挑战30天学完Python:Day19 文件处理
📘 Day 19
🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点知识,但又没有系统学习的使用者。总之如果你想提升自己的Python技能,欢迎加入《挑战30天学完Python》
- 📘 Day 19
- 文件处理
- 读®模式
- 文件写入和更新
- 删除文件
- 文件类型
- .txt
- .json
- JSON转字典
- 字典转JSON
- 保存为JSON文件
- .csv
- .xlsx
- .xml
- 💻 第19天练习
- 练习1级
- 练习2级
- 练习3级
- 文件处理
📘 Day 19
文件处理
此前我们已经见过了不同的Python数据类型。通常也会将我们的数据存储在不同的格式的文件中。在这章节中我们将学习如何处理这些不同的类型的文件(.txt, .json, .xml, .csv, .tsv, .excel)。首先,让我们从最熟悉的txt类型文件开始。
文件处理是程序中很重要的部分,它允许我们进行创建、读取、更新和删除。在Python中处理文件数据使用的是 open 内置方法。
# 语法形式
open('filename', mode) # 模式mode(r, a, w, x, t,b) 表示 读, 写, 更新
- “r” - 英文Read表示读 - 默认值。以读的模式打开一个文件,如果文件不存在它将返回一个错误。Opens a file for reading, it returns an error if the file does not exist
- “a” - 英文Append表示追加 - 以追加模式打开文件,如果文件不存在则会自动创建。Opens a file for appending, creates the file if it does not exist
- “w” - 英文Write表示写 - 以写的模式打开一个文件,如果文件不存在则创建。Opens a file for writing, creates the file if it does not exist
- “x” - 英文Create表示创建 - Creates the specified file, returns an error if the file exists
- “t” - 英文Text表示文本 - Default value. Text mode
- “b” - 英文Binary表示字节 - Binary mode (e.g. images)
读®模式
方法 open 默认模式是只读模式,因此我们可以不需要特别的指定mode= ‘r’ 或 ‘rt’。注意,我已经创建好了一个文件名为 “reading_file_example.txt” 的文件在项目的files目录下。让我们来看看如何读取它。
f = open('./files/reading_file_example.txt')
print(f) # <_io.TextIOWrapper name='./files/reading_file_example.txt' mode='r' encoding='cp936'>>
正如你在例子中看到的,我通过open打开一个文件,并打印了一些加载文件后的一些信息。其中读取文件内容会有几种方法:read(), readline, readlines。关闭文件使用 close() 方法。
- read():将整个文件内容以字符字符串的形式读取。其中如果我们想限制读取的字符,我们可以给定一个整数类型值 read(number) 。
f = open('./files/reading_file_example.txt')
txt = f.read()
print(type(txt))
print(txt)
f.close()
# 读取文件全部内容的输出
<class 'str'>
This is an example to show how to open a file and read.
This is the second line of the text.I love python
让我们指定数量字符读取,比如从文件中读取10个字符。
f = open('./files/reading_file_example.txt')
txt = f.read(10)
print(type(txt))
print(txt)
f.close()
# 指定读取数量输出
<class 'str'>
This is an
- readline(): 读取一行,当第一调用的时候默认为第一行,再次读取依次读取下一行。
f = open('./files/reading_file_example.txt')
line = f.readline()
print(type(line))
print(line) # 第一行print(f.readline()) # 第二行
print(f.readline()) # 因为文件中只用两行所以当尝试第三次readline时候返回是空字符串f.close()
- readlines(): 按行的形式读取所有文本,并且返回一个字符行列表。
f = open('./files/reading_file_example.txt')
lines = f.readlines()
print(type(lines))
print(lines)
f.close()
# readlines测试输出
<class 'list'>
['This is an example to show how to open a file and read.\n', 'This is the second line of the text.I love python']
还有另外一种列表行读取文本的方式是使用 splitlines():
f = open('./files/reading_file_example.txt')
lines = f.read().splitlines()
print(type(lines))
print(lines)
f.close()
# splitlines 输出
<class 'list'>
['This is an example to show how to open a file and read.', 'This is the second line of the text.']
# 两种方式大家可以注意下返回的行列表有什么区别?是的第二种方式不包含 \n 换行符。
当打开一个文件,使用完的时候必须关闭它。其实有一种更高级的方式处理它。我们可以使用 with ,此方式可以自己关闭文件使用。看下一下方法应用的例子:
with open('./files/reading_file_example.txt') as f:lines = f.read().splitlines()print(type(lines))print(lines)
# 实际输出
<class 'list'>
['This is an example to show how to open a file and read.', 'This is the second line of the text.']
