(03)Hive的相关概念——分区表、分桶表
目录
一、Hive分区表
1.1 分区表的概念
1.2 分区表的创建
1.3 分区表数据加载及查询
1.3.1 静态分区
1.3.2 动态分区
1.4 分区表的本质及使用
1.5 分区表的注意事项
1.6 多重分区表
二、Hive分桶表
2.1 分桶表的概念
2.2 分桶表的创建
2.3 分桶表的数据加载
2.4 分桶表的作用
一、Hive分区表
1.1 分区表的概念
Partition分区表是hive的一种优化手段表,当Hive表数据量大,查询时通过 where子句筛选指定的分区,这样的查询效率会提高很多,避免全表扫描。
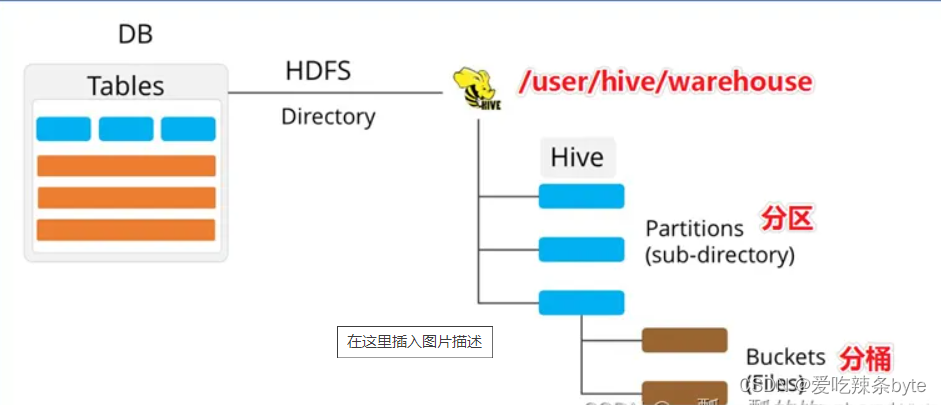
Hive支持根据指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。分区在存储层面上的表现是table表目录下以子文件夹形式存在。一个文件夹表示一个分区。子文件命名标准:分区列=分区值,Hive还支持分区下继续创建分区,所谓的多重分区。
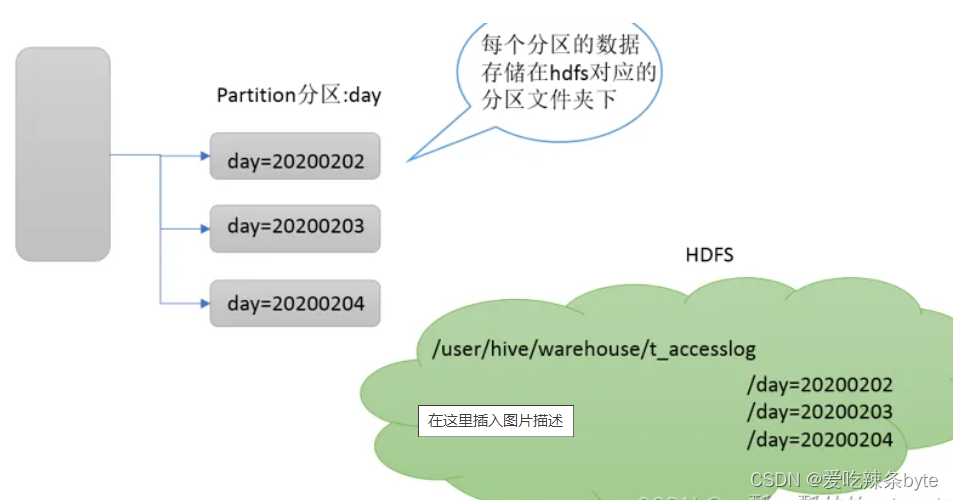
1.2 分区表的创建
- 语法
create table table_name (column1 data_type, column2 data_type)
partitioned by (partition1 data_type, partition2 data_type,….)
