pytorch花式索引提取topk的张量
文章目录
- pytorch花式索引提取topk的张量
- 问题设定
- 代码实现
- 索引方法
- gather方法
- 验证
- 补充知识
- expand方法
- gather方法
- randint
pytorch花式索引提取topk的张量
问题设定

或者说,有一个(bs, dim, L)的大张量,索引的index形状为(bs, X),想得到一个(bs, dim, X)的reduced向量。我们在进行topk操作(以减少计算量)的时候经常碰到这种情况。
给出如下两种实现方法,分别使用花式索引(参考informer的代码)以及pytorch的gather方法
代码实现
索引方法
参考https://blog.csdn.net/qq_36560894/article/details/122005808
feature = torch.rand(2,16,4*4)
indices = torch.randint(0,16, (2, 3))
indices
indices_expand = indices.unsqueeze(1).expand(-1, dim, -1).to(torch.long) # (bs, dim, H*W)
indices_expand.shape
indices_expand[:,1,:] # 结果和indices一致,说明在第二个channel上,每个样本的索引是一样的
bs,dim=feature.shape[:2]
bs,dim
feature_reduce = feature.view(bs, dim, -1)[torch.arange(bs)[:, None, None], torch.arange(dim)[None,:,None], indices_expand]
feature_reduce.shape

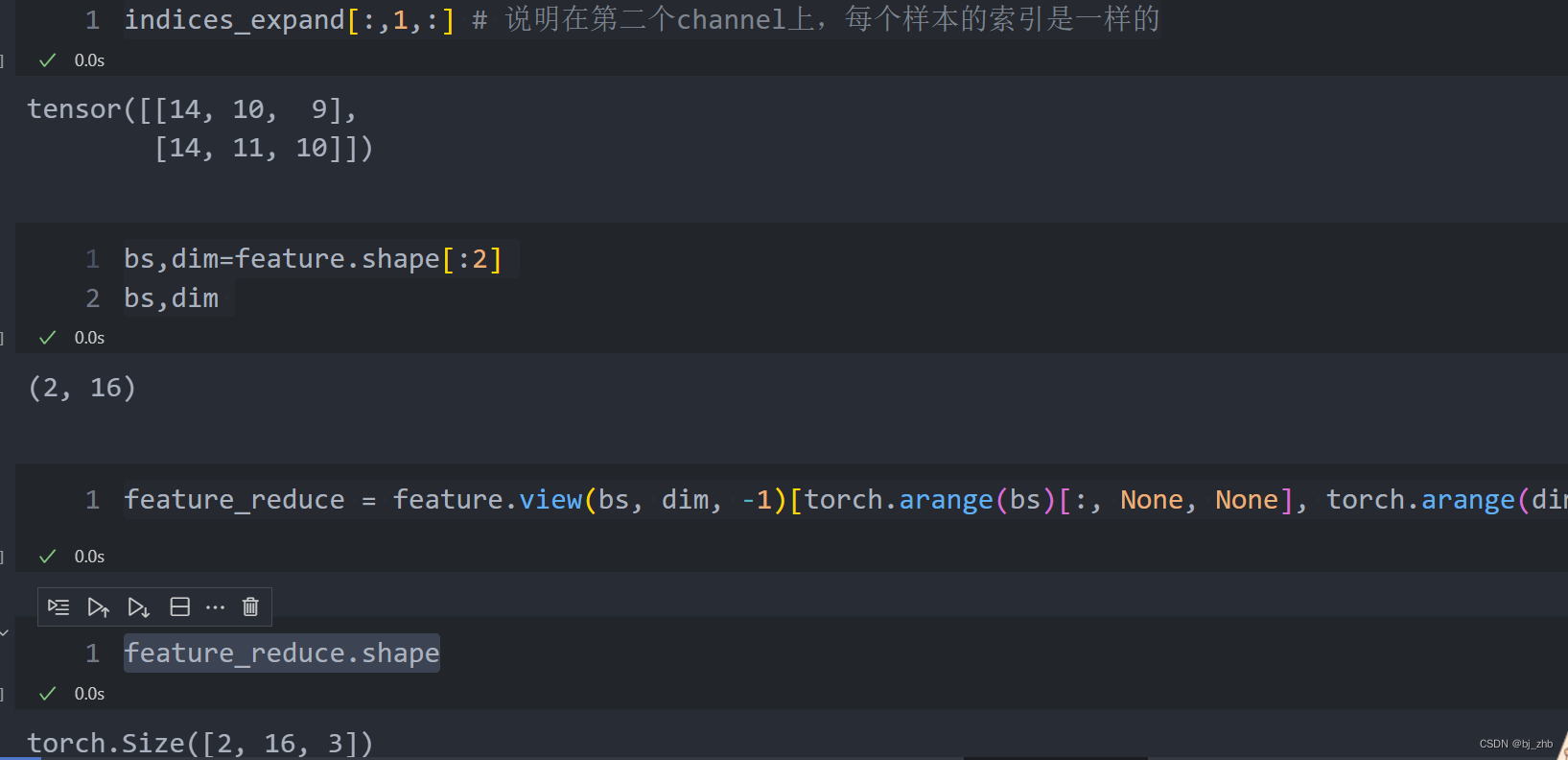
gather方法
reduce_feature = torch.gather(feature, 2, indices_expand)
验证
两种方法得到的结果完全相同

补充知识
expand方法
在 PyTorch 中,expand() 方法用于扩展张量的大小。它会在不实际复制数据的情况下,重复张量的元素以填充新的形状。这个方法可以用于广播操作,以便在执行一些需要相同形状的张量之间的数学运算时,使它们具有相同的形状。
下面是使用 expand() 方法的基本用法:
import torch# 创建一个原始张量
x = torch.tensor([[1, 2, 3],[4, 5, 6]])# 使用 expand 扩展张量的大小
expanded_x = x.expand(2, 3, 4) # 扩展成维度为(2, 3, 4)的张量print(expanded_x)
在上面的例子中,我们首先创建了一个形状为 (2, 3) 的原始张量 x。然后,我们使用 expand() 方法将其扩展成一个维度为 (2, 3, 4) 的新张量 expanded_x,该张量的形状是在原始张量形状的基础上每个维度都扩展了一倍。
