面试必须要知道的常见排序算法
以下排序均为升序
1.直接插入排序
具体思想
把待排序的数据按大小比较插入到一个已经排序好的有序序列中,直到所有的待排序数据全部插入到有序序列中为止.实际生活中,我们平常斗地主摸牌时,就用到了插入排序的思想.
- 当插入第n个数据时,前面n-1个数据已经有序;
- 第n个数据依次与前n-1个数据比较大小,如果遇到比自己大的数x,则数x的位置向后移动一步,直到第一次遇到比自己小的数y停止,然后将这个第n个数据放在数y后面;
- 如果前n-1个数据都比当前这第n个数据要小,那么这第n个数据就插入到最前面.
代码实现
public void insertSort(int[] array){//第一个数字因为只有自身一个,所以本就是有序的,故待排序的数字下标为[0]~[array-1].依次遍历即可.for(int i=1;i<array.length;i++){int index=i-1;int cur=array[i];while(index>=0){if(cur<array[index]){//如果待插入的数字比当前数字要小,则当前数字向后移动一个位置array[index+1]=array[index];}else{//如果待插入的数字比当前数字要大,则直接插在当前数字的后面,结束循环array[index+1]=cur;break;}index--;}if(index<0){array[0]=cur;}}}
算法特性分析
对于要排序的数组,越接近有序,效率越高.该排序为稳定的排序.
时间复杂度:O(N^2)
空间复杂度:O(1),只借助了常数个变量
2. 希尔排序
具体思想
希尔排序又称缩小增量法,是直接插入排序的优化.因为通过直接插入排序我们了解到,数组越接近有序,排序的效率越高.所以希尔排序的大致思想就是先使数组大致有序后,然后再直接插入排序.所以可以将希尔排序理解为直接插入排序的优化.
那怎样做到先将一个数组做到基本有序呢.基本思路如下:
- 先选定一个gap值(gap<元素个数),然后所有距离为gap的数自动分为一组,然后对每组进行插入排序;
- 再更新gap的值(比原值要小),然后重复一的操作;
- 直到gap减小为1,然后数据基本有序了,然后对整组使用直接插入排序.
第三轮排序时,数组已经基本有序了,这时再用直接插入排序效率就很高了.至于这个gap的取值应该怎么取,很多资料也没有一个明确的说法.
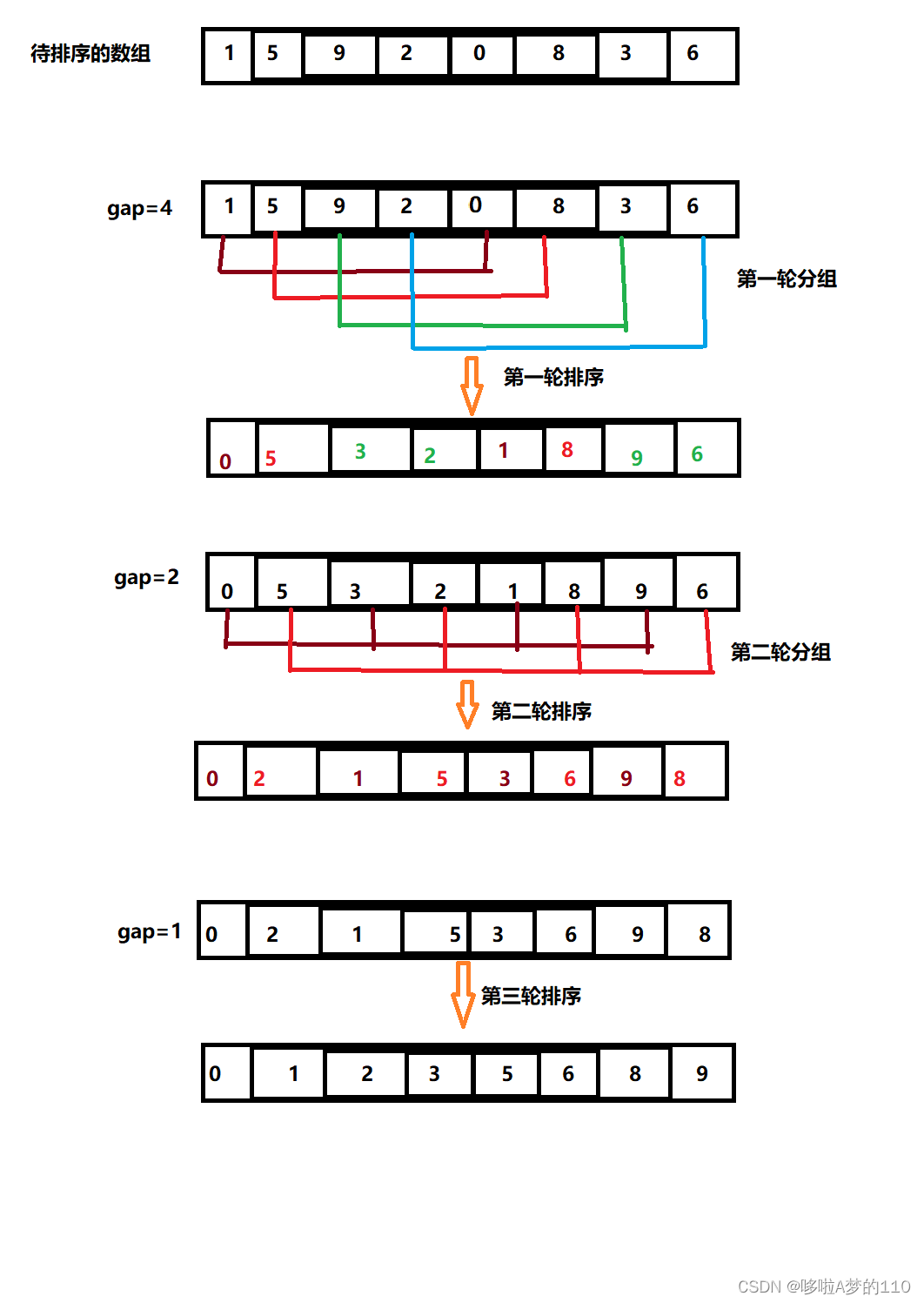


以下代码的实现,增量值我就用gap=(n+1)/2,gap=(gap+1)/2,直到gap=1为止
代码实现
public static void shellSort(int[] array){int gap=(array.length+1)/2;while(gap>1){shell(array,gap);gap=(gap+1)/2;}if(gap==1){shell(array,gap);}} public static void shell(int[] array,int gap){for (int i = gap; i <array.length ; i++) {int j=i-gap;int cur=array[i];while(j>=0){if(cur<array[j]){array[j+gap]=array[j];}else{array[j+gap]=cur;break;}j=j-gap;}if(j<0){array[j+gap]=cur;}}}
算法特性分析
- 该排序不稳定.
