python:xml.etree,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录
请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad++ 转换编码。
xml 是 python 标准库,在 D:\Python39\Lib\xml\etree
pip install xmltodict ;
python 用 xml.etree.ElementTree,用 xmltodict 转换为json数据。
编写 txt_xml_etree_json.py 如下
# -*- coding: utf-8 -*-
""" 读目录.txt文件,用 xmltodict转换为json数据 """
import os
import sys
import codecs
import json
import xml.etree.ElementTree as et
import xmltodictif len(sys.argv) ==2:f1 = sys.argv[1]
else:print('usage: python txt_xml_etree_json.py file1.txt')sys.exit(1)if not os.path.exists(f1):print(f"ERROR: {f1} not found.")sys.exit(1)fn,ext = os.path.splitext(f1)
if ext.lower() != '.txt':print('ext is not .txt')sys.exit(2)fp = codecs.open(f1, mode="r", encoding="utf-8")
# 读取第一行:书名
title = fp.readline()
# 创建主题节点
root = et.Element("node")
root.set("id", '1')
root.set("text", title.strip())# 定义状态:
state = et.SubElement(root, "state")
state.set("opened", 'true')
state.set("disabled", 'true')# 用缩排表现层级关系,假设最多5个层级
indent1 = ' '*2
indent2 = ' '*4
indent3 = ' '*6
indent4 = ' '*8n = 2
for line in fp:txt = line.strip()if len(txt) ==0:continuetxt = txt[0:-3] # 去掉行尾的页数if len(txt) >0 and line[0] !=' ':# 创建主题的子节点(1级节点)node1 = et.SubElement(root, "children")node1.set("id", str(n))node1.set("text", txt)p_node = node1 # 寄存父节点elif line.startswith(indent1) and line[2] !=' ':# 创建node1的子节点(2级节点)try: type(node1)except NameError: node2 = et.SubElement(root, "children")else: node2 = et.SubElement(node1, "children")node2.set("id", str(n))node2.set("text", txt)p_node = node2elif line.startswith(indent2) and line[4] !=' ':# 创建node2的子节点(3级节点)try: type(node2)except NameError: node3 = et.SubElement(node1, "children")else: node3 = et.SubElement(node2, "children")node3.set("id", str(n))node3.set("text", txt)p_node = node3elif line.startswith(indent3) and line[6] !=' ':# 创建node3的子节点(4级节点)try: type(node3)except NameError: node4 = et.SubElement(node2, "children")else: node4 = et.SubElement(node3, "children")node4.set("id", str(n))node4.set("text", txt)p_node = node4elif line.startswith(indent4) and line[8] !=' ':# 创建node4的子节点(5级节点)try: type(node4)except NameError: node5 = et.SubElement(p_node, "children")else: node5 = et.SubElement(node4, "children")node5.set("id", str(n))node5.set("text", txt)else:print(txt)n += 1
fp.close()
print(f"line number: {n}")# 转换成 str,方便导出
root_bytes = et.tostring(root, encoding="utf-8")
xml_str = root_bytes.decode()
try:json_dict = xmltodict.parse(xml_str, encoding='utf-8')json_str = json.dumps(json_dict['node'], indent=2)
except:print("xmltodict.parse error!")
