《区块链公链数据分析简易速速上手小册》第5章:高级数据分析技术(2024 最新版)

文章目录
- 5.1 跨链交易分析
- 5.1.1 基础知识
- 5.1.2 重点案例:分析以太坊到 BSC 的跨链交易
- 理论步骤和工具准备
- Python 代码示例构思
- 步骤1: 设置环境和获取合约信息
- 步骤2: 分析以太坊上的锁定交易
- 步骤3: 跟踪BSC上的铸币交易
- 结论
- 5.1.3 拓展案例 1:使用 Python 分析跨链桥活动
- 准备工作
- Python 代码示例构思
- 连接到以太坊和 BSC 节点
- 分析跨链桥活动
- 结论
- 5.1.4 拓展案例 2:自动追踪多链资产流动
- 准备工作
- Python代码示例构思
- 步骤1: 设置环境
- 步骤2: 跟踪资产从以太坊到BSC的流动
- 步骤3: 分析和关联跨链事件
- 结论
- 5.2 大数据处理技术
- 5.2.1 基础知识
- 5.2.2 重点案例:构建区块链数据分析平台
- 准备工作
- Kafka 生产者示例
- Flink 实时处理示例
- 结论
- 5.1.3 拓展案例 1:使用 Hadoop 处理历史区块链数据
- 理论框架
- 1. 数据收集
- 2. 数据存储
- 3. 数据处理
- 示例步骤(概念性)
- 步骤1: 将区块链数据上传到HDFS
- 步骤2: 使用Hive进行数据分析
- 结论
- 5.2.4 拓展案例 2:构建实时交易监控系统
- 系统组件
- 步骤1: 设置 Kafka 生产者
- 步骤2: 使用 Flink 处理实时数据流
- 结论
- 5.3 预测模型和行为分析
- 5.3.1 基础知识
- 5.3.2 重点案例:加密货币价格预测
- 准备工作
- 实现步骤
- 步骤1: 数据加载和预处理
- 步骤2: 构建 ARIMA 模型
- 步骤3: 进行预测
- 结论
- 5.3.3 拓展案例 1:市场情绪分析
- 准备工作
- 实现步骤
- 步骤1: 加载预训练模型
- 步骤2: 分析文本情绪
- 结论
- 5.3.4 拓展案例 2:用户行为聚类
- 准备工作
- 实现步骤
- 步骤1: 创建模拟数据集
- 步骤2: 应用K-means算法进行聚类
- 步骤3: 可视化聚类结果
- 结论
5.1 跨链交易分析
在区块链的世界中,"跨链"技术允许不同的区块链网络之间进行交互和数据传输。这为资产的多链流通、数据共享和去中心化应用的互操作性打开了新的大门。跨链交易分析帮助我们理解资产如何在不同的区块链之间流动,揭示了加密货币生态系统中的复杂相互作用。
5.1.1 基础知识
- 跨链桥:允许两个独立区块链之间转移资产的技术。跨链桥作为中介,锁定在一条链上的资产并在另一条链上创建相应的代表资产的标记(或代币)。
- 原子交换:一种技术,它允许两个区块链上的用户直接交换不同的加密货币,而无需中心化交易所,保证了交易的原子性。
- 资产映射:跨链技术中的一种方法,通过在目标链上创建源链资产的等价物(通常是代币),实现资产的跨链流通。
5.1.2 重点案例:分析以太坊到 BSC 的跨链交易
实现对以太坊到Binance Smart Chain(BSC)跨链交易的分析涉及到一系列复杂的步骤,因为这需要跟踪资产从一条链转移到另一条链的过程。虽然直接执行这样的分析需要访问特定的跨链桥合约信息和对应链上的交易数据,我们可以构思一个理论上的框架,并介绍如何使用Python开始这个过程。
理论步骤和工具准备
-
理解跨链桥机制:首先,了解你想要跟踪的跨链桥是如何工作的。不同的跨链桥有不同的实现机制,例如,基于锁定和铸币的机制。
-
获取跨链桥合约地址:识别跨链桥在以太坊和BSC上的智能合约地址。这些地址通常可以从跨链桥项目的官方文档或GitHub仓库中找到。
-
访问区块链数据:使用Web3.py或其他库访问以太坊和BSC的区块链数据。你可能需要使用Infura(对于以太坊)和BSC的公共节点或API服务。
Python 代码示例构思
步骤1: 设置环境和获取合约信息
from web3 import Web3# 设置以太坊和BSC的Web3连接
eth_web3 = Web3(Web3.HTTPProvider('https://mainnet.infura.io/v3/YOUR_INFURA_PROJECT_ID'))
bsc_web3 = Web3(Web3.HTTPProvider('https://bsc-dataseed.binance.org/'))# 跨链桥合约地址(示例地址,实际使用时需要替换)
eth_bridge_contract_address = '0xYourEthBridgeContractAddress'
bsc_bridge_contract_address = '0xYourBscBridgeContractAddress'# 跨链桥合约的ABI(部分示例,需要根据实际合约填写)
bridge_contract_abi = '[YOUR_BRIDGE_CONTRACT_ABI]'
步骤2: 分析以太坊上的锁定交易
# 创建以太坊上的跨链桥合约对象
eth_bridge_contract = eth_web3.eth.contract(address=eth_bridge_contract_address, abi=bridge_contract_abi)# 假设你有特定的交易哈希或事件日志来分析
# 这里需要具体的方法来获取和分析这些交易或事件日志
步骤3: 跟踪BSC上的铸币交易
# 创建BSC上的跨链桥合约对象
bsc_bridge_contract = bsc_web3.eth.contract(address=bsc_bridge_contract_address, abi=bridge_contract_abi)# 同样,需要具体的方法来获取和分析BSC上相应的铸币交易或事件日志
结论
尽管这个案例没有提供直接执行的代码,但它概述了分析跨链交易所需的基本步骤和考虑因素。实际的实现将涉及到对特定跨链桥合约的深入分析,包括交易的获取、事件日志的监听和解析,以及跨链资产流动的跟踪。这需要对所涉及的区块链平台和跨链技术有深入的了解,同时也需要能够访问和处理区块链上的实时数据。
5.1.3 拓展案例 1:使用 Python 分析跨链桥活动
由于直接从区块链获取和分析跨链桥活动涉及到底层的区块链交互和可能需要访问特定跨链桥合约的复杂数据,这里我将提供一个理论框架和基于Python的实现思路,帮助你开始这个过程。实际应用中,你需要根据跨链桥合约的具体实现和提供的API来调整这个框架。
准备工作
-
确定跨链桥合约地址和ABI:要分析跨链桥活动,你需要知道跨链桥在源链和目标链上的智能合约地址以及这些合约的ABI。
-
设置Python环境:确保你的Python环境中已安装
web3.py库。 -
选择合适的区块链节点或API服务:为了访问区块链数据,你需要连接到以太坊和BSC的节点。你可以使用Infura为以太坊提供的API服务和Binance Smart Chain的公共节点。
Python 代码示例构思
连接到以太坊和 BSC 节点
from web3 import Web3# 以太坊节点连接
eth_web3 = Web3(Web3.HTTPProvider('https://mainnet.infura.io/v3/YOUR_INFURA_PROJECT_ID'))# BSC节点连接
bsc_web3 = Web3(Web3.HTTPProvider('https://bsc-dataseed.binance.org/'))# 确认连接成功
assert eth_web3.isConnected(), "Failed to connect to Ethereum network!"
assert bsc_web3.isConnected(), "Failed to connect to BSC network!"
