【医学大模型 知识增强】SMedBERT:结构化语义知识 + 医学大模型 = 显著提升大模型医学文本挖掘性能
SMedBERT:结构化语义知识 + 医学大模型 = 显著提升医学文本挖掘任务性能
- 名词解释
- 结构化语义知识
- 预训练语言模型
- 医学文本挖掘任务
- 提出背景
- 具体步骤
- 提及-邻居混合注意力机制
- 实体嵌入增强
- 实体描述增强
- 三元组句子增强
- 提及-邻居上下文建模
- 域内词汇权重学习
- 领域自监督任务预训练
- SMedBERT 图示
- 左半部分:SMedBERT架构
- 右半部分:预训练任务
- 方法部分
- 数学部分
- 效果
论文:https://arxiv.org/pdf/2108.08983.pdf
代码:https://github.com/MatNLP/SMedBERT
名词解释
结构化语义知识
结构化语义知识是指以组织良好的形式(如知识图谱、数据库、分类体系等)存储的信息,这些信息明确描述了实体(如人、地点、事物)之间的关系以及实体的属性和类别。
在结构化语义知识中,数据不仅仅是被保存,还被赋予了明确的意义和上下文,使得机器可以理解和处理复杂的关系和属性。
例如,医学知识图谱可能会包含不同疾病、症状、药物和治疗方法的实体,以及这些实体之间的关系(如“引起”、“治疗”、“副作用”等)。
这种知识的结构化形式使得机器能够执行更加复杂的推理任务,从而支持高级的数据分析和决策制定。
预训练语言模型
预训练语言模型是使用大量文本数据训练的模型,旨在捕捉语言的通用特征和结构。
这些模型在没有特定任务指导的情况下进行训练,学习词汇、短语、句子甚至长文本的表示,以及它们之间的语义和语法关系。
预训练完成后,模型可以在特定的下游任务(如文本分类、情感分析、问答系统等)上进行微调,以提高任务的性能。
代表性的预训练语言模型包括BERT、GPT、RoBERTa等,这些模型通过学习大规模文本语料库中的语言规律,能够有效地理解和生成人类语言。
医学文本挖掘任务
医学文本挖掘是指使用计算机算法从医学文献、临床记录、病历报告等文本中提取、分析和理解有用信息的过程。
这些任务包括但不限于:
- 命名实体识别(NER): 识别文本中的医学实体,如疾病、症状、药物等。
- 关系提取: 确定文本中实体之间的关系,例如识别哪种药物用于治疗哪种疾病。
- 文献检索: 在大规模医学文献数据库中检索与特定查询相关的文档。
- 问答系统: 根据用户的自然语言问题提供准确的答案,这些问题通常与医疗健康状况、治疗方案等相关。
医学文本挖掘的目标是从医学文本中自动提取知识,支持临床决策、医学研究和患者护理等活动。
这些任务通常面临医学术语的复杂性、文本的多样性和专业性等挑战。
提出背景
- 问题1: 预训练语言模型(PLMs)在处理医学文本时,难以捕获医学术语之间复杂的关系和医学事实。
- 背景: 医学领域存在大量的专业术语及其复杂关系,这些细节仅仅通过文本是难以充分理解的。
- 问题2: 现有的知识增强预训练语言模型(KEPLMs)主要关注于实体及其直接链接,忽略了实体之间的结构化语义信息。
- 背景: 医学术语间不仅仅是简单的链接,还包括了类型、关系等丰富的结构化信息,这对于理解医学文本至关重要。
以“视网膜病变”为例,在医学领域,"视网膜病变"不仅是一个单独的医学术语,它与多种因素和疾病有着复杂的关联。
例如,视网膜病变可能由糖尿病(特别是糖尿病视网膜病变)、高血压、遗传疾病等多种原因引起。
每一种原因都代表了与"视网膜病变"有着不同类型关系的实体。
在传统的KEPLMs处理过程中,模型可能识别“视网膜病变”作为一个实体,并可能将其与“糖尿病”通过“导致”这样一个直接链接关联起来。
这种处理忽略了以下几个方面的结构化语义信息:
-
