09、全文检索 -- Solr -- SpringBoot 整合 Spring Data Solr (生成DAO组件 和 实现自定义查询方法)
目录
- SpringBoot 整合 Spring Data Solr
- Spring Data Solr的功能(生成DAO组件):
- Spring Data Solr大致包括如下几方面功能:
- @Query查询(属于半自动)
- 代码演示:
- 1、演示通过dao组件来保存文档
- 1、实体类指定索引库
- 2、修改日志级别
- 3、创建 Dao 接口
- 4、先删除所有文档
- 5、创建测试类
- 6、演示结果
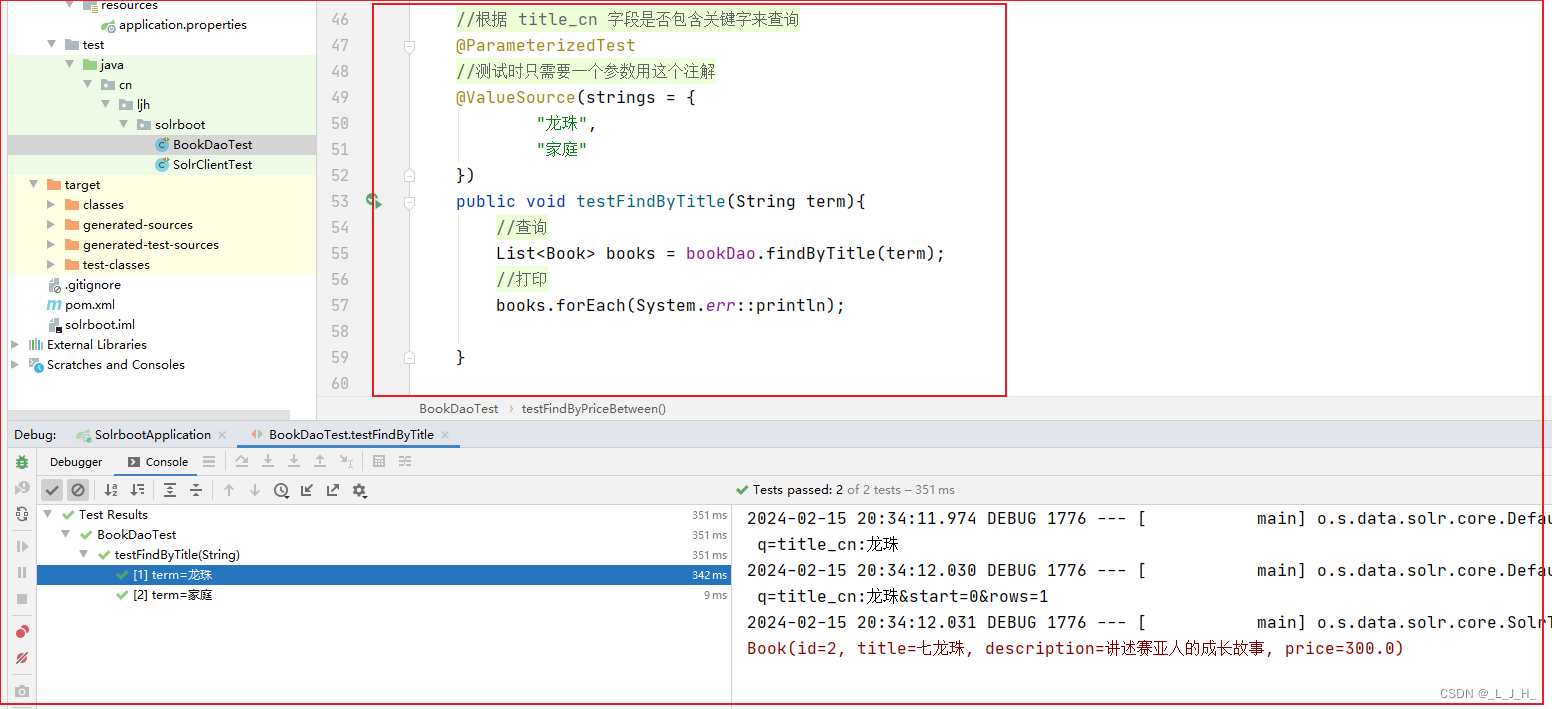
- 2、根据 title_cn 字段是否包含关键字来查询
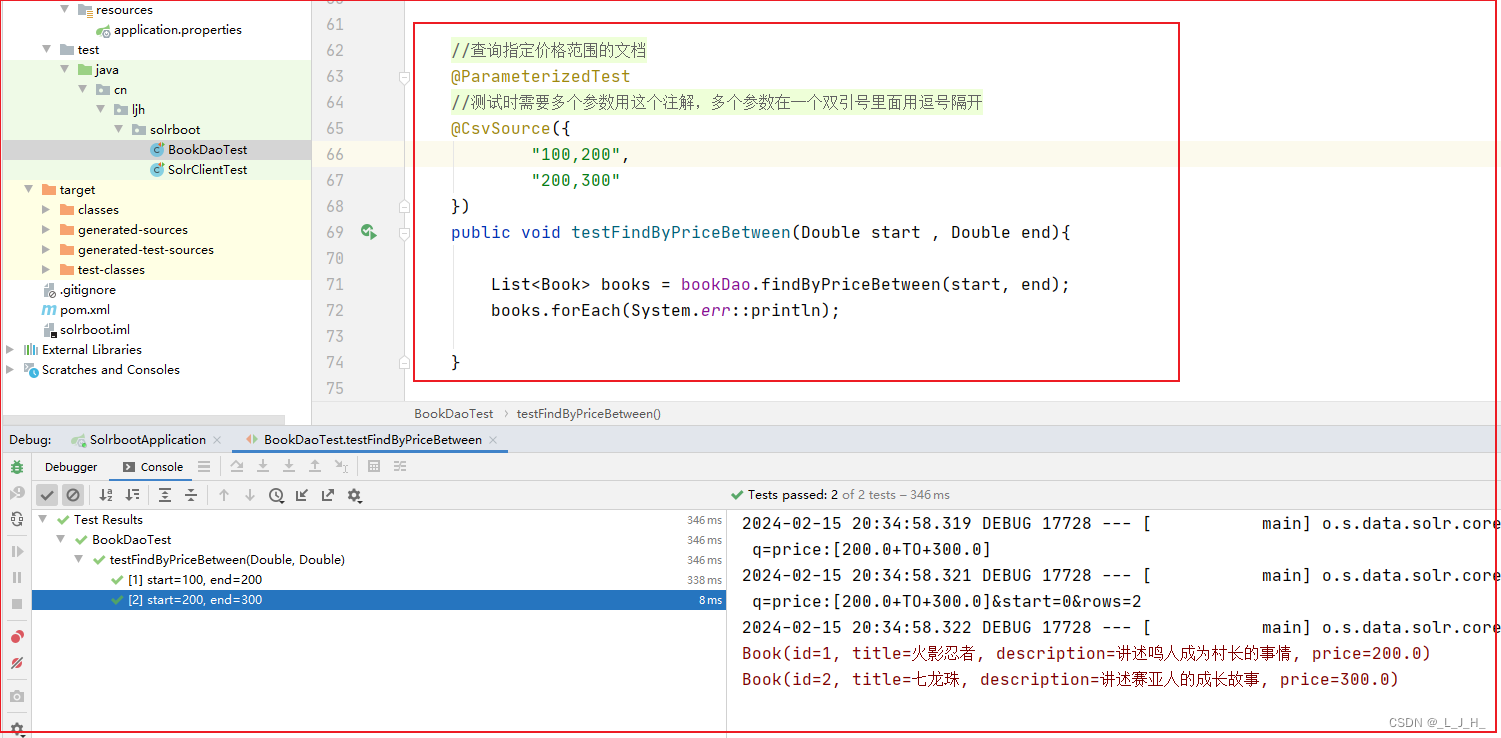
- 3、查询指定价格范围的文档
- 4、查询Description 字段中包含关键词的文档
- 5、查询集合中的这些id的文档
- 6、@Query查询(自定义的半自动查询)
- Spring Data Solr的功能(实现自定义查询方法):
- 自定义查询方法(属于全手动)
- 代码演示:
- 自定义查询方法且高亮显示
- 1、自定义CustomBookDao组件
- 2、CustomBookDaoImpl 实现类写自定义方法
- 3、测试:成功实现关键字的高亮显示
- 4、部分代码解释
- 代码优化:
- @EnableSolrRepositories 注解解释
- 完整代码
- SolrConfig 手动配置自定义的SolrClient
- Book 实体类
- BookDao 组件
- CustomBookDao 自定义dao组件
- CustomBookDaoImpl 自定义查询方法
- application.properties 配置文件
- BookDaoTest 基于DAO组件测试
- SolrClientTest 基于SolrClient测试
- pom.xml 依赖文档