分析跨链桥活动
假设我们有跨链桥合约的地址和ABI,下面的代码将展示如何监听跨链桥合约上的特定事件。请注意,以下代码需要根据你具体的跨链桥合约进行调整。
# 跨链桥合约地址(示例)
eth_bridge_contract_address = '0xYourEthBridgeContractAddress'
bsc_bridge_contract_address = '0xYourBscBridgeContractAddress'# 跨链桥合约的ABI(简化示例,实际需要完整的ABI)
bridge_contract_abi = '[YOUR_BRIDGE_CONTRACT_ABI]'# 创建以太坊和BSC上的跨链桥合约对象
eth_bridge_contract = eth_web3.eth.contract(address=eth_bridge_contract_address, abi=bridge_contract_abi)
bsc_bridge_contract = bsc_web3.eth.contract(address=bsc_bridge_contract_address, abi=bridge_contract_abi)# 假设跨链桥合约在以太坊上有一个'Lock'事件,在BSC上有一个'Mint'事件
# 你需要根据合约实际的事件名称进行调整# 示例:获取以太坊上最新的'Lock'事件
lock_events = eth_bridge_contract.events.Lock.createFilter(fromBlock='latest').get_all_entries()
print("Lock Events on Ethereum:", lock_events)# 示例:获取BSC上最新的'Mint'事件
mint_events = bsc_bridge_contract.events.Mint.createFilter(fromBlock='latest').get_all_entries()
print("Mint Events on BSC:", mint_events)
结论
虽然上述代码无法直接运行,因为需要根据实际的跨链桥合约地址、ABI和事件进行调整,它提供了一个基础框架,帮助你开始使用Python分析跨链桥活动。实际分析时,你需要深入理解跨链桥的工作机制,包括资产如何在链间转移、锁定和铸造等过程,以及如何通过合约事件来追踪这些活动。通过细致的分析,你可以揭示跨链交易的动态,评估跨链桥的流动性和使用情况,甚至发现潜在的安全风险。
5.1.4 拓展案例 2:自动追踪多链资产流动
自动追踪多链资产流动涉及到跨链技术的深入理解和对各个区块链网络的详细分析。由于直接交互和追踪多个链上的资产流动需要复杂的底层操作,这里我们将构思一个理论框架和概念性的Python代码来展示如何开始构建这样的追踪系统。请注意,实际实现将需要适当的API支持、区块链节点访问权限,以及深入的跨链桥合约分析。
准备工作
- 识别资产和跨链桥:确定你想要追踪的资产和它们使用的跨链桥。不同的跨链桥有不同的实现和合约地址。
- 收集必要的API和工具:根据所选的区块链和跨链桥,确定你将需要使用的API服务(如Infura、Alchemy、BSC的公共节点等)和任何特定的库(如
web3.py)。
Python代码示例构思
步骤1: 设置环境
假设我们将追踪从以太坊到Binance Smart Chain(BSC)的资产流动。首先设置Web3连接:
from web3 import Web3# 设置以太坊连接
eth_web3 = Web3(Web3.HTTPProvider('https://mainnet.infura.io/v3/YOUR_INFURA_PROJECT_ID'))# 设置BSC连接
bsc_web3 = Web3(Web3.HTTPProvider('https://bsc-dataseed.binance.org/'))assert eth_web3.isConnected(), "Failed to connect to Ethereum network!"
assert bsc_web3.isConnected(), "Failed to connect to BSC network!"
步骤2: 跟踪资产从以太坊到BSC的流动
理论上,你需要监听在以太坊上资产被锁定的事件和在BSC上对应资产被铸造的事件。以下是概念性的步骤:
# 假设的跨链桥合约地址和ABI
eth_bridge_contract_address = '0x...'
bsc_bridge_contract_address = '0x...'bridge_contract_abi = '[...]'# 创建跨链桥合约实例
eth_bridge_contract = eth_web3.eth.contract(address=eth_bridge_contract_address, abi=bridge_contract_abi)
bsc_bridge_contract = bsc_web3.eth.contract(address=bsc_bridge_contract_address, abi=bridge_contract_abi)# 监听资产锁定和铸造的事件(需要具体的事件名称和过滤条件)
# 示例: eth_bridge_contract.events.AssetLocked.createFilter(fromBlock='latest')...
# 示例: bsc_bridge_contract.events.AssetMinted.createFilter(fromBlock='latest')...
步骤3: 分析和关联跨链事件
在捕获到相关事件后,你需要分析这些事件的数据,将锁定的资产与在另一条链上铸造的资产关联起来。
# 伪代码:分析和关联事件
def analyze_and_link_events(locked_events, minted_events):# 这里需要实现具体的逻辑来分析事件数据# 并尝试将锁定的资产与铸造的资产匹配起来pass
结论
自动追踪多链资产流动是一个复杂但极具价值的任务,能够揭示资产在不同区块链间的流动情况,帮助理解跨链桥的使用模式和资产的流通动态。实际上,这需要对每个涉及的区块链和跨链桥的工作原理有深入的理解,以及对合约事件的准确解析能力。上述概念性示例提供了一个起点,帮助你开始思考如何构建自己的跨链资产追踪工具。实现这样的系统还需要大量的定制开发工作,包括与区块链节点的直接交互、事件日志的解析和跨链交易数据的关联分析。
5.2 大数据处理技术
随着区块链技术的快速发展,我们见证了数据在这个领域的爆炸性增长。从交易记录到智能合约的执行,每一秒都在产生庞大量的数据。处理、分析这些数据,不仅需要对区块链技术有深入的理解,还需要掌握大数据处理技术。
5.2.1 基础知识
- 分布式计算:由于区块链数据量巨大,单台机器往往难以高效处理。分布式计算通过在多台机器上并行处理数据来解决这一问题。
- 实时数据流处理:实时监控和分析区块链上的交易活动需要实时数据流处理技术,如Apache Kafka、Apache Flink。
- 大数据存储:有效地存储和检索大规模的区块链数据需要使用专门的大数据存储解决方案,如Hadoop HDFS、Amazon S3。
5.2.2 重点案例:构建区块链数据分析平台
由于直接实现一个完整的区块链数据分析平台超出了单个代码示例的范围,我们将聚焦于构建一个简化的、理论上的框架,它能够概述如何利用Python进行区块链数据的实时分析。这个框架将结合使用Apache Kafka作为数据流的消息系统,以及Apache Flink用于流数据的实时处理。请注意,实际部署这样的系统需要深入了解这些技术,并配置相应的环境。
