第八篇【传奇开心果系列】python的文本和语音相互转换库技术点案例示例:Google Text-to-Speech虚拟现实(VR)沉浸式体验经典案例
传奇开心果博文系列
- 系列博文目录
- python的文本和语音相互转换库技术点案例示例系列
- 博文目录
- 前言
- 一、雏形示例代码
- 二、扩展思路介绍
- 三、虚拟导游示例代码
- 四、交互式学习示例代码
- 五、虚拟角色对话示例代码
- 六、辅助用户界面示例代码
- 七、实时语音交互示例代码
- 八、多语言支持示例代码
- 九、情感识别示例代码
- 十、自定义语音示例代码
- 十一、场景感知示例代码
- 十二、音效结合示例代码
- 十三、交互式故事体验示例代码
- 十四、个性化导览服务示例代码
- 十五、归纳总结
系列博文目录
python的文本和语音相互转换库技术点案例示例系列
博文目录
前言
 Google Text-to-Speech在虚拟现实(VR)体验中有一些应用场景。通过将Google Text-to-Speech技术与虚拟现实技术相结合,可以为用户带来更加沉浸式、交互式和个性化的虚拟体验,丰富虚拟现实应用的功能和体验。
Google Text-to-Speech在虚拟现实(VR)体验中有一些应用场景。通过将Google Text-to-Speech技术与虚拟现实技术相结合,可以为用户带来更加沉浸式、交互式和个性化的虚拟体验,丰富虚拟现实应用的功能和体验。
一、雏形示例代码
 以下是一个简单的示例代码,演示如何在虚拟现实(VR)环境中使用Google Text-to-Speech技术,为用户提供沉浸式的语音体验。请注意,这只是一个基本示例,实际项目中可能需要更复杂的实现和集成。
以下是一个简单的示例代码,演示如何在虚拟现实(VR)环境中使用Google Text-to-Speech技术,为用户提供沉浸式的语音体验。请注意,这只是一个基本示例,实际项目中可能需要更复杂的实现和集成。
import pyttsx3
import time# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 设置语音属性(可根据需要调整)
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 1.0) # 音量# 要朗读的文本
text = "Welcome to the VR experience. Please look around and enjoy the virtual world."# 使用Text-to-Speech引擎朗读文本
engine.say(text)
engine.runAndWait()# 模拟虚拟现实环境中的体验
time.sleep(5) # 等待5秒# 更换文本
new_text = "You are now exploring a virtual forest. Listen to the sounds of nature around you."# 朗读新文本
engine.say(new_text)
engine.runAndWait()# 关闭Text-to-Speech引擎
engine.stop()
engine.runAndWait()
在这个示例中,我们使用Python中的pyttsx3库,选择Text-to-Speech语音引擎实现目标功能。首先初始化Text-to-Speech引擎,然后设置语音属性(如语速、音量),接着朗读指定的文本。在虚拟现实环境中,可以根据用户的行为或场景切换文本内容,以提供更加沉浸式的体验。
请注意,在实际项目中,您可能需要根据具体的虚拟现实平台和开发环境进行更详细的集成和调整。
二、扩展思路介绍
 当将Google Text-to-Speech技术与虚拟现实(VR)结合时,有许多扩展思路可以进一步提升用户体验和功能性。以下是一些扩展思路的介绍:
当将Google Text-to-Speech技术与虚拟现实(VR)结合时,有许多扩展思路可以进一步提升用户体验和功能性。以下是一些扩展思路的介绍:
-
虚拟导游:在虚拟旅游体验中,Google Text-to-Speech可以用于虚拟导游的角色,为用户提供导览、解说和故事叙述,增强用户对虚拟环境的体验。
-
交互式学习:在虚拟现实教育应用中,Google Text-to-Speech可以用于朗读教学内容、解释概念、提供提示和指导,帮助学生更好地理解知识。
-
虚拟角色对话:在虚拟现实游戏或虚拟社交平台中,Google Text-to-Speech可以为虚拟角色赋予语音,增强游戏的互动性和沉浸感。
-
辅助用户界面:在虚拟现实应用程序中,Google Text-to-Speech可以用于提供用户界面的语音提示、反馈和指导,帮助用户更好地操作和导航虚拟环境。
-
实时语音交互:结合语音识别技术,Google Text-to-Speech可以实现虚拟现实环境中的实时语音交互,用户可以通过语音与虚拟环境进行互动、控制和沟通。
-
多语言支持:通过Text-to-Speech技术,实现多语言的语音合成,为全球用户提供更加个性化和本地化的虚拟现实体验。
-
情感识别:结合情感识别技术,使虚拟角色或导游能够根据用户的情感状态调整语音表达方式,增强交互的情感连接。
-
自定义语音:允许用户选择不同的语音风格、音色或声音特效,以满足用户个性化的偏好和需求。
-
场景感知:根据用户在虚拟现实环境中的位置、动作或情境,动态调整语音内容和反馈,提供更加个性化和沉浸式的体验。
-
音效结合:将Text-to-Speech生成的语音与环境音效结合,创造更加逼真的虚拟环境声音,增强用户的沉浸感。
-
交互式故事体验:结合虚拟现实场景和Text-to-Speech技术,打造交互式故事体验,让用户通过语音与故事角色互动,影响故事情节的发展。
-
个性化导览服务:根据用户的兴趣、偏好和历史行为数据,提供个性化的虚拟导览服务,通过语音引导用户探索、学习和体验虚拟环境。
这些扩展思路可以帮助进一步提升虚拟现实体验的交互性、个性化和沉浸感,让用户在虚拟环境中获得更加丰富和有趣的体验。
三、虚拟导游示例代码
 以下是一个简单的示例代码,演示如何在虚拟旅游体验中使用Google Text-to-Speech技术,实现虚拟导游的角色,为用户提供导览、解说和故事叙述,增强用户对虚拟环境的体验。
以下是一个简单的示例代码,演示如何在虚拟旅游体验中使用Google Text-to-Speech技术,实现虚拟导游的角色,为用户提供导览、解说和故事叙述,增强用户对虚拟环境的体验。
import pyttsx3
import time# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 设置语音属性(可根据需要调整)