SpringBoot 整合 Spring Data Solr
测试类使用 solrClient 进行添加、查询、删除文档的操作在这篇的代码基础上继续演示的
两篇文章的区别:
上一篇是通过SolrClient 连接 Solr,然后用 SolrClient 来调用查询方法进行全文检索
这一篇是 自定义dao组件,通过继承CrudRepository 接口,用 dao 接口来调用查询方法进行全文检索
Spring Data Solr的功能(生成DAO组件):
这种方式在Spring Boot 2.5已经不再推荐使用了,需要手动添加@EnableSolrRepositories来启动DAO组件。
通过这种方式访问Solr索引库,确实不如直接用SolrClient那么灵活。
Spring Data Solr大致包括如下几方面功能:
DAO接口只需继承 CrudRepository,Spring Data Solr 就能为DAO组件提供实现类。
1、Spring Data Solr 支持方法名关键字查询,只不过Solr查询都是全文检查查询。
2、Spring Data Solr 同样支持用 @Query注解指定自定义的查询语句 。
3、Spring Data Solr 同样支持 DAO组件添加自定义的查询方法。
通过添加额外的父接口,并为额外的该接口提供实现类,Spring Data Solr 就能该实现类中的方法“移植”到DAO组件中。
4、不支持Example查询和Specification查询。
【说明:】
与前面介绍的NoSQL技术不同的是,Solr属于全文检索引擎,因此它的方法名关键字查询也是基于全文检索的。
例如对于findByName(String name)方法,假如传入参数为“疯狂”,
这意味着查询name字段中包含“疯狂”关键字的文档,而不是查询name字段值等于“疯狂”的文档。
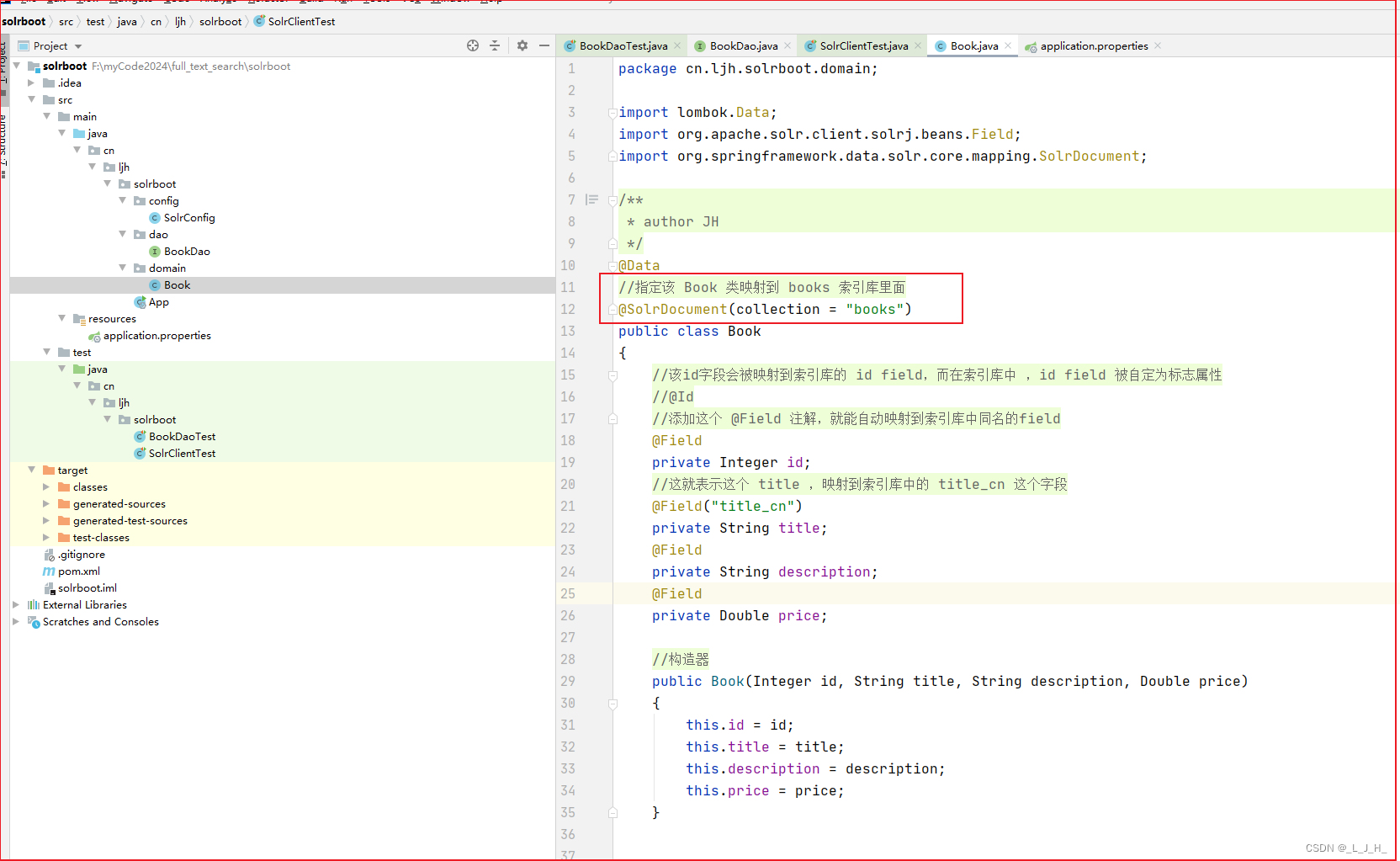
@SolrDocument注解 可指定一个collection属性,用于指定该实体类映射哪个索引库(单机就是Core或集群模式就是Collection)。
