Spark中多分区写文件前可以不排序么
背景
Spark 3.5.0
目前 Spark中的实现中,对于多分区的写入默认会先排序,这是没必要的。可以设置spark.sql.maxConcurrentOutputFileWriters 为大于0来避免排序。
分析
这部分主要分为三个部分:
一个是V1Writes规则的重改;
另一个是FileFormatWriter中的dataWriter的选择;
还有一个是Spark中为什么会加上Sort
这三部分是需要结合在一起分析讨论的
V1Writes规则的重改
直接转到代码部分:
object V1Writes extends Rule[LogicalPlan] with SQLConfHelper {import V1WritesUtils._override def apply(plan: LogicalPlan): LogicalPlan = {if (conf.plannedWriteEnabled) {plan.transformUp {case write: V1WriteCommand if !write.child.isInstanceOf[WriteFiles] =>val newQuery = prepareQuery(write, write.query)val attrMap = AttributeMap(write.query.output.zip(newQuery.output))val writeFiles = WriteFiles(newQuery, write.fileFormat, write.partitionColumns,write.bucketSpec, write.options, write.staticPartitions)val newChild = writeFiles.transformExpressions {case a: Attribute if attrMap.contains(a) =>a.withExprId(attrMap(a).exprId)}val newWrite = write.withNewChildren(newChild :: Nil).transformExpressions {case a: Attribute if attrMap.contains(a) =>a.withExprId(attrMap(a).exprId)}newWrite}} else {plan}}
其中 prepareQuery是对满足条件的计划前加上Sort逻辑排序,其中prepareQuery关键的代码如下:
val requiredOrdering = write.requiredOrdering.map(_.transform {case a: Attribute => attrMap.getOrElse(a, a)}.asInstanceOf[SortOrder])val outputOrdering = empty2NullPlan.outputOrderingval orderingMatched = isOrderingMatched(requiredOrdering.map(_.child), outputOrdering)if (orderingMatched) {empty2NullPlan} else {Sort(requiredOrdering, global = false, empty2NullPlan)}
write.requiredOrdering中涉及到的类为InsertIntoHadoopFsRelationCommand和InsertIntoHiveTable,且这两个物理计划中的requiredOrdering实现都是:
V1WritesUtils.getSortOrder(outputColumns, partitionColumns, bucketSpec, options)
getSortOrder方法关键代码如下:
val sortColumns = V1WritesUtils.getBucketSortColumns(bucketSpec, dataColumns)if (SQLConf.get.maxConcurrentOutputFileWriters > 0 && sortColumns.isEmpty) {// Do not insert logical sort when concurrent output writers are enabled.Seq.empty} else {// We should first sort by dynamic partition columns, then bucket id, and finally sorting// columns.(dynamicPartitionColumns ++ writerBucketSpec.map(_.bucketIdExpression) ++ sortColumns).map(SortOrder(_, Ascending))}
所以说 如果 spark.sql.maxConcurrentOutputFileWriters为0(默认值为0),则会加上Sort逻辑计划,具体的实现可以参考SPARK-37287
如果spark.sql.maxConcurrentOutputFileWriters为0(默认值为0)且 sortColumns为空(大部分情况下为空,除非建表是partition加上bucket),则不会加上Sort逻辑计划
FileFormatWriter 中的dataWriter的选择
在 InsertIntoHadoopFsRelationCommand和InsertIntoHiveTable 这两个物理计划中,最终写入文件/数据的时候,会调用到FileFormatWriter.write方法,这里有个concurrentOutputWriterSpecFunc函数变量的设置:
val concurrentOutputWriterSpecFunc = (plan: SparkPlan) => {val sortPlan = createSortPlan(plan, requiredOrdering, outputSpec)createConcurrentOutputWriterSpec(sparkSession, sortPlan, sortColumns)}val writeSpec = WriteFilesSpec(description = description,committer = committer,concurrentOutputWriterSpecFunc = concurrentOutputWriterSpecFunc)executeWrite(sparkSession, plan, writeSpec, job)
设置concurrentOutputWriterSpecFunc的代码如下:
private def createConcurrentOutputWriterSpec(sparkSession: SparkSession,sortPlan: SortExec,sortColumns: Seq[Attribute]): Option[ConcurrentOutputWriterSpec] = {val maxWriters = sparkSession.sessionState.conf.maxConcurrentOutputFileWritersval concurrentWritersEnabled = maxWriters > 0 && sortColumns.isEmptyif (concurrentWritersEnabled) {Some(ConcurrentOutputWriterSpec(maxWriters, () => sortPlan.createSorter()))} else {None}}
如果 spark.sql.maxConcurrentOutputFileWriters为0(默认值为0),则ConcurrentOutputWriterSpec为None
如果 spark.sql.maxConcurrentOutputFileWriters大于0且 sortColumns为空(大部分情况下为空,除非建表是partition加上bucket),则为Some(ConcurrentOutputWriterSpec(maxWriters, () => sortPlan.createSorter())
其中executeWrite会调用WriteFilesExec.doExecuteWrite方法,从而调用FileFormatWriter.executeTask,这里就涉及到dataWriter选择:
val dataWriter =if (sparkPartitionId != 0 && !iterator.hasNext) {// In case of empty job, leave first partition to save meta for file format like parquet.new EmptyDirectoryDataWriter(description, taskAttemptContext, committer)} else if (description.partitionColumns.isEmpty && description.bucketSpec.isEmpty) {new SingleDirectoryDataWriter(description, taskAttemptContext, committer)} else {concurrentOutputWriterSpec match {case Some(spec) =>new DynamicPartitionDataConcurrentWriter(description, taskAttemptContext, committer, spec)case _ =>new DynamicPartitionDataSingleWriter(description, taskAttemptContext, committer)}}
这里其实会根据 concurrentOutputWriterSpec来选择不同的dataWriter,默认情况下为DynamicPartitionDataSingleWriter
否则就会为DynamicPartitionDataConcurrentWriter
这两者的区别,见下文
Spark中为什么会加上Sort
至于Spark在写入文件的时候会加上Sort,这个是跟写入的实现有关的,也就是DynamicPartitionDataSingleWriter和DynamicPartitionDataConcurrentWriter的区别:
- DynamicPartitionDataSingleWriter 在任何时刻,只有一个writer在写文件,这能保证写入的稳定性,不会在写入文件的时候消耗大量的内存,但是速度会慢
- DynamicPartitionDataConcurrentWriter 会有多个 writer 同时写文件,能加快写入文件的速度,但是因为多个文件的同时写入,可能会导致OOM
对于DynamicPartitionDataSingleWriter 会根据partition或者bucket作为最细粒度来作为writer的标准,如果相邻的两条记录所属不同的partition或者bucket,则会切换writer,所以说如果不根据partition或者bucket排序的话,会导致writer频繁的切换,这会大大降低文件的写入速度。所以说需要根据partition或者bucket进行排序。
参考
- [SPARK-37287][SQL] Pull out dynamic partition and bucket sort from FileFormatWriter
- [SQL] Allow FileFormatWriter to write multiple partitions/buckets without sort
相关文章:

Spark中多分区写文件前可以不排序么
背景 Spark 3.5.0 目前 Spark中的实现中,对于多分区的写入默认会先排序,这是没必要的。可以设置spark.sql.maxConcurrentOutputFileWriters 为大于0来避免排序。 分析 这部分主要分为三个部分: 一个是V1Writes规则的重改; 另一个是FileFormatWriter中…...
)
突破编程_C++_面试(变量与常量)
面试题 1 : C 中的变量存储类别有哪些,并简要描述它们的特点? 在C中,变量的存储类别决定了变量的生命周期和可见性。以下是C中的几种变量存储类别及其特点: 自动存储期 也称为局部存储类别。这类变量在函数或代码块…...
)
k8s的一些关键信息(归类摘抄,非提炼)
零:举例说明 当用户提交一个 Deployment 对象到 Kubernetes 集群时,控制平面的 API Server 接收到该请求,并将其转发给 Controller Manager。Controller Manager 中的 Deployment Controller 监听到该请求,并根据用户定义的配置信…...

海外媒体发稿:8个提升影响力的日韩地区媒体发稿推广策略-华媒舍
在今天的数字化时代,媒体发稿推广成为企业和个人增加影响力的重要方式。特别是在日韩地区,这个拥有庞大媒体市场和活跃社交媒体用户的地区,正确的推广策略将对影响力的提升起到关键作用。我们将介绍8个提升影响力的日韩地区媒体发稿推广策略。…...

面试官:能不能给 Promise 增加取消功能和进度通知功能... 我:???
扯皮 这段时间闲着没事就去翻翻红宝书,已经看到 Promise 篇了,今天又让我翻到两个陌生的知识点。 因为 Promise 业务场景太多了自我感觉掌握的也比较透彻,之前也跟着 Promise A 的规范手写过完整的 Promise,所以这部分内容基本上…...

详解MySQL增删查改
众所周知,MySQL是非常重要的数据库语言,下面我们来回顾一下mysql的增删查改吧 MySQL创建数据库: CREATE DATABASE 数据库名;MySQL删除数据库: DROP DATABASE <database_name>; --直接删除,不检查是否存在 DROP…...