类型信息: “视网膜病变”不仅是由糖尿病引起的,它可以分为多种类型,如糖尿病视网膜病变、高血压视网膜病变等,每种类型的病变与特定的疾病或条件有关。
-
关系多样性: 除了“导致”关系,视网膜病变与其原因之间还可能存在其他类型的关系,如“并发于”糖尿病等。此外,视网膜病变的存在可能影响到患者的视力,这种“影响”关系也是重要的结构化信息。
-
关联实体的属性: 涉及视网膜病变的实体(如糖尿病)自身可能有多种属性,如病程阶段、控制情况等,这些属性也会影响视网膜病变的发展和治疗。
因此,在处理“视网膜病变”这类医学术语时,仅仅关注于实体及其直接链接的KEPLMs方法会丢失大量重要的结构化语义信息。
这种信息对于准确理解医学文本、进行准确的疾病诊断和制定有效的治疗计划至关重要。
例如,了解视网膜病变的具体类型和原因,可以帮助医生选择更加针对性的治疗方法,为患者提供个性化的医疗方案。
论文解法:
- 解法1: 提及-邻居混合注意力机制
“提及”指的是文本中直接出现的实体或概念,而“邻居”则指的是与这些文本提及相关联的知识图谱中的实体。
这种机制不仅关注于知识图谱内的实体关系,还特别关注于如何将这些关系与原始文本中的实体提及相结合,以增强模型的语义理解能力。
强调了两个关键方面的结合:文本中的实体提及(mentions)和这些提及在知识图谱中的邻居(neighbors)之间的信息融合。
- 特征: 为了克服知识噪声并有效利用实体类型和邻近实体信息,提及-邻居混合注意力机制融合了链接实体邻居的节点和类型嵌入到上下文目标提及表示中。
如在处理提到“糖尿病”和“视网膜病变”的文本时,传统模型可能仅识别这两个条件作为独立实体。
然而,使用提及-邻居混合注意力机制,模型不仅识别这些实体,而且还考虑到“糖尿病”作为一个实体可能与“视网膜病变”有直接的临床关联,即“糖尿病”是“视网膜病变”的一个常见原因。
这个机制会将“视网膜病变”作为“糖尿病”的一个邻居节点,并且考虑这种邻居关系的类型——在这个例子中是“导致”。
通过融合这些信息,模型能够更准确地捕捉到两个实体之间的关系,降低了由于缺乏深层次语义理解而导入的知识噪声。
- 解法2: 提及-邻居上下文建模
- 特征: 通过引入两种新颖的自监督学习任务(掩蔽邻居建模和掩蔽提及建模)来促进提及跨度与相应全局上下文之间的交互,从而丰富低频提及跨度的表示。
在同一文本中,提及-邻居上下文建模可以进一步提升模型对于“糖尿病”和“视网膜病变”及其相互关系理解的深度。
通过掩蔽邻居建模,模型学习预测与“糖尿病”直接相关的其他条件或并发症,如“视网膜病变”,基于其在医学知识图谱中的邻居实体。
同时,掩蔽提及建模任务鼓励模型从“糖尿病”与“视网膜病变”的关系中,反向学习到“糖尿病”本身的特性,如是什么类型的疾病,通常会引起哪些并发症等。
这种相互作用不仅丰富了模型对于低频实体“视网膜病变”的表示,还增强了对“糖尿病”这一高频实体深度语义的理解。
通过这两种解法,模型能够更全面和深入地理解医学文本中的复杂信息,提高医学文本挖掘的准确性和效率。
具体步骤
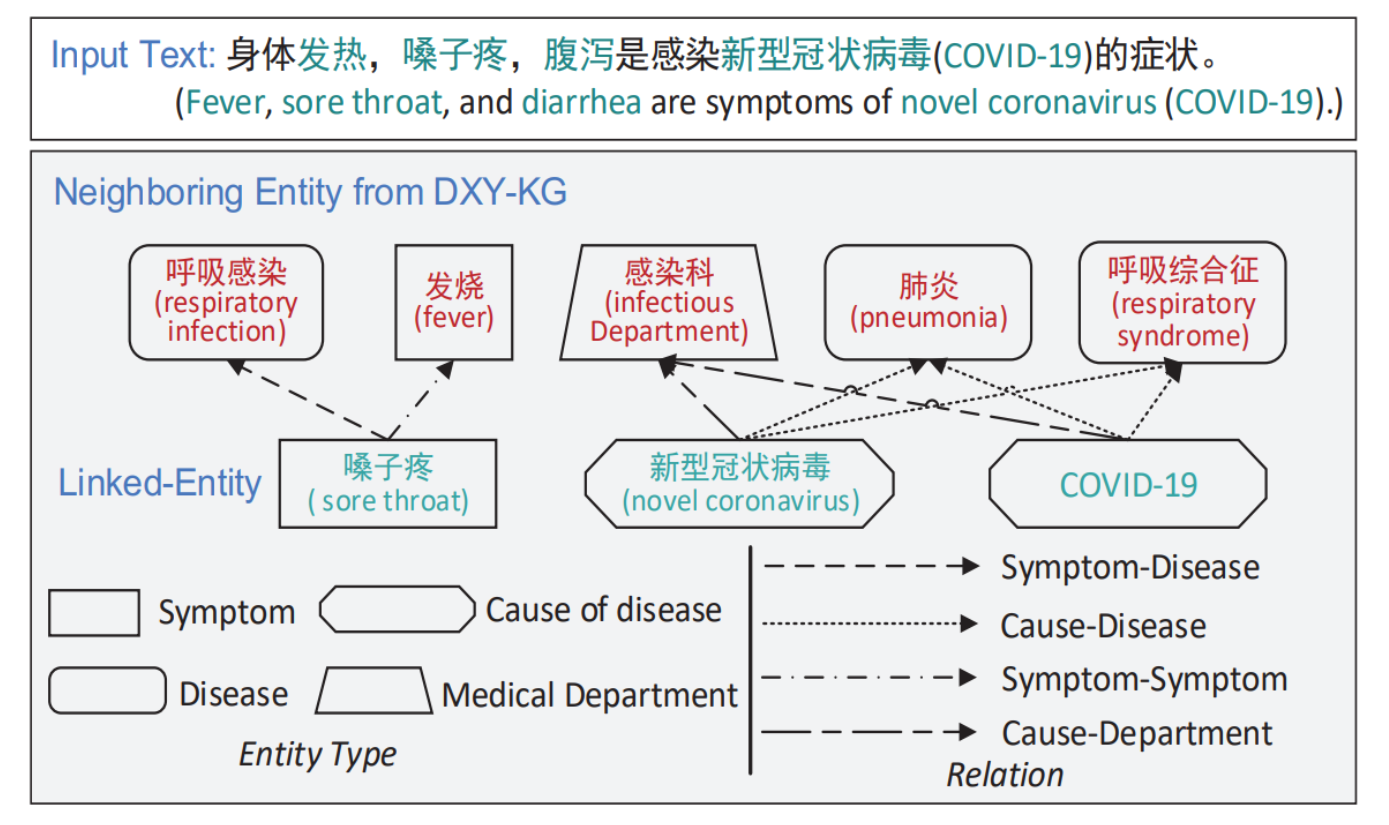
这张图通过一个具体的例子阐释了在医学文本中如何利用知识图谱(在本例中为DXY-KG)来识别和理解文本中提及的医学实体及其关系:
-
输入文本识别:
- 输入文本中的症状被列出:“发热、咽痛、腹泻是新型冠状病毒肺炎(COVID-19)的症状。”
- 这是一个非结构化数据的例子,其中包含了若干医学实体和它们之间的关系。
-
实体识别与分类:
- 在文本中识别出的实体例如“咽痛”被标注为症状类型。
-
知识图谱链接:
- 这些实体被链接到知识图谱中相应的实体上。
- 在本例中,“咽痛”被链接到了“新型冠状病毒”,表示它是由该病毒引起的症状。
-
