网络原理-UDP/TCP协议
协议
在网络通信中,协议是非常重要的一个概念,在下面,我将从不同层次对协议进行分析.
应用层
IT职业者与程序打交道最多的一层,调用系统提供的API写出的代码都是属于应用层的.
应用层中有很多现成的协议,但是更多的,我们需要根据实际情况来进行制作自定义协议.
自定义协议(网络传输的数据要怎么使用,数据是什么样的格式,里面包含什么内容)
自定义协议,需要约定好以下两个方面的内容:
1.服务器和客户端之间要交互哪些信息~~(客户端按照上述约定发送请求,服务器按照上述约定来解析请求)
2.数据的具体格式(服务器按照上述约定来构造响应,客户端也按照上述约定来解析响应)
举一个简单的例子:
1.请求,约定按照行文本的格式来进行表示,
userid,position\n 一个请求以\n为结尾.多个字段之间以,分割
1000,[经纬度]\n
2.响应,也是用行文本来进行表示,一个响应可能会包含多个商家,每个商家都要占一行.每个商家都要返回id,名称,图片,评分,简介(若干行之后,使用空行作为所有数据的结束标记)
(下面的一系列内容是同一个响应的数据)
1001,张亮麻辣烫,[logo图片地址],4.8非常好吃的麻辣烫\n
1002,魏家凉皮,[logo图片地址],4.7,很好吃的\n
\n
客户端和服务器之间往往需要进行交互的"结构化数据"(数据是一个结构体/类,包含许多属性)
网络传输的数据其实是"字符串""二进制bit流"
约定协议的过程,就是把结构化的数据转换成字符串/二进制比特流的过程
把结构化数据转换成字符串/二进制比特流 这个操作称为序列化
把字符串/二进制比特流还原成结构化数据 这个操作称为反序列化
序列化/反序列化具体要组织成什么样的格式,这里包含哪些信息~~
约定好这两件事的过程就是自定义协议的过程.
1.XML协议格式
请求:
<request>
<userId>1000</userId>
<position>[经纬度]</postion>
</request>
响应:
<response>
<shops>
<shop>
<id>1001</id>
<name>张亮麻辣烫</name>
</shop>
</shops>
</response>
这里的标签是成对出现的,<userId>成为开始标签,</userId>成为结束标签,开始标签和结束标签中间夹着的就是标签的值,表现也可以嵌套,这里标签的名字,标签的值标签的嵌套都是自定义的.
优点:可读性和扩展性提高了很多,后续要是增加一个属性,对已有代码影响不大,代码中可以按照名字获取标签的值,新增添的标签对已有代码影响不大
缺点:整个数据过于冗杂,冗余信息过多,标签占据的空间反而比数据本身更多了,尤其是网络传输的时候,这些数据都是要通过网络传输的(需要消耗带宽)
2.json协议格式
请求
{
userId:1000,
position:[经纬度]
}
响应
[
{
id:1001,
name:"张亮麻辣烫"
},
{
id:1002,
name:"魏家凉皮"
}
]
json是以键值对结构,键和值之间使用:分割,
键值对之间使用,分割
把若干个键值对使用{}括起来,此时就是一个json对象
,还可以把多个json对象放到一起,使用,分割开,并且使用[]整体括起来,就形成了一个json数组
优点:可读性很好,扩展性也很好,通过key对数据起到解释说明~
对于xml来说解释说明是用过标签,需要开始和结束两个标签来说,比较占用空间,相比之下,json只使用一个key就能描述,占用的空间比xml少,能节约一点带宽.
缺点:虽然json比xml更节省了带宽,但是很明显,这里的带宽仍然是有浪费的部分~~,尤其是这种数组格式的json.这种情况下,传输的数据字段都是相同的,使刚才这里的key名字被重复传输了.
3.protobuffer协议格式
这是一种更节省带宽的方式,效率最高的方式
只是开发阶段(代码)定义出这里都有哪些资源,描述每个字段的含义
程序真正运行的时候,实际传输的数据是不包含这样的描述信息.
这样的数据是按照二进制的方式来进行组织的~~
这样的设定,目前来看是最高效的做法,(程序运行的效率高)不太有利于程序员进行阅读
虽然protobuffer运行效率高,但是使用并没有json更为广泛.
只是哪些对于性能要求非常高的场景,才会去使用protobuffer
传输层:虽然已经在系统内核实现好了,但是也需要重点关注,这里使用的socket api都是传输层提供的.
端口号:端口号是一个2字节的整数,使用端口号的时候,1-1024都是系统保留自用的端口号(知名端口号)-->HTTP服务器80,HTTPS服务器,443
UDP协议~~
无连接,不可靠传输,面向数据报,全双工
我们在研究一个协议时,主要就是研究报文格式,基于报文格式,了解这个协议的其他各个特性
UDP 数据报=报头(重点) +载荷(应用层数据包)