文件写入和更新
如果想向一个已经存在文件写入内容,我们必须在使用 open() 方法时候添加一个参数模式:
- “a” - append 追加 - 将在文件默认追加内容,如果文件不存在将自动创建一个新的文件。
- “w” - write 写 - 覆盖模式写入内容,如果文件不存在则会创建。
接下来让我们将一些文本添加已经读取的文件中:
with open('./files/reading_file_example.txt','a') as f:f.write('This text has to be appended at the end')
用文本编辑器打开 reading_file_example.txt 看是否将内容写入到了文件末尾。
with open('./files/writing_file_example.txt',mode='w', encoding="utf-8") as f:f.write('写入文件测试,其中还需要指定字符编码,否则中文会乱码。')
删除文件
在之前的篇幅中,我们知道了怎么通过 os 创建一个目录或者文件。现在,我我们看看如何通过它删除一个文件。
import os
os.remove('./files/example.txt')如果删除的文件不存在,它会返回一个错误,因此一个好的编程应该加一个判断,像这样:
import os
if os.path.exists('./files/example.txt'):os.remove('./files/example.txt')
else:print('删除的文件不存在')
文件类型
.txt
带有txt扩展名的文件是最常见的一种数据格式文件,这部分我们已经在上边的一节中讲过了。让我们接下来看一个 JSON 文件。
.json
JSON代表JavaScript对象表示法。实际上,它是一个字符串化的JavaScript对象或Python字典。
Example:
# 字典
person_dct= {"name":"Asabeneh","country":"Finland","city":"Helsinki","skills":["JavaScrip", "React","Python"]
}# JSON: 一个字典格式的字符串
person_json = "{'name': 'Asabeneh', 'country': 'Finland', 'city': 'Helsinki', 'skills': ['JavaScrip', 'React', 'Python']}"# 我们使用三个引号表示多行字符串,让它更具有可读性
person_json = '''{"name":"Asabeneh","country":"Finland","city":"Helsinki","skills":["JavaScrip", "React","Python"]
}'''
JSON转字典
将JSON转成字典,首先我们需要导入 json 模块,然后使用 loads 方法。
import json
# JSON
person_json = '''{"name": "MegaQi","country": "China","city": "ShangHai","skills": ["JavaScrip", "React", "Python"]
}'''
# 接下来 json 转 dict
person_dct = json.loads(person_json)
print(type(person_dct))
print(person_dct)
print(person_dct['name'])
预期输出
<class 'dict'>
{'name': 'MegaQi', 'country': 'China', 'city': 'ShangHai', 'skills': ['JavaScrip', 'React', 'Python']}
MegaQi
字典转JSON
反过来,如果想将字典转成json类型,我们需要使用 json 模块中的 dumps 方法。
import json
# python 字典
person = {"name": "MegaQi","country": "China","city": "ShangHai","skills": ["JavaScrip", "React", "Python"]
}# 转成json
person_json = json.dumps(person, indent=4) # indent could be 2, 4, 8. It beautifies the json
print(type(person_json))
print(person_json)
预期输出
# 需要注意的是,当你打印json的时候,它并没有引号。
# JSON并不是一种特殊类型, 实际上它在python中就是字符串.
<class 'str'>
{"name": "MegaQi","country": "China","city": "ShangHai","skills": ["JavaScrip","React","Python"]
}
保存为JSON文件
我们也可以将数据保存为json文件。对于编写json文件,我们使用 json.dump() 方法,它可以接受字典,输出到文件,ensure_ascii和缩进。
import json
person = {"name": "Asabeneh","country": "Finland","city": "Helsinki","skills": ["JavaScrip", "React", "Python"]
}
with open('./files/json_example.json', 'w', encoding='utf-8') as f:json.dump(person, f, ensure_ascii=False, indent=4)注意:想输出真正的中文需要指定 ensure_ascii=False,因为json.dumps 序列化时对中文默认使用的ascii编码
print(json.dumps('{"language":"中文"}')) # "{\"language\":\"\u4e2d\u6587\"}"
print(json.dumps('{"language":"中文"}', ensure_ascii=False)) # "{\"language\":\"中文\"}"在上面的代码中,我们使用了编码和缩进让json文件易于阅读。
.csv
CSV代表逗号分隔的值。CSV是一种简单的文件格式,用于存储表格数据,如电子表格或数据库。CSV是数据科学中非常常见的数据格式。
例子数据:
"name","country","city","skills"
"Asabeneh","Finland","Helsinki","JavaScript"
例子演示
这里我们借助csv模块来读取csv文件
import csv
with open('./files/csv_example.csv') as f:csv_reader = csv.reader(f, delimiter=',') line_count = 0for row in csv_reader:if line_count == 0:print(f'Column names are :{", ".join(row)}')line_count += 1else:print(f'\t{row[0]} is a teachers. He lives in {row[1]}, {row[2]}.')line_count += 1print(f'Number of lines: {line_count}')
执行代码输出:
Column names are :name, country, city, skillsAsabeneh is a teacher. He lives in Finland, Helsinki.
Number of lines: 2
.xlsx
如果要读取excel文件,我们需要安装 xlrd 包。可以通过终端 pip install xlrd 进行安装,至于pip包管理的更多使用,我们将在下一篇中覆盖。
import xlrd # xlsx格式需要用openpyxl库
excel_book = xlrd.open_workbook('sample.xls)
print(excel_book.nsheets)
print(excel_book.sheet_names)
.xml
XML是另一种看起来像HTML的结构化数据格式。在XML中,标记不是预先定义的。第一行是一个XML声明。person标记是XML的根,并且有性别属性。
XML is another structured data format which looks like HTML. In XML the tags are not predefined. The first line is an XML declaration. The person tag is the root of the XML. The person has a gender attribute.