Mysql开启bin-log日志
目录 一、安装配置 二、mysqlbinlog命令 一、安装配置 yum -y install mariadb mariadb-server#安装mysql数据库#默认配置文件/etc/my.cnfvim /etc/my.cnflog-binmariadb-bin #开启二进制日志 systemctl restart mariadb#会在/car/lib/mysql/产生二进制日志文件࿰…...

Java:性能优化细节01-10
Java:性能优化细节01-10 在Java程序开发过程中,性能优化是一个重要的考虑因素。常见的误解是将性能问题归咎于Java语言本身,然而实际上,性能瓶颈更多地源于程序设计和代码实现方式的不当。因此,培养良好的编码习惯不仅…...
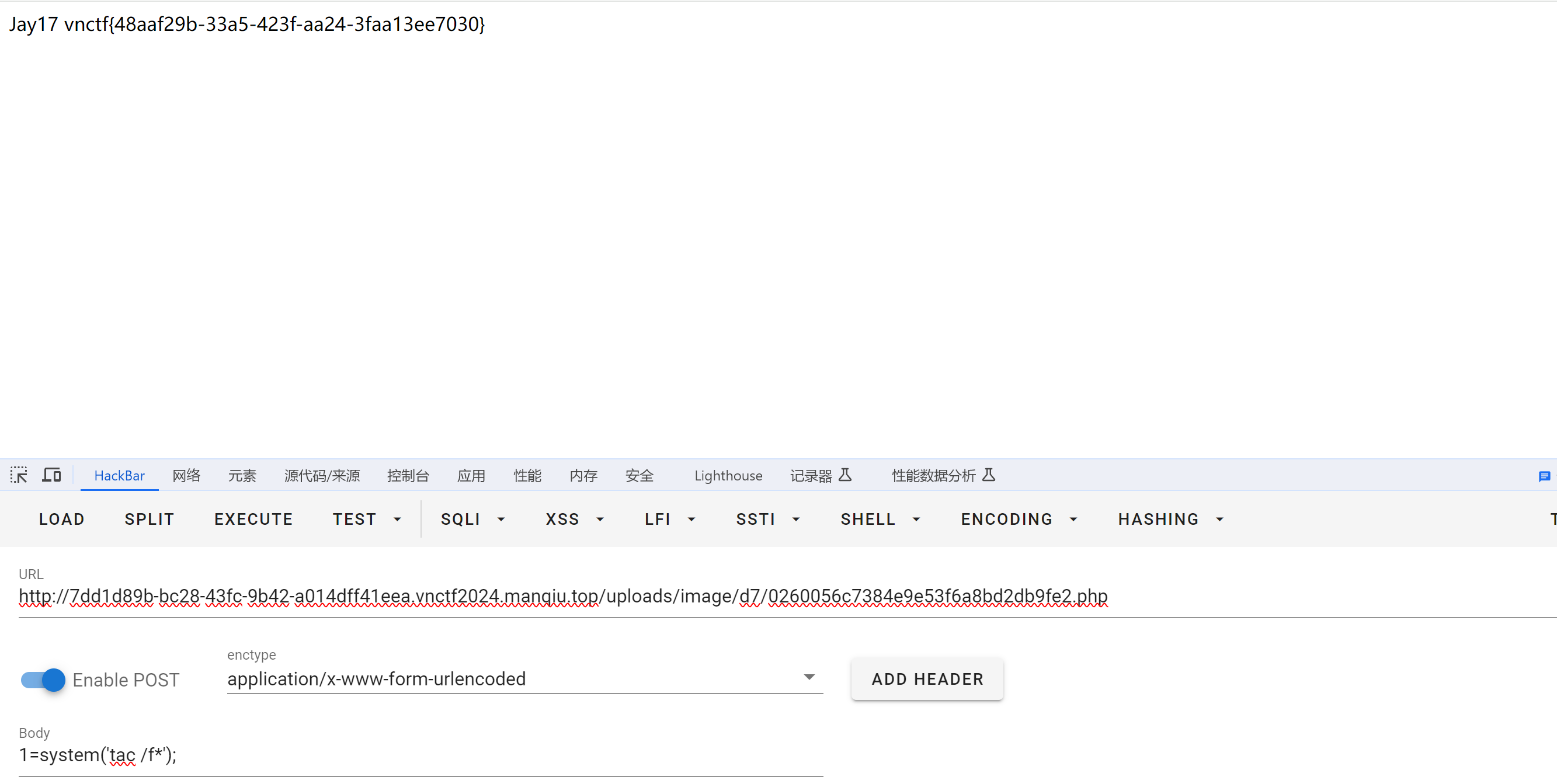
CVE-2022-24652 漏洞复现
CVE-2022-24652 开题 后台管理是thinkphp的,但是工具没检测出漏洞。 登陆后界面如下,上传头像功能值得引起注意 这其实就是CVE-2022-24652,危险类型文件的不加限制上传,是文件上传漏洞。漏洞路由/user/upload/upload 参考文章&a…...
LeetCode、338. 比特位计数【简单,位运算】
文章目录 前言LeetCode、338. 比特位计数【中等,位运算】题目链接与分类思路位运算移位处理前缀思想实现 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java…...