需要注意的是,expand() 方法只能用于增加张量的大小,不能减小。另外,扩展后的张量与原始张量共享底层数据,因此在原始张量上进行的任何修改都会反映在扩展后的张量上,反之亦然。
gather方法
在 PyTorch 中,gather() 方法用于从输入张量中按照指定索引提取元素。这个方法通常用于根据索引收集特定的元素,例如根据类别索引从分类得分张量中获取对应类别的得分。
下面是使用 gather() 方法的基本用法:
import torch# 创建一个输入张量
input_tensor = torch.tensor([[1, 2],[3, 4],[5, 6]])# 创建一个索引张量
indices = torch.tensor([[0, 0],[1, 0]])# 使用 gather 方法根据索引收集元素
output_tensor = torch.gather(input_tensor, dim=1, index=indices)print(output_tensor)
在上面的例子中,我们首先创建了一个形状为 (3, 2) 的输入张量 input_tensor,以及一个形状为 (2, 2) 的索引张量 indices。然后,我们使用 gather() 方法从输入张量 input_tensor 中按照索引张量 indices 收集元素。
在 gather() 方法中,参数 dim 指定了在哪个维度上进行收集操作,而 index 参数指定了收集元素所使用的索引张量。
需要注意的是,索引张量 indices 的形状必须与输出张量的形状一致,或者是可以广播成与输出张量形状一致的形状。
randint
torch.randint() 是 PyTorch 中用于生成随机整数张量的函数。它可以生成一个张量,其中的元素是在指定范围内随机抽样的整数。
下面是 torch.randint() 的基本用法示例:
import torch# 生成一个形状为 (3, 3) 的随机整数张量,范围是 [0, 10)
random_integers = torch.randint(low=0, high=10, size=(3, 3))print(random_integers)
在上面的示例中,我们使用了 torch.randint() 函数来生成一个形状为 (3, 3) 的随机整数张量,其中的元素取值范围在闭区间 [low, high) 内,即从 0 到 9。
torch.randint() 函数的主要参数包括:
low:生成的随机整数的最小值(包含)。high:生成的随机整数的最大值(不包含)。size:生成的张量的形状。
你也可以不指定 low 参数,默认情况下它为 0。此外,还可以使用其他参数来控制生成的随机整数张量的设备类型、数据类型等。
相关文章:
pytorch花式索引提取topk的张量
文章目录 pytorch花式索引提取topk的张量问题设定代码实现索引方法gather方法验证 补充知识expand方法gather方法randint pytorch花式索引提取topk的张量 问题设定 或者说,有一个(bs, dim, L)的大张量,索引的index形状为(bs, X),想得到一个(…...