准备工作
- 安装必要的库和服务:假设Apache Kafka和Apache Flink已经安装并配置好了。对于Python,我们需要安装
confluent_kafka(用于与Kafka交互)和pyflink(用于Flink应用)。 - Kafka集群配置:设定好Kafka的topic,用于发布和订阅区块链的交易数据。
- Flink环境配置:确保Flink可以运行Python API的作业。
Kafka 生产者示例
首先,我们需要一个Kafka生产者来发布区块链交易数据。以下是一个简单的生产者示例,它模拟了发布交易数据到Kafka的过程:
from confluent_kafka import Producer
import json# Kafka配置
conf = {'bootstrap.servers': "localhost:9092"}# 创建生产者实例
producer = Producer(**conf)# Kafka topic
topic = 'blockchain-transactions'# 模拟交易数据
transaction_data = {'txid': '123456', 'value': 1000, 'from': '0x...', 'to': '0x...'}# 发布消息
producer.produce(topic, json.dumps(transaction_data).encode('utf-8'))
producer.flush()print("Published transaction data to Kafka")
Flink 实时处理示例
接下来,构建一个简单的Flink应用,它从Kafka读取交易数据,并进行简单的实时处理,例如过滤高值交易:
# 假设有个 Flink 环境设置的脚本或者配置
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import FlinkKafkaConsumer
from pyflink.common.serialization import SimpleStringSchema
from pyflink.common.typeinfo import Typesenv = StreamExecutionEnvironment.get_execution_environment()# Kafka source配置
kafka_props = {'bootstrap.servers': 'localhost:9092', 'group.id': 'test-group'}
kafka_source = FlinkKafkaConsumer(topics=['blockchain-transactions'],properties=kafka_props,deserialization_schema=SimpleStringSchema())# 添加source
transactions = env.add_source(kafka_source)# 定义处理逻辑:过滤高值交易
high_value_transactions = transactions \.map(lambda x: json.loads(x), output_type=Types.PY_DICT) \.filter(lambda tx: tx['value'] > 1000)# 打印结果到标准输出,实际应用中可能是存储到数据库或文件系统
high_value_transactions.print()# 执行Flink应用
env.execute("Blockchain Transaction Analysis")
结论
这个案例提供了一个构建区块链数据分析平台的基础框架,从Kafka生产者发布区块链交易数据,到使用Flink进行实时数据处理。实际应用中,这个平台可以扩展以支持更复杂的数据处理逻辑,包括交易模式识别、异常检测、以及基于机器学习的预测模型等。重要的是,这个框架为深入探索区块链数据分析提供了启动点,鼓励开发者根据自己的需求进行定制和扩展。
5.1.3 拓展案例 1:使用 Hadoop 处理历史区块链数据
构建一个完整的基于 Hadoop 的区块链数据分析案例超出了简单代码示例的范围,但我将提供一个理论框架和步骤,这些可以帮助你理解如何开始使用Hadoop来处理和分析历史区块链数据。
理论框架
1. 数据收集
- 目标:确定你想要分析的区块链数据类型(例如,以太坊的交易数据)。
- 方法:使用区块链的客户端(如Geth对于以太坊)同步区块链数据,或从区块链浏览器和API服务下载历史数据。
2. 数据存储
- 目标:将收集到的数据存储在Hadoop生态系统中,以便进行分布式处理。
- 方法:使用Hadoop的HDFS(Hadoop Distributed File System)作为数据存储解决方案。将数据格式化为Hadoop支持的格式(如CSV、JSON或Parquet)并上传到HDFS。
3. 数据处理
- 目标:使用MapReduce或其他Hadoop生态工具(如Apache Hive或Apache Spark)处理和分析存储在HDFS中的数据。
- 方法:编写MapReduce作业或Hive查询来分析数据,例如计算每个地址的平均交易金额、识别高频交易地址等。
示例步骤(概念性)
步骤1: 将区块链数据上传到HDFS
假设你已经将区块链数据下载为CSV格式,并想要上传这些数据到HDFS:
hadoop fs -mkdir /blockchain_data
hadoop fs -put local_path_to_blockchain_data/*.csv /blockchain_data
步骤2: 使用Hive进行数据分析
首先,创建一个Hive表来映射到你的数据:
CREATE EXTERNAL TABLE blockchain_transactions (tx_hash STRING,block_number INT,from_address STRING,to_address STRING,value DECIMAL,gas_price DECIMAL,gas_used INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/blockchain_data';
然后,运行一个查询来分析数据,例如计算平均交易费用:
SELECT from_address, AVG(gas_price*gas_used) as avg_transaction_fee
FROM blockchain_transactions
GROUP BY from_address;
结论
虽然这个案例没有直接的Python代码,但它提供了一个使用Hadoop处理和分析历史区块链数据的基础框架。通过将区块链数据导入Hadoop生态系统,你可以利用Hadoop的强大数据处理能力来执行复杂的分析任务。这个框架可以根据你的具体需求进行调整和扩展,以支持更多种类的分析和数据类型。
5.2.4 拓展案例 2:构建实时交易监控系统
构建一个实时交易监控系统涉及到实时数据流的处理,这通常需要结合多个技术组件。以下是一个概念性的框架,用于展示如何使用Apache Kafka和Apache Flink来构建这样一个系统。请注意,实际的实现细节会根据具体的业务需求、数据源和技术栈而有所不同。
系统组件
- Apache Kafka:作为消息队列,用于接收和缓冲实时交易数据。
- Apache Flink:处理实时数据流,执行如异常检测、交易分析等任务。
步骤1: 设置 Kafka 生产者
首先,我们需要设置一个Kafka生产者,用于发布实时交易数据。这里假设你已经有一个运行中的Kafka实例。
from confluent_kafka import Producer
