使用Python+OpenCV2进行图片中的文字分割(支持竖版)
扣字和分割
把图片中的文字,识别出来,并将每个字的图片抠出来;
import cv2
import numpy as npHIOG = 50
VIOG = 3
Position = []'''水平投影'''
def getHProjection(image):hProjection = np.zeros(image.shape,np.uint8)# 获取图像大小(h,w)=image.shape# 统计像素个数h_ = [0]*hfor y in range(h):for x in range(w):if image[y,x] == 255:h_[y]+=1#绘制水平投影图像for y in range(h):for x in range(h_[y]):hProjection[y,x] = 255# cv2.imshow('hProjection2',cv2.resize(hProjection, None, fx=0.3, fy=0.5, interpolation=cv2.INTER_AREA))# cv2.waitKey(0)return h_def getVProjection(image):vProjection = np.zeros(image.shape,np.uint8);(h,w) = image.shapew_ = [0]*wfor x in range(w):for y in range(h):if image[y,x] == 255:w_[x]+=1for x in range(w):for y in range(h-w_[x],h):vProjection[y,x] = 255# cv2.imshow('vProjection',cv2.resize(vProjection, None, fx=1, fy=0.1, interpolation=cv2.INTER_AREA))# cv2.waitKey(0)return w_def scan(vProjection, iog, pos = 0):start = 0V_start = []V_end = []for i in range(len(vProjection)):if vProjection[i] > iog and start == 0:V_start.append(i)start = 1if vProjection[i] <= iog and start == 1:if i - V_start[-1] < pos:continueV_end.append(i)start = 0return V_start, V_enddef checkSingle(image):h = getHProjection(image)start = 0end = 0for i in range(h):pass#分割
def CropImage(image,dest,boxMin,boxMax):a=boxMin[1]b=boxMax[1]c=boxMin[0]d=boxMax[0]cropImg = image[a:b,c:d]cv2.imwrite(dest,cropImg)#开始识别
def DOIT(rawPic):# 读入原始图像origineImage = cv2.imread(rawPic)# 图像灰度化 #image = cv2.imread('test.jpg',0)image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)# cv2.imshow('gray',image)# 将图片二值化retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)# kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))# img = cv2.erode(img, kernel)# cv2.imshow('binary',cv2.resize(img, None, fx=0.3, fy=0.3, interpolation=cv2.INTER_AREA))#图像高与宽(h,w)=img.shape#垂直投影V = getVProjection(img)start = 0V_start = []V_end = []# 对垂直投影水平分割V_start, V_end = scan(V, HIOG)if len(V_start) > len(V_end):V_end.append(w-5)# 分割行,分割之后再进行列分割并保存分割位置for i in range(len(V_end)):#获取行图像if V_end[i] - V_start[i] < 30:continuecropImg = img[0:h, V_start[i]:V_end[i]]# cv2.imshow('cropImg',cropImg)# cv2.waitKey(0)#对行图像进行垂直投影H = getHProjection(cropImg)H_start, H_end = scan(H, VIOG, 40)if len(H_start) > len(H_end):H_end.append(h-5)for pos in range(len(H_start)):# 再进行一次列扫描DcropImg = cropImg[H_start[pos]:H_end[pos], 0:w]d_h, d_w = DcropImg.shape# cv2.imshow("dcrop", DcropImg)sec_V = getVProjection(DcropImg)c1, c2 = scan(sec_V, 0)if len(c1) > len(c2):c2.append(d_w)x = 1while x < len(c1):if c1[x] - c2[x-1] < 12:c2.pop(x-1)c1.pop(x)x -= 1x += 1# cv2.waitKey(0)if len(c1) == 1:Position.append([V_start[i],H_start[pos],V_end[i],H_end[pos]])else:for x in range(len(c1)):Position.append([V_start[i]+c1[x], H_start[pos],V_start[i]+c2[x], H_end[pos]])#根据确定的位置分割字符number=0for m in range(len(Position)):rectMin = (Position[m][0]-5,Position[m][1]-5)rectMax = (Position[m][2]+5,Position[m][3]+5)cv2.rectangle(origineImage,rectMin, rectMax, (0 ,0 ,255), 2)number=number+1#start-cropCropImage(origineImage,'result/' + '%d.jpg' % number,rectMin,rectMax)# cv2.imshow('image',cv2.resize(origineImage, None, fx=0.6, fy=0.6, interpolation=cv2.INTER_AREA))cv2.imshow('image',origineImage)cv2.imwrite('result/' + 'ResultImage.jpg' , origineImage)cv2.waitKey(0)#############################
rawPicPath = r"H:\TEMP\TEXT_PROCCESS\TEST05.jpg"
DOIT(rawPicPath)
#############################原图片:

分割后文件夹:

重命名
可见此时文件都还是数字为文件名称,那么接下来要利用OCR自动给每个文字图片文件命名
我们使用UMIOCR , UMI-OCR的安装建议去GITHUB上查,windows上部署还是很方便的;
这里使用本机安装好的UMI-OCR 的 API地址 http://127.0.0.1:1224/api/ocr
先定义API调用方法
############################################
import base64
import requests
import json#API访问使用
def UMI_OCR_OPT(url,img_path): # url = "http://127.0.0.1:1224/api/ocr"# img_path= './result/123.jpg'with open(img_path,'rb') as f:image_base64 = base64.b64encode(f.read())image_base64 =str(image_base64,'utf-8')data = {"base64": image_base64,# 可选参数# Paddle引擎模式# "options": {# "ocr.language": "models/config_chinese.txt",# "ocr.cls": False,# "ocr.limit_side_len": 960,# "tbpu.parser": "MergeLine",# }# Rapid引擎模式# "options": {# "ocr.language": "简体中文",# "ocr.angle": False,# "ocr.maxSideLen": 1024,# "tbpu.parser": "MergeLine",# }}headers = {"Content-Type": "application/json"}data_str = json.dumps(data)response = requests.post(url, data=data_str, headers=headers)if response.status_code == 200:res_dict = json.loads(response.text)#检测失败与否if(str(res_dict).find('No text found in image')!=-1):# print("返回失败内容\n", res_dict)return ''print("返回值字典\n", res_dict)resText = res_dict['data'][0]['text']return resTextreturn ''
开始批量调用检测
import easyocrimport shutilerror =''#api地址
uni_orc_url="http://127.0.0.1:1224/api/ocr"
#将所有字体
for i in range(1,285):filePath = "./result/"+str(i)+".jpg"# result = reader.readtext(filePath, detail = 0)result = UMI_OCR_OPT(uni_orc_url,filePath)if(len(result)==0 or result == ''):error+= filePath +'\n'continueprint(result)destPath = "./resultX/"+result[0]+".jpg" print('sour :: '+ filePath)print('dest :: '+ destPath)shutil.copyfile(filePath, destPath)print('error:\n'+error)
然后将能够识别出来的所有文字图片都复制并重命名为该字
效果如下:

相关文章:
使用Python+OpenCV2进行图片中的文字分割(支持竖版)
扣字和分割 把图片中的文字,识别出来,并将每个字的图片抠出来; import cv2 import numpy as npHIOG 50 VIOG 3 Position []水平投影 def getHProjection(image):hProjection np.zeros(image.shape,np.uint8)# 获取图像大小(h,w)image.sh…...
Qt中程序发布及常见问题
1、引言 当我们写好一个程序时通常需要发布给用户使用,那么在Qt中程序又是如何实现发布的呢,这里我就来浅谈一下qt中如何发布程序,以及发布程序时的常见问题。 2、发布过程 2.1、切换为release模式 当我们写qt程序时默认是debug模式&#x…...

