【selenium】
selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的。Selenium可以直接调用浏览器,它支持所有主流的浏览器。其本质是通过驱动浏览器,完成模拟浏览器操作,比如挑战,输入,点击等。
下载与打开
下载链接:CNPM Binaries Mirror
找到与自己的谷歌浏览器版本最接近的。
然后点击下载里面win32.zip即可
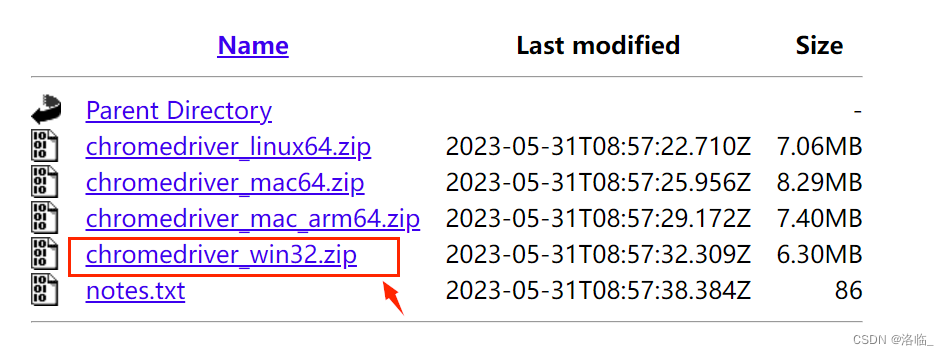 下载的压缩包解压完成后的内容放到python的安装路径。
下载的压缩包解压完成后的内容放到python的安装路径。
python安装路径:可以运行一个空的py文件,第一行的第一个路径就是你的python解释器安装路径
cmd命令提示符中:pip install selenium==3.141.0
卸载:pip uninstall 模块名
from selenium import webdriver
# 导入其中的webdriver来驱动浏览器
url = "https://www.baidu.com/"
# 启动谷歌浏览器
driver = webdriver.Chrome()
# 在地址栏输入网址
driver.get(url)可以打开网页了。
不过可能会报错。根据报错内容查看是哪里出现了问题:
- 问题一:下载的selenium与urllib3不兼容
- 解决方式:cmd中输入pip install selenium==3.141.0和pip install urllib3==1.26.2
- 问题二:谷歌浏览器与下载的chromedriver驱动版本不一致
- 解决方式:右上角三个点--帮助--关于--找到自己浏览器的版本,再对应下载驱动
浏览器对象
get(url=url):地址栏--输入url地址并确认
page_source:HTML结构源码
maxmize_window:浏览器窗口最大化
quit():关闭浏览器窗口
from selenium import webdriver # 导入其中的webdriver来驱动浏览器 url = "https://www.baidu.com/" # 启动谷歌浏览器 driver = webdriver.Chrome() # 在地址栏输入网址 driver.get(url) driver.maximize_window() # 将浏览器窗口最大化 print(driver.page_source) # 打印请求头 driver.quit() # 关掉浏览器
Selenium定位元素
from selenium.webdriver.common.by import By
- find_element(By.ID, '根据标签id属性进行定位')
- find_element(By.NAME, '根据标签name属性进行定位')
- find_element(By.CLASS_NAME, '根据标签class属性进行定位')
- find_element(By.XPATH, '根据xpath语法进行定位')
- find_element(By.CSS_SELECTOR, '根据css语法进行定位')
- find_element(By.LINK_TEXT, '根据标签文本内容进行定位')
from selenium import webdriver from selenium.webdriver.common.by import Byurl = "https://www.baidu.com/" driver = webdriver.Chrome() driver.get(url) driver.maximize_window()driver.find_element(By.ID, "kw").send_keys("CSDN") # 在搜索框上输入CSDN driver.find_element(By.ID, 'su').click() # 点击搜索
无界面模式
from selenium import webdriver
options = webdriver.ChromeOptions()
# 添加无界面参数
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
import timefrom selenium import webdriver from selenium.webdriver.common.by import Byurl = "https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_4f2b917133dd438ab114acdc46cd0f2c"options = webdriver.ChromeOptions() # 添加无界面参数 options.add_argument('--headless') driver = webdriver.Chrome(options=options)driver.get(url) driver.execute_script("window.scrollTo(500, document.body.scrollHeight)" ) time.sleep(2) li_list = driver.find_elements(By.XPATH, '//div[@id="J_feeds"]/ul/li')i = 0 for li in li_list:print(li.text)print('*'*30)i += 1 print(i) # *
打开新窗口和切换页面
通过excute_script()来执行js脚本的形式来打开新窗口。
window.excute_script("window.open('https://www.douban.com')")
打开新窗口后driver当前的页面依然是之前的。
如果想获取新窗口的源代码,就必须先切换过去 :
window.switch_to.window(driver.window_handles[1])
from selenium import webdriver url = 'https://www.baidu.com/' driver = webdriver.Chrome() driver.get(url) driver.maximize_window()js = 'open("https://www.douban.com/")' driver.execute_script(js)print(driver.page_source) # 获取到的是百度页面的信息 driver.quit()切换:
from selenium import webdriver url = 'https://www.baidu.com/' driver = webdriver.Chrome() driver.get(url) driver.maximize_window()js = 'open("https://www.douban.com/")' driver.execute_script(js)driver.switch_to_window(js) # print(driver.window_handles) print(driver.page_source) driver.quit()
import time
from selenium import webdriver
from selenium.webdriver.common.by import Byclass JdSpider():def __init__(self):self.url = 'https://search.jd.com/Search?keyword=%E6%95%B0%E7%A0%81&enc=utf-8&wq=%E6%95%B0%E7%A0%81&pvid=34b0fcf7ed434840a74c057bc97be346'self.driver = webdriver.Chrome()def get_url(self):self.driver.get(self.url)self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")time.sleep(2)li_list = self.driver.find_elements(By.XPATH, '//div[@id="J_goodsList"]/ul/li')detail_urls = []for li in li_list:a = li.find_element(By.XPATH, './/a')detail_urls.append(a.get_attribute('href'))for detail_url in detail_urls:js = f'open("{detail_url}")'self.driver.execute_script(js)self.driver.switch_to_window(self.driver.window_handles[1])time.sleep(2)self.get_detail()self.driver.close()self.driver.switch_to_window(self.driver.window_handles[0])def get_detail(self):print('获取详情')name = self.driver.find_element(By.CSS_SELECTOR, 'body > div:nth-child(10) > div > div.itemInfo-wrap > div.sku-name').textprint(name)if __name__ == '__main__':spider = JdSpider()spider.get_url() # *selenium-iframe