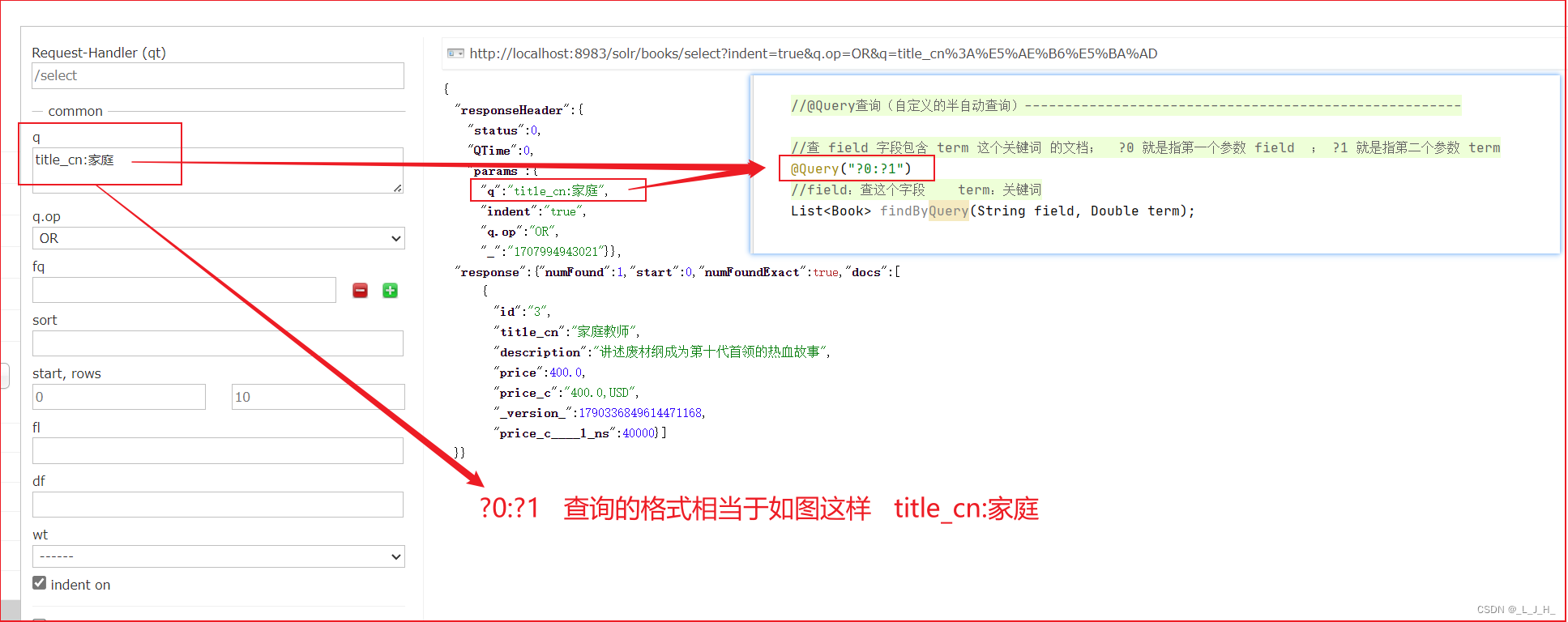
@Query查询(属于半自动)
@Query注解所指定的就是标准的 Lucene 的查询语法
@Query("?0:?1")
List<Book> findByQuery(String field, Double term);
代码演示:
代码是基于:使用 SolrClient 连接 Solr 这篇文章来修改的
1、演示通过dao组件来保存文档
1、实体类指定索引库
指定该 Book 类映射到 books 索引库里面
2、修改日志级别
日志级别,可以用来看sql具体的执行语句
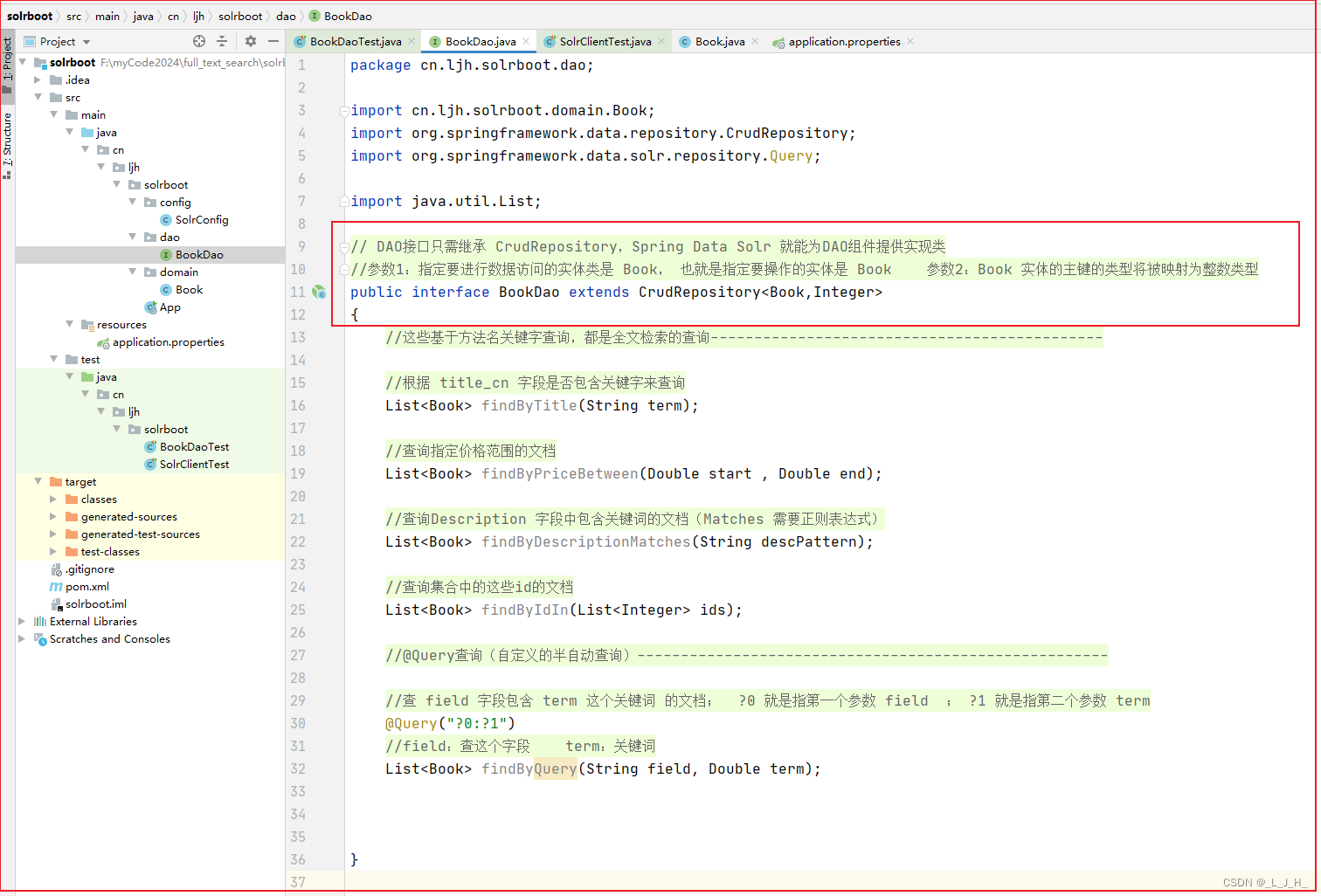
3、创建 Dao 接口
DAO接口只需继承 CrudRepository,Spring Data Solr 就能为DAO组件提供实现类。
此时写的方法还不需要用到。
只是需要用到这个BookDao接口。
4、先删除所有文档
用前面写的测试方法,先把前面测试的文档先删除干净。
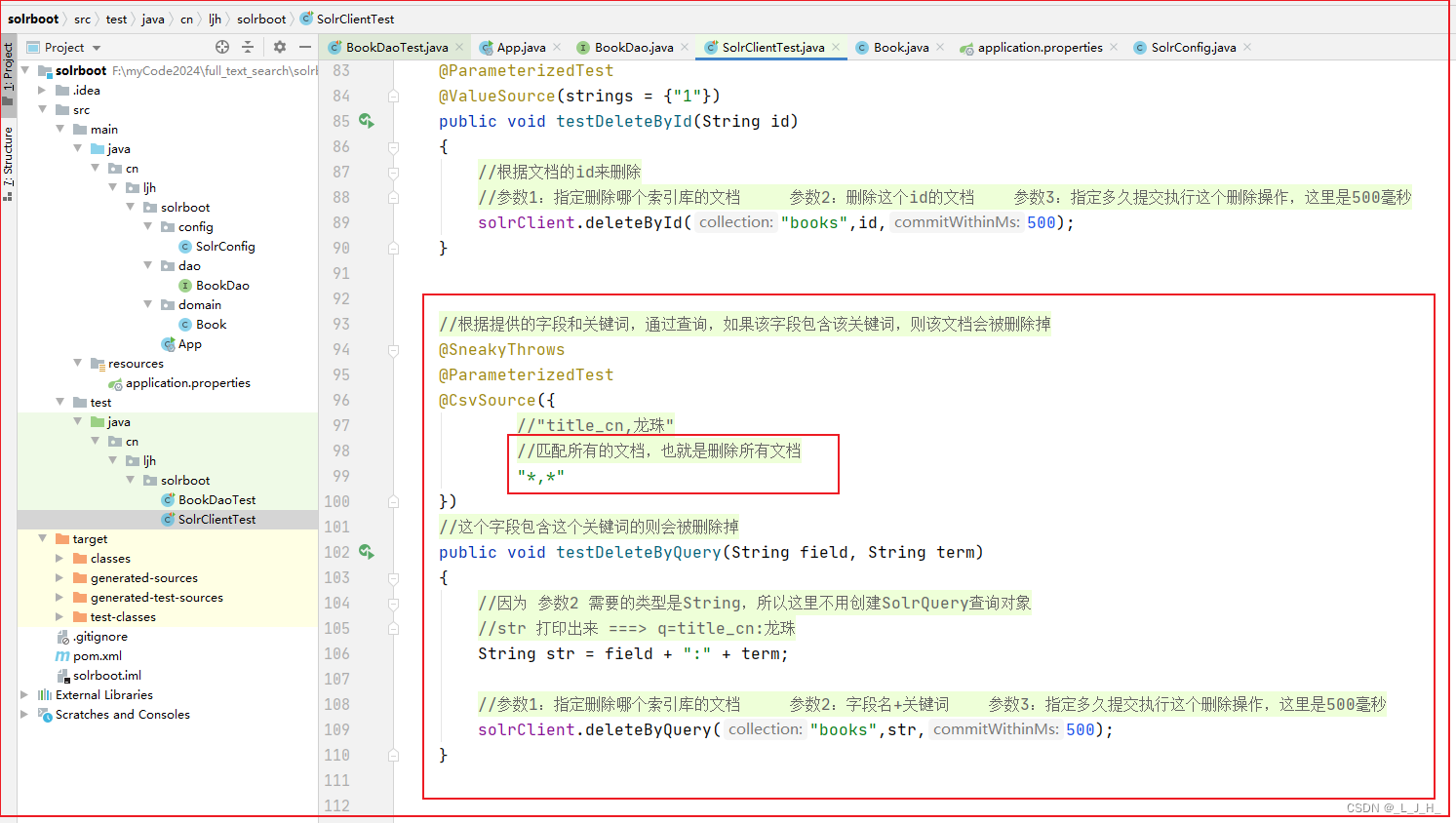
5、创建测试类
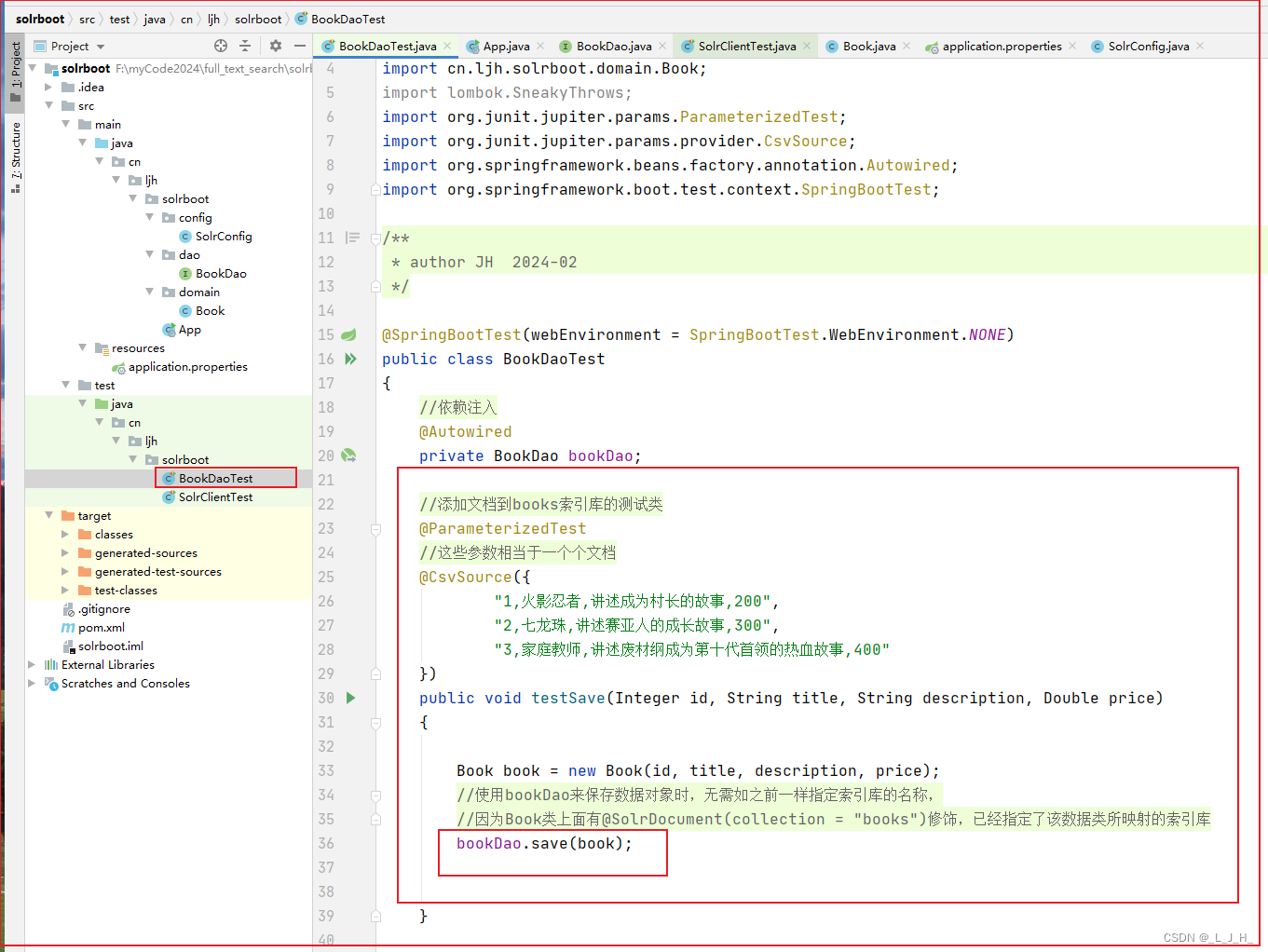
区别:
添加文档的代码都是一样的,只是整合 Spring Data Solr 用到的是 bookDao 接口来实现,之前是使用solrClient来实现。
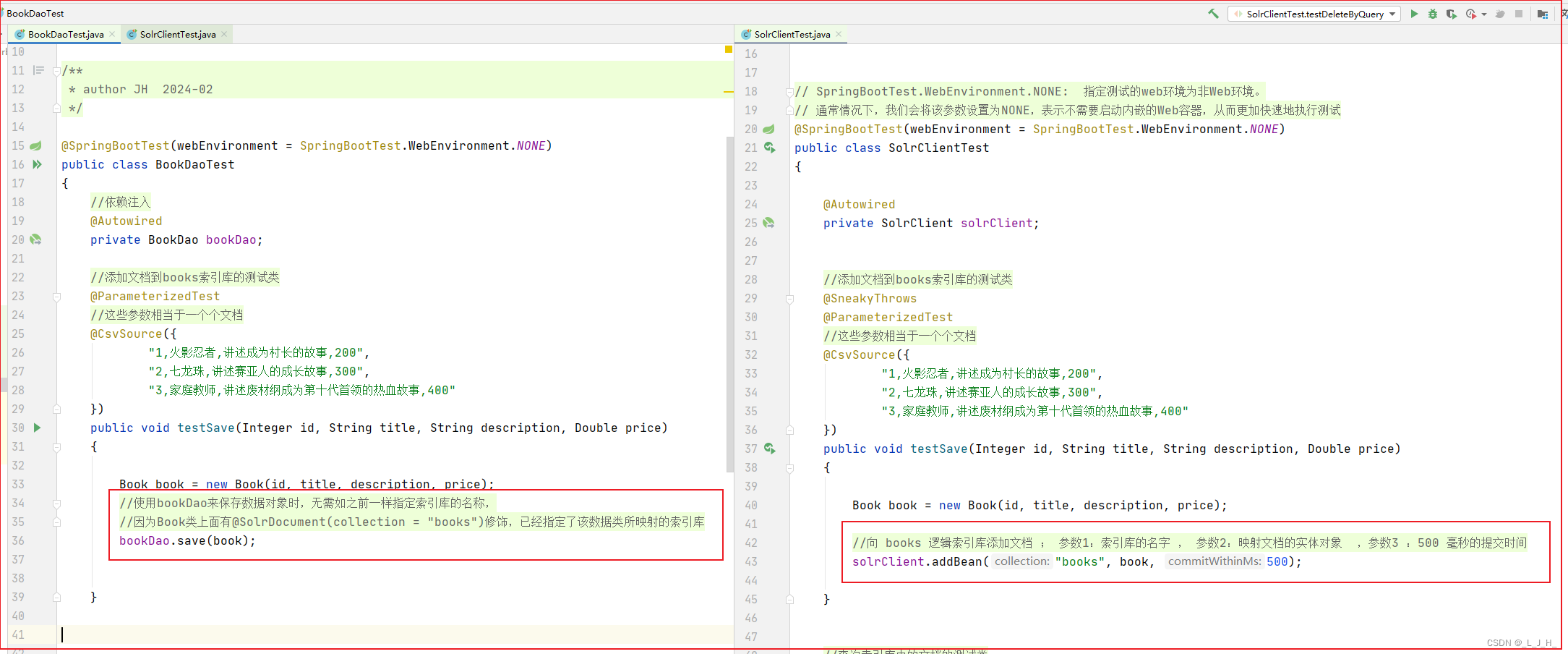
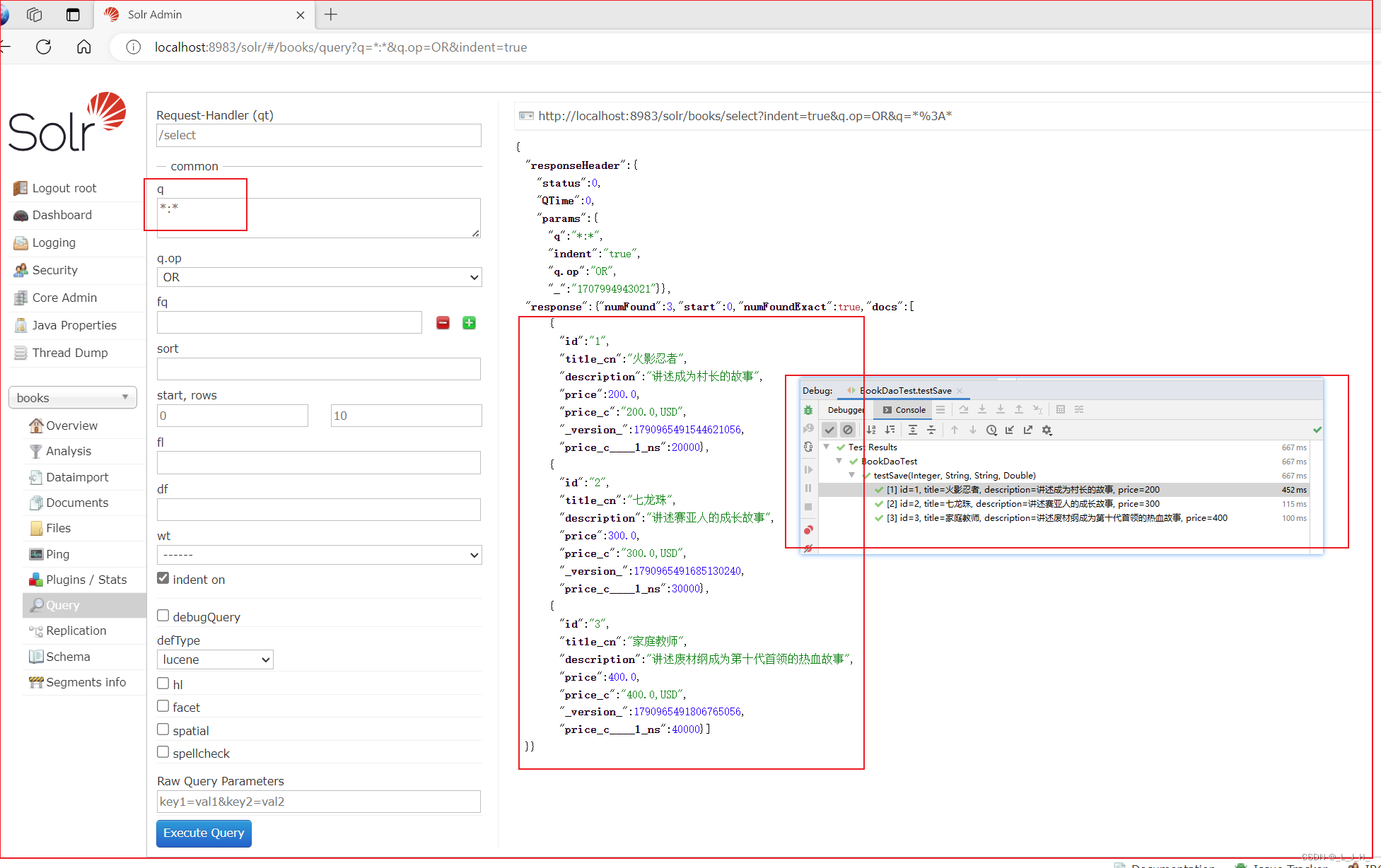
6、演示结果
成功通过 dao 组件来添加文档。
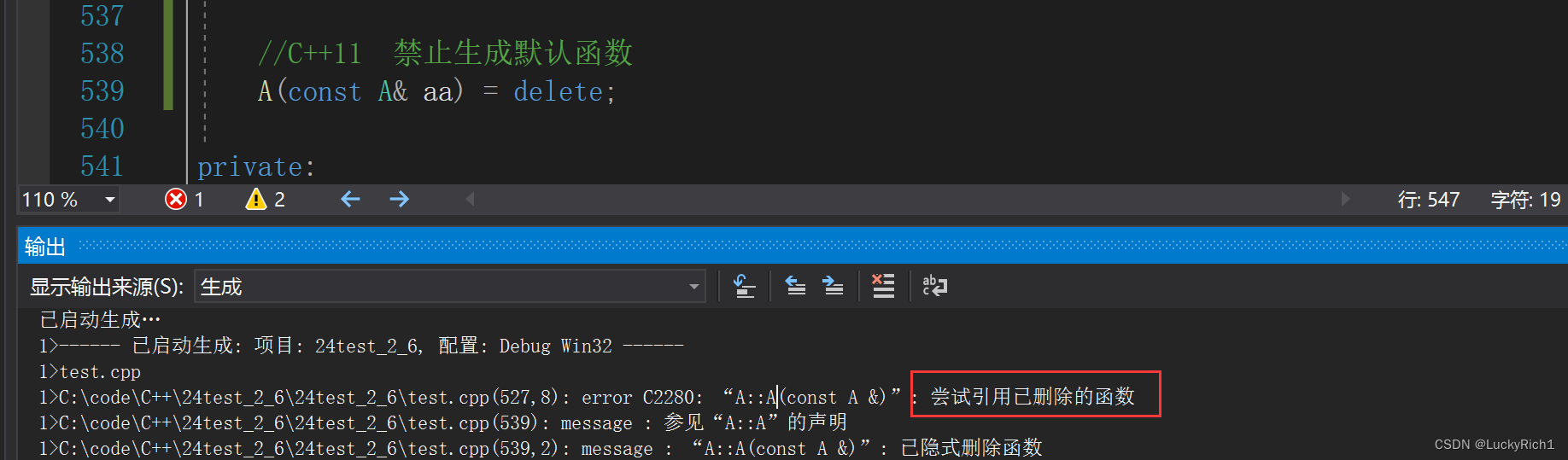
如果代码出错,因为版本问题显示没有bookDao这个bean,那么就通过注解手动启用Dao组件
我依赖是这个,演示的时候能成功执行代码,所以没有手动启用上面说的注解@EnableSolrRepositories

