爬虫基本库的使用(urllib库的详细解析)
学习爬虫,其基本的操作便是模拟浏览器向服务器发出请求,那么我们需要从哪个地方做起呢?请求需要我们自己构造吗? 我们需要关心请求这个数据结构怎么实现吗? 需要了解 HTTP、TCP、IP层的网络传输通信吗? 需要知道服务器如何响应以及响应的原理吗?
可能你无从下手,不过不用担心,Python的强大之处就是提供了功能齐全的类库来帮助我们实现这些需求。最基础的 HTTP 库有 urllib、requests、httpx等。(由于篇幅限制,本帖只讲解urllib库,Request和httpx后续会陆续更新)
拿 urllib 这个库来说,有了它,我们只需要关心请求的链接是什么,需要传递的参数是什么,以及如何设置可选的请求头,而无须深入到底层去了解到底是怎样传输和通信的。有了 urllib库,只用两行代码就可以完成一次请求和响应的处理过程,得到网页内容,是不是感觉方便极了?
目录
urllib的使用
1、发送请求
(1) urlopen
(2)Request
2、异常处理
3、解析链接
(1)urlparse
(2)urlunparse
(3)urlsplit
(4)urlunsplit
4、分析Robots协议
(1) Robots 协议
(2) robotparser
urllib的使用
首先介绍一个 Python库,叫作urllib,利用它就可以实现HTTP请求的发送,而且不需要关心 HTTP 协议本身甚至更底层的实现,我们要做的是指定请求的 URL、请求头、请求体等信息。此外urllib还可以把服务器返回的响应转化为Python 对象,我们通过该对象便可以方便地获取响应的相关信息,如响应状态码、响应头、响应体等。
注意 :在Python 2 中, 有urllib和 urllib2两个库来实现 HTTP 请求的发送。 而在Python 3 中, urllib2库已经不存在了,统一为了 urllib。
首先,我们了解一下 urllib库的使用方法,它是 Python 内置的 HTTP 请求库,也就是说不需要额外安装,可直接使用。urllib 库包含如下4 个模块。
- request:这是最基本的 HTTP 请求模块,可以模拟请求的发送。就像在浏览器里输入网址然后按下回车一样,只需要给库方法传入 URL 以及额外的参数,就可以模拟实现发送请求的过程了。
- error:异常处理模块。如果出现请求异常,那么我们可以捕获这些异常,然后进行重试或其他操作以保证程序运行不会意外终止。
- parse:一个工具模块。提供了许多URL 的处理方法,例如拆分、解析、合并等。
- robotparser: 主要用来识别网站的 robots. txt文件, 然后判断哪些网站可以爬, 哪些网站不可以,它其实用得比较少。
1、发送请求
使用urllib库的 request模块,可以方便地发送请求并得到响应。urllib. request模块提供了最基本的构造 HTTP请求的方法,利用这个模块可以模拟浏览器的请求发起过程, 同时它还具有处理授权验证(Authentication )、重定向(Redirection)、浏览器Cookie 以及其他一些功能。
(1) urlopen
下面以百度为例,抓取该网页:
import urllib.request
url = 'https://www.baidu.com'
response = urllib.request.urlopen(url)
# 获取网页源代码
print("网页源代码:")
print(response.read().decode('utf-8'))
# 获取响应状态码
print("响应状态码:")
print(response.status)
# 获取响应头
print("响应头:")
print(response.getheaders())运行结果:
网页源代码:
<html>
<head><script>location.replace(location.href.replace("https://","http://"));</script>
</head>
<body><noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html>
响应状态码:
200
响应头:
[('Accept-Ranges', 'bytes'), ('Cache-Control', 'no-cache'), ('Content-Length', '227'), ('Content-Security-Policy', "frame-ancestors 'self' https://chat.baidu.com http://mirror-chat.baidu.com https://fj-chat.baidu.com https://hba-chat.baidu.com https://hbe-chat.baidu.com https://njjs-chat.baidu.com https://nj-chat.baidu.com https://hna-chat.baidu.com https://hnb-chat.baidu.com http://debug.baidu-int.com;"), ('Content-Type', 'text/html'), ('Date', 'Tue, 20 Feb 2024 02:54:13 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Pragma', 'no-cache'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BD_NOT_HTTPS=1; path=/; Max-Age=300'), ('Set-Cookie', 'BIDUPSID=30561DE24C7F0F5FF9E66FE3886A5240; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1708397653; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=30561DE24C7F0F5FFA6A431818DB782D:FG=1; max-age=31536000; expires=Wed, 19-Feb-25 02:54:13 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Traceid', '1708397653049913601018294765874260519959'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('X-Xss-Protection', '1;mode=block'), ('Connection', 'close')]使用urloen方法已经可以完成对简单网页的GET请求抓取,该方法的API为:
urllib. request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False, context=None)可以发现,除了第一个参数用于传递URL 之外,我们还可以传递其他内容,例如 data(附加数据)、timeout (超时时间) 等。接下来就详细说明一下 urlopen 方法中几个参数的用法。
- data 参数
data参数是可选的。在添加该参数时,需要使用bytes方法将参数转化为字节流编码格式的内容,即bytes类型。另外,如果传递了这个参数,那么它的请求方式就不再是 GET,而是 POST了。
- timeout 参数
timeout 参数用于设置超时时间,单位为秒,意思是如果请求超出了设置的这个时间,还没有得到响应,就会抛出异常。如果不指定该参数,则会使用全局默认时间。这个参数支持HTTP、HTTPS、FTP 请求。
- 其他参数