C语言第二十三弹---指针(七)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 指针 1、sizeof和strlen的对比 1.1、sizeof 1.2、strlen 1.3、sizeof 和 strlen的对比 2、数组和指针笔试题解析 2.1、⼀维数组 2.2、二维数组 总结 1、si…...
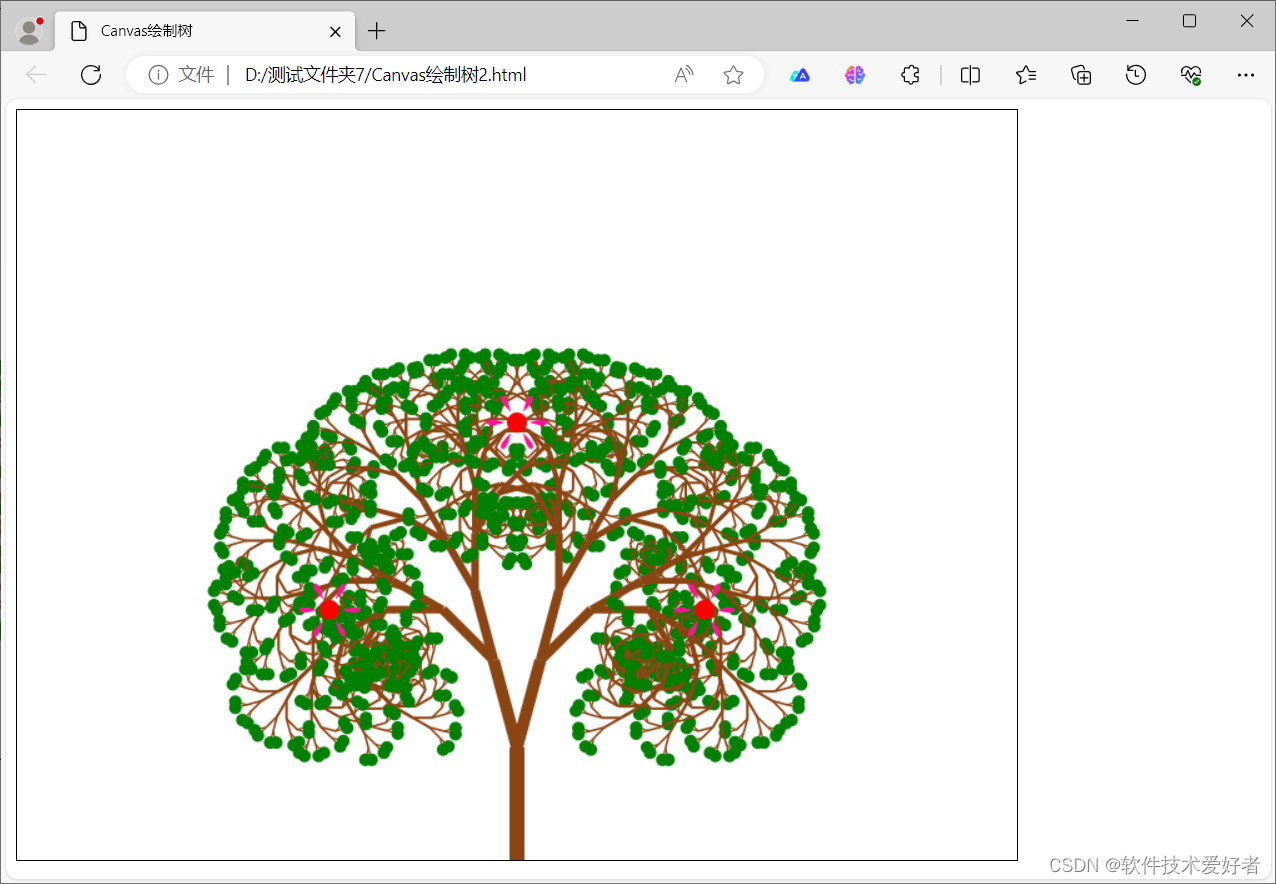
用HTML5 + JavaScript绘制花、树
用HTML5 JavaScript绘制花、树 <canvas>是一个可以使用脚本 (通常为JavaScript) 来绘制图形的 HTML 元素。 <canvas> 标签/元素只是图形容器,必须使用脚本来绘制图形。 HTML5 canvas 图形标签基础https://blog.csdn.net/cnds123/article/details/112…...

Science重磅_让大模型像婴儿一样学习语言
英文名称: Grounded language acquisition through the eyes and ears of a single child 中文名称: 通过一个孩子的眼睛和耳朵基于实践学习语言 文章: https://www.science.org/doi/10.1126/science.adi1374 代码: https://github.com/wkvong/multimodalbaby 作者: Wai Keen V…...
Java 数据结构篇-实现红黑树的核心方法
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 红黑树的说明 2.0 红黑树的特性 3.0 红黑树的成员变量及其构造方法 4.0 实现红黑树的核心方法 4.1 红黑树内部类的核心方法 (1)判断当前…...
【实战】一、Jest 前端自动化测试框架基础入门(中) —— 前端要学的测试课 从Jest入门到TDD BDD双实战(二)
文章目录 一、Jest 前端自动化测试框架基础入门5.Jest 中的匹配器toBe 匹配器toEqual匹配器toBeNull匹配器toBeUndefined匹配器和toBeDefined匹配器toBeTruthy匹配器toBeFalsy匹配器数字相关的匹配器字符串相关的匹配器数组相关的匹配器异常情况的匹配器 6.Jest 命令行工具的使…...