邻居实体的探索:
- 从知识图谱中探索与“咽痛”相关联的其他实体,如“发热”、“肺炎”和“呼吸综合征”。
- 这些邻居实体与“咽痛”之间的关系被识别和标注。
-
关系类型定义:
- 图中定义了实体之间的不同关系类型,比如“症状-疾病”、“原因-疾病”、“症状-症状”和“原因-科室”。
-
可视化表达:
- 通过不同的线条(实线、虚线)和形状,这些实体和关系在图中被可视化。每种关系类型都有相应的图例说明,例如实线表示症状与疾病之间的直接联系。
提及-邻居混合注意力机制
实体嵌入增强
- 步骤1: 在一篇关于肺炎治疗的文章中,模型识别出“肺炎”、“抗生素”和“咳嗽”等实体。
- 步骤2: 使用TransE算法为这些实体生成向量表示,捕捉它们在知识图谱中的位置和关系。
- 步骤3: 在模型的注意力机制中融合这些向量表示,使得在处理与肺炎相关的文本时,模型能够更好地理解“抗生素”是治疗“肺炎”的一种方法。
实体描述增强
- 步骤1: 收集“肺炎”和“抗生素”的描述文本,如“肺炎是一种呼吸系统疾病,常由细菌或病毒引起”。
- 步骤2: 将描述文本融合到模型的输入中,提供更丰富的上下文信息。
三元组句子增强
- 步骤1: 选择“肺炎 - 治疗 - 抗生素”的三元组。
- 步骤2: 将其转换为句子“抗生素可以用来治疗肺炎。”并加入训练语料。
- 步骤3: 通过这种方式,模型学习到“抗生素”和“肺炎”之间的治疗关系。
提及-邻居上下文建模
域内词汇权重学习
- 步骤1: 识别出医学领域特有的术语,如“细菌性肺炎”、“病毒性肺炎”等。
- 步骤2: 使用来自医学数据库的大量文本数据训练模型,为这些专业术语生成词汇表和权重。
- 步骤3: 通过这种方法,模型在处理肺炎相关文本时能够准确识别和理解这些术语。
领域自监督任务预训练
- 步骤1: 定义一个自监督任务,比如随机掩码文本中的“肺炎”并让模型预测它。
- 步骤2: 在预训练阶段通过这个任务让模型学习“肺炎”的上下文信息和与之相关的医学知识。
- 步骤3: 这样做使得模型能够在处理医学查询或诊断文本时,更好地理解和回答有关“肺炎”的问题。
通过结合这些子解法,可以显著提升预训练语言模型在特定领域(如医学)的性能,使其更好地理解和处理专业文本。
SMedBERT 图示
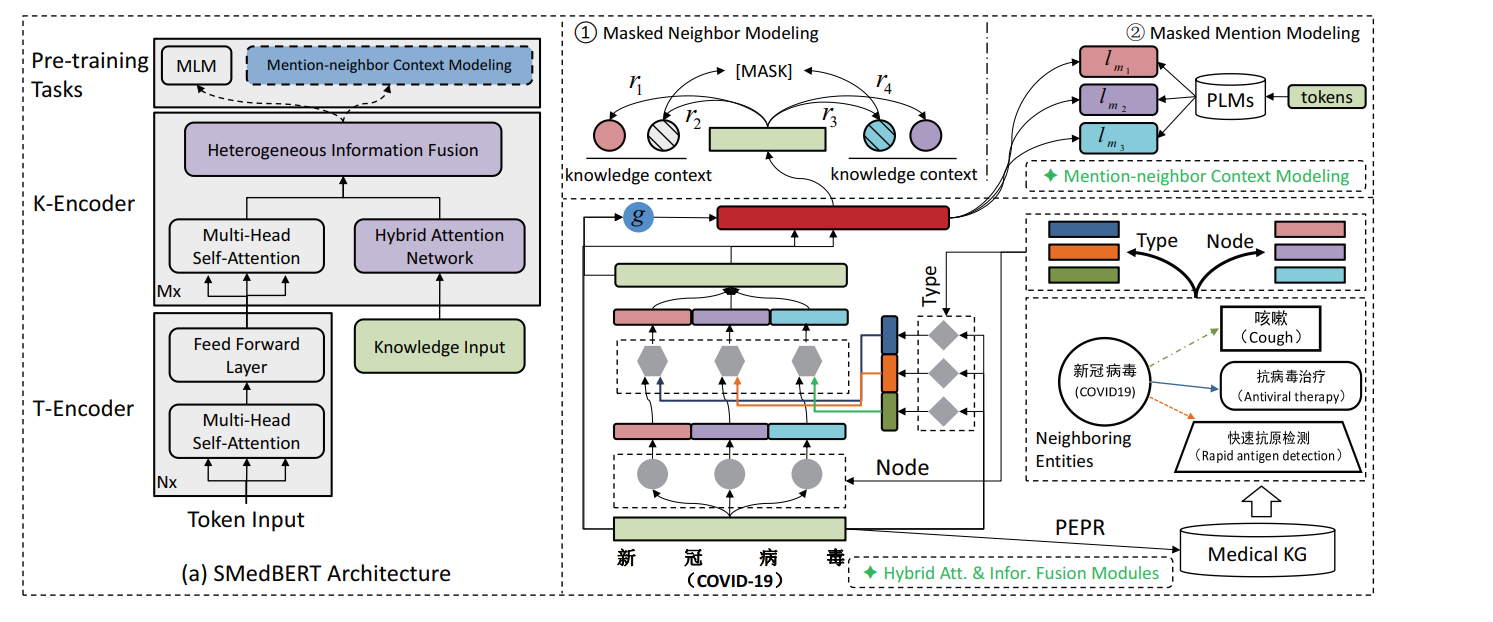
图的左半部分展示了模型的架构,而右半部分详细展示了模型包括混合注意力网络和提及-邻居上下文建模预训练任务的细节。
左半部分:SMedBERT架构
- T-Encoder: 底部是标准的Transformer编码器,它接收文本输入并通过多头自注意力机制处理这些输入。
- K-Encoder: 顶部是知识编码器,它专门处理来自医学知识图谱的输入。它使用混合注意力网络来融合文本输入(通过T-Encoder处理)和外部知识(知识输入)。
右半部分:预训练任务
- 预训练任务: 包括两部分,一是掩蔽邻居建模(Masked Neighbor Modeling),二是掩蔽提及建模(Masked Mention Modeling)。
- 掩蔽邻居建模: 这一任务涉及对知识图谱中的实体邻居进行掩蔽,并要求模型预测缺失的邻居实体,以此来增强模型对知识图谱中实体关系的理解。
- 掩蔽提及建模: 在这个任务中,文本中的实体提及被掩蔽,模型需要预测这些提及,这有助于模型学习实体在文本中的语义表示。
这张图描绘了SMedBERT如何结合传统的Transformer架构与知识图谱信息,通过预训练任务学习医学领域的复杂语义关系。
这种结合可以帮助模型更好地处理医学文本中的专业术语和概念,从而在医学领域的自然语言处理任务中实现更高的准确性和效率。
方法部分
子问题1: 如何在不引入知识噪声的前提下有效地融合知识图谱和文本数据?