- 希尔排序的时间复杂度小于O(N^2),但是具体是多少还不好下定论,与其增量值有关.大概在O(N*1.3)~O(N*1.5)左右
- 空间复杂度:O(1)
3. 选择排序
具体思想
- 在待排序列表中找最小的数,将这个最小数与第一个位置上的数交换位置,这样这个数就有序了;
- 在剩余未被排序的元素中找最小值,将其与第二个位置上的数交换位置,这样这个数也有序了;
- 以此类推,每个数都到了它应该在的位置,自然整个列表就有序了.
代码实现
public static void selectSort(int[] array){for (int i = 0; i <array.length ; i++) {int min=array[i];int index=i;for(int j=i+1;j<array.length;j++){if(min>array[j]){min=array[j];index=j;}}array[index]=array[i];array[i]=min;} }
算法特性分析
- 直接选择排序很好理解,但实际效率不高,很少使用,是不稳定的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
4. 堆排序
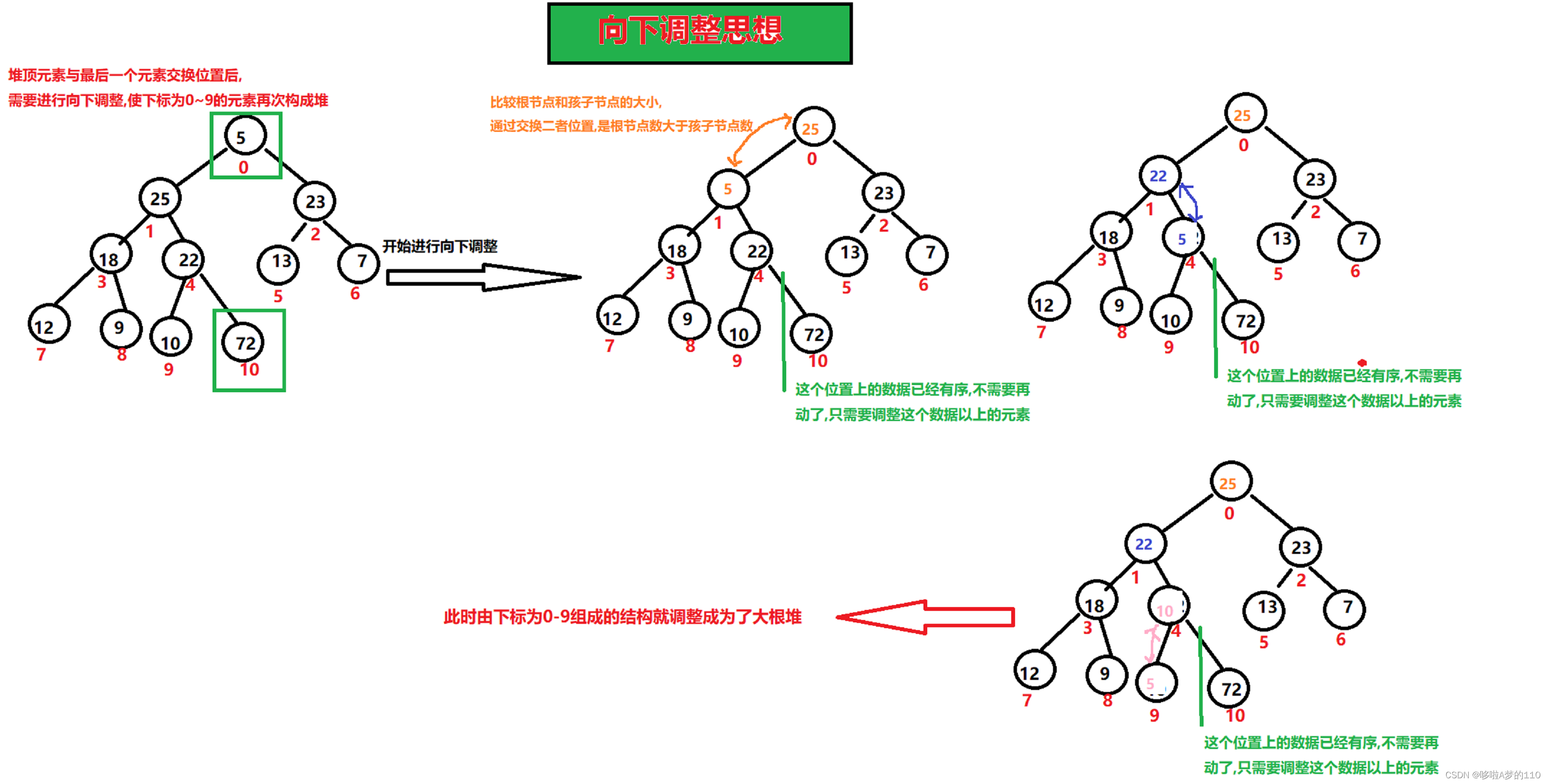
调整一颗子树成为大根堆:
比较根节点和左右孩子的最大值,通过交换二者的位置保证根节点的值比左右子树都大;
如果根节点与孩子节点未发生交换,说明该子树本身就是大根堆;
如果根节点与孩子节点发生过交换,则需要判断交换后的以孩子节点为根节点的子树是否仍为大根堆,重复1的操作,结束条件为该节点没有孩子节点或不需要发生交换.
/** * 向下调整子树* @param array * @param parent 需要调整子树的根节点位置* @param end 该子树的最后一个叶子节点的位置*/ private static void shiftDown(int[] array, int parent, int end) {int child=parent*2+1;while(child<=end){//说明有孩子,找到左右孩子的最大值if(child+1<=end&&array[child]<array[child+1]){child++;}//此时child下标保存的是左右孩子最大值的下标//将根节点与孩子的最大值做比较if(array[parent]<array[child]){int tmp=array[parent];array[parent]=array[child];array[child]=tmp;parent=child;//开始更新下标,继续看下面的子树是不是大根堆child=parent*2+1;}else{break;}}}建堆思想:
1).从最后一颗子树开始调整,使这颗子树成为大根堆
- 确定最后一颗子树的根节点p的下标: p=(len-1-1)/2
2).调整完这颗子树后,找到下一棵树的根节点(p--),然后重复1的操作.
3).直到调整完0下标这棵树就结束了.
具体思想
1.建大根堆
//1.建大根堆(对每颗子树进行向下调整) for(int i=(array.length-1-1)/2;i>=0;i--){shiftDown(array,i,array.length-1); }2.交换大根堆的第一个元素与最后一个元素的位置,然后将数组下标为[0]~[length-1]的所有元素进 行向下调整,使其成为大根堆.
3.再次交换大根堆的第一个元素与大根堆的最后一个元素(即列表倒数第二个元素的位置),然后再将数组下标为[0]~[length-2]的所有元素进行向下调整,使其成为大根堆.
4.以此类推,每次构成大根堆的元素都会减少一个,直到大根堆的元素减少到只有一个时,数组排序完成.
