Open-FWI代码解析(1)
目录
1. dataset文件
1.1初始化网络
1.2load_every函数
1.3 getitem函数
1.4测试函数
2. transforms文件
2.1裁切函数和翻转函数
2.2上\下采样函数
2.3加入随机因子的上\下采样函数
2.4填充函数
2.5标准图像函数
2.6标准化函数
2.7归一化函数
2.8反归一化
2.9添加噪声的函数
2.10转换函数
2.11反归一化函数(全)
3. 类
3.1随机裁剪函数:
3.2中心裁剪类
3.3上\下采样类
3.4随机上\下采样类:
3.5标准图像函数
3.6归一化图像类
3.7随机翻转类
3.8 填充类
3.9采样间隔类
3.10添加噪声类
3.11基本变换log(1+x), 数据变换
3.12 改变维度类
4. 总结
1. dataset文件
1.1初始化网络
初始化参数注释:
anno:注解文件的路径
preload:是否将整个数据集加载到内存中
sample_ratio:地震数据的下采样率(时间域每个几个数据采样, 一般为1)
file_size:每个 NPY 文件中的样本 #
transform_data|label:应用于数据或标签的转换
将anno文件打开, 里面存放的是数据的地址, 用f.readlines(读取文件,每一行作为列表的一个元素)打开. 如果preload选择为true则将数据全部加载到内存中, 接着构造两个列表用于存放数据和标签. 用for读取batches中每一个列表元素(文件的地址), 接着读取文件返回给data_list, label_list
def __init__(self, anno, preload=True, sample_ratio=1, file_size=500,transform_data=None, transform_label=None):if not os.path.exists(anno):print(f'Annotation file {anno} does not exists')self.preload = preloadself.sample_ratio = sample_ratioself.file_size = file_sizeself.transform_data = transform_dataself.transform_label = transform_labelwith open(anno, 'r') as f:self.batches = f.readlines()if preload: self.data_list, self.label_list = [], []for batch in self.batches[:-1]: data, label = self.load_every(batch)self.data_list.append(data)if label is not None:self.label_list.append(label)1.2load_every函数
我们将传入的batch打开,用\t作为中间分隔, batch = batch.split('\t'), 返回的是一个列表,里面是用\t分隔的元素. 接着判断是否有标签,找到data的路径和labels的路径,将其转换为float32(label.astype('float43')).
def load_every(self, batch):batch = batch.split('\t')data_path = batch[0] if len(batch) > 1 else batch[0][:-1]data = np.load(data_path)[:, :, ::self.sample_ratio, :]data = data.astype('float32')if len(batch) > 1:label_path = batch[1][:-1] label = np.load(label_path)label = label.astype('float32')else:label = Nonereturn data, label1.3 getitem函数
拿到数据的索引batch_inx, sample_idx. 若是全部加载到内存里面(preload = true), 直接选取就行. 若没有加载到内存, 读取batches中索引,返回到数据data, label里面.
self.transform_data和self.transform_labels将数据转换为对应的格式(标准化之类的)
def __getitem__(self, idx):batch_idx, sample_idx = idx // self.file_size, idx % self.file_sizeif self.preload:data = self.data_list[batch_idx][sample_idx]label = self.label_list[batch_idx][sample_idx] if len(self.label_list) != 0 else Noneelse:data, label = self.load_every(self.batches[batch_idx])data = data[sample_idx]label = label[sample_idx] if label is not None else Noneif self.transform_data:data = self.transform_data(data)if self.transform_label and label is not None:label = self.transform_label(label)return data, label if label is not None else np.array([])1.4测试函数
if __name__ == '__main__':transform_data = Compose([T.LogTransform(k=1),T.MinMaxNormalize(T.log_transform(-61, k=1), T.log_transform(120, k=1))])transform_label = Compose([T.MinMaxNormalize(2000, 6000)])dataset = FWIDataset(f'data_and_labels.txt', transform_data=transform_data, transform_label=transform_label, file_size=1)data, label = dataset[0]print(data.shape)print(label.shape)这一段没什么讲的---完成数据的读取啦!
2. transforms文件
2.1裁切函数和翻转函数
注释即说明了一切
def crop(vid, i, j, h, w):'''裁剪大小,vid是图像数据, i,j为裁剪起点,h,w为需要保留的大小:param vid::param i::param j::param h::param w::return:'''return vid[..., i:(i + h), j:(j + w)]def center_crop(vid, output_size):'''中心裁剪, vid-数据,outsize-中心裁剪的大小:param vid::param output_size::return:'''h, w = vid.shape[-2:]th, tw = output_sizei = int(round((h - th) / 2.))j = int(round((w - tw) / 2.))return crop(vid, i, j, th, tw)def hflip(vid):'''水平翻转图像, dim必须为元组(若dim = (-2,-1), 则不仅水平翻转,竖直也翻转):param vid::return:'''return vid.flip(dims=(-1,))2.2上\下采样函数
代码注释一目了然(通过插值实现)