- 子解法1: Top-K实体排序(Top-K Entity Sorting),通过个性化PageRank算法筛选与提及最相关的K个邻居实体,减少知识噪声。
子问题2: 在保持文本原有意义的同时,如何增强实体表示与其在知识图谱中邻居实体的关联性?
- 子解法2: 提及-邻居混合注意力(Mention-neighbor Hybrid Attention),结合实体类型和节点注意力,以及门控位置融合。
子问题3: 如何设计预训练任务以利用实体间的结构化语义知识?
- 子解法3: 提及-邻居上下文建模(Mention-neighbor Context Modeling),包括掩蔽邻居建模(Masked Neighbor Modeling)和掩蔽提及建模(Masked Mention Modeling)。
数学部分
- Top-K实体排序: 使用个性化PageRank算法计算每个实体与提及的相关性,然后选择相关性最高的K个实体。
在训练开始时,对于文本中提及的“糖尿病”,我们查询知识图谱以找到与之相关的实体,如“胰岛素”、“高血糖”、“视网膜病变”等。
使用个性化PageRank算法评估“糖尿病”与这些实体的相关性,并选择相关性最高的K个实体。
假设K=3,选出的实体可能是“胰岛素”、“高血糖”和“视网膜病变”。
- 提及-邻居混合注意力机制:
- 实体类型注意力: 计算每个提及与其相应类型的邻居实体的关联度。
模型计算“糖尿病”(疾病类型)与其邻居实体“胰岛素”(治疗类型)、“高血糖”(症状类型)、“视网膜病变”(并发症类型)之间的关联度。
- 节点注意力: 为每个邻居实体分配一个注意力分数,以确定其对提及的贡献程度。
模型为每个选定的邻居实体分配一个注意力分数,基于它们对“糖尿病”描述的贡献程度。
- 门控位置融合: 使用门控机制结合提及的原始文本表示和知识图谱信息,以减少知识噪声。
结合“糖尿病”的文本表示和从知识图谱中提取的邻居实体信息,使用门控机制调整信息融合的程度。
- 提及-邻居上下文建模:
- 掩蔽邻居建模: 预测与提及相关联的掩蔽邻居实体,强化模型对结构化知识的理解。
随机掩蔽一些与“糖尿病”相关的邻居实体(比如“高血糖”),模型需要预测这个被掩蔽的实体,这有助于模型学习实体间的关系。
- 掩蔽提及建模: 从邻居实体的角度预测被掩蔽的提及,促进实体之间的语义联系。
模型尝试从提及“糖尿病”周围的上下文中预测被掩蔽的提及,促进对“糖尿病”的深层语义理解。
- 训练目标: 模型的最终训练目标是最小化上述所有预训练任务的总损失,通常是通过调整超参数来平衡不同部分的损失。
数学公式
-
实体表示(Entity Representation):
- 每个单词或实体在计算机中都通过一个数字列表表示,这个列表称为“向量”。比如,单词“糖尿病”可能被表示为一个向量
[0.2, -0.1, 0.9, ...]。
- 每个单词或实体在计算机中都通过一个数字列表表示,这个列表称为“向量”。比如,单词“糖尿病”可能被表示为一个向量
-
实体类型注意力(Entity Type Attention):
- 我们想计算模型有多关注实体的类型(比如,“糖尿病”是一种“疾病”)。为此,我们使用向量表示的实体(“糖尿病”)和实体类型(“疾病”)来计算一个分数,这个分数告诉我们模型有多关注这个类型。
-
节点注意力(Node Attention):
- 类似地,我们想知道模型有多关注与实体相关联的其他实体(节点)。比如,“糖尿病”与“胰岛素注射”有关联,我们计算一个分数来量化这种关联。
-
门控位置融合(Gated Position Infusion):
- 有时候,我们想结合实体在文本中的位置信息。门控机制就像一个开关,它决定我们是否应该将这个位置信息与实体的表示结合起来。
-
总损失函数(Total Loss Function):
- 在训练模型时,我们需要一种方法来告诉模型它的预测有多好。损失函数就是这样一种方法,它计算模型预测和实际情况之间的差异。总损失是所有不同任务损失的组合。
让我们更详细地看一下这些步骤中的数学公式:
- 实体类型注意力:
AttentionScore = exp ( DotProduct ( h e m , h t y p e ) / d ) SumOfAllScores \text{AttentionScore} = \frac{\exp(\text{DotProduct}(h_{em}, h_{type}) / \sqrt{d})}{\text{SumOfAllScores}} AttentionScore=SumOfAllScoresexp(DotProduct(hem,htype)/d)