UDP报头中一共有4个字段,每个字段2个字节,(一共8个字节)
由于协议报头中使用2个字节表示端口号,端口号的取值是0-65535,
数据报最大长度的64KB
随着网络的发展,大数据时代的到来,各种格式的数据字段越来越大,有可能在大小上突破64KB
,一旦整个数据报的长度超出64kb,此时就会出现截断(本来数据是完整的,后面的部分没了)
总的UDP数据报最大长度是64kb,载荷部分能承担的最大程度应该是64kb-8
解决这种问题方案
方案一:在应用层,把数据包进行拆分,之前一个数据报表示N个广告(把整个页面的广告包含进去,拆成每个广告占用一个UDP数据报,甚至可以进一步的拆成一个广告对应多个UDP数据报~~
开发成本大,测试成本也很大,容易出问题)
方案二:使用TCP代替UDP~~ TCP没有上述长度的限制~因此问题也就解决了.
校验和/检验和:
验证数据在传输过程中是否正确~~
前提:数据在网络传输过程中,可能会坏掉.
网络数据传输,本质上是光信号/电信号/电磁波(这些信号很有可能会受到干扰)
对于电,磁,电磁波,如果加上一个磁场,很有可能之前的高电平变成了低电平,原来的低电平变成了高电平,此时就出现了0变成1,1变成0,也就是比特翻转的情况.
校验和/检验和的作用就是用来识别当前的数据是否出现了比特翻转~~检验当前的数据是否正确
如果发现是出现了,就可以把这个错误的数据包丢弃掉,避免将错就错
网络中的校验和并非是简单的按照长度/数量作为检验的标准的,一定要让数据的内容能够参与进去.
所谓的校验和,其实就是通过数据中的部分内容,进行一系列的计算,得到了一个更短的字符串,通过原来的数据再计算一次这样的结果,进行对比,看是否一致.
校验和是拿着原始信息的一部分内容去参与计算的,有可能会出现,内容虽然错了,但是算出的校验和还是和之前一致的.(但是这种情况概率比较小,实践中可以忽略不计).
严格的来说,校验和只能用来"证伪",证明数据出错了,无法确保这个数据100%正确.但是实践中可以近似的认为校验和一致,原来的数据就一致.
UDP校验和中:
CRC算法实现:
short checksum=0;
for(遍历取出数据报中的每个字节的数据){
checksum+=当前字节的数据;
}
CRC算法:
UDP数据报发送方,在发送之前,先计算一遍CRC,把计算好的CRC值放到UDP数据报中,(设这个CRC值为value1)
接下来这个数据包通过网络传输到达接收端.接收端接收这个数据之后,也会按照同样的算法,再计算一次CRC的值,得到的结果是value2,比较自己计算的value2和收到的value1是否一致~~如果是一致的,说明数据是ok的,如果不一致,说明传输过程中发生了比特翻转.
在上述CRC算法中,如果只有一个bit发生了翻转,此时能够100%发现问题,可是如果有是两个或多个,可能会和翻转之后计算的一样(这种情况概率很低,可以忽略不计)
md5算法:
1.定长:无论原始数据多长,算出来的md5的最终值都是固定长度,常见的md5版本有16位版本(2字节),32位版本(4字节),64位版本(8字节)
2.分散:计算md5的过程中,原始数据,只要变化一点点,算出来的md5值就会差异很大.
网络传输中,如果出现bit翻转,意味着只是极少的bit翻转了.即使只是翻转一个bit,最终得到的md5值都会差异非常大.这样的特性,也决定了md5也可以作为一个字符串hash算法.
3:不可逆性,给一个源字符串,计算md5值,但是给你一个计算好的md5值,让你把他还原回原始的字符串,理论上是无法完成的,原始的字符串=>md5这个过程中,有很多信息量损失了.直接还原不行.
md5也可以用于加密
理解UDP的不可靠
在面向数据报编程中,应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并
TCP协议
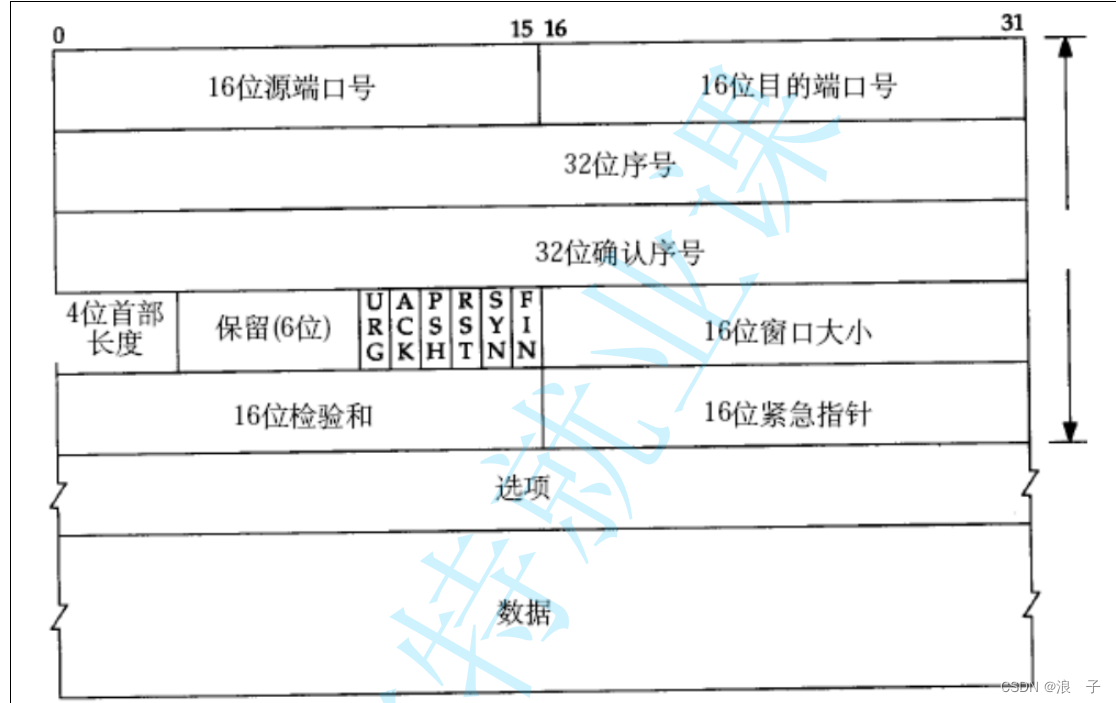
这里的源端口和目的端口和UDP是一样的,选项及以上都是报头,数据是载荷,
4位首部长度
(报头长度)(header),不像UDP的报,固定是8个字节~~
TCP的前20个字节是固定长度的,后面这路包含了选项(optional)部分
4位首部长度,4个bit位,0-15,此处设定的这里的单位是4字节,而不是字节
1111=>15,在15的基础上就是60字节'
保留(6位) reserved 保留位
UDP这个协议 长度受到2个字节的限制,想要进行扩展,发现扩展不了.一旦你改变了这里的报头长度,就会使机器发送的UDP数据报和其他机器不兼容,无法通信了.
因此,我们的TCP在设定报头的时候,就提前准备了几个保留位,(虽然现在不用,但也是先占个位置),后面一旦需要用了,咱们就可以把这些保留位给使用起来.后续一旦需要扩展功能,使用保留位就可以实现,就可以避免tcp的扩展引起不兼容的问题.
 6位标志位,TCP最核心的部分
6位标志位,TCP最核心的部分
16位校验和,类似于UDP的校验和.把报头和数据载荷放到一起计算校验和
TCP内部的机制是很多的.上述报头字段都是针对TCP的各个机制的支撑属性.
需要了解TCP的其他机制,才能认识报头的含义.
TCP特点:有连接,可靠传输,面向字节流,全双工.
可靠传输:TCP安身立命之本,初心是解决"可靠传输"问题.
网络通信过程是复杂的,无法确保发送方发出去的数据,100%能够达到接收方
此处的可靠性是退而求其次,只要尽可能的去进行发送了,发送方能够知道对方是否收到,就认为是可靠传输了.
1.用来确保可靠性,最核心的机制,成为"确认应答"
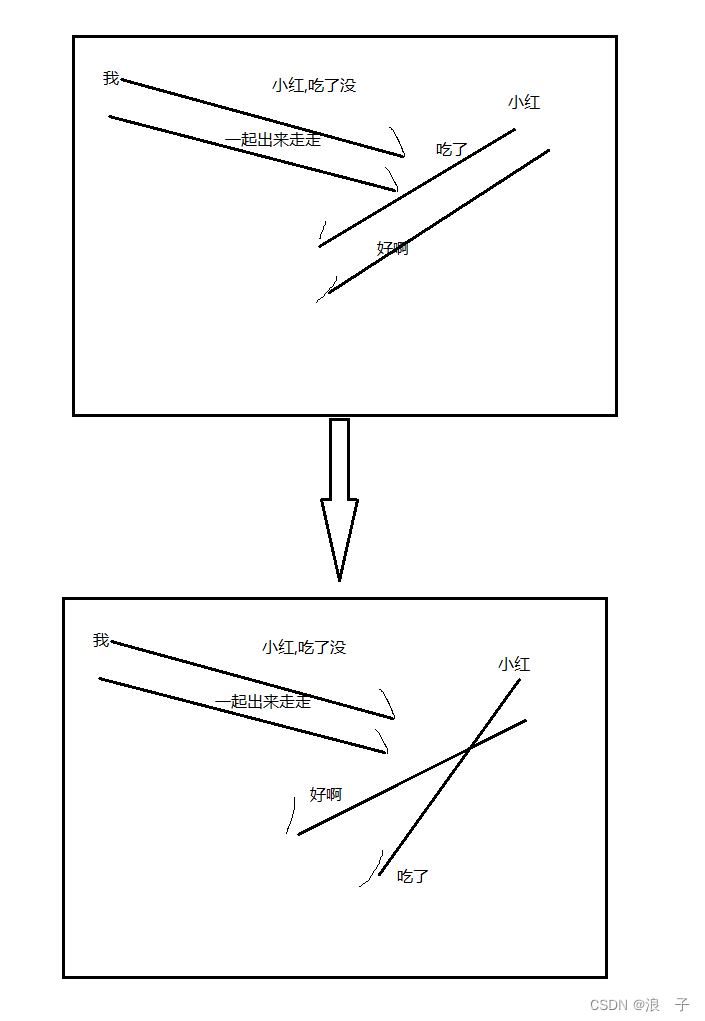
第一种时序有些过于理想化了,但是实际情况会经常出现"后发先至"情况,如果出现了后发先至情况,那么理解起来就有问题了
后发先至:
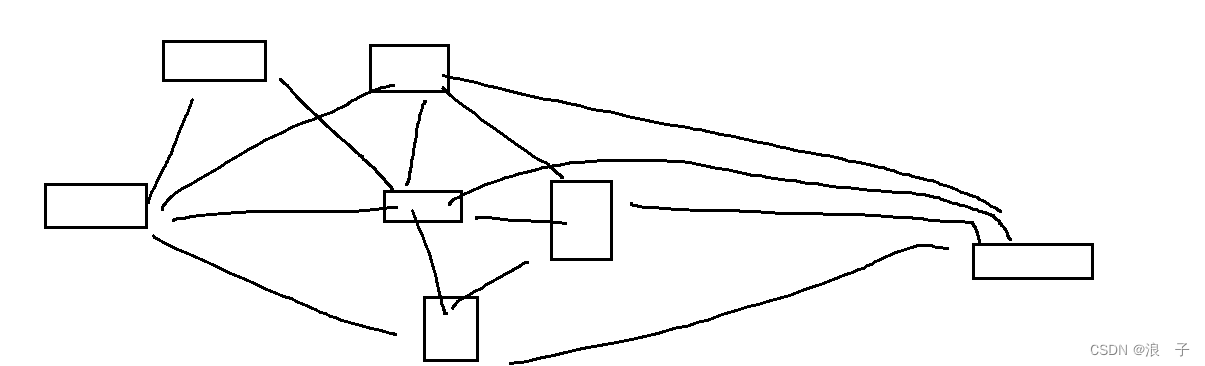
一个数据包从发送方到接收方传输过程中走的路径可能不一样,第一个数据包走路劲一,第二个数据包走路径了,与可能路径二非常畅通,路线一堵车了,第二个数据包虽然发的言辞,但是能先到.
为了解决上述问题,引入了序号和确认序号,对数据进行编号.应答报文里就告诉对方,我这次应答的是哪个数据.

