复杂性,可以提高推理速度,并在一定程度上减少过拟合。剪枝策略包括但不限于权重剪枝、单元剪枝和结构化剪枝。
2) 知识蒸馏(Knowledge Distillation)
知识蒸馏通常是指将一个大型、复杂的“教师”模型的知识转移到一个小型的“学生”模型中。这样做可以让小模型在保持较低计算成本的同时,尽可能地接近大模型的性能。
3) 量化(Quantization)
量化是一种将模型参数和激活函数从浮点数(例如32位float)转换为低位宽度的表示(例如8位整数)。这可以显著减少模型大小和加速推理过程,特别是对于部署在移动和边缘设备的场景。
4) 使用混合精度训练
2.软件级优化(Software level optimization)
- 混合精度训练:使用不同的数据类型(如16-bit半精度浮点数和32-bit单精度浮点数)进行计算,以平衡训练速度和模型表现(减少内存占用并加速训练)
- 并行计算和分布式训练:利用多GPU或多节点进行模型训练,有效降低训练时间。
- 高效的数据加载和预处理:优化数据管道,确保CPU/GPU资源的最大利用率。
3.数据加载优化(Data loading optimization)
使用多线程或异步I/O操作来加速数据加载和预处理
4. 架构搜索和设计(Architecture Search and Design)
- 神经架构搜索(NAS):自动寻找符合特定任务需求的最优模型架构。
- 模块化设计:通过组件化设计使得模型更容易扩展和修改。
- 轻量级模型结构:研发或应用如MobileNets, EfficientNets等轻量级但仍然强大的网络架构。
旋转位置编码及其优点
旋转位置编码(Rotation Position Encoding,RoPE)是一种用于为序列数据中的每个位置添加旋转位置信息的编码方法。RoPE的思路是通过引入旋转矩阵来表示位置之间的旋转关系,从而捕捉序列中位置之间的旋转模式。
传统的绝对位置编码和相对位置编码方法主要关注位置之间的线性关系,而忽略了位置之间的旋转关系。然而,在某些序列数据中,位置之间的旋转关系可能对于模型的理解和预测是重要的。例如,在一些自然语言处理任务中,单词之间的顺序可能会发生旋转,如句子重排或句子中的语法结构变化。
RoPE通过引入旋转矩阵来捕捉位置之间的旋转关系。具体而言,RoPE使用一个旋转矩阵,将每个位置的位置向量与旋转矩阵相乘,从而获得旋转后的位置向量。这样,模型可以根据旋转后的位置向量来识别和理解位置之间的旋转模式。
RoPE的优势在于它能够捕捉到序列数据中位置之间的旋转关系,从而提供了更丰富的位置信息。这对于一些需要考虑位置旋转的任务,如自然语言推理、自然语言生成等,尤为重要。RoPE的引入可以帮助模型更好地理解和建模序列数据中的旋转模式,从而提高模型的性能和泛化能力。
旋转位置编码(RoPE)是一种用于位置编码的改进方法,相比于传统的位置编码方式,RoPE具有以下优点:
解决位置编码的周期性问题:传统的位置编码方式(如Sinusoidal Position Encoding)存在一个固定的周期,当序列长度超过该周期时,位置编码会出现重复。这可能导致模型在处理长序列时失去对位置信息的准确理解。RoPE通过引入旋转操作,可以解决这个周期性问题,使得位置编码可以适应更长的序列。
更好地建模相对位置信息:传统的位置编码方式只考虑了绝对位置信息,即每个位置都有一个唯一的编码表示。然而,在某些任务中,相对位置信息对于理解序列的语义和结构非常重要。RoPE通过旋转操作,可以捕捉到相对位置信息,使得模型能够更好地建模序列中的局部关系。
更好的泛化能力:RoPE的旋转操作可以看作是对位置编码进行了一种数据增强操作,通过扩展位置编码的变化范围,可以提高模型的泛化能力。这对于处理不同长度的序列以及在测试时遇到未见过的序列长度非常有帮助。
总体而言,RoPE相比于传统的位置编码方式,在处理长序列、建模相对位置信息和提高泛化能力方面具有一定的优势。这些优点可以帮助模型更好地理解序列数据,并在各种自然语言处理任务中取得更好的性能。
损失函数和优化算法
在训练和优化大型人工智能模型时,根据不同的任务类型和建模策略,我们会选择相应的损失函数和优化算法。下面是一些常用损失函数和优化算法的分类总结:
损失函数
对于回归问题
- 均方误差损失(MSE):当预测输出是连续值且假设误差为正态分布时。
- 平均绝对误差(MAE):对异常值具有更高的鲁棒性。
- Huber损失:介于MSE和MAE之间,对异常值适度鲁棒。
- 对数余弦相似性损失:当想要比较两个向量之间的角度差异而不是数值差异时使用。
对于二分类问题
- 二元交叉熵损失:当目标变量为0或1时,衡量模型预测概率与实际标签的差异。
对于多分类问题
- 多类别交叉熵损失:当有多个类别且每个样本只属于一个类别时。
- 稀疏多类别交叉熵损失:类似于多类别交叉熵损失,但适用于类别标签以整数形式给出的情况。
特定领域的损失函数
- 结构化损失函数:如序列到序列模型中的编辑距离等,用于结构化输出空间。
- 对抗损失:在生成对抗网络(GANs)中,区分生成器和判别器的学习过程。
- 三重项损失(Triplet Loss):在度量学习和面部识别等任务中,目的是使得相似的样本靠近,不同的样本远离。
处理类不平衡的损失函数