def resize(vid, size, interpolation='bilinear'):# NOTE: using bilinear interpolation because we don't work on minibatches# at this level'''用于上下采样(通过插值改变图像大小),:param vid: 图像数据N,C,H,W:param size: 改变到size大小,size为整数或者元祖(元组:就是将数据缩小到元组大小)(整数:将数据放大或者缩小到整数大小倍):param interpolation: 选择插值模式-bilinear,nearest,linear,bilinear,bicubic,trilinear,area.需要再去查一般默认(bilinear):return:返回修改之后的数据'''scale = Noneif isinstance(size, int):scale = float(size) / min(vid.shape[-2:])size = Nonereturn torch.nn.functional.interpolate(vid, size=size, scale_factor=scale, mode=interpolation, align_corners=False)2.3加入随机因子的上\下采样函数
def random_resize(vid, size, random_factor, interpolation='bilinear'):# NOTE: using bilinear interpolation because we don't work on minibatches# at this level''':param vid:数据N,C,H,W:param size:可以是int形,则直接返回size*随机因子的大小;也可以是元祖,返回(tuple[0],tuple[1])*随机因子大小:param random_factor:放大因子:param interpolation:双线性插值:return:返回N,C,H1,W1'''scale = Noner = 1 + random.random() * (random_factor - 1)if isinstance(size, int):scale = float(size) / min(vid.shape[-2:]) * rsize = Noneelse:size = tuple([int(elem * r) for elem in list(size)])return torch.nn.functional.interpolate(vid, size=size, scale_factor=scale, mode=interpolation, align_corners=False)2.4填充函数
mode:填充模式,默认为padding_mode='constant'。可选的模式包括:'constant':使用常数值填充。'reflect':以边界为轴,镜像反射填充。'replicate':以边界为轴,复制边界值填充。'circular':以边界为轴,循环填充。
def pad(vid, padding, fill=0, padding_mode="constant"):''':param vid: 数据:param padding: 元祖或者整数,在原本数据上填充的维度大小:param fill:填充值(默认为0):param padding_mode:填充模式:return:数据结果'''# NOTE: don't want to pad on temporal dimension, so let as non-batch# (4d) before padding. This works as expectedreturn torch.nn.functional.pad(vid, padding, value=fill, mode=padding_mode)2.5标准图像函数
def to_normalized_float_tensor(vid):'''数据标准化:param vid:数据:return: 通常用于将像素值从 0-255 范围映射到 0-1 之间'''return vid.permute(3, 0, 1, 2).to(torch.float32) / 2552.6标准化函数
这里有点没搞懂的是它的mean和std的维度是什么?还有对应的数据维度,下来到具体示例代码中再看看
def normalize(vid, mean, std):'''这里没有理解:param vid: 数据:param mean:均值:param std:标准差:return:'''shape = (-1,) + (1,) * (vid.dim() - 1)mean = torch.as_tensor(mean).reshape(shape)std = torch.as_tensor(std).reshape(shape)return (vid - mean) / std2.7归一化函数
def minmax_normalize(vid, vmin, vmax, scale=2):'''将像素缩放到0~1 scale= 2;将像素缩放到-1~1 scale = else:param vid: :param vmin: :param vmax: :param scale: :return: '''vid -= vminvid /= (vmax - vmin)return (vid - 0.5) * 2 if scale == 2 else vid2.8反归一化
def minmax_denormalize(vid, vmin, vmax, scale=2):'''用于反归一化:param vid: :param vmin: :param vmax: :param scale: :return: '''if scale == 2:vid = vid / 2 + 0.5return vid * (vmax - vmin) + vmin2.9添加噪声的函数
信噪比, 噪声功率, 信号功率等知识详见---博客
def add_noise(data, snr):'''用于给输入数据添加噪声的函数:param data::param snr::return:'''sig_avg_power_db = 10*np.log10(np.mean(data**2))noise_avg_power_db = sig_avg_power_db - snrnoise_avg_power = 10**(noise_avg_power_db/10)noise = np.random.normal(0, np.sqrt(noise_avg_power), data.shape)noisy_data = data + noisereturn noisy_data 2.10转换函数
def log_transform(data, k=1, c=0):'''转换函数,log(1+(|data|+c))*sign(data):param data: :param k: :param c: :return: '''return (np.log1p(np.abs(k * data) + c)) * np.sign(data)def log_transform_tensor(data, k=1, c=0):'''给予torch的转换函数:param data: :param k: :param c: :return: '''return (torch.log1p(torch.abs(k * data) + c)) * torch.sign(data)def exp_transform(data, k=1, c=0):'''数据转换 (e^(|data|-c)-1)*sign(data)/k:param data::param k::param c::return:'''return (np.expm1(np.abs(data)) - c) * np.sign(data) / k2.11反归一化函数(全)
def tonumpy_denormalize(vid, vmin, vmax, exp=True, k=1, c=0, scale=2):'''对数据进行反归一化, 这里的反归一化和之前minmax_denormalize不同在于 考虑到了vmax和vmin是否为变换过的数据 若vmax和vmin是变换过的数据则修改相应的参数:param vid: :param vmin: :param vmax: :param exp: :param k: :param c: :param scale: :return: '''if exp:vmin = log_transform(vmin, k=k, c=c) vmax = log_transform(vmax, k=k, c=c) vid = minmax_denormalize(vid.cpu().numpy(), vmin, vmax, scale)return exp_transform(vid, k=k, c=c) if exp else vid3. 类
3.1随机裁剪函数:
class RandomCrop(object):'''本质上是关于随机作为像素起点的裁剪ex :randomcrop = RandomCrop(size)result = randomcrop(vid)'''def __init__(self, size):''':param size:裁剪结果的大小'''self.size = size@staticmethoddef get_params(vid, output_size):"""Get parameters for ``crop`` for a random crop."""h, w = vid.shape[-2:]th, tw = output_sizeif w == tw and h == th:return 0, 0, h, wi = random.randint(0, h - th)j = random.randint(0, w - tw)return i, j, th, twdef __call__(self, vid):i, j, h, w = self.get_params(vid, self.size)return crop(vid, i, j, h, w)3.2中心裁剪类
class CenterCrop(object):def __init__(self, size):self.size = sizedef __call__(self, vid):return center_crop(vid, self.size)3.3上\下采样类
class Resize(object):def __init__(self, size):self.size = sizedef __call__(self, vid):return resize(vid, self.size)3.4随机上\下采样类:
class RandomResize(object):def __init__(self, size, random_factor=1.25):self.size = sizeself.factor = random_factordef __call__(self, vid):return random_resize(vid, self.size, self.factor)3.5标准图像函数
class ToFloatTensorInZeroOne(object):def __call__(self, vid):return to_normalized_float_tensor(vid)class Normalize(object):def __init__(self, mean, std):self.mean = meanself.std = stddef __call__(self, vid):return normalize(vid, self.mean, self.std)3.6归一化图像类
class MinMaxNormalize(object):def __init__(self, datamin, datamax, scale=2):self.datamin = dataminself.datamax = datamaxself.scale = scaledef __call__(self, vid):return minmax_normalize(vid, self.datamin, self.datamax, self.scale)3.7随机翻转类
class RandomHorizontalFlip(object):def __init__(self, p=0.5):self.p = pdef __call__(self, vid):if random.random() < self.p:return hflip(vid)return vid3.8 填充类
class Pad(object):def __init__(self, padding, fill=0):self.padding = paddingself.fill = filldef __call__(self, vid):return pad(vid, self.padding, self.fill)3.9采样间隔类
class TemporalDownsample(object):def __init__(self, rate=1):self.rate = ratedef __call__(self, vid):return vid[::self.rate]3.10添加噪声类
class AddNoise(object):def __init__(self, snr=10):self.snr = snrdef __call__(self, vid):return add_noise(vid, self.snr)3.11基本变换log(1+x), 数据变换
class LogTransform(object):def __init__(self, k=1, c=0):self.k = kself.c = cdef __call__(self, data):return log_transform(data, k=self.k, c=self.c)class ToTensor(object):"""Convert ndarrays in sample to Tensors."""# def __init__(self, device):# self.device = devicedef __call__(self, sample):return torch.from_numpy(sample)3.12 改变维度类
这段代码没有搞明白 后面涉及到用法的时候再看看.
class PCD(object):def __init__(self, n_comp=8):self.pca = PCA(n_components=n_comp)def __call__(self, data):data= data.reshape((data.shape[0], -1))feat_mean = data.mean(axis=0)data -= np.tile(feat_mean, (data.shape[0], 1))pc = self.pca.fit_transform(data)pc = pc.reshape((-1,))pc = pc[:, np.newaxis, np.newaxis]return pcclass StackPCD(object):def __init__(self, n_comp=(32, 8)):self.primary_pca = PCA(n_components=n_comp[0])self.secondary_pca = PCA(n_components=n_comp[1])def __call__(self, data):data = np.transpose(data, (0, 2, 1))primary_pc = []for sample in data:feat_mean = sample.mean(axis=0)sample -= np.tile(feat_mean, (sample.shape[0], 1))primary_pc.append(self.primary_pca.fit_transform(sample))primary_pc = np.array(primary_pc)data = primary_pc.reshape((data.shape[0], -1))feat_mean = data.mean(axis=0)data -= np.tile(feat_mean, (data.shape[0], 1))secondary_pc = self.secondary_pca.fit_transform(data)secondary_pc = secondary_pc.reshape((-1,))secondary_pc = pc[:, np.newaxis, np.newaxis]return secondary_pc4. 总结
主要是open-FWI文件中dataset类和transforms类. 两个类的任务分别是加载数据, 和对数据进行一定的转换(裁剪,分割,函数变换等)
存在的问题:有两个函数没弄明白3.12和2.6, 具体等到用法的时候再回来看看
相关文章:
)
Open-FWI代码解析(1)
目录 1. dataset文件 1.1初始化网络 1.2load_every函数 1.3 getitem函数 1.4测试函数 2. transforms文件 2.1裁切函数和翻转函数 2.2上\下采样函数 2.3加入随机因子的上\下采样函数 2.4填充函数 2.5标准图像函数 2.6标准化函数 2.7归一化函数 2.8反归一化 2.9添加噪声的函数 …...