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 1.0) # 音量# 虚拟导游的导览文本
tour_guide_text = ["Welcome to our virtual tour experience. Today, we will explore the ancient ruins of Machu Picchu.","As you look around, you will see the breathtaking views of the Andes mountains surrounding this magnificent Inca citadel.","Imagine the bustling life of the ancient Incas as we walk through the stone pathways and temples.","Don't forget to take a moment to appreciate the intricate stone masonry that has stood the test of time for centuries."
]# 为用户提供虚拟导游的导览和解说
for text in tour_guide_text:engine.say(text)engine.runAndWait()time.sleep(5) # 等待5秒,让用户有时间欣赏环境# 虚拟导游的结束语
end_text = "Thank you for joining us on this virtual tour of Machu Picchu. We hope you enjoyed the experience."# 朗读结束语
engine.say(end_text)
engine.runAndWait()# 关闭Text-to-Speech引擎
engine.stop()
engine.runAndWait()
在这个示例中,我们模拟了一个虚拟导游的角色,为用户提供对Machu Picchu古迹的导览和解说。通过Text-to-Speech技术,虚拟导游可以向用户介绍景点、讲述历史故事,增强用户对虚拟旅游体验的沉浸感和互动性。
在实际项目中,您可以根据具体的虚拟旅游场景和需求,定制更加丰富和个性化的导览内容,结合场景感知和用户交互,为用户打造更加逼真和有趣的虚拟旅游体验。
四、交互式学习示例代码
 以下是一个简单的示例代码,演示如何在虚拟现实教育应用中利用Google Text-to-Speech技术,实现交互式学习环境,为学生朗读教学内容、解释概念、提供提示和指导,帮助他们更好地理解知识。
以下是一个简单的示例代码,演示如何在虚拟现实教育应用中利用Google Text-to-Speech技术,实现交互式学习环境,为学生朗读教学内容、解释概念、提供提示和指导,帮助他们更好地理解知识。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 设置语音属性(可根据需要调整)
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 1.0) # 音量# 教学内容示例
lesson_content = {"introduction": "Welcome to the interactive learning experience. Today, we will explore the solar system.","planets": "Let's start with the inner planets of the solar system: Mercury, Venus, Earth, and Mars.","earth": "Earth is the third planet from the Sun and the only known planet to support life.","quiz": "Now, let's have a quick quiz. What is the closest planet to the Sun?"
}# 交互式学习环境
for key, text in lesson_content.items():input("Press Enter to continue...")engine.say(text)engine.runAndWait()# 朗读结束语
end_text = "That concludes our interactive learning session. Thank you for participating and learning with us."engine.say(end_text)
engine.runAndWait()# 关闭Text-to-Speech引擎
engine.stop()
engine.runAndWait()
在这个示例中,我们模拟了一个交互式学习环境,通过Text-to-Speech技术为学生朗读教学内容、解释概念,并进行简单的问答互动。这种交互式学习方式可以帮助学生更好地理解知识,增强学习的互动性和趣味性。
在实际项目中,您可以根据具体的教育领域和学习内容,定制更加丰富和个性化的教学内容,结合图形化界面、用户交互和反馈机制,打造更加互动和有效的虚拟现实教育应用,提升学生的学习体验和效果。
五、虚拟角色对话示例代码
 以下是一个简单的示例代码,演示如何在虚拟现实游戏或虚拟社交平台中利用Google Text-to-Speech技术,为虚拟角色赋予语音,增强游戏的互动性和沉浸感。
以下是一个简单的示例代码,演示如何在虚拟现实游戏或虚拟社交平台中利用Google Text-to-Speech技术,为虚拟角色赋予语音,增强游戏的互动性和沉浸感。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 设置语音属性(可根据需要调整)
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 1.0) # 音量# 虚拟角色对话示例
character_dialogues = {"character1": "Hello there! I am character 1. Nice to meet you.","character2": "Greetings! I am character 2. Ready for an adventure?","character3": "Hey, I'm character 3. Let's explore this virtual world together."