- 焦点损失(Focal Loss):对难以分类的样本赋予更高的权重,广泛用于解决前景和背景类不平衡的目标检测问题。
优化算法
基本算法
- 随机梯度下降(SGD):最基础的优化方法,适用于大规模数据集。
带动量的算法
- SGD with Momentum:加速SGD并减小震荡,适用于需要克服局部极小值或鞍点的情况。
自适应学习率算法
- Adagrad:适合处理稀疏数据。
- RMSprop:解决了Adagrad学习率急剧下降的问题,适合处理非平稳目标。
- Adam:结合了momentum和RMSprop的优点,对于很多问题都提供了良好的默认配置。
- AdamW:在Adam的基础上加入L2正则化,通常带来更好的泛化性能。
- AdaDelta:改进版的RMSprop,无需手动设置学习率。
大规模训练中的优化算法
- LAMB (Layer-wise Adaptive Moments optimizer for Batch training):针对大批量数据开发,用于大模型和大规模分布式训练。
- LARS (Layer-wise Adaptive Rate Scaling):配合大批量数据进行有效的分布式训练
大规模的数据处理
在面对大规模数据处理的问题时,通常会遵循一个系统化的流程来确保数据是准确、可用和具有分析价值的。以下是处理步骤:
1. 数据清洗
在数据清洗阶段,首要任务是识别并纠正数据集中的错误和不一致性。
- 缺失值处理:根据数据的性质和缺失情况,可以采取多种策略,如删除含有缺失值的记录、填充缺失值(均值、中位数、众数、预测模型等)或者使用算法(例如K近邻)来估计缺失值。
- 异常值检测与处理:可使用统计测试(如IQR、Z-score)来识别异常值,并根据业务逻辑考虑是否需要修正或移除这些值。
- 数据格式标准化:确保所有数据遵循同一格式标准,比如日期时间格式、货币单位、文本编码等。
- 去重:移除数据中的重复记录,以避免在分析时产生偏差。
2. 数据预处理
- 数据转换:包括归一化(将数据缩放到一个小的特定范围)、标准化(基于数据的均值和标准差),以便模型更好地理解数据的结构。
- 数据编码:对分类数据进行编码,如独热编码(One-Hot Encoding)、标签编码(Label Encoding)或使用诸如Word Embedding对文本数据进行编码。
- 时间序列数据处理:如果处理时间序列数据,可能需要考虑数据平滑、趋势和季节性分解、差分等技术来使数据稳定。
- 数据划分:将数据集分为训练集、验证集和测试集,以便进行模型开发和评估。
3. 特征工程
- 特征选择:通过技术如相关性分析、卡方检验、互信息、递归特征消除(RFE)等方法,选择最有影响力的特征。
- 特征构造:结合业务知识和数据探索结果,构建新的特征,以更好地捕获数据中的模式。
- 特征转换:运用主成分分析(PCA)、因子分析、t-SNE等降维技术来减少特征空间,同时尽量保留原始数据的信息。
- 特征学习:利用深度学习方法自动学习特征表示,尤其在图像、音频和文本数据上效果显著。
4. 处理大规模数据集的特别考虑
- 分布式处理:使用如Apache Hadoop、Spark等
使用GPU来加速模型训练和推理
GPU加速计算是指使用图形处理单元(GPU)来加速运算密集型和并行度高的计算任务。GPU最初设计用于处理复杂的图形和图像处理算法,但它们的架构特别适合执行可以并行化的数学和工程计算任务。与传统的中央处理单元(CPU)相比,GPU有成百上千个较小、更专业的核心,这使得它们在处理多个并发操作方面非常有效。
GPU加速计算是通过将计算任务分配到多个GPU核心上并行处理来实现加速的。在模型的训练和推理过程中,通常使用GPU来加速矩阵乘法、卷积等计算密集型操作。通过将数据和模型权重从CPU内存复制到GPU内存中,并使用GPU加速库(如CUDA、cuDNN等)来进行计算,可以大大加快模型的训练和推理速度。
在深度学习和机器学习领域,模型训练和推理涉及到大量的矩阵和向量运算,这些运算可以被分解成小的、可以并行处理的任务。正因为这种计算性质,使用GPU通常会显著提升训练和推理过程的效率。如何使用GPU加速模型训练和推理的:
- 硬件选择:首先确保有访问权限的硬件资源包含支持CUDA(Compute Unified Device Architecture)的NVIDIA GPU,这是目前应用最广泛的平台进行GPU加速。
- 环境配置:安装相应的驱动程序、CUDA Toolkit以及深度学习框架(如TensorFlow、PyTorch等)的GPU版本。这些软件配合工作,能够让开发者通过简洁的API调用GPU进行计算。
- 模型设计时考虑并行性:在设计模型时,优化网络结构以便它能够利用GPU的并行处理能力。例如,选择合适的批处理大小(batch size),既不至于造成内存溢出,也要足够大以填满GPU的计算能力。
- 数据预处理:使用GPU加速数据预处理过程,如图像的缩放、归一化等操作。这可以通过深度学习框架的相关功能实现,如利用TensorFlow的
tf.dataAPI。 - 并行数据加载和增强:在训练时,并行地从磁盘加载数据并进行数据增强,以确保GPU在训练时始终保持充分利用,减少I/O操作导致的闲置时间。
