精读《Function Component 入门》
1. 引言
如果你在使用 React 16,可以尝试 Function Component 风格,享受更大的灵活性。但在尝试之前,最好先阅读本文,对 Function Component 的思维模式有一个初步认识,防止因思维模式不同步造成的困扰。
2. 精读
什么是 Function Component?
Function Component 就是以 Function 的形式创建的 React 组件:
function App() {return (<div><p>App</p></div>);
}
也就是,一个返回了 JSX 或 createElement 的 Function 就可以当作 React 组件,这种形式的组件就是 Function Component。
所以我已经学会 Function Component 了吗?
别急,故事才刚刚开始。
什么是 Hooks?
Hooks 是辅助 Function Component 的工具。比如 useState 就是一种 Hook,它可以用来管理状态:
function Counter() {const [count, setCount] = useState(0);return (<div><p>You clicked {count} times</p><button onClick={() => setCount(count + 1)}>Click me</button></div>);
}
useState 返回的结果是数组,数组的第一项是 值,第二项是 赋值函数,useState 函数的第一个参数就是 默认值,也支持回调函数。更详细的介绍可以参考 Hooks 规则解读。
先赋值再 setTimeout 打印
我们再将 useState 与 setTimeout 结合使用,看看有什么发现。
创建一个按钮,点击后让计数器自增,但是延时 3 秒后再打印出来:
function Counter() {const [count, setCount] = useState(0);const log = () => {setCount(count + 1);setTimeout(() => {console.log(count);}, 3000);};return (<div><p>You clicked {count} times</p><button onClick={log}>Click me</button></div>);
}
如果我们 在三秒内连续点击三次,那么 count 的值最终会变成 3,而随之而来的输出结果是。。?
0
1
2
嗯,好像对,但总觉得有点怪?
使用 Class Component 方式实现一遍呢?
敲黑板了,回到我们熟悉的 Class Component 模式,实现一遍上面的功能:
class Counter extends Component {state = { count: 0 };log = () => {this.setState({count: this.state.count + 1});setTimeout(() => {console.log(this.state.count);}, 3000);};render() {return (<div><p>You clicked {this.state.count} times</p><button onClick={this.log}>Click me</button></div>);}
}
嗯,结果应该等价吧?3 秒内快速点击三次按钮,这次的结果是:
3
3
3
怎么和 Function Component 结果不一样?
这是用好 Function Component 必须迈过的第一道坎,请确认完全理解下面这段话:
首先对 Class Component 进行解释:
- 首先 state 是 Immutable 的,
setState后一定会生成一个全新的 state 引用。 - 但 Class Component 通过
this.state方式读取 state,这导致了每次代码执行都会拿到最新的 state 引用,所以快速点击三次的结果是3 3 3。
那么对 Function Component 而言:
useState产生的数据也是 Immutable 的,通过数组第二个参数 Set 一个新值后,原来的值会形成一个新的引用在下次渲染时。- 但由于对 state 的读取没有通过
this.的方式,使得 每次setTimeout都读取了当时渲染闭包环境的数据,虽然最新的值跟着最新的渲染变了,但旧的渲染里,状态依然是旧值。
为了更容易理解,我们来模拟三次 Function Component 模式下点击按钮时的状态:
第一次点击,共渲染了 2 次,setTimeout 生效在第 1 次渲染,此时状态为:
function Counter() {const [0, setCount] = useState(0);const log = () => {setCount(0 + 1);setTimeout(() => {console.log(0);}, 3000);};return ...
}
第二次点击,共渲染了 3 次,setTimeout 生效在第 2 次渲染,此时状态为:
function Counter() {const [1, setCount] = useState(0);const log = () => {setCount(1 + 1);setTimeout(() => {console.log(1);}, 3000);};return ...
}
第三次点击,共渲染了 4 次,setTimeout 生效在第 3 次渲染,此时状态为:
function Counter() {const [2, setCount] = useState(0);const log = () => {setCount(2 + 1);setTimeout(() => {console.log(2);}, 3000);};return ...
}
可以看到,每一个渲染都是一个独立的闭包,在独立的三次渲染中,count 在每次渲染中的值分别是 0 1 2,所以无论 setTimeout 延时多久,打印出来的结果永远是 0 1 2。
理解了这一点,我们就能继续了。
如何让 Function Component 也打印 3 3 3?
所以这是不是代表 Function Component 无法覆盖 Class Component 的功能呢?完全不是,我希望你读完本文后,不仅能解决这个问题,更能理解为什么用 Function Component 实现的代码更佳合理、优雅。
第一种方案是借助一个新 Hook - useRef 的能力:
function Counter() {const count = useRef(0);const log = () => {count.current++;setTimeout(() => {console.log(count.current);}, 3000);};return (<div><p>You clicked {count.current} times</p><button onClick={log}>Click me</button></div>);
}
这种方案的打印结果就是 3 3 3。
想要理解为什么,首先要理解 useRef 的功能:通过 useRef 创建的对象,其值只有一份,而且在所有 Rerender 之间共享。
所以我们对 count.current 赋值或读取,读到的永远是其最新值,而与渲染闭包无关,因此如果快速点击三下,必定会返回 3 3 3 的结果。
但这种方案有个问题,就是使用 useRef 替代了 useState 创建值,那么很自然的问题就是,如何不改变原始值的写法,达到同样的效果呢?
如何不改造原始值也打印 3 3 3?
一种最简单的做法,就是新建一个 useRef 的值给 setTimeout 使用,而程序其余部分还是用原始的 count:
function Counter() {const [count, setCount] = useState(0);const currentCount = useRef(count);useEffect(() => {currentCount.current = count;});const log = () => {setCount(count + 1);setTimeout(() => {console.log(currentCount.current);}, 3000);};return (<div><p>You clicked {count} times</p><button onClick={log}>Click me</button></div>);
}
通过这个例子,我们引出了一个新的,也是 最重要的 Hook - useEffect,请务必深入理解这个函数。
useEffect 是处理副作用的,其执行时机在 每次 Render 渲染完毕后,换句话说就是每次渲染都会执行,只是实际在真实 DOM 操作完毕后。
我们可以利用这个特性,在每次渲染完毕后,将 count 此时最新的值赋给 currentCount.current,这样就使 currentCount 的值自动同步了 count 的最新值。
为了确保大家准确理解 useEffect,笔者再啰嗦一下,将其执行周期拆解到每次渲染中。假设你在三秒内快速点击了三次按钮,那么你需要在大脑中模拟出下面这三次渲染都发生了什么:
第一次点击,共渲染了 2 次,useEffect 生效在第 2 次渲染:
function Counter() {const [1, setCount] = useState(0);const currentCount = useRef(0);useEffect(() => {currentCount.current = 1; // 第二次渲染完毕后执行一次});const log = () => {setCount(1 + 1);setTimeout(() => {console.log(currentCount.current);}, 3000);};return ...
}
第二次点击,共渲染了 3 次,useEffect 生效在第 3 次渲染:
function Counter() {const [2, setCount] = useState(0);const currentCount = useRef(0);useEffect(() => {currentCount.current = 2; // 第三次渲染完毕后执行一次});const log = () => {setCount(2 + 1);setTimeout(() => {console.log(currentCount.current);}, 3000);};return ...
}
第三次点击,共渲染了 4 次,useEffect 生效在第 4 次渲染:
function Counter() {const [3, setCount] = useState(0);const currentCount = useRef(0);useEffect(() => {currentCount.current = 3; // 第四次渲染完毕后执行一次});const log = () => {setCount(3 + 1);setTimeout(() => {console.log(currentCount.current);}, 3000);};return ...
}
注意对比与上面章节展开的 setTimeout 渲染时有什么不同。