【C语言 - 力扣 - 反转链表】
反转链表题目描述 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 题解1-迭代 假设链表为 1→2→3→∅,我们想要把它改成 ∅←1←2←3。 在遍历链表时,将当前节点的 next 指针改为指向前一个节点。由于节点没…...
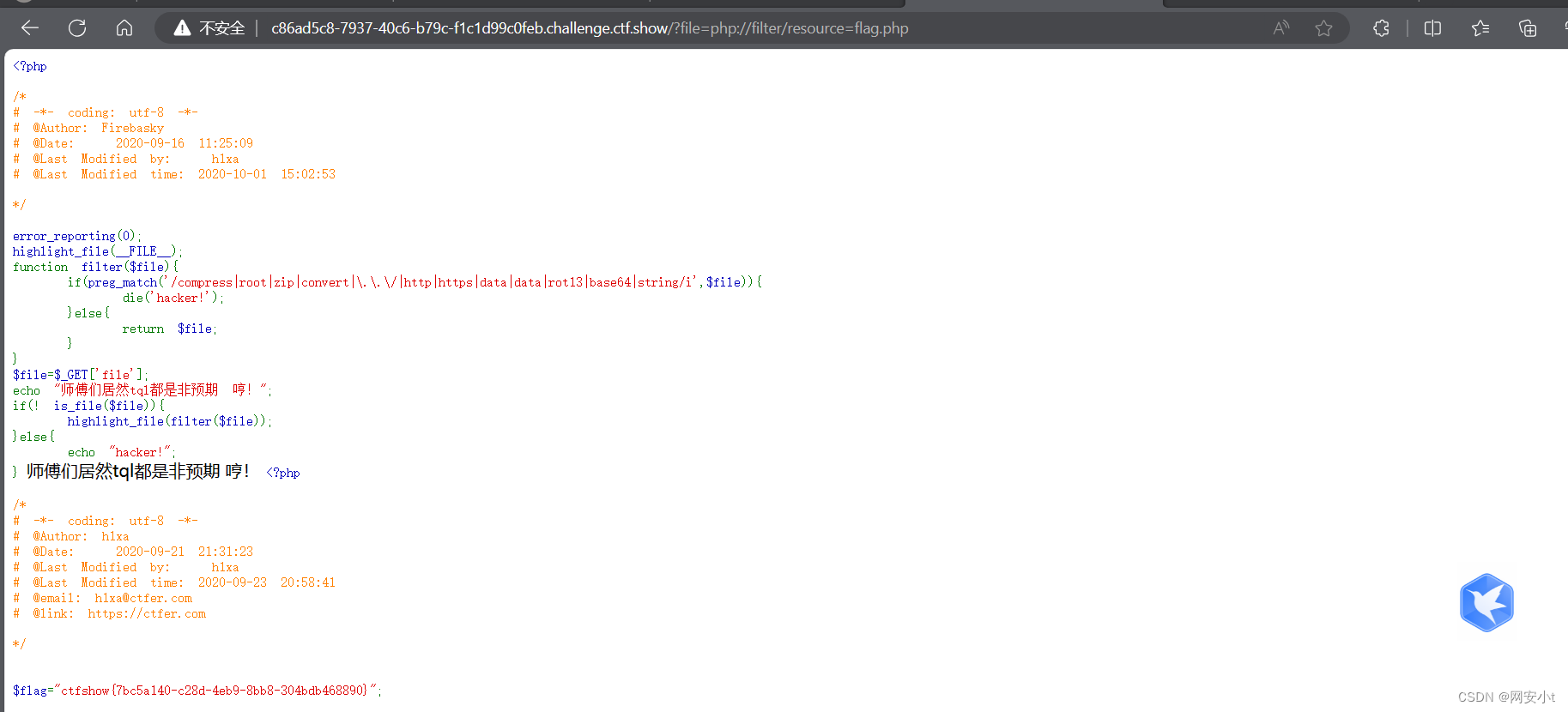
ctfshow-php特性(web102-web115)
目录 web102 web103 web104 web105 web106 web107 web108 web109 web110 web111 web112 web113 web114 web115 实践是检验真理的 要多多尝试 web102 <?php highlight_file(__FILE__); $v1$_POST[V1]; $v2$_GET[v2]; $v3$_GET[v3]; $v4is_numeric($v2)and is…...

python系统学习Day1
section1 python introduction 文中tips只做拓展,可跳过。 PartOne introduction 首先要对于python这门语言有一个宏观的认识,包括特点和应用场景。 特点分析: 优势 提供了完善的基础代码库,许多功能不必从零编写简单优雅 劣势 运…...