这里,DotProduct 表示两个向量的点乘(一个简单的向量相乘和累加操作),h_{em} 是实体的向量,h_{type} 是实体类型的向量,d 是向量的维度。这个分数后来会被归一化成概率,这就是 softmax 函数的作用。
- 节点注意力:
NodeAttentionScore = softmax ( W ⋅ tanh ( V e m + V n o d e + b ) ) \text{NodeAttentionScore} = \text{softmax}(W \cdot \text{tanh}(V_{em} + V_{node} + b)) NodeAttentionScore=softmax(W⋅tanh(Vem+Vnode+b))
这里,V_{em} 和 V_{node} 分别是实体和邻居节点的向量,W 和 b 是模型需要学习的参数。
- 门控位置融合:
h n e w = Gate ⊙ h e m + ( 1 − Gate ) ⊙ p e m h_{new} = \text{Gate} \odot h_{em} + (1 - \text{Gate}) \odot p_{em} hnew=Gate⊙hem+(1−Gate)⊙pem
这里,Gate 是决定使用多少位置信息的门控分数,h_{em} 是实体的向量,p_{em} 是位置的向量。
- 总损失函数:
L t o t a l = λ 1 L t y p e + λ 2 L n o d e + λ 3 L g a t e + L b a s e L_{total} = \lambda_1 L_{type} + \lambda_2 L_{node} + \lambda_3 L_{gate} + L_{base} Ltotal=λ1Ltype+λ2Lnode+λ3Lgate+Lbase
这里, L t y p e , L n o d e , L g a t e L_{type}, L_{node}, L_{gate} Ltype,Lnode,Lgate 分别代表实体类型注意力、节点注意力和门控位置融合的损失函数,而 L b a s e L_{base} Lbase 代表基础的预训练损失(如交叉熵损失)。
λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3 是用来平衡不同损失组件的超参数。
实体类型注意力有助于模型识别“糖尿病”是一种疾病;
节点注意力帮助模型理解“糖尿病”与“胰岛素注射”之间的联系;
门控位置融合确保位置信息以合适的方式被使用;
总损失函数则是在训练过程中,指导模型朝着正确方向改进其预测。
效果
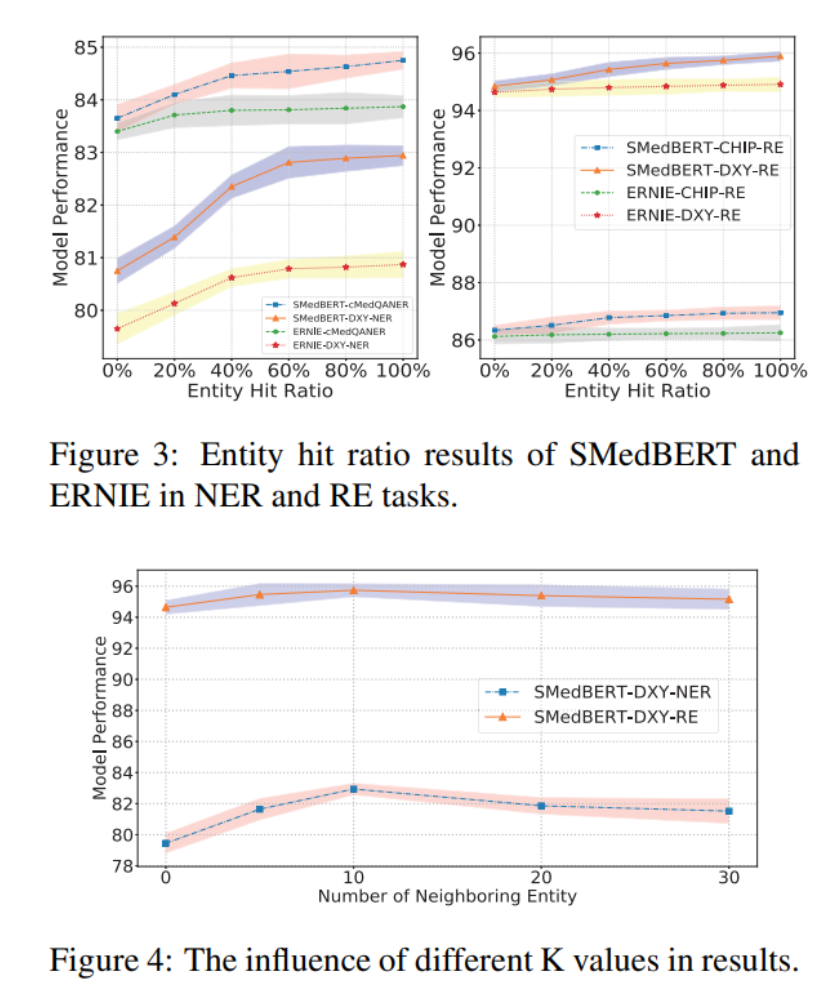
实验结论:
-
SMedBERT模型的优势:
- SMedBERT在包含结构化语义知识的预训练中表现出色,特别是在处理需要深度语义理解的医学文本任务上。
- 通过整合医学领域的知识图谱信息,SMedBERT在各种医学自然语言处理(NLP)任务上显著超越了基线模型,包括命名实体识别(NER)、关系抽取(RE)和问答(QA)等任务。
-
知识图谱的融合有效性:
- 实验结果表明,结构化的知识图谱信息对于提高模型在医学领域任务中的性能至关重要。
- 特别是对于那些具有大量共享邻居的实体对,SMedBERT能够更有效地利用这些全局上下文信息,增强了模型对低频提及的表示能力。
-
实体命中比率和邻居实体数量的影响:
- 对于命名实体识别和关系抽取任务,当增加知识增强提及的比例(即实体命中比率)时,模型性能显著提升,但超过一定阈值后性能趋于稳定。这表明虽然结构化知识对模型有益,但过多的知识可能会引入噪声,影响模型性能。
- 邻居实体数量的实验进一步证实了这一点,合理的邻居实体数量能够提升模型性能,而过多的邻居实体则可能导致知识噪声问题。
-
模型组件的重要性:
- 通过对SMedBERT模型进行消融研究,我们发现混合注意力机制是模型中最关键的组成部分。
- 移除混合注意力机制后,模型性能有最大幅度的下降,这强调了在预训练模型中注入丰富的异构邻居实体知识的重要性。
相关文章:
【医学大模型 知识增强】SMedBERT:结构化语义知识 + 医学大模型 = 显著提升大模型医学文本挖掘性能
SMedBERT:结构化语义知识 医学大模型 显著提升医学文本挖掘任务性能 名词解释结构化语义知识预训练语言模型医学文本挖掘任务 提出背景具体步骤提及-邻居混合注意力机制实体嵌入增强实体描述增强三元组句子增强 提及-邻居上下文建模域内词汇权重学习领域自监督任务…...