代码实现
public static void heapSort(int[] array){//1.建大根堆(对每颗子树进行向下调整)for(int i=(array.length-1-1)/2;i>=0;i--){shiftDown(array,i,array.length-1);}//2.将大根堆的第一个元素与最后一个元素交换位置,然后继续向下调整,直到大根堆只剩一个元素for (int i = array.length-1; i >0 ; i--) {int tmp=array[i];array[i]=array[0];array[0]=tmp;shiftDown(array,0,i-1);}}/*** 向下调整子树* @param array* @param parent 需要调整子树的根节点位置* @param end 该子树的最后一个叶子节点的位置*/private static void shiftDown(int[] array, int parent, int end) {int child=parent*2+1;while(child<=end){//说明有孩子,找到左右孩子的最大值if(child+1<=end&&array[child]<array[child+1]){child++;}//此时child下标保存的是左右孩子最大值的下标//将根节点与孩子的最大值做比较if(array[parent]<array[child]){int tmp=array[parent];array[parent]=array[child];array[child]=tmp;parent=child;//开始更新下标,继续看下面的子树是不是大根堆child=parent*2+1;}else{break;}}}
特性分析
- 堆排序使用堆来选择元素,使效率高了不少.是不稳定排序
- 时间复杂度:O(N*logN)
- 空间复杂度:O(1)
5. 冒泡排序
具体思想
- 将下标为0的元素与下标为1的元素进行比较
- 若下标为0的元素大于下标为1的元素,则交换二者位置;反之则不用交换.
- 将下标为1的元素与下标为2的元素进行比较
- 重复2的操作
- 以此类推,直到将数组的最后一个元素与其前一个元素进行大小比较,交换位置之后,结束本轮循环.此时,最后一个元素就是待排序数组中的最大值,已经有序.
- 除去已经有序的元素,将剩余的元素进行1-5的操作,直到数组元素全部有序
代码实现
public static void bubbleSort(int[] array){int len=array.length;//每一趟排序都会使最后一个元素有序for(int i=0;i<len;i++){//使最后一个元素有序for(int j=0;j<len-1-i;j++){if(array[j]>array[j+1]){//当前者比后者大时,交换二者位置int tmp=array[j];array[j]=array[j+1];array[j+1]=tmp;}}}}但是以上代码效率低下,因为当数组不管是否有序,按照该代码始终都会进行len趟的循环,每一趟使一个元素有序.如果数组在len趟之前就已经有序,那代码依然会走完这len趟,而正常情况下,我们希望数组有序后就结束.对于这个缺陷,可以将代码做一下优化:
public static void bubbleSort(int[] array){int len=array.length;boolean flag=true;//每一趟排序都会使最后一个元素有序for(int i=0;i<len;i++){flag=false;//使最后一个元素有序for (int j = 0; j < len - 1 - i; j++) {if (array[j] > array[j + 1]) {flag = true;//当前者比后者大时,交换二者位置int tmp = array[j];array[j] = array[j + 1];array[j + 1] = tmp;}}//一趟结束之后,发现flag没有被修改,说明此时数组已经有序,可以退出了if(!flag){break;}}}
特性分析
- 非常容易理解的排序,是稳定排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
6.快速排序
具体思想
- 先从待排序数组中选取最左端作为一个基准值(也可以选取最右端),然后通过"某一方法"找到它应该在的位置(即代码最终有序时它所在的位置),这样该位置的左边均小于等于这个基准值,右边均大于等于这个基准值.此时,我们可以理解为这个位置将这个待排序数组分成了左右两个子序列.而我们的接下来就是让这左右两个子序列分别有序.
- 再将左子序列作为待排序数组,重复1的操作,直到所有值都在其对应位置上为止.
- 右子序列的处理方法与左子序列相同.
伪代码如下(partition方法即为上述中的"某一方法"):
private static void quick(int[] array, int left, int right) {if(left>=right)return;//找基准值int pivot=partition(array,left,right);//递归的找左右子序列的基准值quick(array,left,pivot-1);quick(array,pivot+1,right);}
以上提到的"某一方法"是什么呢,也就是如何将最左端的值在它应该放的位置.在这里我将介绍两种方法:Hoare法和挖坑法.
Hoare法思路:
- 先用left指向最左端元素,right指向最右端数据.选取最左边作为key值(基准值).
- 将right所指的数与key值做比较,大于key则right向左走一步(right--),再次进行比较,直到找到比key值小的数停下来;
- 将left所指的数与key值做比较,小于key则left向右走一步(left++),再次进行比较,直到找到比key值大的数停下来;
- 重复2和3的操作,直到right和left相遇,交换最左边位置上的key值与相遇位置上的数,此时key值(基准值)的位置就确定了。
注意看,最后key值8最后放在了它应该在的位置.也就是它的左边元素均小于它,右边元素均大于它
代码实现
/*** 确定基准值的位置* @param array* @param left* @param right* @return*/private static int partition(int[] array, int left, int right) {int tmp=array[left];int start=left;while(left<right){while(left<right&&array[right]>=tmp){right--;}while(left<right&&array[left]<=tmp){left++;}int cur=array[right];array[right]=array[left];array[left]=cur;}array[start]=array[left];array[left]=tmp;return left;}