# 去掉'@'
json_str = '['+ json_str.replace('\"@','"') +']'
#print(json_str)# 导出.json文件
f2 = fn +'.json'
with codecs.open(f2, 'w', encoding='utf8') as fp:fp.write(json_str)
python 用 xml.etree.ElementTree,用 xmltodict 转换为json数据,jinja2 生成jstree模板所需的文件。
编写 txt_xml_etree_htm.py 如下
# -*- coding: utf-8 -*-
""" 读目录.txt文件,用 xmltodict转换为json数据,生成jstree所需的文件 """
import os
import sys
import codecs
import json
import xml.etree.ElementTree as et
import xmltodict
from jinja2 import Environment,FileSystemLoaderif len(sys.argv) ==2:f1 = sys.argv[1]
else:print('usage: python txt_xml_etree_htm.py file1.txt')sys.exit(1)if not os.path.exists(f1):print(f"ERROR: {f1} not found.")sys.exit(1)fn,ext = os.path.splitext(f1)
if ext.lower() != '.txt':print('ext is not .txt')sys.exit(2)fp = codecs.open(f1, mode="r", encoding="utf-8")
# 读取第一行:书名
title = fp.readline()
# 创建主题节点
root = et.Element("node")
root.set("id", '1')
root.set("text", title.strip())# 定义状态:
state = et.SubElement(root, "state")
state.set("opened", 'true')
state.set("disabled", 'true')# 用缩排表现层级关系,假设最多5个层级
indent1 = ' '*2
indent2 = ' '*4
indent3 = ' '*6
indent4 = ' '*8n = 2
for line in fp:txt = line.strip()if len(txt) ==0:continuetxt = txt[0:-3] # 去掉行尾的页数if len(txt) >0 and line[0] !=' ':# 创建主题的子节点(1级节点)node1 = et.SubElement(root, "children")node1.set("id", str(n))node1.set("text", txt)p_node = node1 # 寄存父节点elif line.startswith(indent1) and line[2] !=' ':# 创建node1的子节点(2级节点)try: type(node1)except NameError: node2 = et.SubElement(root, "children")else: node2 = et.SubElement(node1, "children")node2.set("id", str(n))node2.set("text", txt)p_node = node2elif line.startswith(indent2) and line[4] !=' ':# 创建node2的子节点(3级节点)try: type(node2)except NameError: node3 = et.SubElement(node1, "children")else: node3 = et.SubElement(node2, "children")node3.set("id", str(n))node3.set("text", txt)p_node = node3elif line.startswith(indent3) and line[6] !=' ':# 创建node3的子节点(4级节点)try: type(node3)except NameError: node4 = et.SubElement(node2, "children")else: node4 = et.SubElement(node3, "children")node4.set("id", str(n))node4.set("text", txt)p_node = node4elif line.startswith(indent4) and line[8] !=' ':# 创建node4的子节点(5级节点)try: type(node4)except NameError: node5 = et.SubElement(p_node, "children")else: node5 = et.SubElement(node4, "children")node5.set("id", str(n))node5.set("text", txt)else:print(txt)n += 1
fp.close()
print(f"line number: {n}")# 转换成 str,方便导出
root_bytes = et.tostring(root, encoding="utf-8")
xml_str = root_bytes.decode()
try:json_dict = xmltodict.parse(xml_str, encoding='utf-8')json_str = json.dumps(json_dict['node'], indent=2)
except:print("xmltodict.parse error!")
# 去掉'@'
json_str = '['+ json_str.replace('\"@','"') +']'
#print(json_str)# 使用 jinja2 对html模板文件进行数据替换
env = Environment(loader=FileSystemLoader('d:/python/'))
tpl = env.get_template('jstree_template.htm')
# 导出.html文件
f2 = fn +'.htm'
with codecs.open(f2, 'w', encoding='utf8') as fp:content = tpl.render(title=title.strip(), mydir=json_str)fp.write(content)
https://gitee.com/ 搜索 jstree 下载
https://gitee.com/mirrors/jstree?_from=gitee_search
git clone https://gitee.com/mirrors/jstree.git
编写 jstree 模板文件:jstree_template.htm
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=Edge"><meta name="viewport" content="width=device-width, initial-scale=1"><title>{{title}}</title><script src="../js/jquery-3.2.1.min.js"></script><link rel="stylesheet" href="../js/jstree/dist/themes/default/style.css" /><script src="../js/jstree/dist/jstree.min.js"></script>
</head>
<body><!-- 搜索框 --><div class="search_input"><input type="text" id="search_a" /><img src="../js/jstree/dist/search.png" /></div><div id="treeview1" class="treeview"></div>
<script type="text/javascript">var mydir = {{mydir}};$("#treeview1").jstree({'core' : {"multiple" : false,'data' : mydir,'dblclick_toggle': true},"plugins" : ["search"]});//输入框输入时自动搜索var tout = false;$('#search_a').keyup(function(){if (tout) clearTimeout(tout); tout = setTimeout(function(){$('#treeview1').jstree(true).search($('#search_a').val()); }, 250);});
</script>
</body>
</html>
运行 python txt_xml_etree_htm.py your_pdf_dir.txt
生成 your_pdf_dir.htm
相关文章:

python:xml.etree,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad 转换编码。 xml 是 python 标准库,在 D:\Python39\Lib\xml\etree pip install …...