Python爬虫:安全与会话管理
源码分享 https://docs.qq.com/sheet/DUHNQdlRUVUp5Vll2?tabBB08J2 在进行网站数据抓取时,会话管理是保持与目标网站通信连续性的一种机制。这对于模拟登录、保持用户状态、维护cookie等场景至关重要。同时,安全性也是我们不可忽视的一个方面…...
[Python进阶] 识别验证码
11.3 识别验证码 我们再开发某些项目的时候,如果遇到要登录某些网页,那么会经常遇到输入验证码的情况,而每次人工输入验证码的话,比较浪费时间。于是,可以通过调用某些接口进行识别。 11.3.1 调用百度文字识别接口 …...

华为问界M9:全方位自动驾驶技术解决方案
华为问界M9的自动驾驶技术采用了多种方法来提高驾驶的便利性和安全性。以下是一些关键技术: 智能感知系统:问界M9配备了先进的传感器,包括高清摄像头、毫米波雷达、超声波雷达等,这些传感器可以实时监测车辆周围的环境࿰…...

Java 与 JavaScript 的区别与联系
Java 和 JavaScript 两种编程语言在软件开发中扮演着重要的角色。尽管它们都以“Java”命名,但实际上它们是完全不同的语言,各有其独特的特点和用途。本文将深入探讨 Java 和 JavaScript 的区别与联系,帮助大家更好地理解它们在编程世界中的作…...
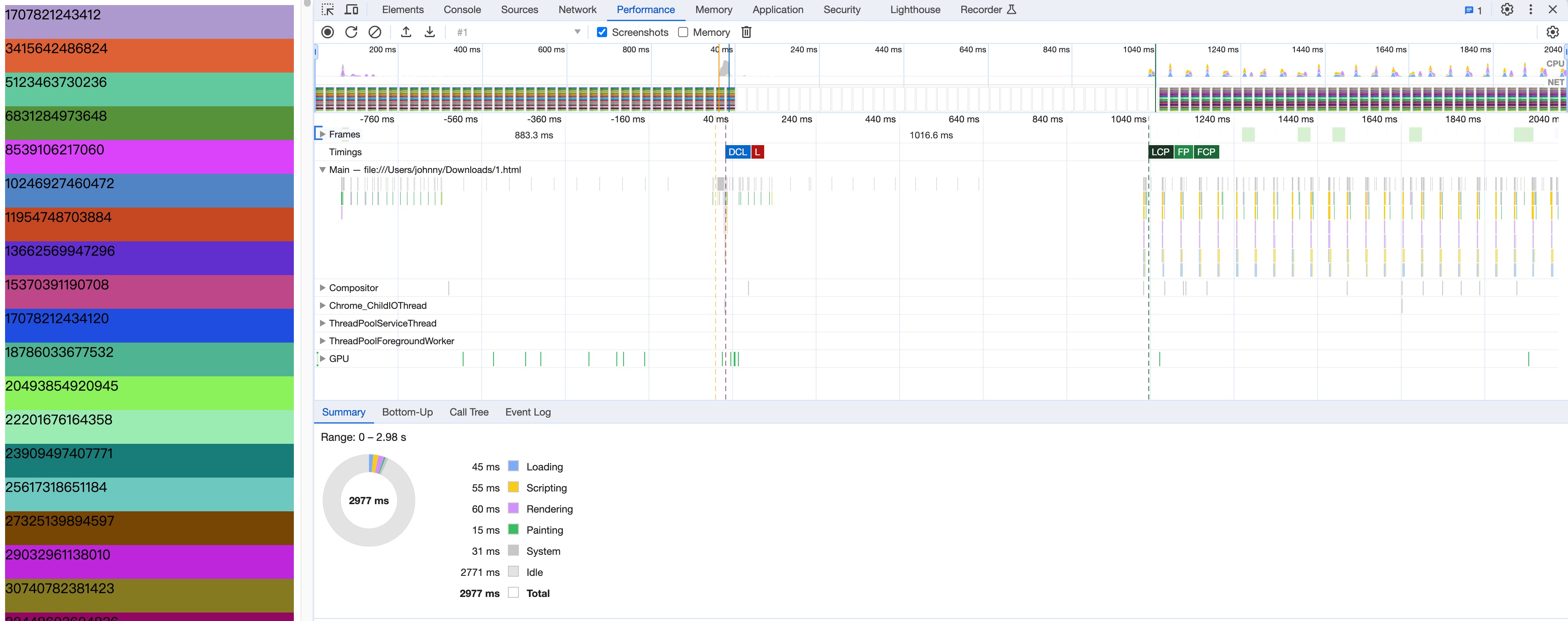
React18原理: 时间分片技术选择
渲染1w个节点的不同方式 1 )案例1:一次渲染1w个节点 <div idroot><div><script type"text/javascript">function randomHexColor() {return "#" ("0000" (Math.random() * 0x1000000 << 0).toS…...