这是简化版本的模型,真实TCP的情况要更为复杂一些,TCP四面向字节流的,以字节为单位进行传输的,没有"一条两条"概念,
实际上,TCP的序号和确认序号都是以字节来进行编号的.

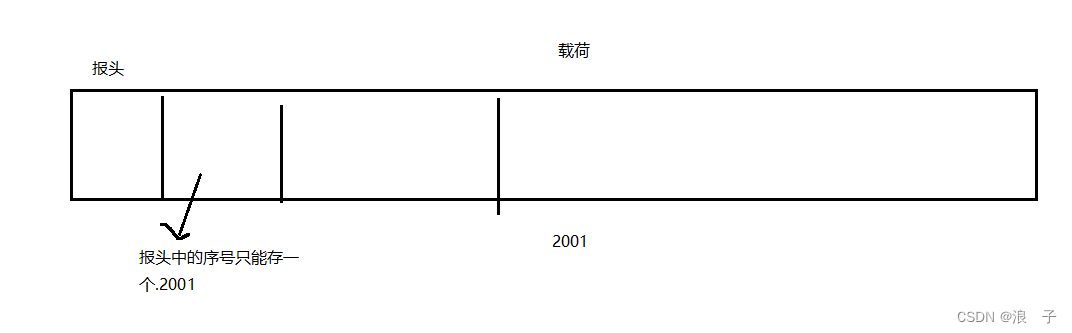
在合理我们假设载荷有1000个字节,有1000个序号~~,由于序号是连续的.只需要在报头中保存第一个字节的序号,即可后续字节的序号都是很容易就计算到的.
应答报文中的确认序号,是按照发送过去的最后一个字节的序号加1进行设定的

主机B收到了1-1000这些字节数据之后,反馈一个应答报文.应答报文中的确认信号的值就是1001
1001的含义:
1.<1001的数据,都已经收到了
2.发送方接下来要给我发1001开始的数据了
TCP的确认应答是确保TCP可靠性的最核心的机制
确认应答中,通过应答报文来反馈给发送方,表示当前的数据正确收到了
应答报文,也叫ack报文.