要注意的是,useEffect 也随着每次渲染而不同的,同一个组件不同渲染之间,useEffect 内闭包环境完全独立。对于本次的例子,useEffect 共执行了 四次,经历了如下四次赋值最终变成 3:
currentCount.current = 0; // 第 1 次渲染
currentCount.current = 1; // 第 2 次渲染
currentCount.current = 2; // 第 3 次渲染
currentCount.current = 3; // 第 4 次渲染
请确保理解了这句话再继续往下阅读:
setTimeout的例子,三次点击触发了四次渲染,但setTimeout分别生效在第 1、2、3 次渲染中,因此值是0 1 2。useEffect的例子中,三次点击也触发了四次渲染,但useEffect分别生效在第 1、2、3、4 次渲染中,最终使currentCount的值变成3。
用自定义 Hook 包装 useRef
是不是觉得每次都写一堆 useEffect 同步数据到 useRef 很烦?是的,想要简化,就需要引出一个新的概念:自定义 Hooks。
首先介绍一下,自定义 Hooks 允许创建自定义 Hook,只要函数名遵循以 use 开头,且返回非 JSX 元素,就是 Hooks 啦!自定义 Hooks 内还可以调用包括内置 Hooks 在内的所有自定义 Hooks。
也就是我们可以将 useEffect 写到自定义 Hook 里:
function useCurrentValue(value) {const ref = useRef(0);useEffect(() => {ref.current = value;}, [value]);return ref;
}
这里又引出一个新的概念,就是 useEffect 的第二个参数,dependences。dependences 这个参数定义了 useEffect 的依赖,在新的渲染中,只要所有依赖项的引用都不发生变化,useEffect 就不会被执行,且当依赖项为 [] 时,useEffect 仅在初始化执行一次,后续的 Rerender 永远也不会被执行。
这个例子中,我们告诉 React:仅当 value 的值变化了,再将其最新值同步给 ref.current。
那么这个自定义 Hook 就可以在任何 Function Component 调用了:
function Counter() {const [count, setCount] = useState(0);const currentCount = useCurrentValue(count);const log = () => {setCount(count + 1);setTimeout(() => {console.log(currentCount.current);}, 3000);};return (<div><p>You clicked {count} times</p><button onClick={log}>Click me</button></div>);
}
封装以后代码清爽了很多,而且最重要的是将逻辑封装起来,我们只要理解 useCurrentValue 这个 Hook 可以产生一个值,其最新值永远与入参同步。
看到这里,也许有的小伙伴已经按捺不住迸发的灵感了:将 useEffect 第二个参数设置为空数组,这个自定义 Hook 就代表了 didMount 生命周期!
是的,但笔者建议大家 不要再想生命周期的事情,这样会阻碍你更好的理解 Function Component。因为下一个话题,就是要告诉你:永远要对 useEffect 的依赖诚实,被依赖的参数一定要填上去,否则会产生非常难以察觉与修复的 BUG。
将 setTimeout 换成 setInterval 会怎样
我们回到起点,将第一个 setTimeout Demo 中换成 setInterval,看看会如何:
function Counter() {const [count, setCount] = useState(0);useEffect(() => {const id = setInterval(() => {setCount(count + 1);}, 1000);return () => clearInterval(id);}, []);return <h1>{count}</h1>;
}
这个例子将引发学习 Function Component 的第二个拦路虎,理解了它,才深入理解了 Function Component 的渲染原理。
首先介绍一下引入的新概念,useEffect 函数的返回值。它的返回值是一个函数,这个函数在 useEffect 即将重新执行时,会先执行上一次 Rerender useEffect 第一个回调的返回函数,再执行下一次渲染的 useEffect 第一个回调。
以两次连续渲染为例介绍,展开后的效果是这样的:
第一次渲染:
function Counter() {useEffect(() => {// 第一次渲染完毕后执行// 最终执行顺序:1return () => {// 由于没有填写依赖项,所以第二次渲染 useEffect 会再次执行,在执行前,第一次渲染中这个地方的回调函数会首先被调用// 最终执行顺序:2}});return ...
}
第二次渲染:
function Counter() {useEffect(() => {// 第二次渲染完毕后执行// 最终执行顺序:3return () => {// 依此类推}});return ...
}
然而本 Demo 将 useEffect 的第二个参数设置为了 [],那么其返回函数只会在这个组件被销毁时执行。
读懂了前面的例子,应该能想到,这个 Demo 希望利用 [] 依赖,将 useEffect 当作 didMount 使用,再结合 setInterval 每次时 count 自增,这样期望将 count 的值每秒自增 1。
然而结果是:
1
1
1
...
理解了 setTimeout 例子的读者应该可以自行推导出原因:setInterval 永远在第一次 Render 的闭包中,count 的值永远是 0,也就是等价于:
function Counter() {const [count, setCount] = useState(0);useEffect(() => {const id = setInterval(() => {setCount(0 + 1);}, 1000);return () => clearInterval(id);}, []);return <h1>{count}</h1>;
}
然而罪魁祸首就是 没有对依赖诚实 导致的。例子中 useEffect 明明依赖了 count,依赖项却非要写 [],所以产生了很难理解的错误。
所以改正的办法就是 对依赖诚实。
永远对依赖项诚实
一旦我们对依赖诚实了,就可以得到正确的效果:
function Counter() {const [count, setCount] = useState(0);useEffect(() => {const id = setInterval(() => {setCount(count + 1);}, 1000);return () => clearInterval(id);}, [count]);return <h1>{count}</h1>;
}
我们将 count 作为了 useEffect 的依赖项,就得到了正确的结果:
1
2
3
...
既然漏写依赖的风险这么大,自然也有保护措施,那就是 eslint-plugin-react-hooks 这个插件,会自动订正你的代码中的依赖,想不对依赖诚实都不行!
然而对这个例子而言,代码依然存在 BUG:每次计数器都会重新实例化,如果换成其他费事操作,性能成本将不可接受。
如何不在每次渲染时重新实例化 setInterval?
最简单的办法,就是利用 useState 的第二种赋值用法,不直接依赖 count,而是以函数回调方式进行赋值:
function Counter() {const [count, setCount] = useState(0);useEffect(() => {const id = setInterval(() => {setCount(c => c + 1);}, 1000);return () => clearInterval(id);}, []);return <h1>{count}</h1>;
}
这这写法真正做到了:
- 不依赖
count,所以对依赖诚实。 - 依赖项为
[],只有初始化会对setInterval进行实例化。
而之所以输出还是正确的 1 2 3 ...,原因是 setCount 的回调函数中,c 值永远指向最新的 count 值,因此没有逻辑漏洞。
但是聪明的同学仔细一想,就会发现一个新问题:如果存在两个以上变量需要使用时,这招就没有用武之地了。
同时使用两个以上变量时?
如果同时需要对 count 与 step 两个变量做累加,那 useEffect 的依赖必然要写上一种某一个值,频繁实例化的问题就又出现了:
function Counter() {const [count, setCount] = useState(0);const [step, setStep] = useState(0);useEffect(() => {const id = setInterval(() => {setCount(c => c + step);}, 1000);return () => clearInterval(id);}, [step]);return <h1>{count}</h1>;
}
这个例子中,由于 setCount 只能拿到最新的 count 值,而为了每次都拿到最新的 step 值,就必须将 step 申明到 useEffect 依赖中,导致 setInterval 被频繁实例化。
这个问题自然也困扰了 React 团队,所以他们拿出了一个新的 Hook 解决问题:useReducer。
什么是 useReducer
先别联想到 Redux。只考虑上面的场景,看看为什么 React 团队要将 useReducer 列为内置 Hooks 之一。
先介绍一下 useReducer 的用法:
const [state, dispatch] = useReducer(reducer, initialState);
useReducer 返回的结构与 useState 很像,只是数组第二项是 dispatch,而接收的参数也有两个,初始值放在第二位,第一位就是 reducer。
reducer 定义了如何对数据进行变换,比如一个简单的 reducer 如下:
function reducer(state, action) {switch (action.type) {case "increment":return {...state,count: state.count + 1};default:return state;}
}
这样就可以通过调用 dispatch({ type: 'increment' }) 的方式实现 count 自增了。
那么回到这个例子,我们只需要稍微改写一下用法即可:
function Counter() {const [state, dispatch] = useReducer(reducer, initialState);const { count, step } = state;useEffect(() => {const id = setInterval(() => {dispatch({ type: "tick" });}, 1000);return () => clearInterval(id);}, [dispatch]);return <h1>{count}</h1>;