XML文件数据
<?xml version="1.0"?>
<person gender="男"><name>MegaQi</name><country>China</country><city>ShangHai</city><skills><skill>JavaScrip</skill><skill>React</skill><skill>Python</skill></skills>
</person>
关于xml更多的操作请自行按需需求,这里只做个简单演示。
import xml.etree.ElementTree as ET
tree = ET.parse('./files/xml_example.xml')
root = tree.getroot()
print('Root tag:', root.tag)
print('Attribute:', root.attrib)
for child in root:print('field: ', child.tag)
代码执行后输出:
Root tag: person
Attribute: {'gender': '男'}
field: name
field: country
field: city
field: skills
🌕 你取得了很大的进步。保持这样的势头,加油加油加油!下面让我们来做一些练习吧。
💻 第19天练习
练习1级
- 写一个给定参数文件和个数的方法,然后统计文件文本单词和数量,最后按照指定个数返回。练习用的所有文件在项目源码 data 目录下。
- a) 读取 obama_speech.txt 文件,进行方法调用
- b) 打开 michelle_obama_speech.txt 文件,进行方法调用
- c) 读取 donald_speech.txt 文件,进行方法调用
- d) 打开 melina_trump_speech.txt,进行方法调用
- 从data目录中读取 countries_data.json 文件,并且创建一个方法,实现返回指定个数口最多的国家。
练习2级
-
从文件email_exchange_big.txt中提取所有电子邮件地址,并作为列表类型。
-
找出英语中最常用的单词。将函数名命名为find_most_common_words,它将接受两个参数:一个字符串或一个文件和一个正整数(表示列表个数)。函数将返回一个按降序排列的元组数组。参考输出
-
定义方法 find_most_frequent_words 实现文件的中最多单词的统计。分别用如下文件:
- /data/obama_speech.txt 前10
- /data/michelle_obama_speech.txt 前10
- /daa/donald_speech.txt 前10
- /data/melina_trump_speech.txt 前10
- 读取文件/data/hacker_news.csv 文件,然后找出:
- 统计包含python或Python行数
- 统计包含JavaScript, javascript or Javascript行数
- 统计包含Java但不包含JavaScript的行数
🎉 CONGRATULATIONS ! 🎉
<< Day 18 | Day 20 >>
练习参考答案请移步 github项目地址 19_exercise.py
相关文章:

挑战30天学完Python:Day19 文件处理
📘 Day 19 🎉 本系列为Python基础学习,原稿来源于 30-Days-Of-Python 英文项目,大奇主要是对其本地化翻译、逐条验证和补充,想通过30天完成正儿八经的系统化实践。此系列适合零基础同学,或仅了解Python一点…...
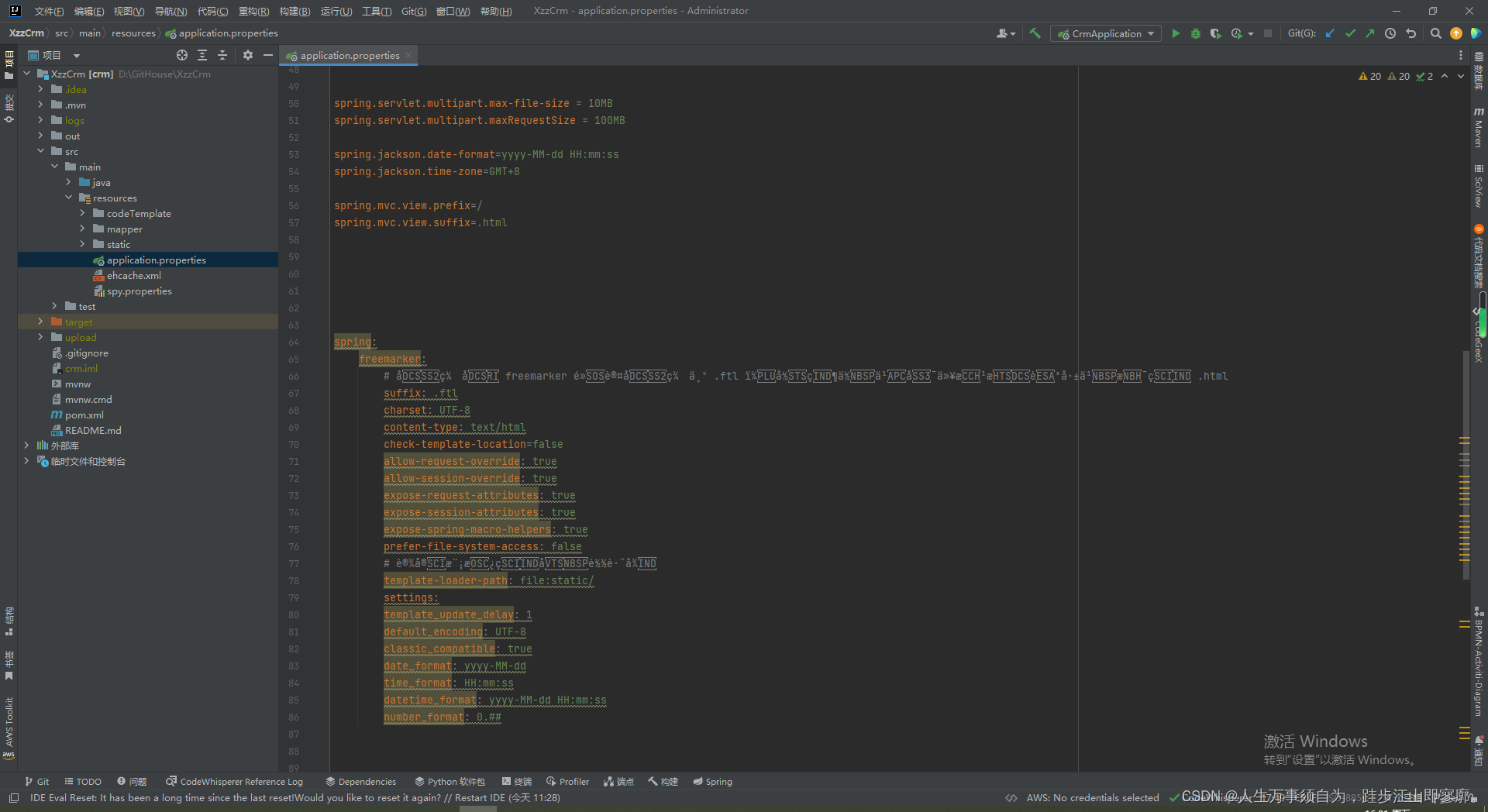
Spring Boot application.properties和application.yml文件的配置
在Spring Boot中,application.properties 和 application.yml 文件用于配置应用程序的各个方面,如服务器端口、数据库连接、日志级别等。这两个文件是Spring Boot的配置文件,位于 src/main/resources 目录下。 application.properties 示例 …...