)
C#log4net日志保存到Sqlserver数据库表(16)
要将log4net的日志保存到SQL Server数据库表中,你需要配置log4net使用一个数据库追加器(appender),通常是AdoNetAppender。以下是一个示例配置,展示如何将log4net的日志输出配置为写入SQL Server数据库表。 首先&…...
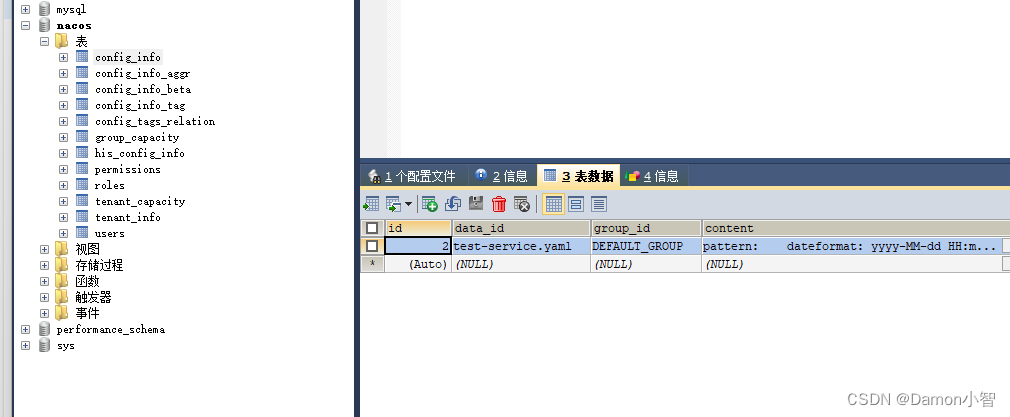
SpringCloud-Nacos集群搭建
本文详细介绍了如何在SpringCloud环境中搭建Nacos集群,为读者提供了一份清晰而详尽的指南。通过逐步演示每个关键步骤,包括安装、配置以及Nginx的负载均衡设置,读者能够轻松理解并操作整个搭建过程。 一、Nacos集群示意图 Nacos࿰…...
软件测试组竞赛规则及说明)
第十五届蓝桥杯全国软件和信息技术专业人才大赛个人赛(软件赛)软件测试组竞赛规则及说明
第十五届蓝桥杯全国软件和信息技术专业人才大赛个人赛 (软件赛)软件测试组竞赛规则及说明 目录...