移动机器人激光SLAM导航(五):Cartographer SLAM 篇
参考 Cartographer 官方文档Cartographer 从入门到精通 1. Cartographer 安装 1.1 前置条件 推荐在刚装好的 Ubuntu 16.04 或 Ubuntu 18.04 上进行编译ROS 安装:ROS学习1:ROS概述与环境搭建 1.2 依赖库安装 资源下载完解压并执行以下指令 https://pa…...

第四篇【传奇开心果微博系列】Python微项目技术点案例示例:美女颜值判官
传奇开心果微博系列 系列微博目录Python微项目技术点案例示例系列 微博目录一、微项目目标二、雏形示例代码三、扩展思路四、添加不同类型的美女示例代码五、增加难度等级示例代码六、添加特殊道具示例代码七、设计关卡系统示例代码八、添加音效和背景音乐示例代码九、多人游戏…...

Python学习之路-初识爬虫:requests
Python学习之路-初识爬虫:requests requests的作用 作用:发送网络请求,返回响应数据 中文文档 : http://docs.python-requests.org/zh_CN/latest/index.html 为什么学requests而不是urllib requests的底层实现就是urllibrequests在pytho…...

Linux 常用的命令
① 基本命令 uname -m 显示机器的处理器架构uname -r 显示正在使用的内核版本dmidecode -q 显示硬件系统部件(SMBIOS / DMI) hdparm -i /dev/hda 罗列一个磁盘的架构特性hdparm -tT /dev/sda 在磁盘上执行测试性读取操作系统信息arch 显示机器的处理器架构uname -m 显示机器的处…...
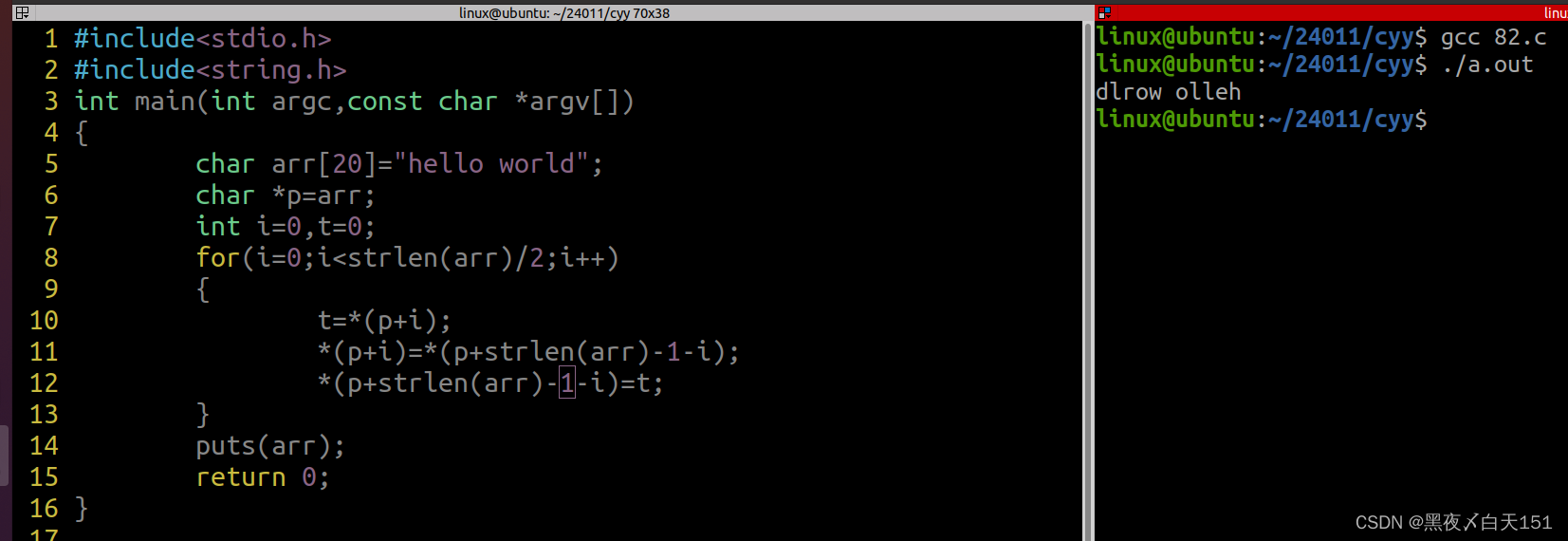
假期作业 10
1.整理磁盘操作的完整流程,如何接入虚拟机,是否成功识别,对磁盘分区工具的使用,格式化,挂载以及取消挂载 U盘接入虚拟机 在虚拟机--->可移动设备--->找到U盘---->连接 检测U盘是否被虚拟机识别 ls /dev/s…...