row format delimited fields terminated by '\t';- 示例
创建一张分区表t_all_hero_part,以role角色作为分区字段。
create table t_all_hero_part(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string
)
partitioned by (role string)
row format delimited
fields terminated by "\t";ps:分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上,可以将分区字段看作表的伪列。
1.3 分区表数据加载及查询
1.3.1 静态分区
-
数据加载
静态分区指的是分区的字段值是由用户在加载数据的时候手动指定的。语法如下:
load data [local] inpath ' ' into table tablename partition(分区字段='分区值'...); 关键字Local存在表示原数据是位于本地文件系统(linux);关键字Local不存在:表示原数据是位于HDFS文件系统。
(1)假设原文件位于HDFS文件系统,则静态加载数据的操作如下:
create external table ods_log_inc
(common struct<ar :string,ba :string,ch :string,is_new :string,md :string,mid :string,os :string,uid :string,vc:string> comment '公共信息',page struct<during_time :string,item :string,item_type :string,last_page_id :string,page_id:string,source_type :string> comment '页面信息',actions array<struct<action_id:string,item:string,item_type:string,ts:bigint>> comment '动作信息',displays array<struct<display_type :string,item :string,item_type :string,order :string,pos_id:string>> comment '曝光信息',start struct<entry :string,loading_time :bigint,open_ad_id :bigint,open_ad_ms :bigint,open_ad_skip_ms:bigint> comment '启动信息',err struct<error_code:bigint,msg:string> comment '错误信息',ts bigint comment '时间戳'
) comment '活动信息表'partitioned by (dt string)row format serde 'org.apache.hadoop.hive.serde2.jsonserde'location '/warehouse/gmall/ods/ods_log_inc/';#==============数据装载
load data inpath '/origin_data/gmall/log/topic_log/2020-06-15' into table ods_log_inc partition(dt='2020-06-15');
(2)假设原文件位于本地的linux系统,则静态加载数据的操作如下:
create table t_order (oid int ,uid int ,otime string,oamount int)comment '订单表'
partitioned by (dt string)
row format delimited fields terminated by ",";
#=========数据加载
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order partition(dt ='2024-02-14'); ps:分区表加载数据时,必须指定分区
ps:分区表加载数据时,必须指定分区
-
数据查询
select * from t_order where dt='2024-02-14';1.3.2 动态分区
所谓动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insert+select。
hive是批处理系统,提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
启用hive动态分区,需要设置两个参数:
# 表示开启动态分区功能能(默认true)
set hive.exec.dynamic.partition=true;
#设置为非严格模式nonstrict
set hive.exec.dynamic.partition.mode=nonstrict;-----动态分区的模式,分为nonstick非严格模式和strict严格模式。,hive动态分区默认是strict,该模式要求至少有一个分区为静态分区 ,nonstrict 模式表示允许所有的分区字段都可以使用动态分区Hive对其创建的动态分区数量实施限制,总结而言:每个节点默认限制100个动态分区,所有节点的总(默认)限制为1000个动态分区,相关参数如下:
#在每个执行MR的节点上,最大可以创建多少个动态分区,默认值为100
hive.exec.max.dynamic.partitions.pernode=100;
ps:该参数需要根据业务数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数
需要设置成大于365,如果使用默认值100,则会报错。#在所有执行 MR 的节点上,最大一共可以创建多少个动态分区,默认1000
hive.exec.max.dynamic.partitions=1000;#整个MR Job 中,最大可以创建多少个HDFS 文件,默认100000
hive.exec.max.created.files=100000;ps:实际生产环境中,动态分区数量的阈值可以根据业务数据情况进行调整。