为了后面方便演示,把文档删了,改成这些。

2、根据 title_cn 字段是否包含关键字来查询
3、查询指定价格范围的文档
4、查询Description 字段中包含关键词的文档
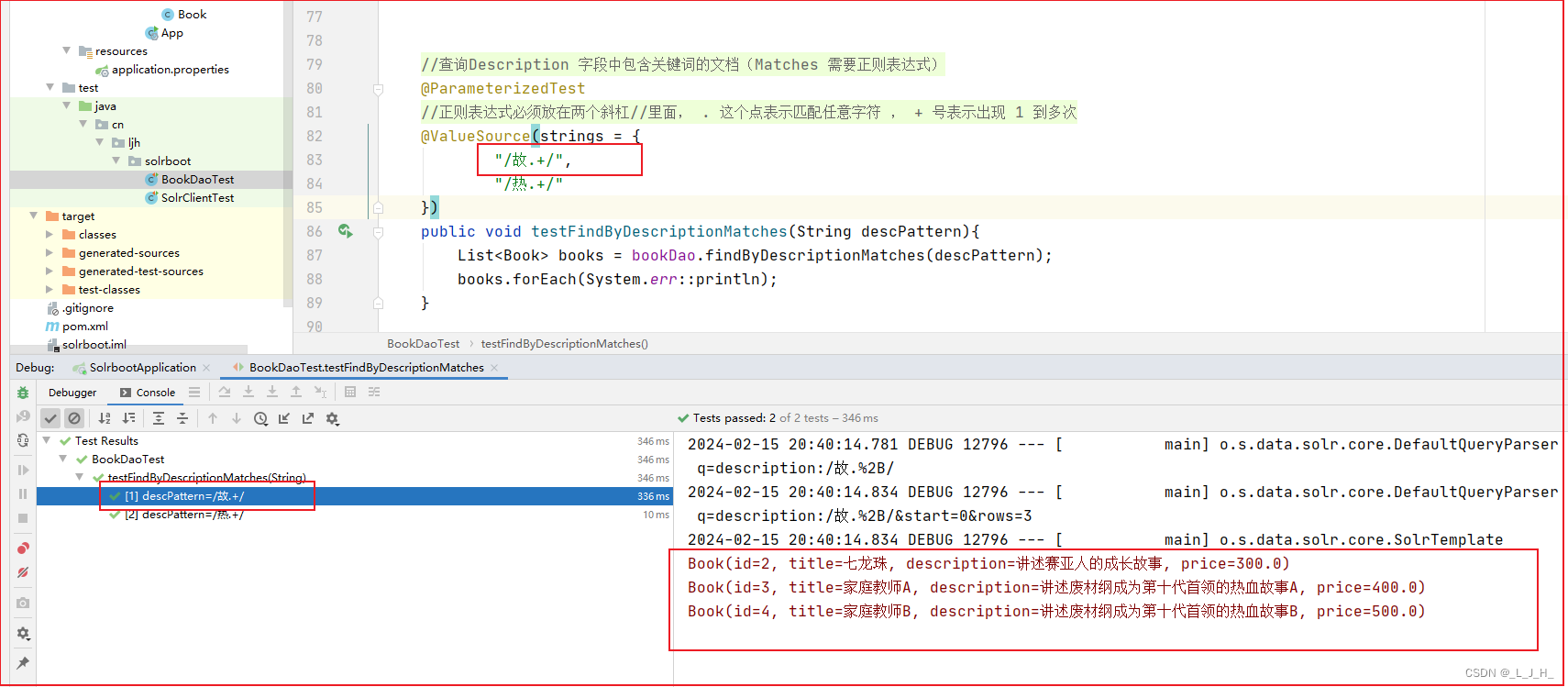
查询Description 字段中包含关键词的文档(Matches 需要正则表达式)
如图:正则表达式里面 ,/故事.+/ 两个字的就查不到,如果是 /故.+/ 一个字就查的到。
/故事.+/ 两个字的就查不到
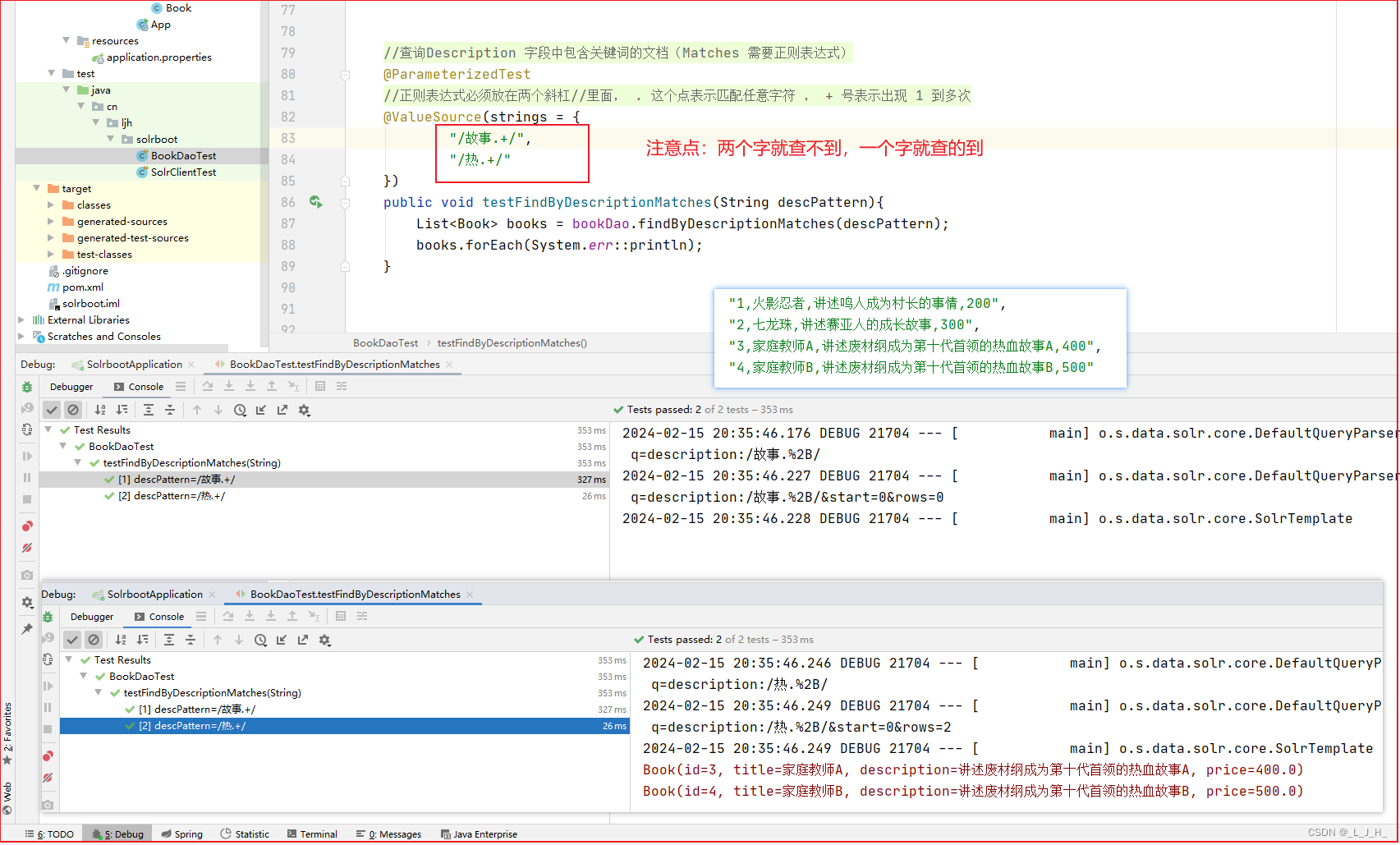
/故.+/ 一个字就查的到
5、查询集合中的这些id的文档
6、@Query查询(自定义的半自动查询)
Spring Data Solr的功能(实现自定义查询方法):
自定义查询方法(属于全手动)
让DAO接口继承自定义DAO接口、并为自定义DAO接口提供实现类,可以为DAO组件添加自定义查询方法。
Spring Data solr会将自定义DAO组件实现的方法移植DAO组件中。
自定义查询方法可使用SolrClient来实现查询方法,SolrClient 是 Solr本身提供的API,功能比较强大。
代码演示:
自定义查询方法且高亮显示
需求:自定义一个关键字查询的方法,返回的结果中,对关键字进行高亮显示。
代码解释:
下面的代码:
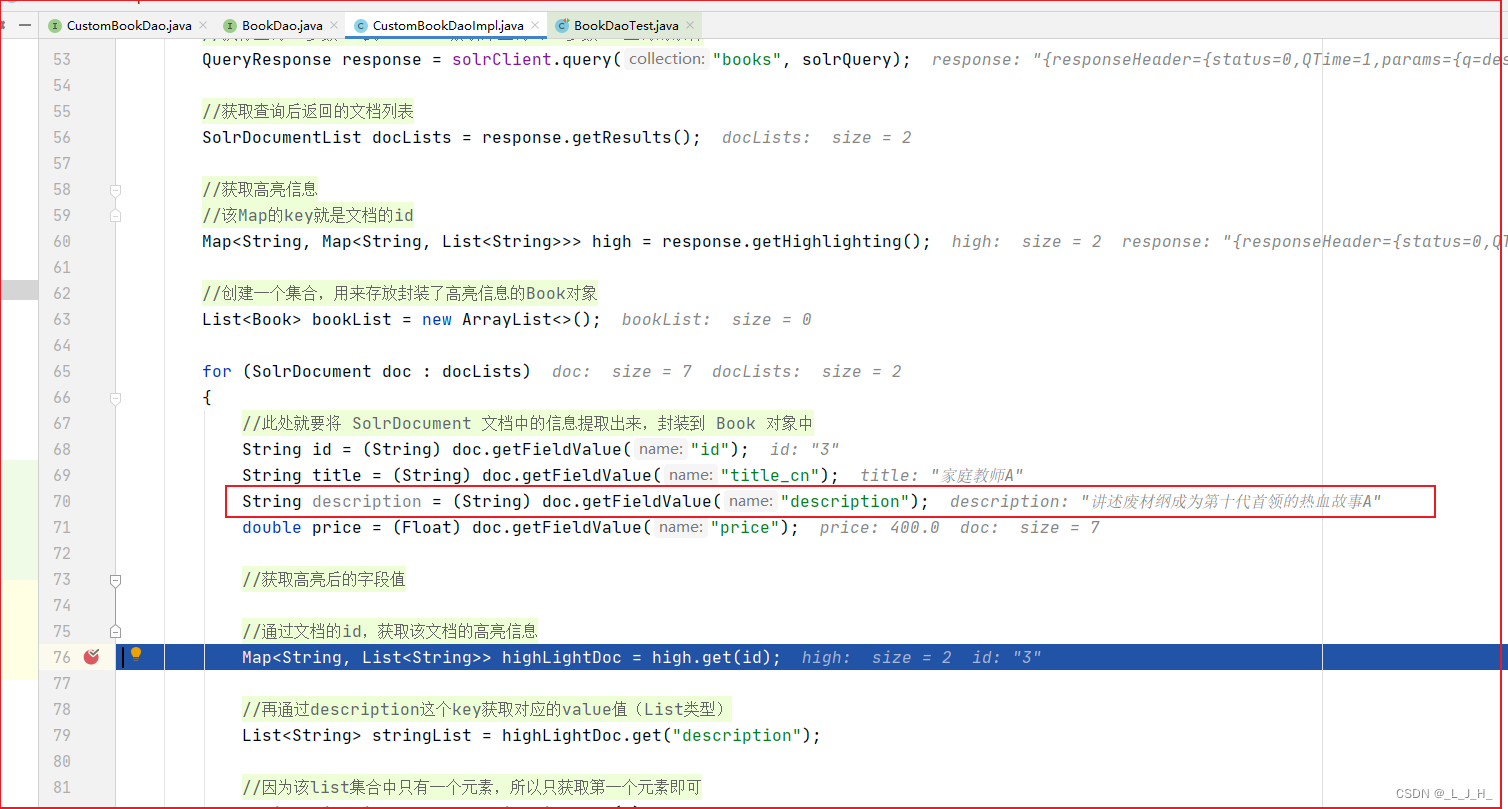
1、先在查询的时候添加实现高亮的代码
2、在查询后返回来的文档中,获取高亮信息
3、将获取到的高亮信息封装回 Book 对象即可。
(其实就是要返回的book对象中的description字段里面的关键字前后多了< span > 标签字符串, 就算是实现了关键字的高亮效果)
1、自定义CustomBookDao组件
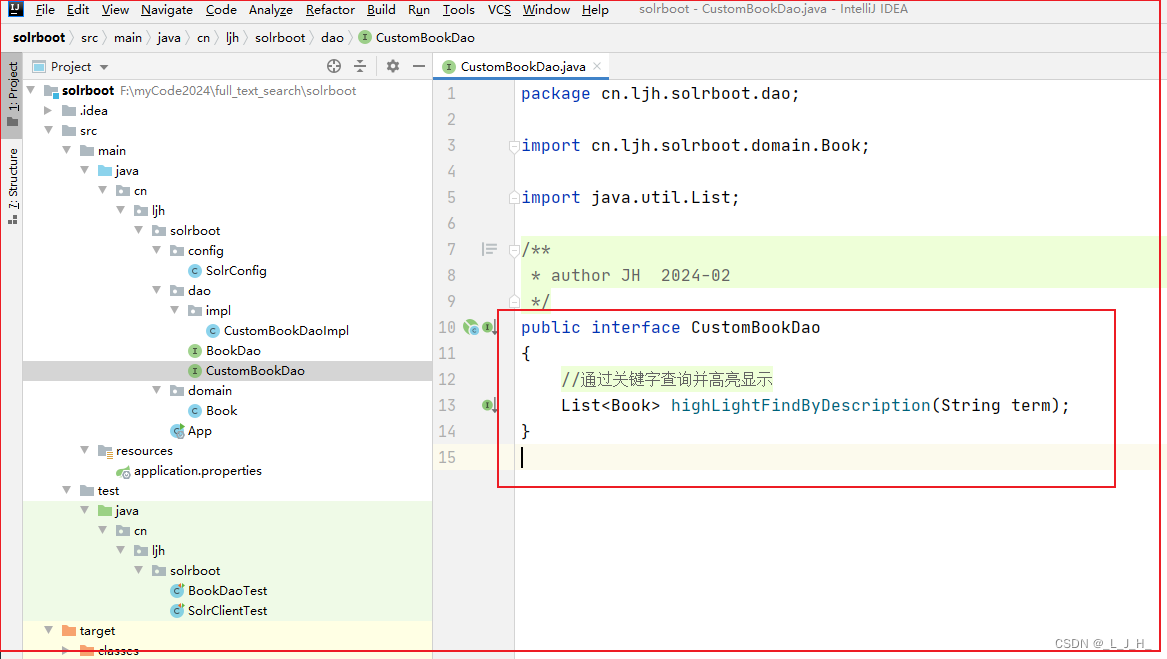
同时让 bookDao 也继承这个 CustomBookDao
为了方便统一用 bookDao 来调用查询方法
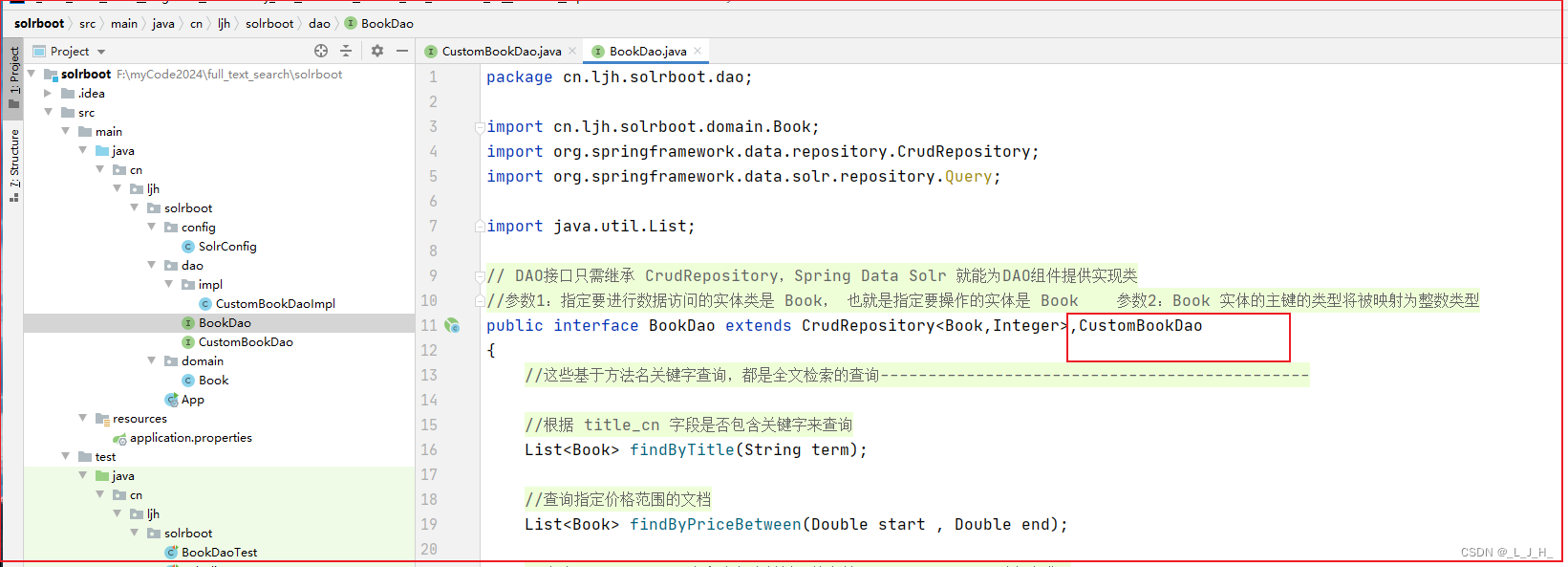
2、CustomBookDaoImpl 实现类写自定义方法
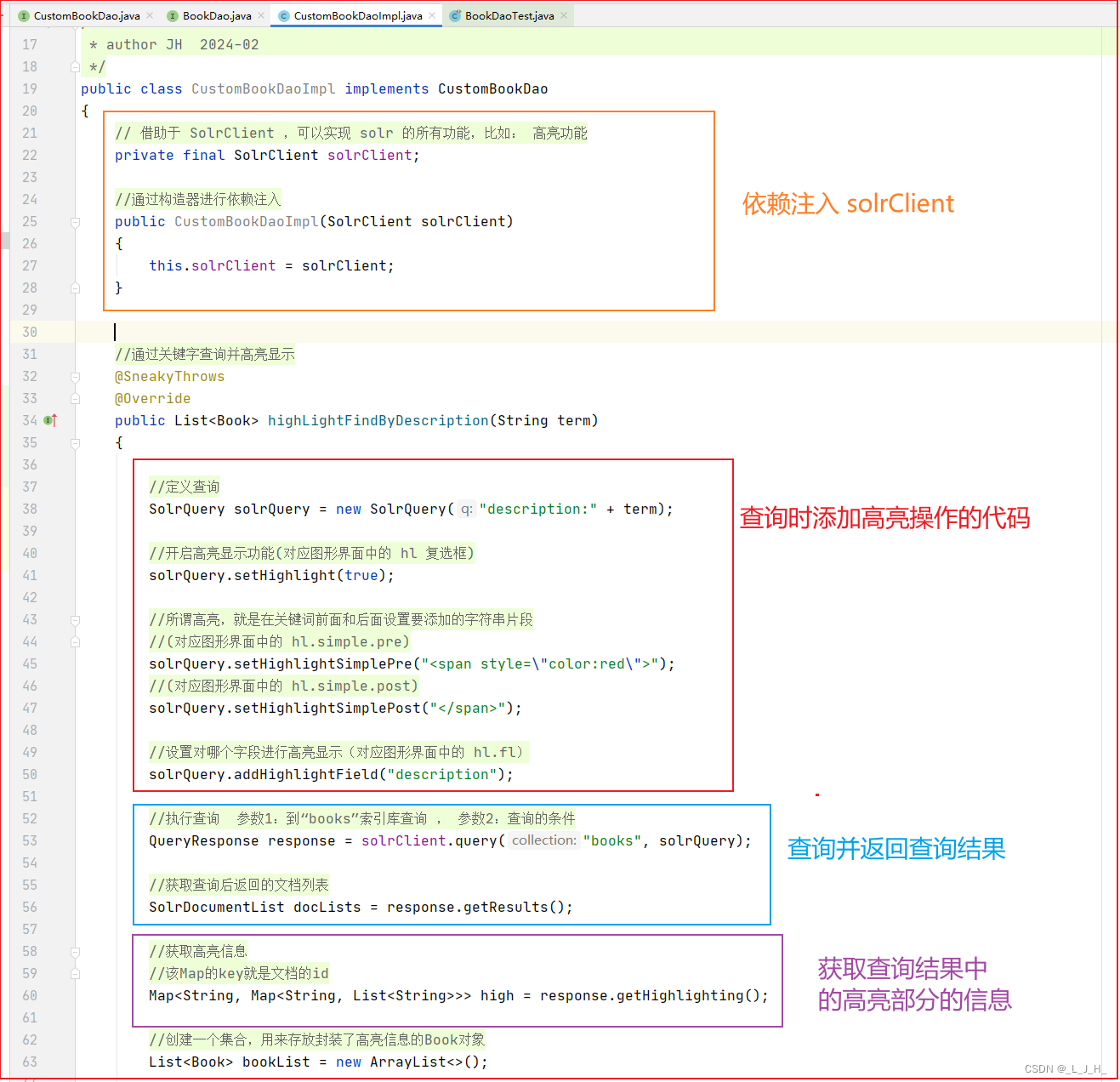