Unity单元测试
Unity单元测试是一个专门用于嵌入式单元测试的库, 现在简单讲下移植以及代码结构. 源码地址: GitHub - ThrowTheSwitch/Unity: Simple Unit Testing for C 1.我们只需要移植三个文件即可: unity.c, unity.h, unity_internals.h 2.然后添加需要测试的函数. 3.在main.c中添加…...

Spring Bean 的生命周期了解么?
Spring Bean 的生命周期基本流程 一个Spring的Bean从出生到销毁的全过程就是他的整个生命周期, 整个生命周期可以大致分为3个大的阶段 : 创建 使用 销毁 还可以分为5个小步骤 : 实例化(Bean的创建) , 初始化赋值, 注册Destruction回调 , Bean的正常使用 以及 Bean的销毁 …...

.ryabina勒索病毒数据怎么处理|数据解密恢复
导言: 随着网络安全威胁的不断增加,勒索软件已成为严重的威胁之一,.ryabina勒索病毒是其中之一。本文将介绍.ryabina勒索病毒的特点、数据恢复方法和预防措施,以帮助用户更好地应对这一威胁。当面对被勒索病毒攻击导致的数据文件…...
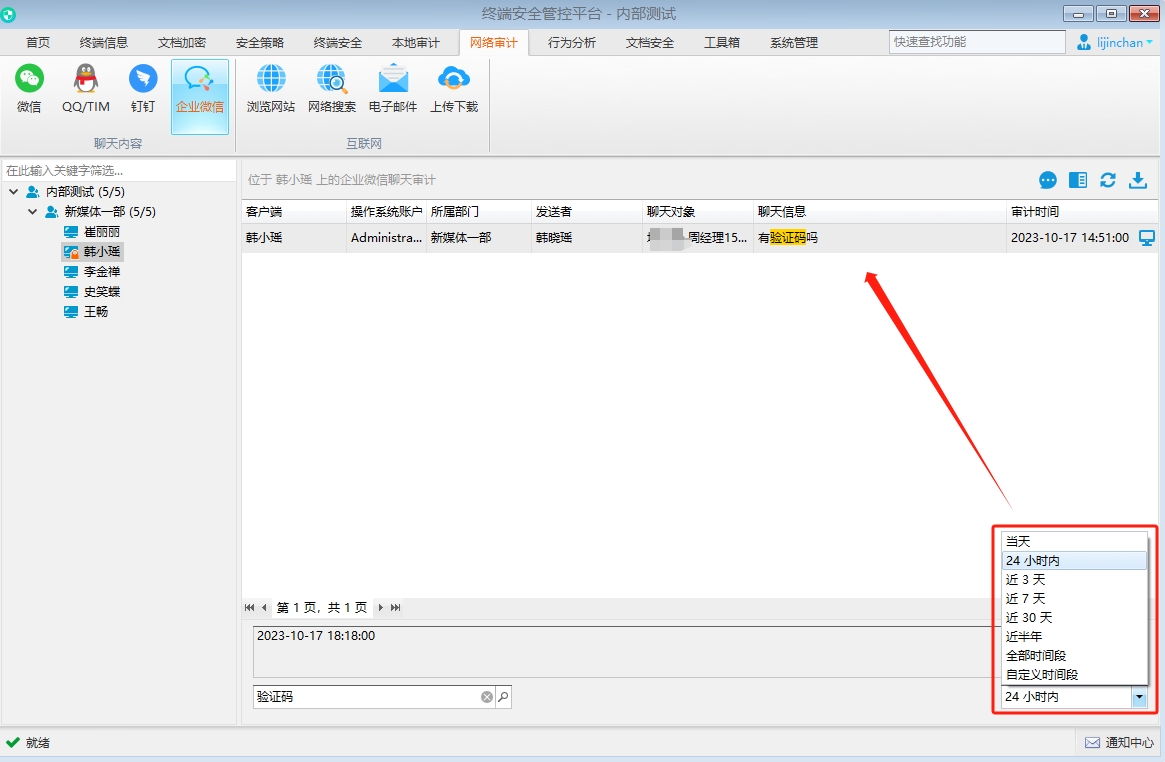
上网行为监控软件能够看到聊天内容吗
随着信息技术的不断发展,上网行为监控软件在企业网络安全管理中扮演着越来越重要的角色。 这类软件主要用于监控员工的上网行为,以确保工作效率和网络安全。 而在这其中,域智盾软件作为一款知名的上网行为监控软件,其功能和使用…...