# 创建一张新的分区表t_all_hero_part_dynamic
create table t_all_hero_part_dynamic(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";# 需求:将t_all_hero表中的数据按照角色(role_main 字段),插入到目标表t_all_hero_part_dynamic的相应分区中。
insert into table t_all_hero_part_dynamic partition(role)
select tmp.*,tmp.role_main from t_all_hero as tmp;#查看目标表的的分区情况show partitions t_all_hero_part_dynamic;#查看分区表结构desc formatted t_all_hero_part_dynamic;动态分区插入时,分区值是根据查询返回字段位置自动推断的。上述代码中,推断出原表t_all_hero中的字段role_main是 目标表t_all_hero_part_dynamic 的动态分区字段
1.4 分区表的本质及使用
- 建表时根据业务场景设置合适的分区字段。比如日期、地域、类别等;
- 查询的时候尽量先使用where进行分区过滤,查询指定分区的数据,避免全表扫描。
1.5 分区表的注意事项
- 分区表不是建表的必要语法规则,是一种优化手段表,可选;
- 分区字段不能是表中已有的字段,不能重复;
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值可以手动指定(静态分区),也可以根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,支持更细粒度的目录划分
1.6 多重分区表
Hive支持多个分区字段:partitioned by (partition1 data_type, partition2 data_type,….);多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。
例如创建一张三分区表,按省份、市、县分区
# 创建分区表
create table t_user_province_city_county (id int,name string,age int
)
partitioned by (province string, city string,county string)
row format delimited fields terminated by ",";#加载数据到三级分区表中
load data local inpath '文件路径' into table t_user_province_city_county partition(province='hubei',city='xiangyang',county='gucheng');
二、Hive分桶表
2.1 分桶表的概念
Bucket分桶表是hive的一种优化手段表。分桶是指数据表中某字段的值,经过hash计算规则将数据分为指定的若干小文件。 Bucket分桶表在hdfs中表现为同一个表目录下的数据根据hash散列之后变成多个文件。分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)。
分桶默认规则是:分桶编号Bucket number = hash_function(分桶字段) % 桶数量。桶编号相同的数据会被分到同一个桶当中。
ps:hash_function函数取决于分桶字段的数据类型,如果是int类型,hash_function(int) == int;
如果是其他数据类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。


2.2 分桶表的创建
- 语法
--分桶表建表语句
create [external] table [db_name.]table_name[(col_name data_type, ...)]
clustered by (col_name) #--根据col_name字段分桶
into n buckets #--分为n桶
row format delimited fields terminated by '\t';- 示例
--创建分桶表,分为4桶
create table stu_buck(id int,name string
)
clustered by(id)
into 4 buckets--创建分桶表,分为4桶,还可以指定分桶内的数据排序规则,根据id倒叙排序
create table stu_buck(id int,name string
)
clustered by(id) sorted by (id desc)
into 4 buckets --查看表结构desc formatted stu_buck;
ps:分桶的字段必须是表中已经存在的字段。
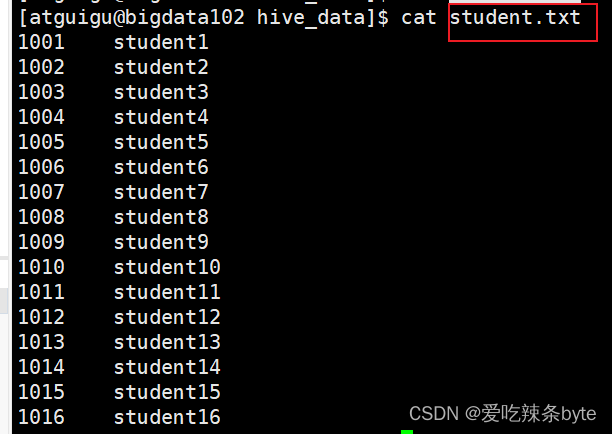
2.3 分桶表的数据加载
load data inpath '/student.txt' into table stu_buck;2.4 分桶表的作用
- 基于分桶字段查询时,减少全表扫描;
- join时可以提高MR程序效率,减少笛卡尔积数量;
对于join操作两个表有一个相同的列,如果对这两个表都进行了分桶操作。那么将保存相同列值的桶进行JOIN操作就可以,这种join方式也称作SMB(Sort Merge Bucket join)
三、总结
- 分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)
- 分区本质是划分hdfs目录,分桶本质是划分数据本身
- 分区字段不能是表中已经存在的字段,分桶的字段必须是表中已经存在的字段
参考文章:
https://blog.51cto.com/alanchan2win/6453477
HiveQL常用查询语句——排序、分桶、分桶抽样子句记录_hive 按分桶查询吗-CSDN博客
相关文章:
(03)Hive的相关概念——分区表、分桶表
目录 一、Hive分区表 1.1 分区表的概念 1.2 分区表的创建 1.3 分区表数据加载及查询 1.3.1 静态分区 1.3.2 动态分区 1.4 分区表的本质及使用 1.5 分区表的注意事项 1.6 多重分区表 二、Hive分桶表 2.1 分桶表的概念 2.2 分桶表的创建 2.3 分桶表的数据加载 2.4 …...