- 优化计算图:使用深度学习框架的自动优化功能,它可以优化计算图,减少不必要的计算,合并可以合并的操作,以减少执行操作的次数。
- 精度调整:根据需要,使用混合精度训练(例如,结合FP32和FP16),这可以减少内存的使用,并可能进一步加速训练过程,尤其是在具备Tensor Cores的新型GPU上。
- 分布式训练:对于非常大的模型或数据集,可以使用多个GPU进行分布式训练,通过策略如模型并行化或数据并行化,在多个GPU间划分工作负载。
- 监控和调优:使用NVIDIA提供的工具,如NVIDIA Visual Profiler和NSight,监控GPU的使用情况,识别瓶颈,并进一步调优以提高效率。
通过这些方法,可以充分利用GPU强大的并行处理能力,大幅度提升模型训练和推理的速度。
模型部署和应用时的稳定性和性能
在大模型的部署和应用方面,以下是通常使用的工具和技术,以及如何确保模型的稳定性和性能:
工具和技术
1. 模型优化工具
- TensorRT:针对NVIDIA GPU优化的高性能深度学习推理(inference)引擎。
- ONNX (Open Neural Network Exchange):提供了一个开放格式来表示深度学习模型,并与ONNX Runtime配合,可以跨不同框架和硬件平台获得一致性的优化。
2. 服务化框架
- TensorFlow Serving、TorchServe:专为生产环境设计的系统,用于部署机器学习模型,支持模型版本控制、模型监测等高级功能。
- Triton Inference Server:支持多种框架、模型并发执行和动态批量处理的推理服务器。
3. 容器化技术
- Docker 和 Kubernetes:使用这些工具将模型封装成容器,便于快速部署、扩展和管理。
4. 云服务和自动化部署
- 利用 AWS Sagemaker、Azure ML、Google AI Platform 等云服务,它们提供了端到端的机器学习生命周期管理。
5. 自动扩缩容
- 结合使用负载均衡器和自动扩缩容策略,根据流量需求自动调整计算资源。
确保稳定性和性能
- 模型量化和简化:对模型进行量化(减少数值精度)和剪枝(移除冗余节点)来降低延时和内存占用,同时尽量保持模型性能。
- 压力测试和基准测试:使用工具如 Locust 或 JMeter 进行压力测试和基凌测试,确保系统在高负载下也能维持稳定运行。
- 持续集成和持续部署 (CI/CD):实施CI/CD流程,自动化模型的测试和部署流程,快速反馈问题并修复。
- 监控和日志:使用 Prometheus、Grafana、ELK stack (Elasticsearch, Logstash, Kibana) 等工具实时监控系统性能和收集日志,快速诊断和解决问题。
- 异常检测和自愈策略:实现异常检测机制和自愈策略,如当模型服务出现问题时自动重启服务或切换到备用实例。
- A/B 测试和金丝雀发布:在实际环境中,采用A/B测试和金丝雀发布策略逐渐更新模型,确保新版本的模型不会影响现有系统的稳定性。
- 资源隔离和优先级设置
资源隔离
资源隔离是指在硬件资源(如CPU、GPU、内存、存储等)使用上,确保不同模型或任务之间相互隔离,以免争用导致性能下降或服务中断。资源隔离可以通过以下方法实现:
1)虚拟化技术
- 使用虚拟机(VMs)或容器技术(如Docker)来隔离不同的应用。
- 为每个模型分配独立的计算资源,确保它们不会因为共享底层硬件而相互干扰。
2) 集群管理系统
- 使用Kubernetes等集群管理系统可以高效地处理容器化工作负载的调度与隔离。
- 可以设置资源配额和限制,避免单个任务占用过多资源。
3) 服务级别的隔离
- 在微服务架构中,每个服务可以运行在独立的资源环境中。
- 确保关键服务,如模型推理服务,获取必需的计算资源。
4) 网络隔离
- 网络流量控制和带宽限制也是确保稳定性的重要方面。
- 防止大量数据传输时对其他服务造成影响。
优先级设置
确保关键任务优先执行,非关键任务在资源紧张时可以暂缓或降级:
1) 优先级队列
- 利用作业队列管理请求,并根据预设优先级处理任务。
- 例如,可以给实时用户请求的模型推理任务更高的优先级,而对于离线批量处理任务则可以降低优先级。
2) 负载监控与动态调整
- 实时监控系统负载情况,当检测到资源压力时,自动降低低优先级任务的资源分配。
- 动态调整服务的规模(如自动扩展),以适应不断变化的负载。
3) 优先级感知的调度器
- 开发或使用支持优先级设置的调度器,确保系统按照既定优先级执行任务。
- 这些调度器可以根据任务的紧急程度和重要性来调整资源分配。
4) 服务质量(QoS)策略
- 通过定义不同服务级别协议(SLAs),明确各类任务对资源的需求。
- QoS策略可确保即使在高负载
选择预训练模型并进行微调
选择适合自己的基座模型(foundation model)需要考虑多种因素,包括你的应用领域、资源限制、可用技术和特定任务需求。以下是选择基座模型时可能需要考虑的情况:
应用领域
- 通用文本处理:如果需要进行文本生成、分类、摘要等通用语言任务,可以选用像GPT-3或BERT这样的大型通用语言模型。
- 专业领域(比如医疗或法律):在这种情况下,你可能需要一个已经针对特定领域预训练过的模型,例如BioBERT(医疗领域BERT变种)。