import jsonconf = {'bootstrap.servers': "YOUR_KAFKA_SERVER"}producer = Producer(**conf)
topic = 'realtime-transactions'def acked(err, msg):if err is not None:print(f"Failed to deliver message: {err.str()}")else:print(f"Message produced: {msg.topic()}")# 模拟发送实时交易数据
for _ in range(100):transaction_data = {'tx_hash': '...', 'value': 1000, 'timestamp': '...'}producer.produce(topic, json.dumps(transaction_data).encode('utf-8'), callback=acked)producer.flush()
步骤2: 使用 Flink 处理实时数据流
下一步,我们将使用Apache Flink来处理这些实时交易数据。Flink能够从Kafka读取数据流,执行实时分析,并输出分析结果。
假设我们的目标是识别异常高值交易。
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import FlinkKafkaConsumer
from pyflink.common.serialization import JsonRowDeserializationSchema
from pyflink.common.typeinfo import Types
from pyflink.datastream import TimeCharacteristicenv = StreamExecutionEnvironment.get_execution_environment()
env.set_stream_time_characteristic(TimeCharacteristic.EventTime)# Kafka消费者配置
kafka_props = {'bootstrap.servers': 'YOUR_KAFKA_SERVER', 'group.id': 'test-group'}
kafka_source = FlinkKafkaConsumer(topics='realtime-transactions',deserialization_schema=JsonRowDeserializationSchema.builder().type_info(type_info=Types.ROW([Types.STRING(), Types.BIG_INT(), Types.STRING()])).build(),properties=kafka_props)# 添加source
transactions = env.add_source(kafka_source)# 定义处理逻辑:识别高值交易
def high_value_filter(transaction):return transaction[1] > 10000 # 假设字段1是交易值high_value_transactions = transactions.filter(high_value_filter)# 输出结果
high_value_transactions.print()# 执行Flink作业
env.execute("Real-time Transaction Monitoring")
结论
本拓展案例提供了一个概念性的框架,展示了如何结合Apache Kafka和Apache Flink来构建一个实时交易监控系统。通过此系统,你可以实时监控交易活动,识别异常或重要的交易事件。虽然示例中的数据处理逻辑相对简单,但Flink提供了强大的流处理能力,支持复杂的事件处理、状态管理和时间窗口操作,可以根据实际需求进行深入开发和定制。
5.3 预测模型和行为分析
随着区块链技术和加密货币市场的成熟,数据科学和机器学习在这个领域的应用变得越来越广泛。预测模型和行为分析可以帮助投资者、开发者和市场分析师更好地理解市场动态,识别趋势,甚至预测未来的价格变化或用户行为。
5.3.1 基础知识
- 时间序列分析:用于分析和预测按时间顺序排列的数据点。在加密货币领域,这通常用于价格预测。
- 分类和聚类:用于识别和分组具有相似特征的数据点。这可以用于识别市场中的不同用户行为模式。
- 自然语言处理(NLP):分析社交媒体和新闻报道中的文本数据,以识别市场情绪变化。
5.3.2 重点案例:加密货币价格预测
为了提供一个更具体的演示,我们将通过一个简化的示例,展示如何使用Python进行加密货币价格预测。这个案例将使用ARIMA(自回归积分滑动平均模型),一个常用于时间序列预测的模型。我们将以比特币为例,但请注意,真实世界的应用需要更复杂的数据预处理和模型调参。
准备工作
-
获取数据:使用任意可靠来源获取比特币历史价格数据。为了简化,我们假设你已经有了一个CSV文件,其中包含两列:
Date和Close,分别代表日期和当天的收盘价。 -
环境准备:确保安装了
pandas、matplotlib和statsmodels库。pip install pandas matplotlib statsmodels
实现步骤
步骤1: 数据加载和预处理
首先,我们加载数据,并进行简单的预处理:
import pandas as pd# 加载数据
df = pd.read_csv('btc_price.csv', parse_dates=['Date'], index_col='Date')# 确保数据按日期排序
df.sort_index(inplace=True)# 检查是否有缺失值
print(df.isnull().sum())# 可视化价格数据
df['Close'].plot(title='Bitcoin Daily Closing Price')
步骤2: 构建 ARIMA 模型
接下来,我们使用statsmodels库中的ARIMA模型进行预测。这个例子中,我们随意选取(p,d,q)参数为(5,1,2),实际应用中需要通过模型诊断和参数调优来确定最佳参数。
from statsmodels.tsa.arima.model import ARIMA# 定义模型
model = ARIMA(df['Close'], order=(5, 1, 2))# 拟合模型
results = model.fit()# 摘要统计
print(results.summary())
步骤3: 进行预测
最后,我们使用拟合好的模型进行未来价格的预测:
import matplotlib.pyplot as plt# 进行预测
forecast = results.get_forecast(steps=30)
mean_forecast = forecast.predicted_mean
confidence_intervals = forecast.conf_int()# 可视化预测结果和置信区间
plt.figure()
plt.plot(df.index, df['Close'], label='observed')
plt.plot(mean_forecast.index, mean_forecast, color='r', label='forecast')
plt.fill_between(mean_forecast.index,confidence_intervals.iloc[:, 0],confidence_intervals.iloc[:, 1], color='pink')
plt.xlabel('Date')