网页中嵌套了网页,先切换到iframe,再执行其他操作
切换到要处理的iframe
browaer.switch_to.frame(frame节点对象)
from selenium import webdriver from selenium.webdriver.common.by import By import infosurl = 'https://douban.com/'driver = webdriver.Chrome() driver.get(url)iframe = driver.find_element(By.XPATH, '//div[@class="login"]/iframe') # print(iframe)driver.switch_to.frame(iframe) # 切进来 # 点击密码登录 driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/ul[1]/li[2]').click() # 输入账号密码 driver.find_element(By.XPATH, '//*[@id="username"]').send_keys(infos.username) driver.find_element(By.XPATH, '//*[@id="password"]').send_keys(infos.username) # 点击登录 driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
验证码处理
数字验证码:
img = driver.find_element(By.XPATH, '复制验证码所在代码段的XPATH(右击--copy)')
img.screenshot("1.png") # 将图片截取下来
【网站:www.ttshitu.com---登录--开发文档--python--可以找到相应代码】
def base64_api(uname, pwd, img, typeid):with open(img, 'rb') as f:base64_data = base64.b64encode(f.read())b64 = base64_data.decode()data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)if result['success']:return result["data"]["result"]else:return result["message"] img_path = "1.jpg" result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3) print(result) # 记得导包滑动验证码:
button = driver.find_element(By.CSS_SELECTOR, '复制验证码所在代码的CSS路径')action = ActionChains(driver) action.click_and_hold(button).perform() # 点击且不松开action.move_by_offset(int(result) - 30, 0) # 滑块与左边框距离30 action.release().perform()
selenium翻页操作
取到第一页数据:
from selenium import webdriver from selenium.webdriver.common.by import Byurl = 'https://www.maoyan.com/board/4?offset=0'driver = webdriver.Chrome() driver.get(url)driver.maximize_window()dds = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl/dd')for dd in dds:print(dd.text.split('\n'))print('-'*30)翻页爬取:
from selenium import webdriver from selenium.webdriver.common.by import Byurl = 'https://www.maoyan.com/board/4?offset=0'option = webdriver.ChromeOptions() option.add_argument('--headless') # 加上这两句就不会弹出页面了(无头模式),,当然也可以不添加driver = webdriver.Chrome() driver.get(url)driver.maximize_window()dds = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl/dd')def get_data():"""一页的数据"""dds = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl/dd')for dd in dds:print(dd.text.split('\n'))print('-' * 30)while True:get_data()try:driver.find_element(By.LINK_TEXT, '下一页').click() # 点击下一页的文本except Exception as e: # 做异常处理,数据爬取100个后就没有下一页,会报错的print(e)print('数据爬取完成') # 没有下一页代表完成driver.quit()break
操作cookie
获取cookie:driver.get_cookies()
根据cookie的key获取value:value=driver.get_cookie(key)
删除所有的cookie:driver.delete_all_cookies()
删除某个cookie:driver.delete_cookie(key)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import infosurl = 'https://douban.com/'driver = webdriver.Chrome()
driver.get(url)iframe = driver.find_element(By.XPATH, '//div[@class="login"]/iframe')
# print(iframe)driver.switch_to.frame(iframe) # 切进来
# 点击密码登录
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/ul[1]/li[2]').click()
# 输入账号密码
driver.find_element(By.XPATH, '//*[@id="username"]').send_keys(infos.username)
driver.find_element(By.XPATH, '//*[@id="password"]').send_keys(infos.password)
# 点击登录
driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[5]/a').click()time.sleep(20)
cookies = driver.get_cookies()cookies_dict = {}
for cookie in cookies:name = cookie['name']value = cookie['value']cookies_dict[name] = valueurl = 'https://douban.com/'import requestsheaders = {'User-Agent': '# 将User-Agent复制过来'
}
print(requests.get(url, cookies=cookies_dict, headers=headers).text) # 获取到登陆后的数据
隐式等待和显式等待
隐式等待:指定一个时间,在这个时间内会一直处于等待状态。使用:driver.implicitly_wait
显式等待:指定在某个时间内,如果某个条件满足了,就不会在等待。使用:from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 隐式等待:后续的标签定位都会建立在5秒之内
# 后续的某个标签在5秒内加载出来就进行爬取,否则继续下一页
driver.implicitly_wait(5)# 显式等待:针对某一个标签定位
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.LINK_TEXT, "地图"))
).click()
相关文章:
【selenium】
selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的。Selenium可以直接调用浏览器,它支持所有主流的浏览器。其本质是通过驱动浏览器,完成模拟浏览器操作,比如挑战,输入,点击等。 下载与打…...