挖坑法思路:
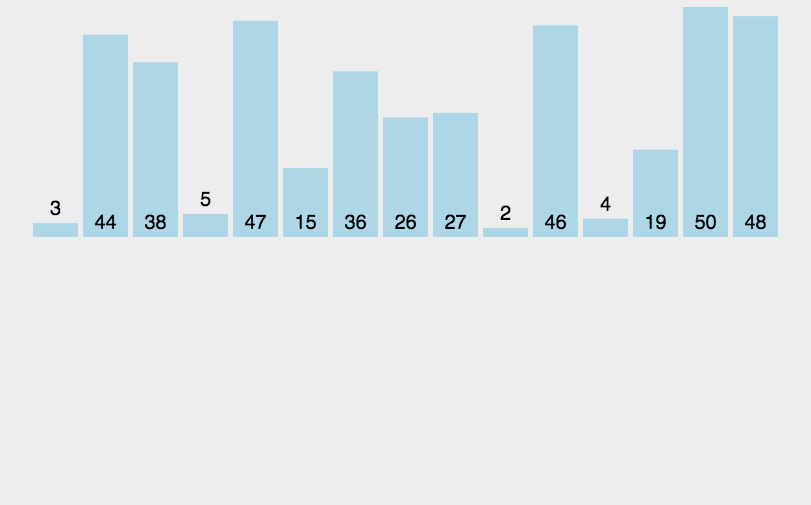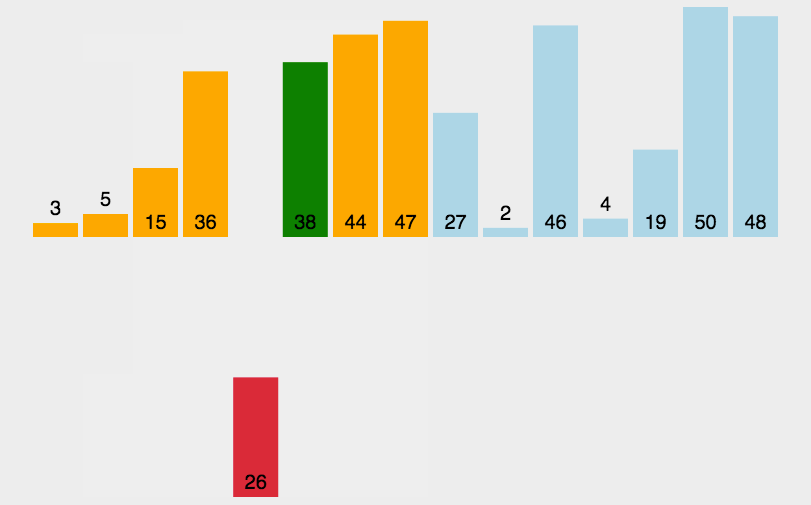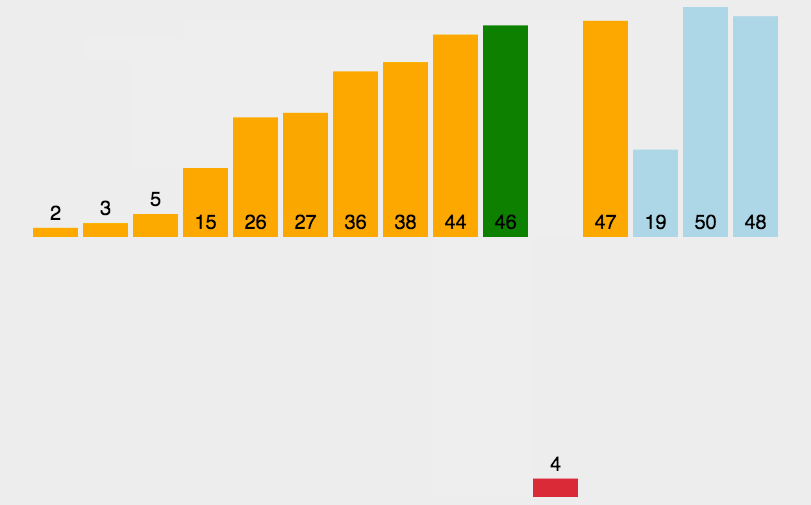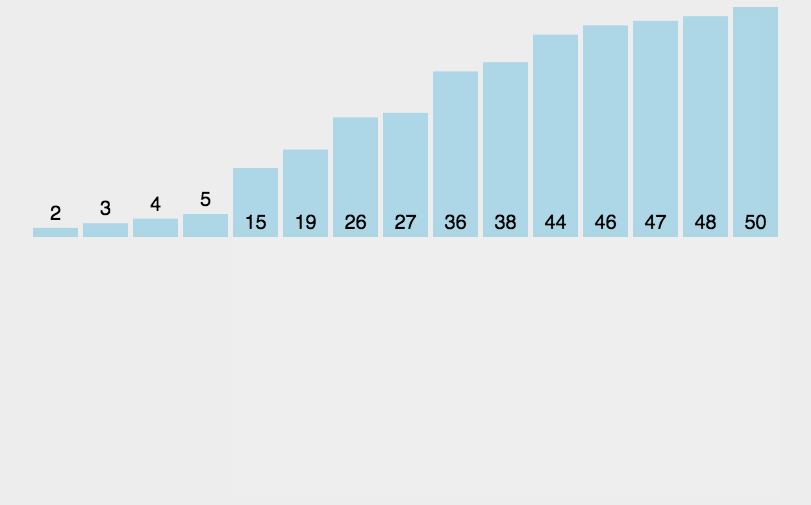
挖坑法和Hoare法有点相似。选取最左边位置为坑,将其坑中的值保存到key中,然后依次左边找小,右边找大,找到后放入坑中。直到左右相遇,将key值放入坑中,此时key值有序,即基准值位置确定。具体思路如下图:
private static int partition(int[] array, int left, int right) {int key=array[left];while(left<right){while(left<right&&array[right]>=key){right--;}array[left]=array[right];while (left<right&&array[left]<=key){left++;}array[right]=array[left];}array[left]=key;return left;}
整体代码实现
public static void quickSort(int[] array){quick(array,0,array.length-1);}private static void quick(int[] array, int left, int right) {if(left>=right)return;int pivot=partition2(array,left,right);quick(array,left,pivot-1);quick(array,pivot+1,right);}//用挖坑法来找基准值private static int partition2(int[] array, int left, int right) {int key=array[left];while(left<right){while(left<right&&array[right]>=key){right--;}array[left]=array[right];while (left<right&&array[left]<=key){left++;}array[right]=array[left];}array[left]=key;return left;}
快速排序的优化
为什么要对快速排序进行优化,其实我们分析一下它的时间复杂度就知道,在找基准值的位置时,我们都会将该序列分为左右两个子序列,左边比基准值小,右边比基准值大.然后去找左子序列基准值的位置,又将这个左子序列分为左右两个子序列,一直递归下去,直到只有一个值,无法分为左右子序列为止.就很像二叉树遍历一样,一直到没有左右子树.接着对有子序列做同样的操作.所以它的时间复杂度是O(N*logN).但是,有没有想过,如果当待排序数组本身就有序的话,再用这个方法排序的话,效率将会非常低下了.因为如果还是将最左端的值当做基准值去找它的位置的话,就不会同时有左右子序列了,那这个结构就像下图这样:
高度为n,那么时间复杂度就变成了O(N*N),就跟冒泡排序差不多了.这很显然不是我们想要看到的结果.我们理想中的结果是,最左边的那个基准值的位置在待排序数组中的中间位置,这样才能保证同时有左右子序列,这样时间复杂度才是O(N*logN).
那我们怎样进行优化呢?搞清楚问题我们才能对症下药,导致快排时间复杂度变为O(N^2)的情况,是因为在数组有序情况下,我们在将最左边作为基准值,去找它对应的位置时,这个基准值的位置就在边上,导致左右子序列元素个数相差很大甚至最后全部呈以上图所示的情况.而理想情况下,应该是基准值的位置刚好将待排序数组分为元素个数相差无几的左右两个序列.所以解决办法是,选取最左边的数为基准值,而这个基准值最终会放在靠中间的位置,将数组分为左右两个元素个数相差无几子序列.因此我们可以用三数取中法.
三数取中法思路:
将子序列中最左端、最右端、和中间位置上的三个数相互比较大小,使第二大的数放在最左端,这时,选取最左端作为基准值,然后去找它所在的位置,这样就能确保它所在的位置能将该序列分为左右两个子序列了。

此时优化后的完整快排如下:
public static void quickSort(int[] array){quick(array,0,array.length-1);}private static void quick(int[] array, int left, int right) {if(left>=right)return;int pivot=partition3(array,left,right);quick(array,left,pivot-1);quick(array,pivot+1,right);}private static int partition3(int[] array, int left, int right) {//选取从最左、最右、中间选取中间大小的值int midIndex=getMidIndex(array,left,right);//将中间大小的值与最左边的值换位置。int tmp=array[left];array[left]=array[midIndex];array[midIndex]=tmp;//用挖坑法找基准值的位置int key=array[left];while(left<right){while(left<right&&array[right]>=key){right--;}array[left]=array[right];while (left<right&&array[left]<=key){left++;}array[right]=array[left];}array[left]=key;return left;}//三数取中private static int getMidIndex(int[] array, int left, int right) {int mid=(left+right)>>>2;if(array[left]<array[right]){if(array[mid]<array[left]){return left;}else if(array[mid]>array[right]){return right;}else{return mid;}}else{if(array[mid]>array[left]){return left;}else if(array[mid]<array[right]){return right;}else{return mid;}}}此时该排序的时间复杂度为O(N*logN),空间复杂度为O(N).不稳定排序.