plt.ylabel('Bitcoin Price')
plt.title('Bitcoin Price Forecast')
plt.legend()
plt.show()
结论
通过这个简化的示例,我们演示了如何使用ARIMA模型对比特币价格进行预测。虽然这个模型提供了一个基本的预测框架,但在实际应用中,预测加密货币价格需要考虑更多因素,如市场情绪、宏观经济指标和其他加密货币的动态。此外,模型的选择、参数调优和风险管理也是成功应用预测模型的关键。希望这个示例能为你提供一个开始探索时间序列预测和加密货币市场分析的起点。
5.3.3 拓展案例 1:市场情绪分析
进行市场情绪分析通常涉及到从文本数据中提取情感倾向,这在加密货币领域尤其有用,因为市场情绪往往对价格波动有显著影响。以下是一个使用Python进行市场情绪分析的简化示例,它利用了transformers库中的预训练模型来分析加密货币相关文本的情绪倾向。
准备工作
-
安装必要的库:确保安装了
transformers和torch库。pip install transformers torch -
选择数据源:假设你已经从Twitter、Reddit或其他社交媒体平台收集了与加密货币相关的文本数据。为简化,我们将直接使用一段示例文本进行分析。
实现步骤
步骤1: 加载预训练模型
我们将使用transformers库中的pipeline功能,它提供了一个简单的API来使用预训练的模型。这里,我们选择一个适用于情绪分析的模型。
from transformers import pipeline# 加载情绪分析pipeline,这将自动下载并加载预训练模型
sentiment_pipeline = pipeline("sentiment-analysis")
步骤2: 分析文本情绪
接下来,我们将使用加载的模型来分析特定文本的情绪倾向。这里,我们用一段关于比特币的示例文本。
# 示例文本
texts = ["Bitcoin is going to the moon!","I'm worried about the recent drop in Bitcoin prices.","The government's stance on Bitcoin could harm its growth.","Bitcoin's technology is revolutionary and has great potential."
]# 对每段文本进行情绪分析
for text in texts:result = sentiment_pipeline(text)print(f"Text: {text}")print(f"Sentiment: {result[0]['label']}, Confidence: {result[0]['score']:.2f}")print("-" * 60)
结论
这个简化的示例展示了如何使用transformers库和预训练的模型来进行文本情绪分析。在实际应用中,你可能需要对来自不同来源的大量文本数据进行分析,并可能需要进一步处理和清洗数据以提高分析的准确性。情绪分析可以作为加密货币市场分析的一个组成部分,帮助你理解公众情绪如何可能影响市场动态。不过,需要注意的是,情绪分析结果的准确性受到所使用模型和数据质量的影响,因此在做出基于这些分析的决策时应谨慎考虑。
5.3.4 拓展案例 2:用户行为聚类
对于加密货币市场来说,理解和分析用户行为可以揭示交易模式、投资偏好和市场趋势。聚类分析是一种强大的数据挖掘技术,它可以帮助我们根据交易行为将用户分组。以下是使用Python进行用户行为聚类的示例,其中利用了scikit-learn库中的K-means算法。
准备工作
-
安装必要的库:确保安装了
scikit-learn、numpy和matplotlib库。pip install scikit-learn numpy matplotlib -
数据准备:假设你已经有了一个数据集,包含用户的交易行为特征,如交易频率、平均交易金额等。为简化,我们将创建一个模拟数据集。
实现步骤
步骤1: 创建模拟数据集
首先,我们创建一个模拟的用户交易行为数据集,用于聚类分析。
import numpy as np
from sklearn.preprocessing import StandardScaler# 模拟数据:用户ID、交易频率、平均交易金额
data = np.array([[1, 10, 1000],[2, 20, 1500],[3, 15, 1200],[4, 5, 800],[5, 8, 900],# 假设还有更多数据
])# 提取特征用于聚类(这里我们不使用用户ID)
X = data[:, 1:]# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
步骤2: 应用K-means算法进行聚类
接下来,使用K-means算法对用户交易行为进行聚类。
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 使用K-means聚类,这里假定我们想要将数据聚类成3个群
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X_scaled)# 获取聚类结果
labels = kmeans.labels_# 将聚类结果添加到原始数据
data_with_labels = np.hstack((data, labels[:, np.newaxis]))
print("Data with Cluster Labels:")
print(data_with_labels)
步骤3: 可视化聚类结果
为了更好地理解聚类结果,我们可以将其可视化。
# 可视化聚类结果
plt.figure(figsize=(10, 6))
plt.scatter(data[:, 1], data[:, 2], c=labels, cmap='viridis', marker='o', edgecolor='k', s=150, alpha=0.5)
plt.title('User Behavior Clustering')
plt.xlabel('Transaction Frequency')
plt.ylabel('Average Transaction Amount')
plt.colorbar()
plt.show()
结论
通过这个简化的示例,我们展示了如何使用K-means算法对用户交易行为进行聚类分析。这种类型的分析可以帮助加密货币市场的参与者理解用户群体的不同特征和偏好,从而为市场营销、产品开发和投资决策提供支持。值得注意的是,聚类分析的质量高度依赖于选取的特征、数据的预处理以及聚类算法的参数选择。在实际应用中,可能需要尝试不同的特征组合和算法参数,以找到最能反映用户行为差异的聚类方案。
相关文章:
《区块链公链数据分析简易速速上手小册》第5章:高级数据分析技术(2024 最新版)
文章目录 5.1 跨链交易分析5.1.1 基础知识5.1.2 重点案例:分析以太坊到 BSC 的跨链交易理论步骤和工具准备Python 代码示例构思步骤1: 设置环境和获取合约信息步骤2: 分析以太坊上的锁定交易步骤3: 跟踪BSC上的铸币交易 结论 5.1.3 拓展案例 1:使用 Pyth…...
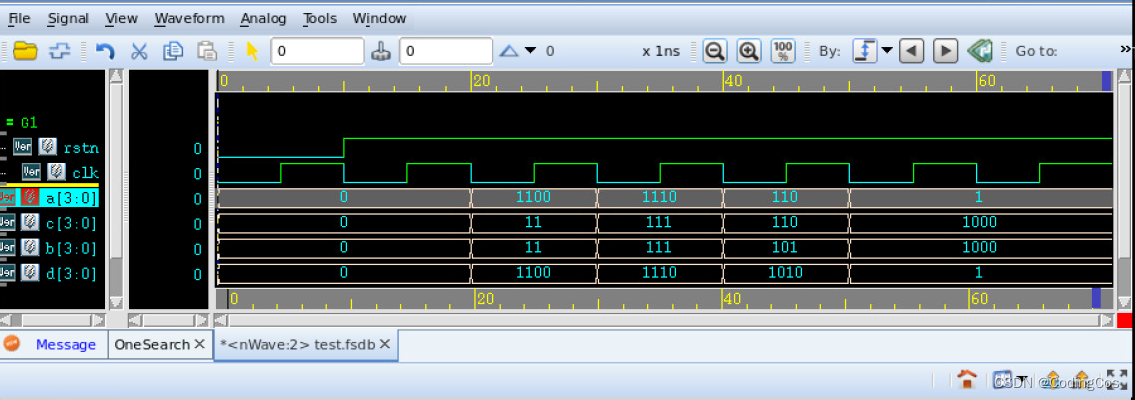
【芯片设计- RTL 数字逻辑设计入门 15 -- 函数实现数据大小端转换】
文章目录 函数实现数据大小端转换函数语法函数使用的规则Verilog and Testbench综合图VCS 仿真波形 函数实现数据大小端转换 在数字芯片设计中,经常把实现特定功能的模块编写成函数,在需要的时候再在主模块中调用,以提高代码的复用性和提高设…...