Swagger2
Swagger2 引入依赖 <!-- springfox-swagger2 --><dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.10.5</version></dependency>编写配置 @Configuration public …...

2024/2/13
数组练习 1、选择题 1.1、若有定义语句:int a[3][6]; ,按在内存中的存放顺序,a 数组的第10个元素是 D A)a[0][4] B) a[1][3] C)a[0][3] D)a[1][4] 1.2、有数组 int a[5] {10,20,30,40&…...
【工具】Android|Android Studio 长颈鹿版本安装下载使用详解
版本:2022.3.1.22, https://redirector.gvt1.com/edgedl/android/studio/install/2022.3.1.22/android-studio-2022.3.1.22-windows.exe 前言 笔者曾多次安装并卸载Android Studio,反复被安卓模拟器劝退。现在差不多是第三次安装,…...

第三代互联网web3.0
Web3.0,通常被称为第三代互联网,代表了互联网技术的下一个演进阶段。它主要基于区块链、去中心化和用户赋权的理念构建,旨在创造一个更加智能、开放且安全的网络环境。以下是Web3.0的一些关键特点: 1. **去中心化**:We…...
FL Studio版本升级-FL Studio怎么升级-FL Studio升级方案
已经是新年2024年了,但是但是依然有很多朋友还在用FL Studio12又或者FL Studio20,今天这篇文章教大家如何升级FL Studio21 FL Studio 21是Image Line公司开发的音乐编曲软件,除了软件以外,我们还提供了FL Studio的升级服务&#…...
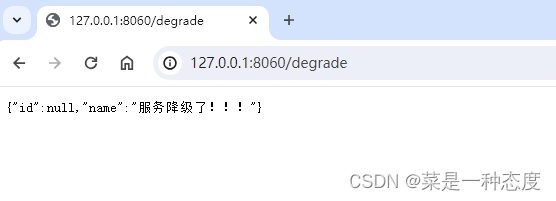
服务降级(Sentinel)
服务降级 采用 SentinelResource 注解方式实现, 必要的 依赖必须引入 以及 切面Bean 接口代码 RequestMapping("/degrade")SentinelResource(value DEGRADE_RESOURCE_NAME, blockHandler "blockHandlerForDegrade",entryType EntryType.IN…...

Rust入门问题: use of undeclared crate or module `rand`
按照官网学rust,程序地址在这里, 写个猜数字游戏 - Rust 程序设计语言 简体中文版 程序内容也很简单, use std::io; use rand::Rng;fn main() {println!("Guess the number!");let secret_number rand::thread_rng().gen_range…...
2024.2.6 模拟实现 RabbitMQ —— 数据库操作
目录 引言 选择数据库 环境配置 设计数据库表 实现流程 封装数据库操作 针对 DataBaseManager 单元测试 引言 硬盘保存分为两个部分 数据库:交换机(Exchange)、队列(Queue)、绑定(Binding࿰…...
dolphinscheduler海豚调度(一)简介快速体验
1、简介 Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。 Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应…...