7.归并排序
具体思想
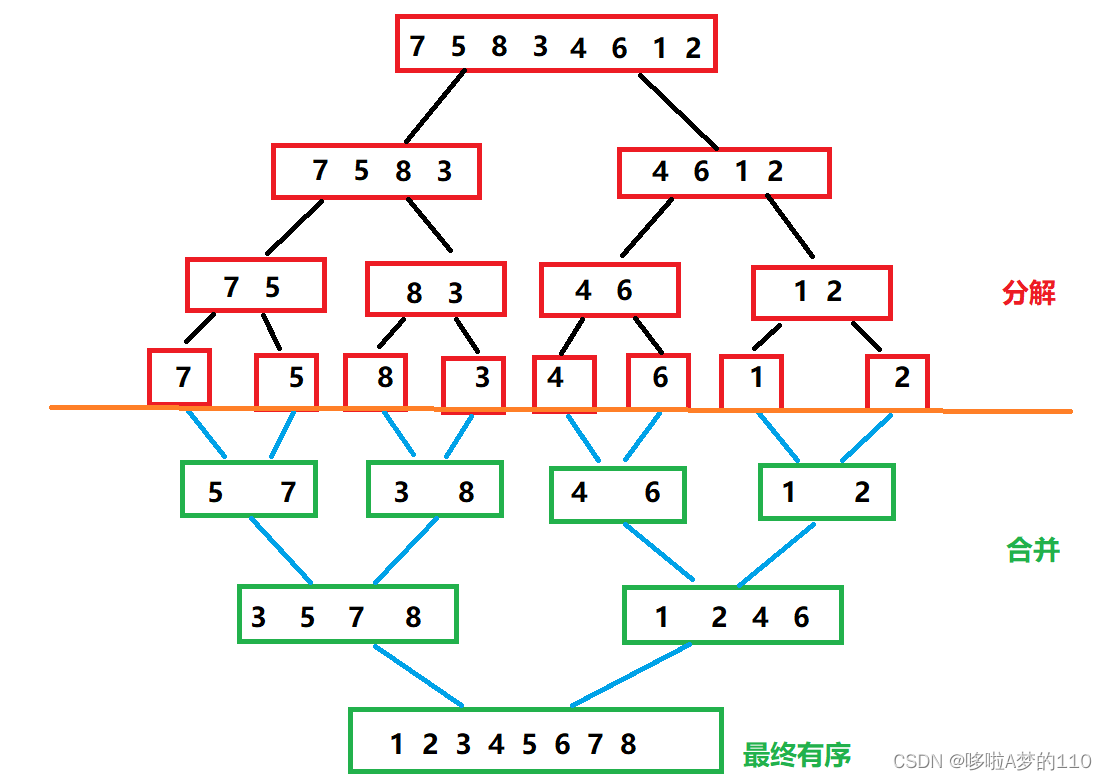
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。将两个有序表合并成一个有序表,称为二路归并。
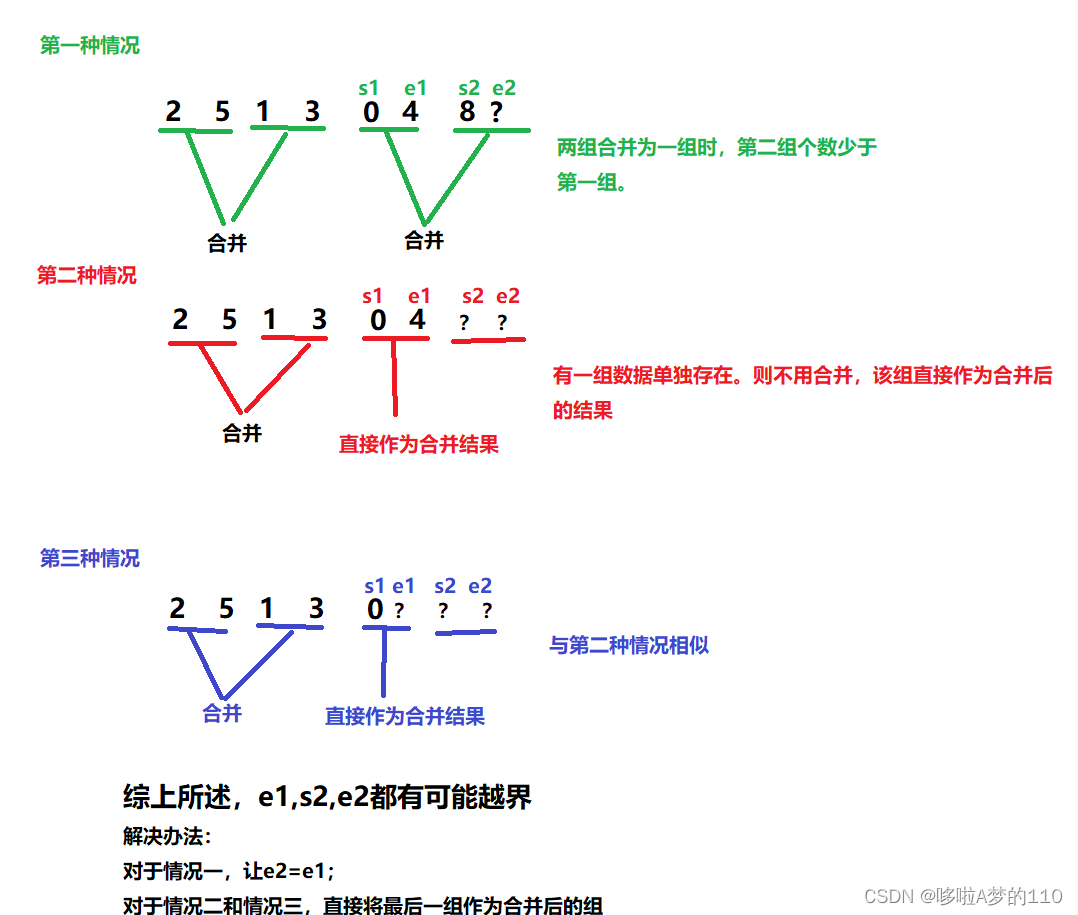
但是以上情况是比较理想的情况,我们在合并的时候恰好是两两一组,这与元素个数紧密关系,但是在普遍情况下,拆分后合并时会有以下各种各样的情况,比如:
代码实现
public static void mergeSort(int[] array){int gap=1;int len=array.length;int[] tmp=new int[len];while(gap<len) {int index=0;for (int i = 0; i < array.length; i += 2 * gap) {int s1 = i;int e1 = i + gap - 1;int s2 = e1 + 1;int e2 = s2 + gap - 1;//e1,s1,e2都有可能越界,所以要针对不同情况对e1,s1,s2做出调整//e1或s1越界,则不需要合并if (e1 >=len||s1>=len){break;}//e2越界if(e2>=len){e2=len-1;}//开始合并while(s1<=e1&&s2<=e2){if(array[s1]<=array[s2]){tmp[index++]=array[s1];s1++;}else{tmp[index++]=array[s2];s2++;}}while(s1<=e1){tmp[index++]=array[s1++];}while(s2<=e2){tmp[index++]=array[s2++];}//把归并好的部分赋值给原数组for(int j=0;j<=e2;j++){array[j]=tmp[j];}}gap*=2;}}
算法特性分析
- 该排序为稳定排序。
- 时间复杂度:O(N*longN) 空间复杂度:O(N).