}# 虚拟角色对话
for character, dialogue in character_dialogues.items():print(f"{character}: {dialogue}")engine.say(dialogue)engine.runAndWait()# 关闭Text-to-Speech引擎
engine.stop()
engine.runAndWait()
在这个示例中,我们模拟了虚拟角色对话的场景,通过Text-to-Speech技术为虚拟角色赋予语音,使其能够与玩家进行互动。这种技术可以增强游戏的沉浸感和互动性,让玩家更加享受虚拟世界的体验。
在实际项目中,您可以根据具体的游戏情境和角色设定,定制更加丰富和个性化的对话内容,结合语音识别技术和自然语言处理,实现更加智能和复杂的虚拟角色对话系统,为玩家带来更加生动和有趣的游戏体验。
六、辅助用户界面示例代码
 以下是一个简单的示例代码,演示如何在虚拟现实应用程序中利用Google Text-to-Speech技术,提供用户界面的语音提示、反馈和指导,帮助用户更好地操作和导航虚拟环境。
以下是一个简单的示例代码,演示如何在虚拟现实应用程序中利用Google Text-to-Speech技术,提供用户界面的语音提示、反馈和指导,帮助用户更好地操作和导航虚拟环境。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 设置语音属性(可根据需要调整)
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 1.0) # 音量# 用户界面语音提示示例
ui_prompts = {"welcome": "Welcome to the virtual reality experience. Please look around and explore the environment.","instructions": "To move forward, press the joystick forward. To turn left or right, use the left or right buttons.","object_interaction": "To interact with objects, point at them and press the interaction button."
}# 提供用户界面的语音提示
for prompt_key, prompt_text in ui_prompts.items():print(prompt_text)engine.say(prompt_text)engine.runAndWait()# 关闭Text-to-Speech引擎
engine.stop()
engine.runAndWait()
在这个示例中,我们模拟了一个虚拟现实应用程序的用户界面语音提示场景,通过Text-to-Speech技术为用户提供操作指导和导航提示。这种方式可以帮助用户更好地了解虚拟环境的操作方式,提升用户体验和互动性。
在实际项目中,您可以根据具体的虚拟现实应用程序需求,定制更加详细和个性化的用户界面语音提示内容,结合语音识别和指令响应技术,实现更加智能和交互式的用户界面辅助系统,为用户提供更加便捷和直观的操作体验。
七、实时语音交互示例代码
 要实现实时语音交互,您需要结合语音识别和Text-to-Speech技术。以下是一个简单的示例代码,演示如何在虚拟现实环境中使用Google Text-to-Speech和语音识别技术实现基本的实时语音交互。
要实现实时语音交互,您需要结合语音识别和Text-to-Speech技术。以下是一个简单的示例代码,演示如何在虚拟现实环境中使用Google Text-to-Speech和语音识别技术实现基本的实时语音交互。
请注意,这个示例代码涉及到语音识别部分,需要使用相应的库来实现,比如Google Speech Recognition或者SpeechRecognition库。
import pyttsx3
import speech_recognition as sr# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 初始化语音识别器
recognizer = sr.Recognizer()# 设置语音属性(可根据需要调整)
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 1.0) # 音量# 语音实时交互示例
def voice_interaction():with sr.Microphone() as source:print("Speak something...")audio = recognizer.listen(source)try:user_input = recognizer.recognize_google(audio)print("User said: " + user_input)engine.say("You said: " + user_input)engine.runAndWait()except sr.UnknownValueError:print("Sorry, I could not understand what you said.")engine.say("Sorry, I could not understand what you said.")engine.runAndWait()except sr.RequestError as e:print("Sorry, could not request results; {0}".format(e))engine.say("Sorry, could not request results.")engine.runAndWait()# 进行语音交互
voice_interaction()# 关闭Text-to-Speech引擎
engine.stop()
engine.runAndWait()
在这个示例中,用户可以通过麦克风说出一些内容,语音识别器会将其转换为文本,然后使用Text-to-Speech技术将文本转换为语音反馈给用户。这种方式可以实现简单的实时语音交互,用户可以通过语音与虚拟环境进行互动。
在实际项目中,您可以根据具体需求扩展这个示例,设计更加复杂和智能的实时语音交互系统,结合自然语言处理技术,实现更加灵活和智能的虚拟现实实时语音交互体验。
八、多语言支持示例代码
 要实现多语言的语音合成,您可以使用Google Text-to-Speech API来支持多种语言。以下是一个示例代码,演示如何使用Google Text-to-Speech API实现多语言的语音合成。
要实现多语言的语音合成,您可以使用Google Text-to-Speech API来支持多种语言。以下是一个示例代码,演示如何使用Google Text-to-Speech API实现多语言的语音合成。