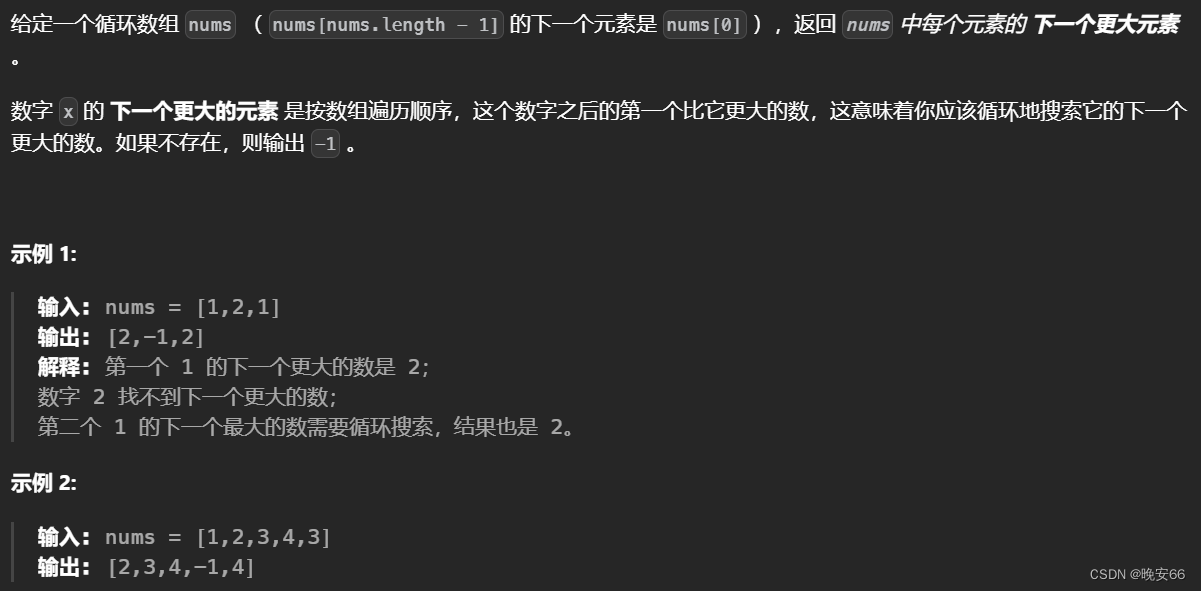
【算法与数据结构】496、503、LeetCode下一个更大元素I II
文章目录 一、496、下一个更大元素 I二、503、下一个更大元素II三、完整代码 所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。 一、496、下一个更大元素 I 思路分析:本题思路和【算法与数据结构】739、LeetCode每日温度类似…...

当AGI遇到人形机器人
为什么人类对人形机器人抱有执念 人形机器人是一种模仿人类外形和行为的机器人,它的研究和开发有着多方面的目的和意义。 人形机器人可以更好地适应人类的环境和工具。人类的生活和工作空间都是根据人的尺寸和动作来设计的,例如门、楼梯、桌椅、开关等…...
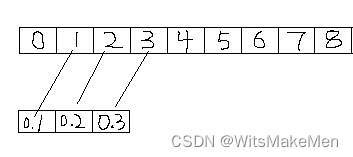
Pytorch卷积层原理和示例 nn.Conv1d卷积 nn.Conv2d卷积
内容列表 一,前提 二,卷积层原理 1.概念 2.作用 3. 卷积过程 三,nn.conv1d 1,函数定义: 2, 参数说明: 3,代码: 4, 分析计算过程 四,nn.conv2d 1, 函数定义 2, 参数: 3, 代码 4, 分析计算过程 …...

Qt 实现无边框窗口1.0
目录 项目需求: 1、没有边框; 2、点击windows系统的状态栏的程序运行图标可实现最大最小化; 3、可以移动窗口; 项目实现: 1、实现 无边框 2、实现 点击windows系统的状态栏的程序运行图标可实现最大最小化 3、实现 窗…...

Flume(二)【Flume 进阶使用】
前言 学数仓的时候发现 flume 落了一点,赶紧补齐。 1、Flume 事务 Source 在往 Channel 发送数据之前会开启一个 Put 事务: doPut:将批量数据写入临时缓冲区 putList(当 source 中的数据达到 batchsize 或者 超过特定的时间就会…...
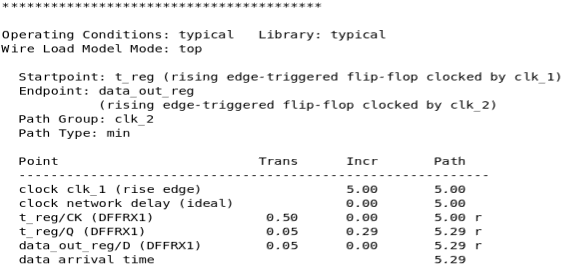
静态时序分析:SDC约束命令set_clock_transition详解
相关阅读 静态时序分析https://blog.csdn.net/weixin_45791458/category_12567571.html?spm1001.2014.3001.5482 在静态时序分析:SDC约束命令create_clock详解一文的最后,我们谈到了针对理想(ideal)时钟,可以使用set_clock_transition命令直…...