)
【洛谷 P3367】【模板】并查集 题解(并查集+路径压缩)
【模板】并查集 题目描述 如题,现在有一个并查集,你需要完成合并和查询操作。 输入格式 第一行包含两个整数 N , M N,M N,M ,表示共有 N N N 个元素和 M M M 个操作。 接下来 M M M 行,每行包含三个整数 Z i , X i , Y i Z_i,X_i,Y…...
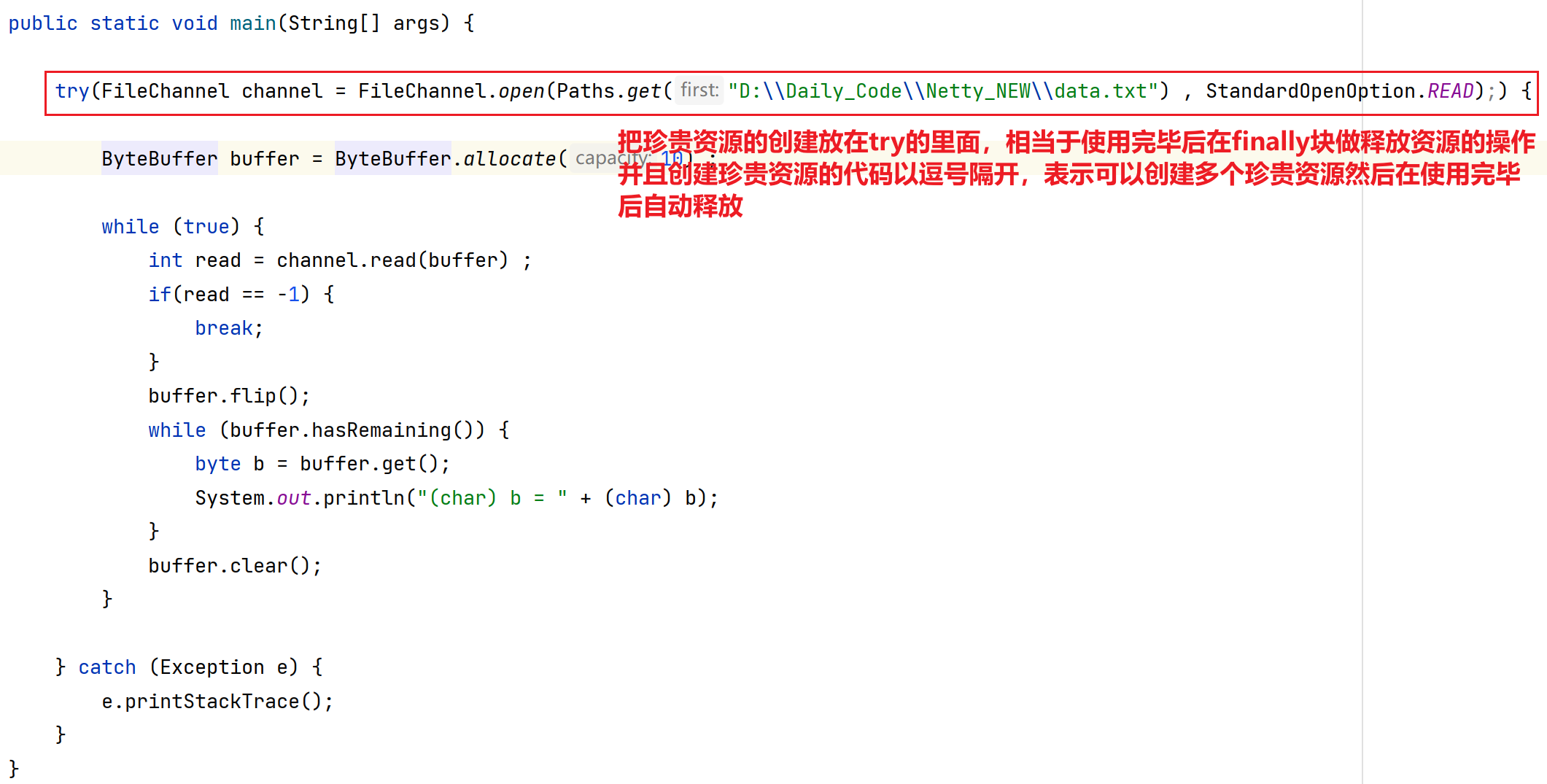
Netty应用(一) 之 NIO概念 基本编程
目录 第一章 概念引入 1.分布式概念引入 第二章 Netty基础 - NIO 1.引言 1.1 什么是Netty? 1.2 为什么要学习Netty? 2.NIO编程 2.1 传统网络通信中开发方式及问题(BIO) 2.1.1 多线程版网络编程 2.1.2 线程池版的网络编程…...
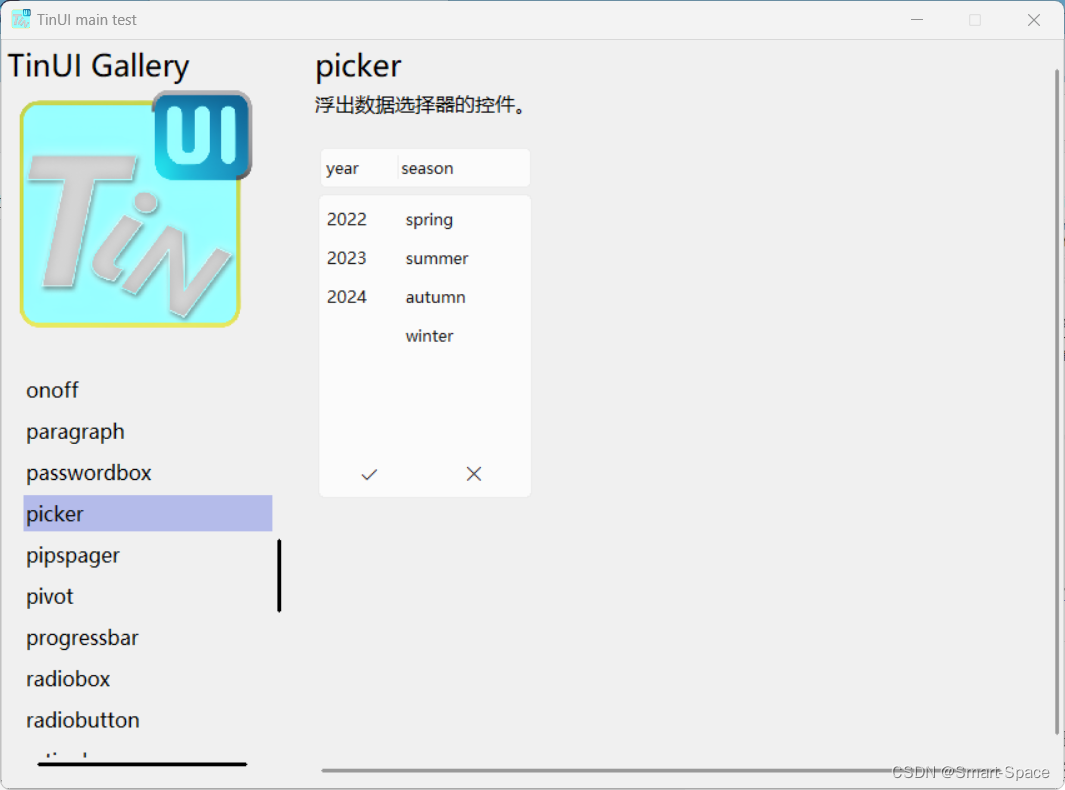
tkinter-TinUI-xml实战(10)展示画廊
tkinter-TinUI-xml实战(10)展示画廊 引言声明文件结构核心代码主界面统一展示控件控件展示界面单一展示已有展示多类展示 最终效果在这里插入图片描述  ………… 结语 引言…...
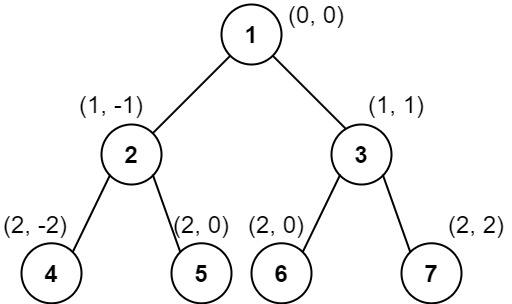
LeetCode二叉树的垂序遍历
题目描述 给你二叉树的根结点 root ,请你设计算法计算二叉树的 垂序遍历 序列。 对位于 (row, col) 的每个结点而言,其左右子结点分别位于 (row 1, col - 1) 和 (row 1, col 1) 。树的根结点位于 (0, 0) 。 二叉树的 垂序遍历 从最左边的列开始直到…...
 函数用法)
[linux c]linux do_div() 函数用法
linux do_div() 函数用法 do_div() 是一个 Linux 内核中的宏,用于执行 64 位整数的除法操作,并将结果存储在给定的变量中,同时将余数存储在另一个变量中。这个宏通常用于内核编程中,特别是在处理大整数和性能敏感的场合。 函数原…...