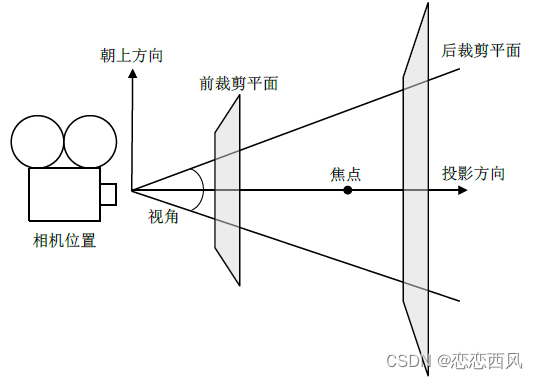
VTK 三维场景的基本要素(相机) vtkCamera
观众的眼睛好比三维渲染场景中的相机,在VTK中用vtkCamera类来表示。vtkCamera负责把三维场景投影到二维平面,如屏幕,相机投影示意图如下图所示。 1.与相机投影相关的要素主要有如下几个: 1)相机位置: 相机所处的位置…...
小游戏和GUI编程(5) | SVG图像格式简介
小游戏和GUI编程(5) | SVG图像格式简介 0. 问题 Q1: SVG 是什么的缩写?Q2: SVG 是一种图像格式吗?Q3: SVG 相对于其他图像格式的优点和缺点是什么?Q4: 哪些工具可以查看 SVG 图像?Q5: SVG 图像格式的规范是怎样的?Q6…...
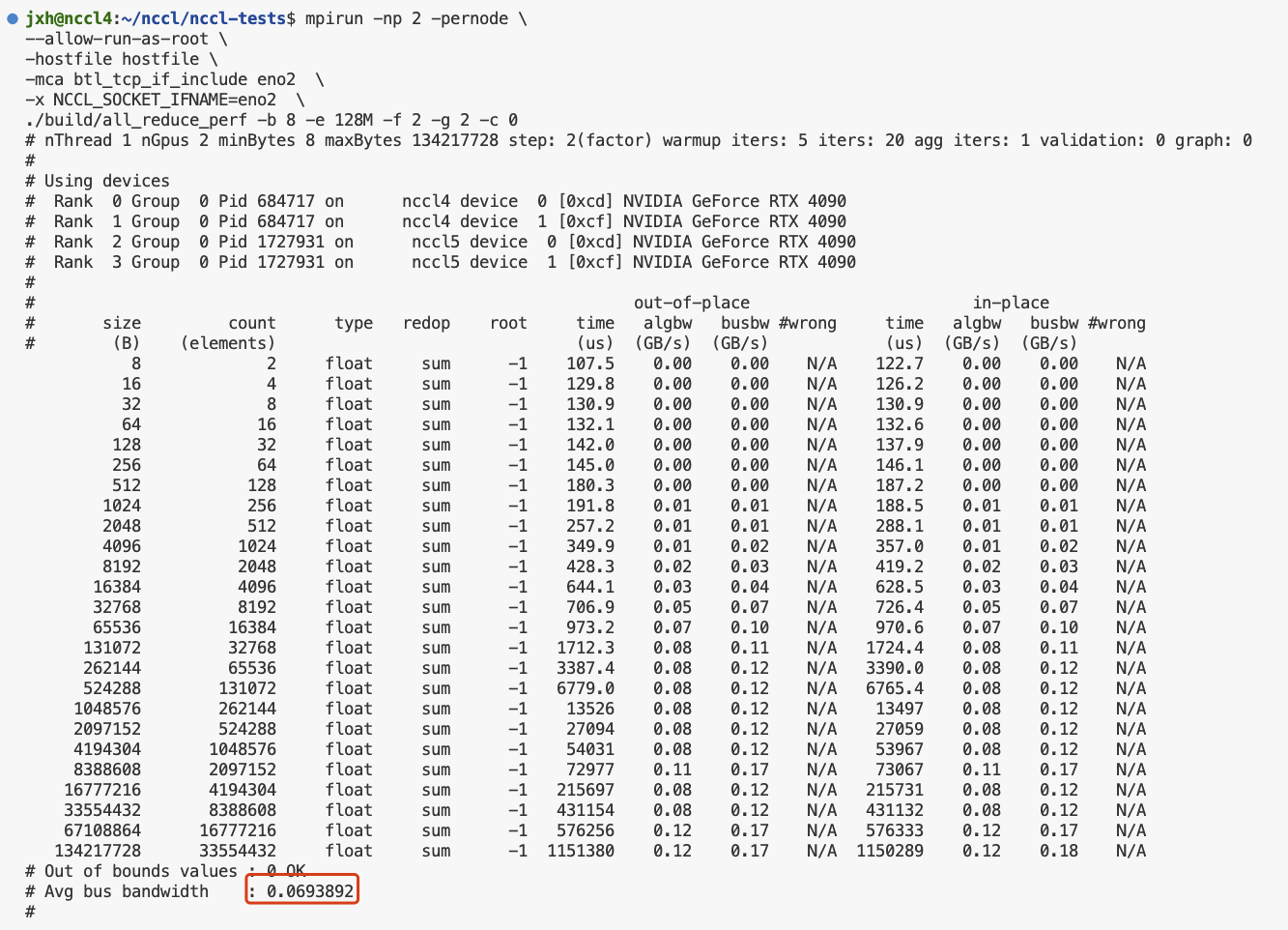
多机多卡运行nccl-tests和channel获取
nccl-tests 环境1. 安装nccl2. 安装openmpi3. 单机测试4. 