平时ACK位为0,如果当前报文为应答报文的话,ACK位为1.
在接收的时候,我们希望应用程序读到的数据是顺序正确的~~顺序不对,对于接收应用程序的逻辑肯定也会有一定的影响~~
接收缓冲区可以认为是一个"优先级队列"以序号作为优先级的参考依据
2.超时重传.是确认应答的补充
如果一切顺利,通过应答报文就可以告诉发送方,当前数据是不是成功收到.
但是,网络上可能存在"丢包"情况,如果数据包丢了,没有到达对方,对方自然就没有ack报文了.
这个情况下,就需要超时重传了.
TCP可靠性就是在对抗丢包~~期望在丢包客观存在的情况下,也能够尽可能的把包给传过去.
发送方发了数据之后要等.等待的时间里:收到了ack(数据报在网络上传输,需要时间的)
如果等了好久,ack还没等到,此时发送方就认为数据的传输出现丢包了.
当认为丢包之后,就会把刚才的数据包再传输一次.(重传)
等待的过程有一个时间的阈值(上限),就是超时
丢包:
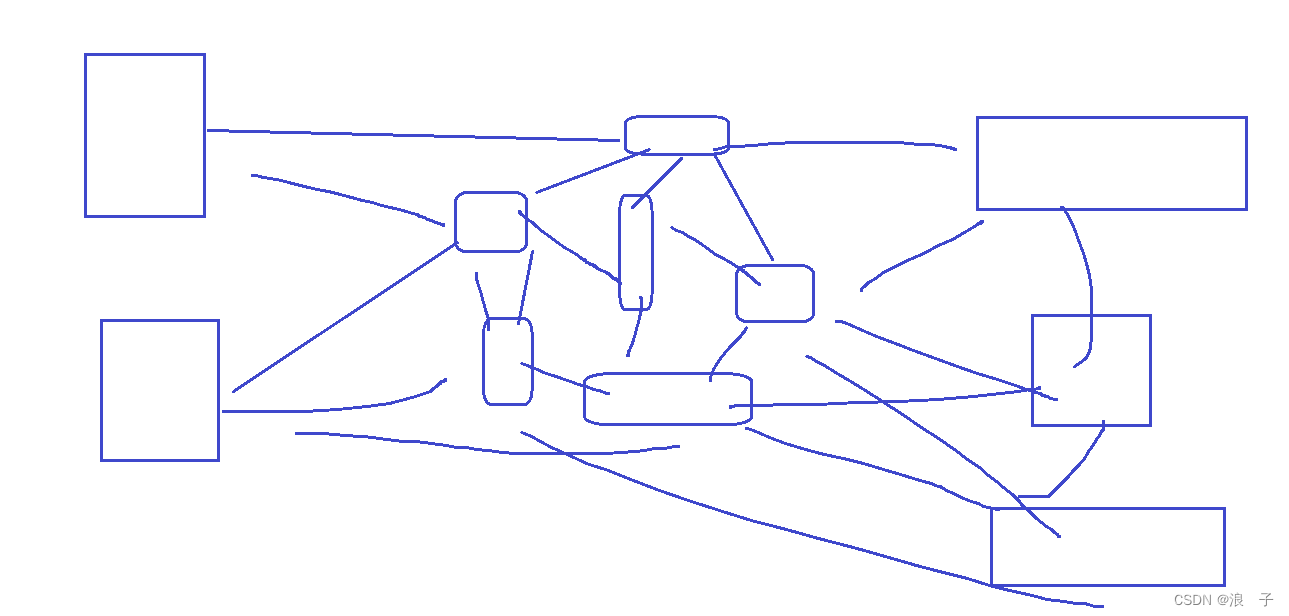
这个网络中的路由器/交换机,不仅仅是给你这一次通信提供服务,还要能支持千千万万的主机之间的通信
整个网络,就可能存在某个交换机/路由器,某个时刻,突然负载量很高,短时间内可能有大量的数据包要经过这个设备转发.
但是要知道,一台设备能够处理的数据量是有限的!很可能瞬间的高负载超出了这个设备能转发的数据量的极限,此时多出来的部分就无了~就被设备丢包了
在传输过程中,碰巧某个数据包遇见了上述情况,就会丢包
上面的过程中,是认为没收到ack就是丢包,
但是,丢包并不一定是数据丢了,也有可能是ack丢了
数据丢了还是ack丢了,在发送方角度看起来,就是区分不了,都是ack没收到~~

正常情况下的丢包,主机A发送的数据没有到达主机B
如果主机A在特定的时间间隔内没有收到主机B的ack应答,就会把数据再发送一次
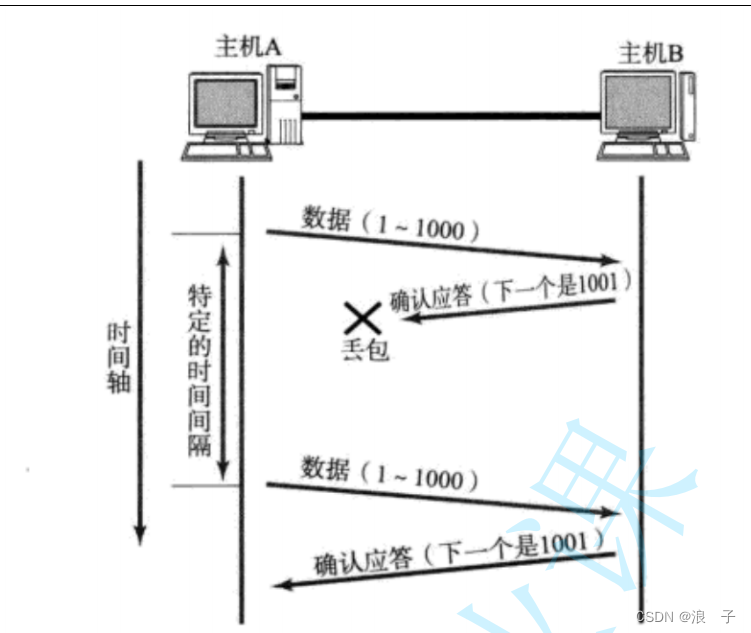
这种情况下,数据已经被B收到了,再传输一次,同一份数据,B就会收到两次.
TCP socket在内核中存在接收缓冲区(一块内存空间)
发送方发来的数据,是要先放到接收缓冲区中的.这里应用程序调用read/scanner.next才能读到数据.这里的读操作其实就是读接收缓冲区
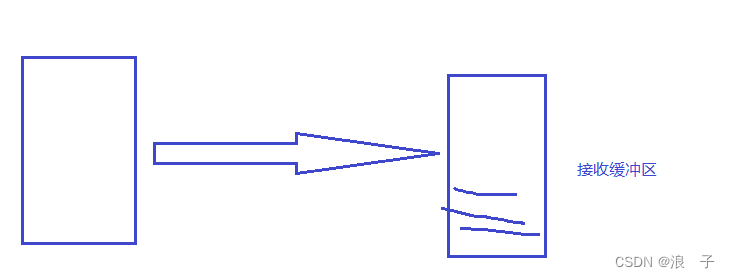
接收缓冲区,除了能够帮助我们进行去重之外,还能够进行排序.对收到的数据进行排序,按照序号来排序,确保应用程序读到的数据和发送的数据顺序是一致的.
当数据到达接收缓冲区的时候,接收方会首先判定一下当前缓冲区中是否已经有这个数据了(或者这个数据曾经在缓冲区存在过)
如果已经存在或者存在过,就直接把重复发来的数据就丢弃掉了~~
就能确保应用程序在调用read/scanner.next的时候,不会出现重复数据了.
接收方判定数据是"重复数据"的核心依据:
1.数据还在接收缓冲区,还没被read走,此时,就拿着新收到的数据,和缓冲区中的所有数据的序号对一下,看看有没有一样的.有一样就是重复了,就可以把新收到的数据丢弃了
2.数据在接收缓冲区中,已经被应用程序给read走了,此时新来的数据序号是无法直接在接收缓冲区中查到的.注意!!应用程序读取数据的时候,是按照序号的先后顺序,连续读取的!
一定是先读序号小的数据,然后再读序号大的数据(可以把接收缓冲区当作一个带有优先级的阻塞队列)
此时socket api上就可以记录上次读的最后一个字节的序号是多少~~
比如上次的的最后一个字节的序号是3000新收到一个数据包的序号是1001,这个1001一定是之前已经度过的了,这个时候同样可以把这个新的数据包判定为"重复的包",直接丢弃掉了.
上述谈到的,ack重传,保证顺序,自动去重,都是TCP内置的.咱们使用TCP的api的时候
outputStream.write()只需要调用一个简单的代码,上述功能就自动生效了,如果使用UDP,上述这些问题就得好好考虑考虑.
超时是会重传,但也不是无限的重传....
1.重传次数是有上限的.重传到一定程度还没有ack,就尝试重置连接,如果重置也失败,就直接放弃连接.
2.重传的超时时间阈值也不是固定不变的,随着重传次数的增加而增大(重传频率越来越低),经历了重传之后还丢包,大概率是网络问题.
相关文章:
网络原理-UDP/TCP协议
协议 在网络通信中,协议是非常重要的一个概念,在下面,我将从不同层次对协议进行分析. 应用层 IT职业者与程序打交道最多的一层,调用系统提供的API写出的代码都是属于应用层的. 应用层中有很多现成的协议,但是更多的,我们需要根据实际情况来进行制作自定义协议. 自定义协议…...
C语言——实用调试技巧——第2篇——(第23篇)
坚持就是胜利 文章目录 一、实例二、如何写出好(易于调试)的代码1、优秀的代码2、示范(1)模拟 strcpy 函数方法一:方法二:方法三:有弊端方法四:对方法三进行优化assert 的使用 方法五…...
broom系列包: 整理模型输出结果
broom包 说明 tidy、augment和glance函数的输出总是一个小tibble。 输出从来没有行名。这确保了您可以将它与其他整洁的输出组合在一起,而不用担心丢失信息(因为R中的行名不能包含重复)。 有些列名保持一致,这样它们就可以跨不同的模型进行组合。 tidy(…...