借助Aspose.BarCode条码控件,C# 中的文本转 QR 码生成器
二维码用于在较小的空间内存储大量数据。它们易于使用,可以通过智能手机或其他设备扫描来打开网站、观看视频或访问其他编码信息。在这篇博文中,我们将学习如何使用 C# 以编程方式生成基于文本的 QR 码。我们将提供分步指南和代码片段,帮助您…...

vue打包优化,webpack的8大配置方案
vue-cli 生成的项目通常集成Webpack ,在打包的时候,需要webpack来做一些事情。这里我们希望它可以压缩代码体积,提高运行效率。 文章目录 (1)代码压缩:(2)图片压缩:&…...
B端系统从0到1:有几步,其中需求分析要做啥?
一款B系统从无到有都经历了啥,而其中的需求分析又要做什么?贝格前端工场给老铁们做一下分析,文章写作不易,如果咱们有界面设计和前端开发需求,别忘了私信我呦,开始了。 一、B端系统从0到1都有哪些要走的步骤…...

django中查询优化
在Django中,查询优化是一个重要的主题,因为不正确的查询可能会导致性能问题,尤其是在处理大量数据时。以下是一些在Django中进行查询优化的建议: 一:使用select_related和prefetch_related: select_related用于优化一…...
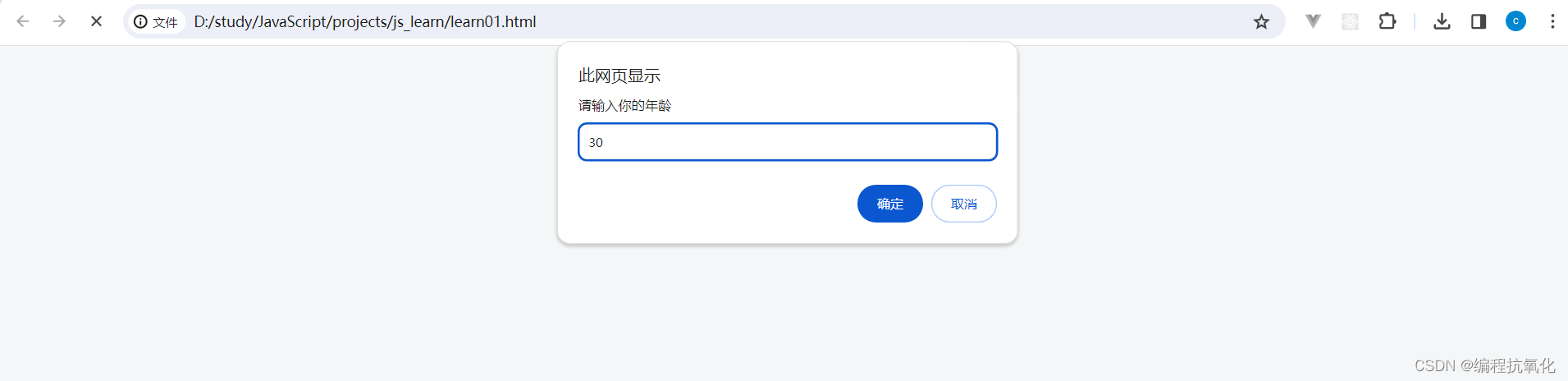
【JavaScript】输入输出语法
目录 一、输出语法 二、输入语法 一、输出语法 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>D…...
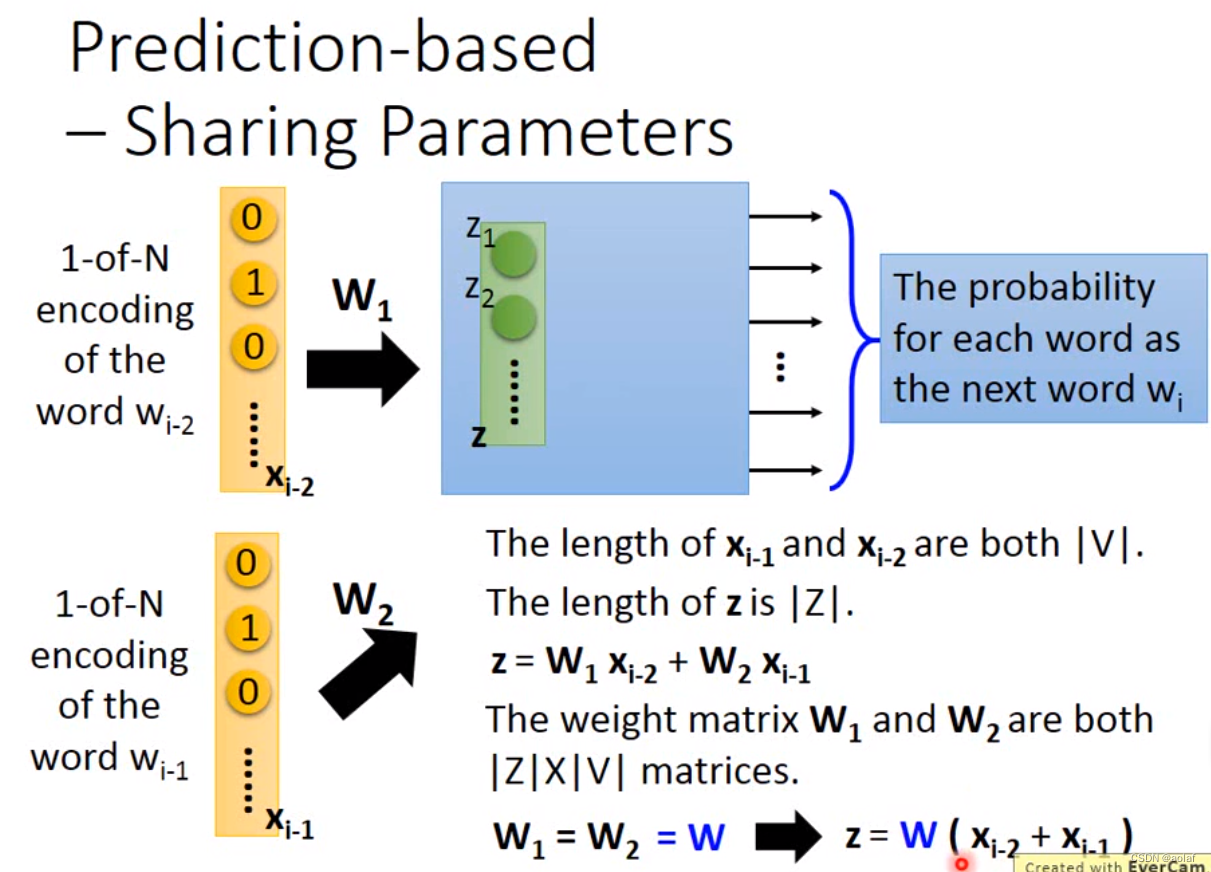
多模态基础--- word Embedding