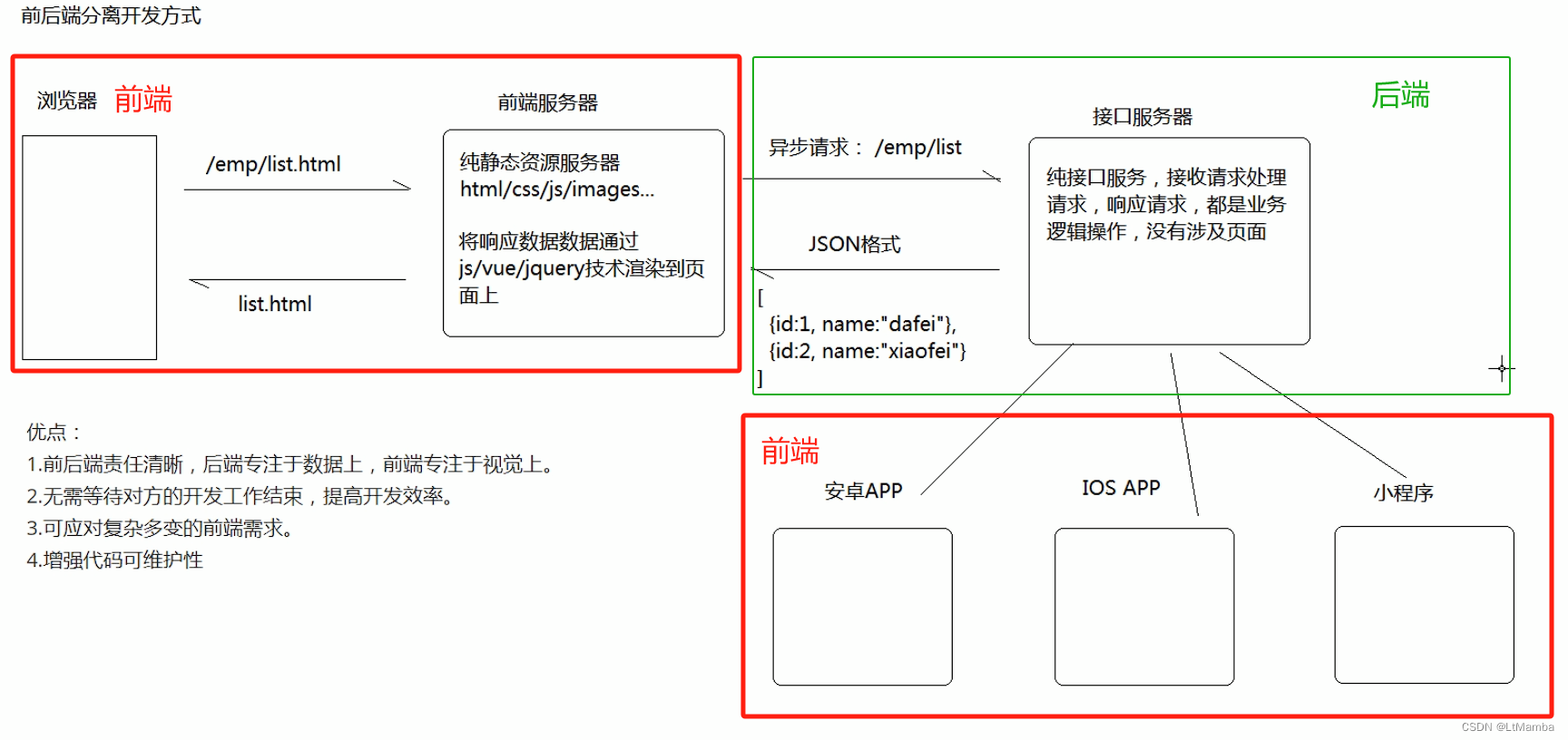
web 发展阶段 -- 详解
1. web 发展阶段 当前处于 移动 web 应用阶段。也是个风口(当然是针对有能力创业的人来说的),如 抖音、快手就是这个时代的产物。 2. web 发展阶段引出前后端分离的过程 2.1 传统开发方式 2.2 前后端分离模式 衍生自移动 web 应用阶段。 3.…...