除了 data 参数和 timeout 参数, urlopen方法还有 context参数,该参数必须是 ss1. SSLContext类型,用来指定 SSL的设置。此外, cafile和 capath 这两个参数分别用来指定 CA证书和其路径, 这两个在请求 HTTPS 链接时会有用。cadefault参数现在已经弃用了, 其默认值为 False。
至此,我们讲解了 urlopen 方法的用法,通过这个最基本的方法,就可以完成简单的请求和网页抓取。
(2)Request
利用urlopen方法可以发起最基本的请求,但它那几个简单的参数并不足以构建一个完整的请求。如果需要往请求中加入Headers等信息,就得利用更强大的 Request 类来构建请求了。
首先,我们用实例感受一下 Request 类的用法:
import urllib. request
request= urllib.request.Request(' https://python.org')
response = urllib. request. urlopen(request)
print(response. read(). decode('utf-8'))可以发现,我们依然是用urlopen方法来发送请求,只不过这次该方法的参数不再是 URL,而是一个Request 类型的对象。通过构造这个数据结构,一方面可以将请求独立成一个对象,另一方面可更加丰富和灵活地配置参数。
下面我们看一下可以通过怎样的参数来构造 Request 类,构造方法如下:
class urllib. request. Request(url, data=None, headers={},
origin req host=None, unverifiable=False, method=None)- 第一个参数url用于请求 URL,这是必传参数,其他的都是可选参数。
- 第二个参数data如果要传数据,必须传bytes类型的。如果数据是字典,可以先用urllib. parse 模块里的 urlencode方法进行编码。
- 第三个参数 headers 是一个字典,这就是请求头,我们在构造请求时,既可以通过 headers 参数直接构造此项,也可以通过调用请求实例的 add header方法添加。
- 添加请求头最常见的方法就是通过修改 User-Agent 来伪装浏览器。默认的 User-Agent 是Python-urllib,我们可以通过修改这个值来伪装浏览器。例如要伪装火狐浏览器,就可以把User-Agent 设置为:Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
- 第四个参数origin req host指的是请求方的 host 名称或者 IP 地址。
- 第五个参数 unverifiable表示请求是否是无法验证的,默认取值是 False,意思是用户没有足够的权限来接收这个请求的结果。例如,请求一个HTML 文档中的图片,但是没有自动抓取图像的权限,这时unverifiable 的值就是 True。
- 第六个参数method是一个字符串,用来指示请求使用的方法,例如GET、POST和 PUT等。
下面我们传入多个参数尝试构建 Request 类:
from urllib import request, parse
url = 'https://www.httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': ' www.httpbin.org'
}
dict = {'name': 'germey'}
data = bytes(parse. urlencode(dict), encoding='utf-8')
req = request. Request(url=url, data=data, headers=headers, method='POST')
response = request. urlopen(req)
print(response. read(). decode('utf-8'))运行结果:
{"args": {}, "data": "", "files": {}, "form": {"name": "germey"}, "headers": {"Accept-Encoding": "identity", "Content-Length": "11", "Content-Type": "application/x-www-form-urlencoded", "Host": "www.httpbin.org", "User-Agent": "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)", "X-Amzn-Trace-Id": "Root=1-65d41be7-0337942e592a7e7a53c9107b"}, "json": null, "origin": "118.212.215.166", "url": "https://www.httpbin.org/post"
}
观察结果可以发现, 我们成功设置了 data、headers 和 method。
通过 add header方法添加 headers 的方式如下:
req = request. Request(url=url, data=data, method='POST')
req add header('User Agent', 'Mozilla/4 0(compatible; MSIE 5 5; Windows NT)')有了 Request类,我们就可以更加方便地构建请求,并实现请求的发送啦。
2、异常处理
我们已经了解了如何发送请求,但是在网络不好的情况下,如果出现了异常,该怎么办呢? 这时要是不处理这些异常,程序很可能会因为报错而终止运行,所以异常处理还是十分有必要的。
urllib库中的 error模块定义了由 request模块产生的异常。当出现问题时, request模块便会抛出 error模块中定义的异常。
- URLError
URLError类来自 urllib库的 error模块,继承自OSError类,是error异常模块的基类, 由 request 模块产生的异常都可以通过捕获这个类来处理。它具有一个属性reason,即返回错误的原因。
下面用一个实例来看一下:
from urllib import request, error
try:
response = request.urlopen(' https://cuiqingcai.com/404')
except error. URLError as e:
print(e. reason)我们打开了一个不存在的页面,照理来说应该会报错,但是我们捕获了 URLError这个异常。
运行结果如下:
Not Found程序没有直接报错,而是输出了错误原因,这样可以避免程序异常终止,同时异常得到了有效处理。
- HTTPError
HTTPError是URLError的子类,专门用来处理HTTP请求错误,例如认证请求失败等。它有如下3个属性。
- code:返回HTTP状态码,例如404表示网页不存在,500表示服务器内部错误等。
- reason:同父类一样,用于返回错误的原因。
- headers: 返回请求头。
下面我们用几个实例来看看:
from urllib import request, error
try:response = request.urlopen(' https://cuiqingcai.com/404')
except error. HTTPError as e:print(e. reason, e. code, e. headers, sep='\n')运行结果如下:
Not Found
404
Server: GitHub.com
Content-Type: text/html; charset=utf-8
Access-Control-Allow-Origin: *
ETag: "64d39a40-24a3"
Content-Security-Policy: default-src 'none'; style-src 'unsafe-inline'; img-src data:; connect-src 'self'