Java知识点一
hello,大家好!我们今天开启Java语言的学习之路,与C语言的学习内容有些许异同,今天我们来简单了解一下Java的基础知识。 一、数据类型 分两种:基本数据类型 引用数据类型 (1)整型 八种基本数…...
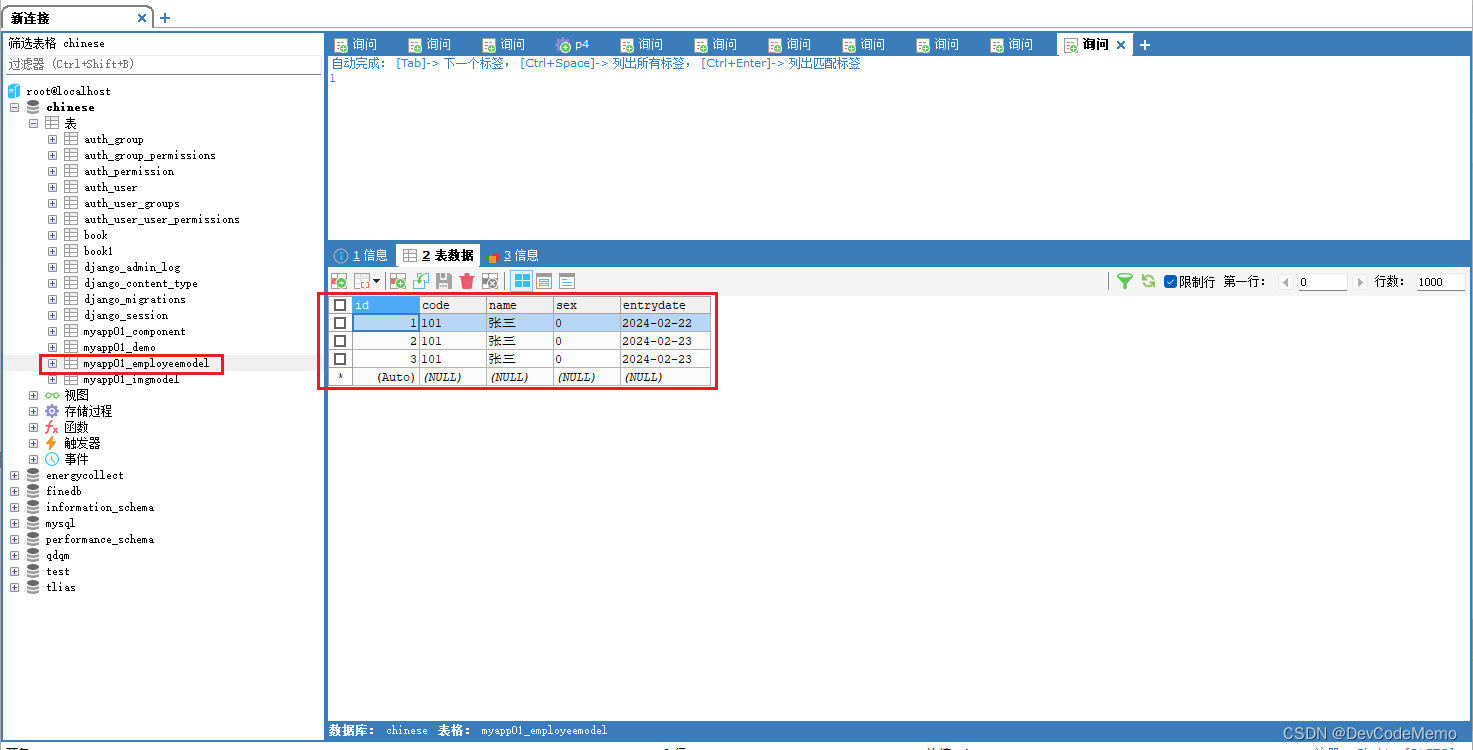
Django学习笔记-forms使用
1.创建forms.py文件,导入包 from django import forms from django.forms import fields from django.forms import widgets2. 创建EmployeeForm,继承forms.Form 3.创建testform.html文件 4.urls.py添加路由 5.views中导入forms 创建testform,编写代码 1).如果请求方式为GET,…...
)
BM100 设计LRU缓存结构(java实现)
一、题目 设计LRU(最近最少使用)缓存结构,该结构在构造时确定大小,假设大小为 capacity ,操作次数是 n ,并有如下功能: Solution(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存get(key):如果关键字 key …...
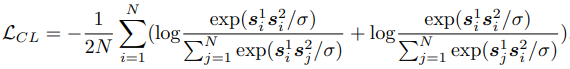
论文阅读——ONE-PEACE
ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES 适应不同模态并且支持多模态交互。 预训练任务不仅能提取单模态信息,还能模态间对齐。 预训练任务通用且直接,使得他们可以应用到不同模态。 各个模态独立编码&am…...