请注意,您需要先在Google Cloud Platform上设置并启用Text-to-Speech API,并获取相应的API密钥。这里的示例代码使用了Python的Google Cloud Text-to-Speech库(google-cloud-texttospeech)。
from google.cloud import texttospeech# 设置要使用的语言代码和待合成的文本
language_code = 'en-US' # 语言代码,这里以英文为例,可以根据需求更换为其他语言代码
text = 'Hello, welcome to the virtual reality experience.' # 待合成的文本# 实例化一个Text-to-Speech客户端
client = texttospeech.TextToSpeechClient()# 配置语音请求
synthesis_input = texttospeech.SynthesisInput(text=text)# 配置语音参数
voice = texttospeech.VoiceSelectionParams(language_code=language_code, ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)audio_config = texttospeech.AudioConfig(audio_encoding=texttospeech.AudioEncoding.MP3)# 发出语音合成请求
response = client.synthesize_speech(input=synthesis_input, voice=voice, audio_config=audio_config)# 将合成的音频写入文件
with open('output.mp3', 'wb') as out:out.write(response.audio_content)print('Audio content written to file "output.mp3".')# 播放合成的音频(可选)
# import playsound
# playsound.playsound('output.mp3')
在这个示例中,您可以根据需要设置不同的语言代码和待合成的文本,通过Google Text-to-Speech API生成对应语言的语音合成音频。这样就可以实现多语言的语音合成,为全球用户提供更加个性化和本地化的虚拟现实体验。
通过这种方式,您可以为虚拟现实应用程序添加多语言支持,使用户可以选择他们熟悉的语言与虚拟环境进行交互,提升用户体验和全球用户的参与度。
九、情感识别示例代码
 要实现情感识别并根据用户情感状态调整语音表达方式,您可以结合情感分析技术和Text-to-Speech技术。以下是一个简单的示例代码,演示如何使用情感分析库(例如TextBlob)来识别用户情感,并根据情感状态调整语音表达方式。
要实现情感识别并根据用户情感状态调整语音表达方式,您可以结合情感分析技术和Text-to-Speech技术。以下是一个简单的示例代码,演示如何使用情感分析库(例如TextBlob)来识别用户情感,并根据情感状态调整语音表达方式。
请注意,这个示例代码是一个简单的演示,实际情感识别系统可能需要更复杂的模型和算法来准确识别用户情感。
from textblob import TextBlob
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 语音合成函数,根据情感状态调整语音表达方式
def speak(text, emotion):if emotion == 'positive':engine.setProperty('rate', 150) # 调整语速engine.say("You sound positive. " + text)elif emotion == 'negative':engine.setProperty('rate', 120) # 调整语速engine.say("You sound negative. " + text)else:engine.say(text)engine.runAndWait()# 用户输入的文本
user_input = "I'm feeling happy and excited."# 使用TextBlob进行情感分析
blob = TextBlob(user_input)
sentiment = blob.sentiment.polarity# 根据情感状态调整语音表达方式
if sentiment > 0:speak(user_input, 'positive')
elif sentiment < 0:speak(user_input, 'negative')
else:speak(user_input, 'neutral')
在这个示例中,用户输入一段文本,然后使用TextBlob进行情感分析,识别用户的情感状态。根据情感状态的不同,调整Text-to-Speech引擎的参数,例如语速、音调等,以增强语音表达方式,使虚拟角色或导游能够更好地与用户建立情感连接。
这种情感识别和调整语音表达方式的方法可以提升虚拟现实环境中的用户体验,使交互更加智能和个性化。在实际项目中,您可以根据需求和情感识别的准确性进一步优化和扩展这个示例代码。
十、自定义语音示例代码
 要实现允许用户选择不同的语音风格、音色或声音特效,以满足个性化需求,您可以使用Text-to-Speech技术提供的参数来调整语音输出的风格和音色。以下是一个示例代码,演示如何让用户选择不同的语音风格,并根据选择播放相应的语音效果。
要实现允许用户选择不同的语音风格、音色或声音特效,以满足个性化需求,您可以使用Text-to-Speech技术提供的参数来调整语音输出的风格和音色。以下是一个示例代码,演示如何让用户选择不同的语音风格,并根据选择播放相应的语音效果。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 获取所有可用的语音
voices = engine.getProperty('voices')# 打印所有可用语音的信息
for voice in voices:print("Voice:")print(" - ID: %s" % voice.id)print(" - Name: %s" % voice.name)print(" - Languages: %s" % voice.languages)print(" - Gender: %s" % voice.gender)print(" - Age: %s" % voice.age)print("\n")# 函数:根据选择的语音ID播放文本