Idea里自定义封装数据警告解决 Spring Boot Configuration Annotation Processor not configured
我们自定对象封装指定数据,封装类上面一个红色警告,虽然不影响我们的执行,但是有强迫症看着不舒服, 去除方式: 在pom文件加上坐标刷新 <dependency><groupId>org.springframework.boot</groupId><…...

【流程图——讲解】
流程图介绍 流程图介绍 流程图介绍 流程图是一种图表,它展示了工作流程或过程中的步骤顺序,它通常由不同的符号表示,每个符号都代表一个步骤或过程中的一个元素,流程图非常有用,因为它们可以提供清晰、视觉化的过程表…...

「计算机网络」物理层
物理层的基本概念 物理层的作用:尽可能屏蔽掉不同传输媒体和通信手段的差异物理层规程:用于物理层的协议主要任务:确定与传输媒体的接口有关的一些特性 机械特性电器特性功能特性过程特性 数据通信的基础知识 数据通信系统的模型 划分为…...

ARM与X86架构的区别与联系
文章目录 1.什么是CPU2.复杂指令集和精简指令集3.ARM架构与X86架构的比较3.1.制造工艺3.2 64位计算3.3 异构计算3.4 功耗 4.ARM和X86的发展现状Reference 1.什么是CPU 中央处理单元(CPU)主要由运算器、控制器、寄存器三部分组成,从字面意思看…...

蓝桥杯每日一题------背包问题(二)
前言 本次讲解背包问题的一些延申问题,新的知识点主要涉及到二进制优化,单调队列优化DP,树形DP等。 多重背包 原始做法 多重背包的题意处在01背包和完全背包之间,因为对于每一个物品它规定了可选的个数,那么可以考虑…...

牛客错题整理——C语言(实时更新)
1.以下程序的运行结果是() #include <stdio.h> int main() { int sum, pad,pAd; sum pad 5; pAd sum, pAd, pad; printf("%d\n",pAd); }答案为7 由于赋值运算符的优先级高于逗号表达式,因此pAd sum, pAd, pad;等价于(…...

CIFAR-10数据集详析:使用卷积神经网络训练图像分类模型
1.数据集介绍 CIFAR-10 数据集由 10 个类的 60000 张 32x32 彩色图像组成,每类 6000 张图像。有 50000 张训练图像和 10000 张测试图像。 数据集分为5个训练批次和1个测试批次,每个批次有10000张图像。测试批次正好包含从每个类中随机选择的 1000 张图像…...

《傲剑狂刀》中的人物性格——龙吟风
在《傲剑狂刀》这款经典武侠题材的格斗游戏中,龙吟风作为一位具有传奇色彩的角色,其性格特征复杂且引人入胜。以下是对龙吟风这一角色的性格特点进行深度剖析: 一、孤高独立的剑客气质 龙吟风的名字本身就流露出一种独特的江湖气息,"吟风"象征着他的飘逸与淡泊名…...
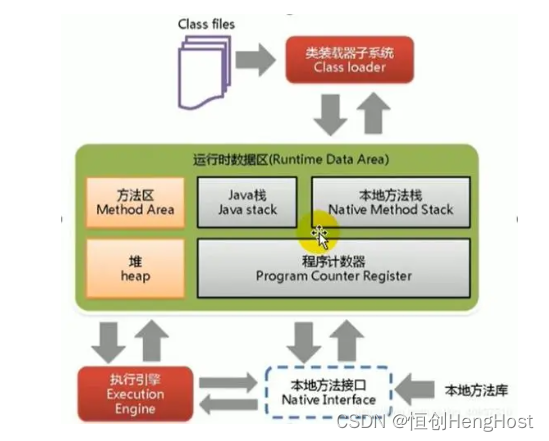
KVM和JVM的虚拟化技术有何区别?
随着虚拟化技术的不断发展,KVM和JVM已成为两种主流的虚拟化技术。尽管它们都提供了虚拟化的解决方案,但它们在实现方式、功能和性能方面存在一些重要的差异。本文将深入探讨KVM和JVM的虚拟化技术之间的区别。 KVM(Kernel-based Virtual Mac…...
 持续更新中)
LeetCode力扣 面试经典150题 详细题解 (1~5) 持续更新中
目录 1.合并两个有序数组 2.移动元素 3.删除有序数组中的重复项 4.删除排序数组中的重复项 II 5.多数元素 暂时更新到这里,博主会持续更新的 1.合并两个有序数组 题目(难度:简单): 给你两个按 非递减顺序 排列的…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...