1 word Embedding 原始的单词编码方式: one-hot,维度太大,不同单词之间相互独立,没有远近关系区分。 wordclass,将同一类单词编码在一起,此时丢失了类别和类别间的相关信息,比如class1和class3…...

Mysql 日志
0 引言 MySQL日志主要分为4类,使用这些日志文件,可以查看MySQL内部发生的事情。这4类日志分别是: ● 错误日志:记录MySQL服务的启动、运行或停止MySQL服务时出现的问题。 ● 查询日志:记录建立的客户端连接和执行的…...

【开源】SpringBoot框架开发服装店库存管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 角色管理模块2.3 服装档案模块2.4 服装入库模块2.5 服装出库模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 角色表3.2.2 服装档案表3.2.3 服装入库表3.2.4 服装出库表 四、系统展示五、核心代码5.…...
云原生之容器编排实践-在K8S集群中使用Registry2搭建私有镜像仓库
背景 基于前面搭建的3节点 Kubernetes 集群,今天我们使用 Registry2 搭建私有镜像仓库,这在镜像安全性以及离线环境下运维等方面具有重要意义。 Note: 由于是测试环境,以下创建了一个 local-storage 的 StorageClass ,并使用本地…...

标准IO 2月4日学习笔记
IO输入输出,操作对象是文件 Linux文件类型: b block 块设备文件 按块扫描设备信息的文件 存储设备 c character 字符设备文件 按字符扫描设备信息的文件 d direct…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...