多机测试mpirun多机多进程多节点运行nccl-testschannel获取 环境 Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)cuda 11.8 cudnn 8nccl 2.15.1NVIDIA GeForce RTX 4090 *2 1. 安装nccl #查看cuda版本 nv…...
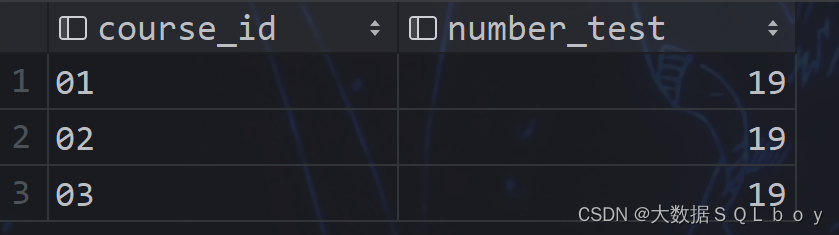
SQL,HQL刷题,尚硅谷
相关表数据: 1、score_info 2、student_info 题目及思路解析: 分组结果的条件 1、查询平均成绩大于60分的学生的学号和平均成绩 代码: selectstu_id,avg(score) score_avg from score_info group by stu_id having score_avg>60; 思路…...
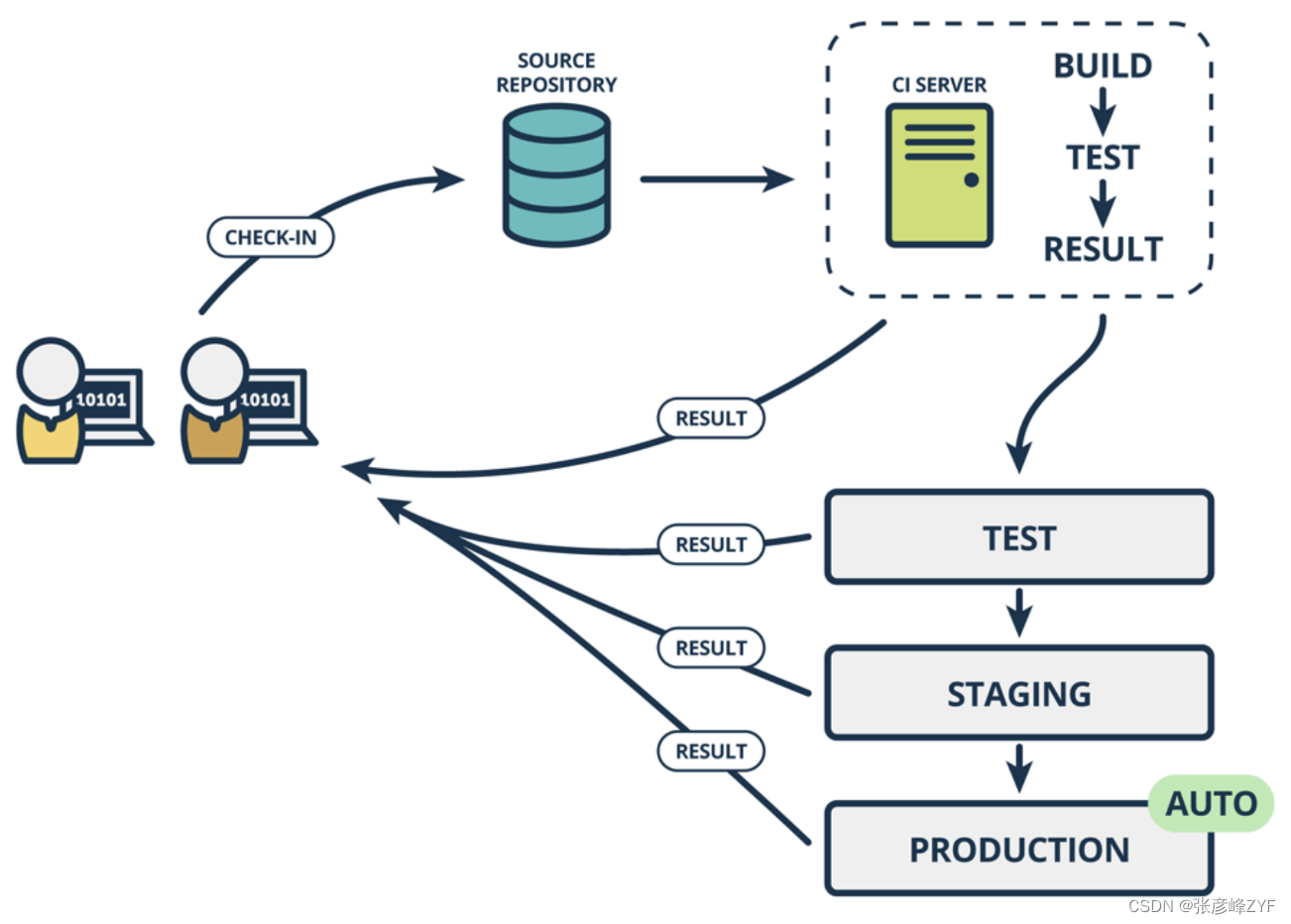
DevOps:CI、CD、CB、CT、CD
目录 一、软件开发流程演化快速回顾 (一)瀑布模型 (二)原型模型 (三)螺旋模型 (四)增量模型 (五)敏捷开发 (六)DevOps 二、走…...
)
[leetcode经典算法题]删除有序数组中的重复项(双指针)
删除有序数组中的重复项 给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。 考虑 nums 的唯一元素…...
)
【国产MCU】-CH32V307-触摸按键检测(TKEY)
触摸按键检测(TKEY) 文章目录 触摸按键检测(TKEY)1、TKEY介绍2、TKEY使用实例触摸检测控制(TKEY)单元,借助ADC 模块的电压转换功能,通过将电容量转换为电压量进行采样,实现触摸按键检测功能。检测通道复用ADC 的16 个外部通道,通过ADC 模块的单次转换模式实现触摸按键…...

Hive的小文件问题
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...

攻防世界——re2-cpp-is-awesome
64位 我先用虚拟机跑了一下这个程序,结果输出一串字符串flag ——没用 IDA打开后 F5也没有什么可看的 那我们就F12查看字符串找可疑信息 这里一下就看见了 __int64 __fastcall main(int a1, char **a2, char **a3) {char *v3; // rbx__int64 v4; // rax__int64 v…...