HX711压力传感器学习一(STM32)
目录 原理图: 引脚介绍: HX711介绍工作原理: 程序讲解: 整套工程: 发送的代码工程,与博客的不一致,如果编译有报错请按照报错和博客进行修改 原理图: 引脚介绍: VCC和GND引…...

作业2.13
1、选择题 1.1、若有定义语句:int a[3][6]; ,按在内存中的存放顺序,a 数组的第10个元素是 D A)a[0][4] B) a[1][3] C)a[0][3] D)a[1][4] 1.2、有数组 int a[5] {10,20,30,40,50},…...

ArcGIS学习(七)图片数据矢量化
ArcGIS学习(七)图片数据矢量化 通过上面几个任务的学习,大家应该已经掌握了ArcGIS的基础操作,并且学习了坐标系和地理数据库这两个非常重要且稍微难一些的专题。从这一任务开始,让我们进入到实战案例板块。 首先进入第一个案例一一图片数据矢量化。 我们在平时的工作学…...

G口大流量服务器选择的关键点有哪些?
G口服务器指的是接入互联网的带宽达到1Gbps以上的服务器,那么选择使用G口大流量服务器的用户需要注意哪些选择 关键点呢?小编为您整理关于G口大流量服务器的关键点。 G口服务器通常被用于需要大带宽支持的业务场景,比如视频流媒体、金融交易平台、电子商…...

MongoDB聚合:$unset
使用$unset阶段可移除文档中的某些字段。从版本4.2开始支持。 语法 移除单个字段,可以直接指定要移除的字段名: { $unset: "<field>" }移除多个字段,可以指定一个要移除字段名的数组: { $unset: [ "<…...

DS Wannabe之5-AM Project: DS 30day int prep day14
Q1. What is Alexnet? Q2. What is VGGNet? Q3. What is VGG16? Q4. What is ResNet? At the ILSVRC 2015, so-called Residual Neural Network (ResNet) by the Kaiming He et al introduced the anovel architecture with “skip connections” and features heavy b…...