车载软件架构 —— Adaptive AUTOSAR软件架构中操作系统
车载软件架构 —— Adaptive AUTOSAR软件架构中操作系统 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师(Wechat:gongkenan2013)。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师&…...

前缀和算法-截断数组
5057. 截断数组 - AcWing题库 给定一个长度为 n 的正整数数组 a1,a2,…,an 和一个正整数 p。 现在,要将该数组从中间截断,得到两个非空子数组。 我们规定,一个数组的价值等于数组内所有元素之和模 p 的结果。 我们希望,将给定数组…...

Kubernetes实战:Kubernetes中网络插件calico Daemon Sets显示异常红色
目录 一、排查步骤与解决方案1.1、POD排查问题定位1.2、针对问题解决错误1.3、继续针对问题解决错误 一、排查步骤与解决方案 1.1、POD排查问题定位 我的k8s集群由3个节点组成的,calico在每个节点上都有一个pod,通过kubectl get pod -A命令发现有一个pod的READY 为…...

深入探究:JSONCPP库的使用与原理解析
君子不器 🚀JsonCPP开源项目直达链接 文章目录 简介Json示例小结 JsoncppJson::Value序列化Json::Writer 类Json::FastWriter 类Json::StyledWriter 类Json::StreamWriter 类Json::StreamWriterBuilder 类示例 反序列化Json::Reader 类Json::CharReader 类Json::Ch…...

字节UC伯克利新研究 | Magic-Me:简单有效的主题ID可控视频生成框架
在生成模型领域,针对特定身份(ID)创建内容已经引起了极大的兴趣。在文本到图像生成(T2I)领域,以主题驱动的内容生成已经取得了巨大的进展,使图像中的ID可控。然而,将其扩展到视频生成…...