x-proxy-cache: MISS
X-GitHub-Request-Id: C988:38DF71:2CD1E:3F291:65D4231A
Accept-Ranges: bytes
Date: Tue, 20 Feb 2024 03:57:15 GMT
Via: 1.1 varnish
Age: 0
X-Served-By: cache-icn1450083-ICN
X-Cache: MISS
X-Cache-Hits: 0
X-Timer: S1708401435.117679,VS0,VE185
Vary: Accept-Encoding
X-Fastly-Request-ID: ebbb650d9a42388fbffef33aa8977ba03d9fd797
X-Cache-Lookup: Cache Miss
Content-Length: 9379
X-NWS-LOG-UUID: 15553444116395185930
Connection: close
X-Cache-Lookup: Cache Miss依然是打开同样的网址, 这里捕获了 HTTPError异常, 输出了 reason、code 和 headers 属性。
因为 URLError 是 HTTPError的父类,所以可以先选择捕获子类的错误,再捕获父类的错误。上述代码的更好写法如下:
from urllib import request, error
try:
response = request.urlopen(' https://cuiqingcai.com/404')
except error. HTTPError as e:
print(e. reason, e. code, e. headers, sep='\n')
except error. URLError as e:
print(e. reason)
else:
print('Request Successfully')这样就可以做到先捕获 HTTPError,获取它的错误原因、状态码、请求头等信息。如果不是HTTPError异常,就会捕获URLError异常,输出错误原因。最后,用else语句来处理正常的逻辑。这是一个较好的异常处理写法。有时候,reason属性返回的不一定是字符串,也可能是一个对象。再看下面的实例:
import socket
import urllib. request
import urllib. error
try:
response = urllib.request.urlopen(' https://www.baidu.com', timeout=0.01)
except urllib. error. URLError as e:
print(type(e. reason))
if isinstance(e. reason, socket. timeout):
print('TIME OUT')这里我们直接设置超时时间来强制抛出 timeout异常。
运行结果如下:
<class 'TimeoutError'>
TIME OUTreason属性的结果是socket.timeout类。所以这里可以用isinstance方法来判断它的类型,做出更详细的异常判断。
3、解析链接
前面说过,urllib库里还提供了 parse 模块,这个模块定义了处理URL的标准接口,例如实现URL 各部分的抽取、合并以及链接转换。它支持如下协议的 URL处理: file、ftp、gopher、hdl 、http、imap、 mailto、 mms、 news、 nntp、 prospero、 rsync、 rtsp、 rtspu、 sftp、 sip、 sips、 snews、 svn、 svn+ssh、telnet 和 wais。
下面我们将介绍parse 模块中的常用方法,看一下它的便捷之处。
(1)urlparse
该方法可以实现URL的识别和分段,这里先用一个实例来看一下:
from urllib. parse import urlparseresult = urlparse('https://www.baidu.com/index.html;user?id=5 #comment')print(type(result))print(result)这里我们利用urlparse方法对一个 URL进行了解析,然后输出了解析结果的类型以及结果本身。
运行结果如下:
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5',fragment='comment')可以看到,解析结果是一个ParseResult类型的对象, 包含6部分,分别是scheme、netloc、path、params、 query和 fragment。再观察一下上述实例中的 URL:
https://www.baidu.com/index.html;user?id=5 #comment
可以发现, urlparse 方法在解析 URL 时有特定的分隔符。例如:// 前面的内容就是 scheme, 代表协议。第一个/ 符号前面便是 netloc, 即域名; 后面是path, 即访问路径。分号;后面是 params,代表参数。问号?后面是查询条件 query, 一般用作 GET 类型的 URL。井号#后面是锚点 fragment,用于直接定位页面内部的下拉位置。
于是可以得出一个标准的链接格式,具体如下:
scheme://netloc/path;params? query#fragment一个标准的URL 都会符合这个规则,利用urlparse方法就可以将它拆分开来。除了这种最基本的解析方式外,urlparse方法还有其他配置吗? 接下来,看一下它的 API用法:
urllib. parse. urlparse(urlstring, scheme='', allow fragments=True)可以看到, urlparse 方法有3 个参数。
- urlstring: 这是必填项, 即待解析的 URL。
- scheme: 这是默认的协议(例如 http 或https等)。如果待解析的 URL 没有带协议信息, 就会将这个作为默认协议。我们用实例来看一下:
from urllib. parse import urlparseresult = urlparse('www.baidu.com/index.html;user?id=5 #comment', scheme='https')print(result)运行结果如下:
ParseResult(scheme='https', netloc='', path='www.baidu.com/index.html',params='user', query='id=5',fragment='comment')可以发现,这里提供的URL 不包含最前面的协议信息,但是通过默认的 scheme 参数,返回了结果 https。
假设带上协议信息:
result = urlparse('http://www.baidu.com/index.html;user?id=5 #comment', scheme='https')则结果如下:
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=5',fragment='comment')可见,scheme参数只有在 URL中不包含协议信息的时候才生效。如果URL中有,就会返回解析出的 scheme。
- allow fragments: 是否忽略 fragment。如果此项被设置为 False, 那么 fragment 部分就会被忽略, 它会被解析为 path、params 或者 query的一部分, 而 fragment 部分为空。
下面我们用实例来看一下:
from urllib. parse import urlparseresult = urlparse(' https://www.baidu.com/index.html;user?id=5#comment',allow fragments=False)print(result)运行结果如下:
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment',fragment='')假设 URL 中不包含 params 和 query, 我们再通过实例看一下:
from urllib. parse import urlparseresult = urlparse('https://www.baidu.com/index.html#comment', allow fragments=False)print(result)运行结果如下:
ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html#comment', params='', query='',fragment='')可以发现, 此时 fragment 会被解析为 path的一部分。返回结果 ParseResult 实际上是一个元组,既可以用属性名获取其内容,也可以用索引来顺序获取。
实例如下:
from urllib. parse import urlparseresult = urlparse('https://www.baidu.com/index.html#comment', allowfragments=False)print(result.scheme, result[0], result.netloc, result[1], sep='\n')这里我们分别用属性名和索引获取了 scheme 和 netloc,运行结果如下:
https
https
www.baidu.com
www.baidu.com可以发现,两种获取方式都可以成功获取,且结果是一致的。
(2)urlunparse
有了 urlparse 方法, 相应就会有它的对立方法urlunparse, 用于构造 URL。这个方法接收的参数是一个可迭代对象,其长度必须是 6,否则会抛出参数数量不足或者过多的问题。先用一个实例看一下:
from urllib. parse import urlunparsedata = ['https', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']print(urlunparse(data))运行结果如下:
https://www.baidu.com/index.html;user?a=6#comment这样我们就成功实现了 URL的构造。
(3)urlsplit
这个方法和urlparse 方法非常相似,只不过它不再单独解析 params 这一部分(params会合并到path中),只返回5个结果。实例如下:
from urllib. parse import urlsplitresult = urlsplit('https://www.baidu.com/index.html;user?id=5#comment')print(result)运行结果如下:
SplitResult(scheme='https', netloc='www.baidu.com', path='/index.html;user', query='id=5',fragment='comment')可以发现,返回结果是 SplitResult,这其实也是一个元组,既可以用属性名获取其值,也可以用索引获取。实例如下:
from urllib. parse import urlsplitresult = urlsplit('https://www.baidu.com/index.html;user?id=5#comment')print(result. scheme, result[0])运行结果如下:
https https(4)urlunsplit
与urlumparse方法类似,这也是将链接各个部分组合成完整链接的方法,传入的参数也是一个可迭代对象,例如列表、元组等,唯一区别是这里参数的长度必须为5。实例如下:
from urllib. parse import urlunsplitdata = ['https', 'www.baidu.com', 'index.html', 'a=6', 'comment']print(urlunsplit(data))运行结果如下:
https://www.baidu.com/index.html?a=6#commenturljoinurlunparse和 urlunsplit 方法都可以完成链接的合并,不过前提都是必须有特定长度的对象,链接的每一部分都要清晰分开。
除了这两种方法,还有一种生成链接的方法,是 urljoin。我们可以提供一个 base url(基础链接)作为该方法的第一个参数,将新的链接作为第二个参数。urljoin 方法会分析 base url的 scheme、netloc 和path这3个内容,并对新链接缺失的部分进行补充,最后返回结果。
下面通过几个实例看一下:
from urllib. parse import urljoinprint(urljoin('https://www.baidu.com', 'FAQ.html'))
print(urljoin('https://www.baidu.com','https://cuiqingcai.com/FAQ.html'))
print(urljoin('https://www.baidu.com/about.html','https://cuiqingcai.com/FAQ.html'))
print(urljoin('https://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2'))
print(urljoin('https://www.baidu.com?wd=abc', 'https://cuiqingcai.com/index.php'))
print(urljoin('https://www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', '?category=2 #comment'))
print(urljoin('www.baidu.com#comment', '?category=2'))运行结果如下:
https://www.baidu.com/FAQ.htmlhttps://cuiqingcai.com/FAQ.htmlhttps://cuiqingcai.com/FAQ.htmlhttps://cuiqingcai.com/FAQ.html?question=2https://cuiqingcai.com/index.phphttps://www.baidu.com?category=2#commentwww.baidu.com?category=2#commentwww.baidu.com?category=2可以发现, base url提供了三项内容: scheme、netloc和 path。如果新的链接里不存在这三项,就予以补充; 如果存在,就使用新的链接里面的,base url中的是不起作用的。通过urljoin 方法,我们可以轻松实现链接的解析、拼合与生成。
4、分析Robots协议
利用 urllib库的 robotparser 模块,可以分析网站的 Robots 协议。我们再来简单了解一下这个模块的用法。
(1) Robots 协议
Robots 协议也称作爬虫协议、机器人协议,全名为网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取、哪些不可以。它通常是一个叫作 robots. txt的文本文件,一般放在网站的根目录下。
搜索爬虫在访问一个站点时,首先会检查这个站点根目录下是否存在 robots. txt文件,如果存在,就会根据其中定义的爬取范围来爬取。如果没有找到这个文件,搜索爬虫便会访问所有可直接访问的页面。
下面我们看一个 robots. txt的样例:
User-agent: *Disallow: /Allow: /public/这限定了所有搜索爬虫只能爬取 public 目录。将上述内容保存成robots. txt文件,放在网站的根目录下, 和网站的入口文件(例如index. php、 index. html和 index. jsp等) 放在一起。上面样例中的User-agent描述了搜索爬虫的名称,这里将其设置为*,代表 Robots协议对所有爬取爬虫都有效。例如,我们可以这样设置:
User-agent: Baiduspider这代表设置的规则对百度爬虫是有效的。如果有多条User-agent记录,则意味着有多个爬虫会受到爬取限制,但至少需要指定一条。
Disallow指定了不允许爬虫爬取的目录,上例设置为 /,代表不允许爬取所有页面。Allow一般不会单独使用,会和Disallow一起用,用来排除某些限制。上例中我们设置为/public/,结合Disallow的设置,表示所有页面都不允许爬取,但可以爬取 public 目录。
下面再来看几个例子。禁止所有爬虫访问所有目录的代码如下:
User-agent: *Disallow: /允许所有爬虫访问所有目录的代码如下:
User-agent: *Disallow:另外,直接把robots. txt文件留空也是可以的。禁止所有爬虫访问网站某些目录的代码如下:
User-agent: *
Disallow: /private/
Disallow: /tmp/只允许某一个爬虫访问所有目录的代码如下:
User-agent: WebCrawler
Disallow:
User-agent: *
Disallow: /以上是 robots. txt的一些常见写法。
(2) robotparser
了解 Robots协议之后, 就可以使用robotparser模块来解析robots. txt文件了。该模块提供了一个类 RobotFileParser,它可以根据某网站的 robots. txt文件判断一个爬取爬虫是否有权限爬取这个网页。该类用起来非常简单,只需要在构造方法里传入 robots. txt文件的链接即可。首先看一下它的声明:
urllib. robotparser. RobotFileParser(url='')
当然,也可以不在声明时传入 robots. txt文件的链接,就让其默认为空,最后再使用set url()方法设置一下也可以。下面列出了 RobotFileParser类的几个常用方法。
- set url: 用来设置 robots. txt文件的链接。如果在创建 RobotFileParser 对象时传入了链接,就不需要使用这个方法设置了。
- read:读取 robots. txt文件并进行分析。注意,这个方法执行读取和分析操作,如果不调用这个方法,接下来的判断都会为False,所以一定记得调用这个方法。这个方法虽不会返回任何内容,但是执行了读取操作。
- parse: 用来解析robots. txt文件, 传入其中的参数是 robots. txt文件中某些行的内容, 它会按照robots. txt的语法规则来分析这些内容。
- can fetch:该方法有两个参数,第一个是User-Agent,第二个是要抓取的 URL。返回结果是 True 或False, 表示 User-Agent 指示的搜索引擎是否可以抓取这个URL。
- Jmtime: 返回上次抓取和分析robots. txt文件的时间, 这对于长时间分析和抓取 robots. txt文件的搜索爬虫很有必要,你可能需要定期检查以抓取最新的 robots. txt文件。
- modified:它同样对长时间分析和抓取的搜索爬虫很有帮助,可以将当前时间设置为上次抓取和分析 robots. txt文件的时间。
下面我们用实例来看一下:
from urllib. robotparser import RobotFileParserrp = RobotFileParser()rp.set url('https://www.baidu.com/robots.txt')rp. read()print(rp.can fetch('Baiduspider', 'https://www.baidu.com'))print(rp.can fetch('Baiduspider', 'https://www.baidu.com/homepage/'))print(rp.can fetch('Googlebot', 'https://www.baidu.com/homepage/'))这里以百度为例, 首先创建了一个 RobotFileParser 对象 rp, 然后通过 set url 方法设置了robots. txt文件的链接。当然,要是不用set url方法,可以在声明对象时直接用如下方法设置:
rp = RobotFileParser('https://www.baidu.com/robots.txt')接着利用 can fetch方法判断了网页是否可以被抓取。运行结果如下:
True
True
False可以看到,这里我们利用Baiduspider可以抓取百度的首页以及 homepage页面,但是 Googlebot就不能抓取 homepage页面。打开百度的 robots. txt文件, 可以看到如下信息:
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?Disallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bhUser-agent: GooglebotDisallow: /baiduDisallow: /s?Disallow: /shiften/Disallow: /homepage/Disallow: /cproDisallow: /ulink?Disallow: /link?Disallow: /home/news/data/Disallow: /bh不难看出, 百度的 robots. txt文件没有限制 Baiduspider 对百度 homepage 页面的抓取, 限制了Googlebot对 homepage页面的抓取。这里同样可以使用parse 方法执行对 robots. txt文件的读取和分析,实例如下:
from urllib. request import urlopenfrom urllib. robotparser import RobotFileParserrp= RobotFileParser()rp.parse(urlopen(' https://www.baidu.com/robots.txt').read().decode('utf-8').split('\n'))print(rp.can fetch('Baiduspider', 'https://www.baidu.com'))print(rp.can fetch('Baiduspider', ' https://www.baidu.com/homepage/'))print(rp.can fetch('Googlebot', ' https://www.baidu.com/homepage/'))运行结果是一样的:
TrueTrueFalse本节介绍了 robotparser 模块的基本用法和实例,利用此模块,我们可以方便地判断哪些页面能抓取、哪些页面不能。
相关文章:
)
爬虫基本库的使用(urllib库的详细解析)
学习爬虫,其基本的操作便是模拟浏览器向服务器发出请求,那么我们需要从哪个地方做起呢?请求需要我们自己构造吗? 我们需要关心请求这个数据结构怎么实现吗? 需要了解 HTTP、TCP、IP层的网络传输通信吗? 需要知道服务器如何响应以及响应的原理吗? 可…...
【PyQt5桌面应用开发】3.Qt Designer快速入门(控件详解)
一、Qt Designer简介 Qt Designer是PyQt程序UI界面的实现工具,可以帮助我们快速开发 PyQt 程序的速度。它生成的 UI 界面是一个后缀为 .ui 的文件,可以通过 pyiuc 转换为 .py 文件。 Qt Designer工具使用简单,可以通过拖拽和点击完成复杂界面…...