Spring Boot 参数校验机制原理以及如何实现一个自定义校验注解
Spring Boot 参数校验原理 Spring Boot 提供了一种方便的参数校验机制,借助于 JSR-303(Bean Validation)规范,通过在方法参数上添加校验注解来实现参数校验。下面是 Spring Boot 参数校验的基本原理: JSR-303 标准注解…...

长短期记忆神经网络
目录 LSTM 神经网络架构 分类 LSTM 网络 回归 LSTM 网络 视频分类网络 更深的 LSTM 网络 网络层 分类、预测和预报 序列填充、截断和拆分 按长度对序列排序 填充序列 截断序列 拆分序列 指定填充方向 归一化序列数据 无法放入内存的数据 可视化 LSTM 层架构 …...

解决vscode每次git pull/push都需要输入账号密码
git如何设置用户名 邮箱 密码 //设置用户 git config --global user.name "xxx"//设置邮箱 git config --global user.email "xxxxxx.com"//设置密码 git config --global user.password "xxxxx"解决每次git pull/push操作都需要输入密码 git …...

Rancher实用篇-使用rancher,部署微服务应用
说到rancher,我们必须先了解一下k8s 一、k8s简介 Kubernetes(通常简写为 K8s)是一个开源的容器管理系统,由Google于2014年发起,并在2015年贡献给Cloud Native Computing Foundation (CNCF)进行维护。它基于Borg项目的…...
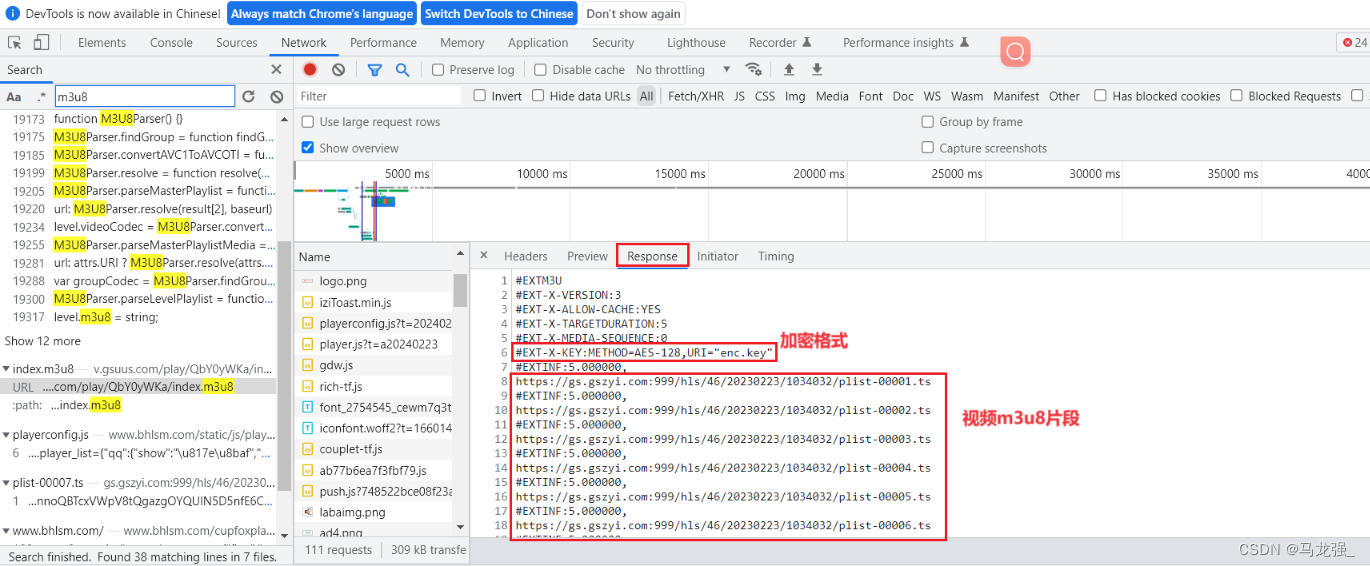
爬取m3u8视频
网址:https://www.bhlsm.com/cupfoxplay/609-3-1/ 相关代码: #采集网址:https://www.bhlsm.com/cupfoxplay/609-3-1/ #正常视频网站:完整视频内容 # pip install pycryptodomex #流媒体文件:M3U8(把完整的…...
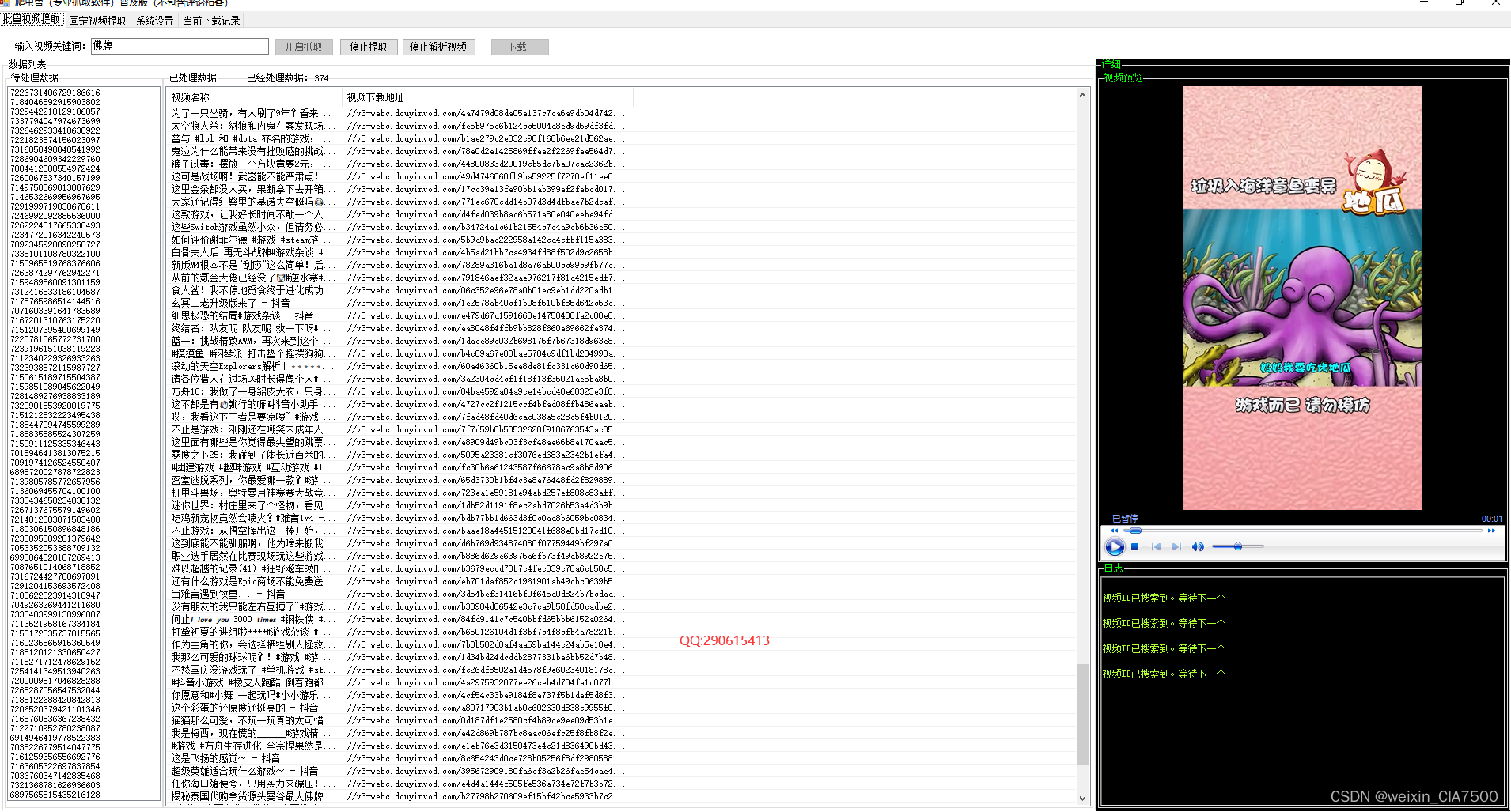
抖音视频抓取软件的优势|视频评论内容提取器|批量视频下载
抖音视频抓取软件在市场上的优势明显: 功能强大:我们的软件支持关键词搜索抓取和分享链接单一视频提取两种方式,满足用户不同的需求。同时,支持批量处理数据,提高用户获取视频的效率。 操作简单:我们的软件…...