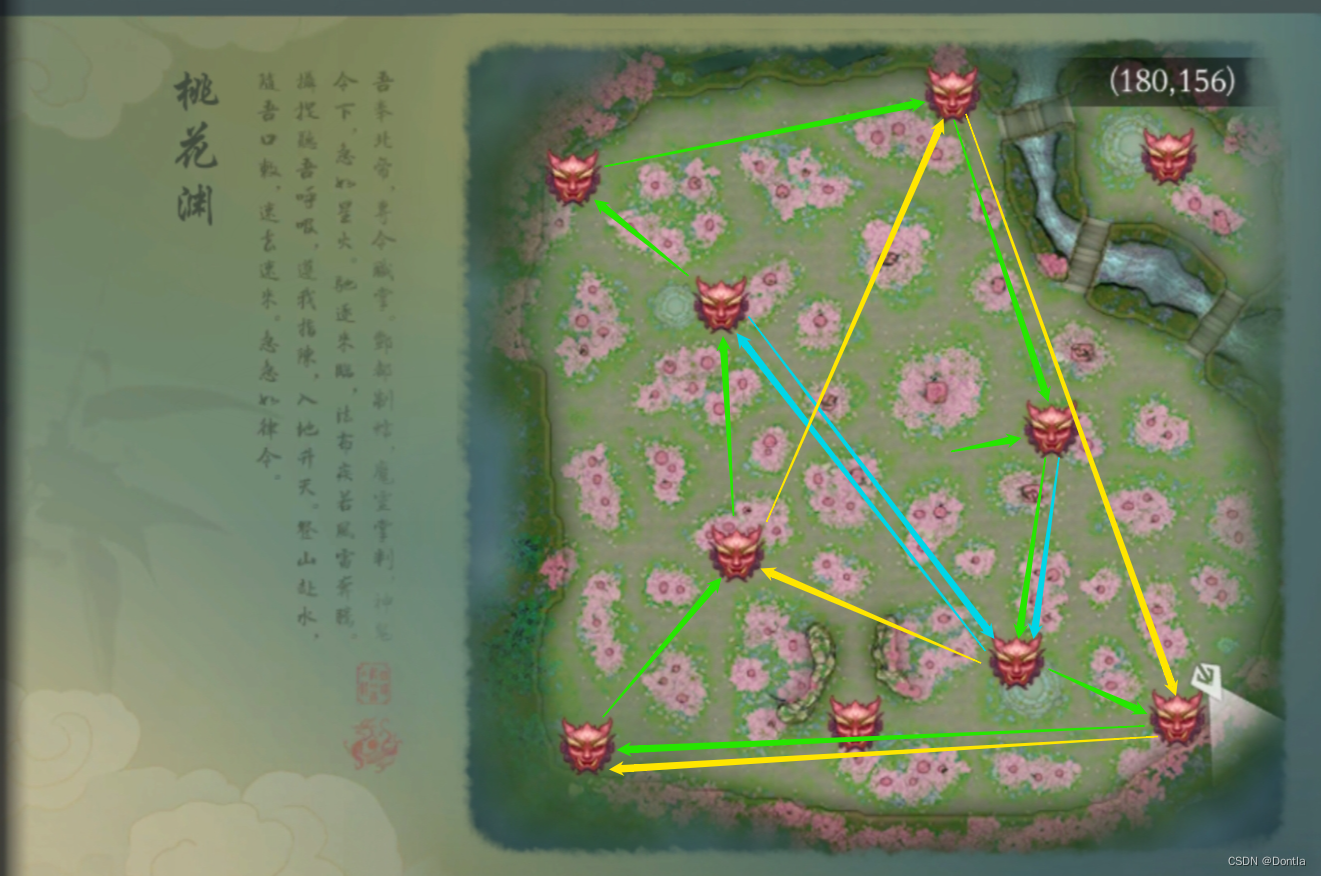
问山海——天涯海角——桃花渊boss攻击顺序
文章目录 桃花渊代码代码解读代码执行结果攻击顺序示意图 桃花渊 规划击杀各个boss顺序。 副本持续时间为30分钟,每个地方的boss被打死后,需要一定时间才能重新刷新。 只考虑其中两种boss,龟将和龟龙。各有四个。 其中我从一个boss地点到…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...