【程序设计竞赛】C++与Java的细节优化
必须强调下,以下的任意一种优化,都应该是在本身采用的算法没有任何问题情况下的“锦上添花”,而不是“雪中送炭”。 如果下面的说法存在误导,请专业大佬评论指正 读写优化 C读写优化——解除流绑定 在ACM里,经常出现…...

Java缓冲流——效率提升深度解析
前言 大家好,我是chowley,在我之前的项目中,用到了缓冲流来提高字符流之间的比较速度,缓冲流的主要作用类似于数据库缓存,提高IO操作效率。 缓冲流 在Java的输入输出操作中,缓冲流是提高性能的重要工具之…...
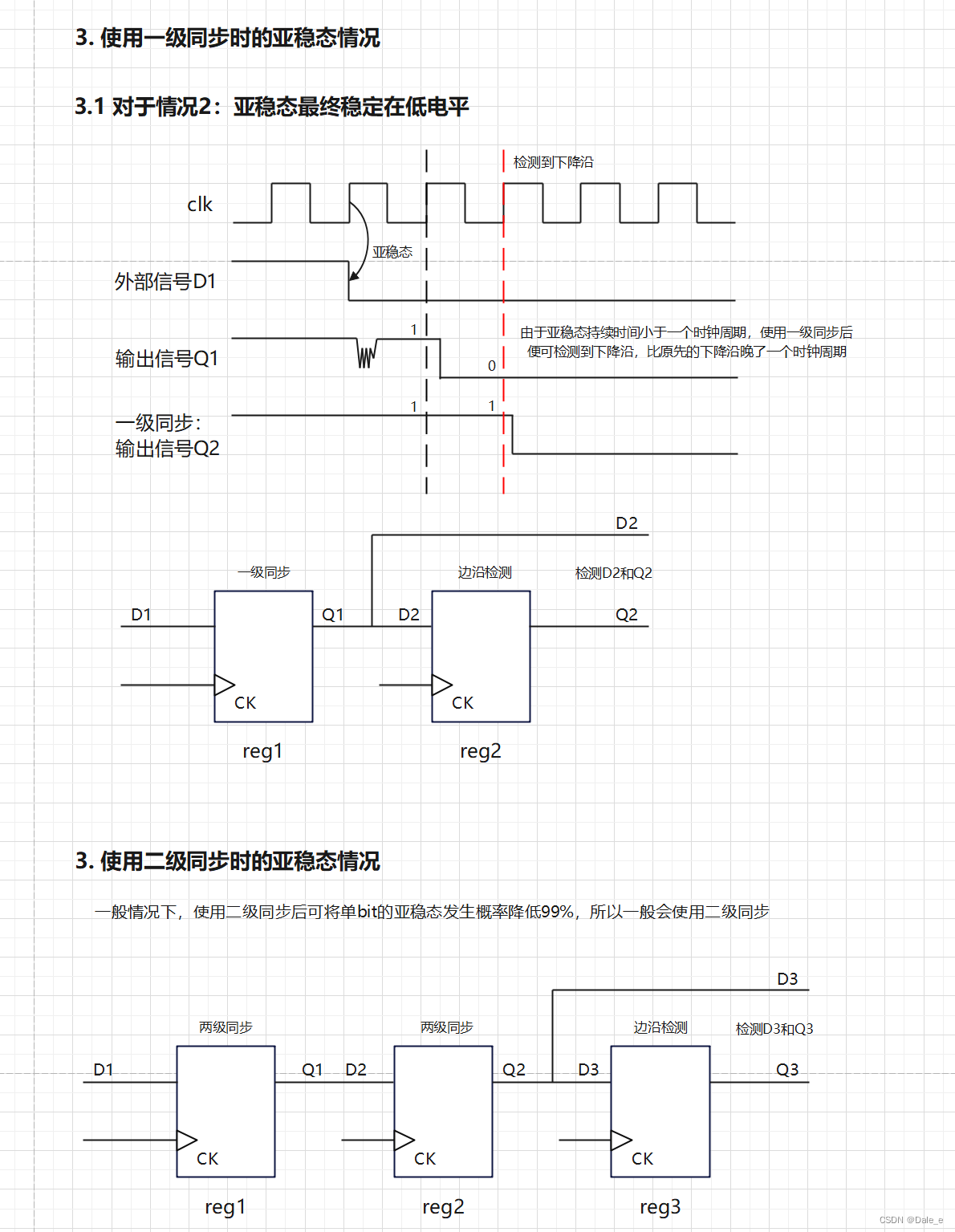
16 亚稳态原理和解决方案
1. 亚稳态原理 亚稳态是指触发器无法在某个规定的时间段内到达一个可以确认的状态。在同步系统中,输入总是与时钟同步,因此寄存器的setup time和hold time是满足的,一般情况下是不会发生亚稳态情况的。在异步信号采集中,由于异步…...