3、测试:成功实现关键字的高亮显示
4、部分代码解释
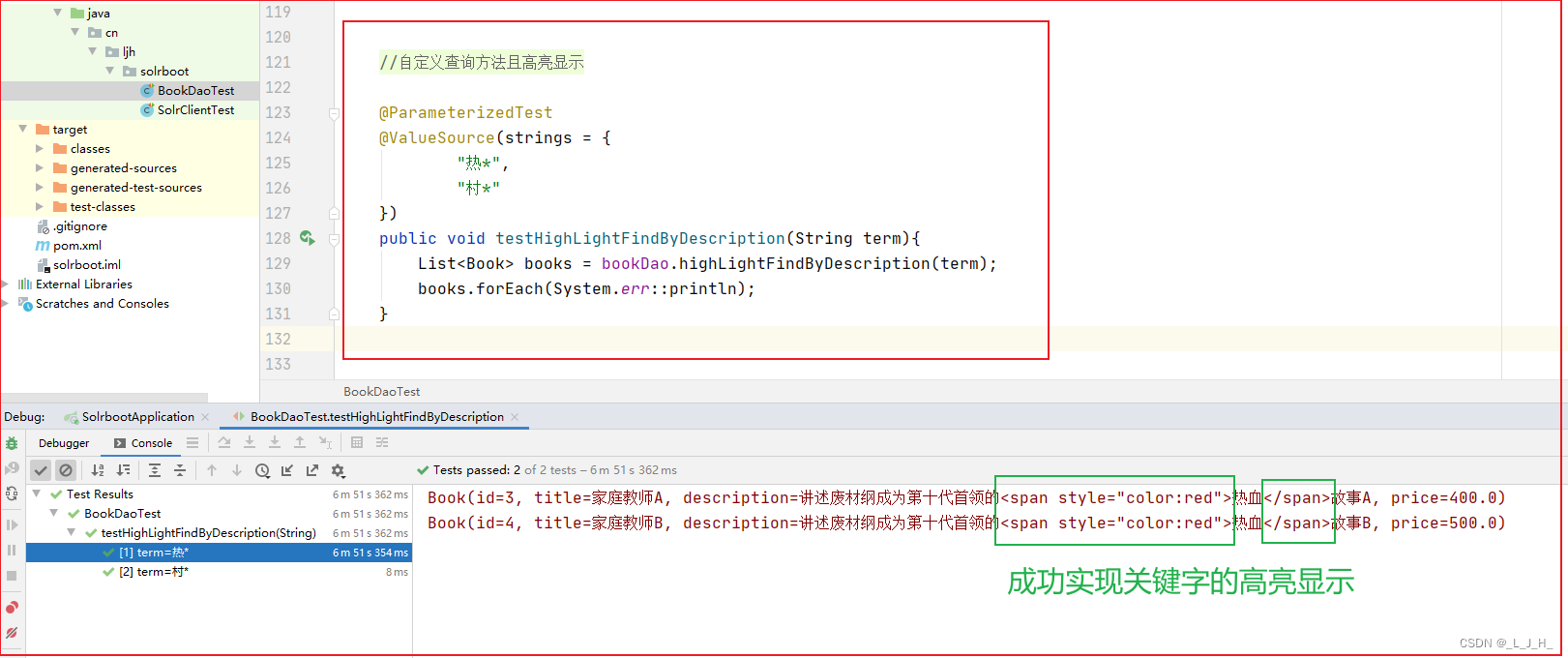
1、代码中的设置对应图形界面中的设置
在查询条件中,添加高亮设置。
如图:通过图形界面跟测试代码的相同条件的查询,来演示代码设置高亮效果时对应的样子
2、对获取高亮信息并封装回book对象的解释
对这部分代码进行详细解释