apidoc接口文档的自动更新与发布
文章目录 一、概述二、环境准备三、接口文档生成1. 下载源码2. 初始化3.执行 四、文档发布五,配置定时运行六,docker运行 一、概述 最近忙于某开源项目的接口文档整理,采用了apidoc来整理生成接口文档。 apidoc是一个可以将源代码中的注释直…...

Oracle EBS R12.1 FA 批量计划外折旧
在资产工作台上可以进行单个资产的计划外折旧,如果进行批量计划外折旧的话就需要进行开发客户化form或者webadi 进行数据上载后调用FA 标准API了 以下是标准API的demo示例 DECLAREl_trans_rec FA_API_TYPES.trans_rec_type; l_asset_hdr_rec FA_API_TYPES.asset_hdr…...

15.3 基于深度学习的WiFi指纹低成本地点识别
文献来源:Nowicki M, Wietrzykowski J. Low-effort place recognition with WiFi fingerprints using deep learning[C]//Automation 2017: Innovations in Automation, Robotics and Measurement Techniques 1. Springer International Publishing, 2017: 575-584. 摘要 使…...

Git基本操作(1)
Git基本操作(1) 初始化git本地仓库git本地仓库配置git config user.name 和git config user.emailgit config --unset user.name和git config --unset user.emailgit config --global 认识工作区,暂存区,版本库更深层次理解 git a…...
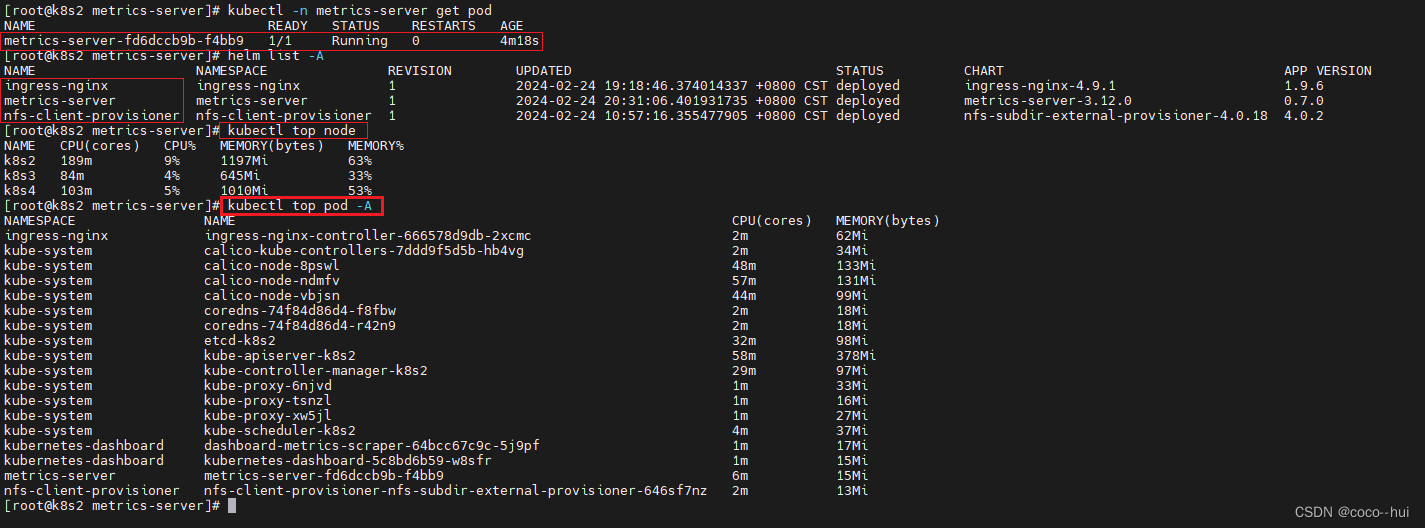
k8s-helm部署应用 19
Helm部署nfs-client-provisioner(存储类): 预先配置好外部的NFS服务器 部署 Helm部署nginx-ingress应用: 添加下载ingress 拉取 解开并修改 部署 测试 回收 helm部署metrics-server: 清除之前的metrics部署 下载…...