def speak_with_voice(text, voice_id):engine.setProperty('voice', voice_id)engine.say(text)engine.runAndWait()# 用户输入的文本
user_input = "Hello, how are you today?"# 用户选择的语音ID(根据上面打印的可用语音信息进行选择)
selected_voice_id = "com.apple.speech.synthesis.voice.Alex"# 播放文本,使用用户选择的语音
speak_with_voice(user_input, selected_voice_id)
在这个示例中,首先列出了所有可用的语音信息,包括语音ID、名称、语言、性别等。然后,用户可以根据打印的语音信息选择自己喜欢的语音。通过设置语音引擎的voice属性为用户选择的语音ID,可以播放相应的语音效果。
用户可以根据自己的喜好选择不同的语音风格、音色或声音特效,从而实现个性化的语音合成体验。这种自定义语音的方法可以增强虚拟现实应用的交互性和个性化,使用户能够根据自己的喜好定制语音输出。
十一、场景感知示例代码
 要实现根据用户在虚拟现实环境中的位置、动作或情境动态调整语音内容和反馈,您可以结合虚拟现实平台的传感器数据和逻辑来实现场景感知。以下是一个简单的示例代码,演示如何根据用户在虚拟现实环境中的位置信息,动态调整语音内容和反馈。
要实现根据用户在虚拟现实环境中的位置、动作或情境动态调整语音内容和反馈,您可以结合虚拟现实平台的传感器数据和逻辑来实现场景感知。以下是一个简单的示例代码,演示如何根据用户在虚拟现实环境中的位置信息,动态调整语音内容和反馈。
请注意,这个示例代码是一个简单的演示,实际应用中可能需要更复杂的逻辑和场景感知算法来实现更加智能和个性化的体验。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 函数:根据用户位置动态调整语音内容
def speak_based_on_location(user_location):if user_location == "living_room":engine.say("Welcome to the living room. Would you like a tour?")elif user_location == "kitchen":engine.say("You are now in the kitchen. How can I assist you?")elif user_location == "bedroom":engine.say("This is the bedroom. Would you like to rest?")else:engine.say("You are in an unknown location.")engine.runAndWait()# 模拟用户在虚拟环境中的位置
user_location = "living_room"# 根据用户位置动态调整语音内容
speak_based_on_location(user_location)
在这个示例中,用户在虚拟现实环境中的位置信息被模拟为一个字符串(例如"living_room"、“kitchen”、"bedroom"等)。根据用户的位置信息,调用相应的语音内容反馈,提供个性化的体验。
通过根据用户的位置、动作或情境动态调整语音内容和反馈,可以增强虚拟现实应用的沉浸性和个性化,使用户感觉更加与虚拟环境互动。在实际项目中,您可以根据具体需求和场景感知的复杂性进一步优化和扩展这个示例代码。
十二、音效结合示例代码
 要将Text-to-Speech生成的语音与环境音效结合,创造更加逼真的虚拟环境声音,增强用户的沉浸感,您可以使用Python中的库来实现音频的混合和播放。以下是一个简单的示例代码,演示如何结合Text-to-Speech生成的语音和环境音效,并播放这些声音以增强虚拟环境的沉浸感。
要将Text-to-Speech生成的语音与环境音效结合,创造更加逼真的虚拟环境声音,增强用户的沉浸感,您可以使用Python中的库来实现音频的混合和播放。以下是一个简单的示例代码,演示如何结合Text-to-Speech生成的语音和环境音效,并播放这些声音以增强虚拟环境的沉浸感。
import pyttsx3
import pygame
import time# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 初始化Pygame
pygame.init()# 函数:播放环境音效
def play_sound_effect(sound_file):pygame.mixer.init()pygame.mixer.music.load(sound_file)pygame.mixer.music.play()# 函数:合成语音并播放
def speak_with_sound_effects(text, sound_file):engine.say(text)engine.runAndWait()# 播放环境音效play_sound_effect(sound_file)# 用户输入的文本
user_input = "Welcome to the virtual world."# 环境音效文件
sound_file = "background_sound.wav"# 合成语音并播放,结合环境音效
speak_with_sound_effects(user_input, sound_file)# 等待一段时间,确保声音播放完成
time.sleep(5)
在这个示例中,首先使用Text-to-Speech引擎生成语音,并结合环境音效文件一起播放。通过结合语音和环境音效,可以增强用户在虚拟环境中的沉浸感,使体验更加逼真和丰富。
请确保环境音效文件存在并与代码中指定的文件名一致。您可以根据需要调整代码以适应更复杂的音效结合和播放逻辑,以创造更加引人入胜的虚拟环境声音体验。
十三、交互式故事体验示例代码
 要创建交互式故事体验,结合虚拟现实场景和Text-to-Speech技术,让用户通过语音与故事角色互动,影响故事情节的发展,您可以使用Python中的库和逻辑来实现这一目标。以下是一个简单的示例代码,演示如何创建一个交互式故事体验,让用户通过语音与故事角色互动并影响故事情节的发展。
要创建交互式故事体验,结合虚拟现实场景和Text-to-Speech技术,让用户通过语音与故事角色互动,影响故事情节的发展,您可以使用Python中的库和逻辑来实现这一目标。以下是一个简单的示例代码,演示如何创建一个交互式故事体验,让用户通过语音与故事角色互动并影响故事情节的发展。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 函数:角色对话和互动