Codeforces Round 925 (Div. 3) D. Divisible Pairs (Java)
Codeforces Round 925 (Div. 3) D. Divisible Pairs (Java) 比赛链接:Codeforces Round 925 (Div. 3) D题传送门:D.Divisible Pairs 题目:D.Divisible Pairs 题目描述 输出格式 For each test case, output a single integer — the num…...

【C语言】实现单链表
目录 (一)头文件 (二)功能实现 (1)打印单链表 (2)头插与头删 (3)尾插与尾删 (4) 删除指定位置节点 和 删除指定位置之后的节点 …...

Hive调优——合并小文件
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...
责任链模式)
设计模式(行为型模式)责任链模式
目录 一、简介二、责任链模式2.1、处理器接口2.2、具体处理器类2.3、使用 三、优点与缺点 一、简介 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,允许你将请求沿着处理者链进行传递,直到有一个处理者能够处理…...
HTTP和HTTPS区别!
http 是我们几乎天天都要打交道的东西,相关知识点有点多,所以也有不少面试必问的点,这里做了一些整理,帮且大家树立完整的 http 知识体系,对面试官说 so easy HTTP 的特点和缺点 特点:无连接、无状态、灵…...
)
麻将普通胡牌算法(带混)
最近在玩腾讯的麻将游戏,但是经常需要充值,于是就想自己实现一个简单的单机麻将游戏.第一个难点就是实现胡牌的判断.这里写一下心得. 术语 本文的胡牌是指手牌构成了3N2的牌型,即一对做将,剩下的牌均为刻子(3张一样的牌)或者顺子(3张连续的牌比如234饼). 下面就是一个14张牌…...