- 归并的缺点在于需要O(N)的空间复杂度,归并排序用的更多的是解决在磁盘中的外部排序问题
外部排序:排序过程需要借助磁盘的外部存储进行的排序。
比如进行海量数据排序时,需要对100G的数据进行排序,但是内存只有1G。我们就可以用归并排序了.
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序,大致思路如下
- 先把文件切分成 200 份,每个 512 M
- 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
- 进行二路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
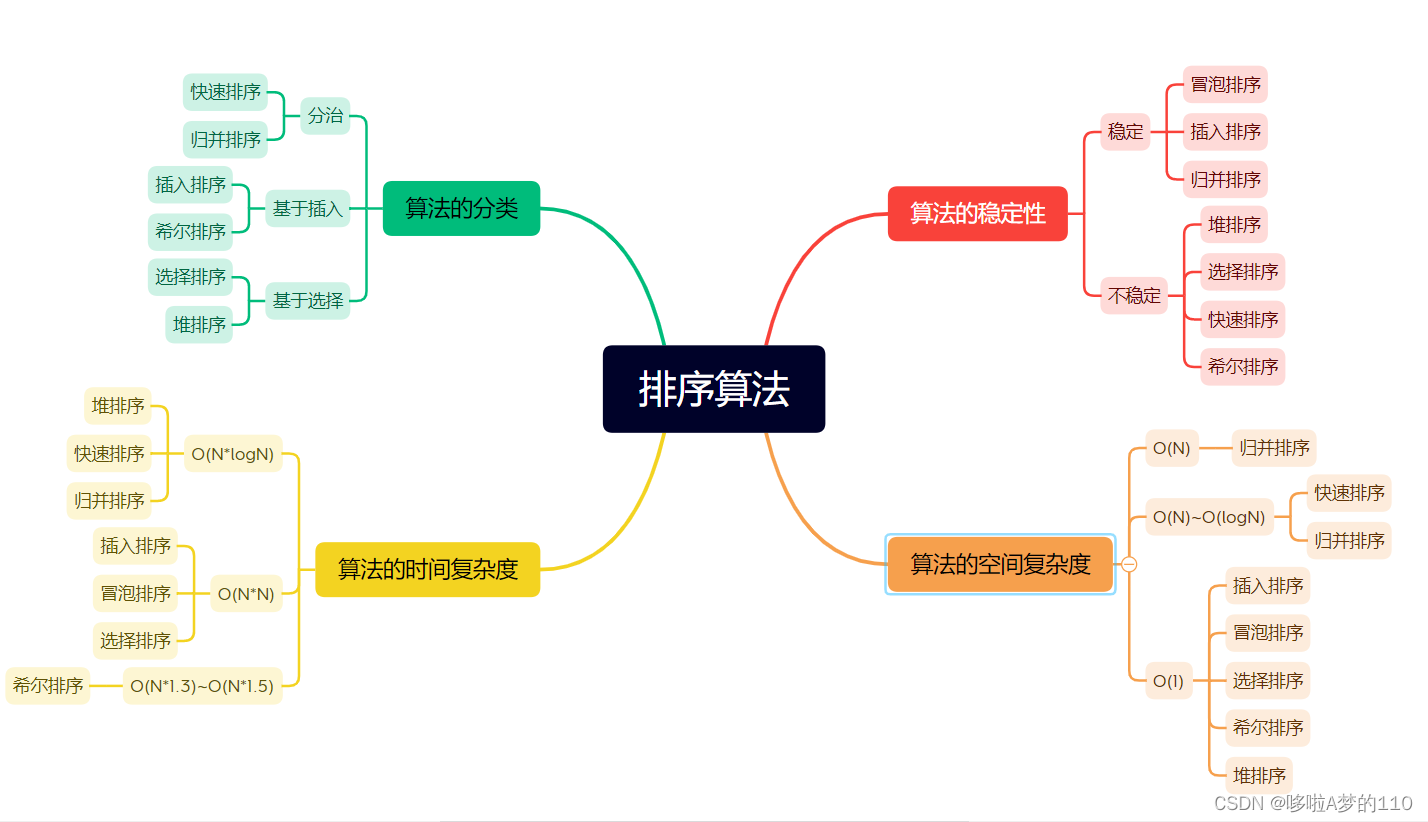
总结:
相关文章:
面试必须要知道的常见排序算法
以下排序均为升序 1.直接插入排序 具体思想 把待排序的数据按大小比较插入到一个已经排序好的有序序列中,直到所有的待排序数据全部插入到有序序列中为止.实际生活中,我们平常斗地主摸牌时,就用到了插入排序的思想. 当插入第n个数据时,前面n-1个数据已经有序;第n个数据依次与前…...

Kubernetes之服务发布
学了服务发现后,svc的IP只能被集群内部主机及pod才可以访问,要想集群外的主机也可以访问svc,就需要利用到服务发布。 NodePort Nodeport服务是外部访问服务的最基本方式。当我们创建一个服务的时候,把服务的端口映射到kubernete…...

【第二章】谭浩强C语言课后习题答案
1. 什么是算法?试从日常生活中找3个例子,描述它们的算法 算法:简而言之就是求解问题的步骤,对特定问题求解步骤的一种描述。 比如生活中的例子: 考大学首先填报志愿表、交报名费、拿到准考证、按时参加考试、收到录取通知书、按照日期到指定学校报到。 去北京听演唱会首先…...

PostgreSQL和PostGISWGS84和CGCS2000与GCJ02和BD09坐标系与之间互转
– 如果转换后结果为null,查看geom的srid是否为4326或者4490 WGS84转GCJ02 select geoc_wgs84togcj02(geom) from test_table GCJ02转WGS84 select geoc_gcj02towgs84(geom) from test_table WGS84转BD09 select geoc_wgs84tobd09(geom) from test_table BD09转WGS84 select …...