def story_interaction():# 故事角色的初始对白engine.say("Welcome to the interactive story. I am the character in this story. What would you like to do?")engine.runAndWait()# 用户互动user_response = input("Your response: ")# 根据用户的回答,影响故事情节if "explore" in user_response:engine.say("Let's explore the mysterious forest together.")elif "fight" in user_response:engine.say("Prepare for battle!")else:engine.say("I'm not sure what you mean. Let's continue the story.")engine.runAndWait()# 开始交互式故事体验
story_interaction()
在这个示例中,用户通过语音输入与故事角色互动,并根据用户的回答来影响故事情节的发展。您可以根据需要扩展这个示例,增加更多的故事情节和用户互动选项,以创造更加丰富和引人入胜的交互式故事体验。
请注意,这只是一个简单的示例代码,实际项目中可能需要更复杂的逻辑和场景设计来实现更加精彩和个性化的交互式故事体验。您可以根据具体需求和创意进一步扩展和优化这个示例代码。
十四、个性化导览服务示例代码
 要实现个性化导览服务,根据用户的兴趣、偏好和历史行为数据提供个性化的虚拟导览服务,您可以结合用户数据和Text-to-Speech技术来实现这一目标。以下是一个简单的示例代码,演示如何根据用户的兴趣和偏好提供个性化的虚拟导览服务。
要实现个性化导览服务,根据用户的兴趣、偏好和历史行为数据提供个性化的虚拟导览服务,您可以结合用户数据和Text-to-Speech技术来实现这一目标。以下是一个简单的示例代码,演示如何根据用户的兴趣和偏好提供个性化的虚拟导览服务。
import pyttsx3# 初始化Text-to-Speech引擎
engine = pyttsx3.init()# 用户兴趣偏好数据(示例数据,可以根据实际情况进行更复杂的数据处理)
user_interests = {"history": True,"art": False,"science": True
}# 函数:个性化导览服务
def personalized_tour_guide(user_interests):# 根据用户兴趣提供个性化的导览服务if user_interests["history"]:engine.say("Welcome to the historical tour. Let me guide you through the historical artifacts in this virtual environment.")if user_interests["art"]:engine.say("Welcome to the art tour. Explore the beautiful artworks in this virtual gallery.")if user_interests["science"]:engine.say("Welcome to the science tour. Discover the wonders of science in this virtual laboratory.")engine.runAndWait()# 开始个性化导览服务
personalized_tour_guide(user_interests)
在这个示例中,根据用户的兴趣偏好数据,通过Text-to-Speech技术提供个性化的虚拟导览服务。您可以根据实际情况扩展这个示例,例如结合更多用户数据、引入机器学习算法来提供更精准的个性化导览服务等。
请注意,这只是一个简单的示例代码,实际项目中可能需要更复杂的数据处理和算法来实现个性化导览服务。根据具体需求和用户群体的特点,您可以进一步优化和扩展这个示例代码。
十五、归纳总结
 在将Google Text-to-Speech技术与虚拟现实(VR)结合,创造沉浸式体验时,以下是一些关键知识点的总结:
在将Google Text-to-Speech技术与虚拟现实(VR)结合,创造沉浸式体验时,以下是一些关键知识点的总结:
-
Google Text-to-Speech(TTS)技术:
- Google TTS是一种语音合成技术,能够将文本转换为自然流畅的语音。
- 它提供多种声音和语言选择,支持多种文本输入格式。
-
虚拟现实(VR)技术:
- 虚拟现实技术通过模拟环境和提供交互性,让用户沉浸于虚拟世界中。
- VR通常需要头戴式设备(如VR头盔)来提供视觉和听觉体验。
-
应用场景:
- 虚拟导游:利用TTS技术为用户提供虚拟导游服务,引导他们探索虚拟环境。
- 交互式学习:通过语音交互和TTS技术,提供个性化学习体验,让用户参与互动学习。
- 虚拟角色对话:让虚拟角色通过TTS技术与用户交流,增强沉浸感和互动性。
- 辅助用户界面:利用语音提示和指导,改善用户在虚拟环境中的体验。
- 语音交互:通过语音命令和回应,让用户与虚拟环境进行互动。
-
示例代码:
- 示例代码可以结合Python等编程语言和TTS库(如pyttsx3)来实现虚拟导游、个性化导览等功能。
- 代码可以根据用户输入和场景需求,调用TTS引擎来生成语音,提供沉浸式体验。
-
个性化体验:
- 根据用户的兴趣、偏好和历史行为数据,提供个性化的虚拟导览服务,增强用户体验和参与度。
- 可以结合机器学习算法和用户数据分析,实现更精准的个性化体验。
 通过将Google Text-to-Speech技术与虚拟现实技术结合,可以为用户提供更加沉浸式、交互式和个性化的体验,增强虚拟环境的吸引力和互动性。
通过将Google Text-to-Speech技术与虚拟现实技术结合,可以为用户提供更加沉浸式、交互式和个性化的体验,增强虚拟环境的吸引力和互动性。
相关文章:
第八篇【传奇开心果系列】python的文本和语音相互转换库技术点案例示例:Google Text-to-Speech虚拟现实(VR)沉浸式体验经典案例
传奇开心果博文系列 系列博文目录python的文本和语音相互转换库技术点案例示例系列 博文目录前言一、雏形示例代码二、扩展思路介绍三、虚拟导游示例代码四、交互式学习示例代码五、虚拟角色对话示例代码六、辅助用户界面示例代码七、实时语音交互示例代码八、多语言支持示例代…...
ubuntu使用LLVM官方发布的tar.xz来安装Clang编译器
ubuntu系统上的软件相比CentOS更新还是比较快的,但是还是难免有一些软件更新得不那么快,比如LLVM Clang编译器,目前ubuntu 22.04版本最高还只能安装LLVM 15,而LLVM 18 rc版本都出来了。参见https://github.com/llvm/llvm-project/…...