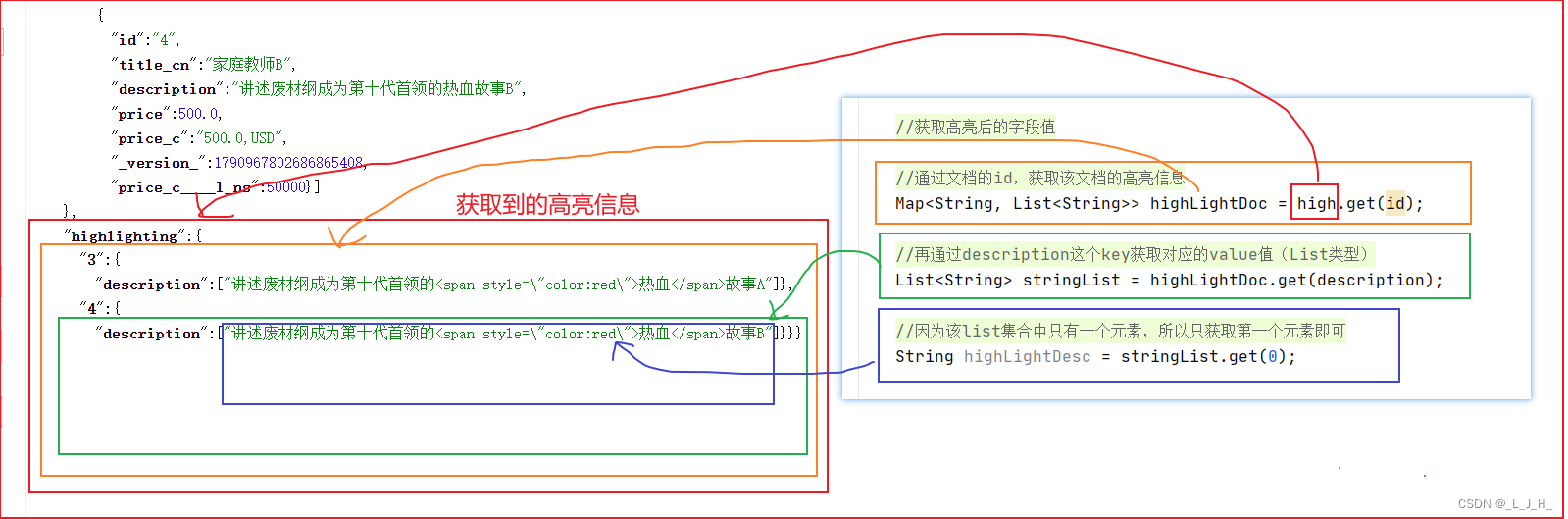
查询时对关键字添加了高亮的操作,此时把具体的高亮信息(就是关键字前后添加了高亮的 < span > 代码,在查询后返回的结果文档里面,生成了如图的这个字符串)拿出来,封装回 description 这个属性里面。
比如查的时候,是查 description 这个字段里面包含“热血” 的关键词,
如果不加高亮的代码,那么返回来的数据是:
“description”:[“讲述废材纲成为第十代首领的热血故事A”]},
如果加高亮的代码,那么返回来的数据是:
“description”:[“讲述废材纲成为第十代首领的<span style=“color:red”>热血< /span >故事A”]},
关键字前后多了 <span style=“color:red”> < /span > 这两个字符串。
所以我们这一步就是要把加高亮后返回的这个多了这两个高亮显示的字符串的数据,给封装到 Book 对象里面的description 字段里面。
如图:通过图形界面跟测试代码的相同条件的查询,来演示代码具体获取到的高亮信息长啥样
如果不封装的话,那么查询后返回来的结果,这个description字段的数据依然是没有加高亮代码的。
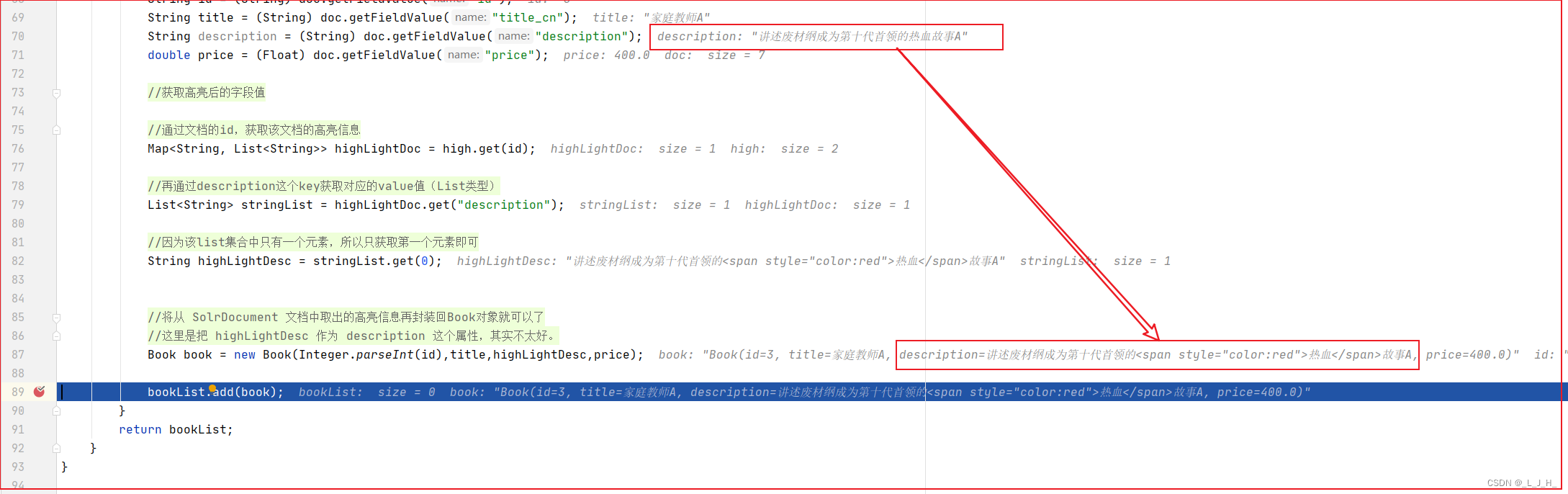
所以需要把高亮的信息获取出来,再设置到 Book 对象里面的 description 字段里面,这样再返回这个 book对象,此时Book对象里面的 description 值就有高亮显示的功能了。
(其实就是要返回的book对象中的description字段里面的关键字前后多了< span > 标签字符串, 就算是实现了关键字的高亮效果)
代码优化:
如图:根据上面的代码解释,可以看出此时的 highLightDesc 字符串相当于就是具有高亮效果的 description 的值。
description 的值长这样:
[“讲述废材纲成为第十代首领的热血故事A”]},
highLightDesc 的值长这样
[“讲述废材纲成为第十代首领的<span style=“color:red”>热血< /span >故事A”]},
我们需要把
[“讲述废材纲成为第十代首领的<span style=“color:red”>热血< /span >故事A”]},
这个具有高亮效果的值封装回 Book 对象里面。
但是这个highLightDesc 这个字符串毕竟不是 description ,
所以如图直接把 highLightDesc 作为 description 字段封装进去,其实是不太合逻辑的。
所以可以优化下