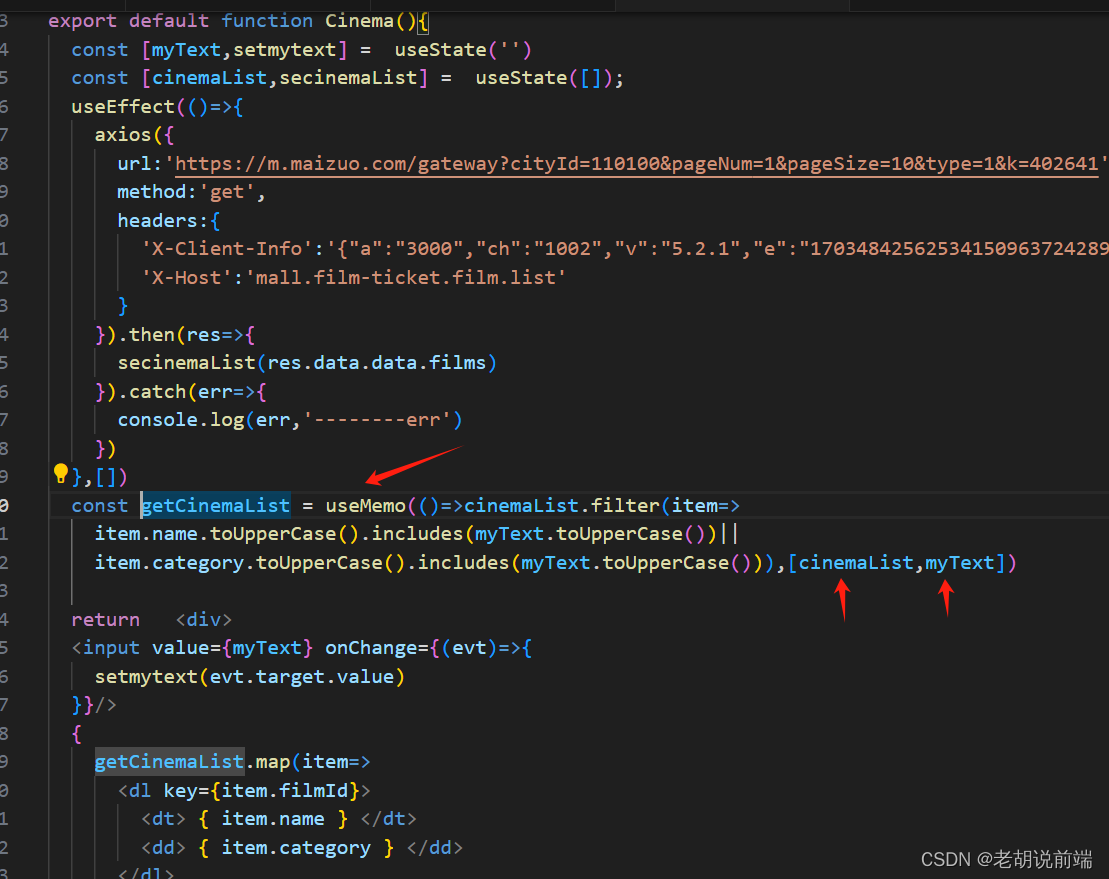
react useMemo 用法
1,useCallback 的功能完全可以由 useMemo 所取代,如果你想通过使用 useMemo 返回一个记忆函数也是完全可以的。 usecallback(fn,inputs)is equivalent to useMemo(()> fn, inputs). 区别是:useCallback不会执行第一个参数函数,而是将它返…...

python学习笔记 - 标准库函数
概述 为了方便程序员快速编写Python脚本程序,Python提供了很多好用的功能模块,它们内置于Python系统,也称为内置函数(Built-in Functions,BlF),Python 内置函数是 Python 解释器提供的一组函数,无需额外导…...
校招失败后,在小公司熬了 2 年终于进了字节跳动,竭尽全力....
其实两年前校招的时候就往字节投了一次简历,结果很明显凉了,随后这个理想就被暂时放下了,但是这个种子一直埋在心里这两年除了工作以外,也会坚持写博客,也因此结识了很多优秀的小伙伴,从他们身上学到了特别…...

PYTHON-使用正则表达式进行模式匹配
目录 Python 正则表达式Finding Patterns of Text Without Regular ExpressionsFinding Patterns of Text with Regular ExpressionsCreating Regex ObjectsMatching Regex ObjectsReview of Regular Expression MatchingMore Pattern Matching with Regular ExpressionsGroupi…...

Fiddler工具 — 19.Fiddler抓包HTTPS请求(二)
5、查看证书是否安装成功 方式一: 点击Tools菜单 —> Options... —> HTTPS —> Actions 选择第三项:Open Windows Certificate Manager打开Windows证书管理器。 打开Windows证书管理器,选择操作—>查看证书,在搜索…...

架构设计:流式处理与实时计算
引言 随着大数据技术的不断发展,流式处理和实时计算在各行各业中变得越来越重要。那么什么是流式处理呢?我们又该怎么使用它?流式处理允许我们对数据流进行实时分析和处理,而实时计算则使我们能够以低延迟和高吞吐量处理数据。本…...

Linux系统安装zookeeper
Linux安装zookeeper 安装zookeeper之前需要安装jdk,确认jdk环境没问题之后再开始安装zookeeper 下载zookeeper压缩包,官方下载地址:Apache Download Mirrors 将zookeeper压缩包拷贝到Linux并解压 # (-C 路径)可以解压到指定路径 tar -zxv…...

【前端素材】推荐优质后台管理系统Modernize平台模板(附源码)
一、需求分析 后台管理系统是一种用于管理和控制网站、应用程序或系统后台操作的软件工具,通常由授权用户(如管理员、编辑人员等)使用。它提供了一种用户友好的方式来管理网站或应用程序的内容、用户、数据等方面的操作,并且通常…...