Windows 远程控制 Mac 电脑怎么操作
要从 Windows 远程控制 Mac 电脑,您可以使用内置 macOS 功能或第三方软件解决方案。以下是一些方法: 一、使用内置 macOS 功能(屏幕共享) 1、在 macOS 上启用屏幕共享 转至系统偏好设置 > 共享;选中“屏幕共享”…...

c# HttpCookie操作,建立cookie工具类
HttpCookie 是一个在.NET Framework中用于管理和操作HTTP Cookie的类。它提供了一种方便的方式来创建、设置、读取和删除Cookie。 Cookie是一种在客户端和服务器之间传递数据的机制,用于跟踪用户的会话状态和存储用户相关的信息。它通常由服务器发送给客户端&#…...

【这个词(Sequence-to-Sequence)在深度学习中怎么解释,有什么作用?】
🚀 作者 :“码上有前” 🚀 文章简介 :深度学习笔记 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 Sequence-to-Sequence(Seq2Seq) Sequence-to-Sequence(Seq2Seq…...

挑战30天学完Python:Day16 日期时间
📘 Day 16 🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点…...

Web3之光:揭秘数字创新的未来
随着数字化时代的深入发展,Web3正以其独特的技术和理念,为我们打开数字创新的崭新视角。作为数字化时代的新兴力量,Web3将深刻影响着我们的生活、工作和社会。本文将揭秘Web3的奥秘,探讨其在数字创新领域的前景和潜力。 1. 重新定…...
Stable Diffusio——采样方法使用与原理详解
简介 当使用稳定扩散(Stable Diffusion)技术生成图像时,首先会生成一张带有噪声的图像。然后,通过一系列步骤逐渐去除图像中的噪声,这个过程类似于从一块毛坯的白色大理石开始,经过多日的精细雕刻…...

小米14 ULTRA:重新定义手机摄影的新篇章
引言 随着科技的飞速发展,智能手机已经不仅仅是一个通讯工具,它更是我们生活中的一位全能伙伴。作为科技领域的佼佼者,小米公司再次引领潮流,推出了全新旗舰手机——小米14 ULTRA。这款手机不仅在性能上进行了全面升级&am…...

【leetcode热题】路径总和 II
难度: 中等通过率: 38.7%题目链接:. - 力扣(LeetCode) 题目描述 给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。 说明: 叶子节点是指没有子节点的节点。 示例: …...

ChatGPT在数据处理中的应用
ChatGPT在数据处理中的应用 今天的这篇文章,让我不断体会AI的强大,愿人类社会在AI的助力下走向更加灿烂辉煌的明天。 扫描下面二维码注册 数据处理是贯穿整个数据分析过程的关键步骤,主要是对数据进行各种操作,以达到最终的…...

微服务-Alibaba微服务nacos实战
1. Nacos配置中心 1.1 微服务为什么需要配置中心 在微服务架构中,当系统从一个单体应用,被拆分成分布式系统上一个个服务节点后,配置文件也必须跟着迁移(分割),这样配置就分散了,不仅如此&…...

Linux Driver | 设备树开发之初识设备树
Linux Driver | 设备树开发之初识设备树 时间:2024年2月22日20:35:13 文章目录 **Linux Driver** | 设备树开发之初识设备树参考1.设备树开发2.`Linux`设备树的由来3.`Linux`设备树的由来-为什么会有设备树4.设备树的由来5.快速编译设备树---**DTC** (`device tree compiler`)…...
2月24日(周六)比赛前瞻:曼联 VS 富勒姆、拜仁 VS 莱比锡
大家好,博主将持续更新胜负14场前瞻,此处每日赛事间歇更新,胃信号每日更新。 精选赛事:曼联 VS 富勒姆 曼联近期状态显著提升,上一轮联赛客场2-1战胜卢顿,连续7场正赛取得6胜1平的成绩,保持不败…...

React18源码: task任务调度和时间分片
任务队列管理 调度的目的是为了消费任务,接下来就具体分析任务队列是如何管理与实现的 在 Scheduler.js 中,维护了一个 taskQueue, 任务队列管理就是围绕这个 taskQueue 展开 // Tasks are stored on a min heap var taskQueue - []; var timerQueue …...
)
【工具类】阿里域名关联ip(python版)
获取代码如下 # codingutf-8import argparse import json import urllib import logging# 加载 ali 核心 SDK from aliyunsdkcore.client import AcsClient from aliyunsdkalidns.request.v20150109 import (DescribeSubDomainRecordsRequest,AddDomainRecordRequest,UpdateDo…...