优化代码:
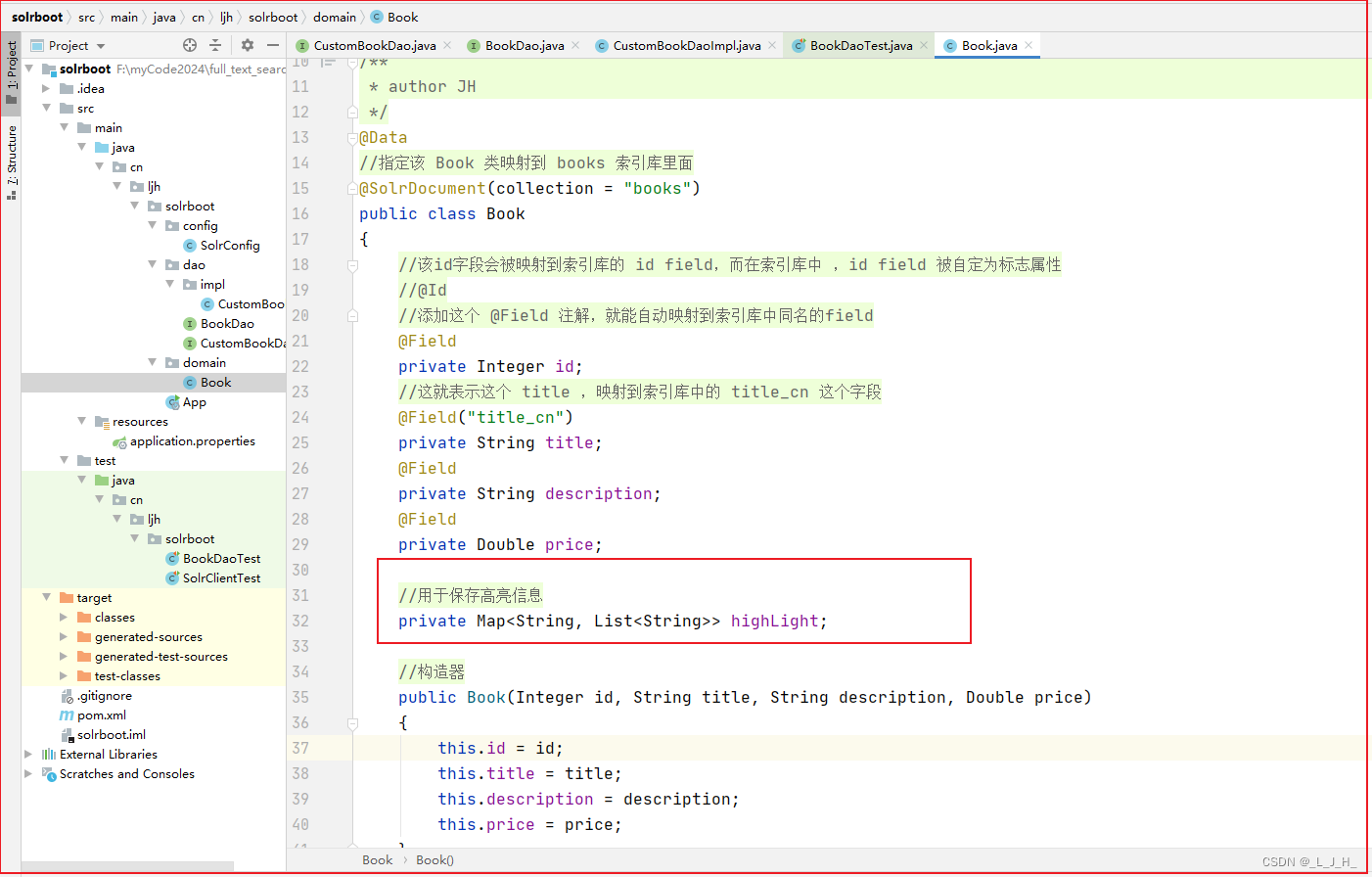
假如我不希望改变Book对象的属性值,但是又希望能将高亮的信息传出去,因此可以考虑为Book对象增加一个Map类型的属性,该属性用于保存高亮信息。
1、先添加一个用于保存高亮信息的字段
2、封装对象时,把 highLightDesc 改回正常的 description 字段,此时可以看到,关键字并没有高亮显示。
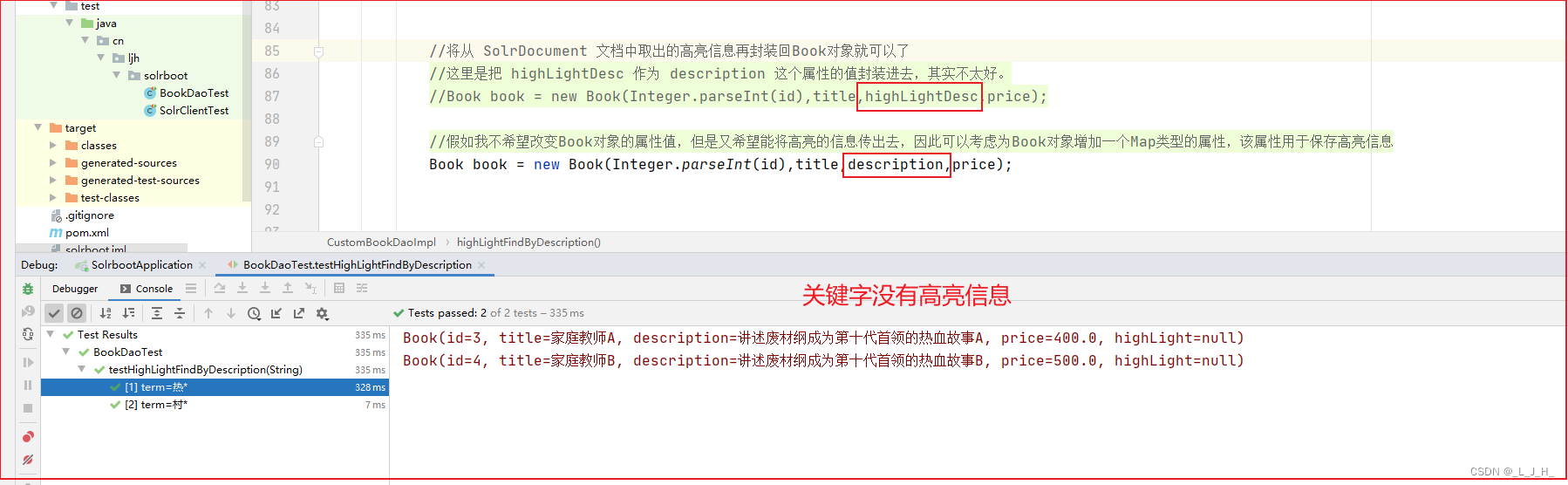
3、把该id的文档的高亮信息设置到这个字段里面
如图:这样也能实现高亮效果
这种写法的好处:
既不会破坏原来这个 Book 对象的属性值,同时也能将高亮信息传出来
@EnableSolrRepositories 注解解释
该注解其实和Spring Boot的其他 @EnableXxxRepositories注解大同小异。
@EnableSolrRepositories注解用于启用Solr Repository支持。
一旦程序显式使用该注解,那Spring Data Solr 的 Repository自动配置就会失效(Spring Boot 2.5本来就没有启用Repository的自动配置)。
因此,当需要连接多个Solr索引库时或进行更多定制时,可手动使用该注解。
使用@EnableSolrRepositories注解时要指定如下属性:
- basePackages:指定扫描哪个包下的DAO组件(Repository组件)。- solrClientRef:指定基于哪个 SolrClient 来实现 Repository 组件,默认值是 solrClient。- solrTemplateRef:指定基于哪个 SolrTemplate 来实现Repository组件,默认是 solrTemplate。
上面 solrClientRef 与 solrTemplateRef 两个属性只要指定其中之一即可。
如图:不过这个注解我暂时没用到。
完整代码
SolrConfig 手动配置自定义的SolrClient
package cn.ljh.solrboot.config;import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.solr.SolrProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.solr.repository.config.EnableSolrRepositories;
import org.springframework.util.StringUtils;import java.util.Arrays;
import java.util.Optional;//手动配置自定义的SolrClient
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({HttpSolrClient.class, CloudSolrClient.class})
@EnableConfigurationProperties(SolrProperties.class)//由于本项目没有配置 SpringBoot 为 Spring Data Solr 提供的 Starter 组件,因此需要手动启用Dao组件
//@EnableSolrRepositories(basePackages = "cn.ljh.solrboot.dao",solrClientRef = "solrClient")
public class SolrConfig
{//把配置文件中的属性值注入到这个成员变量里面@Value("${spring.data.solr.username}")private String username;@Value("${spring.data.solr.password}")private String password;//此处需要配置一个 SolrClient(直接抄SolrAutoConfiguration的源码就可以了)@Beanpublic SolrClient solrClient(SolrProperties properties){//通过系统属性来设置连接Solr所使用的认证信息// 设置使用基本认证的客户端System.setProperty("solr.httpclient.builder.factory","org.apache.solr.client.solrj.impl.PreemptiveBasicAuthClientBuilderFactory");// 设置认证的用户名和密码System.setProperty("basicauth", username + ":" + password);if (StringUtils.hasText(properties.getZkHost())){return new CloudSolrClient.Builder(Arrays.asList(properties.getZkHost()), Optional.empty()).build();}return new HttpSolrClient.Builder(properties.getHost()).build();}}Book 实体类
package cn.ljh.solrboot.domain;import lombok.Data;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.solr.core.mapping.SolrDocument;import java.util.List;
import java.util.Map;/*** author JH*/
@Data
//指定该 Book 类映射到 books 索引库里面
@SolrDocument(collection = "books")
public class Book
{//该id字段会被映射到索引库的 id field,而在索引库中 ,id field 被自定为标志属性//@Id//添加这个 @Field 注解,就能自动映射到索引库中同名的field@Fieldprivate Integer id;//这就表示这个 title ,映射到索引库中的 title_cn 这个字段@Field("title_cn")private String title;@Fieldprivate String description;@Fieldprivate Double price;//用于保存高亮信息private Map<String, List<String>> highLight;//构造器public Book(Integer id, String title, String description, Double price){this.id = id;this.title = title;this.description = description;this.price = price;}}BookDao 组件
package cn.ljh.solrboot.dao;import cn.ljh.solrboot.domain.Book;
import org.springframework.data.repository.CrudRepository;
import org.springframework.data.solr.repository.Query;import java.util.List;// DAO接口只需继承 CrudRepository,Spring Data Solr 就能为DAO组件提供实现类
//参数1:指定要进行数据访问的实体类是 Book, 也就是指定要操作的实体是 Book 参数2:Book 实体的主键的类型将被映射为整数类型
public interface BookDao extends CrudRepository<Book,Integer>,CustomBookDao
{//这些基于方法名关键字查询,都是全文检索的查询---------------------------------------------//根据 title_cn 字段是否包含关键字来查询List<Book> findByTitle(String term);//查询指定价格范围的文档List<Book> findByPriceBetween(Double start , Double end);//查询Description 字段中包含关键词的文档(Matches 需要正则表达式)List<Book> findByDescriptionMatches(String descPattern);//查询集合中的这些id的文档List<Book> findByIdIn(List<Integer> ids);//@Query查询(自定义的半自动查询)------------------------------------------------------//查 field 字段包含 term 这个关键词 的文档; ?0 就是指第一个参数 field ; ?1 就是指第二个参数 term@Query("?0:?1")//field:查这个字段 term:关键词List<Book> findByQuery(String field, String term);}CustomBookDao 自定义dao组件
package cn.ljh.solrboot.dao;import cn.ljh.solrboot.domain.Book;import java.util.List;/*** author JH 2024-02*/
public interface CustomBookDao
{//通过关键字查询并高亮显示List<Book> highLightFindByDescription(String term);
}CustomBookDaoImpl 自定义查询方法
package cn.ljh.solrboot.dao.impl;import cn.ljh.solrboot.dao.CustomBookDao;
import cn.ljh.solrboot.domain.Book;
import lombok.SneakyThrows;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;import java.util.ArrayList;
import java.util.List;
import java.util.Map;/*** author JH 2024-02*/
public class CustomBookDaoImpl implements CustomBookDao
{// 借助于 SolrClient ,可以实现 solr 的所有功能,比如: 高亮功能private final SolrClient solrClient;//通过构造器进行依赖注入public CustomBookDaoImpl(SolrClient solrClient){this.solrClient = solrClient;}//通过关键字查询并高亮显示@SneakyThrows@Overridepublic List<Book> highLightFindByDescription(String term){//定义查询SolrQuery solrQuery = new SolrQuery("description:" + term);//开启高亮显示功能(对应图形界面中的 hl 复选框)solrQuery.setHighlight(true);//所谓高亮,就是在关键词前面和后面设置要添加的字符串片段//(对应图形界面中的 hl.simple.pre)solrQuery.setHighlightSimplePre("<span style=\"color:red\">");//(对应图形界面中的 hl.simple.post)solrQuery.setHighlightSimplePost("</span>");//设置对哪个字段进行高亮显示(对应图形界面中的 hl.fl)solrQuery.addHighlightField("description");//执行查询 参数1:到“books”索引库查询 , 参数2:查询的条件QueryResponse response = solrClient.query("books", solrQuery);//获取查询后返回的文档列表SolrDocumentList docLists = response.getResults();//获取高亮信息//该Map的key就是文档的idMap<String, Map<String, List<String>>> high = response.getHighlighting();//创建一个集合,用来存放封装了高亮信息的Book对象List<Book> bookList = new ArrayList<>();for (SolrDocument doc : docLists){//此处就要将 SolrDocument 文档中的信息提取出来,封装到 Book 对象中String id = (String) doc.getFieldValue("id");String title = (String) doc.getFieldValue("title_cn");String description = (String) doc.getFieldValue("description");double price = (Float) doc.getFieldValue("price");//获取高亮后的字段值//通过文档的id,获取该文档的高亮信息Map<String, List<String>> highLightDoc = high.get(id);//再通过description这个key获取对应的value值(List类型)List<String> stringList = highLightDoc.get("description");//因为该list集合中只有一个元素,所以只获取第一个元素即可String highLightDesc = stringList.get(0);//将从 SolrDocument 文档中取出的高亮信息再封装回Book对象就可以了//这里是把 highLightDesc 作为 description 这个属性的值封装进去,其实不太好。//Book book = new Book(Integer.parseInt(id),title,highLightDesc,price);//假如我不希望改变Book对象的属性值,但是又希望能将高亮的信息传出去,因此可以考虑为Book对象增加一个Map类型的属性,该属性用于保存高亮信息Book book = new Book(Integer.parseInt(id),title,description,price);//把该id的文档的高亮信息设置到这个字段里面book.setHighLight(highLightDoc);bookList.add(book);}return bookList;}
}application.properties 配置文件
# 现在演示的是单机模式,所以先指定这个host
spring.data.solr.host=http://127.0.0.1:8983/solr
# 连接 Solr 索引库的用户名和密码(就是Solr的图形界面)
spring.data.solr.username=root
spring.data.solr.password=123456# 日志级别,可以用来看sql具体的执行语句
logging.level.org.springframework.data.solr=debugBookDaoTest 基于DAO组件测试
package cn.ljh.solrboot;import cn.ljh.solrboot.dao.BookDao;
import cn.ljh.solrboot.domain.Book;
import lombok.SneakyThrows;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.solr.repository.Query;import java.util.List;/*** author JH 2024-02*/@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class BookDaoTest
{//依赖注入@Autowiredprivate BookDao bookDao;//添加文档到books索引库的测试类@ParameterizedTest//这些参数相当于一个个文档@CsvSource({"1,火影忍者,讲述鸣人成为村长的事情,200","2,七龙珠,讲述赛亚人的成长故事,300","3,家庭教师A,讲述废材纲成为第十代首领的热血故事A,400","4,家庭教师B,讲述废材纲成为第十代首领的热血故事B,500"})public void testSave(Integer id, String title, String description, Double price){Book book = new Book(id, title, description, price);//使用bookDao来保存数据对象时,无需如之前一样指定索引库的名称,//因为Book类上面有@SolrDocument(collection = "books")修饰,已经指定了该数据类所映射的索引库bookDao.save(book);}//根据 title_cn 字段是否包含关键字来查询@ParameterizedTest//测试时只需要一个参数用这个注解@ValueSource(strings = {"龙珠","家庭"})public void testFindByTitle(String term){//查询List<Book> books = bookDao.findByTitle(term);//打印books.forEach(System.err::println);}//查询指定价格范围的文档@ParameterizedTest//测试时需要多个参数用这个注解,多个参数在一个双引号里面用逗号隔开@CsvSource({"100,200","200,300"})public void testFindByPriceBetween(Double start , Double end){List<Book> books = bookDao.findByPriceBetween(start, end);books.forEach(System.err::println);}//查询Description 字段中包含关键词的文档(Matches 需要正则表达式)@ParameterizedTest//正则表达式必须放在两个斜杠//里面, . 这个点表示匹配任意字符 , + 号表示出现 1 到多次@ValueSource(strings = {"/故.+/","/热.+/"})public void testFindByDescriptionMatches(String descPattern){List<Book> books = bookDao.findByDescriptionMatches(descPattern);books.forEach(System.err::println);}//查询集合中的这些id的文档@ParameterizedTest@CsvSource({"1,2","1,3"})public void testFindByIdIn(Integer id1 , Integer id2){List<Integer> ids = List.of(id1, id2);List<Book> books = bookDao.findByIdIn(ids);books.forEach(System.err::println);}//@Query查询(自定义的半自动查询)------------------------------------------------------@ParameterizedTest@CsvSource({"title_cn,家庭","description,故事*"})public void testFindByQuery(String field, String term){List<Book> books = bookDao.findByQuery(field, term);books.forEach(System.err::println);}//自定义查询方法且高亮显示@ParameterizedTest@ValueSource(strings = {"热*","村*"})public void testHighLightFindByDescription(String term){List<Book> books = bookDao.highLightFindByDescription(term);books.forEach(System.err::println);}}SolrClientTest 基于SolrClient测试
package cn.ljh.solrboot;import cn.ljh.solrboot.domain.Book;
import lombok.SneakyThrows;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.params.SolrParams;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;// SpringBootTest.WebEnvironment.NONE: 指定测试的web环境为非Web环境。
// 通常情况下,我们会将该参数设置为NONE,表示不需要启动内嵌的Web容器,从而更加快速地执行测试
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class SolrClientTest
{@Autowiredprivate SolrClient solrClient;//添加文档到books索引库的测试类@SneakyThrows@ParameterizedTest//这些参数相当于一个个文档@CsvSource({"1,火影忍者,讲述成为村长的故事,200","2,七龙珠,讲述赛亚人的成长故事,300","3,家庭教师,讲述废材纲成为第十代首领的热血故事,400"})public void testSave(Integer id, String title, String description, Double price){Book book = new Book(id, title, description, price);//向 books 逻辑索引库添加文档 ; 参数1:索引库的名字 , 参数2:映射文档的实体对象 ,参数3 :500 毫秒的提交时间solrClient.addBean("books", book, 500);}//查询索引库中的文档的测试类@SneakyThrows@ParameterizedTest//这个注解用来进行多次测试,一个字符串代表一次测试方法。@CsvSource({"title_cn,忍者","description,成为","description,成*"})//参数1:要查询的字段 参数2:要查询的关键词public void testQuery(String field, String term){//创建查询,表明在 field 字段中查询 term 关键字SolrParams params = new SolrQuery(field + ":" + term);//执行查询操作,去 books 这个索引库里面查询,得到响应QueryResponse queryResponse = solrClient.query("books", params);//返回所得到的文档SolrDocumentList docList = queryResponse.getResults();//遍历所有的文档for (SolrDocument doc : docList){System.err.println("获取所有 field 的名字:" + doc.getFieldNames());//遍历文档中的每个字段名for (String fn : doc.getFieldNames()){//通过字段名获取字段值System.err.println("filed名称:【 " + fn + " 】,field 的值:【" + doc.getFieldValue(fn) + " 】");}}}//根据文档的id来删除文档@SneakyThrows@ParameterizedTest@ValueSource(strings = {"1"})public void testDeleteById(String id){//根据文档的id来删除//参数1:指定删除哪个索引库的文档 参数2:删除这个id的文档 参数3:指定多久提交执行这个删除操作,这里是500毫秒solrClient.deleteById("books",id,500);}//根据提供的字段和关键词,通过查询,如果该字段包含该关键词,则该文档会被删除掉@SneakyThrows@ParameterizedTest@CsvSource({//"title_cn,龙珠"//匹配所有的文档,也就是删除所有文档"*,*"})//这个字段包含这个关键词的则会被删除掉public void testDeleteByQuery(String field, String term){//因为 参数2 需要的类型是String,所以这里不用创建SolrQuery查询对象//str 打印出来 ===> q=title_cn:龙珠String str = field + ":" + term;//参数1:指定删除哪个索引库的文档 参数2:字段名+关键词 参数3:指定多久提交执行这个删除操作,这里是500毫秒solrClient.deleteByQuery("books",str,500);}}pom.xml 依赖文档
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.4.5</version></parent><groupId>cn.ljh</groupId><artifactId>solrboot</artifactId><version>1.0.0</version><name>solrboot</name><properties><java.version>11</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!-- 最基础的Spring Boot Starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- SpringBoot 2.5.3 不再为 Spring Data Solr 提供 Starter,因此只能手动添加 Spring Data Solr 依赖 --><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-solr</artifactId><version>4.3.11</version></dependency><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId><version>1.9</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>相关文章:
09、全文检索 -- Solr -- SpringBoot 整合 Spring Data Solr (生成DAO组件 和 实现自定义查询方法)
目录 SpringBoot 整合 Spring Data SolrSpring Data Solr的功能(生成DAO组件):Spring Data Solr大致包括如下几方面功能:Query查询(属于半自动)代码演示:1、演示通过dao组件来保存文档1、实体类…...

C# CAD SelectionFilter下TypedValue数组
SelectionFilter是用于过滤AutoCAD实体的类,在AutoCAD中,可以使用它来选择具有特定属性的实体。构造SelectionFilter对象时,需要传入一个TypedValue数组,它用于定义选择规则。 在TypedValue数组中,每个元素表示一个选…...

python 爬虫篇(3)---->Beautiful Soup 网页解析库的使用(包含实例代码)
Beautiful Soup 网页解析库的使用 文章目录 Beautiful Soup 网页解析库的使用前言一、安装Beautiful Soup 和 lxml二、Beautiful Soup基本使用方法标签选择器1 .string --获取文本内容2 .name --获取标签本身名称3 .attrs[] --通过属性拿属性的值标准选择器find_all( name , at…...

第十二周学习报告
比赛 参加了一场 div 2 ,B 题,C 题没写出来,B 是一个排序去重+双指针,C题是要观察出一个数学结论(因为数据范围太大,我暴力做直接超时了) 排 6253 ,表现分是 998 &…...