Python学习之路-爬虫提高:常见的反爬手段和解决思路
Python学习之路-爬虫提高:常见的反爬手段和解决思路 常见的反爬手段和解决思路 明确反反爬的主要思路 反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie…...

python_numpy库_ndarray的聚合操作、矩阵操作等
一、ndarray的聚合操作 1、求和np.sum() import numpy as np n np.arange(10) print(n) s np.sum(n) print(s) n np.random.randint(0,10,size(3,5)) print(n) s1 np.sum(n) print(s1) #全部数加起来 s2 np.sum(n,axis0) print(s2) #表示每一列的多行求和 …...
python-自动化篇-终极工具-用GUI自动控制键盘和鼠标-pyautogui
文章目录 用GUI自动控制键盘和鼠标pyautogui 模块鼠标屏幕位置——移动地图——pyautogui.size鼠标位置——自身定位——pyautogui.position()移动鼠标——pyautogui.moveTo拖动鼠标滚动鼠标 键盘按下键盘释放键盘 开始与结束通过注销关闭所有程序 用GUI自动控制键盘和鼠标 在…...
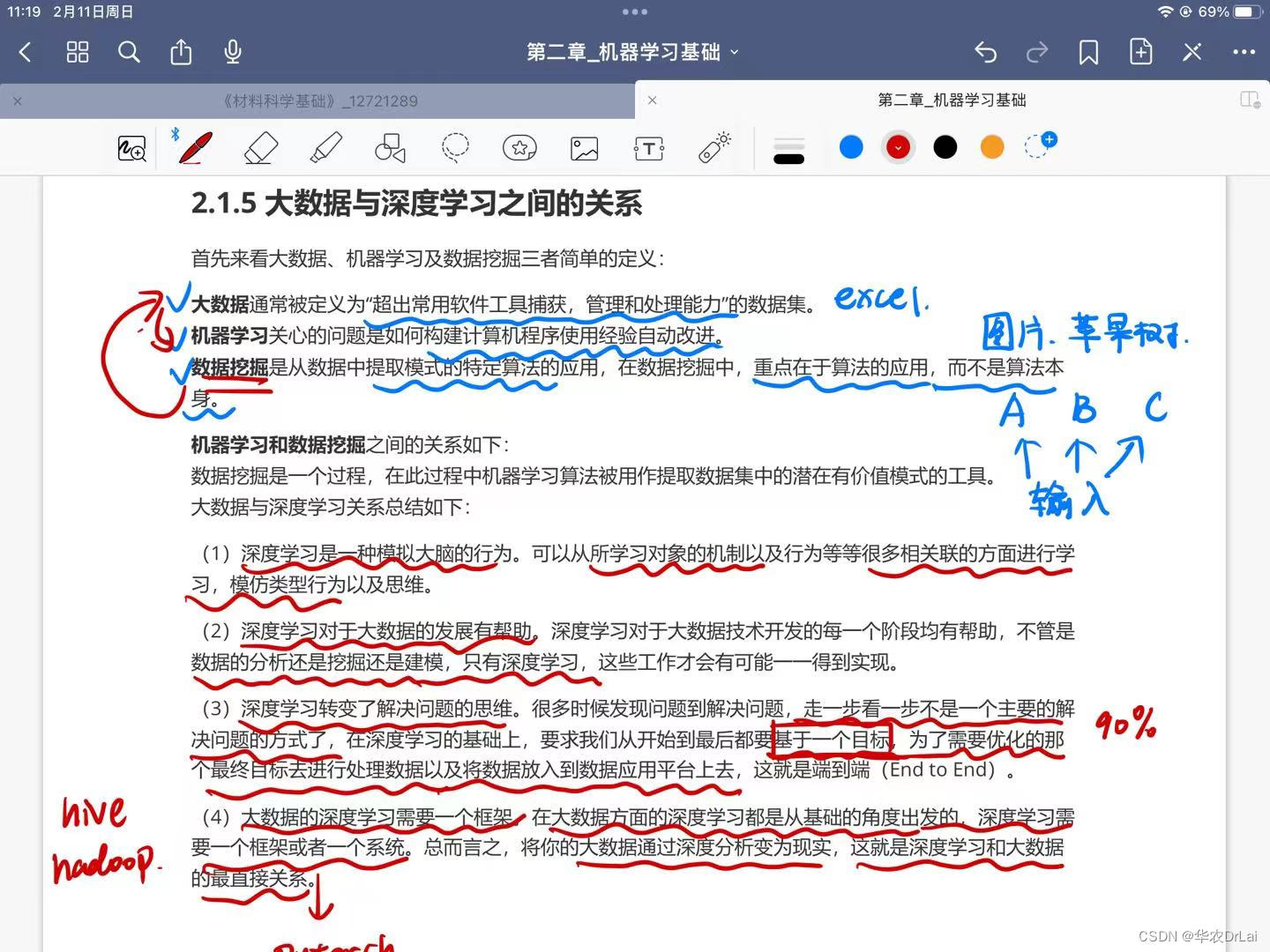
面试:大数据和深度学习之间的关系是什么?
大数据与深度学习之间存在着紧密的相互关系,它们在当今技术发展中相辅相成。 大数据的定义与特点:大数据指的是规模(数据量)、多样性(数据类型)和速度(数据生成及处理速度)都超出了传统数据处理软件和硬件能力范围的数据集。它具有四个主要特点,通常被称…...