OGG-00918 映射中缺少键列 id.
2024-02-23 14:54:49 INFO OGG-02756 从线索文件获取了表 GISTAR.PXPH_PON_ROUTE 的定义。. The following columns did not default because of type mismatches: id OGG-00918 映射中缺少键列 id. 目标端有字段ID,由于mysql自增,所以只能是b…...
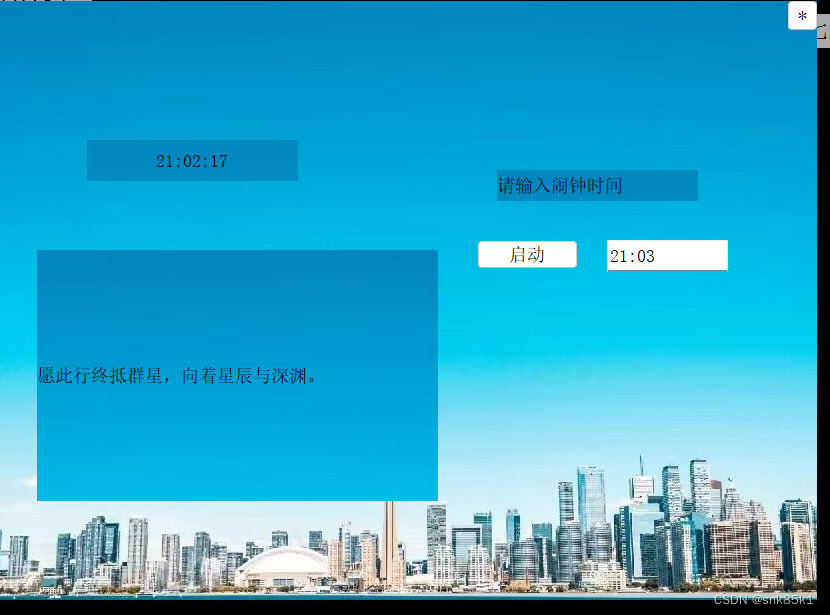
QT_day4
1.思维导图 2. 输入闹钟时间格式是小时:分钟 widget.cpp #include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);id startTimer(1000);flag1;speecher new QTextT…...
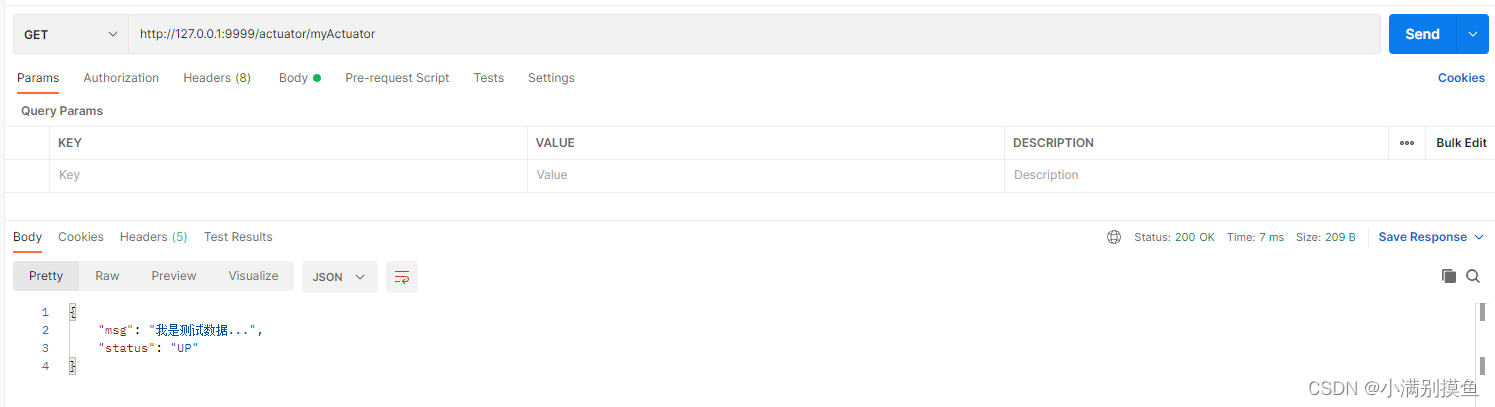
Spring Boot应用集成Actuator组件以后怎么自定义端点暴露信息
一、 前言 在平时业务开发中,我们往往会在spring Boot项目中集成Actuator组件进行系统监控,虽然Actuator组件暴露的端点信息已经足够丰富了,但是特殊场景下,我们也需要自己暴露端点信息,此时应该怎么操作呢࿱…...

C# CAD备忘录
Document doc Application.DocumentManager.MdiActiveDocument; Database db doc.Database; Editor ed doc.Editor; 1、获取打开cad文件-文件路径 string fileName db.Filename;//文件名 输出结果 fileName “L:\目录\200401.dwg” 2、获取打开cad文件-文件名称 string fi…...
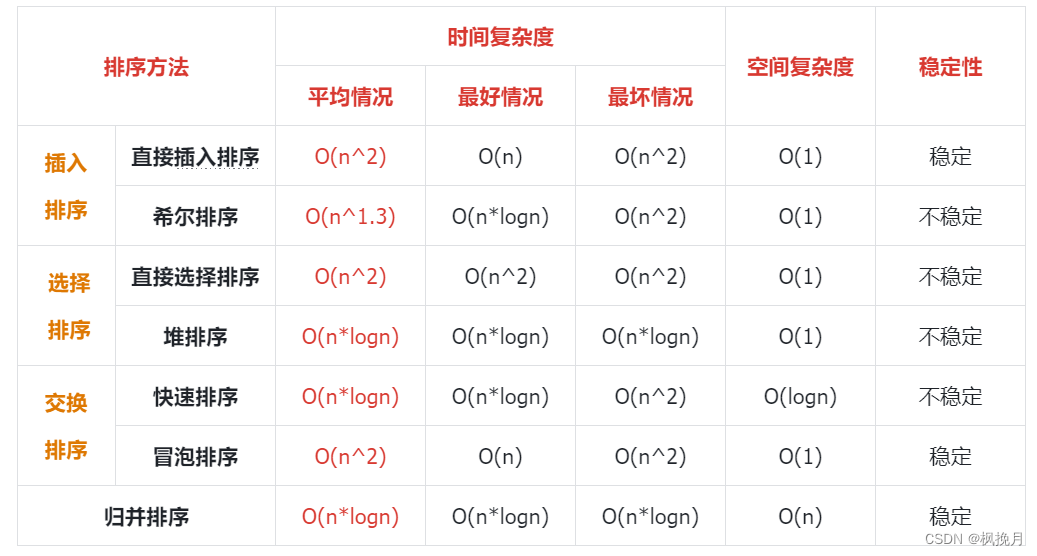
【数据结构】排序(2)
目录 一、快速排序: 1、hoare(霍尔)版本: 2、挖坑法: 3、前后指针法: 4、非递归实现快速排序: 二、归并排序: 1、递归实现归并排序: 2、非递归实现归并排序: 三、排序算法…...
HarmonyOS开发行业前景就业分析与实例解析
HarmonyOS的简介 鸿蒙系统(HarmonyOS)是华为公司自主研发的一种全场景分布式操作系统,旨在为各种设备提供统一的开发和运行环境。它的编程基础主要建立在多种技术和语言之上,包括鸿蒙系统的核心框架和应用程序开发框架。 本章将…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...