}function reducer(state, action) {switch (action.type) {case "tick":return {...state,count: state.count + state.step};}
}
可以看到,我们通过 reducer 的 tick 类型完成了对 count 的累加,而在 useEffect 的函数中,竟然完全绕过了 count、step 这两个变量。所以 useReducer 也被称为解决此类问题的 “黑魔法”。
其实不管被怎么称呼也好,其本质是让函数与数据解耦,函数只管发出指令,而不需要关心使用的数据被更新时,需要重新初始化自身。
仔细的读者会发现这个例子还是有一个依赖的,那就是 dispatch,然而 dispatch 引用永远也不会变,因此可以忽略它的影响。这也体现了无论如何都要对依赖保持诚实。
这也引发了另一个注意项:尽量将函数写在 useEffect 内部。
将函数写在 useEffect 内部
为了避免遗漏依赖,必须将函数写在 useEffect 内部,这样 eslint-plugin-react-hooks 才能通过静态分析补齐依赖项:
function Counter() {const [count, setCount] = useState(0);useEffect(() => {function getFetchUrl() {return "https://v?query=" + count;}getFetchUrl();}, [count]);return <h1>{count}</h1>;
}
getFetchUrl 这个函数依赖了 count,而如果将这个函数定义在 useEffect 外部,无论是机器还是人眼都难以看出 useEffect 的依赖项包含 count。
然而这就引发了一个新问题:将所有函数都写在 useEffect 内部岂不是非常难以维护?
如何将函数抽到 useEffect 外部?
为了解决这个问题,我们要引入一个新的 Hook:useCallback,它就是解决将函数抽到 useEffect 外部的问题。
我们先看 useCallback 的用法:
function Counter() {const [count, setCount] = useState(0);const getFetchUrl = useCallback(() => {return "https://v?query=" + count;}, [count]);useEffect(() => {getFetchUrl();}, [getFetchUrl]);return <h1>{count}</h1>;
}
可以看到,useCallback 也有第二个参数 - 依赖项,我们将 getFetchUrl 函数的依赖项通过 useCallback 打包到新的 getFetchUrl 函数中,那么 useEffect 就只需要依赖 getFetchUrl 这个函数,就实现了对 count 的间接依赖。
换句话说,我们利用了 useCallback 将 getFetchUrl 函数抽到了 useEffect 外部。
为什么 useCallback 比 componentDidUpdate 更好用
回忆一下 Class Component 的模式,我们是如何在函数参数变化时进行重新取数的:
class Parent extends Component {state = {count: 0,step: 0};fetchData = () => {const url ="https://v?query=" + this.state.count + "&step=" + this.state.step;};render() {return <Child fetchData={this.fetchData} count={count} step={step} />;}
}class Child extends Component {state = {data: null};componentDidMount() {this.props.fetchData();}componentDidUpdate(prevProps) {if (this.props.count !== prevProps.count &&this.props.step !== prevProps.step // 别漏了!) {this.props.fetchData();}}render() {// ...}
}
上面的代码经常用 Class Component 的人应该很熟悉,然而暴露的问题可不小。
我们需要理解 props.count props.step 被 props.fetchData 函数使用了,因此在 componentDidUpdate 时,判断这两个参数发生了变化就触发重新取数。
然而问题是,这种理解成本是不是过高了?如果父级函数 fetchData 不是我写的,在不读源码的情况下,我怎么知道它依赖了 props.count 与 props.step 呢?更严重的是,如果某一天 fetchData 多依赖了 params 这个参数,下游函数将需要全部在 componentDidUpdate 覆盖到这个逻辑,否则 params 变化时将不会重新取数。可以想象,这种方式维护成本巨大,甚至可以说几乎无法维护。
换成 Function Component 的思维吧!试着用上刚才提到的 useCallback 解决问题:
function Parent() {const [ count, setCount ] = useState(0);const [ step, setStep ] = useState(0);const fetchData = useCallback(() => {const url = 'https://v/search?query=' + count + "&step=" + step;}, [count, step])return (<Child fetchData={fetchData} />)
}function Child(props) {useEffect(() => {props.fetchData()}, [props.fetchData])return (// ...)
}
可以看出来,当 fetchData 的依赖变化后,按下保存键,eslint-plugin-react-hooks 会自动补上更新后的依赖,而下游的代码不需要做任何改变,下游只需要关心依赖了 fetchData 这个函数即可,至于这个函数依赖了什么,已经封装在 useCallback 后打包透传下来了。
不仅解决了维护性问题,而且对于 只要参数变化,就重新执行某逻辑,是特别适合用 useEffect 做的,使用这种思维思考问题会让你的代码更 “智能”,而使用分裂的生命周期进行思考,会让你的代码四分五裂,而且容易漏掉各种时机。
useEffect 对业务的抽象非常方便,笔者举几个例子:
- 依赖项是查询参数,那么
useEffect内可以进行取数请求,那么只要查询参数变化了,列表就会自动取数刷新。注意我们将取数时机从触发端改成了接收端。 - 当列表更新后,重新注册一遍拖拽响应事件。也是同理,依赖参数是列表,只要列表变化,拖拽响应就会重新初始化,这样我们可以放心的修改列表,而不用担心拖拽事件失效。
- 只要数据流某个数据变化,页面标题就同步修改。同理,也不需要在每次数据变化时修改标题,而是通过
useEffect“监听” 数据的变化,这是一种 “控制反转” 的思维。
说了这么多,其本质还是利用了 useCallback 将函数独立抽离到 useEffect 外部。
那么进一步思考,可以将函数抽离到整个组件的外部吗?
这也是可以的,需要灵活运用自定义 Hooks 实现。
将函数抽到组件外部
以上面的 fetchData 函数为例,如果要抽到整个组件的外部,就不是利用 useCallback 做到了,而是利用自定义 Hooks 来做:
function useFetch(count, step) {return useCallback(() => {const url = "https://v/search?query=" + count + "&step=" + step;}, [count, step]);
}
可以看到,我们将 useCallback 打包搬到了自定义 Hook useFetch 中,那么函数中只需要一行代码就能实现一样的效果了:
function Parent() {const [count, setCount] = useState(0);const [step, setStep] = useState(0);const [other, setOther] = useState(0);const fetch = useFetch(count, step); // 封装了 useFetchuseEffect(() => {fetch();}, [fetch]);return (<div><button onClick={() => setCount(c => c + 1)}>setCount {count}</button><button onClick={() => setStep(c => c + 1)}>setStep {step}</button><button onClick={() => setOther(c => c + 1)}>setOther {other}</button></div>);
}
随着使用越来越方便,我们可以将精力放到性能上。观察可以发现,count 与 step 都会频繁变化,每次变化就会导致 useFetch 中 useCallback 依赖的变化,进而导致重新生成函数。然而实际上这种函数是没必要每次都重新生成的,反复生成函数会造成大量性能损耗。
换一个例子就可以看得更清楚:
function Parent(props) {const [count, setCount] = useState(0);const [step, setStep] = useState(0);const [other, setOther] = useState(0);const drag = useDraggable(props.dom, count, step); // 封装了拖拽函数useEffect(() => {// dom 变化时重新实例化drag()}, [drag])
}
假设我们使用 Sortablejs 对某个区域进行拖拽监听,这个函数每次都重复执行的性能损耗非常大,然而这个函数内部可能因为仅仅要上报一些日志,所以依赖了没有实际被使用的 count step 变量:
function useDraggable(dom, count, step) {return useCallback(() => {// 上报日志report(count, step);// 对区域进行初始化,非常耗时// ... 省略耗时代码}, [dom, count, step]);
}
这种情况,函数的依赖就特别不合理。虽然依赖变化应该触发函数重新执行,但如果函数重新执行的成本非常高,而依赖只是可有可无的点缀,得不偿失。
利用 Ref 保证耗时函数依赖不变
一种办法是通过将依赖转化为 Ref:
function useFetch(count, step) {const countRef = useRef(count);const stepRef = useRef(step);useEffect(() => {countRef.current = count;stepRef.current = step;});return useCallback(() => {const url ="https://v/search?query=" + countRef.current + "&step=" + stepRef.current;}, [countRef, stepRef]); // 依赖不会变,却能每次拿到最新的值
}
这种方式比较取巧,**将需要更新的区域与耗时区域分离,**再将需更新的内容通过 Ref 提供给耗时的区域,实现性能优化。
然而这样做对函数的改动成本比较高,有一种更通用的做法解决此类问题。
通用的自定义 Hooks 解决函数重新实例化问题
我们可以利用 useRef 创造一个自定义 Hook 代替 useCallback,使其依赖的值变化时,回调不会重新执行,却能拿到最新的值!
这个神奇的 Hook 写法如下:
function useEventCallback(fn, dependencies) {const ref = useRef(null);useEffect(() => {ref.current = fn;}, [fn, ...dependencies]);return useCallback(() => {const fn = ref.current;return fn();}, [ref]);
}
再次体会到自定义 Hook 的无所不能。
首先看这一段:
useEffect(() => {ref.current = fn;
}, [fn, ...dependencies]);
当 fn 回调函数变化时, ref.current 重新指向最新的 fn 这个逻辑中规中矩。重点是,当依赖 dependencies 变化时,也重新为 ref.current 赋值,此时 fn 内部的 dependencies 值是最新的,而下一段代码:
return useCallback(() => {const fn = ref.current;return fn();
}, [ref]);
又仅执行一次(ref 引用不会改变),所以每次都可以返回 dependencies 是最新的 fn,并且 fn 还不会重新执行。
假设我们对 useEventCallback 传入的回调函数称为 X,则这段代码的含义,就是使每次渲染的闭包中,回调函数 X 总是拿到的总是最新 Rerender 闭包中的那个,所以依赖的值永远是最新的,而且函数不会重新初始化。
React 官方不推荐使用此范式,因此对于这种场景,利用
useReducer,将函数通过dispatch中调用。 还记得吗?dispatch是一种可以绕过依赖的黑魔法,我们在 “什么是 useReducer” 小节提到过。
随着对 Function Component 的使用,你也渐渐关心到函数的性能了,这很棒。那么下一个重点自然是关注 Render 的性能。
用 memo 做 PureRender
在 Fucntion Component 中,Class Component 的 PureComponent 等价的概念是 React.memo,我们介绍一下 memo 的用法:
const Child = memo((props) => {useEffect(() => {props.fetchData()}, [props.fetchData])return (// ...)
})
使用 memo 包裹的组件,会在自身重渲染时,对每一个 props 项进行浅对比,如果引用没有变化,就不会触发重渲染。所以 memo 是一种很棒的性能优化工具。
下面就介绍一个看似比 memo 难用,但真正理解后会发现,其实比 memo 更好用的渲染优化函数:useMemo。
用 useMemo 做局部 PureRender
相比 React.memo 这个异类,React.useMemo 可是正经的官方 Hook:
const Child = (props) => {useEffect(() => {props.fetchData()}, [props.fetchData])return useMemo(() => (// ...), [props.fetchData])
}
可以看到,我们利用 useMemo 包裹渲染代码,这样即便函数 Child 因为 props 的变化重新执行了,只要渲染函数用到的 props.fetchData 没有变,就不会重新渲染。
这里发现了 useMemo 的第一个好处:更细粒度的优化渲染。
所谓更细粒度的优化渲染,是指函数 Child 整体可能用到了 A、B 两个 props,而渲染仅用到了 B,那么使用 memo 方案时,A 的变化会导致重渲染,而使用 useMemo 的方案则不会。
而 useMemo 的好处还不止这些,这里先留下伏笔。我们先看一个新问题:当参数越来越多时,使用 props 将函数、值在组件间传递非常冗长:
function Parent() {const [count, setCount] = useState(0);const [step, setStep] = useState(0);const fetchData = useFetch(count, step);return <Child fetchData={fetchData} setCount={setCount} setStep={setStep} />;
}
虽然 Child 可以通过 memo 或 useMemo 进行优化,但当程序复杂时,可能存在多个函数在所有 Function Component 间共享的情况,此时就需要新 Hook: useContext 来拯救了。
使用 Context 做批量透传
在 Function Component 中,可以使用 React.createContext 创建一个 Context:
const Store = createContext(null);
其中 null 是初始值,一般置为 null 也没关系。接下来还有两步,分别是在根节点使用 Store.Provider 注入,与在子节点使用官方 Hook useContext 拿到注入的数据:
在根节点使用 Store.Provider 注入:
function Parent() {const [count, setCount] = useState(0);const [step, setStep] = useState(0);const fetchData = useFetch(count, step);return (<Store.Provider value={{ setCount, setStep, fetchData }}><Child /></Store.Provider>);
}
在子节点使用 useContext 拿到注入的数据(也就是拿到 Store.Provider 的 value):
const Child = memo((props) => {const { setCount } = useContext(Store)function onClick() {setCount(count => count + 1)}return (// ...)
})
这样就不需要在每个函数间进行参数透传了,公共函数可以都放在 Context 里。
但是当函数多了,Provider 的 value 会变得很臃肿,我们可以结合之前讲到的 useReducer 解决这个问题。
使用 useReducer 为 Context 传递内容瘦身
使用 useReducer,所有回调函数都通过调用 dispatch 完成,那么 Context 只要传递 dispatch 一个函数就好了:
const Store = createContext(null);function Parent() {const [state, dispatch] = useReducer(reducer, { count: 0, step: 0 });return (<Store.Provider value={dispatch}><Child /></Store.Provider>);
}
这下无论是根节点的 Provider,还是子元素调用都清爽很多:
const Child = useMemo((props) => {const dispatch = useContext(Store)function onClick() {dispatch({type: 'countInc'})}return (// ...)
})
你也许很快就想到,将 state 也通过 Provider 注入进去岂不更妙?是的,但此处请务必注意潜在性能问题。
将 state 也放到 Context 中
稍稍改造下,将 state 也放到 Context 中,这下赋值与取值都非常方便了!
const Store = createContext(null);function Parent() {const [state, dispatch] = useReducer(reducer, { count: 0, step: 0 });return (<Store.Provider value={{ state, dispatch }}><Count /><Step /></Store.Provider>);
}
对 Count Step 这两个子元素而言,可需要谨慎一些,假如我们这么实现这两个子元素:
const Count = memo(() => {const { state, dispatch } = useContext(Store);return (<button onClick={() => dispatch("incCount")}>incCount {state.count}</button>);
});const Step = memo(() => {const { state, dispatch } = useContext(Store);return (<button onClick={() => dispatch("incStep")}>incStep {state.step}</button>);
});
其结果是:无论点击 incCount 还是 incStep,都会同时触发这两个组件的 Rerender。
其问题在于:memo 只能挡在最外层的,而通过 useContext 的数据注入发生在函数内部,会 绕过 memo。
当触发 dispatch 导致 state 变化时,所有使用了 state 的组件内部都会强制重新刷新,此时想要对渲染次数做优化,只有拿出 useMemo 了!
useMemo 配合 useContext
使用 useContext 的组件,如果自身不使用 props,就可以完全使用 useMemo 代替 memo 做性能优化:
const Count = () => {const { state, dispatch } = useContext(Store);return useMemo(() => (<button onClick={() => dispatch("incCount")}>incCount {state.count}</button>),[state.count, dispatch]);
};const Step = () => {const { state, dispatch } = useContext(Store);return useMemo(() => (<button onClick={() => dispatch("incStep")}>incStep {state.step}</button>),[state.step, dispatch]);