航芯ACM32G103开发板评测 08 ADC Timer外设测试
航芯ACM32G103开发板评测 08 ADC Timer外设测试 1. 软硬件平台 ACM32G103 Board开发板MDK-ARM Keil 2. 定时器Timer 在一般的MCU芯片中,定时器这个外设资源是非常重要的,一般可以分为SysTick定时器(系统滴答定时器)、常规定时…...

【Linux学习】生产者-消费者模型
目录 22.1 什么是生产者-消费者模型 22.2 为什么要用生产者-消费者模型? 22.3 生产者-消费者模型的特点 22.4 BlockingQueue实现生产者-消费者模型 22.4.1 实现阻塞队列BlockQueue 1) 添加一个容器来存放数据 2)加入判断Blocking Queue情况的成员函数 3)实现push和pop方法 4)完…...
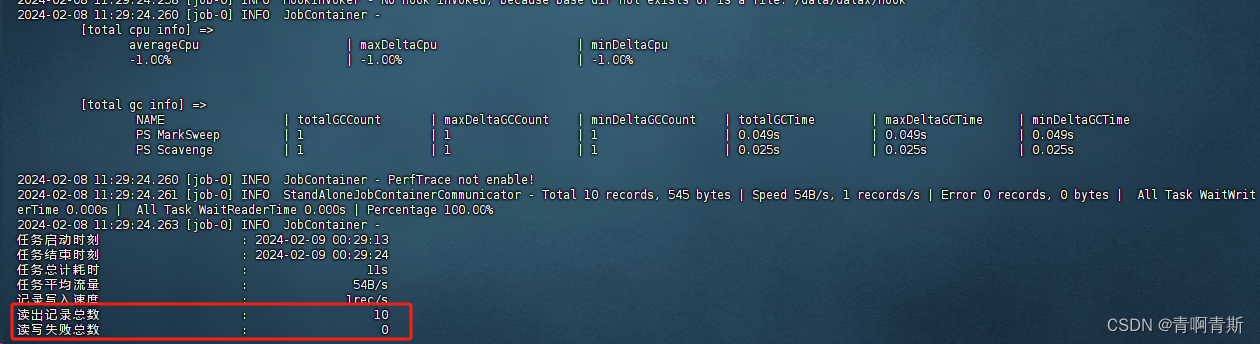
三、案例 - MySQL数据迁移至ClickHouse
MySQL数据迁移至ClickHouse 一、生成测试数据表和数据1.在MySQL创建数据表和数据2.在ClickHouse创建数据表 二、生成模板文件1.模板文件内容2.模板文件参数详解2.1 全局设置2.2 数据读取(Reader)2.3 数据写入(Writer)2.4 性能设置…...