资源限制
- 计算资源丰富:如果有足够的计算资源,可以使用最先进的大型模型,如GPT-4或T5。
- 计算资源受限:在资源受限的情况下,可以选择DistilBERT、MobileBERT等小型化模型,它们旨在保持较好的性能同时减少资源消耗。
技术可用性
- 无需微调能力:如果不打算对模型进行微调,那么可以选择零售即用型API服务,如OpenAI提供的GPT-3.5 API。
- 需要微调能力:如果需要根据自己的数据集对模型进行微调,可能需要选择可以下载并自行训练的开源模型,比如http://huggingface.co提供的各类Transformer模型。
任务需求
- 文本生成:GPT-3.5是一个强大的文本生成模型,在创作故事、代码、文章等方面表现出色。
- 文本理解:BERT及其变体(比如RoBERTa、ALBERT等)在文本分类、问答任务和实体识别等方面表现优异。
举例说明:科研团队需要在生物医药领域进行文献挖掘
- 可以选择Domain-specific的模型,如BioBERT,该模型针对生物医学文献进行了预训练,能更好地理解相关术语和概念。
- 初创公司希望构建聊天机器人服务客户:
- 初期可能资源有限,可以选择使用DistilGPT或者轻量级的ALBERT,并结合Transfer Learning技术进行微调以满足特定任务需求。
- 大型企业希望分析客户反馈来进行情感分析:
- 可以直接使用预训练的BERT或其变种,并在具有大量客户反馈的数据上进行微调,以提高情感分类的准确度。
当然,这些仅是指导性意见。实际选择时,还需要综合考虑数据隐私、成本效益、模型的可解释性、稳定性等其他因素。
对NLP中些基本任务和方法的理解
自然语言处理(NLP)是人工智能领域的一个分支,它涉及到理解、解释和操作人类语言的各种任务。以下是对于NLP中一些基本任务和方法的深度解释:
1. 分词
分词是自然语言处理(Natural Language Processing,简称NLP)中的一项基础任务,其目标是将一个给定的文本字符串切分成若干个有意义的单元,这些单元通常指的是单词、词汇或者短语。在不同的语言中,分词的方式和难度各异。例如,在英语等使用空格作为自然分隔符的西方语言中,基本的分词可以相对简单地通过空格来实现。然而,在中文等没有明显词界分隔符的语言中,分词则更为复杂。
中文分词的挑战
- 无空格分隔:中文文本中词与词之间没有明显的分隔标志,如空格或者标点符号。
- 歧义和多义性:一个字符序列可能对应多种切分方式,且每一种切分方式都有合理的解释。
- 新词问题:语言是持续发展变化的,新词汇层出不穷,传统的基于词典的分词系统可能难以覆盖所有新词。
- 上下文相关性:依存于上下文,同样的字符序列可能在不同的语境下有不同的切分方式。
分词方法的分类
基于规则的分词
- 这种方法依赖预定义的词汇表和一系列切分规则。算法通过扫描文本,尝试匹配最长的词条或按照规则进行拆分。
基于统计的分词
- 统计模型通常通过大量已经分词的文本(语料库)学习词的边界。隐马尔可夫模型(HMM)和条件随机场(CRF)是两种典型的统计模型用于分词任务。
基于深度学习的分词
- 随着深度学习技术的发展,基于深度神经网络的分词方法已经成为主流。比如RNN、LSTM、GRU等循环神经网络及其变体,以及BERT、GPT这类预训练模型都被成功应用于分词任务中。
评估分词效果的指标
- 分词的效果通常通过准确率(Precision)、召回率(Recall)以及它们的调和平均——F1分数来衡量。
实际应用
分词在NLP领域有广泛的应用,如搜索引擎、情感分析等。
2. 词嵌入(Word Embeddings)
嵌入(Embedding)是一种将离散的符号或对象映射到连续向量空间中的技术。在自然语言处理中,嵌入常用于将文本中的单词或字符转换为向量表示,以便计算机可以更好地理解和处理文本数据。
嵌入的原理是通过学习将离散符号映射到连续向量空间中的映射函数。这个映射函数可以是一个神经网络模型,也可以是其他的统计模型。通过训练模型,使得相似的符号在嵌入空间中距离更近,不相似的符号距离更远。嵌入的目标是捕捉符号之间的语义和语法关系,以便计算机可以通过向量运算来理解和推理。
嵌入可以使用不同的数学公式进行解读,其中最常见的是 one-hot 编码和词嵌入。
1).0ne-hot 编码: 将每个符号表示为一个高维稀疏向量,向量的维度等于符号的总数。每个符号都对应向量中的一个维度,该维度上的值为 1,其他维度上的值为 0。例如,对于一个包含 4 个符号(A、B、C、D) 的词汇表,A可以表示为[1,0,0,0],B 可以表示为[0,1,0,0],以此类推
2). 词嵌入: 词嵌入是一种将单词或短语从词汇表映射到连续(实数值)向量空间中的嵌入技术。它通过训练模型来学习单词之间的语义关系。这些向量旨在捕获单词的语义含义,其中语义相似的单词具有相似的表示。
常见的词嵌入方法有 Word2Vec、GloVe 和 BERT 等。例如,可以使用 Word2Vec 模型将单词映射为 300 维的向量表示。
- 举例:
- Word2Vec:通过训练神经网络模型学习词汇的统计属性,生成密集的词向量。
- GloVe:利用全局单词-单词共现矩阵来预测单词之间的关系,并产生词向量。