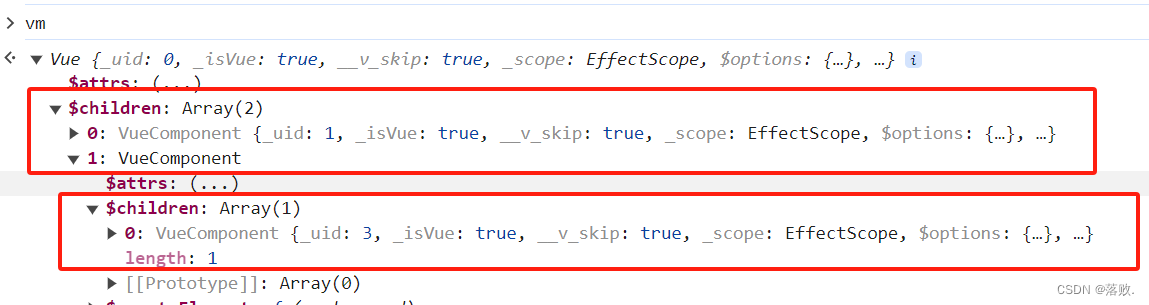
二、Vue组件化编程
2、Vue组件化编程 2.1 非单文件组件 <div id"root"><school></school><hr><student></student> </div> <script type"text/javascript">//创建 school 组件const school Vue.extend({template: <div&…...
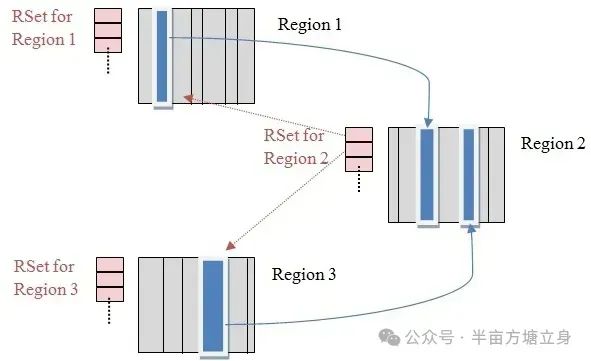
JVM跨代引用垃圾回收
1. 跨代引用概述 在Java堆内存中,年轻代和老年代之间存在的对象相互引用,假设现在要进行一次新生代的YGC,但新生代中的对象可能被老年代所引用的,为了找到新生代中的存活对象,不得不遍历整个老年代。这样明显效率很低…...
AI:135-基于卷积神经网络的艺术品瑕疵检测与修复
🚀点击这里跳转到本专栏,可查阅专栏顶置最新的指南宝典~ 🎉🎊🎉 你的技术旅程将在这里启航! 从基础到实践,深入学习。无论你是初学者还是经验丰富的老手,对于本专栏案例和项目实践都有参考学习意义。 ✨✨✨ 每一个案例都附带关键代码,详细讲解供大家学习,希望…...

C++标准头文件汇总及功能说明
文章目录 algorithmbitsetcctypecerrnoclocalecmathcstdioctimedequeiostreamexceptionfstreamfunctionallimitslistmapiosiosfwdsetsstreamstackstdexceptstreambufcstringutilityvectorcwcharcwctype algorithm algorithm头文件是C的标准算法库,它主要用在容器上。…...
)
glTF 添加数据属性(extras)
使用3D 模型作为可视化界面的一个关键是要能够在3D模型中添加额外的数据属性,利用这些数据属性能够与后台的信息模型建立对应关系,例如后台信息模型是opcua 信息模型的话,在3D模型中要能够包含OPC UA 的NodeId,BrowserName 等基本…...
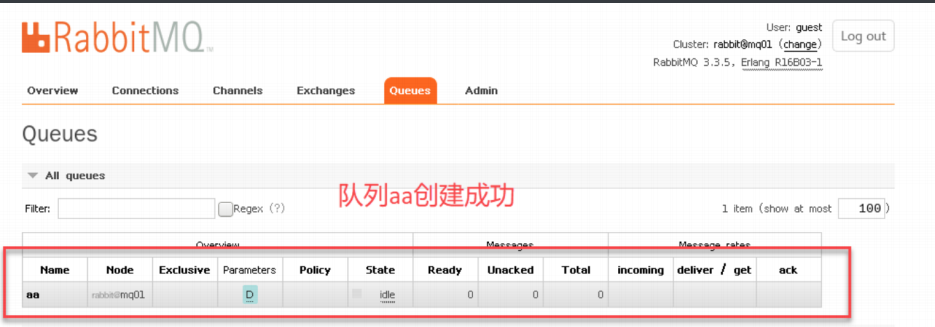
linux系统消息中间件rabbitmq普通集群的部署
rabbitmq普通集群的部署 普通集群准备环境查询版本对应安装rabbitmq软件启动创建登录用户开启用户远程登录查看端口 部署集群创建数据存放目录和日志存放目录:拷⻉erlang.cookie将其他两台服务器作为节点加⼊节点集群中查看集群状态创建新的队列 普通集群准备环境 配置hosts⽂件…...

TextCNN:文本分类卷积神经网络
模型原理 1、前言2、模型结构3、示例3.1、词向量层3.2、卷积层3.3、最大池化层3.4、Fully Connected层 4、总结 1、前言 TextCNN 来源于《Convolutional Neural Networks for Sentence Classification》发表于2014年,是一个经典的模型,Yoon Kim将卷积神…...