[WinForm开源]概率计算器 - Genshin Impact(V1.0)
创作目的:为方便旅行者估算自己拥有的纠缠之缘能否达到自己的目的,作者使用C#开发了一款小型软件供旅行者参考使用。 创作说明:此软件所涉及到的一切概率与规则完全按照游戏《原神》(V4.4.0)内公示的概率与规则(包括保底机制&…...
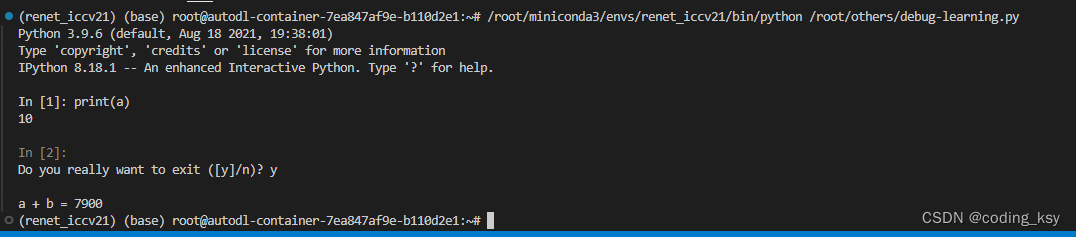
vscode 代码调试from IPython import embed
一、讲解 这种代码调试方法非常的好用。 from IPython import embed上面的代码片段是用于Python中嵌入一个交互式IPython shell的方法。这可以在任何Python脚本或程序中实现,允许在执行到该点时暂停程序,并提供一个交互式环境,以便于检查、…...
【C++】)
CCF-CSP 39-2 水印检查(watermark)【C++】
题目 https://sim.csp.thusaac.com/contest/39/problem/1https://sim.csp.thusaac.com/contest/39/problem/1 思路参考: 80分 暴力求解,遍历所有可能的k,检验是否满足条件,可得80分 时间复杂度:O(L*n^2)࿰…...

用STM32F411和CLion从零搭建三轮全向小车:PID调参、VOFA+上位机调试全记录
用STM32F411和CLion从零搭建三轮全向小车:PID调参、VOFA上位机调试全记录 第一次接触全向轮机器人时,我被它灵活的运动方式深深吸引——不同于传统轮式机器人,它能实现任意方向的平移和旋转。这种独特的移动能力在狭小空间作业、仓储物流等领…...

我的LVDS信号有振铃?可能是端接电阻没选对!从仿真到实测的端接方案选择指南
LVDS信号振铃问题全解析:从端接电阻选择到实测验证 振铃现象是LVDS信号传输中最令人头疼的问题之一。当你在示波器上看到信号边沿出现振荡波形时,第一反应可能是怀疑PCB布局或信号源质量。但经验丰富的工程师都知道,80%的振铃问题根源在于端接…...

KittenTTS终极指南:如何在CPU上实现25MB轻量级TTS语音合成
KittenTTS终极指南:如何在CPU上实现25MB轻量级TTS语音合成 【免费下载链接】KittenTTS State-of-the-art TTS model under 25MB 😻 项目地址: https://gitcode.com/gh_mirrors/ki/KittenTTS KittenTTS是一款革命性的轻量级文本转语音工具&#…...

突破性网络资源嗅探解决方案:从技术困境到智能下载的革命性跨越
突破性网络资源嗅探解决方案:从技术困境到智能下载的革命性跨越 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gi…...

[段错误修复]:Emacs代码补全崩溃的系统排查与版本管理策略
[段错误修复]:Emacs代码补全崩溃的系统排查与版本管理策略 【免费下载链接】doomemacs An Emacs framework for the stubborn martian hacker 项目地址: https://gitcode.com/gh_mirrors/do/doomemacs 副标题:如何诊断LSP服务异常导致的Emacs崩溃…...

六足机器人如何自己“学会”走路?手把手教你用Q-learning实现自适应步态
六足机器人如何自己“学会”走路?手把手教你用Q-learning实现自适应步态 想象一下,当你把一只六足机器人放在崎岖不平的地面上时,它能够像昆虫一样迅速调整自己的步伐,找到最稳定的行走方式。这种看似简单的行为背后,隐…...

3分钟零基础入门:GPU加速MediaPipe TouchDesigner插件完整指南
3分钟零基础入门:GPU加速MediaPipe TouchDesigner插件完整指南 【免费下载链接】mediapipe-touchdesigner GPU Accelerated MediaPipe Plugin for TouchDesigner 项目地址: https://gitcode.com/gh_mirrors/me/mediapipe-touchdesigner 你是否曾想过在TouchD…...
)
别再只用DataParallel了!PyTorch单机多卡训练保姆级教程(从DP到DDP实战避坑)
从DataParallel到DDP:PyTorch单机多卡训练深度优化指南 当你的模型参数突破1亿大关,单卡训练时间从几小时延长到几天时,多GPU并行训练就从一个可选项变成了必选项。但面对PyTorch提供的DataParallel(DP)和DistributedDataParallel(DDP)两种方…...

全域软开关直流变换器TPEL论文仿真复现之旅
全域软开关直流变换器 TPEL论文仿真复现最近一头扎进了全域软开关直流变换器的研究里,主要在琢磨TPEL论文相关内容,那仿真复现就成了关键任务。今天就来和大家唠唠这个过程中的酸甜苦辣。 一、全域软开关直流变换器是啥? 简单来说,…...