- FastText:在Word2Vec的基础上增加了子词信息,使得它可以更好地处理罕见词或外来词。
词嵌入的核心优势在于它能够减少维度灾难,并允许机器学习算法高效地处理文本数据。
词嵌入背景
在深度学习兴起之前,传统的文本表示方法如one-hot编码,会遇到维度灾难和单词间关系无法表示的问题。比如,在one-hot编码中,每个单词都被表示为一个很长的向量,这个向量的维度等于词汇表的大小,其中只有一个位置的值是1,其余位置的值都是0。这种表示方法忽略了单词间的相似性,'king' 和 'queen' 虽然在语义上相近,但它们的one-hot向量却是正交的。
词嵌入原理
词嵌入的基本思想是将单词映射到一个连续的向量空间中,并且希望在这个空间中,语义或者功能相似的词彼此接近。这样的词向量通常是低维的,并且是稠密的,每个维度都是一个实数,相比于稀疏的one-hot向量,可以大大降低模型的复杂度。
词嵌入方法
- 基于计数的方法:如Latent Semantic Analysis(LSA),通过矩阵分解技术来找到词汇和文档之间的隐含关系。
- 预测模型:如Word2Vec(Skip-gram和CBOW),GloVe等。这些模型通常通过定义一个预测任务,例如给定上下文预测当前单词(或反之),通过优化这个任务来学习词向量。
词嵌入特点
- 分布式表示:每个维度不再代表某个具体的语义特征,而是多个特征的组合,信息分布在整个向量中。
- 语义相似性:在向量空间中,语义上相近的词汇通常在距离上也较为接近。
- 处理歧义:一些高级的词嵌入模型如ELMo、BERT可以生成上下文相关的词嵌入,进而能更好地处理词汇的多义性。
词嵌入应用
词嵌入广泛应用于各种NLP任务,如情感分析、机器翻译、命名实体识别等,它提供了一种强大的方式来表达文本数据,对于改善模型的表现至关重要。
3. 文本分类(Text Classification)
文本分类是指使用机器学习方法自动将给定的文本分派到一个或多个预定义的类别中。这是自然语言处理领域中的一项基本任务,广泛应用于垃圾邮件检测、情感分析、新闻分类、主题标签赋予等场景。
基础概念
- 文本: 在此上下文中,文本通常是指任何形式的书面语言表达,例如文章、社交媒体帖子、评论、电子邮件等。
- 分类: 是指识别文本所属的类别或类目的过程。
关键任务
- 特征提取: 将文本转换为模型可处理的数值形式,这涉及到从原始数据中提取出有用的信息作为特征。传统方法包括词袋(Bag-of-Words)、TF-IDF等。深度学习方法则通过嵌入层直接学习单词或短语的密集表示。
- 模型训练: 使用算法如朴素贝叶斯、逻辑回归、支持向量机(SVM)、随机森林或深度神经网络等对特征进行学习,并产生分类决策。
- 评估与优化: 通过精确度、召回率、F1分数等指标来评估模型性能,并根据实际需求对模型进行调整和优化。
方法论
文本分类的方法大致可以分为以下几种:
- 基于规则的方法: 利用特定的关键词或模式来识别文本的类别。其优点在于简单易行,但缺点是灵活性差,无法很好地应对复杂或变化的数据。
- 基于传统机器学习的方法: 这些方法依赖于手工设计的特征(如词频、TF-IDF)。朴素贝叶斯、SVM、决策树等算法在这一框架内广泛使用。
- 基于深度学习的方法: 利用卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和Attention机制或它们的组合来进行特征提取和分类。近年来,Transformer模型及其变体(如BERT、GPT等)由于其出色的表现已成为该领域的主流。
应用场景
文本分类技术被广泛应用于多种业务场景,包括:
- 情感分析: 分析用户评论或产品评价中的情感倾向。
- 垃圾邮件检测: 自动识别并过滤掉垃圾邮件。
- 话题识别: 对文章或文档进行主题分类。
- 意图识别: 在对话系统中判断用户的询问意图。
挑战
- 类别不平衡: 在某些数据集中,一些类别的样本可能远多于其他类别,导致模型偏向于多数类。
- 多标签分类: 一个文本可能属于多个类别,这给分类任务带来了额外的复杂性。
- 文本长度和噪声: 文本长度可能会影响分类效果,而且文本中的噪声(错别字、俚语等)也可能干扰模型的判断。
- 语言和文化差异: 跨语言或跨文化的文本分类需要模型能够理解和适应不同的语言表达和文化背景。
4. 命名实体识别(Named Entity Recognition,NER)
命名实体识别是自然语言处理(NLP)领域中的一项关键技术,旨在从文本中识别出具有特定意义的实体,并将这些实体划归到预定义的类别中。典型的实体类别包括人名、组织名、地点名以及时间表达式等。
基本概念
- 实体: 在文本中可以代指某个具体或抽象事物的连续字符序列。
- 命名实体: 特指那些能够唯一标识个体(如人、组织或地点)的实体。比如,“OpenAI”指的是一个特定的组织。
- 识别: 是指通过算法自动检测文本中的实体,并进行分类的过程。
关键任务
- 实体边界识别: 确定一个实体的起始和结束位置。
- 实体分类: 将识别出的实体分配到适当的类别。
方法论
NER的方法大致可以分为以下几种:
- 基于规则的方法: 依赖手工编写的规则来识别实体。例如,利用正则表达式匹配特定模式的字符串作为时间或日期实体。