2024年首发!高级界面控件Kendo UI全新发布2024 Q1
Kendo UI是带有jQuery、Angular、React和Vue库的JavaScript UI组件的最终集合,无论选择哪种JavaScript框架,都可以快速构建高性能响应式Web应用程序。通过可自定义的UI组件,Kendo UI可以创建数据丰富的桌面、平板和移动Web应用程序。通过响应…...

stable diffusion webui学习总结(2):技巧汇总
一、脸部修复:解决在低分辨率下,脸部生成异常的问题 勾选ADetailer,会在生成图片后,用更高的分辨率,对于脸部重新生成一遍 二、高清放大:低分辨率照片提升到高分辨率,并丰富内容细节 1、先通过…...
java 培训班预定管理系统Myeclipse开发mysql数据库web结构jsp编程servlet计算机网页项目
一、源码特点 java 培训班预定管理系统是一套完善的java web信息管理系统 采用serlvetdaobean,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOMCAT7.0,Myeclipse8.5开发…...

Python内置函数06——join
文章目录 概述语法实例展示注意事项 概述 Python内置函数join()用于将序列中的元素连接成一个字符串。 语法 str.join(iterable) 参数:iterable——一个可迭代对象中元素连接而成,元素之间用str分隔。 实例展示 eg1:用join()连接列表中…...

linux安装单机版redis详细步骤,及python连接redis案例
文章目录 linux相关工具yum方式安装redis使用编译安装redis配置redis为systemctl启动其它: 安装redis6.0python连接redis案例 linux相关工具 ./redis-benchmark #用于进行redis性能测试的工具 ./redis-check-dump #用于修复出问题的dump.rdb文件 ./redis-cli …...

ts总结大全
ts类型 TS类型除了原始js类型之外,还增加类型,例如:枚举、接口、泛型、字面量、自定义、类型断言、any、类型声明文件 数组类型两种写法:类型 [] 或 Array <类型> let arr:number[][1,2,3,4] let arr:string[][a] let arr…...
前端登录随机数字字母组合验证
背景:系统登录页面只有用户名密码一种校验方式,没有验证码,可能导致暴力破解。 实现逻辑: <el-form-item prop="code"><el-inputv-model="loginForm.captchaCode"auto-complete="off"placeholder="验证码"style="wi…...

基于Java+SpringBoot+vue+elementui 实现即时通讯管理系统
目录 系统简介效果图源码结构试用地址源码下载地址技术交流 博主介绍: 计算机科班人,全栈工程师,掌握C、C#、Java、Python、Android等主流编程语言,同时也熟练掌握mysql、oracle、sqlserver等主流数据库,能够为大家提供…...
 ● 322. 零钱兑换 ● 279.完全平方数)
代码随想录算法训练营第50天(动态规划07 ● 70. 爬楼梯 (进阶) ● 322. 零钱兑换 ● 279.完全平方数
动态规划part07 70. 爬楼梯 (进阶)解题思路总结 322. 零钱兑换解题思路总结 279.完全平方数解题思路 70. 爬楼梯 (进阶) 这道题目 爬楼梯之前我们做过,这次再用完全背包的思路来分析一遍 文章讲解: 70. 爬…...