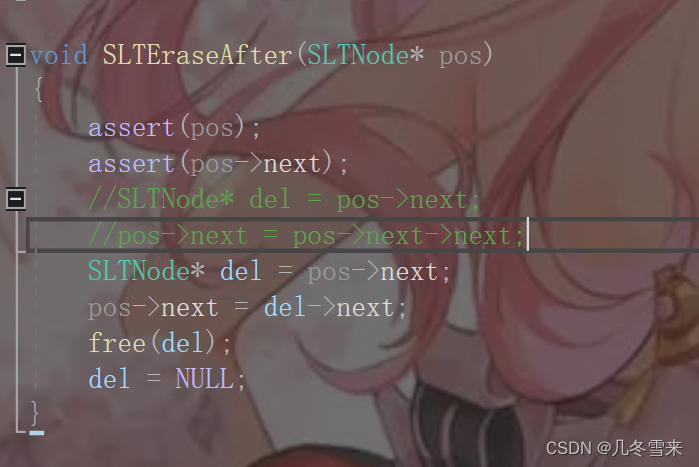
数据结构——链表讲解(2)
作者:几冬雪来 时间:2023年3月5日 内容:数据结构链表讲解 目录 前言: 剩余的链表应用: 1.查找: 2.改写数据: 3.在pos之前插入数据: 4.pos位置删除: 5.在pos的后…...
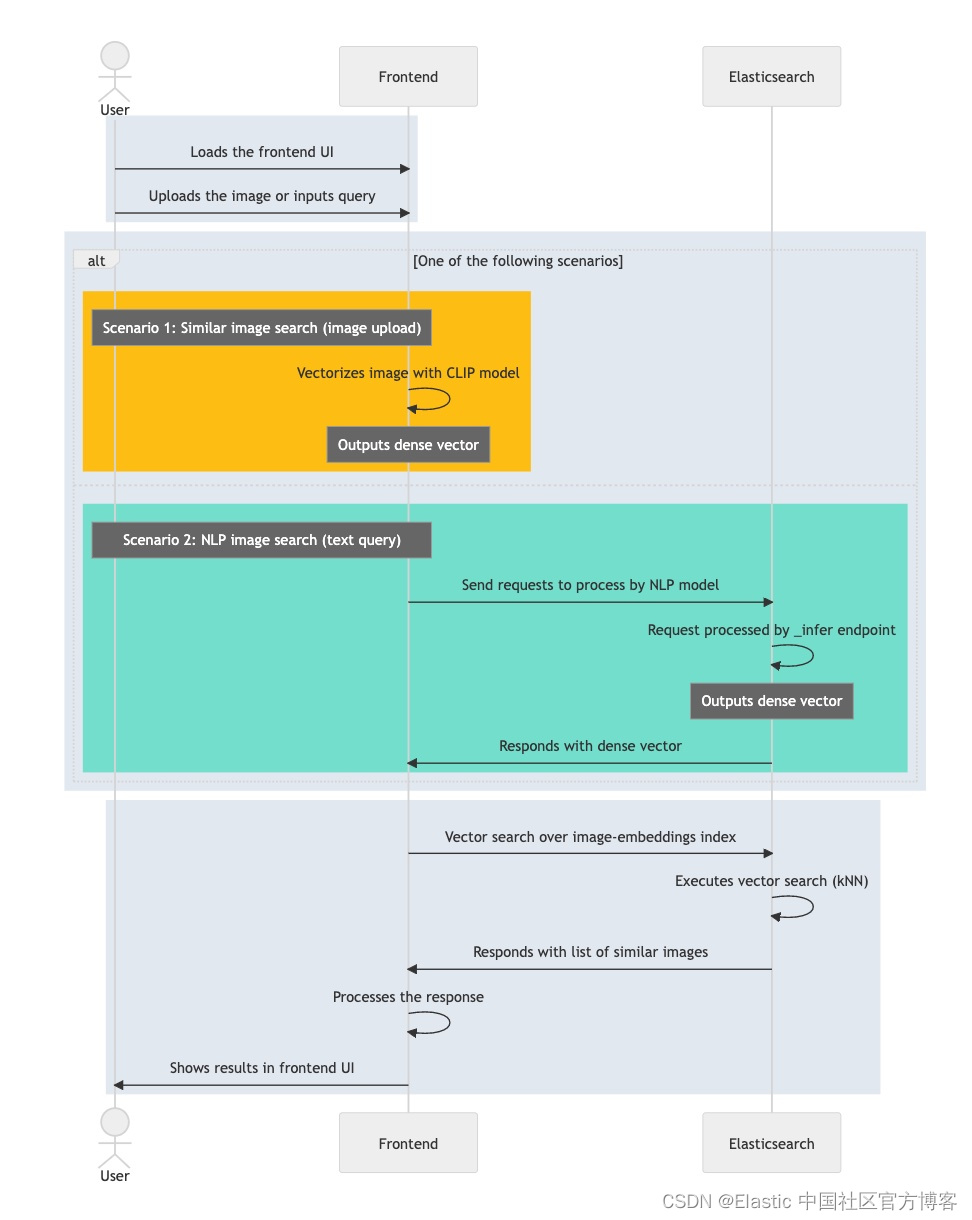
Elasticsearch:图片相似度搜索的 5 个技术组成部分
作者:Radovan Ondas,Bernhard Suhm 在本系列博文的第一部分中,我们介绍了图像相似度搜索,并回顾了一种可以降低复杂性并便于实施的高级架构。 此博客解释了实现图像相似性搜索应用程序所需的每个组件的基本概念和技术注意事项。 学…...
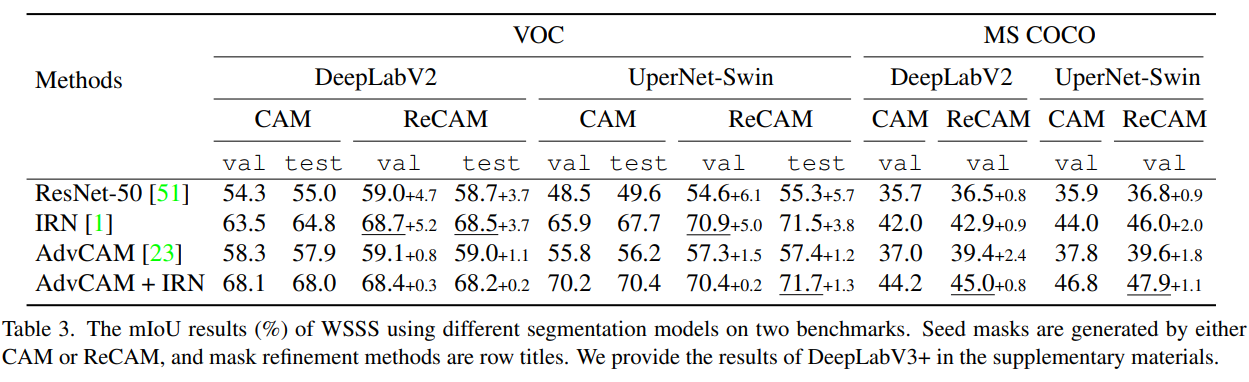
【CVPR2022】Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation
论文标题:Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation收录:CVPR 2022paper: https://arxiv.org/abs/2203.00962code: https://github.com/zhaozhengChen/ReCAM解读:https://zhuanlan.zhihu.com/p/478133151https:…...