Rust结构体详解:定义、使用及方法
Rust 是一门强调安全性和性能的系统级编程语言,它引入了结构体(struct)作为一种自定义的数据类型,允许程序员以更加灵活的方式组织和操作数据。在本篇博客中,我们将深入探讨 Rust 结构体的定义、使用以及相关概念。 什…...
LeetCode、435. 无重叠区间【中等,贪心 区间问题】
文章目录 前言LeetCode、435. 无重叠区间【中等,贪心 区间问题】题目链接及分类思路贪心、区间问题 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技…...
 —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三))
【实战】一、Jest 前端自动化测试框架基础入门(三) —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三)
文章目录 一、Jest 前端自动化测试框架基础入门7.异步代码的测试方法8.Jest 中的钩子函数9.钩子函数的作用域 学习内容来源:Jest入门到TDD/BDD双实战_前端要学的测试课 相对原教程,我在学习开始时(2023.08)采用的是当前最新版本&a…...

信息学奥赛一本通1228:书架
1228:书架 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 18190 通过数: 10557 【题目描述】 John最近买了一个书架用来存放奶牛养殖书籍,但书架很快被存满了,只剩最顶层有空余。 John共有N�头奶牛(1≤N≤20,0001≤…...

红队打靶练习:GLASGOW SMILE: 1.1
目录 信息收集 1、arp 2、nmap 3、nikto 4、whatweb 目录探测 1、gobuster 2、dirsearch WEB web信息收集 /how_to.txt /joomla CMS利用 1、爆破后台 2、登录 3、反弹shell 提权 系统信息收集 rob用户登录 abner用户 penguin用户 get root flag 信息收集…...

网络安全的今年:量子、生成人工智能以及 LLM 和密码
尽管世界总是难以预测,但网络安全的几个强劲趋势表明未来几个月的发展充满希望和令人担忧。有一点是肯定的:2024 年将是非常重要且有趣的一年。 近年来,人工智能(AI)以令人难以置信的速度发展,其在网络安全…...

【FPGA】Verilog:奇偶校验位发生器 | 奇偶校验位校验器
目录 0x00 奇偶校验位发生器 0x01 奇偶校验位校验器 0x02 错误检测器和纠错器...

【心得】关于STM32中RTC的校准方法
最近看了一些关于RTC校准的帖子,发现很多人存在疑惑。正好最近我也在STM32中实现了RTC校准。发些心得。这些对老手来说有些罗索,但对新手有益处。 实现RTC 校准的核心之一是库文件Stm321f0x_bkp.c中的void BKP_SetRTCCalibrationValue (uint8_t Calibra…...