- 基于统计的方法: 利用机器学习算法学习特征与实体类别之间的关系。这包括支持向量机(SVM)、隐马尔可夫模型(HMM)、条件随机场(CRF)等传统机器学习方法。
- 基于深度学习的方法: 近年来,深度学习方法,尤其是循环神经网络(RNNs)、长短期记忆网络(LSTMs)和最近的变换器模型(如BERT、GPT等),因其在文本表示方面的强大能力而成为主流。这些模型能够自动提取复杂的特征并在大规模数据集上进行训练。
应用场景
命名实体识别在多种应用中都非常重要,比如信息提取、问答系统、知识图谱构建、内容推荐、舆情分析等。
挑战
- 跨领域泛化性: 不同领域(如金融、医疗)可能需要识别不同种类的实体,而且对实体精确性的要求各不相同。
- 上下文歧义: 相同的词汇在不同的上下文中可能代表不同的实体类型。
- 数据稀缺: 对于一些特定领域或语言,可能缺乏足够的标注数据进行模型的训练。
- 实体嵌套: 在某些情况下,一个实体内部可能包含另一个实体,这给实体边界的确定带来了困难。
总结
命名实体识别是提取文本信息,增强文本理解能力的基础。随着深度学习技术的不断进步,NER的准确率和效率都有了显著的提升,但仍然存在一些待解决的问题和挑战。在未来,希望能开发出更加鲁棒、泛化能力强,并且可以适应动态发展的实体类型的NER系统。
过拟合和欠拟合的防止
过拟合(Overfitting)
过拟合是指模型在训练数据上学到了太多的细节和噪声,以至于它在新的未见过的数据上表现不佳。具体来说,这意味着模型在训练集上的准确率很高,但是当应用到验证集或测试集上时,性能急剧下降。过拟合的主要原因是模型太复杂,学习能力过强,导致它捕捉到了训练样本中的特定特征,而这些特征并不具有普遍性。
防止过拟合的方法
- 数据增强:通过旋转、缩放、裁剪等方式对图像进行变换,或者在文本和语音数据上应用诸如同义词替换、音频伸缩等技术,从而扩大训练集,增加模型的泛化能力。
- 正则化:引入L1、L2正则化项或使用Elastic Net结合两者的优点,使得模型参数在优化过程中保持较小的值,防止模型过度依赖某些可能是噪声的特征。
- 交叉验证:使用K折交叉验证确保模型在不同的数据子集上都具有良好的性能。
- Dropout:在神经网络中随机丢弃一部分神经元,以增强网络的泛化能力。
- 早停法(Early Stopping):在训练过程中监视验证集的性能,当性能开始下降时停止训练。
- 模型简化:选择更简单的模型或减少网络层数和参数数量,避免创建过于复杂的模型。
欠拟合(Underfitting)
欠拟合指的是模型过于简单,不能在训练集上获得足够低的误差,因此无法捕捉数据中的基本规律,导致在训练集和测试集上都有不好的性能。欠拟合通常是由于模型复杂度不足,或者训练不充分所导致。
防止欠拟合的方法
- 增加模型复杂度:选择更复杂的模型,例如添加更多层次或神经元到神经网络中。
- 特征工程:寻找更好的特征集合,包括特征选择和特征构造,以增强模型的预测能力。
- 更多训练周期:增加训练次数直到模型在训练集上达到较低的误差。
- 减少正则化:如果使用了正则化,减少正则化参数可以让模型更自由地学习训练数据。
- 确保数据质量:检查数据是否干净、完整,且没有错误,因为低质量数据会影响模型性能。
在面对大规模数据时,需要特别注意模型的选择和训练策略。大规模数据集可能会带来计算资源上的挑战,并且可能需要分布式训练或模型压缩技术。同时,也要确保数据的质量和多样性,避免由于数据偏差而导致的过拟合问题。
相关文章:
LLM大模型常见问题解答(2)
对大模型基本原理和架构的理解 大型语言模型如GPT(Generative Pre-trained Transformer)系列是基于自注意力机制的深度学习模型,主要用于处理和生成人类语言。 基本原理 自然语言理解:模型通过对大量文本数据的预训练ÿ…...
这种学习单片机的顺序是否合理?
这种学习单片机的顺序是否合理? 在开始前我有一些资料,是我根据网友给的问题精心整理了一份「单片机的资料从专业入门到高级教程」, 点个关注在评论区回复“888”之后私信回复“888”,全部无偿共享给大家!!…...

13 年后,我如何用 Go 编写 HTTP 服务(译)
原文:Mat Ryer - 2024.02.09 大约六年前,我写了一篇博客文章,概述了我是如何用 Go 编写 HTTP 服务的,现在我再次告诉你,我是如何写 HTTP 服务的。 那篇原始的文章引发了一些热烈的讨论,这些讨论影响了我今…...
flask+python高校学生综合测评管理系统 phl8b
系统包括管理员、教师和学生三个角色; 。通过研究,以MySQL为后端数据库,以python为前端技术,以pycharm为开发平台,采用vue架构,建立一个提供个人中心、学生管理、教师管理、课程类型管理、课程信息管理、学…...
【GameFramework框架内置模块】1、全局配置(Config)
推荐阅读 CSDN主页GitHub开源地址Unity3D插件分享简书地址 大家好,我是佛系工程师☆恬静的小魔龙☆,不定时更新Unity开发技巧,觉得有用记得一键三连哦。 一、前言 【GameFramework框架】系列教程目录: https://blog.csdn.net/q7…...