};
对这个例子来说,点击对应的按钮,只有使用到的组件才会重渲染,效果符合预期。 结合 eslint-plugin-react-hooks 插件使用,连 useMemo 的第二个参数依赖都是自动补全的。
读到这里,不知道你是否联想到了 Redux 的 Connect?
我们来对比一下 Connect 与 useMemo,会发现惊人的相似之处。
一个普通的 Redux 组件:
const mapStateToProps = state => ({count: state.count});const mapDispatchToProps = dispatch => dispatch;@Connect(mapStateToProps, mapDispatchToProps)
class Count extends React.PureComponent {render() {return (<button onClick={() => this.props.dispatch("incCount")}>incCount {this.props.count}</button>);}
}
一个普通的 Function Component 组件:
const Count = () => {const { state, dispatch } = useContext(Store);return useMemo(() => (<button onClick={() => dispatch("incCount")}>incCount {state.count}</button>),[state.count, dispatch]);
};
这两段代码的效果完全一样,Function Component 除了更简洁之外,还有一个更大的优势:全自动的依赖推导。
Hooks 诞生的一个原因,就是为了便于静态分析依赖,简化 Immutable 数据流的使用成本。
我们看 Connect 的场景:
由于不知道子组件使用了哪些数据,因此需要在 mapStateToProps 提前写好,而当需要使用数据流内新变量时,组件里是无法访问的,我们要回到 mapStateToProps 加上这个依赖,再回到组件中使用它。
而 useContext + useMemo 的场景:
由于注入的 state 是全量的,Render 函数中想用什么都可直接用,在按保存键时,eslint-plugin-react-hooks 会通过静态分析,在 useMemo 第二个参数自动补上代码里使用到的外部变量,比如 state.count、dispatch。
另外可以发现,Context 很像 Redux,那么 Class Component 模式下的异步中间件实现的异步取数怎么利用 useReducer 做呢?答案是:做不到。
当然不是说 Function Component 无法实现异步取数,而是用的工具错了。
使用自定义 Hook 处理副作用
比如上面抛出的异步取数场景,在 Function Component 的最佳做法是封装成一个自定义 Hook:
const useDataApi = (initialUrl, initialData) => {const [url, setUrl] = useState(initialUrl);const [state, dispatch] = useReducer(dataFetchReducer, {isLoading: false,isError: false,data: initialData});useEffect(() => {let didCancel = false;const fetchData = async () => {dispatch({ type: "FETCH_INIT" });try {const result = await axios(url);if (!didCancel) {dispatch({ type: "FETCH_SUCCESS", payload: result.data });}} catch (error) {if (!didCancel) {dispatch({ type: "FETCH_FAILURE" });}}};fetchData();return () => {didCancel = true;};}, [url]);const doFetch = url => setUrl(url);return { ...state, doFetch };
};
可以看到,自定义 Hook 拥有完整生命周期,我们可以将取数过程封装起来,只暴露状态 - 是否在加载中:isLoading 是否取数失败:isError 数据:data。
在组件中使用起来非常方便:
function App() {const { data, isLoading, isError } = useDataApi("https://v", {showLog: true});
}
如果这个值需要存储到数据流,在所有组件之间共享,我们可以结合 useEffect 与 useReducer:
function App(props) {const { dispatch } = useContext(Store);const { data, isLoading, isError } = useDataApi("https://v", {showLog: true});useEffect(() => {dispatch({type: "updateLoading",data,isLoading,isError});}, [dispatch, data, isLoading, isError]);
}
到此,Function Component 的入门概念就讲完了,最后附带一个彩蛋:Function Component 的 DefaultProps 怎么处理?
Function Component 的 DefaultProps 怎么处理?
这个问题看似简单,实则不然。我们至少有两种方式对 Function Component 的 DefaultProps 进行赋值,下面一一说明。
首先对于 Class Component,DefaultProps 基本上只有一种大家都认可的写法:
class Button extends React.PureComponent {defaultProps = { type: "primary", onChange: () => {} };
}
然而在 Function Component 就五花八门了。
利用 ES6 特性在参数定义阶段赋值
function Button({ type = "primary", onChange = () => {} }) {}
这种方法看似很优雅,其实有一个重大隐患:没有命中的 props 在每次渲染引用都不同。
看这种场景:
const Child = memo(({ type = { a: 1 } }) => {useEffect(() => {console.log("type", type);}, [type]);return <div>Child</div>;
});
只要 type 的引用不变,useEffect 就不会频繁的执行。现在通过父元素刷新导致 Child 跟着刷新,我们发现,每次渲染都会打印出日志,也就意味着每次渲染时,type 的引用是不同的。
有一种不太优雅的方式可以解决:
const defaultType = { a: 1 };const Child = ({ type = defaultType }) => {useEffect(() => {console.log("type", type);}, [type]);return <div>Child</div>;
};
此时不断刷新父元素,只会打印出一次日志,因为 type 的引用是相同的。
我们使用 DefaultProps 的本意必然是希望默认值的引用相同, 如果不想单独维护变量的引用,还可以借用 React 内置的 defaultProps 方法解决。
利用 React 内置方案
React 内置方案能较好的解决引用频繁变动的问题:
const Child = ({ type }) => {useEffect(() => {console.log("type", type);}, [type]);return <div>Child</div>;
};Child.defaultProps = {type: { a: 1 }
};
上面的例子中,不断刷新父元素,只会打印出一次日志。
因此建议对于 Function Component 的参数默认值,建议使用 React 内置方案解决,因为纯函数的方案不利于保持引用不变。
最后补充一个父组件 “坑” 子组件的经典案例。
不要坑了子组件
我们做一个点击累加的按钮作为父组件,那么父组件每次点击后都会刷新:
function App() {const [count, forceUpdate] = useState(0);const schema = { b: 1 };return (<div><Child schema={schema} /><div onClick={() => forceUpdate(count + 1)}>Count {count}</div></div>);
}
另外我们将 schema = { b: 1 } 传递给子组件,这个就是埋的一个大坑。
子组件的代码如下:
const Child = memo(props => {useEffect(() => {console.log("schema", props.schema);}, [props.schema]);return <div>Child</div>;
});
只要父级 props.schema 变化就会打印日志。结果自然是,父组件每次刷新,子组件都会打印日志,也就是 子组件 [props.schema] 完全失效了,因为引用一直在变化。
其实 子组件关心的是值,而不是引用,所以一种解法是改写子组件的依赖:
const Child = memo(props => {useEffect(() => {console.log("schema", props.schema);}, [JSON.stringify(props.schema)]);return <div>Child</div>;
});
这样可以保证子组件只渲染一次。
可是真正罪魁祸首是父组件,我们需要利用 Ref 优化一下父组件:
function App() {const [count, forceUpdate] = useState(0);const schema = useRef({ b: 1 });return (<div><Child schema={schema.current} /><div onClick={() => forceUpdate(count + 1)}>Count {count}</div></div>);
}
这样 schema 的引用能一直保持不变。如果你完整读完了本文,应该可以充分理解第一个例子的 schema 在每个渲染快照中都是一个新的引用,而 Ref 的例子中,schema 在每个渲染快照中都只有一个唯一的引用。
3. 总结
所以使用 Function Component 你入门了吗?
本次精读留下的思考题是:Function Component 开发过程中还有哪些容易犯错误的细节?
讨论地址是:精读《Function Component 入门》 · Issue #157 · dt-fe/weekly
相关文章:

精读《Function Component 入门》
1. 引言 如果你在使用 React 16,可以尝试 Function Component 风格,享受更大的灵活性。但在尝试之前,最好先阅读本文,对 Function Component 的思维模式有一个初步认识,防止因思维模式不同步造成的困扰。 2. 精读 什…...

类的构造方法
在类中,出成员方法外,还存在一种特殊类型的方法,那就是构造方法。构造方法是一个与类同名的方法,对象的创建就是通过构造方法完成的。每个类实例化一个对象时,类都会自动调用构造方法。 构造方法的特点: 构…...

ChatGPT和LLM
ChatGPT和LLM(大型语言模型)之间存在密切的关系。 首先,LLM是一个更为抽象的概念,它包含了各种自然语言处理任务中使用的各种深度学习模型结构。这些模型通过建立深层神经网络,根据已有的大量文本数据进行文本自动生成…...

「优选算法刷题」:判定字符是否唯一
一、题目 实现一个算法,确定一个字符串 s 的所有字符是否全都不同。 示例 1: 输入: s "leetcode" 输出: false 示例 2: 输入: s "abc" 输出: true限制: 0 < len(s) < 100 s[i]仅包含小写字母 二…...

详解自定义类型:枚举与联合体!
目录 编辑 一、枚举类型 1.枚举类型的声明 2.枚举类型的优点 3.枚举类型的使用 二、联合体类型(共用体) 1.联合体类型的声明 2.联合体的特点 3.相同成员的结构体和联合体的对比 4.联合体大小的计算 5.用联合体判断大小端 三.完结散花 悟已往之不谏&…...