消息中间件面试篇
目录 消息中间件 RabbitMQ 消息不丢失 生产者确认机制 消息持久化 交换机持久化 队列持久化 消息持久化 消费者确认 消息重复消费 出现的场景 解决方案 每条消息设置一个唯一的标识id 幂等方案:【 分布式锁、数据库锁(悲观锁、乐观锁&#…...
)
【MySQL】-20 MySQL综合-6(MySQL创建数据表+MySQL修改数据表+MySQL删除数据表)
MySQL创建数据表MySQL修改数据表MySQL删除数据表 MySQL创建数据表基本语法在指定的数据库中创建表查看表结构 MySQL修改数据表基本语法添加字段修改字段数据类型删除字段修改字段名称修改表名 MySQL删除数据表基本语法删除表 MySQL创建数据表 在创建数据库之后,接下…...

linux查看当前连接的IP
linux下查询当前所有连接的ip_linux查看某个ip的连接-CSDN博客 netstat -ntu | grep tcp | awk {print $5} | cut -d: -f1 | sort | uniq -c | sort -nr...
洛谷_P1923 【深基9.例4】求第 k 小的数_python写法
哪位大佬可以出一下这个的题解?????话说蓝桥杯可以用numpy库吗?????? 这道题有一个很简单的思路就是排序完成之后再访问。 but有很大的问题&…...

Swagger UI完全指南:如何用这款响应式工具动态生成惊艳API文档
Swagger UI完全指南:如何用这款响应式工具动态生成惊艳API文档 【免费下载链接】swagger-ui Swagger UI is a dependency-free collection of HTML, Javascript, and CSS assets that dynamically generate beautiful documentation from a Swagger-compliant API. …...

终极VS Code数据库开发指南:10分钟掌握SQL到NoSQL全流程实战
终极VS Code数据库开发指南:10分钟掌握SQL到NoSQL全流程实战 【免费下载链接】vscode Visual Studio Code 项目地址: https://gitcode.com/GitHub_Trending/vscode6/vscode Visual Studio Code(VS Code)作为现代开发者的首选代码编辑器…...
——Terraform离线部署(linux-amd64))
养成记录好习惯(4)——Terraform离线部署(linux-amd64)
Linux 系统离线安装配置 Terraform(对接 Proxmox/PVE) 前言 本文主要介绍在离线 Linux 环境下安装配置 Terraform,并部署 Proxmox Provider 插件,实现通过 Terraform 集中管理 PVE 虚拟化基础设施,解决离线环境下 Te…...

STM32F407ZGT6+DHT11温湿度传感器实战:从硬件接线到串口打印全流程
STM32F407ZGT6与DHT11温湿度传感器开发实战指南 在嵌入式系统开发领域,环境监测是一个常见且实用的应用场景。本文将详细介绍如何使用STM32F407ZGT6微控制器与DHT11温湿度传感器构建一个完整的监测系统。不同于简单的教程,我们将深入探讨硬件接口设计、软…...

实测速腾16线雷达在自动驾驶小车上的表现:150米测距精度对比与点云优化技巧
速腾RS-LiDAR-16激光雷达在自动驾驶小车上的实战评测:150米测距精度与点云优化全解析 当我在实验室第一次将速腾RS-LiDAR-16安装到自动驾驶小车上时,那密集的点云数据立刻让我意识到——这绝不是普通的传感器。作为一款面向高端机器人应用的16线激光雷达…...

实测LingBot-Depth:一键将RGB图片变3D点云,效果惊艳
实测LingBot-Depth:一键将RGB图片变3D点云,效果惊艳 1. 引言:当照片“活”起来 你有没有想过,手机里的一张普通照片,其实隐藏着一个完整的三维世界?我们看到的只是颜色和光影,但丢失了最重要的…...

新手如何用 GitHub 开源项目高效完成毕业设计:选型、集成与避坑指南
作为一名刚刚经历过毕业设计的过来人,我深知在有限的时间和精力下,找到一个合适的起点是多么重要。GitHub 上的开源项目就像一座宝库,但如果使用不当,也可能变成答辩时的“雷区”。今天,我就结合自己的实战经验&#x…...

py 图片拆分
from PIL import Image import osdef split_chars_and_numbers(image_path, output_dir"split_all_chars", split_lettersTrue, split_numbersTrue):"""一体化切分图片中的字母(A-Z)和数字(1-90):param image_path: 输入图片路径:param output_dir: 输…...

6-2一帮一
“一帮一学习小组”是中小学中常见的学习组织方式,老师把学习成绩靠前的学生跟学习成绩靠后的学生排在一组。本题就请你编写程序帮助老师自动完成这个分配工作,即在得到全班学生的排名后,在当前尚未分组的学生中,将名次最靠前的学…...

faster-whisper-GUI技术解构:从原理到落地的全维度实践
faster-whisper-GUI技术解构:从原理到落地的全维度实践 【免费下载链接】faster-whisper-GUI faster_whisper GUI with PySide6 项目地址: https://gitcode.com/gh_mirrors/fa/faster-whisper-GUI faster-whisper-GUI是一款基于PySide6开发的图形界面工具&am…...