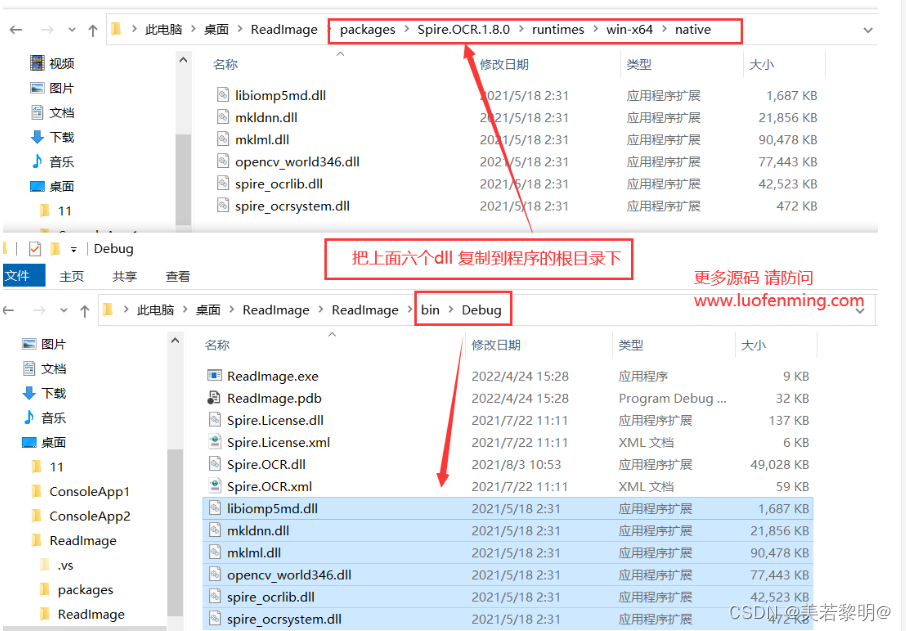
C# OCR识别图片中的文字
1、从NuGet里面安装Spire.OCR 2、安装之后,找到安装路径下,默认生成的packages文件夹,复制该文件夹路径下的 6 个dll文件到程序的根目录 3、调用读取方法 OcrScanner scanner new OcrScanner(); string path "C:\1.png"; scann…...
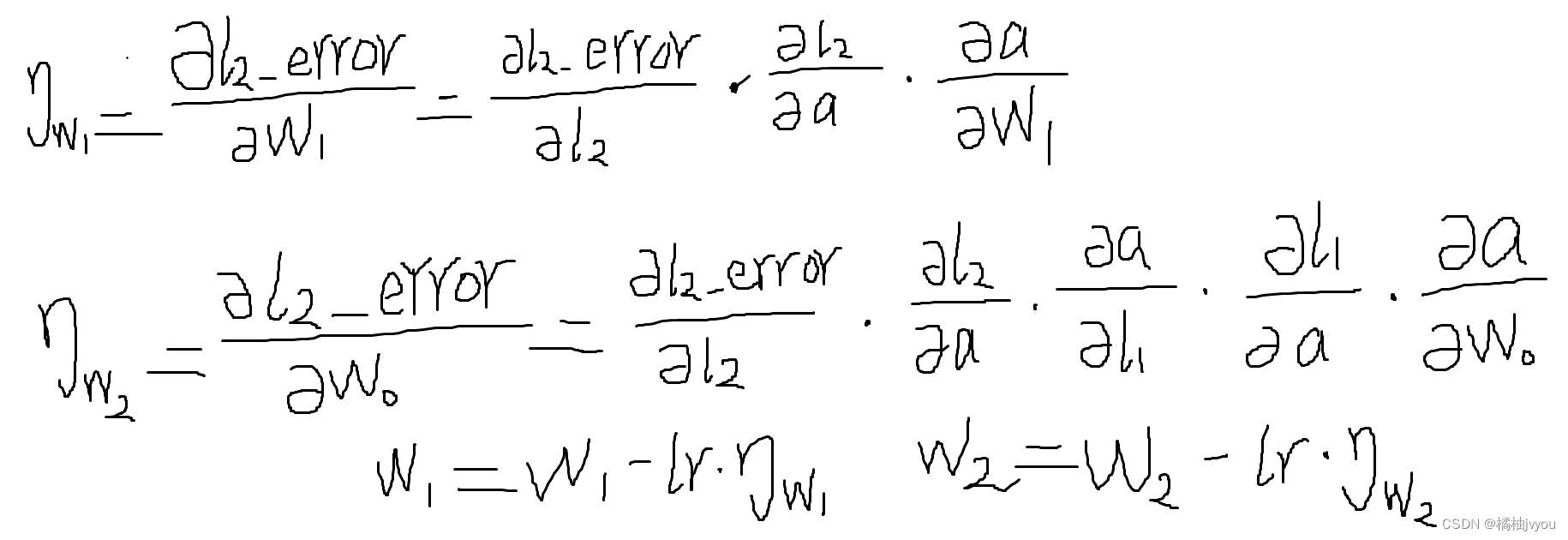
使用python-numpy实现一个简单神经网络
目录 前言 导入numpy并初始化数据和激活函数 初始化学习率和模型参数 迭代更新模型参数(权重) 小彩蛋 前言 这篇文章,小编带大家使用python-numpy实现一个简单的三层神经网络,不使用pytorch等深度学习框架,来理解…...