第13章 网络 Page738~741 13.8.3 TCP/UDP简述
libcurl是C语言写成的网络编程工具库,asio是C写的网络编程的基础类型库 libcurl只用于客户端,asio既可以写客户端,也可以写服务端 libcurl实现了HTTP\FTP等应用层协议,但asio却只实现了传输层TCP/UDP等协议。 在学习http时介绍…...
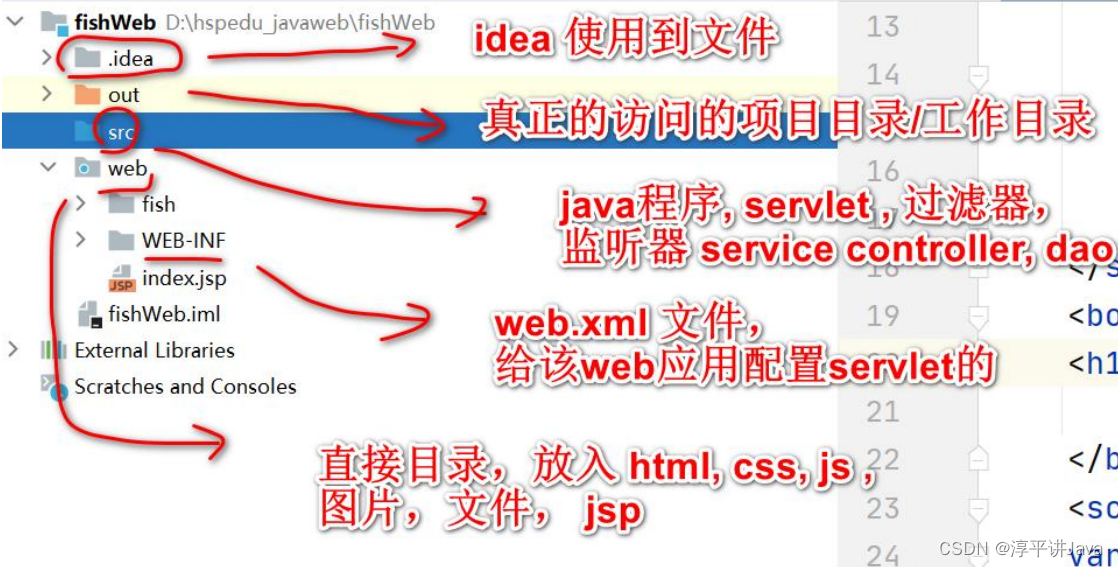
Tomcat要点总结
一、Tomcat 服务中部署 WEB 应用 1.什么是Web应用 (1) WEB 应用是多个 web 资源的集合。简单的说,可以把 web 应用理解为硬盘上的一个目录, 这个目录用于管理多个 web 资源。 (2)Web 应用通常也称之为…...
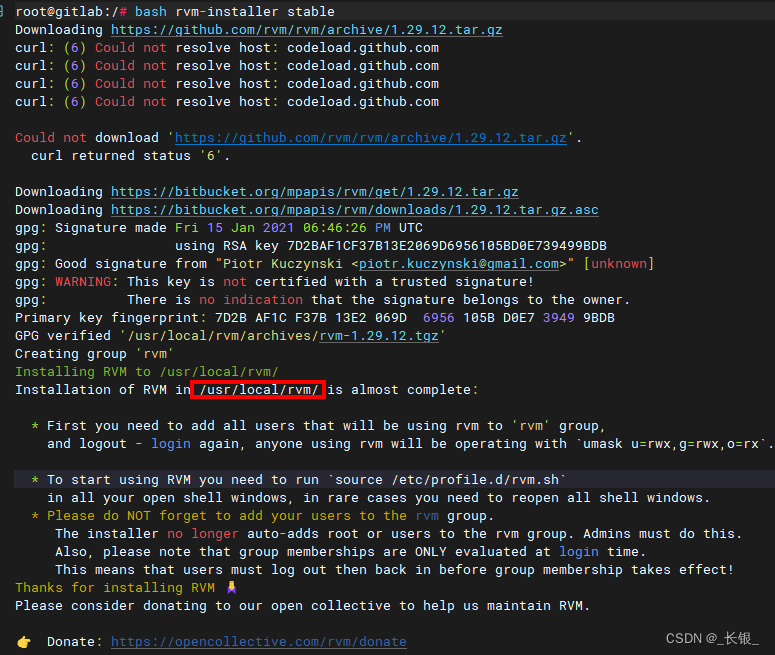
Ubuntu 20.04 安装RVM
RVM是管理Ruby版本的工具,使用RVM可以在单机上方便地管理多个Ruby版本。 下载安装脚本 首先使下载安装脚本 wget https://raw.githubusercontent.com/rvm/rvm/master/binscripts/rvm-installer 如果出现了 Connection refused 的情况, 可以考虑执行以下命令修改dns,再执…...

Ps:污点修复画笔工具
污点修复画笔工具 Spot Healing Brush Tool专门用于快速清除图像中的小瑕疵、污点、尘埃或其他不想要的小元素。 它通过分析被修复区域周围的内容,无需手动取样,自动选择最佳的修复区域来覆盖和融合这些不完美之处,从而实现无痕修复的效果。 …...

JAVA面试题17
什么是Java中的静态内部类?它与非静态内部类有什么区别? 答案:静态内部类是定义在另一个类中的类,并且被声明为静态。与非静态内部类不同,静态内部类不依赖于外部类的实例,可以直接访问外部类的静态成员。 …...

数据备份和恢复
数据备份和恢复 什么情况下会用到数据备份呢 数据丢失的场景 人为误操作造成的某些数据被误操作 软件BUG造成数据部分或者全部丢失 硬件故障造成数据库部分或全部丢失 安全漏洞被入侵数据恶意破坏 非数据丢失场景 基于某个时间点的数据恢复 开发测试环境数据库搭建 相同数据库的…...
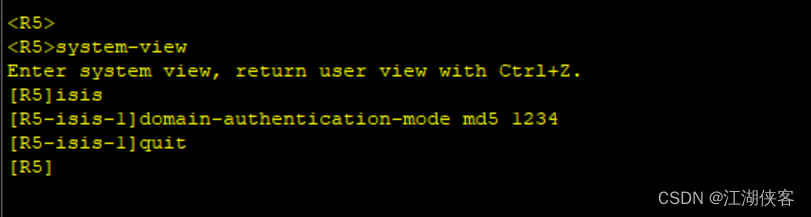
核心篇 - 集成IS-IS配置实战
文章目录 一. 实验专题1.1. 实验1:配置单区域集成IS-IS1.1.1. 实验目的1.1.2. 实验拓扑1.1.3. 实验步骤(1)配置IP地址(2)配置IS-IS 1.1.4. 实验调试(1)查看邻接表(2)查看…...