【软考问题】-- 13 - 知识精讲 - 项目绩效域管理
一、基本问题 问题1:干系人绩效域的预期目标主要包含什么? ①与干系人建立高效的工作关系;②干系人认同项目目标;③支持项目的干系人提高了满意度,并从中收益;④反对项目的干系人没有对项目产生负面影响。问…...
VSCode无法连接远程服务器的两种解决方法
文章目录 VSCode Terminal 报错解决方式1解决方式2you are connected to an OS version that is unsupported by Visual Studio Code解决方法 VSCode Terminal 报错 直接在terminal或cmd中使用ssh命令可以连接服务器,但是在vscode中存在报错,最后一行为…...
【Kuiperinfer】笔记01 项目预览与环境配置
学习目标 实现一个深度学习推理框架设计、编写一个计算图实现常见的算子,例如卷积、池化、全连接学会如何进行算子的优化加速使用自己的推理框架推理常见模型,检查结果是否能够和torch对齐 什么是推理框架? 推理框架用于对已经训练完成的模…...
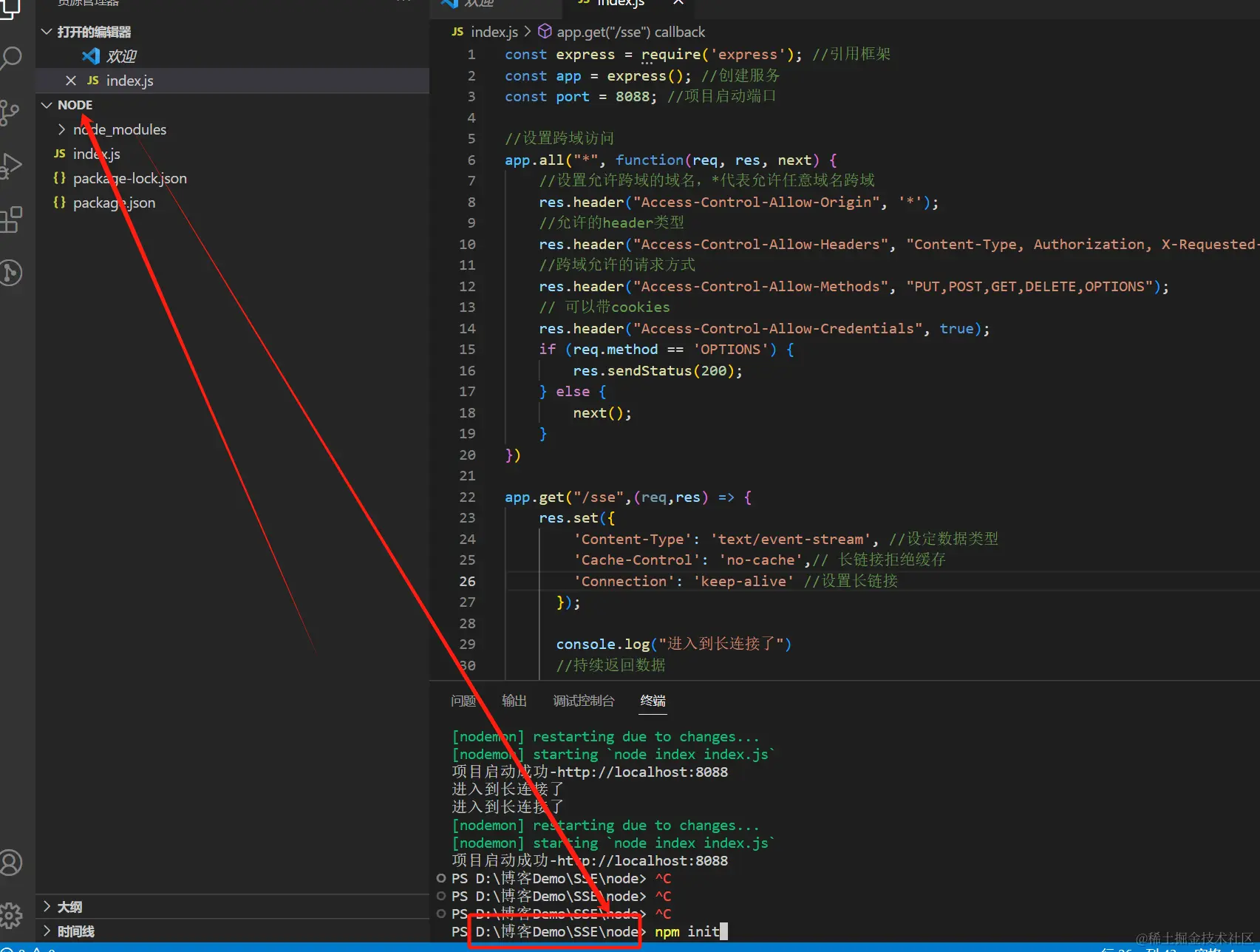
都2024了,你还在使用websocket实现实时消息推送吗?