围剿尚未终止 库迪深陷瑞幸9.9阳谋
文|智能相对论 作者|霖霖 总能被“累了困了”的打工人优先pick的咖啡,刚复工就顺利站上话题C位。 #瑞幸9.9元一杯活动缩水#的话题才爬上新浪微博热搜,“库迪咖啡河北分公司运营总监带头坑害河北联营商”的实名举报帖就出现在了小红书,一时…...
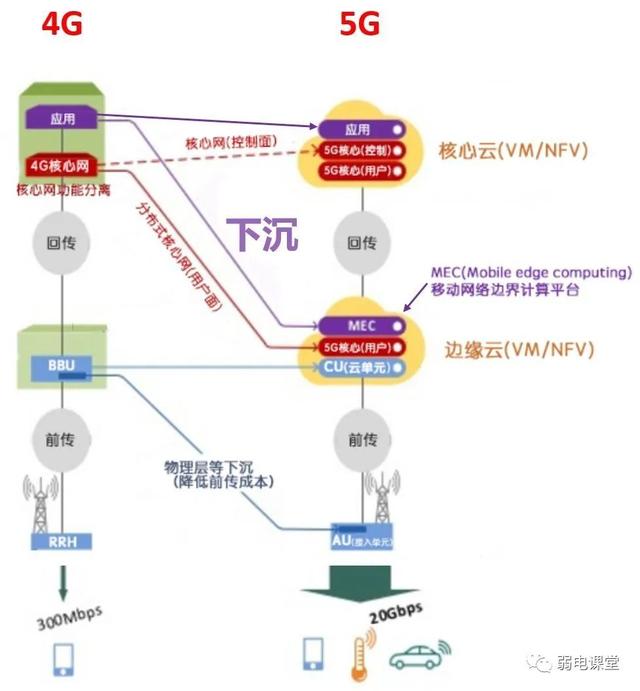
5G网络(接入网+承载网+核心网)
5G网络(接入网承载网核心网) 一、5G网络全网架构图 这张图分为左右两部分,右边为无线侧网络架构,左边为固定侧网络架构。 无线侧:手机或者集团客户通过基站接入到无线接入网,在接入网侧可以通过RTN或者IP…...
学习Markdown
https://shadows.brumm.af 欢迎使用Markdown编辑器 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。 新的改变 我们对Markdown编辑器进行了一些…...
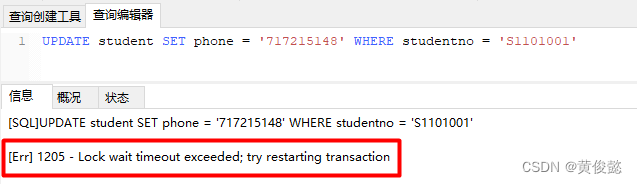
MySQL知识点总结(五)——锁
MySQL知识点总结(五)——锁 锁分类表锁 & 行锁如何添加表锁?如何添加行锁? 读锁 & 写锁行锁 & 间隙锁(gap lock)& 临键锁(next-key lock) 加锁机制分析可重复读隔离…...
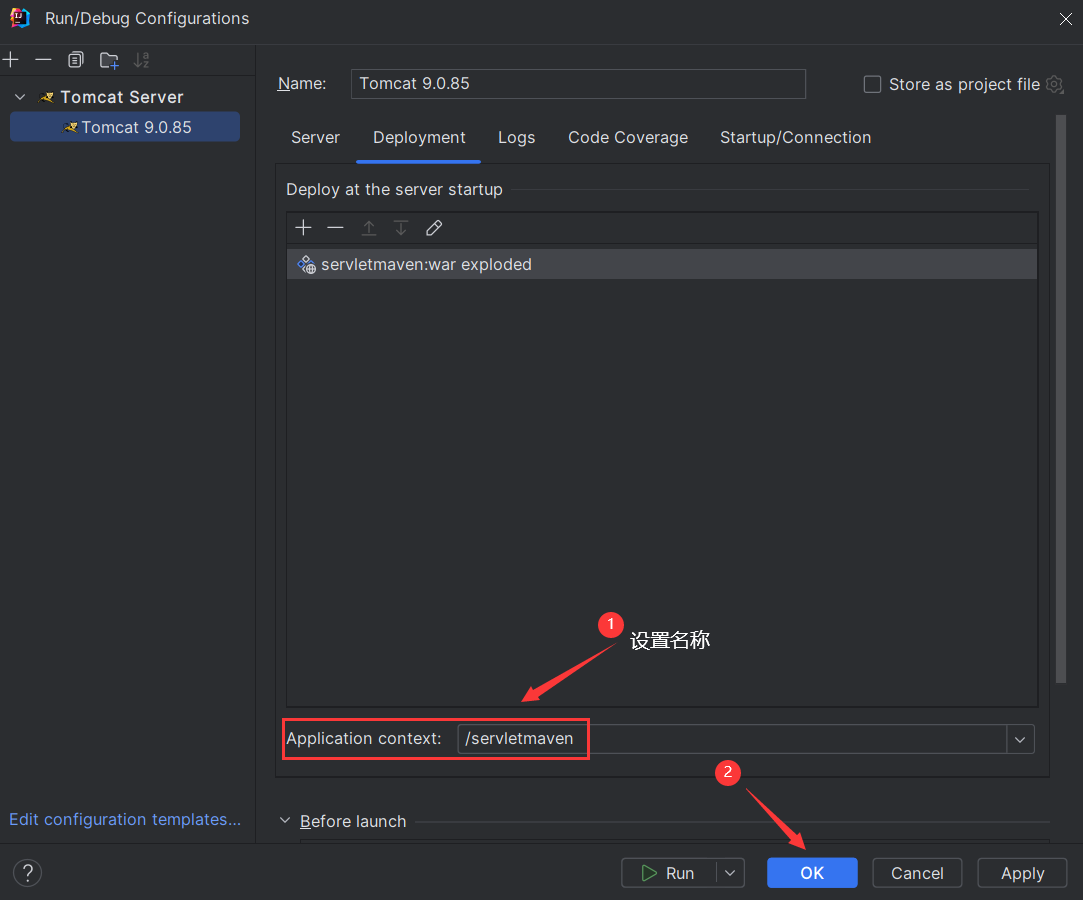
IDEA 2023.2 配置 JavaWeb 工程
目录 1 不使用 Maven 创建 JavaWeb 工程 1.1 新建一个工程 1.2 配置 Tomcat 1.3 配置模块 Web 2 使用 Maven 配置 JavaWeb 工程 2.1 新建一个 Maven 工程 2.2 配置 Tomcat 💥提示:IDEA 只有专业版才能配置 JavaWeb 工程,若是社区版&am…...