)
【QT+QGIS跨平台编译】之三十三:【SpatiaLite+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、SpatiaLite介绍二、文件下载三、文件分析四、pro文件五、编译实践一、SpatiaLite介绍 SpatiaLite是一个开源的空间数据库库,它是在SQLite关系数据库管理系统上扩展而来的。SpatiaLite提供了对地理空间数据的存储、查询和分析功能,使得开发人员可以在应用程序中…...
【JavaEE】_CSS选择器
目录 1. 基本语法格式 2. 引入方式 2.1 内部样式 2.2 内联样式 2.3 外部样式 3. 基础选择器 3.1 标签选择器 3.2 类选择器 3.3 ID选择器 4. 复合选择器 4.1 后代选择器 4.2 子选择器 4.3 并集选择器 4.4 伪类选择器 1. 基本语法格式 选择器若干属性声明 2. 引入…...
Flaurm实现中文搜索
目录 摘要需求本文涉及环境情况如下解决方案最终效果文章其他链接: 摘要 Flarum本身对中文支持并不理想,但随着版本更新,逐渐加强了对中文的优化。然而在1.8.5版本,却还是不支持中文搜索网站文章内容。作者在检索了全网教程&#…...

STM32自学☞定时器外部时钟案例
本案例主要是通过外部时钟实现对射式红外传感器的计次,在oled显示屏上显示CNT的次数 timer_interrupt.c文件 #include "stm32f10x.h" #include "stm32f10x_tim.h" #include "timer_interrupt.h" #include "stdint.h" …...
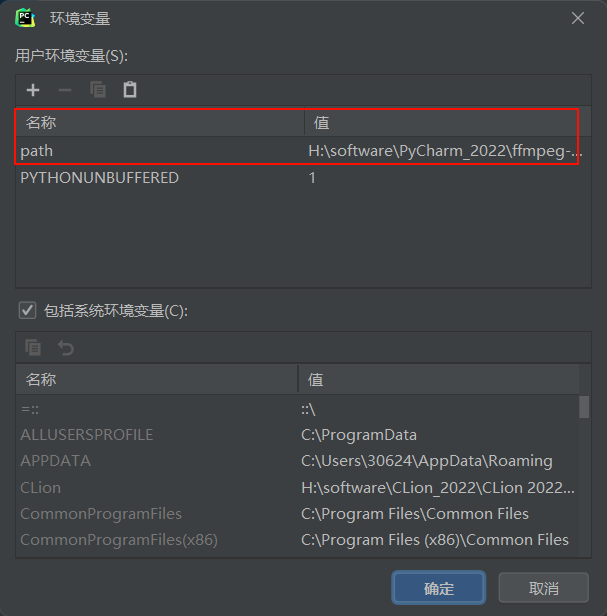
PyCharm中无法调用ffmpeg命令行
问题前提 ffmpeg在系统中正确安装,且在cmd命令行可以正确使用。但在PyCharm中无法调用! 但是在外部系统cmd中使用确是正常的~ 问题关键 我的python解释器使用的是anaconda的虚拟环境,导致在外部环境配置的path路径没有包括在内 解决办法…...

Go基础知识学习-习题题解
这里给出来官方教程中部分题目的答案,都是自己练习的时候写的,可以参考来提供思路。 当然了,练习还是最好自己写,要不对相关的知识点不可能理解透彻。 Exercise: Loops and Functions package mainimport ("fmt" )fu…...
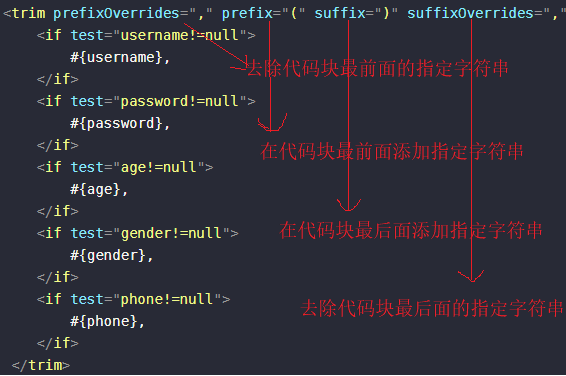
MyBatis中的XML实现和动态SQL实现
文章目录 一、XML实现1.1增1.2删1.3查1.4改 二、XML方式实现动态SQL2.1if标签2.2trim标签2.3where标签2.4set标签2.5foreach标签2.6include标签和sql标签 一、XML实现 先在新建的XML文件中写入如下内容: <?xml version"1.0" encoding"UTF-8&qu…...
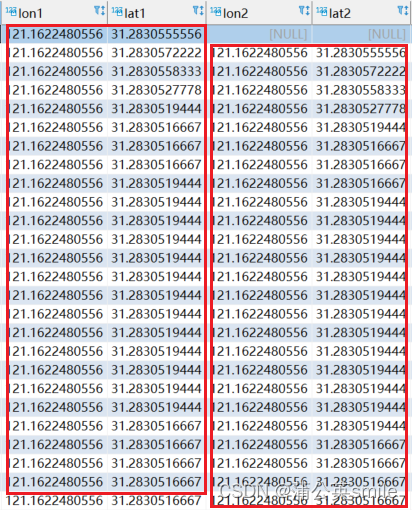
clickhouse计算前后两点间经纬度距离
问题 计算如图所示前后两点经纬度的距离? 方法 1、用开窗函数将如图所示数据下移一行 selectlongitude lon1,latitude lat1,min(longitude) over(order by time1 asc rows between 1 PRECEDING and 1 PRECEDING) lon2,min(latitude) over(order by time1 asc row…...