PySpark(四)PySpark SQL、Catalyst优化器、Spark SQL的执行流程、Spark新特性
目录 PySpark SQL 基础 SparkSession对象 DataFrame入门 DataFrame构建 DataFrame代码风格 DSL SQL SparkSQL Shuffle 分区数目 DataFrame数据写出 Spark UDF Catalyst优化器 Spark SQL的执行流程 Spark新特性 自适应查询(SparkSQL) 动态合并 动态调整Join策略 …...

2024第六届中国济南国际福祉及残疾人用品展览会/失能护理展
龘龘龙年-第六届山东福祉展会-将于5月27-29日在济南黄河国际会展中心举办; 一、引言 2024年,中国龙年,龙象征着力量、繁荣与希望。在这个特殊的年份,一场备受瞩目的盛会即将拉开帷幕。2024年第六届中国(济南…...
SegmentAnything官网demo使用vue+python实现
一、效果&准备工作 1.效果 没啥好说的,低质量复刻SAM官网 https://segment-anything.com/ 需要提一点:所有生成embedding和mask的操作都是python后端做的,计算mask不是onnxruntime-web实现的,前端只负责了把rle编码的mask解…...

Java:字符集、IO流 --黑马笔记
一、字符集 1.1 字符集的来历 我们知道计算机是美国人发明的,由于计算机能够处理的数据只能是0和1组成的二进制数据,为了让计算机能够处理字符,于是美国人就把他们会用到的每一个字符进行了编码(所谓编码,就是为一个…...

RabbitMQ之五种消息模型
1、 环境准备 创建Virtual Hosts 虚拟主机:类似于mysql中的database。他们都是以“/”开头 设置权限 2. 五种消息模型 RabbitMQ提供了6种消息模型,但是第6种其实是RPC,并不是MQ,因此不予学习。那么也就剩下5种。 但是其实3、4…...

项目02《游戏-14-开发》Unity3D
基于 项目02《游戏-13-开发》Unity3D , 任务:战斗系统之击败怪物与怪物UI血条信息 using UnityEngine; public abstract class Living : MonoBehaviour{ protected float hp; protected float attack; protected float define; …...
【Java数据结构】单向 不带头 非循环 链表实现
模拟实现LinkedList:下一篇文章 LinkedList底层是双向、不带头结点、非循环的链表 /*** LinkedList的模拟实现*单向 不带头 非循环链表实现*/ class SingleLinkedList {class ListNode {public int val;public ListNode next;public ListNode(int val) {this.val …...
【ES6】模块化
nodejs遵循了CommonJs的模块化规范 导入 require() 导出 module.exports 模块化的好处: 模块化可以避免命名冲突的问题大家都遵循同样的模块化写代码,降低了沟通的成本,极大方便了各个模块之间的相互调用需要啥模块,调用就行 …...
腾讯云4核8G服务器可以用来干嘛?怎么收费?
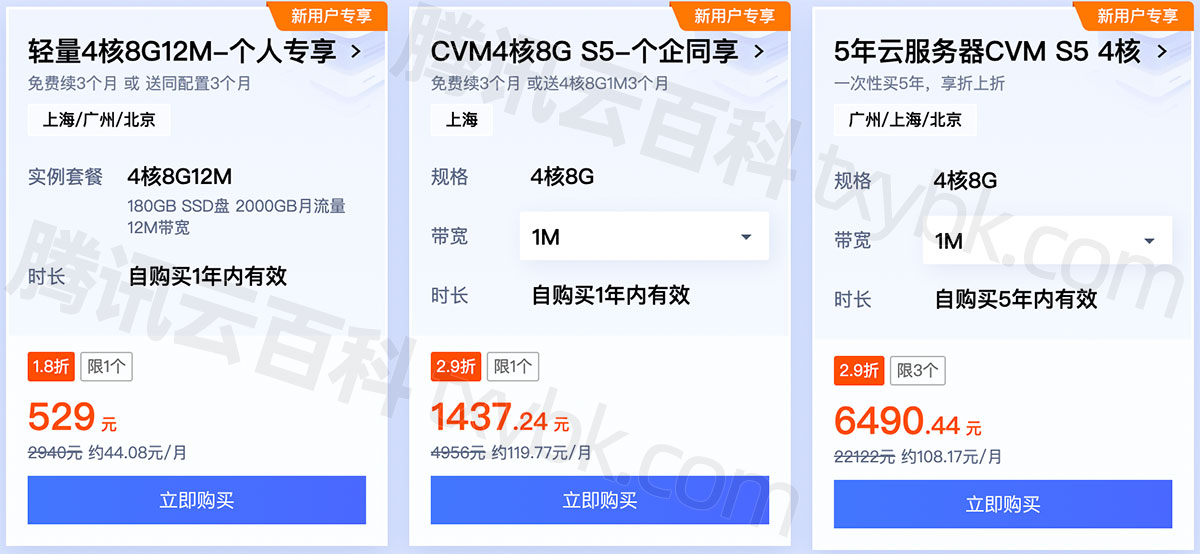
腾讯云4核8G服务器适合做什么?搭建网站博客、企业官网、小程序、小游戏后端服务器、电商应用、云盘和图床等均可以,腾讯云4核8G服务器可以选择轻量应用服务器4核8G12M或云服务器CVM,轻量服务器和标准型CVM服务器性能是差不多的,轻…...