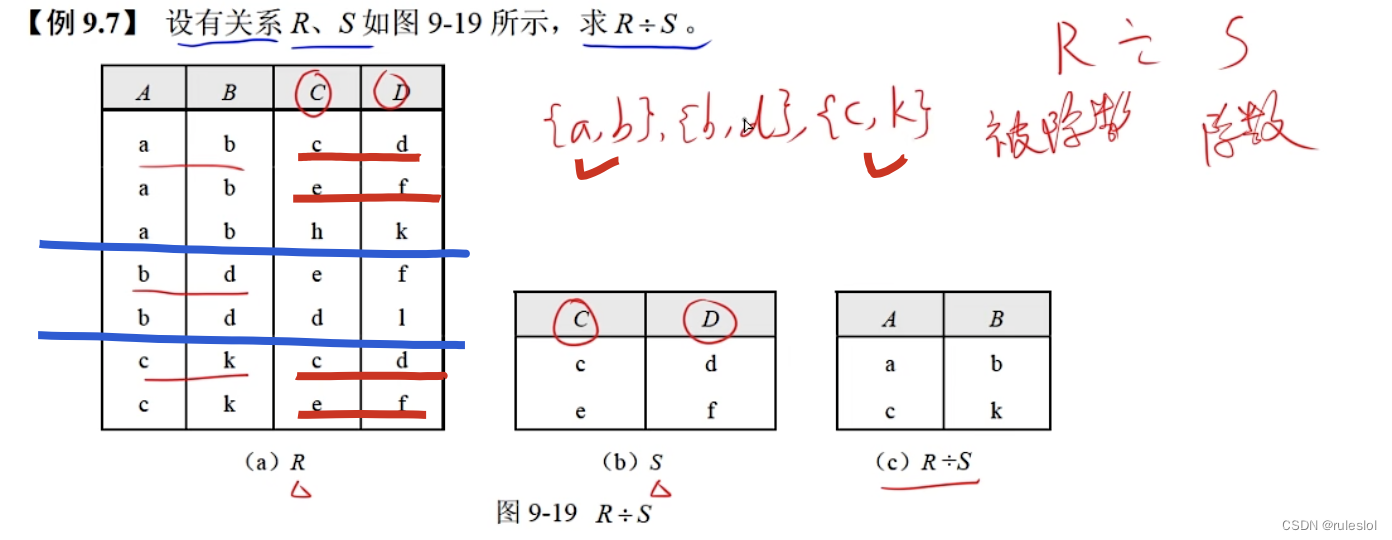
软考40-上午题-【数据库】-关系代数运算2-专门的集合运算
一、专门的集合运算 1、投影 示例: 可以用属性名进行投影,也可以用列的序号进行投影。 2、选择 例题 1、笛卡尔积 2、投影 3、选择 3、连接 第一步都要算:笛卡尔积。 3-1、θ连接 示例: 3-2、等值连接 示例: 3-3、自…...
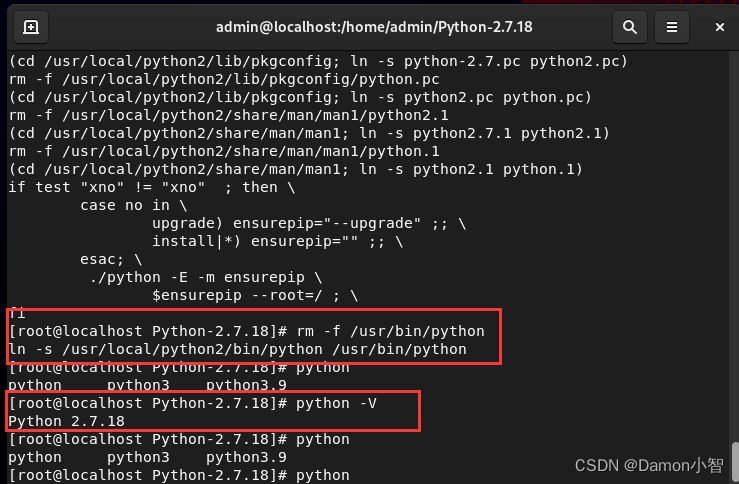
RHEL9安装Python2.7
RHEL9作为2022年5月新推出的版本,较RHEL8有了很多地方的改进,而且自带很多包,功能非常强大,稳定性和流畅度也较先前版本有了很大的提升。RHEL9自带python3.9,但是过高版本的python不可避免地会导致一些旧版本包地不兼容…...