欧几里得和《几何原本》
欧几里得和《几何原本》 欧几里得(Euclid),公元前约300年生于古希腊,被认为是几何学的奠基人之一。他的主要成就是编写了一本名为《几何原本》(Elements)的著作,这本书成为了几何学的经典教材&a…...

linux c++ 开发 tensorrt 安装
tensorrt 官方下载地址(需要注册账号登录):Log in | NVIDIA Developer 根据系统发行版和CUDA版本 (nvcc -V) 选择合适的安装包 EA(early access)版本代表抢先体验。 GA(general availability)代…...
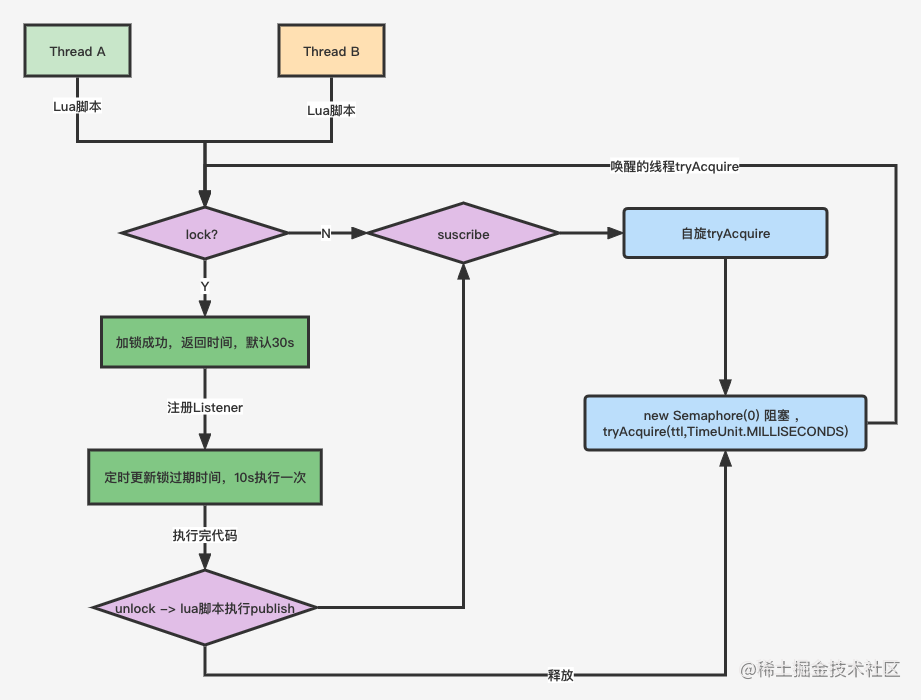
Redis高并发分布锁实战
Redis高并发分布锁实战 问题场景 场景一: 没有捕获异常 // 仅仅加锁 // 读取 stock15 Boolean ret stringRedisTemplate.opsForValue().setIfAbsent("lock_key", "1"); // jedis.setnx(k,v) // TODO 业务代码 stock-- stringRedisTemplate.delete(&quo…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...
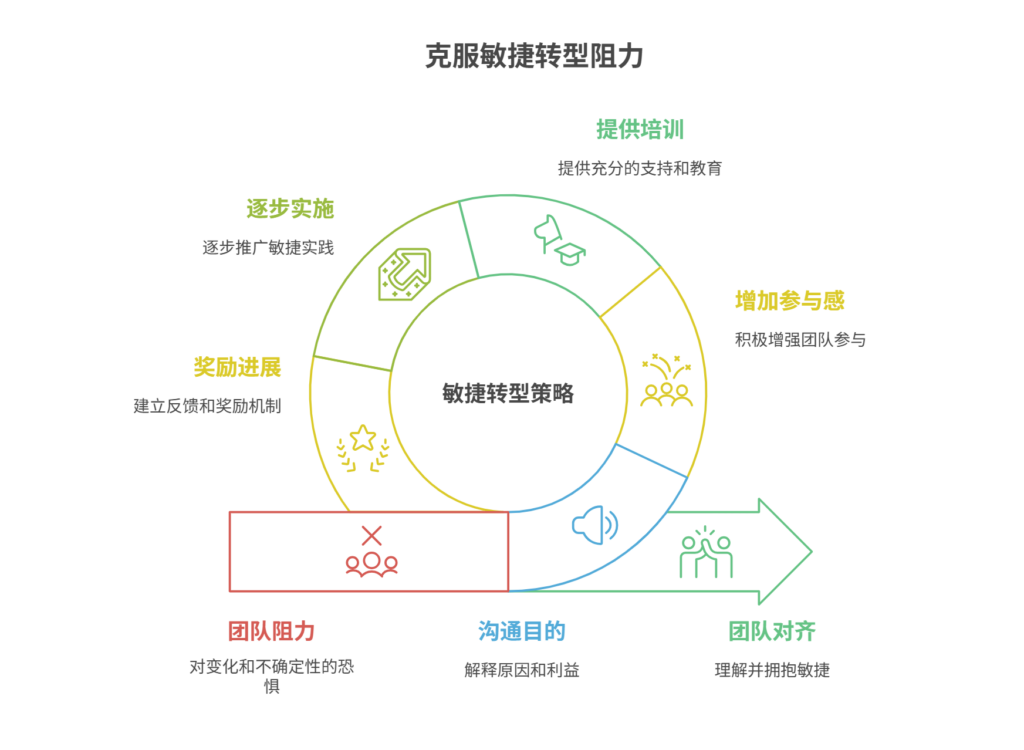
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...