怎么在bash shell中操作复杂json对象
怎么在bash shell中操作复杂json对象 在bash shell中操作复杂JSON对象,jq可以帮助我们在bash环境下轻松地处理这类数据,本文将详细介绍如何使用jq在bash中操作复杂的JSON对象。 jq是一个轻量级且灵活的命令行JSON处理器,它允许你以非常高效的…...

11.div函数
文章目录 函数简介1.函数原型2.div_t结构体3.引用头文件 代码运行 函数简介 1.函数原型 div_t div(int numerator, int denominator);div函数把numerator除以denominator,产生商和余数,用一个div_t的结构体返回。 2.div_t结构体 typedef struct _div…...
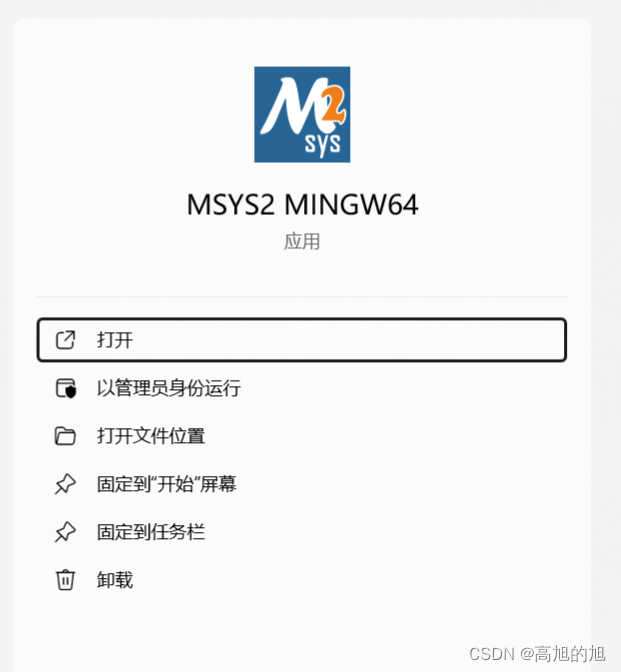
windows11 MSYS2下载安装教程
MSYS2 可以理解为在windows平台上模拟linux编程环境的开源工具集 当前环境:windows11 1. 下载 官网地址可下载最新版本,需要科学上网 https://www.msys2.org/ 2. 安装 按照正常安装软件流程一路next就可以 打开 3. 配置环境 网上很多教程提到需…...
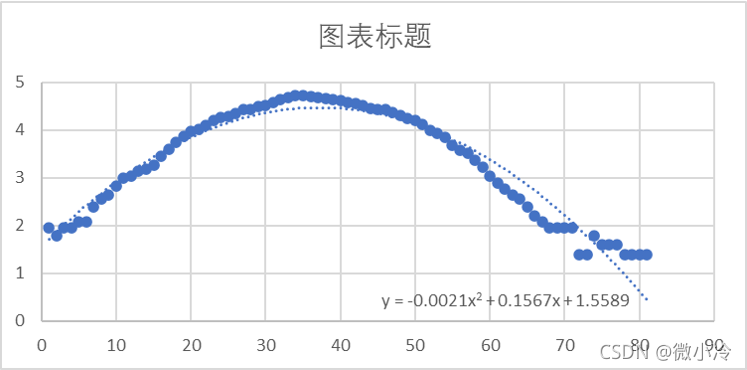
Excel+VBA处理高斯光束
文章目录 1 图片导入与裁剪2 获取图片数据3 数据拟合 1 图片导入与裁剪 插入图片没什么好说的,新建Excel,【插入】->【图片】。 由于图像比较大,所以要对数据进行截取,选中图片之后,点击选项卡右端的【图片格式】…...
如何启动若依框架
Mysql安装 一、下载 链接:https://pan.baidu.com/s/1s8-Y1ooaRtwP9KnmP3rxlQ?pwd1234 提取码:1234 二、安装(解压) 下载完成后我们得到的是一个压缩包,将其解压,我们就可以得到MySQL 5.7.24的软件本体了(就是一个文件夹)&…...
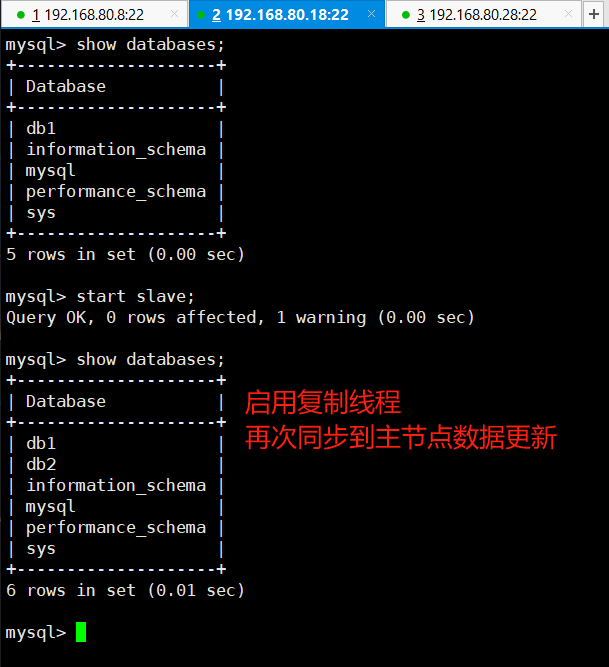
案例:CentOS8 在 MySQL8.0 实现半同步复制
异步复制 MySQL 默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主节点如果 crash 掉了,此时主节点上已经提交的事务可能并没有传…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...