Redis面试题整理(持续更新)
1. 缓存穿透? 缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致DB挂掉,这种情况大概率是遭到了攻击。 解决方案: …...
一周学会Django5 Python Web开发-Django5 Hello World编写
锋哥原创的Python Web开发 Django5视频教程: 2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 Django5 Python web开发 视频教程(无废话版) 玩命更新中~共计14条视频,包括:2024版 Django5 Python we…...
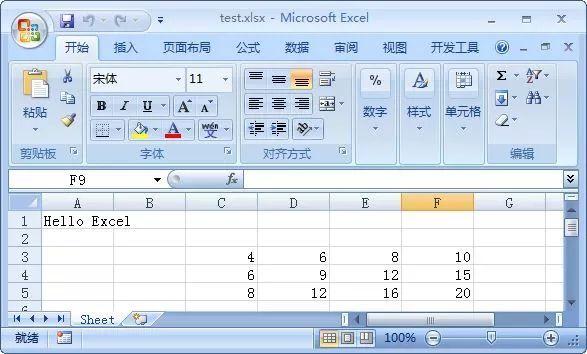
讲解用Python处理Excel表格
我们今天来一起探索一下用Python怎么操作Excel文件。与word文件的操作库python-docx类似,Python也有专门的库为Excel文件的操作提供支持,这些库包括xlrd、xlwt、xlutils、openpyxl、xlsxwriter几种,其中我最喜欢用的是openpyxl,这…...

WEB APIs(1)
变量声明const(修饰常量) const优先,如react,基本const, 对于引用数据类型,可用const声明,因为储存的是地址 何为APIs 可以使用js操作HTML和浏览器 分类:DOM(文档对象…...

C++重新入门-基本输入输出
C 的 I/O 发生在流中,流是字节序列。如果字节流是从设备(如键盘、磁盘驱动器、网络连接等)流向内存,这叫做输入操作。如果字节流是从内存流向设备(如显示屏、打印机、磁盘驱动器、网络连接等),这…...

【C语言】解析刘谦春晚魔术《守岁共此时》
今年的春晚上刘谦表演了魔术《守岁共此时》,台上台下积极互动(尤其是小尼),十分的有趣。刘谦老师的魔术不仅仅是他的高超手法,还有这背后的严谨逻辑,下面我们来用C语言来解析魔术吧。 源代码 #define _CRT…...

剑指offer——数值的整数次方
目录 1. 题目描述2. 一般思路2.1 有问题的思路2.2 全面但不高效的思路2.3 面试小提示 3. 全面又高效的思路 1. 题目描述 题目:实现函数 double Power(double base,int exponent),求base 的exponent 次方。不得使用库函数,同时不需要考虑大数问题 2. 一般…...

Tied Block Convolution: 具有共享较薄滤波器的更简洁、更出色的CNN
摘要 https://arxiv.org/pdf/2009.12021.pdf 卷积是卷积神经网络(CNN)的主要构建块。我们观察到,随着通道数的增加,优化后的CNN通常具有高度相关的滤波器,这降低了特征表示的表达力。我们提出了Tied Block Convolutio…...
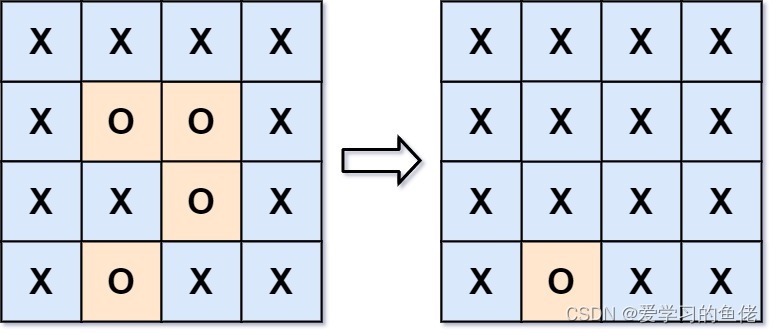
算法沉淀——BFS 解决 FloodFill 算法(leetcode真题剖析)
算法沉淀——BFS 解决 FloodFill 算法 01.图像渲染02.岛屿数量03.岛屿的最大面积04.被围绕的区域 BFS(广度优先搜索)解决 Flood Fill 算法的基本思想是通过从起始点开始,逐层向外扩展,访问所有与起始点相连且具有相同特性…...
wordpress外贸成品网站模板
首页大图slider轮播,橙色风格的wordpress外贸网站模板 https://www.zhanyes.com/waimao/6250.html 蓝色经典风格的wordpress外贸建站模板 https://www.zhanyes.com/waimao/6263.html...
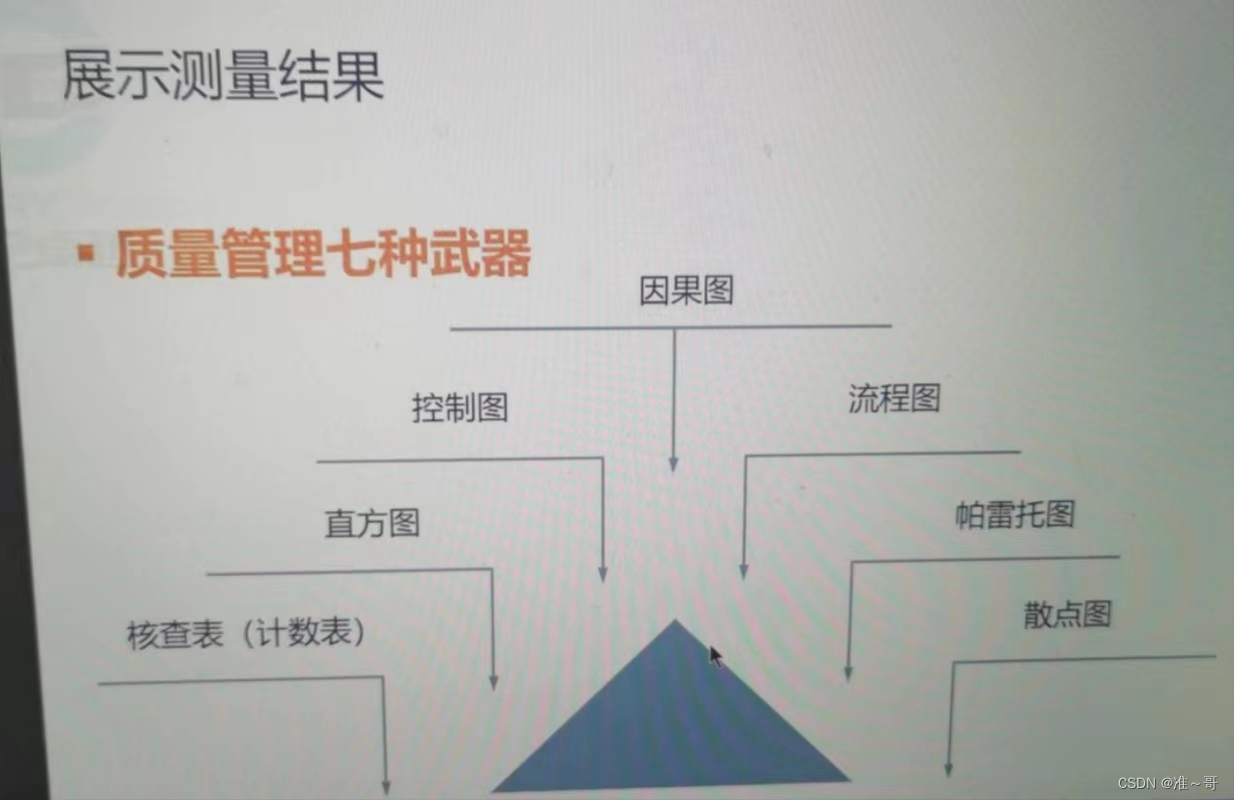
如何使用六图一表七种武器
六图一表七种武器用于质量管理: 描述当遇到问题时应该用那张图来解决: 一、如果题目说出了质量问题需要找原因? 解:用因果图,因果图也称石川图或鱼骨图 二、如果要判断过程是否稳定受控? 解:…...

阿里云游戏服务器租用费用价格组成,费用详单
阿里云游戏服务器租用价格表:4核16G服务器26元1个月、146元半年,游戏专业服务器8核32G配置90元一个月、271元3个月,阿里云服务器网aliyunfuwuqi.com分享阿里云游戏专用服务器详细配置和精准报价: 阿里云游戏服务器租用价格表 阿…...
【C++】C++11上
C11上 1.C11简介2.统一的列表初始化2.1 {} 初始化2.2 initializer_list 3.变量类型推导3.1auto3.2decltype3.3nullptr 4.范围for循环5.final与override6.智能指针7. STL中一些变化8.右值引用和移动语义8.1左值引用和右值引用8.2左值引用与右值引用比较8.3右值引用使用场景和意义…...

【前端高频面试题--git篇】
🚀 作者 :“码上有前” 🚀 文章简介 :前端高频面试题 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 前端高频面试题--git篇 往期精彩内容常用命令git add 和 git stage 有什么区别怎么使用git连接…...

c++创建对象
c创建对象 1.声明一个对象,然后使用默认构造函数来创建对象: class MyClass { public:MyClass() {// 构造函数代码} };int main() {MyClass obj; // 声明并创建一个对象return 0; }2.使用new和指针动态创建对象:不会自动释放 使用 new 运算…...

软件实例分享,洗车店系统管理软件会员卡电子系统教程
软件实例分享,洗车店系统管理软件会员卡电子系统教程 一、前言 以下软件教程以 佳易王洗车店会员管理软件V16.0为例说明 软件文件下载可以点击最下方官网卡片——软件下载——试用版软件下载 1、会员卡号可以绑定车牌号或手机号 2、卡号也可以直接使用手机号&a…...

从七鳃鳗到潜水器:手把手教你用Python生态学模型搞定2024美赛A、B题
从七鳃鳗到潜水器:Python生态学建模实战指南 数学建模竞赛中,生态学问题往往让参赛者望而生畏——复杂的生物系统、多变的环境参数、非线性相互作用,这些要素叠加起来容易让人陷入理论推导的泥潭。但换个角度看,这正是Python科学计…...

Wan2.2-I2V-A14B镜像效果展示:夕阳海滩10秒1080P高清视频生成作品集
Wan2.2-I2V-A14B镜像效果展示:夕阳海滩10秒1080P高清视频生成作品集 1. 惊艳的视频生成效果 想象一下,只需简单描述,就能让电脑自动生成一段夕阳下的海滩视频。Wan2.2-I2V-A14B镜像让这个想象成为现实,它能将文字描述转化为高清…...

PyTorch内存优化实战:深入解析torch.utils.checkpoint的机制与应用
1. 为什么我们需要torch.utils.checkpoint? 第一次用PyTorch训练ResNet50时,我的16GB显存直接被撑爆了。当时怎么都想不明白——明明batch_size只设了32,怎么连这种经典模型都跑不动?后来才发现,问题出在前向传播时PyT…...
)
【限时开源】某金融级TCC事务中间件核心模块源码解析(含TCC-Coordinator状态机设计文档V2.3)
第一章:【限时开源】某金融级TCC事务中间件核心模块源码解析(含TCC-Coordinator状态机设计文档V2.3)本章聚焦于已开源的金融级TCC事务中间件核心协调器(TCC-Coordinator)的实现细节,重点剖析其高可用状态机…...

频繁冲突?数据静默损坏?Obsidian + 坚果云插件打造工业级笔记同步与容灾方案
在个人知识管理(PKM)领域,有一条铁律:比“从未备份”更可怕的,是“错误的同步导致的静默覆盖”。 对于 Obsidian 重度用户而言,几千篇 Markdown 笔记是毕生心血。当你兴冲冲地在手机、iPad 和公司电脑之间…...

创新实训第一周总结
第一周工作产出较少,作为患者端的开发者,为了保证数据库不出现重合或冲突等原因,我等待医生端和管理员端的开发初步完成后再进行的开发。第一篇博客的技术性会较低想到什么说什么本周的工作主要以分析为主首先分析了数据库的结构(…...

GLM-4-9B-Chat-1M惊艳效果:复杂SQL代码库跨文件依赖关系可视化
GLM-4-9B-Chat-1M惊艳效果:复杂SQL代码库跨文件依赖关系可视化 1. 项目背景与核心价值 当你面对一个包含数百个SQL文件的大型数据仓库项目时,最头疼的问题是什么?我相信很多开发者和数据工程师都会说:理不清的表依赖关系。 传统…...

别只盯着Web日志!一次Windows服务器被黑,我是这样用系统日志和FTP记录挖出攻击链的
从Windows系统日志到FTP记录:一次完整的服务器入侵溯源实战 深夜的应急响应中心,刺眼的告警提示打破了宁静。大多数安全工程师的第一反应是打开Web访问日志开始排查——这几乎成了行业条件反射。但真实攻击往往发生在你最意想不到的角落。上周处理的一起…...

从YOLO到A*:手把手教你用PyTorch和OpenCV搭建一个简易的自动驾驶避障仿真器
从YOLO到A*:用PyTorch和OpenCV构建自动驾驶避障仿真器 想象一下,你正坐在一辆自动驾驶汽车里,车辆能够自动识别前方的行人、车辆和障碍物,并规划出安全的行驶路径。这种看似科幻的场景,如今正逐渐成为现实。本文将带你…...

这个网站,我愿称之为生信云平台天花板
刚入门生信的你,是否也曾被这些问题折磨得想摔键盘?• Linux 环境配置:conda install 报错到怀疑人生,环境冲突让你原地崩溃。• 硬件瓶颈: 实验室服务器要排队,自己的轻薄本跑个比对就能当暖气片。• 代码…...