前言 在日常的开发中,我们经常能碰见服务端需要主动推送给客户端数据的业务场景,比如数据大屏的实时数据,比如消息中心的未读消息,比如聊天功能等等。 本文主要介绍SSE的使用场景和如何使用SSE。 服务端向客户端推送数据的实现…...

javaScript实现客户端直连华为云OBS实现文件上传、断点续传、断网重传
写在前面:在做这个调研时我遇到的需求是前端直接对接华为云平台实现文件上传功能。上传视频文件通常十几个G、客户工作环境网络较差KB/s,且保证上传是稳定的,支持网络异常断点重试、文件断开支持二次拖入自动重传等。综合考虑使用的华为云的分…...
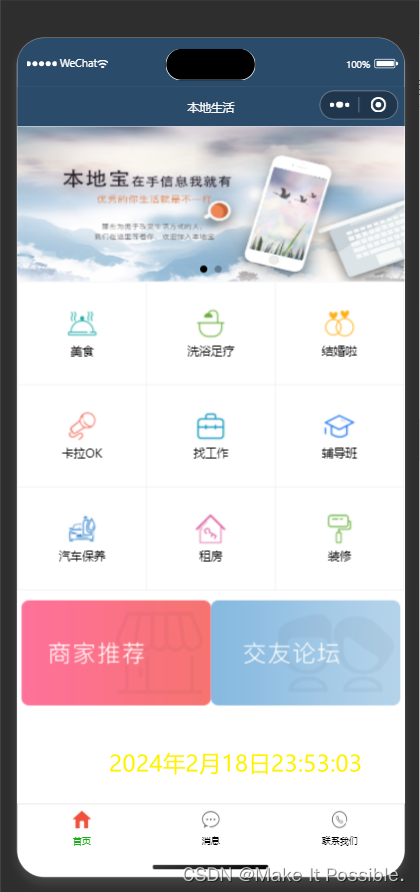
微信小程序:实现微信小程序应用首页开发 (本地生活首页)
文章目录 小程序应用页面开发1、创建项目并配置项目目录结构配置导航栏效果三、配置 tabBar 效果四、轮播图实现4.1 创建轮播图数据容器4.2 定义一个请求轮播图数据的接口4.3 页面加载调用 数据请求接口 五、九宫格实现5.1 获取九宫格数据5.2 结构和样式的完善六、图片布局实现…...

【JavaScript】原型链和继承
文章目录 1. 原型链的概念原型原型链 2. 构建原型链构造函数与原型实例与原型链 3. 继承的实现原型链继承原型链的问题 4. 继承的最佳实践构造函数继承(经典继承)组合继承 5. ES6中的类和继承6. 总结 在 JavaScript 中,原型链和继承是构建对象…...
(二)【Jmeter】专栏实战项目靶场drupal部署
该专栏后续实战示例,都以该篇部署的项目展开操作。 前置条件 参考“(一)【Jmeter】JDK及Jmeter的安装部署及简单配置” 安装部署Jmeter,从文章最后下载“Postman、Rancher.ova、VirtualBox-7.0.12-159484-Win.exe、Xshell-7.0.01…...