2024免费人像摄影后期处理工具Portraiture4.1
Portraiture作为一款智能磨皮插件,确实为Photoshop和Lightroom用户带来了极大的便利。通过其先进的人工智能算法,它能够自动识别并处理照片中的人物皮肤、头发和眉毛等部位,实现一键式的磨皮美化效果,极大地简化了后期处理的过程。…...
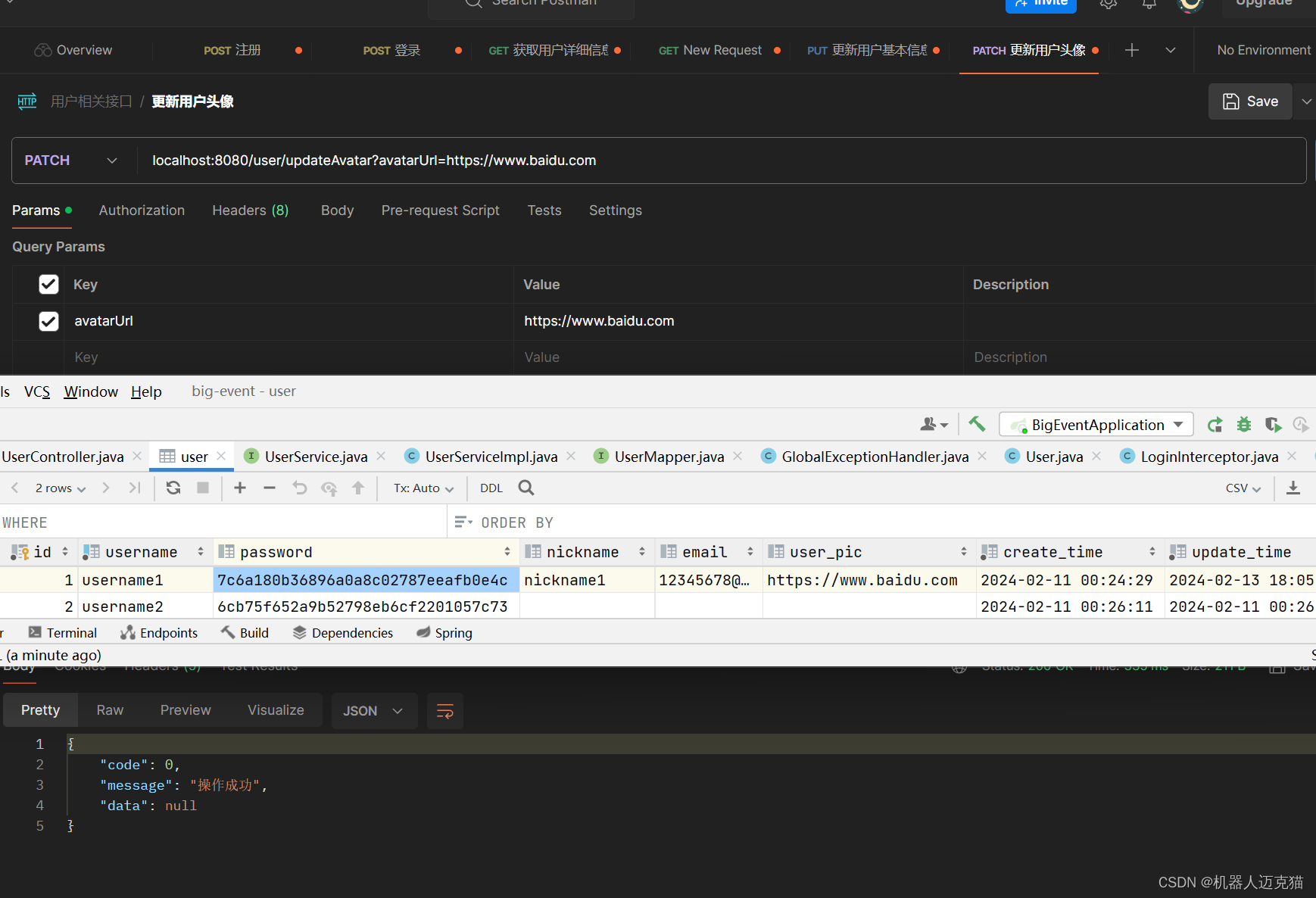
Spring Boot 笔记 010 创建接口_更新用户头像
1.1.1 usercontroller中添加updateAvatar,校验是否为url PatchMapping("updateAvatar")public Result updateAvatar(RequestParam URL String avatarUrl) {userService.updateAvatar(avatarUrl);return Result.success();} 1.1.2 userservice //更新头像…...

认识并使用HttpLoggingInterceptor
目录 一、前情回顾二、HttpLoggingInterceptor1、HttpLoggingInterceptor拦截器是做什么的?2、如何使用HttpLoggingInterceptor?2.1 日志级别2.2 如何看日志?2.2.1 日志级别:BODY2.2.2 日志级别:BASIC2.2.3 日志级别&a…...
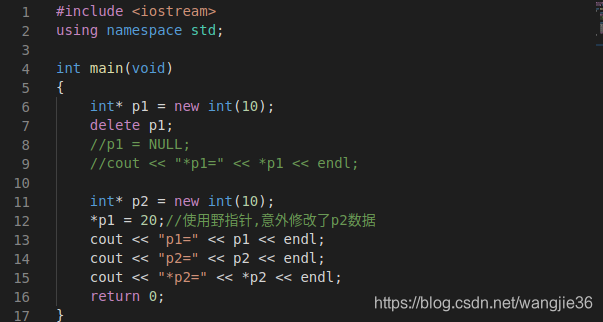
内存块与内存池
(1)在运行过程中,MemoryPool内存池可能会有多个用来满足内存申请请求的内存块,这些内存块是从进程堆中开辟的一个较大的连续内存区域,它由一个MemoryBlock结构体和多个可供分配的内存单元组成,所有内存块组…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...