【OpenAI Sora】开启未来:视频生成模型作为终极世界模拟器的突破之旅
这份技术报告主要关注两个方面:(1)我们的方法将各种类型的视觉数据转化为统一的表示形式,从而实现了大规模生成模型的训练;(2)对Sora的能力和局限性进行了定性评估。报告中不包含模型和实现细节…...
)
MVC 、DDD、中台、Java SPI(Service Provider Interface)
文章目录 引言I 单体架构DDD实现版本1.1 核心概念1.2 DDD四层架构规范1.3 案例1.4 请求转发流程II 领域服务调用2.1 菱形对称架构2.2 中台III Java SPI3.1 概念3.2 实现原理3.3 例子:本地SPI找服务see alsojava -cp</...

C++单例模式的实现
单例模式就是在整个程序运行期都只有一个实例。在代码实现方面,我们要限制new出多于一个对象这种情况的发生。而不是仅仅依靠无保障的约定。 目前大多数的编程语言的做法都是私有化构造函数,对外提供一个获取实例的接口。这样做的目的使实例的创建不能在…...

rust函数 stuct struct方法 关联函数
本文结合2个代码实例主要介绍了rust函数定义方法,struct结构体定义、struct方法及关联函数等相关基础知识。 代码1: main.rc #[derive(Debug)]//定义一个结构体 struct Ellipse {max_semi_axis: u32,min_semi_axis: u32, }fn main() {//椭圆࿰…...

浅谈基于中台模式的大数据生态体系的理解
这篇文章主要浅谈一下我对大数据生态体系建设的理解。 大数据生态系统为高并发,高吞吐,高峰值,高堆积等大规模数据的采集,处理,计算,存储,服务提供了完善的处理体系,致力于打造核心数…...

MySQL的锁机制
一:概述 锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢); 在数据库中,除传统的计算资源(如CPU,RAM,I/O等)的争用以外,数据也是一种供许多用…...

已解决ImportError: cannot import name ‘PILLOW_VERSION‘异常的正确解决方法,亲测有效!!!
已解决ImportError: cannot import name PILLOW_VERSION异常的正确解决方法,亲测有效!!! 文章目录 问题分析 报错原因 解决思路 解决方法 总结 在Python项目开发中,依赖管理是保证项目正常运行的关键环节。然而&…...

力扣:300. 最长递增子序列
动态规划: 1. 先定义dp数组来表示在下标为i时最长递增子序列,先初始化一下每个下标的值为dp【i】1。同时我们要判断在下标i之前的最长的递增子序列为多少,在判断当前的下标i是否满足递增的条件满足的话就进行dp【i】的重新赋值。之后要更新接受的最长递…...

用Coze工作流3步搞定B站视频文案改写:从采集到爆款生成全流程
用Coze工作流3步搞定B站视频文案改写:从采集到爆款生成全流程 在B站内容生态中,爆款视频的诞生往往始于一个抓人眼球的标题和引人入胜的文案。但对于大多数UP主来说,持续产出高质量文案不仅耗时耗力,还常常陷入创意枯竭的困境。Co…...
✅)
计算机毕业设计:Python豆瓣图书数据分析系统 Flask框架 可视化 爬虫 书籍 大数据 机器学习(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,…...

YOLOv8改进之Involution:反转卷积思想,核在空间上共享但在通道上特异,减少冗余
1. 引言 在目标检测领域,YOLO系列模型以其高效、简洁的设计理念一直占据着重要的地位。YOLOv8作为Ultralytics公司推出的最新版本,在检测精度和速度上都达到了新的高度。然而,随着对模型性能要求的不断提高,如何在保持实时性的同时进一步提升检测精度成为了研究的热点。本…...
)
Token限制下的ChatGPT高效对话:如何优化Prompt长度与内容(含计算工具推荐)
Token限制下的ChatGPT高效对话:如何优化Prompt长度与内容(含计算工具推荐) 当ChatGPT成为日常开发和工作的重要工具时,许多用户都会遇到一个共同的瓶颈——Token限制。这个看似技术性的问题,实际上直接影响着我们与AI对…...

别再为上传进度条发愁了!基于MinIO 8.5.3与Spring,手把手实现带进度管理的文件上传组件
构建高体验文件上传组件:MinIO 8.5.3与Spring深度整合实战 在数字化办公场景中,文件上传是高频刚需功能,但传统方案常面临三大痛点:大文件上传超时失败、网络波动导致重复传输、用户无法感知上传状态。本文将基于MinIO 8.5.3的对象…...

英飞凌SMU安全管理单元:从基础到实战应用
1. 英飞凌SMU安全管理单元基础解析 第一次接触英飞凌SMU(Safety Management Unit)时,我完全被这个"安全管家"的设计理念所折服。简单来说,SMU就像汽车的中央行车电脑,实时监控着各个关键部件的运行状态。不同…...

java毕业设计基于springboot头条文章管理系统-编号:project44558
前言 该系统旨在提供一个高效、可靠的文章发布和管理解决方案,使用户能够轻松地发布、编辑和管理自己的文章,并与其他用户进行评论和互动。通过系统提供的文章分类与标签、搜索与过滤等功能,用户能够快速找到感兴趣的文章并参与讨论。一、项目…...

java毕业设计基于springboot图书管理系统-编号:project64080
前言 随着信息技术的不断发展和图书馆规模的不断扩大,传统的图书管理方式已经难以满足现代图书馆的需求。为了提高图书管理的效率和准确性,开发一个基于Spring Boot的图书管理系统显得尤为重要。该系统能够实现对图书的增删改查(CRUD…...
)
科研小白必看:如何用CiteSpace和VOSviewer快速搞定文献可视化分析(附详细操作步骤)
科研新手必备:CiteSpace与VOSviewer文献可视化实战指南 刚踏入科研领域的研究生们,面对海量文献是否感到无从下手?文献计量学工具能帮你从宏观视角快速把握研究脉络。本文将手把手教你用CiteSpace和VOSviewer这两款神器,把枯燥的文…...

基于MATLAB的声纹识别系统:通过MFCC特征提取与DCT法4训练,实现声音信号的识别与验证
基于matlab实现声纹识别,通过提取声音信号的MFCC特征,然后形成特征向量,通过训练语音,对测试语音进行识别,训练方法为DCT 法4,可以识别训练库内的声音,也可以识别出训练库外的声音。 程序已调通…...