STM32自学☞输入捕获测频率和占空比案例
本文是通过PA0口输出PWM波,然后通过PA6口捕获PWM波的频率和占空比,最终在oled屏上显示我们自己设置的频率和占空比。由于和前面的pwm呼吸灯代码有重合部分所以本文中的代码由前者修改而来,对于文件命名不要在意。 pwm_led.c文件 /* 编写步…...
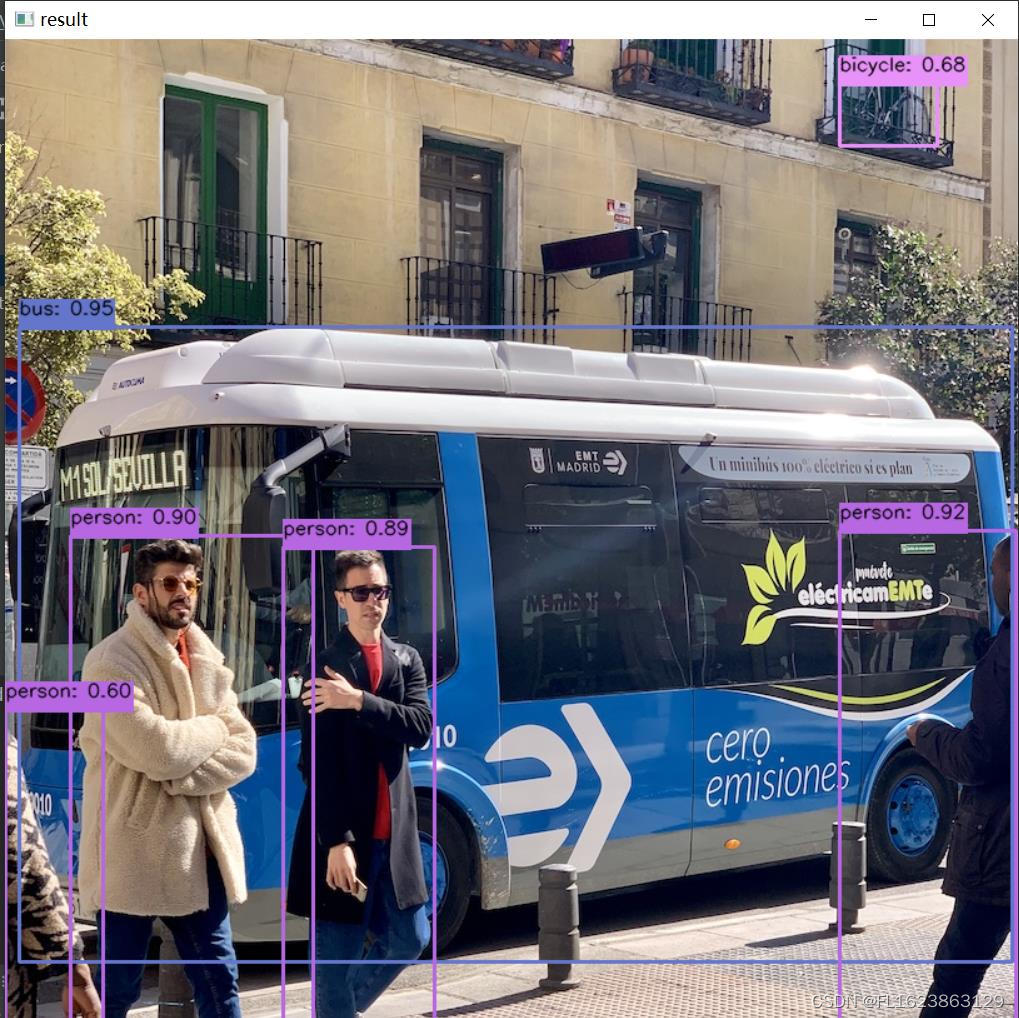
[yolov9]使用python部署yolov9的onnx模型
【框架地址】 https://github.com/WongKinYiu/yolov9 【yolov9简介】 在目标检测领域,YOLOv9 实现了一代更比一代强,利用新架构和方法让传统卷积在参数利用率方面胜过了深度卷积。 继 2023 年 1 月 正式发布一年多以后,YOLOv9 终于来了&a…...

ShellExecute的用法
1、标准用法 ShellExecute函数原型及参数含义如下: function ShellExecute(hWnd: HWND; Operation, FileName, Parameters,Directory: PChar; ShowCmd: Integer): HINST; stdcall; ●hWnd:用于指定父窗口句柄。当函数调用过程出现错误时,它将…...

蓝桥杯:递增三元组
题目 递增三元组(2018年蓝桥杯真题) 题目描述: 给定三个整数数组 A [A1, A2, … AN], B [B1, B2, … BN], C [C1, C2, … CN], 请你统计有多少个三元组(i, j, k) 满足: 1 < i, j, k < N Ai < Bj &…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...