前端中slice和splic的区别
1. slice slice 用于从数组中提取一部分元素,返回一个新的数组。 特点: 不修改原数组:slice 不会改变原数组,而是返回一个新的数组。提取数组的部分:slice 会根据指定的开始索引和结束索引提取数组的一部分。不包含…...
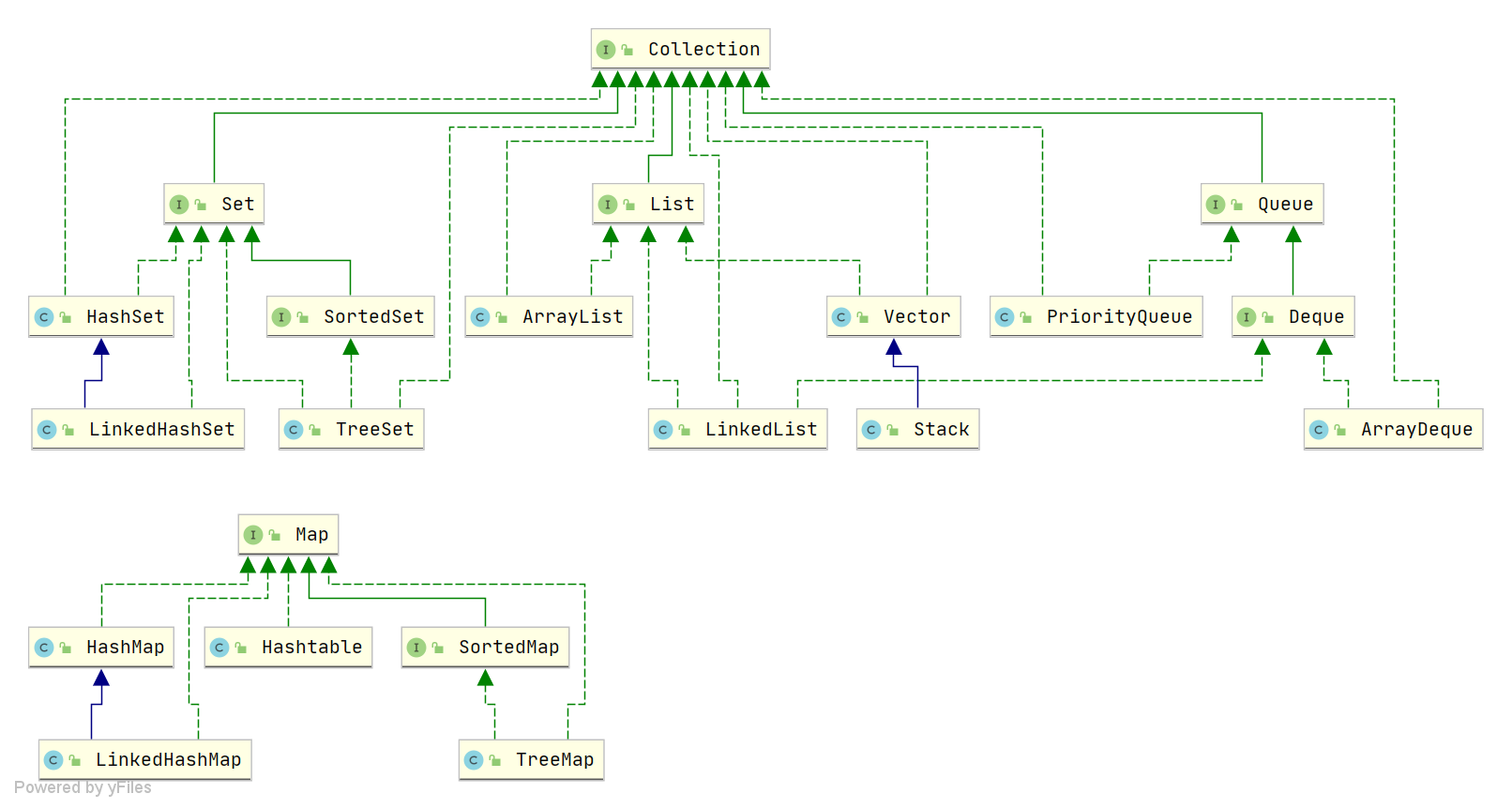
Java中HashMap底层原理深度解析:从数据结构到红黑树优化
一、HashMap概述与核心特性 HashMap作为Java集合框架中最常用的数据结构之一,是基于哈希表的Map接口非同步实现。它允许使用null键和null值(但只能有一个null键),并且不保证映射顺序的恒久不变。与Hashtable相比,Hash…...
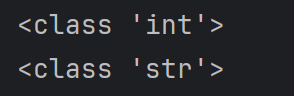
python基础语法Ⅰ
python基础语法Ⅰ 常量和表达式变量是什么变量的语法1.定义变量使用变量 变量的类型1.整数2.浮点数(小数)3.字符串4.布尔5.其他 动态类型特征注释注释是什么注释的语法1.行注释2.文档字符串 注释的规范 常量和表达式 我们可以把python当作一个计算器,来进行一些算术…...

CentOS 7.9安装Nginx1.24.0时报 checking for LuaJIT 2.x ... not found
Nginx1.24编译时,报LuaJIT2.x错误, configuring additional modules adding module in /www/server/nginx/src/ngx_devel_kit ngx_devel_kit was configured adding module in /www/server/nginx/src/lua_nginx_module checking for LuaJIT 2.x ... not…...
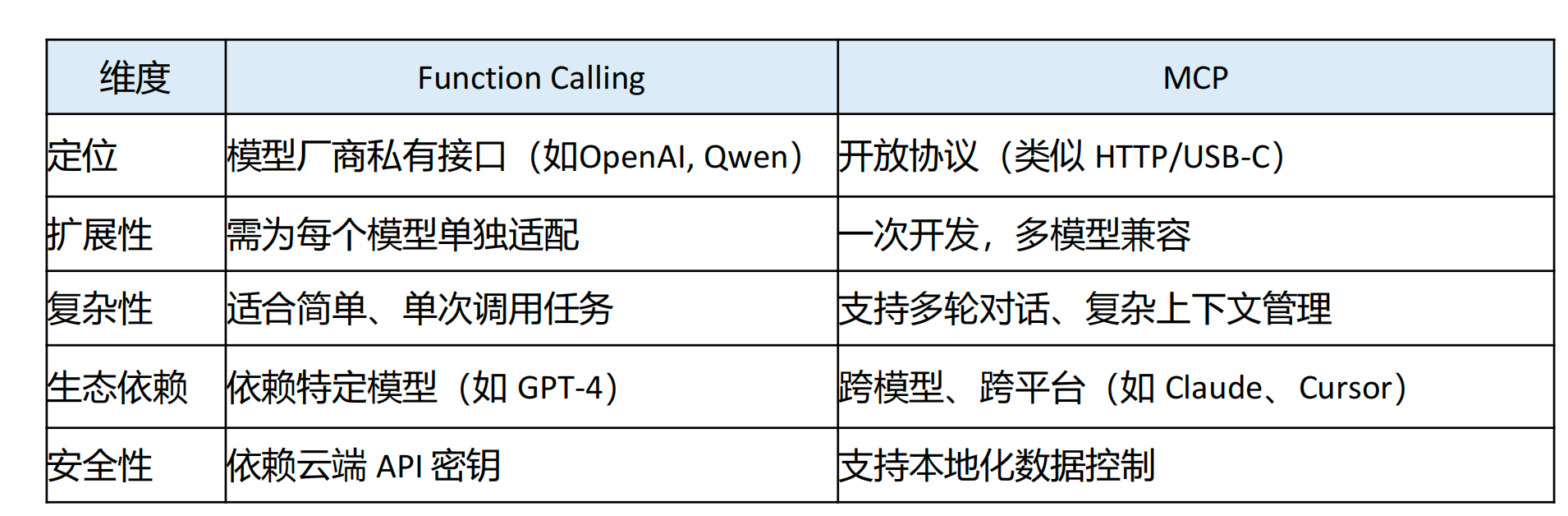
MCP和Function Calling
MCP MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而…...