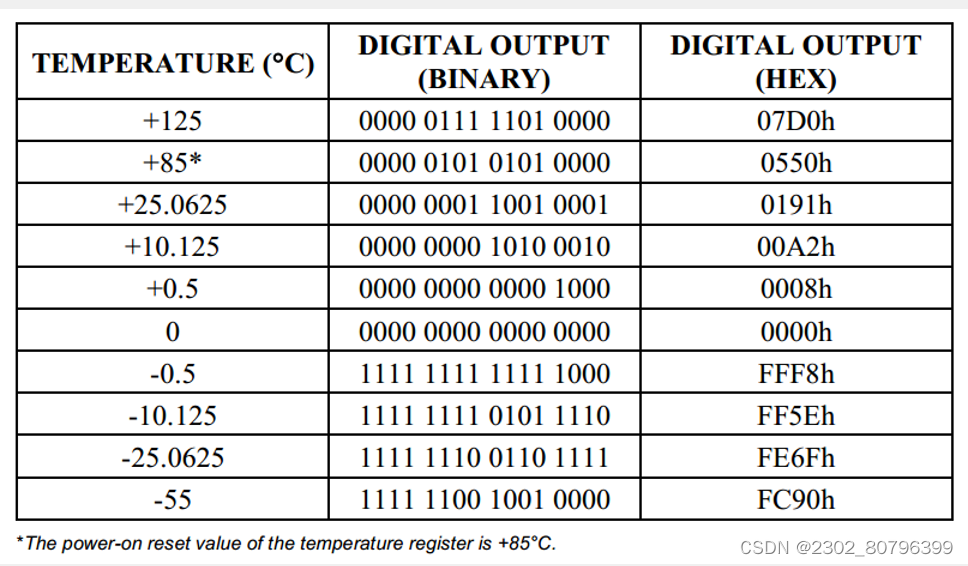
【51单片机】DS18B20(江科大)
一、DS18B20温度传感器 1.DS18B20介绍 DS18B20是一种常见的数字温度传感器,其控制命令和数据都是以数字信号的方式输入输出,相比较于模拟温度传感器,具有功能强大、硬件简单、易扩展、抗干扰性强等特点 测温范围 :- 55℃到125℃ 通信接口:1-Wire(单总线) 其它特征:可形成…...

Windows平台git clone文件路径太长报错
问题描述 在Windows下拉取一些比较大的开源项目经常会提示文件路径太长(filename too long),然后死活都不成功 解决办法 1.配置git git config --system core.longpaths true2.修改文件C:\Program Files\Git\etc\gitconfig(需…...
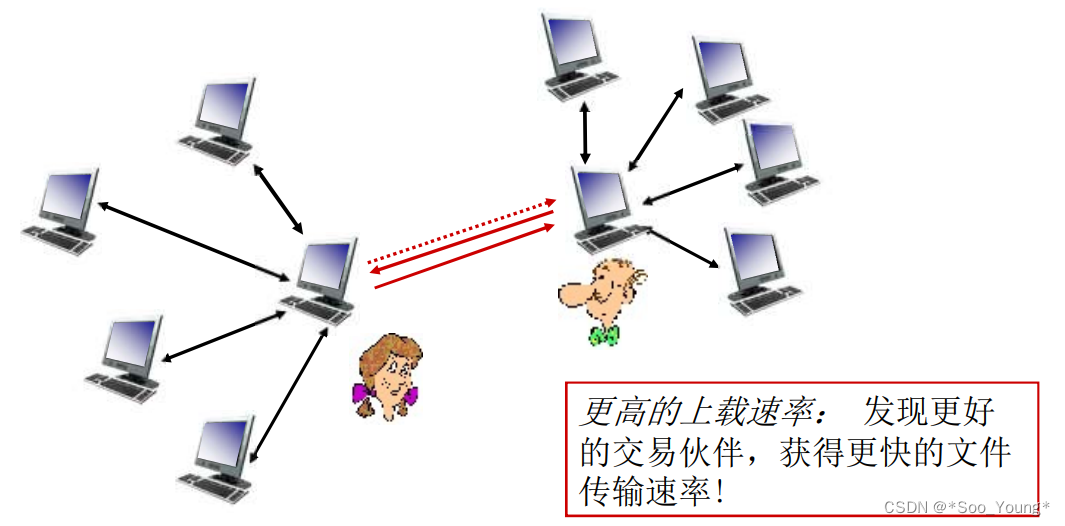
中科大计网学习记录笔记(十):P2P 应用
前言: 学习视频:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程 该视频是B站非常著名的计网学习视频,但相信很多朋友和我一样在听完前面的部分发现信…...

Python算法题集_LRU 缓存
Python算法题集_LRU 缓存 题146:LRU 缓存1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【队列字典】2) 改进版一【有序字典】3) 改进版二【双向链表字典】 4. 最优算法 本文为Python算法题集之一的代码示例 题146:LRU …...

局部加权回归
局部加权回归(Local Weighted Regression)是一种非参数回归方法,用于解决线性回归模型无法很好拟合非线性数据的问题。它通过给不同的样本赋予不同的权重,使得在拟合模型时更加关注靠近目标点附近的样本数据。 局部加权回归的基本…...

国内国外最好的数据恢复软件评测,哪种数据恢复软件最有效?
随着数字和商业格局在多个领域不断发展,变得更加依赖数据,威胁数据的努力也同样存在。 计算机病毒、勒索软件和恶意软件是导致数据丢失的主要威胁,可能会让您的组织陷入停机或严重影响您的工作效率。而解决这个问题的方法就是数据恢复。 什么…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...