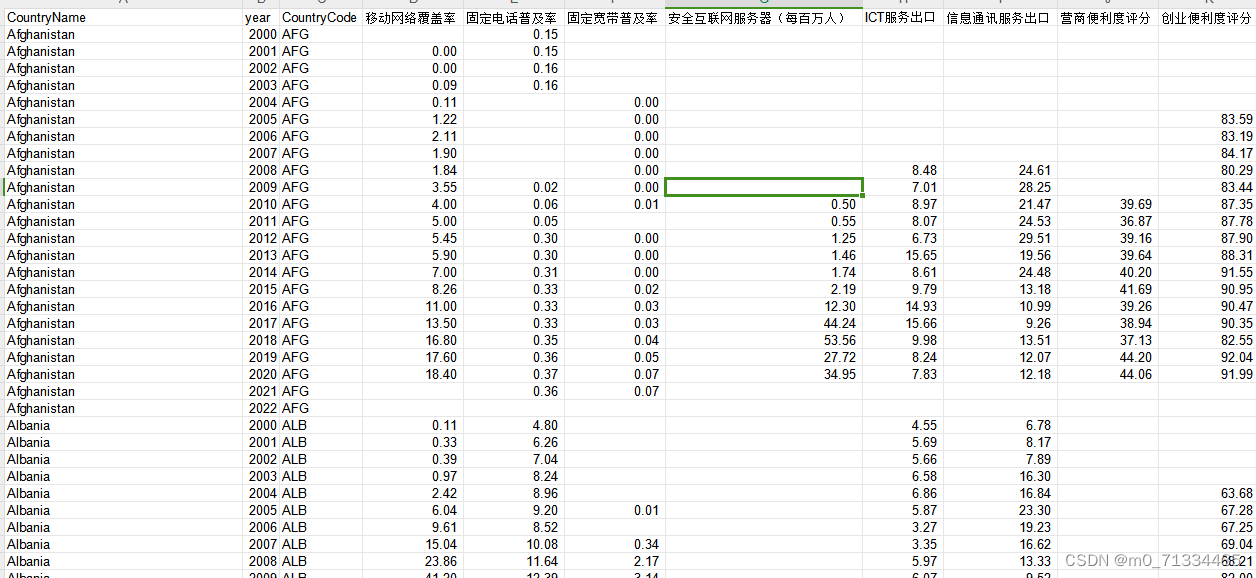
更新至2022年世界各国数字经济发展相关指标(23个指标)
更新至2022年世界各国数字经济发展相关指标(23个指标) 1、时间:具体指标时间见下文 2、来源:WDI、世界银行、WEF、UNCTAD、SJR、国际电联 3、指标:移动网络覆盖率(2000-2022)、固定电话普及率…...
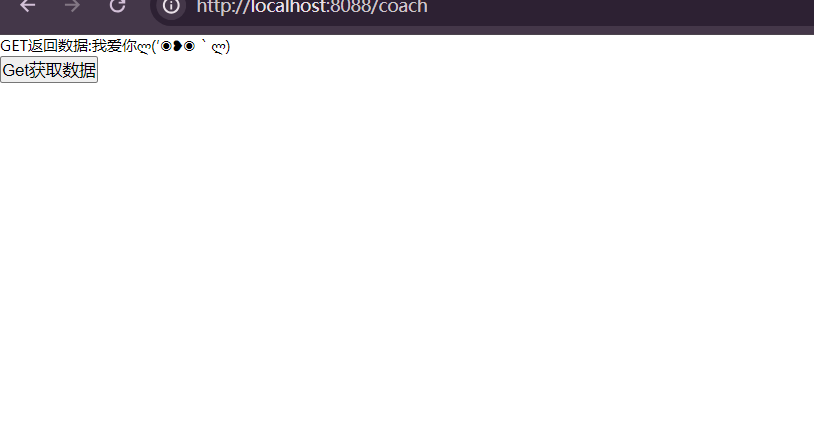
vue从flask获取数据并显示
记录一个前后端分离遇到的问题,即vue前端从flask后端获取数据。具体描述如下:flask只负责连接数据库并获取数据库的数据,并返回给前端vue;vue则需要获取后端返回的数据并显示。 方法如下,分别用一个vue组件和一个flas…...

Kafka生产常见问题分析与总结
Kafka生产常见问题分析与总结 消息丢失 生产者 acks 0 不需要等待任何Broker确认收到消息的回复就可以继续发消息 性能最高,但是最容易丢消息,对于数据丢失不敏感的场景可以使用,如大数据统计报表 acks 1 只要等待Broker中的leader成功写…...

在软件开发中正确使用MySQL日期时间类型的深度解析
在日常软件开发场景中,时间信息的存储是底层且核心的需求。从金融交易的精确记账时间、用户操作的行为日志,到供应链系统的物流节点时间戳,时间数据的准确性直接决定业务逻辑的可靠性。MySQL作为主流关系型数据库,其日期时间类型的…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...