使用 ChatGPT系统学习一门知识的技巧
如何使用 ChatGPT 高效学习一门知识?我探索到一种比较高效的方式:首先让 ChatGPT 给你一个学习提纲,然后以此把提纲内容逐个发给 ChatGPT,进行详情学习。 下面以“学习八木天线”工作原理为例说明。 以八木天线为切入点࿰…...
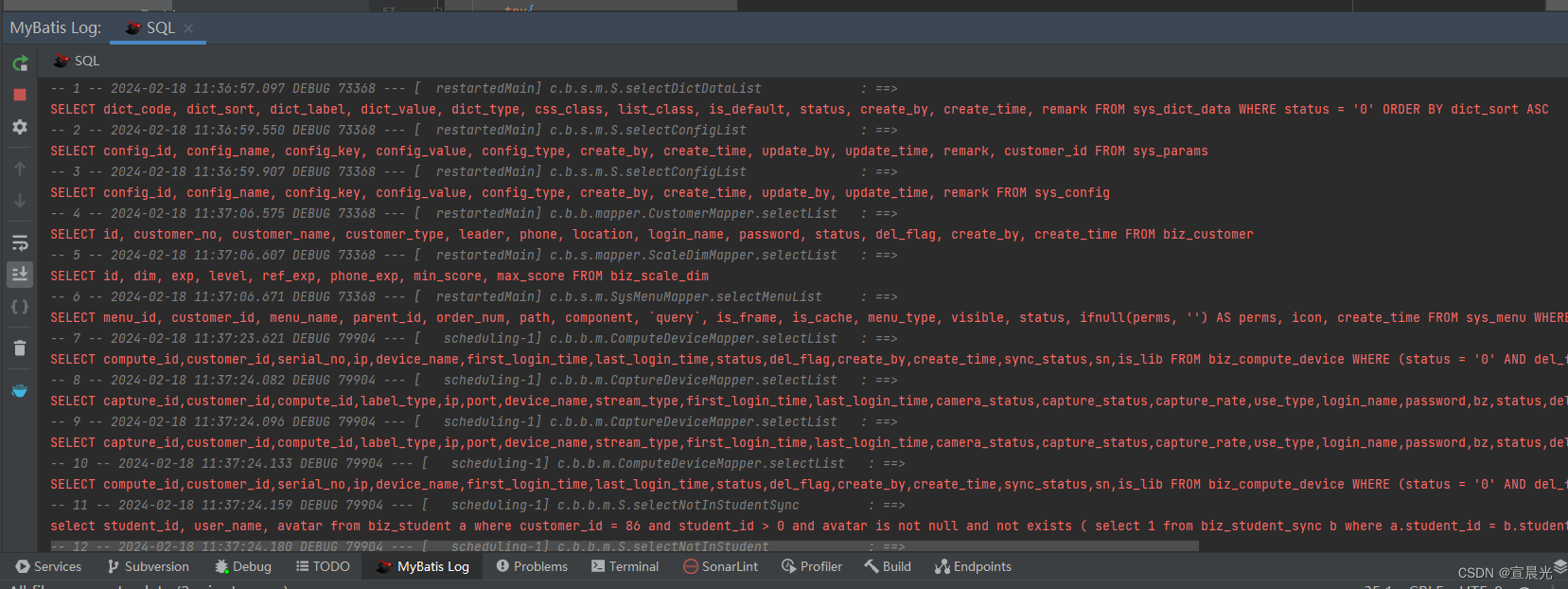
IDEA-常用插件
1、Mybatis Log Free 当我们使用mybatis log在控制台输出sql 内容,输出内容将语句与参数分开打印,还需要手动将参数替换到指定位置。 使用对应插件后,自动将输出内容组装成完整的可直接执行的SQL 在插件市场 查看对应名称,并安装。…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...