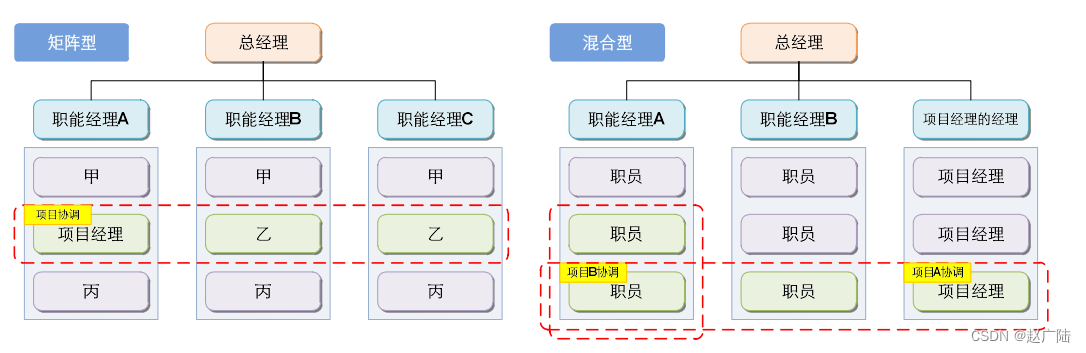
PMP项目管理项目运行环境
目录1 概述2 事业环境因素和组织过程资产3 组织系统3.1 概述3.2 组织治理框架3.2.1 治理框架3.2.2 项目治理3.3 管理要素3.4 组织结构类型3.4.1 组织结构类型3.4.2 项目管理办公室1 概述 项目所处的环境可能对项目的开展产生有利或不利的影响,这些影响的两大主要来…...

Vue 3.0 渲染函数 【Vue3 从零开始】
Vue 推荐在绝大多数情况下使用模板来创建你的 HTML。然而在一些场景中,你真的需要 JavaScript 的完全编程的能力。这时你可以用渲染函数,它比模板更接近编译器。 让我们深入一个简单的例子,这个例子里 render 函数很实用。假设我们要生成一些…...
西电软件体系结构核心考点汇总(期末真题+核心考点)
文章目录前言一、历年真题二、核心考点汇总2.1 什么是软件体系架构?(软件体系结构的定义)2.2 架构风格优缺点2.3 质量属性2.4 质量评估前言 主要针对西安电子科技大学《软件体系结构》的核心考点进行汇总。 【期末期间总结资料如下】 针对西电计科院软件工程专业大三《软件体…...

SRS源码分析-SDP内容解析
前言 在学习SRS的RTC模块之前,首先来分析下SRS在将rtmp推流转成rtc流,通过浏览器拉取webrtc流场景下产生的SDP内容 SDP格式介绍 SDP数据是文本格式,由多个 <key><value> 表达式构成,<key>的值只能是一个字符…...

HTML 颜色
HTML 颜色 HTML 颜色采用的是 RGB 颜色,是通过对红 (R)、绿 (G)、蓝 (B) 三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB 即是代表红、绿、蓝三个通道的颜色。 Color Values HTML 颜色由一个十六进制符号来定义,这个符…...

MySQL高可用架构之InnoDB Cluster部署
MySQL高可用架构之InnoDB Cluster部署InnoDB Cluster适用场景准备工作安装MySQL Shell使用MySQL Shell搭建InnoDB Cluster初始化第一个实例创建InnoDB Cluster添加副本实例创建相关用户MySQL Router部署安装MySQL Router引导MySQL Router启动MySQL Router环境准备 主机名IPOS版…...
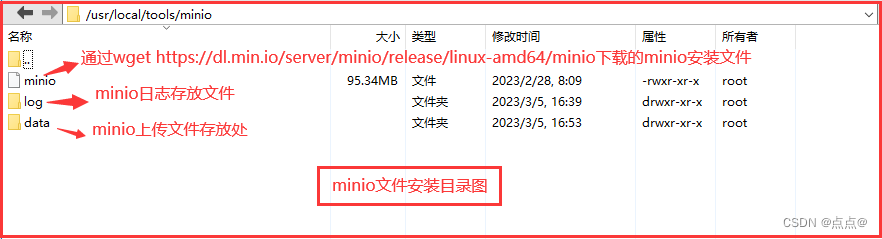
Linux安装minio单机版
说明:因为前面记录了一下minio的使用,这里说一下minio的安装,只是单机版哦 环境准备:Linux系统 说明图: 1.创建文件夹命令 我的是安装在/usr/local 文件夹下面的创建文件夹命令 #进入目标文件夹 cd /usr/local#创建…...
四)
网络总结知识点(网络工程师必备)四
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 目录 前言 71.NAPT有什么特点? 72.ARP欺骗解决方法...
)
数据结构——第三章 栈与队列(5)
共用栈和双队列1.共用栈2.双端队列栈与队列的本章小节1.共用栈 在实际应用中,有时一个应用程序需要多个栈,但这些栈的数据元素类型相同。假设每个栈都采用顺序栈,由于每个栈的使用情况不尽相同,势必会造成存储空间的浪费。若让多…...

CSDN竞赛第33期题解
CSDN竞赛第33期题解 1、题目名称:奇偶排序 给定一个存放整数的数组,重新排列数组使得数组左边为奇数,右边为偶数。(奇数和偶数的顺序根据输入的数字顺序排 列) #include<bits/stdc.h> using namespace std; t…...
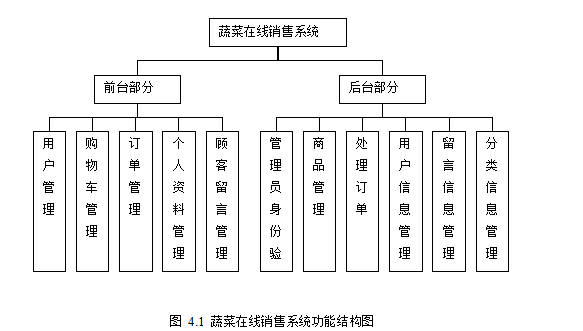
农产品销售系统的设计与实现
技术:Java、JSP等摘要:这篇文章主要描述的是农产品蔬菜在线销售系统的设计与实现。主要应用关于JSP网站开发技术,并联系到网站所处理的数据的结构特点和所学到的知识,应用的主要是Mysql数据库系统。系统实现了网站的基本功能&…...

C语言-基础了解-08-C判断
C判断 一、C判断 判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。 C 语言把任何非零和非空的值假定为 true,把零或 null 假…...

用数组名作函数参数的详解,以及形参实参采用数组名,形参实参采用指针变量的几种情况解析
关于地址,指针,指针变量可以参考我的这篇文章: 地址,指针,指针变量是什么?他们的区别?符号(*)在不同位置的解释?_juechen333的博客-CSDN博客https://blog.csd…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...