CSS定位装饰
网页常见布局方式 标准流 块级元素独占一行---垂直布局 行内元素/行内块元素一行显示多个----水平布局 浮动 可以让原本垂直布局的块级元素变成水平布局 定位 可以让元素自由的摆放在网页的任意位置 一般用于盒子之间的层叠情况 使用定位步骤 设置定位方式 属性名&am…...

java之jvm详解
JVM内存结构 程序计数器 Program Counter Register程序计数器(寄存器) 程序计数器在物理层上是通过寄存器实现的 作用:记住下一条jvm指令的执行地址特点 是线程私有的(每个线程都有属于自己的程序计数器)不会存在内存溢出 虚拟机栈(默认大小为1024kb) 每个线…...

vue3学习——集成sass
安装 pnpm i sass sass-loader -D在vite.config.ts文件配置: export default defineConfig({css: {preprocessorOptions: {scss: {javascriptEnabled: true,additionalData: import "./src/styles/variable.scss";,},},},} }创建三个文件 src/styles/index.scss //…...
开关电源学习之Boost电路
如果我们需要给一个输入电压为5V的芯片供电,而我们只有一个3.3V的电源,那怎么办? 我们能不能把3.3V的电压升到5V? 一、电感的简介 而在升压的电路设计方案中,使用到一个重要的元器件:电感。 电感的特性…...

QRegExp的学习
【QT学习】QRegExp类正则表达式(一文读懂)-CSDN博客 [ ]:匹配括号内输入的任意字符 例:[123]:可以是1或2或3 {m,n}表达式至少重复m次,至多重复n次。 例:"ba{1,3}"可以匹配 "ba"或&…...

28.Stream流
Stream流 1. 概述2. 方法2.1 开始生成方法2.1.1 概述2.1.2 方法2.1.3 代码示例 2.2 中间操作方法2.2.1 概述2.2.2 方法2.2.3 代码示例 2.3 终结操作方法2.3.1 概述2.3.2 方法2.3.3 代码示例 2.4 收集操作方法2.4.1 概述2.4.2 方法2.4.3 代码示例 3. 代码示例14. 代码示例25. 代…...

大数据应用对企业的价值
目录 一、大数据应用价值 1.1 大数据技术分析 1.2 原有技术场景的优化 1.2.1 数据分析优化 1.2.2 高并发数据处理 1.3 通过大数据构建新需求 1.3.1 智能推荐 1.3.2 广告系统 1.3.3 产品/流程优化 1.3.4 异常检测 1.3.5 智能管理 1.3.6 人工智能和机器学习 二、大数…...

【51单片机】LED点阵屏(江科大)
9.1LED点阵屏 1.LED点阵屏介绍 LED点阵屏由若干个独立的LED组成,LED以矩阵的形式排列,以灯珠亮灭来显示文字、图片、视频等。 2.LED点阵屏工作原理 LED点阵屏的结构类似于数码管,只不过是数码管把每一列的像素以“8”字型排列而已。原理图如下 每一行的阳极连在一起,每一列…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

多元隐函数 偏导公式
我们来推导隐函数 z z ( x , y ) z z(x, y) zz(x,y) 的偏导公式,给定一个隐函数关系: F ( x , y , z ( x , y ) ) 0 F(x, y, z(x, y)) 0 F(x,y,z(x,y))0 🧠 目标: 求 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z、 …...
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...